
DIA-TSK: A Dynamic Incremental Adaptive Takagi–Sugeno–Kang Fuzzy Classifier


Abstract
1. Introduction
- (1)
- The static structures of the existing method have difficulty changing flexibly when facing dynamic data streams. Although some online learning and incremental leaning methods manage to adapt to dynamic data scenarios through assembling static sub-classifiers (which are then dropped when the data distribution alters), they still intrinsically work in a static and not dynamic way.
- (2)
- Due to their static structure, existing methods can hardly reach the global optimum for the changing dynamic data in real time. Therefore, there inevitably remains a significant margin between the classification performance of these methods and the separability of the data distribution.
- (3)
- As existing methods utilize a static mechanism, updating their structure may cause unacceptable computational burden in practice, leading these methods to lose their real-time capability (which is widely required in various application scenarios).
- (1)
- DIA-TSK works through a pure dynamic mechanism, automatically adjusting the model parameters in real time under changing data distributions. This ensures that the classifier consistently maintains optimal performance across evolving data environments.
- (2)
- DIA-TSK employs a single, dynamically adaptive classifier, instead of the unified frameworks used in existing online learning and incremental learning method implemented with bagging or boosting approaches. This innovative method continuously adjusts the parameters and structure of the classifier in response to new data. The single-classifier architecture enables more efficient computation, faster adaptation to evolving distributions and a stronger theoretical guarantee of optimality.
- (3)
- DIA-TSK delivers superior performance through its dynamic architecture that continuously optimizes parameters via efficient matrix transformations. This mathematical approach reduces the computational complexity from cubic to quadratic, enabling genuine online incremental learning with minimal overhead. This exceptional efficiency allows for real-time processing of streaming data and immediate adaptation to distribution changes, making DIA-TSK ideal for time-sensitive application environments.
- (4)
- Extensive experiments demonstrate that DIA-TSK outperforms state-of-the-art online learning and incremental learning methods across multiple dynamic data sets. In both online and batch mode incremental forms, DIA-TSK achieves significant advantages in classification efficiency and prediction accuracy.
2. Zero-Order TSK Fuzzy Classifier
- IF BP is “Normal” AND BS is “Normal”, THEN IL is “No Intervention Required”;
- IF BP is “Normal” AND BS is “Slightly Elevated”, THEN IL is “Mild Intervention”;
- IF BP is “High” AND BS is “Normal”, THEN IL is “Moderate Intervention”;
- IF BP is “High” AND BS is “High”, THEN IL is “Severe Intervention”.
- IF BP is 0.5 AND BS is 0.5, THEN IL is 0;
- IF BP is 0.5 AND BS is 0, THEN IL is 1;
- IF BP is 1 AND BS is 0.5, THEN IL is 2;
- IF BP is 1 AND BS is 1, THEN IL is 3.
3. DIA-TSK
- IF BP is 0.5 AND BS is 0.5, THEN IL is 0.1;
- IF BP is 0.5 AND BS is 0, THEN IL is 0.9;
- IF BP is 1 AND BS is 0.5, THEN IL is 2.2;
- IF BP is 1 AND BS is 1, THEN IL is 3.0.
3.1. Online Dynamic Incremental Adaptive TSK Fuzzy Classifier (O-DIA-TSK)
| Algorithm 1: The training process of the O-DIA-TSK fuzzy classifier. |
Step 1. Compute Gaussian membership functions using the input data |
| where is the th feature of sample x, {0, 0.25, 0.5, 0.75, 1} and . The membership of each sample for all initial fuzzy rules is calculated as |
| Construct the antecedent matrix of the initial fuzzy rules |
| forming an overdetermined linear system for the consequent parameter matrix |
| Step 2. Obtain the analytical solution for the consequent parameters [24] |
| Step 3. Compute the output of the classifier as |
|
Output and .
Incremental Training Process Step 4. for to do
|
|
| Step 5. After iterations, compute the final predictions |
| Output and . Main Procedure Step 6. Train the initial TSK fuzzy classifier and output G0 and A0. Step 7. If the training accuracy is unsatisfactory, invoke the incremental training process to output and . |
3.2. Batch Dynamic Incremental Adaptive TSK Fuzzy Classifier (B-DIA-TSK)
| Algorithm 2: The training process of the B-DIA-TSK fuzzy classifier. |
Step 1. Compute Gaussian membership functions using the input data : |
| where is the th feature of the sample, {0, 0.25, 0.5, 0.75, 1} and . The membership of each sample under all initial fuzzy rules is calculated as |
| This yields the antecedent matrix of the initial fuzzy rules |
| forming an overdetermined linear system for the consequent parameters |
| Step 2. Obtain the analytical solution for the consequent parameters [24] |
| Step 3. Predict using the obtained parameters |
| Output and . Incremental Training Process Step 4. for to do
|
|
| where the term is computed recursively as |
|
| Step 5. After completing the incremental learning process, the final consequent parameters are obtained. The predicted output for the final sample is computed as |
|
Output and . Main Procedure Step 6. Train the initial TSK classifier and output and . Step 7. If training accuracy is unsatisfactory, invoke the incremental training process to output and . |
3.3. Complexity Analysis
4. Experimental Results
4.1. Data Sets
4.2. Experimental Comparative Methods
4.3. Experimental Settings and Evaluation Metrics
4.4. Comparative Experimental Study
Performance Comparison of O-DIA-TSK and B-DIA-TSK with Other Algorithms
- (1)
- O-DIA-TSK employs a dynamic parameter adjustment strategy, enabling the real-time updating of posterior parameters as individual samples are gradually added. This strategy avoids the need for global model re-training, as is typical in traditional TSK fuzzy classifiers, significantly improving the model’s responsiveness and computational efficiency in dynamic data environments.
- (2)
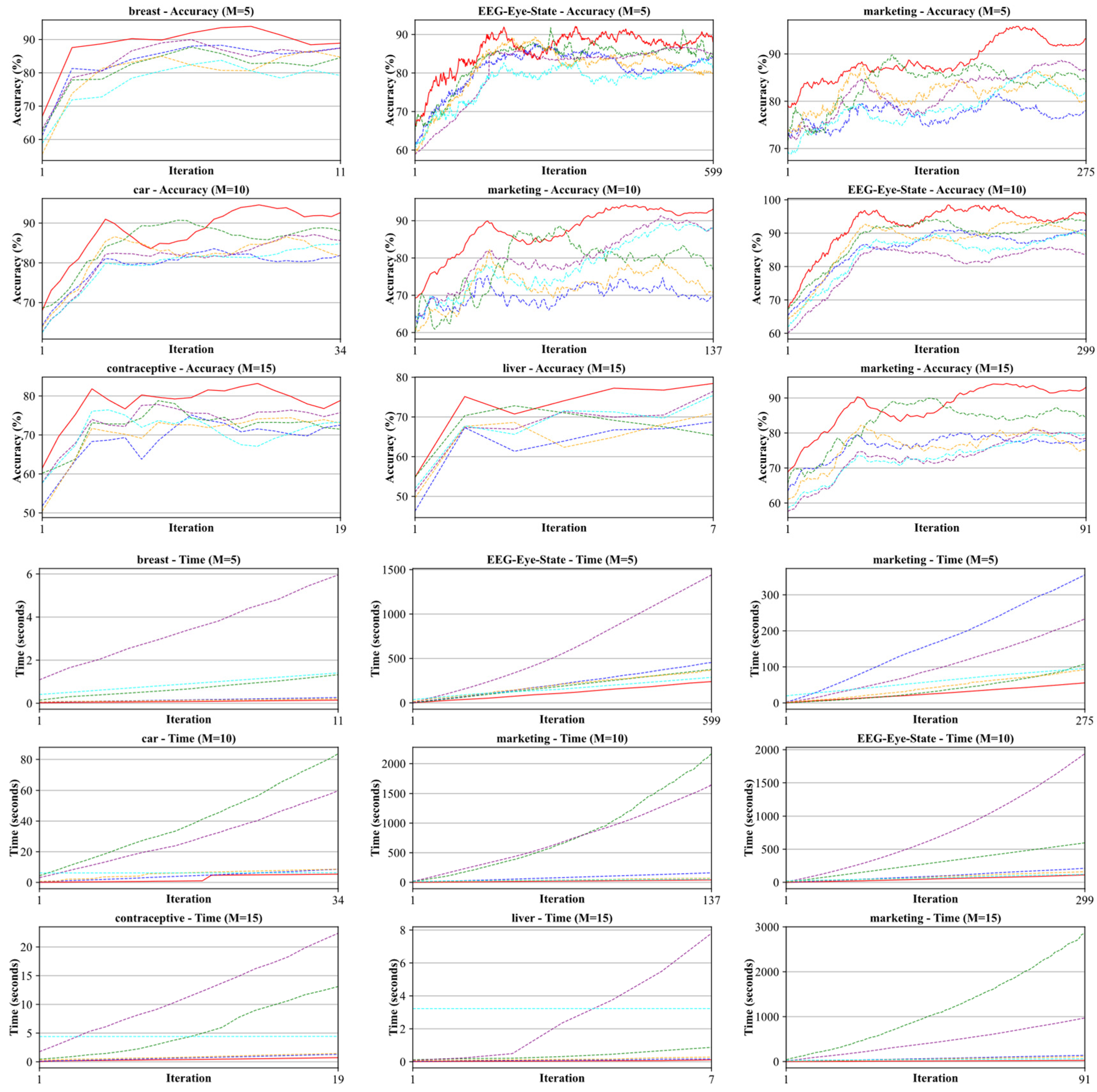
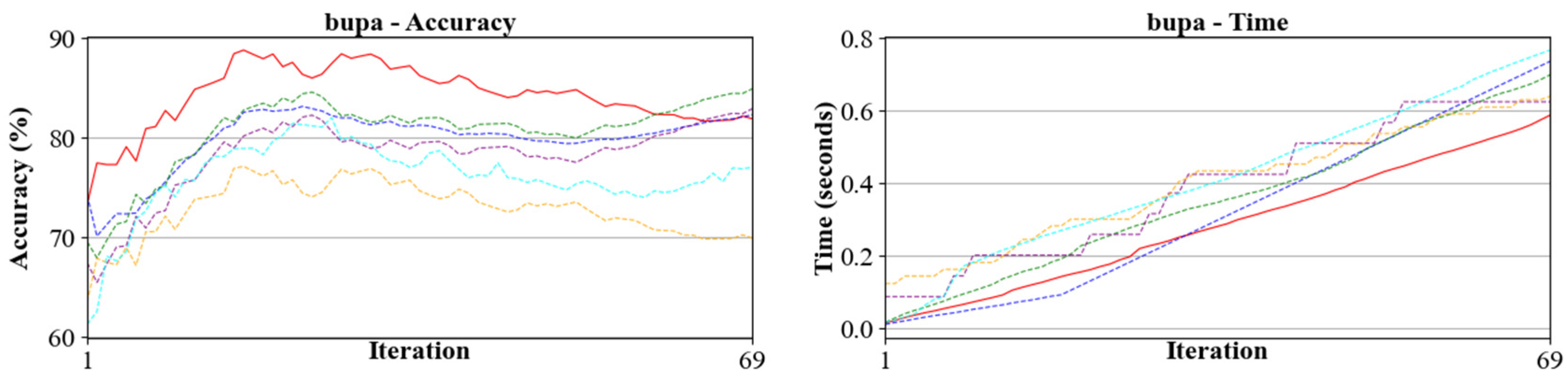
- B-DIA-TSK processes multiple samples in batches and utilizes advanced mathematical methods, such as the Woodbury matrix identity and Cholesky decomposition, to optimize the inverse matrix computation process. This optimization significantly reduces the computational time and lowers the potential for error accumulation. This strategy not only improves the model’s computational efficiency when dealing with large-scale data sets but also enhances its stability and accuracy when processing high-dimensional data. Compared to traditional batch incremental learning algorithms, B-DIA-TSK was found to excel in handling large-scale data sets under resource-constrained computational environments, maintaining both efficient computational performance and high model accuracy and robustness. In particular, it demonstrated powerful adaptability and efficient resource utilization in complex data scenarios. From Figure 2, it can be further observed that significant concept drift emerged for the data sets EEG-Eye-Stage, marketing, liver and contraceptive. The classification accuracies of the comparative methods ILDA (chunk), MvIDA, OSELM (chunk), CICSHL-SVM and KB-IELM declined to different extents, while the proposed B-DIA-TSK maintained a significant advantage in terms of classification performance.
4.5. Application to Real-World Data
4.6. Significance Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zadeh, L.A. On fuzzy algorithms. In Fuzzy Sets, Fuzzy Logic, and Fuzzy Systems: Selected Papers; World Scientific Publishing Co., Pte. Ltd.: Singapore, 1996; pp. 127–147. [Google Scholar]
- Ying, H.A.O.; Chen, G. Necessary conditions for some typical fuzzy systems as universal approximators. Automatica 1997, 33, 1333–1338. [Google Scholar] [CrossRef]
- Wong, S.Y.; Yap, K.S.; Yap, H.J.; Tan, S.C.; Chang, S.W. On equivalence of FIS and ELM for interpretable rule-based knowledge representation. IEEE Trans. Neural Netw. Learn. Syst. 2014, 26, 1417–1430. [Google Scholar] [PubMed]
- Yang, C.F.; Chen, C.L.; Wang, Y.S. Interval type-2 TSK fuzzy neural model for illuminant estimation. In Proceedings of the 2016 12th IEEE International Conference on Control and Automation (ICCA), Kathmandu, Nepal, 1–3 June 2016; pp. 517–522. [Google Scholar]
- Karaboga, D.; Kaya, E. An adaptive and hybrid artificial bee colony algorithm (aABC) for ANFIS training. Appl. Soft Comput. 2016, 49, 423–436. [Google Scholar]
- Pramod, C.P.; Pillai, G.N. K-Means clustering based Extreme Learning ANFIS with improved interpretability for regression problems. Knowl.-Based Syst. 2021, 215, 106750. [Google Scholar]
- Ishibuchi, H.; Nozaki, K.; Yamamoto, N.; Tanaka, H. Selecting fuzzy if-then rules for classification problems using genetic algorithms. IEEE Trans. Fuzzy Syst. 1995, 3, 260–270. [Google Scholar]
- Lin, C.T.; Pal, N.R.; Wu, S.L.; Liu, Y.T.; Lin, Y.Y. An interval type-2 neural fuzzy system for online system identification and feature elimination. IEEE Trans. Neural Netw. Learn. Syst. 2014, 26, 1442–1455. [Google Scholar]
- Zhou, S.M.; Gan, J.Q. Constructing L2-SVM-based fuzzy classifiers in high-dimensional space with automatic model selection and fuzzy rule ranking. IEEE Trans. Fuzzy Syst. 2007, 15, 398–409. [Google Scholar]
- Lu, J.; Zuo, H.; Zhang, G. Fuzzy multiple-source transfer learning. IEEE Trans. Fuzzy Syst. 2019, 28, 3418–3431. [Google Scholar]
- Jhang, J.Y.; Lin, C.J.; Kuo, S.W. Convolutional Takagi-Sugeno-Kang-type Fuzzy Neural Network for Bearing Fault Diagnosis. Sens. Mater. 2023, 35, 2355. [Google Scholar] [CrossRef]
- Hu, K.; Bi, Z.; He, Q.; Peng, Z. A feature extension and reconstruction method with incremental learning capabilities under limited samples for intelligent diagnosis. Adv. Eng. Inform. 2024, 62, 102796. [Google Scholar] [CrossRef]
- Hua, S.; Wang, C.; Lam, H.K.; Wen, S. An incremental learning method with hybrid data over/down-sampling for sEMG-based gesture classification. Biomed. Signal Process. Control 2023, 83, 104613. [Google Scholar] [CrossRef]
- Feng, L.; Zhao, C.; Chen, C.L.P.; Li, Y.; Zhou, M.; Qiao, H.; Fu, C. BNGBS: An efficient network boosting system with triple incremental learning capabilities for more nodes, samples, and classes. Neurocomputing 2020, 412, 486–501. [Google Scholar] [CrossRef]
- Zheng, T.; Cheng, L.; Gong, S.; Huang, X. Model incremental learning of flight dynamics enhanced by sample management. Aerosp. Sci. Technol. 2025, 160, 110049. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, G.; Zhou, T.; Huang, X.; Lam, S.; Sheng, J.; Ding, W. Takagi-Sugeno-Kang fuzzy system fusion: A survey at hierarchical, wide and stacked levels. Inf. Fusion 2024, 101, 101977. [Google Scholar]
- Wu, X.; Jiang, B.; Wang, X.; Ban, T.; Chen, H. Feature Selection in the Data Stream Based on Incremental Markov Boundary Learning. IEEE Trans. Neural Netw. Learn. Syst. 2023, 34, 6740–6754. [Google Scholar]
- Ren, M.; Liu, F.; Wang, H.; Zhang, Z. Addressing Concept Drift in Active Learning for TSK Fuzzy Systems. IEEE Trans. Fuzzy Syst. 2023, 31, 608–621. [Google Scholar]
- Li, Y.; Zhou, E.; Vong, C.M.; Wang, S. Stacked Ensemble of Extremely Interpretable Takagi–Sugeno–Kang Fuzzy Classifiers for High-Dimensional Data. IEEE Trans. Syst. Man Cybern. Syst. 2025, 55, 2414–2425. [Google Scholar]
- Hernández, H.; Díaz-Viera, M.A.; Alberdi, E.; Goti, A. Comparison of Trivariate Copula-Based Conditional Quantile Regression Versus Machine Learning Methods for Estimating Copper Recovery. Mathematics 2025, 13, 576. [Google Scholar] [CrossRef]
- Ji, R.; Chen, Z.; Li, Y.; Wu, P. Resource-Efficient Active Learning Framework for Large-Scale TSK Fuzzy Systems. IEEE Trans. Syst. Man Cybern. Syst. 2024, 54, 245–257. [Google Scholar]
- Guo, Y.; Zheng, Z.; Pu, J.; Jiao, B.; Gong, D.; Yang, S. Robust online active learning with cluster-based local drift detection for unbalanced imperfect data. Appl. Soft Comput. 2024, 165, 112051. [Google Scholar] [CrossRef]
- Xue, L.; Wang, J.; Qin, Y.; Zhang, Y.; Yang, Q.; Li, Z. Two-timescale online coordinated schedule of active distribution network considering dynamic network reconfiguration via bi-level safe deep reinforcement learning. Electr. Power Syst. Res. 2024, 234, 110549. [Google Scholar] [CrossRef]
- Guo, Y.; Pu, J.; Jiao, B.; Peng, Y.; Wang, D.; Yang, S. Online semi-supervised active learning ensemble classification for evolving imbalanced data streams. Appl. Soft Comput. 2024, 155, 111452. [Google Scholar] [CrossRef]
- Fan, W.; Yang, W.; Chen, T.; Guo, Y.; Wang, Y. AOCBLS: A novel active and online learning system for ECG arrhythmia classification with less labeled samples. Knowl.-Based Syst. 2024, 304, 112553. [Google Scholar] [CrossRef]
- Malialis, K.; Panayiotou, C.G.; Polycarpou, M.M. Nonstationary data stream classification with online active learning and siamese neural networks. Neurocomputing 2022, 512, 235–252. [Google Scholar]
- Zhang, J.; Li, Y.; Liu, B.; Chen, H.; Zhou, J.; Yu, H.; Qin, B. A Broad TSK Fuzzy Classifier with a Simplified Set of Fuzzy Rules for Class-Imbalanced Learning. Mathematics 2023, 11, 4284. [Google Scholar] [CrossRef]
- Castorena, G.A.H.; Méndez, G.M.; López-Juárez, I.; García, M.A.A.; Martinez-Peon, D.C.; Montes-Dorantes, P.N. Parameter prediction with Novel enhanced Wagner Hagras interval Type-3 Takagi–Sugeno–Kang Fuzzy system with type-1 non-singleton inputs. Mathematics 2024, 12, 1976. [Google Scholar] [CrossRef]
- Yang, Q.; Gu, Y.; Wu, D. Survey of incremental learning. In Proceedings of the 2019 Chinese Control and Decision Conference (CCDC), Nanchang, China, 3–5 June 2019. [Google Scholar]
- Qin, B.; Nojima, Y.; Ishibuchi, H.; Wang, S. Realizing deep high-order TSK fuzzy classifier by ensembling interpretable zero-order TSK fuzzy subclassifiers. IEEE Trans. Fuzzy Syst. 2021, 29, 3441–3455. [Google Scholar] [CrossRef]
- Wang, S.; Jiang, Y.; Chung, F.L.; Qian, P. Feedforward kernel neural networks, generalized least learning machine, and its deep learning with application to image classification. Appl. Soft Comput. 2015, 37, 125–141. [Google Scholar]
- Qin, B.; Chung, F.; Wang, S. KAT: A knowledge adversarial training method for zero-order Takagi–Sugeno–Kang fuzzy classifiers. IEEE Trans. Cybern. 2022, 52, 6857–6871. [Google Scholar]
- Cheng, W.Y.; Juang, C.F. A fuzzy model with online incremental SVM and margin-selective gradient descent learning for classification problems. IEEE Trans. Fuzzy Syst. 2013, 22, 324–337. [Google Scholar]
- Ertekin, S.; Bottou, L.; Giles, C.L. Nonconvex online support vector machines. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 368–381. [Google Scholar] [CrossRef] [PubMed]
- Xu, J.; Tang, Y.Y.; Zou, B.; Xu, Z.; Li, L.; Lu, Y. The generalization ability of online SVM classification based on Markov sampling. IEEE Trans. Neural Netw. Learn. Syst. 2014, 26, 628–639. [Google Scholar] [PubMed]
- Liang, N.Y.; Huang, G.B.; Saratchandran, P.; Sundararajan, N. A fast and accurate online sequential learning algorithm for feedforward networks. IEEE Trans. Neural Netw. 2006, 17, 1411–1423. [Google Scholar] [PubMed]
- Pang, S.; Ozawa, S.; Kasabov, N. Incremental linear discriminant analysis for classification of data streams. IEEE Trans. Syst. Man Cybern. Part B (Cybern.) 2005, 35, 905–914. [Google Scholar]
- Gu, B.; Quan, X.; Gu, Y.; Sheng, V.S.; Zheng, G. Chunk incremental learning for cost-sensitive hinge loss support vector machine. Pattern Recognit. 2018, 83, 196–208. [Google Scholar]
- Guo, L.; Hao, J.H.; Liu, M. An incremental extreme learning machine for online sequential learning problems. Neurocomputing 2014, 128, 50–58. [Google Scholar] [CrossRef]
- Shivagunde, S.S.; Nadapana, A.; Saradhi, V.V. Multi-view incremental discriminant analysis. Inf. Fusion 2021, 68, 149–160. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| # | Data Set | No. of Samples | No. of Features | No. of Classes |
|---|---|---|---|---|
| 1 | penbased | 10,992 | 16 | 10 |
| 2 | blood | 748 | 4 | 2 |
| 3 | HTRU2 | 17,898 | 8 | 2 |
| 4 | thyroid | 7200 | 21 | 3 |
| 5 | phoneme | 5404 | 5 | 2 |
| 6 | breast | 277 | 9 | 2 |
| 7 | EEG-Eye-State | 14,980 | 14 | 2 |
| 8 | contraceptive | 1473 | 9 | 3 |
| 9 | liver | 583 | 10 | 2 |
| 10 | marketing | 6876 | 13 | 9 |
| 11 | car | 1728 | 6 | 4 |
| 12 | coil2000 | 9822 | 85 | 2 |
| 13 | diabetes | 768 | 8 | 2 |
| 14 | mammographicmasses | 961 | 5 | 2 |
| 15 | bupa | 345 | 6 | 2 |
| Parameters | Ranges and Intervals |
|---|---|
| μ: Center value of the Gaussian membership function | [0, 0.25, 0.5, 0.75, 1] |
| : Initial number of fuzzy rules in the fuzzy classifier | 5:5:500 |
| σ: Width of the Gaussian function | Default value: 1 |
| M: Number of samples for incremental learning | 2:100 |
| η: Kernel function parameter | Default value: 0.5 |
| Approaches | Default Values of Parameters | Ranges and Intervals of Parameters |
|---|---|---|
| FM3 | C = 1.0, eta = 0.1, beta = 0.1, sigma_c = 0.1 | C: [0.1, 1.0, 10.0] eta: [0.01, 0.1, 1.0] beta: [0.1, 0.5, 1.0] sigma_c: [0.1, 0.5, 1.0] |
| LASVMG | kernel = ’rbf’, C = 1.0, degree = 3, gamma = ’scale’, coef = 0.0, tol = 1 × 10−3, max_iter = −1, max_non_svs = 100 | C: [0.1, 1.0, 10.0] gamma: [’scale’, 0.1, 1.0] |
| OnlineSVM (Markov) | dimension = number of features, lambda_param = 0.01 | lambda_param: [0.01, 0.1, 1.0] Markov Order: 1:1:10 |
| OS-ELM | input_size = number of features, hidden_size = 20, output_size = number of classes | hidden_size: [10, 20, 50] |
| ILDA | n_features = number of features, n_classes = number of classes | - |
| CICSHL-SVM | C = 1.0, C_plus = 2.0, C_minus = 1.0, kernel = ’rbf’, gamma = 1.0 | C: [0.1, 1.0, 10.0] C_plus: [1.0, 2.0] C_minus: [0.5, 1.0] gamma: [0.1, 1.0] |
| KB-IELM | nu = 1.0, gamma = 0.1 | nu: [0.1, 1.0, 10.0] gamma: [0.01, 0.1, 1.0] |
| MvIDA | C = 1.0, q = 1.2 | C: [0.1, 1.0, 10.0] q: [1.1, 1.2, 1.3] |
| Method Type | Average Time Improvement (%) | Average Storage Performance Improvement (%) |
|---|---|---|
| O-DIA-TSK vs. FM3 | 32.13 | 28.64 |
| O-DIA-TSK vs. ILDA (sequential) | 30.91 | 13.40 |
| O-DIA-TSK vs. LASVMG | 32.41 | 82.28 |
| O-DIA-TSK vs. OnlineSVM (Markov) | 28.65 | 43.35 |
| O-DIA-TSK vs. OSELM (sequential) | 37.72 | 70.27 |
| B-DIA-TSK vs. ILDA (chunk) | 77.61 | 50.76 |
| B-DIA-TSK vs. MvIDA | 41.47 | 47.84 |
| B-DIA-TSK vs. OSELM (chunk) | 26.27 | 59.99 |
| B-DIA-TSK vs. CICSHL-SVM | 89.48 | 28.63 |
| B-DIA-TSK vs. KB-IELM | 78.27 | 36.2 |
| B-DIA-TSK vs. O-DIA-TSK | 73.21 | 56.38 |
| Method | Ranking |
|---|---|
| O-DIA-TSK | 1 |
| LASVMG | 3.25 |
| FM3 | 3.75 |
| OSELM (sequential) | 4 |
| OnlineSVM (Markov) | 4.5 |
| ILDA (sequential) | 4.5 |
| Method | Ranking |
|---|---|
| B-DIA-TSK | 1 |
| CICSHL-SVM | 2.8333 |
| KB-IELM | 3.1667 |
| MvIDA | 4.1667 |
| OSELM (chunk) | 4.6667 |
| ILDA (chunk) | 5.1667 |
| Method | p | Holm–Hommel | ||
|---|---|---|---|---|
| 5 | ILDA (sequential) | 2.835884 | 0.0046556 | 0.01 |
| 4 | OnlineSVM (Markov) | 2.646927 | 0.0081399 | 0.0125 |
| 3 | OSELM (sequential) | 2.344797 | 0.0187357 | 0.016667 |
| 2 | FM3 | 2.079711 | 0.037525 | 0.025 |
| 1 | LASVMG | 1.701575 | 0.088973 | 0.05 |
| Method | p | Holm–Hommel | ||
|---|---|---|---|---|
| 5 | ILDA (chunk) | 3.857584 | 0.000115 | 0.01 |
| 4 | OSELM (chunk) | 3.394674 | 0.000687 | 0.0125 |
| 3 | MvIDA | 2.931764 | 0.00337 | 0.016667 |
| 2 | KB-IELM | 2.005944 | 0.004486 | 0.025 |
| 1 | CICSHL-SVM | 1.697337 | 0.089633 | 0.05 |
| Method | Unadjusted p | p (Holm) | p (Hommel) | |
|---|---|---|---|---|
| 1 | ILDA (sequential) | 0.0046556 | 0.023278 | 0.0186224 |
| 2 | OnlineSVM (Markov) | 0.0081399 | 0.0325596 | 0.0244197 |
| 3 | OSELM (sequential) | 0.0187357 | 0.0374714 | 0.0321222 |
| 4 | FM3 | 0.037625 | 0.037525 | 0.037525 |
| 5 | LASVMG | 0.088973 | 0.088973 | 0.088973 |
| Method | Unadjusted p | p (Holm) | p (Hommel) | |
|---|---|---|---|---|
| 1 | ILDA (chunk) | 0.000115 | 0.000573 | 0.000573 |
| 2 | OSELM (chunk) | 0.000687 | 0.002748 | 0.002748 |
| 3 | MvIDA | 0.00337 | 0.010111 | 0.010111 |
| 4 | KB-IELM | 0.004486 | 0.008972 | 0.008963 |
| 5 | CICSHL-SVM | 0.089633 | 0.089725 | 0.089633 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, H.; Sha, C.; Jiao, M.; Shao, C.; Gao, S.; Yu, H.; Qin, B. DIA-TSK: A Dynamic Incremental Adaptive Takagi–Sugeno–Kang Fuzzy Classifier. Mathematics 2025, 13, 1054. https://doi.org/10.3390/math13071054
Chen H, Sha C, Jiao M, Shao C, Gao S, Yu H, Qin B. DIA-TSK: A Dynamic Incremental Adaptive Takagi–Sugeno–Kang Fuzzy Classifier. Mathematics. 2025; 13(7):1054. https://doi.org/10.3390/math13071054
Chicago/Turabian StyleChen, Hao, Chenhui Sha, Mingqing Jiao, Changbin Shao, Shang Gao, Hualong Yu, and Bin Qin. 2025. "DIA-TSK: A Dynamic Incremental Adaptive Takagi–Sugeno–Kang Fuzzy Classifier" Mathematics 13, no. 7: 1054. https://doi.org/10.3390/math13071054
APA StyleChen, H., Sha, C., Jiao, M., Shao, C., Gao, S., Yu, H., & Qin, B. (2025). DIA-TSK: A Dynamic Incremental Adaptive Takagi–Sugeno–Kang Fuzzy Classifier. Mathematics, 13(7), 1054. https://doi.org/10.3390/math13071054