3.1. Overview
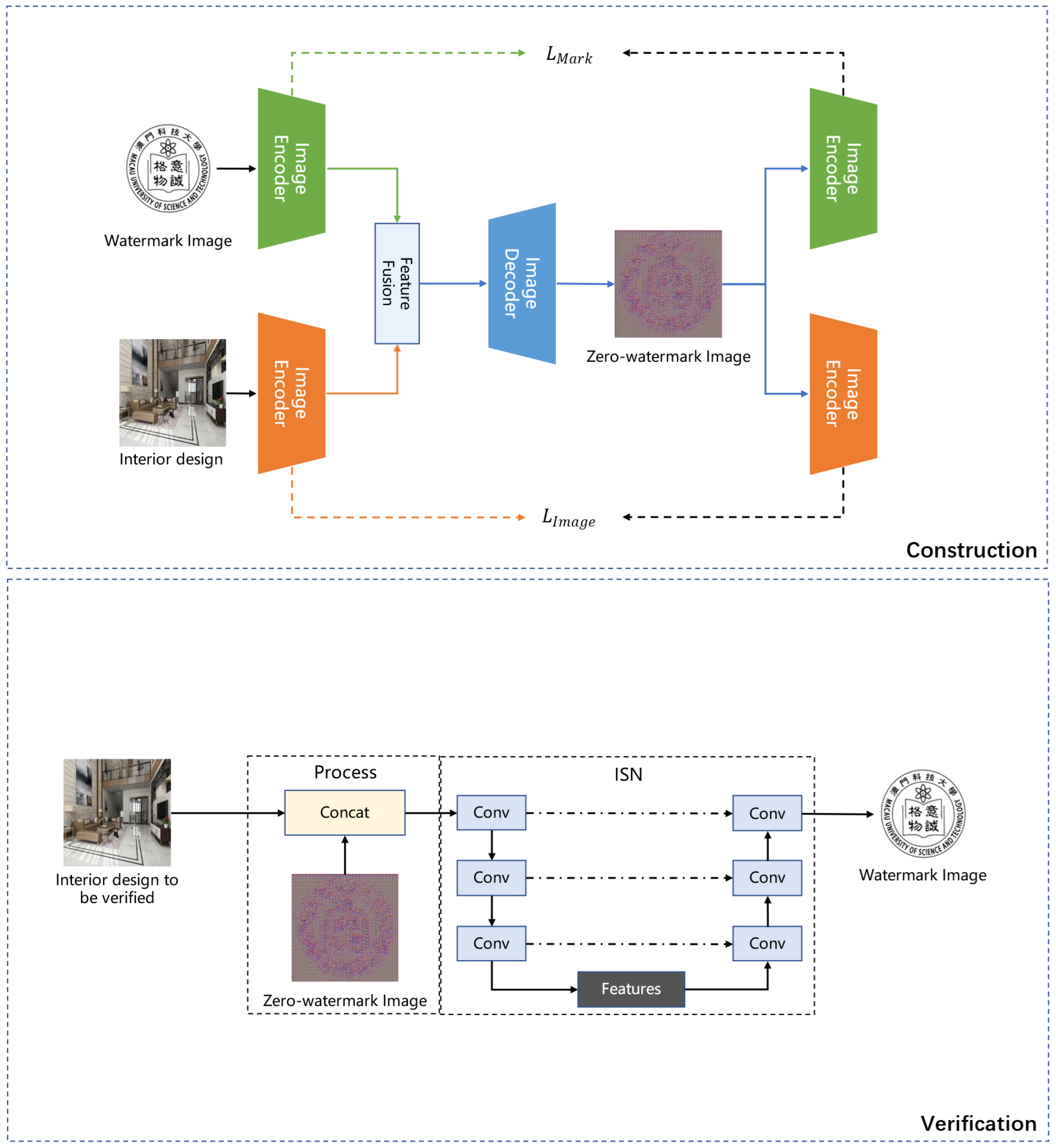
The flowchart of the methodology proposed in this study is shown in
Figure 1. It consists of two primary parts: zero-watermark construction based on an image fusion network and zero-watermark authentication utilizing an inspection network (ISN).
In the zero-watermark construction phase, the protected interior design and watermark images are processed through an encoder to extract their respective features. Subsequently, these extracted features are fused, and the fused feature representation is passed through the decoder to generate a robust zero-watermark image, which is then stored. The construction approach aims to leverage deep learning techniques to integrate the interior design with the watermark image, ensuring that the zero-watermark image contains the salient features of both the interior design and the watermark image. Our construction approach can significantly enhance the robustness of the watermark against various forms of image attacks.
An inspection network (ISN) is employed to verify the zero-watermark image. The ISN is trained to separate the zero-watermark image and reconstruct the embedded watermark image. During the authentication process, the interior design is verified, and the zero-watermark image is used as the input to the network, thereby obtaining the extraction and authentication of the initially embedded watermark image information.
3.2. Zero-Watermark Construction
Here, the interior design is defined as . The watermark image is denoted by . denotes the pixel value at position of . denotes the pixel value at position of .
Firstly, zero-watermark generation takes and as inputs and performs feature extraction based on the encoder.
Secondly, the features extracted from and will undergo feature fusion.
Thirdly, the decoder turns the fused features into a zero-watermark image.
Finally, the zero-watermark image is sent back to the previous feature extraction encoder, and the loss for training is calculated.
3.2.1. Feature Extraction
Input: Interior design and watermark image .
Output: The extracted features of the interior design and the watermark image . H and W represent the height and weight of the feature, respectively. C represents the channel of the feature.
During zero-watermark construction, the encoder can transform the interior design and watermark image into high-dimensional feature representations, providing a reliable base for zero-watermark generation. Considering the efficiency and performance requirements of zero-watermark construction, MobileNet v2 [
23], with its lightweight design, is introduced for the efficient extraction of features from image content. It is a lightweight model that employs depthwise-separable convolution and an inverted residual structure to achieve efficient feature extraction by reducing the amount of computation and the number of parameters. In this study, MobileNet v2 adopts a four-layer inverse residual structure, with a step size of 1 for the first and third layers and a step size of 2 for the second and fourth layers. The feature extraction network is denoted by
, and its structure is summarized in
Table 1.
Firstly, the input interior design
and watermark image
perform convolution operations with a kernel size of
to obtain the shallow features. The process can be represented as follows:
Here, and denote the feature extraction networks for the interior design and the watermark, respectively. and represent the results of the shallow features. denotes convolution operations with a kernel size of , denotes batch normalization, is the activation function, represents the mean value of X, and represents the variance of X. and represent the scaling factor and offset, respectively.
Secondly, four inverted residual blocks are introduced to reduce the model parameters while maintaining model performance. Each block contains an expansion layer, depthwise-separable convolution, and residual connections. The extension layer aims to increase the number of channels through
convolution. After the inverted residual blocks, a convolution layer with a kernel size of
is used to obtain the features extracted from images. The process can be represented as follows:
Here, represents residual blocks that have been inverted four times, and denotes depthwise-separable convolution with a kernel size of . The extracted features of the interior design and watermark image are denoted by and , and they will be used for the subsequent feature fusion.
3.2.2. Feature Fusion
Input: The extracted feature of the interior design is , and the extracted feature of the watermark image is . and represent the height and weight of the extracted feature, and represents the channel of the feature.
Output: The fused feature is . and represent the height and weight of the feature, and represents the channel of the feature.
Generally, zero-watermark images constructed by relying only on a single feature are prone to loss or corruption in the face of common attacks, such as noise, compression, and cropping. To this end, we effectively improve the performance of zero-watermark features by fusing the features of protected and watermarked images to generate more complex and robust feature representations.
After feature extraction, we take
and
as inputs and fuse them to obtain the fused feature
with Equation (
13).
Here, is a control coefficient responsible for regulating the fusion ratio of and .
3.2.3. Zero-Watermark Image Generation
Input: The fused feature
Output: A zero-watermark image Z.
The generation of zero-watermark images is based on the decoder. The decoder reduces the fused features to a zero-watermarked image, aiming to generate a robust zero-watermarked image based on semantic features. This approach ensures that the generated zero-watermark image contains both the fused features of the interior design and the watermark image and makes the generated zero-watermark image highly resistant to attacks, which improves the overall robustness and applicability of the zero-watermarking method.
Here, the decoder achieves feature upsampling and reduction through transpose convolution and batch normalization to gradually generate zero-watermarked images from the fused feature maps. Meanwhile, the ReLU activation function enhances the nonlinear representation capability. The detailed structure is shown in
Table 2.
The calculation process can be represented as follows:
Here, Z denotes the generated zero-watermark image, and denotes the convolution operation to adjust the number of channels. and are the activation functions. denotes a block that has been upsampled three times. represents the transpose convolution operation.
To ensure that the extracted interior design and watermarked image features maintain integrity and their correlation with the generated zero-watermarked image, we designed a two-way reconstruction mechanism. Specifically, the generated zero-watermark image is sequentially fed into the encoder, which extracts the features of the interior design (
) and the watermark image (
) for further processing. It can ensure the quality and feature correlation of the generated zero-watermark image. The process is expressed as follows:
Here, is the generated feature of Z for , and is the generated feature of Z for .
Thus, the overall loss can be defined as
, and the calculation can be expressed as follows:
where
is the control parameter.
This consists of two parts. Firstly,
is used to measure the watermark difference between the watermark image
and the zero-watermark image
Z, and it is expressed as
Here, represents the generated feature of Z for at position , while represents the pixel value of the watermark image at position .
Secondly,
is used to measure the interior design difference between the interior design
and the zero-watermark image
Z, and it is expressed as
Here, represents the generated feature of Z for at position , and represents the pixel value of the watermark image at position .
Through network training and by minimizing the loss , the network constructs a zero-watermark image containing information on both the interior design and the watermark, which provides a certain degree of security and is challenging to illegally crack due to the complexity of the fused features. Further, the zero-watermark image is robust due to the extraction and fusion for the generation of stable image features.
3.3. Zero-Watermark Verification
The zero-watermark verification process consists of two steps. First, the interior design to be tested (denoted by ) and the zero-watermark image are fed into the inspection network (ISN). Second, the ISN transforms the input to obtain the reconstructed copyright image .
ISN
The ISN is based on the UNet [
24] shown in
Figure 1. The network consists of three parts: the encoder, bottleneck layer, and decoder. The encoder section consists of four convolutional blocks, and each is followed by a
max pooling layer, thus gradually reducing the size of the feature map and increasing the number of feature channels. The bottleneck layer contains a convolutional module that processes the feature map output by the encoder for input into the decoder. The decoder restores the feature map size through a stepwise upsampling operation (using transposed convolutional layers) and combines it with the encoder output of the corresponding layer for skip connections. This section contains four convolutional blocks that process the concatenated results of the upsampled feature map and the corresponding layer’s feature map in the encoder. Finally, the output layer uses a
convolution to map the number of channels to the target output channel number.
Firstly, we simulate various image attacks on image
and obtain the set of attacked images
.
is expressed in Equation (
24).
Here, is the attack operation function, and represents the parameter combinations of different attack strategies or intensities.
Secondly, we take the generated zero-watermark image
Z and the set of attacked images
as the input and regard the watermark image
as the target output for ISN training. Secondly, the training loss for verification (denoted by
) is defined in Equation (
25).
Here, denotes the reconstructed copyright image, and is the dimension of the copyright image.
After the ISN completes training, we take the generated zero-watermark image Z and the detected image as the input for the ISN to obtain the reconstructed copyright image for copyright verification.
Compared with traditional verification methods, this method can still effectively recover the original watermark features from a damaged image when facing high-intensity image attacks, enhancing its overall robustness.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}