1. Introduction
Skin cancer is a deadly type of cancer caused by abnormal cell proliferation in the epidermis [
1]. Skin malignancies include melanoma, basal cell carcinoma, and squamous cell carcinoma. Melanoma is the most common. Skin cancer is a major healthcare danger due to rising cases. Early and accurate diagnosis plays a crucial role in improving survival rates. Traditional diagnostic techniques such as histopathological image analysis, clinical screening, and dermoscopic analysis are time-consuming and often rely on subjective interpretation by dermatologists, leading to potential misdiagnosis and delayed treatment. An estimated 9500 Americans are diagnosed with skin cancer daily. More than one million people currently have melanoma [
2]. The American Academy of Dermatology Association estimates 200,340 new melanoma cases in the US. An early identification of melanoma increases the survival rate for five years. The conventional procedures used to detect skin cancer include histopathological image analysis, clinical screening, and dermoscopic analysis [
3]. However, visual inspection using conventional techniques is associated with challenges in detecting cancer in the early stage. Recognition is difficult on different skin surfaces due to the small-sized lesions and slight variations in color, texture, and shape. These complexities may cause the inaccurate identification of disease [
4]. Moreover, the scarcity of expert dermatologists may cause delays in the diagnosis process.
To overcome challenges, computer-aided analysis is essential for skin cancer identification. An automated analysis can help doctors diagnose diseases early and accurately. Automation in medical image analysis has reduced the expert physician burden. Medical image analysis relies heavily on machine learning (ML) and deep learning (DL). Deep learning-based feature extraction combined with classical machine learning classifiers, such as Support Vector Machines (SVMs), has demonstrated promising results in recent studies [
5,
6,
7,
8,
9]. SVM, while traditionally a classical machine learning approach, has been effectively used in hybrid models where deep learning networks extract high-level features, which are then classified using SVM to improve performance. Recently, researchers have employed DL methods in human action recognition [
10,
11,
12], statistical models [
13,
14,
15,
16], gastric diseases [
17], and other medical imaging domains [
18,
19,
20].
Convolutional neural networks (CNNs) performed well and improved skin cancer recognition accuracy [
21,
22]. CNNs have a prominent ability for automated feature learning, derivation of complex patterns, and enhanced prediction and classification. However, training CNN models on large image datasets takes a lot of time. Due to the higher computational time required for deep CNN model training, transfer learning has emerged as an alternative for accurate disease prediction [
23,
24]. Another emerging research topic to enhance skin cancer prediction is combining different CNNs and to create an ensemble model. Studies [
25,
26] show that ensemble models enhance prediction accuracy. The diverse features computed from pre-trained deep CNNs models help in improving classification performance.
Numerous deep learning methodologies have been introduced for skin cancer categorization, utilizing convolutional neural networks (CNNs) and machine learning algorithms. Gupta et al. [
3] suggested an ensemble optimization method for feature selection, with an accuracy of 87% on the ISIC dataset. Khater et al. [
4] developed a system utilizing explainable AI (XAI) for skin cancer detection, achieving a recognition accuracy of 94% on the PH2 dataset. Although these methods demonstrate encouraging outcomes, they frequently encounter issues such as elevated computing complexity, suboptimal feature selection, and overfitting resulting from excessive dimensionality. Moreover, individual CNN-based models exhibit poor generalization across various datasets due to insufficient diversified feature representations.
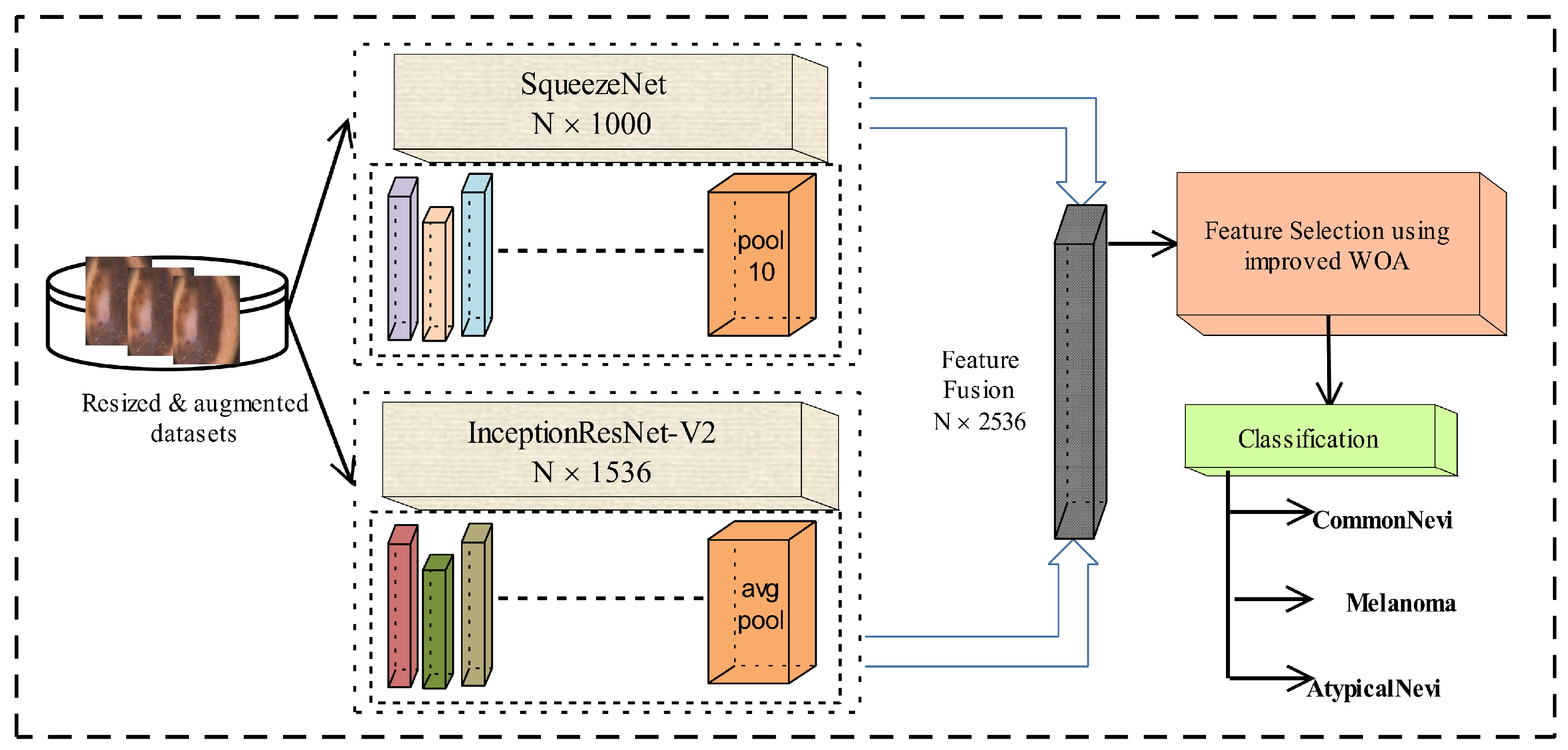
Deep learning uses CNNs to automate feature extraction, improving skin cancer classification accuracy. VGG-16, ResNet-50, and DenseNet-121 are CNN designs with good classification performance, but their processing needs render them unsuitable for real-time and resource-constrained applications. Our hybrid ensemble technique uses InceptionResNet-V2 and SqueezeNet to overcome this, using their complimentary strengths. Deep design with residual connections improves feature learning and prevents vanishing gradient concerns; hence, InceptionResNet-V2 was chosen. The model uses Inception modules to gather multi-scale information from dermoscopic images, which is essential for skin cancer detection. Residual connections improve training stability, making it ideal for complicated classification applications. However, SqueezeNet was chosen for its lightweight architecture, which minimizes computing cost while preserving accuracy. SqueezeNet uses Fire modules instead of convolutional layers, creating a squeeze-and-expand method that reduces parameters while keeping spatial information. This makes it ideal for deployable medical applications that require computing performance.
Metaheuristic optimization techniques have been extensively utilized for feature selection and classification in medical imaging. Conventional methods, including the genetic algorithm (GA), Particle Swarm Optimization (PSO), and the slime mould Algorithm (SMA), encounter challenges such as premature convergence, inadequate exploration–exploitation balance, and sensitivity to parameter adjustments. We present a modified Whale Optimization Algorithm (WOA) that integrates several changes to boost convergence stability, search efficiency, and feature selection efficacy. These innovations enable our modified WOA to attain enhanced feature selection efficacy while diminishing computing complexity. Comparative analyses indicate that our modified WOA surpasses GA, PSO, and SMA for classification accuracy, feature set reduction, and convergence efficiency. Our modified WOA-based feature selection system establishes a new standard in metaheuristic optimization for skin cancer classification through the integration of adaptive search mechanisms with multi-objective optimization.
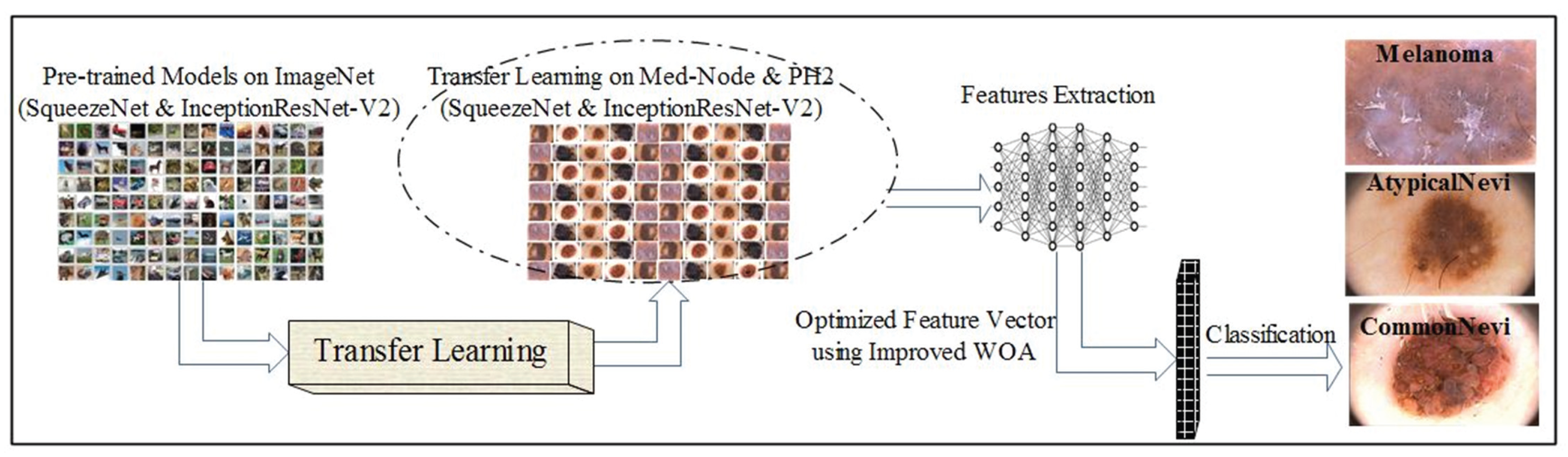
To address these constraints, our research introduces an ensemble approach that integrates two robust CNN architectures—SqueezeNet and InceptionResNet-V2—to extract profound hierarchical features. In contrast to current methodologies that depend on a singular CNN model, our strategy employs transfer learning to harness complementary characteristics from both networks. We provide an enhanced Whale Optimization Algorithm (WOA) that adaptively optimizes hyperparameters through a quadratic decay function, therefore improving feature selection and mitigating premature convergence. The refined feature set is subsequently categorized utilizing various machine learning classifiers, markedly enhancing the robustness and precision of skin cancer diagnosis. Our suggested framework attains a classification accuracy of 95.48% on the PH2 dataset and 98.59% on the Med-Node dataset, surpassing current methodologies. The key highlights of this research work are the following:
An ensemble model is designed using SqueezeNet and InceptionResNet-V2. To extract the deep features, a transfer learning technique is applied to both pre-trained CNNs. Activations are performed on the pool10 layer of SqueezeNet, and the avg_pool layer of IceptionResNet-V2. Extracted features are then combined into a single feature set.
An improved WOA is introduced that utilizes a quadratic decay function and an enhanced mutation mechanism. The modifications provide dynamic parameter tuning for the WOA and prevent fast convergence. The improved WOA is utilized to select the optimized and robust features.
The optimized features are then fed to ML classifiers for the accurate prediction of skin cancer.
This paper is organized as follows:
Section 2 addresses relevant studies,
Section 3 presents the proposed approach with visuals and a mathematical description,
Section 4 examines the detailed results and offers a comparison with existing methodologies, and
Section 5 gives our conclusions and recommends future work.
2. Literature Review
Analysis has been extensively studied [
27,
28,
29,
30,
31] as a powerful tool for improving the representation capacities of Convolutional Neural Networks (CNNs) across several domains. CNNs are also used for person identification [
32], target detection [
33], detection of human movement [
34,
35] and object recognition [
36]. Several techniques have been introduced for the recognition and classification of skin cancer [
37,
38]. In this section, some of the latest existing skin cancer classification techniques are discussed. A transfer learning approach was presented for the classification of the ISBI-2016 dataset [
39].
Deep features were recovered using the pre-trained CNN models DenseNet-201 and MobileNet-V2. Both models’ features are concatenated and sent to the SVM classifier for cancer image classification. The classification techniques obtained a maximum accuracy of 88.02%. Kothapalli et al. [
40] introduced a skin cancer classification technique. The features of the deep CNN model were derived and used for the prediction of disease. The proposed technique achieved 92.6% validation accuracy on the PH2 dataset. The researchers in [
41] presented a modified hunger games search algorithm to optimize and select robust features for skin cancer classification. In the feature extraction phase, the pre-trained MobileNet-V3 model was utilized to extract deep features. The extracted features were then given to the optimization method. The proposed technique showed promising results for the optimizer, and 88.19% classification accuracy was achieved on the ISIC-2016 dataset.
An explainable artificial intelligence (XAI)-based approach was proposed to predict skin cancer [
42]. The method identified melanoma and non-melanoma pictures. The XAI identified the most essential disease categorization features with encouraging results. The PH2 dataset was used for experiments and 94% of recognition accuracy was obtained. Gupta et al. [
43] introduced an ensemble optimization approach for robust feature selection to predict skin cancer. To extract features, the pre-trained CNN model Efficient-Net was utilized. The experiments were performed using the ISIC dataset. The deep features were fed to the ensemble optimizer, giving the best features for disease prediction. The proposed technique obtained a maximum classification accuracy of 0.87. Researchers proposed a lightweight CNN model for skin cancer recognition [
44]. Experiments showed that the performance of the proposed CNN is promising, achieving a classification accuracy of 0.9573 on HAM10000 dataset.
A method combining LBP and HoG characteristics was used to predict skin cancer [
45]. In the initial stage, the images were preprocessed, and noise and artifacts were removed. The enhanced images were then used to extract LBP and HoG features. LBP and HoG features were fed to machine learning classifiers to detect illness. Using the Med-Node dataset, the proposed approach achieved a recognition accuracy of 94%. Waheed et al. [
46] developed a CNN-based skin cancer categorization method. They trained a CNN model on the skin melanoma dataset and achieved 91% recognition accuracy. In [
47], a framework was suggested for skin cancer prediction. The CNN models DenseNet-169 and ResNet-50 were utilized for training and extracting deep features from the HAM10000 and ISIC datasets. After extensive experiments, a maximum classification accuracy of 91.2% was obtained on the DenseNet-169 model. A hybrid approach based on pre-trained CNN models was presented for the classification of skin cancer [
48]. First, DeepLabV3+ was used to segment infected areas in the images. Then, deep features were extracted using three pre-trained CNN models including EfficientNetB0, DenseNet-201, and MobileNet-V2. The extracted features were combined into a single feature vector and robust features were selected using the ReliefF algorithm. After the selection of features, the optimized feature set was provided to machine learning classifiers for the prediction of disease. The proposed approach obtained 94.44% recognition accuracy on the PH2 dataset.
In [
49], the authors analyzed the color histograms of PH2 dataset images and designed a CNN model for classification. The CNN model utilized the residual block with skip connections according to the number of colors. The feature learning was also evaluated using the DeepDream algorithm. The proposed approach achieved 75% classification accuracy. The researchers in [
50] applied transfer learning to pre-trained CNN models. After extensive trials and network fine-tuning, the Xception model performed best. The CNN model was optimized using an artificial bee colony technique. The suggested approach achieved 92% accuracy on the PH2 dataset and 88.24% on the Med-Node dataset.
Deep learning and metaheuristic optimization have enhanced skin cancer classification by improving feature extraction and selection. Many studies have used CNN-based feature extraction and optimization algorithms to increase classification accuracy. A critical study of the contemporary literature reveals various unresolved limits and gaps. Skin lesion classification uses deep learning architectures like VGG-16, ResNet-50, and DenseNet-121, which perform well in feature extraction. These models are too computationally intensive for real-time applications. They overfit on tiny medical datasets and perform differently depending on the dataset. Some studies have integrated CNN-based feature extraction with SVM and k-NN classifiers to boost generalization. These methods still struggle with optimum feature selection since deep learning model high-dimensional feature vectors may contain redundant or irrelevant information, reducing classification performance.
Medical image analysis uses metaheuristic optimization methods like GA, PSO, and SMA for feature selection. These techniques improve classification by reducing feature dimensionality, but they have three drawbacks. GA and PSO often experience premature convergence, where the search process gets stuck in local optima, resulting in inefficient feature selection. Second, typical metaheuristic approaches use constant or linearly decreasing parameters that do not dynamically modify the search process; therefore, they lack an adaptive exploration–exploitation balance. Therefore, they struggle to efficiently explore the search space in early iterations while refining the solution afterward. Third, computational inefficiency in high-dimensional feature spaces persists. Deep learning-based feature extraction yields enormous feature sets, making it difficult for present optimization approaches to reduce redundant features, increasing computing overhead and lowering classification performance.
4. Results and Discussion
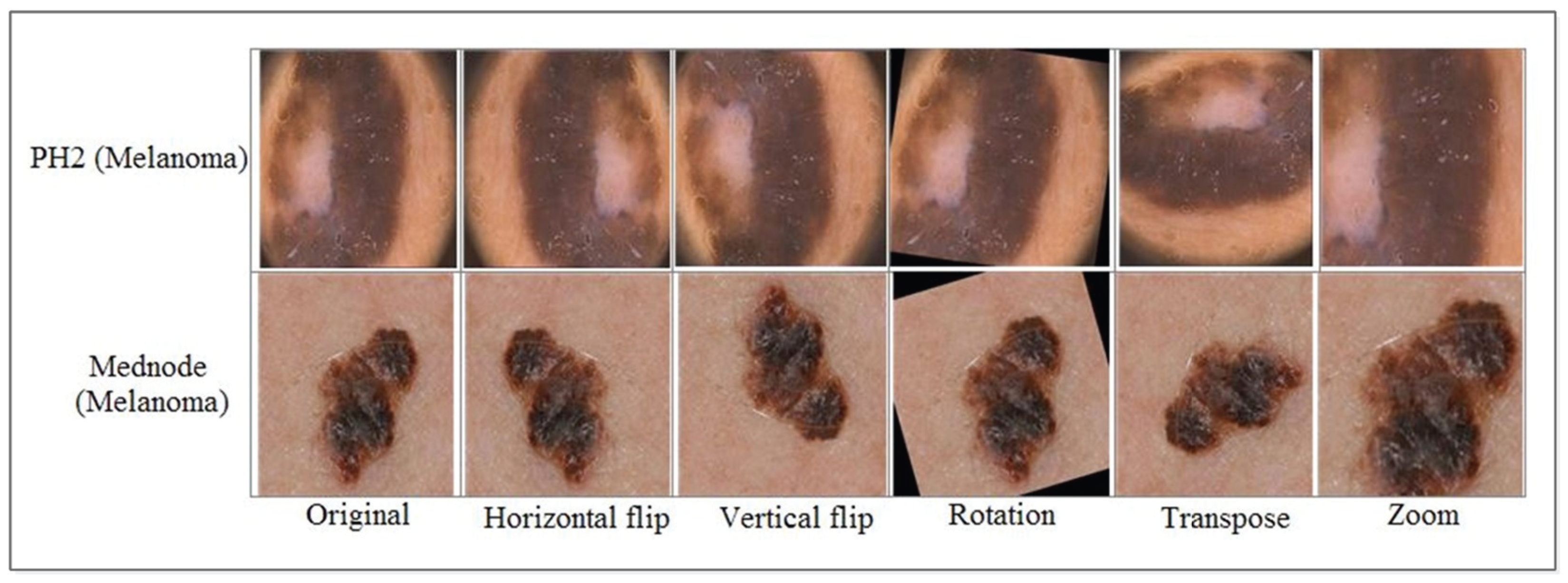
In the present work, the evaluation of the systems was tested on dermoscopic images of two datasets including Med-Node and PH2. The Med-Node dataset initially consisted of 170 images distributed among two types of diseases. After augmentation, the dataset contained a total of 920 images belonging to two classes. The PH2 dataset contains 200 images distributed among three types of classes. After augmentation, the dataset consisted of 1040 images. The Med-Node and PH2 classification experiment used 10-fold cross-validation. MATLAB 2024a was used to evaluate skin cancer datasets utilizing a Core i5 6th gen system (Intel, Santa Clara, CA, USA).
Table 3 displays the results of using the suggested technique on the Med-Node dataset.
The results were taken using five machine learning classifiers on the Med-Node dataset using optimized WOA. The Cubic SVM, Quadratic SVM, Fine KNN, Medium Neural Network, and Wide Neural Network methods achieved accuracies of 98.5%, 98.04%, 96.63%, 97.07%, and 96.96%, respectively. The classification results using the PH2 dataset are presented in
Table 4.
The five machine learning classifiers C-SVM, Q-SVM, F-KNN, M-NN, and W-NN provided accuracies of 95.48%, 93.56%, 93.17%, 90.77%, and 91.73%, respectively, using our improved WOA on the PH2 dataset. The confusion matrix and ROC of C-SVM for both the Med-Node and PH2 datasets are presented in
Figure 4.
The improved WOA is also compared with some other optimization algorithms including the genetic algorithm [
55], particle swarm optimization [
56], and the slime mould algorithm [
57] to ensure the effectiveness of the improved WOA algorithm. A graph is presented in
Figure 5 for a comparison of the number of selected features using different optimization techniques.
A comparison of classification results after feature selection using our improved WOA with other optimization techniques on the Med-Node dataset is illustrated in
Table 5.
Using the genetic algorithm, the C-SVM provides the highest accuracy of 98.00% among all classifiers. Using the particle swarm optimization algorithm, the C-SVM and Q-SVM both provide the highest accuracy of 97.90%, while the slime mould algorithm obtained the highest recognition accuracy of 98.00% on the Q-SVM predictor. The proposed improved WOA provides the highest accuracy of 98.59% using the C-SVM classifier among all the optimization techniques. A comparison of improved WOA with other optimization techniques on the PH2 dataset is given in
Table 6.
On the PH2 dataset, the genetic algorithm provides the highest accuracy of 95.30% by utilizing C-SVM among all the classifiers. Using C-SVM, particle swarm optimization and the slime mould algorithm provided accuracies of 95.3% and 92.1%, respectively, which were highest among all the selected machine learning classifiers. The improved WOA provided the highest classification accuracy among all the optimization techniques, 95.48% using the C-SVM classifier. The proposed framework is compared with existing skin cancer classification techniques in
Table 7, which validates its performance in terms of classification accuracy.
We compared the modified WOA against GA, PSO, and SMA to assess its efficacy. Modified WOA outperforms other approaches in feature selection efficiency and classification accuracy, but it has several drawbacks. Parameter adjustment with a quadratic decay function gives modified WOA an adaptable exploration–exploitation balance, one of its strengths. The linear decay of its exploration parameter causes premature convergence in traditional WOA, restricting its ability to escape local optima. In contrast, our updated version uses quadratic decay to gradually move from exploration to exploitation. This approach lets the algorithm first examine a larger space before fine-tuning feature selection. Modified WOA balances exploration and convergence stability better than PSO, which often converges prematurely due to velocity update reduction. This results in superior feature selection and classification accuracy. The increased mutation mechanism of modified WOA avoids the algorithm from stagnating in local optima. This is especially useful in high-dimensional feature spaces, where GA and SMA suffer from feature redundancy. To avoid excessive randomization, GA mutation rates must be manually calibrated, whereas in modified WOA, the adaptive mutation process introduces controlled unpredictability every few cycles, boosting discriminative feature selection without interrupting convergence. The Med-Node dataset showed that modified WOA outperformed GA, PSO, and SMA, which had maximum accuracies of 98.00%, 97.90%, and 98.00%, respectively.
Modified WOA has drawbacks despite its merits. Its computational complexity is a major issue. Dynamic parameter tweaking and mutation techniques improve feature selection efficiency but increase function evaluations every iteration, increasing computational costs compared to PSO and GA. Due to its simplified velocity–position updating method, PSO performs better in quick optimization circumstances. Modified WOA regularly outperforms alternatives in terms of feature reduction and classification accuracy in accuracy and feature selection. Modified WOA’s dependence on parameter settings, particularly the exploration–exploitation balance decay coefficient, is another issue. We have provided an adaptive tuning technique; however, fine-tuning this parameter for diverse datasets is difficult. GA and SMA are more versatile in areas where parameter optimization is challenging, since exploration decline does not require explicit parameter tweaking. Our experiments show that fine-tuning modified WOA parameters yields performance advantages that outweigh the tuning effort.
To validate the efficacy of the proposed alterations in MWOA, we performed an ablation study by assessing various iterations of the algorithm. The research was conducted by methodically eliminating essential enhancements—quadratic decay, dynamic mutation, and Lévy flight perturbations—while maintaining all other parameters constant. We contrasted the outcomes with the baseline WOA (unmodified standard algorithm) and the comprehensive MWOA (incorporating all suggested enhancements). The assessment was predicated on feature selection efficacy, classification precision, and computational duration. The findings demonstrate that the elimination of any suggested adjustments results in a reduction in classification accuracy and an escalation in computational time, thus affirming that each upgrade is vital for optimizing efficiency. The elimination of the quadratic decay function resulted in a decrease in accuracy from 98.59% to 94.28%, underscoring its significance in sustaining a balanced exploration–exploitation dynamic that averts early convergence. Excluding dynamic mutation resulted in an expanded feature set (670 features compared to 410), indicating that the mutation mechanism is crucial for removing redundant features while maintaining classification efficacy. The lack of Lévy flight disturbances diminished the algorithm’s efficacy in evading local optima, leading to an accuracy of 95.11%. This verifies that Lévy flight enhances global search efficacy and facilitates superior exploration of the feature space.
Conversely, MWOA incorporates three enhancements—quadratic decay, dynamic mutation, and Lévy flight perturbations—that marginally elevate per-iteration complexity while markedly enhancing convergence speed, hence decreasing overall execution time. Empirical findings indicate that MWOA attains an execution time of 54.7 s, representing a 27% improvement over normal WOA (75.4 s) and surpassing GA (78.3 s) and PSO (71.6 s) in efficiency. Moreover, MWOA identifies a notably reduced feature subset (410 features) in contrast to WOA (980), GA (690), and PSO (610), hence enhancing computing efficiency.
The comprehensive MWOA, incorporating all enhancements, attained superior performance by selecting an optimal subset of 410 features, achieving the highest classification accuracy of 98.59%, and markedly decreasing computational time to 54.7 s, in contrast to the baseline WOA, which required 75.4 s with 980 selected features. These data indicate that each upgrade substantially improves feature selection efficiency, reduces computational costs, and enhances classification accuracy. The ablation investigation confirms that the combination of quadratic decay, dynamic mutation, and Lévy flight perturbations results in a more efficient and resilient optimization framework.
The computational complexity of an optimization algorithm is a crucial element in assessing its scalability and real-time viability. The difficulty of the standard WOA is essentially contingent upon the population size , the number of iterations , and the computing expense associated with the evaluation of the fitness function . The conventional WOA has a computational cost of , scaling linearly with the population size and the number of repeats.
To ascertain the statistical significance of the enhancements realized by the modified WOA, we performed statistical significance tests comparing modified WOA with standard WOA, GA, and PSO. We employed the paired t-test and the Wilcoxon signed-rank test, both of which are commonly utilized to determine if the observed performance differences are statistically significant rather than attributable to random variation. A paired t-test was performed to assess classification accuracy over several separate runs, evaluating the null hypothesis () that no significant difference exists between the performance of modified WOA and other optimization techniques. The findings indicated that the accuracy enhancements of the modified WOA were statistically significant, with p-values < 0.05 across all comparisons (modified WOA vs. WOA, modified WOA vs. GA, and modified WOA vs. PSO). Additionally, given that accuracy distributions may not consistently adhere to normality assumptions, we used the Wilcoxon signed-rank test, a non-parametric alternative that does not presuppose a normal distribution. The Wilcoxon test similarly validated significant enhancements, with all comparisons producing p-values substantially below 0.05, thereby validating the efficacy of the updated WOA’s feature selection. The statistical tests validate that the observed enhancements in classification accuracy, feature subset reduction, and computational efficiency are attributable to the improved search mechanisms of the upgraded WOA, rather than random fluctuations. This further substantiates our assertion that the suggested modifications—quadratic decay, dynamic mutation, and Lévy flight perturbations—significantly enhance optimization performance.
The proposed Modified Whale Optimization Algorithm (MWOA)-based classification framework has good accuracy (98.59% on Med-Node and 95.48% on PH2), yet misclassifications occur. We examined improperly classified samples and identified mistake causes to better understand these failures. Visual resemblance between skin lesions is a major cause of misdiagnosis. Even dermatologists have trouble distinguishing benign lesions like seborrheic keratosis from malignant melanomas due to their color, texture, and border abnormalities. Despite optimization, feature extraction can collect overlapping patterns, resulting in inaccurate predictions. Lesions with varied pigmentation and forms can also cause feature selection problems, especially when lesion class borders are unclear.
Image imperfections such hair occlusion, illumination, and noise present another issue. Preprocessing reduces these difficulties; however, shadows and reflections can decrease CNN feature extraction accuracy. While MWOA optimizes feature selection, misclassifications arise when extracted features have noise or lack discriminatory information. Underrepresented classes in the dataset also cause inaccuracies. The algorithm struggles to generalize for uncommon melanomas due to fewer training examples. The classifier may struggle to recognize unusual lesion types when they are underrepresented since the optimization method focuses on the most discriminative features across the dataset. To address these issues, we propose using data augmentation to diversify training samples, especially for minority classes. Explainability methods like Grad-CAM and SHAP will be used to better understand misclassifications and enhance feature extraction and selection.


 ,
, 



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}