

Transformer-Based Models for Probabilistic Time Series Forecasting with Explanatory Variables




Abstract
1. Introduction
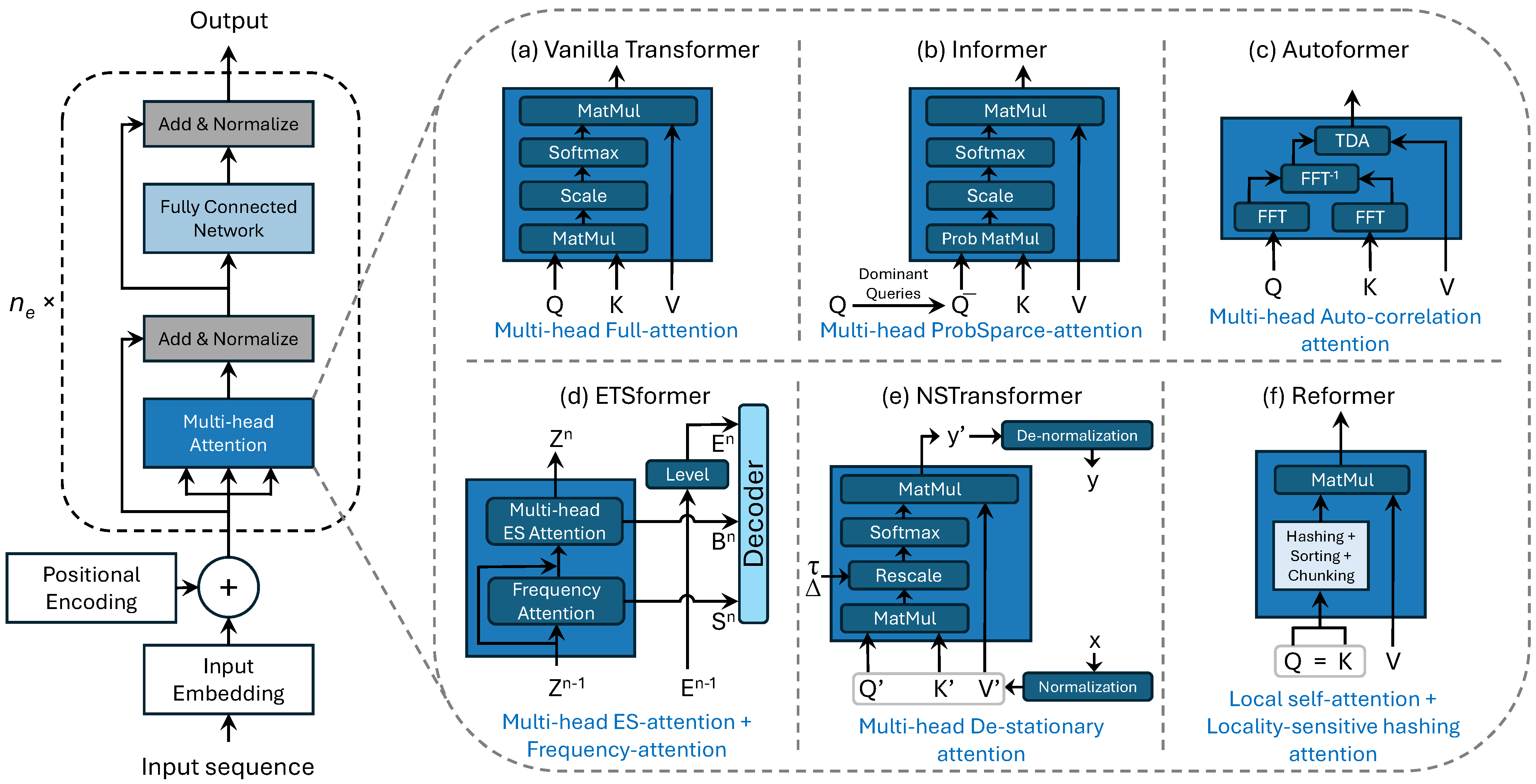
- Development of Transformer-Based Forecasting Models: This study explores various Transformer-based architectures tailored for retail demand forecasting, including Vanilla Transformer, Informer, Autoformer, ETSformer, NSTransformer, and Reformer. These models are evaluated on their ability to capture the long-term dependencies, seasonality, and external factors affecting sales patterns.
- Incorporation of Explanatory Variables: This research emphasizes the importance of integrating explanatory variables, such as calendar events, promotional activities, pricing, and socio-economic factors, in improving forecast accuracy. The models effectively leverage these covariates to address the complexities of retail data. To the best of our knowledge, this is the first study to comprehensively evaluate the impact of such explanatory variables within multiple Transformer-based forecasting architectures for retail demand prediction.
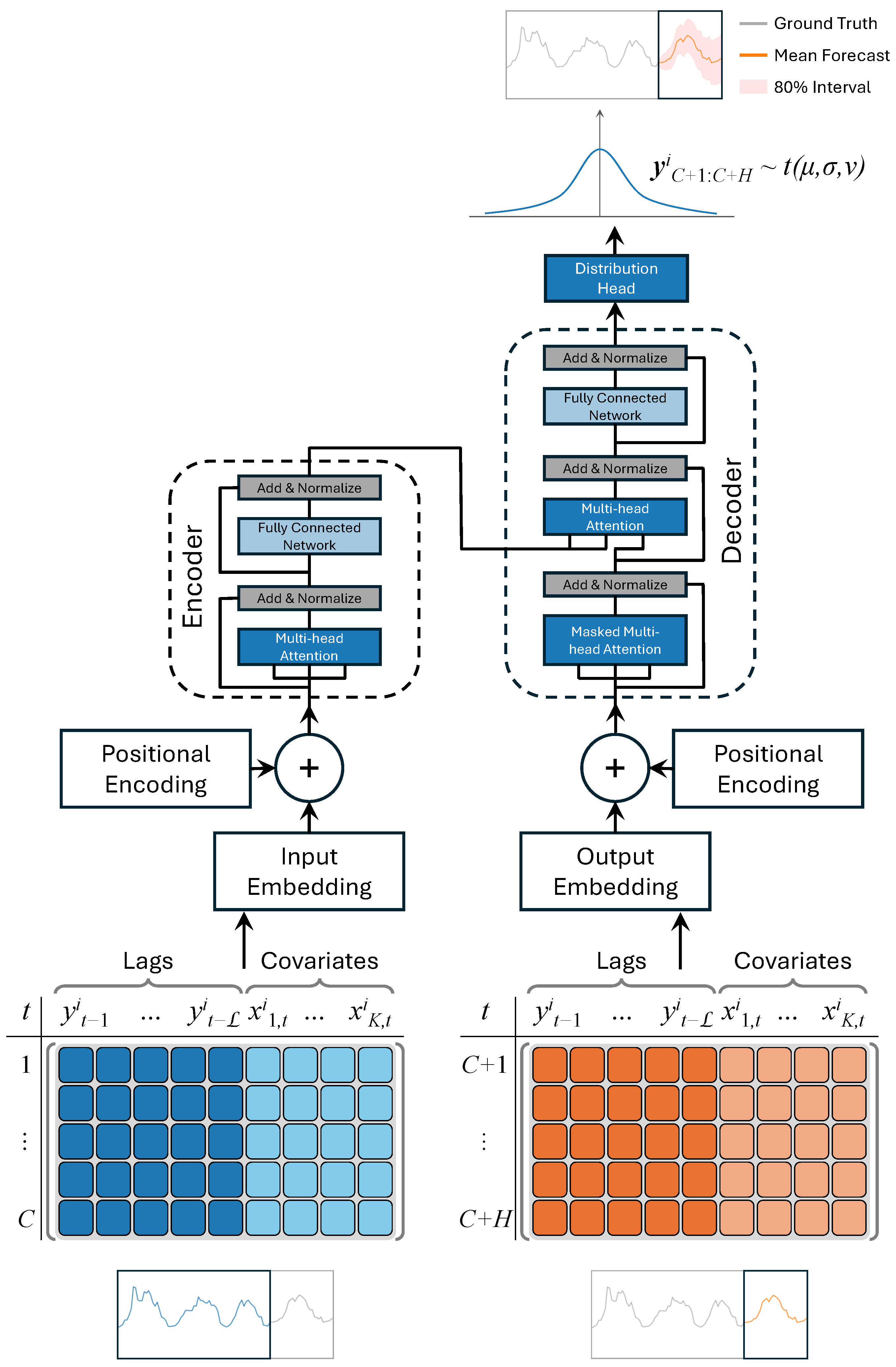
- Probabilistic Forecasting: The models provide probabilistic forecasts, capturing the uncertainty associated with demand predictions. This feature is crucial for risk management and decision-making processes in retail operations, ensuring a more resilient inventory management strategy.
- Empirical Evaluation Using Real-World Data: This paper includes a thorough empirical evaluation using the M5 dataset, a comprehensive retail dataset provided by Walmart. The results demonstrate the robustness and effectiveness of the proposed models in improving forecast accuracy across various retail scenarios.
2. Related Work
2.1. Retail Time Series Forecasting with Deep Learning
2.2. Explanatory Variables in Retail Demand Forecasting
2.3. Probabilistic Forecasting of Time Series Using Deep Learning
3. Probabilistic Forecasting with Transformer-Based Models
3.1. Deep Learning Transformers for Time Series Forecasting
3.2. Probabilistic Forecasting of Time Series Data
4. Empirical Evaluation
4.1. Dataset
4.2. Explanatory Variables
- Calendar-Related Information: This includes a wide range of time-related variables such as the date, week day, week number, month, and year. Additionally, it includes indicators for special days and holidays (e.g., the Super Bowl, Valentine’s Day, and Orthodox Easter), which are categorized into four classes: sporting, cultural, national, and religious. Special days account for about 8% of the dataset, with their distribution across the classes being 11% sporting, 23% cultural, 32% national, and 34% religious.
- Selling Prices: Prices are provided at a weekly level for each store. The weekly average prices reflect consistent pricing across the seven days of a week. If a price is unavailable for a given week, it indicates that the product was not sold during that period. Over time, the selling prices may vary, offering critical information for understanding price elasticity and its impact on sales.
- SNAP Activities: The dataset includes a binary indicator for Supplemental Nutrition Assistance Program (SNAP) activities. These activities denote whether a store allowed purchases using SNAP benefits on a particular date. This variable accounts for about 33% of the days in the dataset and reflects the socio-economic factors affecting consumer purchasing behavior.
4.3. Hyperparameter Tuning
4.4. Performance Metrics
4.5. Results and Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Petropoulos, F.; Apiletti, D.; Assimakopoulos, V.; Babai, M.Z.; Barrow, D.K.; Ben Taieb, S.; Bergmeir, C.; Bessa, R.J.; Bijak, J.; Boylan, J.E.; et al. Forecasting: Theory and practice. Int. J. Forecast. 2022, 38, 705–871. [Google Scholar] [CrossRef]
- Fildes, R.; Ma, S.; Kolassa, S. Retail forecasting: Research and practice. Int. J. Forecast. 2022, 38, 1283–1318. [Google Scholar] [CrossRef]
- Oliveira, J.M.; Ramos, P. Assessing the Performance of Hierarchical Forecasting Methods on the Retail Sector. Entropy 2019, 21, 436. [Google Scholar] [CrossRef] [PubMed]
- Theodoridis, G.; Tsadiras, A. Retail Demand Forecasting: A Multivariate Approach and Comparison of Boosting and Deep Learning Methods. Int. J. Artif. Intell. Tools 2024, 33, 2450001. [Google Scholar] [CrossRef]
- Ramos, P.; Oliveira, J.M. A procedure for identification of appropriate state space and ARIMA models based on time-series cross-validation. Algorithms 2016, 9, 76. [Google Scholar] [CrossRef]
- Benidis, K.; Rangapuram, S.S.; Flunkert, V.; Wang, Y.; Maddix, D.; Turkmen, C.; Gasthaus, J.; Bohlke-Schneider, M.; Salinas, D.; Stella, L.; et al. Deep Learning for Time Series Forecasting: Tutorial and Literature Survey. ACM Comput. Surv. 2022, 55, 1–36. [Google Scholar] [CrossRef]
- Ramos, P.; Oliveira, J.M. Robust Sales Forecasting Using Deep Learning with Static and Dynamic Covariates. Appl. Syst. Innov. 2023, 6, 85. [Google Scholar] [CrossRef]
- Bojer, C.S.; Meldgaard, J.P. Kaggle forecasting competitions: An overlooked learning opportunity. Int. J. Forecast. 2021, 37, 587–603. [Google Scholar] [CrossRef]
- Oliveira, J.M.; Ramos, P. Cross-Learning-Based Sales Forecasting Using Deep Learning via Partial Pooling from Multi-level Data. In Proceedings of the Engineering Applications of Neural Networks, León, Spain, 14–17 June 2023; Iliadis, L., Maglogiannis, I., Alonso, S., Jayne, C., Pimenidis, E., Eds.; Springer: Cham, Switzerland, 2023; pp. 279–290. [Google Scholar] [CrossRef]
- Teixeira, M.; Oliveira, J.M.; Ramos, P. Enhancing Hierarchical Sales Forecasting with Promotional Data: A Comparative Study Using ARIMA and Deep Neural Networks. Mach. Learn. Knowl. Extr. 2024, 6, 2659–2687. [Google Scholar] [CrossRef]
- Oliveira, J.M.; Ramos, P. Investigating the Accuracy of Autoregressive Recurrent Networks Using Hierarchical Aggregation Structure-Based Data Partitioning. Big Data Cogn. Comput. 2023, 7, 100. [Google Scholar] [CrossRef]
- Islam, S.; Elmekki, H.; Elsebai, A.; Bentahar, J.; Drawel, N.; Rjoub, G.; Pedrycz, W. A comprehensive survey on applications of transformers for deep learning tasks. Expert Syst. Appl. 2024, 241, 122666. [Google Scholar] [CrossRef]
- Oliveira, J.M.; Ramos, P. Evaluating the Effectiveness of Time Series Transformers for Demand Forecasting in Retail. Mathematics 2024, 12, 2728. [Google Scholar] [CrossRef]
- Torres, J.F.; Hadjout, D.; Sebaa, A.; Martínez-Álvarez, F.; Troncoso, A. Deep Learning for Time Series Forecasting: A Survey. Big Data 2021, 9, 3–21. [Google Scholar] [CrossRef]
- Bandara, K.; Shi, P.; Bergmeir, C.; Hewamalage, H.; Tran, Q.; Seaman, B. Sales Demand Forecast in E-commerce Using a Long Short-Term Memory Neural Network Methodology. In Proceedings of the Neural Information Processing, ICONIP 2019, Sydney, NSW, Australia, 12–15 December 2019; Lecture Notes in Computer Science. Springer: Cham, Switzerland, 2019; Volume 11955, pp. 462–474. [Google Scholar] [CrossRef]
- Joseph, R.V.; Mohanty, A.; Tyagi, S.; Mishra, S.; Satapathy, S.K.; Mohanty, S.N. A hybrid deep learning framework with CNN and Bi-directional LSTM for store item demand forecasting. Comput. Electr. Eng. 2022, 103, 108358. [Google Scholar] [CrossRef]
- Giri, C.; Chen, Y. Deep Learning for Demand Forecasting in the Fashion and Apparel Retail Industry. Forecasting 2022, 4, 565–581. [Google Scholar] [CrossRef]
- Mogarala Guruvaya, A.; Kollu, A.; Divakarachari, P.B.; Falkowski-Gilski, P.; Praveena, H.D. Bi-GRU-APSO: Bi-Directional Gated Recurrent Unit with Adaptive Particle Swarm Optimization Algorithm for Sales Forecasting in Multi-Channel Retail. Telecom 2024, 5, 537–555. [Google Scholar] [CrossRef]
- De Castro Moraes, T.; Yuan, X.M.; Chew, E.P. Deep Learning Models for Inventory Decisions: A Comparative Analysis. In Proceedings of the Intelligent Systems and Applications; Arai, K., Ed.; Springer: Cham, Switzerland, 2024; pp. 132–150. [Google Scholar] [CrossRef]
- de Castro Moraes, T.; Yuan, X.M.; Chew, E.P. Hybrid convolutional long short-term memory models for sales forecasting in retail. J. Forecast. 2024, 43, 1278–1293. [Google Scholar] [CrossRef]
- Wu, J.; Liu, H.; Yao, X.; Zhang, L. Unveiling consumer preferences: A two-stage deep learning approach to enhance accuracy in multi-channel retail sales forecasting. Expert Syst. Appl. 2024, 257, 125066. [Google Scholar] [CrossRef]
- Sousa, M.; Loureiro, A.; Miguéis, V. Predicting demand for new products in fashion retailing using censored data. Expert Syst. Appl. 2025, 259, 125313. [Google Scholar] [CrossRef]
- Huang, T.; Fildes, R.; Soopramanien, D. The value of competitive information in forecasting FMCG retail product sales and the variable selection problem. Eur. J. Oper. Res. 2014, 237, 738–748. [Google Scholar] [CrossRef]
- Loureiro, A.; Miguéis, V.; da Silva, L.F. Exploring the use of deep neural networks for sales forecasting in fashion retail. Decis. Support Syst. 2018, 114, 81–93. [Google Scholar] [CrossRef]
- Punia, S.; Nikolopoulos, K.; Singh, S.P.; Madaan, J.K.; Litsiou, K. Deep learning with long short-term memory networks and random forests for demand forecasting in multi-channel retail. Int. J. Prod. Res. 2020, 58, 4964–4979. [Google Scholar] [CrossRef]
- Lim, B.; Arık, S.Ö.; Loeff, N.; Pfister, T. Temporal Fusion Transformers for interpretable multi-horizon time series forecasting. Int. J. Forecast. 2021, 37, 1748–1764. [Google Scholar] [CrossRef]
- Wang, C.H. Considering economic indicators and dynamic channel interactions to conduct sales forecasting for retail sectors. Comput. Ind. Eng. 2022, 165, 107965. [Google Scholar] [CrossRef]
- Kao, C.Y.; Chueh, H.E. Deep Learning Based Purchase Forecasting for Food Producer-Retailer Team Merchandising. Sci. Program. 2022, 2022, 2857850. [Google Scholar] [CrossRef]
- Ramos, P.; Oliveira, J.M.; Kourentzes, N.; Fildes, R. Forecasting Seasonal Sales with Many Drivers: Shrinkage or Dimensionality Reduction? Appl. Syst. Innov. 2023, 6, 3. [Google Scholar] [CrossRef]
- Punia, S.; Shankar, S. Predictive analytics for demand forecasting: A deep learning-based decision support system. Knowl.-Based Syst. 2022, 258, 109956. [Google Scholar] [CrossRef]
- Nasseri, M.; Falatouri, T.; Brandtner, P.; Darbanian, F. Applying Machine Learning in Retail Demand Prediction—A Comparison of Tree-Based Ensembles and Long Short-Term Memory-Based Deep Learning. Appl. Sci. 2023, 13, 11112. [Google Scholar] [CrossRef]
- Wellens, A.P.; Boute, R.N.; Udenio, M. Simplifying tree-based methods for retail sales forecasting with explanatory variables. Eur. J. Oper. Res. 2024, 314, 523–539. [Google Scholar] [CrossRef]
- Praveena, S.; Prasanna Devi, S. A Hybrid Deep Learning Based Deep Prophet Memory Neural Network Approach for Seasonal Items Demand Forecasting. J. Adv. Inf. Technol. 2024, 15, 735–747. [Google Scholar] [CrossRef]
- Wen, R.; Torkkola, K.; Narayanaswamy, B.; Madeka, D. A Multi-Horizon Quantile Recurrent Forecaster. arXiv 2018, arXiv:1711.11053. [Google Scholar]
- Salinas, D.; Flunkert, V.; Gasthaus, J.; Januschowski, T. DeepAR: Probabilistic forecasting with autoregressive recurrent networks. Int. J. Forecast. 2020, 36, 1181–1191. [Google Scholar] [CrossRef]
- Rasul, K.; Seward, C.; Schuster, I.; Vollgraf, R. Autoregressive Denoising Diffusion Models for Multivariate Probabilistic Time Series Forecasting. In Proceedings of the 38th International Conference on Machine Learning, Online, 18–24 July 2021; Volume 139, pp. 8857–8868. [Google Scholar]
- Rasul, K.; Sheikh, A.S.; Schuster, I.; Bergmann, U.; Vollgraf, R. Multivariate Probabilistic Time Series Forecasting via Conditioned Normalizing Flows. arXiv 2021, arXiv:2002.06103. [Google Scholar]
- Hasson, H.; Wang, B.; Januschowski, T.; Gasthaus, J. Probabilistic Forecasting: A Level-Set Approach. In Proceedings of the Advances in Neural Information Processing Systems, Online, 7 December 2021; Ranzato, M., Beygelzimer, A., Dauphin, Y., Liang, P., Vaughan, J.W., Eds.; Curran Associates, Inc.: San Jose, CA, USA, 2021; Volume 34, pp. 6404–6416. [Google Scholar]
- Rangapuram, S.S.; Werner, L.D.; Benidis, K.; Mercado, P.; Gasthaus, J.; Januschowski, T. End-to-End Learning of Coherent Probabilistic Forecasts for Hierarchical Time Series. In Proceedings of the 38th International Conference on Machine Learning, Online, 18–24 July 2021; Meila, M., Zhang, T., Eds.; PMLR; Proceedings of Machine Learning Research. Volume 139, pp. 8832–8843. [Google Scholar]
- Kan, K.; Aubet, F.X.; Januschowski, T.; Park, Y.; Benidis, K.; Ruthotto, L.; Gasthaus, J. Multivariate Quantile Function Forecaster. In Proceedings of the 25th International Conference on Artificial Intelligence and Statistics, Virtual, 28–30 March 2022; PMLR; Proceedings of Machine Learning Research. Volume 151, pp. 10603–10621. [Google Scholar]
- Shchur, O.; Turkmen, C.; Erickson, N.; Shen, H.; Shirkov, A.; Hu, T.; Wang, Y. AutoGluon-TimeSeries: AutoML for Probabilistic Time Series Forecasting. In Proceedings of the International Conference on Automated Machine Learning, Potsdam, Germany, 12–15 November 2023; PMLR. pp. 1–9. [Google Scholar]
- Tong, J.; Xie, L.; Yang, W.; Zhang, K.; Zhao, J. Enhancing time series forecasting: A hierarchical transformer with probabilistic decomposition representation. Inf. Sci. 2023, 647, 119410. [Google Scholar] [CrossRef]
- Sprangers, O.; Schelter, S.; de Rijke, M. Parameter-efficient deep probabilistic forecasting. Int. J. Forecast. 2023, 39, 332–345. [Google Scholar] [CrossRef]
- Olivares, K.G.; Meetei, O.N.; Ma, R.; Reddy, R.; Cao, M.; Dicker, L. Probabilistic hierarchical forecasting with deep Poisson mixtures. Int. J. Forecast. 2024, 40, 470–489. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.u.; Polosukhin, I. Attention is All you Need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30, pp. 5998–6008. [Google Scholar]
- Zhou, H.; Zhang, S.; Peng, J.; Zhang, S.; Li, J.; Xiong, H.; Zhang, W. Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting. Proc. AAAI Conf. Artif. Intell. 2021, 35, 11106–11115. [Google Scholar] [CrossRef]
- Wu, H.; Xu, J.; Wang, J.; Long, M. Autoformer: Decomposition Transformers with Auto-Correlation for Long-Term Series Forecasting. In Proceedings of the Advances in Neural Information Processing Systems, Online, 6–14 December 2021; Volume 34, pp. 22419–22430. [Google Scholar]
- Woo, G.; Liu, C.; Sahoo, D.; Kumar, A.; Hoi, S. ETSformer: Exponential Smoothing Transformers for Time-series Forecasting. arXiv 2022, arXiv:2202.01381. [Google Scholar]
- Liu, Y.; Wu, H.; Wang, J. Non-stationary transformers: Exploring the stationarity in time series forecasting. In Proceedings of the 36th Conference on Neural Information Processing Systems (NeurIPS 2022), New Orleans, LA, USA, 28 November–9 December 2022; Volume 35, pp. 9881–9893. [Google Scholar]
- Kitaev, N.; Łukasz, K.; Levskaya, A. Reformer: The Efficient Transformer. arXiv 2020, arXiv:2001.04451. [Google Scholar]
- Rasul, K. Time Series Transformer. Hugging Face. Available online: https://huggingface.co/docs/transformers/en/model_doc/time_series_transformer (accessed on 6 September 2024).
- Casolaro, A.; Capone, V.; Iannuzzo, G.; Camastra, F. Deep Learning for Time Series Forecasting: Advances and Open Problems. Information 2023, 14, 598. [Google Scholar] [CrossRef]
- Ansari, A.F.; Stella, L.; Turkmen, C.; Zhang, X.; Mercado, P.; Shen, H.; Shchur, O.; Rangapuram, S.S.; Arango, S.P.; Kapoor, S.; et al. Chronos: Learning the Language of Time Series. arXiv 2024, arXiv:2403.07815. [Google Scholar]
- Rasul, K.; Ashok, A.; Williams, A.R.; Ghonia, H.; Bhagwatkar, R.; Khorasani, A.; Bayazi, M.J.D.; Adamopoulos, G.; Riachi, R.; Hassen, N.; et al. Lag-Llama: Towards Foundation Models for Probabilistic Time Series Forecasting. arXiv 2024, arXiv:2310.08278. [Google Scholar]
- Alexandrov, A.; Benidis, K.; Bohlke-Schneider, M.; Flunkert, V.; Gasthaus, J.; Januschowski, T.; Maddix, D.C.; Rangapuram, S.; Salinas, D.; Schulz, J.; et al. GluonTS: Probabilistic and Neural Time Series Modeling in Python. J. Mach. Learn. Res. 2020, 21, 4629–4634. [Google Scholar]
- Rasul, K. pytorch-transformer-ts. 2021. Available online: https://github.com/kashif/pytorch-transformer-ts (accessed on 4 December 2024).
- Makridakis, S.; Spiliotis, E.; Assimakopoulos, V. The M5 competition: Background, organization, and implementation. Int. J. Forecast. 2022, 38, 1325–1336. [Google Scholar] [CrossRef]
- Makridakis, S.; Spiliotis, E.; Assimakopoulos, V. M5 accuracy competition: Results, findings, and conclusions. Int. J. Forecast. 2022, 38, 1346–1364. [Google Scholar] [CrossRef]
- Akiba, T.; Sano, S.; Yanase, T.; Ohta, T.; Koyama, M. Optuna: A Next-generation Hyperparameter Optimization Framework. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Anchorage, AK, USA, 4–8 August 2019. [Google Scholar]
- Gasthaus, J.; Benidis, K.; Wang, Y.; Rangapuram, S.S.; Salinas, D.; Flunkert, V.; Januschowski, T. Probabilistic Forecasting with Spline Quantile Function RNNs. In Proceedings of the Twenty-Second International Conference on Artificial Intelligence and Statistics, Naha, Japan, 16–18 April 2019; Chaudhuri, K., Sugiyama, M., Eds.; PMLR; Proceedings of Machine Learning Research. Volume 89, pp. 1901–1910. [Google Scholar]
- Hyndman, R.J.; Koehler, A.B. Another look at measures of forecast accuracy. Int. J. Forecast. 2006, 22, 679–688. [Google Scholar] [CrossRef]
- Koenker, R.; Hallock, K.F. Quantile Regression. J. Econ. Perspect. 2001, 15, 143–156. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
| Data | No. of Variables | Feature | Type | No. of Categories | Encoding |
|---|---|---|---|---|---|
| Sales | 30 | Lags: {1, 2, 3, 4, 5, 6, 7, 8, 13, 14, 15, 20, 21, 22, 27, 28, 29, 30, 31, 56, 84, 363, 364, 365, 727, 728, 729, 1091, 1092, 1093} | Continuous | — | — |
| Time | 9 | Day of week | Categorical | 7 | |
| Day of month | 31 | ||||
| Day of year | 366 | Encoded as zero-based | |||
| Month of year | 12 | index and normalized | |||
| Week of year | 53 | to [−0.5, 0.5] | |||
| Week of month | 6 | ||||
| Year | 6 | ||||
| Is weekend | 2 | Boolean | |||
| Age | Continuous | — | |||
| Price | 3 | Item’s daily price normalized by mean/std | Continuous | — | — |
| Item’s daily price normalized by | |||||
| department’s daily mean/std price | |||||
| Item’s daily price normalized by | |||||
| store’s daily mean/std price | |||||
| Snap | 3 | Supplemental nutrition assistance program days | Categorical | 3 | Boolean |
| in CA, TX, WI | |||||
| Events | 2 | Event name: {nan,ChanukahEnd,Christmas, | Categorical | 31 | |
| CincoDeMayo,ColumbusDay,Easter,EidAl-Fitr, | |||||
| EidAlAdha,Father’sDay,Halloween,IndependenceDay, | |||||
| LaborDay,LentStart,LentWeek2,MartinLutherKingDay, | Encoded as zero-based | ||||
| MemorialDay,Mother’sDay,NBAFinalsEnd,NBAFinalsStart, | index and normalized | ||||
| NewYear,OrthodoxChristmas,OrthodoxEaster,PesachEnd, | to [−0.5, 0.5] | ||||
| PresidentsDay,PurimEnd,RamadanStart,StPatricksDay, | |||||
| SuperBowl,Thanksgiving,ValentinesDay,VeteransDay} | |||||
| 2 | Event type: {nan,Cultural,National,Religious,Sporting} | Categorical | 5 | ||
| ID | 60 | item_id | Categorical | 3049 | Encoded as zero-based |
| dept_id | 7 | index and embedded | |||
| cat_id | 3 | using a learnable | |||
| store_id | 3 | embedding layer with | |||
| state_id | 3 | an embedding | |||
| dimension of | |||||
| min(50,(n_categ+1)//2) |
| Hyperparameter | Range | |
|---|---|---|
| Transformer, Autoformer, Informer NSTransformer, Reformer | ETSformer | |
| Context length | ||
| Batch size | ||
| Number of encoder layers | — | |
| Number of decoder layers | — | |
| Parameter | Value |
|---|---|
| Number of trials | 10 |
| Number of epochs | 10 |
| Number of batches per epoch | 50 |
| Number of samples | 20 |
| Validation function | Mean Weighted Quantile Loss (MWQL) |
| Parameter | Transformer | Autoformer | ETSformer | Informer | NSTransformer | Reformer |
|---|---|---|---|---|---|---|
| Prediction length of decoder | 28 | |||||
| Distribution output | Student’s t | |||||
| Loss function | Negative log likelyhood | |||||
| Learning rate | ||||||
| Size of target | 1 | |||||
| Scale of the input target | mean | std | std | std | — | std |
| Lags sequence | ||||||
| Dimensionality of Transformer layers | 32 | — | 64 | 64 | — | 64 |
| Number of attention heads | 2 | |||||
| Feed-forward hidden size | 32 | 32 | — | 32 | 32 | — |
| Activation function | gelu | relu | — | relu | gelu | — |
| Dropout for fully connected layers | ||||||
| Moving average window | — | 25 | — | — | — | — |
| Autocorrelation factor | — | 1 | — | — | — | — |
| Number of layers | — | — | 2 | — | — | — |
| K largest amplitudes | — | — | 4 | — | — | — |
| Embedding kernel size | — | — | 3 | — | — | — |
| Attention in encoder | — | — | — | ProbAttention | — | — |
| Use distilling in encoder | — | — | — | True | — | — |
| ProbSparse sampling factor | — | — | — | 5 | — | — |
| Hyperparameter | Transformer | Autoformer | ETSformer | Informer | NSTransformer | Reformer |
|---|---|---|---|---|---|---|
| Without features | ||||||
| Context length | 28 | 28 | ||||
| Batch size | 128 | 64 | 128 | 256 | 256 | 64 |
| Number of encoder layers | 16 | 16 | — | 16 | 4 | 4 |
| Number of decoder layers | 2 | 8 | — | 16 | 8 | 4 |
| Best MWQL value | ||||||
| With features | ||||||
| Context length | 28 | 28 | 28 | |||
| Batch size | 256 | 256 | 128 | 128 | 256 | 32 |
| Number of encoder layers | 8 | 4 | — | 2 | 4 | 16 |
| Number of decoder layers | 4 | 4 | — | 2 | 4 | 2 |
| Best MWQL value | ||||||
| Point Forecast Metrics | Probabilistic Forecast Metrics | |||||||
|---|---|---|---|---|---|---|---|---|
| Model | MASE | NRMSE | WQL0.1 | WQL0.5 | WQL0.9 | MWQL | MAE Coverage | |
| Transformer | Without features | |||||||
| With features | ||||||||
| Autoformer | Without features | |||||||
| With features | ||||||||
| ETSformer | Without features | |||||||
| With features | ||||||||
| Informer | Without features | |||||||
| With features | ||||||||
| NSTransformer | Without features | |||||||
| With features | ||||||||
| Reformer | Without features | |||||||
| With features | ||||||||
| MASE | NRMSE | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Model | 1 Step | 7 Steps | 14 Steps | 21 Steps | 1 Step | 7 Steps | 14 Steps | 21 Steps | |
| Transformer | Without features | ||||||||
| With features | |||||||||
| Autoformer | Without features | ||||||||
| With features | |||||||||
| ETSformer | Without features | ||||||||
| With features | |||||||||
| Informer | Without features | ||||||||
| With features | |||||||||
| NSTransformer | Without features | ||||||||
| With features | |||||||||
| Reformer | Without features | ||||||||
| With features | |||||||||
| MWQL | MAE Coverage | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Model | 1 Step | 7 Steps | 14 Steps | 21 Steps | 1 Step | 7 Steps | 14 Steps | 21 Steps | |
| Transformer | Without features | ||||||||
| With features | |||||||||
| Autoformer | Without features | ||||||||
| With features | |||||||||
| ETSformer | Without features | ||||||||
| With features | |||||||||
| Informer | Without features | ||||||||
| With features | |||||||||
| NSTransformer | Without features | ||||||||
| With features | |||||||||
| Reformer | Without features | ||||||||
| With features | |||||||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Caetano, R.; Oliveira, J.M.; Ramos, P. Transformer-Based Models for Probabilistic Time Series Forecasting with Explanatory Variables. Mathematics 2025, 13, 814. https://doi.org/10.3390/math13050814
Caetano R, Oliveira JM, Ramos P. Transformer-Based Models for Probabilistic Time Series Forecasting with Explanatory Variables. Mathematics. 2025; 13(5):814. https://doi.org/10.3390/math13050814
Chicago/Turabian StyleCaetano, Ricardo, José Manuel Oliveira, and Patrícia Ramos. 2025. "Transformer-Based Models for Probabilistic Time Series Forecasting with Explanatory Variables" Mathematics 13, no. 5: 814. https://doi.org/10.3390/math13050814
APA StyleCaetano, R., Oliveira, J. M., & Ramos, P. (2025). Transformer-Based Models for Probabilistic Time Series Forecasting with Explanatory Variables. Mathematics, 13(5), 814. https://doi.org/10.3390/math13050814