
An Improvement of the Alternating Direction Method of Multipliers to Solve the Convex Optimization Problem

Abstract
1. Introduction
| Algorithm 1: Improved alternate direction multiplier algorithm to solve convex optimization problem (1) | |
| Given error tolerance , controls parameter , and relaxation factors defined in (Equation (8)). Choose parameter sequence , which satisfies and . Given initial penalty parameter and initial approximation . Set . Step 1. Computing | |
| , | (9) |
| , | (10) |
| (11) | |
| . | (12) |
| Step 2. If , stop. Otherwise, go to Step 3. Step 3. Updating penalty parameter | |
| (13) | |
| Step 4. Set , and go to Step 1. | |
| Algorithm 2: Algorithm to solve x-subproblem (9) or y-subproblem (11) |
| Given constants , , error tolerance , and initial approximation . Set and . Step 1. Computing , where . Step 2. If , computing where , , . If , stop (in this case, is an approximate solution of the x-subproblem in Algorithm 1). Otherwise, define and set . Go to Step 1. If all of the above are not true, go to Step 3. Step 3. Define and set . Go to Step 2. |
2. Convergence of Algorithm 1
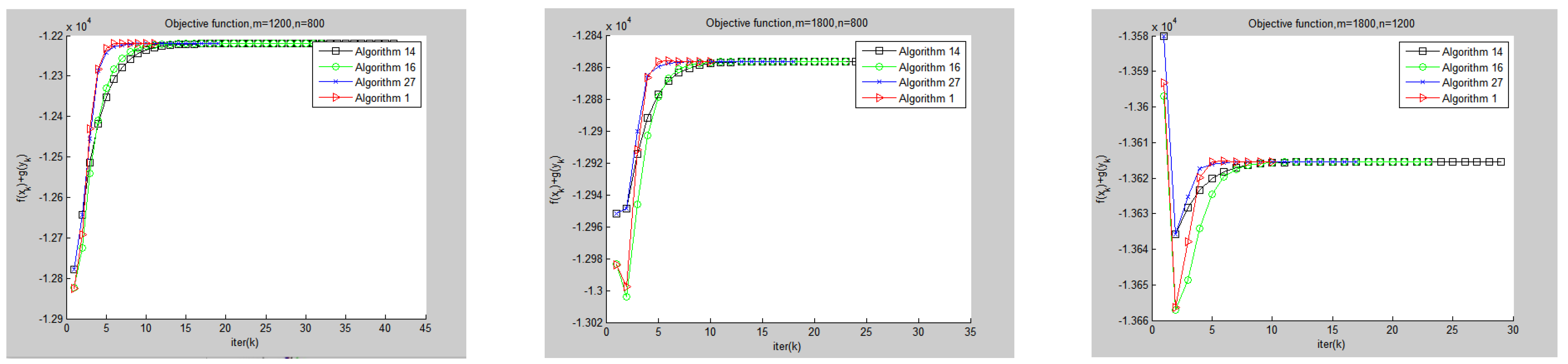
3. Numerical Experiments
3.1. Convex Quadratic Programming Problem
3.2. Image Restoration Problem
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Yang, J.F.; Zhang, Y. Alternating direction algorithms for l1-problems in compressive sensing. SIAM J. Sci. Comput. 2011, 33, 250–278. [Google Scholar] [CrossRef]
- Li, J.C. A parameterized proximal point algorithm for separable convex optimization. Optim. Lett. 2018, 12, 1589–1608. [Google Scholar]
- Tao, M.; Yuan, X.M. Recovering low-rank and sparse components of matrices from incomplete and noisy observations. SIAM J. Optim. 2011, 21, 57–81. [Google Scholar] [CrossRef]
- Hager, W.W.; Zhang, H.C. Convergence rates for an inexact ADMM applied to separable convex optimization. Comput. Optim. Appl. 2020, 77, 729–754. [Google Scholar] [CrossRef]
- Liu, Z.S.; Li, J.C.; Liu, X.N. A new model for sparse and Low-Rank matrix decomposition. J. Appl. Anal. Comput. 2017, 7, 600–616. [Google Scholar]
- Jiang, F.; Wu, Z.M. An inexact symmetric ADMM algorithm with indefinite proximal term for sparse signal recovery and image restoration problems. J. Comput. Appl. Math. 2023, 417, 114628. [Google Scholar] [CrossRef]
- Bai, J.C.; Hager, W.W.; Zhan, H.C. An inexact accelerated stochastic ADMM for separable convex optimization. Comput. Optim. Appl. 2022, 81, 479–518. [Google Scholar] [CrossRef]
- Boyd, S.; Parikh, N.; Chu, E.; Peleato, B.; Eckstein, J. Distributed optimization and statistical learning via the alternation direction method of multipliers. Found. Trends Mach. Learn. 2011, 3, 1–122. [Google Scholar] [CrossRef]
- Chan, T.F.; Glowinski, R. Finite Element Approximation and Iterative Solution of a Class of Mildly Nonlinear Elliptic Equations; Technical Report STAN-CS-78-674; Computer Science Department, Stanford University: Stanford, CA, USA, 1978. [Google Scholar]
- Hestenes, M.R. Multiplier and gradient methods. J. Optim. Theory Appl. 1969, 4, 303–320. [Google Scholar] [CrossRef]
- Lions, P.L.; Mercier, B. Splitting algorithms for the sum of two nonlinear operators. SIAM J. Numer. Anal. 1979, 16, 964–979. [Google Scholar] [CrossRef]
- Cai; X. J.; Gu, G.Y.; He, B.S.; Yuan, X.M. A proximal point algorithm revisit on the alternating direction method of multipliers. Sci. China Math. 2013, 56, 2179–2186. [Google Scholar] [CrossRef]
- Fortin, M.; Glowinski, R. Augmented Lagrangian Methods: Applications to the Numerical Solution of Boundary-Value Problems; North-Holland: Amsterdam, The Netherlands, 1983. [Google Scholar]
- Glowinski, R.; Karkkainen, T.; Majava, K. On the Convergence of Operator-Splitting Methods, in Numerical Methods for Scientific Computing, Variational Problems and Applications; Heikkola, E., Kuznetsov, P.Y., Neittaanm, P., Pironneau, O., Eds.; CIMNE: Barcelona, Spain, 2003; pp. 67–79. [Google Scholar]
- He, B.S.; Liu, H.; Wang, Z.R.; Yuan, X.M. A strictly contractive Peaceman-Rachford splitting method for convex programming. SIAM J. Optim. 2014, 24, 1011–1040. [Google Scholar] [CrossRef] [PubMed]
- He, B.S.; Ma, F.; Yuan, X.M. Convergence study on the symmetric version of ADMM with larger step sizes. SIAM J. Imaging Sci. 2016, 9, 1467–1501. [Google Scholar] [CrossRef]
- Luo, G.; Yang, Q.Z. A fast symmetric alternating direction method of multipliers. Numer. Math. Theory Meth. Appl. 2020, 13, 200–219. [Google Scholar]
- Li, X.X.; Yuan, X.M. A proximal strictly contractive Peaceman-Rachford splitting method for convex programming with applications to imaging. SIAM J. Imaging Sci. 2015, 8, 1332–1365. [Google Scholar] [CrossRef]
- Bai, J.C.; Li, J.C.; Xu, F.M.; Zhang, H.C. Generalized symmetric ADMM for separable convex optimization. Comput. Optim. Appl. 2018, 70, 129–170. [Google Scholar] [CrossRef]
- Wu, Z.M.; Li, M. An LQP-based symmetric Alternating direction method of multipliers with larger step sizes. J. Oper. Res. Soc. China 2019, 7, 365–383. [Google Scholar] [CrossRef]
- Chang, X.K.; Bai, J.C.; Song, D.J.; Liu, S.Y. Linearized symmetric multi-block ADMM with indefinite proximal regularization and optimal proximal parameter. Calcolo 2020, 57, 38. [Google Scholar] [CrossRef]
- Han, D.R.; Sun, D.F.; Zhang, L.W. Linear rate convergence of the alternating direction method of multipliers for convex composite programming. Math. Oper. Res. 2018, 43, 622–637. [Google Scholar] [CrossRef]
- Gao, B.; Ma, F. Symmetric alternating direction method with indefinite proximal regularization for linearly constrained convex optimization. J. Optim. Theory Appl. 2018, 176, 178–204. [Google Scholar] [CrossRef]
- Shen, Y.; Zuo, Y.N.; Yu, A.L. A partially proximal S-ADMM for separable convex optimization with linear constraints. Appl. Numer. Math. 2021, 160, 65–83. [Google Scholar] [CrossRef]
- Adona, V.A.; Goncalves, M.L.N. An inexact version of the symmetric proximal ADMM for solving separable convex optimization. Numer. Algor. 2023, 94, 1–28. [Google Scholar] [CrossRef]
- He, B.S.; Yang, H. Some convergence properties of a method of multipliers for linearly constrained monotone variational inequalities. Oper. Res. Lett. 1998, 23, 151–161. [Google Scholar] [CrossRef]
- He, B.S.; Yang, H.; Wang, S.L. Alternating direction method with Self-Adaptive penalty parameters for monotone variational inequalities. J. Optim. Theory Appl. 2000, 106, 337–356. [Google Scholar] [CrossRef]
- He, B.S.; Liao, L.Z. Improvements of some projection methods for monotone nonlinear variational inequalities. J. Optim. Theory Appl. 2002, 112, 111–128. [Google Scholar] [CrossRef]
- Palomar, D.P.; Scutari, G. Variational inequality theory a mathematical framework for multiuser communication systems and signal processing. In Proceedings of the International Workshop on Mathematical of Issues in Information Sciences-MIIS, Xi’an, China, 7–13 July 2012. [Google Scholar]
- He, B.S. A new method for a class of linear variational inequalities. Math. Programm. 1994, 66, 137–144. [Google Scholar] [CrossRef]
- Han, D.R.; He, H.J.; Yang, H.; Yuan, X.M. A customized Douglas–Rachford splitting algorithm for separable convex minimization with linear constraints. Numer. Math. 2014, 127, 167–200. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
| m | n | r = 0.95 s = 1.12 | r = 0.9 s = 1 | r = s = 1 | r = 1 s = 1.5 | r = 1.54 s = 0.2 | r = 0.1 s = 1.57 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Iter | Time | Iter | Time | Iter | Time | Iter | Time | Iter | Time | Iter | Time | ||
| 800 | 200 | 10.7 | 0.41 | 11.4 | 0.44 | 10.8 | 0.44 | 11.1 | 0.46 | 17.7 | 0.65 | 19.1 | 0.71 |
| 600 | 400 | 10.7 | 0.26 | 11.4 | 0.29 | 11.0 | 0.27 | 11.6 | 0.29 | 16.6 | 0.42 | 18.7 | 0.49 |
| 1600 | 400 | 10.0 | 1.51 | 10.3 | 1.66 | 9.9 | 1.61 | 11.0 | 1.75 | 18.5 | 2.84 | 18.0 | 2.82 |
| 1200 | 800 | 10.0 | 1.13 | 10.7 | 1.26 | 9.9 | 1.16 | 10.7 | 1.27 | 17.8 | 2.05 | 18.0 | 2.08 |
| 2400 | 600 | 9.7 | 6.95 | 10.1 | 7.23 | 9.7 | 6.98 | 10.8 | 7.72 | 19.0 | 13.13 | 17.1 | 12.30 |
| 1800 | 1200 | 9.6 | 2.73 | 10.3 | 3.06 | 9.8 | 2.92 | 11.2 | 3.30 | 18.2 | 5.22 | 17.0 | 5.03 |
| 3200 | 800 | 9.8 | 15.32 | 10.0 | 15.59 | 10.1 | 15.81 | 10.3 | 16.01 | 19.0 | 29.22 | 16.8 | 26.24 |
| 2400 | 1600 | 9.7 | 8.54 | 10.1 | 8.83 | 10.2 | 8.83 | 10.8 | 9.34 | 17.1 | 14.30 | 15.6 | 13.86 |
| m | n | obj | Algorithm 1 | Algorithm 16 | Algorithm 27 | Algorithm 14 | ||||
|---|---|---|---|---|---|---|---|---|---|---|
| r = 0.95, s = 1.12 | r = 0.8, s = 1.17 | |||||||||
| Iter | Time | Iter | Time | Iter | Time | Iter | Time | |||
| 800 | 200 | −9478.39 | 10.6 | 0.41 | 39.1 | 1.41 | 20.2 | 0.68 | 50.1 | 1.79 |
| 600 | 400 | −8939.27 | 10.7 | 0.26 | 42.4 | 1.19 | 20.0 | 0.51 | 54.1 | 1.47 |
| 1600 | 400 | −12,473.27 | 10.0 | 1.51 | 29.1 | 5.13 | 18.9 | 3.06 | 37.5 | 6.62 |
| 1200 | 800 | −12,038.11 | 10.0 | 1.13 | 30.1 | 3.77 | 19.0 | 2.16 | 38.8 | 4.84 |
| 2400 | 600 | −14,789.51 | 9.5 | 6.95 | 21.7 | 15.56 | 17.6 | 12.61 | 27.9 | 20.01 |
| 1800 | 1200 | −14,312.39 | 9.8 | 2.73 | 22.9 | 7.19 | 18.0 | 5.30 | 30.1 | 9.51 |
| 3200 | 800 | −16,191.25 | 9.8 | 15.32 | 18.3 | 28.18 | 17.3 | 27.32 | 23.8 | 36.43 |
| 2400 | 1600 | −14,365.07 | 9.7 | 8.54 | 19.7 | 17.03 | 17.3 | 14.99 | 25.5 | 21.98 |
| Lena (512 × 512) | man (512 × 512) | |||||
|---|---|---|---|---|---|---|
| Iter | Time | SNR | Iter | Time | SNR | |
| Algorithm 1 r = 0.95, s = 1.12 | 26 | 3.93 | 23.02 | 30 | 4.51 | 17.02 |
| Algorithm 16 r =0.8, s = 1.17 | 37 | 5.54 | 23.00 | 40 | 6.08 | 17.00 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Peng, J.; Wang, Z.; Yu, S.; Tang, Z. An Improvement of the Alternating Direction Method of Multipliers to Solve the Convex Optimization Problem. Mathematics 2025, 13, 811. https://doi.org/10.3390/math13050811
Peng J, Wang Z, Yu S, Tang Z. An Improvement of the Alternating Direction Method of Multipliers to Solve the Convex Optimization Problem. Mathematics. 2025; 13(5):811. https://doi.org/10.3390/math13050811
Chicago/Turabian StylePeng, Jingjing, Zhijie Wang, Siting Yu, and Zengao Tang. 2025. "An Improvement of the Alternating Direction Method of Multipliers to Solve the Convex Optimization Problem" Mathematics 13, no. 5: 811. https://doi.org/10.3390/math13050811
APA StylePeng, J., Wang, Z., Yu, S., & Tang, Z. (2025). An Improvement of the Alternating Direction Method of Multipliers to Solve the Convex Optimization Problem. Mathematics, 13(5), 811. https://doi.org/10.3390/math13050811