
Bayesian Estimation of the Stress–Strength Parameter for Bivariate Normal Distribution Under an Updated Type-II Hybrid Censoring



Abstract
1. Introduction
2. Model and Notations
2.1. Type-II Censoring Scheme
2.2. Updated Type-II Hybrid Censoring Scheme
- 1
- If , ; both x and y are observed. Denote .
- 2
- If , ; only x is observed and y is truncated at and recorded as +. Denote .
- 3
- If , ; x is truncated at , and y is only recorded as −. Denote .
- 4
- If ; ; both x and y are not observed and they are truncated at . Denote .
2.3. The Likelihood of Updated Type-II Hybrid Data
- The likelihood of is the same as the pdf in Equation (1). That is,
- The likelihood of can be integrated.where is the standard normal cdf.
- The likelihood of can be integrated in several ways.where is the standard normal pdf. The numerical integration can be carried out by most computing software. For example, the R built-in function ‘integrate’ provides the one dimensional numerical integral. Alternatively,The first term is the normal cdf with mean and variance , and the second term is the bivariate normal cdf, which can be given by some statistical libraries, such as the ‘pmvnorm’ function in the R ‘mvtnorm’ package.
- The likelihood of can be integrated in several ways.Alternatively, the density can be calculated by a bivariate normal cdf.
3. Bayesian Framework
3.1. A Markov Chain Monte Carlo Process
- 1
- sample
- 2
- sample
- 3
- sample
3.2. Bayes Estimation
3.2.1. Bayes Estimate of
3.2.2. Mean Value Monte Carlo Method
4. Monte Carlo Simulation Study
5. Data Analysis
6. Concluding Remarks
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A
- 2.
- The likelihood of can be integrated.
- 3.
- The likelihood of can be integrated in several ways.Alternatively,
- 4.
- The likelihood of can be integrated in several ways.Alternatively,
References
- Birnbaum, Z.W. On a use of Mann-Whitney statistics. Proc. Third Berkley Symp. Math. Stat. Probab. 1956, 1, 13–17. [Google Scholar]
- Enis, P.; Geisser, S. Estimation of the Probability that Y < X. J. Am. Stat. Assoc. 1971, 66, 162–168. [Google Scholar]
- Tong, H. A note on the estimation of P(Y < X) in the exponential case. Technometrics 1974, 16, 625. [Google Scholar]
- Bai, D.S.; Hong, Y.W. Estimation of P(X < Y) in the exponential case with common location parameter. Commun. Stat. Theory Methods 1992, 21, 269–282. [Google Scholar]
- Surles, J.G.; Padgett, W.J. Inference for P(Y < X) in the Burr type X model. J. Appl. Stat. Sci. 1998, 7, 225–238. [Google Scholar]
- Surles, J.G.; Padgett, W.J. Inference for reliability and stress-strength for a scaled Burr Type X distribution. Lifetime Data Anal. 2001, 7, 187–200. [Google Scholar] [CrossRef]
- Ali, M.; Woo, J.; Pal, M. Inference on reliability P(Y < X) in two-parameter exponential distributions. Int. J. Stat. Sci. 2004, 3, 119–125. [Google Scholar]
- Kim, C.; Chung, Y. Bayesian estimation of P(Y < X) from Burr type X model containing spurious observations. Stat. Pap. B 2006, 47, 643–651. [Google Scholar]
- Kundu, D.; Gupta, R.D. Estimation of R = P(Y < X) for the generalized exponential distribution. Metrika 2005, 61, 291–308. [Google Scholar]
- Kundu, D.; Gupta, R.D. Estimation of R = P(Y < X) for Weibull distribution. IEEE Trans. Reliab. 2006, 55, 270–280. [Google Scholar]
- Saracoglu, B.; Kaya, M.F. Maximum likelihood estimation and confidence intervals of system reliability for Gompertz distribution in stress-strength models. Selcuk. J. Appl. Math. 2007, 8, 25–36. [Google Scholar]
- Raqab, M.Z.; Madi, M.T.; Kundu, D. Estimation of R = P(Y < X) for the 3-parameter generalized exponential distribution. Commun. Stat. Theory Methods 2008, 37, 2854–2864. [Google Scholar]
- Kundu, D.; Raqab, M.Z. Estimation of R = P(Y < X) for three parameter Weibull distribution. Stat. Probab. Lett. 2009, 79, 1839–1846. [Google Scholar]
- Saracoglu, B.; Kaya, M.F.; Abd-Elfattah, A.M. Comparison of estimators for stress-strength reliability in Gompertz case. Hacet. J. Math. Stat. 2009, 38, 339–349. [Google Scholar]
- Genç, A.I. Estimation of P(X > Y) with Topp-Leone distribution. J. Stat. Comput. Simul. 2013, 83, 326–339. [Google Scholar] [CrossRef]
- Kotz, S.; Lumelskii, Y.; Pensky, M. The Stress-Strength Model and Its Generalization: Theory and Applications; World Scientific: Singapore, 2003. [Google Scholar]
- Lin, Y.J.; Lio, Y.L. Bayesian inference under progressive type-I interval censoring. J. Appl. Stat. 2012, 39, 1811–1824. [Google Scholar] [CrossRef]
- Saracoglu, B.; Kinaci, I.; Kundu, D. On estimation of R = P(Y < X) for exponential distribution under progressive type-II censoring. J. Stat. Comput. Simul. 2012, 82, 729–744. [Google Scholar]
- Çiftci, F.; Saraçoglu, B.; Akdam, N.; Akdoan, Y. Estimation of stress-strength reliability for generalized Gompertz distribution under progressive type-II censoring. Hacet. J. Math. Stat. 2023, 52, 1379–1395. [Google Scholar] [CrossRef]
- Balakrishnan, N. Progressive censoring methodology: An appraisal (with discussions). Test 2007, 16, 211–296. [Google Scholar] [CrossRef]
- Balakrishnan, N.; Aggarwala, R. Progressive Censoring: Theory, Methods, and Applications; Birkhauser: Boston, MA, USA, 2000. [Google Scholar]
- Balakrishnan, N.; Cramer, E. The Art of Progressive Censoring, Applications to Reliability and Quality; Birkhauser: New York, NY, USA, 2014. [Google Scholar]
- Epstein, B. Truncated Life Tests in the Exponential Case. Ann. Math. Statist. 1954, 25, 555–564. [Google Scholar] [CrossRef]
- Childs, A.; Chandrasekar, B.; Balakrishnan, N.; Kunda, D. Exact likelihood inference based on Type-I and Type-II hybrid censored samples from the exponential distribution. Ann. Inst. Stat. Math. 2003, 55, 319–330. [Google Scholar] [CrossRef]
- Hyun, S.; Lee, J.; Yearout, R. Parameter Estimation of Type-I and Type-II Hybrid Censored Data from the Log-Logistic Distribution. Ind. Syst. Eng. Rev. 2016, 4, 37–44. [Google Scholar] [CrossRef]
- Balakrishnan, N.; Kim, J.A. EM Algorithm for Type-II Right Censored Bivariate Normal Data. In Parametric and Semiparametric Models with Applications to Reliability, Survival Analysis, and Quality of Life; Balakrishnan, N., Nikulin, M.S., Mesbah, M., Limnios, N., Eds.; Statistics for Industry and Technology; Springer: Boston, MA, USA, 2004. [Google Scholar]
- Lin, Y.J.; Lio, Y.L.; Ng, H.K.T. Bayes estimation of Moran—Downton bivariate exponential distribution based on censored samples. J. Stat. Comput. Simul. 2013, 83, 837–852. [Google Scholar] [CrossRef]
- Lin, Y.J.; Lio, Y.L.; Ng, H.K.T.; Wang, L. Bayesian Estimation of Stress—Strength Parameter for Moran—Downton Bivariate Exponential Distribution Under Progressive Type II Censoring. In Bayesian Inference and Computation in Reliability and Survival Analysis; Springer: Cham, Switzerland, 2022; pp. 17–40. [Google Scholar]
- Al-Saadi, S.D.; Young, D.H. Estimators for the correlation coefficient in a bivariate exponential distribution. J. Stat. Comput. Simul. 1980, 11, 13–20. [Google Scholar] [CrossRef]
- Balakrishnan, N.; Ng, H.K.T. Improved estimation of the correlation coefficient in a bivariate exponential distribution. J. Stat. Comput. Simul. 2001, 68, 173–184. [Google Scholar] [CrossRef]
- Chib, S.; Greenberg, E. Understanding the metropolis-hastings algorithm. Am. Stat. 1995, 49, 327–335. [Google Scholar] [CrossRef]
- Zhang, Y.; Yang, Y. Bayesian model selection via mean-field variational approximation. J. R. Stat. Soc. Ser. Stat. Methodol. 2024, 86, 742–770. [Google Scholar] [CrossRef]
- Metropolis, N.; Rosenbluth, A.W.; Rosenbluth, M.N.; Teller, A.H.; Teller, E. Equations of state calculations by fast computing machines. J. Chem. Phys. 1953, 21, 1087–1091. [Google Scholar] [CrossRef]
- Hastings, W.K. Monte Carlo sampling methods using Markov chains and their applications. Biometrika 1970, 57, 97–109. [Google Scholar] [CrossRef]
- Geman, S.; Geman, D. Stochastic relaxation, Gibbs distributions and the Bayesian restoration of images. IEEE Trans. Pattern Anal. Mach. Intell. 1984, 6, 721–741. [Google Scholar] [CrossRef]
- Chen, M.; Shao, Q. Monte Carlo Estimation of Bayesian Credible and HPD Intervals. J. Comput. Graph. Stat. 1999, 8, 69–92. [Google Scholar] [CrossRef]
- Doornik, J.A. Object-Oriented Matrix Programming Using Ox, 3rd ed.; Timberlake Consultants Press and Oxford: London, UK, 2007; Available online: https://www.doornik.com (accessed on 23 February 2025).
- Gelman, A. Prior distributions for variance parameters in hierarchical models. Bayesian Anal. Bayesian Anal. 2006, 1, 515–534. [Google Scholar]
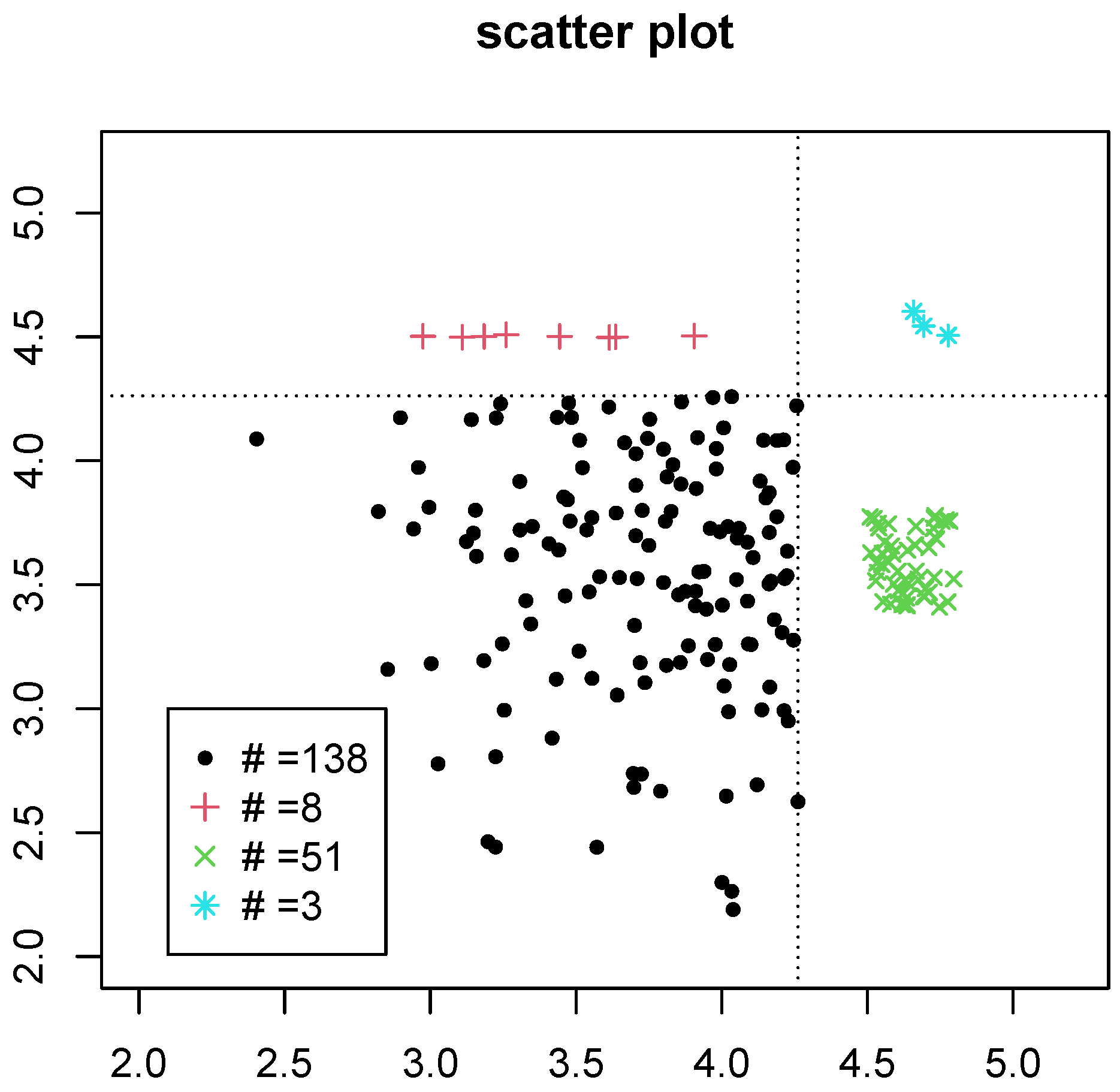
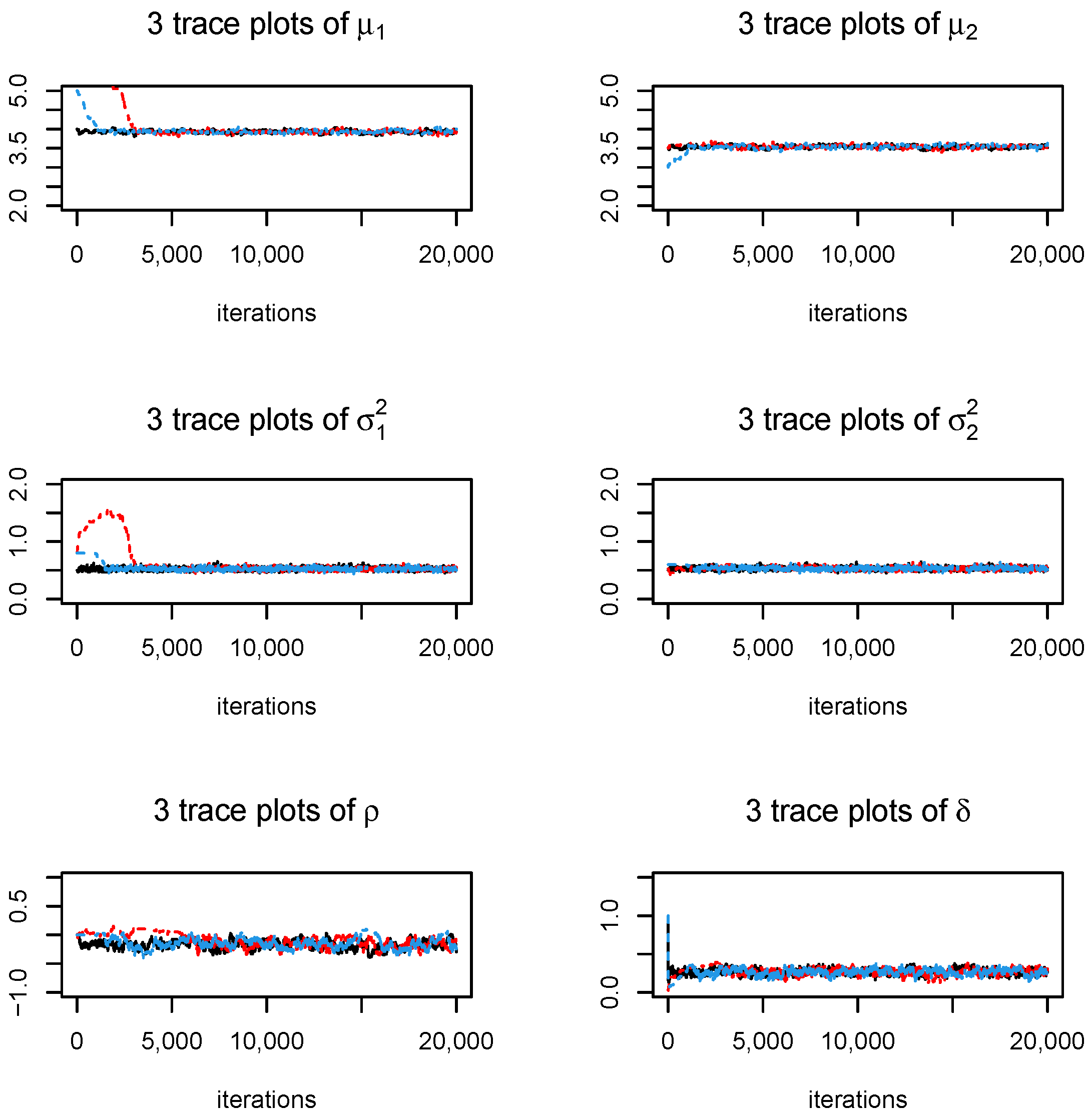

{kind=link}
{kind=link}
| , Target Parameters: | |||||||
|---|---|---|---|---|---|---|---|
| n | r | ||||||
| 30 | 21 | 12.09 | 34.66 | 6.25 | 30.52 | 3.62 | 9.58 |
| (−0.25178) | (0.45034) | (−0.1592) | (0.41183) | (0.07531) | (0.27343) | ||
| 50 | 35 | 9.59 | 33.81 | 5.44 | 23.26 | 3.49 | 10.49 |
| (−0.24495) | (0.48732) | (−0.18328) | (0.39908) | (0.09353) | (0.29814) | ||
| 100 | 70 | 7.73 | 24.24 | 4.99 | 13.53 | 2.81 | 9.88 |
| (−0.24406) | (0.44873) | (−0.19901) | (0.32298) | (0.10475) | (0.30055) | ||
| 200 | 140 | 7.08 | 21.73 | 4.67 | 11.48 | 2.50 | 10.01 |
| (−0.2485) | (0.44442) | (−0.20574) | (0.31519) | (0.12037) | (0.30878) | ||
| 500 | 350 | 6.70 | 2.09 | 4.64 | 9.47 | 2.56 | 10.65 |
| (−0.25198) | (0.44904) | (−0.21074) | (0.29898) | (0.14311) | (0.32308) | ||
| , Target Parameters: | |||||||
| 30 | 27 | 7.03 | 12.27 | 3.82 | 11.04 | 3.05 | 2.07 |
| (−0.09469) | (0.15244) | (−0.06817) | (0.21988) | (0.00744) | (0.06944) | ||
| 50 | 45 | 4.58 | 7.84 | 2.72 | 7.45 | 2.15 | 1.40 |
| (−0.10791) | (0.14755) | (−0.09377) | (0.1915) | (0.00054) | (0.07419) | ||
| 100 | 90 | 2.80 | 4.81 | 2.06 | 4.68 | 1.13 | 0.95 |
| (−0.10582) | (0.14387) | (−0.11208) | (0.16793) | (0.01296) | (0.07356) | ||
| 200 | 180 | 2.12 | 3.76 | 1.82 | 3.50 | 0.68 | 0.89 |
| (−0.11042) | (0.15438) | (−0.11807) | (0.16146) | (0.01701) | (0.08077) | ||
| 500 | 450 | 1.45 | 3.06 | 1.69 | 2.88 | 0.35 | 0.75 |
| (−0.10493) | (0.15942) | (−0.12333) | (0.15947) | (0.02025) | (0.08115) | ||
| , Target Parameters: | |||||||
| 30 | 21 | 33.26 | 63.51 | 7.76 | 30.51 | 8.54 | 9.30 |
| (−0.50789) | (0.69634) | (−0.20115) | (0.39244) | (0.08704) | (0.2808) | ||
| 50 | 35 | 29.79 | 65.49 | 7.167 | 22.55 | 7.61 | 9.95 |
| (−0.49977) | (0.73351) | (−0.22556) | (0.3699) | (0.10369) | (0.2986) | ||
| 100 | 70 | 27.53 | 51.16 | 6.95 | 10.91 | 5.86 | 9.81 |
| (−0.50081) | (0.6837) | (−0.24529) | (0.27187) | (0.125) | (0.3038) | ||
| 200 | 140 | 26.47 | 46.91 | 6.76 | 7.79 | 4.81 | 9.79 |
| (−0.50244) | (0.67149) | (−0.25065) | (0.24689) | (0.14515) | (0.3075) | ||
| 500 | 350 | 25.56 | 47.12 | 7.02 | 5.85 | 4.47 | 10.41 |
| (−0.50097) | (0.68074) | (−0.26143) | (0.2286) | (0.17711) | (0.32049) | ||
| , Target Parameters: | |||||||
| 30 | 27 | 7.04 | 12.27 | 3.82 | 11.04 | 3.05 | 2.07 |
| (−0.22941) | (0.25317) | (−0.06257) | (0.22424) | (−0.0157) | (0.07838) | ||
| 50 | 45 | 9.49 | 11.26 | 2.67 | 6.88 | 2.19 | 1.11 |
| (−0.24389) | (0.24296) | (−0.08879) | (0.17862) | (−0.00003) | (0.08239) | ||
| 100 | 90 | 7.84 | 8.53 | 2.19 | 4.15 | 1.39 | 0.94 |
| (−0.24403) | (0.24386) | (−0.11503) | (0.1524) | (−0.00113) | (0.08572) | ||
| 200 | 180 | 7.49 | 7.84 | 1.91 | 3.13 | 0.81 | 0.96 |
| (−0.25423) | (0.2556) | (−0.12061) | (0.14907) | (0.00019) | (0.09178) | ||
| 500 | 450 | 6.79 | 7.47 | 1.84 | 2.44 | 0.37 | 0.94 |
| (−0.25325) | (0.26354) | (−0.12903) | (0.14488) | (0.00017) | (0.09445) | ||
| , Target Parameters: | |||||||
|---|---|---|---|---|---|---|---|
| n | r | ||||||
| 30 | 21 | 9.26 | 26.56 | 5.75 | 26.27 | 1.98 | 10.10 |
| (−0.17821) | (0.36582) | (−0.12596) | (0.37264) | (0.04714) | (0.27063) | ||
| 50 | 35 | 6.68 | 25.04 | 4.74 | 19.34 | 1.69 | 10.67 |
| (−0.17942) | (0.39978) | (−0.15544) | (0.3586) | (0.04742) | (0.29580) | ||
| 100 | 70 | 5.11 | 17.49 | 3.99 | 11.46 | 1.25 | 9.88 |
| (−0.18255) | (0.36765) | (−0.16994) | (0.29621) | (0.05441) | (0.29728) | ||
| 200 | 140 | 4.24 | 15.01 | 3.43 | 9.69 | 1.03 | 9.63 |
| (−0.1832) | (0.36108) | (−0.17116) | (0.28792) | (0.07129) | (0.30107) | ||
| 500 | 350 | 3.89 | 13.89 | 3.39 | 7.85 | 0.92 | 0.10067 |
| (−0.18925) | (0.36309) | (−0.17826) | (0.27014) | (0.08022) | (0.31324) | ||
| , Target Parameters: | |||||||
| 30 | 27 | 6.65 | 10.92 | 4.03 | 9.89 | 2.34 | 2.52 |
| (−0.0589) | (0.12883) | (−0.05056) | (0.20095) | (0.00325) | (0.06697) | ||
| 50 | 45 | 4.11 | 7.11 | 2.36 | 6.41 | 1.63 | 1.66 |
| (−0.06743) | (0.11896) | (−0.07536) | (0.17033) | (0.00076) | (0.07046) | ||
| 100 | 90 | 2.04 | 4.12 | 1.74 | 4.01 | 0.87 | 1.04 |
| (−0.06258) | (0.12135) | (−0.08946) | (0.14986) | (0.01464) | (0.06984) | ||
| 200 | 180 | 1.33 | 2.89 | 1.35 | 2.97 | 0.48 | 0.87 |
| (−0.06632) | (0.1284) | (−0.09459) | (0.1465) | (0.01392) | (0.07599) | ||
| 500 | 450 | 0.74 | 2.31 | 1.14 | 2.31 | 0.24 | 0.71 |
| (−0.0624) | (0.13451) | (−0.09633) | (0.14108) | (0.01863) | (0.07740) | ||
| , Target Parameters: | |||||||
| 30 | 21 | 45.55 | 75.21 | 7.49 | 25.50 | 6.67 | 8.58 |
| (−0.61387) | (0.77865) | (−0.19284) | (0.32413) | (0.05777) | (0.27256) | ||
| 50 | 35 | 41.29 | 75.45 | 7.01 | 17.73 | 5.62 | 9.23 |
| (−0.60485) | (0.8081) | (−0.21895) | (0.29807) | (0.07702) | (0.28955) | ||
| 100 | 70 | 40.28 | 62.66 | 6.79 | 8.03 | 3.38 | 9.08 |
| (−0.61411) | (0.76446) | (−0.24012) | (0.20838) | (0.07305) | (0.29297) | ||
| 200 | 140 | 39.83 | 59.28 | 6.51 | 5.08 | 2.47 | 9.00 |
| (−0.62047) | (0.7583) | (−0.24456) | (0.18596) | (0.08025) | (0.29572) | ||
| 500 | 350 | 40.14 | 58.65 | 6.72 | 3.43 | 1.62 | 9.35 |
| (−0.62986) | (0.76098) | (−0.25534) | (0.1662) | (0.08718) | (0.30396) | ||
| , Target Parameters: | |||||||
| 30 | 27 | 14.44 | 18.25 | 4.59 | 10.2 | 2.42 | 1.25 |
| (−0.27116) | (0.29286) | (−0.03828) | (0.19868) | (−0.00912) | (0.07857) | ||
| 50 | 45 | 12.27 | 13.66 | 2.51 | 6.21 | 1.81 | 1.03 |
| (−0.29195) | (0.29456) | (−0.06423) | (0.16253) | (0.00189) | (0.08442) | ||
| 100 | 90 | 10.54 | 11.27 | 1.79 | 3.65 | 0.98 | 0.92 |
| (−0.29355) | (0.294) | (−0.08849) | (0.13375) | (−0.00224) | (0.08744) | ||
| 200 | 180 | 10.57 | 10.99 | 1.43 | 2.45 | 0.57 | 0.97 |
| (−0.30723) | (0.31027) | (−0.09409) | (0.12944) | (−0.00342) | (0.09356) | ||
| 500 | 450 | 10.06 | 10.43 | 1.18 | 1.83 | 0.29 | 0.95 |
| (−0.31097) | (0.31556) | (−0.09943) | (0.12336) | (−0.00633) | (0.09588) | ||
| (3.545, 3.472) | (4.165, 3.088) | (3.536, 3.722) | (4.039, 2.19) | (3.183, 3.195) |
| (+, +) | (+, −) | (+, −) | (3.724, 2.737) | (4.008, 3.093) |
| (3.705, 3.902) | (3.581, 3.534) | (+, −) | (3.11, +) | (3.981, 3.968) |
| (4.162, 3.504) | (4.05, 3.521) | (3.278, 3.621) | (2.975, +) | (3.72, 3.187) |
| (4.213, 2.993) | (3.806, 3.757) | (+, −) | (2.403, 4.089) | (3.224, 2.807) |
| (3.745, 4.091) | (+, −) | (3.666, 4.074) | (+, −) | (+, −) |
| (3.727, 3.801) | (3.912, 3.889) | (+, −) | (+, −) | (3.554, 3.123) |
| (+, −) | (+, −) | (+, −) | (2.942, 3.726) | (3.862, 4.238) |
| (3.753, 4.168) | (+, −) | (3.44, 3.641) | (3.812, 3.936) | (2.897, 4.175) |
| (3.435, 4.176) | (3.951, 3.199) | (+, −) | (3.14, 4.167) | (3.328, 3.437) |
| (3.736, 3.106) | (+, −) | (3.832, 3.985) | (4.162, 3.872) | (3.8, 4.048) |
| (4.091, 3.262) | (3.158, 3.616) | (+, −) | (4.137, 2.996) | (3.462, 3.456) |
| (4.034, 2.264) | (4.034, 4.26) | (+, +) | (3.826, 3.796) | (+, −) |
| (4.189, 4.083) | (3.709, 3.525) | (3.147, 3.709) | (3.917, 4.094) | (3.522, 3.973) |
| (+, −) | (3.444, +) | (3.649, 3.53) | (3.253, 2.995) | (3.939, 3.555) |
| (3.857, 3.187) | (3.978, 3.26) | (4.261, 2.626) | (4.228, 2.951) | (3.636, +) |
| (4.027, 3.179) | (3.86, 3.907) | (3.906, +) | (4.244, 3.975) | (+, −) |
| (+, −) | (2.853, 3.159) | (3.909, 3.416) | (4.224, 3.537) | (+, −) |
| (4.257, 4.223) | (2.959, 3.974) | (+, −) | (3.96, 3.728) | (+, −) |
| (3.123, 3.675) | (4.131, 3.919) | (+, −) | (3.47, 3.844) | (4.053, 3.689) |
| (3.969, 4.256) | (4.088, 3.673) | (3.407, 3.666) | (4.143, 4.084) | (4.189, 3.775) |
| (4.169, 3.515) | (+, −) | (4.002, 3.419) | (+, −) | (3.921, 3.553) |
| (4.107, 3.611) | (+, −) | (4.225, 3.636) | (3.637, 3.79) | (+, +) |
| (3.885, 3.255) | (3.226, 4.174) | (3.981, 4.05) | (4.207, 3.308) | (3.749, 3.66) |
| (4.059, 3.728) | (3.24, 4.231) | (4.006, 4.134) | (4.088, 3.435) | (+, −) |
| (3.994, 3.715) | (4.023, 2.988) | (4.015, 2.648) | (3.432, 3.12) | (+, −) |
| (4.001, 2.3) | (3.457, 3.855) | (3.154, 3.802) | (3.696, 2.739) | (3.947, 3.402) |
| (3.7, 3.337) | (+, −) | (4.18, 3.36) | (3.308, 3.722) | (3.185, +) |
| (+, −) | (+, −) | (4.021, 3.735) | (+, −) | (3.003, 3.183) |
| (3.307, 3.918) | (3.35, 3.736) | (+, −) | (+, −) | (3.91, 3.474) |
| (3.344, 3.343) | (3.698, 2.683) | (+, −) | (+, −) | (3.223, 2.442) |
| (+, −) | (3.852, 3.46) | (3.484, 4.176) | (2.821, 3.796) | (+, −) |
| (+, −) | (+, −) | (3.81, 3.176) | (+, −) | (3.705, 3.699) |
| (4.246, 3.277) | (4.1, 3.26) | (4.163, 3.712) | (3.612, 4.218) | (3.571, 2.442) |
| (3.8, 3.51) | (3.026, 2.779) | (3.641, 3.056) | (+, −) | (3.614, +) |
| (+, −) | (3.418, 2.882) | (4.151, 3.851) | (+, −) | (3.474, 4.234) |
| (4.216, 3.526) | (3.26, +) | (3.705, 4.029) | (+, −) | (3.246, 3.262) |
| (3.51, 3.233) | (3.79, 2.668) | (+, −) | (4.121, 2.694) | (3.875, 3.474) |
| (2.995, 3.814) | (3.512, 4.084) | (+, −) | (+, −) | (3.554, 3.772) |
| (3.198, 2.464) | (4.213, 4.085) | (+, −) | (+, −) | (3.479, 3.758) |
| Parameter | Markov Chain 1 | Markov Chain 2 | Markov Chain 3 | |||
|---|---|---|---|---|---|---|
| 3.9312 | (3.8492, 4.0046) | 3.9262 | (3.8492, 4.0046) | 3.9319 | (3.8727, 4.0205) | |
| 3.5370 | (3.4580, 3.6047) | 3.5348 | (3.4530, 3.6103) | 3.5416 | (3.4582, 3.6161) | |
| 0.5282 | (0.4802, 0.5862) | 0.5321 | (0.4793, 0.5907) | 0.5251 | (0.4778, 0.5788) | |
| 0.5341 | (0.4869, 0.5917) | 0.5375 | (0.4814, 0.5987) | 0.5316 | (0.4815, 0.5899) | |
| −0.172 | (−0.318, −0.026) | −0.117 | (−0.319, 0.1032) | −0.148 | (−0.317, 0.0741) | |
| 0.2722 | (0.2032, 0.3455) | 0.2664 | (0.1687, 0.3435) | 0.2673 | (0.1823, 0.3415) | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, Y.-J.; Lio, Y.; Tsai, T.-R. Bayesian Estimation of the Stress–Strength Parameter for Bivariate Normal Distribution Under an Updated Type-II Hybrid Censoring. Mathematics 2025, 13, 792. https://doi.org/10.3390/math13050792
Lin Y-J, Lio Y, Tsai T-R. Bayesian Estimation of the Stress–Strength Parameter for Bivariate Normal Distribution Under an Updated Type-II Hybrid Censoring. Mathematics. 2025; 13(5):792. https://doi.org/10.3390/math13050792
Chicago/Turabian StyleLin, Yu-Jau, Yuhlong Lio, and Tzong-Ru Tsai. 2025. "Bayesian Estimation of the Stress–Strength Parameter for Bivariate Normal Distribution Under an Updated Type-II Hybrid Censoring" Mathematics 13, no. 5: 792. https://doi.org/10.3390/math13050792
APA StyleLin, Y.-J., Lio, Y., & Tsai, T.-R. (2025). Bayesian Estimation of the Stress–Strength Parameter for Bivariate Normal Distribution Under an Updated Type-II Hybrid Censoring. Mathematics, 13(5), 792. https://doi.org/10.3390/math13050792