1. Introduction
Manufacturers are designing and producing more reliable products as a result of today’s heightened consumer demands and growing market competition. With a decreasing time-to-market, it is critical to evaluate and estimate the product’s reliability during the design and development phase. In addition, due to technological advancements, production designs are always changing. Therefore, it is becoming more difficult to find information regarding the lifespan of goods or materials that are highly reliable when tested under normal conditions. To address this, the industrial sector often uses accelerated life testing (ALT) or partially accelerated life testing (PALT) to quickly gather sufficient failure data and understand the relationship between failures and external stress factors. These tests can significantly save time, labor, resources, and costs.
In ALTs, all units are subjected to stress levels higher than usual to induce failures more quickly. In contrast, PALTs involve testing units under both normal and elevated stress conditions intended to collect more failure data within a constrained time frame without subjecting all units to high stress. PALTs are particularly beneficial in scenarios where time and cost are pressing concerns. The information obtained from such tests can be utilized to estimate the failure behavior of the units under normal conditions. DeGroot and Goel performed a proper statistical modeling of PALTs [
1], where the authors considered the tempered random variable model for PALTs.
Nelson [
2] suggested various methods to apply stress under accelerated testing conditions, with constant stress and step stress models being the most widely used. In a step stress partially accelerated life test (SSPALT), units are exposed to progressively higher stress levels either at predetermined times or until a specified number of failures occur. This type of test often involves two stress levels, starting with a normal stress level and transitioning to a higher level after a fixed duration. Additional details about step stress accelerated life testing can be found in [
3]. Several researchers have studied SSPALT, including [
4,
5,
6,
7,
8].
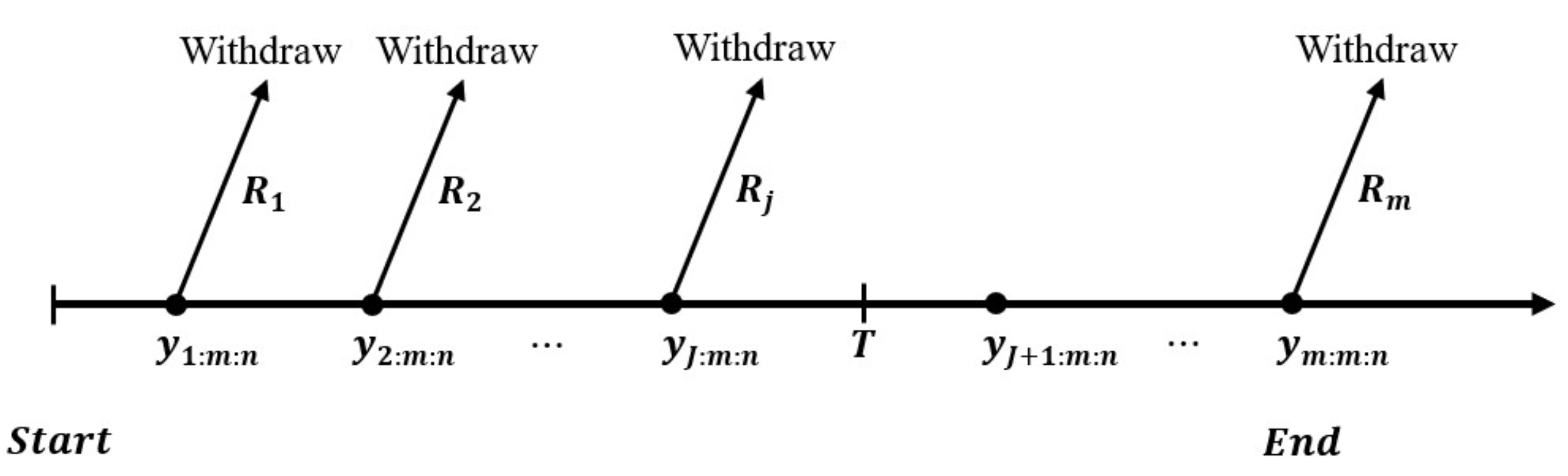
The censoring data are of natural interest in survival, reliability, and medical studies due to cost or time considerations. Although traditional type I and type II censoring methods are widely used, progressive censoring schemes (type I and type II) offer significant advances in data collection in lifetime studies. These progressive schemes address the limitations in the flexibility of conventional methods. The type II progressive censoring (TIIPC) scheme, specifically, generalizes the traditional type II approach by allowing for the removal of units throughout the experiment, not just at the endpoint. In the TIIPC scheme,
n units are placed in a test. Let
denote the times at which the
failure is recorded for
m of the
n units. Immediately after the first failure
,
units are randomly removed from the surviving units. At the time
of the second failure,
units of the remaining
surviving units are randomly eliminated, and so on. The test continues until the failure time
. The experiment ends and the remaining
surviving units are eliminated. Removals
are predetermined in such a way that
. References [
9,
10] discussed the advantages of the TIIPC schemes.
The TIIPC scheme offers flexibility in the design of an experiment by allowing for predetermined removal times (
) of units during the test. However, a crucial limitation of TIIPC is the unknown and potentially lengthy operating time (
T) compared to traditional type II censoring, as highlighted in [
11]. This extended time frame may not be preferable in practical applications due to time constraints or unexpected developments. Consequently, ref. [
11] proposed adaptive type II progressive censoring (ATIIPC) to allow experimenters to adjust the planned removal schedule of the surviving units during the test. Recently, interest has been paid to studying SSPALT models under the ATIIPC scheme, including [
12,
13,
14,
15,
16].
Statistical analysis and modeling of lifetime data play a vital role in various applied sciences, including engineering, economics, insurance, and biological sciences. To address these needs, numerous continuous distributions have been proposed in the statistical literature, such as exponential, Lindley, gamma, log-normal, half-logistic, and Weibull distributions. Among these, the power half-logistic (PHL) distribution has been extensively utilized to analyze lifetime and reliability data. The PHL distribution, introduced by Krishnarani [
17], is defined as follows:
Let
X be a random variable following the half-logistic distribution with a survival function:
Consider the transformation
, then the distribution of
Y follows the PHL distribution, which is characterized by a scale parameter
and a shape parameter
. Its probability density function (pdf), survival function
, and hazard rate function (hf) are defined as follows:
and
where
, and the cumulative distribution function (cdf) is
.
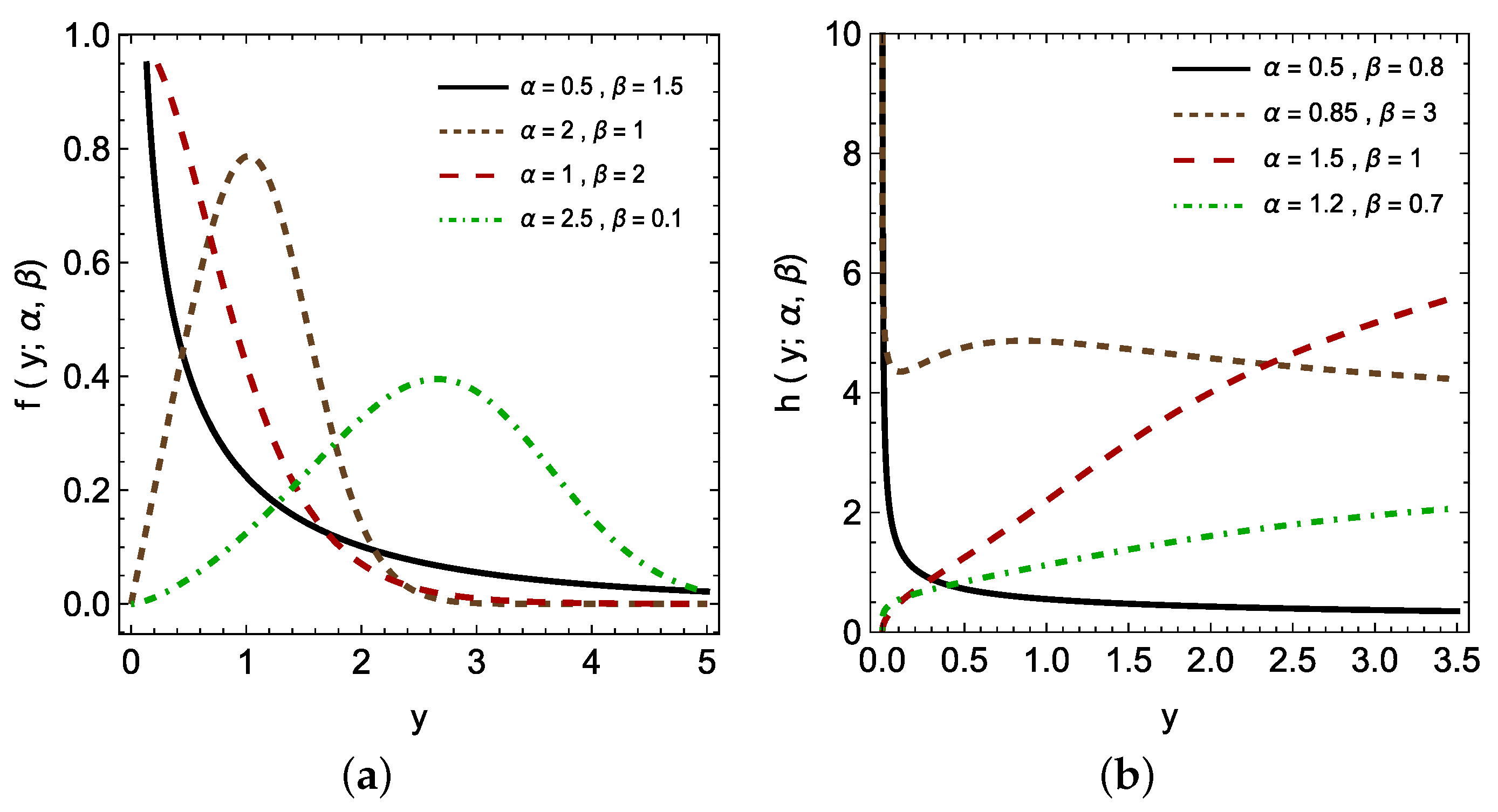
The PHL distribution is a versatile model capable of capturing a wide range of lifetime data, including symmetric and asymmetric types. Its flexibility allows us to represent various data patterns commonly encountered in practical applications effectively. To illustrate the PHL flexibility,
Figure 1 shows the plots of the pdf and the hazard rate function for different values of the parameters
and
. The PHL distribution has found successful applications in various fields. For example, Alomani et al. [
18] demonstrate the flexibility of the PHL distribution in modeling a wide range of datasets, including COVID-19 [
19], time between failures of secondary reactor pumps [
20], and active repair times for 40 airborne communication transceivers [
21]. Additionally, Alomani et al. [
18] addressed various estimation techniques and data analysis methods for constant-partially accelerated life tests for the PHL distribution. El-Awady et al. [
22] further extend this work by investigating the properties and parameter estimation of a generalized form of the PHL distribution, known as the Exponentiated Half-Logistic Weibull (EHLW) distribution. They also examine the stress strength reliability parameter (
) within the context of the EHLW distribution.
This study is motivated by the growing need for robust statistical modeling techniques in reliability and life testing, particularly under complex experimental conditions such as the SSPALT and ATIIPC schemes. These scenarios are highly relevant in engineering and industrial applications, where understanding the reliability of components under varying stress levels is essential. The ATIIPC scheme, in particular, offers enhanced flexibility by allowing experimenters to adapt the the removal schedule of units during the test, making it well suited for real-world applications with time and resource constraints.
As the PHL distribution has proven to provide significant flexibility in modeling a wide range of lifetime data, including symmetric and asymmetric failure patterns, particularly in reliability analysis under accelerated testing conditions, there remains a critical gap in the literature regarding the application of the PHL distribution under complex experimental conditions such as the SSPALT and ATIIPC schemes. This study addresses this gap by focusing on estimating the parameters of the PHL distribution and the acceleration parameter when the data are derived from the ATIIPC scheme under the SSPALT model.
To achieve this, both maximum likelihood estimation (MLE) and Bayesian methods are employed. MLE is utilized for its well-established theoretical properties, such as consistency and asymptotic efficiency, which make it a standard choice for parameter estimation in reliability studies. For the Bayesian inference, Lindley’s approximation and Markov Chain Monte Carlo (MCMC) techniques are used. Lindley’s approximation provides approximate Bayesian estimates when closed-form solutions are unavailable, leveraging its computational simplicity and efficiency for initial parameter estimation. MCMC, on the other hand, is a powerful and flexible technique for sampling from complex posterior distributions, especially in high-dimensional parameter spaces. It provides accurate and robust estimates by converging to the true posterior distribution, even for small sample sizes. Furthermore, this study explores the problem of determining the optimal stress change time using two distinct optimality criteria.
The structure of this paper is organized as follows.
Section 2 introduces the SSPALT model under the ATIIPC scheme using the PHL distribution.
Section 3 provides maximum likelihood estimates (MLEs) and asymptotic confidence intervals (ACIs). In
Section 4, we discuss the derivation of Bayesian estimates using Lindley’s approximation and the Markov Chain Monte Carlo (MCMC) technique.
Section 5 examines two optimality criteria to determine the optimal timing for changing the stress level.
Section 6 presents Monte Carlo simulation studies to showcase the effectiveness of the point and interval estimates for the parameters, as well as the optimal time for altering the stress level.
Section 7 details the data analysis conducted for specific case studies. Finally,
Section 8 concludes the paper with a summary of the findings.
2. Model Assumptions
In the ATIIPC scheme, an initial estimate for the experiment duration, , is set, which can be surpassed if necessary. The desired number of failures (m) is specified. Furthermore, censoring schemes (, ) are predetermined, but these values can be adapted during the experiment. The ATIIPC scheme balances reducing experiment time with acquiring sufficient data (including extreme lifetimes) for robust statistical inference. This is achieved through a dynamic termination strategy based on two cases:
- Case (i):
If , all m failures are observed, and the experiment ends at the predetermined time (T). The preassigned censoring scheme () is followed.
- Case (i):
If
, the experiment continues beyond the planned duration
T. Suppose
J failures have occurred such that
, where
and
. In this scenario, the test is immediately terminated with the
failure. Consequently, the censoring scheme (
) is dynamically adjusted to become
, where
.
Figure 2 and
Figure 3 illustrate the two cases of the ATIIPC schemes.
Under SSPALT, the lifetime of the unit is given as follows:
where
Z is the lifetime of the unit under normal use conditions,
is the stress change time,
is the acceleration factor, and
Y is the total lifetime under SSPALT. The above variable transformation is proposed by [
1]. The pdf of
Y under the SSPALT model can be expressed as
where
is the pdf of the PHL distribution defined in Equation (
2) with the corresponding survival function given in Equation (
3), and
is given by
where
and
. The corresponding survival function is
Figure 2.
The test time .
Figure 2.
The test time .
Figure 3.
The test time .
Figure 3.
The test time .
Under SSPALT with the ATIIPC scheme,
n units undergo testing with a progressive censoring scheme
. Each unit operates under normal conditions and if it does not fail up to time
, it is subjected to accelerated conditions. The experiment continues until censoring time
T. In this scenario, no items are withdrawn except at the time of the
failure, when all remaining surviving units are removed. The applied scheme in this case is
, and the observed data take the form
If , the ATIIPC scheme reduces to the traditional type II censoring scheme. If , the ATIIPC scheme will lead us to the conventional TIIPC scheme.
The statistical inference based on the ATIIPC scheme under SSPALT will be described in the following sections.
4. Bayesian Estimation
In this section, we derive Bayes estimates of the parameters and and the accelerated factor . A loss function is used to evaluate the difference between an estimated value and the true value of the parameter. Although symmetric loss functions such as the squared error (SE) loss function are commonly used, asymmetric loss functions are generally more practical and applicable. In this study, we used the linear exponential (LINEX) loss function, a common choice among asymmetric loss functions.
Under the SE loss, the Bayes estimate
for a parameter
is the posterior mean. The LINEX loss can be written on the form
According to LINEX loss function, the Bayesian estimate of
, denoted as
, is given by
assuming that the expectation of
exists and is finite.
To derive Bayes estimates, we assume independent gamma priors for the parameters
,
, and
with densities
,
, and
, respectively. The joint prior distribution is then given by
where the hyperparameters
for
. The joint posterior density of
,
, and
is given by
where
is the likelihood function given by Equation (
7). Based on Equation (
21), the Bayesian estimate of any function of
,
, and
, e.g.,
, under SE loss function and LINEX loss function can be written as
and
respectively. Analytical solutions to the intractable ratios of integrals in Equations (
22) and (
23) cannot be obtained. Therefore, we adopt two different techniques to compute Bayesian estimates for
,
, and
. These techniques are discussed in the following Subsections.
4.1. Lindley’s Approximation
In this subsection, approximate Bayes estimators for the parameters
,
, and
are derived using Lindley’s approximation technique [
23]. Lindley’s approximation is used in Bayesian inference to approximate posterior means when exact integration is computationally challenging, hence providing fast numerical solutions. Lindley approximation is basically a Taylor series expansion around the MLE. Therefore, it approximates the posterior distribution locally using second-order terms, making it possible to compute expectations analytically. Compared to simulation-based methods like MCMC, Lindley approximation offers a good approach, especially for small-to-moderate sample sizes. In this study, the Lindley approximation is applied to derive approximate Bayes estimators under squared error and LINEX loss functions for the model’s parameters. This approach avoids the need for computationally expensive numerical integration.
Under the squared error loss function, the posterior mean of a function
is given by
where
is the log-likelihood function in Equation (
8),
is the logarithm of the prior density, and
. By applying Lindley’s approximation and expanding about the MLE for
, the posterior mean
is approximated as
where
,
,
,
,
and
is the
element in the inverse of the matrix
.
For the case of three parameters,
, the posterior mean in Equation (
25) can be simplified to obtain the posterior mean of
, under squared error loss function, to be
where
,
,
, and
where
represent the third-order derivatives of the log-likelihood function (
8), obtained by differentiating Equations (
14)–(
19) with respect to
,
and
. These equations are given in
Appendix A.
Using the joint prior density function from Equation (
20), we have
Finally, the Bayes estimates under the SE loss function for the parameters
, and
are derived by employing Equation (
26) as follows:
Under the LINEX loss function, applying Lindley’s approximation to the ratio of integrals in Equation (
23), the posterior mean can be approximated as
The approximate Bayesian estimates for the parameters
,
, and
under the LINEX loss function are then derived as follows:
Note that all the above quantities are evaluated at the MLEs for .
4.2. MCMC Algorithm
In Bayesian inference, MCMC techniques are essential tools for sampling from complex posterior distributions, particularly when analytical computation is intractable. For example, in Equation (
21), MCMC methods facilitate generating samples that approximate the posterior distribution. Two common MCMC methods are Gibbs sampling and the Metropolis–Hastings (MH) algorithm. Gibbs sampling is straightforward, drawing samples from the conditional distributions of each parameter. At the same time, the MH algorithm is more general, sampling from the conditional density of the parameters using a proposal distribution. These samples were subsequently used to compute Bayes estimates and credible intervals (CRIs).
In this study, MCMC is employed because the conditional densities of
, and
(Equations (
35)–(
37)) have no explicit distributional forms. The MH algorithm is specifically chosen for its flexibility in sampling from these complex conditional densities. The MH algorithm generates samples that approximate the posterior distribution. These samples are then used to compute Bayes estimates under the squared error and LINEX loss functions, as well as credible intervals. Consequently, MCMC methods are flexible, capable of handling more complex posterior distributions and yielding asymptotically exact results with sufficient samples.
The joint posterior distribution of
,
, and
from Equation (
7) is expressed as
The conditional densities for
,
and
are derived as follows:
and
Equations (
35)–(
37) do not have explicit distributional forms, and Bayesian estimates of the parameters are obtained using the MCMC algorithm with MH steps as follows:
Start with initial values and set .
Use the following MH algorithm to generate from :
- (i)
Generate a proposal from normal distribution .
- (ii)
Calculate the acceptance probability .
- (iii)
Generate and set if ; otherwise, set .
Use the following MH algorithm to generate from :
- (i)
Generate a proposal from .
- (ii)
Calculate the acceptance probability .
- (iii)
Generate and set if ; otherwise, set .
Use the following MH algorithm to generate from :
- (i)
Generate a proposal from .
- (ii)
Calculate the acceptance probability .
- (iii)
Generate and set if ; otherwise, set .
Repeat steps (2) and (4) N times to obtain for .
Compute Bayesian estimates under the squared error and LINEX loss functions as follows:
- –
For squared error loss: .
- –
For LINEX loss: .
Here, is the number of burn-in iterations discarded to reduce the effect of initial parameter values.
Construct credible intervals (CRIs) for the Bayesian estimates using the and quantiles of the empirical posterior distribution from the MCMC samples.
For more details regarding the MH algorithm, see the work of Robert et al. [
24].
6. Simulation
This section presents the Monte Carlo simulation study conducted to assess the performance of maximum likelihood estimation and Bayesian estimation methods for the model parameter . Bayesian estimation is implemented with two techniques: Lindley approximation and the MCMC technique under squared error and LINEX loss functions, where and . The performance of these estimators is evaluated using the mean squared error (MSE) and average bias (AB) for the point estimates, while the average width (AW) and coverage probability (CP) are used for the confidence intervals . Three cases are considered, each with different values for stress transition time , and experiment duration T:
- Case 1:
, and .
- Case 2:
, and .
- Case 3:
, and .
For each case, 1000 samples were generated using Mathematica (14) software with varying sizes and censoring levels , , , and . Additionally, this study explored three different censoring schemes (CSs), as detailed below:
- CS I:
for .
- CS II:
for (for odd m);
for (for even m).
- CS III:
for .
To simulate data form the proposed model under the ATIIPC scheme, we followed an algorithm based on [
11], with the detailed steps outlined below:
Determine the values of and T and the values of the parameters , , and .
Generate the TIIPC sample
with the censoring scheme
based on the method proposed by [
30].
Generate m-independent observations from .
Calculate for .
Set for . Then, is a PTIIC sample of size m from the distribution.
Under SSPALT with the TIIPC scheme, calculate
where
is the cdf for the PHL distribution and
for
.
Determine the value of J, where , and discard the sample .
Generate the first -order statistics from a truncated distribution with sample size as .
For the Bayesian estimation approach, informative priors are employed, where the hyperparameters are determined using the method of moments. This ensures that the Gamma prior distribution’s mean matches the corresponding parameter’s true value, with a prior variance set to 1. The MCMC procedure was run for 10,000 iterations, discarding the initial 1000 iterations as a burn-in period. In addition, a thinning process was applied, retaining every third observation to reduce autocorrelation.
All estimation methods exhibit satisfactory behavior in terms of the MSEs and AB presented in
Table 1,
Table 2,
Table 3,
Table 4,
Table 5 and
Table 6, indicating their validity across different schemes and sample sizes.
As the sample size increases, the MSEs and ABs across all estimation methods and parameters tend to decrease.
Censoring Scheme I generally shows lower MSEs for most parameter estimates compared to Schemes II and III. This trend implies that Scheme I might be more favorable for achieving accurate estimates.
Across all estimation methods, parameter tends to exhibit larger MSE and AB values compared to parameters and .
For Bayesian estimates obtained through Lindley’s approximation or MCMC techniques, the choice of loss function affects MSE and AB. Symmetric loss functions (the SE loss) consistently produce preferable results compared to asymmetric loss functions.
The MLE and MCMC with SE loss offer the most balanced performance in terms of AB and MSE across all cases, with MCMC slightly outperforming in larger samples. Lindley’s method, while effective for and , appears less reliable for .
Censoring Scheme III, which tends to remove units later in the test, consistently shows higher MSEs and AB across all parameters and estimation methods, particularly in smaller samples. In contrast, Schemes I and II provide more reliable performance with generally lower MSEs and AB, supporting more accurate estimation.
According to the results of the interval estimates shown in
Table 7, the AWs for ACIs and CRIs become narrower as the sample size increases and the CPs are mostly close to the nominal level. The CRIs are narrower and provide better coverage probabilities.
The average values of the optimal stress change time
based on the A-optimality (AO) and D-optimality (DO) are listed in
Table 8. The values of
for both the AO and the DO methods are relatively close within each scheme.
The MLE demonstrates competitive performance across all cases, particularly for smaller sample sizes. Its simplicity and computational efficiency make it a practical choice for applications where quick and reliable estimates are needed.
The MCMC Bayesian estimates with SE loss show slightly better performance in larger samples, where the MLE remains robust and consistent, especially for parameters and .
8. Conclusions
In this study, we applied the SSPALT model to units with lifetimes following the PHL distribution under the ATIIPC scheme. Statistical inferences for the model parameters were derived using maximum likelihood and Bayesian estimations under symmetric and asymmetric loss functions, employing Lindley’s approximation and the MCMC technique. Additionally, we investigated the determination of optimal stress change times using two optimality criteria, A-optimality and D-optimality, to enhance the efficiency of the testing procedure. A comprehensive Monte Carlo simulation study was conducted to assess the performance of the estimation methods and the optimality criteria across various scenarios. The results indicate that all estimation methods perform well. However, we recommend using the MLE method since it offers the most consistent and reliable performance across all scenarios. The optimal stress change times determined using A-optimality and D-optimality criteria were found to be relatively close, highlighting the robustness of the optimization approach.
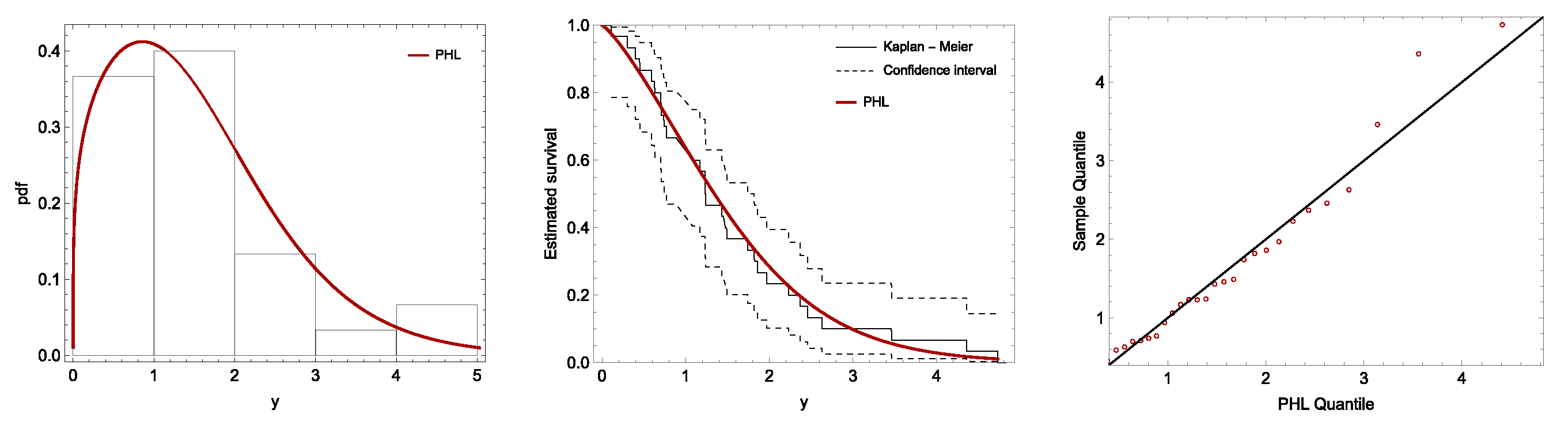
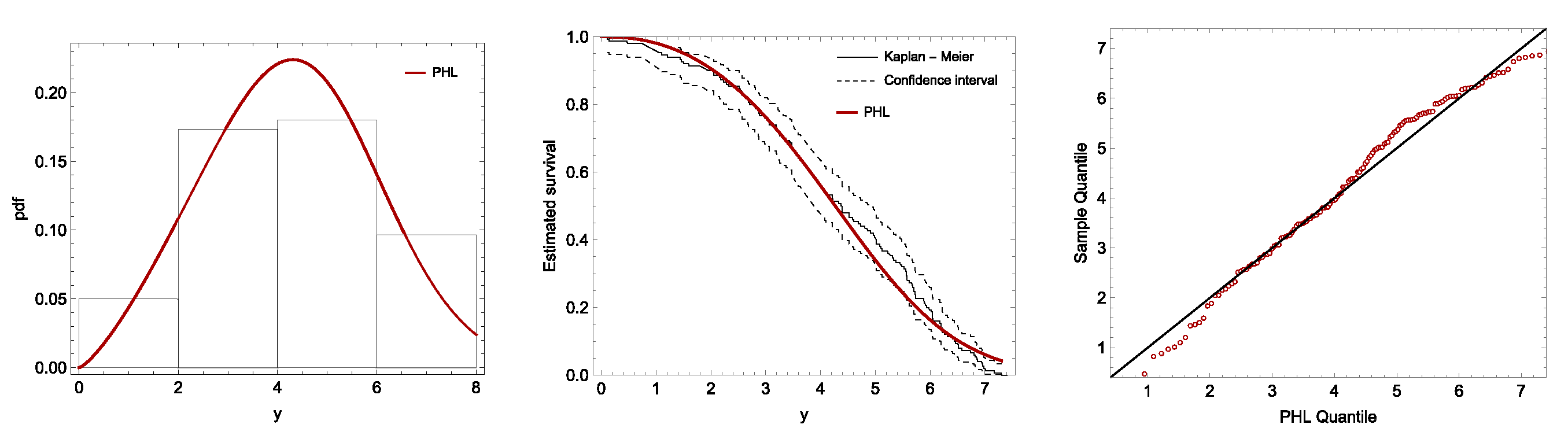
To further illustrate the applicability of the proposed model, we analyzed three different datasets under SSPALT. The analysis demonstrated the impact of applying the ATIIPC scheme on the predetermined duration of the experiment and the necessary adjustments to the censoring scheme. Furthermore, we successfully determined the optimal stress change times for each dataset. The findings confirm that the PHL distribution under complex experimental conditions, such as the SSPALT model with ATIIPC, provides a flexible and efficient framework.
While this study explores the SSPALT model’s effectiveness under the PHL distribution and ATIIPC scheme, several limitations should be noted. The analysis assumes the PHL distribution for lifetimes, and extending the model to other distributions could enhance its applicability. The optimal stress change time is determined numerically due to the lack of closed-form solutions, and future work could explore approximate analytical methods for improved computational efficiency. Additionally, the robustness of the model under varying levels of censoring, small sample sizes, and alternative prior assumptions in the Bayesian framework remains an area for further investigation. Expanding the study to adaptive stress-testing schemes and real-time monitoring could also provide more practical insights. Handling the inclusion of covariates, such as environmental factors and material properties, into the SSPALT model to study the effect of external variables on lifetimes is another open area. Lastly, validating the proposed methods across diverse real-world datasets and industries will further demonstrate their generalization and reliability.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}