
Fatigue Detection Algorithm for Nuclear Power Plant Operators Based on Random Forest and Back Propagation Neural Networks


Abstract
1. Introduction
- 1.
- Detection based on physiological data, such as EEG signals [3], ECG signals [4], etc. This method can accurately reflect the real-time state of the operator, but it usually requires special equipment which the operator needs to wear when testing, which can affect the operator’s ability to perform tasks, while the price of this equipment is high;
- 2.
- Detection based on operator features, such as facial features [5,6,7], eye movement data [8], eye features [9], etc. This method is based on image detection technology. Image recognition technology usually relies on a camera with a fixed angle. When an operator works, they not only need to sit at the console for operation purposes, but also may need to walk, communicate with colleagues, check equipment, operate other control systems, etc. Once the operator leaves the monitoring range of the camera, this method will not be effective;
- 3.
2. Algorithm Construction
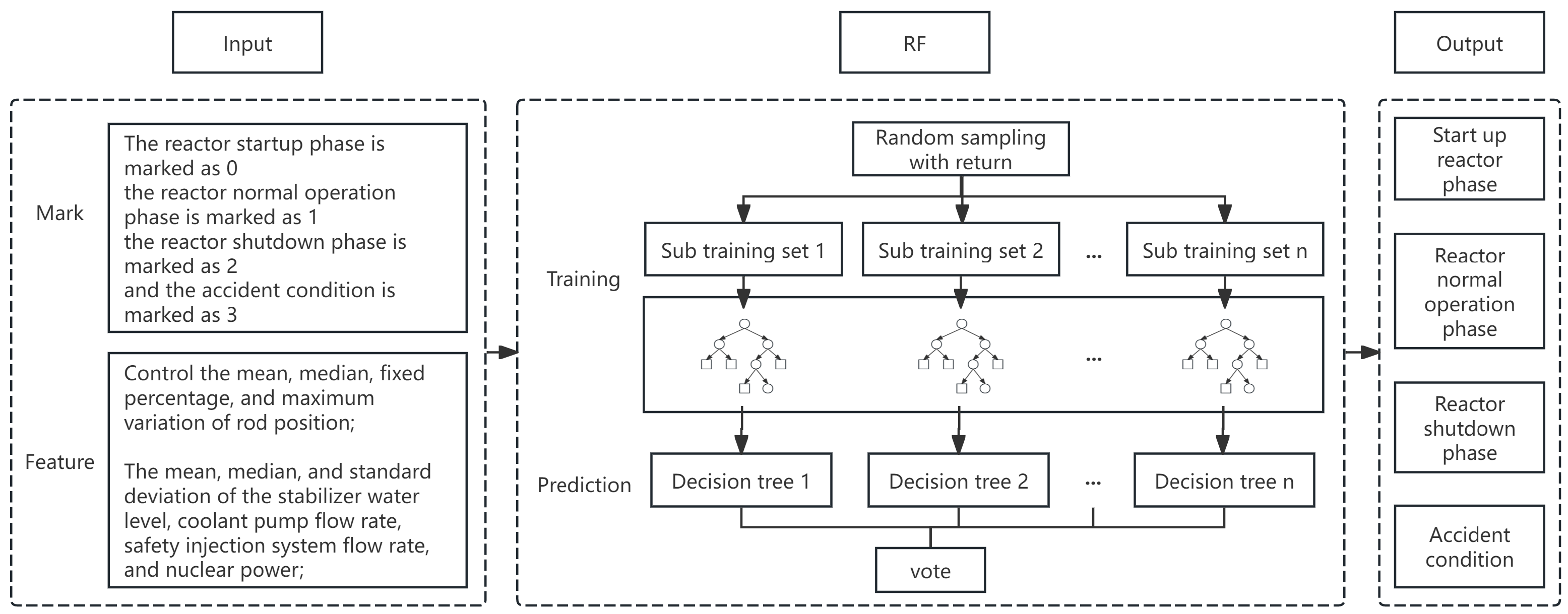
2.1. Random Forest
- 1.
- Randomly select n samples from the original dataset using the bootstrapping method to generate a training set;
- 2.
- Randomly select k features () from all m features as the division basis of the decision tree node to reduce over fitting and improve generalization ability;
- 3.
- Establish a decision tree based on the selected training set and feature set;
- 4.
- Repeat steps (1) to (3) to generate multiple decision trees, and control the size and performance of the random forest by setting the number of decision trees. The training process of each tree is recursive, starting from the root node to select the optimal splitting characteristics, and continue splitting at each child node until the stop conditions (such as maximum depth, minimum number of samples, etc.) are met;
- 5.
- For a new data sample, predict on each decision tree and vote to determine the final result. The voting method is as follows, where mode refers to the category that gets the most votes and represents the prediction result of the nth decision tree.
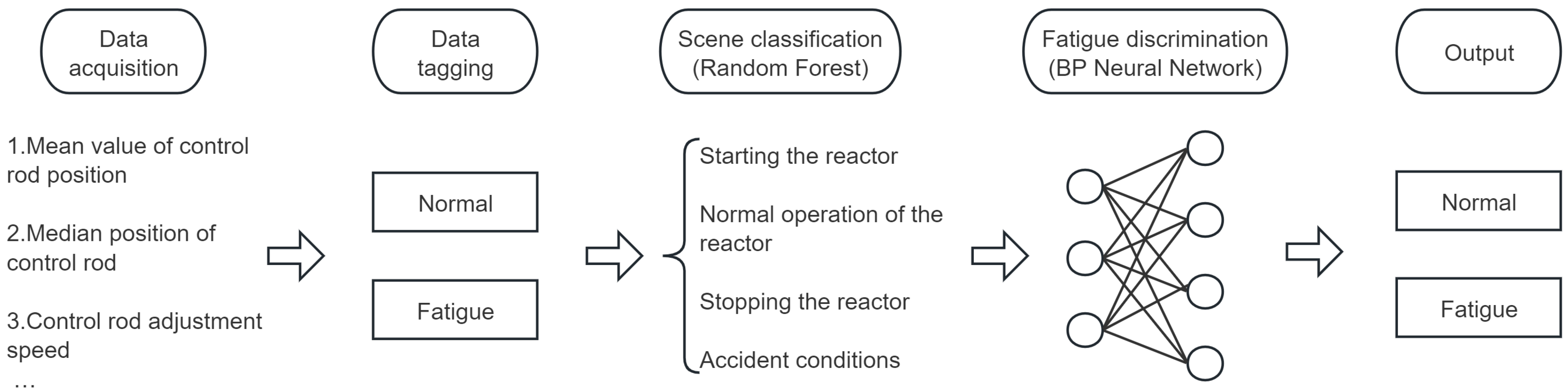
2.2. BP Neural Network
3. Experiment
3.1. Data Acquisition
3.2. Feature Extraction
- 1.
- Control rod position: mean, median, fixed percentage, and maximum variation;
- 2.
- Pressurizer water level: mean, median, and standard deviation;
- 3.
- Coolant pump flow: mean, median, and standard deviation;
- 4.
- Safety injection system flow: mean, median, and standard deviation;
- 5.
- Nuclear power: mean, median, and standard deviation.
3.3. Feature Analysis
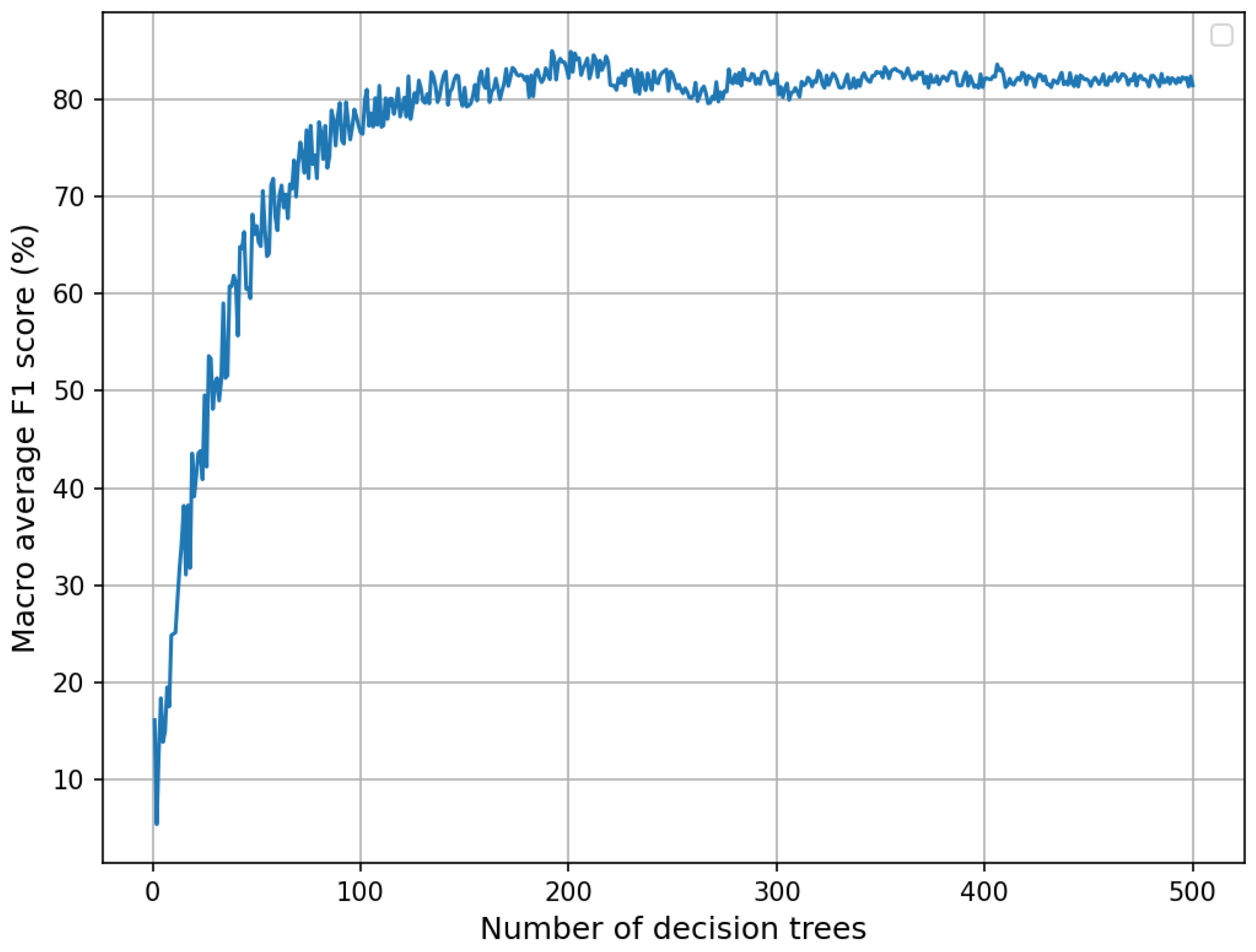
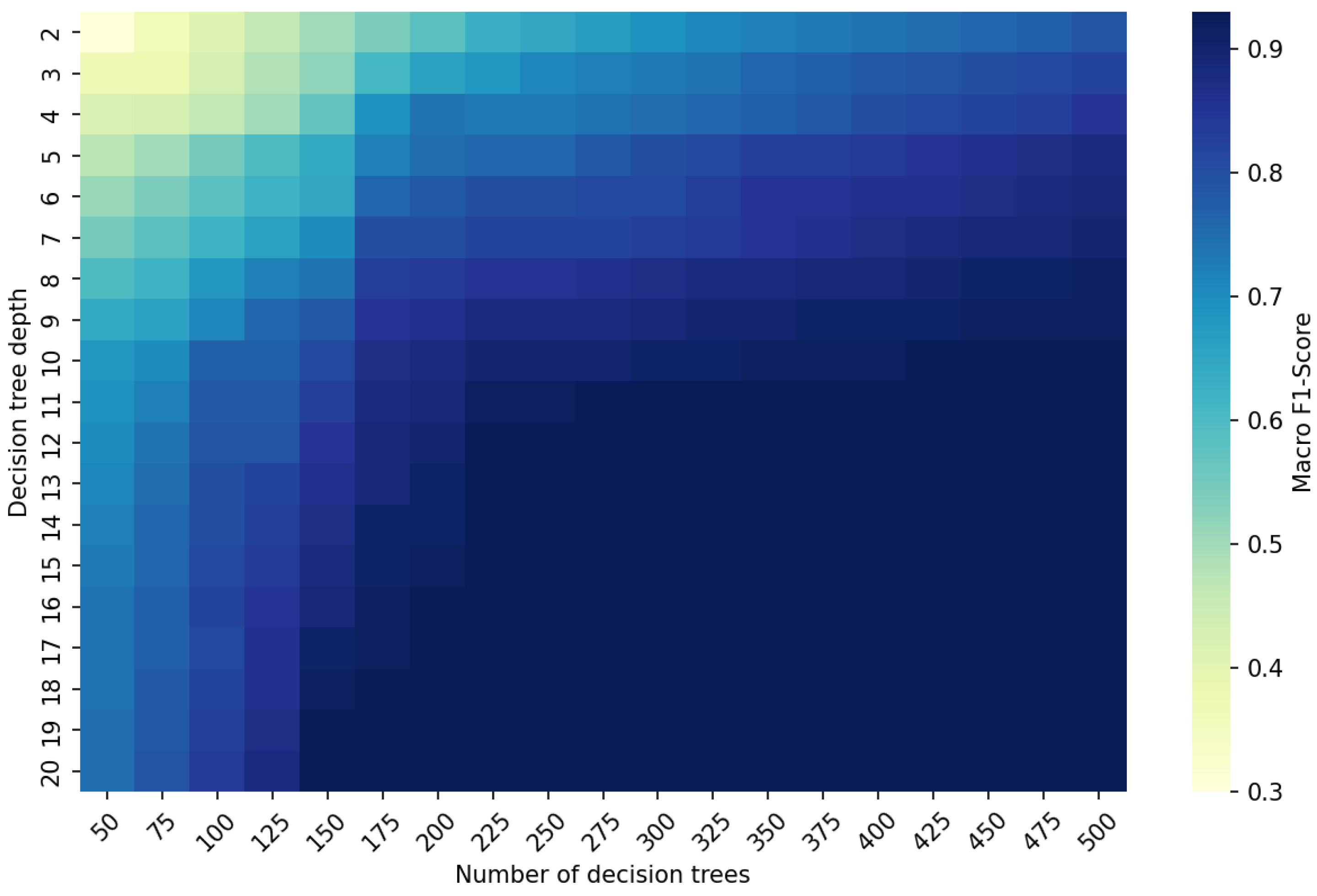
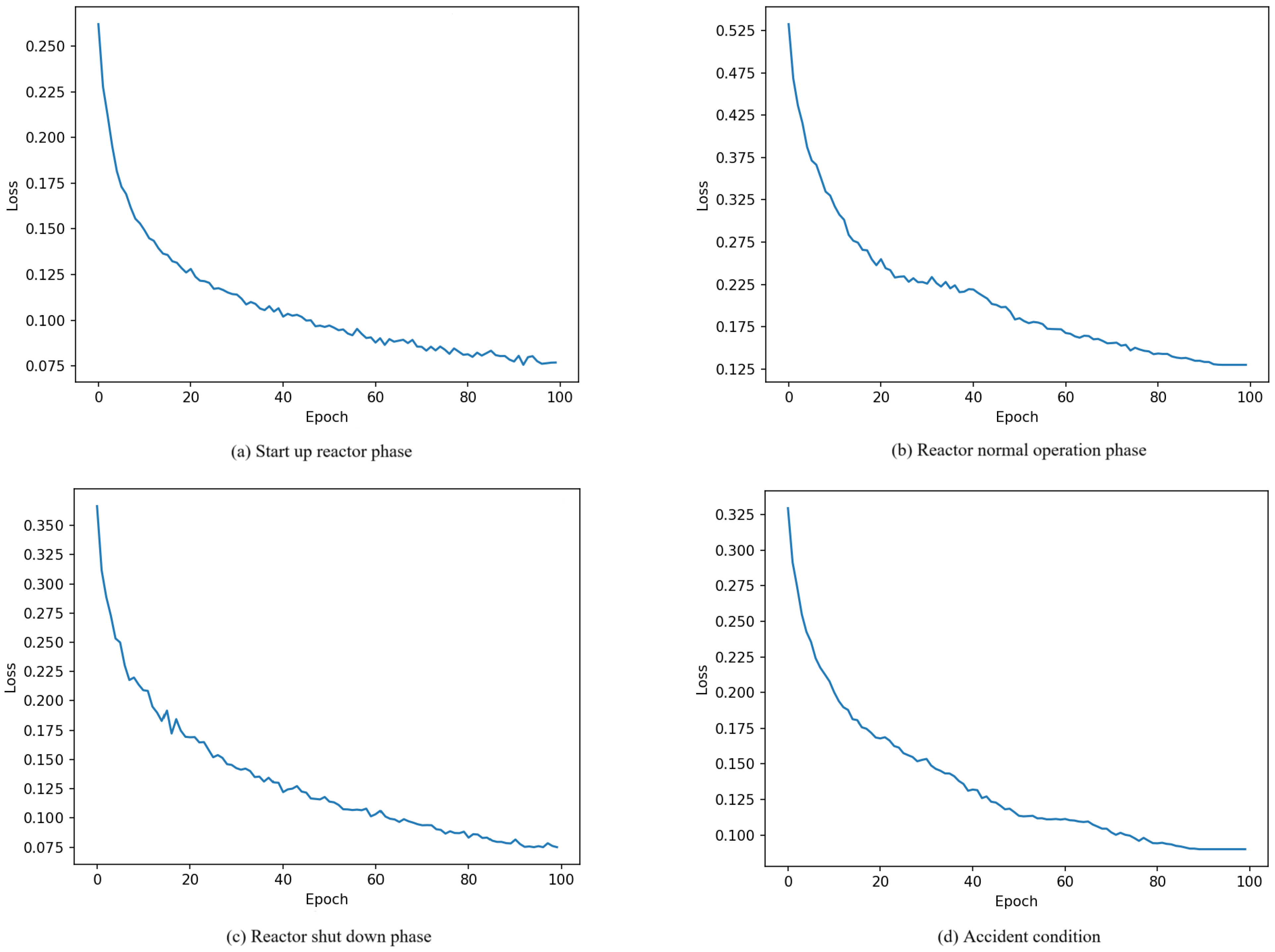
3.4. Model Construction and Verification
3.5. Model Comprehensive Performance Evaluation
4. Summary
4.1. Conclusions
4.2. Future Directions
- 1.
- In this study, fatigue is determined based on the operator’s subjective feelings. Future work could incorporate additional fatigue detection methods, such as physiological data, eye movement data, and the NASA-TLX scale, to more accurately assess whether the operator is fatigued. This would improve the dataset’s accuracy and further enhance the predictive performance of the fatigue detection algorithm;
- 2.
- In addition to operational behavior features, future research could explore integrating image-recognition-based fatigue detection algorithms, combining both approaches to further improve the accuracy of fatigue detection;
- 3.
- Although the model demonstrates high prediction accuracy, its interpretability is relatively limited. In future work, methods to improve model interpretability, such as ACT-R, SHAP, or LIME, could be employed to analyze the model’s decision-making process, helping operators understand which behaviors or actions are most likely to lead to fatigue.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Chen, D. Nuclear Energy and Nuclear Safety: Analysis and Reflection on the Fukushima Nuclear Accident in Japan. J. Nanjing Univ. Aeronaut. Astronaut. 2012, 44, 597–602. [Google Scholar] [CrossRef]
- Fang, X.; Zhao, B. Selection and Experiment of Cognitive Reliability Research Model for Nuclear Power Plant Operators. Nucl. Sci. Eng. 2000, 145, 18–24. [Google Scholar]
- Li, L.; Qing, T.; Xiang, X.; Tang, Y.Q.; Fu, J.H.; Chen, J. Feasibility Study on Fatigue Evaluation of Nuclear Power Plant Operators Using EEG Technology. Sci. Technol. Innov. Appl. 2024, 14, 24–27. [Google Scholar] [CrossRef]
- Dong, Z.; Sun, S.; Wu, Q.; Xu, J.F. Study on the Correlation between Heart Rate Variability and Driver Fatigue. J. Zhejiang Univ. (Eng. Ed.) 2010, 44, 46–50. [Google Scholar]
- Geng, L.; Yuan, F.; Xiao, Z.; Zhang, F.; Wu, J.; Li, Y.L. Driver Fatigue Detection Based on Facial Behavior Analysis. Comput. Eng. 2018, 44, 274–279. [Google Scholar]
- Hijji, M.; Yar, H.; Ullah, F.U.M.; Alwakeel, M.M.; Harrabi, R.; Aradah, F.; Cheikh, F.A.; Muhammad, K.; Sajjad, M. FADS: An Intelligent Fatigue and Age Detection System. Mathematics 2023, 11, 1174. [Google Scholar] [CrossRef]
- Wang, Y.; He, Z.; Wang, L. Truck Driver Fatigue Detection Based on Video Sequences in Open-Pit Mines. Mathematics 2021, 9, 2908. [Google Scholar] [CrossRef]
- Dai, L.; Zhang, M.; Li, Y.; Ma, L.; Han, X.Y.; Chen, X.; Li, P.C. Research on Operator Cognitive Load in Nuclear Power Plant Digital Control Rooms Based on Gaze Entropy. J. Saf. Environ. Eng. 2023, 23, 1985–1993. [Google Scholar]
- Xiang, Y.; Hu, R.; Xu, Y.; Hsu, C.-Y.; Du, C. Gaussian Weighted Eye State Determination for Driving Fatigue Detection. Mathematics 2023, 11, 2101. [Google Scholar] [CrossRef]
- Zhang, X.; Cheng, B.; Feng, R. Real-time Driver Fatigue Detection Method Based on Steering Wheel Operation. J. Tsinghua Univ. (Nat. Sci. Ed.) 2010, 50, 1072–1076+1081. [Google Scholar] [CrossRef]
- Jia, L. Study on Fatigue Driving Detection Method Based on Steering Wheel Operation Features in Real Vehicles. Ph.D. Thesis, Tsinghua University, Beijing, China, 2017. [Google Scholar]
- Li, Z.; Ma, Q. Application of BP Neural Network in Nonlinear Classification Problems. Comput. Intell. Neurosci. 2022, 2154050. [Google Scholar]
- Yang, Y.; Zhang, J. A New Backpropagation Neural Network Algorithm for Classifying Nonlinear Data. Neural Process. Lett. 2021, 53, 1325–1339. [Google Scholar]
- Chen, X.; Wang, Y. Optimized BP Neural Network for Nonlinear Classification Applications. J. Artif. Intell. Neural Netw. 2023, 1–10. [Google Scholar]
- Zhang, Y. The Working Principles and Development Trends of Nuclear Power Plants. Equip. Mach. 2010, 4, 2–7. [Google Scholar]
- Qi, D.; Kang, J. Design of BP Neural Network. Comput. Eng. Des. 1998, 2, 47–49. [Google Scholar] [CrossRef]
- Shukla, A.; Patel, R. A Comprehensive Review on Backpropagation Neural Network (BPNN) and Its Variants. Neural Comput. Appl. 2021, 33, 14297–14318. [Google Scholar]
- Jain, P.; Kumar, P. Exploring the Backpropagation Neural Network for Classification and Optimization Tasks. Comput. Intell. Neurosci. 2022, 9231845. [Google Scholar]
- Hu, J.; Tan, K.; Wu, L. An Improved Polynomial Logistic Regression Method for Hyperspectral Image Classification. Remote. Sens. Technol. Appl. 2015, 30, 135–139. [Google Scholar]
- Tan, X.; Wu, Y.; Yuan, Z.; Li, J. Parallel Computing Optimization of Lagrange Polynomial Logistic Regression Classification Algorithm. Remote Sens. Inf. 2016, 31, 96–101. [Google Scholar]
- Ding, S.; Qi, B.; Tan, H. A Review of Support Vector Machine Theory and Algorithms. J. Univ. Electron. Sci. Technol. 2011, 40, 2–10. [Google Scholar]
- Zhang, X. On Statistical Learning Theory and Support Vector Machines. Acta Autom. Sinica 2000, 1, 36–46. [Google Scholar] [CrossRef]
- Fang, N.; Wu, J.B.; Zhu, J.P.; Xie, B.C. A Review of Random Forest Methods. Stat. Inf. Forum 2011, 26, 32–38. [Google Scholar]
- Fernández-Delgado, M.; Cernadas, E.; Barro, S.; Amorim, D. Do We Need Hundreds of Classifiers to Solve Real World Classification Problems? J. Mach. Learn. Res. 2014, 15, 3133–3181. [Google Scholar]
- Caruana, R.; Niculescu-Mizil, A. An Empirical Comparison of Supervised Learning Algorithms. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 161–168. [Google Scholar]
- Li, Y.; Chen, W. A Comparative Performance Assessment of Ensemble Learning for Credit Scoring. Mathematics 2020, 8, 1756. [Google Scholar] [CrossRef]
- Saito, T.; Rehmsmeier, M. Random Forests and Support Vector Machines: A Comparison of Advantages in Classification Tasks. Comput. Intell. 2021, 37, 823–840. [Google Scholar] [CrossRef]
- Liaw, A.; Wiener, M. Random Forests: Classification and Regression. In Springer Handbook of Computational Intelligence; Springer: Berlin/Heidelberg, Germany, 2007; pp. 531–540. [Google Scholar]
- Li, X. Application of Random Forest Model in Classification and Regression Analysis. Chin. J. Appl. Entomol. 2013, 50, 1190–1197. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Liaw, A.; Wiener, M. Classification and Regression by randomForest. R News 2002, 2, 18–22. [Google Scholar]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning Representations by Back-propagating Errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Hecht-Nielsen, R. Theory of the Backpropagation Neural Network. In Proceedings of the International 1989 Joint Conference on Neural Networks, Washington, DC, USA, 18–22 June 1989; Academic Press: Cambridge, MA, USA, 1989; pp. 65–93. [Google Scholar]
- Liu, X.; Pan, Y.; Yan, Y.; Wang, Y.; Zhou, P. Adaptive BP Network Prediction Method for Ground Surface Roughness with High-Dimensional Parameters. Mathematics 2022, 10, 2788. [Google Scholar] [CrossRef]
- Rumelhart, D.E.; McClell, J.L.; PDP Research Group. Parallel Distributed Processing, Volume 1: Explorations in the Microstructure of Cognition: Foundations; The MIT Press: Cambridge, MA, USA, 1986. [Google Scholar]
- Sokolova, M.; Lapalme, G. A Systematic Analysis of Performance Measures for Classification Tasks. Inf. Process. Manag. 2009, 45, 427–437. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Time Slot/min | Number of Fatigued People |
|---|---|
| 0–15 | 0 |
| 15–30 | 1 |
| 30–45 | 2 |
| 45–60 | 5 |
| 60–75 | 3 |
| 75–90 | 1 |
| Scenario | Number of Samples in the Normal State | Number of Samples in the Fatigued State |
|---|---|---|
| Starting the reactor | 43 | 21 |
| Normal operation of the reactor | 51 | 22 |
| Stopping the reactor | 45 | 22 |
| Accident conditions | 49 | 31 |
| Feature | Pearson Correlation |
|---|---|
| Average value of control rod position | −0.21 |
| Median of control rod position | −0.16 |
| Control rod position fixed percentage | −0.33 |
| Maximum value of control rod position change | 0.16 |
| Mean value of pressurizer water level | −0.15 |
| Median of pressurizer water level | −0.29 |
| Standard deviation of pressurizer water level | 0.17 |
| Average flow of coolant pump | −0.11 |
| Coolant pump flow median | −0.14 |
| Standard deviation of coolant pump flow | 0.08 |
| Mean flow of safety injection system | −0.05 |
| Median flow of safety injection system | −0.08 |
| Standard deviation of safety injection system flow | 0.09 |
| Average nuclear power | −0.08 |
| Median nuclear power | −0.07 |
| Standard deviation of nuclear power | 0.08 |
| Scenario | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| Starting the reactor | 0.87 | 0.85 | 0.84 | 0.84 |
| Normal operation of the reactor | 0.86 | 0.81 | 0.78 | 0.79 |
| Stopping the reactor | 0.88 | 0.82 | 0.86 | 0.84 |
| Accident conditions | 0.85 | 0.80 | 0.82 | 0.81 |
| Macro-average | 0.87 | 0.82 | 0.82 | 0.82 |
| Scenario | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| Starting the reactor | 0.92 | 0.83 | 0.81 | 0.82 |
| Normal operation of the reactor | 0.84 | 0.69 | 0.59 | 0.64 |
| Stopping the reactor | 0.90 | 0.82 | 0.80 | 0.81 |
| Accident conditions | 0.88 | 0.73 | 0.65 | 0.69 |
| Actual Fatigue | Actually Not Fatigue | |
|---|---|---|
| Predicting fatigue | 18 | 8 |
| Predicted not fatigued | 10 | 64 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, Y.; Li, J.; Zhang, Y. Fatigue Detection Algorithm for Nuclear Power Plant Operators Based on Random Forest and Back Propagation Neural Networks. Mathematics 2025, 13, 774. https://doi.org/10.3390/math13050774
Jiang Y, Li J, Zhang Y. Fatigue Detection Algorithm for Nuclear Power Plant Operators Based on Random Forest and Back Propagation Neural Networks. Mathematics. 2025; 13(5):774. https://doi.org/10.3390/math13050774
Chicago/Turabian StyleJiang, Yuhang, Junsong Li, and Yu Zhang. 2025. "Fatigue Detection Algorithm for Nuclear Power Plant Operators Based on Random Forest and Back Propagation Neural Networks" Mathematics 13, no. 5: 774. https://doi.org/10.3390/math13050774
APA StyleJiang, Y., Li, J., & Zhang, Y. (2025). Fatigue Detection Algorithm for Nuclear Power Plant Operators Based on Random Forest and Back Propagation Neural Networks. Mathematics, 13(5), 774. https://doi.org/10.3390/math13050774