1. Introduction
The Birnbaum–Saunders (BS) distribution is a distribution built from the standard normal random variable using a monotone transformation method. The BS distribution is also known as the fatigue life distribution. In fact, Birnbaum and Saunders [
1] introduced the distribution to model the fatigue life of metals subject to periodic stress. The BS distribution has many applications in different fields of science; fatigue failure caused under cyclic loading was provided by Birnbaum and Saunders [
2] as a physical explanation of this model, and based on a biological model. Then, a more general derivation was derived by Desmond [
3], who reduced some of the original propositions to strengthen the physical explanation for the use of this distribution. The hazard-rate property of the BS distribution, i.e., that it cannot be monotone and that it increases up to a point, then decreases, is the case applied to many real-life situations, as in a study of recovery from breast cancer. Langlands et al. [
4] observed that the maximum mortality rate among breast cancer patients occurs about three years after the diagnosis; then, it slowly drops over a fixed interval of time.
For more details, one may refer to the comprehensive review paper by Balakrishnan and Kundu [
5]. In this rich review paper, one may see other applications for the BS distribution, such as insurance data of Swedish third-party motor insurance for 1977 for one of several geographical zones, the survival life in hours for ball bearings of a certain type and the bone mineral density (BMD) measured in gm/cm
2 for newborn babies. In fact, the BS model has received considerable attention in the last few years for various reasons; the probability density function of a BS distribution can take on different shapes; for example, it has a non-monotonic hazard function and a nice physical justification. Furthermore, many generalizations of the BS distribution have been presented in the literature, and abundant applications in many different research areas have been found.
The cumulative distribution function (CDF) and probability density function (PDF) of the Birnbaum–Saunders model with parameters of
and
, respectively, are
and
where
and
are the shape and scale parameters, respectively, and
is the standard normal CDF. From now on, we adopt the notation of
to denote to the BS distribution with parameters of
and
. Many authors in the literature have studied different aspects of the BS distribution; among them, Birnbaum and Saunders [
2] studied the maximum likelihood (ML) estimators of the shape and scale parameters of the BS model, and their asymptotic distributions were obtained by Engelhardt et al. [
6]. Balakrishnan and Zhu [
7] established the existence and uniqueness of the ML estimators. Ng et al. [
8] discussed the ML estimation of the
and
parameters based on type-II right-censored samples. Bayesian inference for the scale parameter (
) was considered by Padgett [
9] with the use of a noninformative prior; it was assumed that the shape parameter was known. The same problem but when both parameters are unknown was considered by Achcar [
10], and Achcar and Moala [
11] addressed the problem in the case of censored data and covariates. Bayesian estimates and associated credible intervals for the parameters of the BS distribution under a general class of priors were handled by Wang et al. [
12]. More recent studies further expanded the use of the BS distribution in various reliability contexts. Liu et al. [
13] introduced a random-effect extension of the BS distribution to refine its modeling flexibility in reliability assessment. Sawlan et al. [
14] applied the BS distribution to model metallic fatigue data, presenting its advantage in predicting fatigue life. Razmkhah et al. [
15] developed a neutrosophic version of the BS distribution to account for uncertainty in data; they presented its application in industrial and environmental data analysis. Park and Wang [
16] proposed a goodness-of-fit test for the BS distribution; they improved the fit evaluation of the test through a new probability plot-based approach. Finally, Dorea et al. [
17] presented a generalized class of BS-type distributions that was used to model the fatigue-life data and address cases where crack damage follows heavy-tailed distributions.
Different types of censoring schemes (CSs) are adopted by authors in the literature, and the most common censoring schemes are usually called type-I and type-II CSs. Usually, the data are censored in reliability and life testing analysis. In type-II censoring, it is assumed that
n items are tested. An integer of
is pre-fixed, and as the
m-th failure is observed, the experiment stops simultaneously. The prediction problem of unseen or removed observations based on the early noticed observations in the current sample has received considerable interest in numerous fields of reliability and life testing conditions. One may refer to Kaminsky and Nelson [
18] for more details. The Bayesian prediction of an unseen observation from a future sample based on a current noticed sample, which is known as the informative sample, is one of the most important aspects in Bayesian analysis. Prediction can be used effectively in the medical field in predicting the future prognosis of patients or future side effects associated of patients treated with medication. For more information about the importance of the prediction problem and its different applications, one may refer to Al-Hussaini [
19], Kundu and Raqab [
20] and Bdair et al. [
21]. The phenomenon of observing censored data is of natural interest in survival, reliability and medical studies for a wide range of reasons (see, for example, Balakrishnan and Cohen [
22]). Several applications of prediction problems can be found in meteorology, hydrology, industrial stress testing, athletic events and the medical field.
Our goals in this paper are two-fold: First we employ importance sampling to compute the Bayesian estimates of and of a BS type-II censored sample. We use very deep computer simulations to compare the executions of the Bayesian estimators with maximum likelihood estimators (MLEs). The symmetric credible intervals (CRIs) are also computed and compared to the confidence intervals (CIs) based on the asymptotic and bootstrap (Boot-t) arguments. The other goal involves considering the prediction of the life lengths of censored values. In this work, we implement the importance and Metropolis–Hastings (M–H) algorithms to estimate the posterior predictive density of unseen units based on current informative data, and we also construct the prediction intervals (PIs) of the these unseen units.
In many real-world applications, such as material testing and clinical trials, data are often incomplete due to censoring or accidental omission. Type-II censoring, in which a fixed number of failures is observed, is particularly common in reliability studies. Accurate estimation of failure parameters and predictions of unobserved data is crucial for understanding material behavior, ensuring the safety of industrial components and making informed decisions in medical research. This study presents a comprehensive comparison of frequentist and Bayesian approaches for estimating the parameters of type-II BS censored data. This paper introduces a perfect Bayesian approach that uses Markov chain Monte Carlo (MCMC) sampling to generate point estimates and credible intervals, providing a more flexible way to quantify uncertainty. The calculation of point predictions and credible intervals via this Bayesian approach effectively indicates the uncertainty associated with the predictions, providing a complete understanding of the possible range of outcomes compared to classical statistical methods. Additionally, this study applies these methods to both simulated and real-world datasets, illustrating their effectiveness in practical reliability analysis.
The practical applications of this work may cover many fields. Understanding the fatigue life of metals and other materials is important for validating the reliability of components used in auto manufacturing and structural engineering; these are some applications of materials science. The methods improved in this paper have strict ways of estimating the fatigue life of materials from censored data, which enables engineers to predict failure times accurately, which, in turn, lets them make better decisions. Another aspect of the application is medical research; it is essential to evaluate the treatment efficacy and patient prognosis, which can be achieved effectively by predicting patient survival times based on data from censored clinical trials. The Bayesian approach discussed in this work provides a useful approach to handling incomplete data and improving the accuracy of predictions. The primary objectives of this study are to explain the advantages of Bayesian inference and provide practical outlines to apply these methods in real-world reliability and survival studies.
Future research will extend the methods developed in this work to study multi-sample progressive censoring. This extension is particularly important in cases where multiple groups or samples are affected by different censoring scenarios, which usually occurs in industrial and clinical trials. By applying the methods to larger datasets, our goal will be to refine the robustness of the proposed approaches and to ensure the application of these methods to a wider range of real-world problems. Additionally, we plan to integrate degradation models, which are commonly used in industrial applications to monitor the deterioration of products over time. These models offer a deeper investigation of reliability, especially of products that deteriorate over time under stress. This approach can also provide more accurate predictions of failure times compared to classical lifetime models. With this combination of the strengths of type-II censoring, Bayesian inference and degradation modeling, we hope to offer more powerful tools for reliability and survival analysis.
The remaining sections of the paper include the following. In
Section 2, we describe the determination of the MLEs of the scale and shape parameters. Asymptotic and Boot-t methods of constructing CIs of the parameters are also studied. In
Section 3, we describe Bayesian estimates using importance sampling for the
and
model parameters. In
Section 4, Gibbs and Metropolis sampling are employed to derive sample-based estimates for the predictive density functions of the parameters, as well as the times to failure of the surviving units (
) based on the noticed sample
. In
Section 5, we present a data analysis and a Monte Carlo simulation for numerical comparison purposes.
2. Maximum Likelihood Method
Let
be independent and identically distributed (iid) lifetimes with the PDF in (
2) put under test. The integer of
is pre-fixed, and the experiment stops as soon as we observe the
m-th failure. The first
m failure times (
) form an ordered type-II right-censored random sample, with the largest
lifetimes having been censored. The likelihood function based on a type-II censored sample is given by (Balakrishnan and Cohen [
22])
and the log-likelihood function of (
3) is
where
Based on Ng et al. [
8], we consider
where
Then, we consider
where
and
The ML estimate of
is the solution of
. The nonlinearity of
urges us to use a numerical procedure to solve it for
. The positive square root of the right-hand side of (
5) gives the maximum likelihood estimate (
of
) after calculating the ML estimate (
) of
.
To construct confidence intervals for
and
, we need the observed Fisher information matrix
, which is the negative of second partial derivatives of the log-likelihood function in (
4). It is well-known that the approximation of
is applicable, where
and
. Therefore, the approximations of
CIs for
and
are
and
, respectively, where
and
are the elements of the main diagonal of
and
is
-th upper-point percentile of the standard Gaussian distribution. Usually, for small sample sizes, the CI based on the asymptotic result does not perform well in calculating the CI. For this reason, the CI based on the Boot-t method is an effective method in evaluating the CI; one may refer to, for example, Ahmed [
23]. The algorithm that best describes this method is summarized as follows:
Step 1: Use the ML estimation to estimate and based on the observed informative sample (denoted by and ;
Step 2: Generate a Boot-t sample using and obtained in Step 1; then, calculate the first m observed censored units () under the BS model. Next, compute the corresponding MLEs ( and ) of and and the elements of the main diagonal of ;
Step 3: Define an estimated Boot-t version,
depending on the Boot-t sample generated in Step 2;
Step 4: Generate M = 1000 Boot-t samples and versions of and ; then, obtain the -th and -th sample quantiles of and ;
Step 5: Compute the approximate CIs for and as
and .
3. Bayesian Method
Here, based on a type-II censored sample from the two-parameter BS distribution, we obtain the posterior densities of the
and
parameters in order to present the corresponding Bayesian estimators of the mentioned parameters. To develop the Bayesian estimates, we first present independent priors for
and
based on the approximation presented by Tsay et al. [
24]. Tsay et al. [
24] stated that the error function (
) can be written in a form of exponential function as
where
and
. It is well known that the standard normal CDF can be written in terms of
as
Using (
6) and (
7), we conclude that
According to (
8), the likelihood function in (
3) can be approximated by
If we use non-informative priors, improper posterior and continuous conjugate priors result, so we use the proper priors with known hyperparameters to support the property of posteriors. As stated by Wang et al. [
12], we assume that
has an inverse gamma
distribution, with parameters
denoted by
, and that
also has an inverse gamma distribution with parameters
denoted by
with the following densities:
where
are positive real constants that mirror prior knowledge about the
and
parameters. By combining (
9) and (
10), the joint posterior density of
and
can be written as
where
and
Based on the observed type-II censored sample, the marginal density of
is given by
where
with
denoting the expectation with respect to
. The conditional density of
, given
and the data, is
Now, we proceed to obtain the Bayesian estimators (BEs) of
and
under the squared error loss (SEL) function. The BE of any function of
and
(e.g.,
) under the SEL function is given by
The BEs for
and
cannot be obtained in explicit form because (
12) cannot be evaluated analytically. For this reason, we use an importance sampling technique, as suggested by Chen and Shao [
25], to approximate (
12) and to construct the corresponding credible intervals. Based on the observed type-II censored sample, the Bayes estimator of
is written as
where
denotes the expectation with respect to
. Based on (
11), we also have
As a result, the Bayesian estimate of
can be written as
Equations (
13) and (
14) cannot be solved analytically, so to produce consistent sample-based estimators for
and
and to construct corresponding credible intervals, we employ an importance sampling technique to approximate Equations (
13) and (
14). The Bayesian point estimators of
and
can be determined using the following algorithm:
- 1.
Generate M values of from (say, );
- 2.
For each generated in Step 1, generate M values of from
;
- 3.
Compute and with respect to the values simulated in Step 2;
- 4.
Compute and ;
- 5.
Average the numerators and the denominators of (
13) and (
14) with respect to the
values simulated in Step 1.
Now, the two-sided Bayesian credible confidence intervals, as well as the highest posterior density (HPD) CIs for
and
, can be improved here. Using the simulated values,
Bayesian CIs for the
and
parameters can be computed. Therefore, a
Bayesian CI for
, or
) is
, where
is the
-th percentile of the
values simulated using the above algorithm, with
being the integer part of
x. Since the Bayesian credible CIs do not clarify whether the values of
located inside these intervals have a higher probability than the values located outside the intervals, we present the HPD CI for
. The HPD CI is considered one of the shortest-width CIs; here, the posterior density of any point outside the interval is less than that of any point within the interval. We use a Monte Carlo technique for importance sampling, which was first presented by Chen and Shao [
25] to address the HPD CI for any function of the involved parameters (e.g.,
). We start by arranging the simulated values of
in ascending order to get
then compute the ratios as
Taking in consideration the fact that
M is sufficiently large, the
HPD interval for
is the shortest interval among the intervals (
) for
, with
where
is
-th percentile of
, which can be taken out as follows:
Then, the HPD CIs of and can be obtained accordingly.
4. Bayesian Prediction Method
Here, we discuss the problem of predicting the unseen items in the type-II censored data from the BS distribution. Precisely, our main interest is in the posterior density of the
s-th-order statistic from a sample of size
unseen items. For this, we predict
based on the observed type-II censored sample
. We start by presenting the posterior predictive density of
, given the observed censored data, which has the form of
where
is the conditional density function of
Y, given
T =
t. According to the Markovian property of order statistics (Arnold et al. [
26]), this conditional density is just the conditional density of
Y given
, that is, the pdf of the
s-th-order statistic out of a sample of
from
F left truncated at
. Precisely, it can be rewritten as
.
Let us consider the case when
, in which case
The predictive density of
at any point (
) is then
Visibly, the Bayesian predictive estimate (
) cannot be evaluated directly from (
15) and (
17). Therefore, we suggest Monte Carlo (MC) simulation to create a sample from the predictive distribution. Under the squared error loss (SEL) function, the Bayesian predictors (BPs) of
can be computed as
Based on MC samples
, the simulation-based estimator of
can be computed as
Using algebra, the sample-based predictor of
Y can be simplified as follows:
Furthermore, the approximate estimator given in (
18) can be used to find a two-sided prediction interval for
Y. The
prediction interval for
Y is
, where
L and
U can be computed numerically as
Now, we discuss the use of the Gibbs sampler in estimating the posterior distribution. In fact, to estimate the posterior distribution using the Gibbs sampler, we need to generate samples from the full conditional distribution for each quantity involved. This is true for
and
but not for
. Consequently, we adopt the M–H algorithm in combination with the Gibbs sampler to sample
and
Y directly from their full conditional distributions. We update
via an M–H algorithm, as explained by Tierney [
27], i.e., the normal distribution is the proposal distribution. Using the extended likelihood in (
9) and the joint prior of
and
, the full Bayesian model can be written as
where
is the PDF of the inverse gamma distribution (
) and
is given by
It can be easily seen that the full conditional distribution of
, given
and
, is a known distribution, while the form of the full conditional distribution of
, given
, in (
19) is not a well-known distribution; therefore, we cannot generate
directly. Accordingly, to generate
from the full conditional distribution of
, given
, we use the M–H algorithm with normal proposed distribution. One of the important things in this process is to decrease the rejection rate among all iterations as much as possible. Below, we present an algorithm that depends on the choice of the normal distribution as a proposal distribution and on the use of the M–H algorithm. This method can also be used to find the BEs and to structure the credible intervals for
and
. The Gibbs sampler is considered a Markov chain Monte Carlo (MCMC) technique that simulates a Markov chain based on the full conditional distributions. We use the Gibbs sampler to obtain an approximation of
and the corresponding credible intervals based on the drawing of MCMC samples (
) from the joint posterior distribution. For this reason, we present the M–H algorithm according to the following steps:
- 1.
Start with the MLEs as the initial values (e.g., );
- 2.
Set J = 1;
- 3.
Given
, generate
from
in (
19) with
as the proposal distribution, where
is the variance of
, which can be picked out to be the inverse of the Fisher information. The new values of
can be updated as follows:
- a.
Generate from and u from ;
- b.
If
, then let
; otherwise, go to (a), where
- 4.
Given , generate from ;
- 5.
Set ;
- 6.
Repeat Steps 3–5 M times;
5. Data Analysis and Simulation
Here, an inclusive simulation study is performed to assess the performance of the sample-based estimates and predictors presented in the previous few sections, and we discuss the analysis of data extracted from a type-II censored BS model. All calculations are carried out using R programming software. The Pseudocodes for the Bayesian Estimation and Prediction, Core Functions in R and Software Versions are presented in the
Appendix A,
Appendix B,
Appendix C and
Appendix D, respectively.
5.1. Real Data Analysis
In this subsection, we start by presenting the analysis of a real dataset to explain the execution of the previously presented methods. The data represent the fatigue life of 6061-T6 aluminum coupons cut parallel to the direction of rolling and oscillated at 18 cycles per second with a maximum stress per cycle of 31,000 psi. These data were originally reported by Birnbaum and Saunders [
2]. The dataset is expressed as follows:
70 90 96 97 99 100 103 104 104 105 107 108 108 108 109
109 112 112 113 114 114 114 116 119 120 120 120 121 121 123
124 124 124 124 124 128 128 129 129 130 130 130 131 131 131
131 131 132 132 132 133 134 134 134 134 134 136 136 137 138
138 138 139 139 141 141 142 142 142 142 142 142 144 144 145
146 148 148 149 151 151 152 155 156 157 157 157 157 158 159
162 163 163 164 166 166 168 170 174 196 212
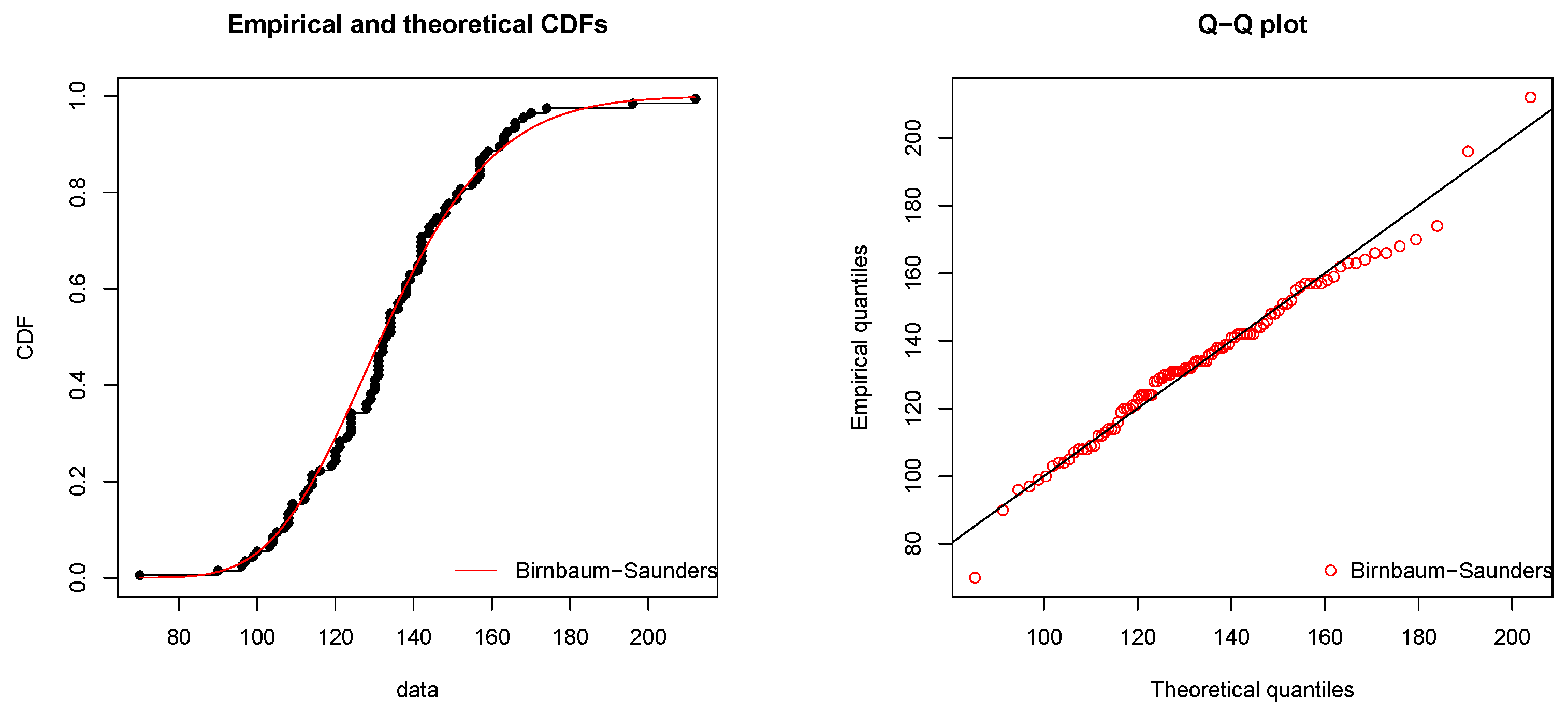
For illustrative purposes, we suggest the following type-II censored samples with (, ) and (, ), i.e., we suggest only 90 and 70 available observations. Before we proceed with further analysis, we first present some basic descriptive statistics concluded from this dataset. The mean, the standard deviation and the coefficient of skewness are 133.73, 22.36 and 0.3355, respectively. The BS model may be used to analyze this dataset because the data are positively skewed. Now, we can simply numerically check the fit of the dataset. The Newton—Raphson method is employed to evaluate the MLEs of the parameters of the BS model. The MLEs of the shape and scale parameters are = 0.1704 and = 131.8213, respectively.
The Kolmogorov–Smirnov (K–S) and Cramer–von Mises (CvM) distances between the empirical and fitted distribution functions and the associated
p-values are given by
,
and
, respectively. These results indicate that the two-parameter Birnbaum–Saunders model fits this dataset perfectly. The empirical and fitted distribution functions are shown in
Figure 1.
Using the observed and noticeable type-II censored data described above, we compute the MLEs and BEs of
and
. We start by generating 50,000 observations to calculate the BEs of
and
using the importance sampler and discard the initial 5000 samples for burn-in. Note that since we do not have any prior knowledge about the data, we assume that the priors are improper (precisely,
) to compute BEs and HPD CIs. The M–H algorithm is also employed to calculate the BEs of
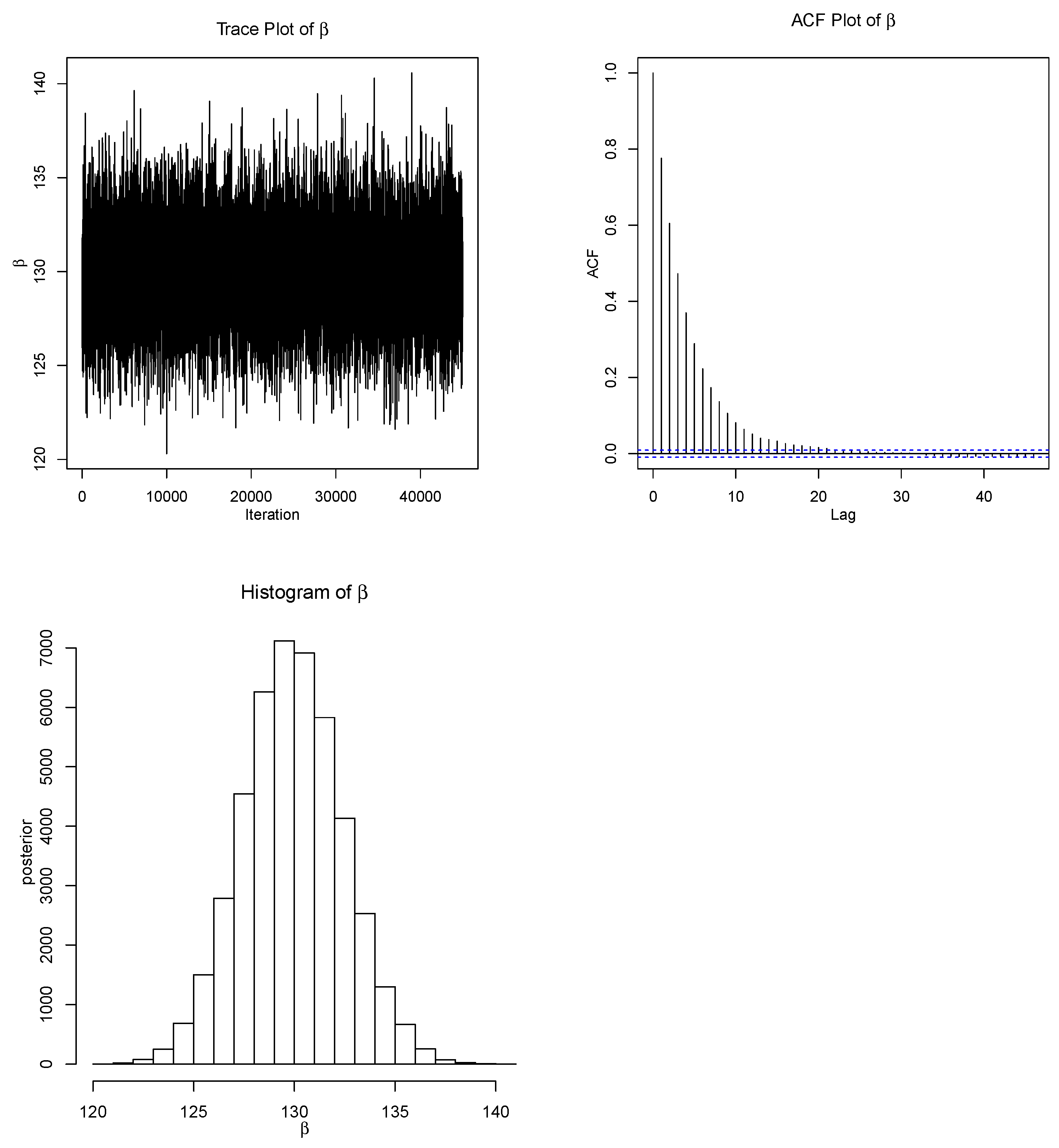
. The Gaussian distribution is an adequate proposal distribution for the full conditional distribution of
, as clearly shown by
Figure 2. Then, we can pick out the parameters of the proposal distribution to determine the best fitted model for the full conditional distribution. As a result, we use the M–H technique with the Gaussian proposal model to generate samples from the target probability distribution. Our natural choice of the initial value of
is its MLE (
), which is computed using the Newton–Raphson method, while the variance of
is the reciprocal of the Fisher information, which is
. We then generate
random variates with
and find that the acceptance rate for this choice of variance is
, which is quite favorable. We burn in the initial 5000 samples and use the remaining observation to compute the BEs.
The trace and ACF plots are used effectively in checking the convergence of the M–H algorithm as a graphical diagnostic convergence tool. The trace and ACF plots for
are shown in
Figure 2. We can easily notice from the trace plot that there is a random scatter about a mean value represented by a solid line, with a fine mixing of the chains for the simulated values of
. We can also easily notice from the ACF plot that the autocorrelation of the chains is very low. Consequently, based on these plots, we can conclude that the M–H algorithm converges rapidly based on the proposed Gaussian distribution.
The outcomes for MLEs and BEs using importance and M–H samplers, in addition to the 95% Boot-t CI, asymptotic CI and HPD CI for
and
, are all displayed in
Table 1.
Now, we consider the prediction of some of the unseen values. The point predicted values and PIs for unseen values are computed as presented in
Table 2. The PIs are constructed under ab SEL function based on importance and M–H algorithms, the details of which are presented in
Section 4. We can easily notice that the PIs established based on the M–H algorithm have the shortest intervals for all cases.
5.2. Simulation Results
Now, we use Monte Carlo simulation to compare the execution of the different estimation and prediction methods presented in the previous sections. We use bias and mean square error (MSE) criteria to compare the performance of the MLEs and BEs. In this simulation, we set the values of the parameters of BS to (, ) and (, ). Additionally, we consider different censoring schemes, along with different effective sample sizes of and 100. To perform the Bayesian analysis effectively, we assume three different priors. For prior 0, i.e., improper prior information, the prior parameters are assumed to take zero values of . Next, two additional proper priors are assumed with same means but different variances to mirror the sensitivity of our inference to variations in the specification of prior parameters. Consequently, prior 1 and prior 2 are assumed to be and , respectively. In this setting, prior 2 is more informative than prior 1. This enables us to evaluate the extent to which the informative prior contributes to the outcomes achieved based on observed values.
Table 3 presents the average widths (AWs) and coverage probabilities (CPs) of 95% CIs for
and
based on Boot-t, asymptotic ML and Bayesian methods with the improper prior (prior 0) and informative priors (prior 1 and prior 2) under the SEL function. For 10,000 replications, the average bias and MSEs of the MLEs and BEs under the SEL of
and
are computed as displayed in
Table 4a,b. We observe from
Table 3a,b that the HPD CIs are shorter than the asymptotic and Boot-t CIs under all priors for
with different values of
m. The performance of HPD CIs tends to be higher under informative priors than that of the asymptotic and Boot-t CIs. The Boot-t method performs well when compared to the asymptotic method in terms of estimating all parameters. It can also be noticed that when
n increases, all CI types tend to become shorter. The simulated CPs are very close to each other for all these CIs. As shown in
Table 4a,b, in terms of bias and MSEs, the BEs perform well for all values of
n and
m. For all sample sizes, we can notice that the Bayesian estimates of
and
are better than the MLEs, as indicated by their lower bias and MSEs compared to MLE results. Additionally, as expected, we can notice that the BEs under the more informative prior 2 are better than the less informative and non-informative priors. Finally, we can clearly conclude that the results of BEs are sensitive to the presumed values of the prior parameters, specifically for the informative prior (prior 2).
For the prediction problem, different type-II censored schemes are randomly generated from the BS model and for
. Then, the average bias and mean square prediction errors (MSPEs) are computed for the predictors and PIs for censored times. The bias and MSPEs of BPs are computed over 10,000 replications for non-informative and informative priors. The values of the bias and MSPEs are reported in
Table 5 and
Table 6 for the predetermined censoring schemes.
Table 7 and
Table 8 include the AWs and CPs of
PIs based on importance, M–H and Boot-t. It can be noticed from
Table 5 and
Table 6 that the BPs using the M–H method perform well compared to the importance sampler method in terms of the reported values of bias and MSPE for all priors. It is observed for all sample sizes that both importance sampling and M–H methods perform well under the more informative prior 2 than those using the less informative or non-informative priors, with obvious privilege for the M–H method due to its lower bias and MSPE values. As foreseen, when
m increases, the MSPEs of the censored times tend to be larger due to the increase in the quantity of observed data. From
Table 7 and
Table 8, in terms of the AW criterion, a clear clue can be observed that supports the conclusion that the Bayesian PIs based on M–H sampling are the best PIs. We can also noticed that the PIs calculated using importance sampling perform better than those calculated using the Boot-t method based on the reported AW values. Furthermore, as anticipated, the farther the censored value is from the last observed value, the larger the AW values are compared to those that are closer. The CP values are close to each other. It can also be seen that the Bayesian PIs under the informative prior (prior 2) behave better than PIs based on other priors. Furthermore, the simulated CPs are high and tend to be close to the accurate prediction coefficient (
).
6. Discussion and Conclusions
In this study, we investigated parameter estimation and prediction methods for type-II censored BS data. We compared frequentist and Bayesian approaches, employing MCMC sampling to estimate parameters and construct credible intervals. Our results shows that that two methods provide comparable estimates for the shape and scale parameters. The Bayesian method provides more reliable and flexible prediction intervals compared to classical methods, especially when prior information is available. By applying these methods to simulated and real-world data, we have shown the practical advantage of the presented approaches in reliability and survival analysis.
Failure data, like the fatigue life of materials, are of credible interest in reliability analysis. Therefore, methods based on degradation data are increasingly common in industries such as manufacturing, healthcare and materials science. When the process leading to failure is slow or progressive with deteriorating performance over time, degradation data models are usually used. These models can employed effectively to better understanding how a product or system degrades before it fails, including through the use of functional models, stochastic processes and random-effects models.
Ruiz et al. [
28], Zhai et al. [
29], and Xu et al. [
30], among others, have recently focused on using degradation models to evaluate product reliability. For example, Ruiz et al. [
28] introduced generalized functional mixed models for accelerated degradation testing, which allowed them to predict failure times accurately by modeling the degradation process under stress. Zhai et al. [
29] suggested a random-effects Wiener process approach to model product degradation with heterogeneity, considering the variability between products that may fail at different rates. Similarly, Xu et al. [
30] developed a multivariate Student-t process model for degradation data with tail-weighted distributions to study common problems in industrial reliability.
Our current study mainly focuses on failure time data under type-II censoring, where the data represent the times at which components fail under stress or other conditions. The two approaches are applied in different contexts. The main advantage of degradation models is their ability to model the gradual deterioration of products, which allows for more careful estimations of remaining beneficial life before failure occurs. On the contrary, failure time analysis under type-II censoring is more convenient when data are collected after a certain number of failures have been observed. This makes it ideal for situations where products are tested to failure.
There is a clear possibility that future research will integrate these models with type-II censoring, as our current methods do not directly associate degradation data models. This combination might provide more accurate and comprehensive reliability assessments, especially when there is a relationship between failure times and degradation patterns for some products. By combining degradation modeling with the Bayesian approach used in this work, we could offer a more flexible and deep approach to handling both types of data, which, in turn, can enable better predictions of the possible failure times of a product based on its degradation path.
Moreover, this study provides valuable insights into parameter estimation and prediction using type-II censored BS data. However, the growing importance of degradation data models in reliability analysis calls for further consideration of how these models can be integrated with our presented methods. Future promising work will study these extensions, as well as the application of our methods to larger datasets, multi-sample progressive censoring schemes and industrial applications involving degradation data.





{kind=link}
{kind=link}