Abstract
With the increasing amount of cloud-based speech files, the privacy protection of speech files faces significant challenges. Therefore, integrity authentication of speech files is crucial, and there are two pivotal problems: (1) how to achieve fine-grained and highly accurate tampering detection and (2) how to perform high-quality tampering recovery under high tampering ratios. Tampering detection methods and tampering recovery methods of existing speech integrity authentication are mutually balanced, and most tampering recovery methods are carried out under ideal tampering conditions. This paper proposes an encrypted speech integrity authentication method that can simultaneously address both of problems, and its main contributions are as follows: (1) A 2-least significant bit (2-LSB)-based dual fragile watermarking method is proposed to improve tampering detection performance. This method constructs correlations between encrypted speech sampling points by 2-LSB-based fragile watermarking embedding method and achieves low-error tampering detection of tampered sampling points based on four types of fragile watermarkings. (2) A speech self-recovery model based on residual recovery-based linear interpolation (R2-Lerp) is proposed to achieve tampering recovery under high tampering ratios. This method constructs the model based on the correlation between tampered sampling points and their surrounding sampling points and refines the scenarios of the model according to the tampering situation of the sampling points, with experimental results showing that the recovered speech exhibits improved auditory quality and intelligibility. (3) A scrambling encryption algorithm based on the Lorenz mapping is proposed as the speech encryption method. This method scrambles the speech sampling points several times through 4-dimensional chaotic sequence, with experimental results showing that this method not only ensures security but also slightly improves the effect of tampering recovery.
Keywords:
encrypted speech integrity authentication; tamper detection; tamper recovery; least significant bit; residual recovery-based linear interpolation MSC:
94A12
1. Introduction
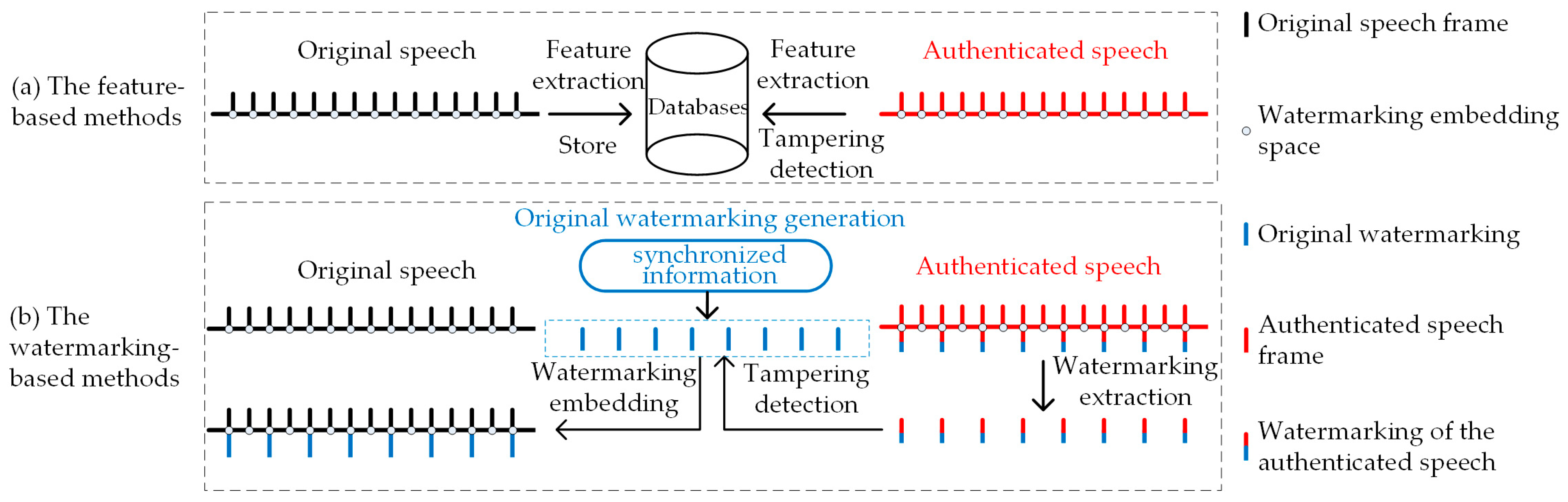
The rapid development and widespread application of digital technologies and cloud computing have greatly facilitated the use and transmission of speech files. Consequently, this has led to illegal activities related to speech files, such as unauthorized distribution, unlawful copying, content modification, piracy, and infringements on the copyright of multimedia content [1]. Cloud-based speech files face privacy protection issues such as privacy leakage and malicious tampering [1,2,3] despite the implementation of security measures like encryption. However, the development of privacy protection for encrypted speech is relatively lagging, which proposes new requirements for integrity authentication of encrypted speech. Integrity authentication of encrypted speech aims to detect and recover; it detects whether the speech has been maliciously tampered and determines the tampered location, then recovers the information at the tampered location. Therefore, it can be observed that existing integrity authentication methods typically consist of tampering detection and tampering recovery. Tampering detection methods can be categorized into the feature-based methods (TFM) and the watermark-based methods (TWM). Tampering recovery methods can be categorized into the recovery information-based methods (TRM) and the correlation-based methods (TCM). However, these two components are not independent: the accuracy of tampering detection affects the tampering recovery effect, and the choice of a tampering recovery method also influences the tampering detection process.
During the tampering detection process in integrity authentication, as shown in Figure 1a, TFM [4,5,6] relies on the databases for storing speech features. In the big data context, extra databases will give rise to problems such as cost, management, and security. Therefore, in the existing research on integrity authentication, there is a growing trend to utilize TWM as the tampering detection method of choice. Synchronized information such as perceptual hash [7,8,9], speech features [10,11], most significant bits (MSB) [12], and compression information [13] often contains original speech information. Researchers have commonly used methods such as Piecewise Linear Chaotic Map (PWLCM) [14], mask [15] and Binaries of Message Size Encoding (BMSE) [16] to encode synchronized information as fragile watermarking to ensure information security. However, as shown in Figure 1b, the TWM-based integrity authentication method often requires a portion of watermarking embedding space to be utilized for embedding additional information, resulting in insufficient watermarking embedding capacity for tampering detection watermarking. Consequently, existing TWM generally exhibits coarse-grained tampering detection, making it insufficient to locate the tampered sampling points, while fine-grained methods suffer from significant tampering detection errors.
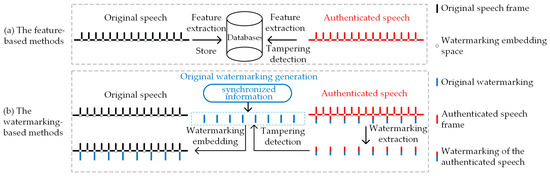
Figure 1.
Principles of existing tampering detection methods: TFM extracts the original speech features to construct the database and extracts the authenticated speech features for authentication during tampering detection. TWM constructs the synchronized information as original watermarking and, then, embeds and extracts the watermarking of the authenticated speech for authentication with original watermarking during tampering detection.
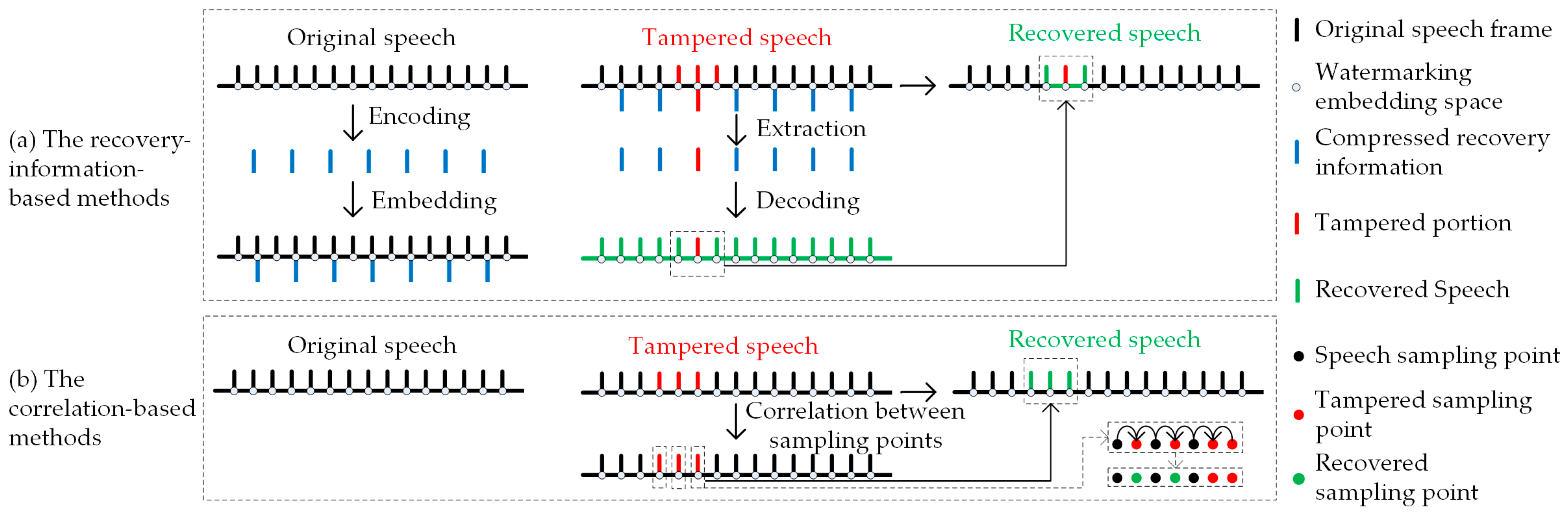
For the tampering detection process in integrity authentication, methods such as speech coding [17,18], compressed sensing [19] and speech features compression [20,21] are commonly used to construct compressed recovery information for TRM. However, as shown in Figure 2a, the compressed recovery information occupies a certain amount of watermarking embedding space, and when both the speech segments and their corresponding recovery information are damaged simultaneously, tampering recovery cannot be performed. Although methods such as misaligned embedding strategies [22] are used to address this problem, there still remains the problem of unrecoverable tampered speech especially under high tampering ratios. In light of these challenges, some researchers propose TCM that does not rely on recovery information. TCM uses linear interpolation (Lerp) [23,24], fitting [6], prediction, and other methods to utilize the correlation between sampling points and recover tampered sampling points. However, as shown in Figure 2b, under high tampering ratios, consecutively tampered sampling points may exhibit poor correlation, making it impossible to recover.
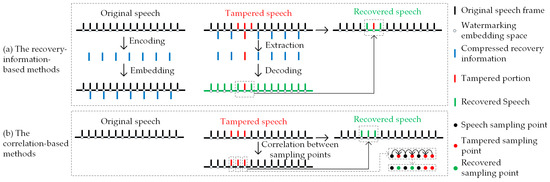
Figure 2.
Principles of existing tampering recovery methods: TRM encodes the original speech as compressed recovery information and embeds and decodes the extracted watermarking in the tampered speech as recovered speech during tampering recovery. TCM recovers the tampered sampling points by correlation between sampling points during tampering recovery.
In summary, there are two pivotal problems in the integrity authentication of encrypted speech: (1) “Granularity and accuracy”: How to refine the tampering detection granularity to the level of sampling points and reduce the tampering detection errors? (2) “High tampering ratio”: How to perform tampering recovery and ensure its effect under high tampering ratios? Existing tampering detection methods are mostly limited by tampering recovery methods, which limits their ability to embed more tampering detection watermarking. Some tampering detection methods require the construction of additional databases, impacting the security of the speech. Tampering recovery methods are often evaluated under ideal tampering conditions [17,20,21] (the tampering process does not destroy the corresponding recovery information even when the tampering ratio reaches 50% [19]) or only discuss scenarios with tampering ratios below 30% [6,23,24], making them unable to meet the practical requirements. These problems simultaneously impose requirements on both tampering detection and tampering recovery, and the mutual influence between tampering detection methods and tampering recovery methods further increases the difficulty. Existing methods generally focus on improving only one of these problems and are unable to address both simultaneously. The presence of these problems significantly affects the practicality of integrity authentication methods and restricts the development of speech integrity authentication techniques.
In order to comprehensively and effectively address these problems, this paper proposes an encrypted speech integrity authentication method based on the principles of TWM and TCM. TCM provides sufficient watermarking embedding space to improve the effect of tampering detection, which imposes higher requirements on the tampering recovery effect under high tampering ratios (comparable to or even better than TRM). Meanwhile, TWM is expected to improve the performance of tampering detection methods by improving the processes of watermarking construction, embedding, and extraction when it has sufficient embedding space.
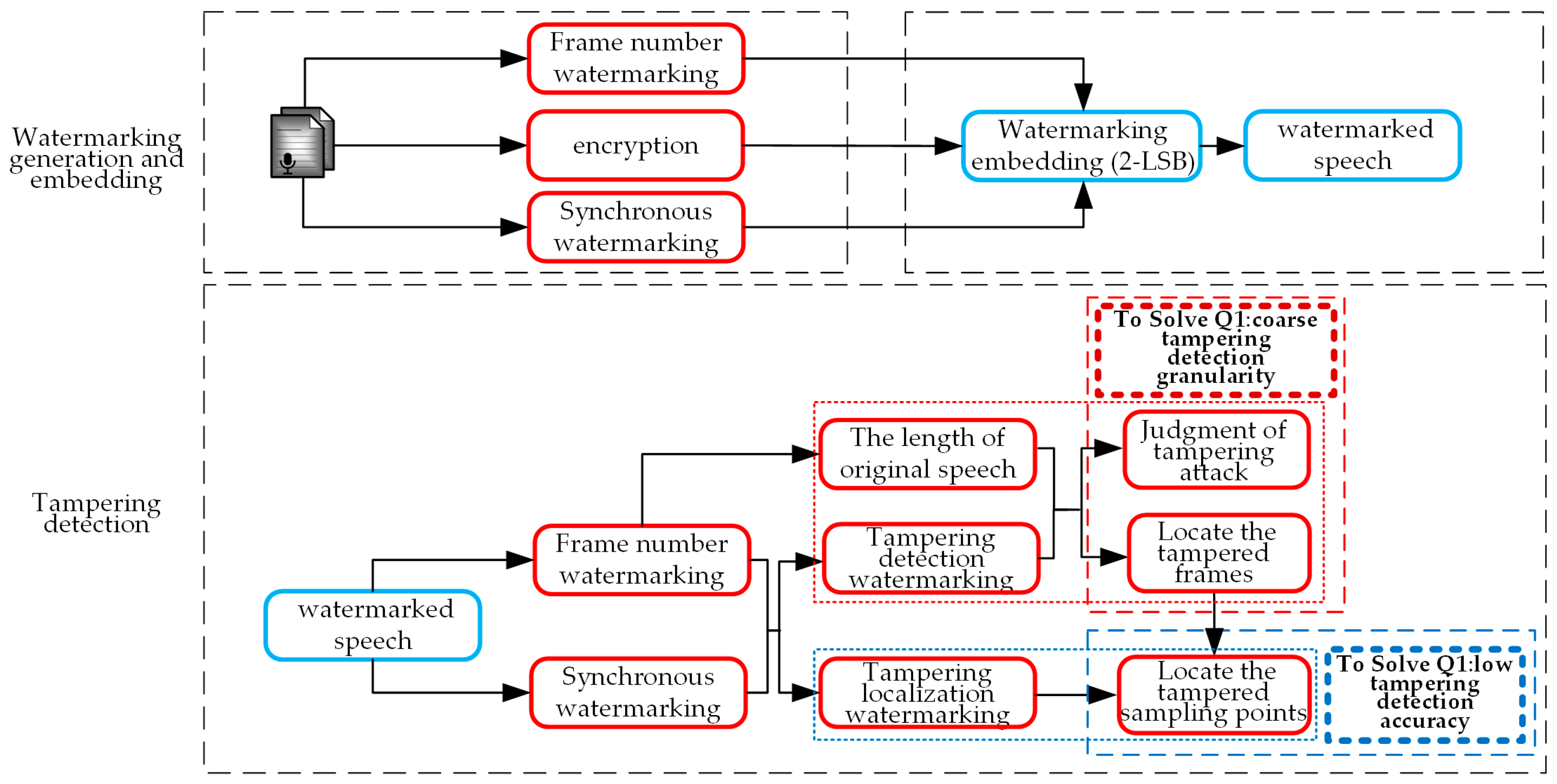
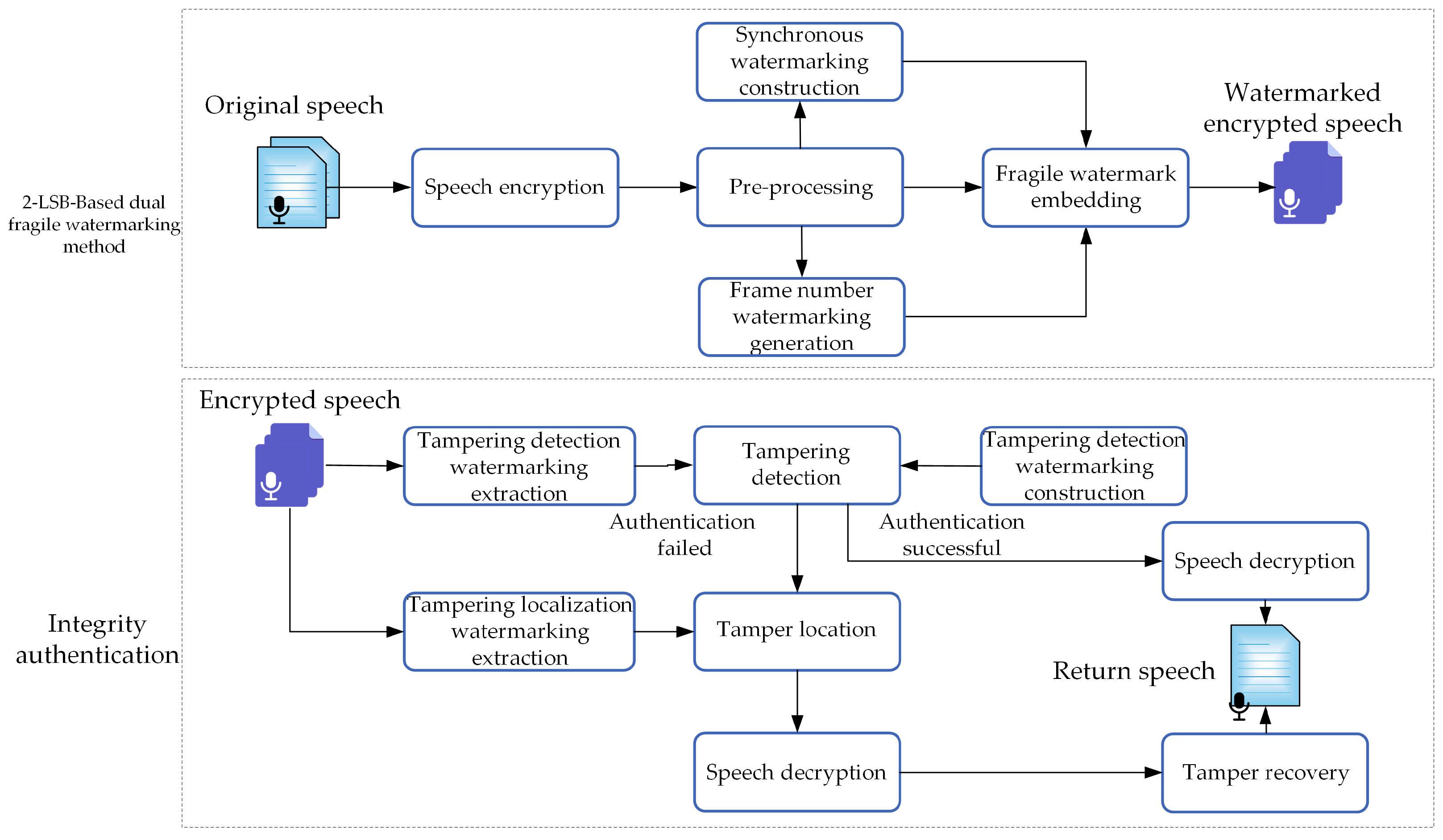
To address these requirements and challenges, this paper proposes an encrypted speech integrity authentication method. For problem (1), this paper proposes a 2-least significant bit (2-LSB)-based dual fragile watermarking method for tampering detection, and the process is shown in Figure 3. During watermarking generation, frame number watermarking constructed from the frame number is used to confirm the length of the original speech, and the correlation of encrypted speech sampling points is constructed synchronization watermarking for detecting the tampered sampling points. During watermarking embedding, 2-bit watermarking information is embedded in a sampling point by 2-LSB to construct the correlation of encrypted speech sampling points. The extracted watermarking can be constructed as tampering detection watermarking by this embedding method during watermarking extraction. During tampering detection, the extracted frame number watermarking and synchronization watermarking are separately constructed as tampering detection watermarking and tampering localization watermarking, in which tampering detection watermarking detects whether speech frames have been tampered, and tampering localization watermarking locates the tampered sampling points.
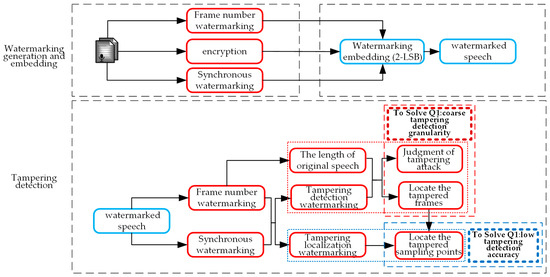
Figure 3.
The 2-LSB-based dual fragile watermarking method.
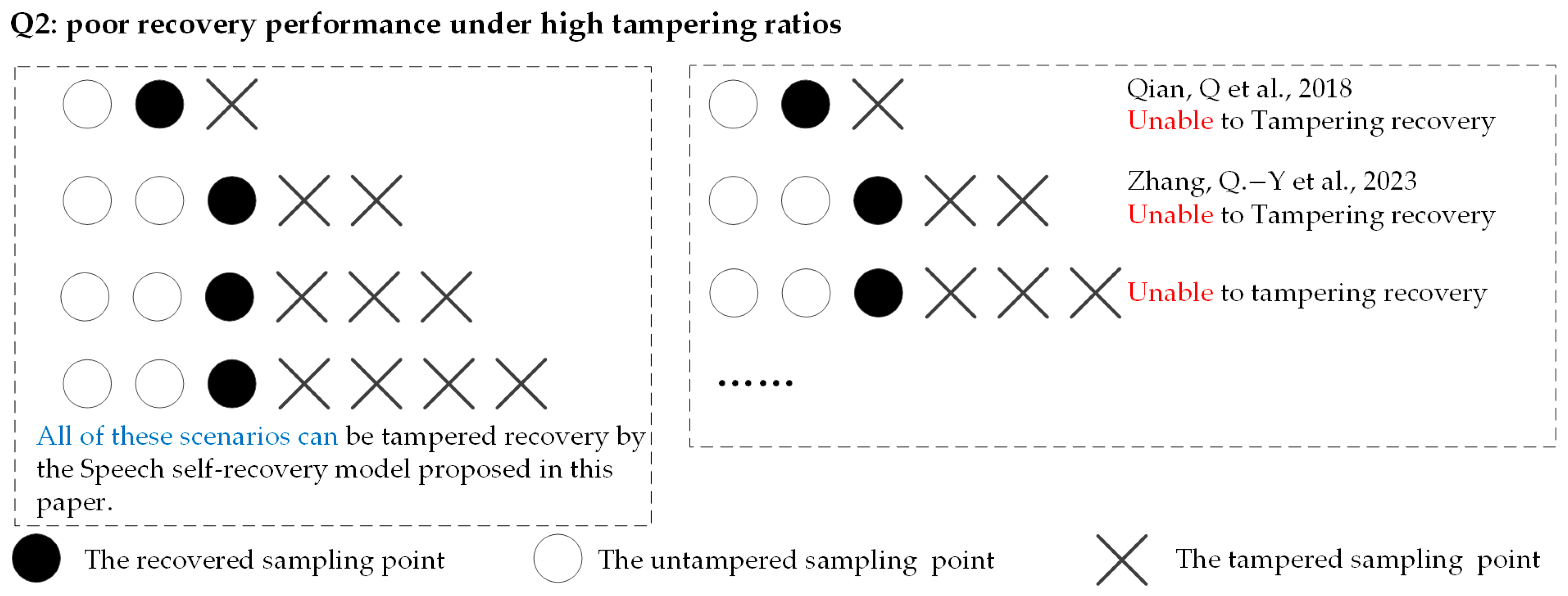
For problem (2), this paper proposes a speech self-recovery model based on residual recovery-based linear interpolation (R2-Lerp). As shown in Figure 4, compared to existing TCM, this model allows for tampering recovery of the target sampling point even when the surrounding sampling points have been arbitrarily tampered. Due to the varying degrees of tampering around the target sampling points under high tampering ratios, this model is refined into 11 scenarios based on the tampered situation of the sampling points. This method constructs corresponding tampering recovery formulas for each scenario in order to expect better recovery performance in each tampering situation.
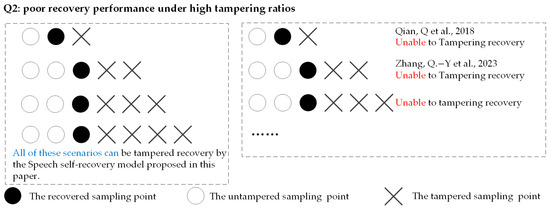
Figure 4.
Advantages of the proposed speech self-recovery model compared to existing methods [23,24].
The main contributions of the proposed method can be summarized as follows:
- (1)
- A 2-LSB-based dual fragile watermarking method is proposed to accurately locate the tampered sampling points. This method introduces a 2-LSB-based fragile watermarking embedding method to establish the correlation of encrypted speech sampling points. Frame number watermarking and synchronization watermarking are constructed as tampering detection watermarking and tampering localization watermarking during the tampering detection process, collectively enhancing the granularity and accuracy of tampering detection.
- (2)
- A speech self-recovery model based on Lerp [23] and R2-Lerp [24] is proposed to perform tampering recovery even under a 50% tampering ratio. This method extends the correlation of tampered sampling points to the surrounding five sampling points and constructs a more refined speech recovery model. This method exhibits favorable tampering recovery results from different perspectives, such as SNR, auditory quality, and intelligibility under different tampering ratios.
- (3)
- A scrambling encryption algorithm based on the Lorenz mapping is proposed to encrypt speech. By comparing the encryption performance and tampering recovery performance with six commonly used traditional scrambling encryption methods, the proposed encryption algorithm maintains a certain degree of security while slightly improving the tampering recovery effect.
The remainder of the work is organized as follows: Section 2 provides a detailed description of Lorenz mapping, LSB, and R2-Lerp. Section 3 introduces the encrypted speech integrity authentication method and describes the processing in detail. Section 4 shows the performance of our presented approach through the experimental results and the performance analysis. Finally, Section 5 concludes the work of this paper.
2. Basic Concepts
This section presents some basic concepts in the proposed method, including Lorenz mappings used for speech encryption, LSB for watermarking embedding, and R2-Lerp for tampering recovery.
2.1. Lorenz Mapping
Lorenz mapping [25], as a type of hyper-chaotic system with complex chaotic behavior, is commonly used as a scrambling sequence for encryption. State variables w1, w2, w3, and w4 are calculated as shown in Equation (1).
When the parameters α = 10, γ = 28, β = 8/3, ρ is in the range of −1.52 < ρ < −0.06, and the system exhibits the hyper-chaotic behavior.
2.2. Least Significant Bit Method
The LSB method embeds information by modifying the least significant bit of the carrier file and is widely applied in speech information hiding and audio steganography [26,27,28]. Compared with the digital watermarking method based on the frequency domain, this method is simple and efficient and provides high transparency, but it has poorer resistance to various audio content-preserving operations. The fragile watermarking method in this paper is mainly used to detect whether the speech has been maliciously tampered, and robustness is typically a key indicator to consider when evaluating robust watermarking for legitimacy authentication. However, the robustness of fragile watermarking can hinder the detection of malicious tampering. Therefore, the method in this paper does not need to consider the robustness of the watermarking method, thus effectively avoiding the problem of poor robustness in the LSB method.
2.3. Residual Recovery-Based Linear Interpolation
Lerp calculates the approximate value y2 at a point x2 within the interval [x1, x3] by known two sampling points (x1, y1) and (x3, y3), and the calculation formula is shown in Equation (2):
Residual recovery-based linear interpolation [24] uses four sampling points (xt−2, yt−2), (xt−1, yt−1), (xt+1, yt+1), and (xt+2, yt+2) to optimize the approximate value yt of the tampered sampling point xt, and the calculation formula is shown in Equation (3):
3. The Proposed Scheme
Figure 5 shows the flowchart of the encrypted speech integrity authentication method. The proposed method is mainly composed of four parts: speech encryption, a 2-LSB-based dual fragile watermarking method, integrity authentication, and tamper recovery. In this section, we will introduce the specific methods for these four parts.
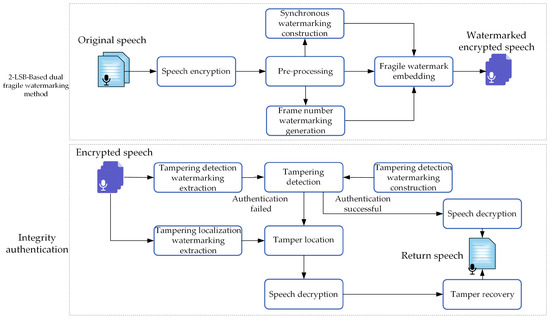
Figure 5.
The flowchart of the encrypted speech integrity authentication method.
The proposed method can be used for tampering detection and tampering recovery of important speech (involving economics, judiciary, etc.). Important speech may face malicious tampering that renders it unusable or misleading alterations during its use, often resulting in serious consequences such as economic losses. The proposed method can detect such malicious tampering, accurately locate the tampered sampling points even under high tampering ratios, and perform high-quality recovery, ensuring the normal use of important speech.
For example, there is an important speech of 60 s length that needs to be stored in the cloud. This speech is encrypted and stored in the cloud using the proposed algorithm as a security measure. Later, we suppose this encrypted speech in the cloud is attacked and the segment from 15 s to 45 s is deleted. When this speech is needed, it is downloaded from the cloud, and integrity authentication is performed by the proposed tampering detection algorithm. This method can detect that the speech has been subjected to the deletion attack and that the deleted sampling points are from 15 s to 45 s. Subsequently, the tampering recovery algorithm is used to restore the deleted sampling points. In this way, the user can obtain a speech that is semantically consistent with the original speech and has comparable auditory quality. This recovered important speech still meets relevant requirements.
3.1. The Speech Encryption Algorithm
The tampering recovery method in this paper requires that the encryption algorithm used should not affect the normal decryption of other sampling points when some encrypted speech sampling points are tampered. The proposed tampering recovery method requires several rounds of scrambling encryption to satisfy the requirements of correlation between the original speech sampling points.
Even after partial tampering of the encrypted speech, the untampered portions can still be decrypted.
Step 1: Speech division. The speech S with length L is cut into non-overlapping frames; the frame length is LF and the number of frames is LN = L/LF, and the speech matrix PS with dimensions LN × LF is generated. If the last frame of PS is shorter than LF, there is zero-padding.
Step 2: Chaotic sequences generation. After setting the initial values of key K and the parameters ρ, the chaotic mapping in Section 2.1 is used to generate the chaotic sequences W1, W2, W3, and W4. The elements of the chaotic sequences are sorted in ascending order, and the indexes WI1, WI2, WI3, and WI4 corresponding to the original position of each element after sorting are used as the new chaotic sequences.
Step 3: Scrambling encryption. After getting LN + LF − 1 groups of diagonal elements from (LN, 1) to (1, LF) of PS and dividing WI1 into LN + LF − 1 groups based on the data size of each group, the elements in each group are sorted in ascending order to obtain the index sequence matrix I1. Each group of diagonal elements is scrambled by I1, and the scrambled diagonal elements are recombined to form matrix PS′1. Then, in order to achieve sufficient scrambling of the sampling points near (LN, 1) and (1, LF), the above process in Step 3 is repeated using WI2 from (LN, LF) to (1, 1) of PS′1, and the encrypted speech matrix PS″1 is obtained.
Step 4: Second-round scrambling encryption. To further enhance the global randomness of encrypted speech sampling points, WI3 into LF groups are divided evenly, and the elements in each group are sorted in ascending order to obtain the index sequence matrix I3. Each column elements of PS″1 are scrambled to obtain matrix PS′2. Then, the above process in Step 4 is repeated using WI4 from (LN, LF) to (1, 1) of PS′2, and matrix PS″2 with dimensions LN × LF is obtained.
Step 5: Reconstructing the speech. PS2″ is converted into a matrix of dimensions L × 1, and then, PS2″ is reconstructed into the encrypted speech.
Step 6: Speech decryption. The decryption process is the inverse of the encryption process.
3.2. 2-LSB-Based Dual Fragile Watermarking Method
The proposed watermarking method consists of two parts: watermarking generation and embedding, and watermarking extraction, with the watermarking extraction taking place during the integrity authentication phase.
3.2.1. Watermarking Generation and Embedding
In this paper’s speech library, the SNR of the speech retained three decimal points with the original speech being more than 45 dB, which means that modifying the fourth decimal place of each sampling point to embed watermarking has little impact on the speech quality.
Step 1: Frame number watermarking generation. Extract the frame number f1 of f-th frame from PS2″, calculate the difference between LN and f1 to construct the frame number f2, reconstruct the order of the digits from the thousands place to the ones place of f1 and f2 into the frame number matrix wf of 8 × 1, in which the frame number less than 1000 is set the insufficient places to zero, and convert wf into a 4-bit binary matrix to construct the frame number watermarking wff of 32 × 1.
Step 2: Synchronous watermarking construction. Take LF = 128 as an example. Extract the fourth decimal place of the last 96 sampling points of f-th frame and convert it into a 4-bit binary matrix spb and extract the third dimension of spb to construct a matrix spb′ of 96 × 1. Taking two sampling points spi and spi+1 as a group, construct 96 sampling points with the synchronous watermarking ws of 96 × 2. Construct the watermarking ws as in Equation (4).
Step 3: Watermarking embedding. Extract the fourth decimal place of the sampling points in f-th frame and convert it into a 4-bit binary matrix bm. Replace the third dimension bm3 and the fourth dimension bm4 of bm with the watermarking to embed the watermarking. The watermarking is embedded in Equations (5) and (6). Convert bm′ back into the fourth decimal place of the sampling points in f-th frame. If the value of the fourth decimal place is 10 or 11, modify it to 6 or 7.
Step 4: Reconstruct the watermarked speech. Repeat the above process for all frames of PS2″ to construct the PSW and then reconstruct the watermarked encrypted speech WE from PSW using Step 5 in Section 3.1.
3.2.2. Watermarking Extraction
The extracted watermarking in this paper mainly includes tampering detection watermarking and tampering localization watermarking. The tampering detection watermarking is used to detect whether the speech to be authenticated has been tampered and to identify the type of tamper; whereas, the tampering localization watermarking is used to locate the tampered sampling points. The tampering localization watermarking is an LF × 2 matrix extracted from the authenticated speech, which includes frame number watermarking and synchronization watermarking embedded during the watermarking embedding process. The tampering detection watermark is an LF × 1 matrix, obtained by performing XOR on the 2 bits of watermarking information in each dimension of the tampering localization watermark.
Step 1: Original tampering detection watermarking construction. The original tampering detection watermarking is constructed as shown in Figure 6, and the length of watermarking is 128 bits (equal to the value of LF), in which the first 32 bits are set to 0 and the remaining 96 bits are the alternations of null and 1 (the first 32 bits are the XOR of the embedded frame number watermarking, and the remaining 96 bits are the XOR of the corresponding position of the synchronized watermarking). The empty positions are skipped during the tampering detection.
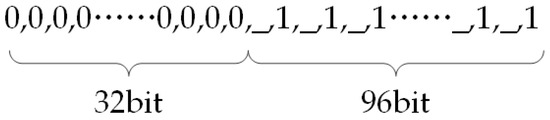
Figure 6.
Construction of the original tampering detection watermarking.
Step 2: Watermarking extraction. The encrypted speech to be authenticated WE′ constructs WEM according to Step 1 in Section 3.1. The fourth decimal place of the WEM sampling points is extracted and converted into a 4-bit binary matrix bm″. The third dimension bm3″ and the fourth dimension bm4″ of bm″ are extracted to construct the tampering localization watermarking wl, wl = [wlf, wls], in which wlf is the extracted frame number watermarking and wls is the extracted synchronous watermarking. XOR is performed with the bm3″ and bm4″ to construct the tampering detection watermarking wd.
3.3. Integrity Authentication
Integrity authentication includes two parts: tampering detection and tampering localization. The tampering detection method can determine whether the authenticated speech has been tampered, as well as the type of attack. If tampering is detected, the tampering localization process is used to identify the tampered sampling points.
3.3.1. Tampering Detection
Step 1: The frame tampering detection. After receiving the WE′ of length L′, construct the tampering detection watermarking according to Step 1 in Section 3.2.2 and extract the tampering detection watermarking according to Step 2 in Section 3.2.2. Measure the similarity between them by the normalized Hamming distance and the sliding window. The sliding window can detect tampered frames even after a desynchronization attack. The number of untampered frames is nf.
Step 2: Determine the length of the original speech. Select an authenticated frame, extract the frame number watermarking from the tampering localization watermarking, and convert the frame number watermarking into the 8-bit binary matrix in groups of 4 bits. Reconstruct every 4 bits of the 8-bit binary matrix into the frame numbers f′1 and f′2 by thousands to ones bits and determine the original speech length Lo by f′1 and f′2 as in Equation (7) where n′f is the number of original speech frames.
Step 3: Judgment of tampering attack. If L′ = Lo and n′f = nf, WE′ has not been attacked; if L′ = Lo and n′f > nf, WE′ has been mute or a substitution; if L′ > Lo, WE′ has been an insertion; if L′ < Lo, WE′ has been a deletion.
3.3.2. Tampering Localization
Step 1: The watermarking of WE′ is extracted and the watermarking of the original speech is reconstructed. When WE′ fails authentication, the frame numbers sf and ef of the untampered frames at both ends of the unauthenticated frame tf are extracted according to Step 2 in Section 3.3.1. The first frame of the tampered sampling point is sf′ = sf + 1 and the last frame of the tampered sampling point is ef′ = ef − 1. The frame number watermarking w′ff and w″ff of sf′ and ef′ are constructed according to Step 1 in Section 3.2.1, and the tampering localization watermarking w′l1 and w′l2 of sf′ and ef′ are extracted according to Step 2 in Section 3.2.2 in which w′lf and w″lf are the extracted frame number watermarking and w′ls and w″ls are the extracted synchronous watermarking.
Step 2: Tampering localization. w′lf and w′f, w″lf and w″ff are tampered localization by similarity measurement, and w′ls and w″ls are tampered localization by Equation (8). The positions of the tampered start xsp and the tampered end xep are located so that the tampered area can be determined as [xsp, xep]. Then, localization of all unauthenticated parts in WE′ is tampered.
Step 3: Tamper localization of deletion attack. Tampering localization on frames sf and ef, sf′ and ef′ is according to Step 2.
3.4. Tampering Recovery Method
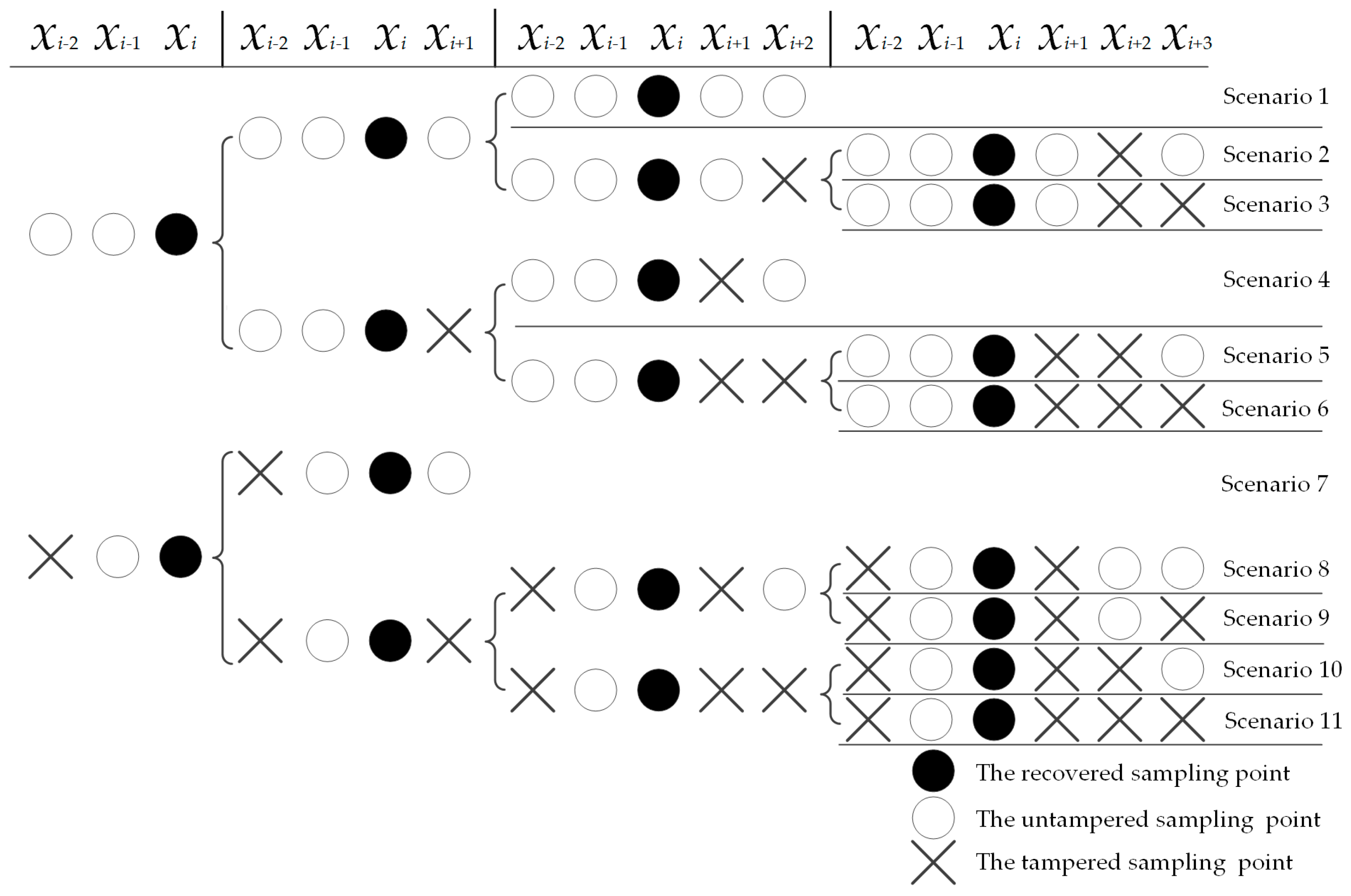
This paper proposes a speech self-recovery model that aims to sequentially recovery tampered sampling points. Based on the correlation of 5 sampling points xi−2, xi−1, xi+1, xi+2, and xi+3 around the tampered sampling point xi, combined with the tampered situation of the 5 sampling points, the tampering recovery scenarios for the tampered sampling point xi are classified into 11 scenarios.
3.4.1. Speech Self-Recovery Model Based on R2-Lerp
The proposed tampering recovery scenarios are shown in Figure 7. To minimize the impact of the destroyed sampling points on the tampering recovery of xi and avoid scenarios that both sampling points xi−2 and xi−1 are destroyed, the method in this paper does not recovery continuously destroyed of four or more sampling points in the first recovery process.
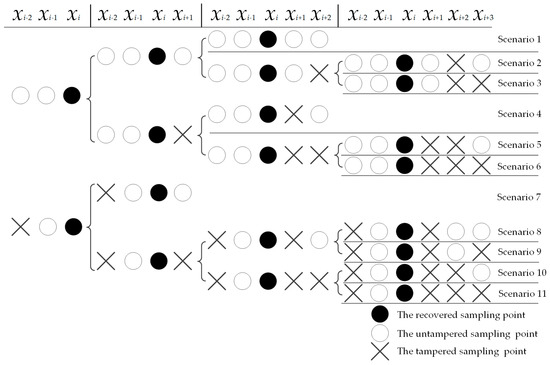
Figure 7.
The proposed tampering recovery scenarios.
Scenario 1: When the sampling points (xi−2, yi−2), (xi−1, yi−1), (xi+1, yi+1), and (xi+2, yi+2) are untampered, the approximate value yi of xi is calculated by R2-Lerp through yi−2, yi−1, yi+1 and yi+2 as in Equation (9).
Scenario 2: When the sampling points (xi+2, yi+2) are tampered, the approximate value yi+2′ of xi+2 is calculated by Lerp through yi+1 and yi+3, and the approximate value yi of xi is calculated by R2-Lerp through yi−2, yi−1, yi+1 and yi+2′ as in Equation (10).
Scenario 3: When the sampling points (xi+2, yi+2) and (xi+3, yi+3) are tampered, the approximate value yi of xi is calculated by Lerp through yi−1 and yi+1 as in Equation (11).
Scenario 4: When the sampling points (xi+1, yi+1) are tampered, the approximate value yi+1′ of xi+1 is calculated by Lerp through yi and yi+2, and the approximate value yi of xi is calculated by R2-Lerp through yi−2, yi−1, yi+1′ and yi+2 as in Equation (12).
Scenario 5: When the sampling points (xi+1, yi+1) and (xi+2, yi+2) are tampered, the approximate value yi+1′ of xi+1 is calculated by Lerp through yi and yi+2, and the approximate value yi+2′ of xi+2 is calculated by R2-Lerp through yi+1′ and yi+3; then, the approximate value yi of xi is calculated by R2-Lerp through yi−2, yi−1, yi+1′ and yi+2′ as in Equation (13).
Scenario 6: When the sampling points (xi+1, yi+1), (xi+2, yi+2), and (xi+3, yi+3) are tampered, the first tamper recovery is abandoned. Then, the second tampering recovery is carried out at the positions of four or more consecutively tampered sampling points. The approximate value y is calculated through (xi−1, yi−1) and (xi+nt, yi+nt) as in Equation (14), in which nt is the number of tampered sampling points, xi−1 and xi+nt are the untampered sampling points.
Scenario 7: When the sampling points (xi−2, yi−2), (xi+2, yi+2), and (xi+3, yi+3) are tampered, tamper recovery by the recovery method of Scenario 3.
Scenario 8: When the sampling points (xi−2, yi−2) and (xi+1, yi+1) are tampered, the approximate value yi+1′ of xi+1 is calculated by R2-Lerp through yi−1, yi, yi+2 and yi+3, and the approximate value yi of xi is calculated by Lerp through yi−1 and yi+1′ as in Equation (15).
Scenario 9: When the sampling points (xi−2, yi−2), (xi+1, yi+1), and (xi+3, yi+3) are tampered, the approximate value yi+1′ of xi+1 is calculated by Lerp through yi and yi+2, and the approximate value yi of xi is calculated by Lerp through yi−1 and yi+1′ as in Equation (16).
Scenario 10: When the sampling points (xi−2, yi−2), (xi+1, yi+1), and (xi+2, yi+2) are tampered, the approximate value yi+2′ of xi+2 is calculated by Lerp through yi+1 and yi+3, and the approximate value yi+1′ of xi+1 is calculated by Lerp through yi and yi+2′; then, the approximate value yi of xi is calculated by Lerp through yi−1 and yi+1′ as in Equation (17).
Scenario 11: When the sampling points (xi−2, yi−2), (xi+1, yi+1), (xi+2, yi+2) and (xi+3, yi+3) are tampered, tamper recovery uses the recovery method of Scenario 6.
3.4.2. Tampering Recovery
If the frames at both ends of the decrypted speech are tampered, the tampered sampling points are set to zero because the beginning and ending of the speech often do not contain any information, and setting them to zero does not affect the semantics of the original speech.
Step 1: Tampering recovery. Based on the tampering situation of the surrounding sampling points, the tampered sampling points are divided into different scenarios and tampered recovery according to the method in Section 3.4.1.
Step 2: Second tampering recovery. After the first tampering recovery, the continuously tampered sampling points are sequentially detected, the second tampering recovery is performed using the recovery method in Scenario 6 of Section 3.4.1, and the speech after tampering recovery is reconstructed.
4. Experimental Results
This section presents the experimental results and analysis of the proposed encrypted speech integrity authentication method. Section 4.1 provides the payload capacity of the proposed method, Section 4.2 offers the transparency analysis, Section 4.3 showcases the accuracy of tampering detection, Section 4.4 demonstrates the effectiveness of tampering recovery through several metrics, and Section 4.5 presents an analysis of the proposed encryption method.
This paper conducted the experiments in MATLAB R2022a on a personal computer with Intel(R) Core (TM) i7-12700H CPU@2.30 GHz, 16 GB installed RAM running on Windows 11. The test speeches for this experiment are obtained from the THCHS-30 speech library [29], and the speech is the 16 kHz 16-bit sampled single-channel file in WAV format. The parameters used in this experiment are as follows: K = (w1(0) = 1.1, w2(0) = 2.2, w3(0) = 3.3, w4(0) = 4.4), ρ = −1, LF = 128.
4.1. Payload Capacity
The payload capacity (Cap) is the maximum amount of data that the audio watermarking method can embed into a carrier speech. The definition of Cap is formulated as Equation (18) [24] in which t is the time of the watermarked speech, v is the number of bits embedded in each frame of speech, and N is the number of frames during the watermarking embedding phase. In this paper, t = 20 s, v = 256 bit, N = 2500, and Cap = 32,000 bit/s. This means that each sampling point embeds 2-bit information.
4.2. Inaudibility
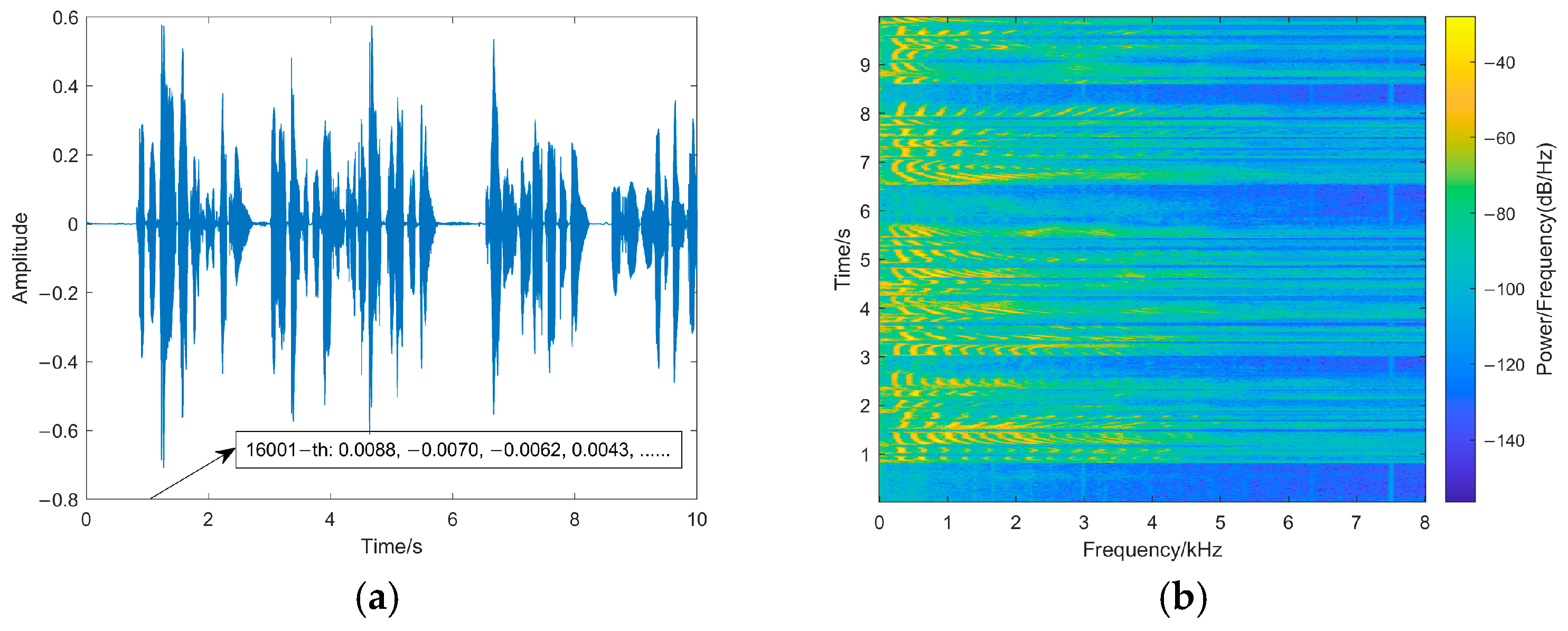
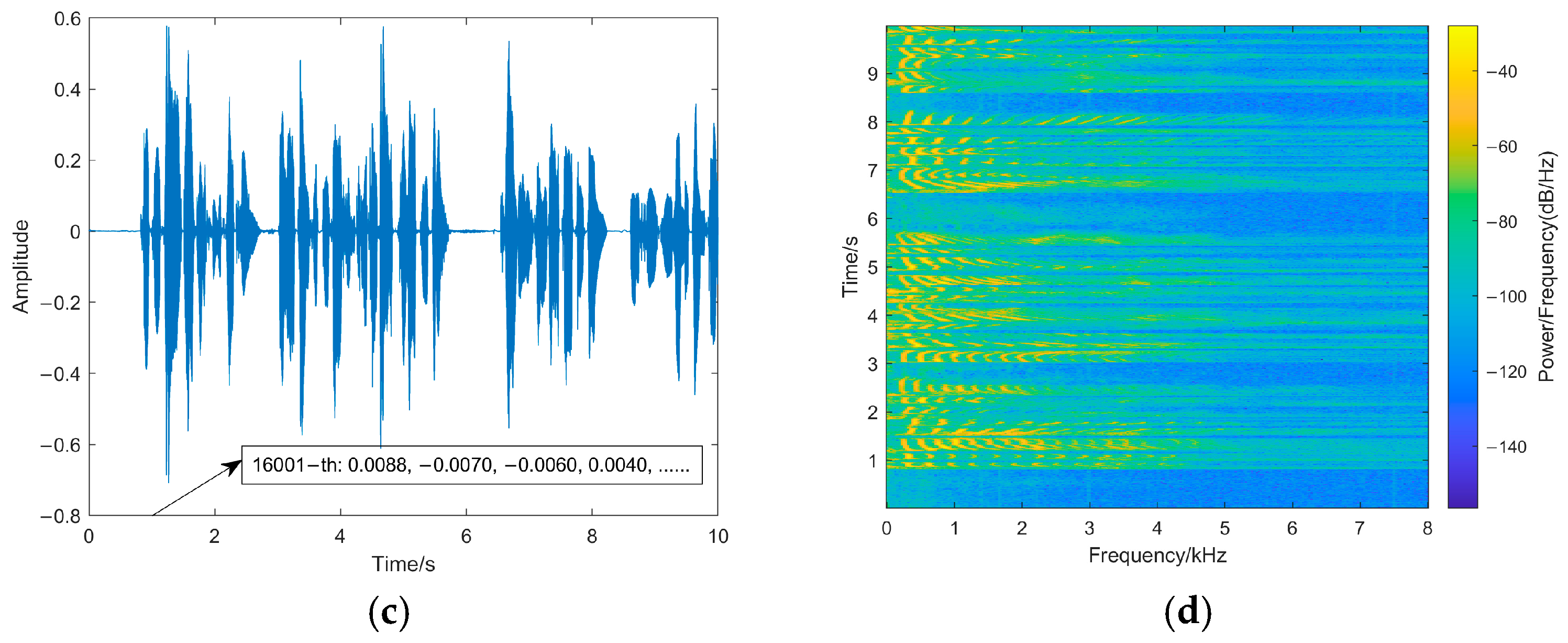
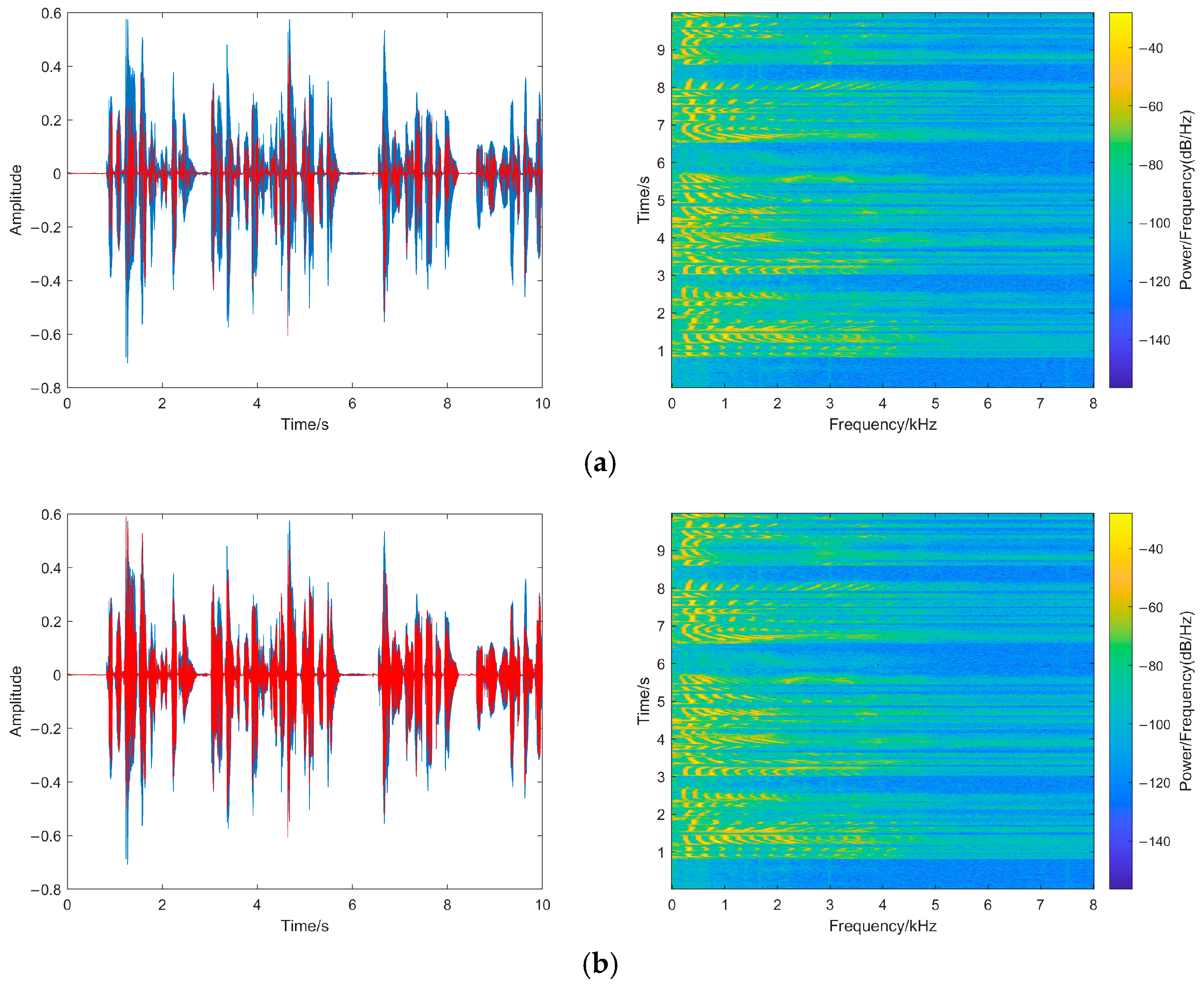
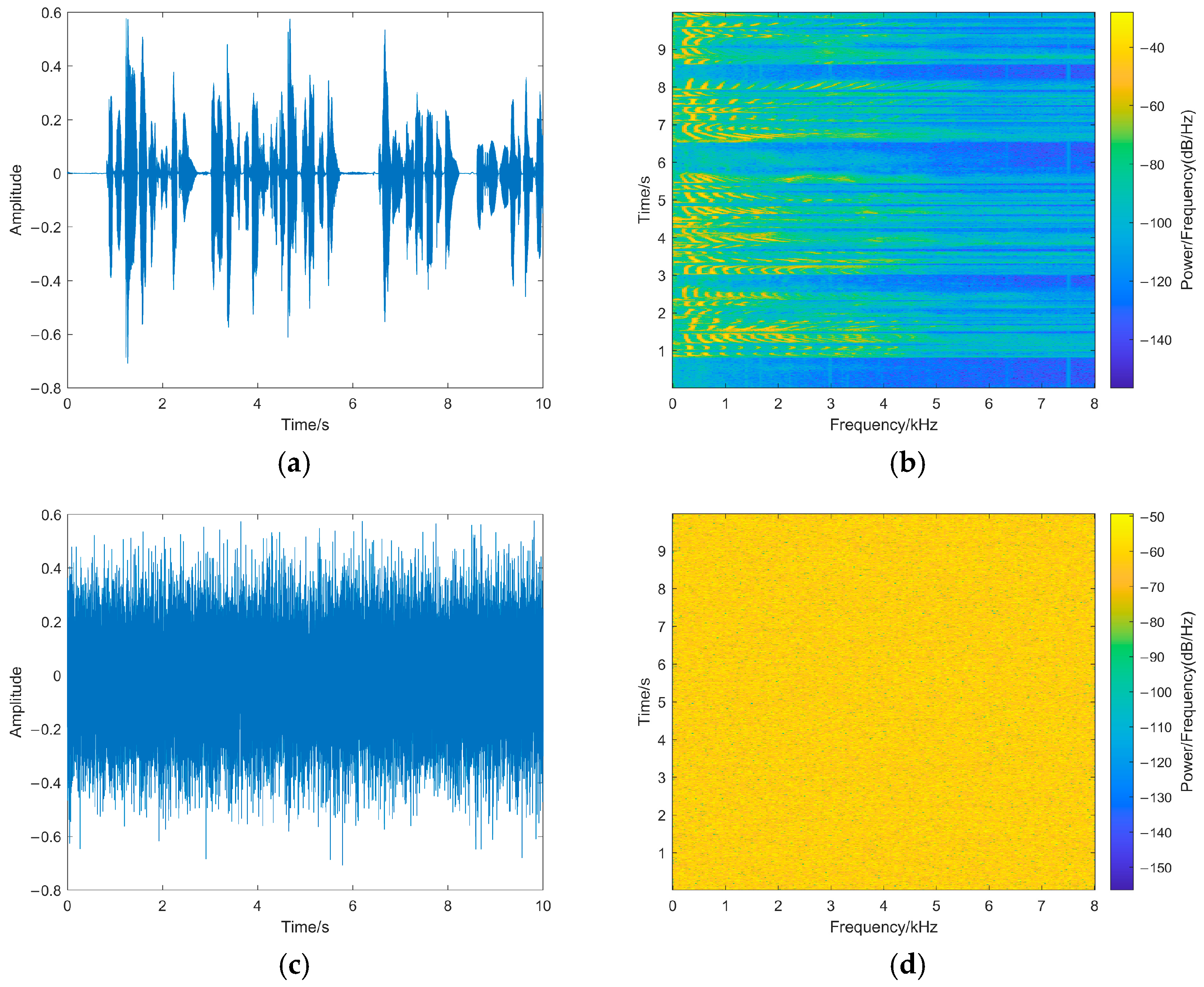
Inaudibility refers to the degree of changes between watermarked speech and original speech: the better the inaudibility, the less noticeable the watermarking. The paper tests the transparency of the watermarking from the perspective of statistical characteristics and the auditory quality of watermarked speech by the signal-to-noise ratio (SNR) and perceptual evaluation of speech quality (PESQ) [24]. SNR is calculated as in Equation (19) [24] in which L is the length of the speech, l is the sampling point, x is the original speech, and y is the watermarked speech. Meanwhile, in order to directly observe the changes in the original speech after embedding the watermarking, the waveforms and spectrograms of the original speech and watermarked speech are shown in Figure 8.
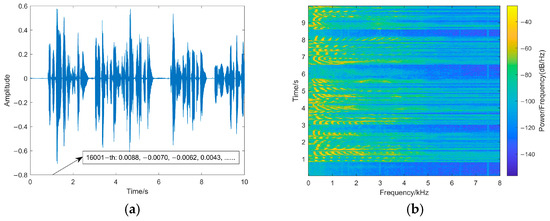
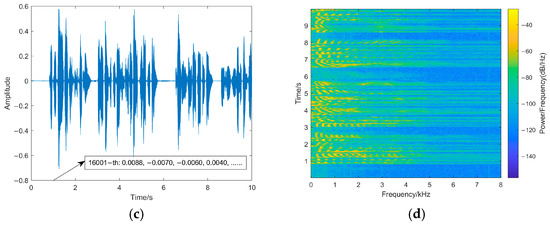
Figure 8.
(a) The original speech waveform. (b) The original speech spectrogram. (c) The watermarked speech waveform. (d) The watermarked speech spectrogram. Waveforms and spectrograms of original speech and watermarked speech.
The SNR of the proposed method is 55.8897 dB, and the PESQ is 4.481. This is because our method only modifies the fourth decimal place of the sampling points, and the difference between the watermarked sampling point and the original sampling point is in the range of 0~0.001, which has little impact on the carrier speech sampling points. As shown in Figure 8, the speech waveform does not change obviously: the changes in the pixel points of the spectrogram are smaller, and the variation of sampling points is relatively small. Therefore, the proposed fragile watermarking method shows high inaudibility, and the watermarked speech shows minimal differences in auditory quality compared to the original speech, making it difficult for the human ear to perceive any anomalies.
4.3. Tampering Detection Analysis
To test the tampering detection accuracy, this experiment tampers with the watermarked encrypted speech of 10 s, including ordinary attacks such as mute, substitution, and desynchronization attacks such as insertion or deletion. The tamper range is 20% of the test speech, and the number of tempered sampling points is 32,000.
4.3.1. Ordinary Attack
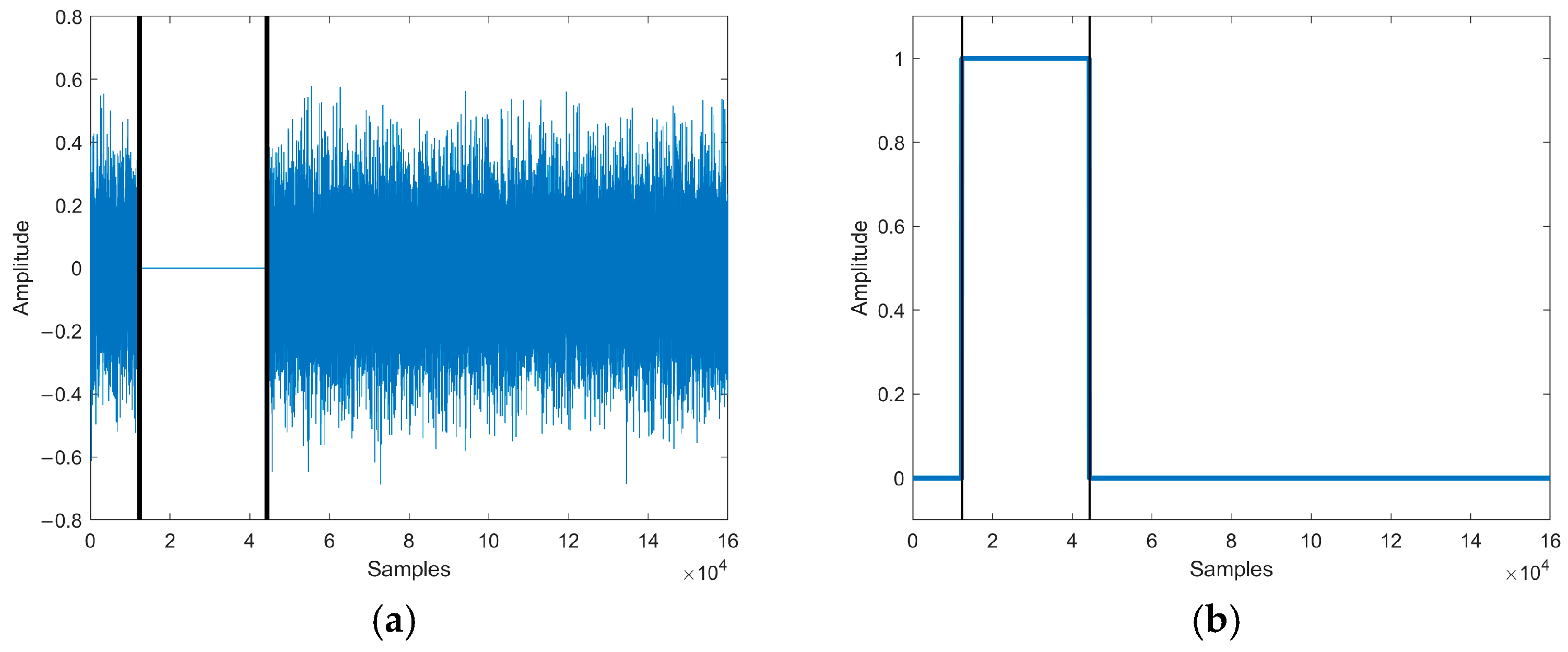
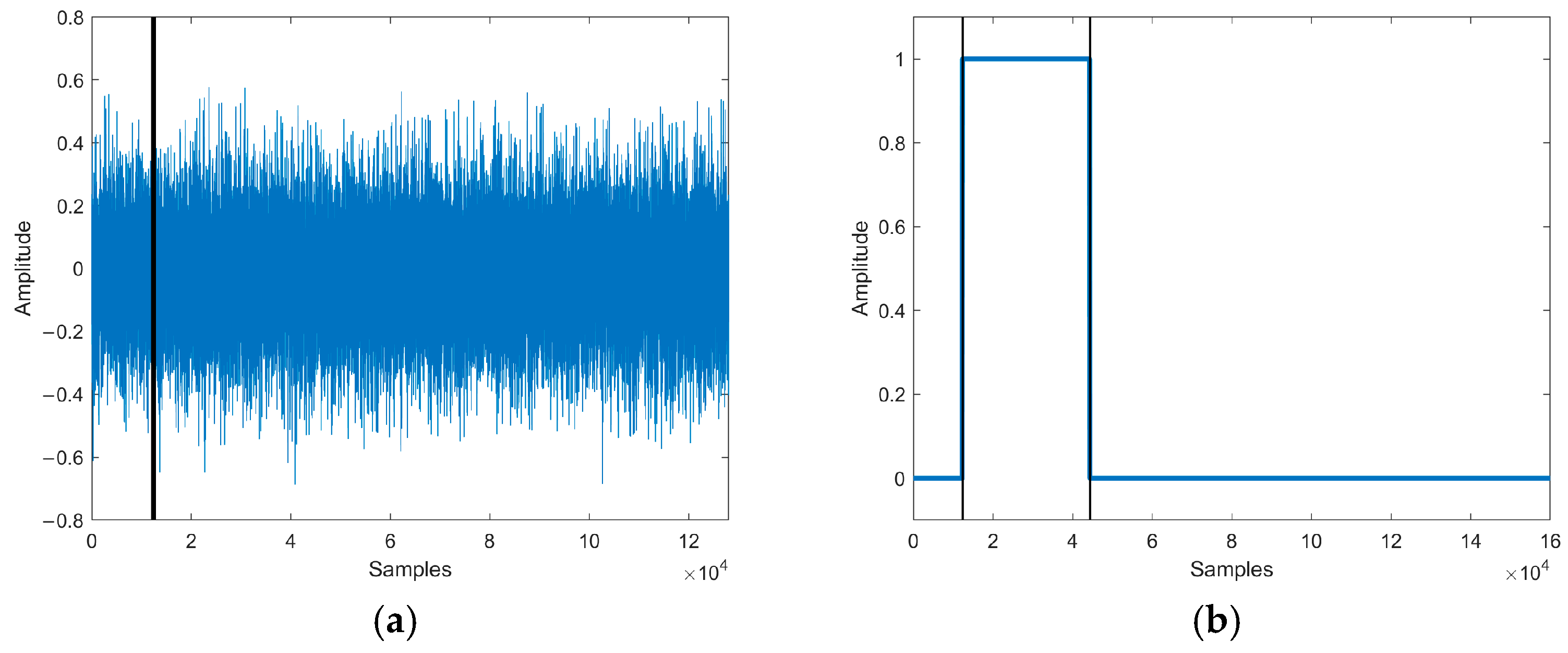
Mute attack realizes tampering by zeroing part of the target speech. In order to simulate the mute attack, the sampling points of the test speech [12345, 44344] were zeroed, and the speech waveform of the mute attack is shown in Figure 9a.
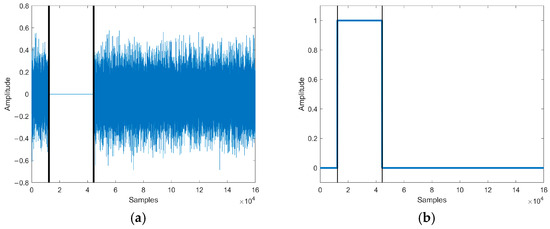
Figure 9.
(a) The speech waveform of mute attack. (b) The localization of tampered speech. Waveform and tampering localization after the mute attack of the test speech.
The tampering detection result of our method is shown in Figure 9b. The tampering detection method detected that the length of the authenticated speech was the same as the length of the test speech and located that 32,002 sampling points of the test speech [12345, 44346] were tampered, producing an error of 2 sampling points compared to the actual tampering situation.
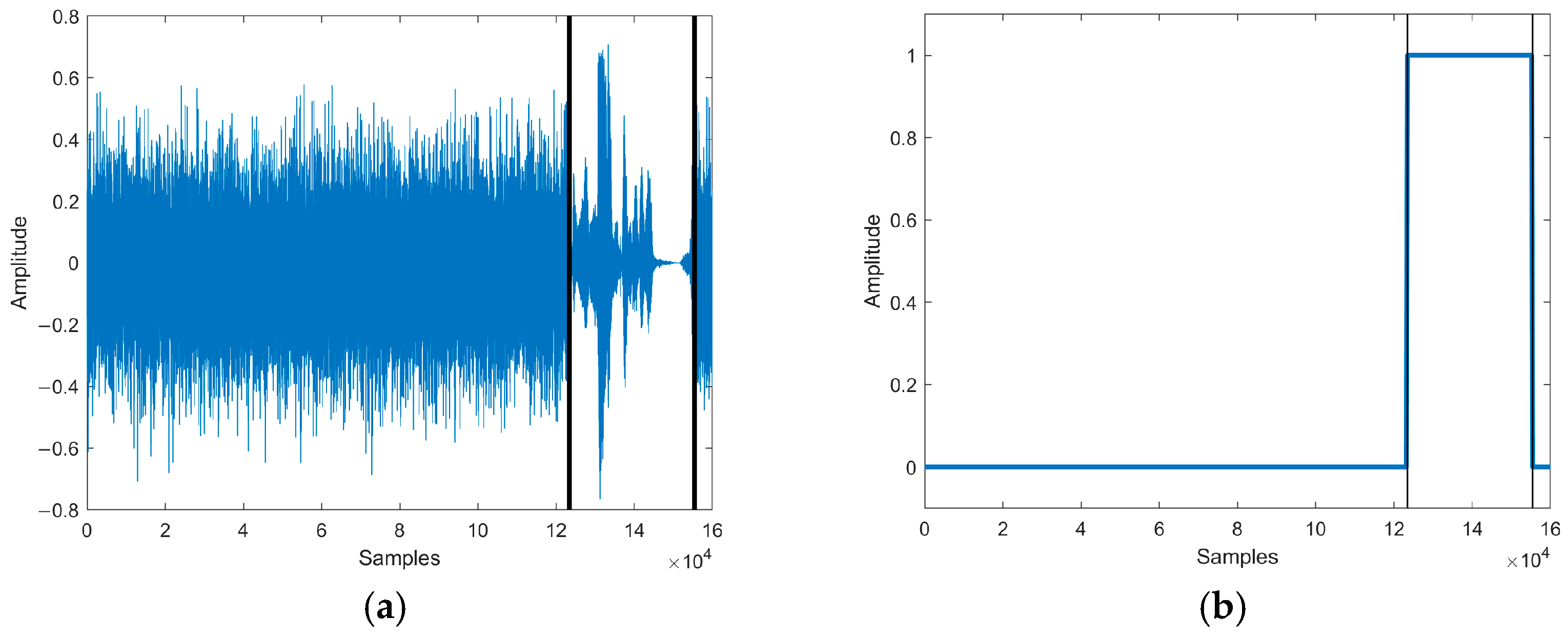
The substitution attack realizes tampering by replacing part of the target speech with noise or irrelevant speech sampling points. In order to simulate the substitution attack, the sampling points of the test speech [123456, 155455] were replaced with sampling points from random speech signals in the speech library. The speech waveform of the substitution attack is shown in Figure 10a.
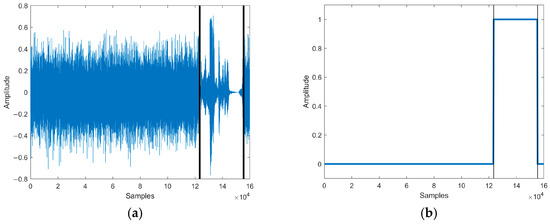
Figure 10.
(a) The speech waveform of substitution attack. (b) The localization of tampered speech. Waveform and tampering localization after the substitution attack of the test speech.
The tampering detection result of our method is shown in Figure 10b. The tampering detection method detected that the length of the authenticated speech was the same as the length of the test speech and located that 31,998 sampling points of the test speech [123457, 155454] were tampered, producing an error of 2 sampling points compared to the actual tampering situation.
4.3.2. Desynchronization Attack
The insertion attack realizes tampering by inserting noise or irrelevant speech in the target speech. In order to simulate the insertion attack, 32,000 sampling points from random speech signals in the speech library were inserted after the 123456-th sampling point of the test speech. The speech waveform of the insertion attack is shown in Figure 11a.
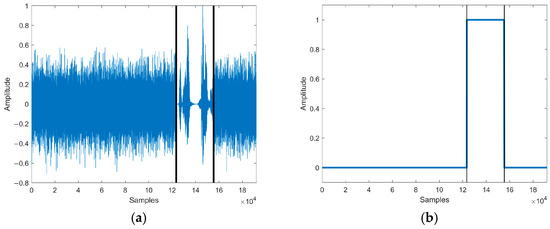
Figure 11.
(a) The speech waveform of insertion attack. (b) The localization of tampered speech. Waveform and tampering localization after the insertion attack of the test speech.
The tampering detection result of our method is shown in Figure 11b. The tampering detection method detected that the authenticated speech was longer than the test speech and located that 32,000 sampling points of the test speech [123457, 155456] were the inserted sampling points, producing an error of 2 sampling points compared to the actual tampering situation.
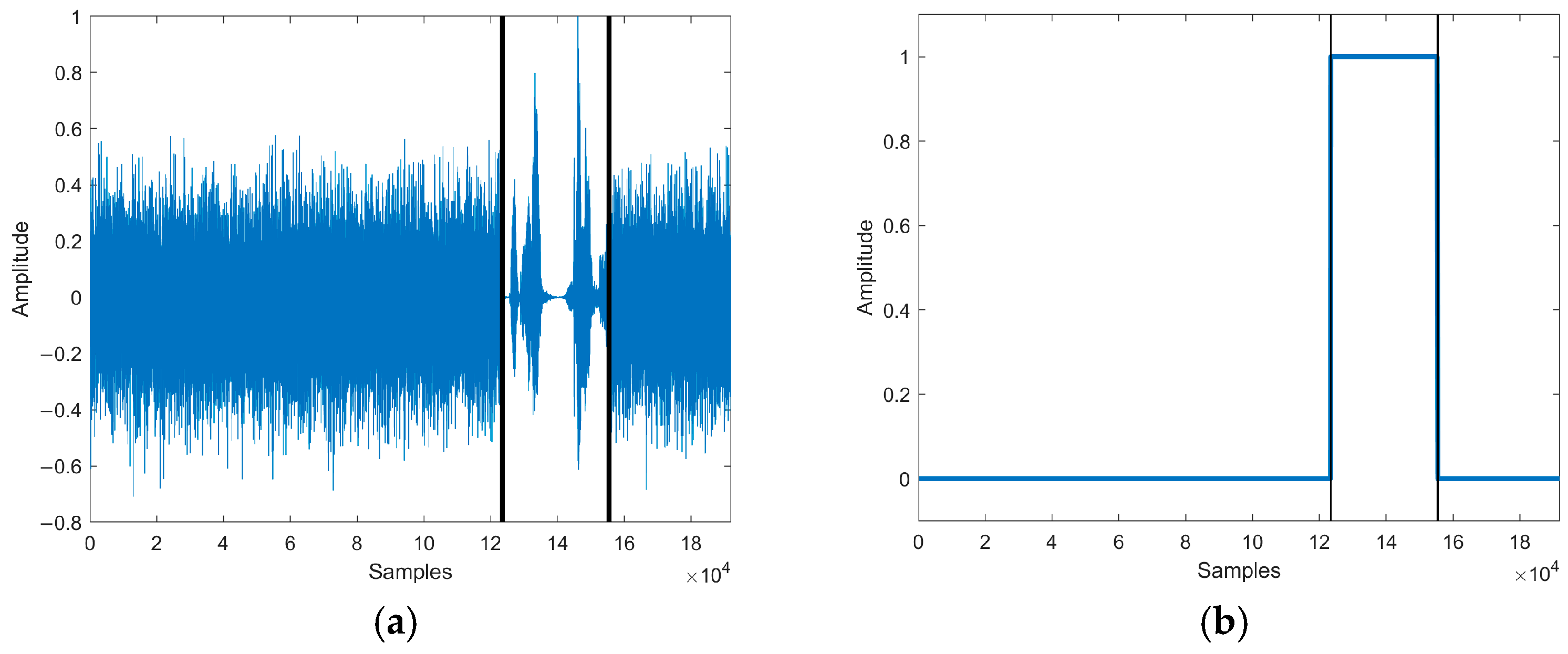
The deletion attack realizes tampering by deleting the sampling points from the target speech. In order to simulate the deletion attack, 32,000 sampling points of the test speech [12345, 44344] were deleted, and the speech waveform of the deletion attack is shown in Figure 12a.
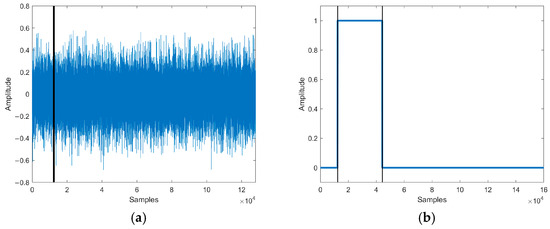
Figure 12.
(a) The speech waveform of deletion attack. (b) The localization of tampered speech. Waveform and tampering localization after the deletion attack of the test speech.
The tampering detection results of our method are shown in Figure 12b. The tampering detection method detected that the authenticated speech was shorter than the test speech and located that 16,000 sampling points of the test speech [12345, 44344] were deleted.
As shown in Figure 9, Figure 10, Figure 11 and Figure 12, our method can detect ordinary speech tampering attacks such as mute, substitution, and desynchronization speech tampering attacks such as insertion and deletion. The tampering detection errors mainly occur because the tampered sampling points exhibit correlations constructed with the surrounding sampling points. However, this situation is accidental, and the detection errors have little impact on the subsequent tampering recovery. Compared with the tampering localization method, which is accurate in the speech frame, our method achieves the tampering localization of tampered sampling points with high accuracy and improves recovery quality in the subsequent tampering recovery process. Additionally, the proposed tampering detection method does not require any information about the original speech, such as length or compression information, which effectively prevents the leakage of the original speech information.
4.4. Tampering Recovery Analysis
To measure the recovery quality of the recovered speech more comprehensively, this paper selects SNR, PESQ, and the frequency-weighted segmental SNR (fwSNRseg) for evaluation. fwSNRseg is calculated as in Equation (20) where M is the number of segments, W(j, m) is the weight on the j-th sub-band in the m-th frame, KB is the number of sub-bands, X(j, m) is the spectrum magnitude of the j-th sub-band in the m-th frame, and (j, m) its distorted spectrum magnitude [30]. fwSNRseg sets different weights for different speech bands on the basis of SegSNR so that the index can adapt to the short-term smoothness characteristics of speech, which is more in line with the human auditory perception.
Table 1 illustrates the comparison of SNR between the proposed method and existing methods based on recovery information such as G723.1 coding (G723.1) [17], compressed sensing (CS) [19], DCT coefficients, and the DWT coefficient (DCT-DWT) [21], and based on correlation of sampling points such as Lerp [23], R2-Lerp [24], and the least squares method (LSM) [6]. The tampering ratios in this experiment are 1%, 5%, 10%, 20%, 30%, 40%, and 50%. When the above methods still have unrecoverable sampling points after tamper recovery, the unrecoverable sampling points are zeroed.

Table 1.
A comparison of SNR between the proposed and existing methods under different tampering ratios.
Table 1 shows that the recovery quality of our method is similar or better than other tampering recovery methods under different tampering ratios. Compared to the existing methods based on the correlation of sampling points, our method achieves a better tamper recovery effect under high tampering ratios while ensuring the performance of tampering recovery under low tampering ratios. Compared to the existing methods based on recovery information, our method achieves a similar recovery effect under high tampering ratios and a better recovery effect under low tampering ratios. Additionally, our method avoids the problem of unrecoverable speech due to the destruction of sampling points containing recovery information.
In order to comprehensively represent the impact of increasing tampering ratios on the quality of recovered speech, Table 2 illustrates the comparison of PESQ between the proposed method and other tampering recovery methods, which evaluates the recovery effect from the perspective of auditory perception.
Table 2.
A comparison of PESQ between the proposed and existing methods under different tampering ratios.
Table 2 shows that the PESQ of our method is superior to other tampering recovery methods within the tampering ratio of 30% and slightly worse than the method of [17] in the tampering ratios between 30% and 50%. When 10% of the speech is tampered, the PESQ of our method is greater than 4, which means that the recovered speech has excellent auditory quality and clear semantics. When 20% of the speech is tampered, the PESQ of our method is greater than 3.5, which means that the recovered speech auditory quality meets the requirements of practical use, and our method maintains a greater advantage compared with other methods in terms of auditory quality. At a 50% tampering ratio, the PESQ of our method is still greater than 1.5, and the semantics are clearly discerned from the recovered speech.
In order to test the intelligibility of the recovered speech, Table 3 illustrates the comparison of fwSNRseg between the proposed method and other methods, which can reflect the intelligibility of the recovered speech. The higher the fwSNRseg, the higher the speech intelligibility. Generally, fwSNRseg for the same speech is lower than SNR.
Table 3.
A comparison of fwSNRseg between the proposed and existing methods under different tampering ratios.
Table 3 shows that the fwSNRseg of our method is superior to other tampering recovery methods in all tampering ratios, which indicates that the speech recovered by our method has higher intelligibility. The frequency weighting in fwSNRseg assigns a higher weight to the high-frequency part of speech, and the recovery effect of the high-frequency part has a greater impact on fwSNRseg; higher fwSNRseg also reflects that our method has a better recovery effect on the high-frequency part of speech.
To represent the quality of recovered speech after tampering more intuitively, Figure 13 shows the waveforms and spectrograms of the recovered speech in this paper under different tampering ratios, in which the red part of the waveform represents the sampling points after tampering recovery.
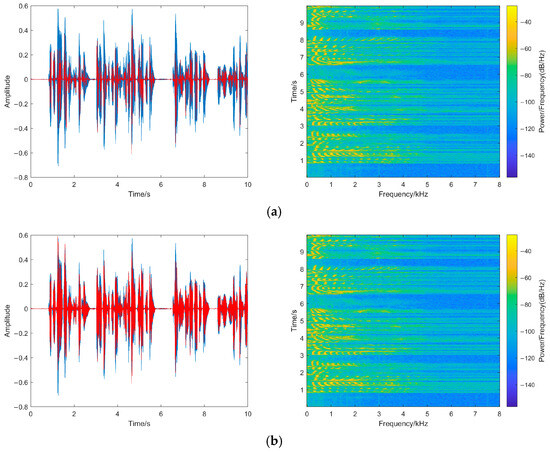
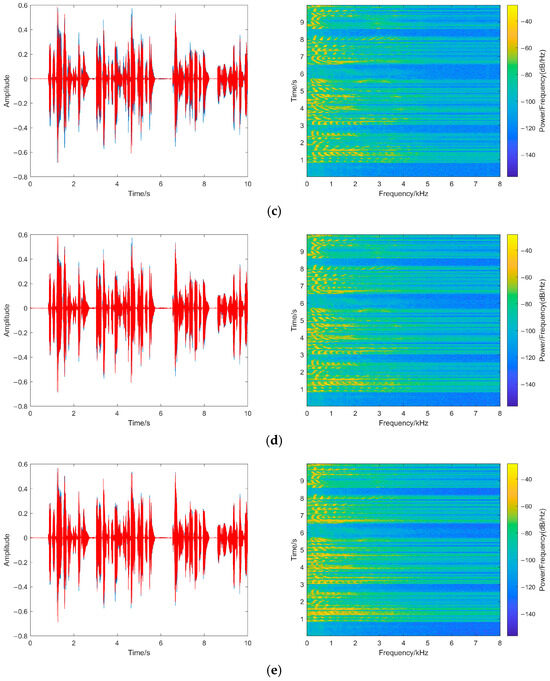
Figure 13.
(a) 1% tampering; (b) 5% tampering; (c) 10% tampering; (d) 30% tampering. (e) 50% tampering. Recovered Speech waveform and spectrogram at different tampering ratios.
As shown in Figure 13, the recovered speech waveforms and the pixel points in the spectrograms at different tampering ratios are similar to the original speech waveform and spectrogram. Even while the tampering ratio reaches 50%, the recovered speech envelope still closely resembles that of the original speech, and the spectrogram only displays slight differences in the high-frequency part.
To demonstrate the adaptability of the proposed tampering recovery method for real-time applications, Table 4 shows the tampering recovery effect under different noise attacks. The types of noise attacks include background noise (B. N), factory noise (F. N), and narrowband Gaussian noise (G. N) at 20 dB, 30 dB, 40 dB, and 50 dB.
Table 4.
The tampering recovery effect under different noise attacks.
From Table 4, it is evident that noise attacks at different decibels have a significant impact on tampering recovery, and different kinds of noise have roughly the same effect on tampering recovery. This is because the proposed tampering recovery method is based on the correlation of sampling points. When the sampling points used for recovery change, the points being recovered will also change, meaning that the recovered points are subjected to the same noise attack.
To more intuitively demonstrate the impact of noise on the recovered sampling points, this paper conducts experimental analysis by testing the SNR of the original sampling points at the tampered locations, as well as the recovered sampling points that were not subjected to noise attacks and those that were affected by noise attacks. Table 5 shows the influence of different types of noise attacks on the tampering recovery sampling points.
Table 5.
The impact of noise attacks on the tampering recovery sampling points.
From Table 5, it can be observed that different types of noise attacks have a roughly similar impact on the tampered sampling points. Various levels of noise have some effect on the tampered sampling points, but this impact decreases as the tampering ratio increases. This indicates that while noise attacks affect the proposed tampering recovery algorithm, their influence on the recovered sampling points is relatively minor.
4.5. Security
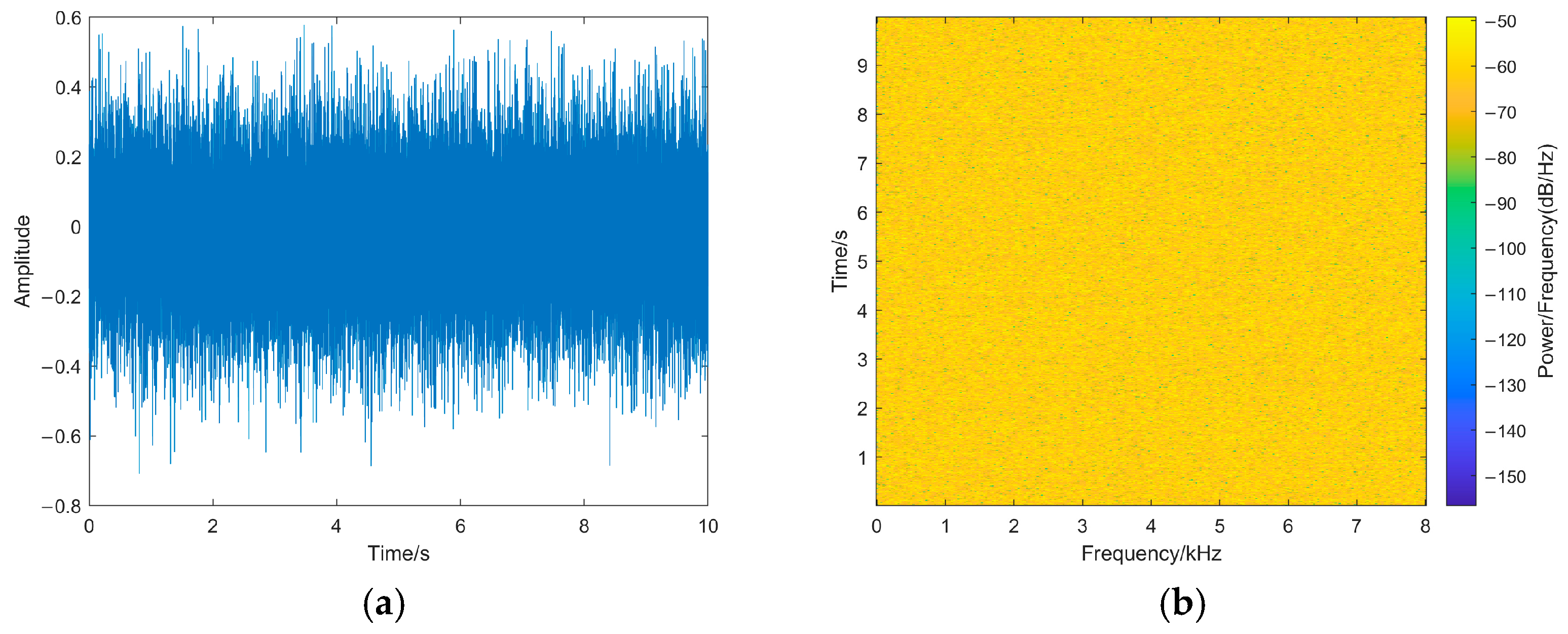
As shown in Figure 14, the sampling points are evenly distributed throughout the speech after encryption, and the envelope of encrypted speech differs significantly from that of the original speech. This means that it is difficult to obtain the correlation features and spectrogram features from the encrypted speech, which intuitively proves that our encryption algorithm has a better encryption effect.
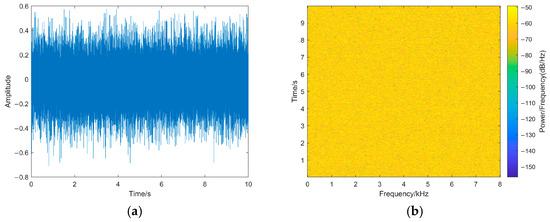
Figure 14.
(a) An encrypted speech waveform. (b) An encrypted speech spectrogram. The waveform and spectrogram of encrypted speech.
To test the key sensitivity, our method sets K = (w1(0), w2(0), w3(0), w4(0)), and K′ = (w1(0) + 10−12, w2(0) + 10−12, w3(0) + 10−12, w4(0) + 10−12). As shown in Figure 15, the waveform of the decrypted speech with the correct key is consistent with that of the original speech, and there are no significant differences in the spectrogram compared to the original speech. However, even a slight change in the key has a significant impact on the chaotic sequence, making it impossible to correctly decrypt the encrypted speech and obtain any useful features from the incorrectly decrypted speech.
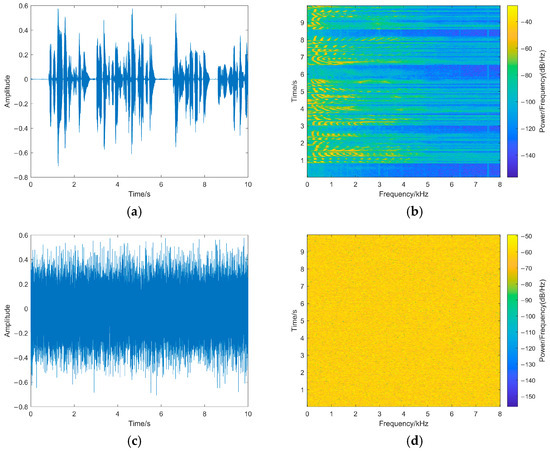
Figure 15.
(a) A speech waveform after the right decryption. (b) A speech spectrogram after the right decryption. (c) A speech waveform after the wrong decryption. (d) A speech spectrogram after the wrong decryption. The waveform and spectrogram of the right initial value and the wrong initial value.
To verify the security and scrambling effect of our method, this experiment analyzed the SNR, PESQ, fwSNRseg, spectral entropy (SE), correlation coefficient (NC) of the encrypted speech, and the effect of tampering recovery at different tampering ratios. SE is calculated as in Equation (20) in which nfft is the length of FFT, k is the frequency component, and p(k) is the probability density corresponding to the k-th frequency component. SE of the original speech is 9.7960, and NC is calculated as in Equation (21) in which Si is the original speech sampling point and ESi is the encrypted speech sampling point.
Table 5 shows the comparison of the proposed method with the traditional scrambling encryption methods such as the Lorenz map (Lorenz), Iterative map (Iterative), Cubic map (Cubic), Piecewise map (Piecewise), Henon map (Henon), and Logistic map (Logistic) [31]. Table 6 shows the comparison of the tampering recovery effect between the proposed method and traditional scrambling encryption methods at different tampering ratios. The traditional scrambling encryption methods used chaotic sequences to scramble the whole speech, while the multidimensional chaotic sequences encrypted the speech in each dimension separately.
Table 6.
The comparison of encryption performance with existing scrambling encryption methods.
Table 6 shows that although the NC of our method is relatively high compared to other encryption methods, SNR, PESQ, fwSNRseg, and SE of our method are lower than most of the encryption algorithms. While the higher correlation coefficient indicates a certain correlation between the encrypted speech and the original speech, there are significant differences in auditory quality between the encrypted speech and the original speech, making it difficult to distinguish semantics. From the perspective of spectral entropy, the proposed method sufficiently disrupts the correlation between the original speech sampling points. It shows that the encryption effect of our method meets the security requirements for encrypted speech.
5. Conclusions
In this paper, an encrypted speech integrity authentication method is proposed to solve “Granularity and accuracy” and “High tampering ratio” comprehensively and deeply through a 2-LSB-based dual fragile watermarking method and a speech self-recovery model based on R2-Lerp. The 2-LSB-based fragile watermarking embedding method is able to construct the correlation of encrypted speech sampling points while embedding the watermarking. The dual watermarking can achieve accurate tampering detection of speech frames based on this correlation and, then, perform tampering localization for the encrypted speech that failed authentication accurately up to the sampling point. The speech self-recovery classifies different tampering recovery scenarios based on the destruction of the 5 sampling points around the tampered sampling point and constructs the tampering recovery methods for tampered sampling points in different scenarios by Lerp and R2-Lerp to realize the tampering recovery under high tampering ratios. In addition, the speech encryption algorithm in this paper sufficiently scrambles the original speech sampling points by Lorenz mapping.
The experimental results show that the encrypted speech integrity authentication scheme in this paper can detect whether speech has been tampered with by ordinary attacks such as mute, substitution, and desynchronization attacks such as insertion or deletion; then, it locates tampered sampling points. The tampering localization error has minimal impact on the subsequent tampering recovery. The speech self-recovery model effectively improves the recovery effect of encrypted speech under a high tampering ratio. Even when the speech is tampered with up to 50%, it still exhibits good speech recovery; when the tampering ratio is below 50%, the semantics of the original speech can be clearly distinguished, which can satisfy the practical requirements of encrypted speech integrity authentication. The proposed speech encryption method spreads the continuously tampered sampling points in the encrypted speech uniformly to the whole speech during the decryption process while guaranteeing security.
Although the proposed tampering localization method can locate the tampered sampling points, it still generates certain errors. Future research work will focus on exploring methods to reduce the tampering localization error based on the correlation of speech, and we will consider tampering detection methods after the speech’s least significant bits are zeroed out. Additionally, the tampering recovery methods based on the recovery information still have certain advantages under high tampering ratios, and future research work will optimize the recovery effect under high tampering ratios through techniques such as prediction. The limited robustness of the LSB-based fragile watermarking method against noise attacks also restricts its usage. Future research will focus on exploring how to enhance robustness while maintaining the high transparency of the LSB method, thereby improving the adaptability of the algorithm for real-time applications.
Author Contributions
Conceptualization: F.X.; data curation: F.X. and X.X.; investigation: F.X.; methodology: F.X. and J.L.; project administration: J.L.; supervision: J.L. and X.X.; writing—original draft: F.X.; writing—review and editing: X.X. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The datasets are available from the corresponding author upon reasonable request.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Singh, R.; Saraswat, M.; Ashok, A.; Mittal, H.; Tripathi, A.; Pandey, A.-C.; Pal, R. From classical to soft computing based watermarking techniques: A comprehensive review. Future Gener. Comput. Syst. 2023, 141, 738–754. [Google Scholar] [CrossRef]
- Makhdoom, I.; Abolhasan, M.; Lipman, J.A. comprehensive survey of covert communication techniques, limitations and future challenges. Comput. Secur. 2022, 120, 102784. [Google Scholar] [CrossRef]
- Shehab, D.-A.; Alhaddad, M.-J. Comprehensive Survey of Multimedia Steganalysis: Techniques, Evaluations, and Trends in Future Research. Symmetry 2022, 14, 117. [Google Scholar] [CrossRef]
- Meng, X.; Li, C.; Tian, L. Detecting Audio Splicing Forgery Algorithm Based on Local Noise Level Estimation. In Proceedings of the 2018 5th International Conference on Systems and Informatics, Nanjing, China, 10–12 November 2018; pp. 861–865. [Google Scholar] [CrossRef]
- Wang, S.; Yuan, W.; Wang, J.; Unoki, M. Detection of speech tampering using sparse representations and spectral manipulations based information hiding. Speech Commun. 2019, 112, 1–14. [Google Scholar] [CrossRef]
- Zhang, Q.-Y.; Zhang, D.-H.; Xu, F.-J. An encrypted speech authentication and tampering recovery method based on perceptual hashing. Multimed. Tools Appl. 2021, 80, 24925–24948. [Google Scholar] [CrossRef]
- Narla, V.-L.; Gulivindala, S.; Chanamallu, S.-R.; Gangwar, D.-P. BCH encoded robust and blind audio watermarking with tamper detection using hash. Multimed. Tools Appl. 2021, 80, 32925–32945. [Google Scholar] [CrossRef]
- Hu, H.; Lee, T. Hybrid Blind Audio Watermarking for Proprietary Protection, Tamper Proofing, and Self-Recovery. IEEE Access 2019, 7, 180395–180408. [Google Scholar] [CrossRef]
- Zhou, S.-Y.; Song, M.-X.; Qian, Q.; Liao, W.-J.; Gong, X.-F. GRACED: A Novel Fragile Watermarking for Speech Based on Endpoint Detection. Secur. Commun. Netw. 2022, 2022, 496748. [Google Scholar] [CrossRef]
- Liu, Z.-H.; Cao, Y.; Lin, K.-J. A watermarking-based authentication and recovery scheme for encrypted audio. Multimed. Tools Appl. 2024, 83, 10969–10987. [Google Scholar] [CrossRef]
- Liu, Z.-H.; Huang, J.-W.; Sun, X.-M.; Qi, C.-D. A security watermark scheme used for digital speech forensics. Multimed. Tools Appl. 2017, 76, 9297–9317. [Google Scholar] [CrossRef]
- Lu, W.-H.; Chen, Z.-L.; Li, L.; Cao, X.-C.; Wei, J.-G.; Xiong, N.-X.; Li, J.; Dang, J.-W. Watermarking Based on Compressive Sensing for Digital Speech Detection and Recovery. Sensors 2018, 18, 2390. [Google Scholar] [CrossRef]
- Qian, Q.; Zhou, S.-Y.; Song, M.-X.; Cui, Y.-H.; Wang, H. VICTOR: An Adaptive Framing-based Speech Content Authentication and Recovery Algorithm. In Proceedings of the 2022 IEEE 24th Int Conf on High Performance Computing & Communications; 8th Int Conf on Data Science & Systems; 20th Int Conf on Smart City; 8th Int Conf on Dependability in Sensor, Cloud & Big Data Systems & Application, Hainan, China, 18–20 December 2022; pp. 649–1654. [Google Scholar] [CrossRef]
- Elshoush, H.-T.; Mahmoud, M.-M. Ameliorating LSB Using Piecewise Linear Chaotic Map and One-Time Pad for Superlative Capacity, Imperceptibility and Secure Audio Steganography. IEEE Access 2023, 11, 33354–33380. [Google Scholar] [CrossRef]
- Sultani, Z.-N.; Dhannoon, B.-N. Image and audio steganography based on indirect LSB. Kuwait J. Sci. 2021, 48, 1–12. [Google Scholar] [CrossRef]
- Mahmoud, M.-M.; Elshoush, H.-T. Enhancing LSB Using Binary Message Size Encoding for High Capacity, Transparent and Secure Audio Steganography—An Innovative Approach. IEEE Access 2022, 10, 29954–29971. [Google Scholar] [CrossRef]
- Qian, Q.; Cui, Y.-H.; Wang, H.-X.; Deng, M.-S. REPAIR: Fragile watermarking for encrypted speech authentication with recovery ability. Telecommun. Syst. 2020, 75, 273–289. [Google Scholar] [CrossRef]
- Fan, M.-Q. A source coding scheme for authenticating audio signal with capability of self-recovery and anti-synchronization counterfeiting attack. Multimed. Tools Appl. 2020, 79, 1037–1055. [Google Scholar] [CrossRef]
- Hu, Y.-X.; Lu, W.-H.; Ma, M.-D.; Sun, Q.-L.; Wei, J.-G. A semi fragile watermarking algorithm based on compressed sensing applied for audio tampering detection and recovery. Multimed. Tools Appl. 2022, 81, 17729–17746. [Google Scholar] [CrossRef]
- Liu, Z.-H.; Li, Y.-L.; Sun, F.; He, J.-J.; Qi, C.-D.; Luo, D. A Robust Recoverable Algorithm Used for Digital Speech Forensics Based on DCT. Cloud Comput. Secur. 2018, 11068, 300–311. [Google Scholar] [CrossRef]
- Liu, Z.-H.; Luo, D.; Huang, J.-W.; Wang, J.; Qi, C.-D. Tamper recovery algorithm for digital speech signal based on DWT and DCT. Multimed. Tools Appl. 2017, 76, 12481–12504. [Google Scholar] [CrossRef]
- Wang, S.-B.; Yuan, W.-T.; Zhang, Z.; Wang, L. Speech watermarking based tamper detection and recovery scheme with high tolerable tamper rate. Multimed. Tools Appl. 2024, 83, 6711–6729. [Google Scholar] [CrossRef]
- Qian, Q.; Wang, H.-X.; Sun, X.-M.; Cui, Y.-H.; Wang, H.; Shi, C.-H. Speech authentication and content recovery scheme for security communication and storage. Telecommun. Syst. 2018, 67, 635–649. [Google Scholar] [CrossRef]
- Zhang, Q.-Y.; Xu, F.-J. Encrypted speech authentication and recovery scheme based on fragile watermarking. Telecommun. Syst. 2023, 82, 125–140. [Google Scholar] [CrossRef]
- Shahna, K.-U. Novel chaos based cryptosystem using four-dimensional hyper chaotic map with efficient permutation and substitution techniques. Chaos Solitons Fractals 2023, 170, 113383. [Google Scholar] [CrossRef]
- Varghese, F.; Sasikala, P. A detailed review based on secure data transmission using cryptography and steganography. Wirel. Pers. Commun. 2023, 129, 2291–2318. [Google Scholar] [CrossRef]
- Pejas, J.; Cierocki, L. A systematic review of highly transparent steganographic methods for the digital audio. In Information Systems and Industrial Management, Proceedings of the CISIM 2022, Barranquilla, Colombia, 15–17 July 2022; Springer: Cham, Switzerland, 2022; Volume 13293, pp. 63–77. [Google Scholar] [CrossRef]
- AlSabhany, A.-A.; Ali, A.-H.; Ridzuan, F.; Azni, A.-H.; Mokhtar, M.-R. Digital audio steganography: Systematic review, classification, and analysis of the current state of the art. Comput. Sci. Rev. 2020, 38, 100316. [Google Scholar] [CrossRef]
- Wang, D.; Zhang, X. Thchs-30: A free Chinese speech corpus. arXiv 2015, arXiv:1512.01882. [Google Scholar]
- Kondo, K. Estimation of forced-selection word intelligibility by comparing objective distances between candidates. Appl. Acoust. 2016, 106, 113–121. [Google Scholar] [CrossRef]
- Nidaa, A.-A.; Zeina, H. Review of dct and chaotic maps in speech scrambling. J. Theor. Appl. Inf. Technol. 2019, 97, 569–582. [Google Scholar]
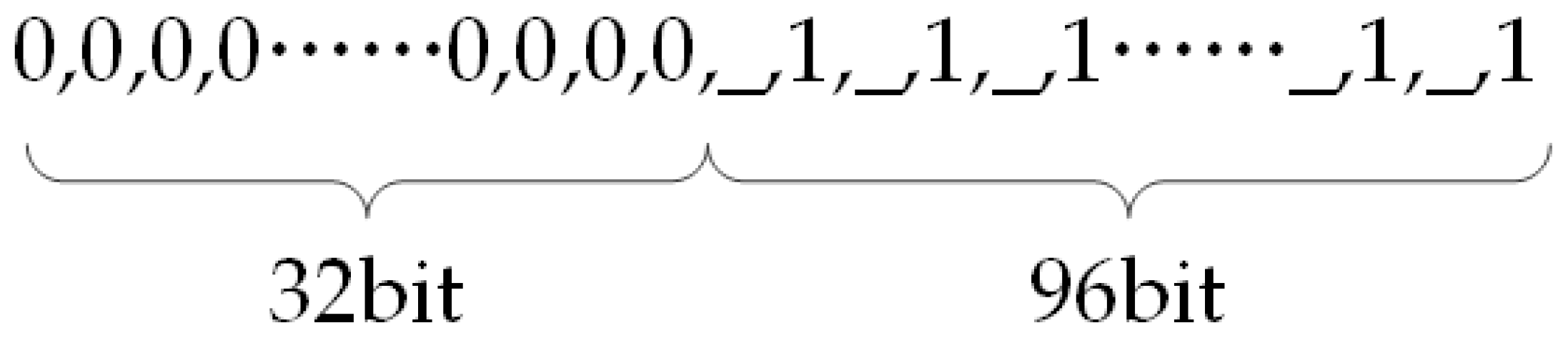
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).