

Espresso Crema Analysis with f-AnoGAN


Abstract
1. Introduction
- Apply the f-AnoGAN model using the small dataset collected and evaluate its performance.
- Propose a new VAE combination algorithm and validate its usefulness in various application fields.
- Optimize the lambda gp hyperparameter in the combination of WGAN and VAE to enhance the performance in anomaly detection.
2. Related Work
2.1. GrabCut Crop
2.2. Generative Adversarial Network
2.3. Autoencoder- and Variational Autoencoder-Based Generative Model
- Encodes the input data x into a probability distribution over latent variables z. Typically, this distribution is parameterized by a mean and variance . The encoder outputs the mean and variance . To sample from the latent variable, the reparameterization trick is used: (where is sampled from a standard normal distribution).
- Reconstructs the original data x from the latent variable z. The decoder network takes z as input and outputs the reconstructed data .
- VAE loss function consists of two parts:
- Measures the difference between the input data and the reconstructed data (Equation (2)).
- Divergence: Measures the difference between the latent variable distribution of the encoder and the previous distribution (usually a standard normal distribution) (Equation (3)).
- Total loss function for VAE is as follows (Equation (4)):
- Loss function trains the VAE to both reconstruct the data well and ensure that the latent variable distribution resembles the prior distribution.
2.4. f-AnoGAN
- The Gradient Penalty was introduced in WGAN-GP (Wasserstein GAN with Gradient Penalty). In conventional GANs, training instability can be an issue. WGAN improves stability by using the Wasserstein distance. However, WGAN must enforce the Lipschitz continuity by ensuring that the discriminator gradient does not exceed 1. The Gradient Penalty is introduced to enforce this Lipschitz continuity. It does so by penalizing the discriminator’s gradient norm, encouraging it to stay close to 1, which helps to achieve more stable training.
3. Experiment
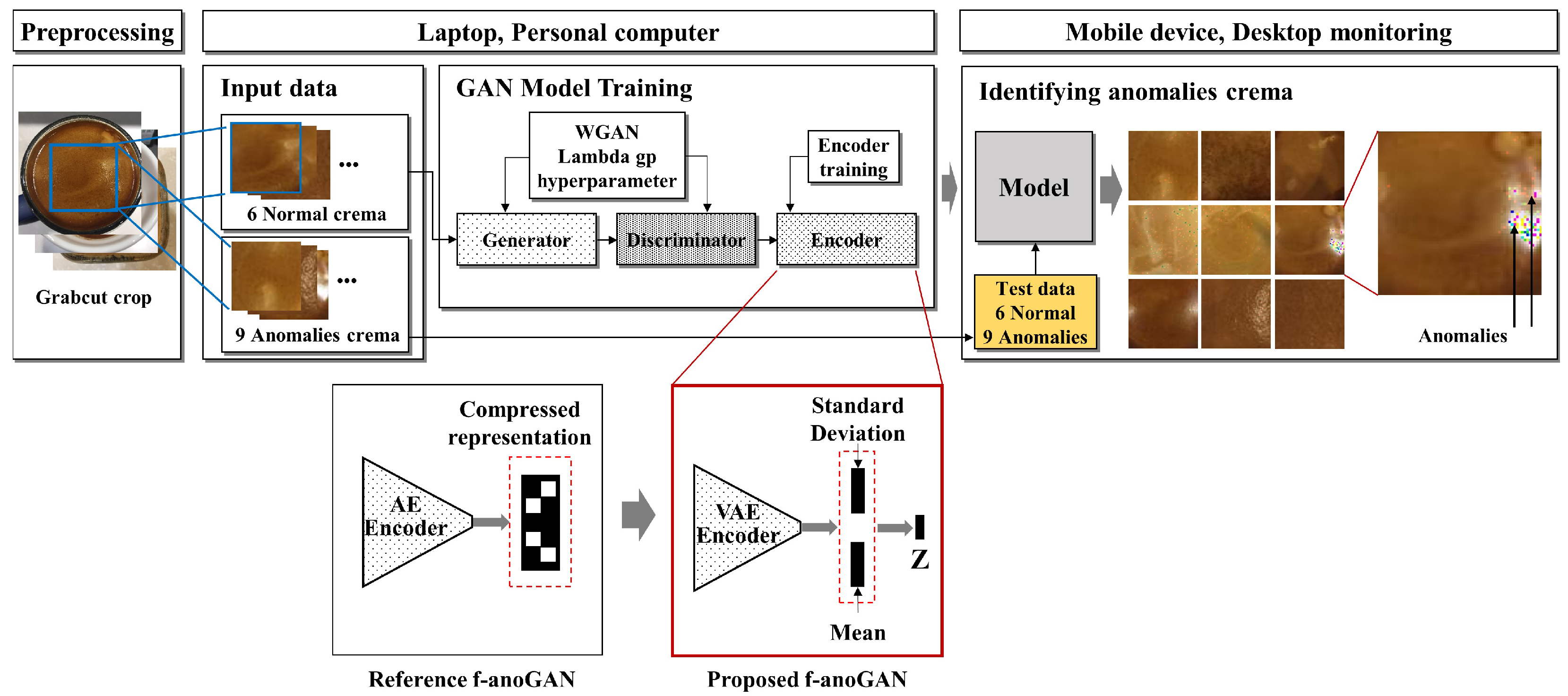
3.1. Overall Design
- Desktop i7: Windows 11, Intel(R) Core(TM) i7-8700 CPU 3.2 GHz, DDR4 32GB;
- Laptop i7: Windows 10 Pro, Intel(R) Core(TM) i7-10510U CPU 1.8 GHz, DDR4 16GB;
- Nvidia Jetson Nano (B01): Ubuntu 20.04, Quad-core ARM Cortex A57 1.43 GHz, LPDDR4 4GB, 64GB microSD, disable CUDA;
- Nvidia Jetson NX: Ubuntu 20.04, 6-core Nvidia Carmel ARM v8.2 2-core 1.9GHz, LPDDR4 8GB, 128GB SSD, disable CUDA;
- Model parameters: epochs = 500, batch size = 128, lr = 0.0002, b1 = 0.5, b2 = 0.999, latent dim = 100, img size = 64, channels = 3, n critic = 5, sample interval = 400, training label = 0, lambda gp = 50, weight decay = 0.00005, Adam optimizer.
3.2. Data Selection and Preprocessing
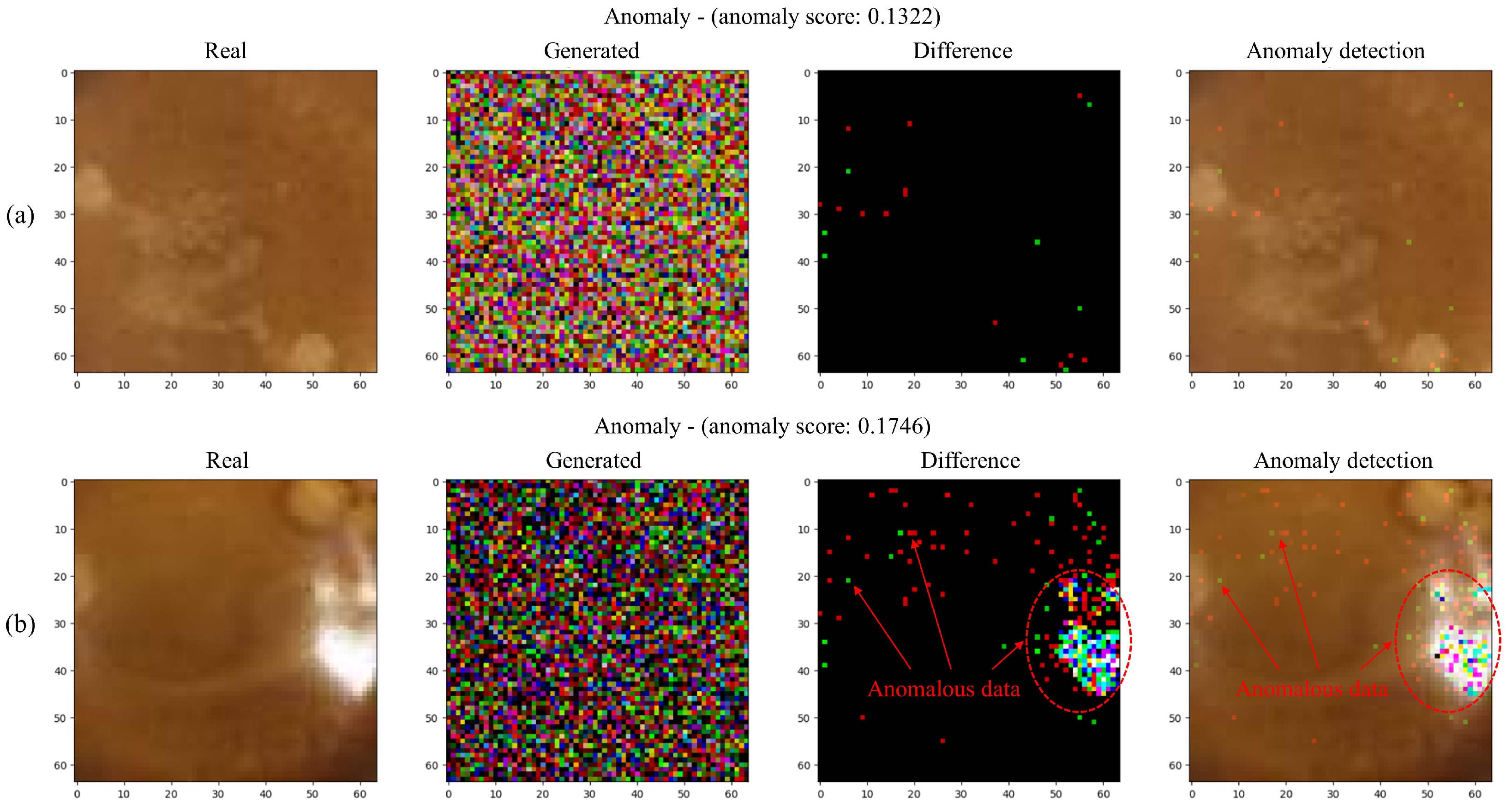
3.3. Evaluation Using Anomaly Score
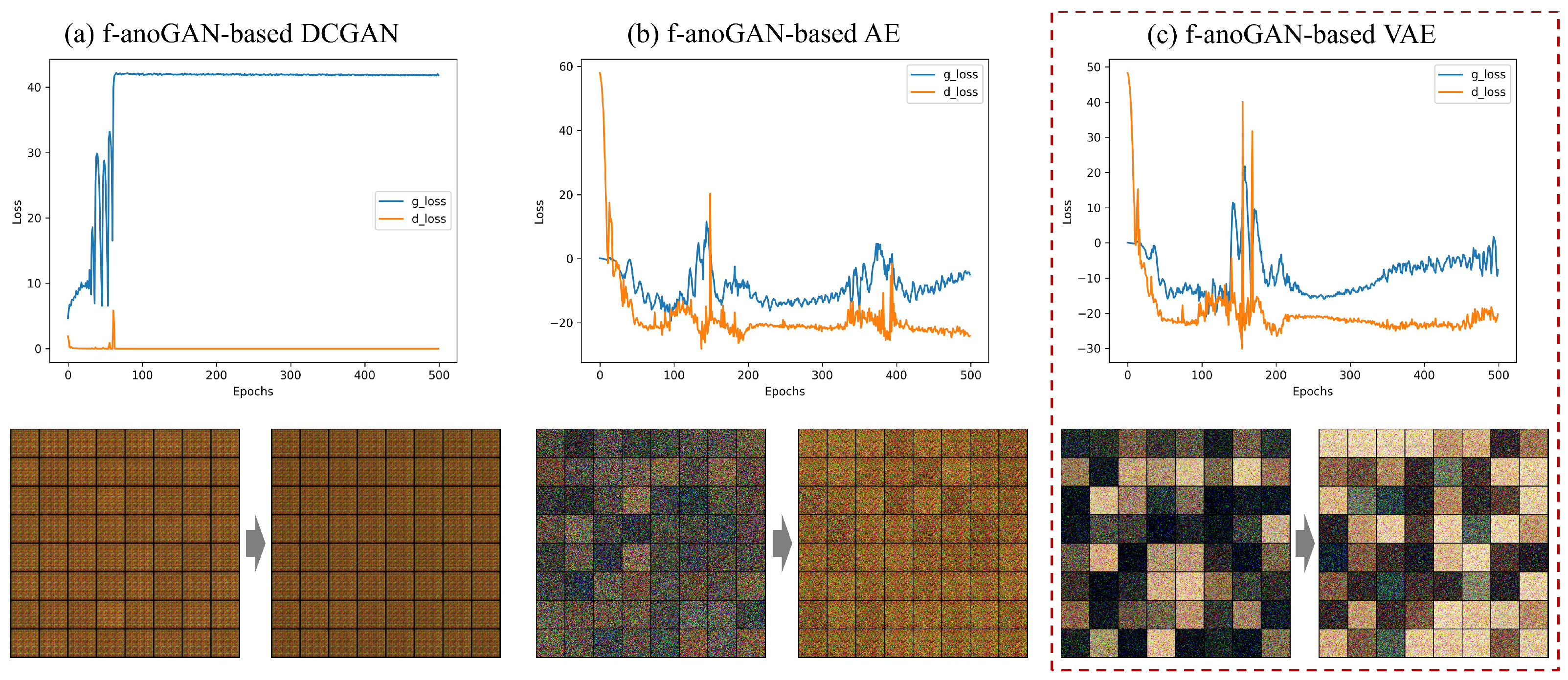
3.4. Experimental Results
3.5. Discussion
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| ML | Machine Learning |
| IoT | Internet of Things |
| AUC | Area Under the Curve |
| VAE | Variational Autoencoder |
| f-AnoGAN | Fast Unsupervised Anomaly Detection with Generative Adversarial Networks |
| AnoGAN | Unsupervised Anomaly Detection with Generative Adversarial Networks |
| GPU | Graphic Processing Unit |
| DCGAN | Deep Convolutional Generative Adversarial Network |
| WGAN | Wasserstein GAN |
| WCET | Worst-Case Execution Time |
| SBC | Single-Board Computer |
Appendix A

Appendix B
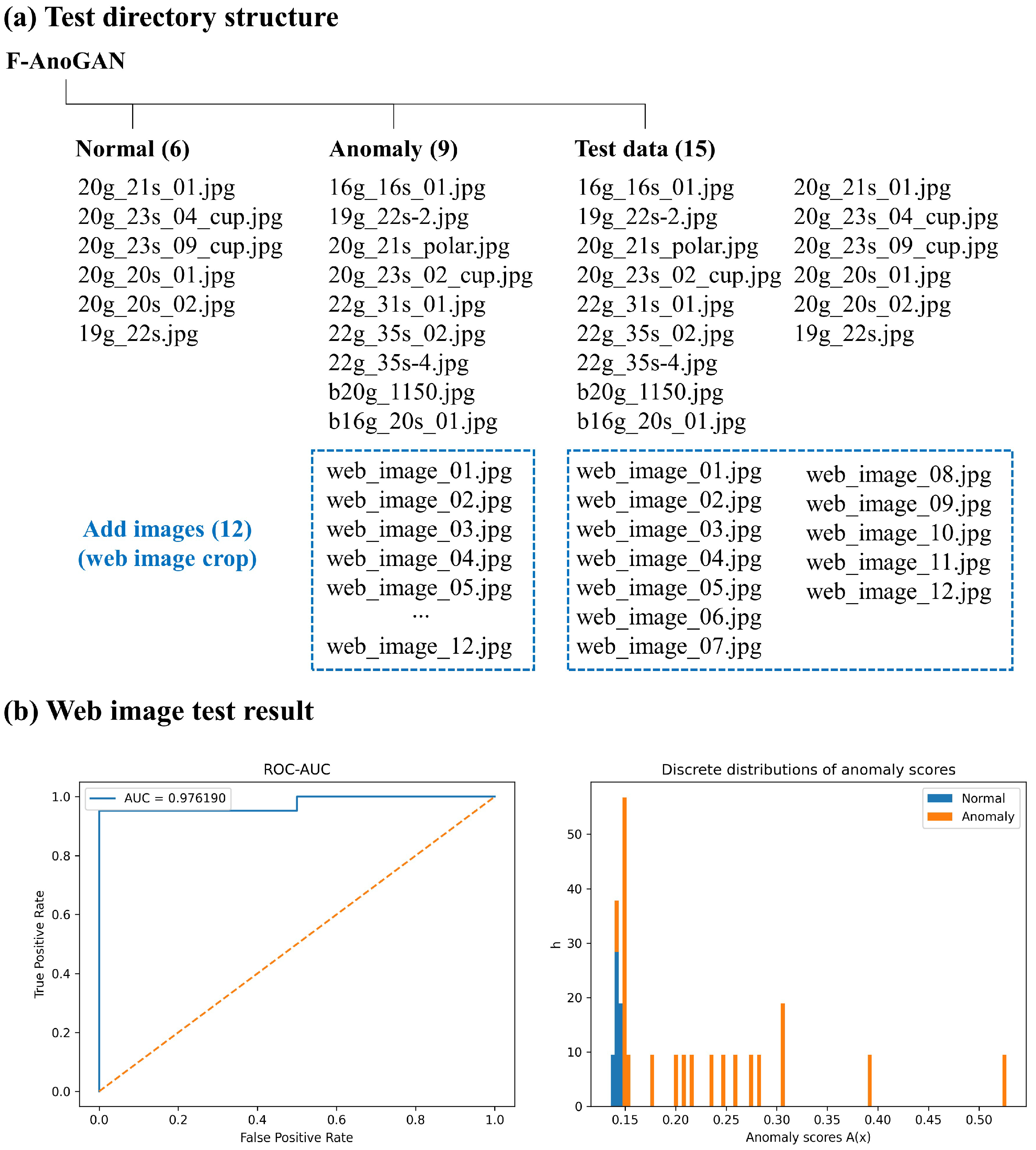
Appendix C
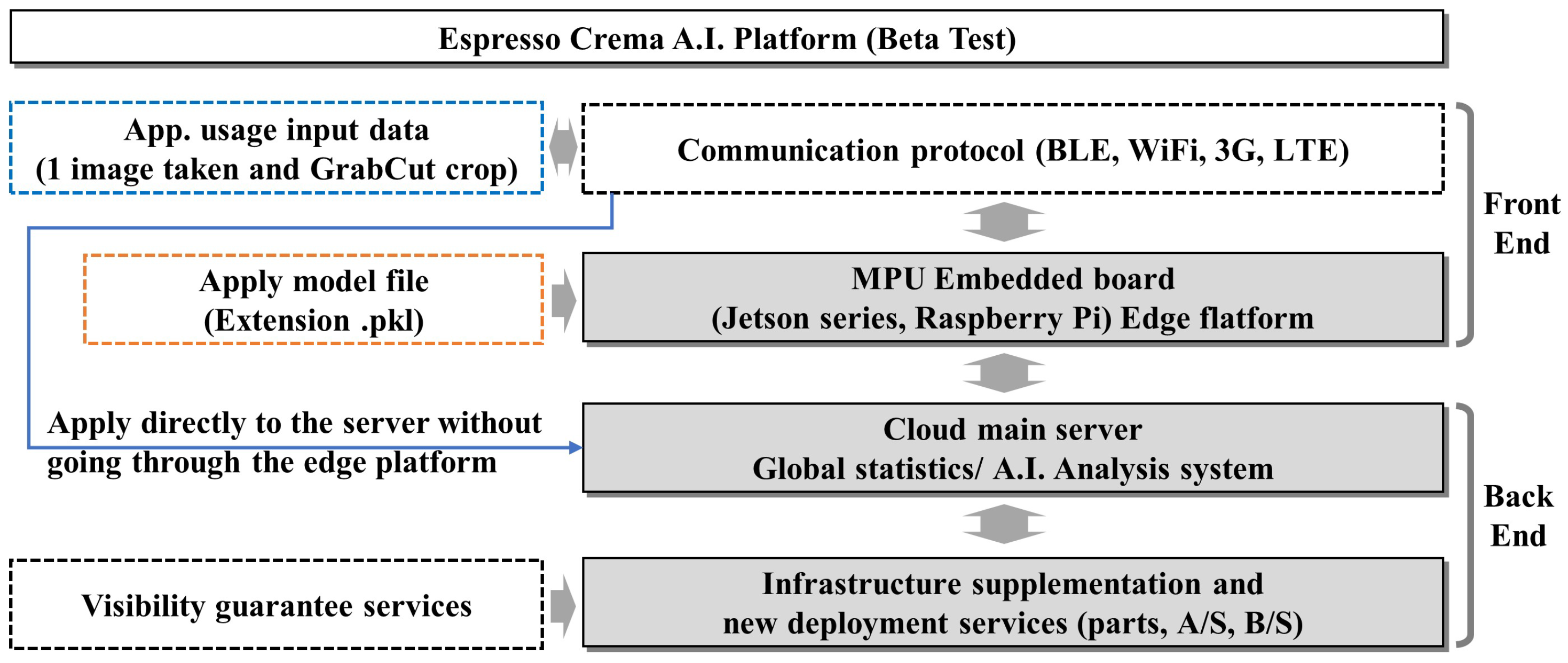
References
- Illy, E.; Navarini, L. Neglected food bubbles: The espresso coffee foam. Food Biophys. 2011, 6, 335–348. [Google Scholar] [CrossRef]
- Illy, E. The complexity of coffee. Sci. Am. 2002, 286, 86–91. [Google Scholar] [CrossRef] [PubMed]
- Illy, A.; Viani, R. Espresso Coffee: The Science of Quality; Academic Press: Cambridge, MA, USA, 2005. [Google Scholar]
- Sandua, D. The Art of Coffee: Techniques and Varieties for the Discerning Barista; David Sandua: Toscana, Italy, 2024. [Google Scholar]
- Thurston, R.W. Coffee: From Bean to Barista; Rowman & Littlefield: Louisville, CO, USA, 2018. [Google Scholar]
- Mahmud, M. Chemical and Sensory Analysis of Formulated Iced-Coffee. Ph.D. Thesis, Deakin University, Geelong, Australia, 2021. [Google Scholar]
- Andueza, S.; Vila, M.A.; Paz de Peña, M.; Cid, C. Influence of coffee/water ratio on the final quality of espresso coffee. J. Sci. Food Agric. 2007, 87, 586–592. [Google Scholar] [CrossRef]
- Sepúlveda, W.S.; Chekmam, L.; Maza, M.T.; Mancilla, N.O. Consumers’ preference for the origin and quality attributes associated with production of specialty coffees: Results from a cross-cultural study. Food Res. Int. 2016, 89, 997–1003. [Google Scholar] [CrossRef]
- de Azeredo, A.M.C. Coffee Roasting: Color and Aroma-Active Sulfur Compounds; University of Florida: Gainesville, FL, USA, 2011. [Google Scholar]
- Choi, J.; Lee, S.; Kang, K.; Suh, H. Lightweight Machine Learning Method for Real-Time Espresso Analysis. Electronics 2024, 13, 800. [Google Scholar] [CrossRef]
- Rother, C.; Kolmogorov, V.; Blake, A. “GrabCut” interactive foreground extraction using iterated graph cuts. ACM Trans. Graph. (TOG) 2004, 23, 309–314. [Google Scholar] [CrossRef]
- Schlegl, T.; Seeböck, P.; Waldstein, S.M.; Schmidt-Erfurth, U.; Langs, G. Unsupervised anomaly detection with generative adversarial networks to guide marker discovery. In International Conference on Information Processing in Medical Imaging; Springer: Cham, Switzerland, 2017; pp. 146–157. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. arXiv 2014, arXiv:1406.2661. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Goodfellow, I. Nips 2016 tutorial: Generative adversarial networks. arXiv 2016, arXiv:1701.00160. [Google Scholar]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Gondara, L. Medical image denoising using convolutional denoising autoencoders. In Proceedings of the 2016 IEEE 16th International Conference on Data Mining Workshops (ICDMW), Barcelona, Spain, 12–15 December 2016; pp. 241–246. [Google Scholar]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein generative adversarial networks. In Proceedings of the International Conference on Machine Learning, PMLR, Sydney, NSW, Australia, 6–11 August 2017; pp. 214–223. [Google Scholar]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A.C. Improved training of wasserstein gans. arXiv 2017, arXiv:1704.00028. [Google Scholar]
- Xia, X.; Pan, X.; Li, N.; He, X.; Ma, L.; Zhang, X.; Ding, N. GAN-based anomaly detection: A review. Neurocomputing 2022, 493, 497–535. [Google Scholar] [CrossRef]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Vahdat, A.; Kautz, J. NVAE: A deep hierarchical variational autoencoder. Adv. Neural Inf. Process. Syst. 2020, 33, 19667–19679. [Google Scholar]
- Rezende, D.J.; Mohamed, S.; Wierstra, D. Stochastic backpropagation and approximate inference in deep generative models. In Proceedings of the International Conference on Machine Learning, PMLR, Beijing, China, 21–26 June 2014; pp. 1278–1286. [Google Scholar]
- Gregor, K.; Danihelka, I.; Graves, A.; Rezende, D.; Wierstra, D. Draw: A recurrent neural network for image generation. In Proceedings of the International Conference on Machine Learning, PMLR, Lille, France, 7–9 July 2015; pp. 1462–1471. [Google Scholar]
- Schlegl, T.; Seeböck, P.; Waldstein, S.M.; Langs, G.; Schmidt-Erfurth, U. f-AnoGAN: Fast unsupervised anomaly detection with generative adversarial networks. Med. Image Anal. 2019, 54, 30–44. [Google Scholar] [CrossRef] [PubMed]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- LeCun, Y.; Cortes, C.; Burges, C. MNIST Handwritten Digit Database. ATT Labs. 2010. Available online: http://yann.lecun.com/exdb/mnist (accessed on 1 July 2023).
- Krizhevsky, A. Learning Multiple Layers of Features from Tiny Images; Technical Report; 2009. Available online: https://www.cs.toronto.edu/~kriz/cifar.html (accessed on 1 July 2023).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Grabcut | WGAN lambda gp Parameter | ||||
|---|---|---|---|---|---|---|
| 30 | 40 | 50 | 60 | 70 | ||
| AE | (a) Transparent | 0.6852 | 0.8519 | 0.6481 | 0.8148 | 0.6111 |
| (b) Circle crop | 0.8704 | 0.6481 | 0.8889 | 0.6111 | 0.6296 | |
| (c) Square crop | 0.8148 | 0.7778 | 0.6296 | 0.9630 | 0.9074 | |
| VAE | (a) Transparent | 0.8889 | 0.8704 | 0.7222 | 0.8704 | 0.8704 |
| (b) Circle crop | 0.8889 | 1.0000 | 1.0000 | 0.9444 | 0.8889 | |
| (c) Square crop | 0.9259 | 1.0000 | 1.0000 | 0.9815 | 0.7407 | |
| Model | WGAN lambda gp Hyperparameter | ||||
|---|---|---|---|---|---|
| 30 | 40 | 50 | 60 | 70 | |
| (a) DCGAN+AE | 0.5741 | 0.5556 | 0.6296 | 0.5370 | 0.5926 |
| (b) DCGAN+VAE | 0.5741 | 0.5741 | 0.5741 | 0.5926 | 0.7222 |
| (c) f-AnoGAN+AE | 0.8148 | 0.7778 | 0.6296 | 0.9630 | 0.9074 |
| (d) f-AnoGAN+VAE | 0.9259 | 1.0000 | 1.0000 | 0.9815 | 0.7407 |
| System Device | Model Execution Time | |||
|---|---|---|---|---|
| Cold Start | Standard Start | |||
| Full | Test Load Image | Full | Test Load Image | |
| Desktop i7 | 7.6 s ± 1.43 | 1.5 s ± 0.06 | 2.1 s ± 0.01 | 1.5 s ± 0.02 |
| Laptop i7 | 7.8 s ± 0.18 | 2.0 s ± 0.06 | 2.7 s ± 0.04 | 2.0 s ± 0.04 |
| Jetson Nano | 105.4 s ± 10.14 | 36.9 s ± 9.54 | 45.0 s ± 4.09 | 17.3 s ± 2.68 |
| Jetson NX | 36.0 s ± 4.22 | 20.4 s ± 2.77 | 22.3 s ± 1.60 | 18.7 s ± 1.68 |
| Model | Weight Initialization Parameter | ||||
| 0.02 | 0.03 | 0.04 | 0.05 | 0.06 | |
| (a) DCGAN+AE | 0.3897 | 0.4811 | 0.4476 | 0.4373 | 0.3446 |
| Model | WGAN lambda gp hyperparameter | ||||
| 30 | 40 | 50 | 60 | 70 | |
| (b) DCGAN+VAE | 0.5251 | 0.5249 | 0.5250 | 0.5261 | 0.5267 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Choi, J.; Lee, S.; Kang, K. Espresso Crema Analysis with f-AnoGAN. Mathematics 2025, 13, 547. https://doi.org/10.3390/math13040547
Choi J, Lee S, Kang K. Espresso Crema Analysis with f-AnoGAN. Mathematics. 2025; 13(4):547. https://doi.org/10.3390/math13040547
Chicago/Turabian StyleChoi, Jintak, Seungeun Lee, and Kyungtae Kang. 2025. "Espresso Crema Analysis with f-AnoGAN" Mathematics 13, no. 4: 547. https://doi.org/10.3390/math13040547
APA StyleChoi, J., Lee, S., & Kang, K. (2025). Espresso Crema Analysis with f-AnoGAN. Mathematics, 13(4), 547. https://doi.org/10.3390/math13040547