
An Optimized Weighted-Voting-Based Ensemble Learning Approach for Fake News Classification

 ,
,  ,
,
Abstract
1. Introduction
- Introducing a weighted voting ensemble model combining LR, SVM, GRU, and LSTM for enhanced fake news detection.
- Comparing text vectorization techniques such as Bag of Words, TF-IDF, and GloVe to identify the most effective representation.
- Evaluating performance using metrics like accuracy, precision, recall, and F1-score, with hyperparameter tuning through Grid Search, achieving superior results.
2. Related Work

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Author | Methodology | Pros | Cons |
|---|---|---|---|
| Seddari et al. [5] | Enhanced feature extraction with linguistic and fact-verification features. | Easy to test; relative effectiveness compared to existing systems. | Overlooks important features, possibly limiting its overall utility. |
| Chi-Square [22] | Classic method for feature selection based on category distribution. | Simple and well-understood technique for classification. | Struggles with imbalanced datasets; dependent on category distribution for accuracy and reliability. |
| Osman et al. [23] | Iterated Greedy Algorithm with feature selection via Information Gain and Chi-Square. | Effective for sentiment classification, it uses minimal-dimensional feature vectors. | Not ideal for larger datasets, and effectiveness may be reduced with more complex datasets. |
| Ahmad et al. [24] | Feature selection using TF, Bag of Words, and TF-IDF with Binary Salp Swarm Optimization. | Good accuracy for smaller datasets (74.5%) using TF-IDF and feature extraction. | Limited scalability and lower accuracy on complex, large datasets. |
| Too et al. [25] | Hyper Learning Binary Dragonfly Algorithm (HLBDA) for feature selection. | Uses personal and global solutions to avoid local optima. | Computationally intensive; may require significant resources. |
| Eren Sahin et al. [27] | LSTM with word embeddings and TF-IDF for feature extraction. | High accuracy in specific domains. | Limited to specific domains; not generalized for other datasets. |
| Y. Zhou et al. [29] | Multigrained Multimodal Fusion Network (MMFN) with transformer-based pre-trained models. | Resolves ambiguity well in token-level feature representation. | Performance on large datasets is difficult to evaluate and computationally expensive. |
| Zulqarnain and Saqlain [30] | Overview of text classification techniques. | Provides a broad comparison of methods. | Does not focus on specific deep learning models or solutions for fake news detection. |
| Hassan et al. [31] | Comparative analysis of machine learning algorithms for text classification. | Provides a comprehensive comparison of various algorithms. | Does not offer specific solutions to the problem of fake news detection but provides a general overview. |
| Occhipinti et al. [32] | Overview of 12 machine learning models for fake news detection. | Extensive comparison of different models for fake news detection. | Does not focus on the practical application of models to real-world datasets. |
| Tong and Koller [33] | Support vector machine (SVM) active learning for text classification. | Valuable contribution to active learning for classification tasks. | Active learning may not always be effective, depending on dataset and domain. |
| Surekha et al. [34] | Combination of WoT with Asian social networks for feature extraction. | Improves feature extraction and detection rates for digital misinformation. | Limited to specific regions and datasets. |
| Bangyal et al. [35] | Novel deep learning models for COVID-19 propaganda detection. | Effective for detecting COVID-related misinformation. | May not generalize to other topics or domains beyond public health. |
| Dubey et al. [36] | Combination of vectorization and machine learning techniques for fake news detection. | More robust solution for fake news detection. | May have difficulty handling diverse sources of fake news. |
| SY et al. [37] | Identification of key argument components within text for fake news detection. | Robust voting mechanism enhances prediction accuracy. | Macro-F1 scores of unit identification (77.08%) and classification (57.90%) suggest limitations. |
| R. Hoque et al. [38] | LSTM on a dataset of various social media and news platforms. | High accuracy (92.01%) on a multi-source dataset. | May struggle with datasets from domains not included in the training set. |
| M. Mhamed et al. [39] | Machine learning and deep learning models for fake news detection. | High accuracy with models like LSTM and RMuBERT (up to 94%). | RMuBERT’s performance may drop with datasets that differ from the ones used in testing. |
| C.N. Hang et al. [40] | Introduced TrumorGPT, a generative AI that uses machine learning with natural language to differentiate tumors and overcome hallucination in LLMs. | Overcomes hallucination issue; enhances efficiency with knowledge graphs. | Limited in scope to tumor differentiation; focus on specific medical applications; may not generalize across other domains. |
| Vallidevi Krishnamurthy et al. [41] | Yours Truly framework with FactStore database for fact-checking. | Achieves excellent F1 score (94%) with good precision and recall. | Focuses mainly on fact-checking and may not generalize well across various fake news types. |
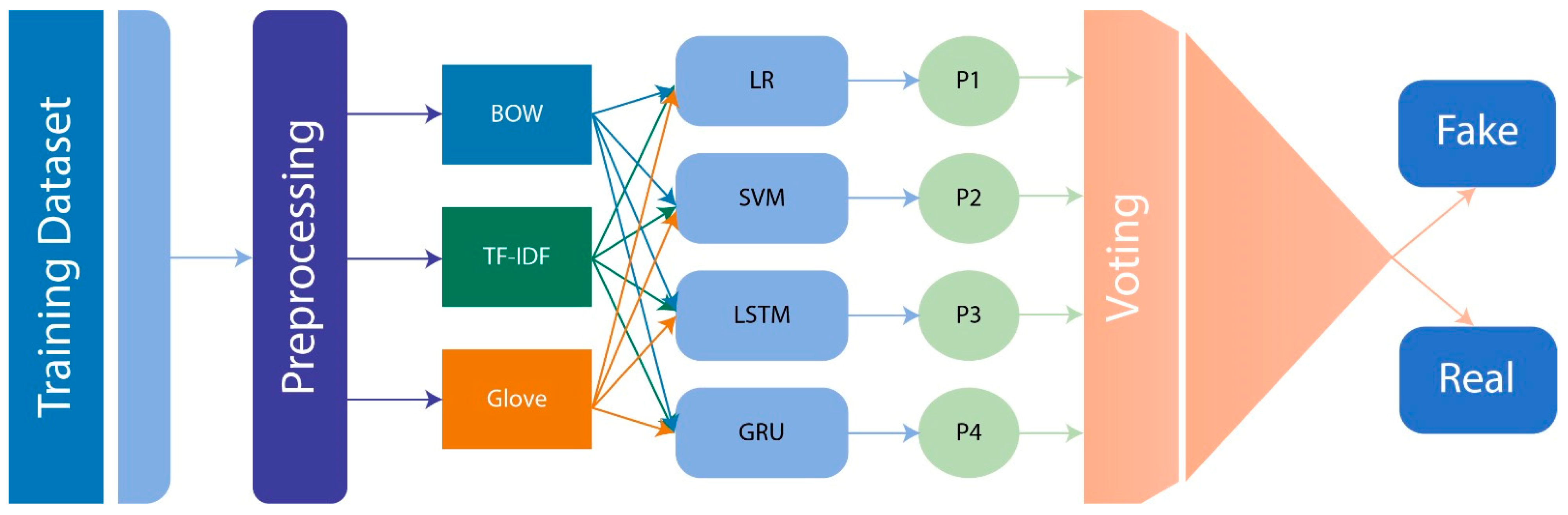
3. Proposed Methodology
3.1. Preprocessing
- Stop word removal. Stop words are the low-value words of a language that cause noise in text classification features if they appear. Articles, prepositions, conjunctions, and some pronouns commonly add structure or link concepts in sentences. Stop words are “a”, “an”, “the”, “by”, “in”, “on”, “is”, “was”, “that”, “which”, “who”, “what”, and “where”. Preliminary preprocessing attempts are mainly towards eliminating such stop words from the document, making the dataset clear and more efficient by removing irrelevant content. It will reduce extraneous terms, minimize noise in the dataset, and allow the model to focus on more significant and distinctive words for enhanced overall efficiency.
- Tokenization. Tokenization divides text into smaller meaningful units, like words, symbols, or phrases. That way, further analysis may be performed. It will take a sentence and divide it into its tokens, representing the significant sequence or element of the sentence. The following sentence, “Natural language processing is complex”, tokenizes into the set [Natural, language, processing, is, complex]. Tokenization disaggregates text into smaller, manageable units such as words or phrases, enabling the model to consider each piece as an individual characteristic, hence facilitating detailed analysis.
- Stemming. Following tokenization, the subsequent step is standardizing tokens. Here, the process is performed by converting words into their root form using stemming. Stemming reduces the number of word forms that data may contain. The process helps reduce unique word forms as related words are reduced to a common base. Examples include words like “Running”, “Run”, “Ran”, and “Runner”, all of which become reduced to “run”. This makes the process easier and faster in terms of classification. A well-known algorithm for this task is the Porter Stemmer, a reliable and effective tool. This technique simplifies words to their base forms, consolidating multiple forms of a single word into one feature to enhance classification efficiency and improve model generalization capability.
- Punctuation Removal. Removing punctuation is an important preprocessing step in text analysis that involves removing punctuation symbols because they are considered noise. This way, text can be simplified so that only meaningful terms remain, which helps in analysis. For instance, the sentence “Hello, world!” is converted to “Hello world” by removing all punctuation. This step is convenient for tasks like sentiment analysis or text classification, as the punctuation would usually contribute minimally to the intended meaning of the content. This avoids superfluous punctuation marks, allowing for a focus on content and enhancing the identification of significant patterns or relationships within a text.
3.2. Text Vectorization
3.2.1. Bag of Words
3.2.2. TF-IDF
3.2.3. GloVe
3.3. Ensemble Classifiers
3.3.1. Logistic Regression
3.3.2. Support Vector Machine (SVM)
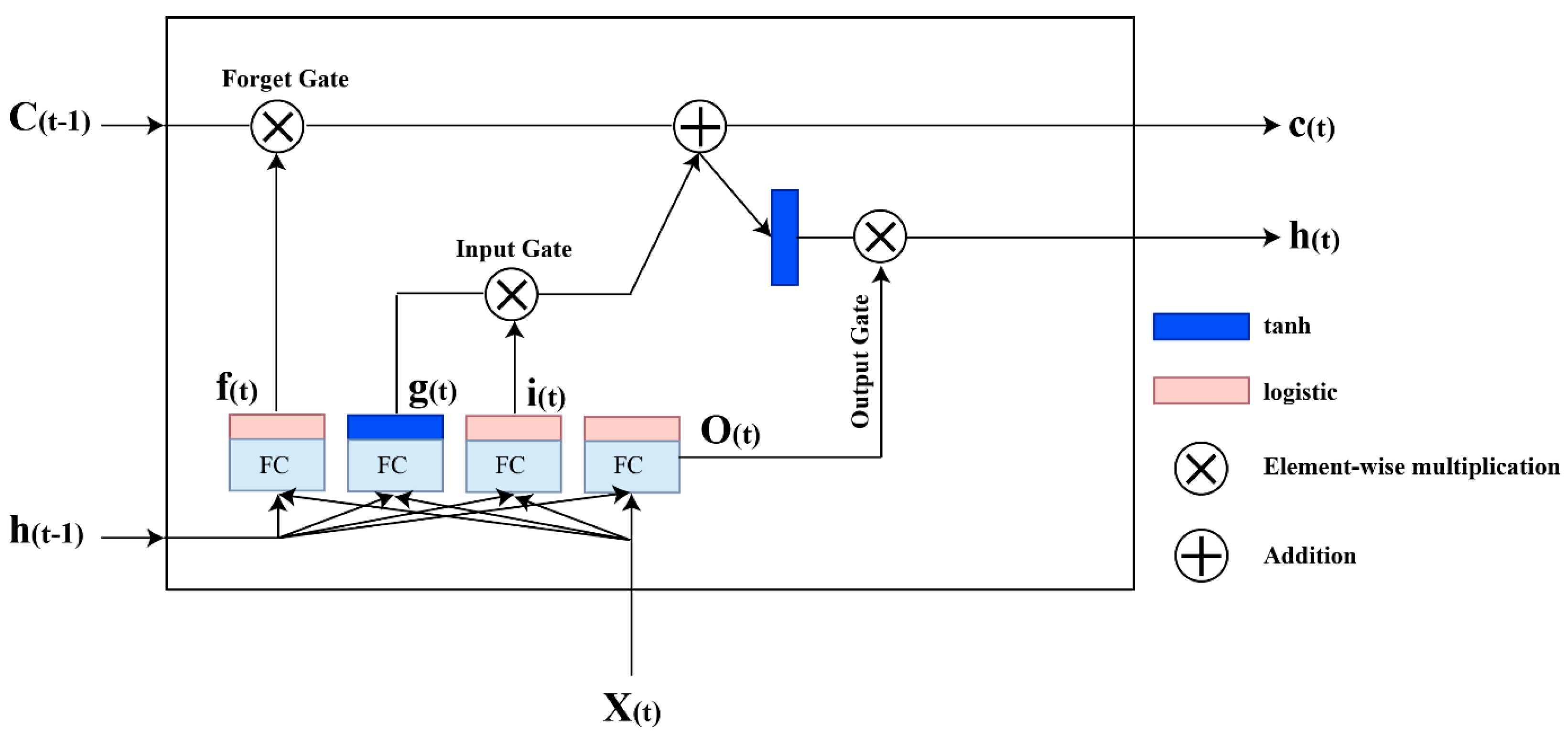
3.3.3. Long Short-Term Memory (LSTM)
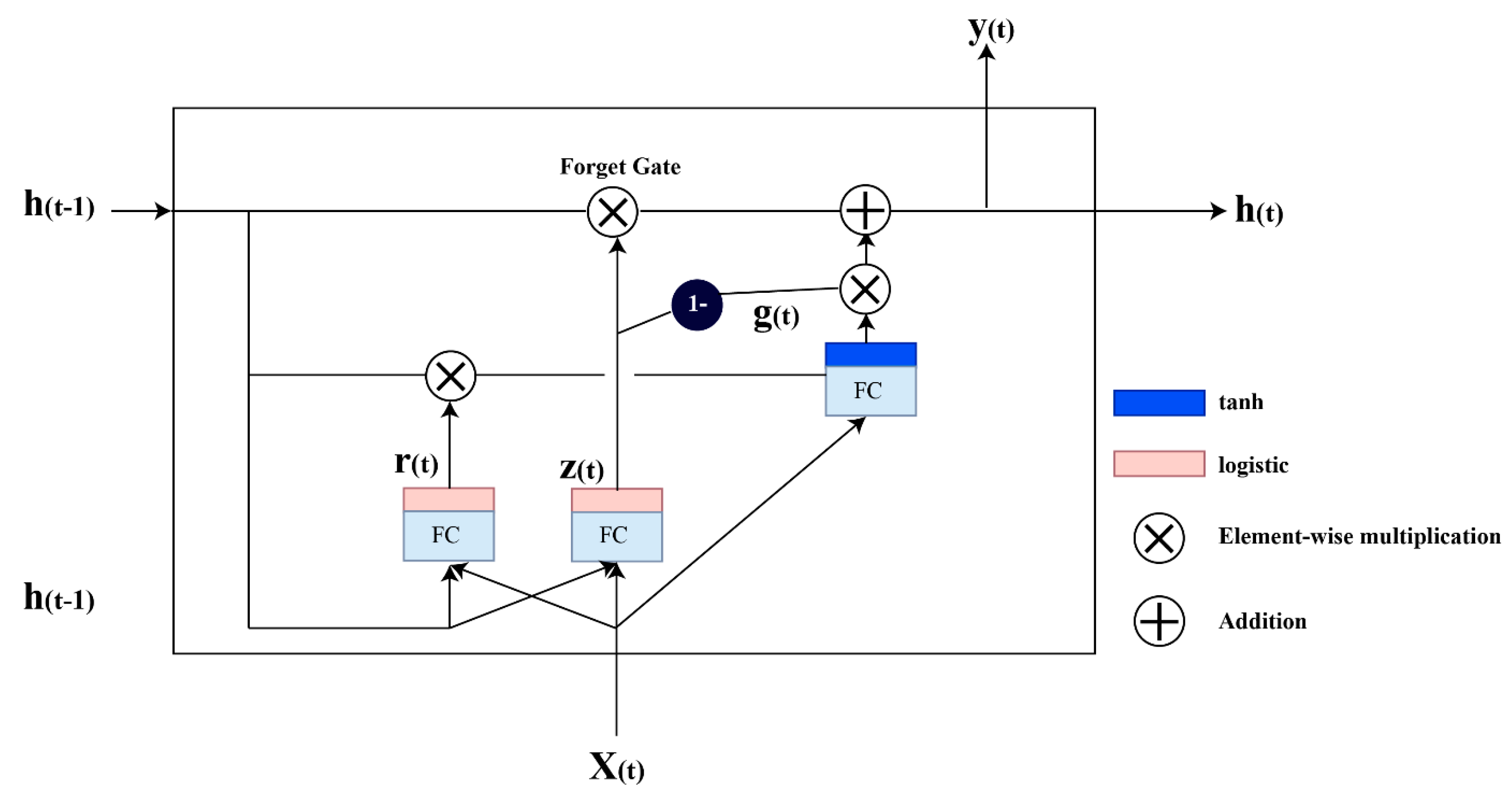
3.3.4. GRU
3.3.5. Voting-Based Ensemble Classifier
4. Experimental Results
4.1. Dataset and Experimental Setup
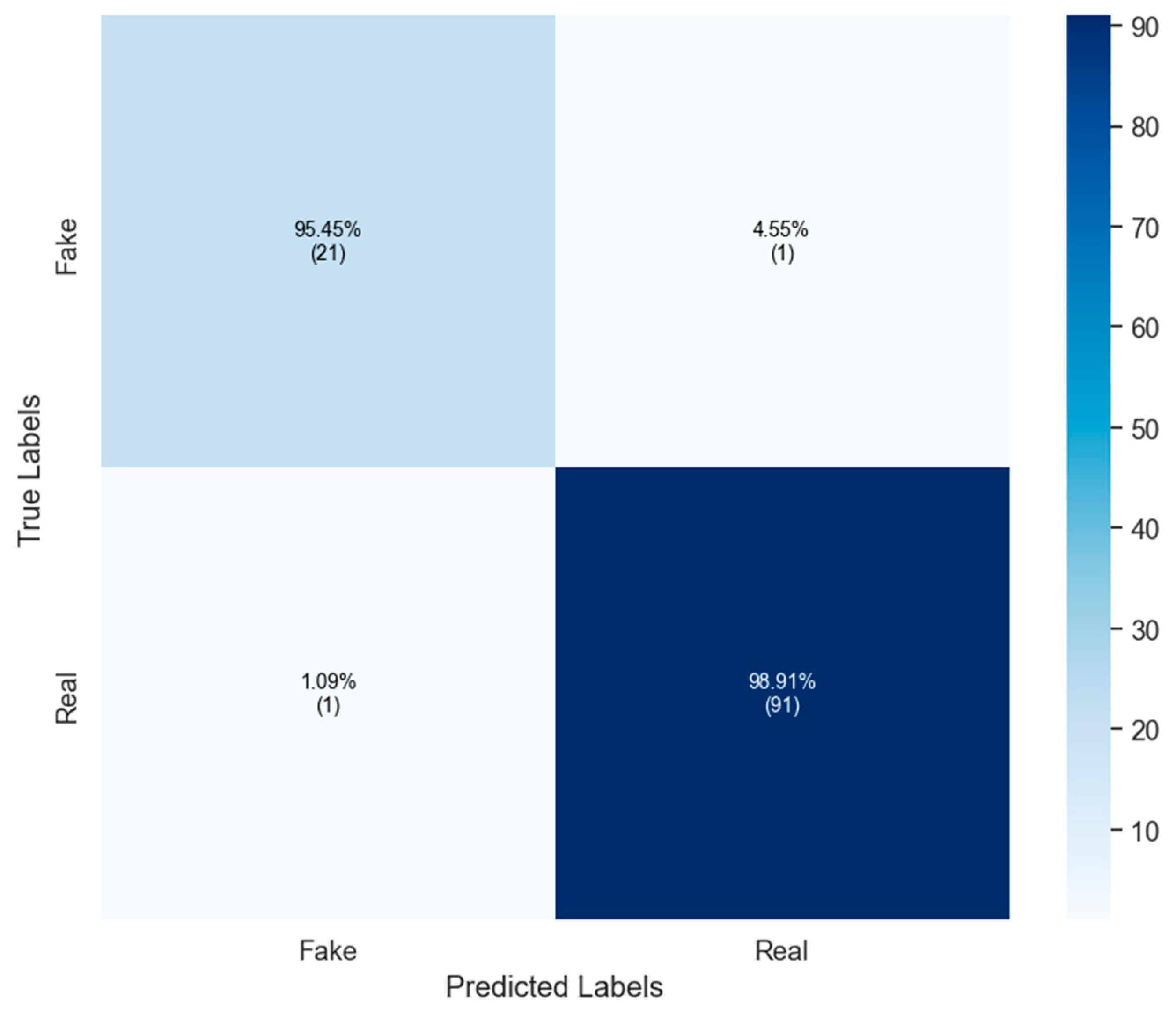
4.2. Results on Politifact Dataset
4.3. Results on BuzzFeed Dataset
4.4. Ablation Studies
4.5. Comparison with State of the Art
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Shu, K.; Sliva, A.; Wang, S.; Tang, J.; Liu, H. Fake news detection on social media: A data mining perspective. ACM SIGKDD Explor. Newsl. 2017, 19, 22–36. [Google Scholar] [CrossRef]
- Shu, K.; Wang, S.; Liu, H. Understanding user profiles on social media for fake news detection. In Proceedings of the 2018 IEEE Conference on Multimedia Information Processing and Retrieval (MIPR), Miami, FL, USA, 10–12 April 2018. [Google Scholar]
- Monti, F.; Frasca, F.; Eynard, D.; Mannion, D.; Bronstein, M.M. Fake news detection on social media using geometric deep learning. arXiv 2019, arXiv:1902.06673. [Google Scholar]
- Pulido, C.M.; Ruiz-Eugenio, L.; Redondo-Sama, G.; Villarejo-Carballido, B. A new application of social impact in social media for overcoming fake news in health. Int. J. Environ. Res. Public Health 2020, 17, 2430. [Google Scholar] [CrossRef] [PubMed]
- Seddari, N.; Derhab, A.; Belaoued, M.; Halboob, W.; Al-Muhtadi, J.; Bouras, A. A hybrid linguistic and knowledge-based analysis approach for fake news detection on social media. IEEE Access 2022, 10, 62097–62109. [Google Scholar] [CrossRef]
- Agarwal, I.Y.; Rana, D.P. An improved fake news detection model by applying a recursive feature elimination approach for credibility assessment and uncertainty. J. Uncertain Syst. 2023, 16, 2242008. [Google Scholar] [CrossRef]
- Lazer, D.M.J.; Baum, M.A.; Benkler, Y.; Berinsky, A.J.; Greenhill, K.M.; Menczer, F.; Metzger, M.J.; Nyhan, B.; Pennycook, G.; Rothschild, D.; et al. The science of fake news. Science 2018, 359, 1094–1096. [Google Scholar] [CrossRef]
- Higdon, N. The Anatomy of Fake News: A Critical News Literacy Education; University of California Press: Berkeley, CA, USA, 2020. [Google Scholar]
- Soll, J. The long and brutal history of fake news. Politico Mag. 2016, 18, 2016. [Google Scholar]
- Hua, J.; Shaw, R. Corona virus (COVID-19) “infodemic” and emerging issues through a data lens: The case of China. Int. J. Environ. Res. Public Health 2020, 17, 2309. [Google Scholar] [CrossRef]
- Vosoughi, S.; Roy, D.; Aral, S. The spread of true and false news online. Science 2018, 359, 1146–1151. [Google Scholar] [CrossRef]
- Manzoor, S.I.; Singla, J. Fake news detection using machine learning approaches: A systematic review. In Proceedings of the 2019 3rd International Conference on Trends in Electronics and Informatics (ICOEI), Tirunelveli, India, 23–25 April 2019. [Google Scholar]
- Wu, X.; Kumar, V.; Ross Quinlan, J.; Ghosh, J.; Yang, Q.; Motoda, H.; McLachlan, G.J.; Ng, A.; Liu, B.; Yu, P.S.; et al. Top 10 algorithms in data mining. Knowl. Inf. Syst. 2008, 14, 1–37. [Google Scholar] [CrossRef]
- Cristianini, N.; Shawe-Taylor, J. An Introduction to Support Vector Machines and Other Kernel-Based Learning Methods; Cambridge University Press: Cambridge, UK, 2000. [Google Scholar]
- Cho, K. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Hochreiter, S. Long Short-Term Memory; Neural Computation MIT-Press: La Jolla, CA, USA, 1997. [Google Scholar]
- Ahmad, I.; Yousaf, M.; Yousaf, S.; Ahmad, M.O. Fake news detection using machine learning ensemble methods. Complexity 2020, 2020, 8885861. [Google Scholar] [CrossRef]
- Allcott, H.; Gentzkow, M. Social media and fake news in the 2016 election. J. Econ. Perspect. 2017, 31, 211–236. [Google Scholar] [CrossRef]
- Conroy, N.K.; Rubin, V.L.; Chen, Y. Automatic deception detection: Methods for finding fake news. Proc. Assoc. Inf. Sci. Technol. 2015, 52, 1–4. [Google Scholar] [CrossRef]
- Rubin, V.L.; Conroy, N.; Chen, Y.; Cornwell, S. Fake news or truth? using satirical cues to detect potentially misleading news. In Proceedings of the Second Workshop on Computational Approaches to Deception Detection, San Diego, CA, USA, 12–17 June 2016. [Google Scholar]
- Jwa, H.; Oh, D.; Park, K.; Kang, J.M.; Lim, H. exBAKE: Automatic fake news detection model based on bidirectional encoder representations from transformers (bert). Appl. Sci. 2019, 9, 4062. [Google Scholar] [CrossRef]
- Cai, L.-J.; Lv, S.; Shi, K.-B. Application of an improved chi feature selection algorithm. Discret. Dyn. Nat. Soc. 2021, 2021, 9963382. [Google Scholar] [CrossRef]
- Gokalp, O.; Tasci, E.; Ugur, A. A novel wrapper feature selection algorithm based on iterated greedy metaheuristic for sentiment classification. Expert Syst. Appl. 2020, 146, 113176. [Google Scholar] [CrossRef]
- Al-Ahmad, B.; Al-Zoubi, A.M.; Abu Khurma, R.; Aljarah, I. An evolutionary fake news detection method for COVID-19 pandemic information. Symmetry 2021, 13, 1091. [Google Scholar] [CrossRef]
- Too, J.; Mirjalili, S. A hyper learning binary dragonfly algorithm for feature selection: A COVID-19 case study. Knowl.-Based Syst. 2020, 212, 106553. [Google Scholar] [CrossRef]
- Parlak, B.; Uysal, A.K. A novel filter feature selection method for text classification: Extensive Feature Selector. J. Inf. Sci. 2021, 49, 59–78. [Google Scholar] [CrossRef]
- Sahin, M.E.; Tang, C.; Al-Ramahi, M.A. Fake News detection on social media: A word embedding-based approach. In Proceedings of the 28th annual Americas Conference on Information Systems, Minneapolis, MN, USA, 10–14 August 2022. [Google Scholar]
- Wang, H.; Tang, P.; Kong, H.; Jin, Y.; Wu, C.; Zhou, L. DHCF: Dual disentangled-view hierarchical contrastive learning for fake news detection on social media. Inf. Sci. 2023, 645, 119323. [Google Scholar] [CrossRef]
- Zhou, Y.; Yang, Y.; Ying, Q.; Qian, Z.; Zhang, X. Multi-modal fake news detection on social media via multi-grained information fusion. In Proceedings of the 2023 ACM International Conference on Multimedia Retrieval, Thessaloniki, Greece, 12–15 June 2023. [Google Scholar]
- Zulqarnain, M.; Saqlain, M. Text readability evaluation in higher education using CNNs. J. Ind. Intell. 2023, 1, 184–193. [Google Scholar] [CrossRef]
- Hassan, S.U.; Ahamed, J.; Ahmad, K. Analytics of machine learning-based algorithms for text classification. Sustain. Oper. Comput. 2022, 3, 238–248. [Google Scholar] [CrossRef]
- Occhipinti, A.; Rogers, L.; Angione, C. A pipeline and comparative study of 12 machine learning models for text classification. Expert Syst. Appl. 2022, 201, 117193. [Google Scholar] [CrossRef]
- Baig, M.D.; Akram, W.; Haq, H.B.U.; Rajput, H.Z.; Imran, M. Optimizing misinformation control: A cloud-enhanced machine learning approach. Inf. Dyn. Appl. 2024, 3, 1–11. [Google Scholar] [CrossRef]
- Surekha, T.L.; Rao, N.C.S.; Shahnazeer, C.; Yaseen, S.M.; Shukla, S.K.; Bharat, S.; Arumugam, M. Digital misinformation and fake news detection using WoT integration with Asian social networks fusion based feature extraction with text and image classification by machine learning architectures. Theor. Comput. Sci. 2022, 927, 1–14. [Google Scholar] [CrossRef]
- Kurasinski, L.; Mihailescu, R.-C. Towards machine learning explainability in text classification for fake news detection. In Proceedings of the 2020 19th IEEE International Conference on Machine Learning and Applications (ICMLA), Virtual Event, 14–17 December 2020. [Google Scholar]
- Dubey, Y.; Wankhede, P.; Borkar, A.; Borkar, T.; Palsodkar, P. Framework for fake news classification using vectorization and machine learning. In Combating Fake News with Computational Intelligence Techniques; Springer: Cham, Switzerland, 2022; pp. 327–343. [Google Scholar]
- Sy, E.; Peng, T.C.; Lin, H.Y.; Huang, S.H.; Chang, Y.C.; Chung, C.P. Ensemble BERT Techniques for Financial Sentiment Analysis and Argument Understanding with Linguistic Features in Social Media Analytics. J. Inf. Sci. Eng. 2025, 41, 579–599. [Google Scholar]
- Hoque, R.; Islam, S.; Sarkar, S.; Habiba, S.U.; Rahman, M.; Palas, R.; Hoque, M. Depressive and Suicidal Text-Based Sentiment Analysis in Bangla Using Deep Learning Models. Bus. IT 2024, XIV, 136–150. [Google Scholar] [CrossRef]
- Mhamed, M.; Sutcliffe, R.; Feng, J. Benchmark Arabic news posts and analyzes Arabic sentiment through RMuBERT and SSL with AMCFFL technique. Egypt. Informatics J. 2025, 29, 100601. [Google Scholar] [CrossRef]
- Hang, C.N.; Yu, P.-D.; Tan, C.W. TrumorGPT: Query Optimization and Semantic Reasoning over Networks for Automated Fact-Checking. In Proceedings of the 2024 58th Annual Conference on Information Sciences and Systems (CISS), Princeton, NJ, USA, 13–15 March 2024; pp. 1–6. [Google Scholar]
- Krishnamurthy, V.; Balaji, V. Yours Truly: A Credibility Framework for Effortless LLM-Powered Fact Checking. IEEE Access 2024, 12, 195152–195173. [Google Scholar] [CrossRef]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014. [Google Scholar]
- Chang, C.-C.; Lin, C.-J. LIBSVM: A library for support vector machines. ACM Trans. Intell. Syst. Technol. (TIST) 2011, 2, 1–27. [Google Scholar] [CrossRef]
- Santia, G.; Williams, J. Buzzface: A news veracity dataset with facebook user commentary and egos. In Proceedings of the International AAAI Conference on Web and Social Media, Palo Alto, CA, USA, 25–28 June 2018; Volume 12, pp. 531–540. [Google Scholar]
- Haq, A.U.; Li, J.; Memon, M.; Khan, J.; Din, S.U.; AHAD, I.; Sun, R.; Lai, Z. Comparative analysis of the classification performance of machine learning classifiers and deep neural network clas-sifier for prediction of Parkinson disease. In Proceedings of the 2018 15th International Computer Conference on Wavelet Active Media Technology and Information Processing (ICCWAMTIP), Chengdu, China, 14–16 December 2018. [Google Scholar]
- Brochu, E.; VCora, M.; De Freitas, N. A tutorial on Bayesian optimization of expensive cost functions, with application to active user modeling and hierarchical reinforcement learning. arXiv 2010, arXiv:1012.2599. [Google Scholar]
- Ghourabi, A. A security model based on lightgbm and transformer to protect healthcare systems from cyberattacks. IEEE Access 2022, 10, 48890–48903. [Google Scholar] [CrossRef]
- Qu, Z.; Meng, Y.; Muhammad, G.; Tiwari, P. QMFND: A quantum multimodal fusion-based fake news detection model for social media. Inf. Fusion 2024, 104, 102172. [Google Scholar] [CrossRef]
- Al Obaid, A.; Khotanlou, H.; Mansoorizadeh, M.; Zabihzadeh, D. Multimodal fake-news recognition using ensemble of deep learners. Entropy 2022, 24, 1242. [Google Scholar] [CrossRef]
- Güler, G.; Gündüz, S. Deep learning based fake news detection on social media. Int. J. Inf. Secur. Sci. 2023, 12, 1–21. [Google Scholar] [CrossRef]
- Ozbay, F.A.; Alatas, B. Fake news detection within online social media using supervised artificial intelligence algorithms. Phys. A Stat. Mech. Its Appl. 2020, 540, 123174. [Google Scholar] [CrossRef]
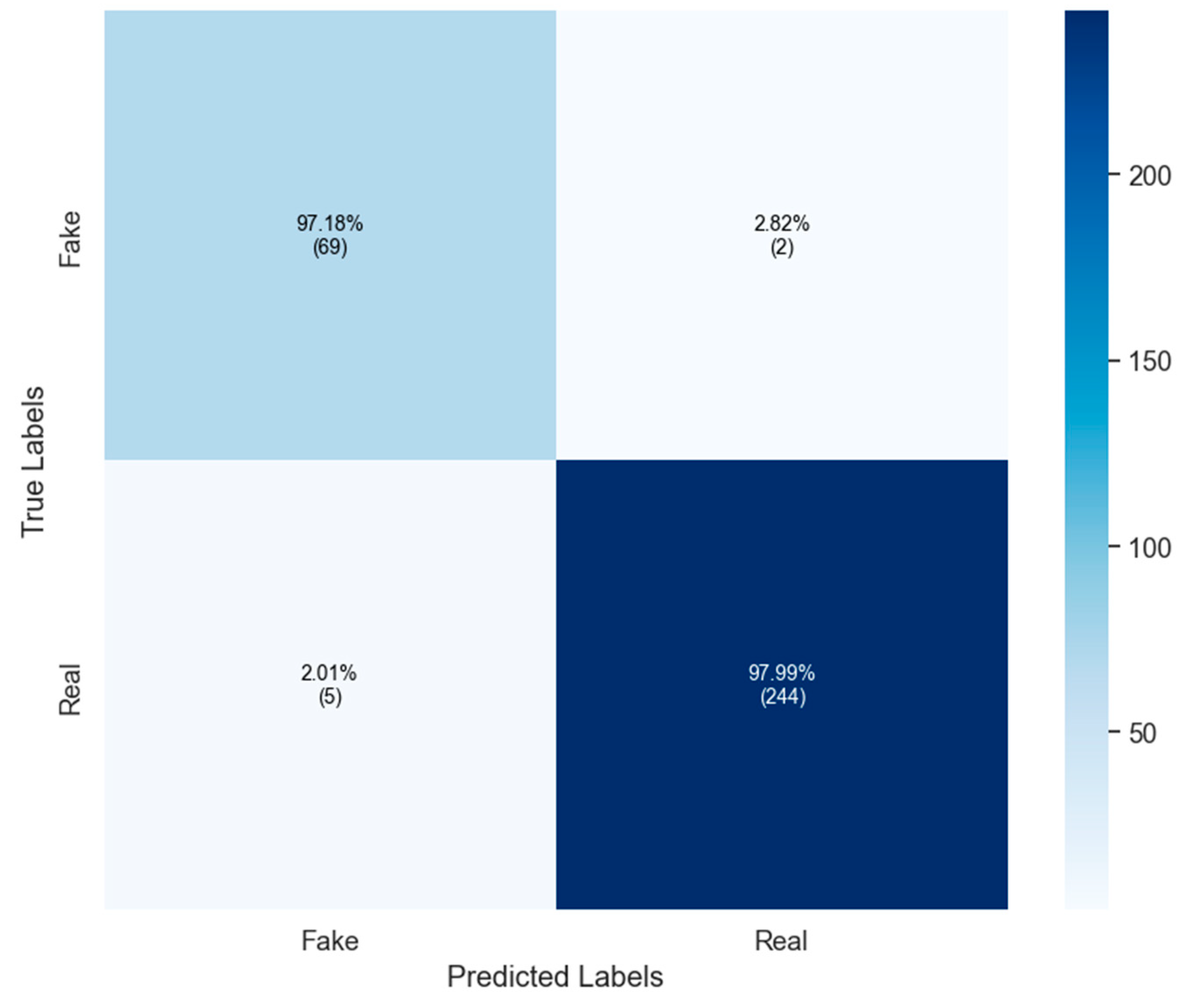
| Models | BoW | TF-IDF | GloVe | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Acc (%) | Pre (%) | F1 (%) | Time (s) | Acc (%) | Pre (%) | F1 (%) | Time (s) | Acc (%) | Pre (%) | F1 (%) | Time (s) | |
| SVM | 81.62 | 80.45 | 80.03 | 347 | 86.45 | 84.67 | 85.59 | 382 | 82.31 | 80.45 | 81.22 | 537 |
| LR | 76.78 | 74.34 | 74.32 | 294 | 78.93 | 77.43 | 78.76 | 426 | 74.65 | 73.12 | 73.90 | 509 |
| LSTM | 77.42 | 74.21 | 74.65 | 281 | 82.54 | 79.56 | 81.34 | 328 | 76.23 | 75.43 | 75.38 | 522 |
| GRU | 80.83 | 79.46 | 78.35 | 347 | 80.45 | 79.22 | 79.57 | 332 | 88.39 | 87.54 | 88.65 | 558 |
| KNN | 64.58 | 60.39 | 60.82 | 282 | 66.67 | 63.45 | 64.21 | 456 | 62.87 | 62.87 | 61.21 | 552 |
| RF | 67.34 | 64.67 | 63.18 | 294 | 70.43 | 69.38 | 69.19 | 459 | 71.32 | 70.63 | 70.90 | 400 |
| XGBoost | 72.75 | 70.46 | 70.52 | 262 | 73.98 | 71.67 | 72.30 | 391 | 69.45 | 68.40 | 68.66 | 580 |
| LightGBM | 71.47 | 68.38 | 68.97 | 321 | 77.43 | 76.48 | 75.44 | 477 | 71.56 | 70.18 | 70.42 | 545 |
| Proposed | 94.57 | 94.12 | 93.33 | 347 | 98.76 | 98.03 | 97.98 | 334 | 96.68 | 94.79 | 95.67 | 577 |
| Ensemble Techniques | Acc (%) | Pre (%) | F1 (%) |
|---|---|---|---|
| Bagging | 89.46 | 88.32 | 88.87 |
| Boosting | 94.34 | 92.89 | 93.58 |
| Soft Voting | 91.29 | 90.47 | 90.23 |
| Stacking | 95.40 | 93.78 | 94.59 |
| Weighted Voting | 98.76 | 98.03 | 97.98 |
| Model | Acc (%) | Pre (%) | F1 (%) | Time (s) |
|---|---|---|---|---|
| BERT | 86.56 | 85.67 | 85.22 | 515 |
| DistilBERT | 91.45 | 90.71 | 90.56 | 472 |
| AlBERT | 84.98 | 84.08 | 84.65 | 505 |
| RoBERTa | 93.12 | 91.76 | 92.69 | 530 |
| Proposed | 98.76 | 98.03 | 97.98 | 334 |
| Models | BoW | TF-IDF | GloVe | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Acc (%) | Pre (%) | F1 (%) | Time (s) | Acc (%) | Pre (%) | F1 (%) | Time (s) | Acc (%) | Pre (%) | F1 (%) | Time (s) | |
| SVM | 82.54 | 81.46 | 81.60 | 341 | 91.85 | 91.21 | 91.45 | 359 | 83.45 | 82.48 | 92.32 | 507 |
| LR | 75.95 | 75.13 | 75.24 | 299 | 76.96 | 76.45 | 76.11 | 436 | 78.58 | 77.16 | 77.91 | 489 |
| LSTM | 79.32 | 77.98 | 78.45 | 280 | 82.41 | 81.78 | 82.04 | 319 | 77.36 | 76.34 | 76.14 | 515 |
| GRU | 84.45 | 83.64 | 83.21 | 348 | 83.23 | 81.94 | 82.68 | 331 | 87.21 | 86.27 | 86.67 | 526 |
| KNN | 60.12 | 58.86 | 59.67 | 274 | 62.35 | 61.45 | 61.48 | 451 | 62.45 | 60.98 | 61.22 | 551 |
| RF | 64.09 | 63.12 | 63.54 | 300 | 74.68 | 73.86 | 73.91 | 456 | 66.23 | 65.47 | 65.19 | 392 |
| XGBoost | 73.67 | 73.01 | 73.12 | 265 | 76.43 | 75.45 | 75.48 | 388 | 61.81 | 61.25 | 61.42 | 570 |
| LightGBM | 75.48 | 74.36 | 74.11 | 314 | 77.64 | 74.97 | 75.18 | 470 | 63.94 | 63.11 | 63.07 | 540 |
| Proposed | 93.29 | 92.57 | 92.68 | 343 | 97.67 | 96.98 | 97.14 | 335 | 95.58 | 94.87 | 94.68 | 375 |
| Ensemble Techniques | Acc (%) | Pre (%) | F1 (%) |
|---|---|---|---|
| Bagging | 91.54 | 90.47 | 90.67 |
| Boosting | 89.67 | 88.99 | 88.76 |
| Soft Voting | 92.45 | 91.86 | 91.98 |
| Stacking | 92.78 | 92.14 | 92.03 |
| Weighted Voting | 97.67 | 96.98 | 97.14 |
| Model | Acc (%) | Pre (%) | F1 (%) | Time (s) |
|---|---|---|---|---|
| BERT | 84.67 | 83.54 | 84.21 | 530 |
| DistilBERT | 82.91 | 81.67 | 82.18 | 475 |
| AlBERT | 94.56 | 93.62 | 93.27 | 510 |
| RoBERTa | 91.82 | 91.14 | 91.33 | 522 |
| Proposed | 97.67 | 96.98 | 97.14 | 335 |
| Dataset | 5-Fold | 10-Fold | 15-Fold |
|---|---|---|---|
| BuzzFeed | 97.67 | 97.45 | 97.32 |
| PoltiFact | 98.76 | 98.34 | 98.12 |
| Model | Dataset | Acc (%) | Pre (%) | F1 (%) |
|---|---|---|---|---|
| [48] | PolitiFact | 88.40 | 87.90 | 92.40 |
| [49] | PolitiFact | 85.58 | 70.59 | 76.19 |
| [50] | BuzzFeed | 65.50 | 65.50 | 66.80 |
| [51] | BuzzFeed | 93.41 | 89.90 | 93.68 |
| Proposed | PolitiFact | 98.76 | 98.03 | 97.98 |
| BuzzFeed | 97.67 | 96.98 | 97.14 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Toor, M.S.; Shahbaz, H.; Yasin, M.; Ali, A.; Fitriyani, N.L.; Kim, C.; Syafrudin, M. An Optimized Weighted-Voting-Based Ensemble Learning Approach for Fake News Classification. Mathematics 2025, 13, 449. https://doi.org/10.3390/math13030449
Toor MS, Shahbaz H, Yasin M, Ali A, Fitriyani NL, Kim C, Syafrudin M. An Optimized Weighted-Voting-Based Ensemble Learning Approach for Fake News Classification. Mathematics. 2025; 13(3):449. https://doi.org/10.3390/math13030449
Chicago/Turabian StyleToor, Muhammad Shahzaib, Hooria Shahbaz, Muddasar Yasin, Armughan Ali, Norma Latif Fitriyani, Changgyun Kim, and Muhammad Syafrudin. 2025. "An Optimized Weighted-Voting-Based Ensemble Learning Approach for Fake News Classification" Mathematics 13, no. 3: 449. https://doi.org/10.3390/math13030449
APA StyleToor, M. S., Shahbaz, H., Yasin, M., Ali, A., Fitriyani, N. L., Kim, C., & Syafrudin, M. (2025). An Optimized Weighted-Voting-Based Ensemble Learning Approach for Fake News Classification. Mathematics, 13(3), 449. https://doi.org/10.3390/math13030449