1. Introduction
Within production organizations, scheduling plays an extremely important role, especially in the context of manufacturing planning [
1]. The efficacy of a manufacturing planning system is determined by the performance of its scheduling approach. Scheduling is categorized based on the job environment, job characteristics, and optimization criteria [
2]. The job environment can also be referred to as a machine environment. Scheduling is further divided into single-stage and multi-stage based on machine setup. In single-stage scheduling, there is only one machine and a few tasks, whereas in multi-stage scheduling, there are multiple machines and jobs.
Job Shop Scheduling (JSP) is a critical issue in resource allocation. Resources in this context are referred to as machines, and the basic units of work are called jobs. Each job can consist of several sub-tasks, known as operations, which are interconnected by priority constraints. JSP is a significant class of nondeterministic polynomial-time (NP) problems, similar to the traveling salesman problem [
3].
In a static JSP, deterministic jobs are handled by a pre-determined number of machines. The sequence of actions for every individual job is pre-established, and each task must be completed exactly once. It is not possible to perform two tasks simultaneously on the same machine and must wait until the previous operation is completed on that machine. Arranging the operating slots on the device, or computer, is referred to as a schedule. The maximum completion time (makespan) is one of the most common objectives for the JSP.
The bi-objective integrated scheduling of job shop problems and material handling robots (MHR) with setup time, known as BI-JSP-MHR, is a generalization of production scheduling issues. Unlike the classic JSP, which does not consider transportation resources and assumes an unlimited number of MHRs. The BI-JSP-MHR takes into account the practical constraints of workshops. Workshops often have a finite number of MHRs due to the high costs and the limitations of the workshop layout. Setup time is an essential auxiliary factor required for different operations and processes to be carried out on a machine, and it plays a significant role in the overall cycle time of an operation. A shorter setup time can boost productivity by minimizing machine idle time between production runs. Conversely, excessive setup time can significantly slow down the production process, leading to higher costs and longer lead times for customers. Therefore, optimizing the concerned problems with setup time is a key factor in enhancing the efficiency and competitiveness of manufacturing operations. Consequently, research on BI-JSP-MHR aligns more closely with the actual conditions of production, making it highly significant in theoretical studies. BI-JSP-MHR must address two sub-issues: the selection of MHRs and the scheduling of tasks.
Due to the sequential logic constraints between the transport and processing stages, the problem is not easily decoupled. Compared with JSP, BI-JSP-MHR is significantly more challenging, as detailed below:
(1) In addition to the problem of scheduling for processing machines with operational constraints, it is also necessary to address the task assignment for the MHRs.
(2) There is a significant difference between the transport behavior of MHRs and that of machines. These actions are performed alternately, and there may be required waiting periods during execution. This leads to a more complex cascade effect in the calculation of the number of completed jobs.
(3) It is difficult to decouple the interdependence of processing tasks and transport tasks, which implies that a layered or decoupling mechanism might lose its optimal solution.
Clearly, BI-JSP-MHR is a more complex NP-hard problem than JSP. The complexity of BI-JSP-MHR makes it more challenging to study its intrinsic properties and solutions.
The novel contributions this work aims to make include the following:
(1) Establish a double-objective mathematics model for the integration of job shop problems and material processing robots.
(2) Improve different meta-heuristics, including Artificial Bee Colony (ABC), Genetic Algorithm (GA), and Particle Swarm Optimization (PSO), are developed to solve the problems.
(3) Seven local search operators based on problem features are devised for enhancing the quality of algorithms.
(4) Q-learning and SARSA-based local search operators are developed and embedded into meta-heuristics to select high-quality local search strategies.
The designed algorithms enable efficient solving of 82 benchmark instances with different sizes, which provides valuable insights for practical production applications.
The rest of this paper is organized as follows.
Section 3 develops a double-objective mathematics model for the integration of the job shop problem and material processing robot.
Section 4 presents three meta-heuristics with reinforcement learning-based improved strategies in detail.
Section 5 presents experimental results and comparisons. Finally, this study is summarized, and future research directions are suggested in
Section 6.
3. Problem Description
3.1. Problem Description
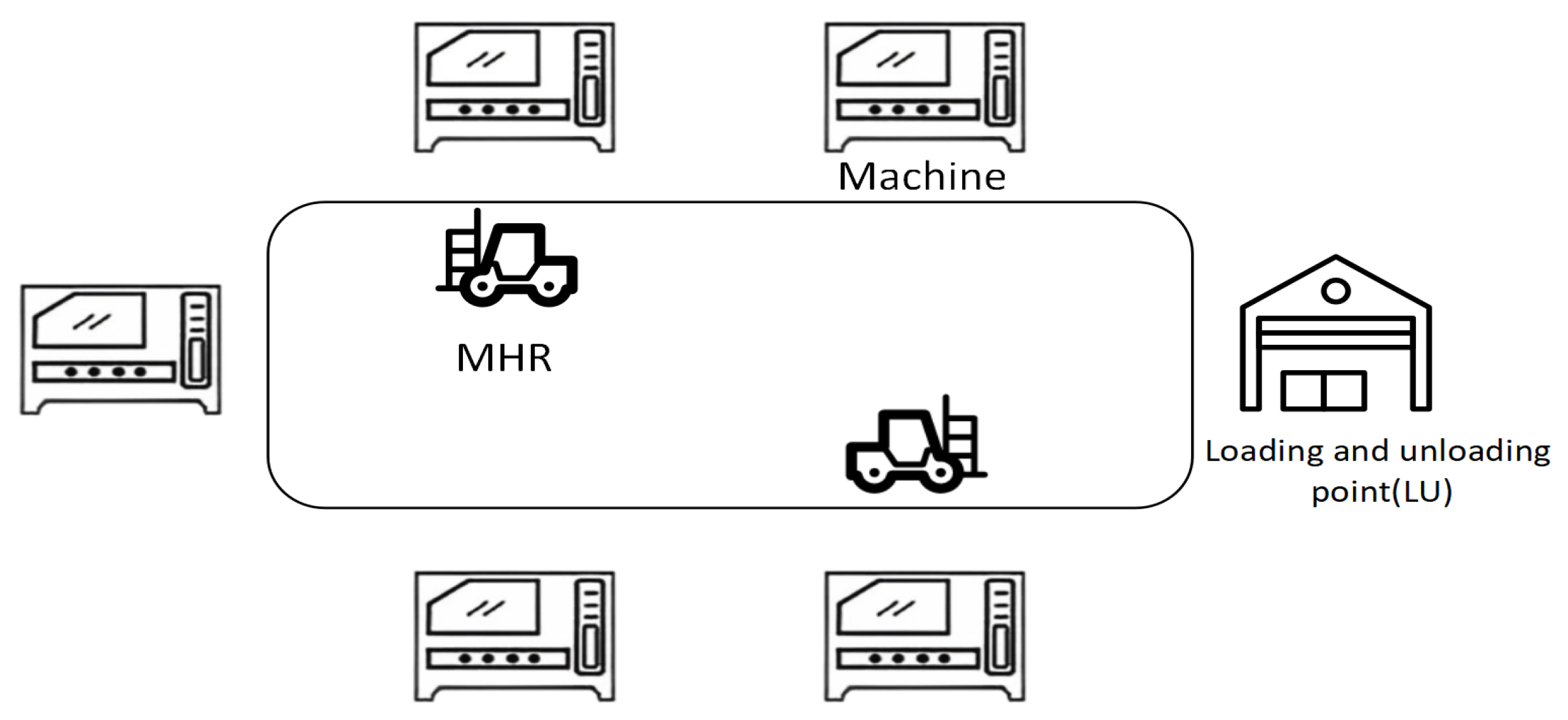
This study establishes a two-objective mathematical model to describe the integration of the job shop problem and the material handling robot with setup time. In the problem, part of the work is processed on certain machines, with each job comprising more than one operation. The MHR is responsible for transporting jobs. The work initiates at the Loading and Unloading (LU) station, which is located at a certain distance from the machinery. The MHR transportation takes time, and the movement of the MHR can be categorized into empty and loaded trips. An empty trip refers to the MHR’s journey from its current position to the designated machine to pick up a job, while a loaded trip is the MHR’s movement from picking up a job to delivering it to the destination machine.
Figure 1 illustrates a production scenario with two MHRs and five machines. Our goal is to assign the most suitable processing machine and MHR to each job. Then, determine the order in which operations are performed on both the machines and the MHRs to minimize the objective. Specifically, once the final step in the work process is completed, an MHR is scheduled to deliver the finished product to the warehouse where finished goods are stored. Although transportation time is not included in the processing time of the job, it is crucial to monitor the MHR’s loading and unloading states.
The BI-JSP-MHR meets the following conditions:
(1) At time 0, all machines and MHRs are available.
(2) The time of loading and unloading is included in the transportation time.
(3) Each machine can handle a maximum of one operation.
(4) Each MHR can carry a maximum of one job.
(5) It is not possible to pre-empt an MHR when a transport task has begun.
(6) All MHRs have a fixed velocity, and the transmission time depends only on the location of the job.
(7) Each job can only be handled on one machine and can only be carried by one MHR when it is transferred from one machine to another. Once a job begins, it cannot be stopped until finished.
(8) After completion, work is returned to LU, but time is not taken into account.
(9) Different tasks have different setup times on the same machine.
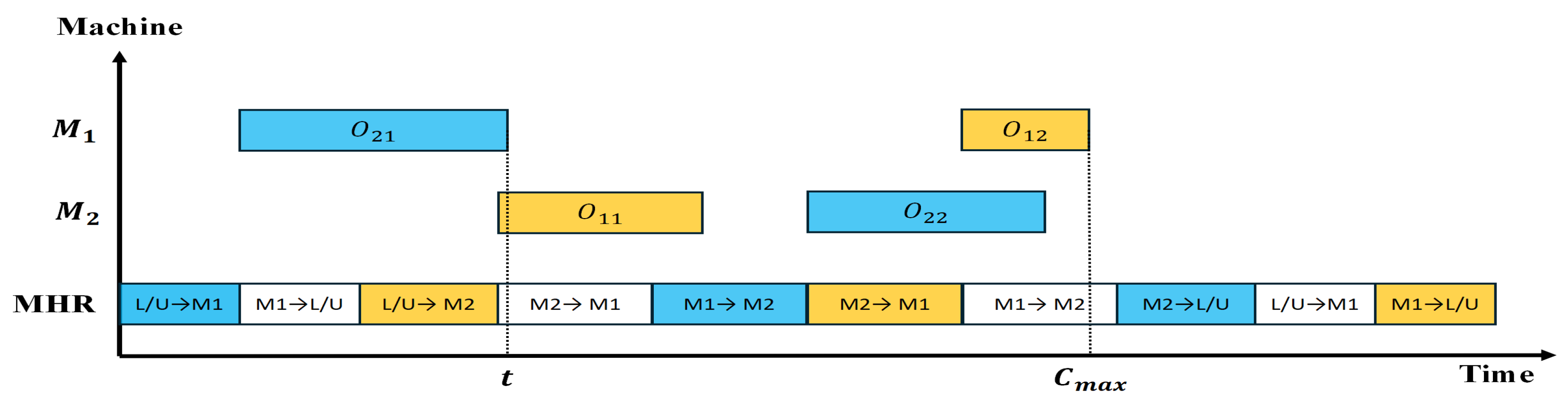
Figure 2 offers a visual representation of a Gantt chart for BI-JSP-MHR involving two jobs, two machines, and one MHR. Initially, the MHR moves
to
, and then
starts processing
. Following it, the MHR has to travel to the loading/unloading area and transport
to
. At time
t,
waits for the MHR transportation from
to
, and then it can start transporting
from
to
. The following steps are executed in a similar way. Finally, the makespan, denoted as
, is defined as the completion time of
.
Setup time primarily refers to the time spent on preparatory activities, such as cleaning the machine and replacing fixtures, molds, and other auxiliary tasks, when the machine is processing the next operation [
54]. Setup time can be classified into two types: sequence-independent setup time and sequence-dependent setup time. Sequence-independent setup time suggests that the setup time for a machine depends solely on the current operation and not on the previous operations of the same machine; thus, it can be considered independent and unaffected by other operations. However, typically, the setup time of an operation is related not only to the current operation but also to the previous operation of the machine. That is, the setup time is linked to the processing sequence of the operation. Different processing sequences of operations result in different setup times for the machine. In such cases, constraints on the sequence among operations should be considered when accounting for the number of machine setup times. The timing typically includes the time required to replace fixtures and molds, as well as the time needed for preparatory activities such as loading and unloading the job and starting the machine after the job arrives. Regardless of whether the auxiliary time is before or after the job’s arrival, it is treated as separate setup time. In this study, the setup time due to equipment setup after the job’s arrival during the waiting time is considered, which reduces the impact of waiting times on scheduling and aligns better with actual production conditions. Some example data on time are presented in
Table 1.
Setup time is an essential auxiliary time required for different operations and processes to be carried out on a machine, and it plays a significant role in the overall cycle time of an operation. There are typically two approaches to handling setup time in the optimization scheduling problem of a workshop: one is to include it within the processing time; the other is to consider it separately, distinct from the processing time. As research evolves, treating setup time as a separate component is becoming a trend in the study of workshop scheduling problems. In this paper, we explore the impact of setup time on the classical job shop. By considering setup time as a separate component, the optimization of shop floor scheduling becomes more reflective of real-world workshop scenarios, enhancing its practical utility.
As shown in
Figure 3, treating the setup time of the machine tools in the production process as part of the processing time effectively extends the production time. The number shown in
Figure 3 is example time from
Table 1. In this case, the shop scheduling problem only considers the processing time of the operation, which makes the final completion time of the operation closer to the actual production time, but the improvement in optimizing the shop scheduling problem is not particularly significant.
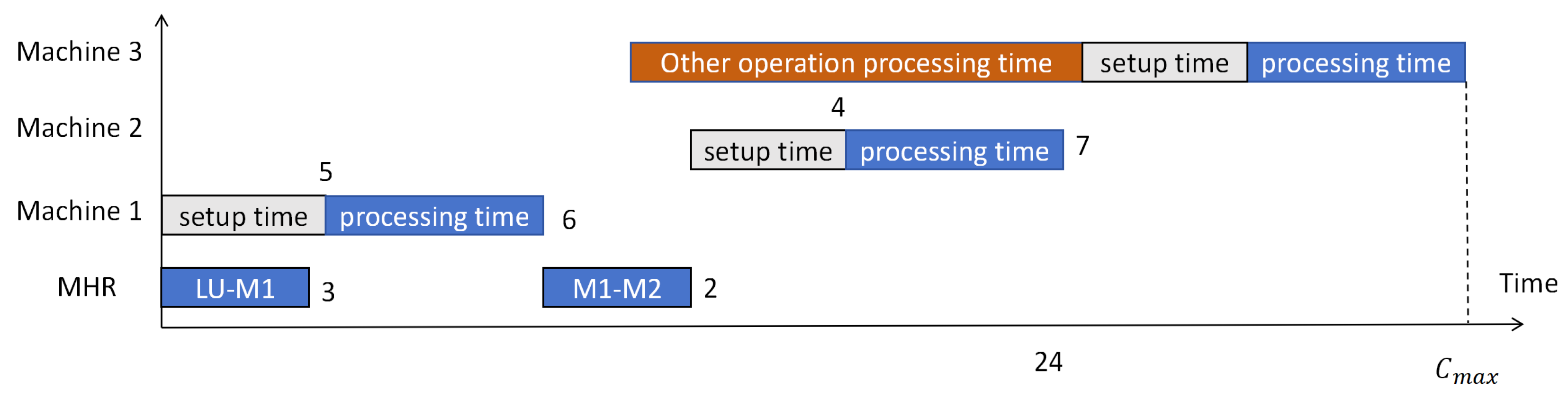
As shown in
Figure 4, considering the setup time as a separate part makes it more aligned with real-world conditions of store production, making the optimization of store production scheduling more practically applicable.
3.2. Mathematical Model
The symbols employed in our model are detailed in
Table 2.
The mathematical model can be described as follows:
Constraint (1) presents the objective function, which aims to minimize both the makespan and the earliness and tardiness (E/T). Constraints (2) and (3) make sure that the makespan is longer than the finish time of any job. Constraint (4) calculates the ET. Constraint (5) provides for the allocation of traffic among the MHRs and for each transport to be allocated only one MHR. Constraints (6) and (7) indicate that each pair of concurrent operations is assigned a unique priority regardless of their processing time. Constraint (8) guarantees that a processing task must wait until the associated transport task has been finished before it can commence. Constraint (9) implies that the commencement of a transport activity is conditional on the completion of a previous activity, with the exception of the commencement of the work. Constraints (10) and (11) show the sequential relation of any two transports of the same MHR, ensuring that only one transport can be carried out by the MHR. The MHR will have an extra trip if the starting point of the ongoing transfer of the MHR and the last transmission are not the same. Constraints (12) and (13) ensure that the commencement times for both the processing and the loading of an operation are non-zero. Constraints (14), (15), and (16) define the decision variables.
3.3. Multi-Objective Optimization
The criterion of makespan has been extensively studied by researchers in the JSP domain. For manufacturing firms operating under a Just-In-Time (JIT) philosophy, adherence to due dates is paramount. The essence of JIT production lies in minimizing inventory, enhancing responsiveness, cash flow, and customer satisfaction. In the JIT paradigm, delivering early results in excess inventory, while late delivery leads to tardiness. Consequently, this study addresses the reduction of both the makespan in JSP and the average of earliness and tardiness. These objectives are mildly conflicting and have been referenced in existing literature.
4. Proposed Algorithm
4.1. Solution Representation
There are two sub-problems in BI-JSP-MHR, which are job scheduling and MHR scheduling. So, according to the characteristics of the concerned problem, a two-layer representation of the solution is used. The first layer (operation layer) is responsible for the expression of all operations. The second layer (MHR layer) is an indicator of the MHRs carrying the corresponding job.
Figure 5 gives an example of an instance of a size 3 job, 3 machines, and 3 MHRs. The comprehensive scheduling scheme in this example can be described as a combination of operations and MHRs
. Every
means
carries
. Accordingly, the scheduling scheme may be described as follows:
,
,
and
.
4.2. Meta-Heuristics
Meta-heuristics have been improved and refined to deal with complex optimization problems. Three classic meta-heuristics are used in this work, including ABC, PSO, and GA. They begin from an initial population, then are updated iteratively using algorithms and specific strategies. The main steps of the three meta-heuristics are as follows:
Step 1. Initialization of population and parameters.
Step 2. Evaluate the original solution.
Step 3. Execute strategies specific to algorithms.
Step 4. Produce new solutions and assess them.
Step 5. If the new solution is superior to the existing one, the population will be updated. Otherwise, keep the old one.
Step 6. If the stopping criterion is satisfied, output results. If not, return to Step 3.
4.2.1. GA
The GA is well suited for addressing production scheduling issues because it operates on a set of potential solutions instead of focusing on a single solution as heuristic searches do. In GA, each chromosome or individual corresponds to a specific sequence of tasks. The algorithm is fundamentally an evolutionary technique that is based on the principle of natural selection, where the fittest survive. The fundamental unit of a GA is the solution encoding, often referred to as a chromosome or an individual, which embodies a potential solution to the problem at hand.
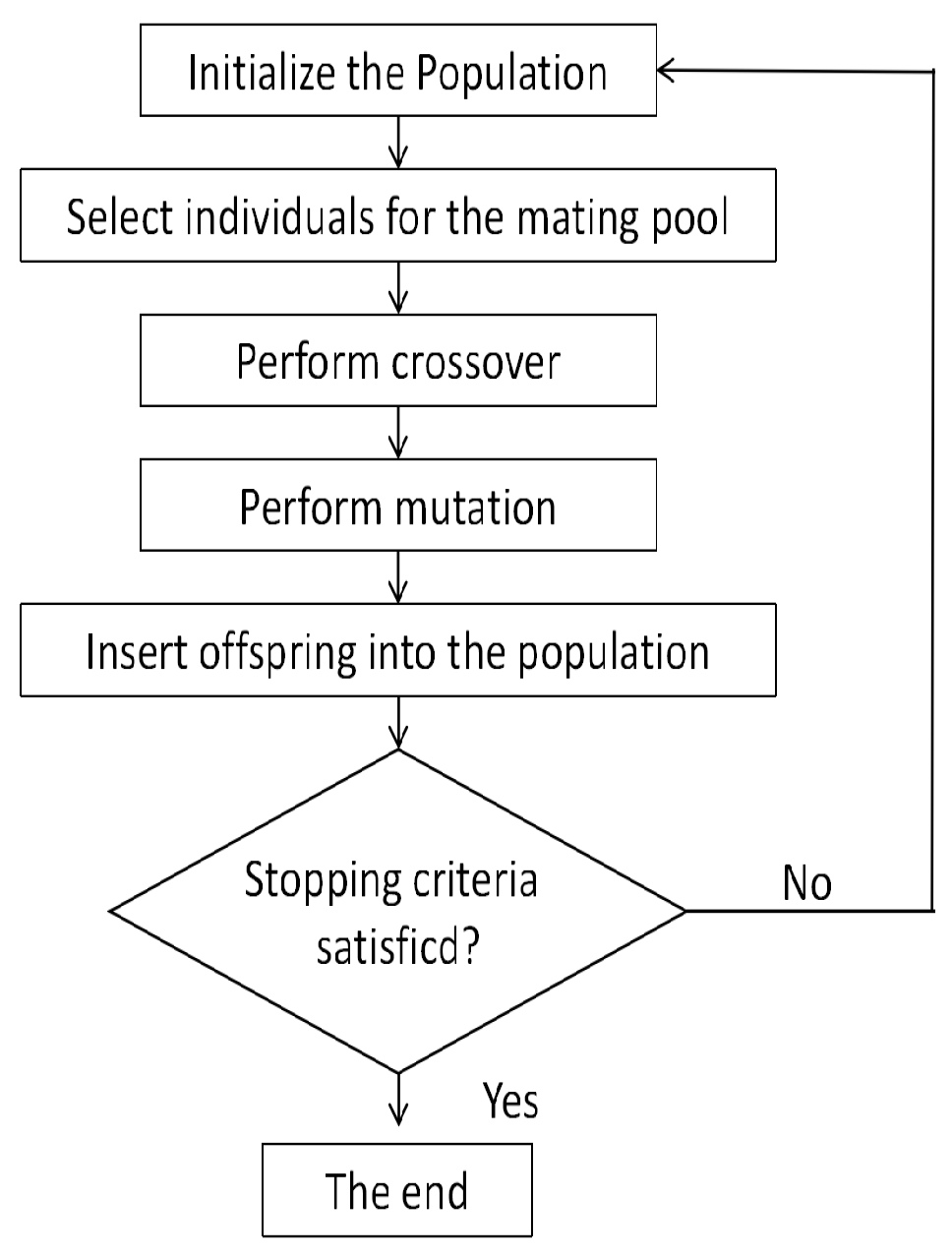
Figure 6 depicts the flowchart of the GA process.
(1) Initial solution: The initial solution is obtained randomly as a set of job variations in each machine. The number of operations to perform is equal to the total generations for each chromosome.
(2) Selection: the work is performed using the roulette wheel tournament method.
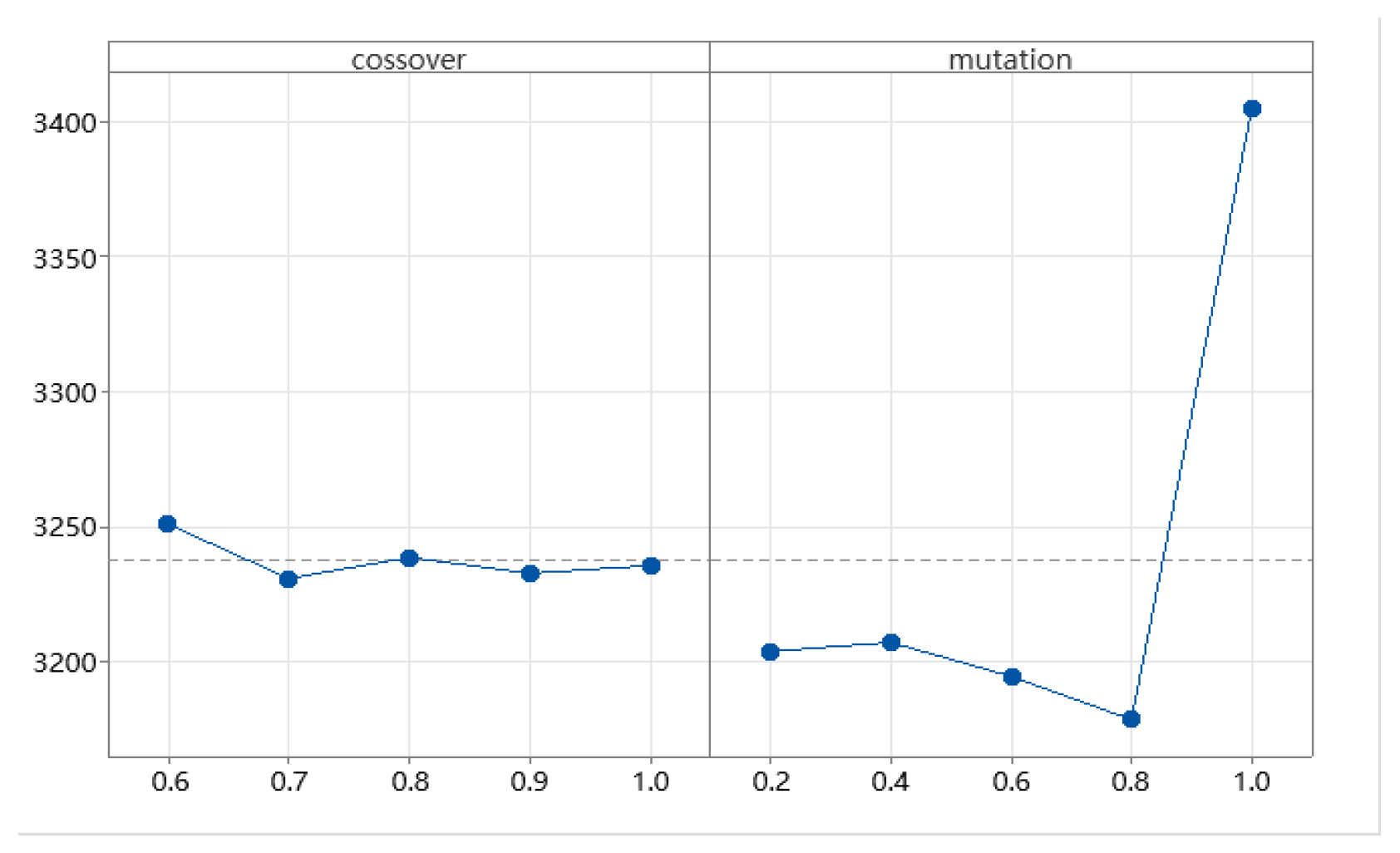
(3) Crossover: a random procedure is used to cross two points.
(4) Mutation: the exchange mutation is used to avoid the deterioration of the population in its local optimum solution.
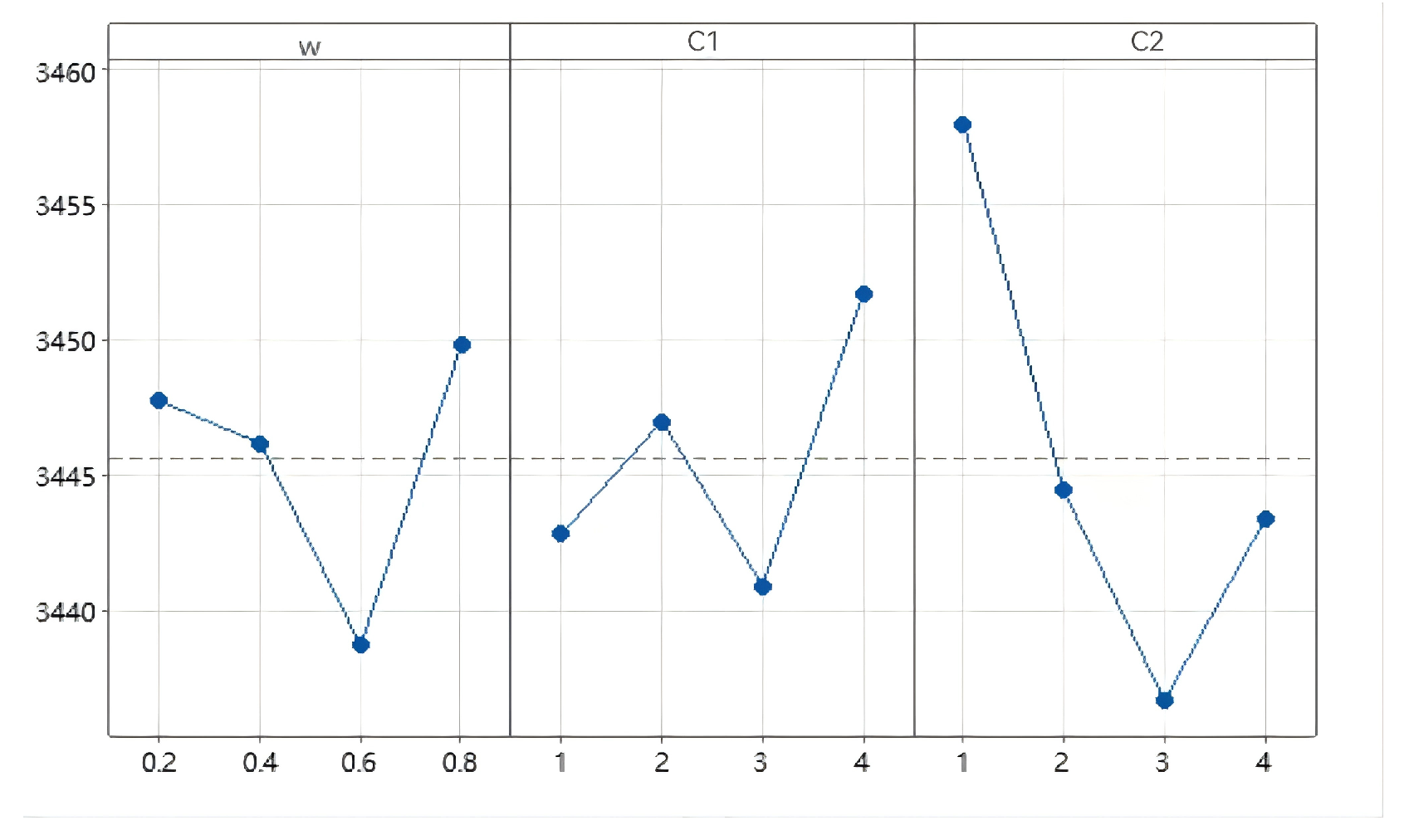
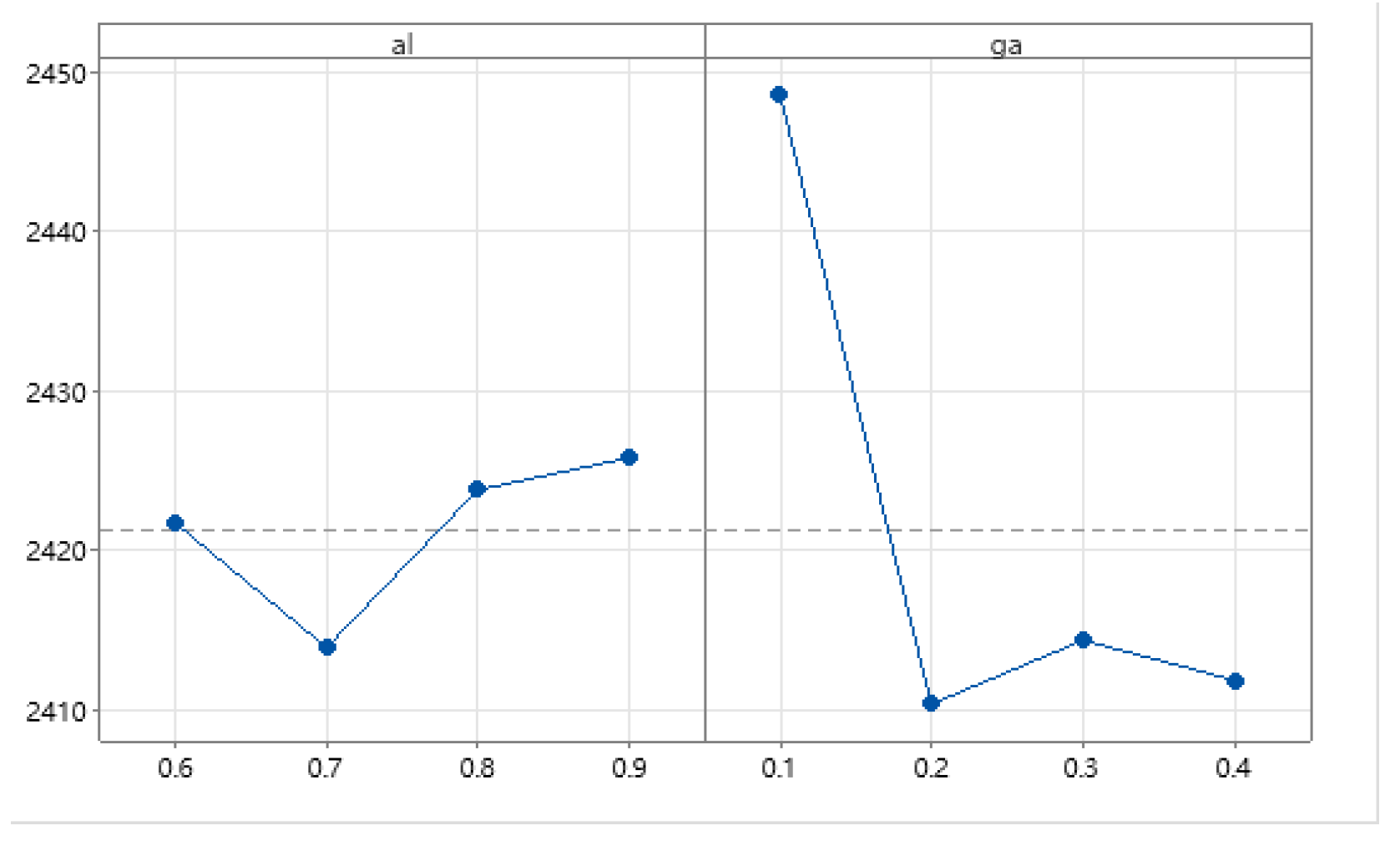
(5) Stopping criteria: Generation count is used as a stop condition. In order to solve this problem, we adopt three GA factors, which are population size, crossing probability (
), and mutation probability (
).
Figure 6 illustrates the flow pattern of GA factors.
4.2.2. PSO
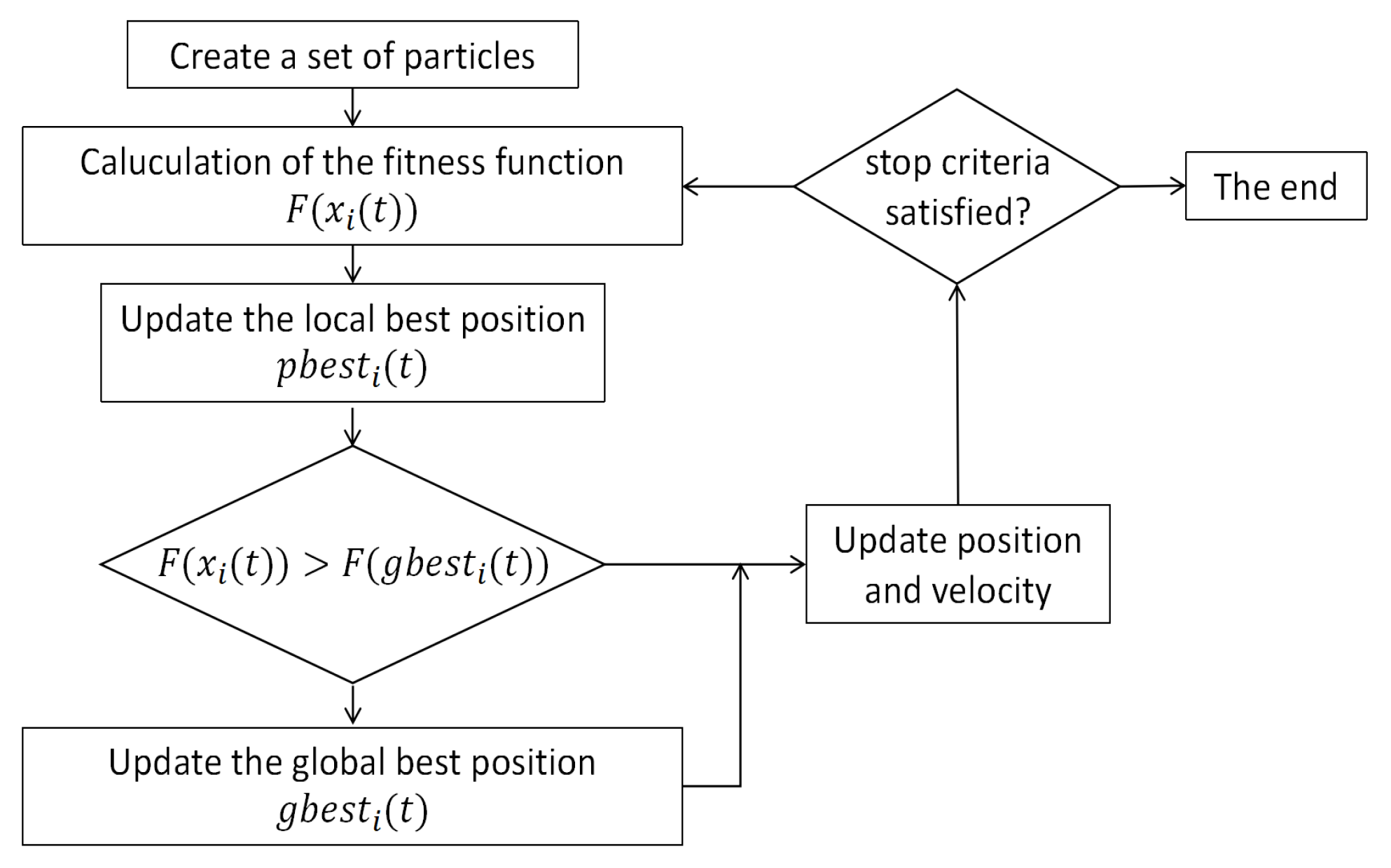
PSO was developed based on the assumption that birds were social. This paper presents a PSO algorithm that simulates the movement patterns of birds and their information sharing methods to solve an optimization problem. PSO is considered to be one of the most effective algorithms in the real world.
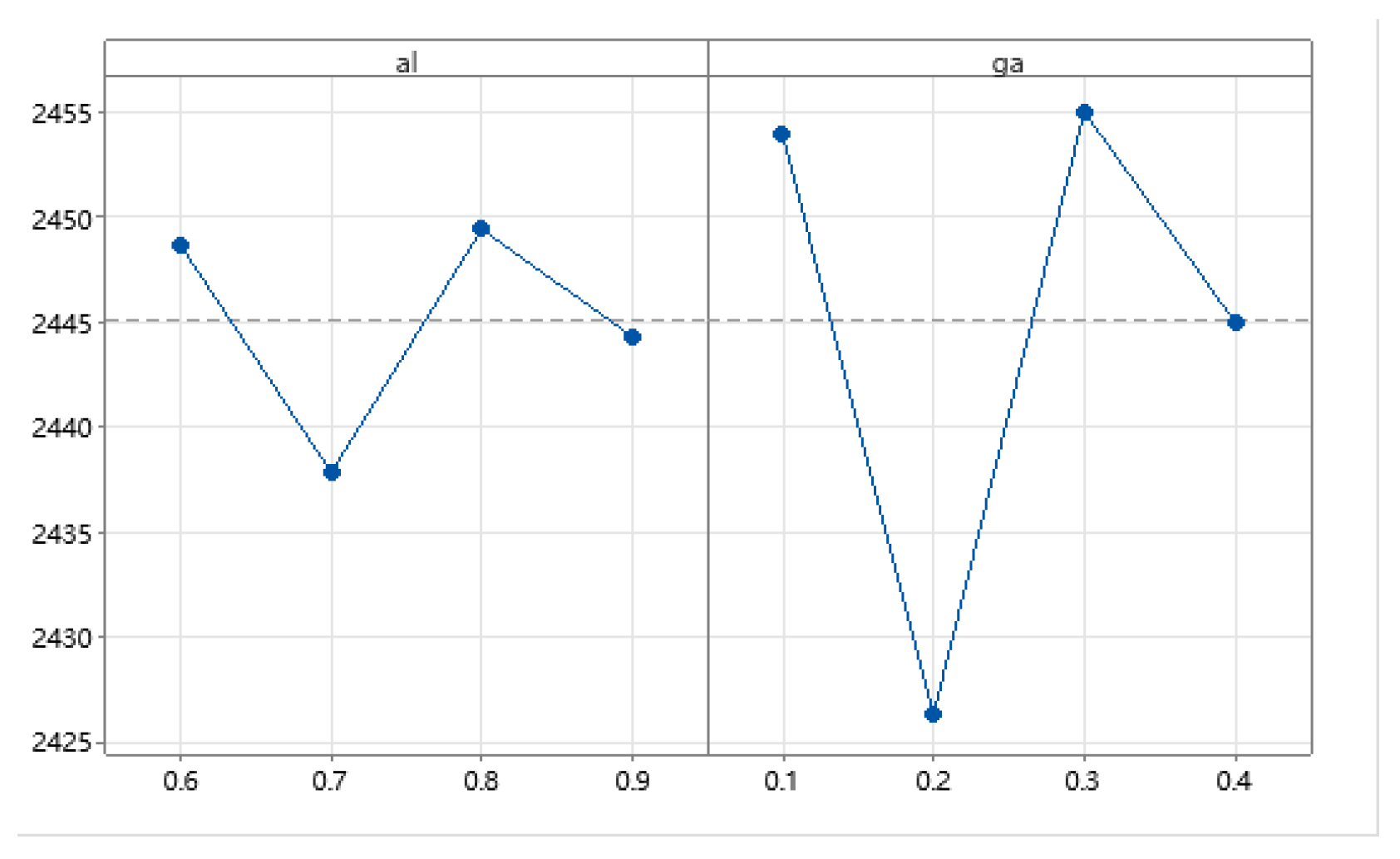
PSO is instrumental in tackling scheduling and routing challenges. The core parameters of PSO include the problem’s dimensionality, the swarm size (number of particles), the inertia weight, the range of iterations, the acceleration constants, and the social cognition factor.
Figure 7 shows the operational flow of PSO.
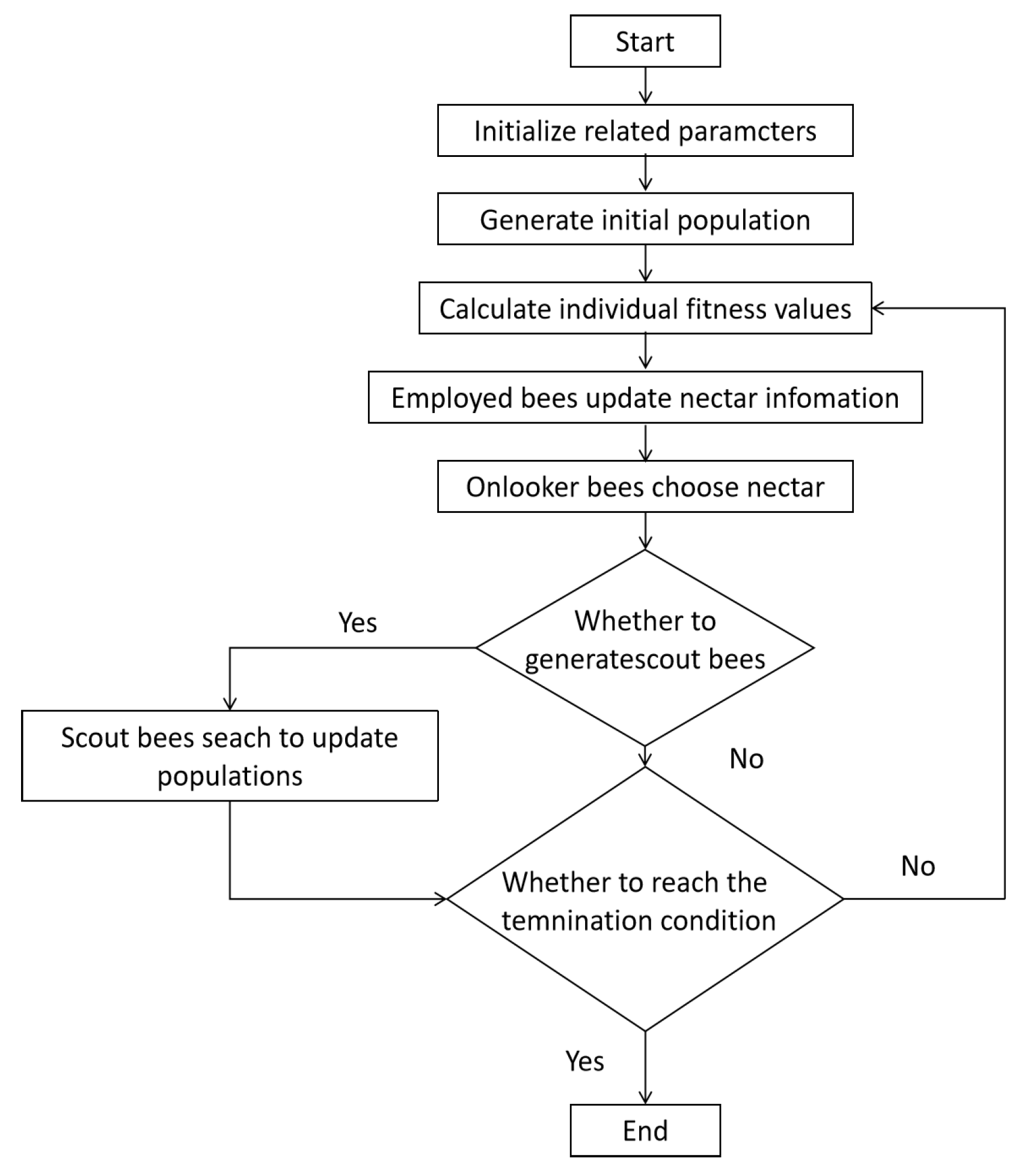
4.2.3. ABC
The problem’s solution space is presumed to be D-dimensional. The count of workers and onlookers is SN, equivalent to the number of nectar sources. The standard ABC algorithm addresses the optimization problem within a 2D search space framework. Each nectar source’s location symbolizes a potential solution, with the number of sources aligning with the fitness of the suitable solution. Employed bees are directly linked to nectar sources. To gain insight into the ABC algorithm, a flowchart is provided. The flowchart of the ABC algorithm is depicted in
Figure 8.
4.3. Local Search
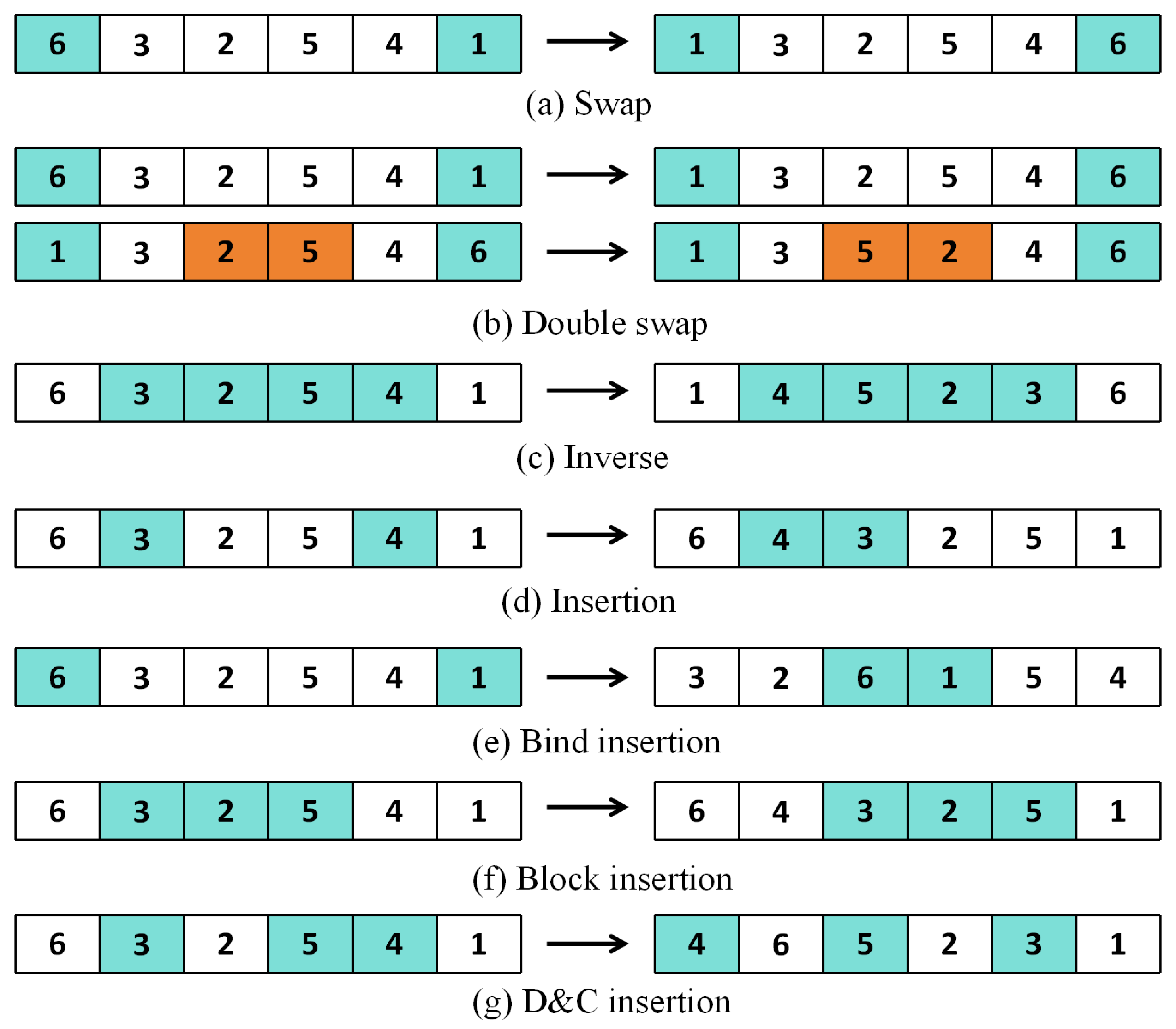
Meta-heuristics are known for their simplicity in implementation and rapid convergence. However, they are prone to falling into local optima during the iterative process. To circumvent settling for a suboptimal solution, this study designs seven local search techniques tailored to the problem’s characteristics. In the BI-JSP-MHR context, we conduct local searches on both the MHR sequences and the job sequence. The details of these seven local search operators are outlined as follows.
(1) Swap: within a solution, two jobs are randomly selected and their positions are interchanged, as shown in
Figure 9a.
(2) Double swap: two separate swap operations are performed on a solution, as shown in
Figure 9b.
(3) Reverse: two positions are arbitrarily chosen from a solution; reverse all the jobs between the two positions, as depicted in
Figure 9c.
(4) Insert: two jobs are randomly chosen, their positional relationship is determined, the second job is inserted into the position of the first, and the subsequent jobs are shifted one position backward, as illustrated in
Figure 9d.
(5) Bind insertion: Two jobs are randomly selected and placed in all possible locations while maintaining their order. The process is detailed in
Figure 9e.
(6) Block insertion: two different positions within a solution are randomly chosen, treated as a single block, and the block is inserted into all possible locations within the solution, as shown in
Figure 9f.
(7) D&C insertion: A set of jobs is randomly extracted from a solution, and these tasks are then randomly inserted back into all potential spots within the solution.
Figure 9g shows the arrangement before and after the D&C insertion.
4.4. Reinforcement Learning
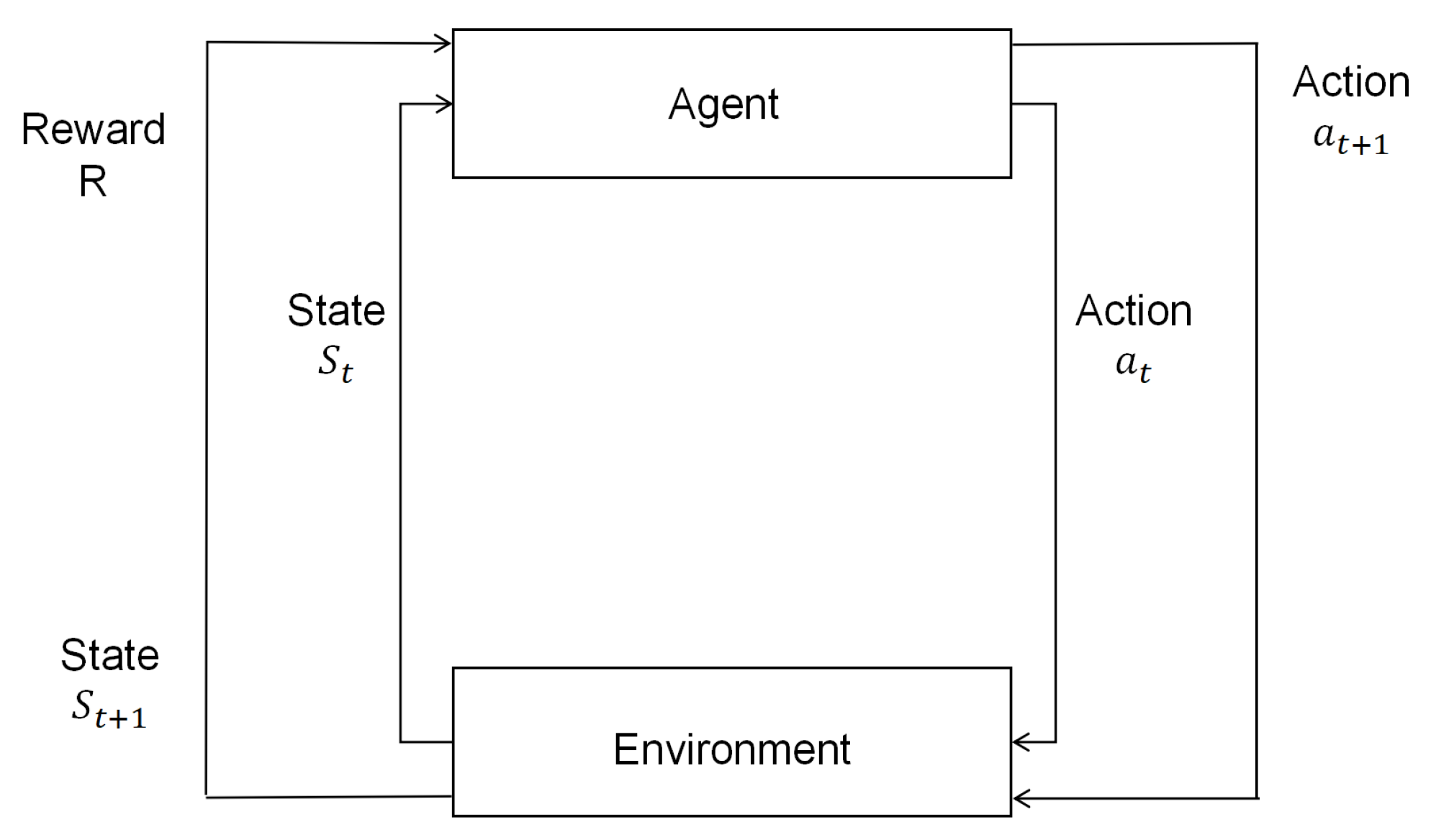
Reinforcement Learning (RL) is a type of machine learning framework in which an intelligent agent learns to make decisions by interacting with its environment to achieve specific goals. Through the process, the agent acquires knowledge and improves its performance over time based on feedback received from the environment. The foundation of RL lies in the ongoing exchange between the agent entities and their environment. Within the dynamic environment, the agent adjustment methods, in accordance with their accumulated experiences, have the objective of amplifying the aggregate value of sustained rewards over an extended period.
Using reinforcement learning to guide the local search process, the algorithm can focus on the most promising regions of the search space and select appropriate local structure. It can also learn to use more efficient search strategies, such as parallel exploration of different regions or adaptive adjustment of the search granularity. It can improve the scalability and efficiency of the algorithm, making it more suitable for solving large-scale and complex optimization problems.
4.4.1. Q-Learning
Q-learning is a decision-making method that does not directly train an agent to choose the correct action. Instead, it evaluates the agent’s actions based on responses from the environment. Through continuous interactions with the environment, agents select actions in response to feedback, with the ultimate goal of making the best decisions. The objective of Q-learning is to identify the Q-value for a specific state-action pair and subsequently determine the optimal action based on these values. Q-values are stored in a Q-table, which is initially a single matrix where the rows correspond to the number of states and the columns correspond to the number of possible actions.
In this study, the concepts of state and action are utilized as components of local search operators within the Q-learning framework. As depicted in
Figure 10, the agent selects actions based on the roulette wheel selection approach, which leads to the acquisition of an appropriate reward. Initially, at time
t, an agent acquires the current environmental state
and performs the action
. Consequently, the environment transitions to the state
, and the agent receives the corresponding reward
R. Furthermore, the agent refines its strategy for action selection, enabling the selection of an appropriate action
in subsequent cycles.
At the beginning, the Q-values in the Q-table are initialized to be identical. With each execution of a local search operator by the algorithm, the Q-values in the Q-table are updated. The Q-table itself is refreshed after every iteration. Under certain conditions, Q-learning, being highly probable, can guide the selection of an appropriate local search operator (action). In other words, if an individual performs
in state
, it can select any of the seven local search operators in the next state, which is determined on the basis of Q-values in the Q-table. Thus, Q-learning is designed to assist meta-heuristics in the selection of local search operators. The Q-table appears in
Table 3.
The Q-value in the Q-table is updated after an operation is performed. The update formula is as follows:
In this context,
represents the Q-value associated with performing an action
in the present state
. The parameter
denotes the learning rate,
R signifies the reward received,
is the discount factor, and
refers to the maximum Q-value that can be obtained by selecting an action
in the next state
using a roulette wheel selection method. The expression for
R is given by
where
,
are the makespan and E/T of the new solution while the
and
are the old one.
4.4.2. SARSA
Unlike Q-Learning, SARSA is a web-based online learning algorithm. If the Q function is updated, it uses the action value of the following action that the agent actually receives: . It means that SARSA takes into account the agent’s existing policy throughout the learning process. Therefore, the policy that SARSA has learned has a close relationship with the practice of the agent in the course of training.
The main difference between Q-learning and SARSA is the update strategy for Q-values. In Q-learning, the expected maximum Q-value obtained by all possible actions in the next state is selected as a factor to update the Q-value under the current state. However, the action with the expected maximum value may not necessarily be executed in the next state. In SARSA, a Q-value obtained by an action in the next state is also used to update the current Q-value, and the action is executed in the next state.
The SARSA algorithm updates the estimation of the value function in every strategy step.The agent operates based on the
approach. It only needs to know the state of the preceding step (
), the prior action (
), the reward value (
R), the present state (
), and the action (
). The formula for updating the action value function is given in the equation below.
is used as the Q-value for the states to perform the action
a,
is the learning rate, and
is the discount factor.
Despite differences in action selection and Q-value update methodologies, there are similarities between SARSA and Q-learning in various aspects of their learning processes. Both algorithms initialize the Q-table with arbitrary values, typically zeros, and update their Q-value using equivalent reward values. Moreover, the objective of these two algorithms is to learn an optimal strategy that maximizes the cumulative reward.
In summary, SARSA introduces a more exploratory approach to action selection than Q-learning, which uses existing policies to decide what to do in the update. This may result in better environmental research and, in certain cases, quicker convergence towards optimum policies.
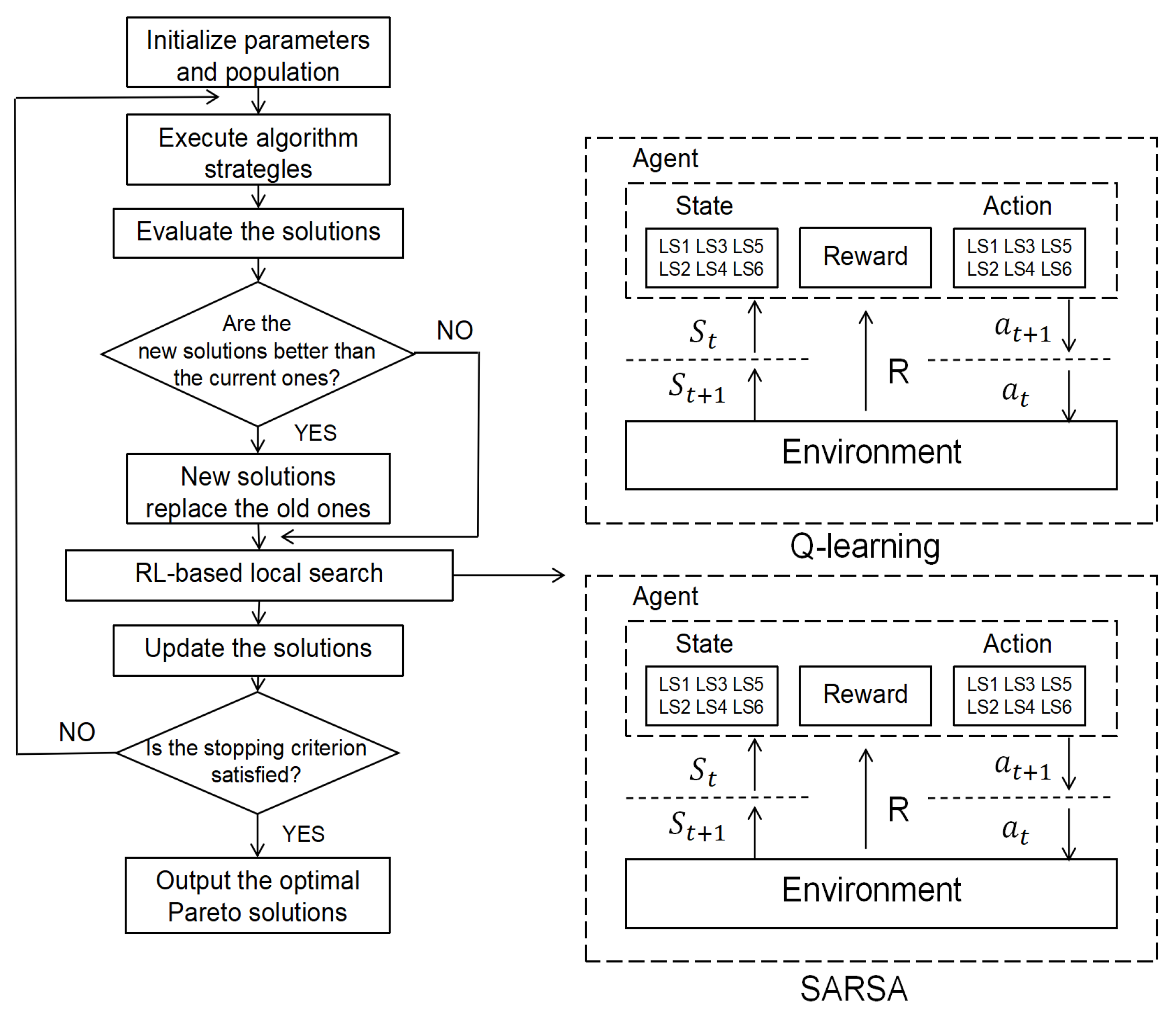
4.5. The Framework of Proposed Algorithms
This work designs three enhanced meta-heuristics with Q-learning and SARSA.
Figure 11 illustrates the architecture of the Q-learning and SARSA process. Initially, parameters and the population are established. Then, a novel solution is generated through a unique algorithmic approach. After that, the population is adjusted based on the newly generated solution. Next, a local search operator is determined using Q-learning or SARSA. If the Q-learning or SARSA strategy obtains a solution with better performance, it means that the chosen action (e.g., local search operator) is more conducive to maximizing the cumulative reward. Subsequently, the Q-values in the Q-table are updated. The larger the Q-value, the higher the probability that a local search operator will be selected in subsequent iterations. In conclusion, these steps are repeated in a loop until a predefined stopping criterion is met. At that point, the result of the process is reported as the final outcome.
6. Conclusions and Future Work
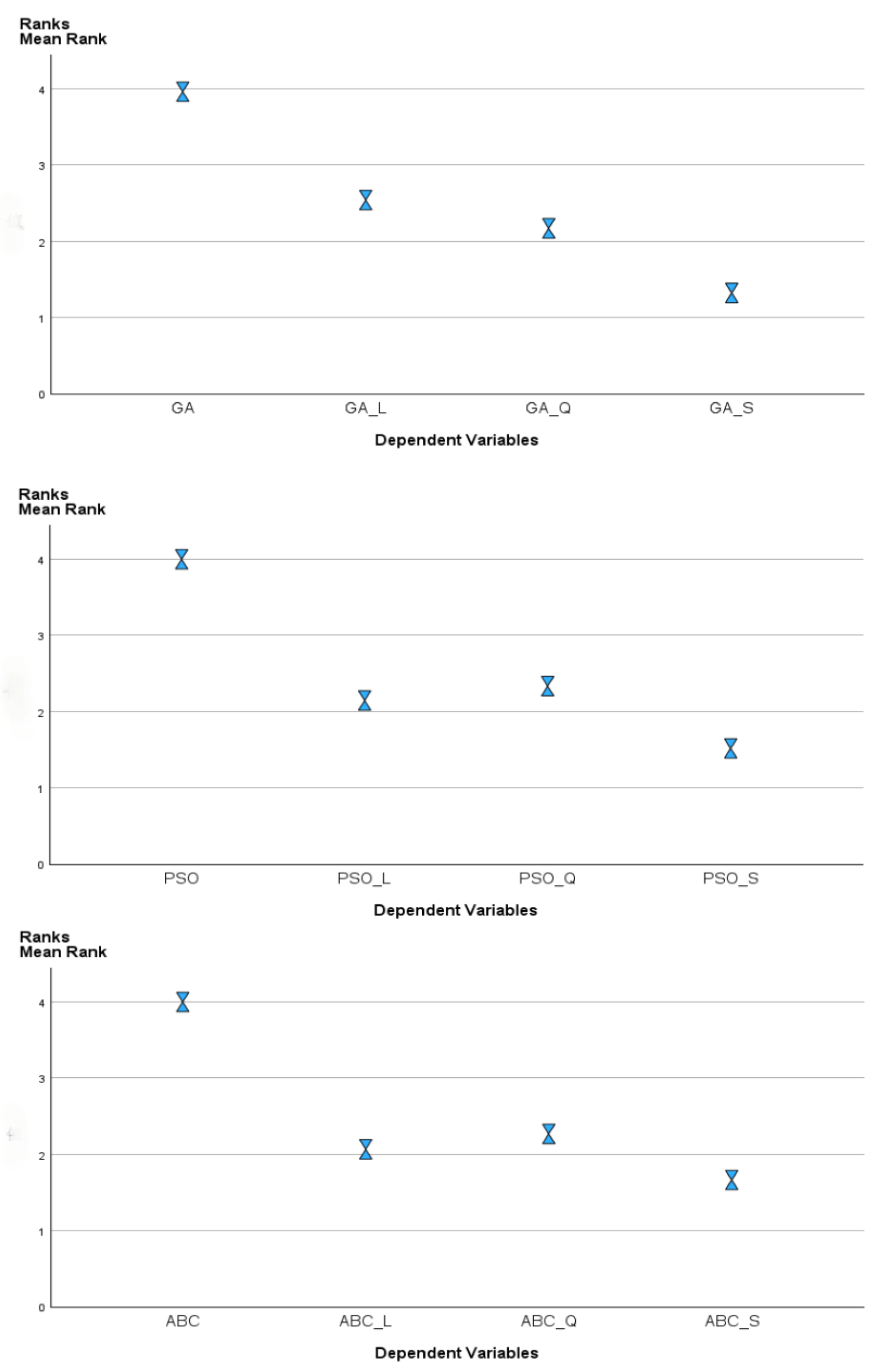
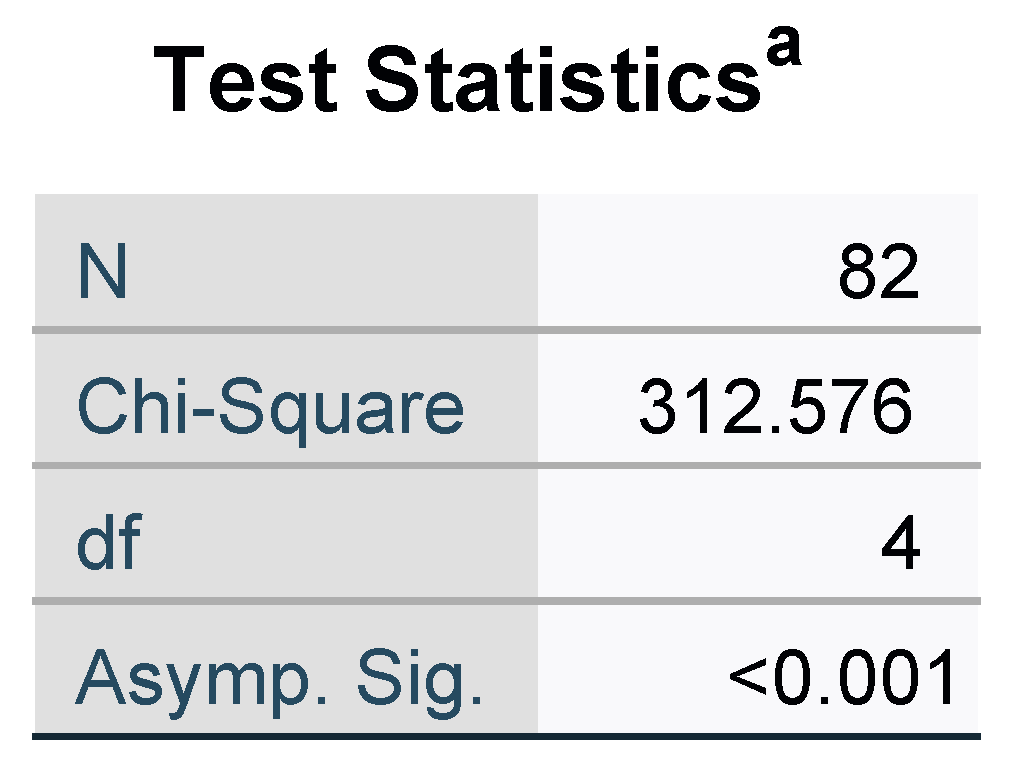
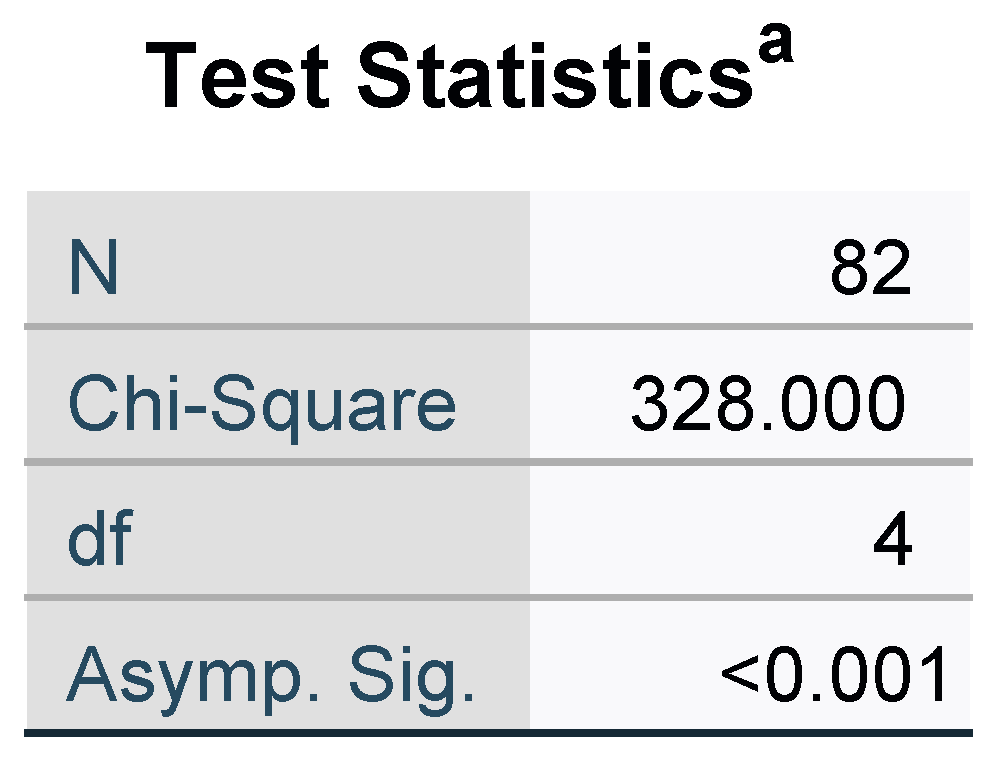
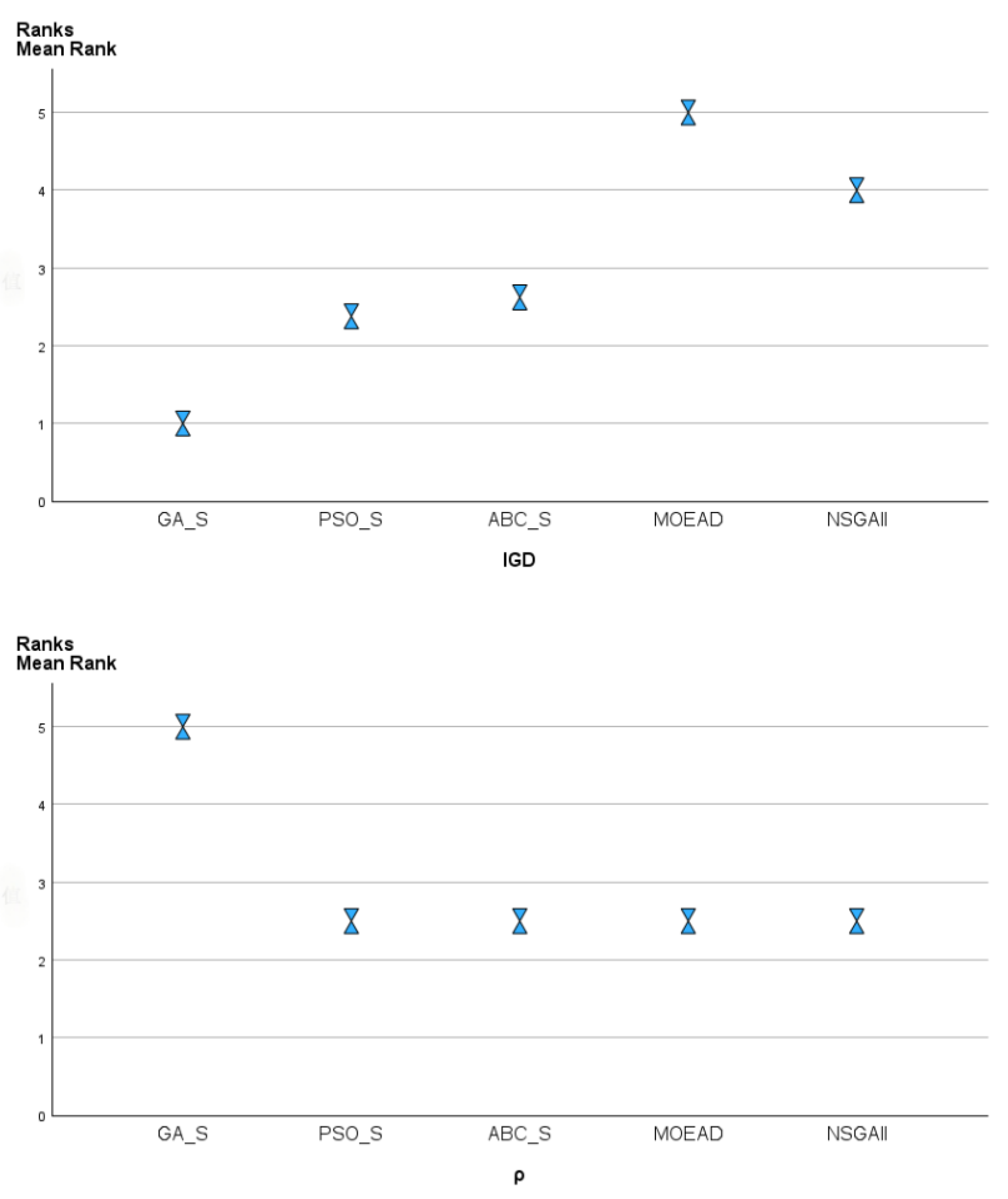
This work develops a multi-objective mathematical model to solve the integrated scheduling of job shop problems and material handling robots with setup time. Then, we improve three meta-heuristics to address the problems. To enhance the performance of these algorithms, seven local search operators are developed. Finally, 82 benchmark instances with different scales are solved. Experimental results and comparisons show that GA with SARSA-based local search operators is the most competitive among all compared algorithms.
This study optimizes resource allocation and job scheduling through a collaborative mechanism between the MHR and machines, enhancing factory efficiency. It minimizes the maximum completion time and earliness and tardiness, ensuring production continuity and maximizing resource utilization. However, there are still some limitations. In the future, we will focus on the following research directions: (1) consider more objectives, such as machine workload and carbon emission-related ones; (2) add additional constraints, e.g., blocking time; (3) design more local search operators and more reinforcement learning methods to enhance performance, e.g., graph neural networks and deep Q-networks; (4) extend designed algorithms to other production scheduling problems; and (5) collaborate with industry partners to put the suggested models and algorithms to the scope of real-world applications. This study will offer valuable insights into their performance, scalability, and adaptability within actual production settings.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}