1. Introduction
This paper considers the following nonconvex, nonsmooth optimization problem with nonlinear coupled constraints:
where
is a proper lower semicontinuous function,
is a continuously differentiable function with local Lipschitz continuous gradients,
is a function with local Lipschitz continuous gradients
, where
, and
is a mapping with a locally continuous Jacobian matrix.
is a full-row rank matrix with the smallest eigenvalue
.
Problem (
1) is equivalent to many important problems, such as the risk parity portfolio selection problem [
1], the robust phase recovery problem [
2], and generative adversarial networks (GANs) [
3]. When
(where
I is the identity matrix), problem (
1) is equivalent to the following problem:
The typical example of problem (
2) is the following Logistic Matrix Factorization problem [
4]:
where elements
and
are regularization coefficients, and
is a given constant.
In previous studies, when problem (
1) is convex and involves linear coupled constraints, that is,
is an affine mapping, the alternating direction multiplier method (ADMM) has been extensively studied in many studies. In particular, when
and
A and
B are both full-rank, the global convergence of ADMM was established in references [
5,
6]. Researchers have found that many limitations arise when the problem is set as convex, while nonconvex formulations can better describe the problem model. So, the focus of research gradually shifted toward applying ADMM to nonconvex optimization problems. For example, references [
7,
8,
9,
10] established the global convergence of ADMM for nonconvex models with linear constraints.
Although the formulation of nonconvex problems has addressed some practical scenarios, the limitations of linear coupled constraint problems become evident as real-world constraints increase. As a result, researchers have shifted their focus to the study of nonlinear coupled constraint problems. For nonlinear coupled constraint problems, paper [
11] proposed the concept of an information region within the Lagrange algorithm framework, where the boundedness of the multiplier sequence is a key assumption for the effect of the information region. The selection of parameters in the paper is related to the upper bound constant of the multiplier sequence, and in practice, determining the upper bound for the multipliers can be very challenging. Building on the idea of an information region from [
11], paper [
12] designed a proximal linearized alternating direction multiplier method with a backtracking process. Although convergence analysis does not rely on the boundedness of the multiplier sequence, it requires dynamically generated parameters during the backtracking process to ensure the boundedness of the generated sequence. Paper [
13] used the upper bound minimization method to update the primal block variables. Building on this, paper [
4] introduced inertia techniques and proposed a convergent alternating direction multiplier method with scaling factors to establish update rules. However, this requires the use of appropriate proxy functions to recover proximal points and proximal gradient descent steps, which is also challenging in practice.
In this paper, we propose a proximal linearized alternating direction multiplier method for problem (
1). The core idea of this method is to use the proximal linearized alternating direction multiplier method and update the dual variables using a discount strategy. This method does not require selecting an additional proxy function and the parameter selection is fixed, eliminating the need to adjust the parameters to ensure the decreasing nature of the generated sequence, which leads to the convergence analysis of the algorithm.
The structure of this paper is as follows.
Section 2 introduces the preliminary knowledge required for the convergence analysis of the algorithm.
Section 3 describes the algorithm in detail and provides the convergence theorem.
Section 4 presents the numerical experimental results of the algorithm for the non-negative matrix factorization problem.
Section 5 concludes the paper and provides final remarks. In the
Appendix A, we provide the proof process for some propositions.
2. Materials and Methods
In this section, we present the preliminaries needed for the convergence analysis. Based on the variational analysis of the problem (refer to [
14]), we introduce the following constraint qualification conditions for problem (
1). Here,
represents the Jacobian matrix of
h.
Definition 1 (Constraint Qualification [
13])
. A point satisfies the constraint qualification (CQ) for problem (1) if the following conditions hold:- (i)
The subdifferential of f in x is regular.
- (ii)
, i.e., the limiting subdifferential of f at x does not overlap with the range of the transpose of the gradient of the mapping hat x.
The [CQ] conditions ensure the smoothness and regularity of the constraint set, providing the necessary subdifferential calculus rules to establish the necessary first-order optimality conditions for problem (
1).
Lemma 1 (First-Order Optimality Condition). Let be a local minimum of problem (1), and let satisfy the [CQ] condition. Then, we have the following:
- (i)
- (ii)
There exists such that
This paper mainly considers the nonconvex and nonsmooth problem (
1). Therefore, we provide some definitions and lemmas for convergence analysis [
14,
15,
16].
Definition 2 (Subdifferential). Let E be a Euclidean vector space, and let be a proper lower semicontinuous function. If , then we have the following:
- (i)
The Fréchet (regular) subdifferential of Ψ
at Z, denoted by , is defined as follows: For any vector , we have - (ii)
The limiting subdifferential of Ψ at Z, denoted by , is defined as follows: For any vector , there exists a sequence and such that , , , and .
- (iii)
The horizontal subdifferential of Ψ at Z, denoted by , is similar to the definition in (ii), but for some real number sequence , we do not have , but instead, . For , we define .
Proposition 1. Let be an extended value function, and be a smooth function. Then, we have the following: In problem (
1), we consider the concept of Lipschitz functions and local Lipschitz continuity. Next, we provide the relevant concepts.
Definition 3. Let be a non-empty set, and let be a continuous map on S. Then, we have the following:
- (i)
If for all and , then φ is L-Lipschitz continuous on S.
- (ii)
If for each , there exist , and a neighborhood such that φ is -Lipschitz continuous on , i.e.,
When (i) or (ii) holds for , is called L-Lipschitz continuous or locally Lipschitz continuous, respectively.
Lemma 2 (Local Lipschitz Continuity of
[
12])
. The function satisfies that for every non-empty and compact set , there exists such that This means that is locally Lipschitz continuous. Proposition 2 (Local Lipschitz Continuity and Compact Sets [
17])
. Let be a non-empty set, and let the mapping be locally Lipschitz continuous on S. Then, for every non-empty compact set , there exists such that φ is L-Lipschitz continuous on C, i.e., Proposition 3 (Differential Mapping and Lipschitz Continuity [
18])
. Let be a -mapping. Then, the following statements hold:- (i)
φ is locally Lipschitz continuous.
- (ii)
Let be a closed ball, i.e., for some and . If φ is L-Lipschitz continuous on B, with , then , for all .
3. Results
3.1. Algorithm
First, we define the augmented Lagrangian function associated with problem (
1),
, with penalty parameter
:
where
denotes the standard Euclidean
-norm.
To distinguish between the smooth and nonsmooth components in
L, we define
as
Thus,
Next, we present Algorithm 1 proposed in this paper.
| Algorithm
1 Proximal Linearized ADMM (PADMM) |
| Input: Initial values , , , , and let . |
| Repeat: |
| Primal update: |
|
|
| Dual update: |
|
| Until the convergence criterion is satisfied. |
Remark 1. For Equation (6), we first provide the properties of the proximal mapping [14]: when be a proper lower semicontinuous function, with , let . When , the proximal mapping is defined as So, Equation (6) is essentially a proximal gradient update step: For Equation (7), we note that ψ is a strongly convex function. Since for any matrix , we can derive the explicit update expression for from the first-order optimality condition of (7): For Equation (8), we adopt a discount update scheme: In contrast, the dual update for the ADMM method with nonlinear coupling constraints is typically In the proximal alternating direction method of multipliers (proximal ADMM), the primal and dual updates alternate until the stopping criteria are met.
3.2. Convergence Analysis
Our analysis will focus on the function
. For the convenience of subsequent proofs, we first present some formulas:
We also state the assumptions required for our proof. We assume that the functions g and p have lower bounds, that is, and
First, we provide the relationship between y and u.
Proposition 4. Assume , for all ; then, we have Let . For all , let this be the regularized AL function. We have the following proposition to quantify the change in the regularized AL function over successive iterations.
In particular, the authors of [
19] built a general framework to establish convergence for nonconvex settings, comprising two key steps: (1) identifying a so-called sufficiently decreasing Lyapunov function and (2) establishing the lower boundness property of the Lyapunov function. The augmented Lagrangian (AL) function has often been used as the Lyapunov function in nonconvex settings. In Proposition 5,
is the regularized AL function. We observe that the sufficient descent property of the AL function can only hold when the primal update restricts the dual update, i.e.,
, for the sufficient descent property of the AL function to hold. First, based on the ascent–descent relationship established in Proposition 6, we introduce the Lyapunov function
, defined as
where
is a constant parameter required to ensure the sufficient descent and lower bound properties of the Lyapunov function. Next, we establish the sufficient descent property of the Lyapunov function. For convenience, we define the sequence
as a descent sequence for the Lyapunov function
. Based on Proposition 4 and Proposition 5, the following proposition can be easily obtained.
Proposition 6. For ,where , and . This implies that when , and , the Lyapunov function we constructed maintains sufficient descent properties. Another key step for the convergence of the algorithm is to establish the lower bound properties of the Lyapunov function. To do so, we first prove the lower bound property of the Lagrange multipliers generated by the discounted dual update scheme.
Proposition 7. Let be the constraint residual at iteration k, and let represent the maximum constraint residual over the feasible set. Algorithm 1, starting from any given initial dual variable , guarantees that is bounded, i.e.,or equivalently, Proof. From Equation (
12), we have
□
The first inequality follows from the triangle inequality, the second inequality comes from , and the final inequality holds because . Furthermore, by applying the inequality , we can establish the lower bound property of the Lyapunov function.
Proposition 8. For the sequence generated by the algorithm, we have for all .
Proof. Observe the construction of
. Clearly,
is non-negative and has a lower bound, and, by Proposition 7, since
is bounded,
is also bounded. Therefore, we need to prove the boundedness of
. Observe that
, based on our assumptions, has
and
, and
is non-negative and has a lower bound. Thus, we only need to prove the lower bound of
. Based on dual update (
10), we have
We know that is bounded, so we conclude that has a lower bound. The proof is complete. □
3.3. Main Result
To demonstrate the convergence result of the algorithm, we first define the notion of an approximate stationary solution.
Definition 4. For all ϵ, when is an ϵ-approximate stationary solution of problem (1), we have Theorem 1. Assume that the parameters used in the algorithm satisfy the conditions under which the lemmas hold. Then, we have the following:
- (i)
The sequences , , and generated by the algorithm are bounded and converge, i.e., - (ii)
Suppose there is a limit point . Then, when , the point is a -approximate stationary solution to problem (1).
Proof. From Proposition 6, we have
Let
, and we obtain
Since
, we have
Therefore, sequences , , and converge to , and , i.e., as , we have , and and also , and
From the dual updates,
satisfies
As we defined , we know that . Thus, by setting , we have .
Next, for part (ii), we consider the first-order optimality conditions for the update when
, and by taking
, we have
From (
19), according to [
7], there exists
such that
Therefore, from (
18) and (
21), we obtain
Next, we consider the convergence of
depending on
and
, which we can still achieve by setting the initial points and parameters. First, from Proposition 7, we know that
and from (
17), we obtain
This is because
,
,
, and the remaining terms are non-negative. Next, we prove by induction that
. For
, we can appropriately choose the initial point to satisfy the inequality. For
k, assume
and consider two cases for the
-th iteration: if
, we can directly conclude that
. If
, based on (
22), we can again conclude the desired result. Therefore, we can infer that
. Clearly, there exists a constant
c such that
. Thus, there exists an
such that
. Therefore, we conclude the following:
□
4. Discussion
In this study, we tested the algorithm proposed in this paper on problem (
3). All tests were conducted using Matlab R2023b on a Macbook Air M2.
We primarily focused on the application of the proposed algorithm to the Logistic Matrix Factorization problem. Problem (
3) is written in the same form as problem (
1):
where
and
The augmented Lagrangian function for the problem is
From Equation (
6),
U is updated as follows:
W is updated using the explicit expression in Equation (
7):
Finally,
is updated as
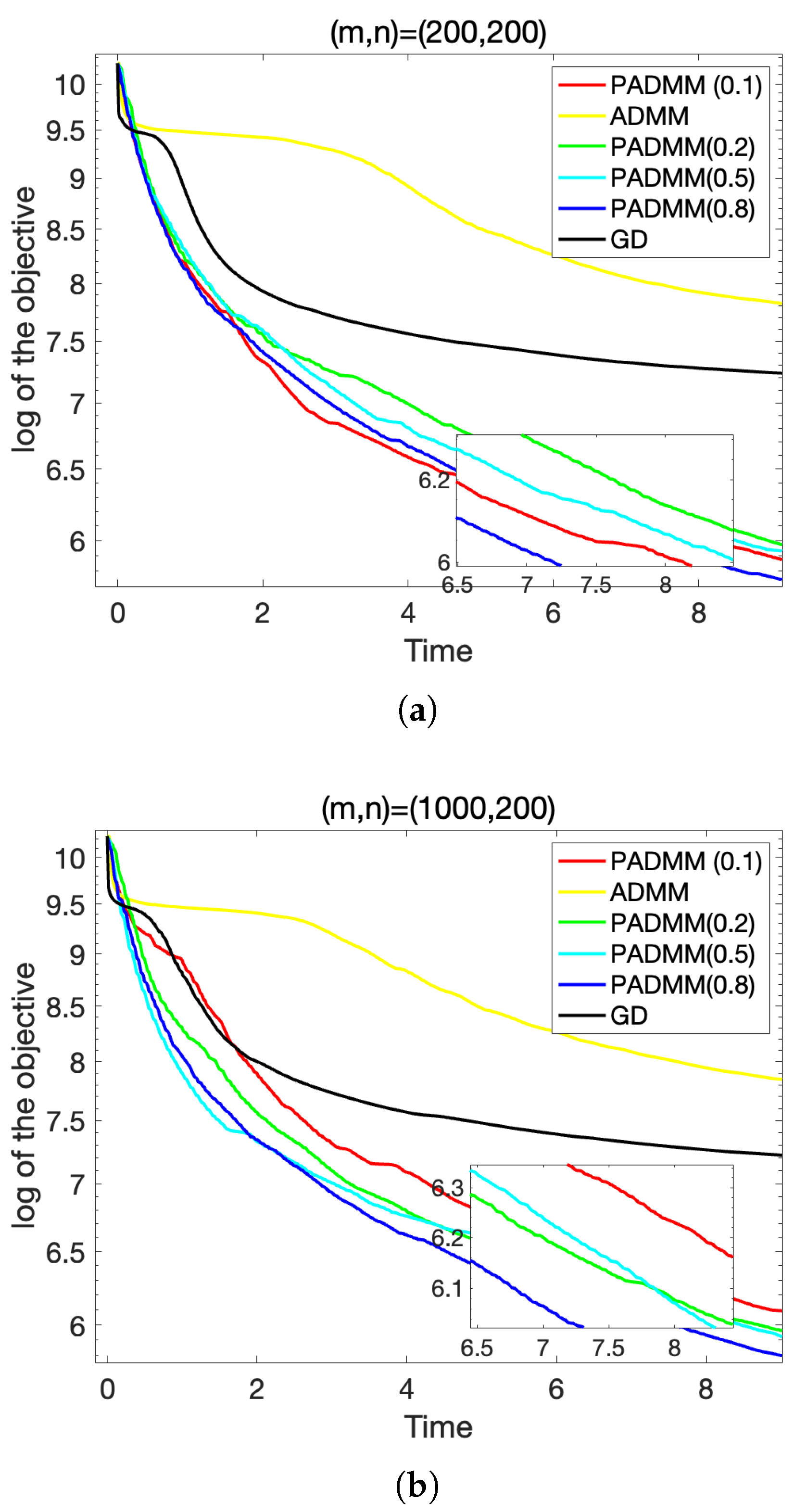
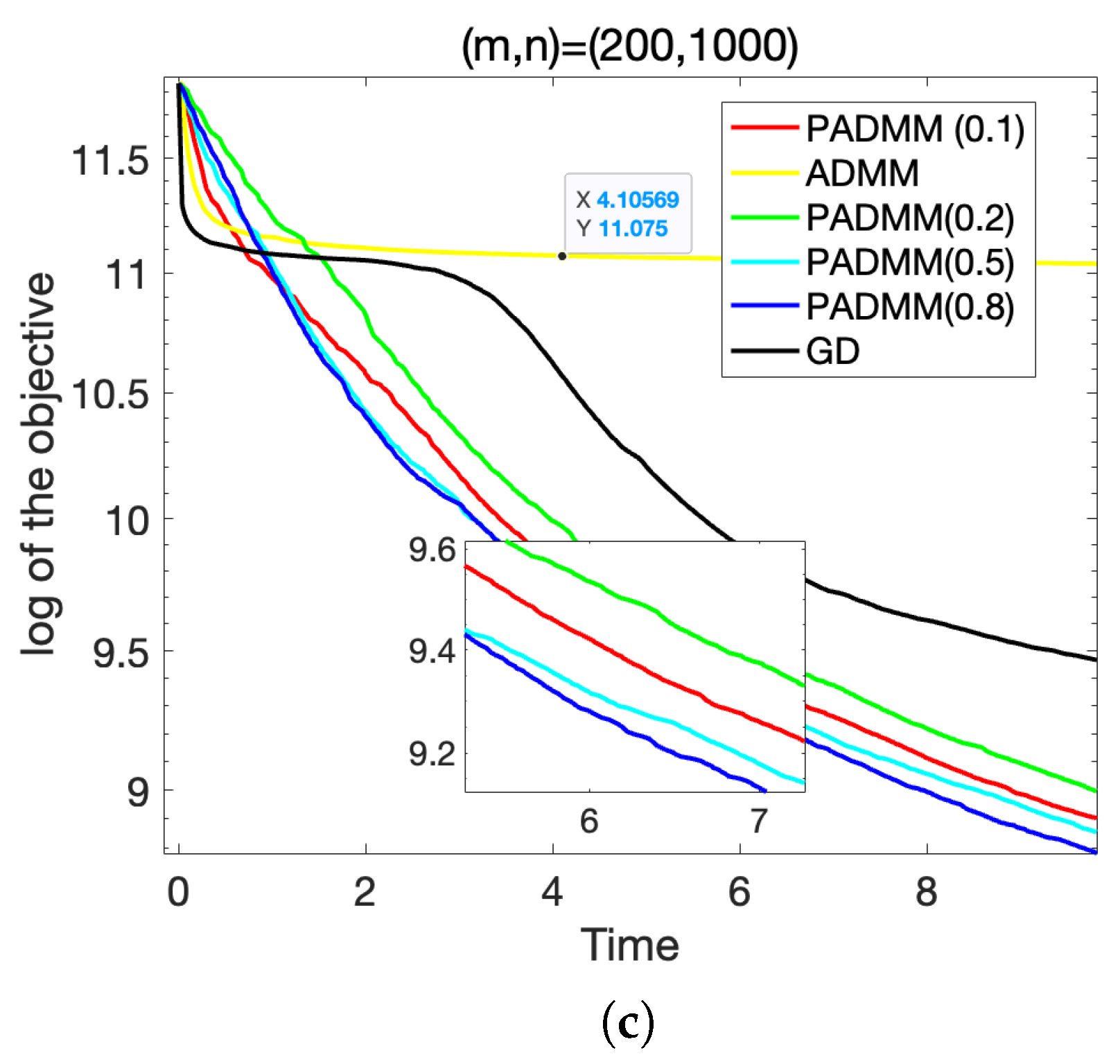
To generate sparse data , where each element , we used the Matlab command sprand(m, n, s) and assigned them to W such that . In subsequent experiments, for each , we randomly generated a matrix Y and set , meaning that 90% of the elements in Y were 0, with parameters , and . For each Y, we randomly generated initial points and ran each algorithm with the same initial points and running time. The running time for was set to 10 s, and for , the running time was set to 20 s.
We conducted a comparative analysis of the proposed algorithm against two traditional methods: ADMM and the GD alternating gradient multiplier method. The GD alternating gradient multiplier method works by alternately updating matrices U and V using gradient descent steps. In our experiments, we evaluated the performance of the algorithm for different values of the regularization parameter , specifically .
To assess the performance of each method, we calculated the objective value of problem (
3) throughout the iterations, and we present the change in this objective value over time in
Figure 1 and
Table 1. The experimental results clearly show that the proposed algorithm consistently outperforms both the ADMM and GD alternating gradient multiplier methods on all values tested of
.
In particular, we observe that for , the proposed algorithm achieves the best performance, with the objective value converging more rapidly and reaching a lower final value compared to the other methods. This suggests that the choice of plays a crucial role in optimizing the algorithm’s performance. Based on the experimental findings, we conclude that provides the optimal balance between efficiency and accuracy, making it the most effective choice for solving the problem at hand. This was also validated in subsequent experiments with real-world data.
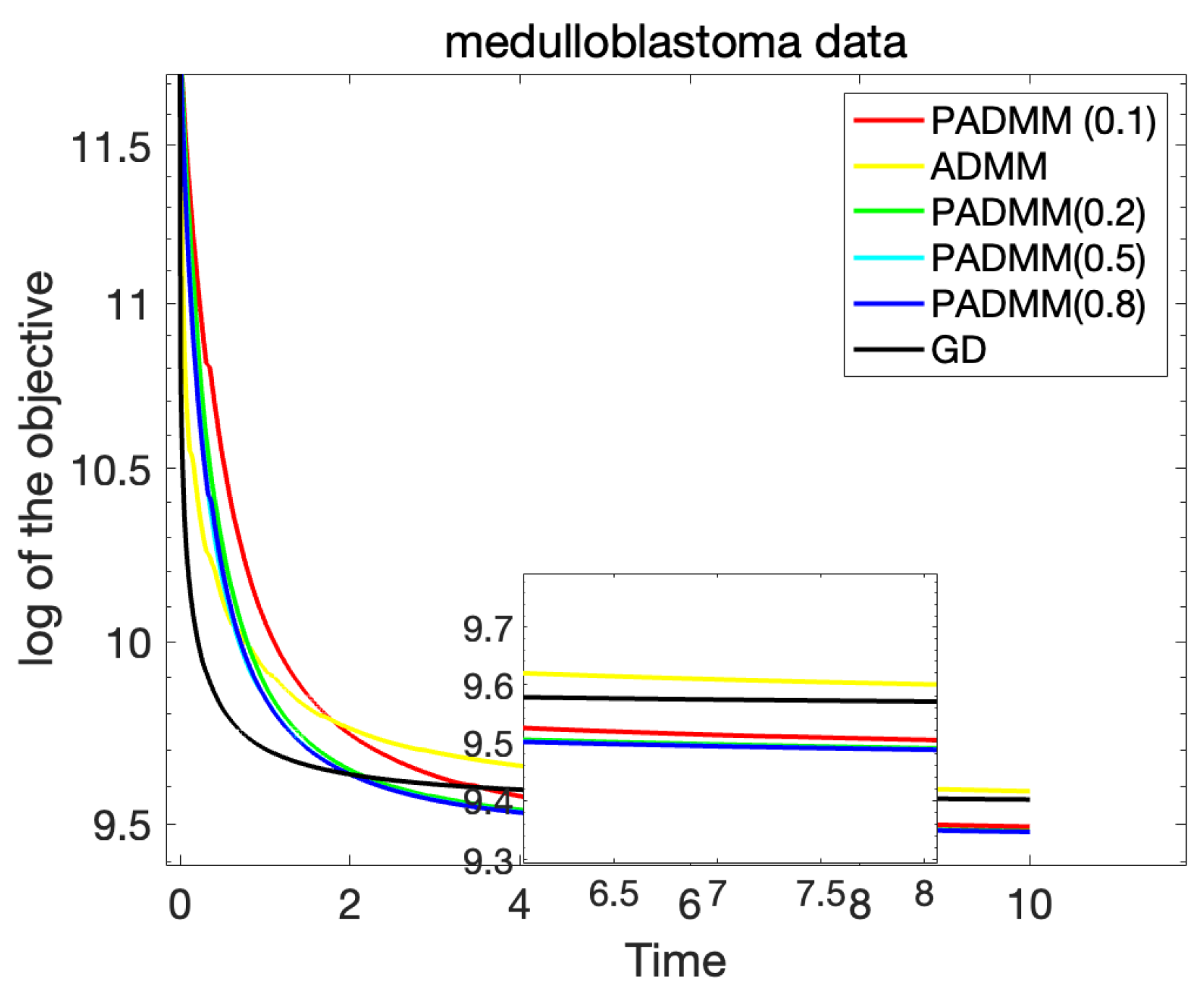
Similarly, we applied the proposed algorithm to a dataset containing medulloblastoma matrix data [
20] and a real-world biomedical dataset and analyzed several key factors, including the relationship between the training values and the number of iterations, as well as the difference between the training value and the optimal value. This allowed us to evaluate how effectively the algorithm converges and whether it consistently approaches the optimal solution.
In
Figure 2, we present the results of this analysis, which clearly highlight the superior performance of the PADMM algorithm in addressing real-world problems, particularly in the context of complex medical data. The graph shows that the proposed algorithm converges quickly and accurately, maintaining a small gap between the training value and the optimal value over time.
From these results, we can further conclude that, similarly to our earlier experiments, the regularization parameter delivers the best performance in this real-world scenario as well. The results validate the robustness and efficiency of the proposed algorithm, confirming that it can effectively handle practical, large-scale datasets while providing high accuracy and fast convergence.



{kind=link}
{kind=link}
{kind=link}