Abstract
The growing Deaf and Hard-of-Hearing community faces communication challenges due to a global shortage of certified sign language interpreters. Therefore, developing efficient and secure sign language machine translation (SLMT) systems is essential. Current work addresses the accuracy of the sign language translation task. However, there is a need for an SLMT system that encompasses privacy, efficiency, translation accuracy, and Machine Learning development operations. This paper addresses this void by proposing a novel consent-aware privacy-preserving end-to-end edge, cloud, and blockchain integrated computing system. We evaluate the system by comparing the mostly used Encoder–Decoder Transformer and a lightweight Adaptive Transformer (ADAT), using two datasets: the most comprehensive sign language dataset RWTH-PHOENIX-Weather-2014T (PHOENIX14T), and MedASL, our newly developed medical-domain dataset. A comparative analysis of translation quality on PHOENIX14T shows that ADAT improves BLEU-4 by 0.02 absolute points and ROUGE-L by 0.11. On MedASL, ADAT gains 0.01 in BLEU-4 and 0.02 in ROUGE-L. For runtime efficiency on MedASL, ADAT reduces training time by 50% and lowers both edge–cloud and end-to-end system communication times by 2%.
Keywords:
artificial intelligence; assistive technology; blockchain; cloud computing; computer vision; deep learning; edge computing; natural language processing; neural machine translation; sign language translation; transformers MSC:
68T05; 68T07; 68T10; 68T35; 68T50; 68U10; 94A08
1. Introduction
More than 430 million people are Deaf or Hard-of-Hearing (DHH) worldwide; this figure is expected to exceed 700 million by 2050 [1]. While DHH individuals communicate using sign language, there is a shortage of certified interpreters. For instance, the ratio of DHH individuals to interpreters in the United States is 4800:1 [2]. The situation is more severe in the least developed countries, where there are fewer interpreters [3]. This disparity underscores the need for automated and efficient sign language machine translation (SLMT) systems.
SLMT systems are Assistive Technologies (ATs) that help DHH individuals overcome communication barriers and foster inclusion and independence, particularly when a human interpreter is unavailable. These systems must be real-time, reliable, and secure as described in [4]. Developing such systems can save lives in natural and medical emergencies [5]. Consequently, building an accurate and real-time software-based SLMT system is crucial.
Several works investigate SLMT systems [6,7,8,9,10,11,12,13,14,15,16]. However, these systems consider only a few components of the building blocks of an end-to-end privacy-preserving, real-time, and efficient SLMT. In particular, most studies focus on optimizing translation quality without addressing deployment challenges such as runtime performance and user privacy. In this paper, we fill this gap by proposing an end-to-end SLMT system that integrates edge and cloud computing with blockchain-based consent management. We evaluate its performance in a real-world setting through a comparative analysis of the Encoder–Decoder Transformer [17] and a lightweight Adaptive Transformer (ADAT), based on [18] using the RWTH-PHOENIX-Weather-2014T (PHOENIX14T) [19] and MedASL datasets. We created MedASL to exemplify conversations between DHH people and a medical professional.
This proposed system considers deployment factors, including the various components required to build a real-time system, the computational costs of each component, and user privacy requirements. It also enables secure, traceable deployment through blockchain integration, which has not been previously explored in the SLMT literature. The proposed system integrates five components: (1) a sign language recognition (SLR) module to capture sign videos, (2) an artificial intelligence (AI)-enabled application that serves as a gateway between the user and the edge, (3) edge nodes to extract and preprocess keypoints from the sign videos for inference, (4) cloud servers to develop and deploy the SLMT AI model, and (5) an integrated blockchain–cloud computing architecture as in [20] to record and manage user consent for data collection, ensuring compliance with relevant regulations [21,22]. We address user privacy through consent mechanisms, which we categorize into (1) system-level consents in which the DHH individual allows systems administrators to access user data for system failure diagnosis and recovery, and (2) application-level consents to obtain users’ permission on data sharing and privacy management.
The main contributions of this paper are as follows:
- We propose an end-to-end edge, cloud, and blockchain computing integrated system for SLMT.
- We evaluate our proposed system in comparison with the most used Encoder–Decoder Transformer using the largest publicly available German sign language dataset, PHOENIX14T, and our new MedASL dataset.
- We conduct experiments and numerical analysis of our system’s performance in terms of Bilingual Evaluation Understudy (BLEU), Recall-Oriented Understudy for Gisting Evaluation (ROUGE), training time, translation time, and overall end-to-end system time.
- We deploy the Encoder–Decoder Transformer and ADAT models in a unified setup, demonstrating the feasibility of our proposed system for real-world applications.
The rest of the paper is organized as follows. Section 2 reviews the related work. Section 3 explains the proposed end-to-end edge–cloud–blockchain architecture for SLMT. Section 4 describes the materials and methods. Numerical experiments and comparative results are provided in Section 5. Section 6 discusses the responsible deployment of the proposed system. Finally, Section 7 concludes the paper.
2. Related Work
Several works applied machine and deep learning models for SLMT [6,7,8,9,10,11,12,13,14,15,16]. Table 1 summarizes these works by comparing translation formulation, input modality, preprocessing techniques, and learning algorithms. It also compares the deployment environments, including edge, cloud, and blockchain, as well as consent mechanisms and runtime measurements.

Table 1.
Comparison between sign language machine translation systems in the literature.
The table shows that current works focus on sign-to-gloss (S2G) translation [6,8,9,10,11,12,13,14,15,16], where a gloss is a written representation of a sign. In an end-to-end SLMT system, sign videos are translated either into gloss then text (S2G2T) or directly into text (S2T). Therefore, S2G, without text output, offers limited benefits for real-world applications [4]. In terms of input modalities, previous studies relied mainly on RGB video [7,8,9,10,11,12,13,14]. While these inputs capture rich visual information such as facial expressions, they are sensitive to environmental factors, including lighting, background, and signer features and appearance [23]. These variations can degrade the model’s performance and require extensive preprocessing and computationally intensive backbones for feature extraction compared to keypoints [24]. In addition, RGB inputs preserve identifiable features and contextual details that raise privacy concerns, such as re-identification and unintended data exposure [25]. In contrast, the use of keypoints in the proposed system retains abstract visual content, including skeletal landmarks and poses, while omitting identifiable details, hence mitigating privacy risks. This abstraction preserves essential spatiotemporal features for sign language understanding and consequently reduces computational cost [26].
The trade-offs between computational costs and privacy implications highly impact the deployment choices. This can be addressed by adopting architectures that integrate edge processing with cloud support and blockchain-based governance mechanisms. However, few works partially explore these architectures, focusing on the edge as an offloading component, which limits the system scalability. While many works employ edge devices [6,7,8,9,15,16], VisioSLR [16] extends this by incorporating cloud servers, and none integrate a privacy-preserving blockchain system.
The deployment environment influences runtime behavior, making it necessary to measure training, preprocessing, inference, and communication times. Few works report inference time [6,8,9,13,15,16] and only VisioSLR [16] measures training time. However, no works compute preprocessing and edge–cloud communication times. Moreover, despite the importance of user consent in privacy-sensitive applications, existing SLMT works do not implement system-level consent, whereas DeepASL [6] addresses application-level consent.
Due to the limited adoption of consent mechanisms in SLMT systems, we provide a cross-domain comparison of both consent mechanism applications in Table 2. Prior works show that system-level consents preserve privacy and anonymity when reporting platform crashes, such as in browsers [27] and operating systems [28]. On the other hand, application-level consents anonymize personal data in contexts including research participation [29], emergency and crime reporting [30,31,32], and digital health data sharing [33].
Table 2.
Comparison of consent applications across domains.
In summary, prior works on SLMT focused on S2G translation using RGB video inputs, despite their computational overhead and privacy vulnerabilities. Keypoint representations offer a more efficient and privacy-preserving alternative. Nevertheless, comprehensive evaluations of deployment factors and runtime measurements in SLMT remain scarce. Similarly, while cross-domain works highlight the benefits of consent mechanisms for privacy-sensitive applications, such mechanisms remain unexplored in the current SLMT literature. In this work, we propose an end-to-end system for SLMT, integrating a camera, an AI-enabled application, edge nodes, cloud servers, and blockchain. To our knowledge, no existing SLMT work provides such a unified framework that evaluates translation quality and computational efficiency while addressing user data governance.
3. Proposed End-to-End System for Sign Language Translation
The overview of our proposed end-to-end edge–cloud–blockchain system for SLMT is presented in Figure 1. We explain the system components in the following subsections.
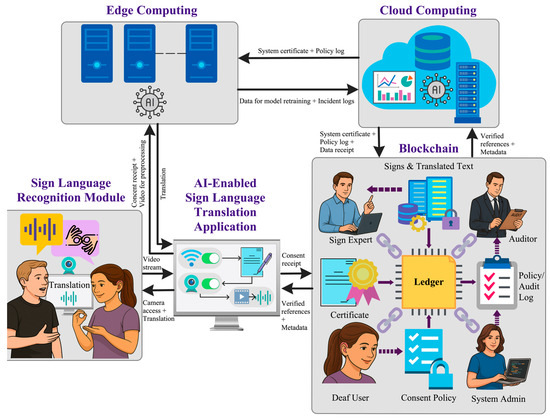
Figure 1.
Overview of the proposed end-to-end edge–cloud–blockchain architecture for sign language translation.
3.1. Sign Language Recognition Module
Sign language is based on visual cues, making video capture and feature extraction essential components for translation. The SLR module captures sign videos within a conversation through a camera and transmits them to the edge for keypoint extraction and translation. This enables direct communication between DHH and hearing individuals without relying on a human interpreter. The technical feasibility and operation reliability of the SLR module depend on the following specifications:
- Camera configuration: Higher resolution and frame rate per second improve fine-grained feature extraction [34], but increase computation and video uplink load [24]. Keypoint extraction mitigates this issue by reducing uplink demand and latency.
- Device computation: CPU, GPU, and RAM capacities determine the feasibility of capturing frames, extracting keypoints, and performing inference [35].
- Connectivity: Wi-Fi and 5G networks enable low-latency and high-throughput communication [36,37].
- Operating System (OS): The OS manages camera access, hardware accelerators, security, and user experience. User-driven access controls reduce unauthorized access. Hardware accelerators determine the feasibility of keypoint extraction and inference. Security policies enforce user privacy and implement tamper-evident safeguards, including integrity checks and tamper detection modules [38]. Permissions for camera, network, and storage are tied to user consent, ensuring legal compliance [39].
Our proposed system provides an accurate translation with low latency. CNN-based keypoint extraction achieves state-of-the-art accuracy [40]. Therefore, we recommend 1080p at 30 or 60 fps for video streaming, aligning with the public sign language datasets [4]. Privacy is ensured through encryption, secure access controls, and revocable consent, forming the first layer of protection in the overall SLMT.
3.2. AI-Enabled Sign Language Translation Application
The AI-enabled application serves as a user gateway to the system, acquiring sign video input and transmitting it to the edge. The interaction flow proceeds as follows: (1) enable Wi-Fi or 5G connectivity, (2) establish an authenticated session through credential-based login, (3) obtain user consent, (4) capture sign videos and extract keypoints for preprocessing and inference, and (6) receive and display the translation.
Translation is best performed using Transformer-based models [4,17], which surpass earlier CNN- and RNN-based approaches. This is due to the Transformer’s ability to capture long-range spatiotemporal dependencies, enabling parallel sequence processing and improving representation learning [17].
To ensure transparency, user consents are explained in spoken and sign languages, clearly defining the purpose, types of collected data, and retention periods. Once the user grants consent, the application generates a consent receipt, which is a blockchain-recorded metadata record confirming the user’s authorization for specific data processing under a defined policy version. It includes a unique consent identifier, consent scope, corresponding policy version, its validity period, timestamp, and digital signature verifying authenticity. Each obtained consent is bound to a policy and an audit log. A policy log is a metadata record that contains the consent scope, data retention period, and data storage and transmission rules [41]. An audit log is an immutable blockchain ledger entry that traces all consent, translation, and model-related transactions in the SLMT system [42]. Both logs contain only content-free metadata such as version identifiers, hashes, timestamps, and digital signatures, ensuring transparency and accountability without revealing any user identity or sign content. Table 3 presents the consent types in our end-to-end system.
Table 3.
Consent types in the proposed AI-enabled sign language translation application.
3.3. Edge Computing
Once the video streams are transmitted, the edge device performs keypoint extraction, preprocessing, and translation. Keypoint extraction is a crucial step as it reduces bandwidth consumption, communication overhead, and privacy risks [26]. The edge preprocesses keypoints by normalization, rescaling, and padding, before translating sign language into spoken language using a Transformer-based model. The resulting translation is returned to the application for display to the user.
When the user grants an application-level consent for model improvement, the edge forwards the raw videos, corresponding keypoints, and generated translations to the cloud. Under system-level consent, the edge transmits incident logs and associated sign videos to the cloud. These logs include system performance, inference latency, and incident traces. Independent of the consent, all data transmitted by the edge is encrypted and follows policy-defined rules.
The edge also records tamper-evident, content-free metadata on the blockchain, describing every translation and event. Each blockchain submission includes the following metadata: a unique translation session identifier, reference to the consent receipt, reference to the system certificate that defines the deployed model and its version, hash of the processed keypoints, hash of the translation, policy version, processed and retained data receipts, timestamp, and digital signature of the edge device ensuring authenticity. This signed record, known as a data receipt, is periodically transmitted to the blockchain through a secure gateway.
3.4. Cloud Computing
The edge communicates with the cloud only when the user grants application-level consent for model improvement and/or system-level consent. Under application-level consent, sign experts annotate uploaded sign videos for future model retraining whenever translation precision falls below predefined thresholds. Updated models are then rolled out to the edge. Under system-level consent, system administrators analyze incident logs and raw videos to diagnose and resolve reliability issues before deploying new updates. In both consent scenarios, the cloud generates a system certificate, a policy log, and a cloud digital signature. Moreover, the cloud appends the following metadata fields: a reference to the system certificate associated with the deployed model, the policy version, the cloud’s signature to ensure integrity, and a timestamp. These records are encrypted and transmitted to the blockchain to ensure auditability without exposing user content. Figure 2 illustrates the deep learning operations pipeline between the edge and cloud in our proposed system.
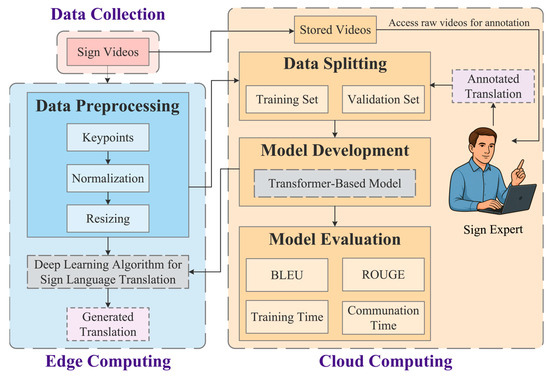
Figure 2.
Edge–cloud pipeline for the proposed end-to-end sign language translation system.
3.5. Blockchain
Ensuring the security and privacy of user data is a key requirement in SLMT system deployment. In particular, storing user data on infrastructures, such as the cloud, offers scalability but limits traceability of data access and policy enforcement, which is critical in healthcare, as demonstrated in [43]. To address this issue, our proposed system integrates a blockchain [44] that serves as a tamper-evident audit layer for user transactions, consents, data access and usage, system certificates, and policy logs. Within this layer, all records are linked through a chain of hashes and replicated across the edge and cloud, ensuring that any attempt to alter or remove data is immediately detectable. This distributed verification mechanism enhances confidentiality, integrity, and accountability while maintaining cloud scalability.
As illustrated in Figure 3, the process begins with the cloud generating the system certificate and the policy log, each containing a unique identifier, a version number, and a cryptographic hash. These are transmitted to the blockchain and the edge to establish a baseline of trust. When the user grants consent, the application creates a consent receipt and submits it to the blockchain. The blockchain verifies the system certificate, policy log, and consent receipt to ensure consistency and authenticity, then forwards verified references to the edge. The edge cross-verifies these records against the cloud to confirm alignment before starting the translation session.
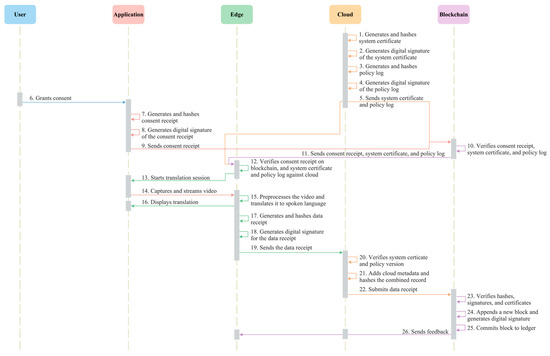
Figure 3.
Sequence diagram for the transactions and ledger update process in the proposed system.
During translation, the application streams the sign video to the edge for keypoint extraction and translation. The edge then hashes the processed keypoints and generated text, combines them with the verified references, creates a data receipt, and transmits it to the cloud. The cloud re-verifies the certificate and policy version, appends its own metadata, and submits the final transaction to the blockchain. Upon receipt, the blockchain validates all hashes, signatures, and certificate references, appends a new block, and commits it to the distributed ledger. The ledger stores only content-free metadata, forming a lightweight audit trail that ensures verifiability without exposing personal identifiers [20]. Verified entries are shared with the edge and cloud to maintain synchronized, policy-compliant operation [45]. Table 4 summarizes the proposed blockchain layer, listing the participants, events, and the associated actions that affect the ledger transactions, log assets, scope, and system effects.
Table 4.
Participants, events, transactions, assets, and system effects in the blockchain layer for sign language translation.
In summary, the proposed system integrates the SLR module, AI-enabled application, edge, cloud, and blockchain. This design enables scalability, privacy, and reliability while providing accurate and trustworthy sign language translation.
4. Materials and Methods
This section presents the experimental setup and numerical comparative analysis of our proposed system. To evaluate system performance, we employ two datasets covering distinct sign languages and domains, benchmarking the Encoder–Decoder Transformer, the widely adopted algorithm in SLMT, and its variant, ADAT. We assess the performance using BLEU [46] and ROUGE [47] for translation precision, as well as training time, translation time, edge–cloud communication time, and overall system time.
4.1. Datasets
We conduct experiments on PHOENIX14T [19], the most used benchmark dataset for SLMT, and MedASL. MedASL contains 2000 medical-related statements reflecting conversations between DHH and medical professionals. The recordings were collected in varied environments, including changes in lighting and background, to enhance robustness. Using a large, multi-signer dataset (PHOENIX14T) and a smaller, single-signer dataset (MedASL) allows comparative analysis of efficiency and generalization across different scales. Table 5 summarizes the characteristics of both datasets.
Table 5.
Dataset characteristics.
4.2. Data Preprocessing
We adopt a consistent preprocessing pipeline for training and inference. We use MediaPipe [48] to extract the following per-frame keypoints: 21 landmarks per hand, 468 face landmarks, 5 iris landmarks per eye, and 6 upper body pose landmarks. We then normalize and rescale these keypoints. Next, we concatenate frames belonging to the same sentence into a temporal sequence and zero-pad them for batch processing. During inference, we segment the input stream into sliding windows before passing them to the model.
Regarding the translation output, we construct a vocabulary that includes special tokens, such as start- and end-of-sequence (<SOS> and <EOS>) and <UNK> for unknown words. We then tokenize the text sequences, index each token, and pad them to a fixed length to enable batched training and evaluation.
During evaluation, we use the predefined train/dev/test sets of PHOENIX14T. For MedASL, we allocate 80% for 5-fold cross-validation and 20% for testing.
4.3. Model Development
We evaluate our proposed end-to-end system using two AI models: Encoder–Decoder Transformer [17] and ADAT [18].
4.3.1. Encoder–Decoder Transformer
The Encoder–Decoder Transformer maps sequences of visual features extracted from sign videos to sequences of spoken-language tokens. It is the most used and accurate model for SLMT due to its ability to capture long-range spatiotemporal dependencies, which are relationships between distant frames in a sign sequence and their corresponding linguistic units [4]. In particular, its encoder processes a sequence of sign input embeddings and generates feature representations that are fed into the decoder, which predicts the target text sequence. During decoding, cross-attention aligns the encoder outputs with the linguistic context at each step. This Encoder–Decoder interaction enables precise translation of sign video inputs into grammatically correct sentences. The attention mechanisms are presented in Equations (1)–(3).
where Q, K, and V represent query, key, and value, respectively. is the dimension.
where is a learned weight that adds parameters in a single-head self-attention.
where is the decoder query and are from the encoder output.
4.3.2. Adaptive Transformer (ADAT)
ADAT modifies the Encoder–Decoder Transformer by integrating convolutional layers for localized feature extraction, LogSparse Self-Attention (LSSA) [49] to reduce the quadratic cost, and an adaptive gating mechanism [50] that balances short- and long-range dependencies.
The Encoder–Decoder Transformer’s self-attention computes pairwise attention scores between every pair of tokens in a sequence of frames, resulting in a quadratic computational cost. On the other hand, ADAT’s LSSA restricts each frame to attend only to a logarithmically spaced subset of preceding frames, sampled at exponentially increasing intervals. This structure preserves long-range temporal dependencies while reducing the complexity from to . Consequently, LSSA reduces redundant attention operations, making ADAT faster and more efficient for long sign sequences while maintaining contextual accuracy.
Equations (4) and (5) show LSSA and the gating mechanism, respectively.
where is the patch indices that a current patch can attend during a logarithmic computation from to .
where is the gate value computed via a gate neural network to adaptively weight between LSSA, i.e., long-range dependencies, and Global Average Pooling (GAP), i.e., short-range dependencies.
Prior studies have shown that the adaptive gating mechanism achieves comparable or superior translation quality to the Encoder–Decoder Transformer while significantly improving efficiency and scalability [18].
In summary, an accurate SLMT model is achieved by training on temporally ordered visual embeddings, ensuring that attention mechanisms learn spatial relationships between keypoints and temporal dynamics across the signing sequence.
4.4. Experimental Setup
The proposed system operates in two stages: (1) S2T translation, executed by the AI-enabled application in coordination with the edge device, and (2) SLMT development, which trains AI models on benchmark datasets and retrains them on consented, annotated user videos.
In the first stage, sign videos are captured at 30 frames per second using an Intel RealSense D455 camera, connected to the edge, represented by a desktop in our experiments. The videos are streamed to the application, and the edge device extracts keypoints via MediaPipe, applies preprocessing, and performs inference. In the second stage, the edge connects to a cloud server for model training. Retrained models are periodically deployed back to the edge for updated inference. Figure 4 illustrates the experimental setup, where a user signs in ASL in front of an Intel RealSense D455 camera connected to the edge device.

Figure 4.
Experimental setup with a user signing in ASL. The video feed with overlaid keypoints is displayed on screen. (a) A status message is displayed during inference; (b) the translated text is displayed once inference is complete.
4.5. Experiments
We evaluate the translation quality and runtime efficiency of the proposed system under scenarios that mirror real-world operation. To assess translation quality, we compare generated translations to human-annotated references using BLEU [46] and ROUGE [47] scores. Applying these metrics across both datasets allows direct comparison between the Encoder–Decoder Transformer and ADAT architectures.
Regarding efficiency, we record the time required for model convergence during training and measure detailed runtime behavior during inference. At the beginning of inference, the edge device retrieves the most recent trained model from the cloud to stay synchronized with the latest deployment, defining the cloud-to-edge communication time. The edge then continuously captures video and processes it in short overlapping segments of 30 consecutive frames. Once the first segment is complete, the device begins generating translations, applying a brief warmup period to stabilize performance. At each translation step, the edge records preprocessing and inference times. The former covers feature extraction, normalization, and batching, while the latter measures the duration of sign language translation. After processing video segments, the edge uploads the extracted keypoints and corresponding translations to the cloud, defining the edge-to-cloud communication time.
We measure the overall end-to-end system time as perceived by the user. This interval spans from the first captured frame to the display of the translated text, including capture, preprocessing, inference, and edge–cloud communication. The system maintains synchronized clocks across both components to ensure timing consistency. These experiments provide the methodological basis for the runtime evaluation in Section 5.
5. Performance Evaluation
This section evaluates the models under study within a unified experimental setup, focusing on translation quality and runtime efficiency. We structure the evaluation into four components: the metrics used to assess translation and runtime performance, the hyperparameter tuning strategy, the hardware specifications for training and inference, and an in-depth numerical analysis of the results.
5.1. Evaluation Metrics
To ensure a comparable assessment of linguistic accuracy and system-level efficiency, we measure translation quality using BLEU and ROUGE. We use NLTK’s BLEU [46] and Rouge-score [51] Python 3.10 libraries. We assess runtime efficiency by reporting training, translation, communication, and end-to-end system times.
5.1.1. Bilingual Evaluation Understudy (BLEU)
We use a BLEU score with n-grams ranging from 1 to 4, as shown in Equations (6) and (7).
where is the precision of n-grams, is the weight of each n-gram size, and is the Brevity Penalty.
where is the length of the generated translation. is the reference corpus length.
5.1.2. Recall-Oriented Understudy for Gisting Evaluation (ROUGE)
We assess the similarity between generated translations and their references using ROUGE-1 and ROUGE-L. ROUGE-1 measures unigram overlap, while ROUGE-L assesses the longest sequence of overlapping words. We normalize both metrics through precision and recall. ROUGE-L is calculated using Equations (8)–(10).
where is the generated translation. is the reference translation. is the length of the longest common subsequence between and . is the number of tokens in the translation.
5.1.3. Runtime Metrics
We measure the runtime efficiency by calculating the training time and the latency across training, preprocessing, inference, translation, edge–cloud communication, and the overall end-to-end system time, as presented in Table 6. These measurements capture the backend operational overhead and the user-perceived latency.
Table 6.
Runtime efficiency metrics, definitions, and equations.
5.2. Hyperparameter Tuning
We perform systematic hyperparameter tuning to achieve the best translation performance across both models. The search space includes optimization strategies, training setups, model architectures, and decoding choices. The final hyperparameters are selected based on validation BLEU-4 scores with early stopping. Table 7 summarizes the hyperparameters investigated, the ranges explored, and the chosen settings.
Table 7.
Hyperparameter search space and selected configurations.
5.3. Hardware Specifications
The evaluation was conducted using a distributed setup consisting of a capture unit, an edge device, and a cloud server. The capture unit provides lightweight video acquisition, the edge device handles preprocessing and inference, and the cloud server supports model development and data storage. This division reflects practical deployment, where time-sensitive tasks are executed closer to the user while high-compute workloads are offloaded to the cloud. Table 8 lists the specifications of each device. All software components are implemented using Python 3.10.
Table 8.
Hardware specifications for performance evaluation.
5.4. Experimental Results Analysis
This section presents a numerical evaluation of the Encoder–Decoder Transformer and ADAT in terms of translation quality and runtime efficiency.
5.4.1. Translation Quality
Table 9 compares the translation quality of the Encoder–Decoder Transformer and ADAT models using the PHOENIX14T and MedASL datasets. On PHOENIX14T, ADAT surpasses the Encoder–Decoder Transformer in all metrics, with +0.02 and +0.11 absolute points in BLEU-4 and ROUGE-L, respectively. Similarly, on MedASL, ADAT outperforms the Encoder–Decoder Transformer with +0.01 and +0.02 in BLEU-4 and ROUGE-L, respectively. This is because ADAT integrates LSSA, which retains key temporal segments across signing sequences, and an adaptive gating mechanism to balance short- and long-range dependencies.
Table 9.
Comparison of models for sign language translations (scores range between 0 and 1; higher being better). Best results are in bold.
ADAT shows larger performance gains than the Encoder–Decoder Transformer using ROUGE-L across datasets. This is because ADAT’s LSSA component enables preservation of global semantic consistency rather than focusing on word-level matches. BLEU-n measures exact overlaps of n-gram sequences; therefore, its smaller improvement reflects limited changes in local accuracy. In contrast, ROUGE-L evaluates the overall sentence structure and semantic alignment with the reference translation, which explains ADAT’s gains at the sentence level.
In addition, ADAT achieves +0.11 gain in ROUGE-L using PHOENIX14T versus +0.02 gain using MedASL. This is because PHOENIX14T has longer and more structured sentences, where maintaining global information order is essential. Conversely, MedASL sentences are shorter and more diverse, which limits the improvement in the overall sentence-level structure.
In summary, our experimental results demonstrate that while ADAT’s BLEU score gains are minimal, ROUGE-L score confirms its effectiveness in SLMT. In particular, ADAT is designed to preserve sentence-level organization and global semantic coherence. Therefore, it delivers translations that maintain the overall structure and meaning of the original message, making it a more effective model for real-world SLMT systems.
5.4.2. Runtime Efficiency
We assess the models’ runtime efficiency within the edge–cloud pipeline using the MedASL dataset. Figure 5 presents the model training time in both datasets. Table 10 presents the runtime and system performance for both models. Figure 6 illustrates ADAT’s relative improvements over the Encoder–Decoder Transformer.
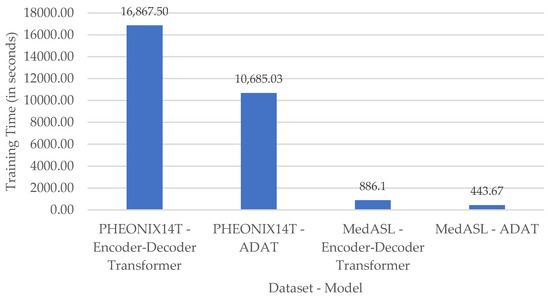
Figure 5.
Comparison of sign language training time for the models under study in our proposed translation system.
Table 10.
Comparison of sign language translation runtime and system performance. Best results are in bold.
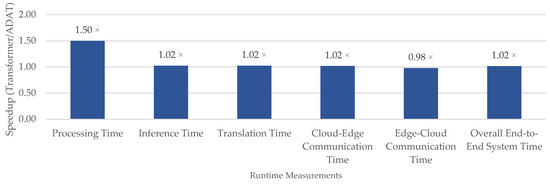
Figure 6.
Relative improvement by component (>1 showing ADAT is faster).
The results indicate that training on PHOENIX14T takes longer than on MedASL due to its larger size and vocabulary. Within each dataset, ADAT consistently converges faster than the Encoder–Decoder Transformer, reflecting its reduced computational overhead. In particular, ADAT reduces training time by 1.6× on PHOENIX14T and by half on MedASL, due to its adaptive attention mechanism.
In real-world deployment, translation and communication times are critical constraints. In our experiments, ADAT slightly reduces translation time from 188.28 ms to 183.77 ms by enabling faster inference, resulting in a 1.02× relative improvement. It also achieves 1.02× speedup in cloud–edge communication. This is explained by ADAT’s 22% smaller model size compared to the Encoder–Decoder Transformer (104.9 MB vs. 134.8 MB), which reduces computational overhead. When considering the complete pipeline, ADAT delivers a 1.02× reduction in overall end-to-end time, showing that latency gains are consistent across the entire pipeline. These findings confirm that ADAT sustains efficiency advantages during training and inference in distributed environments.
Comparing ADAT with the Encoder–Decoder Transformer highlights the trade-off between efficiency and translation quality. ADAT improves sentence-level fluency with lower computational overhead due to its sparse attention and adaptive gating. However, the Encoder–Decoder Transformer achieves comparable translations but is more complex than ADAT due to quadratic attention computation.
In summary, ADAT is faster in training, translation, and data transfer. These characteristics make it well-suited for deployment in SLMT systems operating in distributed edge–cloud environments with blockchain integration.
6. Responsible Deployment of the Proposed System
The experimental results, presented and discussed in Section 5, demonstrate the technical feasibility of SLMT systems in an edge–cloud architecture. However, real-world SLMT deployment requires specific considerations, which we address in this section.
6.1. Ethical, Legal, and Data Rights Considerations
Sign language video recordings contain sensitive biometric and contextual information. As outlined in the Experimental Setup (Section 4.4), the deployed system captures high-resolution videos and extracts and stores the signer’s keypoints for inference and model retraining. Managing such data requires clear protocols for ownership, consent, and accountability, guided by international and national frameworks, such as the General Data Protection Regulation (GDPR) [21] and the UAE Federal Decree Law concerning the Protection of Personal Data (PDPL) [22].
Users must grant consent, which they fully understand and can withdraw at any time. These consents must be auditable to ensure accountability and transparency. The blockchain ledger, described in Section 3.5, provides an immutable record for each consent-related event [44]. Once logged, entries cannot be altered or erased; instead, any changes are appended as new records. This design preserves the whole history of modifications and prevents record tampering.
Furthermore, users should retain ownership of raw video recordings and extracted keypoints, while also having the right to withdraw. Moreover, the collected data must not be repurposed for unrelated applications without renewed consent. In addition, transparency is ensured through blockchain-based logs, providing verifiable and tamper-resistant records of data usage [20].
6.2. Security Threats and Mitigations
An edge–cloud–blockchain SLMT pipeline introduces security risks that must be addressed to ensure trustworthy deployment. The system processes data and metadata across its components. The data include raw sign videos, extracted keypoints, generated translations, and incident logs that the edge produces and, when users grant consent, transmits to the cloud. In the cloud, the system generates additional data, including annotated sign videos used for model retraining, trained model files, and diagnostic records. We classify the metadata into two categories: (1) consent-related metadata, which includes consent receipts, policy logs, and audit logs, and (2) system-generated metadata, which consists of system certificates, data receipts, hashes of processed keypoints and translations, policy versions, timestamps, and digital signatures.
All data and metadata are encrypted during transmission and storage using Advanced Encryption Standard (AES-256) [56] and Elliptic Curve Cryptography (ECC) [57]. AES-256 provides symmetric encryption, securing data through a shared encryption key known only to authorized components. ECC enables asymmetric key exchange and digital signatures. During key exchange, each component, i.e., edge, cloud, and blockchain, uses its private key along with the other component’s public key to compute an identical shared AES encryption key, without exposing it. These cryptographic mechanisms ensure confidentiality, integrity, and authenticity across all components of the distributed architecture. However, while encryption secures data when stored and transmitted, the system must also address broader security threats across the operational pipeline.
- Video tampering poses a significant risk, as it can lead to consent violations, model corruption, and unauthorized access during training and validation [58]. This can be mitigated by applying a cryptographic chain of hashing to the videos to ensure integrity, and by employing homomorphic encryption and secure computation over encrypted data, which allows processing without exposing personal data [59].
- Data manipulation, such as unauthorized alteration of consent receipts, policy records, or audit logs, threatens the reliability and accountability of the SLMT system. The blockchain layer mitigates this by making all committed records immutable, validating each new transaction through distributed consensus, and replicating the ledger across distributed nodes. Since all nodes retain synchronized copies, any inconsistency reveals manipulation and is automatically rejected. These mechanisms maintain consistent, tamper-evident records and preserve the integrity [44].
- Unauthorized access to stored data and trained models at the edge and cloud must be protected through strong encryption, multi-factor authentication, and role-based access control [60].
- Consent and policy misuse, such as using data beyond the approved scope, is reduced through a feedback loop [45], where edge and cloud continuously reference the latest consent receipts and policy logs before processing or updating models [61].
- Deanonymization risks from signer keypoints or metadata are reduced through local differential privacy methods, which introduce noise at the edge to prevent identity exposure [62].
In summary, the proposed SLMT system employs a layered set of security mechanisms that extend beyond encryption to ensure end-to-end trust. These measures preserve data reliability, regulatory compliance, and user confidentiality throughout capture, transmission, processing, and storage.
6.3. Minimum Requirements for Responsible Sign Language Translation System Deployment
The empirical evaluation and the ethical and security considerations discussed above define the following minimum requirements for deploying SLMT systems:
- Translation quality must be sufficient to support transparent and precise communication between DHH individuals and the broader society. Section 5.1 shows that ADAT consistently outperforms the Encoder–Decoder Transformer across all metrics, demonstrating the feasibility of achieving precise translation.
- Latency must be minimized to ensure an efficient end-to-end translation. Section 5.2 demonstrates ADAT’s reductions in inference and communication times in the edge–cloud setup.
- Generalization across signers and environmental conditions is essential to ensure inclusivity. Achieving this requires continuous data collection from different signers, domains, and environments.
- Data collection and model retraining must comply with international and national regulations, such as GDPR [21] and UAE PDPL [22]. These principles ensure that users have control over their data, can withdraw their consent, and determine how their data is used. The blockchain-based logging mechanism described in Section 3.5 provides a solid foundation for meeting these obligations and ensuring accountability.
- Security and robustness are critical for reliable deployment. As discussed in Section 6.2, proper safeguards must be integrated into the system design.
- Scalability must be maintained as the number of users and translation requests increases. Employing an efficient clustered lightweight blockchain as proposed in [63], where only representative nodes replicate and validate the ledger, sustains responsiveness as workloads grow. This approach reduces communication load, improves ledger synchronization across clusters, and provides high throughput.
In summary, integrating a precise AI model into an edge–cloud–blockchain architecture demonstrates that advances in translation and runtime efficiency must be accompanied by ethical, legal, and security safeguards. This alignment is essential for deployment in domains such as healthcare, where translation quality and data privacy are critical. By adhering to established regulations, incorporating blockchain-based auditability, and employing robust security protections, the proposed architecture serves as a blueprint for future SLMT technologies that strike a balance between technical effectiveness and responsible deployment. Beyond SLMT, this work also provides a transferable model for the responsible deployment of AI in other biometric domains, including speech and facial recognition.
7. Conclusions
In this work, we present a novel end-to-end sign language machine translation (SLMT) system built on an edge–cloud–blockchain architecture. The proposed system consists of a sign language recognition (SLR) module, an AI-enabled SLMT application, edge nodes, cloud servers, and a blockchain layer that provides immutable logging, ensuring compliance with data protection regulations.
Within this framework, we develop and evaluate the Encoder–Decoder Transformer and the Adaptive Transformer (ADAT) with respect to translation quality and runtime efficiency. We conduct a comparative analysis on RWTH-PHOENIX-Weather-2014T (PHOENIX14T) and the newly extended MedASL dataset. The results show that ADAT consistently outperforms the Encoder–Decoder Transformer in translation accuracy and achieves a twofold reduction in training time, with lower inference and communication latency.
Future work should expand multilingual sign language datasets that incorporate diverse signers across various domains, integrate multimodal inputs with advanced feature extraction to enhance semantic alignment, explore lightweight models for constrained edge devices, and extend blockchain frameworks to support cross-institutional governance and enable broader, transparent adoption across domains.
Author Contributions
Conceptualization, L.I.; methodology, L.I.; software, N.S. and L.I.; validation, N.S. and L.I.; formal analysis, N.S. and L.I.; investigation, N.S. and L.I.; resources, L.I.; data curation, N.S.; writing—original draft preparation, N.S.; writing—review and editing, L.I.; visualization, L.I. and N.S.; supervision, L.I.; project administration, L.I.; funding acquisition, L.I. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Emirates Center for Mobility Research, United Arab Emirates University, grant number 12R199.
Data Availability Statement
Our proposed MedASL dataset and the implementation code is publicly available at https://github.com/INDUCE-Lab/, accessed on 6 November 2025.
Acknowledgments
The authors would like to acknowledge the support of the Emirates Center for Mobility Research of the United Arab Emirates, and thank the anonymous reviewers for the valuable comments and feedback which helped us to improve the paper.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- World Health Organization. Ageing and Health. Available online: https://www.who.int/news-room/fact-sheets/detail/ageing-and-health (accessed on 21 August 2025).
- Registry of Interpreters for the Deaf Registry. Available online: https://rid.org (accessed on 22 August 2025).
- Kaula, L.T.; Sati, W.O. Shaping a Resilient Future: Perspectives of Sign Language Interpreters and Deaf Community in Africa. J. Interpret. 2025, 33, 2. [Google Scholar]
- Shahin, N.; Ismail, L. From Rule-Based Models to Deep Learning Transformers Architectures for Natural Language Processing and Sign Language Translation Systems: Survey, Taxonomy and Performance Evaluation. Artif. Intell. Rev. 2024, 57, 271. [Google Scholar] [CrossRef]
- Tonkin, E. The Importance of Medical Interpreters. Am. J. Psychiatry Resid. J. 2017, 12, 13. [Google Scholar] [CrossRef]
- Fang, B.; Co, J.; Zhang, M. DeepASL: Enabling Ubiquitous and Non-Intrusive Word and Sentence-Level Sign Language Translation. In Proceedings of the 15th ACM Conference on Embedded Network Sensor Systems, Delft, The Netherlands, 6–8 November 2017; ACM: New York, NY, USA, 2017; pp. 1–13. [Google Scholar]
- S Kumar, S.; Wangyal, T.; Saboo, V.; Srinath, R. Time Series Neural Networks for Real Time Sign Language Translation. In Proceedings of the 17th IEEE International Conference on Machine Learning and Applications (ICMLA), Orlando, FL, USA, 17–20 December 2017; IEEE: Los Alamitos, CA, USA, 2018; pp. 243–248. [Google Scholar]
- Dhanawansa, I.D.V.J.; Rajakaruna, R.M.T.P. Sinhala Sign Language Interpreter Optimized for Real—Time Implementation on a Mobile Device. In Proceedings of the 2021 10th International Conference on Information and Automation for Sustainability (ICIAfS), Negombo, Sri Lanka, 11 August 2021; IEEE: Los Alamitos, CA, USA, 2021; pp. 422–427. [Google Scholar]
- Gan, S.; Yin, Y.; Jiang, Z.; Xie, L.; Lu, S. Towards Real-Time Sign Language Recognition and Translation on Edge Devices. In Proceedings of the 31st ACM International Conference on Multimedia, Ottawa, ON, Canada, 27 October 2023; ACM: New York, NY, USA, 2023; pp. 4502–4512. [Google Scholar]
- Zhang, B.; Müller, M.; Sennrich, R. SLTUNET: A Simple Unified Model for Sign Language Translation. In Proceedings of the International Conference on Learning Representations, Kigali, Rwanda, 1–5 May 2023. [Google Scholar]
- Miah, A.S.M.; Hasan, M.A.M.; Tomioka, Y.; Shin, J. Hand Gesture Recognition for Multi-Culture Sign Language Using Graph and General Deep Learning Network. IEEE Open J. Comput. Soc. 2024, 5, 144–155. [Google Scholar] [CrossRef]
- Shin, J.; Miah, A.S.M.; Akiba, Y.; Hirooka, K.; Hassan, N.; Hwang, Y.S. Korean Sign Language Alphabet Recognition Through the Integration of Handcrafted and Deep Learning-Based Two-Stream Feature Extraction Approach. IEEE Access 2024, 12, 68303–68318. [Google Scholar] [CrossRef]
- Baihan, A.; Alutaibi, A.I.; Alshehri, M.; Sharma, S.K. Sign Language Recognition Using Modified Deep Learning Network and Hybrid Optimization: A Hybrid Optimizer (HO) Based Optimized CNNSa-LSTM Approach. Sci. Rep. 2024, 14, 26111. [Google Scholar] [CrossRef]
- Huang, J.; Chouvatut, V. Video-Based Sign Language Recognition via ResNet and LSTM Network. J. Imaging 2024, 10, 149. [Google Scholar] [CrossRef]
- Wei, D.; Hu, H.; Ma, G.-F. Part-Wise Graph Fourier Learning for Skeleton-Based Continuous Sign Language Recognition. J. Imaging 2025, 11, 286. [Google Scholar] [CrossRef] [PubMed]
- Ismail, L.; Shahin, N.; Tesfaye, H.; Hennebelle, A. VisioSLR: A Vision Data-Driven Framework for Sign Language Video Recognition and Performance Evaluation on Fine-Tuned YOLO Models. Procedia Comput. Sci. 2025, 257, 85–92. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J. Attention Is All You Need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Shahin, N.; Ismail, L. GLoT: A Novel Gated-Logarithmic Transformer for Efficient Sign Language Translation. In Proceedings of the 2024 IEEE Future Networks World Forum (FNWF), Dubai, United Arab Emirates, 15 October 2024; IEEE: Los Alamitos, CA, USA, 2024; pp. 885–890. [Google Scholar]
- Camgoz, N.C.; Hadfield, S.; Koller, O.; Ney, H.; Bowden, R. Neural Sign Language Translation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 7784–7793. [Google Scholar]
- Ismail, L.; Materwala, H.; Hennebelle, A. A Scoping Review of Integrated Blockchain-Cloud (BcC) Architecture for Healthcare: Applications, Challenges and Solutions. Sensors 2021, 21, 3753. [Google Scholar] [CrossRef] [PubMed]
- European Parliament and Council of the European. Union General Data Protection Regulation GDPR; European Parliament and Council of the European Union: Strasbourg, France, 2018. [Google Scholar]
- Government of United Arab Emirates. Federal Decree by Law No. (45) of 2021 Concerning the Protection of Personal Data; Government of United Arab Emirates: Abu Dhabi, United Arab Emirates, 2021.
- Kwak, J.; Sung, Y. Automatic 3D Landmark Extraction System Based on an Encoder–Decoder Using Fusion of Vision and LiDAR. Remote Sens. 2020, 12, 1142. [Google Scholar] [CrossRef]
- Wu, Y.-H.; Liu, Y.; Xu, J.; Bian, J.-W.; Gu, Y.-C.; Cheng, M.-M. MobileSal: Extremely Efficient RGB-D Salient Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 10261–10269. [Google Scholar] [CrossRef]
- Climent-Pérez, P.; Florez-Revuelta, F. Protection of Visual Privacy in Videos Acquired with RGB Cameras for Active and Assisted Living Applications. Multimed. Tools Appl. 2021, 80, 23649–23664. [Google Scholar] [CrossRef]
- Ahmad, S.; Morerio, P.; Del Bue, A. Event Anonymization: Privacy-Preserving Person Re-Identification and Pose Estimation in Event-Based Vision. IEEE Access 2024, 12, 66964–66980. [Google Scholar] [CrossRef]
- Satvat, K.; Shirvanian, M.; Hosseini, M.; Saxena, N. CREPE: A Privacy-Enhanced Crash Reporting System. In Proceedings of the Tenth ACM Conference on Data and Application Security and Privacy, New Orleans, LA, USA, 16–18 March 2020; pp. 295–306. [Google Scholar]
- Kim, S.-J.; You, M.; Shin, S. CR-ATTACKER: Exploiting Crash-Reporting Systems Using Timing Gap and Unrestricted File-Based Workflow. IEEE Access 2025, 13, 54439–54449. [Google Scholar] [CrossRef]
- Struminskaya, B.; Toepoel, V.; Lugtig, P.; Haan, M.; Luiten, A.; Schouten, B. Understanding Willingness to Share Smartphone-Sensor Data. Public Opin. Q. 2021, 84, 725–759. [Google Scholar] [CrossRef] [PubMed]
- Qureshi, A.; Garcia-Font, V.; Rifà-Pous, H.; Megías, D. Collaborative and Efficient Privacy-Preserving Critical Incident Management System. Expert Syst. Appl. 2021, 163, 113727. [Google Scholar] [CrossRef]
- Zhu, L.; Zhang, J.; Zhang, C.; Gao, F.; Chen, Z.; Li, Z. Achieving Anonymous and Covert Reporting on Public Blockchain Networks. Mathematics 2023, 11, 1621. [Google Scholar] [CrossRef]
- Shi, R.; Yang, Y.; Feng, H.; Yuan, F.; Xie, H.; Zhang, J. PriRPT: Practical Blockchain-Based Privacy-Preserving Reporting System with Rewards. J. Syst. Archit. 2023, 143, 102985. [Google Scholar] [CrossRef]
- Lee, A.R.; Koo, D.; Kim, I.K.; Lee, E.; Yoo, S.; Lee, H.-Y. Opportunities and Challenges of a Dynamic Consent-Based Application: Personalized Options for Personal Health Data Sharing and Utilization. BMC Med. Ethics 2024, 25, 92. [Google Scholar] [CrossRef]
- Feichtenhofer, C.; Fan, H.; Malik, J.; He, K. SlowFast Networks for Video Recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6202–6211. [Google Scholar]
- Lee, J.; Shi, W.; Gil, J. Accelerated Bulk Memory Operations on Heterogeneous Multi-Core Systems. J. Supercomput. 2018, 74, 6898–6922. [Google Scholar] [CrossRef]
- Liu, R.; Choi, N. A First Look at Wi-Fi 6 in Action: Throughput, Latency, Energy Efficiency, and Security. Proc. ACM Meas. Anal. Comput. Syst. 2023, 7, 1–25. [Google Scholar] [CrossRef]
- Agiwal, M.; Abhishek, R.; Saxena, N. Next Generation 5G Wireless Networks: A Comprehensive Survey. IEEE Commun. Surv. Tutor. 2016, 18, 1617–1655. [Google Scholar] [CrossRef]
- Ghimire, S.; Choi, J.Y.; Lee, B. Using Blockchain for Improved Video Integrity Verification. IEEE Trans. Multimed. 2020, 22, 108–121. [Google Scholar] [CrossRef]
- Roesner, F.; Kohno, T.; Moshchuk, A.; Parno, B.; Wang, H.J.; Cowan, C. User-Driven Access Control: Rethinking Permission Granting in Modern Operating Systems. In Proceedings of the 2012 IEEE Symposium on Security and Privacy, San Francisco, CA, USA, 20–23 May 2012; IEEE: Los Alamitos, CA, USA, 2012; pp. 224–238. [Google Scholar]
- Gong, C.; Zhang, Y.; Wei, Y.; Du, X.; Su, L.; Weng, Z. Multicow Pose Estimation Based on Keypoint Extraction. PLoS ONE 2022, 17, e0269259. [Google Scholar] [CrossRef]
- Di Francesco Maesa, D.; Mori, P.; Ricci, L. A Blockchain Based Approach for the Definition of Auditable Access Control Systems. Comput. Secur. 2019, 84, 93–119. [Google Scholar] [CrossRef]
- Regueiro, C.; Seco, I.; Gutiérrez-Agüero, I.; Urquizu, B.; Mansell, J. A Blockchain-Based Audit Trail Mechanism: Design and Implementation. Algorithms 2021, 14, 341. [Google Scholar] [CrossRef]
- Ismail, L.; Materwala, H.; P. Karduck, A.; Adem, A. Requirements of Health Data Management Systems for Biomedical Care and Research: Scoping Review. J. Med. Internet Res. 2020, 22, e17508. [Google Scholar] [CrossRef] [PubMed]
- Ismail, L.; Materwala, H. A Review of Blockchain Architecture and Consensus Protocols: Use Cases, Challenges, and Solutions. Symmetry 2019, 11, 1198. [Google Scholar] [CrossRef]
- Li, Q.; Tian, Y.; Wu, Q.; Cao, Q.; Shen, H.; Long, H. A Cloud-Fog-Edge Closed-Loop Feedback Security Risk Prediction Method. IEEE Access 2020, 8, 29004–29020. [Google Scholar] [CrossRef]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.-J. BLEU: A Method for Automatic Evaluation of Machine Translation. In Proceedings of the 40th Annual Meeting on Association for Computational Linguistics—ACL ’02, Ottawa, ON, Canada, 6 July 2002; Association for Computational Linguistics: Morristown, NJ, USA, 2001; p. 311. [Google Scholar]
- Lin, C.-Y. Rouge: A Package for Automatic Evaluation of Summaries. In Text Summarization Branches Out; University of Southern California: Los Angeles, CA, USA, 2004; pp. 74–81. [Google Scholar]
- Google AI MediaPipe Solutions Guide. Available online: https://ai.google.dev/edge/mediapipe/solutions/guide (accessed on 20 November 2024).
- Li, S.; Jin, X.; Xuan, Y.; Zhou, X.; Chen, W.; Wang, Y.-X.; Yan, X. Enhancing the Locality and Breaking the Memory Bottleneck of Transformer on Time Series Forecasting. In Proceedings of the Advances in Neural Information PROCESSING systems, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Chattopadhyay, R.; Tham, C.-K. A Position Aware Transformer Architecture for Traffic State Forecasting. In Proceedings of the IEEE 99th Vehicular Technology Conference, Singapore, 26 July 2024; IEEE: Los Alamitos, CA, USA, 2024. [Google Scholar]
- See, A.; Liu, P.J.; Manning, C.D. Get To The Point: Summarization with Pointer-Generator Networks. arXiv 2017, arXiv:1704.04368. [Google Scholar] [CrossRef]
- Graves, A.; Fernández, S.; Gomez, F.; Schmidhuber, J. Connectionist Temporal Classification: Labelling Unsegmented Sequence Data with Recurrent Neural Networks. In Proceedings of the 23rd international conference on Machine learning—ICML’06, Pittsburgh, PA, USA, 25–29 June 2006; ACM Press: New York, NY, USA, 2006; pp. 369–376. [Google Scholar]
- Heafield, K. KenLM: Faster and Smaller Language Model Queries. In Proceedings of the Sixth Workshop on Statistical Machine Translation, Edinburgh, UK, 30 July 2011; pp. 187–197. [Google Scholar]
- Kudo, T.; Richardson, J. SentencePiece: A Simple and Language Independent Subword Tokenizer and Detokenizer for Neural Text Processing. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Brussels, Belgium, 2–4 November 2018; Association for Computational Linguistics: Stroudsburg, PA, USA, 2018; pp. 66–71. [Google Scholar]
- Sennrich, R.; Haddow, B.; Birch, A. Neural Machine Translation of Rare Words with Subword Units. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Berlin, Germany, 7–12 August 2016; Association for Computational Linguistics: Stroudsburg, PA, USA, 2016; pp. 1715–1725. [Google Scholar]
- Daemen, J.; Rijmen, V. The Design of Rijndael: AES—The Advanced Encryption Standard; Springer: Berlin/Heidelberg, Germany, 2002; ISBN 978-3-642-07646-6. [Google Scholar]
- Koblitz, N. Elliptic Curve Cryptosystems. Math. Comput. 1987, 48, 203–209. [Google Scholar] [CrossRef]
- Ma, H.; Li, Q.; Zheng, Y.; Zhang, Z.; Liu, X.; Gao, Y.; Al-Sarawi, S.F.; Abbott, D. MUD-PQFed: Towards Malicious User Detection on Model Corruption in Privacy-Preserving Quantized Federated Learning. Comput. Secur. 2023, 133, 103406. [Google Scholar] [CrossRef]
- Feng, J.; Yang, L.T.; Zhu, Q.; Choo, K.-K.R. Privacy-Preserving Tensor Decomposition Over Encrypted Data in a Federated Cloud Environment. IEEE Trans. Dependable Secur. Comput. 2020, 17, 857–868. [Google Scholar] [CrossRef]
- Sasikumar, K.; Nagarajan, S. Enhancing Cloud Security: A Multi-Factor Authentication and Adaptive Cryptography Approach Using Machine Learning Techniques. IEEE Open J. Comput. Soc. 2025, 6, 392–402. [Google Scholar] [CrossRef]
- Sun, X.; Yu, F.R.; Zhang, P.; Sun, Z.; Xie, W.; Peng, X. A Survey on Zero-Knowledge Proof in Blockchain. IEEE Netw. 2021, 35, 198–205. [Google Scholar] [CrossRef]
- Zhang, P.; Sun, H.; Zhang, Z.; Cheng, X.; Zhu, Y.; Zhang, J. Privacy-Preserving Recommendations With Mixture Model-Based Matrix Factorization Under Local Differential Privacy. IEEE Trans. Ind. Inform. 2025, 21, 5451–5459. [Google Scholar] [CrossRef]
- Ismail, L.; Materwala, H.; Zeadally, S. Lightweight Blockchain for Healthcare. IEEE Access 2019, 7, 149935–149951. [Google Scholar] [CrossRef]






Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).