Abstract
Characterizingthe spatial variability of agricultural data is a fundamental step in precision agriculture, especially in soil management and the creation of differentiated management units for increasing productivity. Modeling the spatial dependence structure using geostatistical methods is of great importance for efficiency, estimating the parameters that define this structure, and performing kriging-based interpolation. This work presents diagnostic techniques for global and local influence and generalized leverage using the displacement of the conditional expectation of the logarithm of the joint-likelihood, called the Q-function. This method is used to identify the presence of influential observations that can interfere with parameter estimations, geostatistics model selection, map construction, and spatial variability. To study spatially correlated data, we used reparameterized t-Student distribution linear spatial modeling. This distribution has been used as an alternative to the normal distribution when data have outliers, and it has the same form of covariance matrix as the normal distribution, which enables a direct comparison between them. The methodology is illustrated using one real data set, and the results showed that the modeling was more robust in the presence of influential observations. The study of these observations is indispensable for decision-making in precision agriculture.
MSC:
62; 3-10
1. Introduction
Geostatistics differs from classical statistics because the models of classical statistics usually focus on frequency checking and incorporate the interpretation of the spatial correlation of the samples. It assumes that the difference between two sample points depends on the distance between them and the orientation of the points, that is, closer pairs of observations are more similar to each other than pairs of more distant observations. However, in practice, atypical observations can affect the behavior of spatial dependence, especially when the normal distribution is assumed. Several authors, such as [1,2,3,4] have presented more robust approaches, with model estimates that are less sensitive to these observations. An alternative proposal by [5], studied later by [6], is to use the reparametrized t-Student distribution, which belongs to the symmetric distribution class and enables us to reduce the influence of outliers, as well as allowing for the existence of the second finite moment and a direct comparison between the matrix t-Student and the normal distribution. According to [7], it is possible that a single observation has a significant influence on the results of an analysis of spatial data, being able to considerably alter the results that define the spatial dependence structure, consequently changing the construction of the maps.
Following this thinking, diagnostic analysis is extremely important for detecting these observations. Several diagnostic analyses are presented as follows: Ref. [8] assessed local influence using elliptical linear models with a longitudinal structure; Ref. [9] used diagnostic techniques to assess the sensitivity of maximum likelihood estimators, the covariance function, and the linear predictor to small perturbations in the data and the assumptions of the spatial linear model. Refs. [10,11] worked with diagnostic techniques in Gaussian spatial linear models with repetition. Ref. [12] worked with the diagnostics of influence in spatial models with censored responses.
The purpose of this paper is to extend the work of [6] for the application of diagnostic analysis in the reparametrized t-Student distribution, through global and local influence techniques developed using the maximum likelihood and Q-function, which is an alternative to Cook’s procedure [13].
This paper proceeds as follows. The Section 2 is divided into subsections as follows: The t-Student spatial linear model subsection presents the reparametrized t-Student linear spatial model. The maximum likelihood estimation subsection presents the maximum likelihood estimation and the development of the parameter estimation process. The iterative algorithm subsection describes the algorithm. The asymptotic standard error estimation subsection explains how to obtain an estimate of the asymptotic standard errors. The selection of the parameter of form subsection describes the criteria for selecting the parameter of the form . The QQ-plot subsection describes the methodology for obtaining the QQ-plot graph. The influence diagnostics subsection presents the development of diagnostic tools to detect influential points using techniques of global and local influence and generalized leverage. The Section 3 presents the application of the methodology to a real data set and illustrates the method for analyzing real data for the reparameterized t-Student model, presenting the results obtained. The Section 4 presents a brief discussion of the results compared to the works found in the literature. The Section 5 presents the conclusions of the work.
2. Materials and Methods
2.1. The t-Student Spatial Linear Model
An alternative to the multivariate normal distribution is the multivariate t-Student distribution; this distribution has been widely used in the study of real data because it has heavier tails and allows for the incorporation of the atypical points present in the data set. Furthermore, it is a symmetrical distribution with an additional parameter, the degree of freedom, which is represented by v () and allows us to model the kurtosis of the data.
Ref. [5] suggests reparameterizing the t-Student distribution to allow for a direct comparison between the estimation of the mean vector parameters and the covariance matrix with the normal model. The reparameterization of this distribution is a transformation of the degrees of freedom, considering . This reparameterization is justified by the importance of modeling the spatial dependence structure, since the new shape parameter () is bounded () due to the assumption of the process having a finite second moment. This allows estimation of the model parameters using the EM algorithm, which is used in Kriging interpolation and later in map construction [14].
Following the methodology of [6], which presents the reparametrized multivariate t-Student distribution, the transformation is applied. It considers that , where a random vector follows a reparametrized t-Student distribution with a parameter of form fixed, where , with covariance matrix , , and mean vector . Its probability density function is given in Equation (1) as follows:
where
with is the Mahalanobis distance, for . Let denote a random vector following an n-multivariate reparameterized t-Student distribution. The stochastic representation of is given by
where , , , ; V add independent.
To study spatial dependence, consider an isotropic second-order stochastic process , where and is a bi-dimensional Euclidean space. Let be an response vector corresponding to the sites with , following an n-multivariate reparameterized t-Student distribution, denoted by , where each element can be written as , , where both the deterministic term and stochastic may depend on the spatial location at which is observed. It is assumed that random errors have an expectation equal to zero, that is, , and the variation between points is determined by some covariance function , for . Suppose that for some known function of , , the mean of the stochastic process is given in Equation (2) as follows:
where are unknown parameters for estimation.
In matrix notation, the spatial linear model is given by
where , is an full rank matrix, with i-th row an vector with explanatory variables at the site , is a vector of unknown parameters to estimate and are components correlated with variance with .
The spatial modeling given in Equation (3) depends on the structure of the covariance matrix , where for of the stochastic process . A covariance function is used in the spatial dependence study of the stationary process and is specified by a three-dimensional vector . As presented by [15], the parametric form is given in Equation (4) as follows:
where is the nugget effect, ; is known as sill, ; is an identity matrix of order n; is an symmetric matrix, where the elements are functions of , , where , and for , and for , , where depends on the Euclidean distance, , between points and . An alternative reparametrization of the covariance function is suggested by [16] and adapted by [6], assisting in the identifiability of the model. In this paper, we considered the parameters , and . This last parameter was considered fixed, and reparametrization of was based on the same criteria established by [6].
2.2. Maximum Likelihood Estimation
Under the assumption that , where is the fixed form parameter and , with and with and as unknown parameters and as a parameter to be defined and fixed according to the semivariogram, the log-likelihood of the reparameterized t-Student distribution is given in Equation (5) by:
where
- ,
- , , .
The scores function can be written as:
- ,
- ,
- where for , , and .
The vector of parameters can be estimated by maximum likelihood (ML) from the solution of the score functions and .
For the parameter estimated by the maximum likelihood, the solution of the function is obtained immediately as follows:
with k representing the k-th iteration.
To obtain the parameter estimated by maximum likelihood, with is determined through the system resolution (6). From we have:
where .
Considering , where and , (6) is applied:
Notice that in matrix notation, the system (7) can be written as:
where the matrix of order , with elements and a vector of order , with elements , which correspond to , , , and . The estimation process is given in Equation (8) by the system resolution:
The iterative algorithm section describes the algorithm for obtaining the estimation of the parameters of through iteration; in other words, it will obtain when it reaches the convergence criterion in the k-th iteration.
2.3. Iterative Algorithm
Based on [17], to obtain the parameter estimation of , we must use an iterative algorithm and the following procedures:
Initial Iteration: Set , where k represents the iteration phase:
- step: Define an initial shot to the parameter to be estimated , in what . In this study, we choose to define the initial parameters and , obtaining them in a regression model with a normal distribution, and is fixed and defined for all iterations, which will later be chosen by the cross-Validation criterion () and Trace () presented in the selection of the parameter of form section.
- step: We calculate the following Equations from the initial parameters obtained from the step:, in which is fixed on the initial shot.,,,,,,where is the covariance function that depends on the exponential, Gaussian, or Matérn family models, where is introduced by [9]. Verify that these equations calculated in the step are being considered as initials where .
- step: from this moment, we will update the parameters to where . Consider the following procedures:
- step: Updating the linear parameters and of , through the linear system (9):where the matrix of order , with elements and a vector of order with elements , where correspond to , , , to the vector and .
- step: Getting from the steps , we update , which will be used to update the parameter , by the expression given in Equation (10) by:
- step: the iteration ends, defining , obtained by updating step and step . From apply the convergence criterion that is defined for this algorithm: if as and are fixed, only verify the convergence to and () or stop and define , otherwise return to the step. Having and constant tolerance. In general, typical tolerance values are and , respectively.
2.4. Asymptotic Standard Error Estimation
Asymptotic standard errors can be calculated by inverting the expected information matrix, , where , with . For the reparametrized t-Student is given in Equation (11) by [18],
where
and
where , is the commutation matrix of order , and is the identity matrix of order (see [19]).
2.5. Selection of the Parameter of Form
According to [20,21], the log-likelihood function given in Equation (5) is decreasing in , so the estimation of this parameter cannot be obtained through the maximization of the log-likelihood (). As an alternative, Ref. [22] proposes using a matrix trace of the asymptotic covariance of an estimated average as a criterion in the selection of a better model for the class of elliptical distributions. Following this thought, Ref. [21] shows the trace criterion and cross-validation to select the degree of freedom v of the spatial liner t-Student model. From these propositions, Ref. [6] presents the trace criterion and the cross-validation criterion to select the form parameter to the reparameterized t-Student spatial linear model. For both methods, the best parameter of the form is determined by the smallest cross-validation and trace values. After choosing, the model parameter Matérn [23] is selected according to the smallest asymptotic standard error.
2.6. QQ-Plot
Following the methodology presented in [24] and the set of data , we determine the vector of the residuals , where , being the parameter vector and the covariance matrix, obtained due to the iterative algorithm section and the selection of the parameter of form . From the estimate of the covariance matrix , we use the Cholesky decomposition obtained by , where is the inferior triangular matrix of order n. Using the inverse matrix , we determine , defined as the vector of uncorrelated residuals. Then we used the methodology [25] with the packages qqplotr and ggplot2 in the R program to build QQ plots, considering as sample data the vector of uncorrelated residuals and as theoretical data the random vector with the distribution of the t-Students of both orders n. To obtain the confidence intervals, we utilized the [26] package with the application of the boot method, which creates confidence bands based on a parametric Bootstrap.
2.7. Influence Diagnostics
A study of great importance in the analysis of diagnosis is the influential observation detection; in other words, points exercising a disproportionate weight in the estimations of the model parameters or even in the significance of the parameters. Point detection may be the most well-known technique for evaluating the impact of the particular observation removal regression’s estimates. This paper considers two types of influence diagnostics: global and local influence.
2.8. Global Influence
Deleting cases is a common way to assess the effect of an observation on the estimation process. This is a global influence analysis, since the effect of the observation is evaluated by eliminating it from the data set.
2.8.1. Global Influence Based on the Likelihood
The global influence analysis is based on the elimination of one or more observations considered influential in the data set, and thus assesses the impact on the parameter estimates. This type of diagnostic technique is discussed by [27,28,29,30]. One of the most used measures of the changes in estimated parameters after excluding the observations is called Cook’s distance (see [31]). This measure was initially proposed for normal models and was quickly expanded to several model classes. Following the proposal of [30], the Cook’s distance, based on the ML estimator , of , is given by Equation (12):
which can be decomposed into , for , where and , where and are the score functions of estimators and respectively, without the i-th observation.
2.8.2. Global Influence Based on the Q-Function
According to [30], it is difficult to extend the case exclusion method to other models if the likelihood function has no analytical form. So, Refs. [11,30] present Cook’s distance when using the conditional expectation of the logarithm of the joint-likelihood, called the Q-function. Following this reasoning, consider that the Q-function is given in Equation (13) by:
where , with , , the digamma function, for , Ref. [32] proposed a global influence measure as an alternative to obtaining , with the following approximation: , for , where and .
According to [11,30], the new modification of the Cook’s distance based on the Q-function is given by Equation (14):
where represents a block diagonal matrix in relation to and . The modified Cook statistics in (14) can be written as:
, for ,
where
and
.
Thus,
,
,
,
,
with , , and .
2.9. Local Influence Diagnostics
The local influence method proposed by [33] involves evaluating the robustness of the estimated obtained considering an influence measure and under small perturbations applied to the model and/or the data, i.e., to verify the presence of observations that can cause distortion of the results, under small perturbations. This method does not require the elimination of observations.
Consider the spatial linear model given in Equation (3). Under the assumption that the error random vector follows a t-Student distribution, with a mean equal to a vector of zeros and covariance matrix , i.e., , it is possible to obtain the regression model .
Thus, when the observation causes relevant changes in the results, it is called influential.
The appropriate perturbation scheme for the response variable according to [21], is given in Equation (15) by:
where is a vector belonging to the perturbation space .
2.9.1. Likelihood Displacement Diagnostics
Let be the perturbed log-likelihood. The influence of the perturbation, caused by the vector , on estimates of the ML parameters can be evaluated by likelihood displacement, defined as
where is the ML estimator of of the postulated model and is the ML estimator of of the model perturbed by . Ref. [33] proposed studying the local behavior of around , such that . Thus, the normal curvature of in in the direction of a unit vector is defined in Equation (16):
where ; : is the hessian matrix evaluated in ; : is a , matrix given by , evaluated in and in , where and .
Ref. [21] considered the generalized appropriate perturbation of [34] , on the response variable using the matrix , , which does not depend on neither on , such that the Fisher information matrix for with respect to the perturbed vector is , where c is a positive constant. In general, , however, if , then where the appropriate perturbation, considering the reparameterized t-Student, , is as given in Equation (15). In this study, the matrix evaluated in and in , is given by
and with elements , with , , , , and .
Consider the matrix and , for , where is the element of the main diagonal of the matrix . The plot of versus i (order of the data) can be used to detect potential influential observations. Ref. [35] proposed considering the ith observation with as a potential influential observation, where .
Another proposal presented by [33] defines as the first eigenvector, normalized and associated with the greatest eigenvalue of the matrix . Thus, with the elements of versus i (order of the data), we obtain a graph that can reveal which type of perturbation has the greatest influence on in [33]. High-order influential cases are those with strong influence compared to the average of the values of all cases [36]. , where denotes the standard deviation of can be used as a reference to determine the significance of contributions from an individual case [13].
2.9.2. Q-Function Based Diagnostics
The main goal is to compare , the ML estimate of of the postulate model, and the ML estimate of of the perturbed model, when . Close values indicate that the perturbation has a small effect on the estimation procedure. On the other hand, if they differ considerably, then it is possible that the estimation procedure is sensitive to the presence of some observations. To measure this distance, Refs. [32,34] proposed the Q-function displacement, calculating the difference between and , defined by:
where and are defined in Equation (13), with , and . Similarly to [32,33] study the behavior of the surface and calculate the normal curvature to the unitary direction , is defined in Equation (17)
where ; , evaluated at ; is a matrix, given by , evaluated at , thus:
where
and the matrix has elements
,
with elements
,
where , with and . The potential influential observation is the ith observation with , where .
Similar to , we have the local influence measure , constructed by shifting the conditional expectation of the joint likelihood logarithm, the Q-function. The cases of high-order influence are the cases with strong influence compared to the average of the values of all cases. , where denotes the standard deviation of , which can be used as a reference to determine the significance of contributions from an individual case [13].
2.10. Generalized Leverage
The concept of generalized leverage is to measure the influence of the observed value on the response variable on its own fitted value [37,38,39].
Let be the expected value of . Then, based on the generalized leverage for [39], the generalized leverage matrix, , where and ML estimator of . The generalized leverage is defined in Equation (18):
where , and with
,
with elements
,
for with , and .
After some algebra, we have , where
and
, such that
,
, with elements
, for
, with elements
, for
The diagonal elements for , of the matrix are used as a diagnostic tool of influence in the vector . The ith response is potentially influential if , where and is the standard deviation of [21].
Based on the proposal of [39], and [32], the generalized leverage matrix for models with complete data takes the form governed by Equation (19):
such that
, with
and
, with elements,
,
for , with , and . The ith response is potentially influential if , where and is the standard deviation of .
3. Results
Application to Real Data Set
The data set was collected from a commercial agricultural area of ha of grain production, located near the city of Cascavel, in the Western region of Paraná, Brazil. The latitude and longitude coordinates of the area are approximately 24.95° S and 53.57° W, with an average altitude of 650 m. According to the classification of Köppen, the climate of the region is type Cfa, and the soil was classified as Oxisol.
The response variable is the soybean productivity (Prod) [t ha−1], with the chemical contents of the soil considered explanatory variables—phosphorus (P) [mg dm−3], potassium (K) [cmolc dm−3], hydrogen potential (pH) and organic matter (OM) [g dm−3]. The linear spatial model for the soybean productivity at the site is given by , .
A brief descriptive analysis is presented in Table 1. It can be seen that the minimum production was t ha−1, the maximum was t ha−1 and the average soybean production was t ha−1. This information is the first preliminary analysis that serves to identify and understand the data set.

Table 1.
Descriptive statistics to the variables productivity (Prod), Phosphorus (P), Potassium (K), hydrogen potential (pH), and organic matter (OM).
The boxplot of soybean productivity presented in Figure 1a shows an outlier, corresponding to observation , which is the maximum value of the data with productivity equal to t ha−1 (Table 1). According to the post-plot given in Figure 1b, the observation is surrounded by observations with a soybean productivity lower than t ha−1.
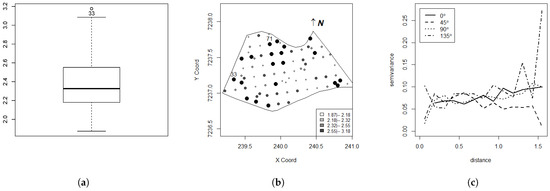
Figure 1.
Boxplot (a), post-plot (b) and directional semivariogram (c) for the soybean productivity data set (t ha−1).
Three outliers were observed in the boxplots of the explanatory variables. For the variable P, these were the observations , and with respective values of , and mg dm−3. For the variable pH, the graph highlighted the observations , , , and with respective values of , , , and , and for the variable OM, only one outlier was detected—observation with g dm−3. The analysis of the directional semivariogram, given in Figure 1c for directions 0°, 45°, 90°, and 135°, indicates that it is reasonable to assume isotropy, since the spatial dependence structure is similar in the constructed directions.
Table 2 presents the parameter estimates for the reparameterized t-Student linear model considering different values for the parameter and different values of for the Matérn family of geostatistical models and asymptotic standard errors (in parentheses). The parameter was fixed at , as obtained from a previous analysis using the ordinary least squares method.
Table 2.
Parameters estimates and asymptotic standard errors in parenthesis.
The chosen model is , with an estimated covariance matrix given by , where the elements of the correlation matrix determined from the Matérn family of models with and were selected according to the cross-validation criterion () and the trace () of the criteria of the asymptotic covariance matrix.
In the diagnostic analysis of the response variable, shown in Figure 2 and Figure 3, observations , , , , , , and are highlighted as influential points by Cook’s distance, and observations , , , , and are highlighted as influential points by the distance of the Q-function.
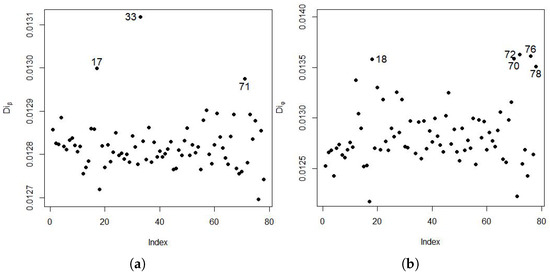
Figure 2.
Global influence diagnostic plots (a) and (b).
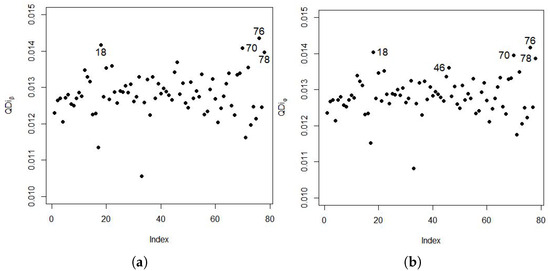
Figure 3.
Global influence diagnostics plots (a) and (b).
Figure 4 and Figure 5 show the local influence graphs; observations and were considered influential points for plot vs. index, vs. index, and vs. index. However, observations , , , and are considered influential by the plot . Observation is the same as the one detected in Figure 1a in the boxplot.
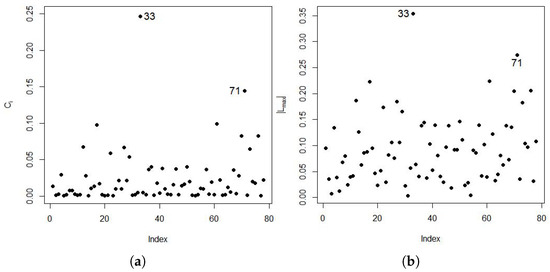
Figure 4.
Local influence diagnostic plots (a) and (b).
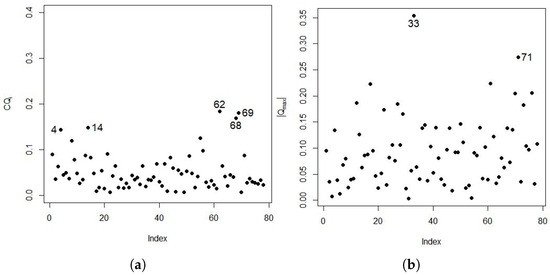
Figure 5.
Local influence diagnostic plots (a) and (b).
Figure 6 presents the graphs for the generalized leverage, which detected observations that had also been detected in the boxplots of the explanatory variables. The observations are and for P, and for pH and for OM.
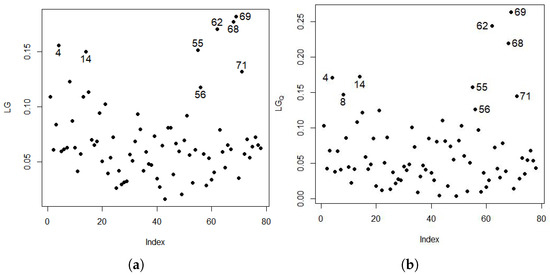
Figure 6.
Generalized leverage plots considering the (a) log-likelihood function (LG) and (b) the Q-function .
Figure 7 presents the QQ-plots of the residuals. It can be observed that when observation is removed, a better fit is detected at the top of the QQ-plot (Figure 7b), with most of the points closest to the line and all points belonging to the confidence interval in both graphs, showing that the data follow the assumed distribution.
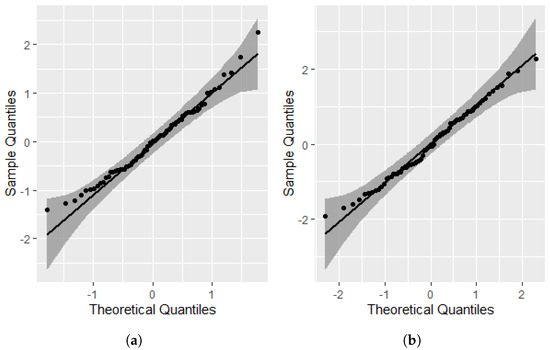
Figure 7.
QQ-plots of the residuals (a) with all points and (b) without point #33.
Figure 8 presents the maps of predicted values considering all observations and deleting observation #33, which is evident in the substantial change on the map where observation #33 is located, see also Figure 1b. Thus, this observation is an outlier and an influential observation in obtaining the predicted values.
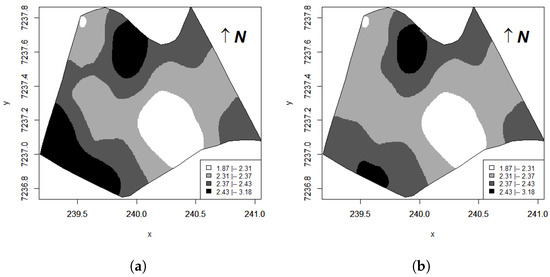
Figure 8.
Maps for the data set (a) with all observations and (b) deleting observation #33.
To measure the similarity between the reference map (all points) and the model map (without point #33), global accuracy, the Kappa, and Tau were determined with AG = 0.73, T = 0.64 and Kp = 0.59, suggesting a difference between thematic maps [40,41].
4. Discussion
To explain the average soybean productivity, a multiple spatial linear regression model was constructed, considering as explanatory variables the chemical contents of the soil, P, K, pH, and OM, with spatially correlated errors. The parameters estimated by maximum likelihood are presented in Table 2, where the best model chosen for the spatial dependence structure, considering CV criteria and the trait (Tr), was the Matérn model with the shape parameters (exponential model) and the shape parameter of the reparameterized t-Student distribution with .
Point , considered an outlier (Figure 1), was globally and locally influential (Figure 2, Figure 4 and Figure 5) when removed showing that the QQ-plot of the residues (Figure 7) has a better behavior, indicating that this observation is also an influential point in the probability distribution of the residues, as [5] values that deviate considerably from the straight line indicate influential cases.
When comparing the map generated with all sample points and the map without points (Figure 8), it can be seen that the global accuracy indicator (AG) is less than 0.73, indicating that the maps are dissimilar [40]. According to the classification of similarity indices, Tau () and Kappa () indicate that the maps have low similarity [40,41]. Thus, it is possible to verify that there is a difference in the classification of the constructed thematic maps with and without a point and with a point detected as influential in the elaboration of the map. The formulas for the indices , T, and are presented by [42].
The graphs of the generalized leverage indices LG and LG_Q (Figure 6 detected leverage points, indicating the existence of influential points in the explanatory variables and in the spatial linear regression model, affecting the estimates of the model parameters. Figure 6 detected observations , , and for phosphorus (P); observations , , , and for hydrogen potential (pH); and observation for organic matter (OM), with potassium (K) not being a leverage point.
With information from the productivity map and explanatory variables, differentiated management units (DMUs) can be created, detecting subareas in the agricultural property under study that have similar characteristics in terms of production potential, helping the farmer apply differentiated management strategies for each subarea.
5. Conclusions
The reparameterized t-Student distribution was presented in the geostatistical framework. The reparametrization enables a straightforward comparison between the covariance matrix of multivariate distributions, especially for comparison with the multivariate normal distributions. The study also used global and local influence diagnostics to choose a more appropriate model to fit the data.
The reparametrized t-Student linear spatial modeling allows for more robust modeling in the presence of influential observations. It is extremely important to detect the influential points and correlate their spatial location, in order to draaw valuable conclusions about whether to remove these points or not, defined by the analysis of diagnostics. Investigation of theses points is indispensable for making a decision, ensuring that the information contained in the created maps is more consistent with reality and may be used in precision agriculture for the creation of differentiated management units.
Author Contributions
Conceptualization, M.A.U.-O., R.C.S., F.D.B. and M.G.; methodology, M.A.U.-O., F.D.B. and M.G.; software, R.C.S., F.D.B., R.A.B.A. and T.C.M.; validation, M.A.U.-O., R.C.S., F.D.B., M.G., R.A.B.A. and T.C.M.; formal analysis, M.A.U.-O., R.C.S., F.D.B., M.G. and T.C.M.; investigation, M.A.U.-O., R.C.S., F.D.B., M.G., R.A.B.A. and T.C.M.; resources, M.A.U.-O., R.C.S., F.D.B., M.G. and T.C.M.; data curation, M.A.U.-O., R.C.S., F.D.B., M.G. and T.C.M.; writing—original draft preparation, M.A.U.-O., R.C.S., F.D.B., M.G. and T.C.M.; writing—review and editing, M.A.U.-O., R.C.S., F.D.B., M.G. and T.C.M.; visualization, M.A.U.-O., R.C.S., F.D.B., M.G. and T.C.M.; supervision, M.A.U.-O., R.C.S., F.D.B., M.G., R.A.B.A. and T.C.M.; project administration, M.A.U.-O., R.C.S., F.D.B., M.G. and T.C.M.; funding acquisition, M.A.U.-O., F.D.B., M.G. and T.C.M. All authors have read and agreed to the published version of the manuscript.
Funding
The authors would like to thank the Coordination for the Improvement of Higher Education Personnel (CAPES), Financing Code 001, the Arauc´aria Foundation of the State of Paraná, and the National Council for Scientific and Technological Development (CNPq) for their financial support. The process numbers: 306561/2020-4, 310050/2019-7, 404872/2023-9, and 302413/2022-7, and Fundação de Amparo a Ciência e Tecnologia de Pernambuco (FACEPE).
Data Availability Statement
The data sets presented in this article are not readily available because the data belong to a group of researchers at the University and are currently part of ongoing studies by researchers in the field of spatiotemporal statistics.
Acknowledgments
The authors thank the Laboratory of Spatial-Temporal Statistics (LEE), UNIOESTE, Cascavel, PR, Brazil.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| AG | Global accuracy |
| CV | cross-validation criterion |
| DMUs | Differentiated management units |
| K | Potassium |
| Model parameter Matérn | |
| Kp | Kappa |
| ML | Maximum likelihood |
| n | Number of observations |
| OM | Organic matter |
| P | Phosphorus |
| pH | Hydrogen potential |
| Prod | Productivity |
| T | Tau |
| Tr | Trace |
References
- Galea, M.; Bolfarine, H.; Vilcalabra, F. Influence diagnostics for the structural errors-in-variables model under the Student-t distribution. J. Appl. Stat. 2002, 29, 1191–1204. [Google Scholar] [CrossRef]
- Galea, M.; de Castro, M. Robust inference in a linear functional model with replications using the t distribution. J. Multivar. Anal. 2017, 160, 134–145. [Google Scholar] [CrossRef]
- Martínez, S.; Giraldo, R.; Leiva, V. Birnbaum–Saunders functional regression models for spatial data. Stoch. Environ. Res. Risk Assess. 2019, 33, 1765–1780. [Google Scholar] [CrossRef]
- Ordoñez, J.A.; Prates, M.O.; Matos, L.A.; Lachos, V.H. Objective Bayesian analysis for spatial Student-t regression models. J. Spat. Sci. 2020. [Google Scholar] [CrossRef]
- Lange, K.L.; Little, R.J.A.; Taylor, J.M.G. Robust statistical modeling using the t distribution. JASA 1989, 84, 881–896. [Google Scholar] [CrossRef]
- Uribe-Opazo, M.A.; De Bastiani, F.; Galea, M.; Schemmer, R.C.; Assumpção, R.A.B. Appropriate perturbation scheme for the covariance matrix of a t-Student spatial linear model. Spat. Stat. 2021, 41, 100481. [Google Scholar] [CrossRef]
- Richetti, J.; Uribe-Opazo, M.A.; De Bastiani, F.; Johann, J.S. Techniques for detection of influencing points in regionalized continuous variables. Eng. Agríc. 2016, 36, 152–165. [Google Scholar] [CrossRef]
- Osorio, F.; Paula, G.A.; Galea, M. Assessment of local influence in elliptical linear models with longitudinal structure. Comput. Stat. Data Anal. 2007, 51, 4354–4368. [Google Scholar] [CrossRef]
- Uribe-Opazo, M.A.; Borssoi, J.A.; Galea, M. Influence diagnostics in Gaussian spatial linear models. J. Appl. Stat. 2012, 39, 615–630. [Google Scholar] [CrossRef]
- De Bastiani, F.; Galea, M.; Cysneiros, A.H.M.A.; Uribe-Opazo, M.A. Gaussian spatial linear models with repetitions: An application to soybean productivity. Spat. Stat. 2017, 21, 319–335. [Google Scholar] [CrossRef]
- De Bastiani, F.; Uribe-Opazo, M.A.; Galea, M.; Cysneiros, A.H.M.A. Case-deletion diagnostics for spatial linear mixed models. Spat. Stat. 2018, 28, 284–303. [Google Scholar] [CrossRef]
- Lachos, V.H.; Matos, L.A.; Barbosa, T.S.; Garay, A.M.; Dey, D.K. Influence diagnostics in spatial models with censored response. Environmetrics 2017, 28, e2464. [Google Scholar] [CrossRef]
- Zhu, H.; Lee, S.; Wei, B.; Zhou, J. Case-Deletion Measures for Models with Incomplete Data. Biometrika 2001, 88, 727–737. [Google Scholar] [CrossRef]
- Osorio, F. MVT: Estimation and Testing for the Multivariate t-Distribution. R Package Version 0.3-8. 2023. Available online: https://CRAN.R-project.org/package=MVT (accessed on 1 August 2024).
- Mardia, K.V.; Marshall, R.J. Maximum likelihood estimation of models for residual covariance in spatial regression. Biometrika 1984, 71, 135–146. [Google Scholar] [CrossRef]
- Stein, M.L. Interpolation of Spatial Data: Some Theory for Kriging; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2012; pp. 1–249. [Google Scholar]
- Acosta, J.; Osorio, F.; Vallejos, R. Effective sample size for line transect sampling models with an application to marine macroalgae. J. Agric. Biol. Environ. Stat. 2016, 21, 407–425. [Google Scholar] [CrossRef]
- Waller, L.A.; Gotway, C.A. Applied Spatial Statistics for Public Health Data; John Wiley & Sons: Hoboken, NJ, USA, 2004; p. 368. [Google Scholar]
- Magnus, J.R.; Neudecker, H. Matrix Differential Calculus with Applications in Statistics and Econometrics; John Wiley & Sons: Hoboken, NJ, USA, 2019; p. 479. [Google Scholar]
- Zellner, A. Bayesian and non-Bayesian analysis of the regression model with multivariate Student-t error terms. JASA 1976, 71, 400–405. [Google Scholar] [CrossRef]
- De Bastiani, F.; Cysneiros, A.H.L.A.; Uribe-Opazo, M.A.; Galea, M. Influence diagnostics in elliptical spatial linear models. Test 2015, 4, 322–340. [Google Scholar] [CrossRef]
- Kano, Y.; Berkane, M.A.; Bentler, M. Statistical inference based on pseudo-maximum likelihood estimators in elliptical populations. JASA 1993, 88, 135–143. [Google Scholar]
- Matérn, B. Spatial Variation; Lecture Notes in Statistics; Springer: Berlin/Heidelberg, Germany, 1986; Volume 36. [Google Scholar]
- Dalposso, G.H.; Uribe-Opazo, M.A.; Johann, J.A.; Galea, M.; De Bastiani, F. Gaussian spatial linear model of soybean yield using bootstrap methods. Eng. Agríc. 2018, 38, 110–116. [Google Scholar] [CrossRef]
- Almeida, A.; Loy, A.; Hofnann, H. ggplo2 compatible quanttile-quantile plots in R. R J. 2018, 10, 248–261. [Google Scholar]
- Wickham, H. ggplot2. Wiley Interdiciplinary Rev. Stat. 2011, 3, 180–185. [Google Scholar] [CrossRef]
- Cook, R.D.; Weisberg, S. Residuals and Influence in Regression; Chapman and Hall: New York, NY, USA, 1982. [Google Scholar]
- Chatterjee, S.; Hadi, A.S. Sensitivity Analysis in Linear Regression; John Wiley & Sons: Hoboken, NJ, USA, 1986; p. 327. [Google Scholar]
- Christensen, R.; Johnson, W.; Pearson, L.M. Brediction diagnostics for spatial linear models. Biometrika 1992, 79, 583–591. [Google Scholar] [CrossRef]
- Pan, J.; Fei, Y.; Foster, P. Case-deletion diagnostics for linear mixed models. Technometrics 2014, 56, 269–281. [Google Scholar] [CrossRef][Green Version]
- Cook, R.D. Detection of influential observation in linear regression. Technometrics 1977, 19, 15–18. [Google Scholar] [CrossRef]
- Zhu, H.; Lee, S. Local influence for incomplete data models. J. R. Stat. Soc. B Stat. Methodol. 2001, 63, 11–126. [Google Scholar] [CrossRef]
- Cook, R.D. Assessment of local influence. J. R. Stat. Soc. B Methodol. 1986, 48, 133–155. [Google Scholar] [CrossRef]
- Zhu, H.; Ibrahim, J.G.; Lee, S.; Zhang, H. Perturbation selection and influence measures in local influence analysis. Ann. Stat. 2007, 35, 2565–2588. [Google Scholar] [CrossRef]
- Verbeke, G.; Molenberghs, G. Linear Mixed Models for Longitudinal Data; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Poon, W.Y.; Poon, Y.S. Conformal normal curvature and assessment of local influence. Stat. Methol. 1999, 61, 51–61. [Google Scholar] [CrossRef]
- Hoaglin, D.C.; Welsch, R.E. The hat matrix in regression and ANOVA. Ann. Stat. 1978, 32, 17–22. [Google Scholar] [CrossRef]
- St Laurent, R.T.; Cook, R.D. Leverage and superleverage in nonlinear regression. JASA 1992, 87, 985–990. [Google Scholar] [CrossRef]
- Wei, X.; Samarabandu, J.; Devdhar, R.S.; Siegel, A.J.; Acharya, R.; Berezney, R. Segregation of transcription and replication sites into higher order domains. Science 1998, 281, 1502–1505. [Google Scholar] [CrossRef] [PubMed]
- Anderson, J.R. A Land Use and Land Cover Classification System for Use with Remote Sensor Data; US Government Printing Office: Washinton, DC, USA, 1976; p. 964.
- Krippendorff, K. Content Analysis: An Introduction to Its Methodology; Sage Publications: Thousand Oaks, CA, USA, 1980. [Google Scholar]
- De Bastiani, F.; Uribe-Opazo, M.A.; Dalposso, G.H. Comparison of maps of spatial variability of soil resistance to penetration constructed with and without covariables using a spatial linear model. Eng. Agríc. 2012, 32, 393–404. [Google Scholar] [CrossRef]








Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).