
Reinforcement Learning for Bipedal Jumping: Integrating Actuator Limits and Coupled Tendon Dynamics

 and
and {kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
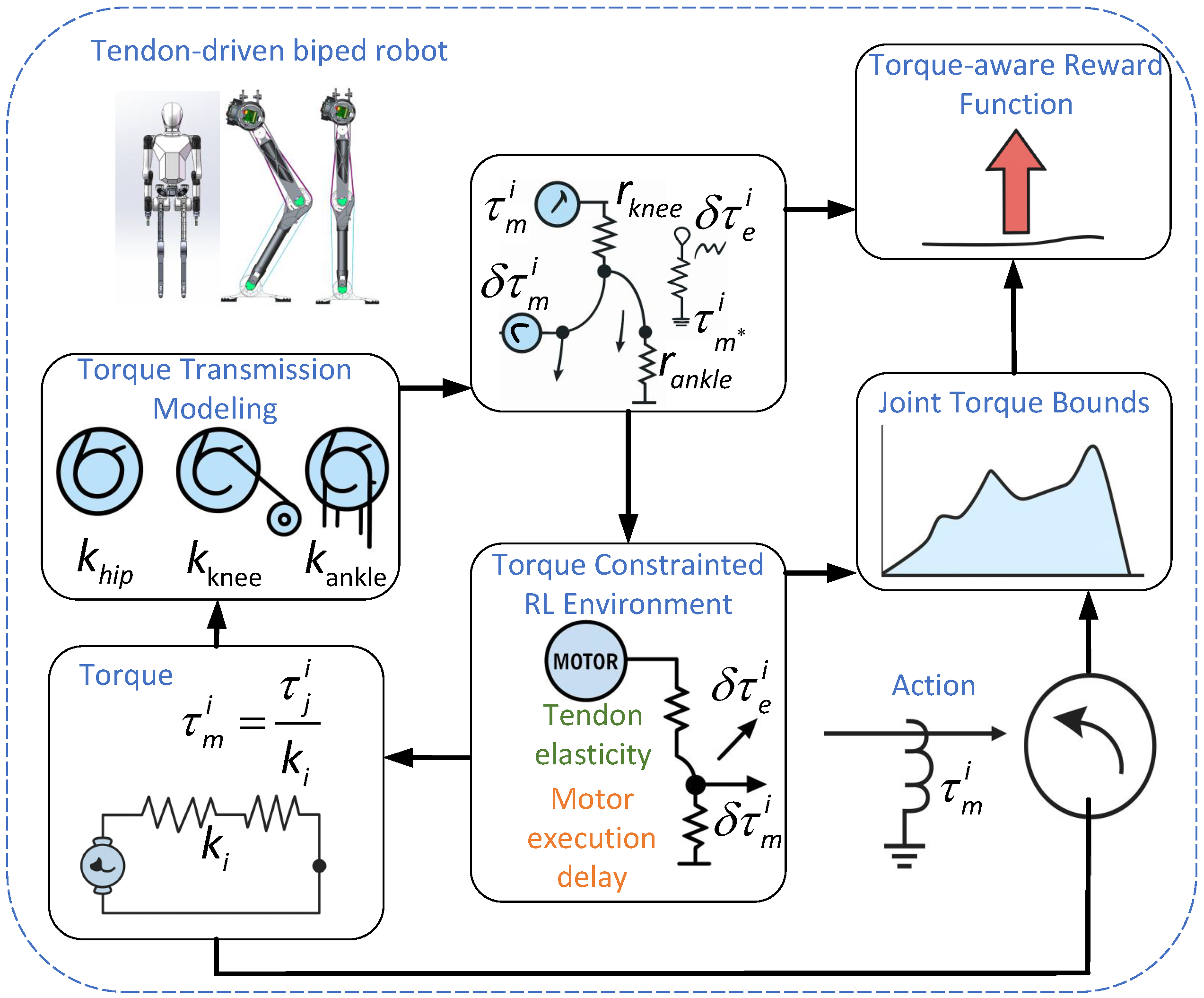
1. Introduction
- Torque Error-Compensation Modeling: By incorporating the effects of tendon elasticity and motor actuation delay, a dynamically adjustable joint torque safety boundary is derived as a function of joint velocity. This significantly enhances the simulation model’s fidelity and stability in approximating the real-world system;
- Torque Transmission Modeling: A linear mapping model from joint space to motor space is constructed to account for the characteristics of tendon-driven bipedal robots. By defining the pulley radii of the hip, knee, and ankle joints, the model systematically captures the torque coupling effects introduced by the tendon-driven mechanism, laying a solid foundation for high-precision control;
- Physically Consistent RL Framework: In the RL training process, this study integrates a dynamic torque boundary constraint into the reward function, guiding the policy to learn and comply with velocity-dependent torque limits. This approach allows the policy to implicitly adjust its outputs, ensuring efficient jumping while respecting the physical constraints of the actuators.
2. Materials and Methods
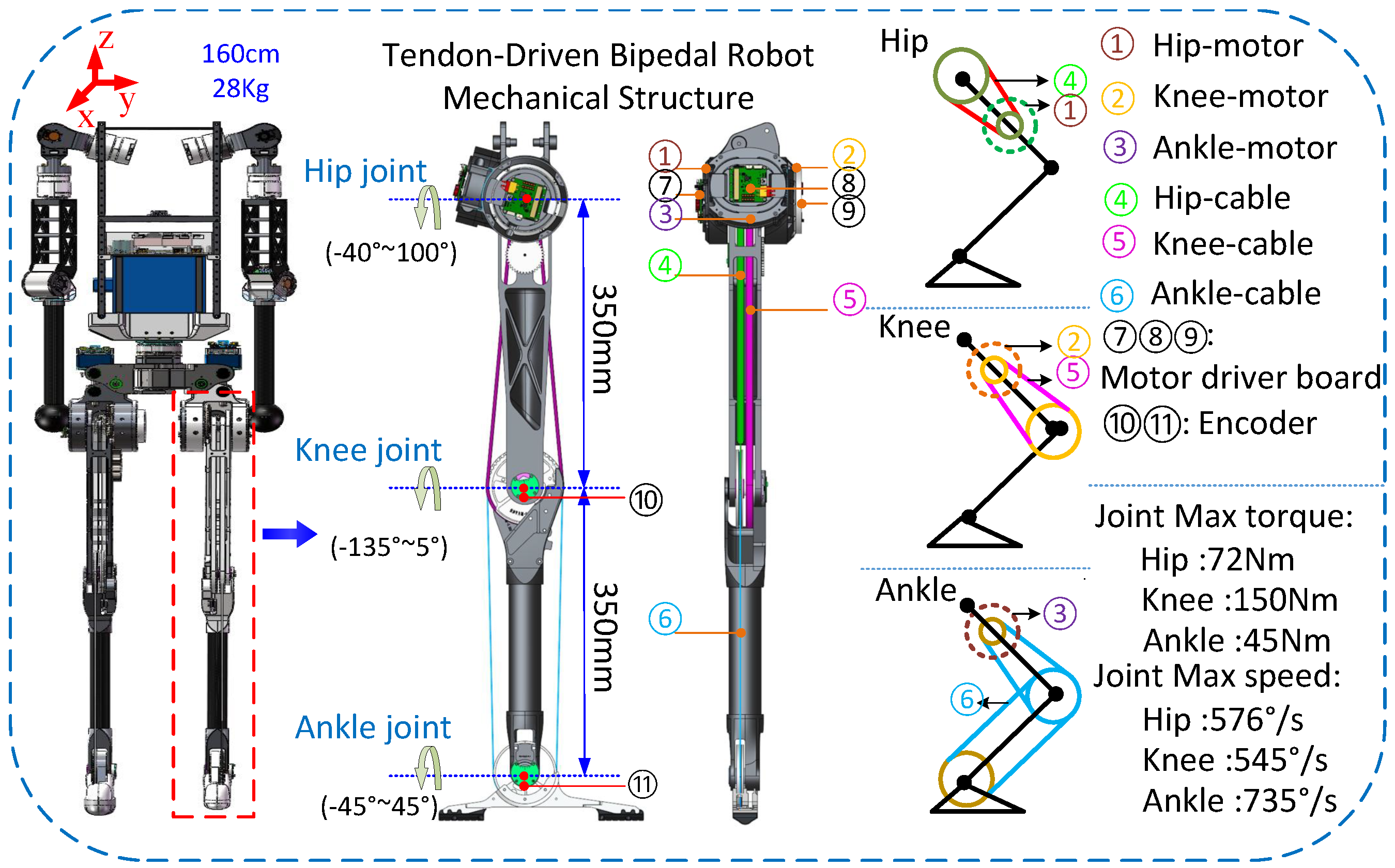
2.1. Mechanism Description for Robot
2.1.1. Overall Structural Design of the Robot
2.1.2. Two-Stage Rope Drive System for the Knee Joint
2.1.3. Knee and Ankle Combined Three-Stage Rope Drive System
2.2. Torque Constraint Modeling
- The hip joint is directly actuated by the motor, with a torque transmission ratio of ;
- The knee joint is driven via a two-stage tendon-driven mechanism, with a ratio of ;
- The ankle joint is driven through a three-stage tendon-driven mechanism, with a ratio of ;
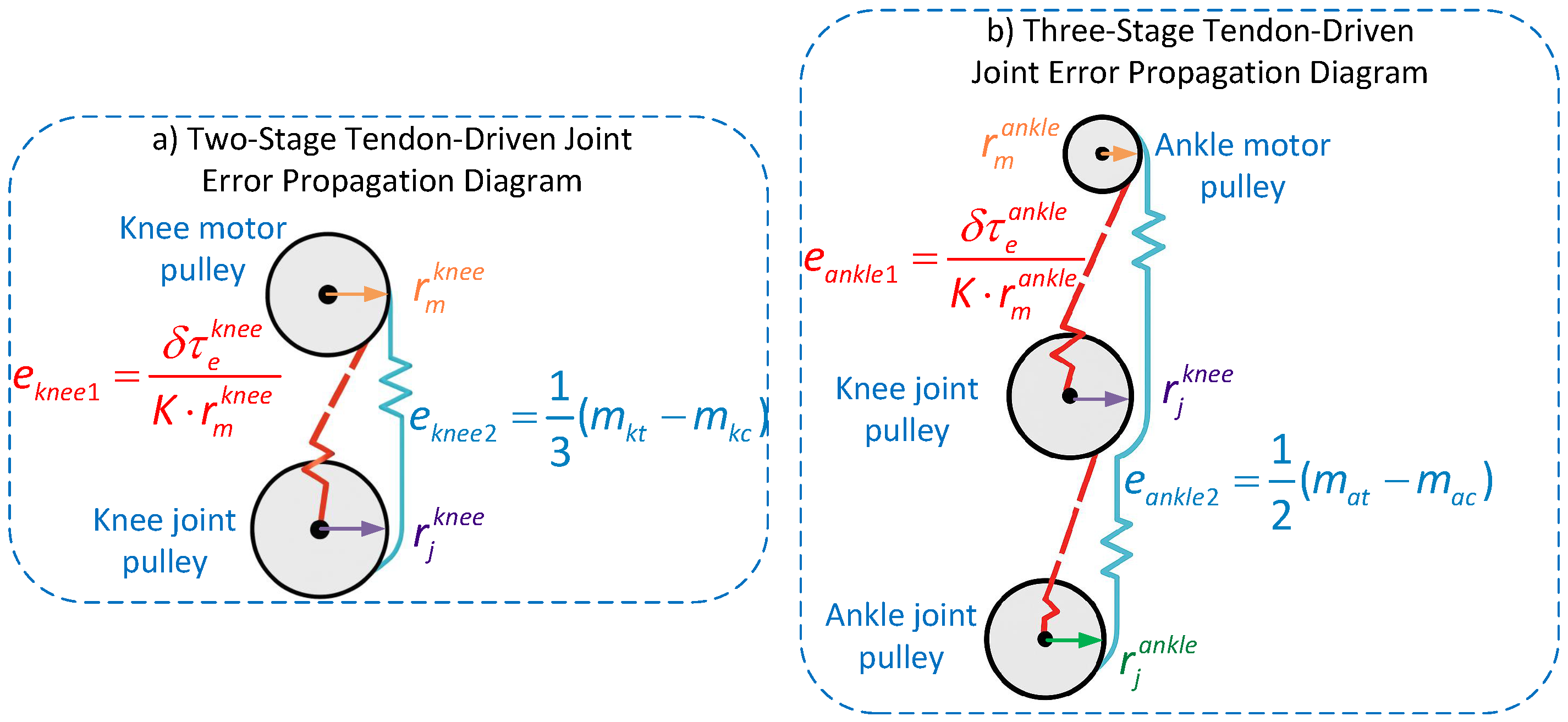
2.2.1. Leg Modeling Driven by Mixed Tendons
- (1)
- Knee-joint two-stage tendon-driven error modeling.
- (2)
- Ankle-joint three-stage tendon error modeling.
2.2.2. Modeling of Leg-Joint Error Compensation in Hybrid Tendon-Driven Mechanism
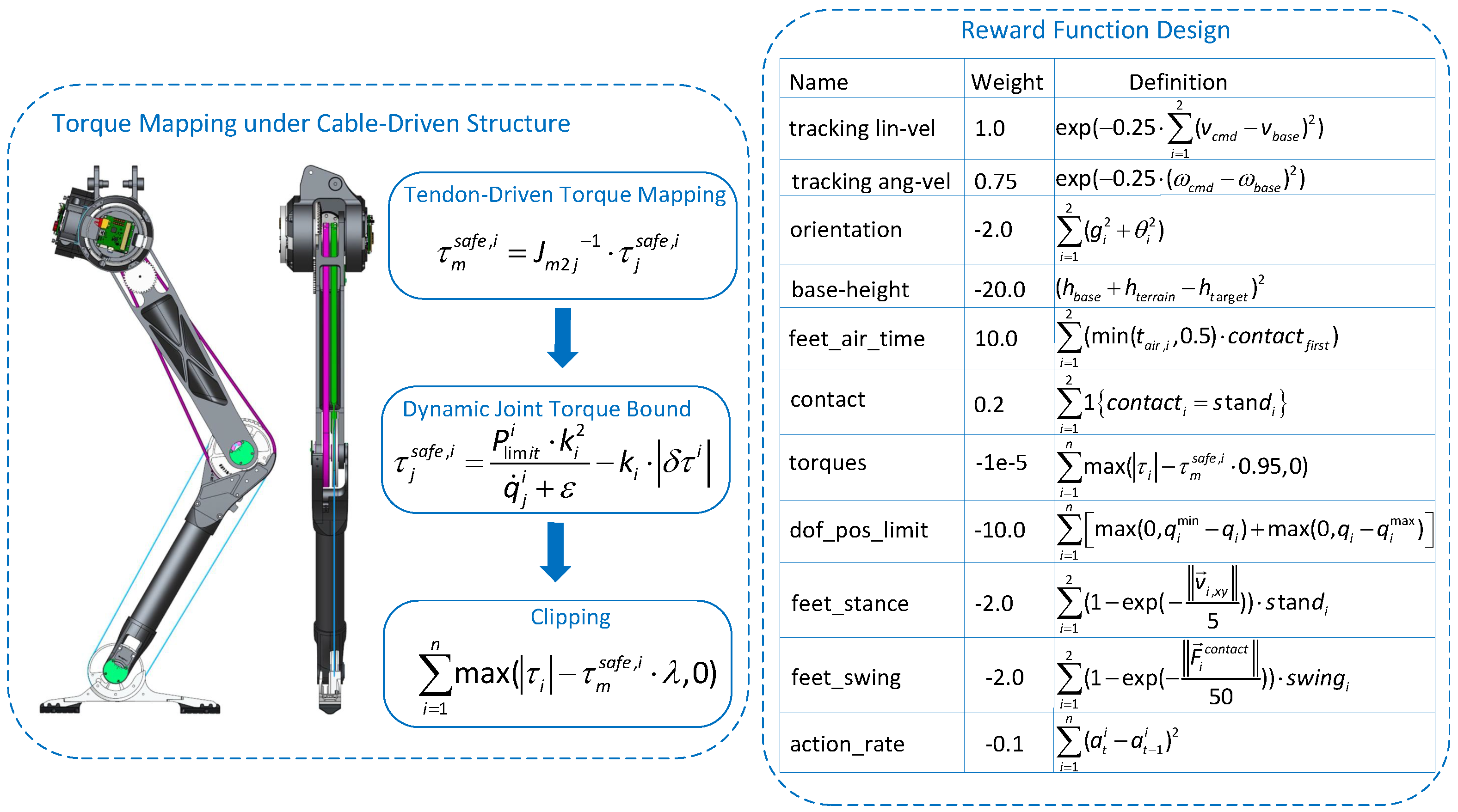
2.3. Torque Constraint Modeling
- is the motor output torque at joint i;
- is the angular velocity of the motor;
- is the maximum allowable power of the motor, as constrained by peak limits.
- : actual output torque at joint i;
- : joint velocity;
- : torque amplification factor for joint i, determined by pulley radii.
2.4. Reinforcement Learning Framework
2.4.1. Torque Mapping in Tendon-Driven Mechanism
2.4.2. Velocity-Dependent Torque Limit Modeling in Joint Space
2.4.3. Reward Function Design
3. Results
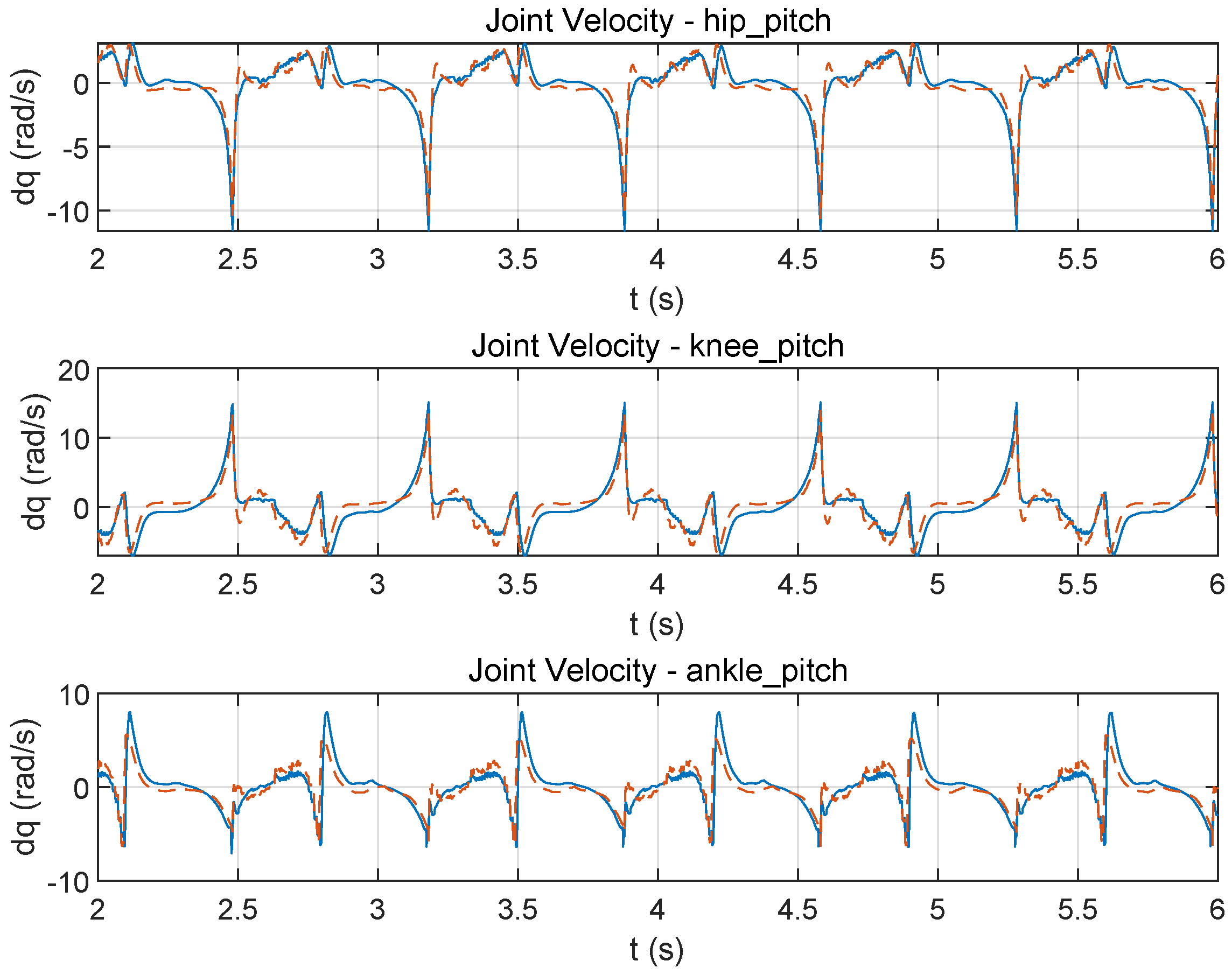
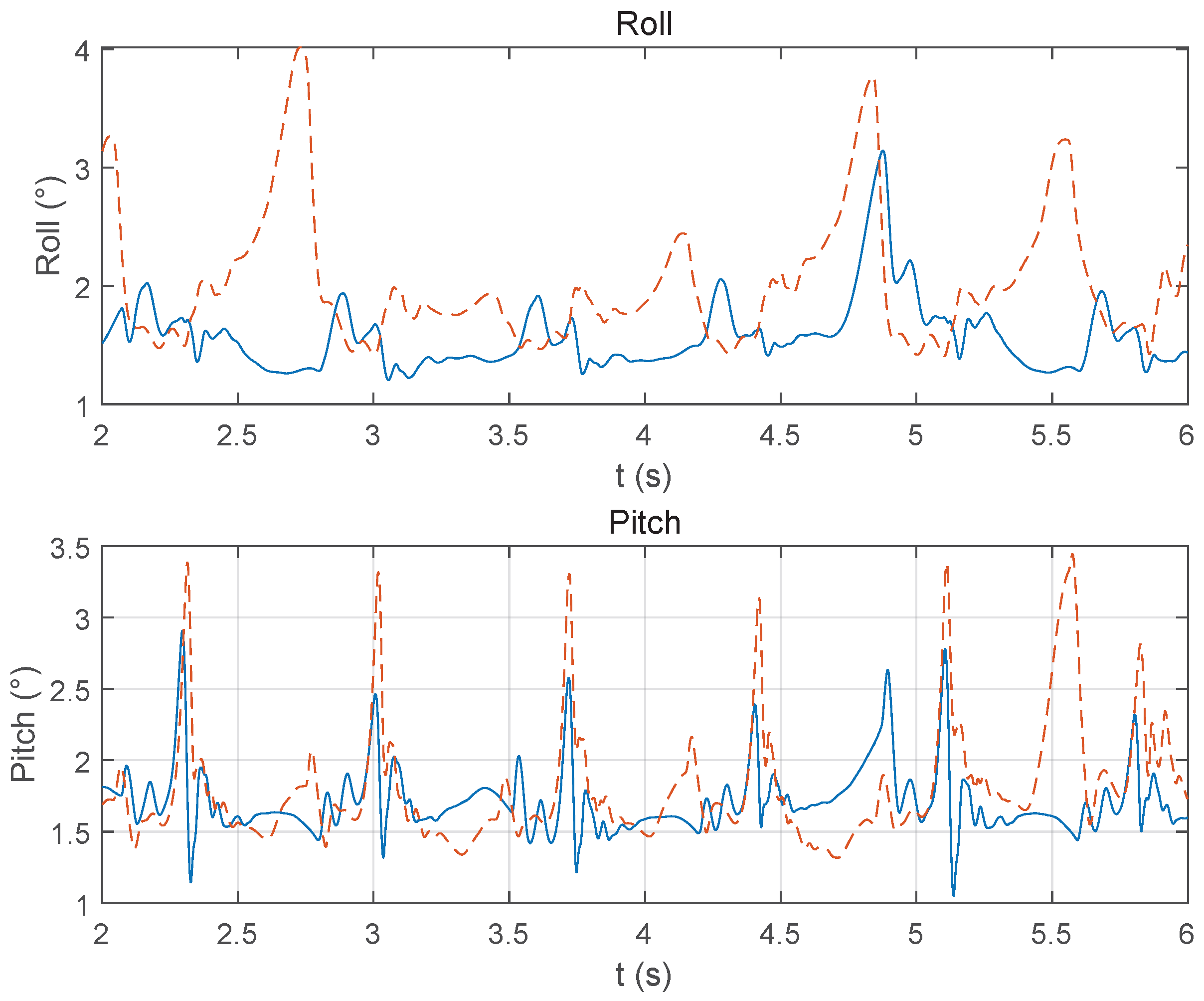
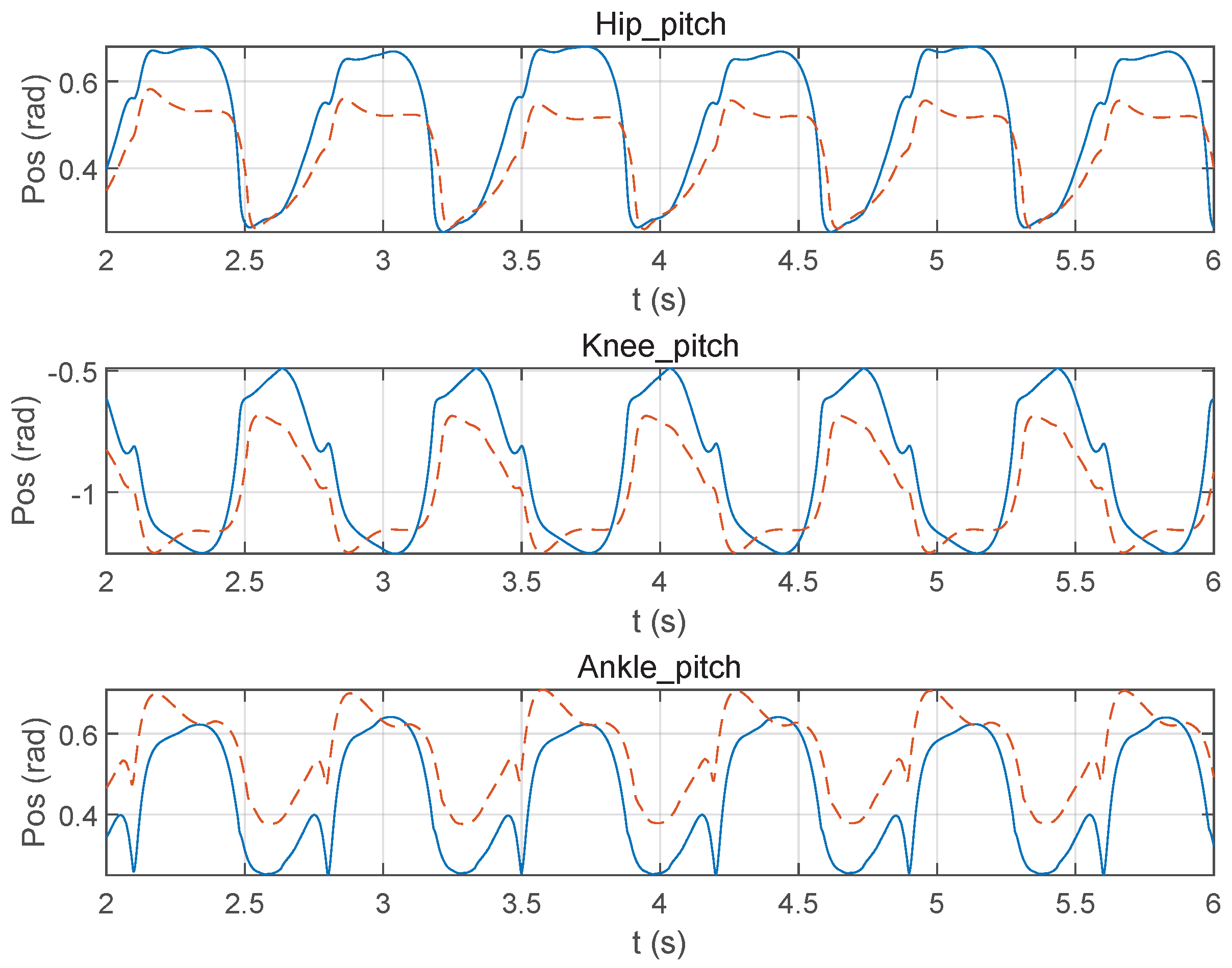
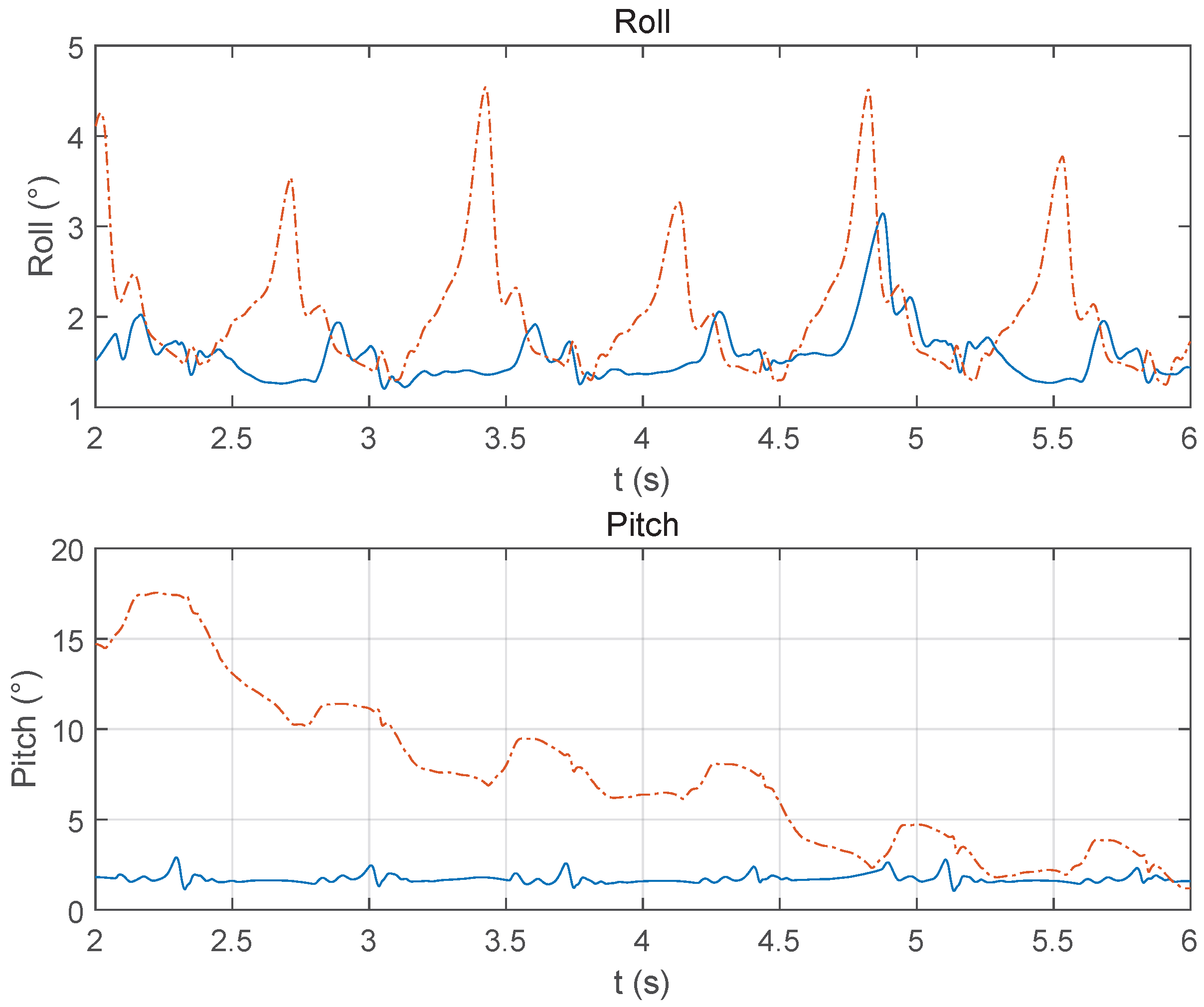
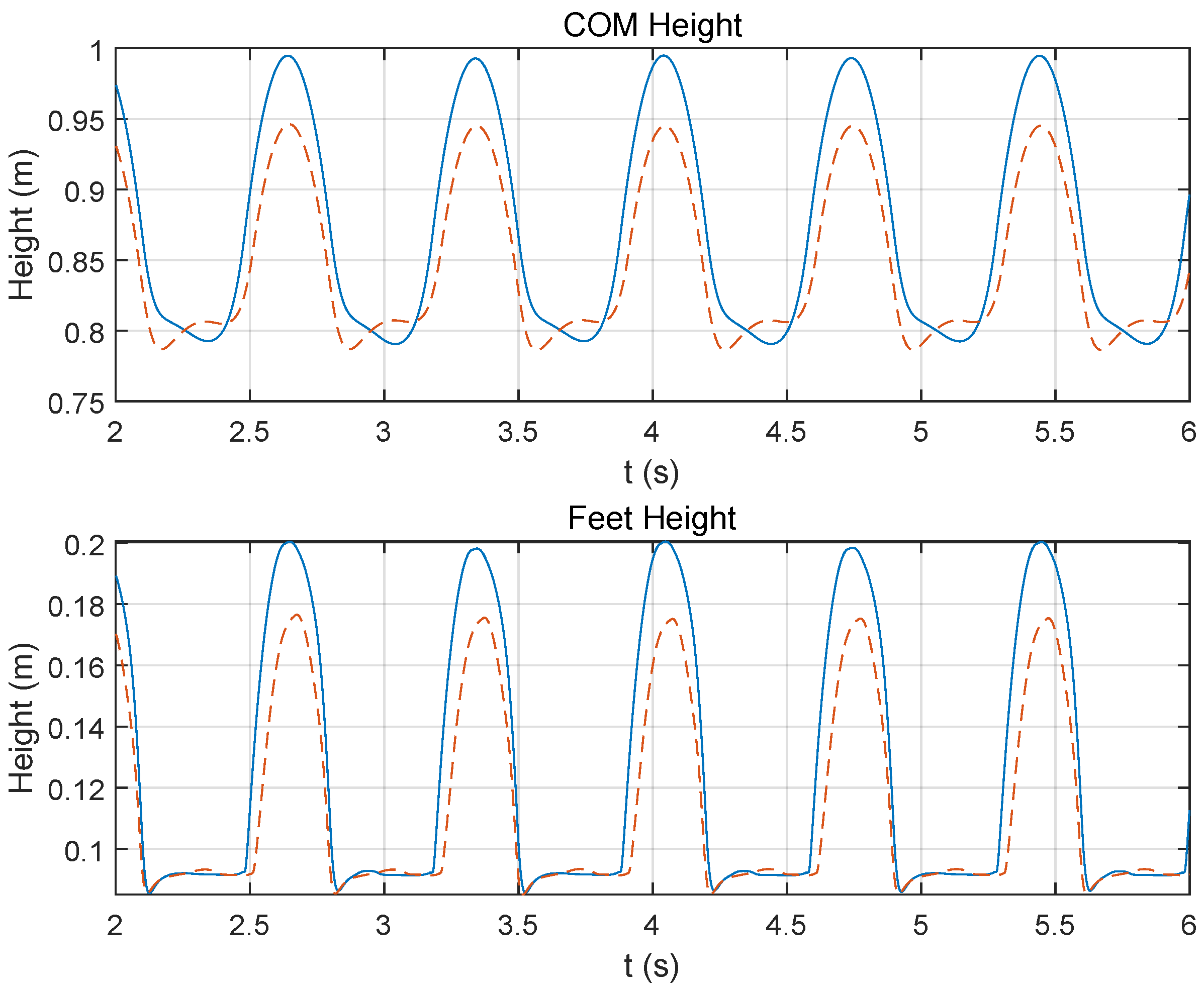
3.1. Torque Coupling Modeling Impact
3.2. Dynamic Torque Limit vs. Static Limit
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Peng, X.B.; Coumans, E.; Zhang, T.; Lee, T.W.; Tan, J.; Levine, S. Learning agile robotic locomotion skills by imitating animals. arXiv 2020, arXiv:2004.00784. [Google Scholar]
- Miki, T.; Lee, J.; Hwangbo, J.; Wellhausen, L.; Koltun, V.; Hutter, M. Learning robust perceptive locomotion for quadrupedal robots in the wild. Sci. Robot. 2022, 7, eabk2822. [Google Scholar] [CrossRef]
- Hwangbo, J.; Lee, J.; Dosovitskiy, A.; Bellicoso, D.; Tsounis, V.; Koltun, V.; Hutter, M. Learning agile and dynamic motor skills for legged robots. Sci. Robot. 2019, 4, eaau5872. [Google Scholar] [CrossRef]
- Li, Z.; Peng, X.B.; Abbeel, P.; Levine, S.; Berseth, G.; Sreenath, K. Robust and versatile bipedal jumping control through multi-task reinforcement learning. arXiv 2023, arXiv:2302.09450. [Google Scholar]
- Xiong, X.; Ames, A.D. Bipedal Hopping: Reduced-Order Model Embedding via Optimization-Based Control. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 3821–3828. [Google Scholar] [CrossRef]
- Lee, J.; Hwangbo, J.; Wellhausen, L.; Koltun, V.; Hutter, M. Learning quadrupedal locomotion over challenging terrain. Sci. Robot. 2020, 5, eabc5986. [Google Scholar] [CrossRef] [PubMed]
- Florence, P.; Lynch, C.; Zeng, A.; Ramirez, O.A.; Wahid, A.; Downs, L.; Wong, A.; Lee, J.; Mordatch, I.; Tompson, J. Implicit behavioral cloning. In Proceedings of the Conference on Robot Learning, Auckland, New Zealand, 14–18 December 2022; pp. 158–168. [Google Scholar]
- Rajeswaran, A.; Kumar, V.; Gupta, A.; Vezzani, G.; Schulman, J.; Todorov, E.; Levine, S. Learning Complex Dexterous Manipulation with Deep Reinforcement Learning and Demonstrations. In Proceedings of the 14th Conference on Robotics: Science and Systems XIV, Pittsburgh, PA, USA, 26–30 June 2018. [Google Scholar]
- Peng, X.B.; Andrychowicz, M.; Zaremba, W.; Abbeel, P. Sim-to-Real Transfer of Robotic Control with Dynamics Randomization. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 3803–3810. [Google Scholar] [CrossRef]
- Yu, T.; Quillen, D.; He, Z.; Julian, R.; Narayan, A.; Shively, H.; Bellathur, A.; Hausman, K.; Finn, C.; Levine, S. Meta-World: A Benchmark and Evaluation for Multi-Task and Meta Reinforcement Learning. arXiv 2021, arXiv:1910.10897. [Google Scholar]
- Xie, A.; Singh, A.; Levine, S.; Abbeel, P. Dynamics-Aware Embedding for Meta-Reinforcement Learning. In Proceedings of the 37th International Conference on Machine Learning, Virtual, 13–18 July 2020; Volume 119, pp. 10534–10544. [Google Scholar]
- Haarnoja, T.; Zhou, A.; Abbeel, P.; Levine, S. Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor. arXiv 2018, arXiv:1801.01290. [Google Scholar]
- Bellegarda, G.; Nguyen, C.; Nguyen, Q. Robust quadruped jumping via deep reinforcement learning. Robot. Auton. Syst. 2024, 182, 104799. [Google Scholar] [CrossRef]
- Zhang, C.; Zou, W.; Cheng, N.; Zhang, S. Towards Jumping Skill Learning by Target-guided Policy Optimization for Quadruped Robots. Mach. Intell. Res. 2024, 21, 1162–1177. [Google Scholar] [CrossRef]
- Atanassov, V.; Ding, J.; Kober, J.; Havoutis, I.; Santina, C. Curriculum-Based Reinforcement Learning for Quadrupedal Jumping: A Reference-free Design. arXiv 2024, arXiv:2401.16337. [Google Scholar] [CrossRef]
- Zhu, W.; Rosendo, A. PSTO: Learning energy-efficient locomotion for quadruped robots. Machines 2022, 10, 185. [Google Scholar] [CrossRef]
- Yan, Z.; Ji, H.; Chang, Q. Energy consumption minimization of quadruped robot based on reinforcement learning of DDPG algorithm. Actuators 2024, 13, 18. [Google Scholar] [CrossRef]
- Chen, Z.; Hou, Y.; Huang, R.; Cheng, Q. Neural network compensator-based robust iterative learning control scheme for mobile robots nonlinear systems with disturbances and uncertain parameters. Appl. Math. Comput. 2024, 469, 128549. [Google Scholar] [CrossRef]
- Luo, R.; Hu, Z.; Liu, M.; Du, L.; Bao, S.; Yuan, J. Adaptive Neural Computed Torque Control for Robot Joints With Asymmetric Friction Model. IEEE Robot. Autom. Lett. 2025, 10, 732–739. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, W.; Yang, J.; Pu, W. Bioinspired soft robotic fingers with sequential motion based on tendon-driven mechanisms. Soft Robot. 2022, 9, 531–541. [Google Scholar] [CrossRef]
- Choi, J.; Lee, D.Y.; Eo, J.H.; Park, Y.J.; Cho, K.J. Tendon-driven jamming mechanism for configurable variable stiffness. Soft Robot. 2021, 8, 109–118. [Google Scholar] [CrossRef]
- Tang, J.; Mou, H.; Hou, Y.; Zhu, Y.; Liu, J.; Zhang, J. A Low-Inertia and High-Stiffness Cable-Driven Biped Robot: Design, Modeling, and Control. Mathematics 2024, 12, 559. [Google Scholar] [CrossRef]
- Ko, D.; Kim, J.; Chung, W.K. Ensuring Joint Constraints of Torque-Controlled Robot Manipulators under Bounded Jerk. In Proceedings of the 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Abu Dhabi, United Arab Emirates, 14–18 October 2024; pp. 11954–11961. [Google Scholar]
- Liu, X.; Sun, Y.; Wen, S.; Cao, K.; Qi, Q.; Zhang, X.; Shen, H.; Chen, G.; Xu, J.; Ji, A. Development of wheel-legged biped robots: A review. J. Bionic Eng. 2024, 21, 607–634. [Google Scholar] [CrossRef]
- Dahl, R.A. The concept of power. Behav. Sci. 1957, 2, 201–215. [Google Scholar] [CrossRef]
- Thompson, J.O. Hooke’s law. Science 1926, 64, 298–299. [Google Scholar] [CrossRef]
- Kaelbling, L.P.; Littman, M.L.; Moore, A.W. Reinforcement learning: A survey. J. Artif. Intell. Res. 1996, 4, 237–285. [Google Scholar] [CrossRef]
- Szepesvári, C. Algorithms for Reinforcement Learning; Springer Nature: Cham, Switzerland, 2022. [Google Scholar]
- Kumar, A.; Fu, K.; Večerík, M.; Handa, A.; Bai, Y.C.; Zhang, J.T.; Kalakrishnan, M.; Levine, S. RMA: Rapid Motor Adaptation for Legged Robots. In Proceedings of the Robotics: Science and Systems (RSS), Virtual, 12–16 July 2021. [Google Scholar]
- Gehring, C.; Coros, S.; Hwangbo, J.; Siegwart, R.; Hutter, M. Practice makes perfect: Learning to balance in a day. In Proceedings of the International Conference on Intelligent Robots and Systems (IROS), Daejeon, Republic of Korea, 9–14 October 2016; pp. 2639–2644. [Google Scholar]
- Kim, S.; Lee, J.; Hwangbo, J.; Hutter, M. Domain randomization and curriculum learning for robust locomotion policies. In Proceedings of the Conference on Robot Learning, London, UK, 8–11 November 2021; pp. 164–180. [Google Scholar]





Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, Y.; Jiang, X.; Ma, X.; Tang, J.; Li, Q.; Zhang, J. Reinforcement Learning for Bipedal Jumping: Integrating Actuator Limits and Coupled Tendon Dynamics. Mathematics 2025, 13, 2466. https://doi.org/10.3390/math13152466
Zhu Y, Jiang X, Ma X, Tang J, Li Q, Zhang J. Reinforcement Learning for Bipedal Jumping: Integrating Actuator Limits and Coupled Tendon Dynamics. Mathematics. 2025; 13(15):2466. https://doi.org/10.3390/math13152466
Chicago/Turabian StyleZhu, Yudi, Xisheng Jiang, Xiaohang Ma, Jun Tang, Qingdu Li, and Jianwei Zhang. 2025. "Reinforcement Learning for Bipedal Jumping: Integrating Actuator Limits and Coupled Tendon Dynamics" Mathematics 13, no. 15: 2466. https://doi.org/10.3390/math13152466
APA StyleZhu, Y., Jiang, X., Ma, X., Tang, J., Li, Q., & Zhang, J. (2025). Reinforcement Learning for Bipedal Jumping: Integrating Actuator Limits and Coupled Tendon Dynamics. Mathematics, 13(15), 2466. https://doi.org/10.3390/math13152466