1. Introduction
Single-image super-resolution (SISR) [
1] is an essential and challenging task in computer vision, aiming to reconstruct high-resolution (HR) images from corresponding low-resolution (LR) inputs, and its core lies in inferring high-frequency details from limited information to improve the visual quality and readability of the image. It has extensive applications in various fields, including medical imaging [
2,
3], satellite and aerial imagery [
4], surveillance systems [
5], defect detection [
6], and multimedia entertainment [
7]. Prior to the deep learning era, traditional SISR methods were largely based on interpolation and reconstruction. Interpolation-based methods, such as bicubic [
8] and bilinear interpolation [
9], are simple and efficient, but they often result in overly smooth images that lack high-frequency details and exhibit ringing artifacts. Reconstruction-based methods [
10,
11,
12], on the other hand, rely on the prior knowledge of natural images and attempt to reconstruct HR images by solving an optimization problem. Although they produce sharper results than interpolation methods, these algorithms are typically computationally expensive and sensitive to scaling factors, which limits their practical use in complex scenarios.
As deep learning is developing, particularly CNNs, SISR has seen remarkable progress. Depending on the position of the upsampling module within the network, deep learning-based SISR frameworks can be broadly categorized into front-end and back-end upsampling approaches [
13]. The front-end upsampling strategy, adopted in early models such as SRCNN [
14], first upsamples the LR image using bicubic interpolation before feeding it into the network for refinement. Although this approach simplifies the learning process by operating in HR space, it also amplifies noise and increases computational overhead. Subsequent models, such as VDSR [
15], RED [
16], and LapSRN [
17], extended this framework by incorporating deeper networks, encoder–decoder structures, and progressive residual learning strategies to enhance performance.
To mitigate the drawbacks of front-end upsampling, researchers proposed shifting the upsampling operation to the latter stages of the network. In this back-end upsampling paradigm, the network extracts and processes features in the LR space and performs upsampling only at the end, thereby reducing computational costs and improving efficiency. Notable examples include FSRCNN [
18], which introduces a deconvolution layer for efficient upsampling, and ESPCN [
19], which leverages subpixel convolution to learn the upsampling operation directly. EDSR [
20] further advances this idea by removing batch normalization layers and employing residual scaling to stabilize deep training, achieving state-of-the-art performance. Lightweight architectures such as IMDN [
21] also follow this design philosophy, emphasizing both efficiency and reconstruction quality. Nevertheless, these methods primarily employ conventional convolution operations with fixed kernel structures, which inherently limits their adaptability to diverse and intricate spatial patterns. This limitation inevitably affects the networks’ capacity to accurately recover high-frequency details, resulting in suboptimal performance in handling complicated scenarios.
To address these challenges, recent studies have explored dynamic convolutional techniques that adaptively adjust convolution kernels based on input features, thus improving network adaptability and representational power. Deformable convolution networks [
22] introduced spatial offsets to traditional convolution kernels, dynamically adjusting receptive fields and enhancing the capability of CNNs to capture geometric transformations. Dai et al. proposed SAN [
23], which incorporates second-order channel attention and nonlocal operations to better capture high-frequency textures and contextual dependencies. However, existing dynamic convolution approaches typically focus only on spatial adaptability, neglecting critical dimensions such as channel-wise adaptivity and kernel-level adjustments, thereby restricting their overall potential for feature extraction and representation.
Motivated by the limitations of current approaches, in this paper, we propose an Omni-dimensional Dynamic Convolutional Network (ODConvNet) for SISR tasks. The core component of our method is the Omni-dimensional Dynamic Convolution (ODConv) module, which adaptively adjusts convolutional kernels across multiple dimensions—including spatial positions, kernel sizes, channel interactions, and kernel quantities—through an advanced multidimensional attention mechanism. By doing so, ODConv significantly enhances the network’s ability to capture diverse local patterns and context-sensitive features, thereby achieving superior performance in recovering detailed information from LR images.
Moreover, to stabilize training and improve the gradient flow, we introduce an improved residual learning framework that employs effective skip connections and feature fusion strategies. Additionally, we incorporate the Charbonnier loss function as a robust alternative to traditional loss functions, further ensuring stable optimization and robust handling of noisy or complex datasets.
The main contributions of this work are summarized as follows:
We propose ODConvNet, an innovative SR network featuring an Omni-dimensional Dynamic Convolution module, significantly improving adaptability and feature extraction capability.
We integrate an enhanced residual network structure and the Charbonnier loss function, effectively mitigating common problems such as gradient instability and sensitivity to noise.
Experimental results demonstrate substantial improvements over existing approaches, validating the effectiveness and robustness of our proposed method.
The remainder of this paper is organized as follows:
Section 2 discusses related works.
Section 3 elaborates on our proposed ODConvNet methodology.
Section 4 presents experimental results, ablation studies, and analysis. Finally,
Section 5 provides conclusions and insights for future research directions.
3. Method
3.1. Overall Network Architecture
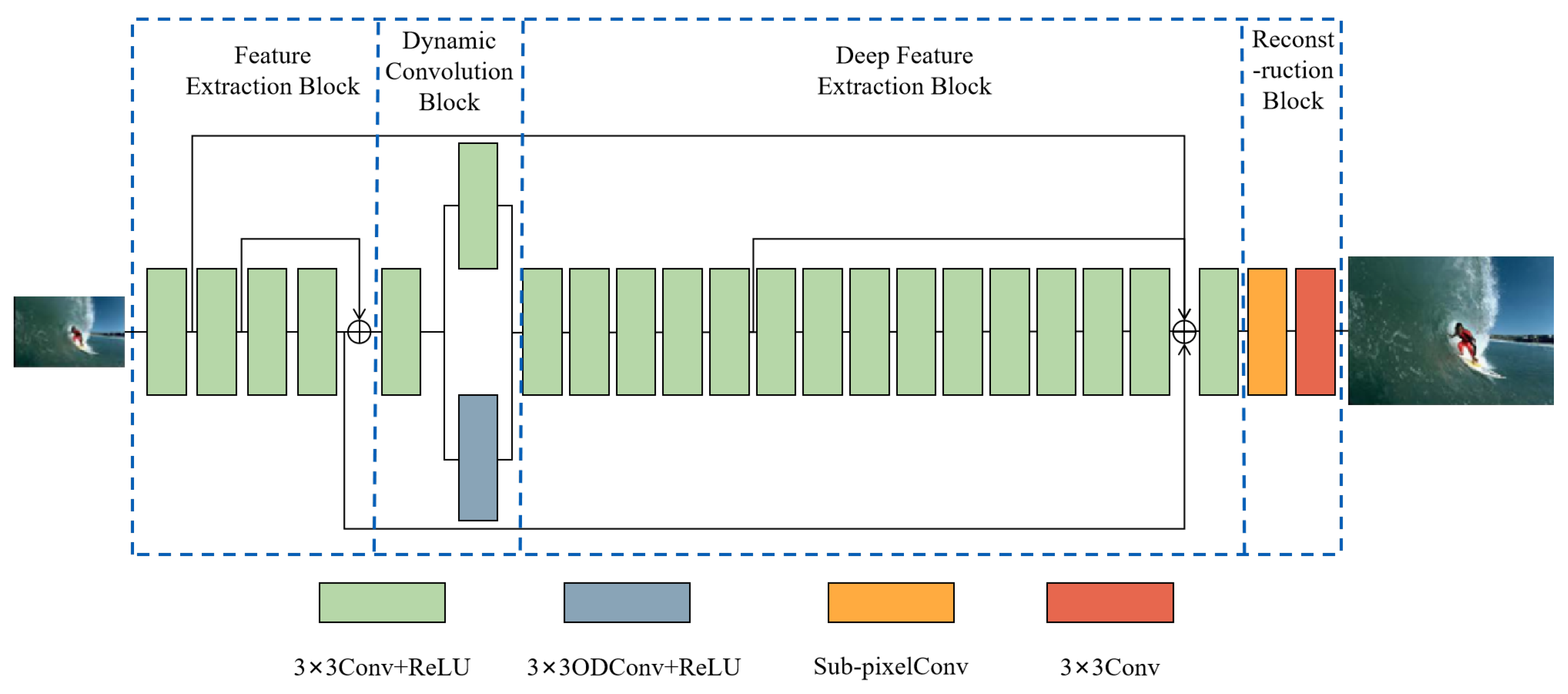
Figure 1 illustrates the overall architecture of ODConvNet, consisting of four sequential modules: a Feature Extraction Block (FEB), a Dynamic Convolution Block (DCB), a Deep Feature Extraction Block (DFEB), and a Reconstruction Block (RB). Each block is designed with specific responsibilities: FEB captures low-level spatial features; DCB introduces adaptive feature modulation via dynamic convolution; DFEB performs progressive deep feature refinement; and RB reconstructs the final high-resolution output. The arrows between modules indicate data flow, and internal skip connections are shown where applicable.
Specifically, the input LR image is first processed by the FEB, which employs four sequential convolutional layers combined with ReLU activation functions. Residual connections are introduced within the FEB to preserve shallow features and improve the model’s capability to memorize and represent detailed image structures. Then, these low-frequency features are input to the DCB block for further enhancement and refinement of the features. To enhance feature flexibility and adaptability, the DCB integrates Omni-dimensional Dynamic Convolution (ODConv) and traditional convolution operations in parallel. This allows the network to dynamically adjust convolution kernels based on input features across kernel-wise, spatial, input channel, and output channel dimensions, enhancing feature robustness. The outputs from these convolution operations are weighted and merged through a learnable scalar
, providing an effective trade-off between dynamic adaptability and computational efficiency. Following the DCB, the DFEB, comprising 15 convolutional layers with ReLU activations, is designed to further extract and refine deeper feature representations. By stacking multiple convolutional layers, DFEB significantly enhances the depth and expressiveness of features, capturing complex image structures and subtle texture details.To reconstruct high-quality SR images, the RB utilizes a two-stage upsampling strategy. Initially, a subpixel convolution layer is employed to upscale low-frequency features into high-frequency representations, effectively enlarging image dimensions. Subsequently, a
convolutional layer refines high-frequency information, precisely reconstructing and synthesizing image details. In summary, the SR process using ODConvNet can be described as
where
is the input low-resolution image,
denotes the network, and
,
,
, and
represent the function of FEB, DCB, DFEB, and RB, respectively.
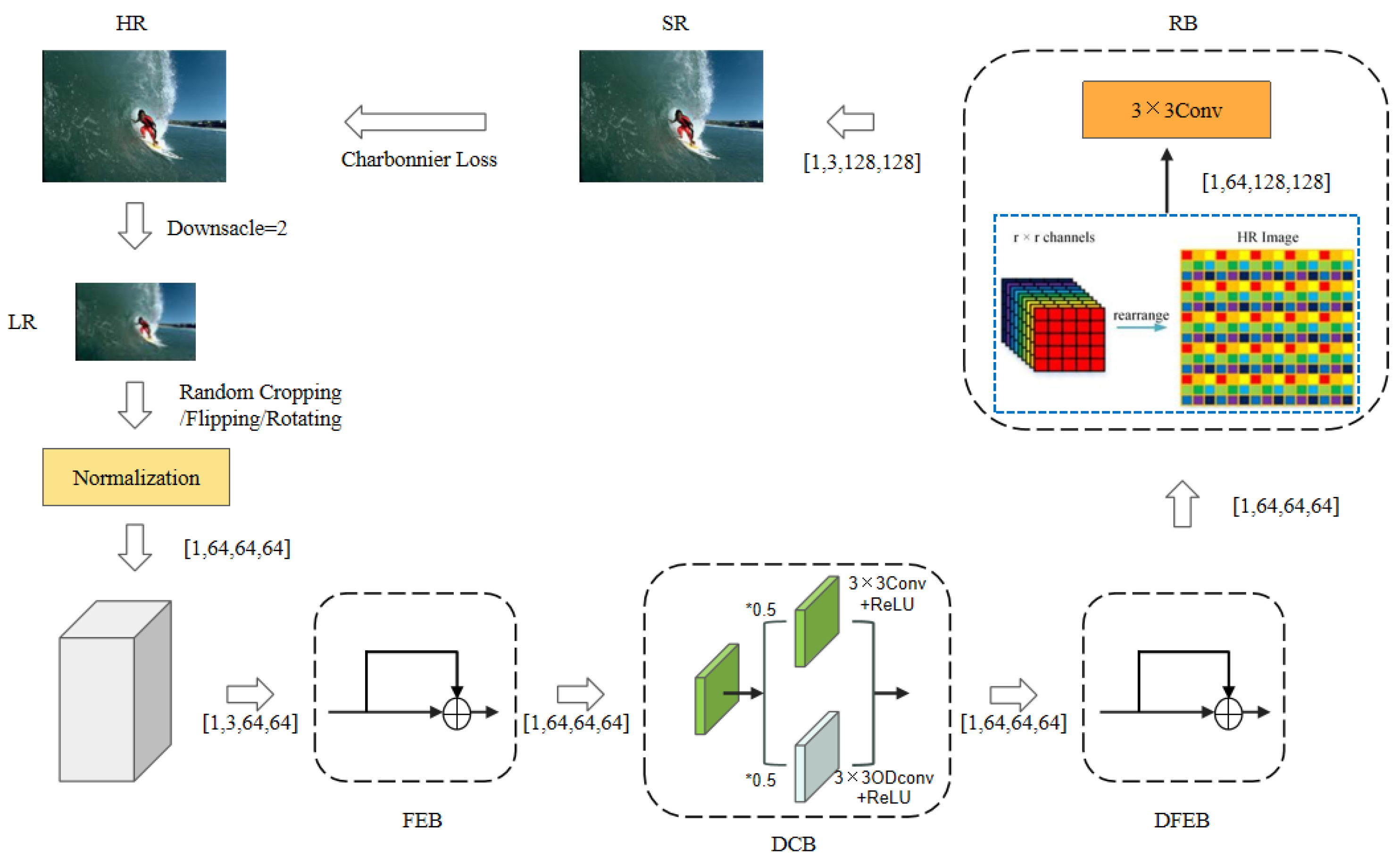
The complete data flow and processing pipeline of ODConvNet are illustrated in
Figure 2. The input low-resolution (LR) image undergoes random data augmentation and normalization before being fed into the network. The FEB captures shallow features, which are enhanced via both standard and dynamic convolutions in the DCB. These features are further refined through deep residual layers in the DFEB, followed by subpixel convolution and refinement in the RB to produce the final high-resolution (HR) image. Charbonnier loss is applied between the SR output and the ground truth HR image during training.
3.2. Feature Extraction Block
The Feature Extraction Block (FEB) serves as the initial component of ODConvNet, designed specifically to extract and enhance low-level features from the input low-resolution image. FEB is comprised of four sequential convolutional layers, each paired with a ReLU activation function to introduce nonlinearity and facilitate effective feature learning. Each convolutional layer uses a 3 × 3 kernel, where the first layer processes the 3-channel RGB input, and the subsequent layers maintain 64 output channels.
To effectively capture essential structural details such as edges and textures, the FEB employs residual learning, enabling better retention and propagation of shallow features throughout the network. Specifically, residual connections are strategically implemented between convolutional layers, combining outputs from earlier and subsequent layers to preserve valuable information and enhance the expressive capability of shallow representations.
The computational procedure of the FEB can be formally described as follows:
where
denotes the input LR image, and
represents n consecutive convolutional and ReLU layers.
The FEB thus plays a pivotal role in preparing a robust and discriminative feature foundation, enabling deeper subsequent blocks of ODConvNet to further refine and reconstruct high-quality, high-resolution images.
3.3. Dynamic Convolution Block
The proposed model defines the dynamics of the network as the process of adaptively modulating convolution kernel weights according to the input feature map through attention applied along four axes: kernel index, spatial position, input channel, and output channel. This is implemented via the use of an Omni-dimensional Dynamic Convolution (ODConv) layer. To fully leverage this capability, we design the Dynamic Convolution Block (DCB) by integrating the ODConv module with a standard convolution branch in a parallel structure. The outputs of both branches are fused through a learnable scalar weight, enabling the model to balance adaptability and stability. This architectural design enhances ODConvNet’s flexibility and feature representation, allowing it to dynamically adjust convolution behavior across multiple dimensions and effectively capture diverse features, particularly in scenarios with complex spatial or structural variations.
Specifically, the DCB employs two parallel convolutional branches. One branch applies an ODConv layer, which adaptively adjusts convolutional kernel weights through learned attention mechanisms in kernel-wise, spatial, input-channel, and output-channel dimensions. The other branch employs a traditional convolutional layer to maintain stable feature extraction capabilities. The outputs from these two branches are then combined through a learnable scalar parameter
, enabling the network to dynamically balance feature contributions from each branch. The architecture of the ODConv layer is illustrated in
Figure 3, which shows the detailed components and flow of the ODConv operation.
Formally, the operation of DCB can be expressed as follows:
where
represents the shallow features output from the FEB module,
denotes the Omni-dimensional Dynamic Convolution operation, and
denotes a conventional convolution operation. The scalar parameter
is learnable during training and determines the relative weight assigned to dynamic and conventional convolutions.
Specifically, given an input feature map
X, the output of the ODConv operation is formulated as
where
denotes the
k-th convolution kernel, ∗ represents the convolution operation, and ⊗ indicates element-wise multiplication.
,
,
, and
correspond to the kernel-wise, output-channel-wise, input-channel-wise, and spatial-wise attention weights, respectively.
The generation of attention weights begins with a global average pooling (GAP) applied to
X across spatial dimensions, producing a channel-wise descriptor
:
This descriptor is then mapped to a low-dimensional embedding through a fully connected (FC) layer:
Finally, the four attention maps are generated by applying the sigmoid activation function to the transformed features:
where
denotes the element-wise sigmoid function.
Through this mechanism, ODConv dynamically adapts its kernels to better suit the input content, offering greater flexibility in handling diverse structural variations within images. The inclusion of ODConv enhances the network’s capability to extract meaningful features and improves its robustness in high-frequency detail recovery, thereby delivering superior performance in SR tasks.
3.4. Deep Feature Extraction Block
The Deep Feature Extraction Block (DFEB) is specifically designed to further refine and enrich feature representations extracted from the preceding Dynamic Convolution Block (DCB). By stacking multiple convolutional layers, the DFEB enhances the depth and complexity of the extracted features, thereby capturing detailed textures and semantic structures necessary for effective SR reconstruction.
In particular, DFEB comprises a sequential stack of 15 convolutional layers, each paired with a ReLU activation function to ensure nonlinear transformations and stable gradient flow. This stacked architecture allows the network to progressively distill complex image information from shallower to deeper layers, enabling the effective capture of both fine-grained local details and broader contextual semantics.
The operation of the DFEB can be formally described as follows:
where
represents the features obtained from the Dynamic Convolution Block,
denotes the resulting deeply extracted feature representation,
is the input LR image, and
represents
n consecutive convolutional and ReLU layers.
By aggregating these deep, hierarchical feature representations, DFEB significantly improves the network’s ability to recover intricate image structures and subtle high-frequency details, ultimately contributing to superior image reconstruction quality in single-image SR tasks.
3.5. Restruction Block
The RB is the final component in the ODConvNet architecture, specifically designed to transform the deeply extracted features into a HR image. The RB employs a two-stage upsampling strategy to accurately reconstruct and refine detailed high-frequency textures, effectively improving the visual fidelity of the final output.
Initially, a subpixel convolution layer is utilized to upscale the spatial dimensions of the deep feature maps, effectively converting learned low-frequency information into refined high-frequency details. Subsequently, a convolutional refinement layer follows to precisely enhance the reconstructed image, refining edges and textures for improved visual quality.
Formally, the reconstruction process can be described as
where
represents the deep features obtained from the Deep Feature Extraction Block,
denotes the subpixel convolution operation for spatial upscaling, and
represents the final convolutional refinement layer.
is the final output, representing the reconstructed HR image.
By integrating these modules, the Reconstruction Block effectively synthesizes the hierarchical features extracted by previous layers, accurately reconstructing high-frequency textures and ensuring high-quality SR results.
3.6. Loss Function
The loss function is a non-negative real-valued function that quantifies the discrepancy between the predicted output of the model and the ground truth label Y. It is denoted as , and a smaller loss value typically indicates better robustness and accuracy of the model. During training, a batch of input data is passed through the network to obtain predictions via forward propagation. The loss function then evaluates the prediction error, and its value is used to guide backpropagation, allowing the model to update its parameters and reduce the difference between predicted and actual values iteratively.
In conventional SISR tasks, the L1 loss [
44] and L2 loss [
45] are widely used. The L1 loss computes the mean absolute error between predictions and ground truth, offering robustness to outliers, but it suffers from discontinuous gradients, resulting in slower convergence. In contrast, the L2 loss minimizes the squared error, providing smoother gradient updates and faster convergence, yet it is sensitive to outliers and may cause gradient explosion.
To overcome these limitations, we adopted the Charbonnier loss [
46] as the optimization objective in our network. Charbonnier loss is a differentiable variant of the L1 loss that is robust to noise while maintaining stable gradient computation. As illustrated in Equation (
10), it introduces a small constant
to ensure differentiability at zero and smooth convergence:
where
denotes the predicted pixel value,
represents the corresponding ground truth,
N is the total number of pixels, and
is a small constant (typically set to
) to guarantee numerical stability and differentiability at
. The Charbonnier loss approximates the L1 norm near zero and ensures smooth gradient flow across the entire input domain.
By combining the advantages of both L1 and L2 losses, the Charbonnier loss achieved a balanced trade-off between convergence speed and robustness to outliers. This makes it particularly suitable for SR tasks, where subtle detail preservation and noise resilience are both essential. In our experiments, the adoption of Charbonnier loss contributed significantly to stable training and high-quality image reconstruction.
4. Experiment
4.1. Conducted Datasets
To comprehensively evaluate the effectiveness and robustness of the proposed ODConvNet, extensive experiments were conducted using publicly available benchmark datasets commonly employed for SISR tasks. Specifically, we selected the widely recognized DIV2K [
47] dataset for model training and validation and four additional standard datasets, namely, Set5 [
48], Set14 [
49], B100 [
50], and Urban100 [
51], for comprehensive performance evaluation.
The DIV2K dataset contains 800 high-resolution images for training and 100 images for validation. During the training phase, the 800-image training set was employed, while the validation set was used to monitor the convergence and select optimal model checkpoints. The four benchmark datasets are widely adopted to rigorously test SR algorithms across diverse scenarios: Set5 [
48] consists of five natural images commonly utilized as a baseline for initial performance evaluation. Set14 [
49] includes 14 images representing a variety of textures and structures, providing a balanced evaluation of reconstruction capability. B100 [
50] contains 100 diverse images from the Berkeley segmentation dataset extensively used to evaluate reconstruction consistency and robustness. Urban100 [
51] comprises 100 urban scenes featuring complex architectural structures extensively utilized to test the model’s ability to recover detailed textures and geometrical patterns.
All images were converted into the YCbCr color space, and quantitative evaluations were performed exclusively on the luminance (Y) channel, following common practice in the literature. The Peak Signal-to-Noise Ratio (PSNR) and Structural Similarity Index (SSIM) were used as primary metrics to quantitatively assess SR quality and effectiveness. Additionally, we adopted the Feature Similarity Index (FSIM) and Learned Perceptual Image Patch Similarity (LPIPS) as supplementary perceptual metrics, where the FSIM evaluates structural fidelity based on phase congruency and gradient information, and LPIPS leverages deep neural network features to align with human visual perception.
PSNR quantifies image quality by calculating the mean squared error between the original and reconstructed images. As illustrated in Equation (
11), the mathematical formulation is
where
represents the maximum possible pixel value, and
denotes the mean squared error between the two images. The PSNR is measured in decibels (dB), with higher values indicating smaller differences between the reconstructed and original images and thus better quality.
The SSIM evaluates image similarity from three dimensions of human visual perception: luminance, contrast, and structure. It follows the formulation in Equation (
12):
where
represents the local mean,
denotes the standard deviation,
is the covariance, and
and
are stabilization constants. The SSIM output ranges from 0 to 1, with values closer to 1 indicating higher structural similarity between images and better perceptual quality.
The FSIM evaluates the perceptual similarity between images by incorporating low-level features that closely align with the Human Visual System (HVS), primarily the Phase Congruency (PC) and Gradient Magnitude (GM). It is designed to capture salient structural information and visual attention. The mathematical formulation of FSIM is expressed in Equation (
13):
where
denotes the spatial domain of the image,
is the maximum phase congruency at location
x, and
is the similarity function combining phase congruency and gradient magnitude similarities at pixel
x. The FSIM values range from 0 to 1, with higher values indicating better perceptual quality and structural fidelity.
The LPIPS is a deep learning-based perceptual metric that measures the distance between image patches using features extracted from pretrained convolutional neural networks. It aligns well with human perceptual judgments. The LPIPS distance is defined in Equation (
14):
where
and
are the deep features extracted at layer
l for images
x and
y, respectively,
denotes channel-wise unit normalization,
are learned weights for each channel, and
are the spatial dimensions of layer
l. Lower LPIPS values indicate better perceptual similarity.
4.2. Experimental Setting
The experimental environment setup was the following: The operating system was Ubuntu 20.04.5, and the hardware configuration included an AMD EPYC 7502P 32-Core Processor (Advanced Micro Devices, Inc., Santa Clara, CA, USA), a RTX 3090 GPU (NVIDIA Corporation, Santa Clara, CA, USA), and 128 GB of RAM. The model code used in the experiments was written in Python, version 3.8.18. Additionally, the version of CUDA used was 11.7.
For experimental setups, we followed standard practice in SISR research by feeding low-resolution RGB images into the network. This ensured consistency with the preprocessing pipelines of prior work and enabled fair comparisons across benchmarks.
The overall architecture consists of four consecutive components: the Feature Extraction Block (FEB), the Dynamic Convolution Block (DCB), the Deep Feature Extraction Block (DFEB), and the Reconstruction Block (RB). Specifically, the FEB comprises four 3 × 3 convolutional layers, with each followed by a ReLU activation. The DCB integrates a 3 × 3 convolutional layer in a parallel structure that combines both dynamic convolution and standard convolution. The DFEB stacks fifteen 3 × 3 convolutional layers with ReLU activations to progressively refine features. Finally, the RB employs a subpixel convolution layer followed by a 3 × 3 convolutional layer to reconstruct the high-resolution output, producing a 3-channel RGB image.
For the hyperparameter setup, the batch size was set to 64, and the image patch size was 64. Data augmentation strategies included random cropping, random flipping, and random rotation, followed by normalization. The Adam [
52] optimizer was used, with an initial learning rate of 0.0001, which was halved every 400,000 iterations. The PSNR and SSIM were used to evaluate the SR performance.
In the experimental configuration, each epoch consisted of 1000 iterations, and the model was trained for a total of 900 epochs. For ablation studies, 600 epochs were run, with the batch size and image patch size adjusted to 32 and 16, respectively.
4.3. Experimental Analysis
The proposed ODConvNet integrates three essential components: the Charbonnier loss function, the ODConv module, and a residual network structure. These are specifically designed to enhance feature representation, improve robustness to outliers, and facilitate gradient flow, ultimately contributing to superior performance in the SISR task. Therefore, this section presents a detailed analysis of each component and their combined effect through a series of ablation experiments on the Set5, Set14, and B100 datasets, with a 4× upscaling factor.
The Charbonnier loss replaces the traditional L2 loss function in the baseline model. Unlike L2 loss, which is sensitive to outliers, Charbonnier loss is a differentiable approximation of the L1 norm, providing better convergence and stability during training. As shown in
Table 1, introducing the Charbonnier loss improved the PSNR on Set5 from 31.52 dB to 31.62 dB and the SSIM from 0.8854 to 0.8877, demonstrating its superior error modeling capability and robustness.
ODConv module: The ODConv module is designed to dynamically adjust convolutional kernels across multiple dimensions, including spatial, channel, and kernel axes. When integrated with the Charbonnier loss, the model achieved significant performance gains, with the PSNR increasing to 31.75 dB and SSIM to 0.8890 on Set5. These results suggest that ODConv enhances the network’s ability to capture spatially adaptive features and complex image structures.
Residual network structure: To further improve information flow and feature reuse, we incorporated a residual network design atop the Charbonnier loss and ODConv-based backbone. This structure facilitates deeper networks without degradation, enabling finer reconstruction of high-frequency details. The full model, with all three components, achieved the best performance—31.79 dB PSNR and 0.8894 SSIM on Set5—along with consistent improvements on Set14 and B100.
These results collectively validate the individual effectiveness of each component, and more importantly, their synergistic contribution to the overall performance of ODConvNet in SISR tasks. Additionally, ODConvNet demonstrates competitive computational efficiency, with training times and memory usage comparable to other advanced models like VDSR and DnCNN. Despite the increased complexity due to dynamic convolutions, ODConvNet maintains practical computational requirements, making it suitable for real-time applications. Qualitative results also highlight the superior visual quality of ODConvNet, particularly on challenging datasets like U100, where the network preserves fine details such as textures and edges more effectively than other methods. At higher scaling factors ( and ), ODConvNet shows a notable reduction in artifacts such as blurring and aliasing, ensuring a clearer and more accurate reconstruction. Overall, the experimental results confirm that ODConvNet is a powerful and efficient solution for SISR, offering both high-quality image reconstruction and practical applicability for real-world tasks.
4.4. Experimental Results
This section presents the quantitative evaluation of ODConvNet across standard benchmark datasets (Set5, B100, and U100) at three magnification scales (, , and ). Comparative analysis with contemporary advanced methods was conducted using the established image quality metrics PSNR and SSIM.
The results show that ODConvNet outperformed all the compared methods across all datasets and scaling factors. As shown in
Table 2, on the Set5 dataset, ODConvNet achieved a PSNR of 37.72 dB and an SSIM of 0.9593 at
, which was superior to other methods such as Bicubic, SRCNN, and VDSR. Similarly, as shown in
Table 3, ODConvNet achieved a PSNR of 32.06 dB and an SSIM of 0.8981 at
on B100, surpassing methods like LESRCNN and NDRCN. In more complex urban landscapes in U100, ODConvNet was also able to achieve optimal performance. As shown in
Table 4, ODConvNet achieved the highest PSNR of 31.81 dB and SSIM of 0.9253, outperforming all other competing methods. To provide a more comprehensive evaluation beyond traditional distortion-based metrics, we supplemented the PSNR and SSIM with perceptual metrics such as the FSIM and LPIPS. These indicators better reflect human visual perception and help assess the realism of reconstructed textures. As shown in
Table 5, our ODConvNet achieved the best performance across all four metrics on the Urban100 dataset.
In addition to the quantitative performance, the qualitative results also demonstrate the superiority of ODConvNet. Visual inspection of the super-resolution images reveals that ODConvNet was able to recover finer details, such as textures and edges, more effectively than other methods. As shown in
Figure 4, we conducted a comparative analysis on img100 in the B100 test set. By comparison, we can observe that the SR technology proposed in this section is significantly better than other methods in terms of authenticity. For example, in the enlarged area in the
Figure 4, other traditional interpolation methods and deep learning methods failed to effectively restore the second corner of the snow edge in the original image, while the method proposed in this section successfully reconstructed the details of the snow edge, which is more in line with the visual perception of the human eye. In addition, through comparative analysis of the img011 image in the Set14 test set in the
Figure 5, it can be clearly seen that ODConvNet restored the edge part of the butterfly wing texture more realistically and closer to the area shown in the original image, showing superiority compared to the contrasting interpolation method and deep learning method. Finally, we selected the img011 image in the Set14 test set for comparative analysis. It can be clearly observed that the ODConvNet method achieved better clarity in visual presentation. In particular, in the enlarged area shown in the
Figure 6, this method is more realistic in restoring the color boundary of the mandrill’s face, with more accurate colors and closer to the area shown in the original image, showing its obvious superiority compared to other interpolation methods and deep learning methods.
As shown in
Table 6, our proposed ODConvNet achieved the best overall performance across all scaling factors on the B100 dataset while maintaining a favorable trade-off between model complexity and computational cost. Specifically, ODConvNet obtained the highest PSNR/SSIM at ×2 (32.06/0.8981), ×3 (28.97/0.8017), and ×4 (27.48/0.7332), outperforming the advanced methods such as LESRCNN, CARN-M, and EMASRN. Although ODConvNet has a moderately higher parameter count (1.8692 M) than CARN-M and LESRCNN, it avoids the excessive FLOPs of EMASRN (480.3 G), operating efficiently at 98.58 GFLOPs. These results demonstrate that ODConvNet not only delivers superior reconstruction quality but also maintains computational efficiency, making it well suited for both high-performance and resource-constrained SR applications.
The experimental results demonstrate ODConvNet’s advanced performance across all metrics, surpassing existing methods in PSNR/SSIM scores, visual quality, and computational efficiency and making it particularly suitable for practical deployment.
5. Conclusions
In this paper, we present ODConvNet, a novel SISR architecture integrating dynamic convolutions with hierarchical feature extraction. The network achieved advanced performance across Set5, Set14, B100, and U100 benchmarks, excelling in both objective metrics (PSNR/SSIM) and subjective quality while maintaining computational efficiency for practical applications.
The ablation studies further reveal the importance of the Dynamic Convolution Block (DCB) and the Deep Feature Extraction Block (DFEB) in enhancing the network’s ability to recover fine-grained image details and adapt to dynamic feature scales. These components contribute significantly to ODConvNet’s ability to achieve superior results across a range of image complexities and scaling factors.
Additionally, ODConvNet maintains competitive training times and memory usage, even with the increased complexity due to dynamic convolutions. This makes the network an efficient solution for high-quality image reconstruction in real-time applications.
Overall, ODConvNet represents a promising approach for SISR, offering both high-quality results and practical applicability for a wide range of imaging tasks. Its codes can be available at
https://github.com/chenxi12434/ODConvNet (accessed on 22 July 2025).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}