1. Introduction
With the deep integration of information technology and intelligent manufacturing technology, the chemical system has become more complex, which places higher requirements on the safety and reliability of chemical processes [
1]. In response to these challenges, advanced monitoring technologies for chemical processes are essential for maintaining equipment safety and improving production efficiency. Since chemical processes are highly coupled and dynamic, even minor deviations can lead to serious safety incidents or economic losses. Thus, intelligent diagnostic techniques are becoming increasingly important, which can promptly detect abnormalities and accurately identify faults in large-scale industrial datasets [
2].
In order to achieve effective monitoring of complex chemical processes, fault detection and diagnosis (FDD) techniques have become prevalent in industrial applications. FDD methods are usually categorized into signal-based, model-based, and data-driven methods [
3]. Signal-based FDD methods aim to identify faults by analyzing the variation characteristics inherent in processing variable signals. Typical signal-based FDD methods include time-domain analysis, frequency-domain analysis (such as Fourier transform), and time-frequency analysis (such as wavelet transform). These methods generally do not rely on physical mechanism modeling of the process but instead utilize the intrinsic patterns of the signals and data-driven feature pattern recognition. Márquez-Vera et al. proposed an inverse fuzzy fault model for fault detection and isolation. In their approach, the signals are preprocessed using the wavelet transform to highlight faulty features, and least angle regression is applied for variable selection to reduce the amount of data to be processed. The method was validated in the TE process, demonstrating its superior fault detection performance [
4]. Within model-based FDD approaches, faults are detected, isolated, and identified by constructing and analyzing mathematical models of the system. The core idea is to use the difference between the system model and actual operating data to infer the existence and type of faults. Common model-based FDD methods include state estimation and fault tree analysis (FTA). State estimation methods include estimating the system state via a particle filter (PF) or Kalman filter (KF). By modeling the system’s physical rules, control logic, or process dynamics, experts can effectively identify and localize faults in the absence of rich historical data. Sadhukhan et al. proposed an adaptive traceless KF-based model for fault diagnosis of three-tank systems [
5]. Cao and Du used an improved PF method based on a modified beetle swarm tentacle search algorithm validated in a doubly-fed induction generator fault diagnosis application [
6]. Zhang et al. used FTA to analyze the causes of detector failures in nuclear power plants [
7]. Although model-based FDD methods are characterized by high interpretability and low dependence on samples, they require high system modeling accuracy and rely heavily on experts’ knowledge and experience. Additionally, model construction and subsequent maintenance typically require lots of labor and time, resulting in high overall costs. In modern production processes, this method has difficulty efficiently coping with the large amounts of data continuously generated in intelligent factories, which limits its practical application.
In contrast, driven by significant progress in sensor technology and data acquisition methods, a large quantity of real-time, multidimensional operational data accumulated in industrial processes has become more accessible. As a result, data-driven FDD methods have gradually become a hotspot for research and application [
8]. Data-driven FDD methods rely on the statistical analysis and modeling of process operation data. Machine learning or deep learning is then employed to automatically extract features and uncover hidden patterns from historical or real-time data. Then, the mapping relationship between fault categories and data is constructed to realize automatic system state identification and accurate fault type identification. It primarily consists of statistical analysis methods, as well as shallow and deep learning methods. The statistical analysis methods include Partial Least Squares (PLS) [
9], Principal Component Analysis (PCA) [
10], Canonical Correlation Analysis (CCA) [
11], and Independent Component Analysis (ICA) [
12]. Li et al. combined PCA with Liang–Kleeman Information Flow (LKIF) to quantify the causal interactions between nodes by introducing information flow, which improves the diagnostic efficiency of the TE process [
13]. Xiu and Miao proposed a novel robust sparse CCA method for fault detection in the TE process [
14]. These methods are relatively simple to implement and computationally efficient. However, they usually rely on linear assumptions and are sensitive to the data distribution, which makes it challenging to effectively handle the nonlinear features and complex coupling relationships in real industrial operations, ultimately affecting the accuracy of fault identification. Shallow learning methods are k-Nearest Neighbors (KNN) [
15], Random Forest (RF) [
16], Support Vector Machine (SVM) [
17], artificial neural network (ANN) [
18], Naive Bayes (NB) [
19], and so on. Ye and Wei proposed a method based on SVM and a modified particle swarm optimization algorithm, which improved the accuracy of gas turbine fault diagnosis [
20]. Han et al. developed a KPCA-RF fault diagnosis method based on kernel PCA (KPCA) and RF to address the issues existing in mainstream fault diagnosis methods for the TE process [
21]. These methods have good nonlinear modeling capabilities, a strong classification performance, and low data distribution requirements. However, they require manual feature engineering and lack automatic feature learning capabilities. Additionally, their ability to process high-dimensional and complex data is restricted.
To overcome aforementioned problems, deep learning methods have been extensively studied in FDD tasks owing to their powerful ability to learn discriminative features. Some typical deep learning methods include the recurrent neural network (RNN) [
22], Autoencoder (AE) [
23], Deep Belief Network (DBN) [
24], and CNN [
25]. The CNN is one of the most common models, which can learn multi-level information representations from raw data automatically. It avoids a reliance on manual feature extraction and effectively improves fault recognition efficiency. The parameter sharing and sparse connection mechanisms not only achieve a significant reduction in parameter count and computational demands but also alleviate the overfitting problem and enhance the generalization capacity. The structure of the CNN is flexible and scalable. It can be embedded into other network structures or adjusted according to different tasks. Niu and Yang applied an improved one-dimensional CNN (1D-CNN) to the task of TE process fault diagnosis, which significantly improved diagnostic capability [
26]. Xing et al. developed an optimized network structure based on 1D-CNN and its variant spatio-temporal CNN, introduced causal convolution to learn the historical information more efficiently, and applied it to fault diagnosis in chemical processes, which verified the superiority of the approach [
27]. All these studies show the great potential of the CNN in fault diagnosis.
However, the CNN operates with a restricted perceptual scope due to its fixed-size convolution kernels, making it difficult to entirely grasp global contextual information from the raw data. To address this issue, researchers have proposed methods such as multi-scale convolution, dilated convolution, and attention mechanisms. Song and Jiang proposed a fault diagnosis approach for chemical processes by integrating a multi-scale CNN (MsCNN) with matrix graph representations, extracting multi-scale features through convolution kernels of different sizes [
28]. Liang and Zhao designed a residual-enhanced one-dimensional dilated convolutional network, introducing a “zigzag” dilated convolution into the CNN, which effectively improves the receptive field of the convolutional layers [
29]. Zhou et al. integrated a global attention mechanism with the convolutional architecture, which not only expands the receptive field but also dynamically adjusts the attention weights of different regions during feature extraction [
30]. However, chemical processes are inherently dynamic systems, where process variables exhibit spatial coupling as well as significant temporal correlations, time delays, and dynamic evolution characteristics. Modeling based solely on static features is insufficient to fully capture system behavior. Therefore, recent research studies have increasingly focused on combining the local feature extraction capabilities of convolution with time-series modeling mechanisms. Through this combination, the dynamic features of process variables over time can be effectively captured, thus enhancing the robustness of FDD. Sun and Fan combined a long short-term memory (LSTM) network with a CNN, proposing a model incorporating a wide first-layer convolution and an LSTM network, which enables the joint learning of spatial and temporal features from process data [
31]. Liang and Zhao proposed a multi-scale CNN integrated with bidirectional LSTM (BiLSTM) to capture multi-scale temporal information and correlated fault semantic features, which contributed to higher reliability in bearing fault diagnosis [
32]. To improve the accuracy and efficiency of fault diagnosis under high-dimensional, nonlinear, and time-varying data, Zhang et al. proposed an enhanced deep CNN (EDCNN) model based on GRU, which effectively improved the fault diagnosis accuracy [
33].
Although FDD methods based on deep learning have achieved relatively satisfactory outcomes, there are still several limitations. For instance, although convolutional structures enhance the feature extraction capability, they often come with a large number of parameters, which leads to high training costs [
34]. Moreover, existing methods frequently overlook the integration of temporal dependencies and channel-wise information, making it difficult to fully capture the dynamic interactions among variables in complex industrial processes [
35,
36]. For example, although traditional LSTM-Fully Convolutional Network (LSTM-FCN) models combine temporal modeling and convolutional feature extraction, their convolutional parts often use single-scale fixed kernels, making it difficult to adapt to multi-scale faults. In addition, they lack attention mechanisms, resulting in limited recognition capability [
37]. Models based on dilated convolutions, such as a temporal convolutional network (TCN), can capture long-term dependencies, but the causal convolution structure restricts the use of future information and lacks channel modeling, leading to weak sensitivity [
38]. Multi-scale convolution models like MsCNN have a strong multi-scale feature extraction ability, but their complex structure and large number of parameters hinder deployment and generalization.
To overcome these difficulties, this paper proposes a novel network named the DMCA-BiGRUN, which integrates the DMCNN with the CAM and BiGRU, aiming to simultaneously take into account the high efficiency of spatial feature extraction, the selective attention ability of the CAM, and the temporal expression ability of sequence modeling.
In this paper, the main contributions are as follows:
- (1)
A hybrid model integrating the DMCNN, CAM, and BiGRU is constructed for fault diagnosis in the industrial process. This model can realize multi-scale feature extraction, effectively overcoming the limitation of a CNN, which only extracts local features and suffers from redundant parameters. In addition, temporal dependencies among variables are captured, which enhances the identification of abnormal patterns in complex dynamic processes. This structure can achieve both efficient spatial feature extraction and the capture of temporal information, thereby improving the fault classification performance.
- (2)
A CAM is proposed, which preserves global channel information and key features while incorporating positional information to reweight the original features. This enables the model to adaptively concentrate on critical feature information.
- (3)
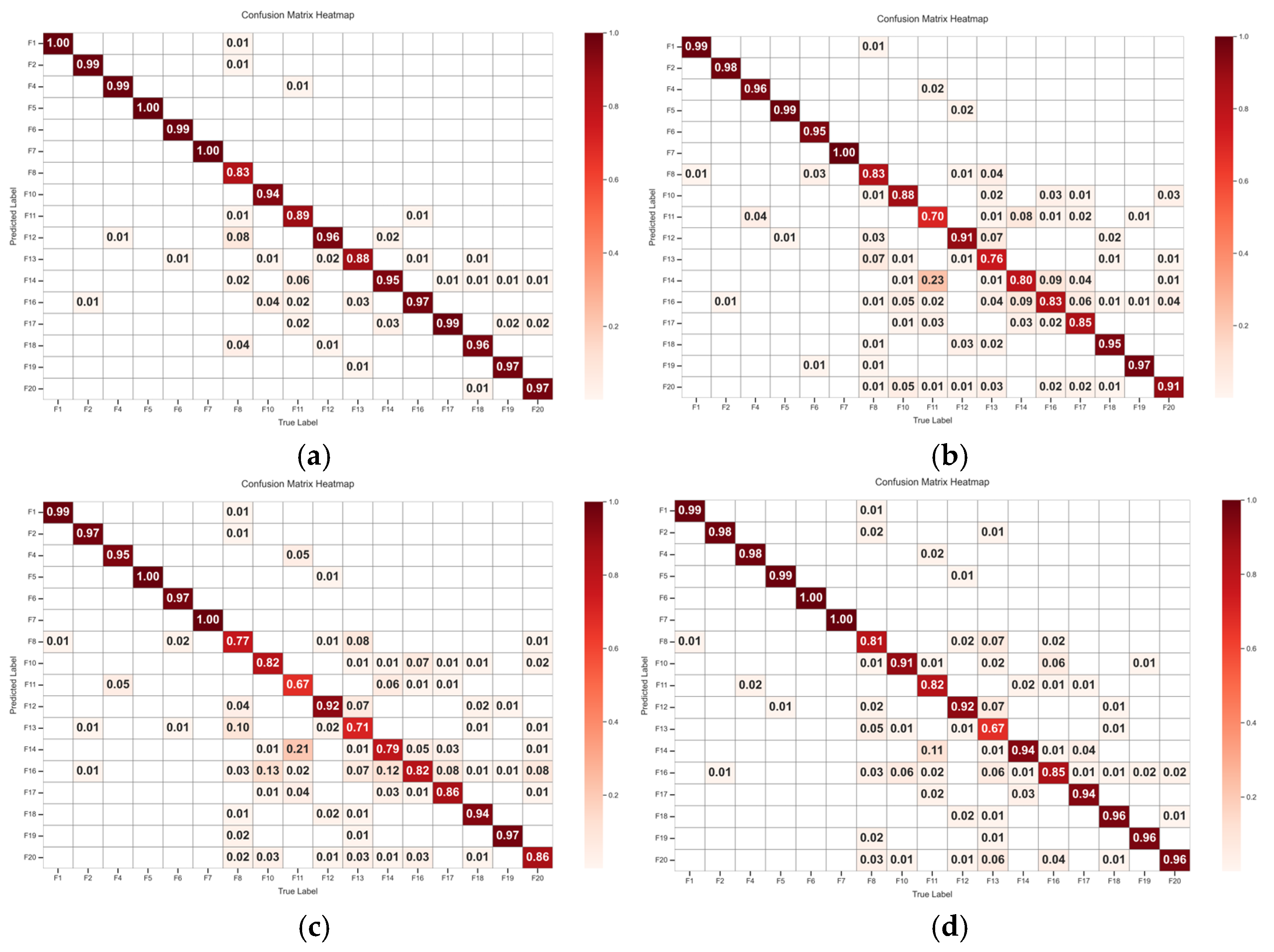
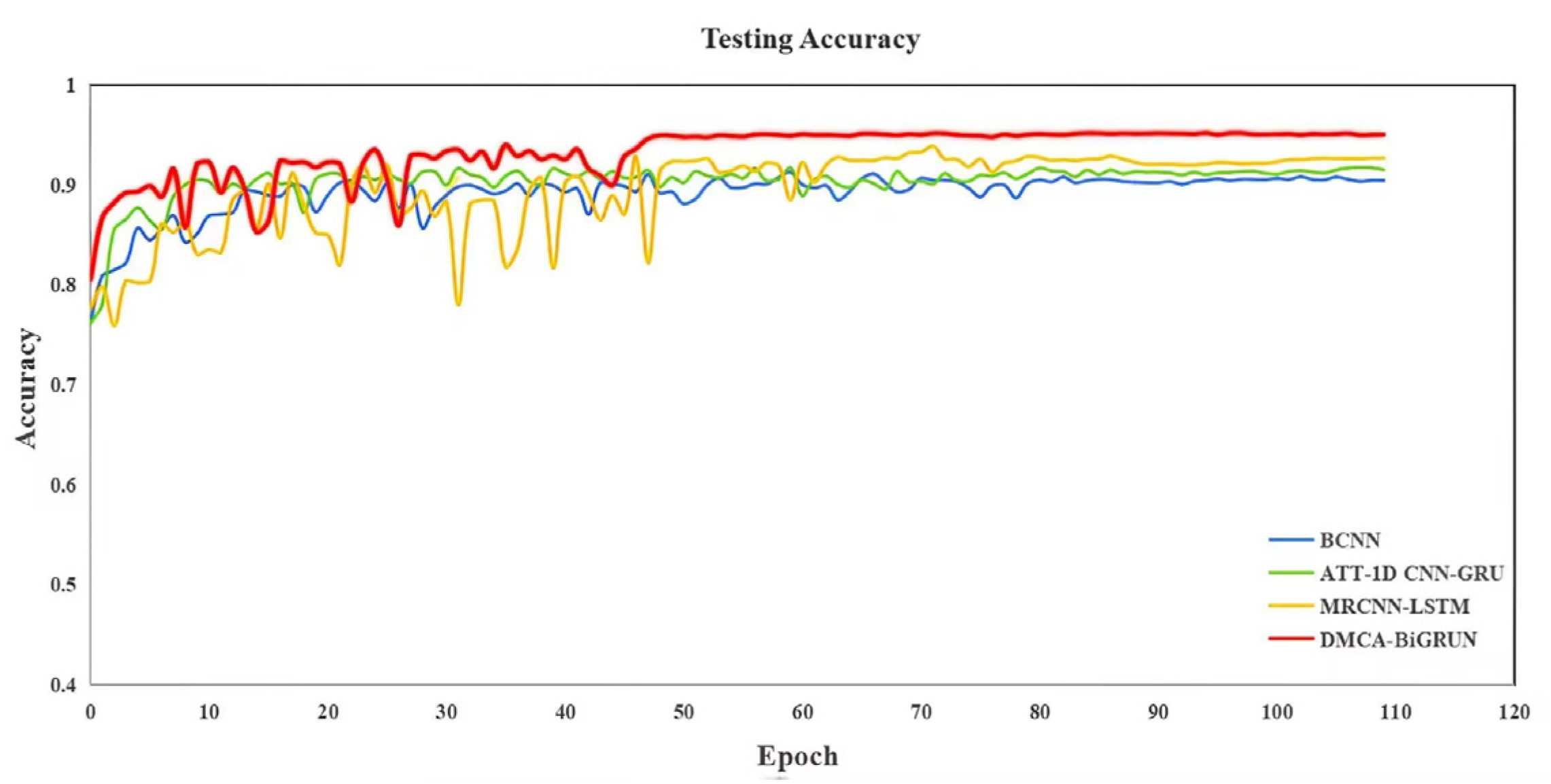
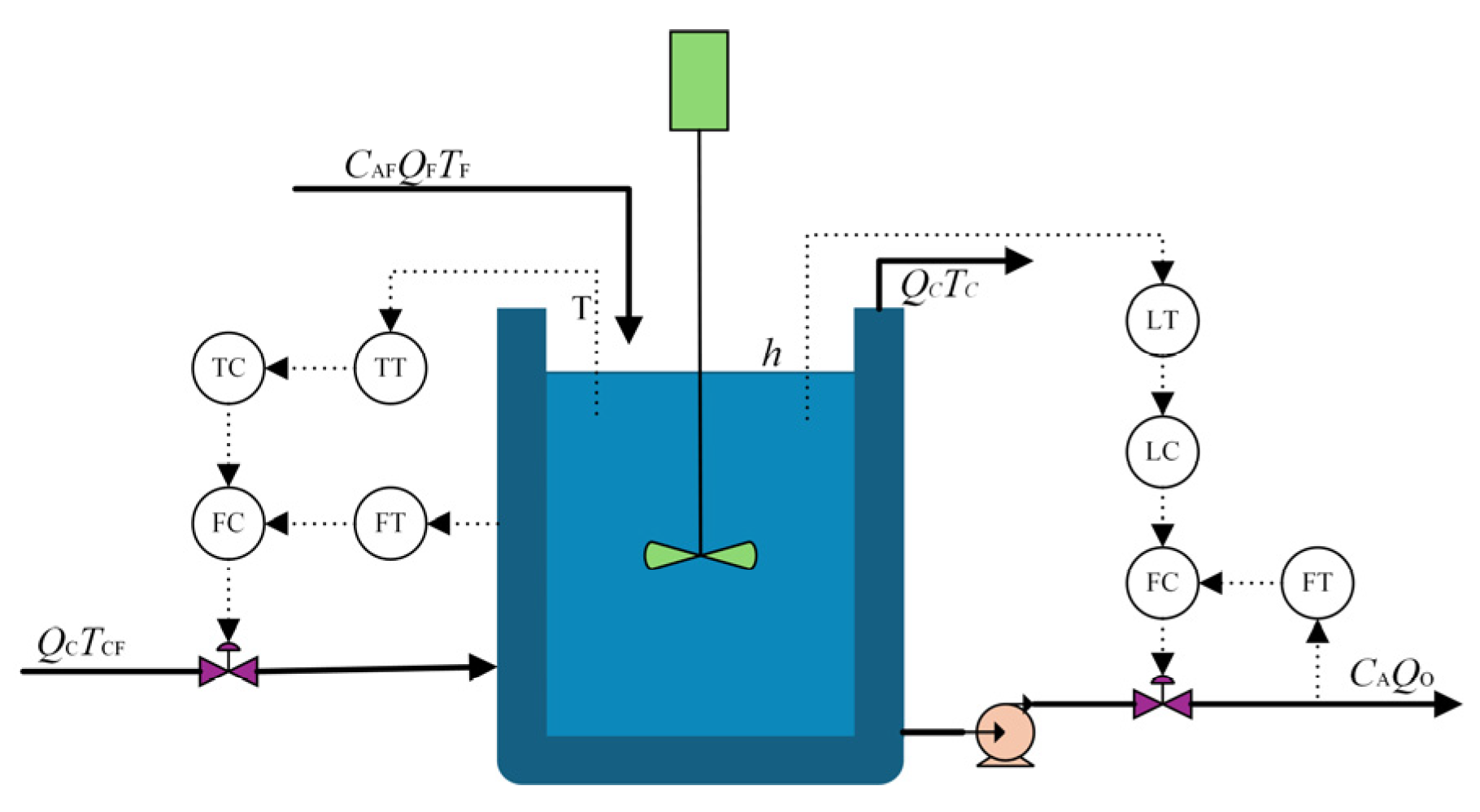
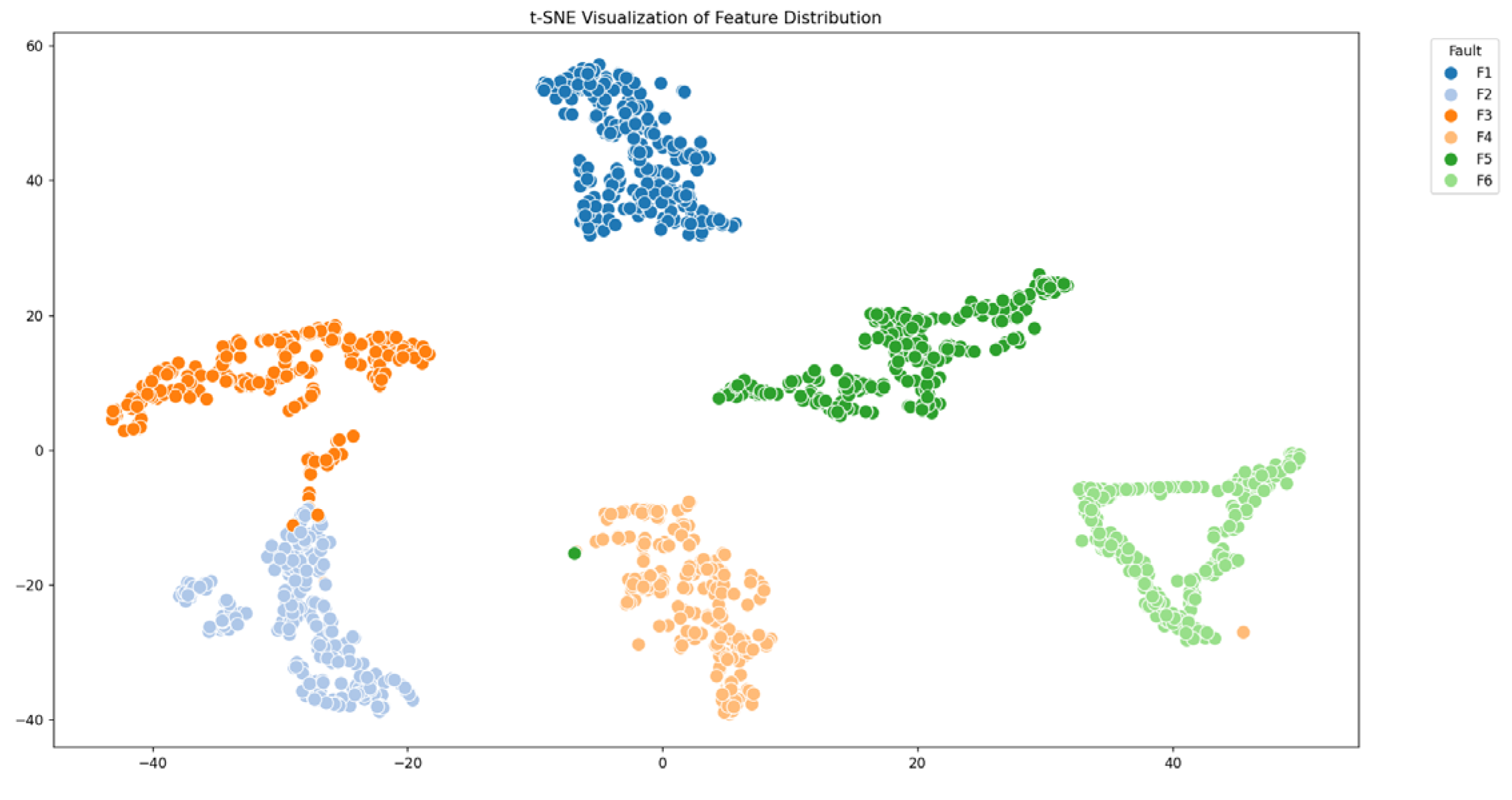
The proposed DMCA-BiGRUN is employed in the CSTR process and TE process to evaluate its performance. The experimental results demonstrate that the proposed method attains a 95.80% fault diagnostic accuracy in the TE process, which markedly outperforms the ablation and comparison models. In the CSTR process, the method also achieves an accuracy as high as 98.67%. These two sets of simulation experiments demonstrate the proposed method’s effectiveness and superiority in chemical processes’ fault diagnosis.
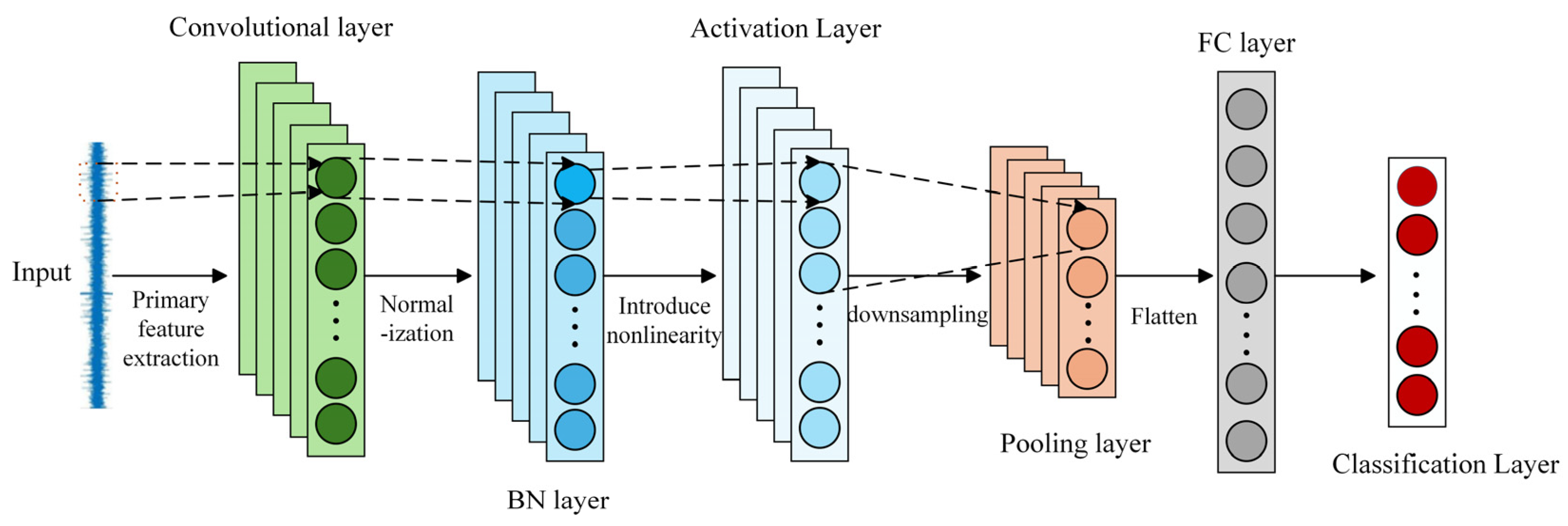
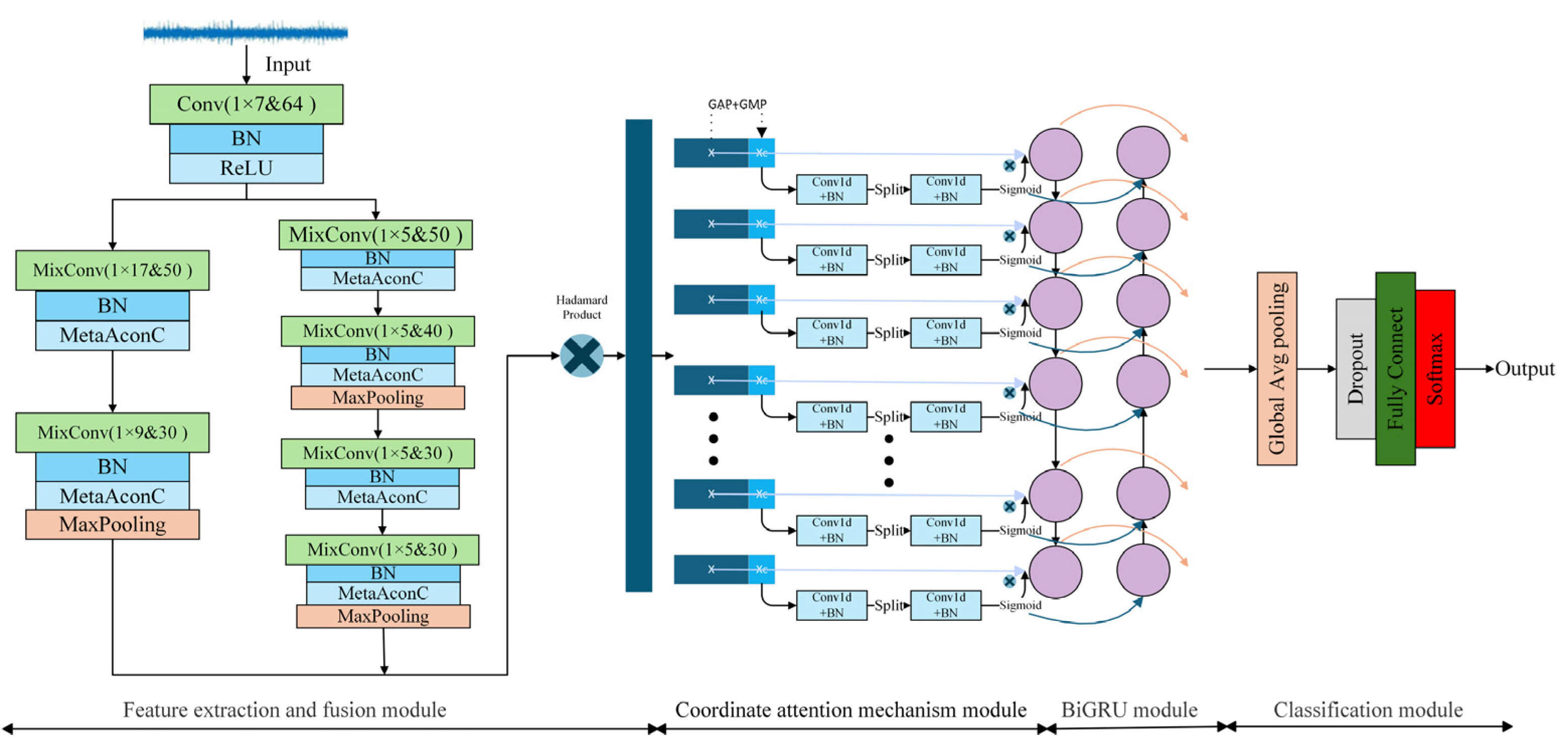
3. DMCA-BiGRUN
This paper proposes a model of a dual-path mixed convolutional attention-BiGRU network (DMCA-BiGRUN) for industrial fault diagnosis. It mainly consists of four modules: feature extraction module, coordinate attention mechanism module, BiGRU module, and classification module.
Figure 3 displays the detailed architecture of the proposed DMCA-BiGRUN.
3.1. Feature Extraction and Fusion Module
This section proposes an improved CNN model, DMCNN, to address the challenges of multi-scale feature extraction and multi-variate coupling in fault diagnosis. DMCNN adopts dual-path convolution, using convolution kernels of different sizes to extract local details and global features, respectively. To reduce the parameters, each channel is individually processed through depthwise convolution, and residual connections are employed to supplement global information. Finally, pointwise convolution is used to fuse the channel features, and element-wise multiplication is applied to nonlinearly fuse the dual-path features. This helps the model learn complex relationships among variables while reducing the impact of noise.
The overall structure of the DMCNN is presented in
Figure 4. First, the standardized data is fed into a standard convolutional layer with a kernel size of 1 × 7. The relatively large kernel helps filter out high-frequency noise and irrelevant features from the raw input during training. Low-level but global features of the faults are quickly extracted through a larger receptive field. The output from the standard convolutional layer is subsequently fed into a parallel dual-path mixed convolution network. The first path, referred to as the coarse-grained path, utilizes larger convolution kernels (1 × 17 and 1 × 9) to capture low-frequency, long-period signal features in industrial processes. It focuses on global information and long-term variation patterns. The kernel size is relatively reduced to avoid the problem of detail loss associated with a single oversized kernel. The choice of these larger kernels was guided by the fact that certain faults, such as those in the TE or CSTR processes, tend to develop gradually and require a sufficiently large receptive field for effective modeling. The second path is a fine-grained path designed to extract local and high-frequency features that typically occur over short time scales. Industrial systems often contain abrupt faults and localized disturbances, such as short-term sensor fluctuations or sudden anomalies, which require a smaller receptive field for accurate detection. Therefore, this path employs a uniform 1 × 5 convolution kernel to extract local and high-frequency transient features in the signal. By stacking four layers of small-kernel convolutions, the network is able to progressively capture higher-order feature representations for more refined feature expression. To ensure that the kernel sizes for both paths are appropriate for the characteristics of industrial time-series data, a grid search was conducted during model tuning. In addition, the first path applies a single max-pooling operation to retain more original feature information, while the second path adopts two max-pooling operations to rapidly reduce the sequence length and focus on extracting key local features.
To cope with the problems of excessive parameters in CNNs and their limited ability to handle multi-variable coupling in complex industrial processes, a mixed convolutional structure is designed. Its architecture can be seen in
Figure 5. The preprocessed data is conducted by the convolutional layer to derive
Yconv, which is obtained as shown in Equation (4).
where
n,
c, and
l represent the
n-th sample, the
c-th output channel, and the
l-th position, respectively.
W denotes the convolution kernel’s weight matrix,
K stands for the length of the kernel,
x refers to the input data, and
b is the bias term.
To alleviate the gradient vanishing problem and accelerate training, BN is applied to the next step of the convolutional operation. Its output
YBN is calculated as
YBN =
BN[
Yconv], and the corresponding calculation steps of BN are as follows [
42]:
where
γc is the scaling factor and
βc is the shifting factor, both of which are learnable parameters in the neuron.
N denotes the mini-batch size, and
P indicates the length of the feature map after convolution.
Subsequently, the ReLU function is adopted to introduce nonlinearity, alleviate the vanishing gradient problem, and enhance the feature representation capability, which is formulated as follows:
The overall output of the standard convolutional layer is expressed as
Yout =
YReLU [
YBN]. Immediately after that, each output channel of the standard convolutional layer is convolved with an independent convolution kernel through depthwise convolution to generate a feature map for each channel. Depthwise convolution significantly reduces the number of model parameters, while maintaining a performance comparable to traditional convolution. The ultimate result of the depthwise convolution is calculated as follows:
To diminish the loss of information and mitigate the gradient vanishing problem, a residual connection is established between the output of the standard convolution layer and the depthwise convolution. The output of the residual connection
can be represented as follows:
Due to the existence of complex coupling relationships between variables in industrial processes, while depthwise convolution only extracts local features in the channel, it cannot capture the correlation information between different channels. To fully utilize the information at the same spatial positions across different channels, pointwise convolution is employed for a linear combination of the features from different channels, thereby enabling inter-channel feature fusion and facilitating the learning of complex coupling relationships among multiple variables. The result of the pointwise convolution after BN and activation is as follows:
Finally, the outputs from the two convolution paths are fused using the Hadamard product, i.e., element-wise multiplication, to achieve nonlinear feature integration. Assuming the outputs of the coarse-grained and fine-grained paths are
q1 and
q2, respectively, the fused output is given by the following:
Multi-scale, multi-path, and multi-level feature extraction is achieved through the DMCNN, which allows the capture of both local detailed features and global information of the input signals. Meanwhile, it reduces the overall parameter count of the network and improves the ability to learn complex multi-variable coupling features in industrial processes.
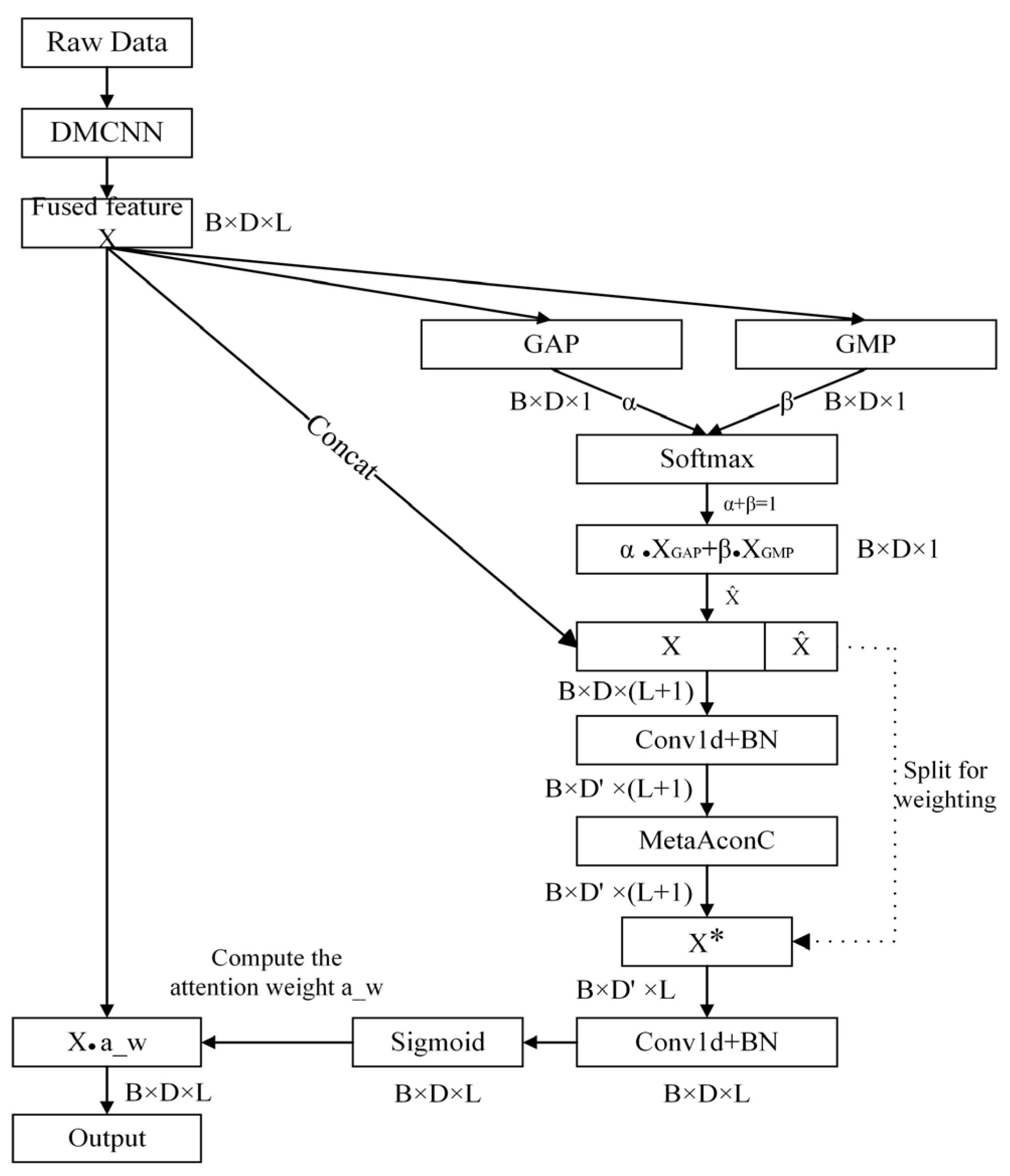
3.2. Coordinate Attention Mechanism Module
This section focuses on the CAM of the proposed method. It effectively integrates channel information with spatial positional information. The CAM enables the model to automatically focus on important features in the raw input while ignoring redundant information. Specifically, global contextual information from each channel is first extracted through global max pooling (GMP) and global average pooling (GAP). Then, the pooled results are weighted and fused using learnable parameters, allowing the model to adaptively learn the optimal combination of the two pooling methods and obtain richer information. Next, convolution operation is used to compute inter-channel features and generate attention weights while preserving spatial location information. Finally, the input features are reweighted using the attention weight, achieving dynamic weighting across different channels and spatial locations, thereby further enhancing the feature expression capability.
The specific structure of the CAM is illustrated in
Figure 6. The fused input signal X needs to simultaneously capture long-term steady-state trends and transient anomalies in industrial process fault diagnosis. Hence, a dual-pooling strategy is employed. GAP calculates the mean value across each channel, focusing on global information and reflecting the overall operating condition of process variables, which is suitable for detecting long-term drifts. GMP computes the maximum value in each channel, which highlights abrupt transient changes. Therefore, it is particularly appropriate for identifying sudden anomalies. For the
c-th channel, the outputs of GAP and GMP are computed as follows:
After the global pooling operation, the outputs of GAP and GMP are weighted and fused with the learnable parameters
α and
β, in which the initial sizes are both 0.5, and the sum of
α and
β is constrained to be 1 by the softmax function. Their relative weights are dynamically adjusted during training via backpropagation. This adaptive fusion method allows the model to extract global information without losing critical local features, thereby achieving optimal information integration and enhancing feature representation capability. The principle of weighted fusion is as follows:
Furthermore, the original input features
X are concatenated with the pooled
to fully utilize the spatial location information and enrich the feature information. The combined feature is then processed by a 1 × 1 convolution operation
H1 to fuse the original input and pooled information while capturing inter-channel relationships. To encode channel dependencies, an intermediate feature connection matrix
Q is generated, which is computed as follows:
where
g represents the MetaAconC activation function.
The concatenated result is then split into
and other parts. At this time,
contains feature information of the original input as well as global information and key features after pooling. Next, 1 × 1 convolution operation
H2 is applied to project channels in
back to their original dimensionality and generate the attention weights. Then, the weight values are mapped to the interval (0, 1) by a sigmoid function
σ, which indicates the importance of each spatial location. Finally, each channel of the original input
Xc is reweighted using the attention weights to generate the final output
Yc.
Yc is calculated as follows:
The CAM combines global average pooling and max pooling, and it introduces learnable parameters to adaptively balance their contributions, enabling the generation of differentiated weight coefficients for each input channel. This effectively reflects the contribution of each variable to the current fault mode. As a result, during prediction, the model can highlight key variables that are sensitive to faults while also providing quantifiable weight information for subsequent visualization and interpretability analysis, making it easier to explain the model’s diagnostic logic. In addition, the CAM concatenates the input with the pooled features and applies lightweight convolution together with the MetaAconC activation function, which enhances nonlinear feature representation while preserving local positional information and global statistical context. Compared with traditional attention mechanisms that only apply channel-wise weighting, this design maintains high efficiency and lightweight computation, while also retaining spatial information and enabling an adaptive focus on critical features. Therefore, the CAM not only strengthens the relevance and effectiveness of feature extraction but also significantly improves the interpretability and traceability of the model outputs, which helps to understand the diagnostic basis and decision-making process for different fault types.
3.3. BiGRU Module
To solve the problem of classifying time series, this paper employs a BiGRU module, which captures both forward and backward dependencies of the time series. Such a bidirectional modeling approach allows the model to acquire richer contextual information at each time step, thereby enhancing its ability to understand and predict sequence data.
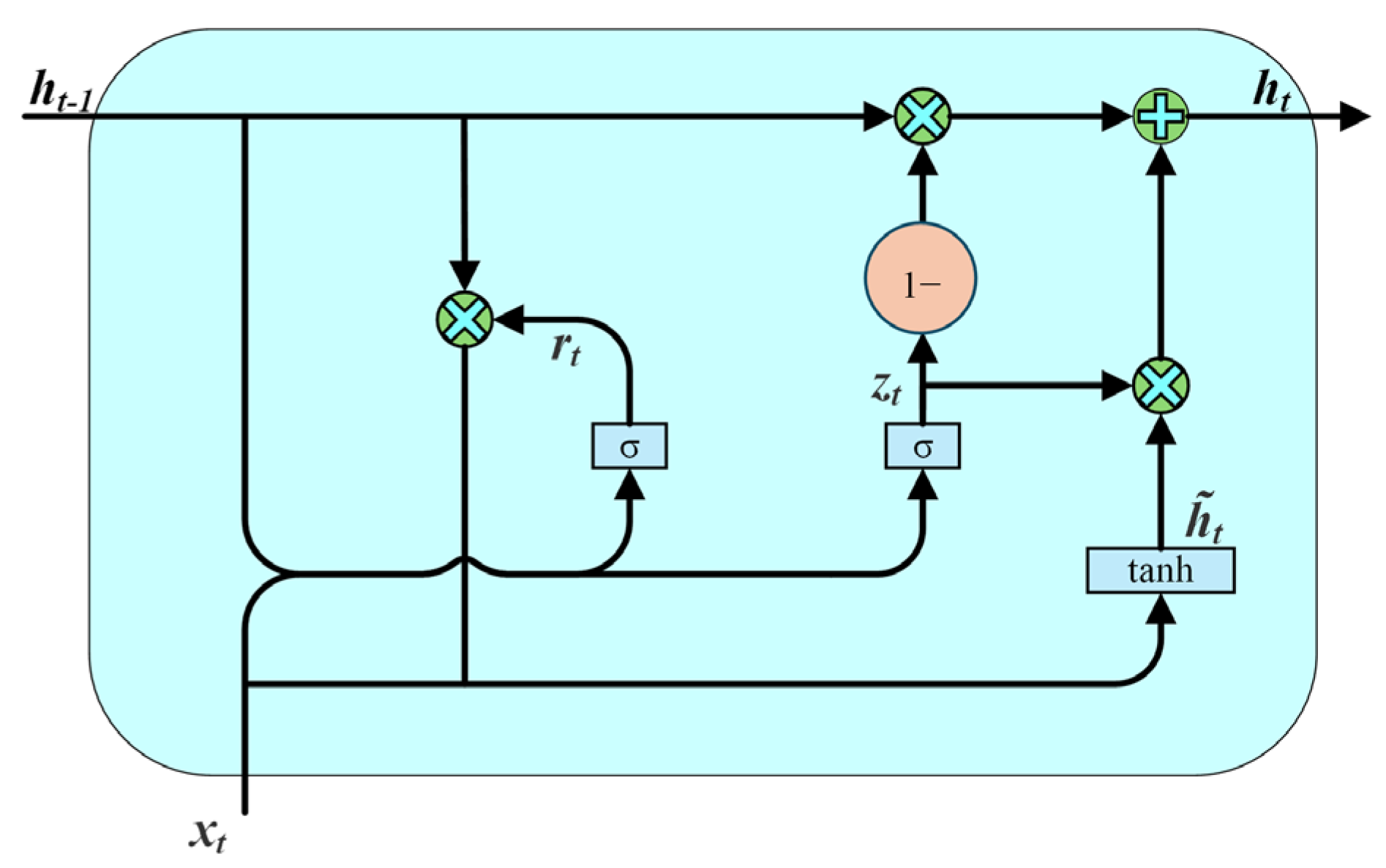
Recurrent neural networks (RNNs) are capable of handling sequential data. Nevertheless, they are vulnerable to the vanishing or exploding gradient during long sequence processing, which makes it challenging for the model to capture long-term dependencies. To tackle this issue, long short-term memory (LSTM) was proposed on the basis of RNNs. By introducing the gating mechanism, LSTM can more effectively capture long-distance dependencies and mitigate the vanishing and exploding gradient caused by RNNs [
43]. Based on LSTM, the GRU further simplifies the structure by merging the input and forget gates into a single update gate and introducing a reset gate to control the propagation of information. The GRU retains the core capabilities of LSTM while using fewer parameters and achieving faster training [
44]. Its structure is shown in
Figure 7, and its related computational flow is described in Equations (22)–(25):
where
Wz,
Wr, and
W refer to weight matrices,
σ represents the sigmoid activation function,
xt represents the input to the network at the current moment
t,
is the candidate hidden state at time
t,
ht−1 represents the previous hidden state,
ht denotes the hidden state at the current time
t, and
zt and
rt refer to the update gate and reset gate, respectively. [·] denotes connecting two vectors, and * represents the product between matrix elements. The update gate is used to control how much information from the last hidden state is retained to the current moment. If
zt is close to 1, it means that most of the information from
ht−1 will be retained to the current moment. The reset gate controls the proportion of hidden information in the previous time step that should be forgotten. If
rt approaches 1, more information from the past hidden state is preserved.
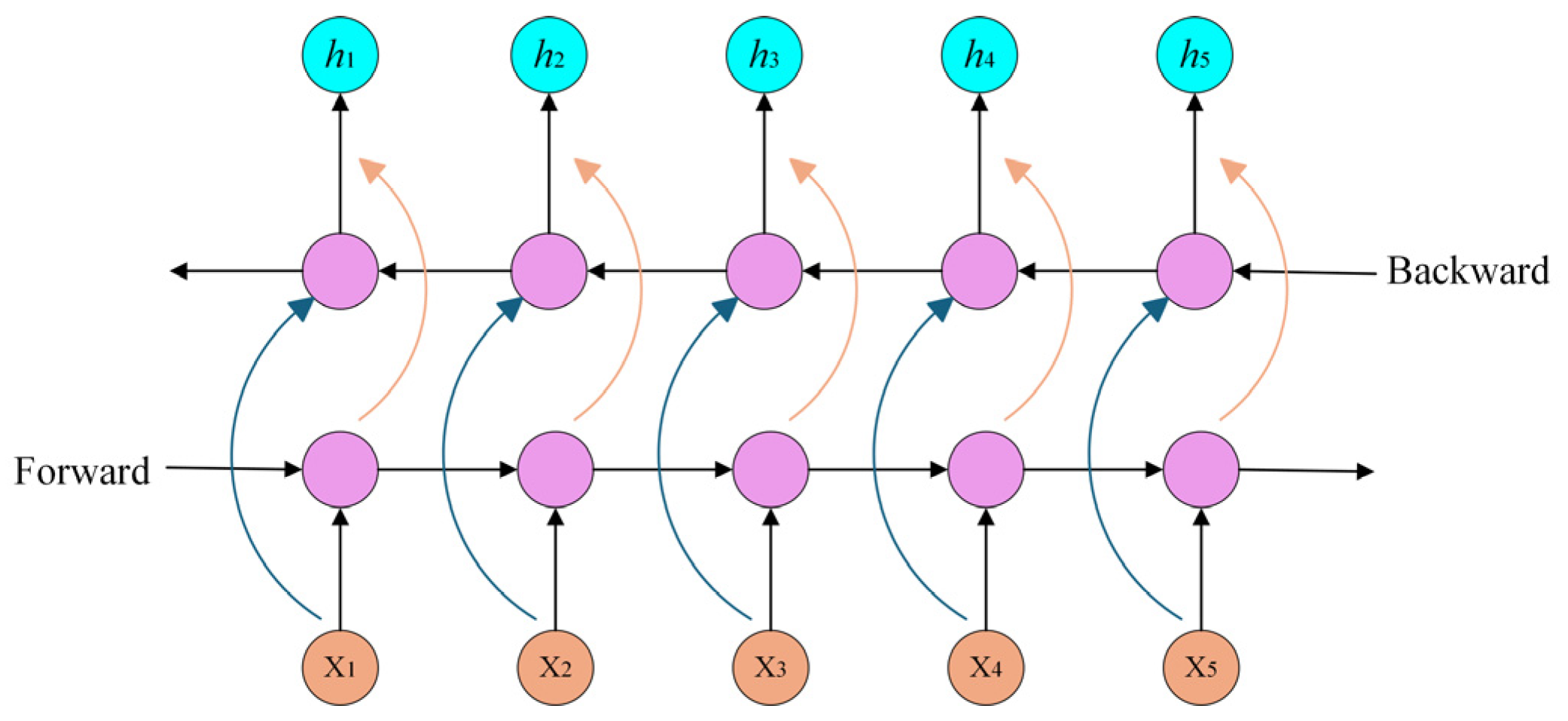
However, the traditional GRU can only process sequential information in a single direction along the time dimension. The fault characteristics of industrial equipment typically exhibit bidirectional temporal dependencies. For this reason, the BiGRU architecture is adopted in this study, and the schematic of its structure is depicted in
Figure 8. The forward GRU processes the input features from past to future, while the backward GRU processes them from future to past. This bidirectional mechanism enables the output
ht at each time step to be composed of both a forward hidden state
and a reverse hidden state
, which are calculated as follows:
where
G(·) denotes the GRU computational process,
denotes the forward hidden state at the preceding time step,
represents previous backward hidden states,
Wt is the weight of the forward hidden state,
vt corresponds to the weights of the backward hidden state, and
bt refers to the bias term.
3.4. Classification Module
The classification module is composed of four key components: a GAP layer, a fully connected (FC) layer, a dropout layer, and a softmax layer. The application of GAP before the fully connected (FC) layer serves two primary purposes: on the one hand, it reduces the model complexity and prevents overfitting; on the other hand, it is able to extract the global features of the timing information captured by the BiGRU module. After the FC layer merges features using a weight matrix, the number of parameters increases significantly, so the dropout layer is employed to prevent overfitting and enhance the model’s generalization ability. The merged features are then passed to a softmax classifier for category prediction. Instead of using standard cross-entropy loss, LSR is employed on top of it to soften the label distribution, improving robustness. Finally, the model is optimized by minimizing the loss function through backpropagation with the help of an optimization algorithm.
3.5. Fault Diagnosis Process
Figure 9 illustrates the overall framework for fault diagnosis. The fault diagnosis process contains offline modeling and online diagnosis.
Offline modeling stage:
Step 1: Acquire historical data from industrial processes, label the data, and randomly shuffle the dataset.
Step 2: Data preprocessing. Apply min–max normalization to scale the historical data into the [0, 1] range, and divide the dataset into training and testing sets.
Step 3: The DMCA-BiGRUN is established and trained on the training set.
Step 4: Feed the testing data into the trained model and evaluate the model performance. If the performance is suboptimal, continue to adjust model parameters. The best-performing model is saved whenever the performance improves.
Online diagnosis stage:
Step 1: Acquire the real-time industrial process monitoring data.
Step 2: The unlabeled data are normalized utilizing the min–max standardization method as the offline modeling stage.
Step 3: The preprocessed online data are fed into the trained DMCA-BiGRUN model to perform online diagnosis and identify fault types.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}