
Toward Adaptive Unsupervised and Blind Image Forgery Localization with ViT-VAE and a Gaussian Mixture Model


Abstract
1. Introduction
- To mitigate gradient instability, such as gradient explosion, we analyze the KL term in VAEs with GMMs and apply Jensen’s inequality to eliminate mixing coefficients and log-sum-exp functions, thereby reducing computational complexity.
- To optimize the estimation of GMM mixing coefficients in existing GMM-VAEs, we replace the multilayer perceptron (MLP) with a one-dimensional convolutional neural network (1D CNN). This substitution enhances computational efficiency and improves adaptability for image datasets.
- We evaluate DVVG on several benchmark datasets, demonstrating that our model achieves superior performance with lower computational complexity compared to other GMM-based VAE methods.
2. Related Works
3. Preliminaries
4. Methodology
4.1. Vanilla VAE Framework
4.2. Gaussian Mixture Model
4.3. VAE Enhanced by a GMM
| Algorithm 1: ViT-VAE with GMM algorithm |
 |
5. Experiments
5.1. Datasets
- COVERAGE: The COVERAGE [37] dataset is a novel benchmark designed specifically for evaluating copy–move forgery detection techniques. It consists of high-resolution images that include realistic forgeries created through various copy–move operations. These manipulations involve copying a region within an image and pasting it elsewhere in the same image, often with transformations such as rotation, scaling, or color adjustments to make the forgery less conspicuous. COVERAGE provides annotations for both the original and tampered regions, enabling precise evaluation of detection algorithms. COVERAGE contains 100 original–forged image pairs, where each original contains similar-but-genuine objects (SGOs), making the discrimination of forged from genuine objects highly challenging.
- DSO [38]: The DSO dataset is a specialized resource for image forgery detection and tampering localization, featuring a variety of forged and original images with corresponding pixel-level ground-truth masks, and contains 100 images. It encompasses common forgery types like splicing, copy–move, and post-processing effects (e.g., blurring and noise addition) to simulate realistic manipulation scenarios. With diverse content in terms of lighting, resolution, and image subjects, the dataset is widely used in training and benchmarking deep learning models for forgery detection and tampered-region localization. It serves as a critical tool in advancing research in digital forensics and image integrity verification.
- CASIA V1 [39]: The CASIA V1 dataset is a publicly available image dataset commonly used in research on image forgery detection. It contains 920 tampered images. The forgeries in this dataset were created using various manipulation techniques, such as copy–move and splicing, making it a valuable resource for developing and evaluating image forensic algorithms. The dataset covers diverse scenes and objects, contributing to its robustness for generalizing forgery detection models. Researchers often use CASIA V1 as a benchmark for assessing the effectiveness of different image authenticity verification methods.
- NIST2016 [40]: The NIST2016 dataset is a publicly available dataset designed for research on image and video forensics. It was developed as part of the Nimble Challenge to support the detection and localization of manipulations in visual media. The dataset contains 1124 images, including 560 authentic and 564 forged images, with forgery types such as splicing, copy–move, and content removal. It provides a standardized benchmark for evaluating forensic algorithms in tasks like image authenticity verification and provenance analysis.
5.2. Experimental Settings
5.3. Baseline
- NOI [9] utilizes the wavelet transform, and the wavelet coefficients of the tampered region are compared with those of the background region, thereby identifying the tampered area.
- ForSim [32] utilizes a novel forensic similarity metric to assess the similarity between digital images, aiming to detect tampering and forgery in images.
- Splicebuster [30] is a new blind image-splicing detector capable of detecting splicing forgeries in images without relying on prior information.
- Noiseprint [31] uses a CNN-based method for extracting camera model fingerprints, which can be used for source camera identification and tampering detection in image forensics.
- Mantra-Net [26] is a method for detecting and localizing forgeries in images, with a particular focus on identifying anomalous features.
- CAT-Net [27] is a method for detecting and localizing compression artifacts in image splicing, improving accuracy in image forensics.
- MVSS-Net [28] is a multi-view steganalysis and segmentation network for forgery detection, enabling localization of tampered regions in images.
- DFCN [2] uses a dual-branch fully convolutional network for image-splicing detection, effectively capturing features of tampered regions.
- OSN [29] builds a baseline detector. Through a systematic analysis of the introduced noise, the noise is decoupled into two types of independent modeling: predictable noise and unknown noise.
- ViT-VAE [18] is a Vision Transformer-based variational autoencoder for image anomaly detection, effectively capturing abnormal patterns in images.
5.4. Metrics
- Area Under the Curve (AUC): The AUC represents the area under the Receiver Operating Characteristic (ROC) curve, which plots the true positive rate (TPR) against the false positive rate (FPR) at various threshold settings. It provides a comprehensive measure of a model’s performance across all classification thresholds, where a higher AUC indicates better discrimination capability.
- F1 Score: The F1 score is the harmonic mean of precision and recall, defined aswhere precision measures the proportion of true positive predictions out of all positive predictions, and recall measures the proportion of true positive predictions out of all actual positives. The F1 score balances precision and recall, making it a useful metric in cases of imbalanced datasets.
- Intersection over Union (IoU): IoU, also known as the Jaccard Index, is a metric used to evaluate the overlap between two regions and is commonly used in object detection and segmentation tasks. It is calculated aswhere the intersection area is the common region between the predicted and ground-truth bounding boxes or masks, and the union area is the total area covered by both. An IoU closer to 1 indicates better overlap.
5.5. Results
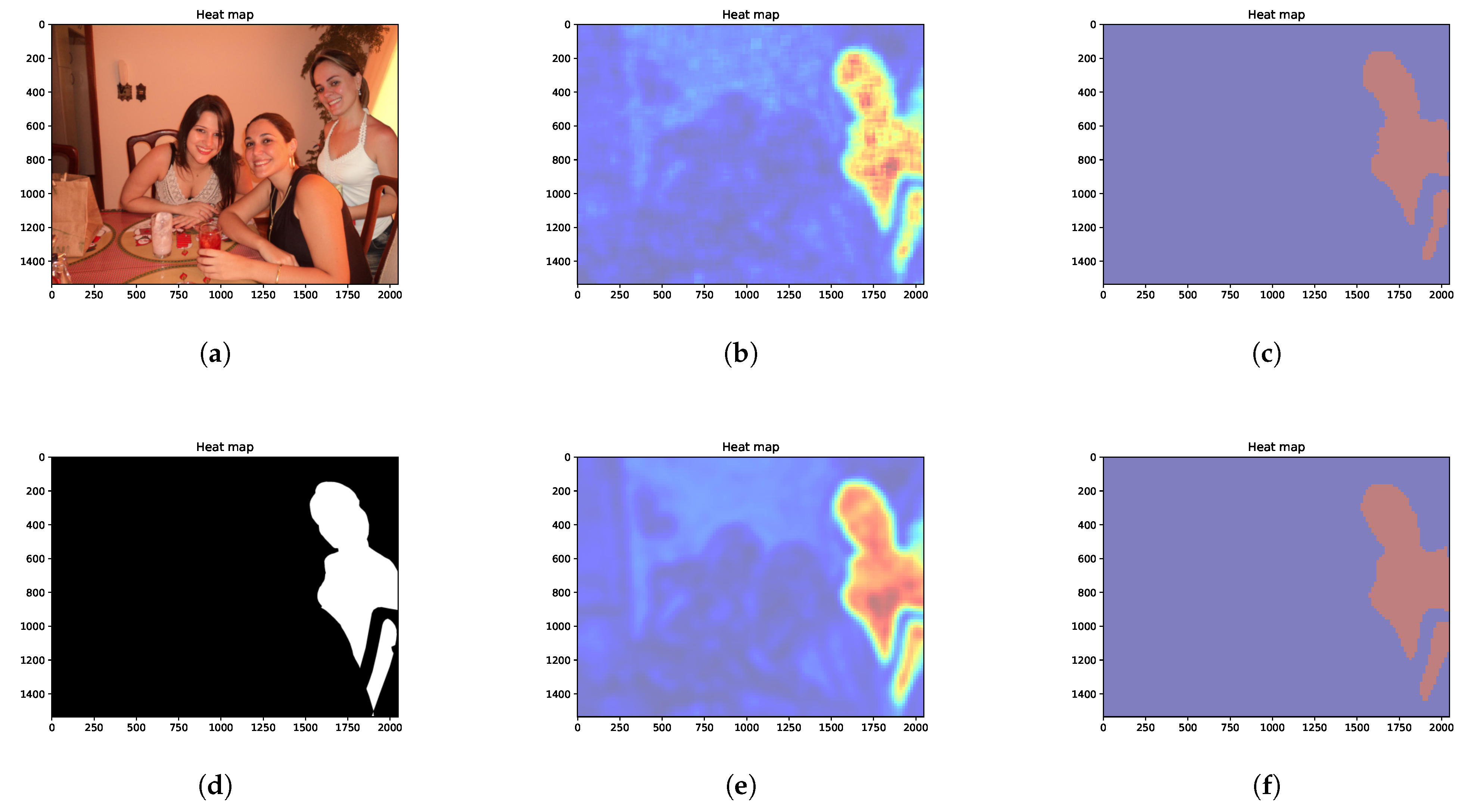
5.6. Latent Distribution Representation
5.7. Time and Space Complexity Analysis
5.8. Ablation Study and Parameter Sensitivity Analysis
6. Discussion and Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Chennamma, H.; Madhushree, B. A comprehensive survey on image authentication for tamper detection with localization. Multimed. Tools Appl. 2023, 82, 1873–1904. [Google Scholar] [CrossRef]
- Zhuang, P.; Li, H.; Tan, S.; Li, B.; Huang, J. Image Tampering Localization Using a Dense Fully Convolutional Network. IEEE Trans. Inf. Forensics Secur. 2021, 16, 2986–2999. [Google Scholar] [CrossRef]
- Bayar, B.; Stamm, M.C. Constrained convolutional neural networks: A new approach towards general purpose image manipulation detection. IEEE Trans. Inf. Forensics Secur. 2018, 13, 2691–2706. [Google Scholar] [CrossRef]
- Bappy, J.H.; Roy-Chowdhury, A.K.; Bunk, J.; Nataraj, L.; Manjunath, B. Exploiting spatial structure for localizing manipulated image regions. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4970–4979. [Google Scholar]
- Chen, X.; Dong, C.; Ji, J.; Cao, J.; Li, X. Image manipulation detection by multi-view multi-scale supervision. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 14185–14193. [Google Scholar]
- Amerini, I.; Ballan, L.; Caldelli, R.; Del Bimbo, A.; Serra, G. A sift-based forensic method for copy–move attack detection and transformation recovery. IEEE Trans. Inf. Forensics Secur. 2011, 6, 1099–1110. [Google Scholar] [CrossRef]
- Pandey, R.C.; Singh, S.K.; Shukla, K.K.; Agrawal, R. Fast and robust passive copy-move forgery detection using SURF and SIFT image features. In Proceedings of the 2014 9th International Conference on Industrial and Information Systems (ICIIS), Gwalior, India, 15–17 December 2014; pp. 1–6. [Google Scholar]
- Farid, H.; Lyu, S. Higher-order wavelet statistics and their application to digital forensics. In Proceedings of the 2003 Conference on Computer Vision and Pattern Recognition Workshop, Madison, WI, USA, 16–22 June 2003; Volume 8, p. 94. [Google Scholar]
- Mahdian, B.; Saic, S. Using noise inconsistencies for blind image forensics. Image Vis. Comput. 2009, 27, 1497–1503. [Google Scholar] [CrossRef]
- Popescu, A.C.; Farid, H. Exposing digital forgeries in color filter array interpolated images. IEEE Trans. Signal Process. 2005, 53, 3948–3959. [Google Scholar] [CrossRef]
- Stamm, M.C.; Liu, K.R. Forensic detection of image manipulation using statistical intrinsic fingerprints. IEEE Trans. Inf. Forensics Secur. 2010, 5, 492–506. [Google Scholar] [CrossRef]
- Xiang, Y.; Zhao, K.; Yin, H. SCCA-Net: A Novel Network for Image Manipulation Localization Using Split-Channel Contextual Attention. In Proceedings of the Asian Conference on Computer Vision (ACCV), Hanoi, Vietnam, 8–12 December 2024; pp. 4473–4487. [Google Scholar]
- Li, S.; Xu, S.; Ma, W.; Zong, Q. Image Manipulation Localization Using Attentional Cross-Domain CNN Features. IEEE Trans. Neural Netw. Learn. Syst. 2023, 34, 5614–5628. [Google Scholar] [CrossRef]
- Xu, D.; Shen, X.; Shi, Z.; Ta, N. Semantic-agnostic progressive subtractive network for image manipulation detection and localization. Neurocomputing 2023, 543, 126263. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Lin, X.; Wang, S.; Deng, J.; Fu, Y.; Bai, X.; Chen, X.; Qu, X.; Tang, W. Image manipulation detection by multiple tampering traces and edge artifact enhancement. Pattern Recognit. 2023, 133, 109026. [Google Scholar] [CrossRef]
- Xiang, Y.; Yuan, X.; Zhao, K.; Liu, T.; Xie, Z.; Huang, G.; Li, J. Image Manipulation Localization Using Dual-Shallow Feature Pyramid Fusion and Boundary Contextual Incoherence Enhancement. IEEE Trans. Emerg. Top. Comput. Intell. 2024, 1–11. [Google Scholar] [CrossRef]
- Chen, T.; Li, B.; Zeng, J. Learning traces by yourself: Blind image forgery localization via anomaly detection with ViT-VAE. IEEE Signal Process. Lett. 2023, 30, 150–154. [Google Scholar] [CrossRef]
- Liao, W.; Guo, Y.; Chen, X.; Li, P. A unified unsupervised gaussian mixture variational autoencoder for high dimensional outlier detection. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018; pp. 1208–1217. [Google Scholar]
- Zhou, C.; Ban, H.; Zhang, J.; Li, Q.; Zhang, Y. Gaussian mixture variational autoencoder for semi-supervised topic modeling. IEEE Access 2020, 8, 106843–106854. [Google Scholar] [CrossRef]
- Zong, B.; Song, Q.; Min, M.R.; Cheng, W.; Lumezanu, C.; Cho, D.; Chen, H. Deep autoencoding gaussian mixture model for unsupervised anomaly detection. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Khan, W.; Haroon, M.; Khan, A.N.; Hasan, M.K.; Khan, A.; Mokhtar, U.A.; Islam, S. Dvaegmm: Dual variational autoencoder with gaussian mixture model for anomaly detection on attributed networks. IEEE Access 2022, 10, 91160–91176. [Google Scholar] [CrossRef]
- Gu, C.; Xie, H.; Lu, X.; Zhang, C. Cgmvae: Coupling gmm prior and gmm estimator for unsupervised clustering and disentanglement. IEEE Access 2021, 9, 65140–65149. [Google Scholar] [CrossRef]
- Kumari, R.; Garg, H. Image splicing forgery detection: A review. Multimed. Tools Appl. 2025, 84, 4163–4201. [Google Scholar] [CrossRef]
- Pham, N.T.; Park, C.S. Toward deep-learning-based methods in image forgery detection: A survey. IEEE Access 2023, 11, 11224–11237. [Google Scholar] [CrossRef]
- Wu, Y.; AbdAlmageed, W.; Natarajan, P. Mantra-net: Manipulation tracing network for detection and localization of image forgeries with anomalous features. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9543–9552. [Google Scholar]
- Kwon, M.J.; Yu, I.J.; Nam, S.H.; Lee, H.K. CAT-Net: Compression Artifact Tracing Network for Detection and Localization of Image Splicing. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Virtual, 5–9 January 2021; pp. 375–384. [Google Scholar]
- Dong, C.; Chen, X.; Hu, R.; Cao, J.; Li, X. Mvss-net: Multi-view multi-scale supervised networks for image manipulation detection. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 3539–3553. [Google Scholar] [CrossRef]
- Wu, H.; Zhou, J.; Tian, J.; Liu, J.; Qiao, Y. Robust image forgery detection against transmission over online social networks. IEEE Trans. Inf. Forensics Secur. 2022, 17, 443–456. [Google Scholar] [CrossRef]
- Cozzolino, D.; Poggi, G.; Verdoliva, L. Splicebuster: A new blind image splicing detector. In Proceedings of the 2015 IEEE International Workshop on Information Forensics and Security (WIFS), Rome, Italy, 16–19 November 2015; pp. 1–6. [Google Scholar]
- Cozzolino, D.; Verdoliva, L. Noiseprint: A CNN-based camera model fingerprint. IEEE Trans. Inf. Forensics Secur. 2019, 15, 144–159. [Google Scholar] [CrossRef]
- Mayer, O.; Stamm, M.C. Forensic Similarity for Digital Images. IEEE Trans. Inf. Forensics Secur. 2019, 15, 1331–1346. [Google Scholar] [CrossRef]
- Lou, Z.; Cao, G.; Guo, K.; Yu, L.; Weng, S. Exploring Multi-View Pixel Contrast for General and Robust Image Forgery Localization. IEEE Trans. Inf. Forensics Secur. 2025, 20, 2329–2341. [Google Scholar] [CrossRef]
- Şahinuç, F.; Koç, A. Fractional Fourier transform meets transformer encoder. IEEE Signal Process. Lett. 2022, 29, 2258–2262. [Google Scholar] [CrossRef]
- Bouguila, N.; Fan, W. Mixture models and Applications; Springer: Berlin/Heidelberg, Germany, 2020. [Google Scholar]
- Liang, G.; U, K.; Chen, J.; Jiang, Z. Real-time traffic anomaly detection based on gaussian mixture model and hidden markov model. Concurr. Comput. Pract. Exp. 2021, e6714. [Google Scholar] [CrossRef]
- Wen, B.; Zhu, Y.; Subramanian, R.; Ng, T.T.; Shen, X.; Winkler, S. COVERAGE—A novel database for copy-move forgery detection. In Proceedings of the 2016 IEEE international conference on image processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 161–165. [Google Scholar]
- Carvalho, T.J.D.; Riess, C.; Angelopoulou, E.; Pedrini, H.; de Rezende Rocha, A. Exposing digital image forgeries by illumination color classification. IEEE Trans. Inf. Forensics Secur. 2013, 8, 1182–1194. [Google Scholar] [CrossRef]
- Dong, J.; Wang, W.; Tan, T. Casia image tampering detection evaluation database. In Proceedings of the 2013 IEEE China Summit and International Conference on Signal and Information Processing, Beijing, China, 6–10 July 2013; pp. 422–426. [Google Scholar]
- NIST Nimble 2016 Datasets. Online. 2016. Available online: https://www.nist.gov/itl/iad/mig/ (accessed on 23 January 2022).
- Cozzolino, D.; Verdoliva, L. Single-image splicing localization through autoencoder-based anomaly detection. In Proceedings of the 2016 IEEE International Workshop on Information Forensics and Security (WIFS), Abu Dhabi, United Arab Emirates, 4–7 December 2016; pp. 1–6. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | DSO | CASIA V1 | COVERAGE | NIST | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AUC | F1 | IoU | AUC | F1 | IoU | AUC | F1 | IoU | AUC | F1 | IoU | |
| Mantra-net [26] | 0.795 | 0.344 | 0.253 | 0.776 | 0.130 | 0.086 | 0.708 | 0.219 | 0.128 | 0.634 | 0.088 | 0.054 |
| CAT-Net [27] | 0.778 | 0.482 | 0.395 | 0.925 | 0.676 | 0.563 | 0.776 | 0.389 | 0.296 | 0.699 | 0.214 | 0.151 |
| MVSS [28] | 0.599 | 0.271 | 0.188 | 0.718 | 0.451 | 0.397 | 0.736 | 0.454 | 0.386 | 0.648 | 0.292 | 0.245 |
| DFCN [2] | 0.935 | 0.665 | 0.569 | 0.511 | 0.160 | 0.095 | 0.445 | 0.186 | 0.106 | 0.634 | 0.196 | 0.149 |
| OSN [29] | 0.854 | 0.436 | 0.308 | 0.873 | 0.509 | 0.465 | 0.777 | 0.266 | 0.180 | 0.783 | 0.332 | 0.255 |
| NOI [9] | 0.468 | 0.227 | 0.139 | 0.588 | 0.172 | 0.100 | 0.571 | 0.203 | 0.119 | 0.522 | 0.081 | 0.047 |
| ForSim [32] | 0.796 | 0.487 | 0.371 | 0.554 | 0.169 | 0.102 | 0.558 | 0.015 | 0.009 | 0.642 | 0.188 | 0.123 |
| Splicebuster [30] | 0.846 | 0.316 | 0.206 | 0.401 | 0.136 | 0.078 | 0.361 | 0.182 | 0.103 | 0.710 | 0.156 | 0.098 |
| Noiseprint [31] | 0.902 | 0.339 | 0.253 | 0.467 | 0.117 | 0.082 | 0.516 | 0.153 | 0.106 | 0.672 | 0.119 | 0.078 |
| ViT-VAE [18] | 0.938 | 0.745 | 0.663 | 0.587 | 0.159 | 0.106 | 0.599 | 0.173 | 0.108 | 0.738 | 0.232 | 0.171 |
| Our model | 0.938 | 0.754 | 0.681 | 0.589 | 0.169 | 0.111 | 0.599 | 0.194 | 0.117 | 0.738 | 0.265 | 0.204 |
| Model | Time Complexity of GMM in Theory | Real Time Consumption per Epoch |
|---|---|---|
| EM | 6.7620 s | |
| DVAEGMM [22] | 294.10 ms | |
| Our model | 141.00 ms |
| Model | AUC | F1 | IoU |
|---|---|---|---|
| AE [41] | 0.767 | 0.511 | 0.425 |
| VAE-CNN | 0.930 | 0.689 | 0.602 |
| ViT-VAE [18] | 0.938 | 0.745 | 0.663 |
| ViT-VAE + EM | 0.835 | 0.694 | 0.561 |
| 0.918 | 0.715 | 0.634 | |
| 0.930 | 0.721 | 0.614 | |
| 0.938 | 0.754 | 0.681 | |
| 0.912 | 0.723 | 0.643 | |
| 0.928 | 0.748 | 0.669 | |
| 0.934 | 0.751 | 0.673 | |
| 0.938 | 0.754 | 0.681 | |
| 0.930 | 0.743 | 0.656 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yin, H.; U, K.; Wang, J.; Ma, W. Toward Adaptive Unsupervised and Blind Image Forgery Localization with ViT-VAE and a Gaussian Mixture Model. Mathematics 2025, 13, 2285. https://doi.org/10.3390/math13142285
Yin H, U K, Wang J, Ma W. Toward Adaptive Unsupervised and Blind Image Forgery Localization with ViT-VAE and a Gaussian Mixture Model. Mathematics. 2025; 13(14):2285. https://doi.org/10.3390/math13142285
Chicago/Turabian StyleYin, Haichang, KinTak U, Jing Wang, and Wuyue Ma. 2025. "Toward Adaptive Unsupervised and Blind Image Forgery Localization with ViT-VAE and a Gaussian Mixture Model" Mathematics 13, no. 14: 2285. https://doi.org/10.3390/math13142285
APA StyleYin, H., U, K., Wang, J., & Ma, W. (2025). Toward Adaptive Unsupervised and Blind Image Forgery Localization with ViT-VAE and a Gaussian Mixture Model. Mathematics, 13(14), 2285. https://doi.org/10.3390/math13142285