
A Deep Learning-Driven Solution to Limited-Feedback MIMO Relaying Systems

 , , , and
, , , and 
Abstract
1. Introduction
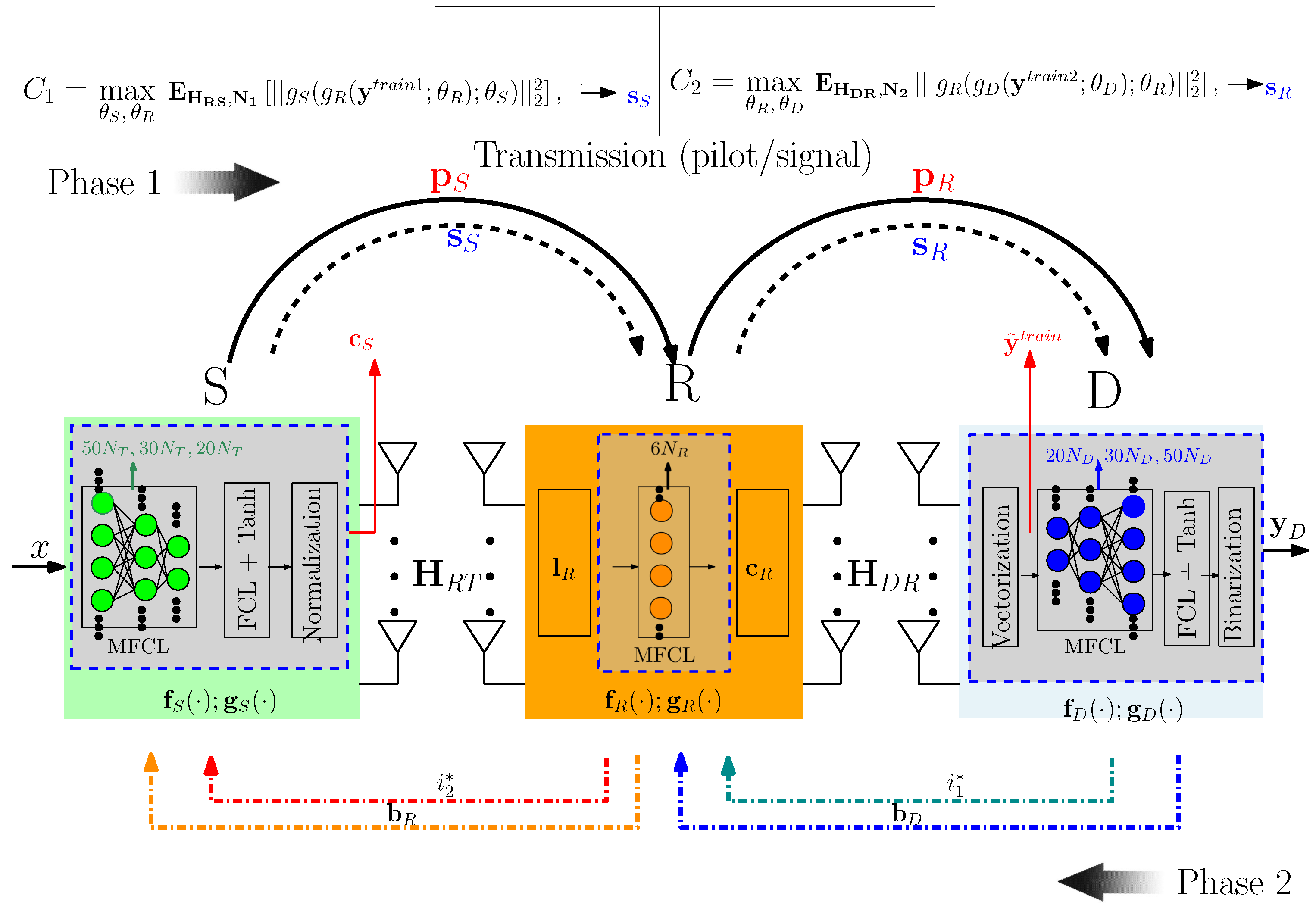
2. System Model and Problem Formulation
2.1. Conventional Approach
2.2. DNN Approach
2.2.1. Pilot Signal Modeling and Aggregation
2.2.2. DNN Training and Learning
2.2.3. Transformation of Optimization Problem Resulting from Chaining
2.2.4. Stochastic Binarization
3. Configuration and Training of DNN Model
Complexity Analysis
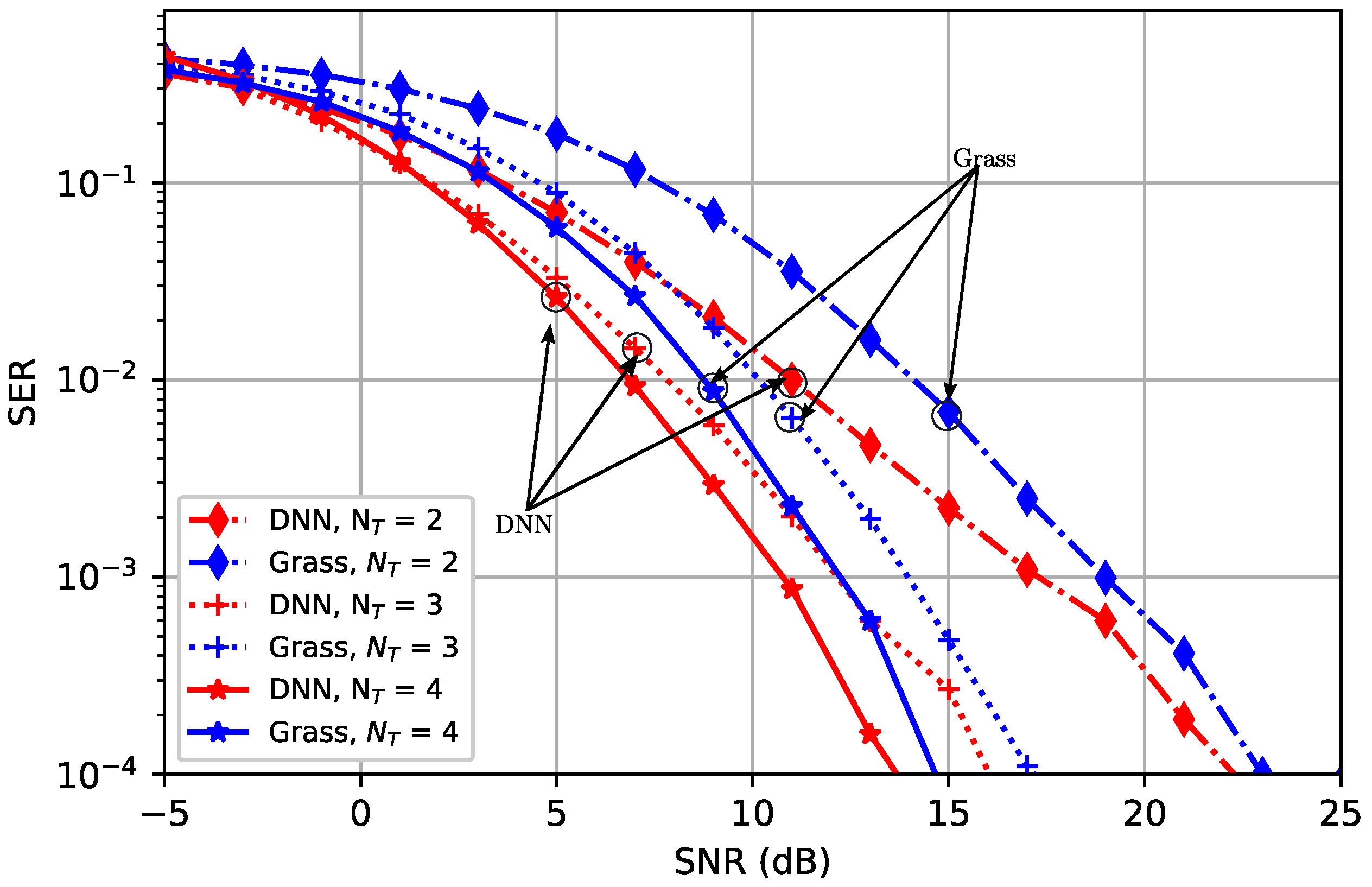
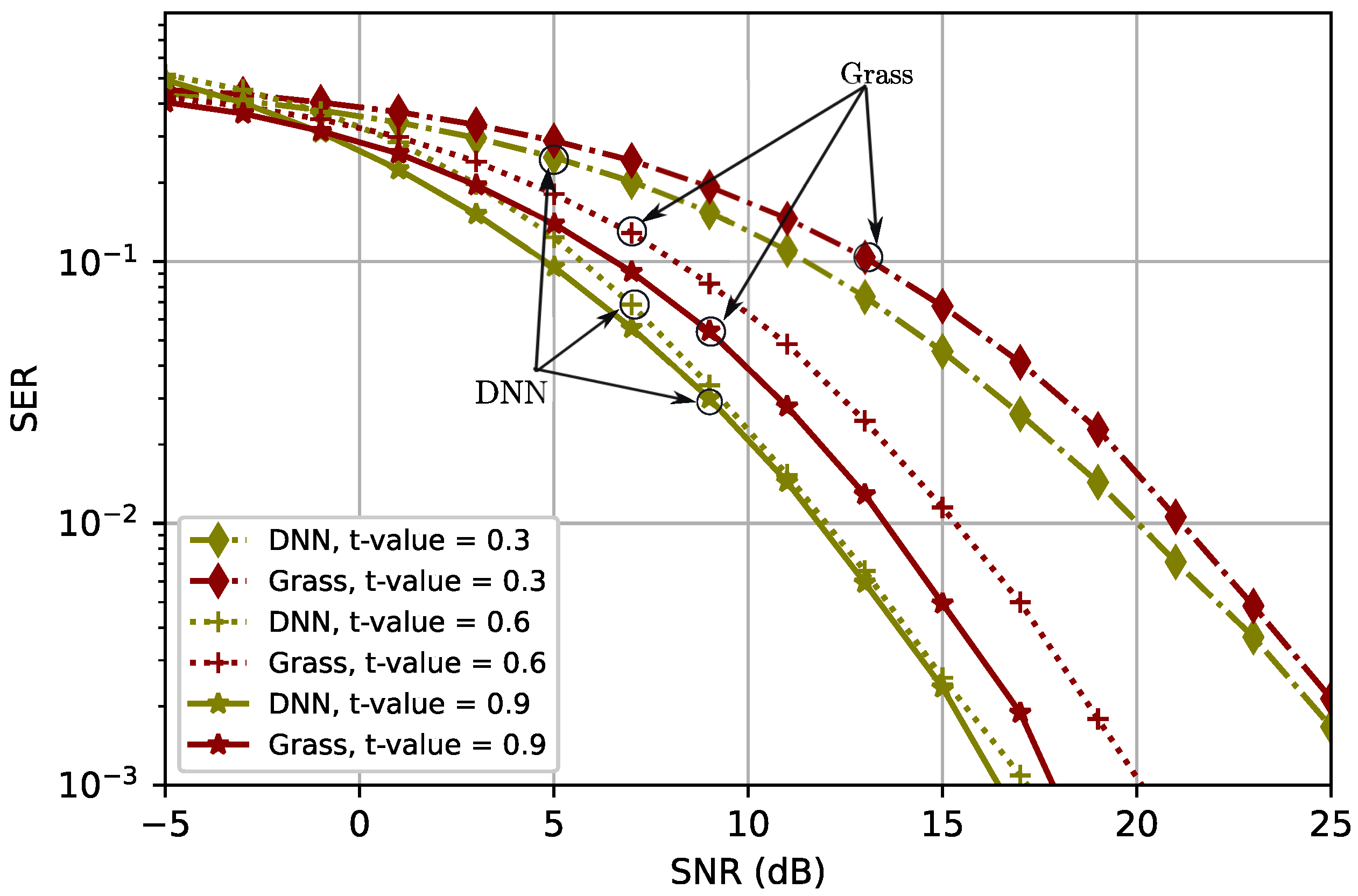
4. Simulation Results
4.1. Grassmannian-Based Benchmark
4.2. Analysis
4.3. Deployment, Practical Considerations, and Limitations
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| AF | Amplify-and-Forward |
| CE | Channel Estimation |
| CSI | Channel State Information |
| DF | Decode-and-Forward |
| DFT | Discrete Fourier Transform |
| DL | Deep Learning |
| DNN | Deep Neural Network |
| FCL | Fully Connected Layers |
| FDD | Frequency-Division Duplexing |
| GB | Grassmannian Codebook |
| GD | Gradient Descent |
| GPU | Graphic Processing Units |
| MFCL | Multiple Fully Connected Layers |
| MIMO | Multiple-Input Multiple-Output |
| ML | Machine Learning |
| MMSE | Minimum Mean-Squared Error |
| PMI | Precoding Matrix Index |
| ReLU | Rectified Linear Unit |
| SER | Symbol Error Rate |
| SGD | Stochastic Gradient Descent |
| SVD | Singular Value Decomposition |
| TPU | Tensor Processing Unit |
References
- Guo, J.; Wen, C.K.; Chen, M.; Jin, S. Environment Knowledge-Aided Massive MIMO Feedback Codebook Enhancement Using Artificial Intelligence. IEEE Trans. Commun. 2022, 70, 4527–4542. [Google Scholar] [CrossRef]
- Liang, P.; Fan, J.; Shen, W.; Qin, Z.; Li, G.Y. Deep Learning and Compressive Sensing-Based CSI Feedback in FDD Massive MIMO Systems. IEEE Trans. Veh. Technol. 2020, 69, 9217–9222. [Google Scholar] [CrossRef]
- Zhu, Z.; Yang, R.; Zhang, J.; Xu, S.; Li, C.; Huang, Y.; Yang, L. Sparse Bayesian Learning-Based Adaptive Codebook for Near-Field Channel Estimation. In Proceedings of the ICC 2024—IEEE International Conference on Communications, Denver, CO, USA, 9–13 June 2024; pp. 2366–2371. [Google Scholar] [CrossRef]
- Yoon, S.G.; Lee, S.J. Improved Hierarchical Codebook-Based Channel Estimation for mmWave Massive MIMO Systems. IEEE Wirel. Commun. Lett. 2022, 11, 2095–2099. [Google Scholar] [CrossRef]
- Fu, X.; Le Ruyet, D.; Visoz, R.; Ramireddy, V.; Grossmann, M.; Landmann, M.; Quiroga, W. A Tutorial on Downlink Precoder Selection Strategies for 3GPP MIMO Codebooks. IEEE Access 2023, 11, 138897–138922. [Google Scholar] [CrossRef]
- Mabrouki, S.; Dayoub, I.; Li, Q.; Berbineau, M. Codebook Designs for Millimeter-Wave Communication Systems in Both Low- and High-Mobility: Achievements and Challenges. IEEE Access 2022, 10, 25786–25810. [Google Scholar] [CrossRef]
- Schwarz, S.; Rupp, M.; Wesemann, S. Grassmannian Product Codebooks for Limited Feedback Massive MIMO with Two-Tier Precoding. IEEE J. Sel. Top. Signal Process. 2019, 13, 1119–1135. [Google Scholar] [CrossRef]
- Jang, J.; Lee, H.; Hwang, S.; Ren, H.; Lee, I. Deep learning-based limited feedback designs for MIMO systems. IEEE Wirel. Commun. Lett. 2019, 9, 558–561. [Google Scholar] [CrossRef]
- Ahmed, Y.N.; Fahmy, Y. On the complexity reduction of codebook search in FDD massive MIMO using hierarchical search. In Proceedings of the 2018 International Conference on Innovative Trends in Computer Engineering (ITCE), Aswan, Egypt, 19–21 February 2018; pp. 175–179. [Google Scholar] [CrossRef]
- Ofori-Amanfo, K.B.; Asiedu, D.K.P.; Ahiadormey, R.K.; Lee, K.J. Multi-Hop MIMO Relaying Based on Simultaneous Wireless Information and Power Transfer. IEEE Access 2021, 9, 144857–144870. [Google Scholar] [CrossRef]
- Lee, K.J.; Sung, H.; Park, E.; Lee, I. Joint Optimization for One and Two-Way MIMO AF Multiple-Relay Systems. IEEE Trans. Wirel. Commun. 2010, 9, 3671–3681. [Google Scholar] [CrossRef]
- Song, C.; Lee, K.J.; Lee, I. Performance Analysis of MMSE-Based Amplify and Forward Spatial Multiplexing MIMO Relaying Systems. IEEE Trans. Commun. 2011, 59, 3452–3462. [Google Scholar] [CrossRef]
- Zhang, Y.; El-Hajjar, M.; Yang, L.L. Adaptive Codebook-Based Channel Estimation in OFDM-Aided Hybrid Beamforming mmWave Systems. IEEE Open J. Commun. Soc. 2022, 3, 1553–1562. [Google Scholar] [CrossRef]
- Wen, C.K.; Shih, W.T.; Jin, S. Deep learning for massive MIMO CSI feedback. IEEE Wirel. Commun. Lett. 2018, 7, 748–751. [Google Scholar] [CrossRef]
- Brilhante, D.d.S.; Manjarres, J.C.; Moreira, R.; de Oliveira Veiga, L.; de Rezende, J.F.; Müller, F.; Klautau, A.; Leonel Mendes, L.; de Figueiredo, F.A.P. A literature survey on AI-aided beamforming and beam management for 5G and 6G systems. Sensors 2023, 23, 4359. [Google Scholar] [CrossRef] [PubMed]
- Nada, A.E.R.; Mehana, A.M.H. A Comparative Study of PMI/RI Selection Schemes for LTE/LTEA Systems. IEEE Trans. Veh. Technol. 2018, 67, 1444–1453. [Google Scholar] [CrossRef]
- Zhang, M.; Shafi, M.; Smith, P.J.; Dmochowski, P.A. Precoding Performance with Codebook Feedback in a MIMO-OFDM System. In Proceedings of the 2011 IEEE International Conference on Communications (ICC), Kyoto, Japan, 5–9 June 2011; pp. 1–6. [Google Scholar] [CrossRef]
- Asiedu, D.K.P.; Lee, H.; Lee, K.J. Simultaneous Wireless Information and Power Transfer for Decode-and-Forward Multihop Relay Systems in Energy-Constrained IoT Networks. IEEE Internet Things J. 2019, 6, 9413–9426. [Google Scholar] [CrossRef]
- Laue, H.E.A.; du Plessis, W.P. A Coherence-Based Algorithm for Optimizing Rank-1 Grassmannian Codebooks. IEEE Signal Process. Lett. 2017, 24, 823–827. [Google Scholar] [CrossRef]
- Schwarz, S.; Tsiftsis, T. Codebook Training for Trellis-Based Hierarchical Grassmannian Classification. IEEE Wirel. Commun. Lett. 2022, 11, 636–640. [Google Scholar] [CrossRef]
- Li, S.; Jia, H.; Kang, J. Robust Codebook Design Based on Unitary Rotation of Grassmannian Codebook. In Proceedings of the 2010 IEEE 72nd Vehicular Technology Conference—Fall, Ottawa, ON, Canada, 6–9 September 2010. [Google Scholar] [CrossRef]
- Lim, S.; Shin, M.; Paik, J. Point Cloud Generation Using Deep Adversarial Local Features for Augmented and Mixed Reality Contents. IEEE Trans. Consum. Electron. 2022, 68, 69–76. [Google Scholar] [CrossRef]
- Melgar, A.; de la Fuente, A.; Carro-Calvo, L.; Barquero-Pérez, Ó.; Morgado, E. Deep Neural Network: An Alternative to Traditional Channel Estimators in Massive MIMO Systems. IEEE Trans. Cogn. Commun. Netw. 2022, 8, 657–671. [Google Scholar] [CrossRef]
- Villardi, G.P.; Ishizu, K.; Kojima, F. Reducing the Codeword Search Complexity of FDD Moderately Large MIMO Beamforming Systems. IEEE Trans. Commun. 2019, 67, 273–287. [Google Scholar] [CrossRef]
- Baek, S.; Moon, J.; Park, J.; Song, C.; Lee, I. Real-Time Machine Learning Methods for Two-Way End-to-End Wireless Communication Systems. IEEE Internet Things J. 2022, 9, 22983–22992. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
| Nodal Components and Roles | ||||
|---|---|---|---|---|
| Component | S | R | D | Role |
| Fully Connected Layers (FCL) | ✓ | ✓ | ✓ | combines features from previous layer into single vector |
| Multiple Fully Connected Layers (MFCL) | ✓ | ✓ | ✓ | a chain of ReLU activated FCLs |
| Binarization | ✗ | ✗ | ✓ | Removes combinatorial constraint of (13) |
| Computational Complexity | ||
|---|---|---|
| Component | Traditional System | DNN-Based System |
| Beamforming (e.g., MRT, ZF) | Matrix-vector or matrix inverse () | NN forward pass () |
| Feedback encoding | Codebook search: () for M-size codebook | Neural encoder () |
| Memory & Training Complexities | ||
| Criterion | Traditional System | DNN-Based System |
| Storage needed | Explicityly stored codebooks (()) | Params of nodes |
| Training cost | None | High & higher inference |
| Feedback Overhead | ||
| Criterion | Traditional System | DNN-Based System |
| Number of feedback bits | Explicit bits to codebook index | Neural quantization-based |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ofori-Amanfo, K.B.; Antwi-Boasiako, B.D.; Anokye, P.; Shin, S.; Lee, K.-J. A Deep Learning-Driven Solution to Limited-Feedback MIMO Relaying Systems. Mathematics 2025, 13, 2246. https://doi.org/10.3390/math13142246
Ofori-Amanfo KB, Antwi-Boasiako BD, Anokye P, Shin S, Lee K-J. A Deep Learning-Driven Solution to Limited-Feedback MIMO Relaying Systems. Mathematics. 2025; 13(14):2246. https://doi.org/10.3390/math13142246
Chicago/Turabian StyleOfori-Amanfo, Kwadwo Boateng, Bridget Durowaa Antwi-Boasiako, Prince Anokye, Suho Shin, and Kyoung-Jae Lee. 2025. "A Deep Learning-Driven Solution to Limited-Feedback MIMO Relaying Systems" Mathematics 13, no. 14: 2246. https://doi.org/10.3390/math13142246
APA StyleOfori-Amanfo, K. B., Antwi-Boasiako, B. D., Anokye, P., Shin, S., & Lee, K.-J. (2025). A Deep Learning-Driven Solution to Limited-Feedback MIMO Relaying Systems. Mathematics, 13(14), 2246. https://doi.org/10.3390/math13142246