
Towards Analysis of Covariance Descriptors via Bures–Wasserstein Distance



Abstract
1. Introduction
2. Methodology
2.1. Mathematical Properties of the BW Metric
- 1.
- .
- 2.
- .
- 3.
- for any .
- 4.
- .
- 5.
- for nonsingular M.
- 6.
- .
- 7.
- 8.
- In the Löwner order, if and , then
- 9.
- .
- 1.
- .
- 2.
- When , if and only if .
- 3.
- for any .
- 4.
- .
- 5.
- .
- 6.
- In the Löwner order, .
- 1.
- , where U is a certain orthogonal matrix occurring in a polar decomposition of , i.e., .
- 2.
- . In particular, if is PSD (such as when ), then .
- 1.
- If and , then
- 2.
- If satisfy that for , then
- Let U be an orthogonal matrix in the polar decomposition of . When , Bhatia, Jain, and Lim showed that (see [33], Theorem 1): , which can be extended to the following property of BW distance.
- The tangent space at a PD matrix can be identified with the space of real symmetric matrices. The logarithm function projects a neighborhood of A to a neighborhood of 0 in such that for : The inverse of logarithm function is the exponential function, which maps a neighborhood of 0 in to a neighborhood of A in . Both functions, illustrated in Figure 1A, can be extended to the boundary of under mild conditions (for a PSD matrix A, the domain of the exponential function at A only covers part of ; seeTheorem 8). With the logarithm and exponential functions, many methods that work in Euclidean tangent space are applicable to the manifold. Therefore, the following derivation of the log and exp functions is imperative for further analysis.
- The spectral decomposition implies that every can be written as in which is real orthogonal and is nonnegative diagonal with eigenvalues of A as its diagonal entries. Lemma A1 in Appendix A suggests that the BW metric in the vicinity of A can be effectively transformed to correspond with that around the diagonal matrix . This transformation plays a pivotal role in simplifying the computations that follow.
- The exponential map under the BW metric has been described in [35,41]. In this work, we present a succinct formulation of the exponential map, explicitly delineating its precise domain. We also provide an approximation of when X is a Hermitian matrix near 0. For matrices , let denote the Hadamard product of A and B.
- Similarly, the exponential function and its approximation derived in Lemma A2 for the case of A being a positive diagonal matrix can also be further defined for general cases.
2.2. Barycenter Estimation with BW Distance
- Inductive Mean Algorithm (Algorithm 1) estimates the barycenter of along the geodesic that connects two points on , as illustrated in Figure 1B with four data points as an example. The initial barycenter is set to be the first data point, , and then the barycenter is updated as the middle point along the geodesic that connects and , i.e., . In the iteration process, given , the updated barycenter is the point along the geodesic connecting and , with for all .
| Algorithm 1: Inductive Mean Algorithm |
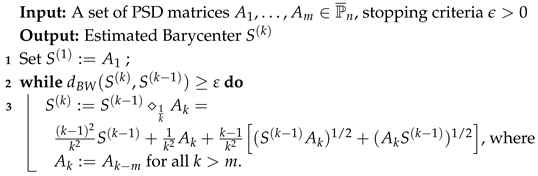 |
- Projection Mean Algorithm (Algorithm 2) accounts for the fact that the arithmetic center of the projections of onto the tangent space at the barycenter C is exactly the projection of C (i.e., ). Inspired by this, the iteration starts with projecting the data points from onto the tangent space at the arithmetic center of the original data. Then, the arithmetic mean of the tangent vectors is computed and projected back to as the updated barycenter. The iteration stops when the distance between the estimated barycenter obtained in two consecutive iterations are less than the preset error tolerance . The details of the algorithm are summarized below.
| Algorithm 2: Projection Mean Algorithm |
 |
- Cheap Mean Algorithm [48] (Algorithm 3) also utilizes the Log and Exp functions to project matrices between and the tangent space. Different from the Projection Algorithm that only updates the estimated barycenter, the Cheap Mean Algorithm updates the estimated barycenter as well as the original matrices. Moreover, unlike the Projection Mean Algorithm that only spans the tangent space at the estimated barycenter in the iterations, the Cheap Mean Algorithm spans the tangent space at each data matrix. Specifically, for each original matrix , which also serves as the initiation of , all matrices are projected onto the tangent space spanned at , then the arithmetic mean of the tangent vectors are projected back to and serve as the update of , denoted as . Each data matrix is updated during the iteration process, and the iteration stops when the changes of the arithmetic mean of all updated matrices () is less than . The iterative process is outlined as follows:
| Algorithm 3: Cheap Mean Algorithm |
 |
2.3. Classification with BW Barycenter
3. Simulation Results
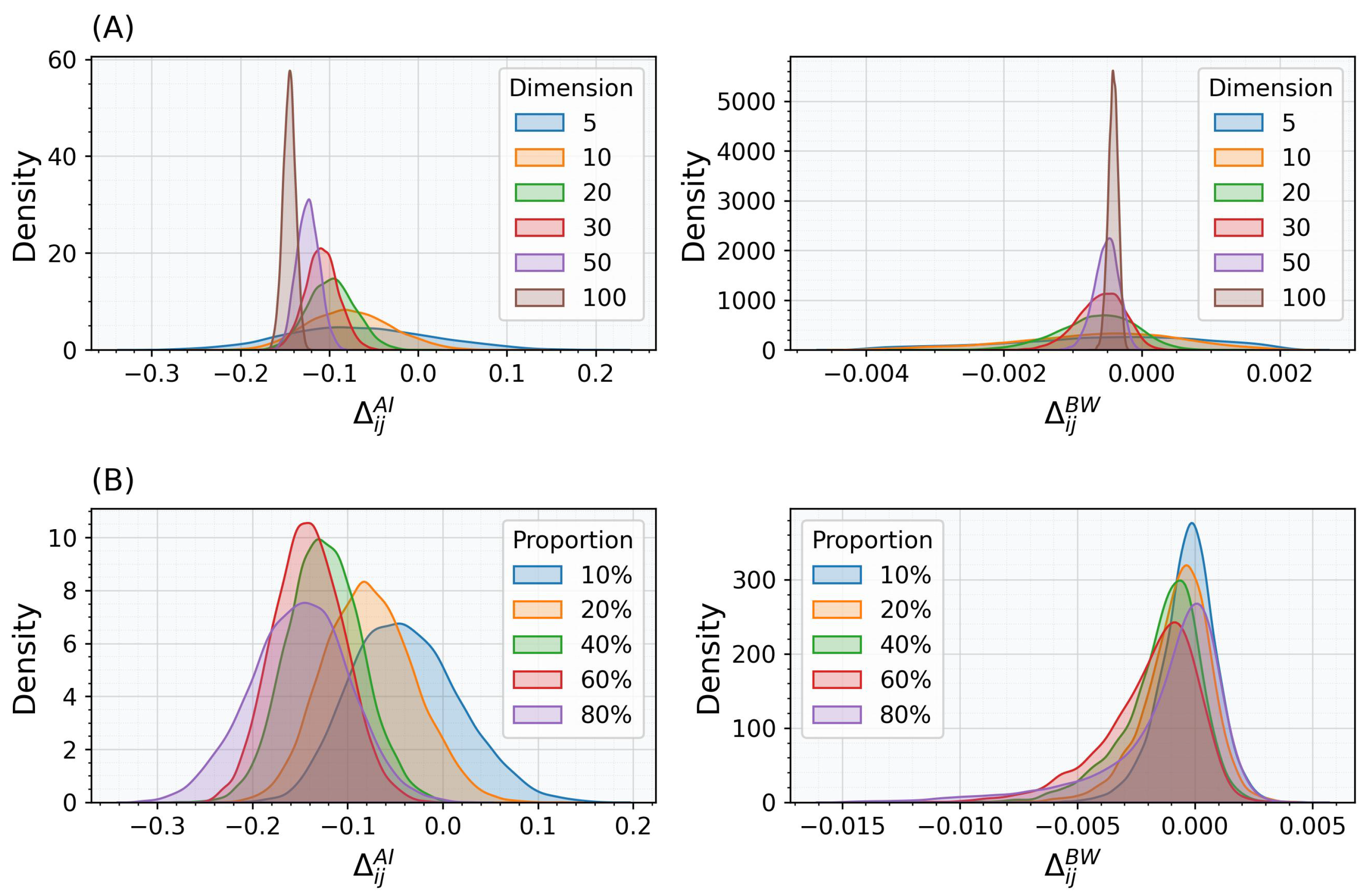
3.1. Robustness of BW Distance
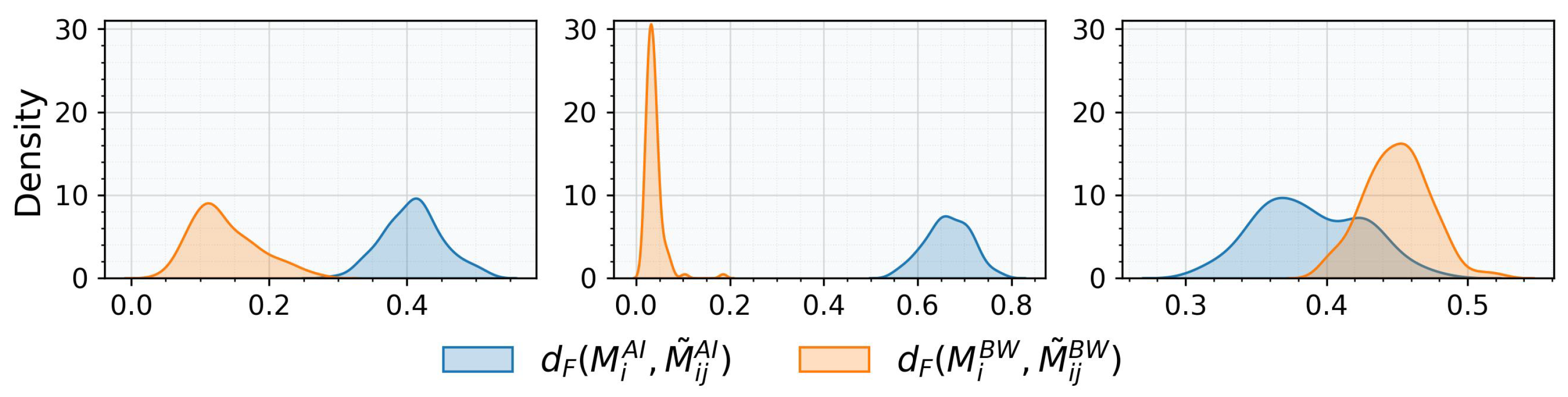
3.2. Robustness of BW Barycenter for Two Matrices
3.3. Properties of BW Barycenter for More than Two Matrices
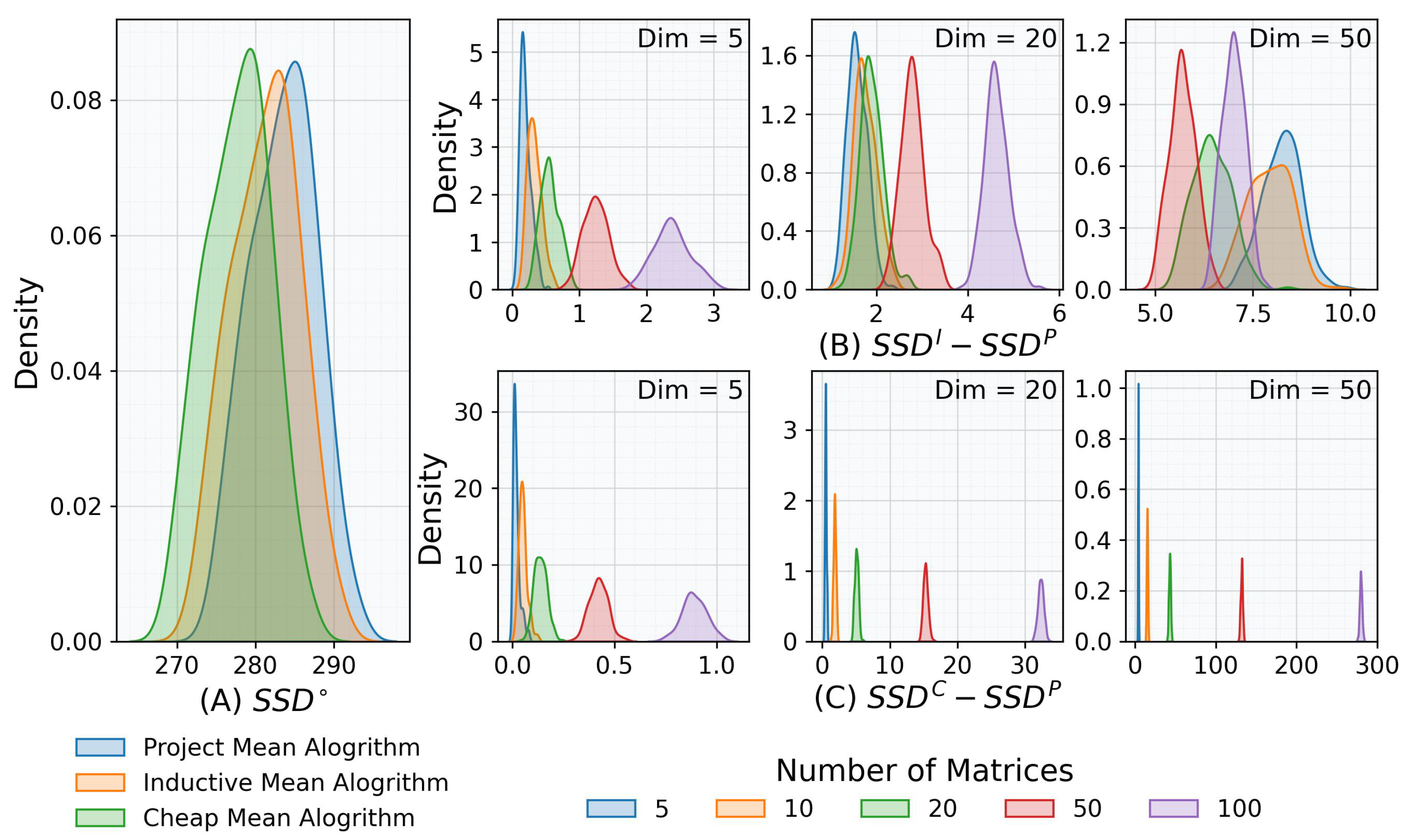
3.3.1. Efficiency of Barycenter Estimation with BW Distance
3.3.2. Accuracy of Barycenter Estimation with BW Distance
3.3.3. Robustness of Barycenter Estimation with BW Distance
4. Real Data Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A
- 1.
- If and , then
- 2.
- If satisfy that for , then
References
- Schirrmeister, R.T.; Springenberg, J.T.; Fiederer, L.D.J.; Glasstetter, M.; Eggensperger, K.; Tangermann, M.; Hutter, F.; Burgard, W.; Ball, T. Deep learning with convolutional neural networks for EEG decoding and visualization. Hum. Brain Mapp. 2017, 38, 5391–5420. [Google Scholar] [CrossRef]
- Zheng, J.; Liang, M.; Sinha, S.; Ge, L.; Yu, W.; Ekstrom, A.; Hsieh, F. Time-frequency analysis of scalp EEG with Hilbert-Huang transform and deep learning. IEEE J. Biomed. Health Inform. 2021, 26, 1549–1559. [Google Scholar] [CrossRef] [PubMed]
- Qiu, A.; Lee, A.; Tan, M.; Chung, M.K. Manifold learning on brain functional networks in aging. Med. Image Anal. 2015, 20, 52–60. [Google Scholar] [CrossRef] [PubMed]
- Varoquaux, G.; Baronnet, F.; Kleinschmidt, A.; Fillard, P.; Thirion, B. Detection of brain functional-connectivity difference in post-stroke patients using group-level covariance modeling. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2010: 13th International Conference, Beijing, China, 20–24 September 2010; Proceedings, Part I 13. Springer: Berlin/Heidelberg, Germany, 2010; pp. 200–208. [Google Scholar]
- Barachant, A.; Bonnet, S.; Congedo, M.; Jutten, C. Riemannian Geometry Applied to BCI Classification. In Proceedings of the Latent Variable Analysis and Signal Separation, St. Malo, France, 27–30 September 2010; Vigneron, V., Zarzoso, V., Moreau, E., Gribonval, R., Vincent, E., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; pp. 629–636. [Google Scholar]
- Barachant, A.; Bonnet, S.; Congedo, M.; Jutten, C. Classification of Covariance Matrices Using a Riemannian-Based Kernel for BCI Applications. Neurocomput. 2013, 112, 172–178. [Google Scholar] [CrossRef]
- Miah, A.S.M.; Islam, M.R.; Molla, M.K.I. EEG classification for MI-BCI using CSP with averaging covariance matrices: An experimental study. In Proceedings of the 2019 International Conference on Computer, Communication, Chemical, Materials and Electronic Engineering (IC4ME2), Rajshahi, Bangladesh, 1–12 July 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–5. [Google Scholar]
- Chen, K.X.; Ren, J.Y.; Wu, X.J.; Kittler, J. Covariance descriptors on a Gaussian manifold and their application to image set classification. Pattern Recognit. 2020, 107, 107463. [Google Scholar] [CrossRef]
- Porikli, F.; Tuzel, O.; Meer, P. Covariance tracking using model update based on lie algebra. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006; IEEE: Piscataway, NJ, USA, 2006; Volume 1, pp. 728–735. [Google Scholar]
- Sivalingam, R.; Boley, D.; Morellas, V.; Papanikolopoulos, N. Tensor sparse coding for region covariances. In Proceedings of the Computer Vision–ECCV 2010: 11th European Conference on Computer Vision, Heraklion, Crete, Greece, 5–11 September 2010; Proceedings, Part IV 11. Springer: Berlin/Heidelberg, Germany, 2010; pp. 722–735. [Google Scholar]
- Jagarlamudi, J.; Udupa, R.; Daumé III, H.; Bhole, A. Improving bilingual projections via sparse covariance matrices. In Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing, Edinburgh, UK, 27–29 July 2011; pp. 930–940. [Google Scholar]
- Zhang, W.; Fung, P. Discriminatively trained sparse inverse covariance matrices for speech recognition. IEEE/ACM Trans. Audio Speech Lang. Process. 2014, 22, 873–882. [Google Scholar] [CrossRef]
- Cui, Z.; Li, W.; Xu, D.; Shan, S.; Chen, X.; Li, X. Flowing on Riemannian Manifold: Domain Adaptation by Shifting Covariance. IEEE Trans. Cybern. 2014, 44, 2264–2273. [Google Scholar] [CrossRef]
- Zhang, Z.; Wang, M.; Huang, Y.; Nehorai, A. Aligning infinite-dimensional covariance matrices in reproducing kernel hilbert spaces for domain adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3437–3445. [Google Scholar]
- He, N.; Fang, L.; Li, S.; Plaza, A.; Plaza, J. Remote sensing scene classification using multilayer stacked covariance pooling. IEEE Trans. Geosci. Remote Sens. 2018, 56, 6899–6910. [Google Scholar] [CrossRef]
- Eklundh, L.; Singh, A. A comparative analysis of standardised and unstandardised principal components analysis in remote sensing. Int. J. Remote Sens. 1993, 14, 1359–1370. [Google Scholar] [CrossRef]
- Yang, D.; Gu, C.; Dong, Z.; Jirutitijaroen, P.; Chen, N.; Walsh, W.M. Solar irradiance forecasting using spatial-temporal covariance structures and time-forward kriging. Renew. Energy 2013, 60, 235–245. [Google Scholar] [CrossRef]
- Meyer, K. Factor-analytic models for genotype× environment type problems and structured covariance matrices. Genet. Sel. Evol. 2009, 41, 21. [Google Scholar] [CrossRef]
- Huang, Z.; Wang, R.; Shan, S.; Chen, X. Face recognition on large-scale video in the wild with hybrid Euclidean-and-Riemannian metric learning. Pattern Recognit. 2015, 48, 3113–3124. [Google Scholar] [CrossRef]
- Arsigny, V.; Fillard, P.; Pennec, X.; Ayache, N. Geometric means in a novel vector space structure on symmetric positive-definite matrices. SIAM J. Matrix Anal. Appl. 2007, 29, 328–347. [Google Scholar] [CrossRef]
- Jayasumana, S.; Hartley, R.; Salzmann, M.; Li, H.; Harandi, M. Kernel methods on the Riemannian manifold of symmetric positive definite matrices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 73–80. [Google Scholar]
- Huang, Z.; Wang, R.; Shan, S.; Li, X.; Chen, X. Log-euclidean metric learning on symmetric positive definite manifold with application to image set classification. In Proceedings of the International Conference on Machine Learning, PMLR, Lille, France, 6–11 July 2015; pp. 720–729. [Google Scholar]
- Lin, Z. Riemannian geometry of symmetric positive definite matrices via Cholesky decomposition. SIAM J. Matrix Anal. Appl. 2019, 40, 1353–1370. [Google Scholar] [CrossRef]
- Pennec, X. Manifold-valued image processing with SPD matrices. In Riemannian Geometric Statistics in Medical Image Analysis; Elsevier: Amsterdam, The Netherlands, 2020; pp. 75–134. [Google Scholar]
- Ledoit, O.; Wolf, M. A well-conditioned estimator for large-dimensional covariance matrices. J. Multivar. Anal. 2004, 88, 365–411. [Google Scholar] [CrossRef]
- Kotz, S.; Johnson, N.L. (Eds.) Breakthroughs in Statistics: Methodology and Distribution; Springer Series in Statistics; Perspectives in Statistics; Springer: New York, NY, USA, 1992; Volume II, pp. xxii+600. [Google Scholar]
- Villani, C. Topics in Optimal Transportation; Graduate Studies in Mathematics; American Mathematical Society: Providence, RI, USA, 2003; Volume 58, pp. xvi+370. [Google Scholar] [CrossRef]
- Villani, C. Optimal Transport: Old and New; Grundlehren der Mathematischen Wissenschaften [Fundamental Principles of Mathematical Sciences]; Springer: Berlin/Heidelberg, Germany, 2009; Volume 338, pp. xxii+973. [Google Scholar] [CrossRef]
- Hayashi, M. Quantum Information Theory: Mathematical Foundation, 2nd ed.; Graduate Texts in Physics; Springer: Berlin/Heidelberg, Germany, 2017; pp. xli+636. [Google Scholar] [CrossRef]
- Bengtsson, I.; Życzkowski, K. Geometry of Quantum States: An Introduction to Quantum Entanglement, 2nd ed.; Cambridge University Press: Cambridge, UK, 2017; pp. xv+619. [Google Scholar] [CrossRef]
- Oostrum, J.v. Bures-Wasserstein geometry for positive-definite Hermitian matrices and their trace-one subset. Inf. Geom. 2022, 5, 405–425. [Google Scholar] [CrossRef]
- Bhatia, R. Positive Definite Matrices; Princeton Series in Applied Mathematics; Princeton University Press: Princeton, NJ, USA, 2007; pp. x+254. [Google Scholar]
- Bhatia, R.; Jain, T.; Lim, Y. On the Bures—Wasserstein distance between positive definite matrices. Expo. Math. 2019, 37, 165–191. [Google Scholar] [CrossRef]
- Bhatia, R.; Jain, T.; Lim, Y. Inequalities for the Wasserstein mean of positive definite matrices. Linear Algebra Its Appl. 2019, 576, 108–123. [Google Scholar] [CrossRef]
- Thanwerdas, Y.; Pennec, X. O(n)-invariant Riemannian metrics on SPD matrices. Linear Algebra Its Appl. 2023, 661, 163–201. [Google Scholar] [CrossRef]
- Hwang, J.; Kim, S. Two-variable Wasserstein means of positive definite operators. Mediterr. J. Math. 2022, 19, 110. [Google Scholar] [CrossRef]
- Thanwerdas, Y. Riemannian and Stratified Geometries of Covariance and Correlation Matrices. Ph.D. Thesis, Université Côte d’Azur, Nice, France, 2022. [Google Scholar]
- Kim, S.; Lee, H. Inequalities of the Wasserstein mean with other matrix means. Ann. Funct. Anal. 2020, 11, 194–207. [Google Scholar] [CrossRef]
- Hwang, J.; Kim, S. Bounds for the Wasserstein mean with applications to the Lie-Trotter mean. J. Math. Anal. Appl. 2019, 475, 1744–1753. [Google Scholar] [CrossRef]
- Massart, E.; Absil, P.A. Quotient geometry with simple geodesics for the manifold of fixed-rank positive-semidefinite matrices. SIAM J. Matrix Anal. Appl. 2020, 41, 171–198. [Google Scholar] [CrossRef]
- Malagò, L.; Montrucchio, L.; Pistone, G. Wasserstein Riemannian geometry of Gaussian densities. Inf. Geom. 2018, 1, 137–179. [Google Scholar] [CrossRef]
- Kubo, F.; Ando, T. Means of positive linear operators. Math. Ann. 1980, 246, 205–224. [Google Scholar] [CrossRef]
- Lee, H.; Lim, Y. Metric and spectral geometric means on symmetric cones. Kyungpook Math. J. 2007, 47, 133–150. [Google Scholar]
- Gan, L.; Huang, H. Order relations of the Wasserstein mean and the spectral geometric mean. Electron. J. Linear Algebra 2024, 40, 491–505. [Google Scholar] [CrossRef]
- Yger, F.; Berar, M.; Lotte, F. Riemannian Approaches in Brain-Computer Interfaces: A Review. IEEE Trans. Neural Syst. Rehabil. Eng. 2017, 25, 1753–1762. [Google Scholar] [CrossRef]
- Lim, Y.; Pálfia, M. Weighted inductive means. Linear Algebra Appl. 2014, 453, 59–83. [Google Scholar] [CrossRef]
- Álvarez Esteban, P.C.; del Barrio, E.; Cuesta-Albertos, J.; Matrán, C. A fixed-point approach to barycenters in Wasserstein space. J. Math. Anal. Appl. 2016, 441, 744–762. [Google Scholar] [CrossRef]
- Bini, D.A.; Iannazzo, B. A note on computing matrix geometric means. Adv. Comput. Math. 2011, 35, 175–192. [Google Scholar] [CrossRef]
- Jeuris, B.; Vandebril, R.; Vandereycken, B. A survey and comparison of contemporary algorithms for computing the matrix geometric mean. Electron. Trans. Numer. Anal. 2012, 39, 379–402. [Google Scholar]
- Barachant, A.; Bonnet, S.; Congedo, M.; Jutten, C. Multiclass Brain–Computer Interface Classification by Riemannian Geometry. IEEE Trans. Biomed. Eng. 2012, 59, 920–928. [Google Scholar] [CrossRef]
- Blankertz, B.; Muller, K.R.; Krusienski, D.J.; Schalk, G.; Wolpaw, J.R.; Schlogl, A.; Pfurtscheller, G.; Millan, J.R.; Schroder, M.; Birbaumer, N. The BCI competition III: Validating alternative approaches to actual BCI problems. IEEE Trans. Neural Syst. Rehabil. Eng. 2006, 14, 153–159. [Google Scholar] [CrossRef]
- Schlögl, A. GDF-A general dataformat for biosignals. arXiv 2006, arXiv:cs/0608052. [Google Scholar]
- Dornhege, G.; Blankertz, B.; Curio, G.; Muller, K.R. Boosting bit rates in noninvasive EEG single-trial classifications by feature combination and multiclass paradigms. IEEE Trans. Biomed. Eng. 2004, 51, 993–1002. [Google Scholar] [CrossRef] [PubMed]
- Tangermann, M.; Müller, K.R.; Aertsen, A.; Birbaumer, N.; Braun, C.; Brunner, C.; Leeb, R.; Mehring, C.; Miller, K.J.; Mueller-Putz, G.; et al. Review of the BCI competition IV. Front. Neurosci. 2012, 6, 55. [Google Scholar]
- Brunner, C.; Leeb, R.; Müller-Putz, G.; Schlögl, A.; Pfurtscheller, G. BCI Competition 2008–Graz Data Set A; IEEE DataPort: Piscataway, NJ, USA, 2008; Volume 16, pp. 1–6. [Google Scholar] [CrossRef]
- Leeb, R.; Brunner, C.; Müller-Putz, G.; Schlögl, A.; Pfurtscheller, G. BCI Competition 2008–Graz Data Set B; Graz University of Technology: Graz, Austria, 2008; Volume 16, pp. 1–6. [Google Scholar]
- Liang, M.; Starrett, M.J.; Ekstrom, A.D. Dissociation of frontal-midline delta-theta and posterior alpha oscillations: A mobile EEG study. Psychophysiology 2018, 55, e13090. [Google Scholar] [CrossRef]
- Lotte, F.; Guan, C. Regularizing common spatial patterns to improve BCI designs: Unified theory and new algorithms. IEEE Trans. Biomed. Eng. 2010, 58, 355–362. [Google Scholar] [CrossRef]
- Barachant, A.; Bonnet, S.; Congedo, M.; Jutten, C. BCI Signal Classification using a Riemannian-based kernel. In Proceedings of the 20th European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning (ESANN 2012), Bruges, Belgium, 25–27 April 2012; pp. 97–102. [Google Scholar]
- Congedo, M.; Barachant, A.; Bhatia, R. Riemannian geometry for EEG-based brain–computer interfaces; a primer and a review. Brain-Comput. Interfaces 2017, 4, 155–174. [Google Scholar] [CrossRef]
- Ledoit, O.; Wolf, M. Honey, I shrunk the sample covariance matrix. J. Portf. Manag. 2004, 30, 110–119. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Simulation Parameter | Values |
|---|---|
| n: Dimension of Matrices | |
| m: Number of Matrices | |
| p: Proportion of zero eigenvalues |
| BCI III | BCI IV | Lab Data | |||
|---|---|---|---|---|---|
| Dataset IIIa | Dataset IVa | Dataset IIa | Dataset IIb | ||
| Number of subjects | 3 | 5 | 9 | 9 | 16 |
| Number of channels | 60 | 118 | 22 | 3 | 64 |
| Trials per class | 30/45 | 28–224 | 72 | 60/70/80 | 9–17 |
| Sampling rate | 250 Hz | 1000 Hz | 250 Hz | 250 Hz | 500 Hz |
| Filter Band | 8–30 Hz | 8–30 Hz | 8–30 Hz | 8–30 Hz | 1–30 Hz |
| Classification Performance | |||||
| Accuracy (BW) | 0.68 | 0.72 | 0.70 | 0.66 | 0.99 |
| Accuracy (BW with LWF) | 0.59 | 0.65 | 0.76 | 0.58 | 0.89 |
| Accuracy (AI) | 0.58 | 0.62 | 0.66 | 0.66 | 0.88 |
| Accuracy (AI with LWF) | 0.63 | 0.71 | 0.75 | 0.58 | 0.90 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, H.; Li, Y.; Lin, S.-C.; Yi, Y.; Zheng, J. Towards Analysis of Covariance Descriptors via Bures–Wasserstein Distance. Mathematics 2025, 13, 2157. https://doi.org/10.3390/math13132157
Huang H, Li Y, Lin S-C, Yi Y, Zheng J. Towards Analysis of Covariance Descriptors via Bures–Wasserstein Distance. Mathematics. 2025; 13(13):2157. https://doi.org/10.3390/math13132157
Chicago/Turabian StyleHuang, Huajun, Yuexin Li, Shu-Chin Lin, Yuyan Yi, and Jingyi Zheng. 2025. "Towards Analysis of Covariance Descriptors via Bures–Wasserstein Distance" Mathematics 13, no. 13: 2157. https://doi.org/10.3390/math13132157
APA StyleHuang, H., Li, Y., Lin, S.-C., Yi, Y., & Zheng, J. (2025). Towards Analysis of Covariance Descriptors via Bures–Wasserstein Distance. Mathematics, 13(13), 2157. https://doi.org/10.3390/math13132157