1. Introduction
The current development of artificial intelligence (AI) is strongly associated with high costs and extensive computational resources [
1], and the field of reinforcement learning (RL) is no exception to this challenge. Algorithms such as the Deep Q-Network (DQN) [
2] have achieved significant results in advancing RL by integrating neural networks. However, the requirement for thousands or millions of training episodes persists [
3]. Training agents in parallel has proven to be an effective strategy for reducing the number of episodes required [
4,
5], which is feasible in simulated environments but poses significant implementation challenges in real-world physical training environments.
In the context of reinforcement learning, Markov Decision Processes (MDPs) are typically used as the mathematical model to describe the working environment [
6,
7]. MDPs have enabled the development of classical algorithms such as Value Iteration [
8], Monte Carlo, State-Action-Reward-State-Action SARSA, and Q-Learning, among others.
One of the most widely used algorithms is Q-Learning, introduced by Christopher Watkins in 1989 [
9], upon which various proposals have been based [
10]. The main advantage of this algorithm is an optimal policy that maximizes the reward obtained by the agent if the action-state set is visited an infinite number of times [
9]. The Q-Learning algorithm implemented in this work was taken from [
9] and is shown in Algorithm 1.
| Algorithm 1: Q-Learning algorithm |
Algorithm parameters: step size , small Initialize , for all , , arbitrarily except that Loop for each episode: - Initialize s - Loop for each step of the episode: - - Choose a from s using policy derived from Q (e.g., -greedy) - - Take action a, observe , - - Update - until is terminal |
Some disadvantages of Q-Learning include a rapid table size growth as the number of states and actions increases, leading to the problem of dimensional explosion [
11]. Furthermore, this algorithm tends to require a significant number of iterations in order to solve a problem, and adjusting its multiple parameters can prolong this process.
Regarding its parameters, Q-Learning requires directly assigning the learning rate
and the discount factor
, which are generally tuned empirically through trial and error by observing the rewards obtained in each training session [
12].
The learning rate
directly influences the magnitude of the updates made by the agent to its memory table. In [
13], eight different methods for tuning this parameter are explored, including iteration-dependent variations and changes based on positive or negative table fluctuation. The experimental results of [
13] show that, for the Frozen Lake environment, the rewards converge above 10,000 iterations across all conducted experiments.
In Q-Learning, the exploration–exploitation dilemma is commonly addressed using the
-greedy policy, where an agent decides to choose between a random action and the action with the highest Q-value with a certain probability. Current research around the algorithm focuses extensively on the exploration factor
, as described in [
14], highlighting its potential to cause exploration imbalance and slow convergence [
15,
16,
17].
The reward function significantly impacts the agent’s performance, as reported in various applications. For instance, in path planning tasks for mobile robots [
18], routing protocols in unmanned robotic networks [
19], and the scheduling of gantry workstation cells [
20], the reward function plays a crucial role by influencing the observed agent performance variations.
Regarding the initial values of the Q-table, the algorithm does not provide specific recommendations for their assignment. Some works, such as [
21], which utilize the whale optimization algorithm proposed in [
22], aim to optimize the initial values of the Q-table, addressing the slow convergence caused by Q-Learning’s initialization issues.
The reward function directly impacts the agent’s training time. The reward can guide the agent through each state or be sparse across the state space, requiring the agent to take many actions and visit many states before receiving any reward, generally at the end of the episode, thereby learning from delayed rewards. As concluded in [
23] (p. 4), when analyzing the effect of dense and sparse rewards in Q-Learning, “an important lesson here is that sparse rewards are indeed difficult to learn from, but not all dense rewards are equally good”.
The proposed heuristic is inspired by key conceptual elements of Q-Learning, such as the use of a table for storage, and suggests an alternative approach to addressing the exploration–exploitation dilemma based on the probability of actions. This heuristic also aims to reduce the complexity of adjustments and the time required to apply Q-Learning. This algorithm, termed M-Learning, will be explained in detail and referenced throughout this document.
The primary contributions of this study revolve around the development of the M-Learning algorithm, designed to tackle reinforcement learning challenges involving delayed rewards. Firstly, the algorithm introduces a self-regulating mechanism for the exploration–exploitation trade-off, eliminating the necessity for additional parameter tuning typically required by -greedy policies. This advancement simplifies the configuration process and enables the system to dynamically balance exploration and exploitation. Secondly, M-Learning employs a probabilistic framework to assess the value of actions, allowing for a comprehensive update of all action probabilities within a state through a single environmental interaction. This design enhances the algorithm’s responsiveness to changes, improving the utilization of computational resources and increasing the overall effectiveness of the learning process.
2. Defining the M-Learning Algorithm
The main idea of M-Learning is to determine what constitutes a solution in an MDP task for the agent and how this solution can be understood in terms of the elements that make up Markov processes. The purpose is to find solutions that are not necessarily optimal. On the other hand, Q-Learning searches for the optimal solution through the reward function and the -greedy policy, both of which are aspects to be tuned when solving general tasks.
The first consideration involves establishing a foundation for the reward function. In the MDP framework, the solutions to a task are represented as trajectories composed of sequences of states. In Q-Learning, the objective is to find the trajectory that maximizes the reward function. However, our approach focuses on trajectories that connect to a specific state. The objective of M-Learning is to find a particular s within the set S, referred to as the objective state . Thereupon, this work proposes assigning the maximum reward value to the state and the minimum reward value to the terminal states . The rationale behind this approach is to encourage the agent to remain active throughout the episode.
During the RL cycle, the reward signal aims to guide the agent in searching for a solution. Through it, the agent obtains feedback from the environment as to whether its actions are favorable. Q-Learning uses a reward factor to modify the action-state value and estimate it. However, in environments where the reward is sparsely distributed and the agent does not receive feedback from the Q-Learning environment for most of the time, the algorithm must solve the search for the reward with exploration time, thus reaching the exploitation–exploration dilemma, which is usually tackled with an -greedy policy.
Using the -greedy policy as a decision-making mechanism requires setting the decay rate parameter , which determines how long the agent will explore while seeking feedback from the environment. This parameter is decisive in reducing the number of iterations needed to find a solution. Additionally, this parameter is not related to the learning process; rather, it is external to the knowledge being acquired. It is only possible to assign a favorable value by interacting with the problem through computation, making variations in the decay rate and the number of iterations. It should be kept in mind that this is also conditioned by the other parameters that need to be defined.
If the reward is considered to be the only source of stimulus for the agent in an environment with dispersed rewards, the agent must explore the state space in order to interact with states where it obtains a reward and, based on them, modify its behavior. As these states are increasingly visited, the agent should be able to reduce the level of exploration and exploit more of its knowledge about the rewarded states. The agent explores in search of stimuli, and, to the extent that it acquires knowledge, it also reduces arbitrary decision making. The exploration–exploitation process can be discretely understood with regard to each state in the state space. Thus, the agent can propose regions that it knows in the state space and, depending on how favorable or unfavorable they are, reinforce the behaviors that lead it to achieve its objective or seek to explore other regions.
As previously mentioned, exploration and decision-making are closely linked to how the reward function is interpreted. The specific proposal of M-Learning consists of the following:
First, the reward function is limited to values between −1 and 1, assigning the maximum value for reaching the goal state and the minimum for terminal states .
Second, each action in a state has a percentage value that represents the level of certainty regarding the favorability of said action. Consequently, the sum of all actions in a state is 1. Initially, all actions are equally probable.
Q-Learning also rewards and penalizes the agent in a similar way, but the effect of this process can be obscured by the -probability. For example, if the agent reaches a terminal state in the initial phase of an episode, the environment punishes it through the reward function, and this learning is stored in its table. In subsequent episodes, this learned information has a low probability of being used by the agent since the exploration probability is high. In M-Learning, this learned knowledge is available for the next episode because it modifies the value of the actions that lead to .
Note that the values of the actions are expressed as probabilities, which are used to select the action in each state. Thus, when interacting with the environment, favorable actions are more likely to be selected—unlike unfavorable ones. The principle is that, when the agent has no prior knowledge of a state, all actions have an equal probability. As the agent learns, this knowledge is stored in the variations of these probabilities. The M-Learning algorithm is presented in Algorithm 2 and the notations with their definitions are shown in
Table 1.
| Algorithm 2: M-Learning |
Initialize Q(s,a) for all s ∈, a, with , and set Loop for each episode: - Initialize s - Loop for each step of the episode: - - Choose a from s using probability Q(s,) for - - Take action a, observe , - - Update - - Resize the probability of to 1, - until is terminal |
The first step in the M-Learning algorithm is to initialize the table, unlike in Q-Learning, where the initial value can be set arbitrarily. The value of each state-action is initialized as a percentage of the state according to the number of actions available. Thus, the initial value for each action in a state will be the same as shown in (
1).
Once the table has been initialized, the cycle of episodes begins. The initial state of the agent is established by observing the environment. The cycle of steps begins within the episode, and, based on its initial state, the agent chooses an action to take. To this effect, it evaluates the current state according to its table, obtains the values for each action, and randomly selects one using its value as the probability of choice. Thus, the value of each action represents its probability of choice for a given state, as presented in Equation (
2).
After selecting an action, the agent acts on the environment and observes its response in the form of a reward and a new state. After transitioning to the new state, it evaluates the action taken and modifies the value of the action-state according to (
3).
The percent modification value
of the previous state-action
is computed while considering the existence of the reward (
4). If
exists,
is calculated based on the current reward or on both the current and previous rewards. If there is no reward, it is calculated as the differential of information contained in the current state and the previous
.
When the environment rewards the agent for his action,
.
is a measure of the approach to
. Specifically, the best case of the new state will be the target state
, with a maximum positive reward
. In the other case, the new state will be radically opposite to the target state and its reward will be a maximum but negative
. When the reward is not maximal, the value of
(
5) may be calculated through a function that maps the reward differential within the range
. For this case, a first-order relationship is proposed.
For the case when , it is necessary to calculate dynamically in proportion to the magnitude of . This presents a challenge for tuning and increases the difficulty of adjusting the algorithm. Consequently, using terminal rewards of 1 and −1 provides an advantage as it simplifies the reward structure by eliminating the need for fine-grained adjustments. Since this setup corresponds to a more complex environment that extends beyond the primary objective of this work’s target environment, further exploration of this aspect is not pursued.
If the reward function of the environment is described in such a way that its possible values are (1, 0, −1), the calculation of
m can be rewritten by replacing
with
. This describes environments where it is difficult to establish a continuous signal that correctly guides the agent through the state space. In these situations, it may be convenient to generate a stimulus for the agent only upon achieving the objective or causing the end of the episode. Accordingly, Equation (
4) can be rewritten as (
6):
When the environment does not return a reward
, the agent evaluates the correctness of its action based on the difference in the information stored regarding its current and previous state, as depicted in Equation (
7). This is the way in which the agent spreads the reward stimulus.
To calculate the information for a state
, Equation (
8) evaluates the difference between the value of the maximum action
and the mean of the possible actions in said state. The mean value of an action is also its initial value, which indicates that no knowledge is available in that state for the agent to use in the selection process. In other words, the variation with respect to the mean is a percentage indicator of the agent’s level of certainty when selecting a particular action.
Since the number of actions available in the previous and current states may differ, it is necessary to put them on the same scale to allow for comparison. When calculating the mean value of the actions, the maximum variation in information is also determined, which represents the change required in the value of an action for it to have a probability of 1. The maximum information is, therefore, the difference between the maximum and the mean action value, as shown in Equation (
9).
In order to modify the previous state-action, the information value of the current state is adjusted to align with the information scale of the previous state, as shown in Equation (
10). Suppose two states with different numbers of available actions and the following values:
and
. The certainty of the best action is
, but the information differs due to the number of actions in each state. Action 2, with a value of
in state
, competes with two additional options; therefore, the information of the states must be adjusted for a correct comparison.
It is possible that, for a state
, all actions are restricted to the extent that the value of all possible actions becomes zero, making it impossible to calculate the maximum information for
. Therefore, a negative constant is assigned to indicate that the action taken leads to an undesirable state. Consequently, the information differential is defined according to Equation (
11).
The magnitude is a parameter that controls the maximum saturation of an action during propagation. This value allows controlling how closely the value of an action can approach the possible extremes of 0 and 1.
This parameter represents the maximum certainty for an action and the lowest probability value for one action. To establish this, derive it from the number of actions
, as given by (
12):
After calculating
m and modifying the action-state
, the probabilities within the state must be distributed to maintain
. This is performed by applying (
13) to previous state actions.
Thus, variations in the value of the selected action affect the rest of the actions. The principle is that, as the agent becomes increasingly certain about one action, the likelihood of selecting other actions decreases. Conversely, reducing the likelihood of selecting a particular action increases the certainty of choosing the others.
Similarly to the
-greedy approach, if a minimum level of exploration is to be maintained, it is necessary to restrict the maximum value that an action can reach. This is controlled by the parameter
, which affects the redistribution of probabilities when the maximum action exceeds the saturation limit, i.e., when
. In such cases, the value of
is reduced so that it matches the saturation limit
when applying Equation (
14).
Finally, the process returns to the beginning of the cycle for the specified number of steps and continues executing the algorithm until either the step limit is reached or a terminal state is encountered.
Example of an M-Learning Application
Suppose that the agent is in the state preceding the objective state, i.e.,
, for the first time, and four actions are available to the agent, denoted as
. The initial values of these actions in the table for
are shown (
15):
The agent selects an action using an equal probability of
for each option. Suppose that the agent selects the action leading to state
, for instance, action two. The agent executes the action, the environment transitions to state
, and the agent receives a reward of
. The agent updates its state, as expressed in Equation (
16).
Now, the agent updates its table according to Equation (
3). First, the value of
m is computed using Equation (
4), since
and
. Therefore,
, following Equation (
6) for environments with (1, 0, −1) rewards. The updated value for
is calculated in Equation (
17).
The new value of action two in the table for
is shown in Equation (
18). Clearly, the sum of the action values now exceeds 1, requiring normalization in the next step of the M-Learning algorithm.
Applying Equation (
13) for state
, the normalized values of the actions are computed as follows in Equation (
19):
The next time the agent reaches state , it will be more likely to choose action to obtain the reward, progressively reinforcing this action for this state as it continues to receive rewards.
3. Experimental Setup
To compare the performance of M-Learning and Q-Learning, agents were trained in two distinct environments: one deterministic and one stochastic.
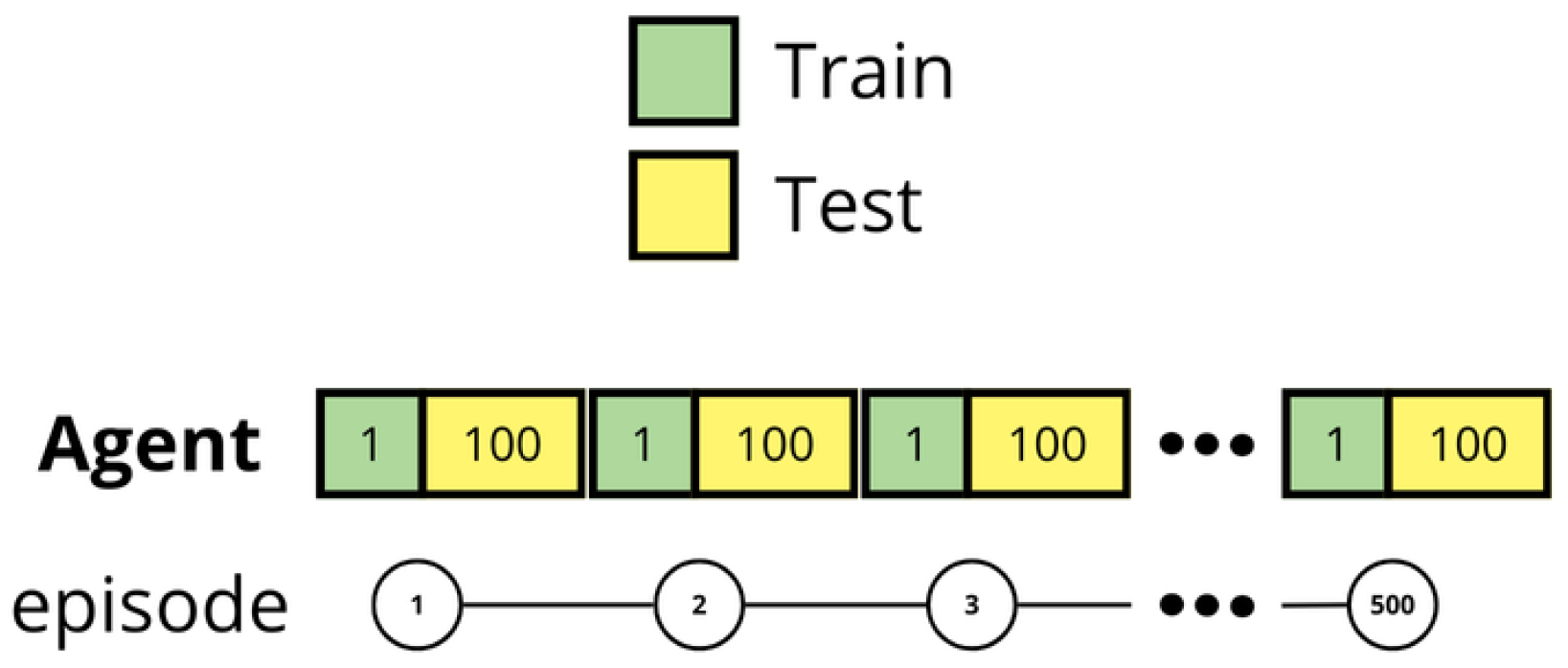
The methodology involved evaluating the agents after each training episode. During the training process, the agent was allowed to update its memory table according to the specific algorithm being employed. Following each training episode, the agent attempted to achieve the objective in the environment using the resulting memory table. This evaluation was repeated 100 times, during which the agent’s memory table remained fixed and could no longer be modified. As illustrated in
Figure 1, during the training phase, the agent updates its memory table; whereas, during the testing phase, it utilizes its current memory table without making further modifications. During the test, exploration methods are disabled, including
in Q-Learning and the action probability in M-Learning.
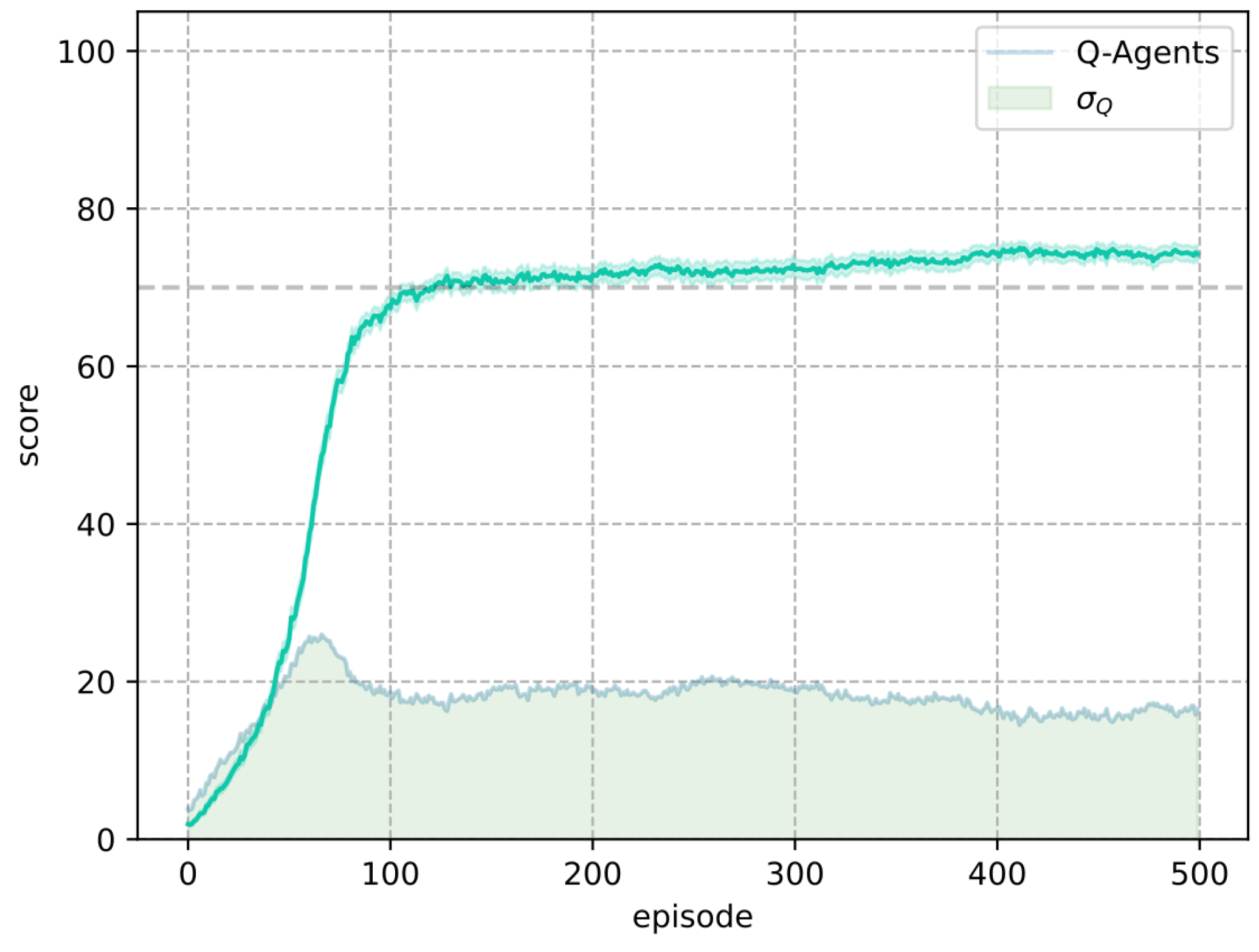
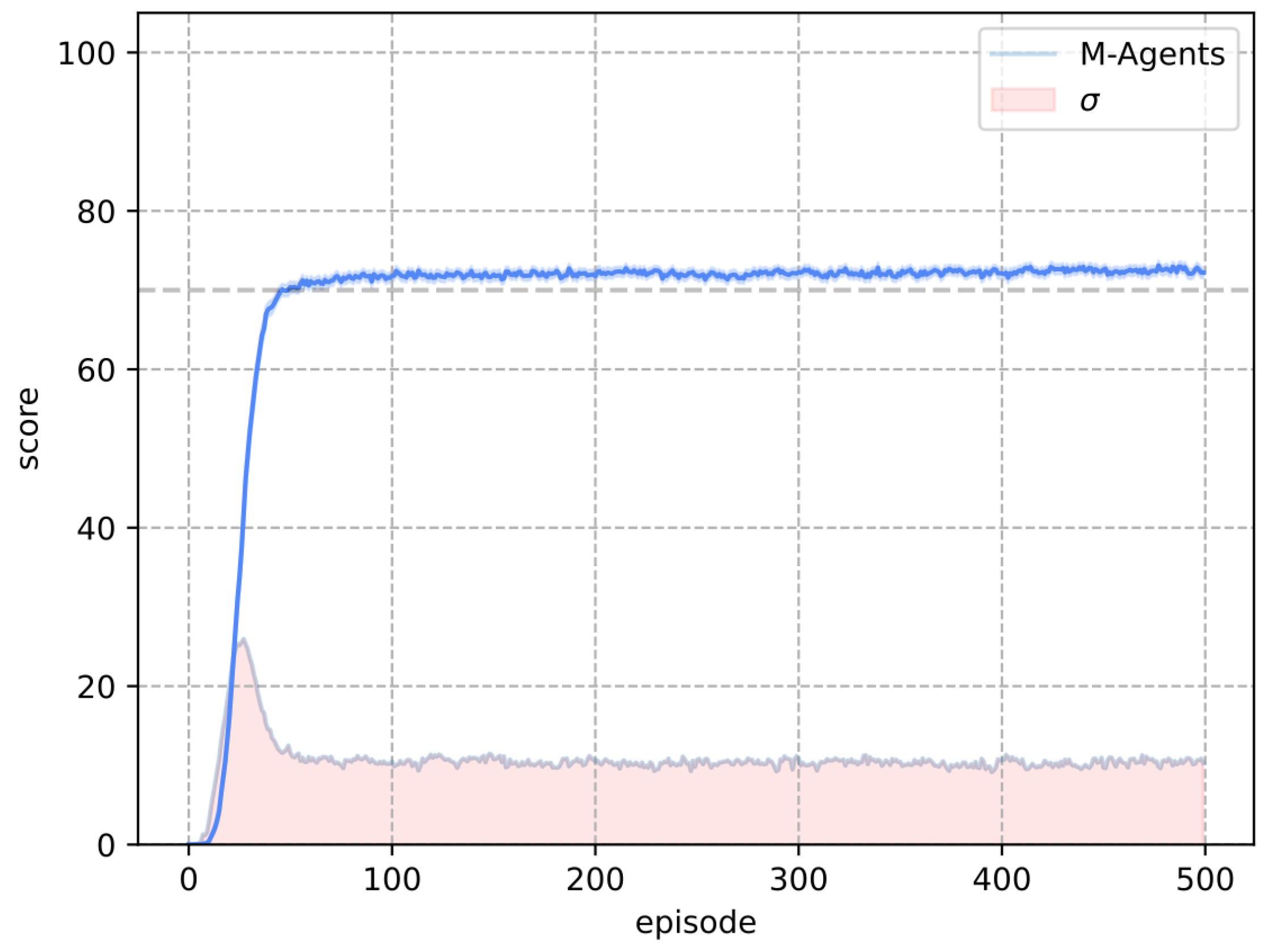
The test score used to compare both algorithms is based on the number of times the agents successfully locate the objective during testing. Evaluation is conducted over 100 attempts, measuring how often the agent achieves success following a training episode. In a deterministic environment, the outcomes are binary, resulting in either a 100% loss rate or a 100% success rate. This evaluation method is particularly valuable in stochastic environments, as it assesses the agent’s success rate under uncertain conditions.
The purpose of this test score is to evaluate how effectively the agents learn in each episode when applying the respective algorithm (Q-Learning or M-Learning). The policy implemented by both algorithms in the test involves always selecting the action with the highest value . This approach enables us to measure the agents’ learning progress and their ability to retain the knowledge acquired during training.
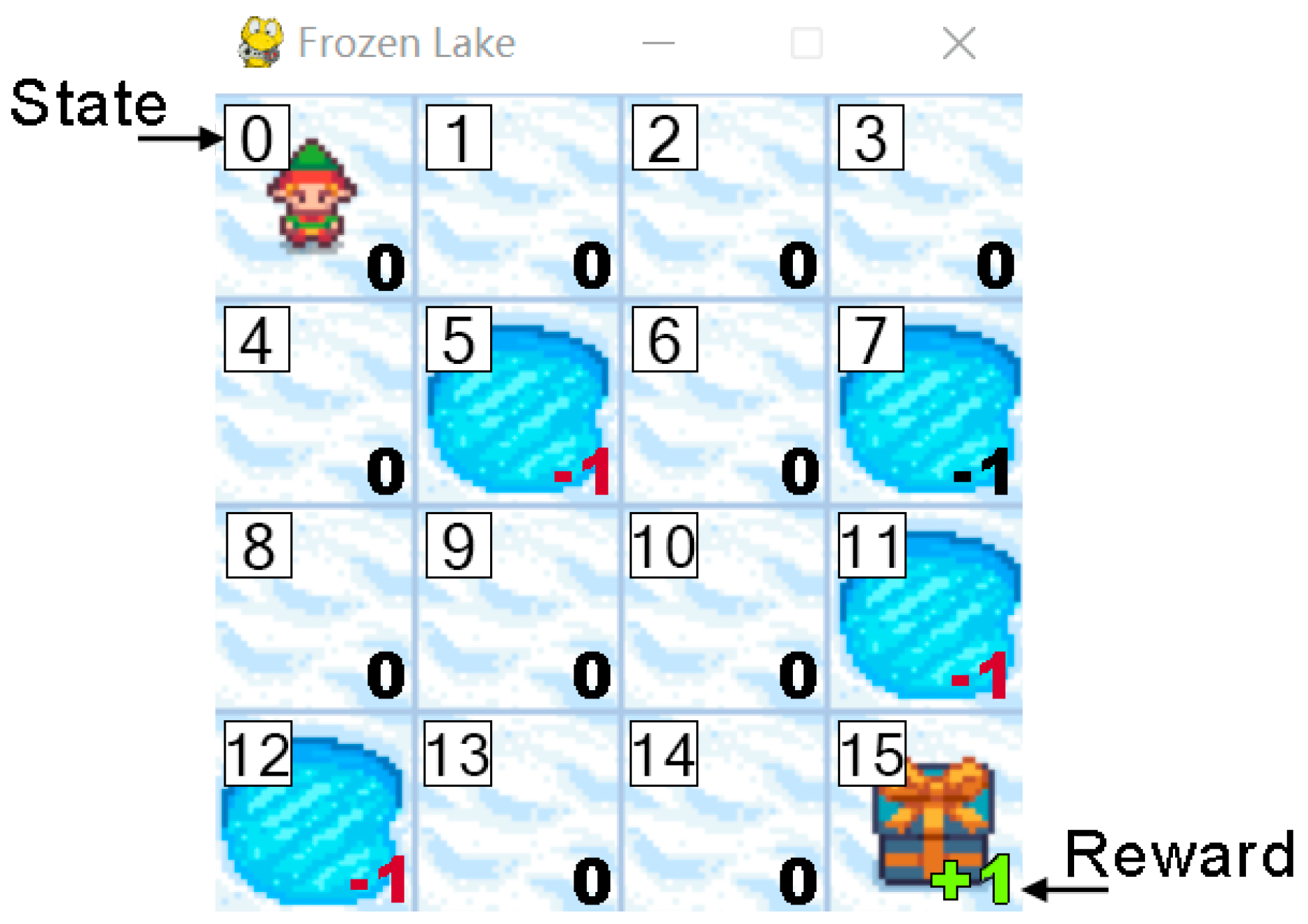
The game used for this study is Frozen Lake (
Figure 2), where the objective is to cross a frozen lake without falling through a hole. The game is tested in its two modes: slippery and non-slippery, representing stochastic and deterministic environments, respectively. The tiles and, thus, the possible states of the environment are represented as integers from 0 to 15. From any position, the agent can move in four possible directions: left, down, right, or up. If the agent moves to a hole, it receives a final reward of −1, and the learning process terminates. Conversely, reaching the goal results in a reward of 1. Any other position where the agent moves results in a reward of 0.
This environment presents two variations, each representing a distinct problem for the agent. In the first variation, the environment allows the agent to move in the intended direction and the state transition function is deterministic. In the second variation, when the agent attempts to move in a certain direction, the environment may or may not guide it as intended, depending on a predefined probability. Specifically, the probability of slipping and consequently moving in an orthogonal direction to the intended one is . In this case, the state transition function is stochastic.
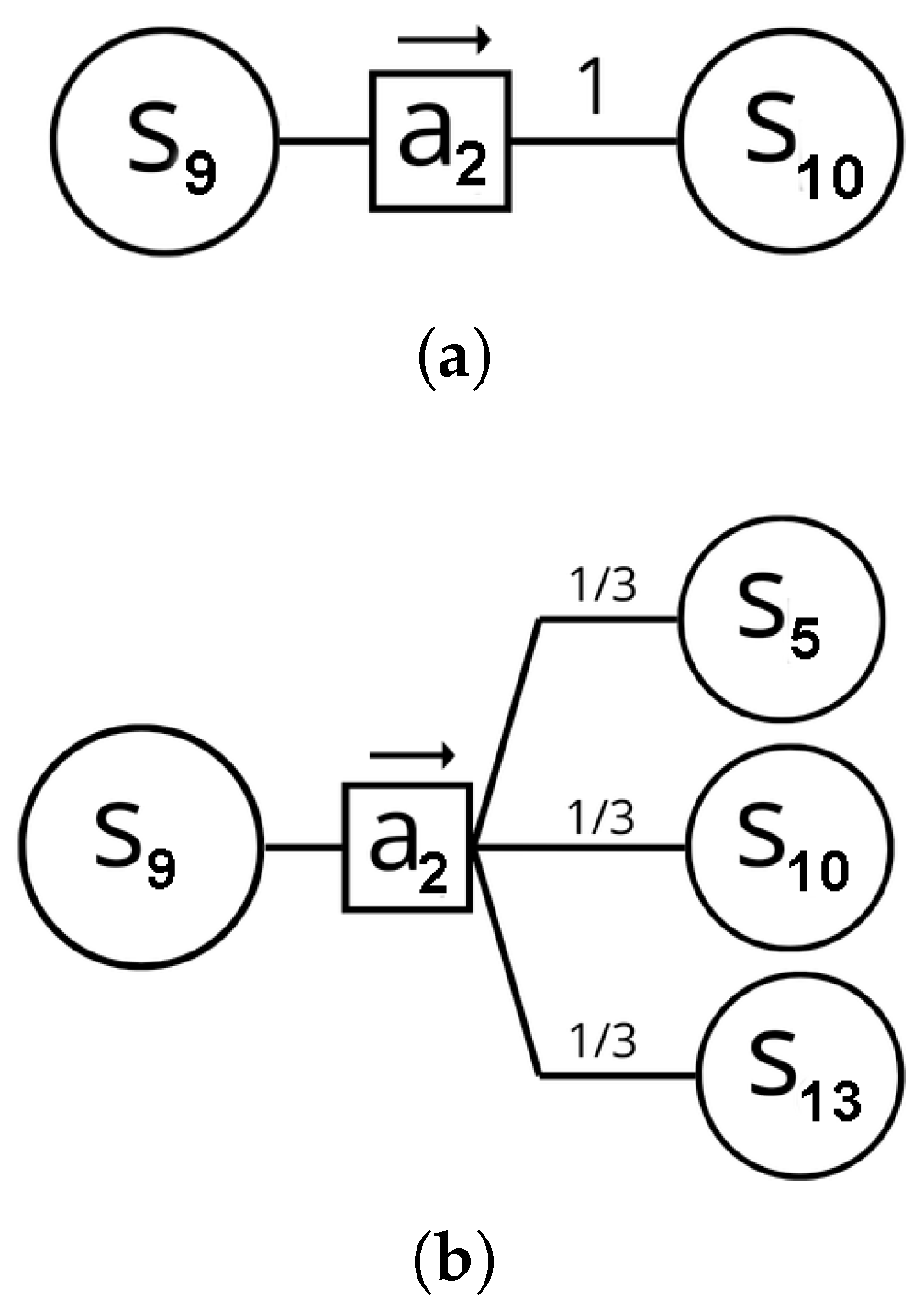
Refer to
Figure 3 for a representation of the transitions. Suppose that the agent is in state
and takes action
, moving to the right. In the deterministic environment, the probability of transitioning to state
from
upon taking action
is 1,
. In the stochastic environment, the probability of transitioning to state
from
upon taking action
is
. Additionally, there are two other possible outcomes: moving to orthogonal directions,
and
. In conclusion, in the stochastic environment, the agent has a
probability of moving in the intended direction and a
probability of moving in an orthogonal direction.
Frozen Lake is available in the Gymnasium library, a maintained fork of OpenAI’s Gym [
24], which is described as “an API standard for reinforcement learning”. This environment is fully documented in the Gymnasium resources.
Table 2 provides a detailed description of these environments.
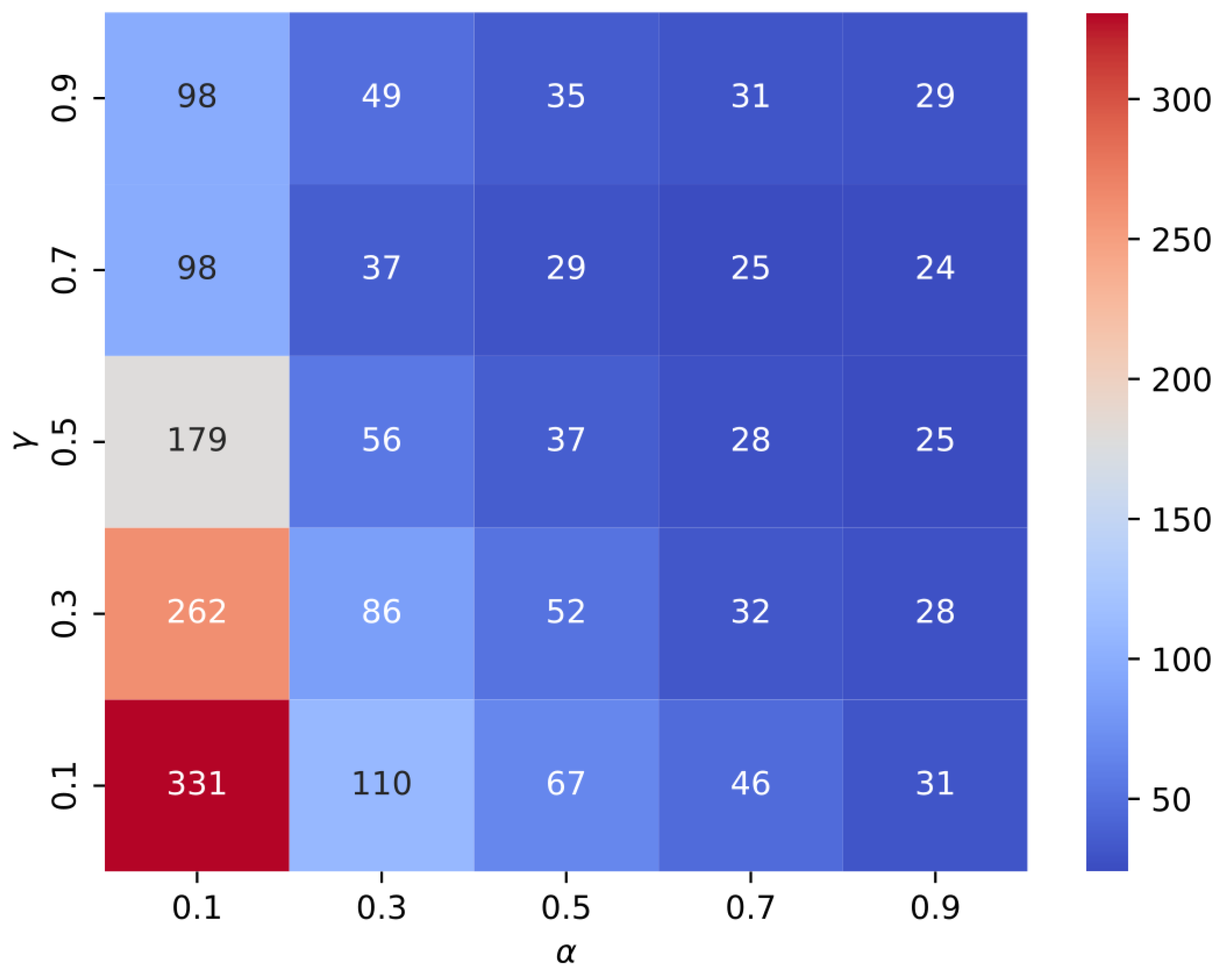
For the grid parameter search in Q-Learning, 200 agents were trained for each combination of algorithm parameters. After selecting the optimal parameter set for Q-Learning, an additional 1000 agents were trained to compare their results with those obtained using M-Learning.
Table 3 summarizes the experimental configuration. The grid parameter search included five values for
, five values for
, and four values for
, resulting in a total of
parameter combinations.
Tuning the Algorithms’ Parameters
To train agents using Q-Learning, it is crucial to appropriately configure the algorithm’s parameters. The initial values of the Q-table were initialized with pseudo-random values within the range of 0 to 1. The minimum value (
) for the
-greedy policy was set to 0.005. A grid search (
Table 4) was performed for
,
, and
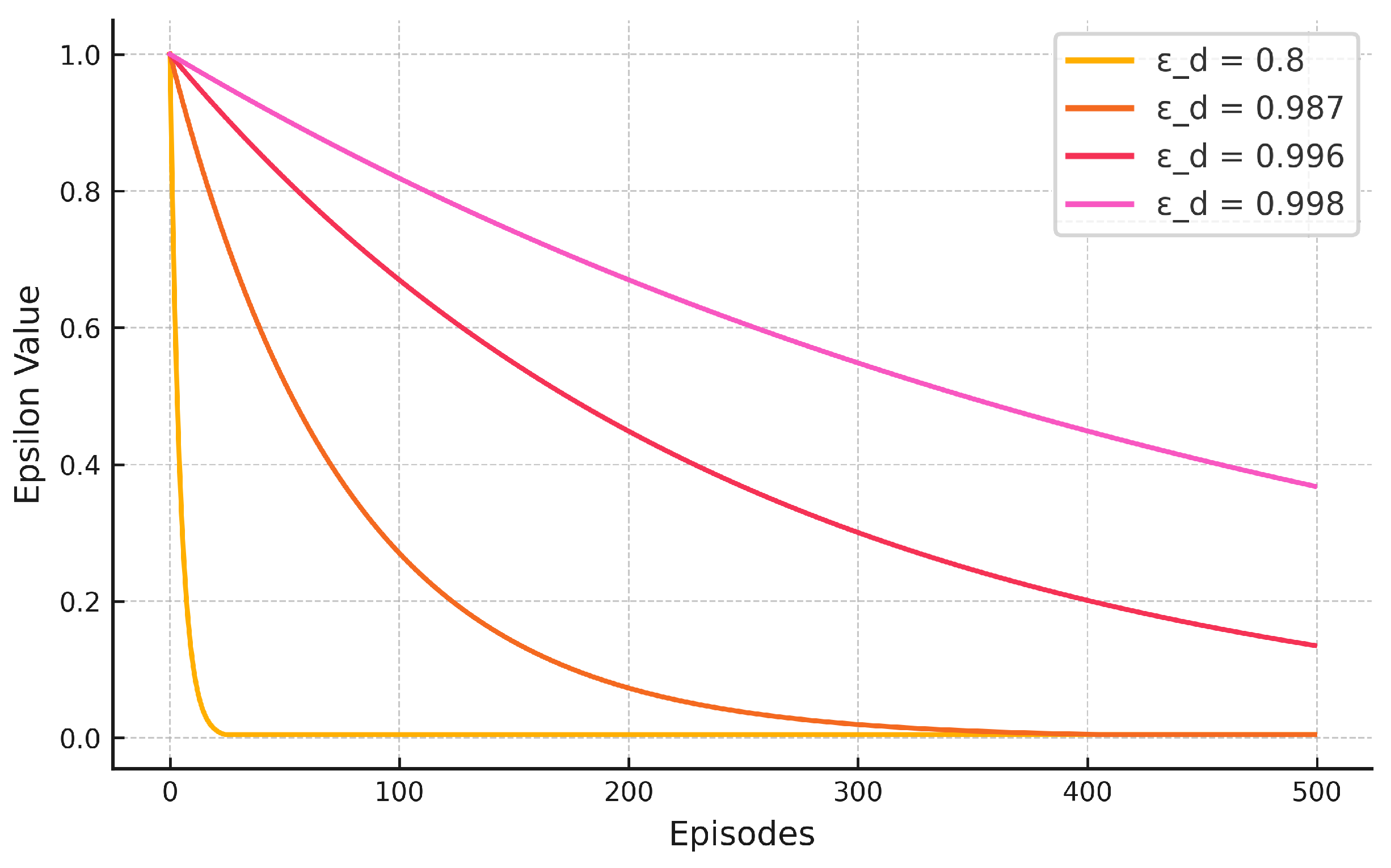
, as these parameters have a significant influence on the algorithm’s performance.
The parameters of the Q-Learning algorithm in (
Table 4) are proposed to explore the space of the parameter grid search. The purpose is to see the algorithm’s behavior over the parameter space. Values of alpha and gamma are proposed to be searched uniformly since both are independent of the number of episodes. For
, four values are proposed that maintain the exploration–exploitation balance within the range of episodes.
Figure 4 shows the behavior of
with these values of
.
The training of agents using our proposed M-Learning method involved setting the parameter
to 0.96, as proposed by Equation (
12).
6. Conclusions
This paper presents a grid search for parameters for the deterministic and stochastic Frozen Lake environments (
Figure 5 and
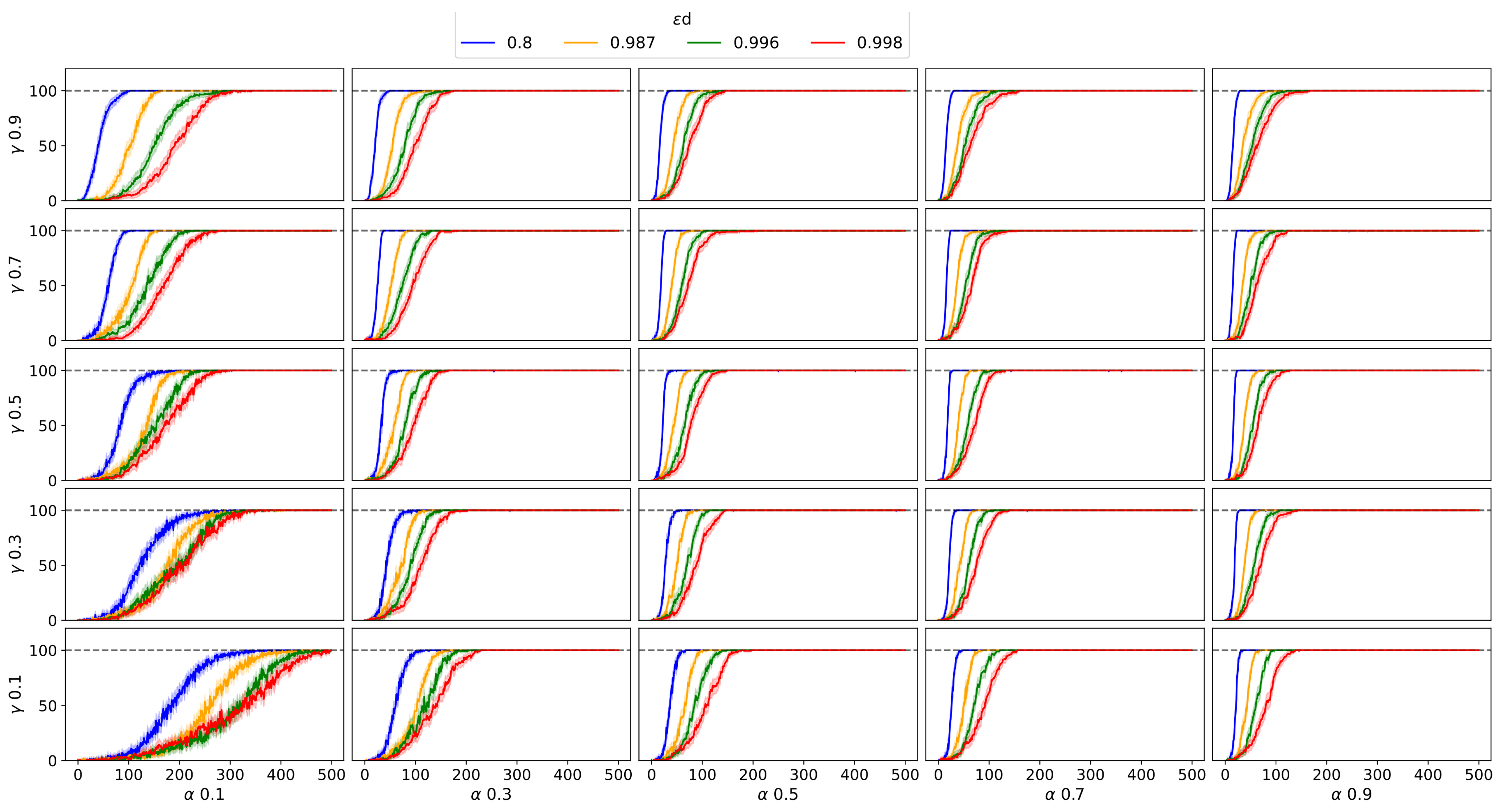
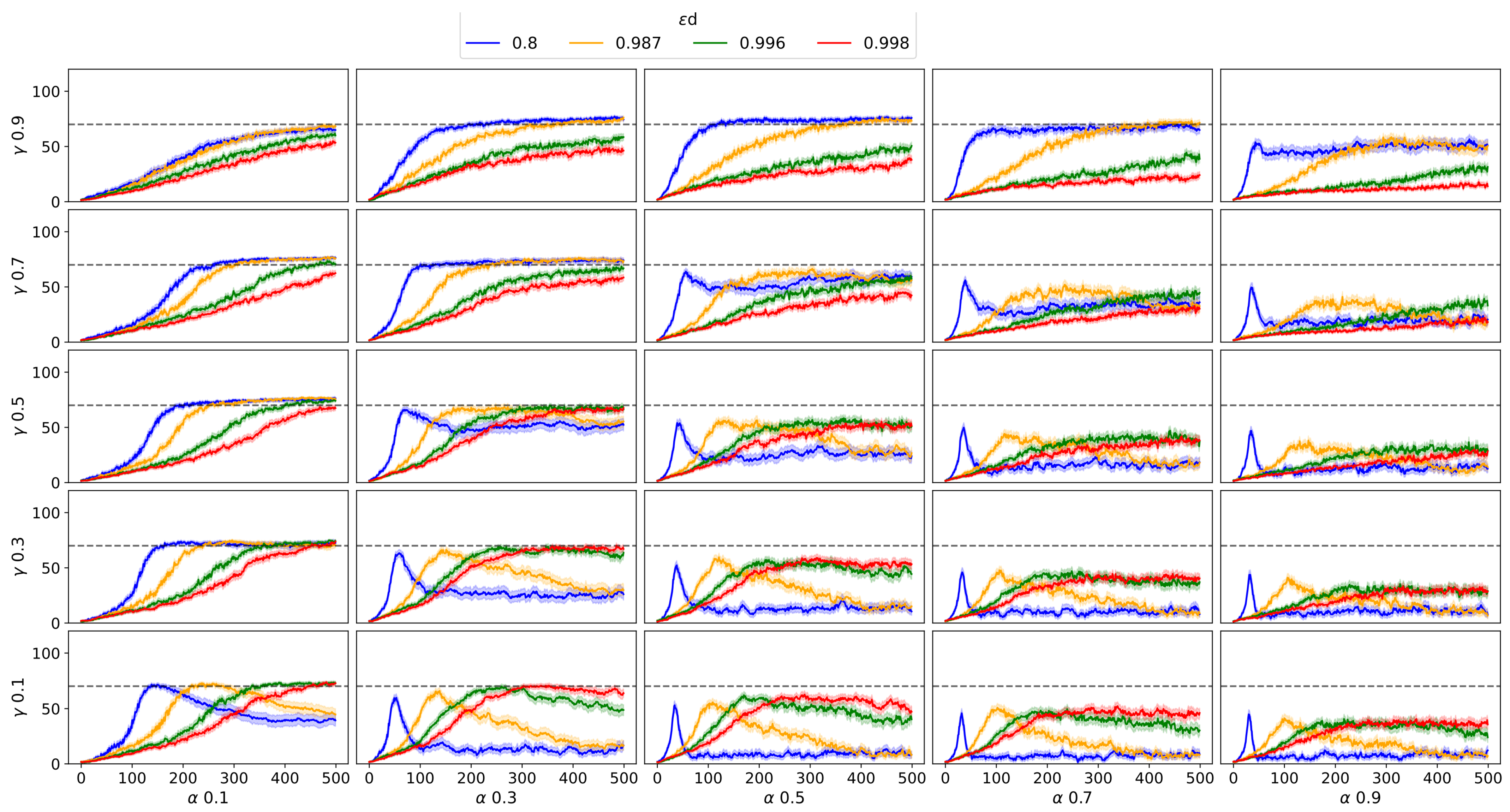
Figure 6, respectively) when using Q-Learning. As Frozen Lake is one of the earliest and most recognized environments in RL, these experiments may be helpful for those who wish to conduct further experiments with this environment and Q-Learning.
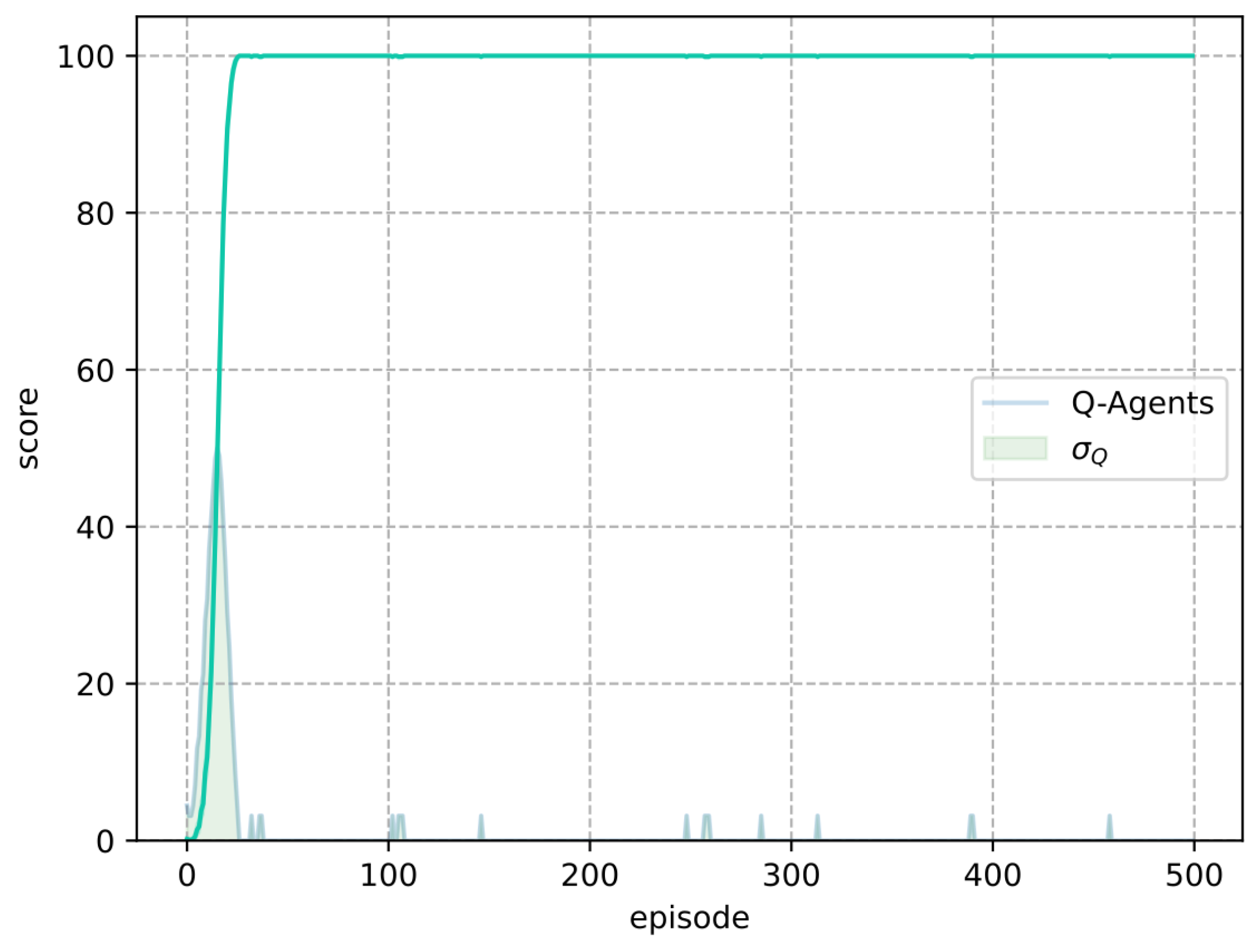
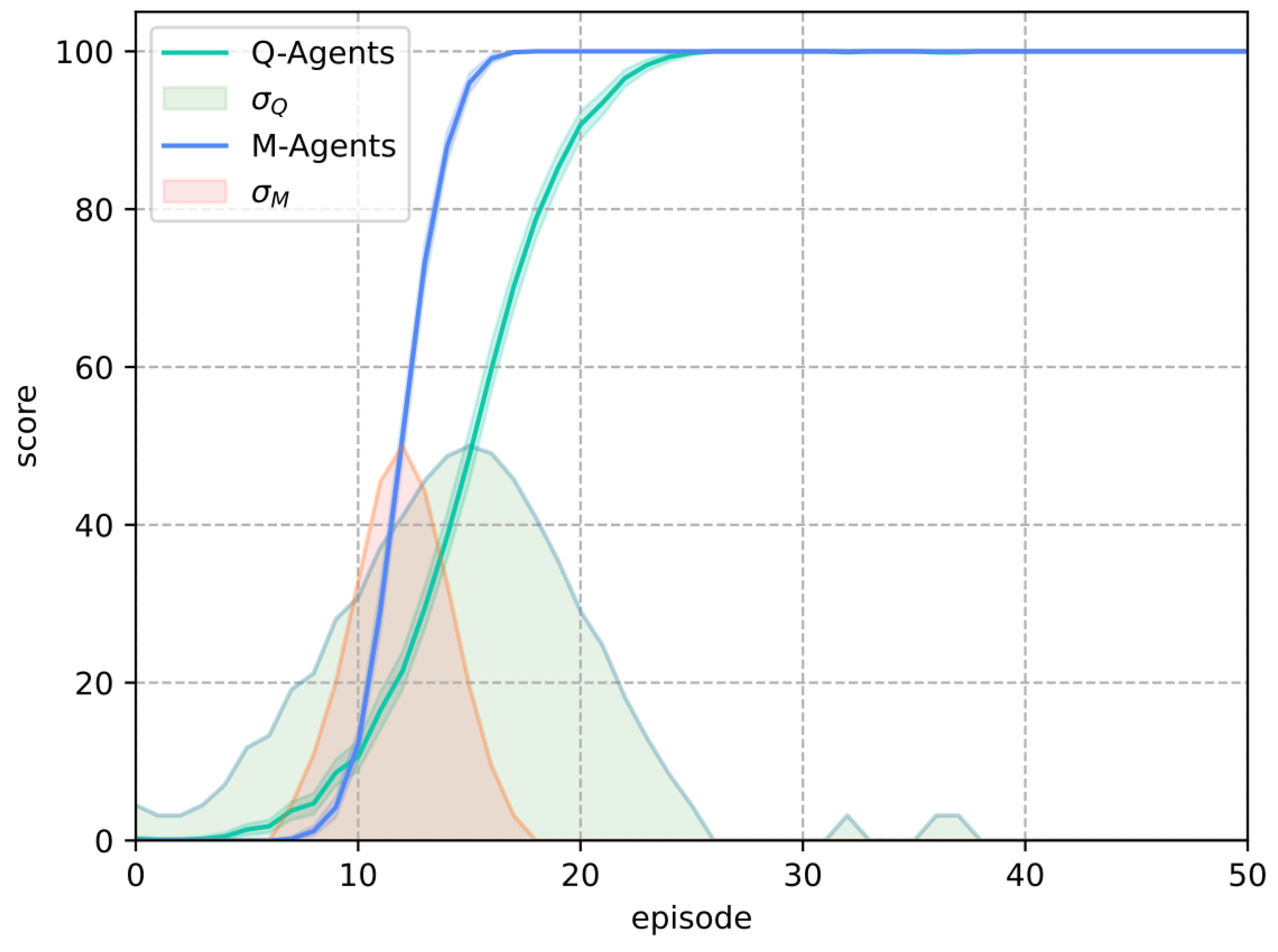
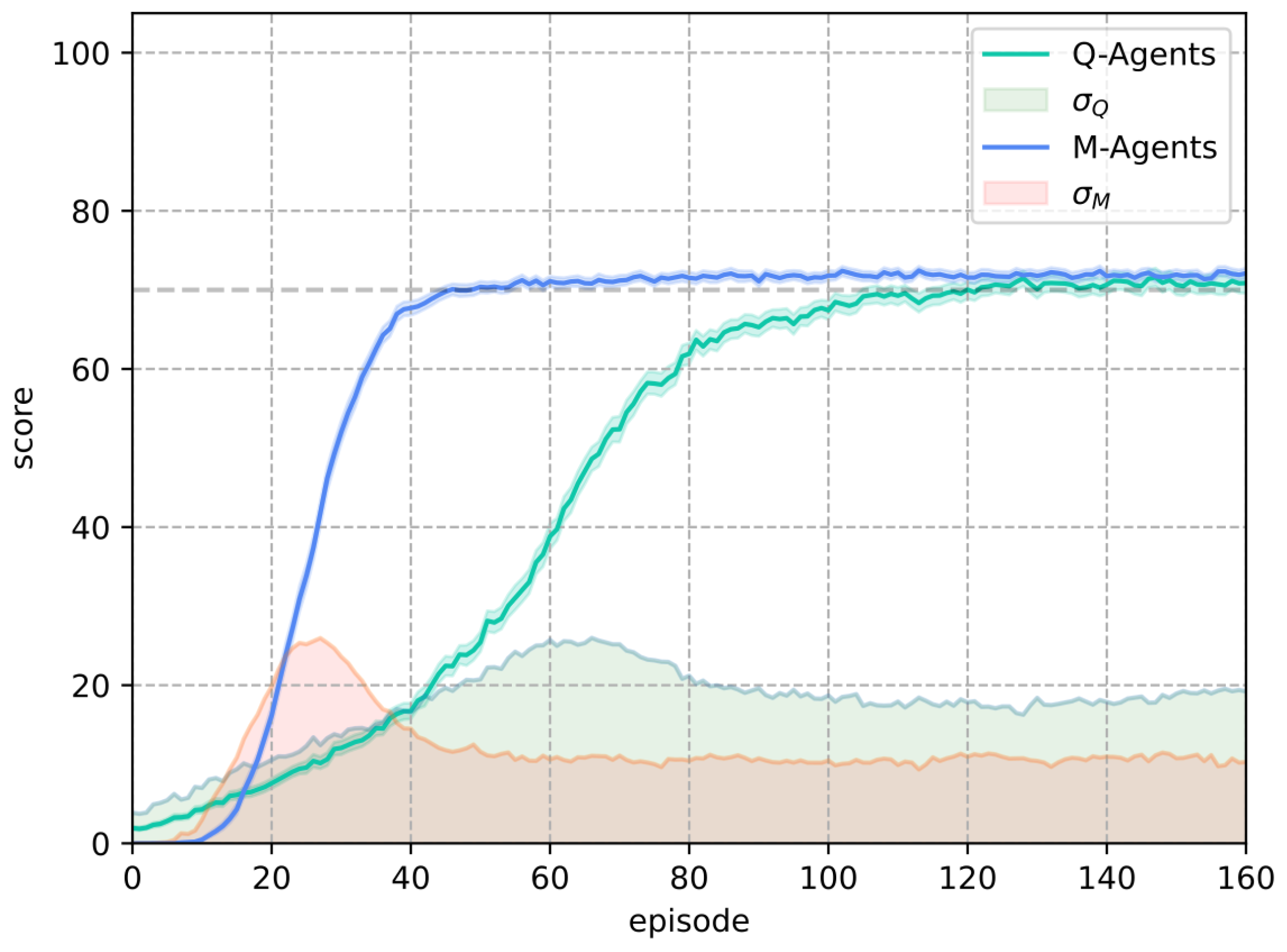
In Frozen Lake, the M-Learning algorithm trains agents faster than Q-Learning. In the deterministic environment, the number of episodes necessary for all agents to achieve a score of 100 is lower (eight episodes) for M-Learning when compared to Q-Learning. In the stochastic environment, the former requires fewer episodes (74) on average.
Additionally, in terms of the standard deviation of the score, M-Learning demonstrates greater consistency in the training results. Compared to the standard deviation of Q-Learning, M-Learning shows a reduction of in the deterministic environment, as well as a reduction of in the stochastic environment.
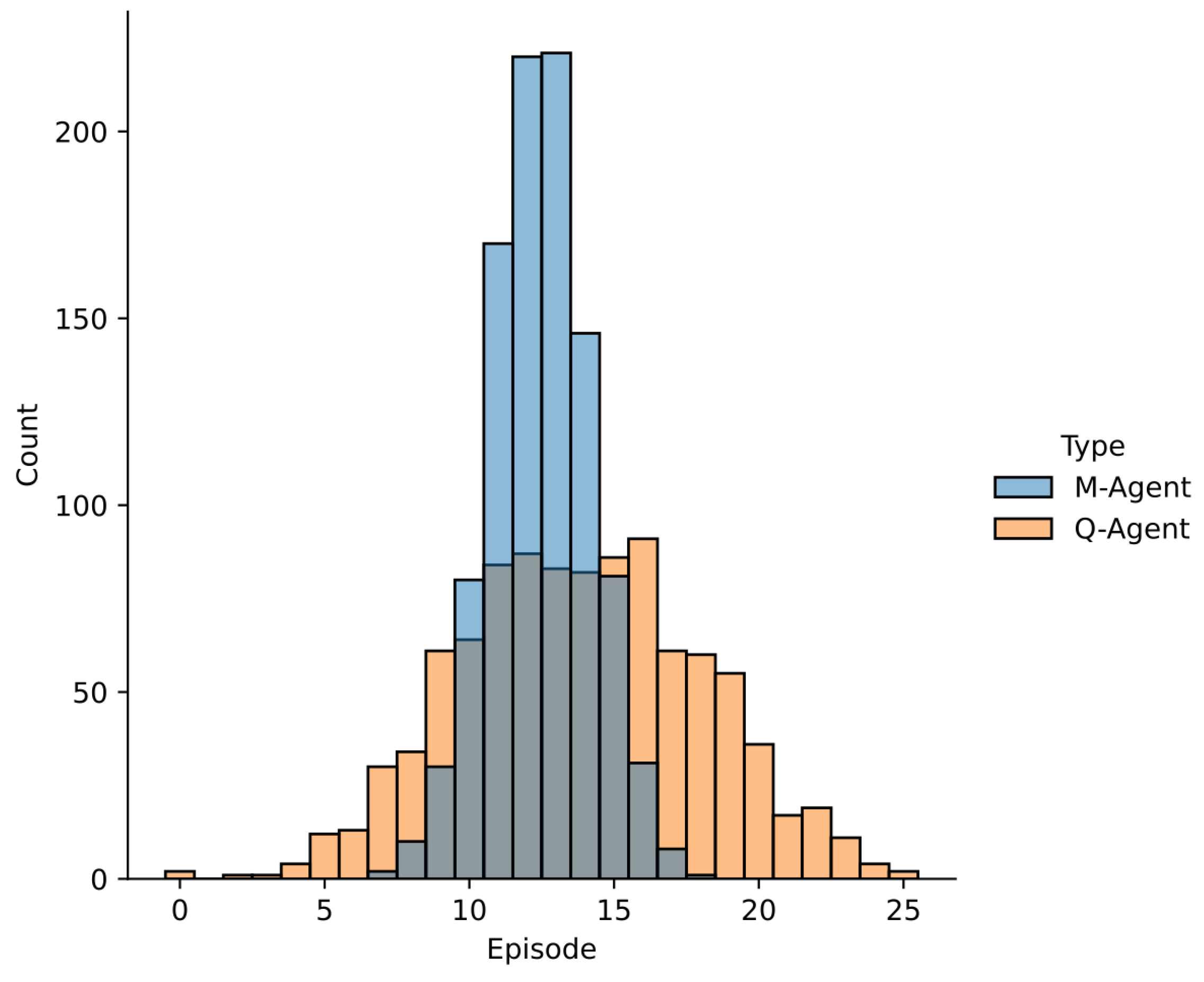
Furthermore, in both deterministic and stochastic environments, the difference in M-Learning’s result distributions (
Figure 13 and
Figure 15) compared to Q-Learning becomes more pronounced as complexity increases. This highlights M-Learning’s consistency despite growing environmental complexity, without requiring parameter adjustments. Notably, M-Learning maintained the same parameter
, while Q-Learning required a grid search to optimize its parameters, which varied across environments.
Finally, the main contribution of this paper consists of two interconnected aspects, both of which stem from the formulation of the proposed M-Learning algorithm.
The most relevant aspect is that the exploration–exploitation dilemma can be self-regulated based on the value of actions in the states, which eliminates the need to use the additional parameters demanded by the -greedy policy.
The second one is that considering the value of actions with a probabilistic approach allows modifying the value of all actions in a state through a single interaction with the environment.
While the above can be understood from different perspectives, it is ultimately the result of a unified approach.
Future Work
With the results obtained for M-Learning, we suggest that future research should focus on evaluating its performance in other environments with the purpose of identifying the specific problems where it may prove most useful.
The factor , which modifies the value of an action, offers a promising avenue for further exploration. Future studies could investigate alternative methods for calculating this factor, either to simplify the process or to incorporate additional sources of information beyond the reward and the knowledge stored in the states.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}