
Prediction of Water Quality in Agricultural Watersheds Based on VMD-GA-LSTM Model


Abstract
1. Introduction
2. Data Source and Preprocessing
2.1. Study Area and the Data
2.2. Missing Value Handling
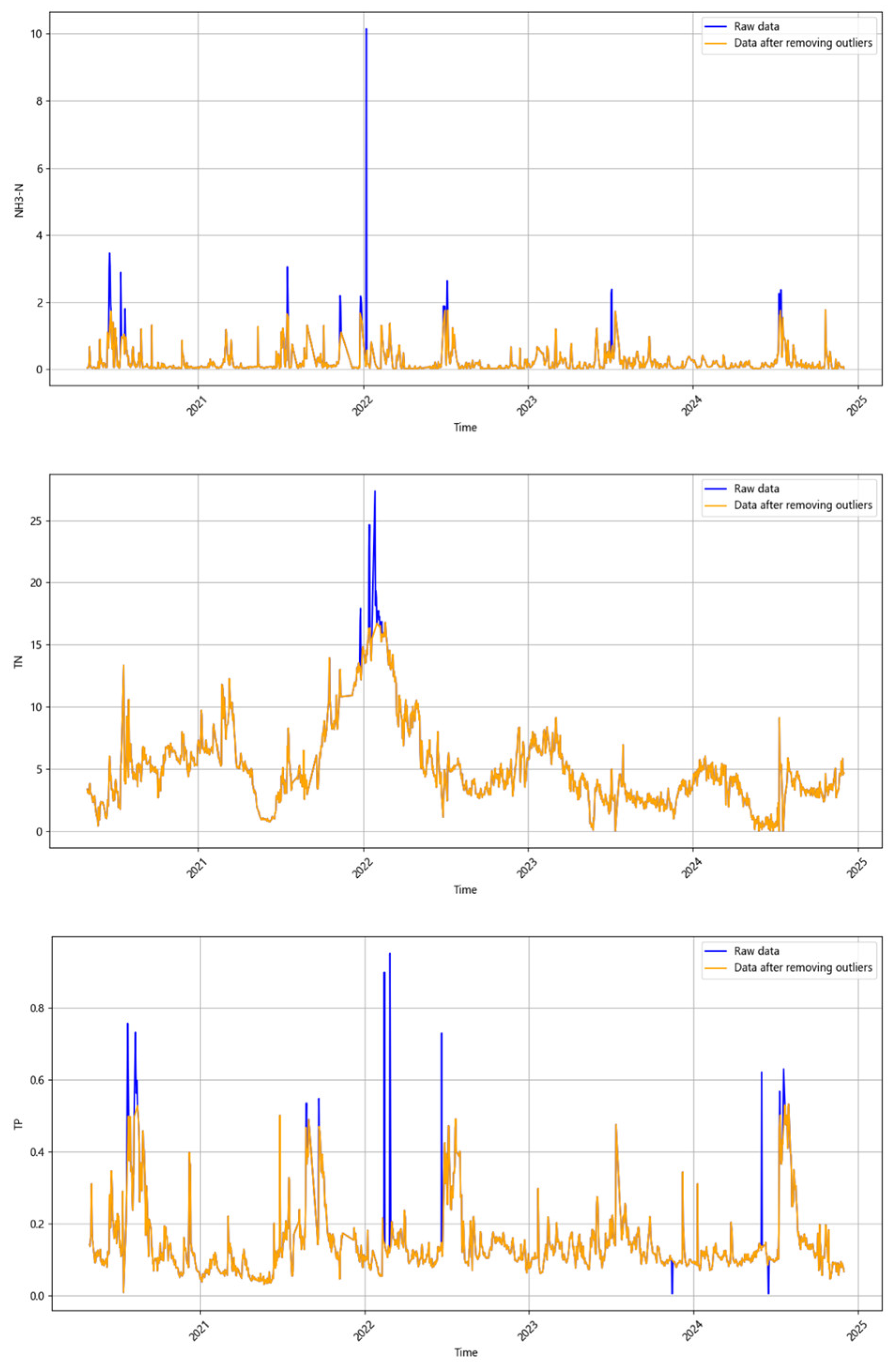
2.3. Outlier Handling
2.4. Data Normalization
3. Methods
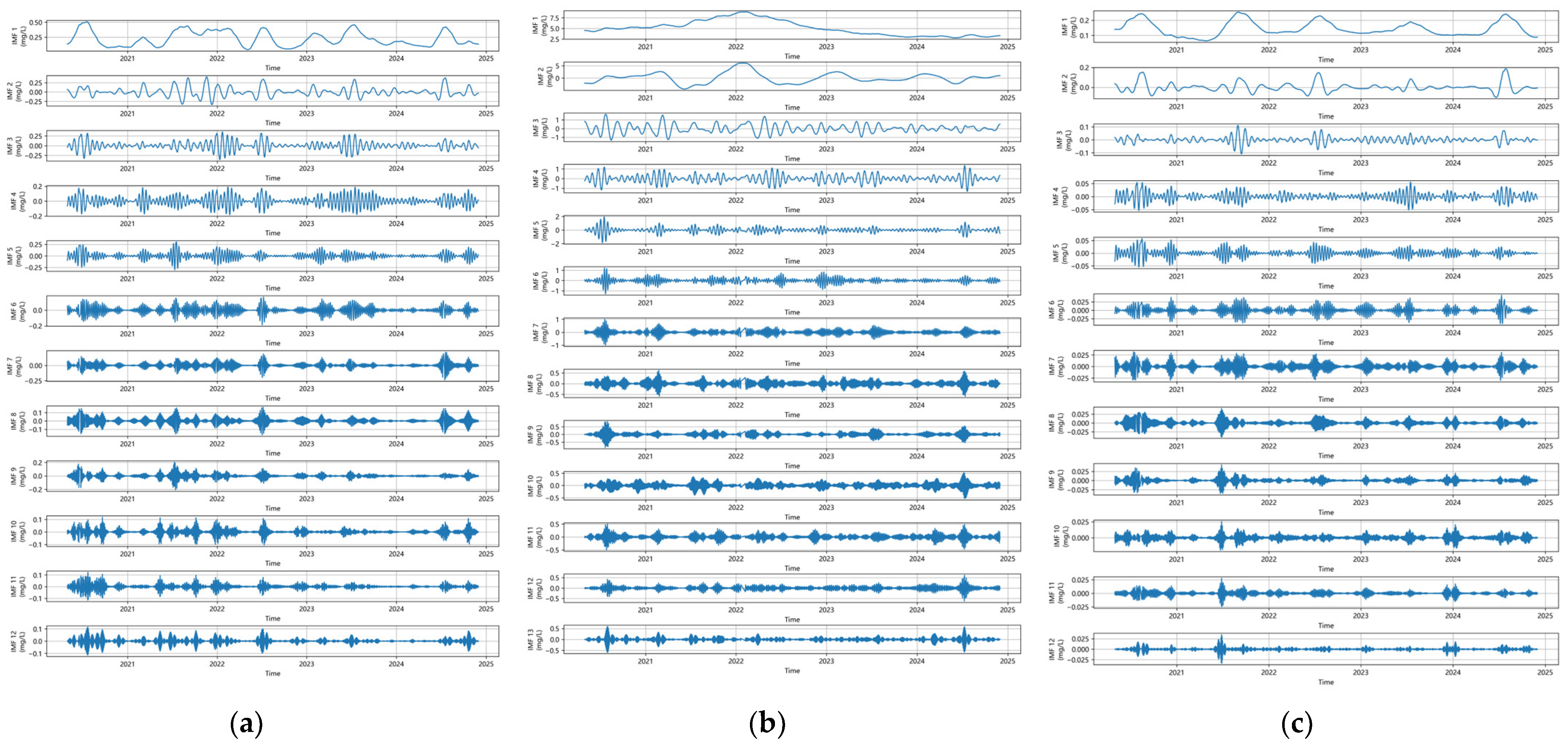
3.1. Variational Mode Decomposition
- 1.
- Each IMF in the frequency domain is updated as:
- 2.
- The central frequency is updated as the centroid of the corresponding IMF power spectrum:
- 3.
- The Lagrangian multiplier is updated to penalize reconstruction errors:
- 4.
- The iteration stops when the relative change in IMFs falls below a tolerance ϵ:
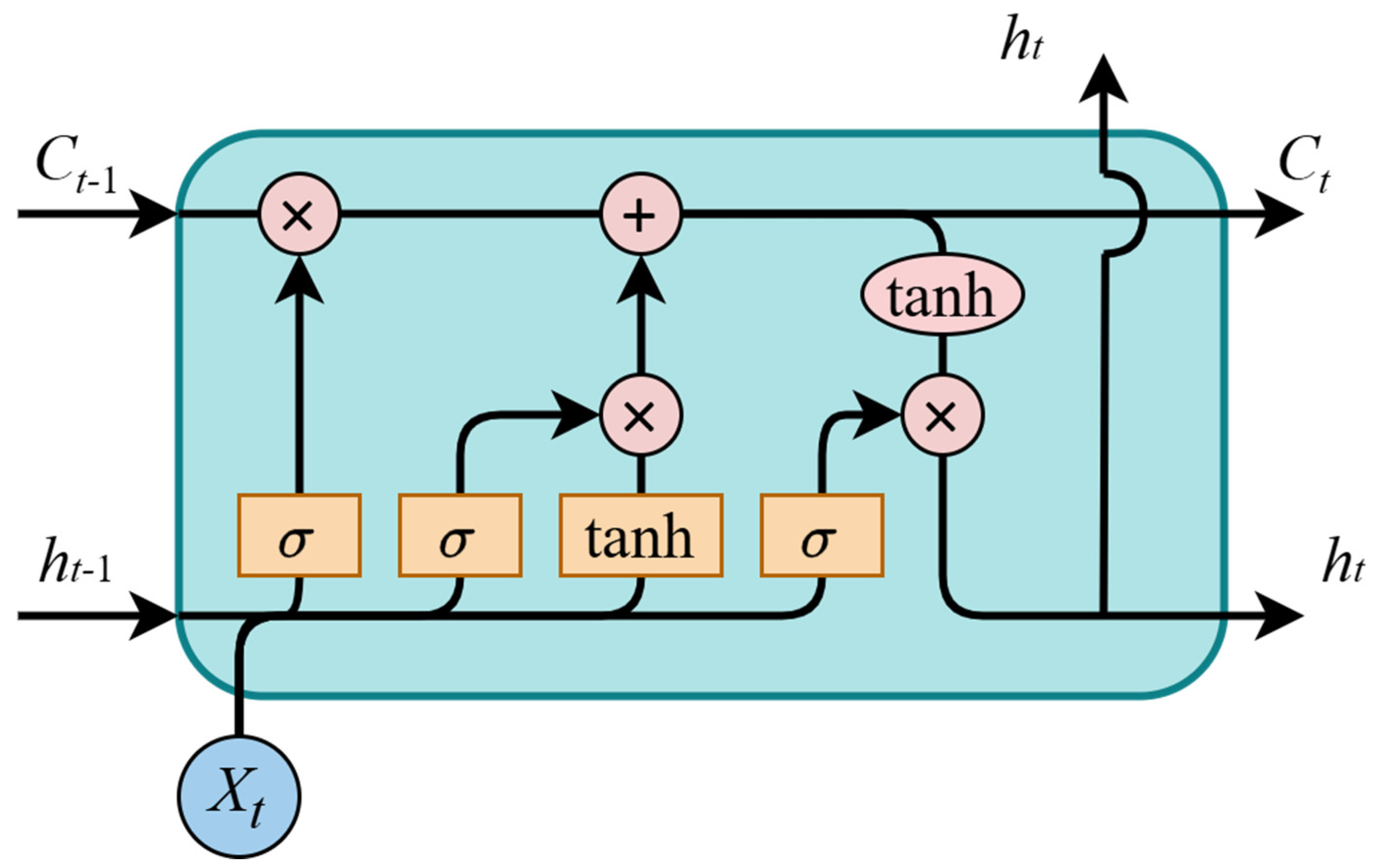
3.2. Long Short-Term Memory Networks
3.3. Genetic Algorithm
- Tournament selection: Groups of several individuals were randomly selected, retaining only the one with the best fitness to populate the mating pool. This approach effectively maintains population diversity while ensuring selection pressure, reducing premature convergence risks compared to roulette wheel selection [41].
- Arithmetic crossover: Parent hyperparameters were blended using domain-specific rules. Learning rates were averaged in logarithmic space, training epochs were integer-averaged, and activation functions were randomly inherited from either parent.
- Gaussian mutation: The learning rate was randomly adjusted according to a log-normal distribution, while the activation function and the number of training epochs were randomly replaced based on probability. This ensures the local search capability while maintaining the possibility of exploring new solution spaces [42].
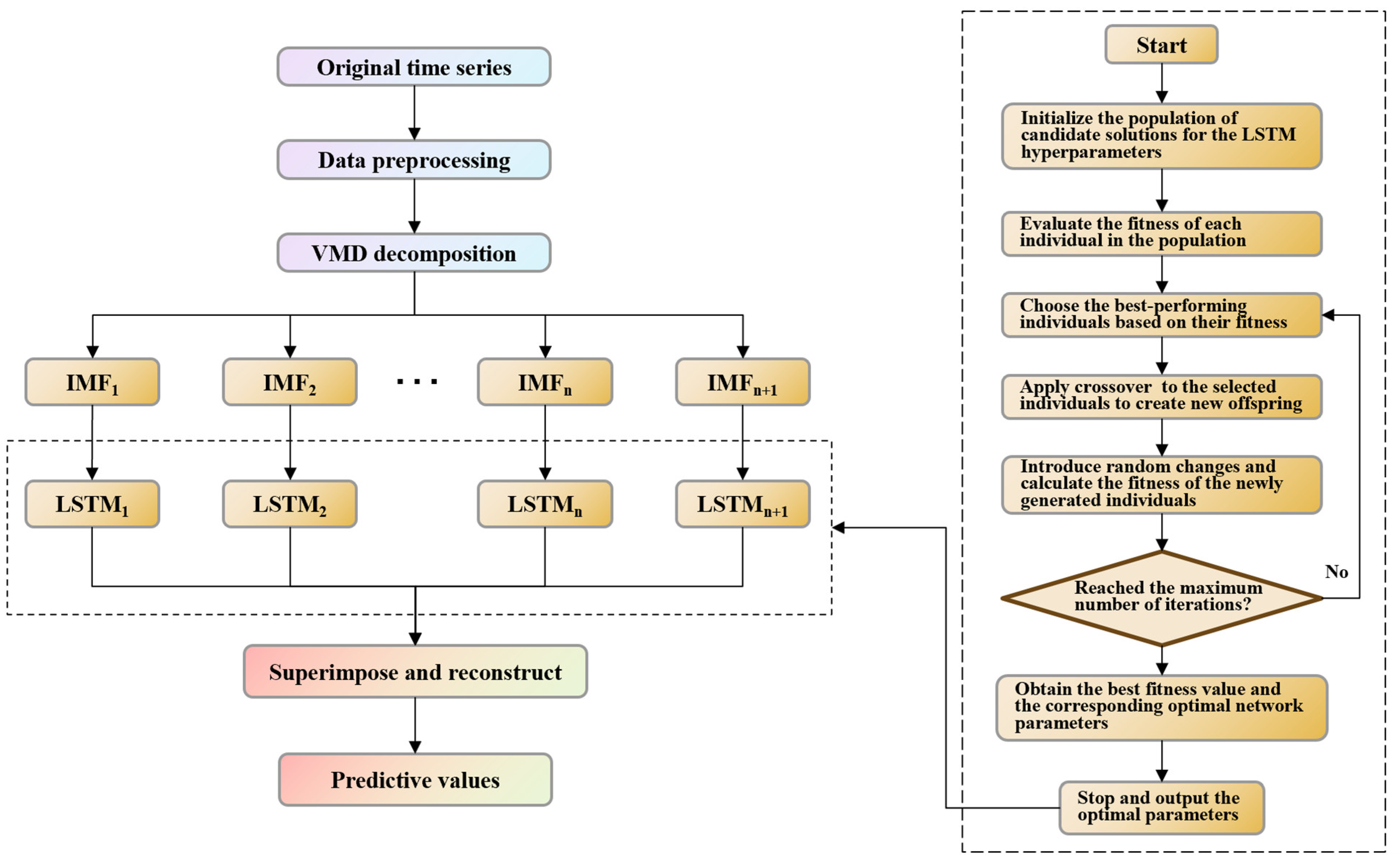
3.4. VMD-GA-LSTM Model
- The preprocessed water quality time series data is first decomposed using variational mode decomposition (VMD), splitting it into multiple intrinsic mode functions (IMFs). Each IMF represents a specific frequency component of the water quality parameters. This decomposition helps isolate different frequency characteristics in the data.
- After decomposition, each IMF is individually processed using long short-term memory (LSTM) networks. These LSTMs are trained separately for each IMF to capture short-term and long-term temporal dependencies. The LSTM model is optimized to minimize the prediction error, providing a forecast for each IMF.
- The convergence of each IMF-LSTM pair is achieved through iterative optimization. During training, the LSTM parameters (weights and biases) are adjusted to minimize the prediction error for each IMF, ensuring the model has captured the temporal dynamics. The convergence occurs when the error stabilizes to a minimum value, indicating effective model performance.
- A genetic algorithm (GA) is employed to optimize the hyperparameters of the LSTM networks for each IMF. The GA searches for the best set of parameters (e.g., learning rate, number of layers, batch size) by evaluating the LSTM performance through a fitness function.
- After each IMF is processed by its corresponding LSTM, the final water quality prediction is obtained by linearly summing the individual predictions of all IMFs. This summation combines the information from all frequency components, providing a comprehensive prediction of water quality parameters (NH3-N, TP, TN).
3.5. Evaluation Indicators
3.6. Experimental Environment
4. Results and Discussion
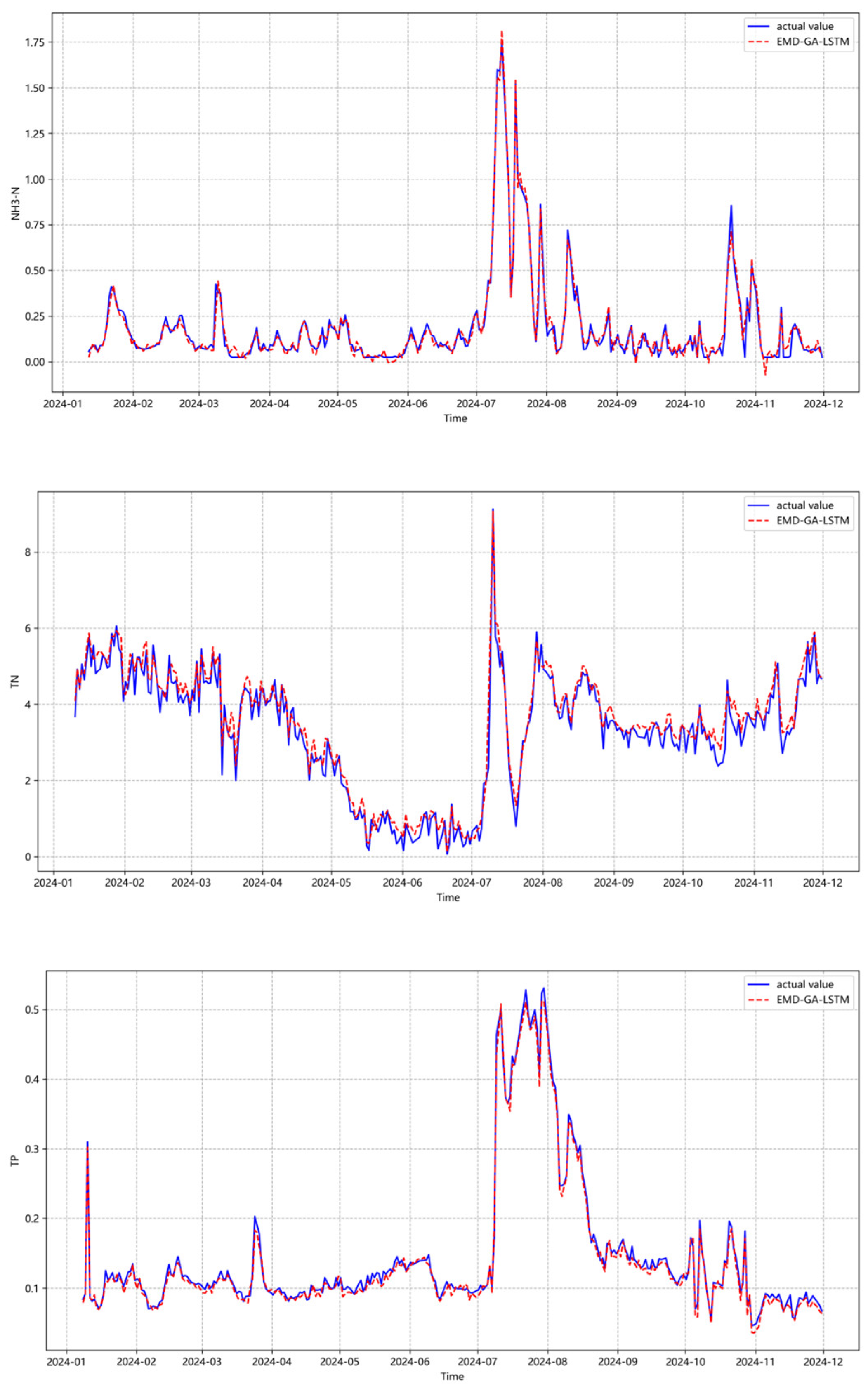
4.1. Empirical Analysis of EMD-GA-LSTM Model
4.2. Model Comparison
4.3. Sensitivity Analysis on Data Noise Robustness
4.4. Policy Recommendations for Sustainable Agricultural Management
4.4.1. Precision Agriculture Practices
4.4.2. Policy Incentives for Circular Agricultural Systems
4.4.3. Farmer Education and Cross-Sectoral Collaboration
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zahoor, I.; Mushtaq, A. Water pollution from agricultural activities: A critical global review. Int. J. Chem. Biochem. Sci. 2023, 23, 164–176. [Google Scholar]
- Cooper, C. Biological effects of agriculturally derived surface water pollutants on aquatic systems—A review. J. Environ. Qual. 1993, 22, 402–408. [Google Scholar] [CrossRef]
- Hussain, F.; Ahmed, S.; Muhammad Zaigham Abbas Naqvi, S.; Awais, M.; Zhang, Y.; Zhang, H.; Raghavan, V.; Zang, Y.; Zhao, G.; Hu, J. Agricultural Non-Point Source Pollution: Comprehensive Analysis of Sources and Assessment Methods. Agriculture 2025, 15, 531. [Google Scholar] [CrossRef]
- Juncal, M.J.L.; Masino, P.; Bertone, E.; Stewart, R.A. Towards nutrient neutrality: A review of agricultural runoff mitigation strategies and the development of a decision-making framework. Sci. Total Environ. 2023, 874, 162408. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Xiao, H.; Fang, H. Component-based reconstruction prediction of runoff at multi-time scales in the source area of the Yellow River based on the ARMA model. Water Resour. Manag. 2022, 36, 433–448. [Google Scholar] [CrossRef]
- Montanari, A.; Rosso, R.; Taqqu, M.S. Fractionally differenced ARIMA models applied to hydrologic time series: Identification, estimation, and simulation. Water Resour. Res. 1997, 33, 1035–1044. [Google Scholar] [CrossRef]
- Thoe, W.; Lee, J.H. Daily forecasting of Hong Kong beach water quality by multiple linear regression models. J. Environ. Eng. 2014, 140, 04013007. [Google Scholar] [CrossRef]
- Faruk, D.Ö. A hybrid neural network and ARIMA model for water quality time series prediction. Eng. Appl. Artif. Intell. 2010, 23, 586–594. [Google Scholar] [CrossRef]
- Chen, Y.; Song, L.; Liu, Y.; Yang, L.; Li, D. A review of the artificial neural network models for water quality prediction. Appl. Sci. 2020, 10, 5776. [Google Scholar] [CrossRef]
- Karthikeyan, L.; Kumar, D.N. Predictability of nonstationary time series using wavelet and EMD based ARMA models. J. Hydrol. 2013, 502, 103–119. [Google Scholar] [CrossRef]
- Zhang, F.; O’Donnell, L.J. Support vector regression. In Machine Learning; Elsevier: Amsterdam, The Netherlands, 2020; pp. 123–140. [Google Scholar] [CrossRef]
- Pham, L.T.; Luo, L.; Finley, A.O. Evaluation of Random Forest for short-term daily streamflow forecast in rainfall and snowmelt driven watersheds. Hydrol. Earth Syst. Sci. Discuss. 2020, 25, 2997–3015. [Google Scholar] [CrossRef]
- Neu, D.A.; Lahann, J.; Fettke, P. A systematic literature review on state-of-the-art deep learning methods for process prediction. Artif. Intell. Rev. 2022, 55, 801–827. [Google Scholar] [CrossRef]
- Han, Z.; Zhao, J.; Leung, H.; Ma, K.F.; Wang, W. A review of deep learning models for time series prediction. IEEE Sens. J. 2019, 21, 7833–7848. [Google Scholar] [CrossRef]
- Bi, J.; Lin, Y.; Dong, Q.; Yuan, H.; Zhou, M. Large-scale water quality prediction with integrated deep neural network. Inf. Sci. 2021, 571, 191–205. [Google Scholar] [CrossRef]
- Mengdi, Z.; Qing, X.; Zhenhong, L.; Chunyan, M.; Pin, G. Prediction of water quality time series based on the dynamic sliding window BP neural network model. J. Environ. Eng. Technol. 2022, 12, 809–815. [Google Scholar] [CrossRef]
- Li, L.; Jiang, P.; Xu, H.; Lin, G.; Guo, D.; Wu, H. Water quality prediction based on recurrent neural network and improved evidence theory: A case study of Qiantang River, China. Environ. Sci. Pollut. Res. 2019, 26, 19879–19896. [Google Scholar] [CrossRef]
- Noh, S.-H. Analysis of gradient vanishing of RNNs and performance comparison. Information 2021, 12, 442. [Google Scholar] [CrossRef]
- Landi, F.; Baraldi, L.; Cornia, M.; Cucchiara, R. Working memory connections for LSTM. Neural Netw. 2021, 144, 334–341. [Google Scholar] [CrossRef]
- Li, Q.; Yang, Y.; Yang, L.; Wang, Y. Comparative analysis of water quality prediction performance based on LSTM in the Haihe River Basin, China. Environ. Sci. Pollut. Res. 2023, 30, 7498–7509. [Google Scholar] [CrossRef]
- Farhi, N.; Kohen, E.; Mamane, H.; Shavitt, Y. Prediction of wastewater treatment quality using LSTM neural network. Environ. Technol. Innov. 2021, 23, 101632. [Google Scholar] [CrossRef]
- Gao, Z.; Chen, J.; Wang, G.; Ren, S.; Fang, L.; Yinglan, A.; Wang, Q. A novel multivariate time series prediction of crucial water quality parameters with Long Short-Term Memory (LSTM) networks. J. Contam. Hydrol. 2023, 259, 104262. [Google Scholar] [CrossRef] [PubMed]
- Doğan, E. Robust-LSTM: A novel approach to short-traffic flow prediction based on signal decomposition. Soft Comput. 2022, 26, 5227–5239. [Google Scholar] [CrossRef]
- Xu, R.; Hu, S.; Wan, H.; Xie, Y.; Cai, Y.; Wen, J. A unified deep learning framework for water quality prediction based on time-frequency feature extraction and data feature enhancement. J. Environ. Manag. 2024, 351, 119894. [Google Scholar] [CrossRef] [PubMed]
- Yang, M.; Tong, L.; Xia, A.; Fang, K. A multi-factor water quality prediction method based on wavelet transform and lstm. In Proceedings of the International Conference on Heterogeneous Networking for Quality, Reliability, Security and Robustness, Shenzhen, China, 8–9 October 2023; pp. 130–144. [Google Scholar] [CrossRef]
- Junsheng, C.; Dejie, Y.; Yu, Y. Research on the intrinsic mode function (IMF) criterion in EMD method. Mech. Syst. Signal Process. 2006, 20, 817–824. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, C.; Jiang, Y.; Sun, L.; Zhao, R.; Yan, K.; Wang, W. Accurate prediction of water quality in urban drainage network with integrated EMD-LSTM model. J. Clean. Prod. 2022, 354, 131724. [Google Scholar] [CrossRef]
- Dong, J.; Zhang, Y.; Hu, J. Short-term air quality prediction based on EMD-transformer-BiLSTM. Sci. Rep. 2024, 14, 20513. [Google Scholar] [CrossRef]
- Yujun, Y.; Yimei, Y.; Wang, Z. Research on a hybrid prediction model for stock price based on long short-term memory and variational mode decomposition. Soft Comput. 2021, 25, 13513–13531. [Google Scholar] [CrossRef]
- Ding, T.; Wu, D.a.; Shen, L.; Liu, Q.; Zhang, X.; Li, Y. Prediction of significant wave height using a VMD-LSTM-rolling model in the South Sea of China. Front. Mar. Sci. 2024, 11, 1382248. [Google Scholar] [CrossRef]
- Wei, Y.; Qiao, X.; Zhang, Z.; Yang, Y.; Niu, H. Trade-off and driving mechanisms for farmland ecosystem services basedon climatic zones and agricultural regionalization. Trans. Chin. Soc. Agric. Eng. 2022, 38, 220–228. (In Chinese) [Google Scholar]
- Dębska, K.; Rutkowska, B.; Szulc, W.; Gozdowski, D. Changes in selected water quality parameters in the Utrata River as a function of catchment area land use. Water 2021, 13, 2989. [Google Scholar] [CrossRef]
- Gnauck, A. Interpolation and approximation of water quality time series and process identification. Anal. Bioanal. Chem. 2004, 380, 484–492. [Google Scholar] [CrossRef] [PubMed]
- Liu, F.T.; Ting, K.M.; Zhou, Z.-H. Isolation-based anomaly detection. ACM Trans. Knowl. Discov. Data (TKDD) 2012, 6, 3. [Google Scholar] [CrossRef]
- Ali, P.J.M.; Faraj, R.H.; Koya, E.; Ali, P.J.M.; Faraj, R.H. Data normalization and standardization: A technical report. Mach. Learn. Tech. Rep. 2014, 1, 1–6. [Google Scholar] [CrossRef]
- Liu, Y.; Yang, G.; Li, M.; Yin, H. Variational mode decomposition denoising combined the detrended fluctuation analysis. Signal Process. 2016, 125, 349–364. [Google Scholar] [CrossRef]
- Kurbatsky, V.G.; Sidorov, D.N.; Spiryaev, V.A.; Tomin, N.V. Forecasting nonstationary time series based on Hilbert-Huang transform and machine learning. Autom. Remote Control 2014, 75, 922–934. [Google Scholar] [CrossRef]
- Boyd, S.; Parikh, N.; Chu, E.; Peleato, B.; Eckstein, J. Distributed optimization and statistical learning via the alternating direction method of multipliers. Found. Trends Mach. Learn. 2011, 3, 1–122. [Google Scholar] [CrossRef]
- Sherstinsky, A. Fundamentals of recurrent neural network (RNN) and long short-term memory (LSTM) network. Phys. D Nonlinear Phenom. 2020, 404, 132306. [Google Scholar] [CrossRef]
- Ding, S.; Su, C.; Yu, J. An optimizing BP neural network algorithm based on genetic algorithm. Artif. Intell. Rev. 2011, 36, 153–162. [Google Scholar] [CrossRef]
- Shapiro, J. Genetic algorithms in machine learning. In Advanced Course on Artificial Intelligence; Springer: Cham, Switzerland, 1999; pp. 146–168. [Google Scholar] [CrossRef]
- Saravanan, N.; Fogel, D.B.; Nelson, K.M. A comparison of methods for self-adaptation in evolutionary algorithms. BioSystems 1995, 36, 157–166. [Google Scholar] [CrossRef]
- Zhang, X.; Miao, Q.; Zhang, H.; Wang, L. A parameter-adaptive VMD method based on grasshopper optimization algorithm to analyze vibration signals from rotating machinery. Mech. Syst. Signal Process. 2018, 108, 58–72. [Google Scholar] [CrossRef]
- Zhang, S.; Wang, S.; Yuan, L.; Liu, X.; Gong, B. The impact of epidemics on agricultural production and forecast of COVID-19. China Agric. Econ. Rev. 2020, 12, 409–425. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar] [CrossRef]
- Xu, H.; Tan, X.; Liang, J.; Cui, Y.; Gao, Q. Impact of agricultural non-point source pollution on river water quality: Evidence from China. Front. Ecol. Evol. 2022, 10, 858822. [Google Scholar] [CrossRef]
- Zadgaonkar, L.A.; Darwai, V.; Mandavgane, S.A. The circular agricultural system is more sustainable: Emergy analysis. Clean Technol. Environ. Policy 2022, 24, 1301–1315. [Google Scholar] [CrossRef]
- Wang, C.; Luo, D.; Zhang, X.; Huang, R.; Cao, Y.; Liu, G.; Zhang, Y.; Wang, H. Biochar-based slow-release of fertilizers for sustainable agriculture: A mini review. Environ. Sci. Ecotechnol. 2022, 10, 100167. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Water Quality Indicators | RMSE | MAE | R2 |
|---|---|---|---|
| NH3-N | 0.019 ± 0.002 | 0.014 ± 0.001 | 0.994 ± 0.003 |
| TN | 0.136 ± 0.008 | 0.104 ± 0.006 | 0.993 ± 0.002 |
| TP | 0.004 ± 0.000 | 0.003 ± 0.000 | 0.995 ± 0.001 |
| Parameter | Meaning | NH3-N | TN | TP |
|---|---|---|---|---|
| Learning rate | Controls the step size for updating model weights | 0.001 | 0.001 | 0.001 |
| Hidden layer | The number of intermediate layers in the neural network | 1 | 1 | 1 |
| Units | The number of neurons in each hidden layer | 300 | 200 | 100 |
| Activation | The activation function | Tanh | Tanh | Tanh |
| Batch size | The number of samples used in each training iteration | 16 | 32 | 16 |
| Epochs | The number of dataset iterations during training | 50 | 60 | 60 |
| Water Quality Indicators | Model | RMSE | MAE | R2 |
|---|---|---|---|---|
| NH3-N | SVR | 0.129 | 0.069 | 0.697 |
| BP | 0.127 | 0.073 | 0.712 | |
| LSTM | 0.120 | 0.067 | 0.741 | |
| EMD-LSTM | 0.041 | 0.029 | 0.975 | |
| VMD-GA-LSTM | 0.024 | 0.017 | 0.991 | |
| TN | SVR | 0.758 | 0.435 | 0.763 |
| BP | 0.840 | 0.551 | 0.712 | |
| LSTM | 0.737 | 0.434 | 0.778 | |
| EMD-LSTM | 0.332 | 0.251 | 0.955 | |
| VMD-GA-LSTM | 0.152 | 0.115 | 0.990 | |
| TP | SVR | 0.034 | 0.020 | 0.877 |
| BP | 0.037 | 0.024 | 0.853 | |
| LSTM | 0.033 | 0.015 | 0.886 | |
| EMD-LSTM | 0.011 | 0.008 | 0.988 | |
| VMD-GA-LSTM | 0.007 | 0.005 | 0.993 |
| Water Quality Indicators | Noise Level | RMSE | MAE | R2 |
|---|---|---|---|---|
| NH3-N | 0% (Baseline) | 0.024 | 0.017 | 0.991 |
| 5% | 0.025 | 0.019 | 0.990 | |
| 10% | 0.025 | 0.022 | 0.987 | |
| TN | 0% (Baseline) | 0.152 | 0.115 | 0.990 |
| 5% | 0.154 | 0.120 | 0.988 | |
| 10% | 0.159 | 0.122 | 0.985 | |
| TP | 0% (Baseline) | 0.007 | 0.005 | 0.993 |
| 5% | 0.007 | 0.005 | 0.991 | |
| 10% | 0.009 | 0.007 | 0.989 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Luo, Y.; Meng, X.; Zhai, Y.; Zhang, D.; Ma, K. Prediction of Water Quality in Agricultural Watersheds Based on VMD-GA-LSTM Model. Mathematics 2025, 13, 1951. https://doi.org/10.3390/math13121951
Luo Y, Meng X, Zhai Y, Zhang D, Ma K. Prediction of Water Quality in Agricultural Watersheds Based on VMD-GA-LSTM Model. Mathematics. 2025; 13(12):1951. https://doi.org/10.3390/math13121951
Chicago/Turabian StyleLuo, Yuxuan, Xianglan Meng, Yutong Zhai, Dongqing Zhang, and Kaiping Ma. 2025. "Prediction of Water Quality in Agricultural Watersheds Based on VMD-GA-LSTM Model" Mathematics 13, no. 12: 1951. https://doi.org/10.3390/math13121951
APA StyleLuo, Y., Meng, X., Zhai, Y., Zhang, D., & Ma, K. (2025). Prediction of Water Quality in Agricultural Watersheds Based on VMD-GA-LSTM Model. Mathematics, 13(12), 1951. https://doi.org/10.3390/math13121951