
Curvature-Based Change Detection in Road Segmentation: Ascending Hierarchical Clustering vs. K-Means

 ,
,  , , and
, , and
Abstract
1. Introduction
- We pre-process the data before labeling by reducing its dimensionality through segmentation, which is a specific form of clustering.
- We propose features that better characterize changes in road structure.
- We adapt abstract algorithmic approaches -specifically, AHC and k-means- to road segmentation.
- We demonstrate that the segmentation problem in time series is analogous to binary classification or -labeling, enabling the use of a confusion matrix for evaluating the performance of the proposed algorithms.
- We introduce a novel change detection metric called the rate of agreement with the change.
2. Related Work
2.1. Road Condition Detection and Classification
2.2. Trajectory Segmentation
2.2.1. Sliding Window and Bottom up Method
| Algorithm 1 BUA (T: Time Series, : error threshold) |
| {} while do end while for to do if then end if end for while and do for to do if then end if end for end while Return |
| Algorithm 2 SWAB (T: Time Series, N: Window’s length, : error threshold) |
| {} /* Temporary cluster*/ {} /* Final cluster*/ {} /* The window*/ while () do () and () and () while do () and () and () end while end while Return |
2.2.2. Overlapping Windows Method
| Algorithm 3 OWA (T: Time Series, N: Length of the window, K: Number de Clusters) |
| {} /* The final cluster*/ /* The current position of a first cursor in T */ /* C is a cluster from in K classes */ /* The current position of a second cursor in T */ while () do if () or () then else end if end while Return |
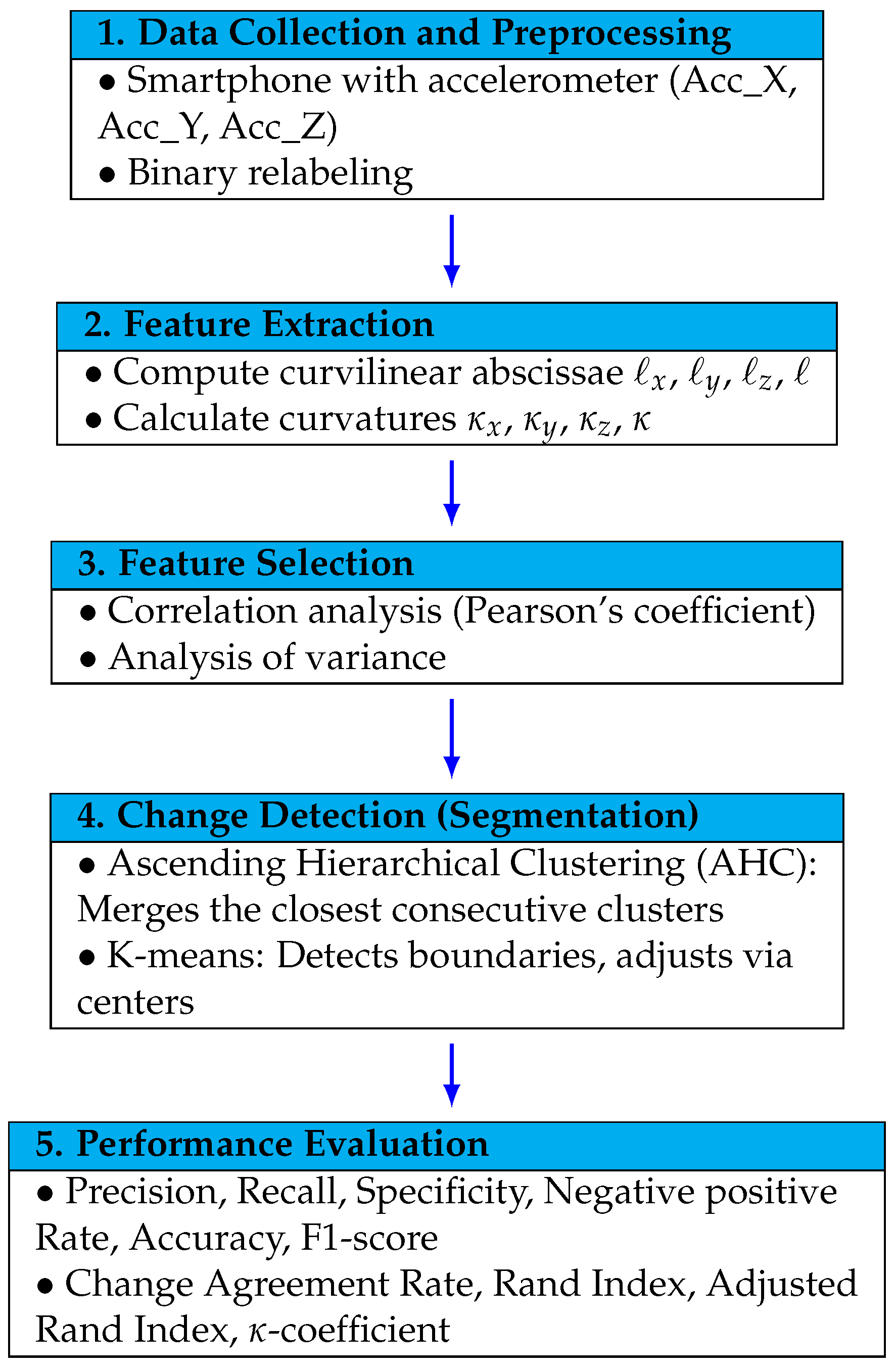
3. Methodology of the Work
3.1. Data Collection and Pre-Processing
3.1.1. Description of the Dataset
- Timestamps: sampling instants in milliseconds.
- Raw data: raw measurements of the components of the acceleration vector for the X, Y and Z axes.
- Adjusted data: Adjusted access data from the telephone’s co-ordination system for a universal co-ordination system.
- Route labels: character string that can take the values ’smooth’, ’bumpy’ or ’rough’.
3.1.2. Extraction of Features
3.2. Change Detection Algorithms
- Reformulate K-means and AHC into segmentation algorithms that respect the sequential structure of the data.
- Introduce a new dissimilarity measure that respects the characteristics of road surfaces.
3.2.1. Ascending Hierarchical Classification
| Algorithm 4 AHC (T: Time Series) |
| /*the final cluster*/ N /*the number of classification attempts*/ for do if then /*the list of distances between elements of taken by twos*/ for do end for while do if then else end if end while end if end for return |
3.2.2. K-Means Algorithm
| Algorithm 5 K-means (T: Time Series, K: Number of Clusters) |
| /* Number of points in T */ /* Randomly select distinct values in */ /* are the point before change */ {} /* Initialize Centers */ for to do if {} then else end if end for while do {} {} for to do if then else end if while and do if then else end if end while if then else end if end for if then end if end while /*the final cluster*/ for ( to length()) do end for return |
3.3. Tools for Performance Evaluation
3.3.1. Feature Selection and Dissimilarity Distance
3.3.2. Performance Metrics
4. Results and Discussions
4.1. Visualization of Data and Selection of Features
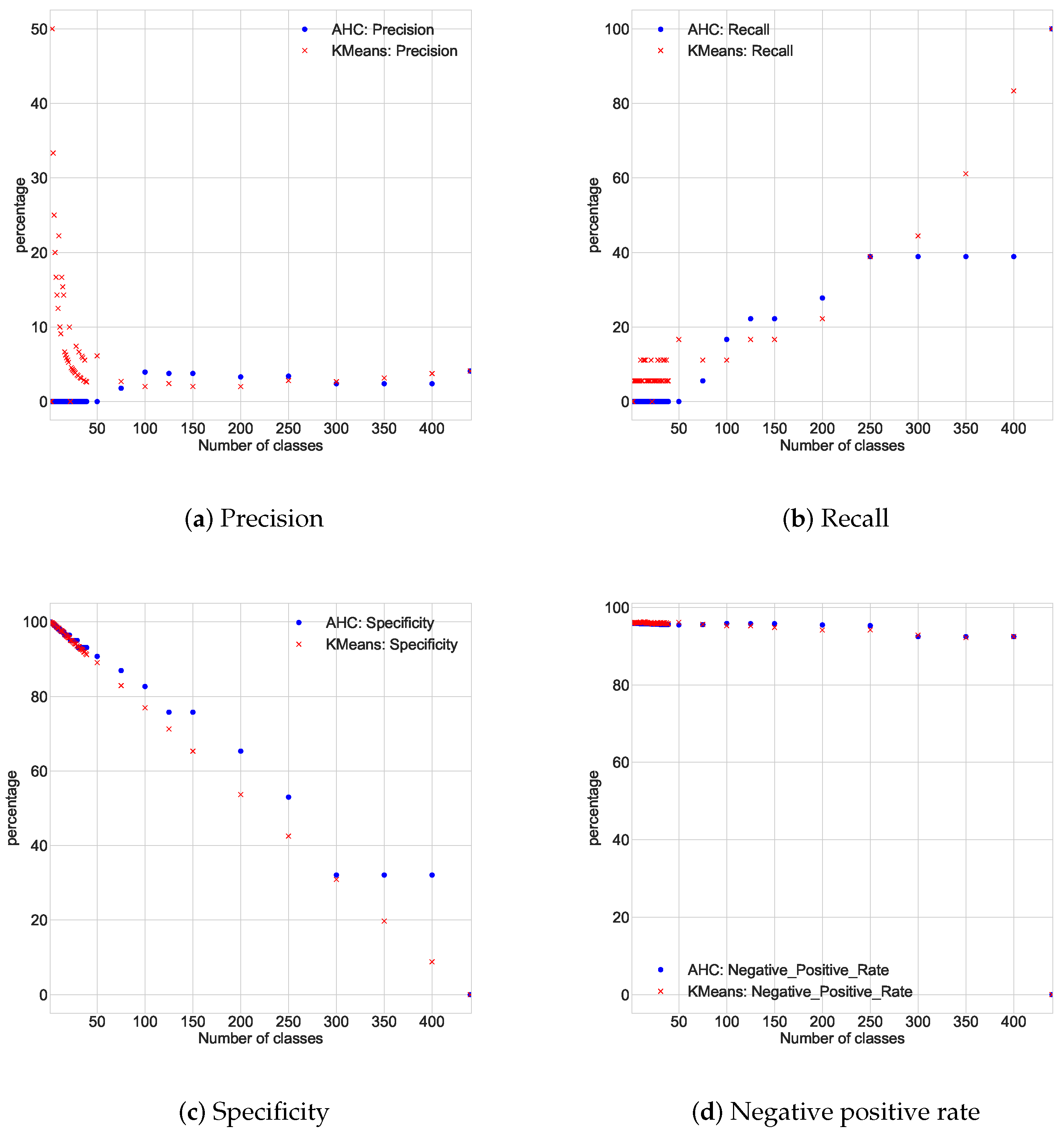
4.2. Comparison Between AHC and K-Means Performances
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Al-Sabaeei, A.M.; Souliman, M.I.; Jagadeesh, A. Smartphone applications for pavement condition monitoring: A review. Constr. Build. Mater. 2024, 410, 134207. [Google Scholar] [CrossRef]
- Dhiman, A.; Klette, R. Pothole detection using computer vision and learning. IEEE Trans. Intell. Transp. Syst. 2019, 21, 3536–3550. [Google Scholar] [CrossRef]
- Guan, J.; Yang, X.; Ding, L.; Cheng, X.; Lee, V.C.; Jin, C. Automated pixel-level pavement distress detection based on stereo vision and deep learning. Autom. Constr. 2021, 129, 103788. [Google Scholar] [CrossRef]
- Rajamohan, D.; Gannu, B.; Rajan, K.S. MAARGHA: A prototype system for road condition and surface type estimation by fusing multi-sensor data. ISPRS Int. J. Geo-Inf. 2015, 4, 1225–1245. [Google Scholar] [CrossRef]
- Anaissi, A.; Khoa, N.L.D.; Rakotoarivelo, T.; Alamdari, M.M.; Wang, Y. Smart pothole detection system using vehicle-mounted sensors and machine learning. J. Civ. Struct. Health Monit. 2019, 9, 91–102. [Google Scholar] [CrossRef]
- Martinez-Ríos, E.A.; Bustamante-Bello, M.R.; Arce-Sáenz, L.A. A review of road surface anomaly detection and classification systems based on vibration-based techniques. Appl. Sci. 2022, 12, 9413. [Google Scholar] [CrossRef]
- Seraj, F.; Zwaag, B.J.v.d.; Dilo, A.; Luarasi, T.; Havinga, P. RoADS: A road pavement monitoring system for anomaly detection using smart phones. In Big Data Analytics in the Social and Ubiquitous Context; Springer: Berlin/Heidelberg, Germany, 2015; pp. 128–146. [Google Scholar]
- Sattar, S.; Li, S.; Chapman, M. Developing a near real-time road surface anomaly detection approach for road surface monitoring. Measurement 2021, 185, 109990. [Google Scholar] [CrossRef]
- Boateng, F.G.; Klopp, J.M. Beyond bans. J. Transp. Land Use 2022, 15, 651–670. [Google Scholar] [CrossRef]
- Egaji, O.A.; Evans, G.; Griffiths, M.G.; Islas, G. Real-time machine learning-based approach for pothole detection. Expert Syst. Appl. 2021, 184, 115562. [Google Scholar] [CrossRef]
- Wu, S.; Hadachi, A. Road surface recognition based on deepsense neural network using accelerometer data. In Proceedings of the 2020 IEEE Intelligent Vehicles Symposium (IV), Las Vegas, NV, USA, 19 October–13 November 2020; pp. 305–312. [Google Scholar]
- Amarbayasgalan, T.; Pham, V.H.; Theera-Umpon, N.; Ryu, K.H. Unsupervised anomaly detection approach for time-series in multi-domains using deep reconstruction error. Symmetry 2020, 12, 1251. [Google Scholar] [CrossRef]
- Aminikhanghahi, S.; Cook, D.J. A survey of methods for time series change point detection. Knowl. Inf. Syst. 2017, 51, 339–367. [Google Scholar] [CrossRef] [PubMed]
- Benevento, A.; Durante, F. Correlation-based hierarchical clustering of time series with spatial constraints. Spat. Stat. 2024, 59, 100797. [Google Scholar] [CrossRef]
- Tran, D.H. Automated change detection and reactive clustering in multivariate streaming data. In Proceedings of the 2019 IEEE-RIVF International Conference on Computing and Communication Technologies (RIVF), Danang, Vietnam, 20–22 March 2019; pp. 1–6. [Google Scholar]
- Bezdan, T.; Stoean, C.; Naamany, A.A.; Bacanin, N.; Rashid, T.A.; Zivkovic, M.; Venkatachalam, K. Hybrid fruit-fly optimization algorithm with k-means for text document clustering. Mathematics 2021, 9, 1929. [Google Scholar] [CrossRef]
- Javed, A.; Lee, B.S.; Rizzo, D.M. A benchmark study on time series clustering. Mach. Learn. Appl. 2020, 1, 100001. [Google Scholar] [CrossRef]
- Holder, C.; Middlehurst, M.; Bagnall, A. A review and evaluation of elastic distance functions for time series clustering. Knowl. Inf. Syst. 2024, 66, 765–809. [Google Scholar] [CrossRef]
- Keogh, E.; Chu, S.; Hart, D.; Pazzani, M. An online algorithm for segmenting time series. In Proceedings of the 2001 IEEE International Conference on Data Mining, San Jose, CA, USA, 29 November–2 December 2001; pp. 289–296. [Google Scholar]
- Basavaraju, A.; Du, J.; Zhou, F.; Ji, J. A machine learning approach to road surface anomaly assessment using smartphone sensors. IEEE Sens. J. 2019, 20, 2635–2647. [Google Scholar] [CrossRef]
- Nguyen, V.K.; Renault, É.; Milocco, R. Environment monitoring for anomaly detection system using smartphones. Sensors 2019, 19, 3834. [Google Scholar] [CrossRef]
- Wu, C.; Wang, Z.; Hu, S.; Lepine, J.; Na, X.; Ainalis, D.; Stettler, M. An automated machine-learning approach for road pothole detection using smartphone sensor data. Sensors 2020, 20, 5564. [Google Scholar] [CrossRef]
- Rajput, P.; Chaturvedi, M.; Patel, V. Road condition monitoring using unsupervised learning based bus trajectory processing. Multimodal Transp. 2022, 1, 100041. [Google Scholar] [CrossRef]
- Bustamante-Bello, R.; García-Barba, A.; Arce-Saenz, L.A.; Curiel-Ramirez, L.A.; Izquierdo-Reyes, J.; Ramirez-Mendoza, R.A. Visualizing street pavement anomalies through fog computing v2i networks and machine learning. Sensors 2022, 22, 456. [Google Scholar] [CrossRef]
- Kim, G.; Kim, S. A road defect detection system using smartphones. Sensors 2024, 24, 2099. [Google Scholar] [CrossRef] [PubMed]
- He, D.; Shi, Q.; Xue, J.; Atkinson, P.M.; Liu, X. Very fine spatial resolution urban land cover mapping using an explicable sub-pixel mapping network based on learnable spatial correlation. Remote Sens. Environ. 2023, 299, 113884. [Google Scholar] [CrossRef]
- van Kuppevelt, D.; Heywood, J.; Hamer, M.; Sabia, S.; Fitzsimons, E.; van Hees, V. Segmenting accelerometer data from daily life with unsupervised machine learning. PLoS ONE 2019, 14, e0208692. [Google Scholar] [CrossRef]
- Etemad, M.; Júnior, A.S.; Hoseyni, A.; Rose, J.; Matwin, S. A Trajectory Segmentation Algorithm Based on Interpolation-based Change Detection Strategies. In Proceedings of the EDBT/ICDT Workshops, Lisbon, Portugal, 26 March 2019; p. 58. [Google Scholar]
- Tapia, G.; Colomé, A.; Torras, C. Unsupervised Trajectory Segmentation and Gesture Recognition through Curvature Analysis and the Levenshtein Distance. In Proceedings of the 2024 7th Iberian Robotics Conference (ROBOT), Madrid, Spain, 6–8 November 2024; pp. 1–8. [Google Scholar]
- Chilov, G. Fonctions d’une Variable [Tome 1], 1ère er 2eme Parties; Mir: Moscou, Russie, 1973. [Google Scholar]
- Fortin, A. Analyse Numérique pour Ingénieurs; Presses Inter Polytechnique: Montréal, QC, Canada, 2011. [Google Scholar]
- Saporta, G. Probabilités, Analyse des Données et Statistique; Editions Technip: Paris, France, 2006. [Google Scholar]
- Rand, W.M. Objective criteria for the evaluation of clustering methods. J. Am. Stat. Assoc. 1971, 66, 846–850. [Google Scholar] [CrossRef]
- Hubert, L.; Arabie, P. Comparing partitions. J. Classif. 1985, 2, 193–218. [Google Scholar] [CrossRef]
- Zhang, H.; Ho, T.B.; Zhang, Y.; Lin, M.S. Unsupervised feature extraction for time series clustering using orthogonal wavelet transform. Informatica 2006, 30, 305–319. [Google Scholar]
- Gates, A.J.; Ahn, Y.Y. The impact of random models on clustering similarity. J. Mach. Learn. Res. 2017, 18, 1–28. [Google Scholar]
- Zheng, Z.; Zhou, M.; Chen, Y.; Huo, M.; Sun, L. QDetect: Time series querying based road anomaly detection. IEEE Access 2020, 8, 98974–98985. [Google Scholar] [CrossRef]
- Zheng, Z.; Zhou, M.; Chen, Y.; Huo, M.; Sun, L.; Zhao, S.; Chen, D. A fused method of machine learning and dynamic time warping for road anomalies detection. IEEE Trans. Intell. Transp. Syst. 2020, 23, 827–839. [Google Scholar] [CrossRef]






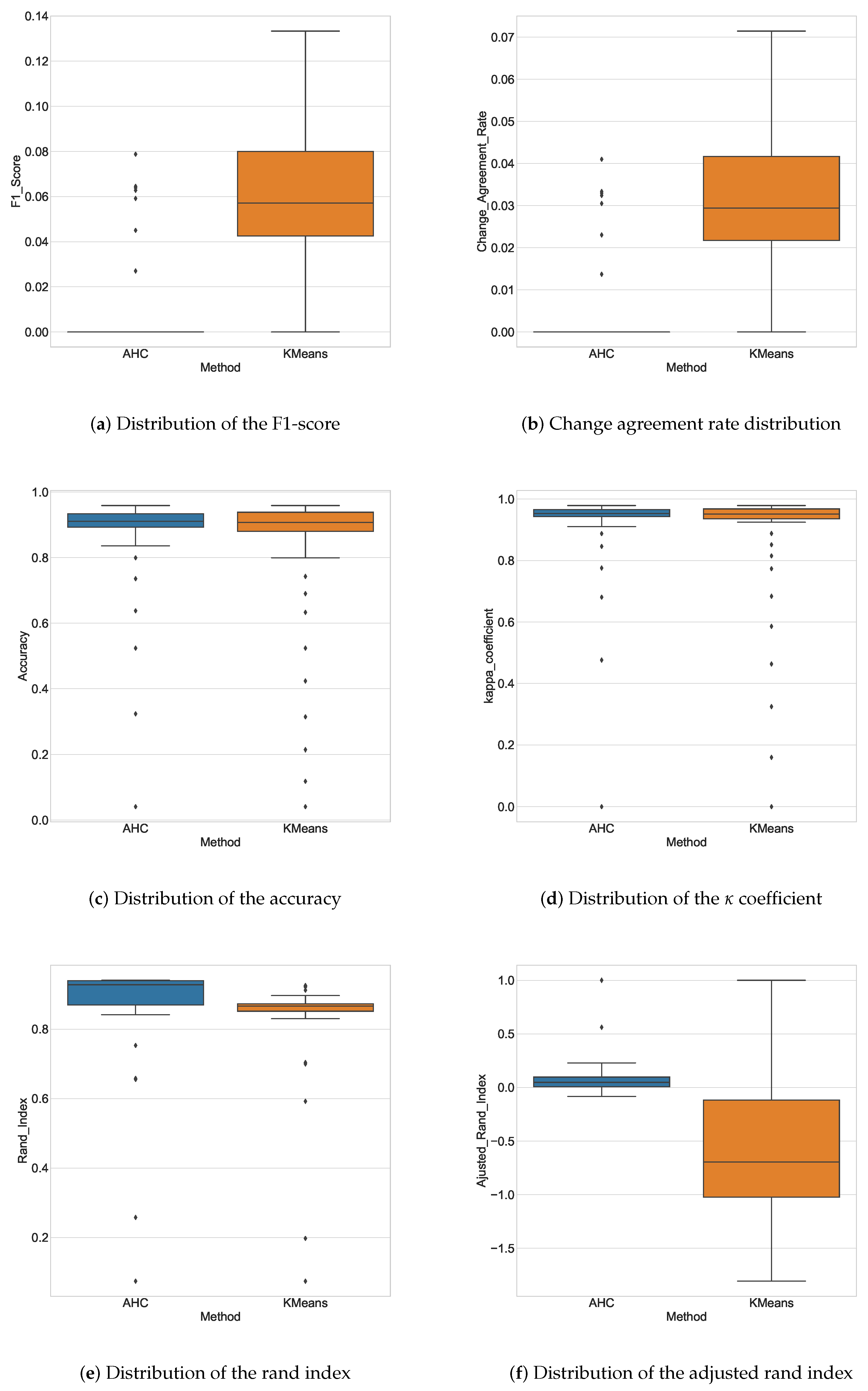

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Year | Ref. | App. Type | Road Mon. | Curv. | Segm. | Data Type | Feature Extraction | Application Domain | Evaluation Metrics |
|---|---|---|---|---|---|---|---|---|---|
| 2019 | [27] | Uns. | No | No | Yes | Accele- rometer | Time-windowed signal embeddings | Human Activity Monitoring | qualitative analysis |
| 2019 | [28] | Uns. | No | No | Yes | Generic trajectory data | Interpolation-based descriptors | Trajectory Mining | Interpolation error, temporal accuracy |
| 2019 | [20] | Sup. | Yes | No | No | Accele- rometer/image | Raw image + vibration amplitudes | Road Surface Classification | Accuracy, Precision, Recall, F1-score |
| 2019 | [21] | Sup. | Yes | No | No | Accele- rometer & GPS | Spatial features, GPS thresholds | Road Condition Detection | Detection rate, False positive rate |
| 2020 | [22] | Sup. | Yes | No | No | Accele- rometer | FFT, Mean, std, skewness, kurtosis, RMS | Road Condition Monitoring | Accuracy, Precision, Recall, AUC |
| 2022 | [23] | Uns. | Yes | No | Yes | Accele- rometer | Extreme Value, variance | Road Monitoring (Bus) | Silhouette score, qualitative map |
| 2022 | [24] | Sup. | Yes | No | No | Accele- rometer | Mean, min, max, std, energy computed | Road Condition Monitoring | Accuracy, Confusion Matrix |
| 2024 | [25] | Sup. | Yes | No | No | Spatio- temporal sequences | Learned features (CNN, LSTM, RF) | Road Condition Mapping | Precision, Recall, F1-score, MAE, RMSE |
| 2024 | [29] | Uns. | No | Yes | Yes | Trajectory gestures | Curvature + curvature derivative | Gesture segmentation via curvature | Segmentation accuracy, Levenshtein distance |
| 2025 | Our work | Uns. | Yes | Yes | Yes | Accelerometer | Curvilinear abscissas, curvatures | Road Segmentation and Change Detection | Accuracy, F1-score, Rand Index, ARI, , |
| Change Agreement Rate |
| Attribute | Description |
|---|---|
| Data types | Accelerometer signals (accX, accY, accZ) |
| Data source | github.com/simonwu53/.../sensor_data_v2.zip (13 November 2024) |
| Data resolution | 10 Hz sampling frequency |
| Data acquisition date | 2020 |
| Device used | Smartphone with built-in accelerometer |
| N° | Textual Label | Binary Label | |
|---|---|---|---|
| 1 | Smooth | → | 0 |
| 2 | Bumpy | → | 1 |
| 3 | Bumpy | → | 1 |
| 4 | Bumpy | → | 1 |
| 5 | Rough | → | 0 |
| Measurements Available in the Dataset | Calculated by Ourselves | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Timestamp | Textual label | Binary label | ℓ | ||||||||||
| Metric | Formula |
|---|---|
| Precision | |
| Recall | |
| Specificity | |
| Negative Positive Rate | |
| Accuracy | |
| F1-Score | |
| Agreement rate on change |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fotsa-Mbogne, D.J.; Nguensie-Wakponou, A.B.; Nlong, J.M., II; Atemkeng, M.; Tchuente, M. Curvature-Based Change Detection in Road Segmentation: Ascending Hierarchical Clustering vs. K-Means. Mathematics 2025, 13, 1921. https://doi.org/10.3390/math13121921
Fotsa-Mbogne DJ, Nguensie-Wakponou AB, Nlong JM II, Atemkeng M, Tchuente M. Curvature-Based Change Detection in Road Segmentation: Ascending Hierarchical Clustering vs. K-Means. Mathematics. 2025; 13(12):1921. https://doi.org/10.3390/math13121921
Chicago/Turabian StyleFotsa-Mbogne, David Jaurès, Addie Bernice Nguensie-Wakponou, Jean Michel Nlong, II, Marcellin Atemkeng, and Maurice Tchuente. 2025. "Curvature-Based Change Detection in Road Segmentation: Ascending Hierarchical Clustering vs. K-Means" Mathematics 13, no. 12: 1921. https://doi.org/10.3390/math13121921
APA StyleFotsa-Mbogne, D. J., Nguensie-Wakponou, A. B., Nlong, J. M., II, Atemkeng, M., & Tchuente, M. (2025). Curvature-Based Change Detection in Road Segmentation: Ascending Hierarchical Clustering vs. K-Means. Mathematics, 13(12), 1921. https://doi.org/10.3390/math13121921