
Towards Efficient HPC: Exploring Overlap Strategies Using MPI Non-Blocking Communication

Abstract
1. Introduction
2. MPI Communication Mechanisms
2.1. The MPI Communication Model
2.2. Non-Blocking Communication in MPI
3. Key Techniques to Overlap Communication with Computation
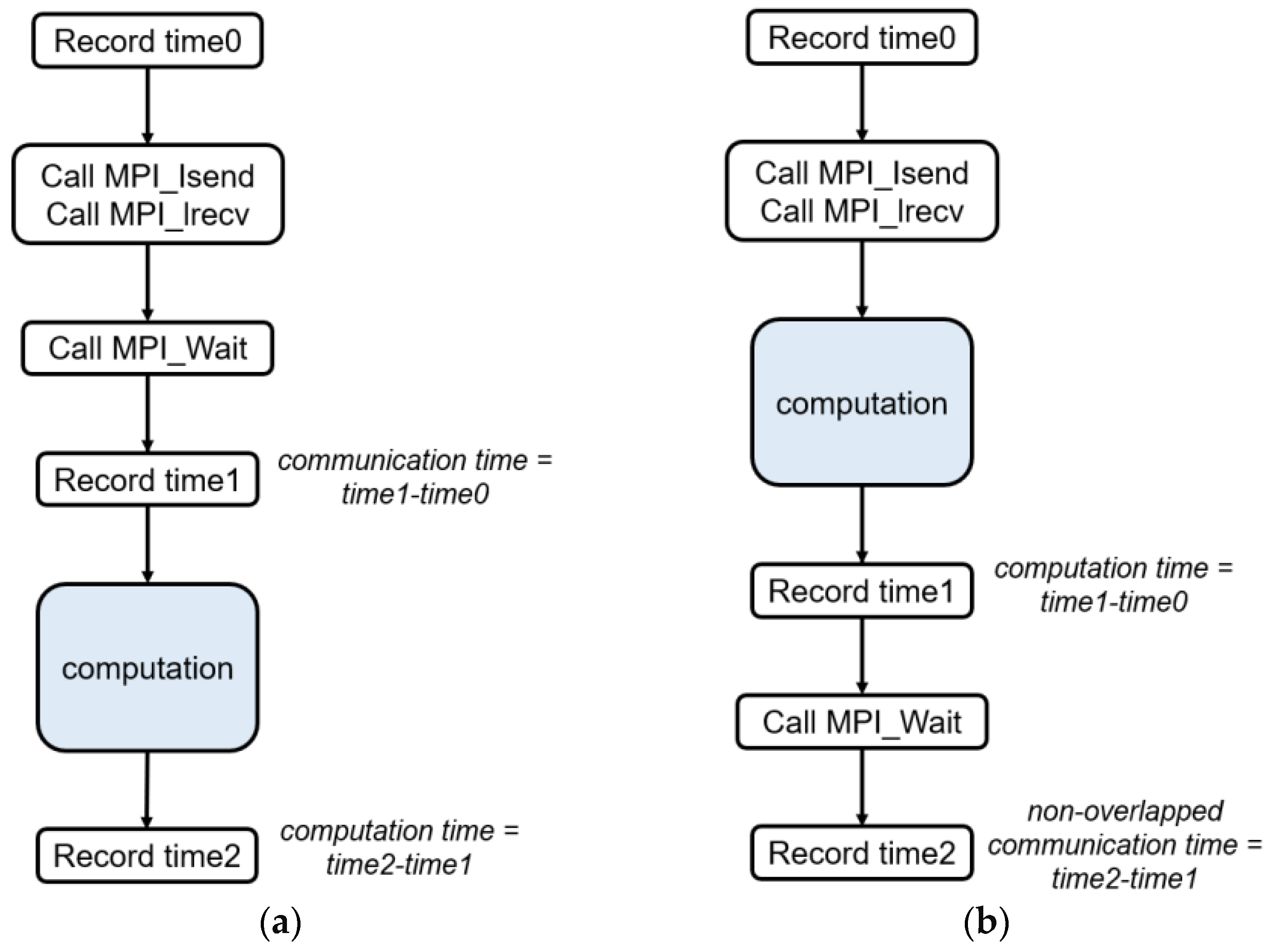
3.1. Relevant Definitions and Evaluation Metrics
- Cooperative (weak progression);
- Coercive (strong progression via interrupt-driven mechanisms);
- Co-located (strong progression using multitasking);
- Concurrent (strong progression using dedicated CPU cores);
- Offloaded (strong progression using dedicated non-CPU hardware).
3.2. Achieving Progress for Non-Blocking Communication
- Manual Progress via Explicit MPI Calls:
- 2.
- Offloading Progress to Dedicated Hardware:
- 3.
- Use of Asynchronous Progress Threads:
3.3. Advances in Supporting Hardware and Software Technologies
4. Applications of Computation-Communication Overlap
4.1. Comparative Analysis of the Performance Using MPICH3
4.2. Practical Implementations in Supercomputing Applications
5. Conclusion and Outlook
Author Contributions
Funding
Conflicts of Interest
References
- Betzel, F.; Khatamifard, K.; Suresh, H.; Lilja, D.J.; Sartori, J.; Karpuzcu, U. Approximate Communication: Techniques for Reducing Communication Bottlenecks in Large-Scale Parallel Systems. ACM Comput. Surv. 2019, 51, 1–32. [Google Scholar] [CrossRef]
- Wei, X.; Cheng, R.; Yang, Y.; Chen, R.; Chen, H. Characterizing Off-path SmartNIC for Accelerating Distributed Systems. In Proceedings of the 17th USENIX Symposium on Operating Systems Design and Implementation (OSDI ‘23), Boston, MA, USA, 10–12 July 2023; pp. 987–1004. [Google Scholar]
- Wang, Z.; Wang, H.; Song, X.; Wu, J. Communication-Aware Energy Consumption Model in Heterogeneous Computing Systems. Comput. J. 2024, 67, 78–94. [Google Scholar] [CrossRef]
- Pereira, R.; Roussel, A.; Carribault, P.; Gautier, T. Communication-Aware Task Scheduling Strategy in Hybrid MPI+OpenMP Applications. In OpenMP: Enabling Massive Node-Level Parallelism, IWOMP 2021; McIntosh-Smith, S., de Supinski, B.R., Klinkenberg, J., Eds.; Springer: Cham, Switzerland, 2021; Volume 12870, pp. 199–213. [Google Scholar] [CrossRef]
- Barbosa, C.R.; Lemarinier, P.; Sergent, M.; Papauré, G.; Pérache, M. Overlapping MPI communications with Intel TBB computation. In Proceedings of the 2020 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW), New Orleans, LA, USA, 18–22 May 2020; pp. 958–966. [Google Scholar] [CrossRef]
- Ouyang, K.; Si, M.; Hori, A.; Chen, Z.; Balaji, P. Daps: A Dynamic Asynchronous Progress Stealing Model for MPI Communication. In Proceedings of the 2021 IEEE International Conference on Cluster Computing (CLUSTER), Portland, OR, USA, 7–10 September 2021; pp. 516–527. [Google Scholar] [CrossRef]
- Temuçin, Y.H.; Sedeh, A.B.; Schonbein, W.; Grant, R.E.; Afsahi, A. Utilizing Network Hardware Parallelism for MPI Partitioned Collective Communication. In Proceedings of the 2025 32nd Euromicro International Conference on Parallel, Distributed and Network-Based Processing (PDP), Turin, Italy, 12–14 March 2025. [Google Scholar]
- Lescouet, A.; Brunet, É.; Trahay, F.; Thomas, G. Transparent Overlapping of Blocking Communication in MPI Applications. In Proceedings of the 2020 IEEE 22nd International Conference on High Performance Computing and Communications; IEEE 18th International Conference on Smart City, Yanuca Island, Fiji, 14–16 December 2020; pp. 744–749. [Google Scholar] [CrossRef]
- Liu, D.; Wu, J.; Pan, X.; Wang, Y. The development of overlapping computation with communication and its application in numerical weather prediction models. In Proceedings of the International Conference on Electronic Information Technology (EIT 2022), Chengdu, China, 23 May 2022; Volume 12254. [Google Scholar] [CrossRef]
- Liu, H.; Lei, K.; Yang, H.; Luan, Z.; Qian, D. Towards Optimized Hydrological Forecast Prediction of WRF-Hydro on GPU. In Proceedings of the 2023 IEEE International Conference on High Performance Computing & Communications, Melbourne, VIC, Australia, 17–21 December 2023; pp. 138–145. [Google Scholar] [CrossRef]
- Jiang, T.; Wu, J.; Liu, Z.; Zhao, W.; Zhang, Y. Optimization of the parallel semi-Lagrangian scheme based on overlapping communication with computation in the YHGSM. Q. J. R. Meteorol. Soc. 2021, 147, 2293–2302. [Google Scholar] [CrossRef]
- Liu, D.; Liu, W.; Pan, L.; Zhang, Y.; Li, C. Optimization of the Parallel Semi-Lagrangian Scheme to Overlap Computation with Communication Based on Grouping Levels in YHGSM. CCF Trans. High Perform. Comput. 2024, 6, 68–77. [Google Scholar] [CrossRef]
- Punniyamurthy, K.; Hamidouche, K.; Beckmann, B.M. Optimizing Distributed ML Communication with Fused Computation-Collective Operations. In Proceedings of the SC24: International Conference for High Performance Computing, Networking, Storage and Analysis, Atlanta, GA, USA, 17–22 November 2024; pp. 1–17. [Google Scholar] [CrossRef]
- Wahlgren, J. Using GPU-Aware Message Passing to Accelerate High-Fidelity Fluid Simulations. 2022. Available online: https://www.diva-portal.org/smash/record.jsf?pid=diva2%3A1710487&dswid=7070 (accessed on 16 November 2022).
- Khalilov, M.; Timofeev, A.; Polyakov, D. Towards OpenUCX and GPUDirect Technology Support for the Angara Interconnect. In Supercomputing. RuSCDays 2022; Lecture Notes in Computer Science; Voevodin, V., Sobolev, S., Yakobovskiy, M., Shagaliev, R., Eds.; Springer: Cham, Switzerland, 2022; Volume 13708, pp. 514–526. [Google Scholar] [CrossRef]
- Jammer, T.; Bischof, C. Compiler-enabled optimization of persistent MPI Operations. In Proceedings of the 2022 IEEE/ACM International Workshop on Exascale MPI (ExaMPI), Dallas, TX, USA, 13–18 November 2022; pp. 1–10. [Google Scholar] [CrossRef]
- Guo, J.; Yi, Q.; Meng, J.; Zhang, J.; Balaji, P. Compiler-Assisted Overlapping of Communication and Computation in MPI Applications. In Proceedings of the 2016 IEEE International Conference on Cluster Computing (CLUSTER), Taipei, Taiwan, 26–29 September 2016; pp. 60–69. [Google Scholar] [CrossRef]
- Soga, T.; Yamaguchi, K.; Mathur, R.; Watanabe, O.; Musa, A.; Egawa, R.; Kobayashi, H. Effects of Using a Memory Stalled Core for Handling MPI Communication Overlapping in the SOR Solver on SX-ACE and SX-Aurora TSUBASA. Supercomput. Front. Innov. 2020, 7, 4–15. [Google Scholar] [CrossRef]
- Klemm, M.; Cownie, J. High Performance Parallel Runtimes: Design and Implementation; Walter de Gruyter GmbH & Co KG: Berlin, Germany, 2021. [Google Scholar]
- Katragadda, S. Optimizing High-Speed Data Transfers Using RDMA in Distributed Computing Environments. Available online: https://www.researchgate.net/profile/Santhosh-Katragadda/publication/388618653_OPTIMIZING_HIGH-SPEED_DATA_TRANSFERS_USING_RDMA_IN_DISTRIBUTED_COMPUTING_ENVIRONMENTS/links/679f16b6645ef274a45da115/OPTIMIZING-HIGH-SPEED-DATA-TRANSFERS-USING-RDMA-IN-DISTRIBUTED-COMPUTING-ENVIRONMENTS.pdf (accessed on 12 December 2022).
- Luo, X. Optimization of MPI Collective Communication Operations. Ph.D. Dissertation, University of Tennessee, Knoxville, TN, USA, 2020. Available online: https://trace.tennessee.edu/utk_graddiss/5818 (accessed on 5 May 2020).
- Wang, J.; Zhuang, Y.; Zeng, Y. A Transmission Optimization Method for MPI Communications. J. Supercomput. 2024, 80, 6240–6263. [Google Scholar] [CrossRef]
- Shafie Khorassani, K.; Hashmi, J.; Chu, C.H.; Chen, C.C.; Subramoni, H.; Panda, D.K. Designing a ROCm-Aware MPI Library for AMD GPUs: Early Experiences. In High Performance Computing. ISC High Performance 2021; Lecture Notes in Computer Science; Chamberlain, B.L., Varbanescu, A.L., Ltaief, H., Luszczek, P., Eds.; Springer: Cham, Switzerland, 2021; Volume 12728. [Google Scholar] [CrossRef]
- Ruhela, A.; Subramoni, H.; Chakraborty, S.; Bayatpour, M.; Kousha, P.; Panda, D.K. Efficient Design for MPI Asynchronous Progress without Dedicated Resources. Parallel Comput. 2019, 85, 13–26. [Google Scholar] [CrossRef]
- Denis, A.; Jaeger, J.; Jeannot, E.; Reynier, F. One Core Dedicated to MPI Nonblocking Communication Progression? A Model to Assess Whether It Is Worth It. In Proceedings of the 2022 IEEE International Symposium on Cluster, Cloud and Internet Computing (CCGrid), Taormina, Italy, 16–19 May 2022; pp. 736–746. [Google Scholar] [CrossRef]
- Holmes, D.J.; Skjellum, A.; Schafer, D. Why Is MPI (Perceived to Be) So Complex? Part 1—Does Strong Progress Simplify MPI? In Proceedings of the 27th European MPI Users’ Group Meeting, 21–24 September 2020; pp. 21–30. [Google Scholar] [CrossRef]
- Bayatpour, M.; Sarkauskas, N.; Subramoni, H.; Hashmi, J.M.; Panda, D.K. BluesMPI: Efficient MPI Non-Blocking Alltoall Offloading Designs on Modern BlueField Smart NICs. In High Performance Computing. ISC High Performance 2021; Lecture Notes in Computer Science; Chamberlain, B.L., Varbanescu, A.L., Ltaief, H., Luszczek, P., Eds.; Springer: Cham, Switzerland, 2021; Volume 12728. [Google Scholar] [CrossRef]
- Medvedev, A.V. IMB-ASYNC: A Revised Method and Benchmark to Estimate MPI-3 Asynchronous Progress Efficiency. Clust. Comput. 2022, 25, 2683–2697. [Google Scholar] [CrossRef]
- Brightwell, R.; Underwood, K.D. An Analysis of the Impact of MPI Overlap and Independent Progress. In Proceedings of the 18th Annual International Conference on Supercomputing (ICS ’04), Saint Malo, France, 26 June–1 July 2004; pp. 298–305. [Google Scholar] [CrossRef]
- Holmes, D.J.; Skjellum, A.; Jaeger, J.; Grant, R.E.; Bangalore, P.V.; Dosanjh, M.G.; Bienz, A.; Schafer, D. Partitioned Collective Communication. In Proceedings of the 2021 Workshop on Exascale MPI (ExaMPI), St. Louis, MO, USA, 14 November 2021; pp. 9–17. [Google Scholar] [CrossRef]
- Reynier, F. A Study on Progression of MPI Communications Using Dedicated Resources. Ph.D. Thesis, Université de Bordeaux, Pessac, France, 2022. [Google Scholar]
- Dongarra, J.; Tourancheau, B.; Denis, A.; Jaeger, J.; Jeannot, E.; Pérache, M.; Taboada, H. Study on Progress Threads Placement and Dedicated Cores for Overlapping MPI Nonblocking Collectives on Manycore Processor. Int. J. High Perform. Comput. Appl. 2019, 33, 1240–1254. [Google Scholar] [CrossRef]
- Bayatpour, M.; Ghazimirsaeed, S.M.; Xu, S.; Subramoni, H.; Panda, D.K. Design and Characterization of InfiniBand Hardware Tag Matching in MPI. In Proceedings of the 2020 20th IEEE/ACM International Symposium on Cluster, Cloud and Internet Computing (CCGRID), Melbourne, VIC, Australia, 11–14 May 2020; pp. 101–110. [Google Scholar] [CrossRef]
- Levy, S.; Schonbein, W.; Ulmer, C. Leveraging High-Performance Data Transfer to Offload Data Management Tasks to SmartNICs. In Proceedings of the 2024 IEEE International Conference on Cluster Computing (CLUSTER), Kobe, Japan, 24–27 September 2024; pp. 346–356. [Google Scholar] [CrossRef]
- Cardellini, V.; Fanfarillo, A.; Filippone, S. Overlap Communication with Computation in MPI Applications. 2016. Available online: https://art.torvergata.it/handle/2108/140530 (accessed on 1 February 2016).
- Horikoshi, M.; Gerofi, B.; Ishikawa, Y.; Nakajima, K. Exploring Communication-Computation Overlap in Parallel Iterative Solvers on Manycore CPUs Using Asynchronous Progress Control. In Proceedings of the HPCAsia ’22 Workshops, Virtual, 11–14 January 2022; pp. 29–39. [Google Scholar] [CrossRef]
- Denis, A.; Jaeger, J.; Jeannot, E.; Reynier, F. A Methodology for Assessing Computation/Communication Overlap of MPI Nonblocking Collectives. Concurr. Comput. Pract. Exp. 2022, 34, e7168. [Google Scholar] [CrossRef]
- Hoefler, T.; Lumsdaine, A. Message Progression in Parallel Computing—To Thread or Not to Thread? In Proceedings of the 2008 IEEE International Conference on Cluster Computing, Tsukuba, Japan, 29 September–1 October 2008; pp. 213–222. [Google Scholar] [CrossRef]
- Nguyen, V.M.; Saillard, E.; Jaeger, J.; Barthou, D.; Carribault, P. Automatic Code Motion to Extend MPI Nonblocking Overlap Window. In High Performance Computing. ISC High Performance 2020; Lecture Notes in Computer Science; Jagode, H., Anzt, H., Juckeland, G., Ltaief, H., Eds.; Springer: Cham, Switzerland, 2020; Volume 12321. [Google Scholar] [CrossRef]
- Nigay, A.; Mosimann, L.; Schneider, T.; Hoefler, T. Communication and Timing Issues with MPI Virtualization. In Proceedings of the 27th European MPI Users’ Group Meeting (EuroMPI/USA ‘20). Association for Computing Machinery, New York, NY, USA, 11–20 September 2020. [Google Scholar] [CrossRef]
- Zhou, H.; Latham, R.; Raffenetti, K.; Guo, Y.; Thakur, R. MPI Progress for All. In Proceedings of the SC24 Workshops of the International Conference for High Performance Computing, Networking, Storage and Analysis, Atlanta, GA, USA, 17–22 November 2024; pp. 425–435. [Google Scholar] [CrossRef]
- Bayatpour, M.; Hashmi Maqbool, J.; Chakraborty, S.; Kandadi Suresh, K.; Ghazimirsaeed, S.M.; Ramesh, B.; Subramoni, H.; Panda, D.K. Communication-Aware Hardware-Assisted MPI Overlap Engine. In High Performance Computing. ISC High Performance 2020; Lecture Notes in Computer Science; Sadayappan, P., Chamberlain, B.L., Juckeland, G., Ltaief, H., Eds.; Springer: Cham, Switzerland, 2020; Volume 12151. [Google Scholar] [CrossRef]
- Sarkauskas, N.; Bayatpour, M.; Tran, T.; Ramesh, B.; Subramoni, H.; Panda, D.K. Large-Message Nonblocking MPI_Iallgather and MPI_Ibcast Offload via BlueField-2 DPU. In Proceedings of the 2021 IEEE 28th International Conference on High Performance Computing, Data, and Analytics (HiPC), Bengaluru, India, 17–20 December 2021; pp. 388–393. [Google Scholar] [CrossRef]
- Liang, C.; Dai, Y.; Xia, J.; Xu, J.; Peng, J.; Xu, W.; Xie, M.; Liu, J.; Lai, Z.; Ma, S.; et al. The Self-Adaptive and Topology-Aware MPI_Bcast Leveraging Collective Offload on Tianhe Express Interconnect. In Proceedings of the 2024 IEEE International Parallel and Distributed Processing Symposium (IPDPS), San Francisco, CA, USA, 27–31 May 2024; pp. 791–801. [Google Scholar] [CrossRef]
- Castillo, E.; Jain, N.; Casas, M.; Moreto, M.; Schulz, M.; Beivide, R.; Valero, M.; Bhatele, A. Optimizing Computation-Communication Overlap in Asynchronous Task-Based Programs. In Proceedings of the ACM International Conference on Supercomputing (ICS ’19), Phoenix, AZ, USA, 26–28 June 2019; pp. 380–391. [Google Scholar] [CrossRef]
- Michalowicz, B.; Suresh, K.K.; Subramoni, H.; Abduljabbar, M.; Panda, D.K.; Poole, S. Effective and Efficient Offloading Designs for One-Sided Communication to SmartNICs. In Proceedings of the 2024 IEEE 31st International Conference on High Performance Computing, Data, and Analytics (HiPC), Bangalore, India, 18–21 December 2024; pp. 23–33. [Google Scholar] [CrossRef]
- Dreier, N. Hardware-Oriented Krylov Methods for High-Performance Computing. Ph.D. Thesis. ProQuest Dissertations & Theses Global, 2021. Order No. 28946756. Available online: https://www.proquest.com/dissertations-theses/hardware-oriented-krylov-methods-high-performance/docview/2607316034/se-2 (accessed on 3 August 2021).
- Thomadakis, P.; Tsolakis, C.; Chrisochoides, N. Multithreaded Runtime Framework for Parallel and Adaptive Applications. Eng. Comput. 2022, 38, 4675–4695. [Google Scholar] [CrossRef]
- Guo, X.W.; Li, C.; Li, W.; Cao, Y.; Liu, Y.; Zhao, R.; Zhang, S.; Yang, C. Improving Performance for Simulating Complex Fluids on Massively Parallel Computers by Component Loop-Unrolling and Communication Hiding. In Proceedings of the 2020 IEEE 22nd International Conference on High Performance Computing and Communications; IEEE 18th International Conference on Smart City, Yanuca Island, Fiji, 14–16 December 2020; pp. 130–137. [Google Scholar] [CrossRef]
- Liu, D.; Ren, X.; Wu, J.; Liu, W.; Zhao, J.; Peng, S. Pipe-AGCM: A Fine-Grain Pipelining Scheme for Optimizing the Parallel Atmospheric General Circulation Model. In Euro-Par 2024: Parallel Processing. Euro-Par 2024; Lecture Notes in Computer Science; Carretero, J., Shende, S., Garcia-Blas, J., Brandic, I., Olcoz, K., Schreiber, M., Eds.; Springer: Cham, Switzerland, 2024; Volume 14803. [Google Scholar] [CrossRef]
- Tiwari, M. Communication Overlap Krylov Subspace Methods for Distributed Memory Systems. Ph.D. Thesis, Indian Institute of Science, Bangalore, India, 2022. [Google Scholar]
- Xiong, H.; Li, K.; Liu, X.; Li, K. A Multi-Block Grids Load Balancing Algorithm with Improved Block Partitioning Strategy. In Proceedings of the 2019 IEEE 21st International Conference on High Performance Computing and Communications (HPCC), Zhangjiajie, China, 10–12 August 2019; pp. 37–44. [Google Scholar] [CrossRef]
- Nakajima, K. Communication-Computation Overlapping for Parallel Multigrid Methods. In Proceedings of the 2024 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW), San Francisco, CA, USA, 27–31 May 2024; pp. 751–760. [Google Scholar] [CrossRef]
- Yepes-Arbós, X.; van den Oord, G.; Acosta, M.C.; Carver, G.D. Evaluation and Optimisation of the I/O Scalability for the Next Generation of Earth System Models: IFS CY43R3 and XIOS 2.0 Integration as a Case Study. Geosci. Model Dev. 2022, 15, 379–394. [Google Scholar] [CrossRef]
- Castelló, A.; Quintana-Ortí, E.S.; Duato, J. Accelerating distributed deep neural network training with pipelined MPI allreduce. Clust. Comput. 2021, 24, 3797–3813. [Google Scholar] [CrossRef]
- Jangda, A.; Huang, J.; Liu, G.; Sabet, A.H.N.; Maleki, S.; Miao, Y.; Musuvathi, M.; Mytkowicz, T.; Saarikivi, O. Breaking the computation and communication abstraction barrier in distributed machine learning workloads. In Proceedings of the 27th ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS ‘22), Lausanne, Switzerland, 28 February–4 March 2022; Association for Computing Machinery: New York, NY, USA, 2022; pp. 402–416. [Google Scholar] [CrossRef]
- Guo, X.; Pimentel, A.D.; Stefanov, T. Automated Exploration and Implementation of Distributed CNN Inference at the Edge. IEEE Internet Things J. 2023, 10, 5843–5858. [Google Scholar] [CrossRef]
- Tran, T.; Kuncham, G.K.R.; Ramesh, B.; Xu, S.; Subramoni, H.; Abduljabbar, M.; Panda, D.K.D. OHIO: Improving RDMA Network Scalability in MPI_Alltoall Through Optimized Hierarchical and Intra/Inter-Node Communication Overlap Design. In Proceedings of the 2024 IEEE Symposium on High-Performance Interconnects (HOTI), Albuquerque, NM, USA, 21–23 August 2024; pp. 47–56. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Configuration Item | Platform A | Platform B |
|---|---|---|
| CPU | Intel(R) Core(TM) i5-10210U CPU @ 1.60GHz | 13th Gen Intel(R) Core(TM) i9-13900H |
| Thread(s) per core | 2 | 2 |
| Core(s) | 4 | 10 |
| Cache | L1d: 128 KiB; L1i: 128 KiB; L2: 1 MiB; L3: 6 MiB | L1d: 480 KiB; L1i: 320 KiB; L2: 12.5 MiB; L3: 24 MiB |
| Memory | 16 GB | 32 GB |
| OS | Windows 11 + WSL2 + Ubuntu 20.04.4 LTS | Windows 11 + WSL2 + Ubuntu 20.04.6 LTS |
| Configuration Item | Laptop A | Laptop B |
|---|---|---|
| CPU | Intel(R) Xeon(R) Platinum 9242 CPU @ 2.30GHz | Intel(R) Xeon(R) Gold 6150 CPU @ 2.70GHz |
| Thread(s) per core | 1 | 1 |
| Core(s) | 96 | 36 |
| Interconnect | InfiniBand | InfiniBand |
| Memory | 384 GB | 186 GB |
| OS | Linux | Linux |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zheng, Y.; Wu, J. Towards Efficient HPC: Exploring Overlap Strategies Using MPI Non-Blocking Communication. Mathematics 2025, 13, 1848. https://doi.org/10.3390/math13111848
Zheng Y, Wu J. Towards Efficient HPC: Exploring Overlap Strategies Using MPI Non-Blocking Communication. Mathematics. 2025; 13(11):1848. https://doi.org/10.3390/math13111848
Chicago/Turabian StyleZheng, Yuntian, and Jianping Wu. 2025. "Towards Efficient HPC: Exploring Overlap Strategies Using MPI Non-Blocking Communication" Mathematics 13, no. 11: 1848. https://doi.org/10.3390/math13111848
APA StyleZheng, Y., & Wu, J. (2025). Towards Efficient HPC: Exploring Overlap Strategies Using MPI Non-Blocking Communication. Mathematics, 13(11), 1848. https://doi.org/10.3390/math13111848