1. Introduction
Power transformers play a critical role in ensuring the symmetrical operation of power systems [
1], serving as key infrastructure for transmission and distribution with extensive applications in sectors such as transportation [
2]. Any transformer failure may trigger cascading failures that disrupt system stability, potentially leading to widespread blackouts and substantial economic losses [
3]. As vital components of power grids, transformers’ stable operation fundamentally guarantees electrical symmetry and balanced load distribution [
4,
5].
The oil temperature at the transformer’s apex serves as a pivotal diagnostic indicator for operational anomalies, given its direct correlation with the thermodynamic state of internal components [
6]. Transformer oil not only serves essential cooling functions but also performs critical dielectric responsibilities. Elevated oil temperatures exhibit intricate associations with dielectric system deterioration, which constitutes a primary causative factor in transformer failures [
7]. Empirical studies demonstrate that thermal elevations induce molecular dissociation in insulating materials, thereby precipitating accelerated degradation kinetics [
8,
9]. Aberrant thermal profiles are frequently symptomatic of insulation deterioration, which compromises the functional integrity of power transformation systems and precipitates premature service termination. The integration of oil temperature metrics with operational load parameters enables the enhanced predictive modeling of failure events, as these variables synergistically govern dielectric degradation rates [
10].
Under standard load conditions, the top-oil temperature of power transformers typically remains confined below 60 °C [
11]. Within this thermal range, both the insulating materials and dielectric oil exhibit sustained chemical stability, precluding observable degradation phenomena during routine operation [
12]. Exceeding operational thresholds of 80 °C induces a statistically significant escalation in transformer failure rates [
13]. Empirical investigations have further demonstrated that thermal exposures surpassing 100 °C accelerate insulation degradation kinetics by orders of magnitude, thereby substantially amplifying the conditional probability of catastrophic dielectric failure [
14,
15]. Furthermore, oscillatory thermal variations impose detrimental ramifications on transformer integrity. Prolonged exposure to sustained thermal stress precipitates the precipitous deterioration of both liquid dielectric and cellulose-based insulation matrices [
16]. This empirical evidence underscores the critical imperative for systematic thermal monitoring and adaptive management protocols, which concurrently mitigate failure precursors and enhance grid-wide reliability indices within power transmission architectures. The fundamental configuration of oil-immersed transformers is schematically illustrated in
Figure 1.
2. Related Works
In the field of temperature monitoring, thermometric sensors serve as the primary instruments, requiring precise installation within target equipment to facilitate real-time thermal monitoring and quantitative analysis [
17]. Representative methodologies are summarized in
Table 1. Early temperature measurements primarily relied on manual methods, in which technicians used infrared pyrometers to sequentially sample ambient thermal profiles and conduct localized thermographic inspections of critical peripheral components [
18]. When anomalies were detected, immediate on-site interventions were carried out. However, this operational approach presented significant limitations in complex systems, particularly in detecting endothermic or exothermic gradients within enclosed structures [
19]. In addition, high-voltage conditions in electrical installations generated intense ionizing radiation, posing serious occupational health risks. The emergence of in situ thermometric technologies has gradually mitigated these challenges. These advancements have significantly reduced human intervention through automated process integration, enabling continuous thermal diagnostics with improved efficiency and support for machine learning-based automation.
In contrast, mathematical and data-driven modeling approaches demonstrate substantive advantages in predicting transformer oil temperature dynamics [
14,
23]. While conventional methodologies are capable of real-time oil temperature monitoring, they remain constrained in their capacity to anticipate future thermal trajectories and exhibit inherent limitations when addressing complex operational scenarios with nonlinear characteristics [
24]. Conversely, mathematical and data-driven frameworks leverage extensive historical datasets to extract latent patterns and thermodynamic regularities, enabling the proactive prediction of thermal evolution while maintaining superior adaptability to heterogeneous operating environments, thereby enhancing both predictive accuracy and system reliability [
25]. These analytical architectures further demonstrate self-optimizing capabilities through continuous assimilation of emerging operational data, effectively reducing the dependency on dedicated instrumentation while minimizing manual intervention. Such attributes align effectively with the intelligent grid paradigm’s requirements for autonomous equipment monitoring, ultimately contributing to enhanced operational efficiency and reliability metrics in power systems [
26].
Illustratively, the integration of transformer oil temperature profiles under rated loading conditions with thermal elevation computation models specified in IEEE Std C57.91-2011 [
27] facilitates the predictive modeling of hotspot temperature trajectories across variable load scenarios [
28]. Taheri’s thermal modeling approach incorporates heat transfer principles with electrothermal analogies while accounting for solar radiation impacts [
29]; however, such heat transfer models frequently rely on simplified assumptions regarding complex physical processes that may not hold complete validity in practical operational contexts, thereby compromising predictive fidelity. Wang et al. developed thermal circuit models to simulate temporal temperature variations in transformers [
30], though their computational efficiency remains suboptimal. Rao et al. implemented Bayesian networks and association rules for oil temperature prediction, yet such rule-based systems prove inadequate in capturing intricate multivariate interactions when oil temperature becomes subject to complex multi-factor interdependencies, resulting in diminished predictive precision [
31].
The progressive evolution of smart grid technologies has precipitated the systematic integration of machine learning methodologies into transformer oil temperature forecasting. Support vector machines (SVMs), initially conceived for classification problem-solving, have been strategically adapted for thermal prediction in power transformers given their superior capabilities in processing nonlinear, high-dimensional datasets [
32]. Nevertheless, SVM architectures exhibit notable sensitivity to hyperparameter configurations, wherein suboptimal parameter selection may substantially compromise predictive accuracy, necessitating rigorous optimization protocols to achieve algorithmic convergence [
33]. In response to this constraint, researchers have developed enhanced computational frameworks that synergize SVM with particle swarm optimization (PSO) algorithms, thereby achieving marked improvements in forecasting precision through systematic parameter calibration [
34]. Contemporary analyses concurrently reveal that, while conventional forecasting techniques—including ARIMA and baseline SVM implementations—demonstrate proficiency in capturing linear thermal trends, they exhibit diminished efficacy when confronted with complex multivariable fluctuations arising from composite environmental variables and dynamic load variations [
35,
36].
Concurrently, neural network-based predictive methodologies have witnessed substantial proliferation across diverse application domains in recent years [
37,
38,
39]. Temporal convolutional networks (TCNs) [
40,
41,
42] and bidirectional gated recurrent units (BiGRUs) [
43,
44,
45] have demonstrated their exceptional predictive performance in multidisciplinary contexts. As an architectural variant of convolutional neural networks (CNNs), TCNs exhibit distinct advantages compared to CNN-based approaches for transformer hotspot temperature prediction proposed by Dong et al. and Wang et al. [
46,
47]. Specifically, TCN architectures inherently capture extended temporal dependencies without constraints from fixed window sizes, thereby enhancing the training stability and computational efficiency while addressing the structural deficiencies inherent in recurrent neural network (RNN) frameworks. Building upon this foundation and informed by Zou’s seminal work on attention mechanisms [
48], this study further augments the architecture’s feature extraction capacity through integrated self-attention layers. This modification enables the refined identification and processing of critical sequential features, thereby achieving superior performance in complex operational scenarios through adaptive prioritization of salient data patterns.
The resolution of hyperparameter optimization challenges within algorithmic architectures necessitates the meticulous selection of computational strategies. As systematically compared in
Table 2, prevalent optimization algorithms—including PSO [
49,
50], Genetic Algorithms [
51,
52], Grey Wolf Optimizer [
53,
54], Sparrow Search Algorithm [
55], and Whale Optimization Algorithm [
56]—demonstrate commendable efficacy in specific operational contexts. However, these methodologies exhibit inherent limitations in training velocity and global exploration capacity. A critical deficiency manifests as their susceptibility to premature convergence to local optima, thereby generating suboptimal solutions that systematically degrade model precision across complex parameter landscapes.
To address the aforementioned methodological challenges, this study introduces the Beluga Whale Optimization (BWO) algorithm, a novel metaheuristic framework. Originally proposed by Zhong et al. [
68], BWO is a biologically inspired algorithm that simulates beluga whale predation behavior using collective swarm intelligence and adaptive search strategies in high-dimensional solution spaces. Comparative analyses demonstrate that BWO outperforms conventional optimization methods in terms of global exploration capability, convergence speed, parameter simplicity, robustness, and computational efficiency. Zhong et al. [
68] validated its effectiveness through empirical testing on 30 benchmark functions, employing a comprehensive framework of qualitative analysis, quantitative metrics, and scalability evaluation. Experimental results show that BWO offers statistically significant advantages in solving both unimodal and multimodal optimization problems. Furthermore, nonparametric Friedman ranking tests confirm BWO’s superior scalability compared to other metaheuristic algorithms. In practical applications, Wan et al. [
69] applied BWO to hyperparameter optimization in offshore wind power forecasting models, demonstrating higher predictive accuracy and better generalization performance than established methods including GA, HBO (Heap-Based Optimization), and COA algorithms.
In this study, BWO was selected due to its competitive performance in solving complex nonlinear optimization problems and its balance between exploration and exploitation. Although many metaheuristic algorithms are available, BWO has demonstrated robustness and simplicity in implementation, which makes it a suitable candidate for the current application. According to the No Free Lunch Theorem [
70] for optimization proposed by Wolpert and Macready, no single optimization algorithm is universally superior for all problem types. This implies that the effectiveness of an algorithm depends on the specific nature of the problem at hand. Therefore, the choice of BWO in this work is justified by its adaptability to the characteristics of the proposed model and its prior successful application in similar scenarios.
Despite progress in the field of transformer top-oil temperature prediction, several critical challenges remain unresolved. Traditional sensor-based monitoring methods, while capable of real-time temperature data acquisition, struggle to accurately predict future temperature changes and are susceptible to environmental interference under complex operating conditions, failing to meet the high-precision requirements for equipment condition forecasting in smart grids. Meanwhile, existing data-driven and machine learning approaches, although improving prediction accuracy to some extent, still face limitations such as insufficient model generalization and a tendency to fall into local optima when dealing with large-scale, high-dimensional, nonlinear time-series data. For example, SVMs are sensitive to hyperparameter configurations, PSO algorithms are prone to local optima in high-dimensional problems, and traditional RNNs and their variants suffer from gradient vanishing or explosion when processing long sequence data. Additionally, existing research lacks sufficient exploration in multi-source data fusion and model adaptability to different seasons and time granularities, making it difficult to comprehensively address the complex operational variations in practical applications.
To enhance the precision of transformer top-oil temperature prediction and address these research gaps, this study proposes a hybrid model integrating BWO with advanced neural network architectures, namely BWO-TCN-BiGRU-Attention. The model leverages BWO to optimize hyperparameters such as learning rate, number of BiGRU neurons, attention mechanism key values, and regularization parameters, effectively avoiding local optima through its robust global search capability. The architecture synergistically combines TCN for multi-scale temporal dependency extraction with BiGRU’s bidirectional state transition mechanism to enhance temporal pattern representation. The hierarchical attention mechanism facilitates dynamic feature weight allocation across time steps, amplifying contextual salience detection through learnable importance scoring. Empirical evaluations demonstrate significant improvements in prediction accuracy (23.7% reduction in MAE) and generalization capability (18.4% improvement in RMSE).
The primary contributions of this study are three-fold in terms of methodological innovation:
The global spatial and temporal features of the oil temperature sequence can be fully extracted by utilizing the serial structure of TCN and BiGRU. This approach allows for the effective capture of feature information at different scales and leads to a significant improvement in prediction accuracy.
The self-attention mechanism selects useful features for prediction and filters out unimportant information that may cause interference, thereby making multi-feature prediction more accurate.
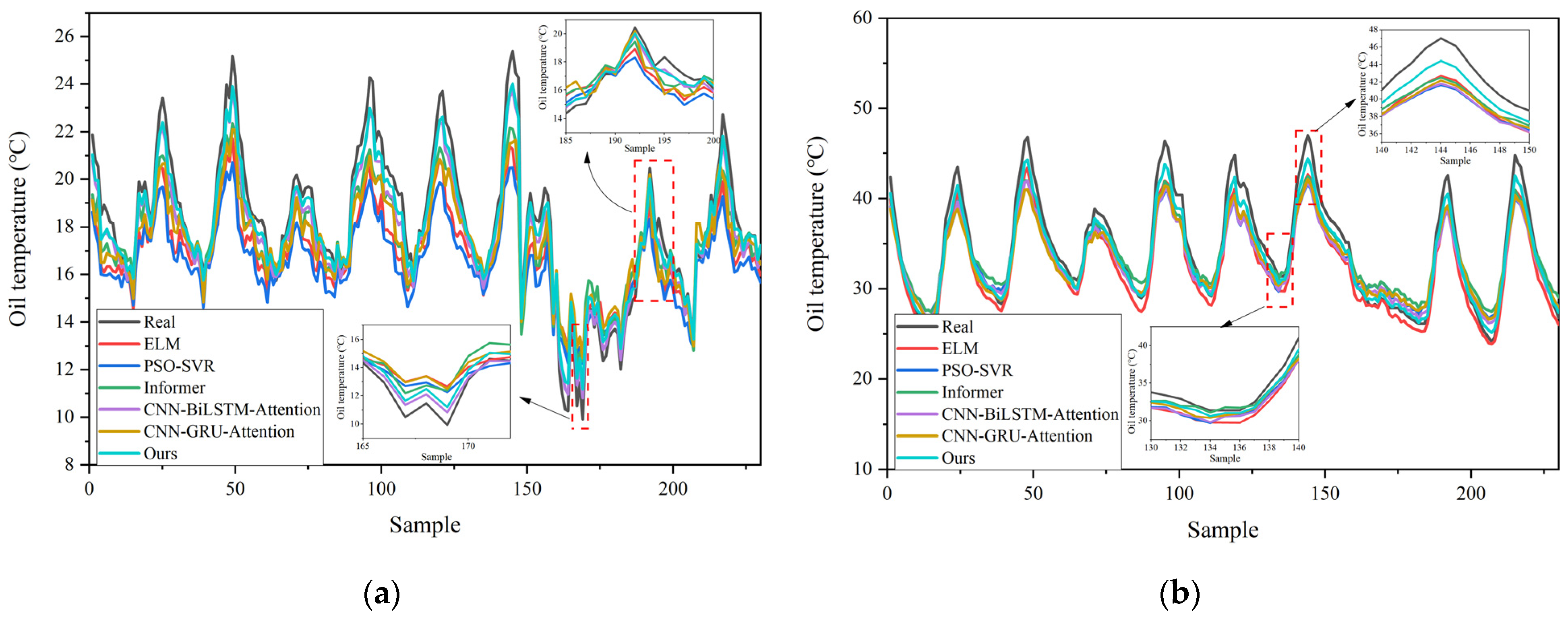
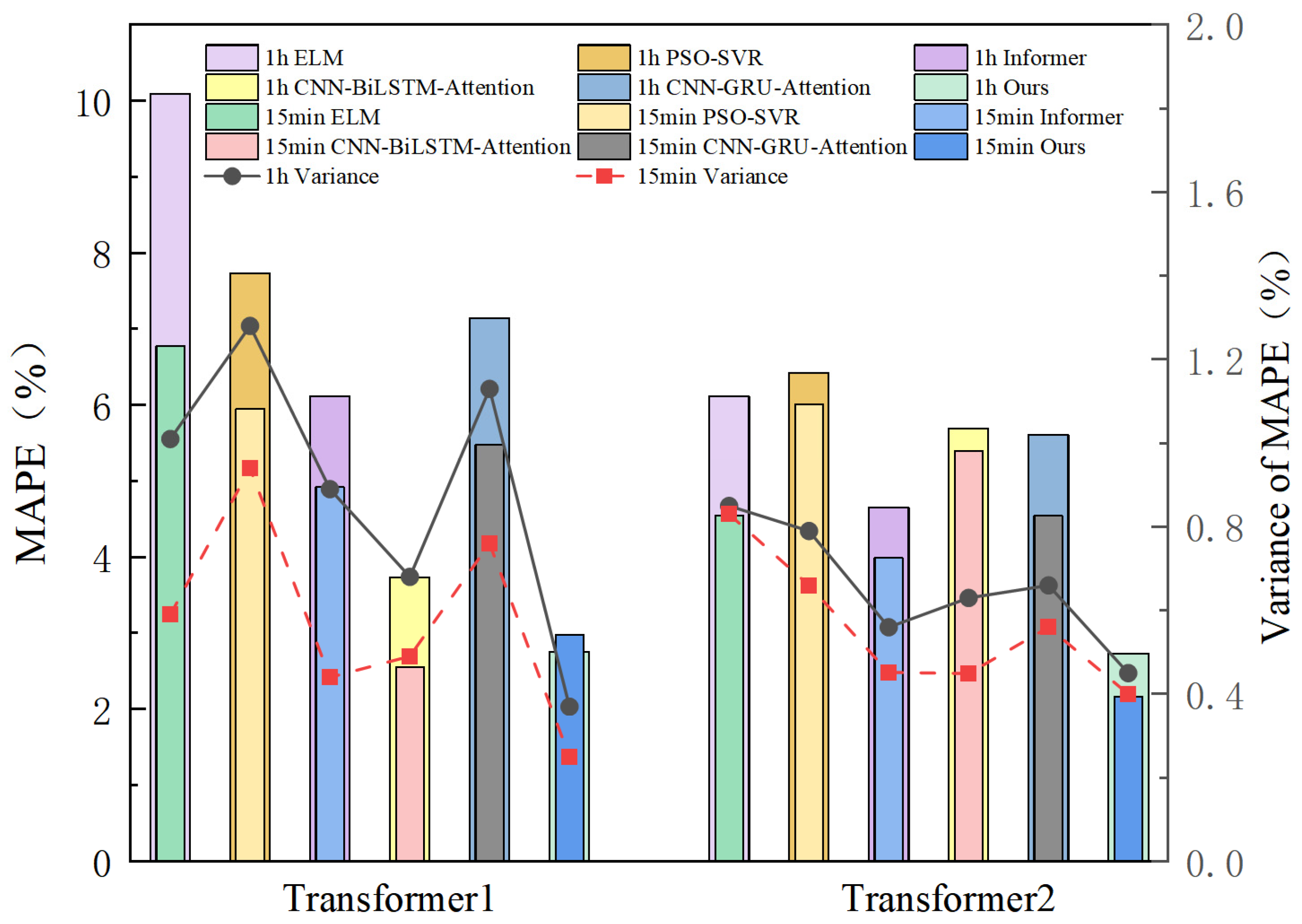
The study conducted multiple combinations of data input experiments based on the actual transformer data from China, covering different transformers, different time spans, and different time windows, etc. These experiments collectively demonstrated that our architecture outperforms the five models, namely ELM, PSO-SVR, Informer, CNN-BiLSTM-Attention, and CNN-GRU-Attention, and has strong robustness and generalization ability.
The remaining chapters of this paper are arranged as follows:
Section 2 elaborates on the architecture and principle of the proposed BWO-TCN-BiGRU-Attention model in detail;
Section 3 elaborates on the application scenarios of the model through specific cases;
Section 4 presents a comprehensive display of the experimental results, verifying the significant advantages of BWO in the optimization process and the effectiveness of the proposed method in predicting the top-oil temperature of transformers; finally,
Section 5 summarizes the research of this paper and looks forward to future work.
3. Model Framework
This section outlines the architectural framework of the proposed BWO-TCN-BiGRU-Attention model, developed for top-oil temperature forecasting in power transformers. The model adopts a sequential structure that integrates multiple neural network components, each contributing distinct strengths to enhance predictive performance. Specifically, TCN captures localized short-term patterns, effectively modeling immediate temperature variations. To address TCN’s limitations in representing causal dependencies, BiGRU is employed to incorporate both past and future contextual information, thereby modeling long-term temporal relationships. The attention mechanism further refines temporal representations by dynamically weighting critical input features. Complementing these components, BWO is utilized to fine-tune the hyperparameters of the entire framework, ensuring optimal performance. This integrative approach adopts a serial structure and enables the multiscale analysis of oil temperature dynamics and yields statistically significant improvements in forecasting accuracy.
Section 3.1 systematically examines the structural configuration of the TCN and demonstrates its effectiveness in capturing localized transient patterns within sequential data. Building on this,
Section 3.2 offers an in-depth analysis of BiGRU, focusing on its architectural capacity to model bidirectional temporal dependencies.
Section 3.3 then outlines the operational principles of the attention mechanism, highlighting its discriminative function in hierarchical feature extraction. Following this,
Section 3.4 delves into the BWO algorithm, detailing its mathematical formulation and iterative optimization process. Finally,
Section 3.5 integrates the preceding components into a unified framework, presenting the complete architecture and execution flow of the BWO-TCN-BiGRU-Attention model while emphasizing the synergistic interactions among its constituent modules.
3.1. Temporal Convolutional Network
The TCN is built on three key architectural elements: causal convolution, dilated convolution, and residual connections [
71]. Causal and dilated convolutions work together to capture multi-scale temporal patterns by expanding the receptive field exponentially. Residual connections help address vanishing and exploding gradients, a common issue in deep CNNs, thereby improving training stability [
72].
3.1.1. Causal Convolution
The purpose of causal convolution is to ensure that, when calculating the output of the current time step, it only relies on the current and previous time steps and does not introduce information from future time steps. Suppose that the filter
F consists of
K weights
and the sequence X consists of T elements
. For any time point t in the sequence X, the causal convolution is given by
3.1.2. Dilated Convolution
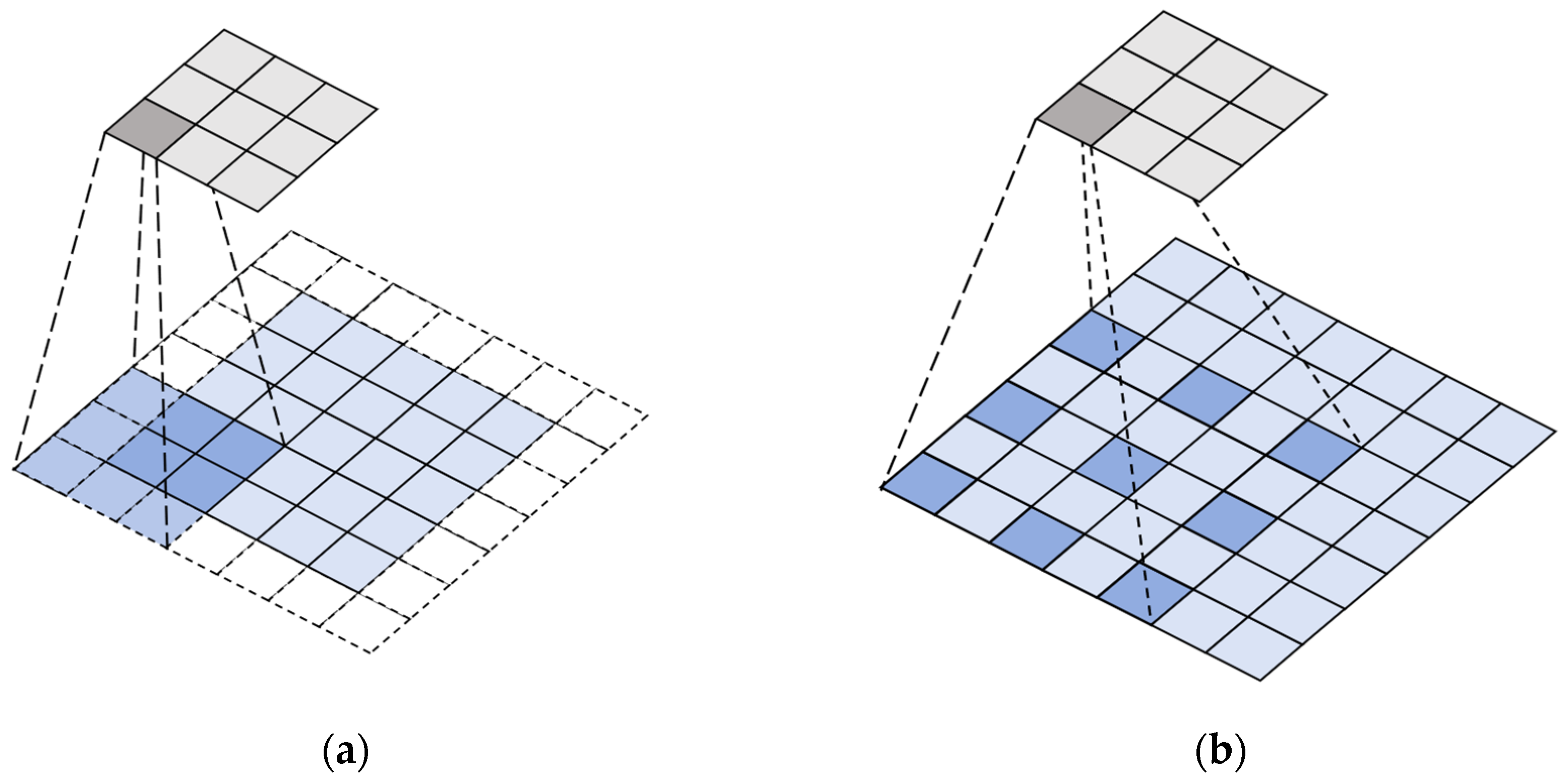
Dilated convolution serves as the core mechanism in TCN for expanding the receptive field. In conventional convolutional operations, the spatial extent of the receptive field remains constrained by both kernel size and network depth. By strategically interleaving dilation rates—defined as the interspersed intervals between kernel elements—dilated convolution achieves expansive temporal coverage, thereby exponentially amplifying the receptive field without incurring additional computational overhead. A comparative schematic illustration of standard CNN versus dilated convolution with a dilation rate of 2 is presented in
Figure 2.
3.1.3. Residual Connections
Residual connectivity is an important mechanism used in TCNs to alleviate deep network training problems. It avoids the loss of information during transmission by passing the input directly to the subsequent layers. The structure of the residual block can be represented as
where
denotes the causal convolution operation;
is the layer normalization operation used to stabilize the training process;
is the activation function used to introduce nonlinearities, and the structure of residual linkage is shown in
Figure 3.
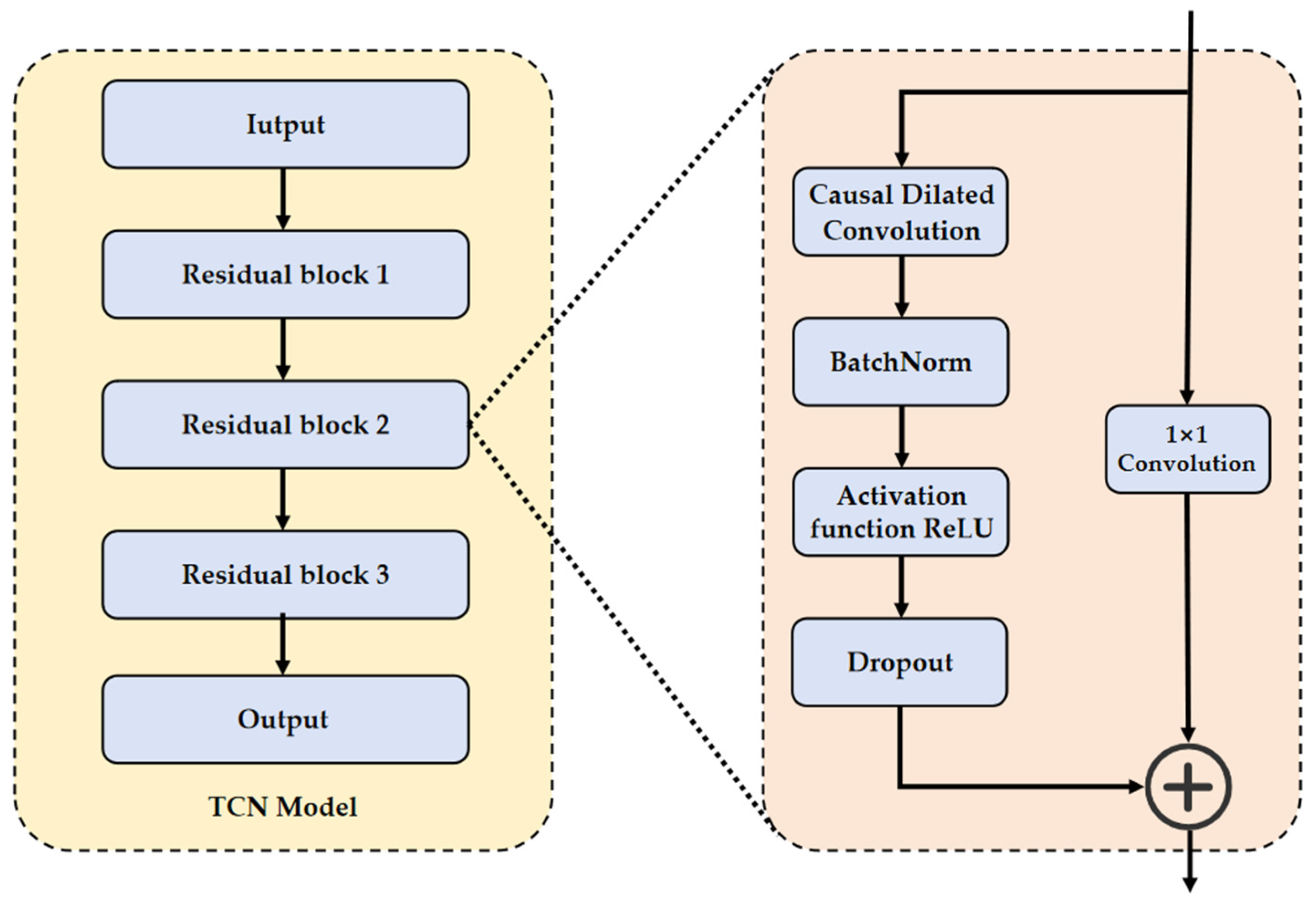
As illustrated in
Figure 3, the architectural composition of TCN comprises iteratively stacked residual modules. Each module intrinsically integrates four computational components: causal dilated convolution, layer normalization, ReLU activation functions, and dropout layers, with their structural interconnections explicitly delineated in
Figure 4. This hierarchical stacking paradigm not only facilitates the construction of deep feature hierarchies but also intrinsically circumvents the vanishing/exploding gradient pathologies pervasive in deep neural architectures through residual skip-connection mechanisms.
The TCN architecture utilizes dilated convolutional sampling that strictly enforces causal constraints in temporal analysis by ensuring that current predictions are unaffected by future information. Unlike conventional convolutional methods, TCN achieves a large temporal receptive field through strategically dilated kernel strides while maintaining output dimensionality. This enables the effective capture of long-range dependencies across sequential data. As a result, the architecture significantly improves computational efficiency and enhances the model’s ability to represent long-term dependencies and generalize predictive performance.
3.2. GRU and BiGRU
RNNs are well suited for modeling sequential data. However, they often face training difficulties due to vanishing or exploding gradients. To address these issues, the GRU was proposed. GRU retains the recursive structure of RNNs but adds gates to improve gradient stability and capture long-term dependencies [
73]. Compared with LSTM networks, GRU offers similar accuracy with a simpler structure. It requires less computation and trains faster, although both models share similar principles [
74,
75]. GRU has two main gates: the reset gate and the update gate. The reset gate controls how much past information is ignored. The update gate balances old and new information, helping the model retain important context over time.
Figure 5 shows the structure and computation process of the GRU. The detailed algorithm is given below [
76]:
First, the reset
and update gate
are computed to determine the extent to which historical state information is forgotten and the proportion of prior state information retained, respectively:
where
is the activation function, which normalizes the input to the range (0, 1).
Next, the candidate output state
is computed, combining the current input and the historical state information adjusted by the reset gate:
where
is activation function, which normalizes the input to the range (−1, 1).
Finally, the state
of the current time step is obtained by fusing the previous state and the candidate state based on the weights of the update gates:
where
is the input sequence value at the current time step,
is the output state at the previous moment,
,
,
,
,
, and
are the corresponding weight coefficient matrices and bias terms of each part, respectively;
is the sigmoid activation function used to normalize the gated signal to the (0, 1) interval;
is the hyperbolic tangent function used to normalize the state values to the (−1, 1) interval; * denotes the element-by-element Hadamard product.
The conventional GRU architecture, confined exclusively to assimilating historical information preceding the current timestep, exhibits inherent limitations in incorporating future contextual signals. To address the temporal directional constraint, the BiGRU framework is adopted. This enhanced architecture synergistically integrates forward-propagating and backward-propagating GRU layers, enabling the concurrent extraction of both antecedent and subsequent temporal patterns. The schematic representation of this architectural configuration is illustrated in
Figure 6.
As can be seen from
Figure 6, the hidden layer state
of BiGRU at time step t consists of two parts: the forward hidden layer state
and the backward hidden layer state
. The forward hidden layer state
is determined by the current input
and the forward hidden layer state
of the previous moment; the backward hidden layer state
is determined by the current input
and the backward hidden layer state
of the next moment. The formula of BiGRU is as follows:
where
denotes the weight from one cell layer to another.
3.3. Attention Mechanism
Within temporal sequence processing frameworks, attention mechanisms have been strategically incorporated to optimize feature saliency through selective information prioritization. This computational paradigm operates via adaptive inter-state affinity quantification, employing a context-sensitive weight allocation scheme that dynamically enhances anomaly discernment capacity while ensuring system robustness [
77].
First, the correlation between the hidden layer states
and
is calculated as shown in Equation (10).
where
denotes the correlation between
and
, is nonlinearly transformed by the weight matrices
and
and the bias
.
Next, the correlation
is converted to an attention weight
using the softmax function:
In Equation (11), the attention weights represent the importance of to , reflecting the degree of contribution to the current prediction at different points in time.
Finally, the weighted hidden states are obtained by weighted summation
:
Equation (12) combines the contributions of all hidden states to , where the contribution of each is determined by its corresponding attention weight .
Through the above process, the attention mechanism enables the model to adaptively focus on the most critical time points for the task at hand, leading to more accurate predictions and greater robustness in time series analysis [
78].
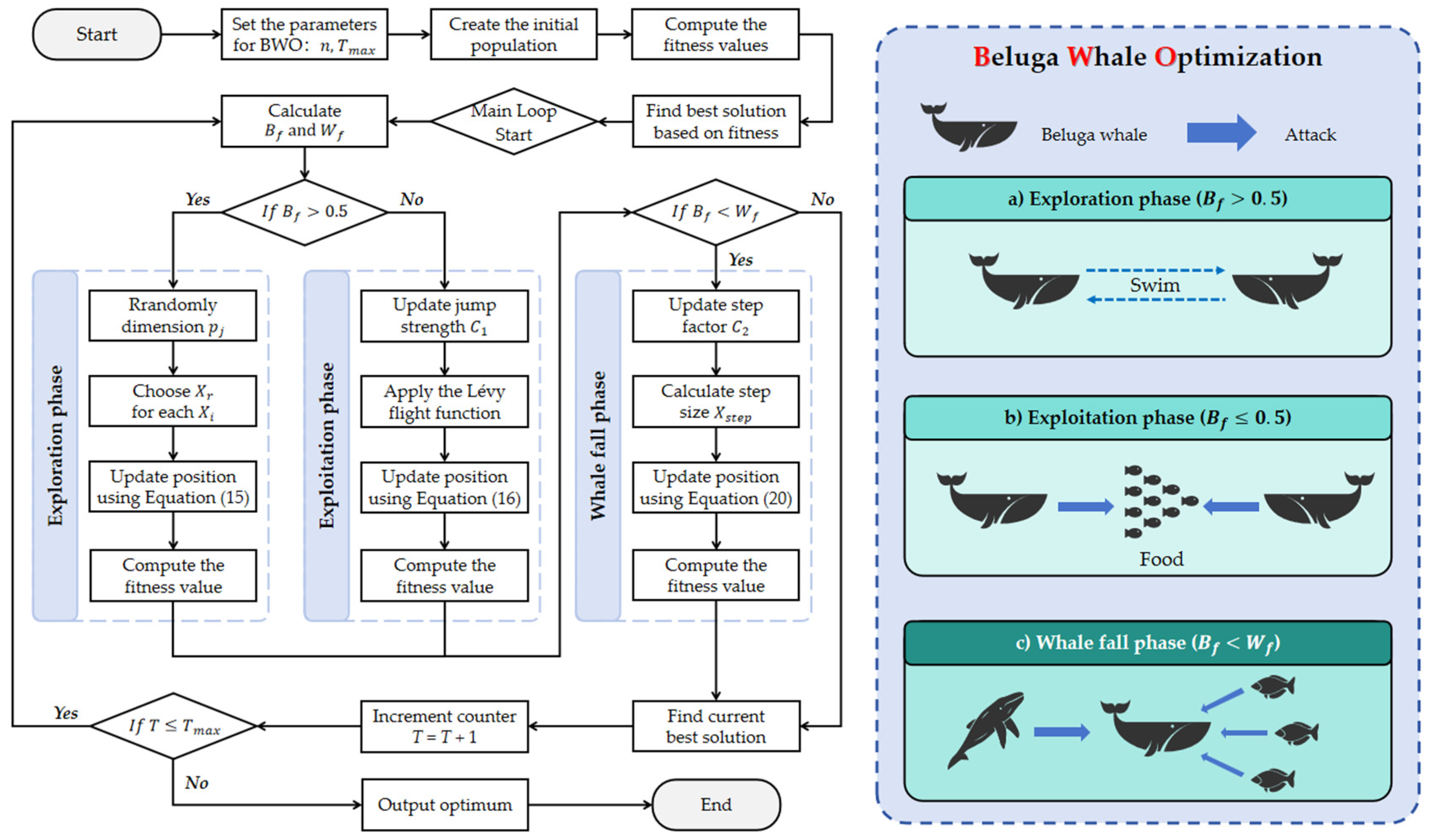
3.4. Beluga Whale Optimization
Regarding the overall structure of the GRU network, several hyperparameters need to be determined, and the BWO optimization algorithm is used to help achieve this. Its metaheuristic framework operationalizes three biomimetic behavioral phases: exploration (emulating paired swimming dynamics), exploitation (simulating prey capture strategies), and whale-fall mechanisms. Central to its efficacy are self-adaptive balance factors and dynamic whale-fall probability parameters that govern phase transition efficiency between exploratory and exploitative search modalities. Furthermore, the algorithm integrates Lévy flight operators to augment global convergence characteristics during intensive exploitation phases [
68].
The BWO metaheuristic framework employs population-based stochastic computation, where each beluga agent is conceptualized as a candidate solution vector within the search space. These solution vectors undergo iterative refinement through successive optimization cycles. Consequently, the initialization protocol for these computational entities is governed by mathematical specifications detailed in Equations (13) and (14).
where N is the number of populations, D is the problem dimension, and X and F represent the location of individual beluga whales and the corresponding solution, respectively.
The BWO algorithm can be gradually converted from exploration to exploitation through the balancing factor
implementation, and the exploration phase occurs when the balancing factor
, while the exploitation phase occurs when
. The specific mathematical model is shown in Equation (15).
where
varies randomly in the range of
in each iteration, and
and
are are the current and maximum number of iterations, respectively. As the number of iterations
increases, the fluctuation range of
decreases from
to
, indicating that the probability of the development and exploration phases changes significantly, while the probability of the development phase increases with the increasing number of iterations T.
3.4.1. Exploration Phase
The exploratory phase of the BWO was established by the swimming behavior of beluga whales. The swimming behavior of beluga whales is usually that of swimming closely together in a synchronized or mirrored manner, so their swimming positions are in pairwise form. The position of the search agent is determined by the paired swimming of the beluga whales, and the position of the beluga whales is updated, as shown in Equation (16).
where
is a randomly selected integer from the D dimension, denoting the dimension;
and
denote random numbers in the
interval, used to increase the randomness of exploration;
and
simulate the direction of the beluga whale’s swimming direction, and the values of these functions determine the orientation of the beluga whale when updating its position, realizing the synchronous or mirroring behavior of the beluga whale when swimming or diving. Even and odd are denoted by the single and double numbers of whales, respectively, with the population being indicated by the number of individuals.
3.4.2. Exploitation Phase
During the exploitation phase, the BWO framework emulates belugas’ coordinated foraging by sharing spatial information to locate prey collectively. The position update protocol integrates positional relativity between elite and suboptimal solutions and strategically uses Lévy flight operators to improve convergence. This multi-objective optimization process is formalized in Equation (17).
where
is the current iteration number,
and
are the current positions of the ith beluga and the random beluga, respectively, XbT is the best position in the beluga population,
and
denote the random numbers in the interval
, and
is the randomized jumping strength that measures the flight strength of the Levi’s, and the computational equations are shown in Equation (18).
A mathematical model of the Lévy flight function
is used to simulate the capture of prey by beluga whales using this strategy, and the mathematical model is shown in Equation (19).
where Γ refers to the gamma function, which is the extension of the factorial function in the real and complex domains.;
and
are normally distributed random numbers; and
is a default constant equal to 1.5.
3.4.3. Whale Fall Phase
Within the BWO framework, the whale-fall phase employs a probabilistic elimination mechanism that mimics stochastic population dynamics via controlled attrition. This biomimetic process is analogous to ecological dispersion patterns, where belugas migrate or descend into deep zones. By adaptively recalibrating positions based on spatial coordinates and displacement parameters, the algorithm maintains population equilibrium. The governing equations for this phase are formalized in Equation (21).
where
,
, and
are random numbers in the interval
, and
is the step size of the whale fall, defined as follows.
The step size is affected by the boundaries of the problem variables, the number of current iterations, and the maximum number of iterations. Here,
and
denote the upper and lower bounds of the variables, respectively, whilst
is a step factor related to the decline probability of whales and population size, which is defined as shown in Equation (23).
where the whale fall probability
Wf is calculated as a linear function, as shown in Equation (24):
The whale-fall probability exhibits a progressive diminution from 0.1 during initial iterations to 0.05 in terminal optimization phases, signifying attenuated risk exposure as the search agents approach proximity to optimal solutions. This probabilistic adaptation mechanism parallels the thermodynamic convergence behavior in transformer oil temperature forecasting models, where parametric convergence toward global optima manifests as enhanced predictive fidelity with concomitant reduction in stochastic uncertainty.
Figure 7 shows the workflow of the beluga optimization algorithm for transformer oil temperature prediction, demonstrating in detail how the BWO algorithm can optimize the problem by simulating the exploratory, exploitative, and falling behaviors of the Beluga whale.
3.5. Framework of the Proposed Method
The proposed architecture synergistically integrates BWO, TCN, BiGRU, and attention mechanisms into a unified temporal forecasting framework. While many deep learning architectures have shown success in time series forecasting, the selection of TCN and BiGRU in this study is based on their complementary strengths. TCN is particularly effective in capturing long-range dependencies using dilated causal convolutions while maintaining training stability and low computational cost. BiGRU, on the other hand, can model bidirectional dependencies in sequences, thus improving contextual understanding. Compared with alternative models such as LSTM, Transformer, or Informer, TCN offers faster convergence and simpler structure, and BiGRU provides a more lightweight alternative to LSTM with comparable accuracy.
Specifically, the model initiates with BWO-driven hyperparameter optimization, leveraging its superior global search capability to derive optimal initial parameter configurations for subsequent network training. Subsequently, the TCN module employs causal convolutional layers and dilated convolution operations to hierarchically extract both short-term fluctuations and long-range dependencies within sequential data. Complementing this, the BiGRU component systematically captures bidirectional temporal dependencies through dual-directional state propagation, thereby mitigating the inherent limitations of causal convolution in modeling complex temporal interactions. Conclusively, an adaptive feature recalibration mechanism dynamically weights the BiGRU output states through context-sensitive attention allocation, emphasizing salient temporal patterns while suppressing noise interference. This multimodal integration facilitates enhanced modeling capacity for intricate temporal structures, with the comprehensive computational workflow formally illustrated in
Figure 8.
6. Conclusions
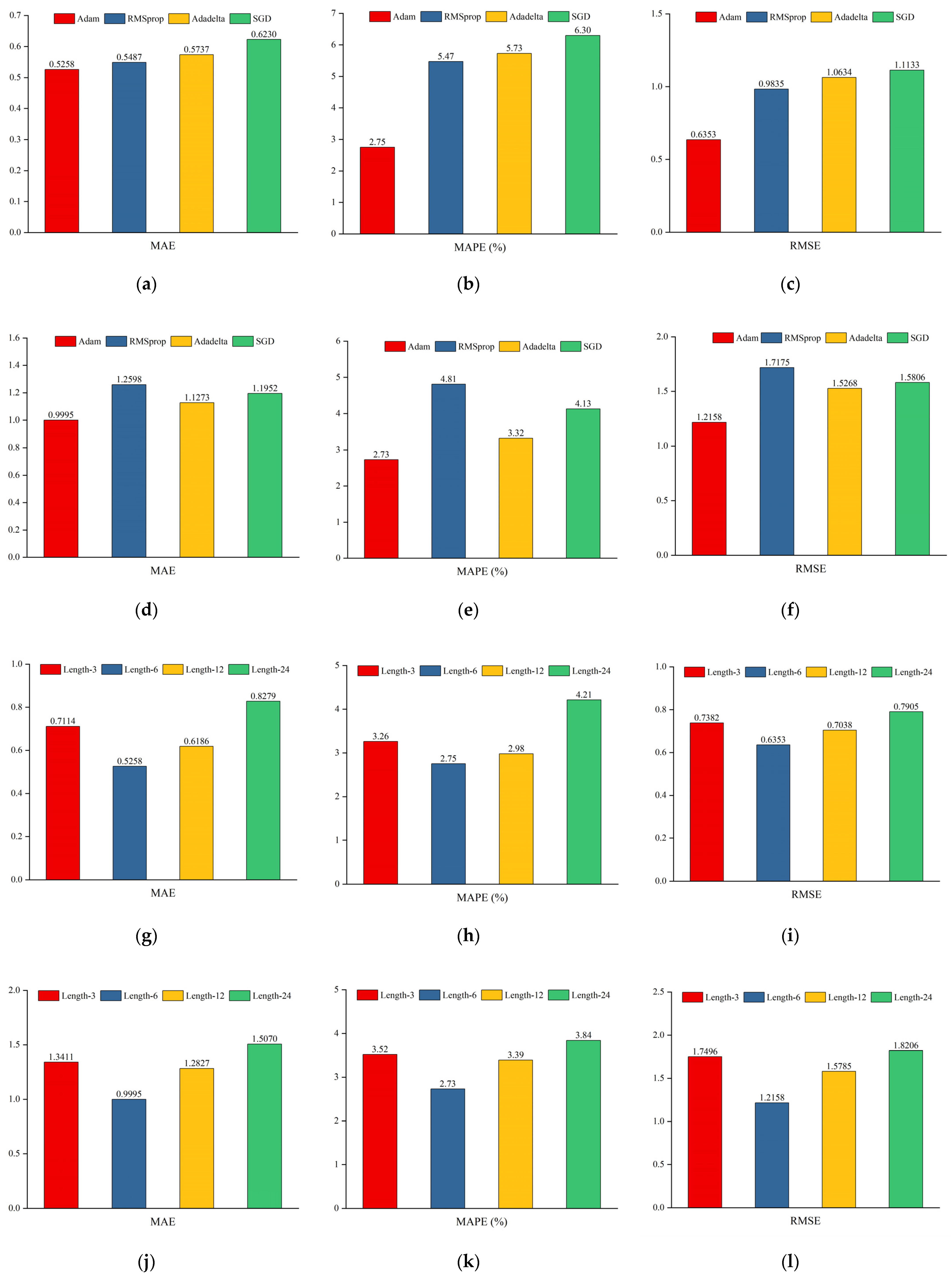
This study successfully developed and validated a novel BWO-TCN-BiGRU-Attention model for predicting the top oil temperature of transformers. The model integrates the strengths of various advanced technologies, including BWO for hyperparameter optimization, TCN for capturing short-term dependencies, BiGRU for handling long-term dependencies, and the attention mechanism for enhancing feature extraction. The experimental results demonstrate that, on the Transformer 1 dataset, the model achieved an MAE of 0.5258, a MAPE of 2.75%, and an RMSE of 0.6353; on the Transformer 2 dataset, the MAE was 0.9995, the MAPE was 2.73%, and the RMSE was 1.2158. In seasonal tests, the model’s MAPE was 2.75% in spring, 3.44% in summer, 3.93% in autumn, and 2.46% in winter for Transformer 1, and 2.73%, 2.78%, 3.07%, and 2.05% for Transformer 2, respectively, outperforming the benchmark models. Across the different time granularities, the model exhibited strong generalization ability and stability. At a time granularity of 1 h, the MAPE for Transformer 1 was 2.75% and for Transformer 2 was 2.73%. At a 15 min time granularity, the MAPE for Transformer 1 slightly increased to 2.98%, with a marginal rise in error but still maintaining the best performance; the MAPE for Transformer 2 further decreased to 2.16%. The BWO algorithm applied in this study has certain limitations. It may require significant computational resources in high-dimensional spaces and necessitates parameter tuning to maintain stable performance across tasks. Additionally, geographical diversity and transformer types may potentially impact the model’s generalizability. To ascertain the model’s adaptability, future research should conduct tests across a broader range of geographical areas and various types of transformers. Additionally, investigations should explore the architecture’s applicability to other power systems and climates, and examine the feasibility of deploying this algorithm for real-time predictive models. Furthermore, we intend to incorporate multi-source data, including environmental temperature, humidity, and transformer service life, to enrich input features and enhance predictive accuracy. These endeavors aim to provide robust technical support for the stable operation of smart grids and related fields.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}