
Telecom Fraud Recognition Based on Large Language Model Neuron Selection

 , , , and
, , , and
Abstract
1. Introduction
2. Related Work
2.1. Technical Progress and Data Challenges in Chinese Telecom Fraud Detection
2.2. Loss Function Optimization
3. Methods
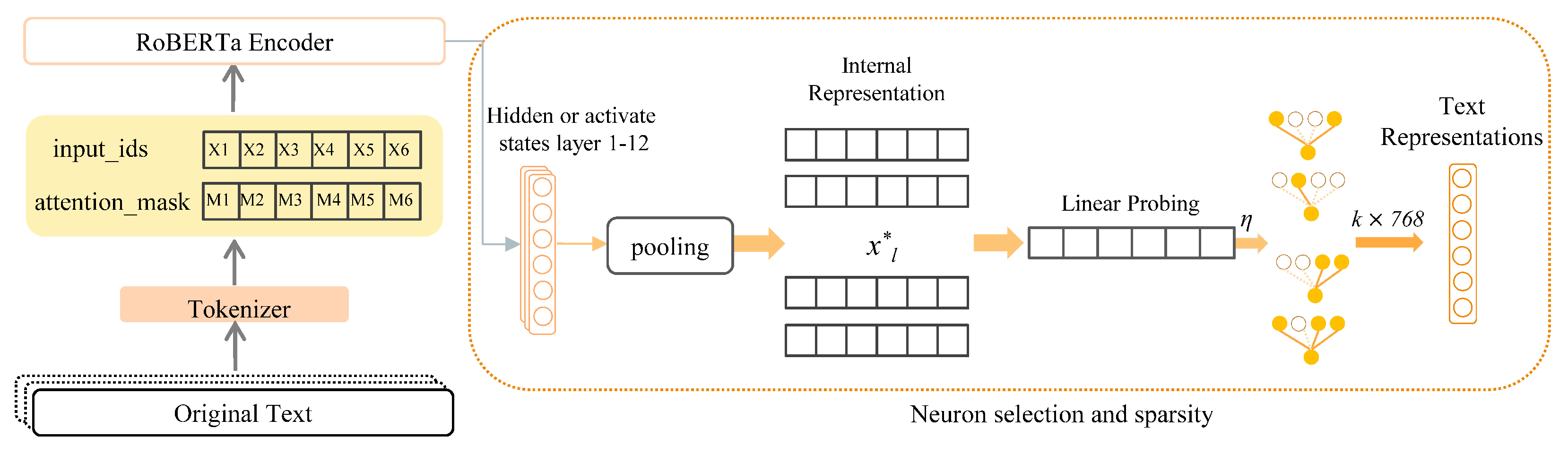
3.1. Utilization and Selection of Internal Neurons
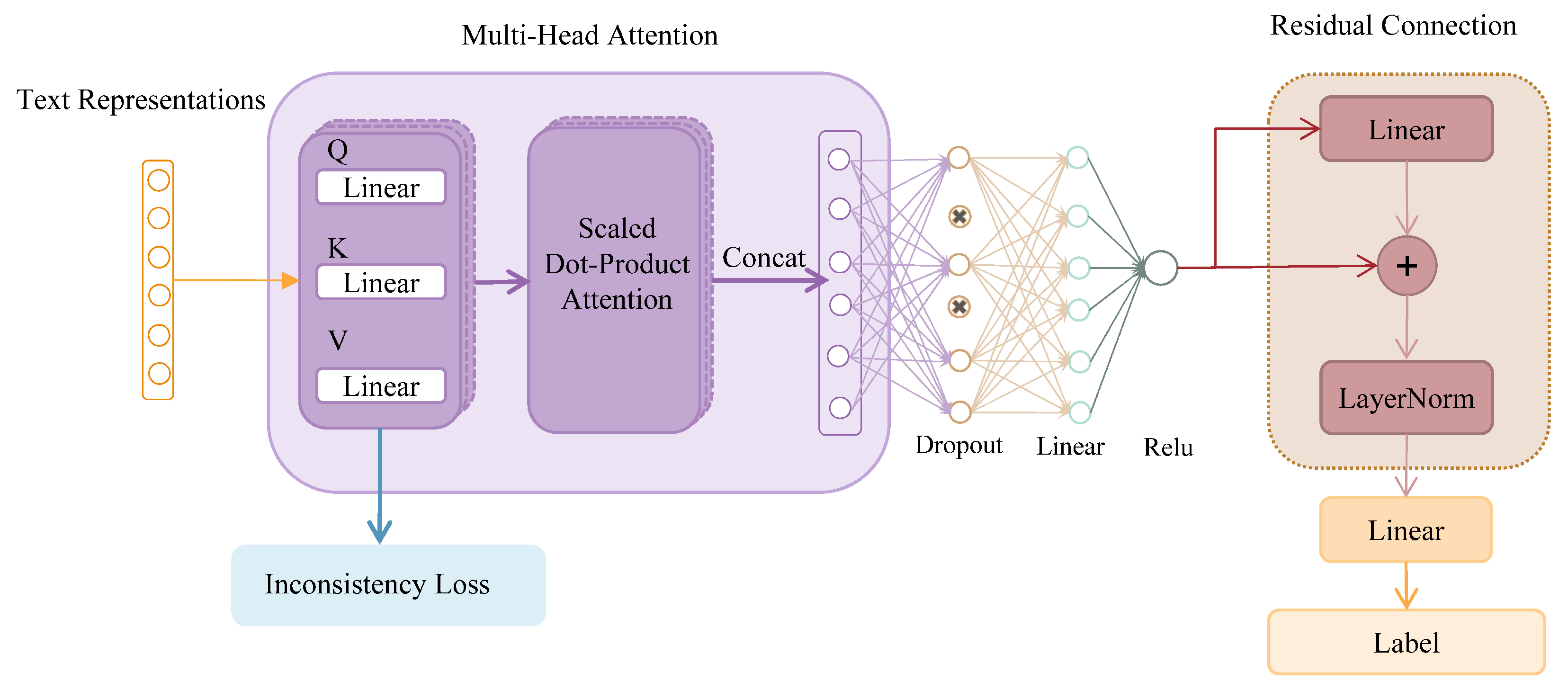
3.2. Design and Optimization of Loss Function
3.3. Model Architecture
4. Experiment and Analysis
4.1. Datasets
4.1.1. Self-Built Dataset
4.1.2. Multi-Category News Datasets
4.1.3. Fake Rumor News Datasets
4.2. Data Processing
4.3. Model Description and Parameter Settings
4.4. Experiment
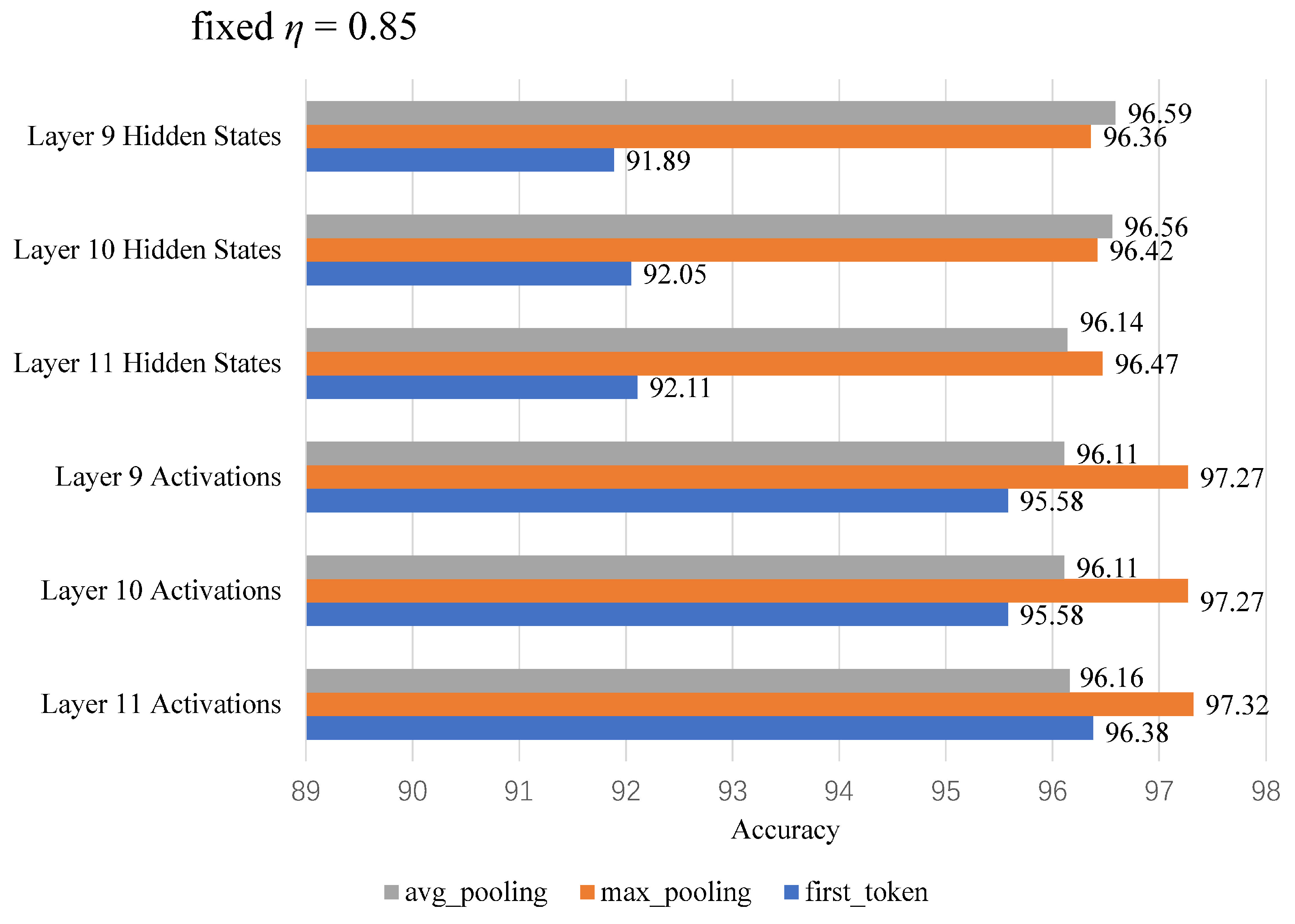
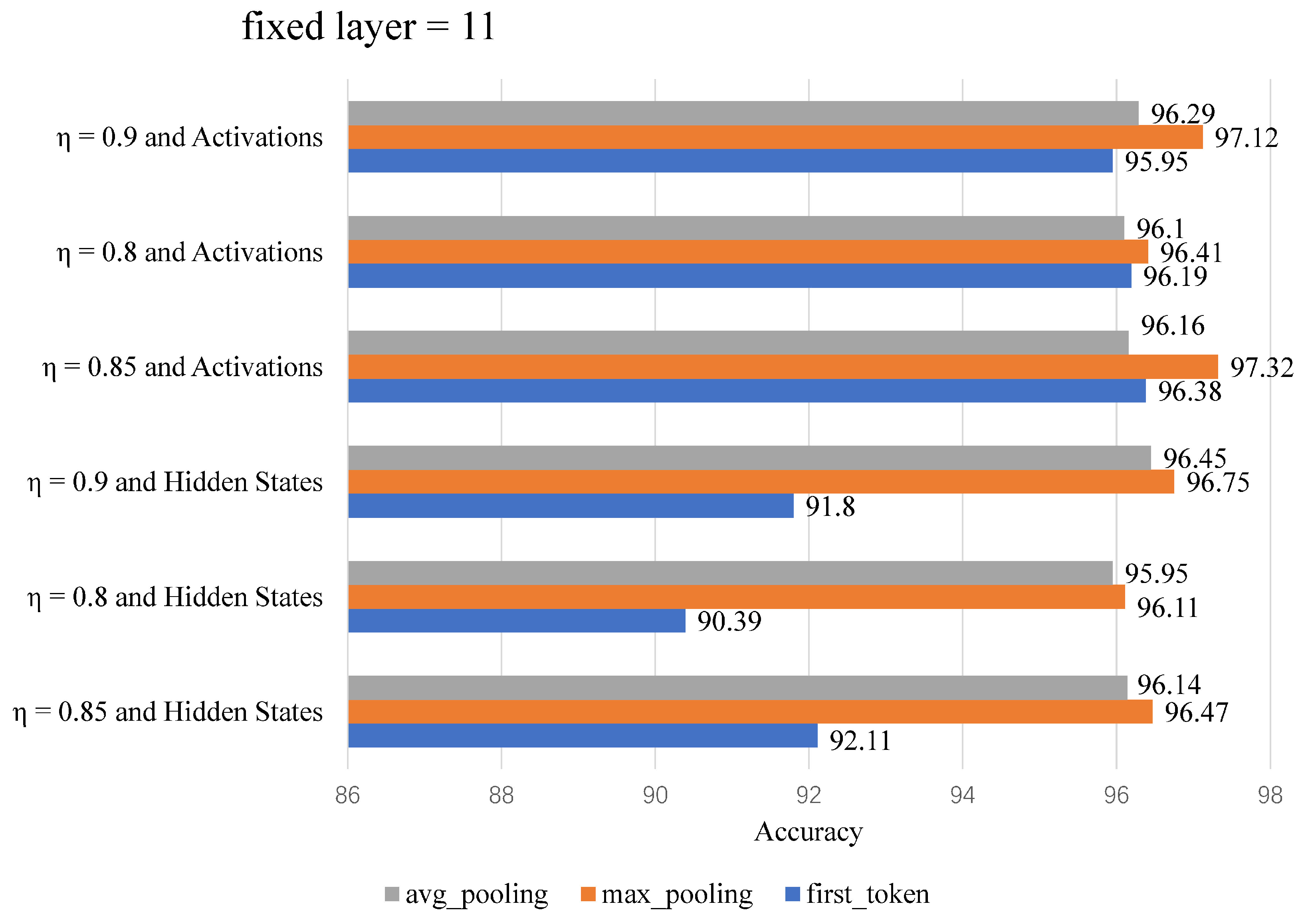
4.4.1. Determining the Screening Method for Middle Layer Neurons
4.4.2. Text Classification Task Based on Intermediate Layer Neurons
4.4.3. Rumor Classification Performance
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Liu, A.; Piao, S. Research on Laws, Regulations, and Policies of Internet Fraud. J. Educ. Humanit. Soc. Sci. 2024, 28, 257–264. [Google Scholar] [CrossRef]
- Qu, J.; Cheng, H. Policing telecommunication and cyber fraud: Perceptions and experiences of law enforcement officers in China. Crime Law Soc. Change 2024, 82, 283–305. [Google Scholar] [CrossRef]
- Maras, M.H.; Ives, E.R. Deconstructing a form of hybrid investment fraud: Examining ‘pig butchering’ in the united states. J. Econ. Criminol. 2024, 5, 100066. [Google Scholar] [CrossRef]
- Han, B. Individual Frauds in China: Exploring the Impact and Response to Telecommunication Network Fraud and Pig Butchering Scams. Ph.D. Thesis, University of Portsmouth, Portsmouth, UK, 2023. [Google Scholar]
- Luo, B.; Zhang, Z.; Wang, Q.; Ke, A.; Lu, S.; He, B. Ai-powered fraud detection in decentralized finance: A project life cycle perspective. ACM Comput. Surv. 2024, 57, 1–38. [Google Scholar] [CrossRef]
- Chatterjee, P.; Das, D.; Rawat, D.B. Digital twin for credit card fraud detection: Opportunities, challenges, and fraud detection advancements. Future Gener. Comput. Syst. 2024, 158, 410–426. [Google Scholar] [CrossRef]
- Shungube, P.S.; Bokaba, T.; Ndayizigamiye, P.; Mhlongo, S.; Dogo, E. A Deep Learning Approach for Healthcare Insurance Fraud Detection. Res. Sq. 2024. [Google Scholar] [CrossRef]
- Zhuoxian, L.; Tuo, S.; Xiaofeng, H. A Text Classification Model Combining Adversarial Training with Pre-trained Language Model and neural networks: A Case Study on Telecom Fraud Incident Texts. arXiv 2024, arXiv:2411.06772. [Google Scholar]
- Cao, J.; Cui, X.; Zheng, C. Tfd-gcl: Telecommunications fraud detection based on graph contrastive learning with adaptive augmentation. In Proceedings of the 2024 International Joint Conference on Neural Networks (IJCNN), Yokohama, Japan, 30 June–5 July 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 1–7. [Google Scholar]
- Wu, J.; Hu, R.; Li, D.; Ren, L.; Huang, Z.; Zang, Y. Beyond the individual: An improved telecom fraud detection approach based on latent synergy graph learning. Neural Netw. 2024, 169, 20–31. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, B.; Lu, C.; Li, Z.; Duan, H.; Hao, S.; Liu, M.; Liu, Y.; Wang, D.; Li, Q. Lies in the air: Characterizing fake-base-station spam ecosystem in china. In Proceedings of the 2020 ACM SIGSAC Conference on Computer and Communications Security, Virtual Event, 9–13 November 2020; pp. 521–534. [Google Scholar]
- Li, J.; Zhang, C.; Jiang, L. Innovative Telecom Fraud Detection: A New Dataset and an Advanced Model with RoBERTa and Dual Loss Functions. Appl. Sci. 2024, 14, 11628. [Google Scholar] [CrossRef]
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.; Salakhutdinov, R.R.; Le, Q.V. Xlnet: Generalized autoregressive pretraining for language understanding. Adv. Neural Inf. Process. Syst. 2019, 32. Available online: https://proceedings.neurips.cc/paper_files/paper/2019/file/dc6a7e655d7e5840e66733e9ee67cc69-Paper.pdf (accessed on 1 May 2025).
- He, P.; Gao, J.; Chen, W. Debertav3: Improving deberta using electra-style pre-training with gradient-disentangled embedding sharing. arXiv 2021, arXiv:2111.09543. [Google Scholar]
- Gurnee, W.; Nanda, N.; Pauly, M.; Harvey, K.; Troitskii, D.; Bertsimas, D. Finding neurons in a haystack: Case studies with sparse probing. arXiv 2023, arXiv:2305.01610. [Google Scholar]
- Jiao, D.; Liu, Y.; Tang, Z.; Matter, D.; Pfeffer, J.; Anderson, A. SPIN: Sparsifying and Integrating Internal Neurons in Large Language Models for Text Classification. arXiv 2023, arXiv:2311.15983. [Google Scholar]
- Sun, C.J.; Ji, J.; Shang, B.; Liu, B. CCL23-Eval 任务 6 总结报告: 电信网络诈骗案件分类 (Overview of CCL23-Eval Task 6: Telecom Network Fraud Case Classification). In Proceedings of the 22nd Chinese National Conference on Computational Linguistics (Volume 3: Evaluations), Harbin, China, 3–5 August 2023; pp. 193–200. [Google Scholar]
- Hajiabadi, H.; Molla-Aliod, D.; Monsefi, R.; Yazdi, H.S. Combination of loss functions for deep text classification. Int. J. Mach. Learn. Cybern. 2020, 11, 751–761. [Google Scholar] [CrossRef]
- Li, J.; Tu, Z.; Yang, B.; Lyu, M.R.; Zhang, T. Multi-head attention with disagreement regularization. arXiv 2018, arXiv:1810.10183. [Google Scholar]
- Awasthi, P.; Mao, A.; Mohri, M.; Zhong, Y. H-consistency bounds for surrogate loss minimizers. In Proceedings of the International Conference on Machine Learning. PMLR, London, UK, 8–11 November 2022; pp. 1117–1174. [Google Scholar]
- Mao, A.; Mohri, M.; Zhong, Y. Cross-entropy loss functions: Theoretical analysis and applications. In Proceedings of the International Conference on Machine Learning. PMLR, Honolulu, HI, USA, 23–29 July 2023; pp. 23803–23828. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. Available online: https://proceedings.neurips.cc/paper_files/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf (accessed on 1 May 2025).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Grattafiori, A.; Dubey, A.; Jauhri, A.; Pandey, A.; Kadian, A.; Al-Dahle, A.; Letman, A.; Mathur, A.; Schelten, A.; Vaughan, A.; et al. The llama 3 herd of models. arXiv 2024, arXiv:2407.21783. [Google Scholar]
- Liu, A.; Feng, B.; Xue, B.; Wang, B.; Wu, B.; Lu, C.; Zhao, C.; Deng, C.; Zhang, C.; Ruan, C.; et al. Deepseek-v3 technical report. arXiv 2024, arXiv:2412.19437. [Google Scholar]
- Liu, Y.; He, M.; Shi, M.; Jeon, S. A novel model combining transformer and bi-lstm for news categorization. IEEE Trans. Comput. Soc. Syst. 2022, 11, 4862–4869. [Google Scholar] [CrossRef]
- Ma, J.; Gao, W.; Wong, K.F. Detect rumors in microblog posts using propagation structure via kernel learning. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (ACL 2017), Vancouver, ON, Canada, 30 July–4 August 2017; Association for Computational Linguistics: Stroudsburg, PA, USA, 2017. [Google Scholar]
- Huang, X. Weibo Rumor Event Detection Dataset. 2022. Available online: https://www.scidb.cn/en/detail?dataSetId=1085347f720f4cfc97a157e469734a66 (accessed on 1 March 2025).
- Cui, Y.; Che, W.; Liu, T.; Qin, B.; Yang, Z. Pre-training with whole word masking for chinese bert. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 3504–3514. [Google Scholar] [CrossRef]
- Zhang, X.; Huang, R.; Jin, L.; Wan, F. A BERT-GCN-Based Detection Method for FBS Telecom Fraud Chinese SMS Texts. In Proceedings of the 2023 4th International Conference on Intelligent Computing and Human-Computer Interaction (ICHCI), Guangzhou, China, 4–6 August 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 448–453. [Google Scholar]
- Ruan, J.; Caballero, J.M.; Juanatas, R.A. Chinese news text classification method based on attention mechanism. In Proceedings of the 2022 7th International Conference on Business and Industrial Research (ICBIR), Bangkok, Thailand, 19–20 May 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 330–334. [Google Scholar]
- Wang, Y.; Wang, Y.; Hu, H.; Zhou, S.; Wang, Q. Knowledge-graph-and gcn-based domain chinese long text classification method. Appl. Sci. 2023, 13, 7915. [Google Scholar] [CrossRef]
- Yu, H.; Liu, C.; Zhang, L.; Wu, C.; Liang, G.; Escorcia-Gutierrez, J.; Ghoneim, O.A. An intent classification method for questions in “Treatise on Febrile diseases” based on TinyBERT-CNN fusion model. Comput. Biol. Med. 2023, 162, 107075. [Google Scholar] [CrossRef] [PubMed]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Number | Example |
|---|---|---|
| non-fraudulent text | 17,048 | Ctrip Travel: Weekend Special Offer! Domestic air tickets have dropped by 30%, hurry up now! Reject, please reply to T. |
| public security fraud | 1415 | Hello, I am a police officer from Furong Public Security Bureau in Changsha. I have something important to inform you of. Please join our QQ group first, and we will communicate in the group. We have found that you have a passbook under your name with many deposits and withdrawals, suspected of money laundering. |
| loans | 2017 | Hello, I am XX Loan Company. Do you have any financial needs recently? We provide low interest rate and fast approval loan services. If you need to apply for a loan or learn more details, please reply with “1”, add my QQ number XXXXXXX to the group to collect the information, fill out the form, and proceed with the review and approval of the payment! |
| impersonating customer service | 1336 | Hello, I’m the customer service representative from Tiktok. We have noticed that your card information may have been mistakenly used as an agent’s identity. To solve this problem and protect your rights, we need to confirm some details and take corresponding actions. |
| impersonating leadership acquaintances | 1534 | I am your grandson. I was just arrested by the public security organs for fighting. We need your help to transfer the funds to the designated account now, otherwise we may face more severe penalties. I know this matter is very serious, but please believe me that this money is the only way to solve this problem. |
| fake rebates | 2809 | Hello, we have a WeChat task platform that offers high rebates. You just need to add our WeChat official account [XXXXX] to enter a profitable group with red envelopes and simple tasks. [XXXX] will bring you tangible benefits! Click on the link to download and log in to the "E-commerce Assistant" app to get more high priced small orders! Looking forward to your participation! |
| dating fraud | 627 | Hello! I am a netizen who cherishes the internet, and I want to make friends with you. We can chat on WeChat. You can download the Changliao AW APP, register an account, and send me the QR code. I will add you as a friend on the app. I hope we can become good friends! |
| fraudulent online game product transactions | 1571 | Hello! I am your friend Chenxi, and I am delighted to meet you in the world of superpowers! I heard that you have encountered some difficulties in the game, and I can help you solve them. Please first upload your account to the Tiehuage website, and I will recharge and help you unlock your account. Please complete the operation as soon as possible, thank you! |
| Total | 28,357 | - |
| Dataset | Total | Number of Categories | Category Description |
|---|---|---|---|
| FBS | 14,058 | 4 | illegal promotion, advertising, other, and fraud. |
| THUCNews | 50,000 | 10 | sports, entertainment, furniture, real estate, education, fashion, politics, games, technology, and finance. |
| Model | Precision | Recall | F1 | F1 Improve |
|---|---|---|---|---|
| 1 | 90.70 | 93.19 | 91.61 | +2.58 |
| 2 | 92.39 | 93.29 | 92.64 | +1.55 |
| 3.1 | 93.17 | 93.42 | 93.24 | +0.95 |
| 3.2 | 92.82 | 93.59 | 93.17 | +1.02 |
| 3.3 | 92.53 | 93.53 | 92.95 | +1.24 |
| 4.1 (LENS-RMHR) | 93.71 | 94.86 | 94.19 | - |
| 4.2 | 92.72 | 94.59 | 93.46 | +0.73 |
| 4.3 | 93.12 | 94.31 | 93.52 | +0.67 |
| FBS | |||
|---|---|---|---|
| Model | Precision | Recall | F1 |
| 2 | 96.07 | 97.30 | 96.64 |
| 3 | 96.44 | 97.36 | 96.87 |
| 4.1 (LENS-RMHR) | 97.03 | 97.62 | 97.29 |
| BERT-GCN [31] | 96.62 | 93.56 | 92.68 |
| RoBERTa [31] | 92.96 | 87.33 | 87.79 |
| Logistic [31] | 94.90 | 94.64 | 94.32 |
| THUCNews | |||
| 2 | 96.89 | 96.95 | 96.88 |
| 3 | 97.36 | 97.39 | 97.35 |
| 4.1 (LENS-RMHR) | 97.56 | 97.57 | 97.55 |
| Att-CNLSTM [32] | 96.32 | 96.24 | 96.26 |
| Att-BILSTM [32] | 96.16 | 96.20 | 96.11 |
| KGBGCN [33] | 93.19 | 93.19 | 93.16 |
| TinyBERT-CNN [34] | 93.3 | 93.2 | 93.2 |
| Datasets | Method | Accuracy | NR | FR | TR | UR |
|---|---|---|---|---|---|---|
| F1 | F1 | F1 | F1 | |||
| Twitter 15 | BU-RvNN | 0.708 | 0.695 | 0.728 | 0.759 | 0.653 |
| TD-RvNN | 0.723 | 0.682 | 0.758 | 0.821 | 0.654 | |
| 2 | 0.766 | 0.734 | 0.798 | 0.812 | 0.751 | |
| 3 | 0.802 | 0.737 | 0.834 | 0.851 | 0.766 | |
| Twitter 16 | BU-RvNN | 0.718 | 0.723 | 0.712 | 0.779 | 0.659 |
| TD-RvNN | 0.737 | 0.662 | 0.743 | 0.835 | 0.708 | |
| 2 | 0.793 | 0.776 | 0.745 | 0.812 | 0.788 | |
| 3 | 0.834 | 0.724 | 0.833 | 0.851 | 0.728 | |
| BU-RvNN | 0.689 | 0.646 | 0.724 | 0.769 | 0.678 | |
| TD-RvNN | 0.711 | 0.667 | 0.736 | 0.801 | 0.657 | |
| 2 | 0.841 | 0.756 | 0.854 | 0.852 | 0.787 | |
| 3 | 0.833 | 0.768 | 0.866 | 0.882 | 0.806 |
| Datasets | Neuron Selection | Accuracy | NR | FR | TR | UR | |
|---|---|---|---|---|---|---|---|
| F1 | F1 | F1 | F1 | ||||
| Twitter 15 | Model 2 | Before | 0.722 | 0.668 | 0.754 | 0.771 | 0.707 |
| After | 0.766 | 0.734 | 0.798 | 0.812 | 0.751 | ||
| Model 3 | Before | 0.756 | 0.689 | 0.764 | 0.813 | 0.726 | |
| After | 0.802 | 0.737 | 0.834 | 0.851 | 0.766 | ||
| Twitter 16 | Model 2 | Before | 0.725 | 0.711 | 0.684 | 0.747 | 0.713 |
| After | 0.793 | 0.776 | 0.745 | 0.812 | 0.788 | ||
| Model 3 | Before | 0.755 | 0.668 | 0.789 | 0.802 | 0.661 | |
| After | 0.834 | 0.724 | 0.833 | 0.851 | 0.728 | ||
| Model 2 | Before | 0.775 | 0.714 | 0.817 | 0.814 | 0.734 | |
| After | 0.841 | 0.756 | 0.854 | 0.852 | 0.787 | ||
| Model 3 | Before | 0.788 | 0.703 | 0.812 | 0.841 | 0.782 | |
| After | 0.833 | 0.768 | 0.866 | 0.882 | 0.806 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, L.; Zhang, C.; Qin, X.; Zhou, Y.; Huang, G.; Li, H.; Li, J. Telecom Fraud Recognition Based on Large Language Model Neuron Selection. Mathematics 2025, 13, 1784. https://doi.org/10.3390/math13111784
Jiang L, Zhang C, Qin X, Zhou Y, Huang G, Li H, Li J. Telecom Fraud Recognition Based on Large Language Model Neuron Selection. Mathematics. 2025; 13(11):1784. https://doi.org/10.3390/math13111784
Chicago/Turabian StyleJiang, Lanlan, Cheng Zhang, Xingguo Qin, Ya Zhou, Guanglun Huang, Hui Li, and Jun Li. 2025. "Telecom Fraud Recognition Based on Large Language Model Neuron Selection" Mathematics 13, no. 11: 1784. https://doi.org/10.3390/math13111784
APA StyleJiang, L., Zhang, C., Qin, X., Zhou, Y., Huang, G., Li, H., & Li, J. (2025). Telecom Fraud Recognition Based on Large Language Model Neuron Selection. Mathematics, 13(11), 1784. https://doi.org/10.3390/math13111784