
A Novel Metaheuristic-Based Methodology for Attack Detection in Wireless Communication Networks


Abstract
1. Introduction
- Adaptive machine learning-based IDS for 5G/6G communication: We develop and implement a hybrid framework integrating two optimized, practical, efficient, and lightweight machine learning-based models for detecting malicious traffic in the complex, high-dimensional, and dynamic landscape of 5G/6G communication networks. The first approach uses a novel, lightweight 2D CNN architecture with 11 layers specifically designed to handle high-dimensional input data efficiently. The architecture includes convolutional, pooling, and fully connected layers optimized for real-time traffic analysis. Additionally, an optimized attention-based XGBoost classifier is developed, utilizing regularized boosting and incremental training to handle evolving threat patterns. The XGBoost classifier’s parallel processing capability, ensembled with the attention process, significantly improves classification accuracy and efficiency by focusing on the most relevant features, making it suitable for high-dimensional and complex traffic patterns. To identify both single-label and multilabel malicious traffic patterns, these architectures were developed from scratch and trained on an extensive dataset of 5G network traffic.
- Metaheuristic-based parameter tuning algorithm: We introduce and apply the Cat Swarm Optimization (CSO) Algorithm for the optimization of the baseline 2DCNN and XGBoost models. The strategy involves fine-tuning the convolutional neural network (CNN) and the XGBoost algorithm, which have been developed for binary and multiclass classifications, thereby improving the model’s ability to adapt to network conditions dynamically. The adaptive selection and fine-tuning of traffic patterns and hyperparameters enable the model to maintain high detection accuracy and adaptability in the dynamic 5G/6G environment. In addition to improving model performance, the CSO algorithm optimization process significantly improves model performance, as demonstrated in numerous tests.
- Comprehensive development methodology: This encompasses data preprocessing, baseline model development, and adaptive optimization, ensuring a holistic approach to attack detection. Additionally, the inclusion of a diverse dataset covering nine types of attacks enhances the model’s applicability and real-world relevance.
- Rigorous performance evaluation: The developed framework is evaluated using established performance metrics, including accuracy, precision, recall, Kappa statistics, and F1-score. Performance evaluations demonstrate high accuracy, low false-favorable rates, and robustness against various types of attacks. This ensures a thorough understanding of the model’s efficacy in detecting network traffic attacks.
2. Related Work
2.1. Machine Learning-Based IDSs
2.2. Optimization-Based IDSs
3. Background Challenges and Problem Definition
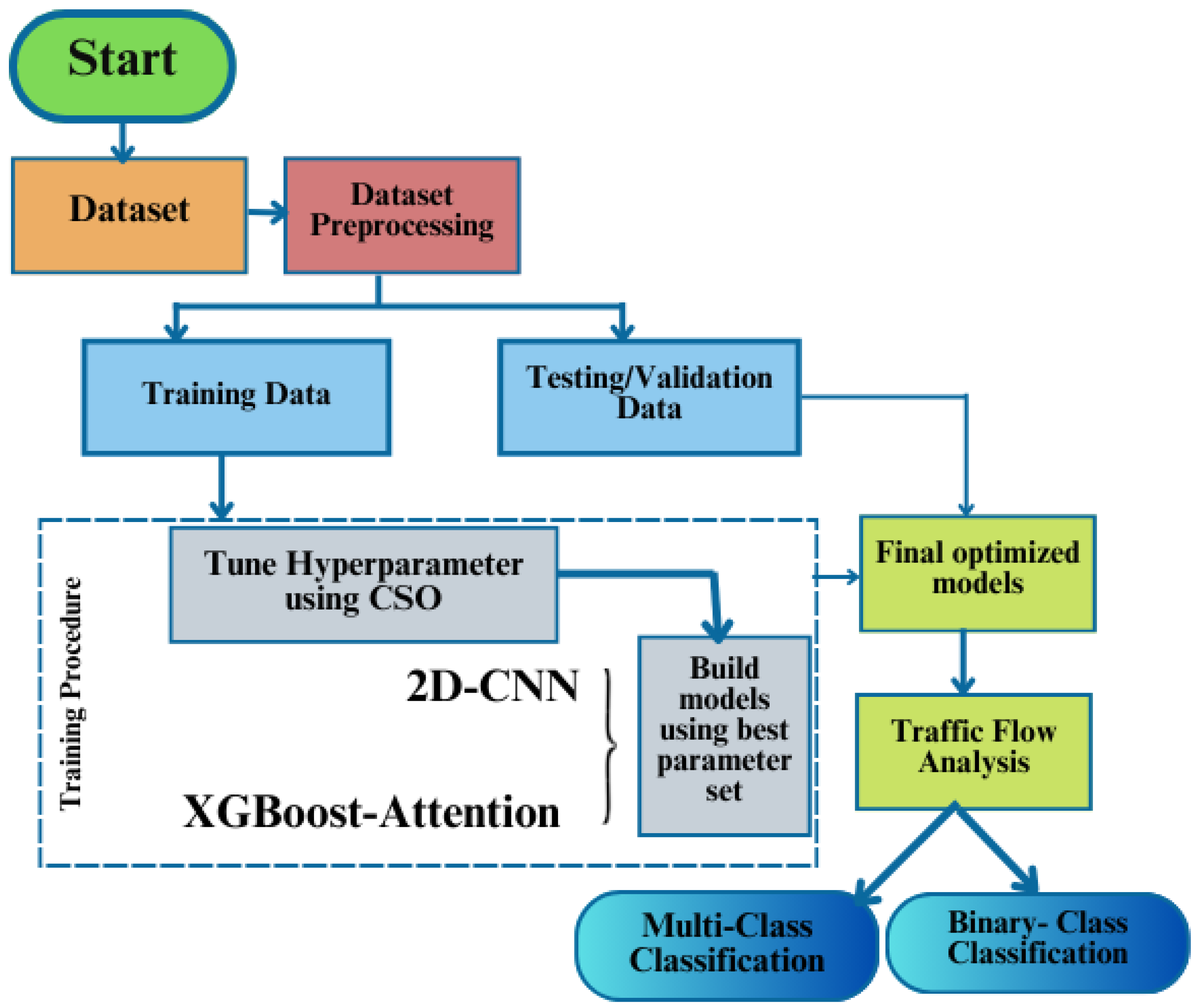
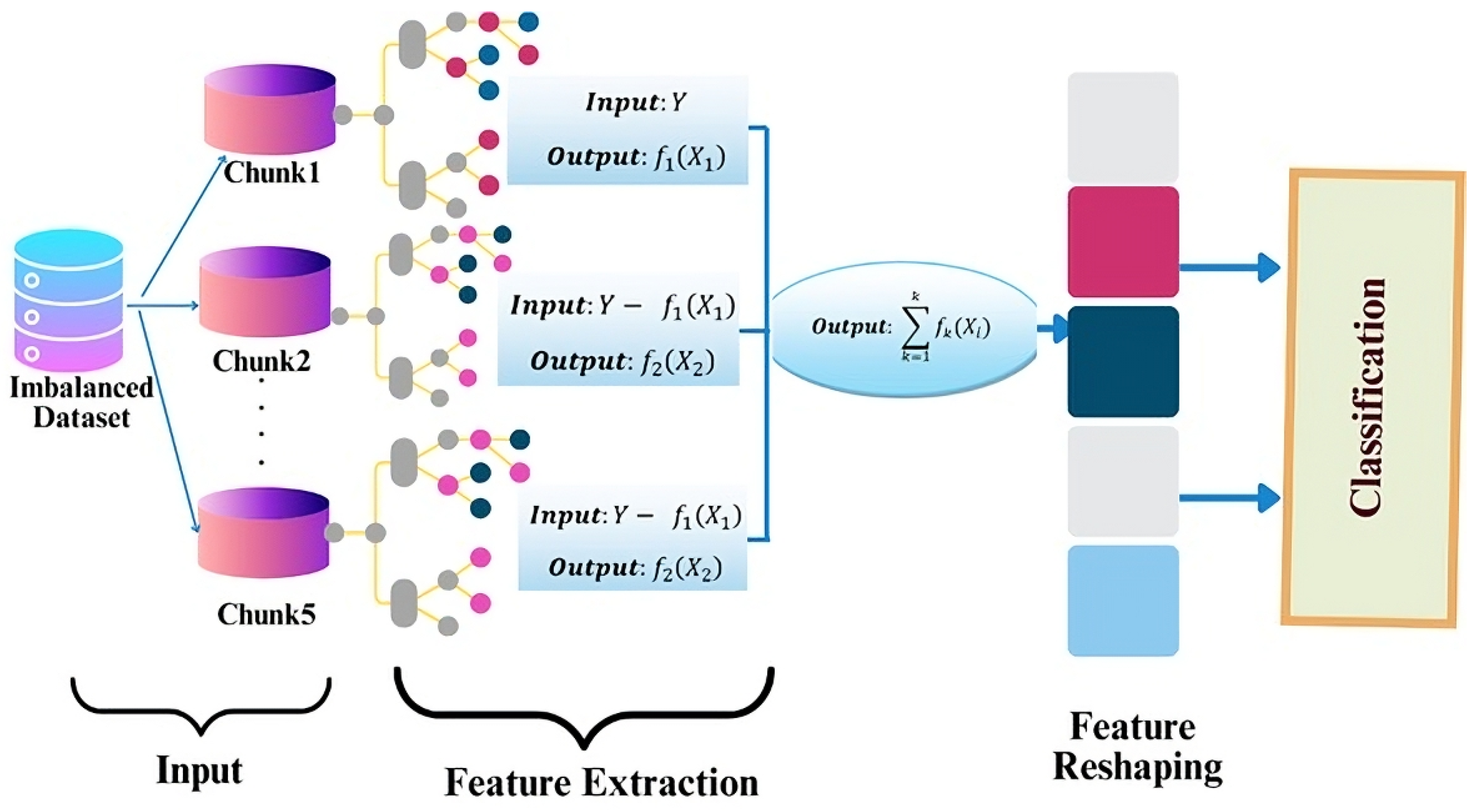
4. Proposed Intrusion Detection System Architecture
| Algorithm 1: IoT intrusion detection algorithm. |
 |
- Data preprocessing: The dataset, describing nine types of attacks, undergoes thorough preprocessing. This involves handling missing and duplicate values, scaling the data, and encoding categorical variables.
- Model training: Two baseline machine learning-based approaches are devised to extract spatial and temporal features indicative of attacks from traffic data. These baseline models serve as a foundation for subsequent optimization.
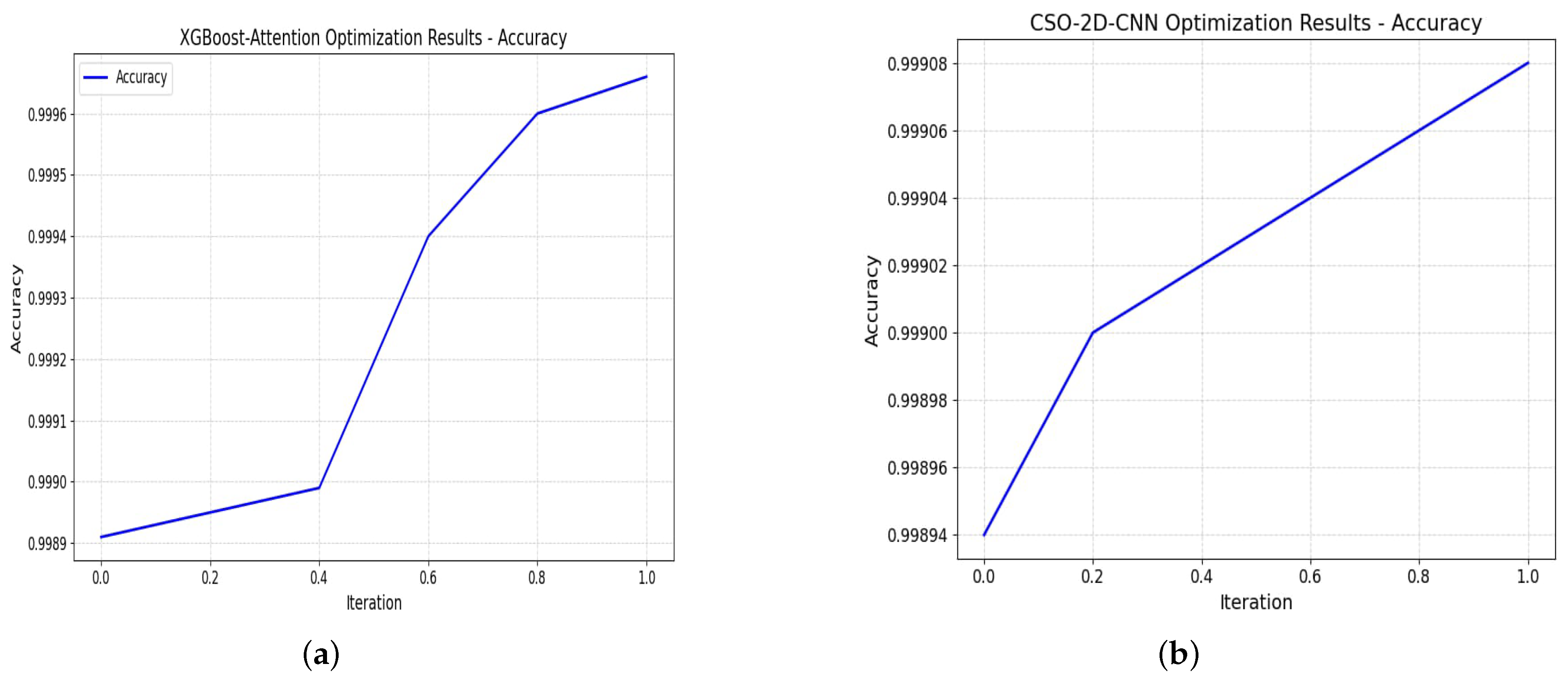
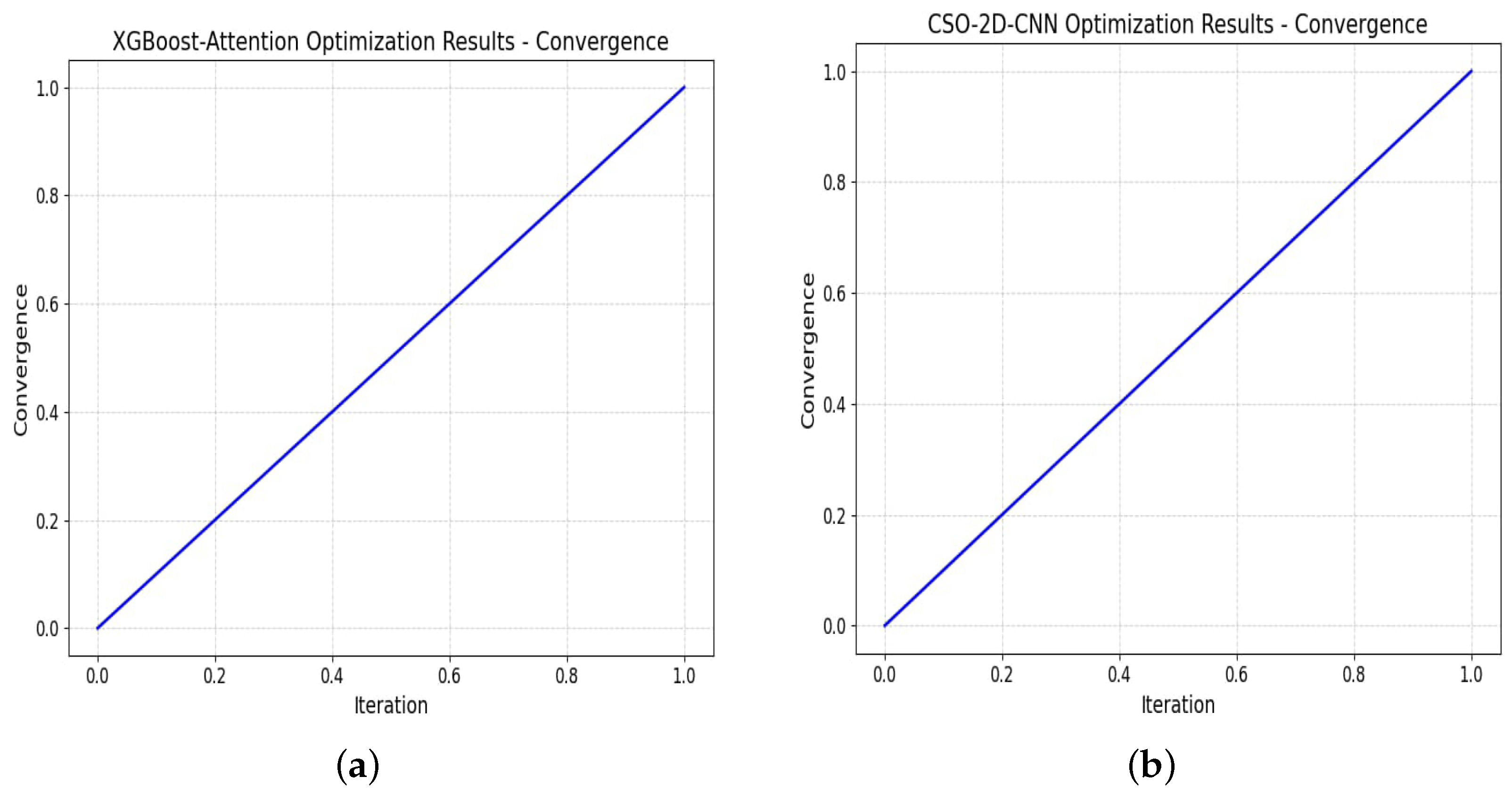
- Optimization with the CSO algorithm: The baseline models are further enhanced through the Cat Swarm Optimization (CSO) algorithm. This approach facilitates adaptability to changing network conditions and ensures improved performance.
- Traffic analysis and performance evaluation: The optimized models then analyze traffic for either binary or multiclass labels. Additionally, a rigorous evaluation using metrics such as accuracy, precision, recall, and F1 Score is applied to the obtained results. This step ensures the model’s effectiveness in detecting traffic attacks while maintaining simplicity and robustness.
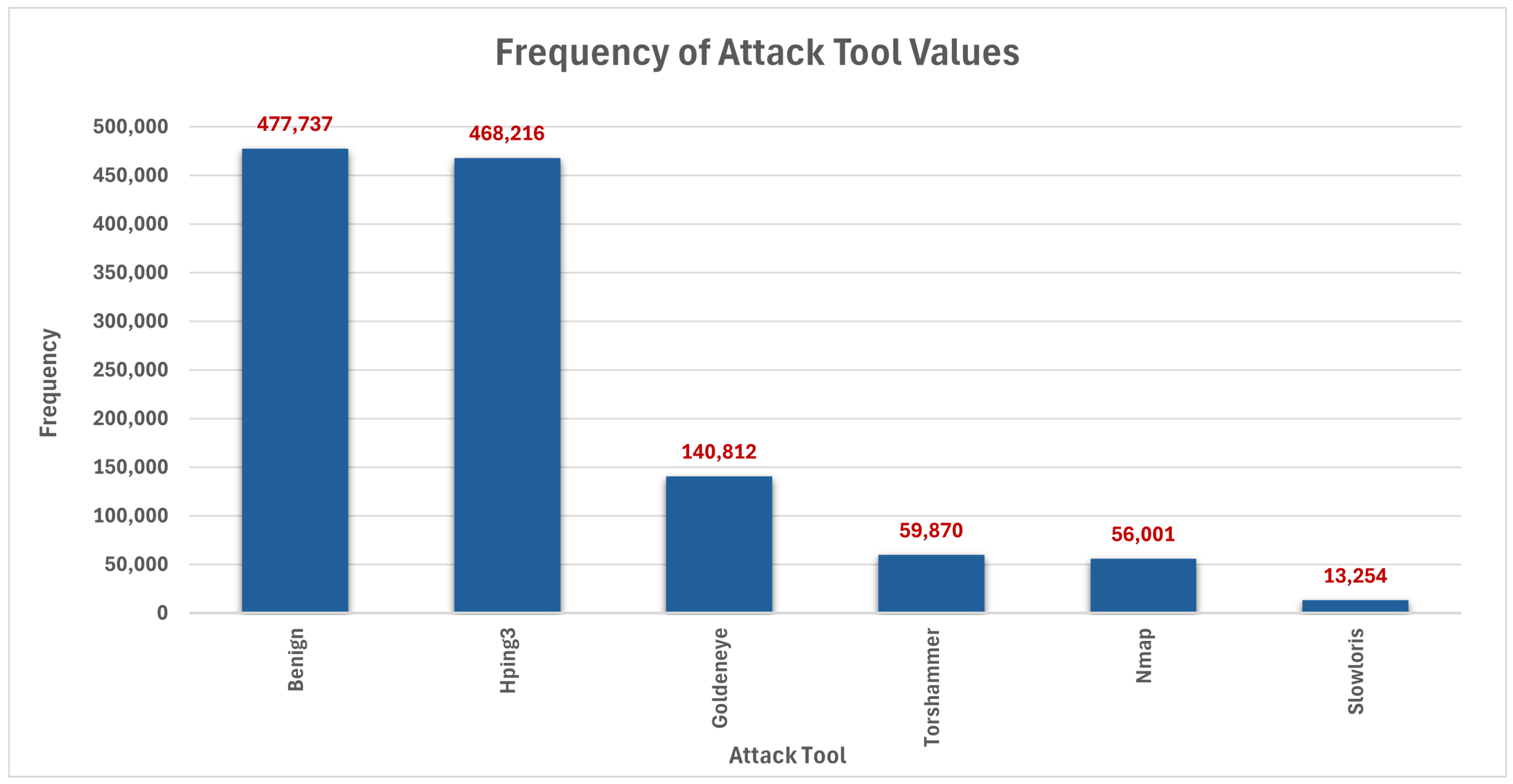
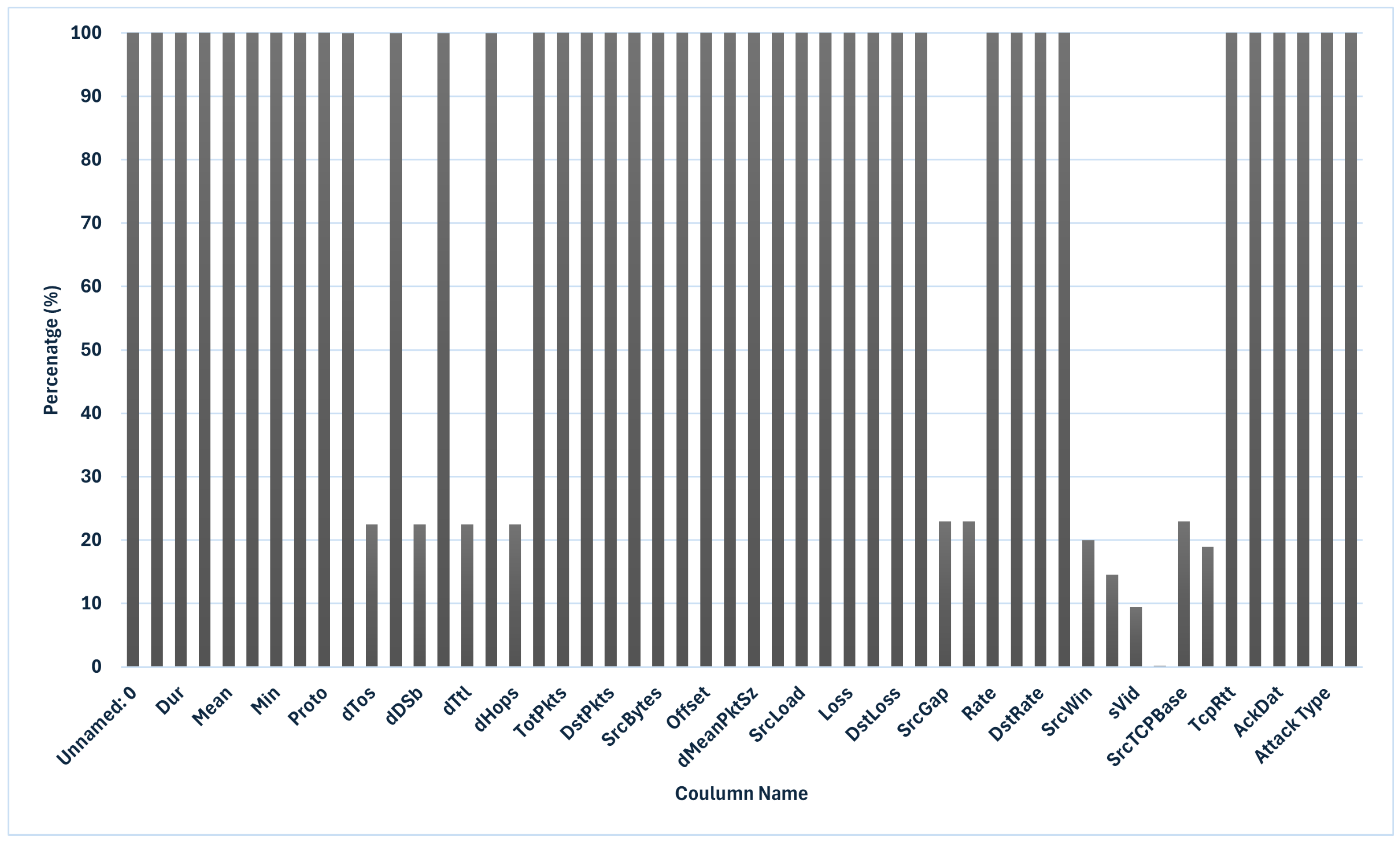
4.1. Data Collection and Preprocessing
| Algorithm 2: Interquartile range (IQR) procedure: |
# Define a function for IQR method def iqr_method(5G-NIDD dataset): begin # Compute the first quartile (Q1) Q1 = np.percentile(data, 25) # Compute the third quartile (Q3) Q3 = np.percentile(data, 75) # Compute the Interquartile Range (IQR) IQR = Q3 −~Q1 # Determine the outlier boundaries lower_bound = Q1 − 1.5 * IQR upper_bound = Q3 + 1.5 * IQR # Identify outliers outliers = [× for × in data if × < lower_bound or × > upper_bound] return outliers, lower_bound, upper_bound outliers, lower_bound, upper_bound = iqr_method(data) print(“Outliers:”, outliers) print(“Lower_Bound:”, lower_bound) print(“Upper_Bound:”, upper_bound) end |
4.2. Model #1: Convolutional-Based Neural Network for IDS
- Input layer: The model is initiated with an “inputs_cnn” layer designed to handle data with an input shape of (30, 1, 1), which matches the dimensions of the input data.
- Convolutional layers: CNN layers compute output feature maps by convolution where the kernel K is moved over the input . The output feature map is computed as follows:Three well-designed convolutional layers (Conv2D) were used, enhanced by batch normalization for stable training. The first layer applies 64 filters with a (6, 1) kernel, while the subsequent layers use 64 filters, each with a (3, 1) kernel. Max-pooling layers are thoughtfully inserted after each convolutional layer to downsample feature maps effectively.The region of the input that influences neurons in deeper layers is referred to as the receptive field, denoted by its size at layer l. The size is determined recursively bywhere is the kernel size at layer l and is the stride at layer i. The 3D tensor is produced when a convolutional layer employs many kernels to identify various features, resulting in a stack of feature maps. Each filter produces a corresponding feature map , resulting in a 3D output tensor of shape , where N is the number of filters. The output spatial dimensions are computed asThe input dimensions are H and W, the filter dimensions are h and w, the padding size is p, and the stride width is s. Convolutional layers are equivariant to translation, meaning that if the input is shifted, the output will move accordingly (i.e., ). To achieve translation invariance, where the output remains relatively unchanged under small shifts in the input (i.e., ), pooling layers such as max-pooling are often employed.
- Flattening and fully connected layers:The ReLU activation function is applied in two fully connected layers, with 64 and 32 units, respectively.After the convolutional and pooling operations, the output tensor has the following dimensions:where:
- -
- D is the number of feature maps.
- -
- is the height of each feature map.
- -
- is the width of each feature map.
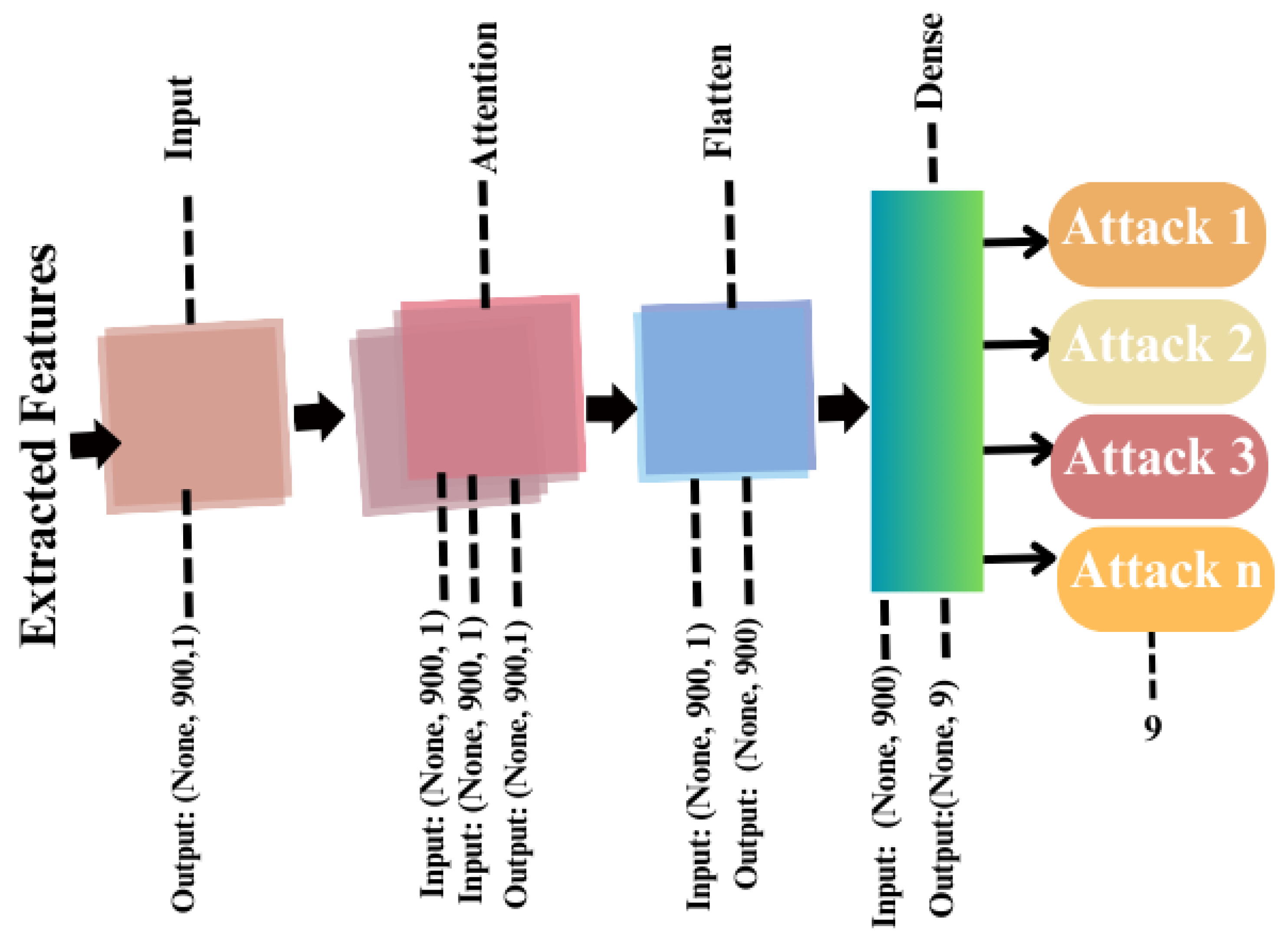
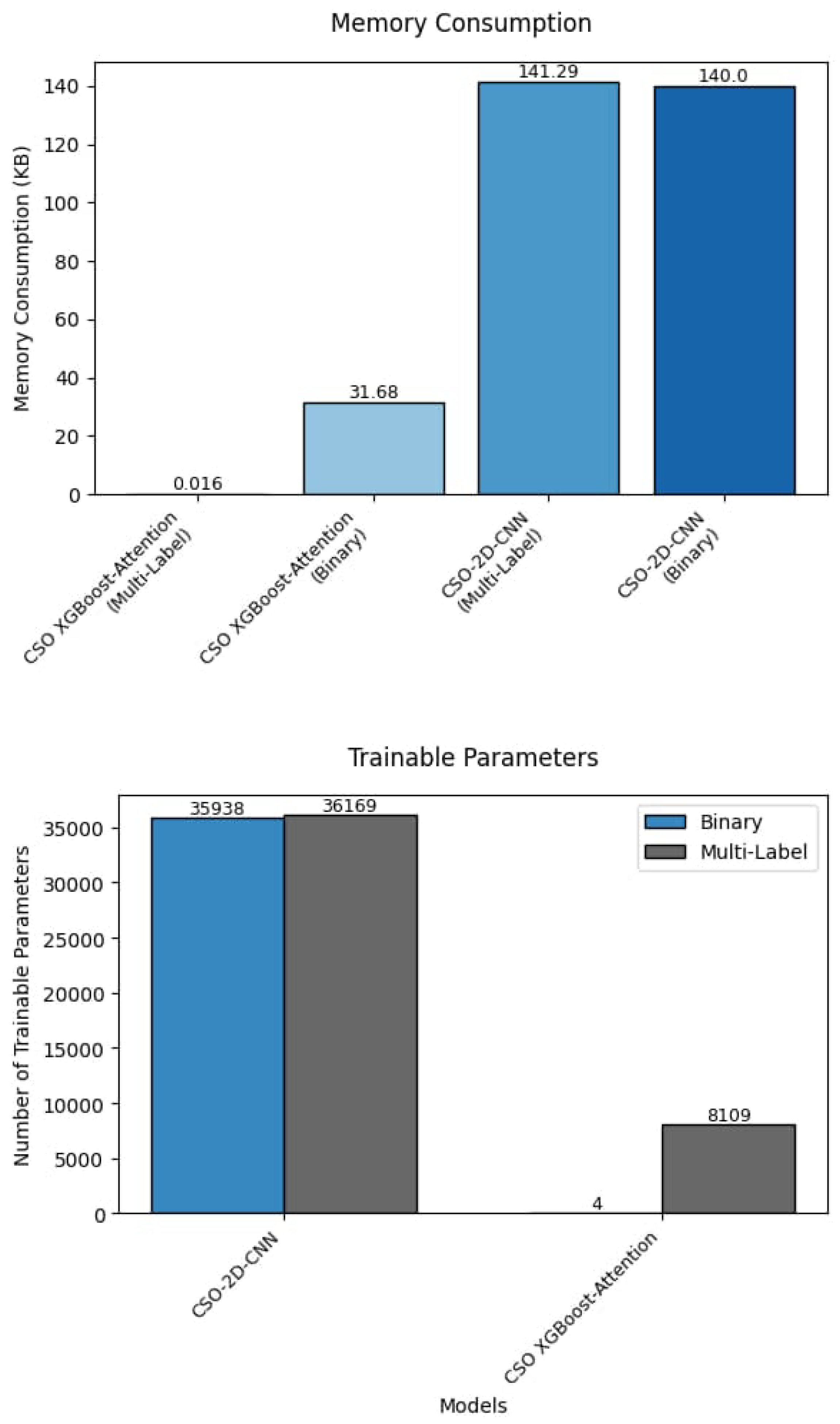
The 2D feature maps are then converted into 1D vectors by a flattening operation following the convolutional layers.The purpose of this transformation is to convert all the elements in the feature map into a single vector using a fully connected layer:The IDS’s performance is significantly influenced by the features chosen and designed. A thoughtful approach to feature development and feature selection is crucial to achieving the best results. To obtain high-quality information from X-rays and CT scans, a pretrained CNN model was used with a proposed 16-layer CNN architecture. Consequently, the eight convolution layers that comprise the basic CNN model are utilized to extract features. Following data preprocessing, the next crucial step is to train the model using state-of-the-art techniques. The objective of this study was to present a “single yet simple” model for multilabel attack types. As shown in Figure 5, the proposed CNN model is broken down into layers. The model was trained using just 16 batches of training and 100 epochs in total. The current technique was tested with several inputs, yielding encouraging results. The 2D-CNN architecture was trained on a total of 36,553 params (142.79 KB), 36,169 trainable parameters (141.29 KB), and 384 non-trainable parameters (1.50 KB).The expected architecture produced the expected outcomes for the provided collection of input features.A correlation analysis, denoted by C, is used to measure the linear relationship between two variables, as shown in Equation (14). By applying an identity matrix-based calculation, Equation (15) improves the evaluation of correlations and extracts their characteristics. The importance-weighted correlation coefficient is defined asA random integer between 0 and 1 is designated by in this case. - Output layer: To facilitate the multiclass classification task, a softmax activation function is used for the “main_output” layer as follows:This layer completes the model architecture by aligning nine units to the dataset’s classes.
- -
- is the ground truth label for class i.
- -
- is the predicted probability for class i.
4.3. Model #2: Attention-Based Neural Network for IDS
- Initialize the IDS model with a single decision tree.
- Calculate the regularization parameters and residuals using an appropriate loss function tailored for the first tree.
- Subsequent trees use the predictions from the previous tree as residual inputs.
- The similarity score is computed based on the Hessian (which corresponds to the number of residuals m), the squared gradient (which represents the squared sum of residuals), and the regularization hyperparameter .
- Nodes with higher similarity scores are identified as having greater homogeneity in their classification outcomes.
- Calculate the information gain by subtracting the combined similarities of the left and right child nodes from the similarity score of the root node.
- Estimate the residual values for the nodes in the decision tree.
- Sum the predicted values, adjust them using the learning rate, and incorporate these adjustments into the residuals to obtain new residuals.
- Repeat the process starting from step 3 for each tree in the ensemble.
| Algorithm 3: IDS with XGBoost and attention-based neural network. |
 |
| Algorithm 4: Cat Swarm Optimization-based model for IDS. |
 |
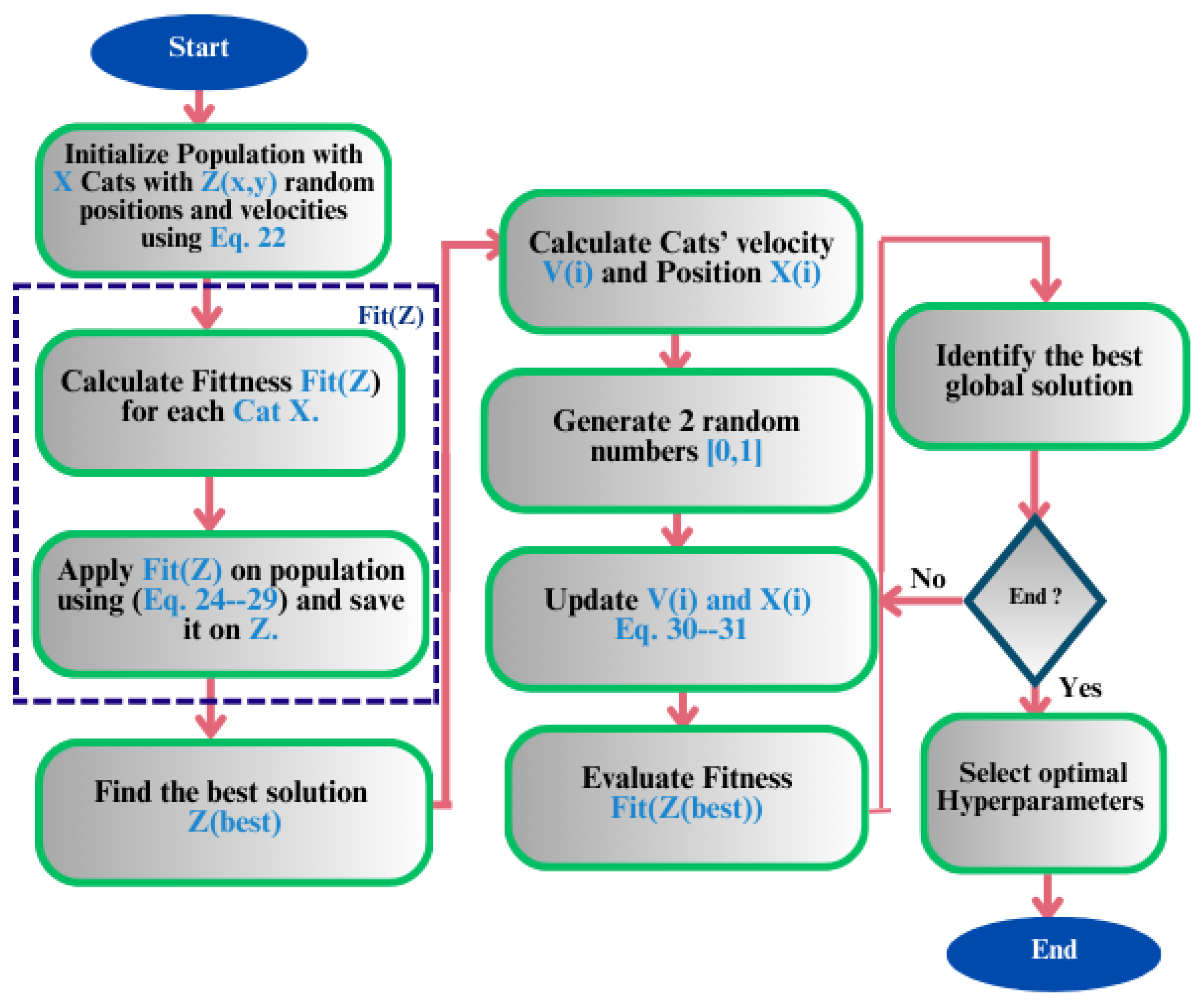
4.4. Hybridization with Cat Swarm Optimization (CSO)
- -
- MR evaluates the system’s past prediction accuracy through joining the seeking mode together with the tracing mode as follows:where represents the ground-truth (actual) value at time step t and is the predicted value at time step t.
- -
- Learning Decay () is defined as the average normalized prediction error which gradually reduces the learning rate (r) at time (t) by a decay factor.In this way, CSO refines the search space around promising cat locations, thereby promoting convergence and preventing irregular updates or instability.Lastly, CSO and Particle Swarm Optimization (PSO) have similar computational complexity, as both algorithms update positions and evaluate fitness for all agents in the population [57,58]. Consequently, the computational complexity of CSO per iteration is generally considered to be . Due to its linear scalability, CSO is well suited to respond effectively to imbalanced and evolving data in real-time applications with resource-constrained environments, such as intrusion detection systems in wireless sensor networks.
- learning_rate controls the rate at which the model updates its weights to minimize detection errors.
- max_depth sets the maximum depth of the decision trees, helping to capture complex attack patterns.
- Gamma determines the minimum gain needed to perform additional splitting of nodes in the tree, helping to avoid overfitting to noisy attack data.
- min_child_weight specifies the minimum number of data instances required in a node before further splitting, ensuring robust detection of low-frequency attacks.
- colsample_by_tree indicates the fraction of features to be used when constructing each tree, promoting diversity in the model’s detection strategies.
- subsample defines the proportion of the dataset used for training each tree, aiding in generalizing the model to unseen attacks.
- alpha represents the L1 regularization term to reduce model complexity and prevent overfitting to specific attack scenarios.
- eval_metric specifies the metric used to evaluate the model’s performance on validation data, ensuring accurate detection of attacks during training.
4.5. Performance Metrics
- = true positives (correctly identified attacks).
- = true negatives (correctly identified normal traffic).
- = false positives (normal traffic incorrectly identified as attacks).
- = false negatives (attacks incorrectly identified as normal traffic).
- Observed agreement (): Proportion of times the IDS agrees with the actual classifications.
- Expected agreement (): Proportion of times the IDS would be expected to agree with the actual classifications by chance.
5. Results Presentation and Analysis
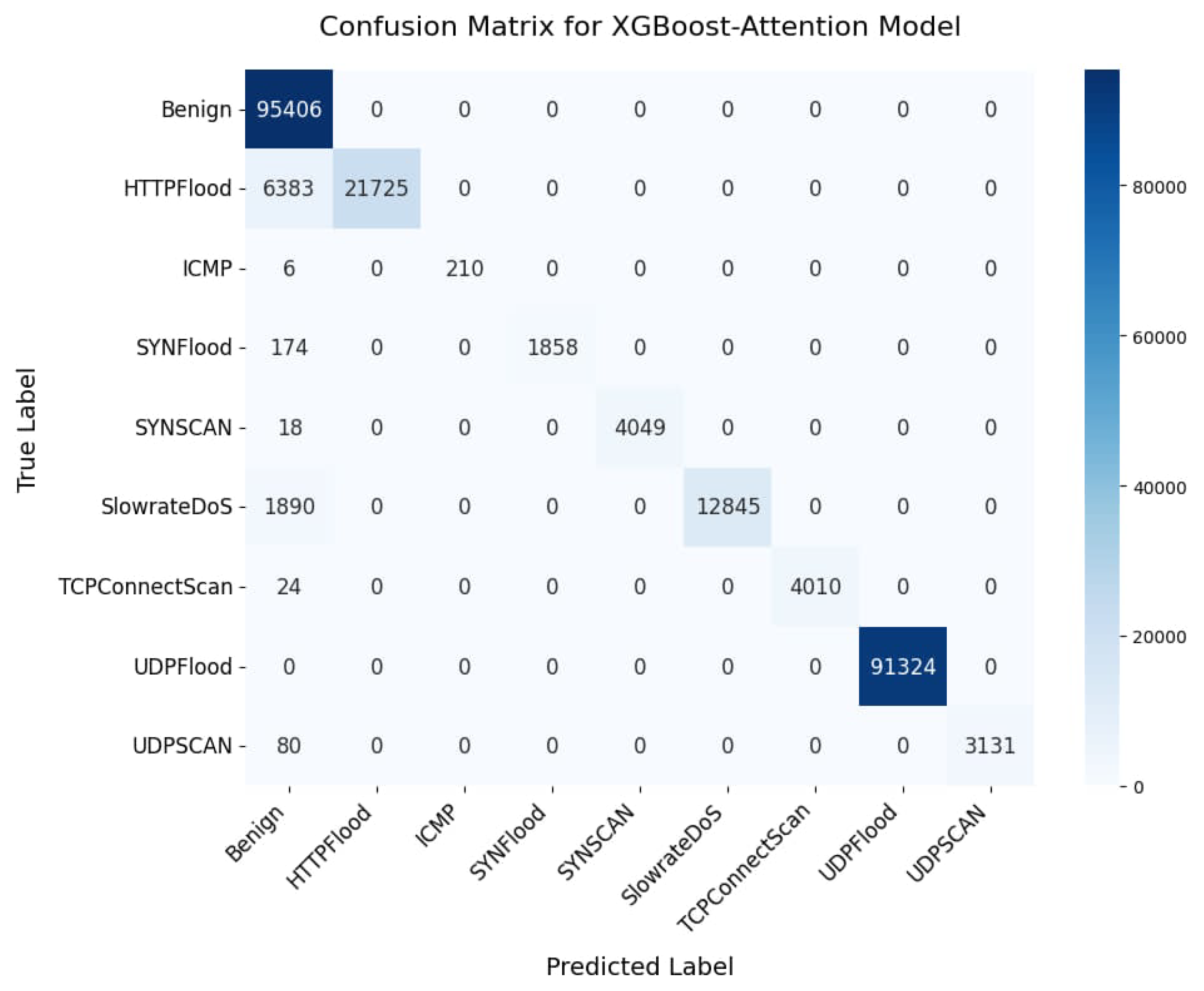
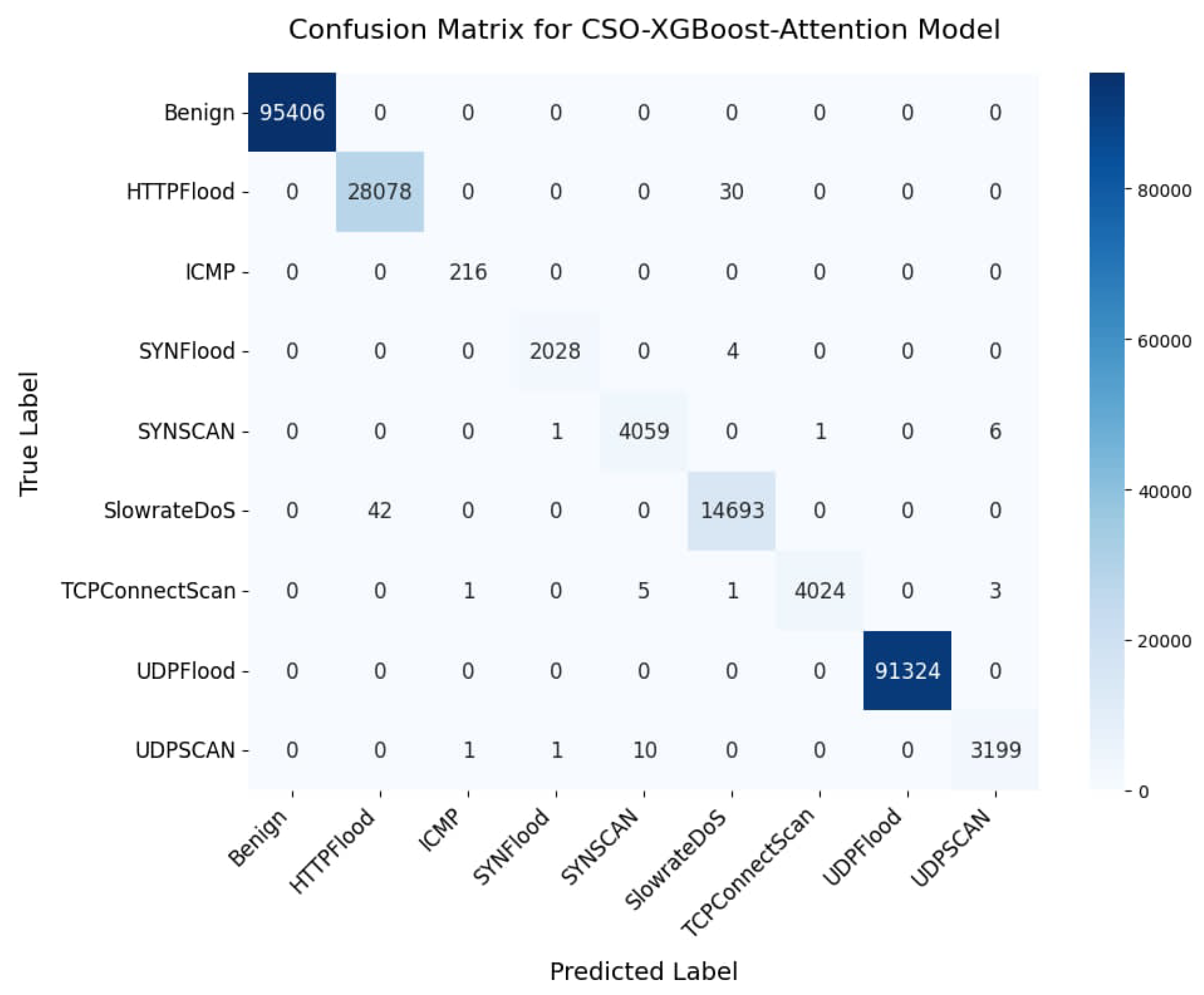
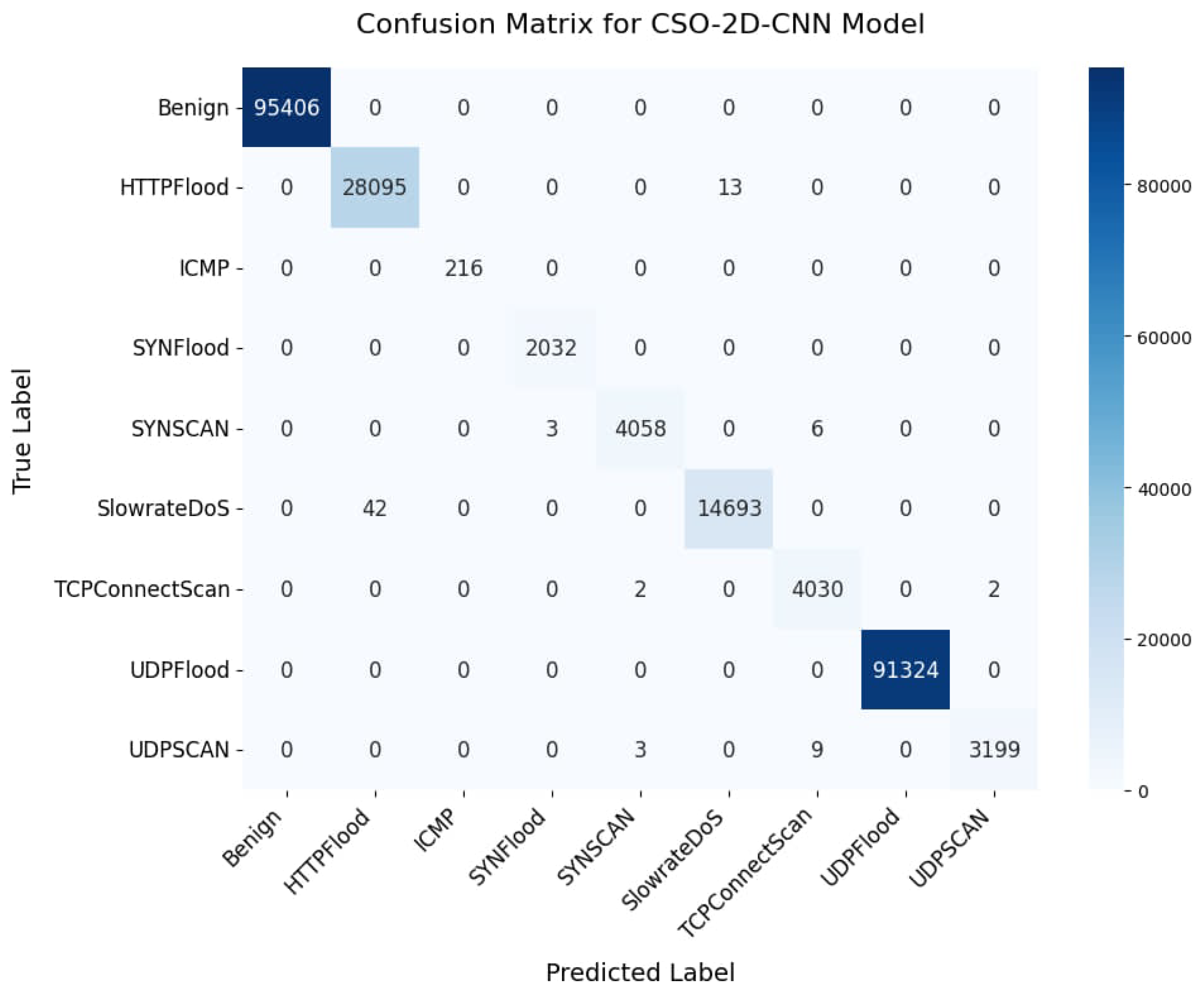
5.1. Multilabel Classification Performance
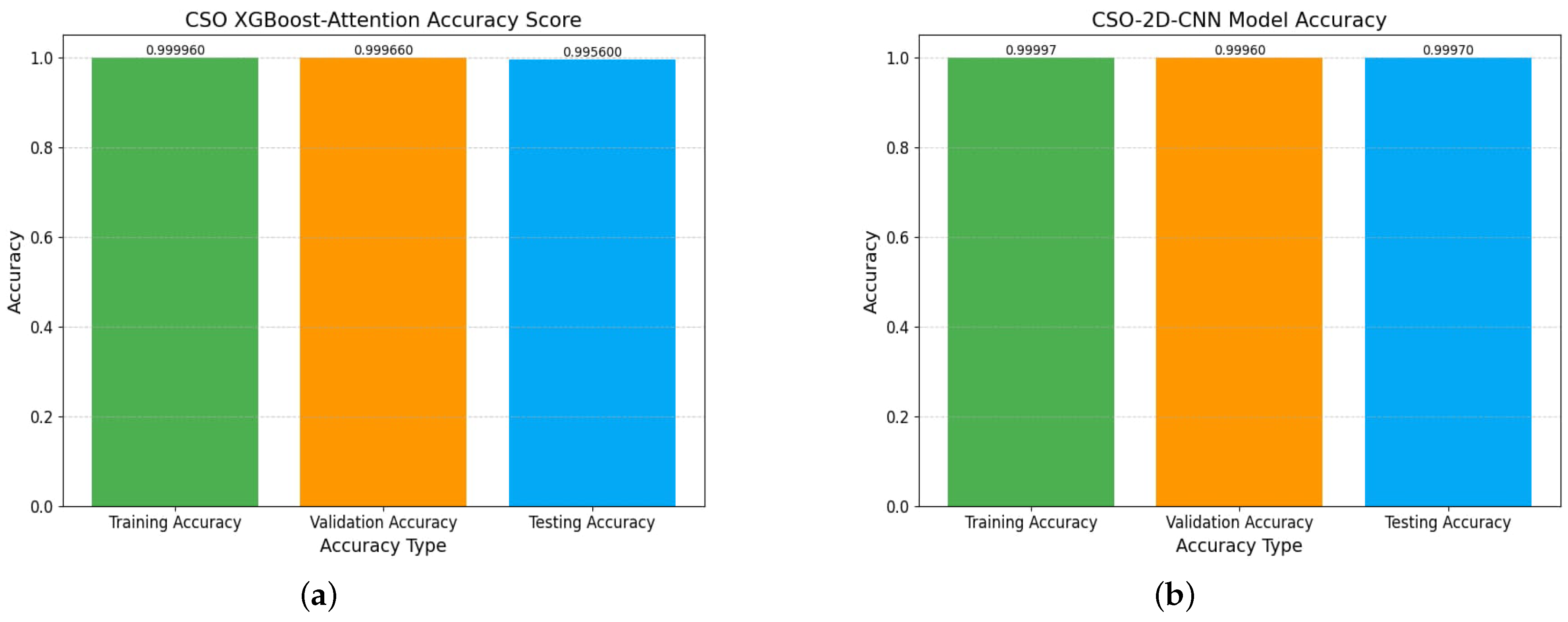
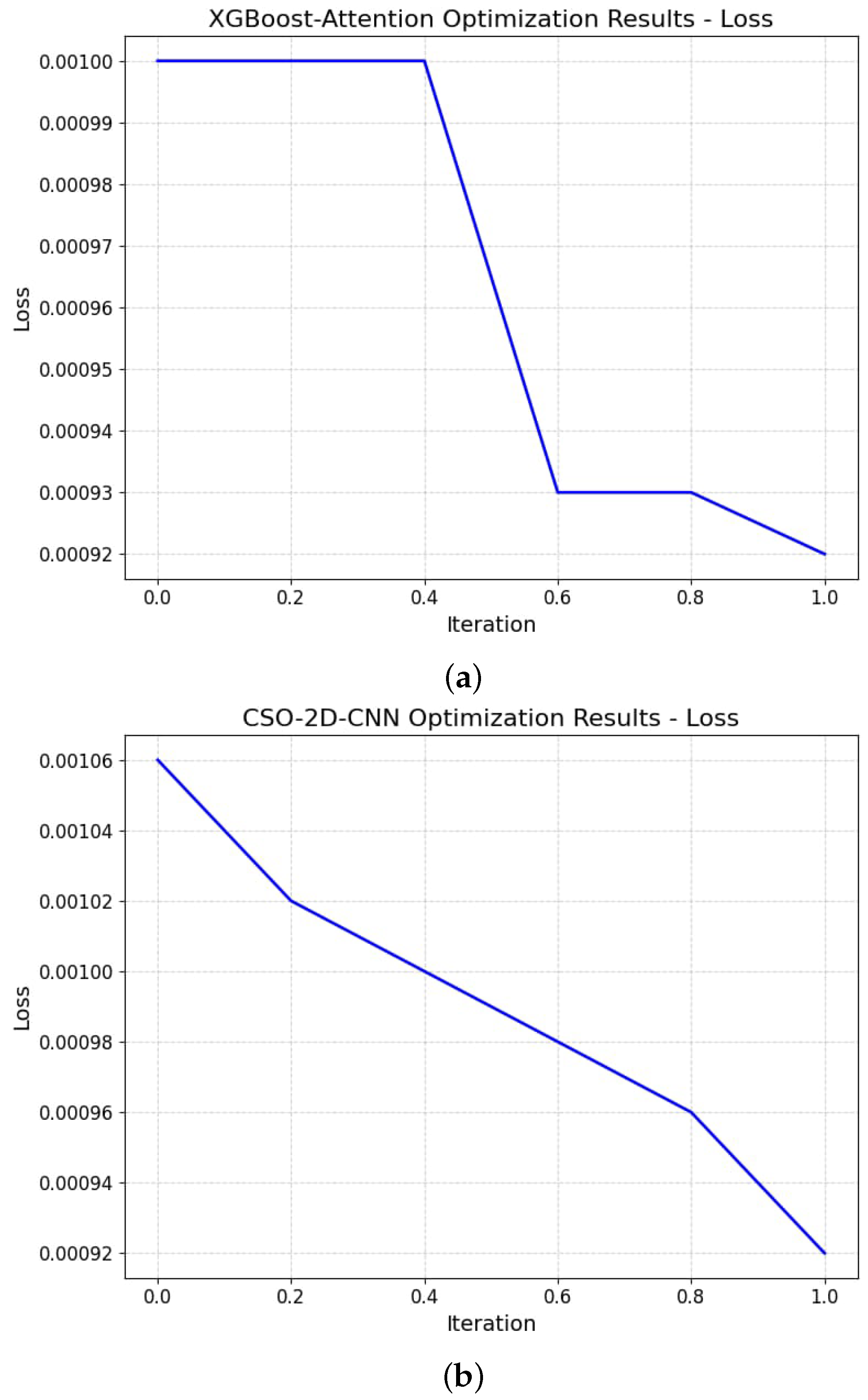
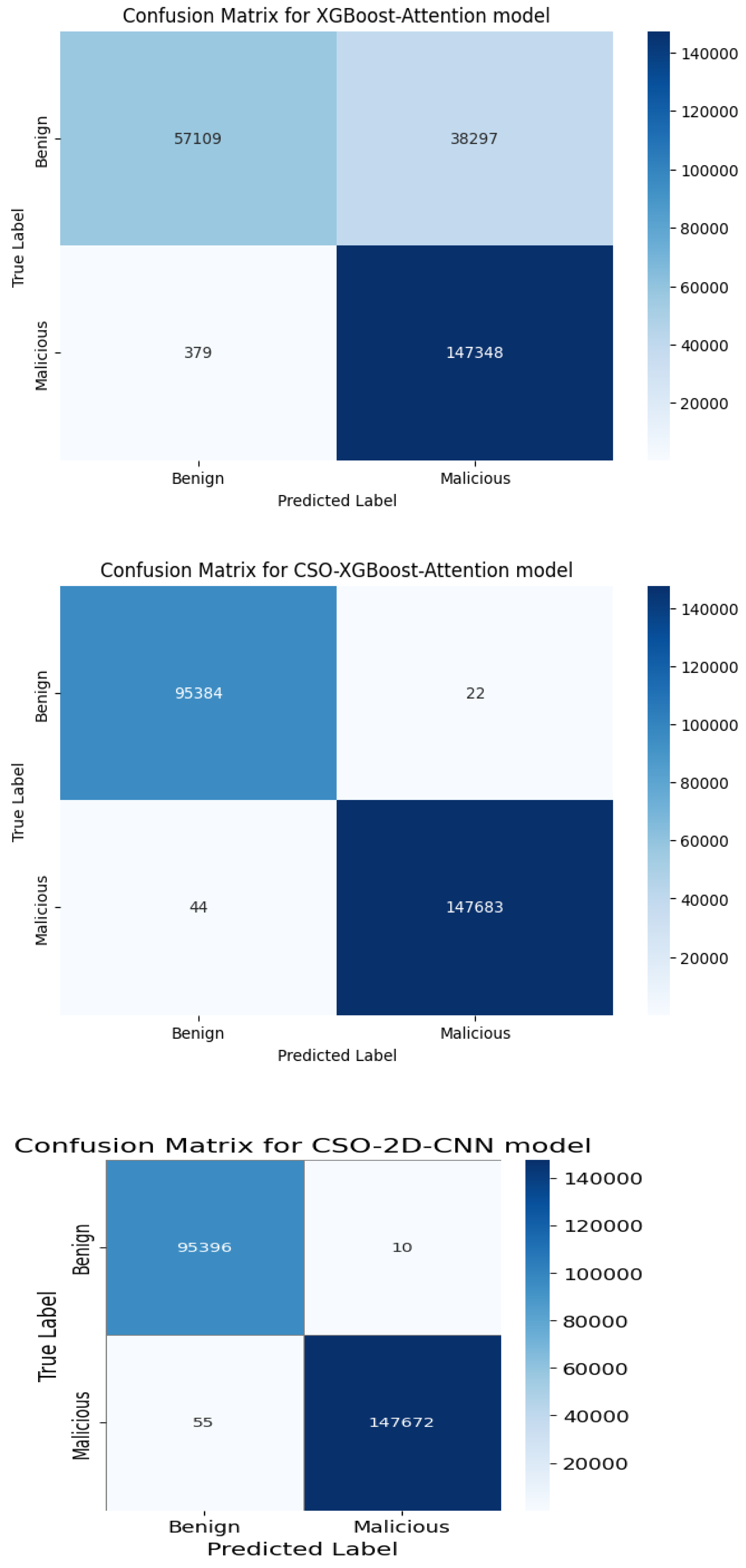
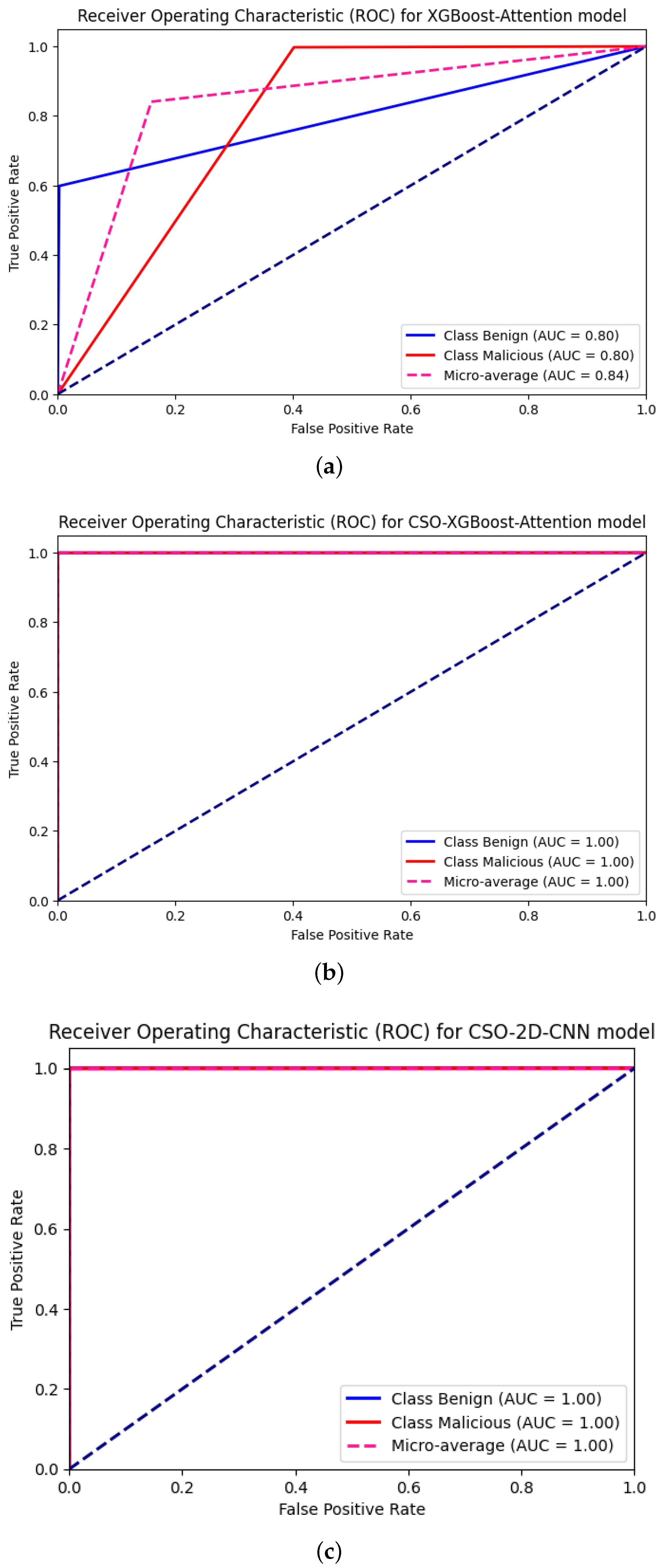
5.2. Binary Attacks Classification Performance
5.3. The Effect of Optimized Models on Trainable Parameters
5.4. Ablation Study
- W/o CSO: The XGBoost-Attention model is trained to incorporate CSO optimization.
- W/o CSE: Optimization is excluded from the XGBoost-Attention model.
- W/o WXG: The XGBoost model is trained without incorporating CSO optimization or attention applied.
- W/o CSNN: The 2D-CNN model is trained using CSO optimization.
- W/o CSNNE: The 2D-CNN model is trained without using CSO optimization.
- W/o Hybrid: A dynamic weight adjustment mechanism is used for combining the predictions of the CSO-2D-CNN and CSO-XGBoost-Attention models.
5.5. Comparison
6. Discussion
7. Conclusions
Funding
Data Availability Statement
Conflicts of Interest
References
- Chavhan, S. Shift to 6G: Exploration on trends, vision, requirements, technologies, research, and standardization efforts. Sustain. Energy Technol. Assess. 2022, 54, 102666. [Google Scholar]
- Salahdine, F.; Han, T.; Zhang, N. 5G, 6G, and Beyond: Recent advances and future challenges. Ann. Telecommun. 2023, 78, 525–549. [Google Scholar] [CrossRef]
- Zawish, M.; Dharejo, F.A.; Khowaja, S.A.; Raza, S.; Davy, S.; Dev, K.; Bellavista, P. AI and 6G into the metaverse: Fundamentals, challenges and future research trends. IEEE Open J. Commun. Soc. 2024, 5, 730–778. [Google Scholar] [CrossRef]
- Reshmi, T.; Abhishek, K. 5G and 6G Security Issues and Countermeasures. In Secure Communication in Internet of Things; CRC Press: Boca Raton, FL, USA, 2024; pp. 300–310. [Google Scholar]
- Siriwardhana, Y.; Porambage, P.; Liyanage, M.; Ylianttila, M. AI and 6G security: Opportunities and challenges. In Proceedings of the IEEE 2021 Joint European Conference on Networks and Communications & 6G Summit (EuCNC/6G Summit), Porto, Portugal, 8–11 June 2021; pp. 616–621. [Google Scholar]
- Jahankhani, H.; Kendzierskyj, S.; Hussien, O. Approaches and Methods for Regulation of Security Risks in 5G and 6G. In Wireless Networks: Cyber Security Threats and Countermeasures; Springer: Berlin/Heidelberg, Germany, 2023; pp. 43–70. [Google Scholar]
- Akshay Kumaar, M.; Samiayya, D.; Vincent, P.D.R.; Srinivasan, K.; Chang, C.Y.; Ganesh, H. A hybrid framework for intrusion detection in healthcare systems using deep learning. Front. Public Health 2022, 9, 824898. [Google Scholar] [CrossRef]
- Vu, L.; Nguyen, Q.U.; Nguyen, D.N.; Hoang, D.T.; Dutkiewicz, E. Deep generative learning models for cloud intrusion detection systems. IEEE Trans. Cybern. 2022, 53, 565–577. [Google Scholar] [CrossRef]
- Karthikeyan, M.; Manimegalai, D.; RajaGopal, K. Firefly algorithm based WSN-IoT security enhancement with machine learning for intrusion detection. Sci. Rep. 2024, 14, 231. [Google Scholar] [CrossRef]
- Krishnan, R.; Krishnan, R.S.; Robinson, Y.H.; Julie, E.G.; Long, H.V.; Sangeetha, A.; Subramanian, M.; Kumar, R. An intrusion detection and prevention protocol for internet of things based wireless sensor networks. Wirel. Pers. Commun. 2022, 124, 3461–3483. [Google Scholar] [CrossRef]
- Idris, S.; Ishaq, O.O.; Juliana, N.N. Intrusion Detection System Based on Support Vector Machine Optimised with Cat Swarm Optimization Algorithm. In Proceedings of the IEEE 2019 2nd International Conference of the IEEE Nigeria Computer Chapter (NigeriaComputConf), Zaria, Nigeria, 14–17 October 2019; pp. 1–8. [Google Scholar]
- Jovanovic, D.; Marjanovic, M.; Antonijevic, M.; Zivkovic, M.; Budimirovic, N.; Bacanin, N. Feature selection by improved sand cat swarm optimizer for intrusion detection. In Proceedings of the IEEE 2022 International Conference on Artificial Intelligence in Everything (AIE), Lefkosa, Cyprus, 2–4 August 2022; pp. 685–690. [Google Scholar]
- Chandol, M.K.; Rao, M.K. Border collie cat optimization for intrusion detection system in healthcare IoT network using deep recurrent neural network. Comput. J. 2022, 65, 3181–3198. [Google Scholar] [CrossRef]
- Khan, F.; Kanwal, S.; Alamri, S.; Mumtaz, B. Hyper-parameter optimization of classifiers, using an artificial immune network and its application to software bug prediction. IEEE Access 2020, 8, 20954–20964. [Google Scholar] [CrossRef]
- Wolpert, D.H.; Macready, W.G. No free lunch theorems for optimization. IEEE Trans. Evol. Comput. 1997, 1, 67–82. [Google Scholar] [CrossRef]
- Mustafa, Z.; Amin, R.; Aldabbas, H.; Ahmed, N. Intrusion detection systems for software-defined networks: A comprehensive study on machine learning-based techniques. Clust. Comput. 2024, 27, 9635–9661. [Google Scholar] [CrossRef]
- Rajesh, K.; Vetrivelan, P. Comprehensive analysis on 5G and 6G wireless network security and privacy. Telecommun. Syst. 2025, 88, 52. [Google Scholar] [CrossRef]
- Pradhan, A.; Singh, N.; Kumar, N.; Agarwal, T.; Rampal, S. Machine Learning Techniques for Intrusion Detection in Software-Defined Networks. In Proceedings of the IEEE 2025 International Conference on Automation and Computation (AUTOCOM), Dehradun, India, 4–6 March 2025; pp. 613–618. [Google Scholar]
- Negi, L.; Kumar, D. ECC based certificateless aggregate signature scheme for healthcare wireless sensor networks. J. Reliab. Intell. Environ. 2024, 10, 489–500. [Google Scholar] [CrossRef]
- Gurusamy, V.; Praveenkumar; Jebaraj, J.R.; Ranjithi, M.; Raphael, B.L. A lightweight multi-layer authentication protocol for wireless sensor networks in IoT applications. In AIP Conference Proceedings; AIP Publishing LLC: Melville, NY, USA, 2024; Volume 2966, p. 020003. [Google Scholar]
- Azam, Z.; Islam, M.M.; Huda, M.N. Comparative analysis of intrusion detection systems and machine learning based model analysis through decision tree. IEEE Access 2023, 11, 80348–80391. [Google Scholar] [CrossRef]
- Kavitha, S.; Uma Maheswari, N.; Venkatesh, R. Intelligent intrusion detection system using enhanced arithmetic optimization algorithm with deep learning model. Teh. Vjesn. 2023, 30, 1217–1224. [Google Scholar]
- Altamimi, S.; Abu Al-Haija, Q. Maximizing intrusion detection efficiency for IoT networks using extreme learning machine. Discov. Internet Things 2024, 4, 1–37. [Google Scholar] [CrossRef]
- Bostani, H.; Sheikhan, M. Hybrid of anomaly-based and specification-based IDS for Internet of Things using unsupervised OPF based on MapReduce approach. Comput. Commun. 2017, 98, 52–71. [Google Scholar] [CrossRef]
- Sajid, M.; Malik, K.R.; Almogren, A.; Malik, T.S.; Khan, A.H.; Tanveer, J.; Rehman, A.U. Enhancing intrusion detection: A hybrid machine and deep learning approach. J. Cloud Comput. 2024, 13, 123. [Google Scholar] [CrossRef]
- Nazir, A.; Khan, R.A. A novel combinatorial optimization based feature selection method for network intrusion detection. Comput. Secur. 2021, 102, 102164. [Google Scholar] [CrossRef]
- Awajan, A. A novel deep learning-based intrusion detection system for IOT networks. Computers 2023, 12, 34. [Google Scholar] [CrossRef]
- Azar, A.T.; Shehab, E.; Mattar, A.M.; Hameed, I.A.; Elsaid, S.A. Deep learning based hybrid intrusion detection systems to protect satellite networks. J. Netw. Syst. Manag. 2023, 31, 82. [Google Scholar] [CrossRef]
- Yadav, N.; Pande, S.; Khamparia, A.; Gupta, D. Intrusion detection system on IoT with 5G network using deep learning. Wirel. Commun. Mob. Comput. 2022, 2022, 9304689. [Google Scholar] [CrossRef]
- Benmessahel, I.; Xie, K.; Chellal, M. A new evolutionary neural networks based on intrusion detection systems using multiverse optimization. Appl. Intell. 2018, 48, 2315–2327. [Google Scholar] [CrossRef]
- Madhuridevi, L.; Sree Rathna Lakshmi, N. Metaheuristic assisted hybrid deep classifiers for intrusion detection: A bigdata perspective. Wirel. Netw. 2024, 31, 1205–1225. [Google Scholar] [CrossRef]
- Gupta, S.K.; Tripathi, M.; Grover, J. Hybrid optimization and deep learning based intrusion detection system. Comput. Electr. Eng. 2022, 100, 107876. [Google Scholar] [CrossRef]
- Alzubi, Q.M.; Anbar, M.; Sanjalawe, Y.; Al-Betar, M.A.; Abdullah, R. Intrusion detection system based on hybridizing a modified binary grey wolf optimization and particle swarm optimization. Expert Syst. Appl. 2022, 204, 117597. [Google Scholar] [CrossRef]
- Stiawan, D.; Heryanto, A.; Bardadi, A.; Rini, D.P.; Subroto, I.M.I.; Idris, M.Y.B.; Abdullah, A.H.; Kerim, B.; Budiarto, R. An approach for optimizing ensemble intrusion detection systems. IEEE Access 2020, 9, 6930–6947. [Google Scholar] [CrossRef]
- Injadat, M.; Moubayed, A.; Nassif, A.B.; Shami, A. Multi-stage optimized machine learning framework for network intrusion detection. IEEE Trans. Netw. Serv. Manag. 2020, 18, 1803–1816. [Google Scholar] [CrossRef]
- Kasongo, S.M. An advanced intrusion detection system for IIoT based on GA and tree based algorithms. IEEE Access 2021, 9, 113199–113212. [Google Scholar] [CrossRef]
- Alzaqebah, A.; Aljarah, I.; Al-Kadi, O.; Damaševičius, R. A modified grey wolf optimization algorithm for an intrusion detection system. Mathematics 2022, 10, 999. [Google Scholar] [CrossRef]
- Kunhare, N.; Tiwari, R.; Dhar, J. Intrusion detection system using hybrid classifiers with meta-heuristic algorithms for the optimization and feature selection by genetic algorithm. Comput. Electr. Eng. 2022, 103, 108383. [Google Scholar] [CrossRef]
- Eesa, A.S.; Orman, Z.; Brifcani, A.M.A. A novel feature-selection approach based on the cuttlefish optimization algorithm for intrusion detection systems. Expert Syst. Appl. 2015, 42, 2670–2679. [Google Scholar] [CrossRef]
- Wang, Z. Deep learning-based intrusion detection with adversaries. IEEE Access 2018, 6, 38367–38384. [Google Scholar] [CrossRef]
- Afzaliseresht, N.; Miao, Y.; Michalska, S.; Liu, Q.; Wang, H. From logs to stories: Human-centred data mining for cyber threat intelligence. IEEE Access 2020, 8, 19089–19099. [Google Scholar] [CrossRef]
- Jayalaxmi, P.; Saha, R.; Kumar, G.; Alazab, M.; Conti, M.; Cheng, X. Pignus: A deep learning model for ids in industrial Internet-of-things. Comput. Secur. 2023, 132, 103315. [Google Scholar] [CrossRef]
- Mezina, A.; Burget, R.; Travieso-González, C.M. Network anomaly detection with temporal convolutional network and U-Net model. IEEE Access 2021, 9, 143608–143622. [Google Scholar] [CrossRef]
- Wang, Z.; Chen, H.; Yang, S.; Luo, X.; Li, D.; Wang, J. A lightweight intrusion detection method for IoT based on deep learning and dynamic quantization. PeerJ Comput. Sci. 2023, 9, e1569. [Google Scholar] [CrossRef]
- Yang, K.; Wang, J.; Zhao, G.; Wang, X.; Cong, W.; Yuan, M.; Luo, J.; Dong, X.; Wang, J.; Tao, J. NIDS-CNNRF Integrating CNN and random forest for efficient network intrusion detection model. Internet Things 2025, 32, 101607. [Google Scholar] [CrossRef]
- Alqahtany, S.S.; Shaikh, A.; Alqazzaz, A. Enhanced Grey Wolf Optimization (EGWO) and random forest based mechanism for intrusion detection in IoT networks. Sci. Rep. 2025, 15, 1916. [Google Scholar] [CrossRef]
- Punitha, A.; Ramani, P.; Ezhilarasi, P.; Sridhar, S. Dynamically stabilized recurrent neural network optimized with intensified sand cat swarm optimization for intrusion detection in wireless sensor network. Comput. Secur. 2025, 148, 104094. [Google Scholar] [CrossRef]
- Aljabri, J. Attack resilient IoT security framework using multi head attention based representation learning with improved white shark optimization algorithm. Sci. Rep. 2025, 15, 14255. [Google Scholar] [CrossRef] [PubMed]
- Zivkovic, M.; Bacanin, N.; Arandjelovic, J.; Rakic, A.; Strumberger, I.; Venkatachalam, K.; Joseph, P.M. Novel harris hawks optimization and deep neural network approach for intrusion detection. In Proceedings of the International Joint Conference on Advances in Computational Intelligence: IJCACI 2021; Springer: Berlin/Heidelberg, Germany, 2022; pp. 239–250. [Google Scholar]
- Dakic, P.; Zivkovic, M.; Jovanovic, L.; Bacanin, N.; Antonijevic, M.; Kaljevic, J.; Simic, V. Intrusion detection using metaheuristic optimization within IoT/IIoT systems and software of autonomous vehicles. Sci. Rep. 2024, 14, 22884. [Google Scholar] [CrossRef] [PubMed]
- Chu, S.C.; Tsai, P.W.; Pan, J.S. Cat swarm optimization. In Proceedings of the PRICAI 2006: Trends in Artificial Intelligence: 9th Pacific Rim International Conference on Artificial Intelligence, Guilin, China, 7–11 August 2006; Proceedings 9. Springer: Berlin/Heidelberg, Germany, 2006; pp. 854–858. [Google Scholar]
- Samarakoon, S.; Siriwardhana, Y.; Porambage, P.; Liyanage, M.; Chang, S.Y.; Kim, J.; Kim, J.; Ylianttila, M. 5g-nidd: A comprehensive network intrusion detection dataset generated over 5g wireless network. arXiv 2022, arXiv:2212.01298. [Google Scholar]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd Acm Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Zhang, P.; Jia, Y.; Shang, Y. Research and application of XGBoost in imbalanced data. Int. J. Distrib. Sens. Netw. 2022, 18, 15501329221106935. [Google Scholar] [CrossRef]
- Samidi, F.S.; Mohamed Radzi, N.A.; Mohd Azmi, K.H.; Mohd Aripin, N.; Azhar, N.A. 5G technology: ML hyperparameter tuning analysis for subcarrier spacing prediction model. Appl. Sci. 2022, 12, 8271. [Google Scholar] [CrossRef]
- Aljebreen, M.; Alrayes, F.S.; Maray, M.; Aljameel, S.S.; Salama, A.S.; Motwakel, A. Modified Equilibrium Optimization Algorithm with Deep Learning-Based DDoS Attack Classification in 5G Networks. IEEE Access 2023, 11, 108561–108570. [Google Scholar] [CrossRef]
- Chu, S.C.; Tsai, P.W. Computational intelligence based on the behavior of cats. Int. J. Innov. Comput. Inf. Control 2007, 3, 163–173. [Google Scholar]
- Yang, X.S. Engineering Optimization: An Introduction with Metaheuristic Applications; John Wiley & Sons: Hoboken, NJ, USA, 2010. [Google Scholar]
- Bouke, M.A.; El Atigh, H.; Abdullah, A. Towards robust and efficient intrusion detection in IoMT: A deep learning approach addressing data leakage and enhancing model generalizability. Multimed. Tools Appl. 2024, 1–20. [Google Scholar] [CrossRef]
- Idrissi, I.; Boukabous, M.; Grari, M.; Azizi, M.; Moussaoui, O. An intrusion detection system using machine learning for internet of medical things. In Proceedings of the International Conference on Electronic Engineering and Renewable Energy Systems; Springer: Berlin/Heidelberg, Germany, 2022; pp. 641–649. [Google Scholar]
- Jadav, D.; Jadav, N.K.; Gupta, R.; Tanwar, S.; Alfarraj, O.; Tolba, A.; Raboaca, M.S.; Marina, V. A trustworthy healthcare management framework using amalgamation of AI and blockchain network. Mathematics 2023, 11, 637. [Google Scholar] [CrossRef]
- Hadi, H.J.; Cao, Y.; Li, S.; Xu, L.; Hu, Y.; Li, M. Real-time fusion multi-tier DNN-based collaborative IDPS with complementary features for secure UAV-enabled 6G networks. Expert Syst. Appl. 2024, 252, 124215. [Google Scholar] [CrossRef]
- Bouke, M.A.; Abdullah, A. An empirical assessment of ML models for 5G network intrusion detection: A data leakage-free approach. E-Prime Electr. Eng. Electron. Energy 2024, 8, 100590. [Google Scholar] [CrossRef]
- Dhanya, L.; Chitra, R. A novel autoencoder based feature independent GA optimised XGBoost classifier for IoMT malware detection. Expert Syst. Appl. 2024, 237, 121618. [Google Scholar] [CrossRef]
- Wang, Z.; Fok, K.W.; Thing, V.L. Exploring Emerging Trends in 5G Malicious Traffic Analysis and Incremental Learning Intrusion Detection Strategies. arXiv 2024, arXiv:2402.14353. [Google Scholar]
- Korba, A.A.; Boualouache, A.; Ghamri-Doudane, Y. Zero-X: A Blockchain-Enabled Open-Set Federated Learning Framework for Zero-Day Attack Detection in IoV. IEEE Trans. Veh. Technol. 2024, 73, 12399–12414. [Google Scholar]
- Farzaneh, B.; Shahriar, N.; Al Muktadir, A.H.; Towhid, M.S. DTL-IDS: Deep transfer learning-based intrusion detection system in 5G networks. In Proceedings of the IEEE 2023 19th International Conference on Network and Service Management (CNSM), Niagara Falls, ON, Canada, 30 October–2 November 2023; pp. 1–5. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Methodology | Advantages | Limitations |
|---|---|---|---|
| [42] | Cascade Forward Backpropagation NNs with Autoencoders for feature selection. |
|
|
| [19] | An aggregate signature scheme for healthcare wireless sensor networks. | A formal security study based upon a random Oracle model demonstrates the scheme’s resistance to forgery attacks. | These cryptography-based solutions are computationally intensive and challenging to implement on resource-constrained devices. |
| [20] | Lightweight multilayer token-based authentication for WBAN sensing. | The devised protocol ensures the security, confidentiality, and integrity of the WBAN data by utilizing secure authentication and creating group keys. | |
| [43] | A method based on the U-Net model and Temporal Convolution Networks. | In real-time detection applications, the approach maximizes model training efficiency while lowering computation overhead. | The convolutional layers and the rigid design of U-Net might not be as flexible in a dynamic environment, where new attack methods could emerge over time. |
| [44] | A hybrid approach combining PCA and DNNs with bidirectional LSTM networks. | An incremental PCA considerably enhances detection performance by reducing data dimensionality. | The network deep architecture may require substantial computing power when operating on devices that have limited capabilities. |
| [45] | A novel IDS that integrates a CNN for feature extraction, PCA to address feature redundancies, and RF for classifying traffic attacks. | Precise identification of various attacks. | PCA is based on linear subspaces, and it is difficult to represent the non-linear attack patterns that often occur in WSNs within a lower-dimensional linear subspace. |
| Ref. | Methodology | Advantages | Limitations |
|---|---|---|---|
| [46] | A hybrid approach that uses enhanced GWO for feature selection to eliminate redundant qualities. RF is used to assess the importance of features for IoT intrusion detection. | Combining multiple decision trees enables the model to achieve an accuracy of 98.95%. | In highly scalable environments, this method may lead to additional location reevaluations within the search space, increasing computational complexity. |
| [37] | an IDS using a modified GWO and ELM classification. | ELMs are known for their extremely fast training time, as they do not require iterative weight updates. | It cannot handle multiclass attacks with detection accuracy of 81%. |
| [47] | A dynamically stabilized RNN with enhanced SCSO and the WBOA to detect intrusions in wireless sensor networks. | A multiscale improved differential filter is used in the preprocessing step to eliminate biased and redundant records from incoming data. | Overhead problems and processing complexity are associated with deploying hybrid optimization for feature selection and hyperparameter optimization. |
| [48] | Bidirectional gated recurrent unit with multihead attention intrusion detection mechanism in IoT networks. The SCSO model is used for the feature selection. | The approach effectively ensures robust performance with an average accuracy of 98.28%. | The model was evaluated on a small dataset of only 30,000 records. A small sample size may not fully reflect the variability in more extensive, real-world situations, which could affect the model’s general performance. |
| [49] | An advanced HHO is combined with a DNN. | The approach reduces dimensionality and improves feature selection, yielding an accuracy rate of 99.5%. | Overhead problems and processing complexity are associated with deploying the HHO algorithm for DNN hyperparameter optimization. |
| [50] | A hybrid approach integrating XGBoost and KNN classifiers and a modified version of the PSO algorithm. | Improves the precision and effectiveness of attack detection systems and enhancement of the possibility of effective threat avoidance. | The top models achieved over 89% accuracy, demonstrating encouraging performance; however, the presence of misclassifications suggests that further refinement and validation are needed to enhance dependability in practical applications. |
| Gaps Found | Proposed Method Contributions |
|---|---|
Data with high dimensionality
|
|
Exploration and exploitation balance
|
|
Hyperparameter optimization
|
|
Deployment scalability challenges
|
|
| Measurement | Value |
|---|---|
| Dataset size | 14.4 MB |
| Number of normal samples | 477,737 (39.29%) |
| Number of attack samples | 738,153 (60.7%) |
| Total number of samples | 1,215,890 |
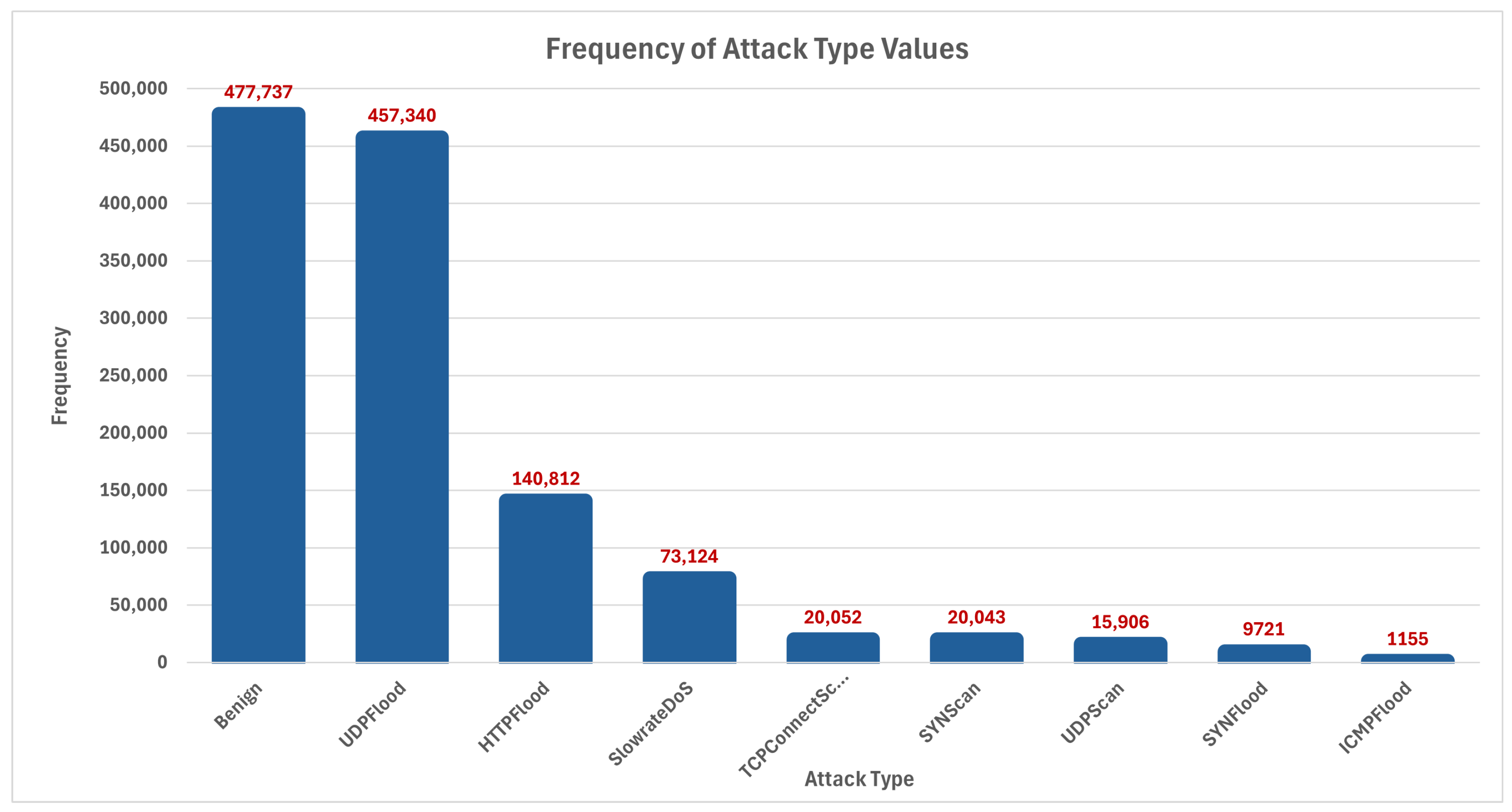
| Attack Name | DDoS Attack Definition |
|---|---|
| ICMP Flood | An incredible number of ICMP packets are sent to overwhelm the target’s network resources. |
| UDP Flood | A large number of UDP packets are sent to random ports on a victim’s network. |
| SYN Flood | Numerous SYN requests are sent to a target’s server without actually completing the handshake. |
| HTTP Flood | An excessive number of HTTP requests are sent to a web server, attempting to exhaust the server’s resources to prevent legitimate users from accessing it. |
| Slowrate DoS/DoS | An attack that sends incomplete HTTP requests slowly to a server, gradually draining server resources and resulting in a denial of service. |
| SYN Scan | A process of sending SYN packets to identify open ports on a target machine without completing the TCP handshake. |
| TCP Connect Scan | A Full Port Scan utilizes TCP handshakes to determine which ports are open, providing detailed information about the target’s available services. |
| UDP Scan | A scan for identifying open UDP services on a target machine that sends UDP packets to a variety of ports. |
| Feature | Mathematical Component | Role in IDS Context |
|---|---|---|
| Dual-Mode Search | Seeking: softmax over sampled positions.Tracing: directional vector to global best. | Strives to balance developing new attack patterns and refining existing ones. |
| Adaptability | Mixture ratio (MR), Learning Decay . | A flexible approach to adapting to changing cyber-threats and traffic patterns. |
| Efficiency | complexity for position updates and fitness evaluation. | It enables lightweight processing, making it suitable for real-time intrusion detection. |
| Metric | Definition | Formula |
|---|---|---|
| Accuracy | Proportion of correctly identified instances (attacks and normal traffic) among all evaluated cases. | |
| F1-score | Averages mean of precision and recall. | |
| Kappa (Cohen’s Kappa) | Measures agreement between predicted and actual classifications. | |
| Specificity | Proportion of normal traffic correctly identified by the IDS. | |
| Sensitivity | Proportion of actual attacks correctly identified by the IDS. | |
| Precision | Proportion of correctly identified attacks among all instances identified as attacks by the IDS. |
| Model | Accuracy | Kappa | Loss | F1-Score | Sensitivity | Specificity |
|---|---|---|---|---|---|---|
| CSO-2D-CNN | 99.97 | 99.9 | 0.00075 | 99.9 | 100 | 100 |
| XGBoost-Attention | 96.47 | 94.79 | 0.003 | 96.35 | 94 | 99 |
| CSO-XGBoost-Attention | 99.95 | 99.94 | 0.0008 | 99.96 | 100 | 100 |
| CSO-XGBoost-Attention Model | CSO-2D-CNN Model | |||||||
|---|---|---|---|---|---|---|---|---|
| Class | Precision | Recall | F1-Score | Support | Precision | Recall | F1-Score | Support |
| Benign | 1.00 | 1.00 | 1.00 | 95,406 | 1.00 | 1.00 | 1.00 | 95,406 |
| HTTPFlood | 1.00 | 1.00 | 1.00 | 28,108 | 1.00 | 1.00 | 1.00 | 28,108 |
| ICMPFlood | 0.99 | 1.00 | 1.00 | 216 | 1.00 | 1.00 | 1.00 | 216 |
| SYNFlood | 1.00 | 1.00 | 1.00 | 2032 | 1.00 | 1.00 | 1.00 | 2032 |
| SYNSCan | 1.00 | 1.00 | 1.00 | 4067 | 1.00 | 1.00 | 1.00 | 4067 |
| SlowrateDoS | 1.00 | 1.00 | 1.00 | 14,735 | 1.00 | 1.00 | 1.00 | 14,735 |
| TCPConnectScan | 1.00 | 1.00 | 1.00 | 4034 | 1.00 | 1.00 | 1.00 | 4034 |
| UDPFlood | 1.00 | 1.00 | 1.00 | 91,324 | 1.00 | 1.00 | 1.00 | 91,324 |
| UDPScan | 1.00 | 1.00 | 1.00 | 3211 | 1.00 | 1.00 | 1.00 | 3211 |
| Accuracy | 1.00 | 243,133 | 1.00 | 243,133 | ||||
| Macro Avg | 1.00 | 1.00 | 1.00 | 243,133 | 1.00 | 1.00 | 1.00 | 243,133 |
| Weighted Avg | 1.00 | 1.00 | 1.00 | 243,133 | 1.00 | 1.00 | 1.00 | 243,133 |
| Model | Accuracy | Kappa | Loss | F1-Score | Sensitivity | Specificity |
|---|---|---|---|---|---|---|
| CSO-2D-CNN | 99.99 | 99.94 | 0.000633 | 99.97 | 99.97 | 99.96 |
| XGBoost-Attention | 84.09 | 64.11 | 0.475 | 83.02 | 80 | 80 |
| CSO-XGBoost-Attention | 99.97 | 99.94 | 0.00013 | 99.97 | 99.97 | 99.97 |
| CSO-XGBoost-Attention Model | CSO-2D-CNN Model | |||||||
|---|---|---|---|---|---|---|---|---|
| Precision | Recall | F1-Score | Support | Precision | Recall | F1-Score | Support | |
| Benign | 1.00 | 1.00 | 1.00 | 95,406 | 1.00 | 1.00 | 1.00 | 95,406 |
| Malicious | 1.00 | 1.00 | 1.00 | 147,727 | 1.00 | 1.00 | 1.00 | 147,727 |
| Accuracy | 1.00 | 243,133 | 1.00 | 243,133 | ||||
| Macro avg | 1.00 | 1.00 | 1.00 | 243,133 | 1.00 | 1.00 | 1.00 | 243,133 |
| Weighted avg | 1.00 | 1.00 | 1.00 | 243,133 | 1.00 | 1.00 | 1.00 | 243,133 |
| Parameters | Name | Value | Parameters | Name | Range | Value |
|---|---|---|---|---|---|---|
| CSO-2D-CNN Architecture | XGBoost-Attention Architecture | |||||
| h1 | Epoch | 10 | h12 | colsample_bytree | [0.5, 1] | 0.5 |
| h2 | Activation Fun | Relu | h13 | Min weight_Child | [1, 30] | 1 |
| h3 | Batch Size | 16 | h14 | No. Of estimators | [1, 1000] | 100 |
| h4 | Test Batch Size | 16 | h15 | # of Classes | [2, 9] | [2, 9] |
| h5 | Channels | 3 | h16 | Max_tree | [1, 15] | 6 |
| h6 | # of Classes | [2, 9] | h17 | Learning Rate | [0.001, 1] | 0.1 |
| h7 | Dropout Rate | 0.5 | h18 | Optimization | CSO | |
| h8 | Learning Rate | 0.01 | h19 | subsample | [0.5, 1] | 0.976 |
| h9 | Optimization | CSO | h20 | gamma | [0, 1] | 0.0623 |
| h10 | Weight Decay | 0.0001 | h21 | Max number_of_Leaf nodes | 40 | |
| h11 | Layers | 11 | h22 | eval_metric | “logloss” | |
| Model | Binary Classification (s) | Multiclass Classification (s) |
|---|---|---|
| CSO-2D-CNN | 180 | 300 |
| XGBoost-Attention | 60 | 90 |
| CSO-XGBoost-Attention | 120 | 240 |
| Model | Binary Classification (s) | Multiclass Classification (s) |
|---|---|---|
| CSO-2D-CNN | 0.002 | 0.06 |
| XGBoost-Attention | 0.01 | 0.222 |
| CSO-XGBoost-Attention | 0.0001 | 0.008 |
| Model | Accuracy | Sensitivity | Specificity | F1-Score | Kappa |
|---|---|---|---|---|---|
| W/o CSO | 99.95 | 100.0 | 100.0 | 99.96 | 99.9 |
| W/o CSE | 96.47 | 94.0 | 99.0 | 96.35 | 94.79 |
| W/o WXG | 97.0 | 97.0 | 97.0 | 97.0 | 96.2 |
| W/o CSNN | 99.97 | 100 | 100 | 99.9 | 99.9 |
| W/o CSNNE | 97.36 | 97.62 | 98.57 | 97.50 | 97.71 |
| W/o Fusion | 98.5 | 98.4 | 98.35 | 98.38 | 98.3 |
| Study | Methodology | Target Traffic | Dataset | Acc | P | S | F1 | K |
|---|---|---|---|---|---|---|---|---|
| Bouke [59] | Sequential-based DL | Legitimate vs. malicious | WUSTL EHMS2020 | 99% | 99% | 99% | 99% | - |
| Idris [60] | GBM (XGBoost, LightGBM, CatBoost) | Legitimate vs. malicious | WUSTL EHMS2020 | 99.28% | 99.46% | 94.79% | 97.07% | - |
| Jadav [61] | LSTM | Legitimate vs. malicious | WUSTL EHMS2020 | 93% | 88% | 100% | 93% | - |
| Hadi [62] | Fusion of multitier (CNN, GAN, MLP) | Legitimate vs. malicious | 5D-NIDD | 99.15% | - | - | - | - |
| Bouke [63] | K-Nearest Neighbors | Legitimate vs. malicious | 5G-NIDD | 99.6% | 99.7% | 99.3% | 99.5% | - |
| Hadi [62] | CNN | Legitimate vs. malicious | 5D-NIDD | 87.71% | - | - | - | - |
| Bouke [63] | Neural networks | Legitimate vs. malicious | 5G-NIDD | 98% | 99.8% | 95% | 97.4 | - |
| Dhanya [64] | Stacked autoencoder with GA-optimized XGBoost classifier | Legitimate vs. malicious | WUSTL EHMS2020 | 98.98% | 93.02% | 98.97% | 95.91% | 95.33% |
| Wang [65] | Incremental learning algorithms using SVM, logistic regression, and perceptron | Legitimate vs. malicious | 5D-NIDD | 99.10% | 99.54% | 99.42% | 99.48% | - |
| Dhanya [64] | Stacked autoencoder with GA-optimized XGBoost classifier | Legitimate vs. malicious | Malware PE headers-Clamp | 98.69% | 99.79% | 98.48% | 99.13% | 96.37% |
| Korba [66] | DNN with Open-Set Recognition | Multilabel | 5D-NIDD | 92.27 | 95.51 | - | 94.26 | - |
| Farzaneh [67] | BiLSTM and CNN | Multilabel | 5G-NIDD | 93.36% | 94.56% | 92.18% | 93.34% | - |
| Optimized 2D-CNN | Legitimate vs. malicious | 99.99% | 99.97% | 99.97% | 99.97% | 99.9% | ||
| Our study | Optimized XGBoost | Legitimate vs. malicious | 5D-NIDD | 99.97% | 99.97% | 99.97% | 99.97% | 99.94% |
| Optimized 2D-CNN | Multilabel | 99.97% | 100% | 100% | 99.9% | 99.9% | ||
| Optimized XGBoost | Multilabel | 99.95% | 100% | 100% | 99.96% | 99.94% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ismail, W.N. A Novel Metaheuristic-Based Methodology for Attack Detection in Wireless Communication Networks. Mathematics 2025, 13, 1736. https://doi.org/10.3390/math13111736
Ismail WN. A Novel Metaheuristic-Based Methodology for Attack Detection in Wireless Communication Networks. Mathematics. 2025; 13(11):1736. https://doi.org/10.3390/math13111736
Chicago/Turabian StyleIsmail, Walaa N. 2025. "A Novel Metaheuristic-Based Methodology for Attack Detection in Wireless Communication Networks" Mathematics 13, no. 11: 1736. https://doi.org/10.3390/math13111736
APA StyleIsmail, W. N. (2025). A Novel Metaheuristic-Based Methodology for Attack Detection in Wireless Communication Networks. Mathematics, 13(11), 1736. https://doi.org/10.3390/math13111736