1. Introduction
The scenarios of rumor detection research mainly focus on social media platforms. In the early days, the primary form of social media platforms was forums. A post on a forum primarily comprises an original message posted by the poster and reply messages. The reply and original messages were presented in the same format, taking up much space. A long post could often reach the length of dozens of web pages. With the development of the information age, Weibo gradually replaced forums as the mainstream application for information exchange. A Weibo post mainly consists of text within a limited number of characters and images or videos. The comment and forward chains can be easily traced. It has become more convenient for people to browse posts and the comments and opinions of others. There is no need to jump between web pages repeatedly, and previous records can be viewed without returning to a specific page.
The research on the content features of rumor detection mainly focuses on the following two modalities: text and image. A specific scenario (as shown in
Figure 1) is selected for analysis. The content features of the text are divided into two aspects. One is the semantic features of text entities. For example, in the text of User 1, the entities “Mary” and “cat” represent roles, the entity “supermarket” represents a location, and “fly away” represents an event. The other is the logical features of the text. From the perspective of a single text, it is the concatenation relationship between entities. “Mary’s cat flew away near the supermarket” represents the logical relationship of a role having an event occur at a specific place. At the same time, the logical features of the text also include the correctness of the relationship between entities. According to the statement of User 1 and combined with the actual situation, a “cat” cannot act “flying away”. In the process of feature extraction by the model, this is manifested as the distance between entities in the dictionary. The closer the distance, the stronger the correlation. Through a comprehensive analysis combined with tweet comments, the text of User 2 mentions a new entity “dog”, which has a logical conflict with the statement of User 1, that is, the logical features of the text context. Finally, by combining the two modalities of text and image, the entity in the text of User 1 is a “cat”, but in the image, it is a small dog. The inconsistency between the text and the image is a logical feature between the text and the image.
Currently, in the research on rumor detection based on content features, the methods with the core of mining multimodal features mainly involve extracting the content features of texts and images. After fusing these two multimodal features, the fused features are input into a classifier for classification prediction. Such algorithms have learned the common content features of texts and images in social posts and achieved a high accuracy rate. However, the following two aspects can be improved: Firstly, the perspective of learning the content features of texts and images is rather singular. Usually, it only focuses on one aspect, either the basic semantic features or the logical features, for feature learning. There is still room for improvement in comprehensively learning the content features. Secondly, existing studies mainly adopt fusion methods such as attention mechanisms for multimodal feature fusion. At the same time, there is relatively little research on reducing the differences between the features of different modalities before the fusion process.
Aiming at the above two problems, this paper proposes a rumor detection algorithm based on double-chain multimodal feature learning (DMFL). This algorithm adopts the method of double-chain learning to learn the basic semantic features and logical connection features of multimodalities in parallel. In the essential semantic feature learning chain, modal alignment is carried out for the text and image modal features, enabling the model to learn the mutual representation information between different modalities and reducing the differences between the features of different modalities. In the logical feature learning chain, by injecting image features into the multi-head attention layer of the text logical feature encoder, the text logical features fused with the logical features of text and images can be obtained. The fused multimodal content features are obtained by fusing the basic semantic features and logical features through cross-modal attention. Finally, these features are input into a classifier for classification prediction to determine the label of the input post, whether it is a rumor or not.
The research contributions made in this paper can be summarized as follows:
A method of double-chain multimodal feature learning is proposed. The learning processes of semantic and logical features are separated and carried out in parallel, paying more comprehensive attention to various existing logical features, namely, the logical features of text entities and the logical features between texts and images. Finally, more comprehensive and in-depth content features are obtained through the double-chain learning method for rumor detection.
Modal alignment operations are performed on the semantic features of the two modalities of text and image before fusion, narrowing the differences between features of different modalities and improving the effect of multimodal fusion. Feature extraction plays a role in feature enhancement, making the ultimately obtained multimodal semantic features more conducive to rumor detection.
Empirical evaluations on two public real-world datasets (Pheme and Weibo) reveal that the DMFL model achieves statistically significant improvements in accuracy, surpassing state-of-the-art baselines by 1.65% and 3.89%, respectively, underscoring its efficacy in multimodal rumor detection. The model’s robustness and generalizability are further validated through comprehensive ablation studies, parameter sensitivity analysis, and cross-modal correlation assessments.
2. Related Work
Early rumor detection research [
1,
2] introduced recurrent neural networks to learn hidden representations from the textual content of relevant articles, setting a precedent for deep learning to extract rumor text features automatically. Ref. [
3] used convolutional neural networks to obtain key and hidden semantic features from text content. However, these studies only used the full text as input, losing the original structure of the article. Therefore, ref. [
4] adopts the hierarchical structure of “word-sentence-article” to understand the text, and it extracts the word and sentence levels as features to understand the text. Refs. [
5,
6] proposed learning word-level and sentence-level representations of declarative texts and news articles as text features. However, the above studies only considered the text modality and ignored visual features.
In general, rumors carry multimodal information, such as images and videos. Many studies have combined visual features with features for rumor detection. Early research in [
7] first attempted to manually extract information, such as the propagation time of false images on Twitter, and proposed a classification model to identify false images on Twitter. In recent years, most studies have directly utilized deep learning pre-trained models to extract high-dimensional representations of images from visual information (e.g., images and videos) for computation. For example, Ref. [
8] extracts fake news, rumors, and tweet image information by a pre-trained convolutional neural network (CNN) to mine deep visual features and extract high-dimensional representations of the visual information as combined text and other modal features. There is also research on converting images to matrices using image embedding methods. Ref. [
9] embeds visual information into a matrix via image2sentence [
10] and then extracts visual features using TextCNN. It computes the similarity between different modal data and increases the sensory field compared to models pre-trained using convolutional neural networks such as VGG [
11]. In another study, Wang [
12] et al. consider the introduction of a knowledge graph and propose the KMGCN model to model the global structure between text, images, and knowledge concepts to obtain a comprehensive semantic representation.
The above research on rumor detection based on multimodal data enhances rumor feature representation for classification detection by investigating the multimodal representation of rumor features. However, there is still a lack of in-depth research on multi-level multimodal data features and multimodal fusion.
3. Problem Definition
This section will introduce the basic scenarios and important definitions studied in this chapter. In a multimodal social platform, an event is a collection of multimedia posts containing text and images on social media. For an event S containing n posts, it can be expressed as . For each post , where , represent the text and image of the post, and represents the user who posted the post. represents the set of forwarded comments on post , where each forwarded comment is posted by the corresponding user . is the set of labels for n posts. This paper defines rumor detection as a binary classification task, that is, represents the classification label, where indicates non-rumor and indicates that the post is a rumor.
This paper aims to predict the label of a given post by learning the function to determine whether the post is a rumor.
For each post
, where
represents the forwarding relationship of post
.
, where
refers to the number of posts in the forwarding relationship
,
is the source post, each
represents the
j-th comment forwarding the source post, and
refers to the propagation structure. Specifically,
is defined as a graph
,
is the root node, where
is a node set containing source post nodes, comment nodes, and forwarding nodes.
represents the edge set between posts. If
is a forwarded or commented post of
, there is a directed edge
, i.e.,
. If
forwards or comments
, there is a directed edge
, i.e.,
.
represents the adjacency matrix, where
In addition,
Table 1 summarizes the symbols used in this chapter and their descriptions.
4. Model Design and Description
4.1. Algorithm Model Framework
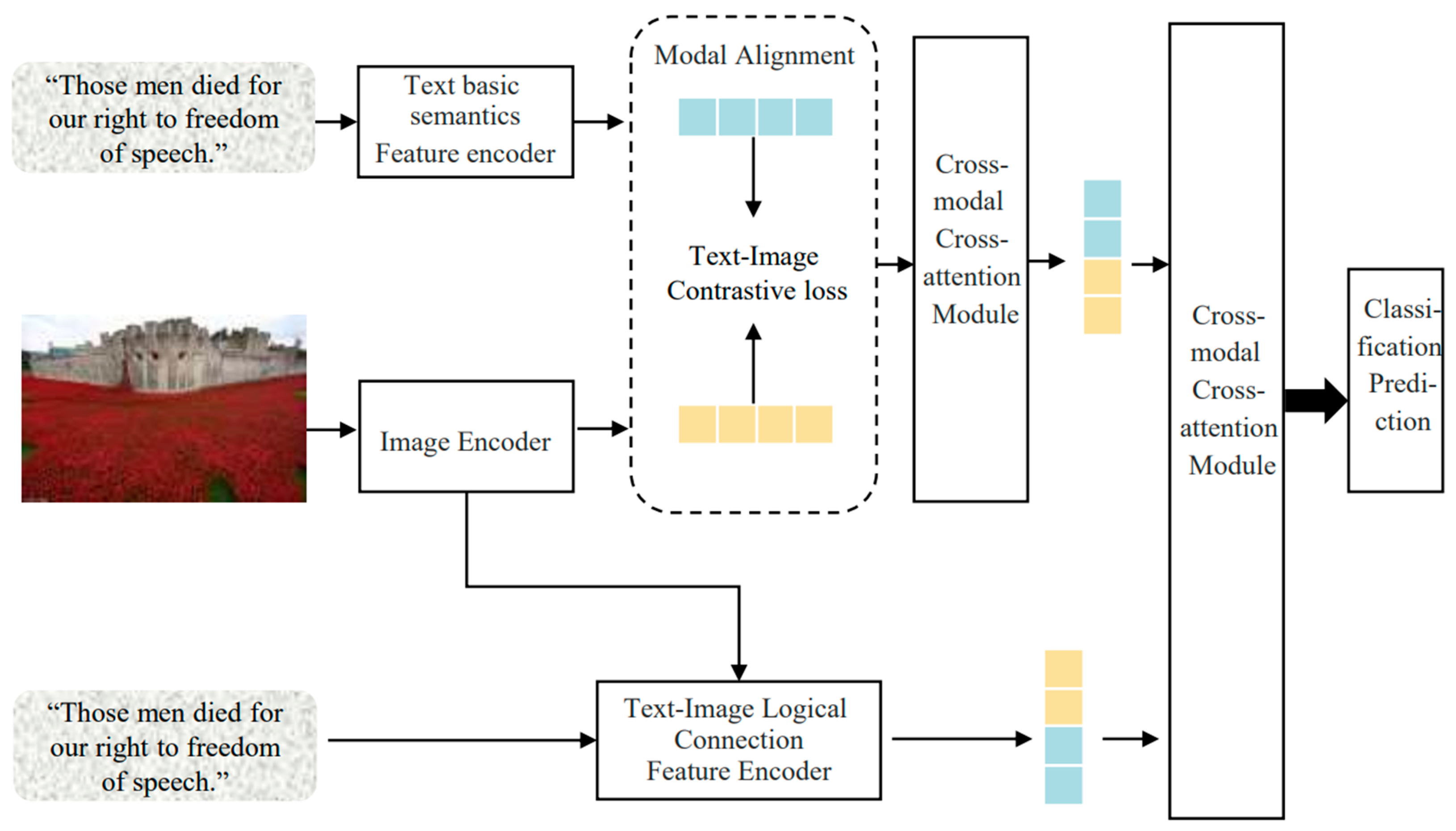
The rumor detection algorithm model based on the double-chain multimodal feature learning proposed in this paper is divided into four modules as follows: the basic semantic feature extraction module, the logical connection feature extraction module, the text–image modality alignment module, and the classification prediction module. The algorithm framework is shown in
Figure 2.
First, the essential semantic feature extraction module extracts the basic semantic features of the text from the semantic content of the text words. The text–image multimodal basic semantic features are obtained after passing through the cross-attention mechanism with the extracted image content features. At the same time, the logical connection feature extraction module inputs the image features through the cross-attention mechanism inside the text encoder to obtain the representation of the text–image multimodal logical connection features. Then, the modal alignment is carried out for the text and image features to reduce the differences in features of different modalities, and the multimodal features in the unified representation space are obtained. Finally, in the classification prediction module, the fused multimodal features are obtained through the fusion of the cross-modal cross-attention layer, which is finally used for classification prediction to obtain labels.
4.2. Text Basic Semantic Feature Encoder
The input natural language must first be processed into a vector form to enable computers to understand and process natural language. The model’s basic semantic feature extraction module in this paper uses Word2vec, which leverages neural networks to learn and generate word vectors. It simplifies text content into vectors in the vector space. It expresses the similarity of text content by calculating the cosine similarity in the vector space, converting natural language words in the input text into low-dimensional dense vectors. In this process, words with similar meanings will be mapped to similar positions in the vector space. The CBOW model and Skip–Gram are two essential models of Word2vec. This paper uses the Skip–Gram model based on the hierarchical Softmax framework, which utilizes a binary tree with words as leaves to calculate the probability of each word.
Each word can be reached from the root node through several random node paths. Therefore, the probability of calculating the output word vector
based on the input word vector
is calculated as follows:
where
is an indicator function. If the value of
x is true,
is 1; otherwise, it is −1. After obtaining the embedded word vector of the text, CNN and pooling focus on the local word vector to extract the semantic features of the input text. First, for each post
, we pad or truncate its embedding vector
so that all input text vectors have the same length, that is, the length is
L, expressed as follows:
Among them,
, where
d is the dimension of the word embedding, and
represents the
j-th word embedding of
.
Then, the obtained word embedding matrix
is input into the convolutional layer to obtain the feature map
. By setting the receptive field size as
k, the feature matrix
can be expressed as Formula (
4), as follows:
We perform the max-pooling operation on the feature matrix, as shown in Equation (
5), to obtain
. Next, this paper uses
filters with different receptive fields where
to obtain semantic features at different granularities. Finally, the outputs of all filters are concatenated to form the overall text basic semantic features of
as follows:
4.3. Image Encoder
At the same time, the Vision Transformer (ViT) is used to process the input image and extract the features of the image content. The module structure is shown in
Figure 3:
The standard Transformer takes a one-dimensional embedding sequence with position encoding as input. To process two-dimensional images, this module reshapes the image
into a sequence of flattened two-dimensional patches
, where
is the resolution of the original image,
C is the number of channels,
is the resolution of each image patch, and
is the number of generated image patches, which also serves as the effective input sequence length of the Transformer. The Transformer uses a fixed latent vector size
D in all its layers. Therefore, the image patches are flattened and mapped to the
D dimension using a trainable linear projection. Like the learnable position encoding used in the BERT model, this paper’s image feature extraction module adds a learnable embedding in front of the sequence of embedded patches. A standard learnable one-dimensional position embedding is used to retain the position information, and the position embedding is added to the image patch embedding. The obtained sequence of embedding vectors is used as the input of the encoder to obtain the projected output patch embedding, and the expression is as follows:
Among them,
,
is the added position information embedding, which is used to provide position information, and
is the class token embedding associated with the
i-th element.
The Transformer encoder consists of alternating layers of multi-head self-attention (MSA) and an MLP module that contains two layers with GELU nonlinearities. Layer normalization (LN) is applied before each module, and residual connections are used after each module. The process by which the encoder outputs the image feature representation
is as follows:
4.4. Cross-Modal Cross Attention
The model in this paper uses a cross-modal cross-attention mechanism to capture the mutual information between different modalities and learn the attention weights between features of different modalities to enhance cross-modal features. The essence of the cross-modal cross-attention mechanism is similar to that of the multi-head attention mechanism. Its core idea is to divide the hidden state vector into multiple independent heads, each responsible for processing a subset of the vector dimensions, thus forming multiple sub-semantic spaces. Specifically, each head independently performs a linear transformation on the input to generate a new set of vector representations. These heads work in subspaces independently, enabling each head to focus on capturing different features and patterns in the input data.
That is, each head is an independent attention mechanism that can focus on the information of different parts in the input sequence. For example, if the input vector is in the text modality, one head focuses on the relationship between nouns and verbs in a sentence. In contrast, another head focuses on the tense and mood of the sentence. Multiple heads can cover a broader range of semantic information through such division of labor and cooperation.
This multi-head attention design enables the model to analyze the input data from multiple perspectives. Each head extracts features in its unique sub-semantic space. By concatenating or combining these features, the model can obtain a more comprehensive and rich representation. In this way, the model can capture the input data’s local features and understand the global context and complex semantic relationships, thus achieving multimodal fusion and obtaining fused multimodal features.
Multi-head self-attention is first used for each modality to enhance the intra-modal feature representation. For the basic text semantic feature
, we use
,
and
to calculate its query matrix, key matrix, and value matrix. Among them,
are linear transformations, and
H is the number of heads. Then, a weighted operation is performed on the results of each head to obtain the multi-head self-attention features of the basic text semantic modality. The calculation formula is as follows:
Among them,
h represents the
h-th head, and
is the output linear transformation. We perform the same operation on the image feature
derived above to obtain the image modality’s multi-head self-attention feature
.
Then, an enhanced multimodal feature is generated through the cross-attention mechanism. To obtain the text–image multimodal basic semantic features of the post
, we perform an operation similar to the self-attention procedure described above, but we replace
with
to obtain the query matrix
, and we replace
with
to receive the key matrix
and the value matrix
. Finally, a weighted operation is carried out to obtain the text–image multimodal essential semantic feature
, and the calculation formula is as follows:
Among them,
is the output linear transformation.
4.5. Extraction of Text–Image Multimodal Logical Connection Features
The characteristics of rumor content include semantic features and require learning of logical features. In the text–image multimodal environment, there are logical relationships between words within the text and logical errors such as self-contradictions and mismatches between text and images. Moreover, extracting the logical features of rumor content from previous studies is considered a single perspective. It did not profoundly explore the logical features within and between the text and the image. This paper designs a text–image multimodal logical connection feature extraction module to deeply learn the text–image logical connections and extract multimodal logical features. Visual information is injected by inserting an additional cross-attention (CA) layer between the bidirectional self-attention (Bi-SA) layer and the feed-forward network (FFN) layer of the text logical feature encoder. Finally, the output features are used as the multimodal representation of the text–image logical connection features. The specific structure is shown in
Figure 4.
Different from the way of processing text embeddings in the previous section, to learn the contextual relationships of the text, a unique classification token, denoted as
, is inserted at the beginning of the text word vector sequence. The aggregated sequence of the final hidden states of this token will be used as the representation for the final classification task. Meanwhile, a unique token, denoted as
, is inserted into the text vector sequence to separate the specific post text. A learned embedding is added to each token to indicate its specific attribution. Suppose the text input embedding is denoted as
. In that case, the final hidden vector of the classification token
is represented as
, and the final hidden vector of the
i-th input token is
. Therefore, the calculation process of the text–image multimodal logical connection features is as follows:
4.6. Modality Alignment
In multimodal research, data from different modalities usually have different data distributions and feature representation methods, which makes it difficult for models to model and fuse multimodal data directly. To address this issue, this paper maps data from different modalities into a unified representation space through modality alignment, enabling the model to perform unified modeling and analysis. At the same time, this method can also help eliminate the feature differences between different modalities, allowing the model to pay more attention to the semantic similarities and correlations between modalities. By combining the results of modality alignment, the model can better integrate information from different modalities, thereby improving the generalization ability and performance of the model.
In this paper, modality alignment is carried out by forcing the enhanced text features of the post to align with its enhanced image features to enhance the representations learned in each modality and learn the inherent correlations between different modalities. For post
, its enhanced text features
and enhanced image feature
are transformed into the same modal feature space, that is,
Among them,
and
are learnable parameters. Then, the Mean Squared Error (MSE) loss is used to reduce the distance between
and
, shown in Equation (
17), as follows:
Among them,
n is the total number of posts. By calculating the loss, the text–image basic semantic multimodal features
and the logical connection multimodal features
are obtained, and these are used for fusion and classification operations.
4.7. Classification Prediction Module
By fusing the above text–image multimodal features, the essential semantic multimodal feature
and the logical connection multimodal feature
are input into the cross-modal cross-attention mechanism to obtain the following two cross-modal enhanced fusion features:
and
. Then, a weighted operation is performed on them to obtain the final fused multimodal feature for classification prediction as follows:
Finally, the final multimodal feature
of the post
is input into the fully connected layer to predict the label of
and determine whether it is a rumor.
Among them,
represents the probability that the post
is a rumor. The cross-entropy loss function is used to optimize the classification task, and the calculation process is as follows:
We assign custom weights, respectively, to the loss
of the modality alignment task, and we then add them together. The calculation formula of the final loss function is as follows:
Among them, the parameters
and
are the weight values of the classification task and the modality alignment task, respectively, which are used to balance the two losses.
6. Analysis of Experimental Results
6.1. Performance Comparison and Analysis of DMFL
The comparison experimental results between the rumor detection algorithm based on dual-chain multimodal feature learning (DMFL) proposed in this paper and the baseline models on two public datasets are shown in
Table 2 and
Table 3 and
Figure 5. In the tables, the sub-optimal results among the baseline models are underlined, and the best results among all the models are marked in bold.
The results of the comparative experiments can prove that the DMFL model performs excellently in the rumor detection task. Specifically, in terms of accuracy, compared with the best performance of the baseline model, the MFAN model that fuses text semantics and image features, the DMFL model shows improvements of 1.65% and 3.89 respectively, on the Pheme and Weibo datasets. This experimental result verifies the research findings of this paper, that is, paying attention to the internal logical connections of rumor content and extracting multi-level rumor content features are conducive to improving the effectiveness of the rumor detection task.
In addition, by comparing the experimental results of the CARMN and SAFE models on the two datasets, it can be found that on the Pheme dataset, the accuracy of the CARMN model, which extracts multi-level text feature representations, is lower than that of the SAFE model, which focuses on the connection between text and visual features. However, the situation is the opposite on the Weibo dataset. This is because the text length of the Weibo dataset is much longer than that of the Pheme dataset. For the Pheme dataset with short texts, the SAFE model that focuses on the connection between text and images performs better. For the Weibo dataset with long texts, studying the text’s multi-level content features significantly improves the accuracy of rumor detection.
In conclusion, the DMFL’s dual-chain learning fuses the multi-level text features, the text–image logical connection multimodal features that connect text and images, and the text–image basic semantic multimodal features for rumor detection, and it performs better on both datasets.
6.2. Performance Analysis of the Feature Extraction Module of DMFL
To evaluate the role and influence of each principal component on the DMFL model, this paper designs seven variants of DMFL for ablation experiments. By controlling variables, one important module is removed at a time from the complete DMFL model for experiments, and the contribution of this module to the model performance is analyzed through the results. The seven designed variant models are as follows:
DMFL-TB: The text–image basic semantic feature extraction module is removed, and rumor detection is performed only by extracting text–image logical connection multimodal features. The design of this variant aims to discuss the influence of text–image basic semantic features on the model performance.
DMFL-TL: The text–image logical connection feature extraction module is removed, and rumor detection is performed only through text–image basic semantic multimodal features. The design of this variant aims to discuss the influence of text–image logical connection features on model performance.
DMFL-A: The modality alignment module is removed. The basic semantic features of the text and image modalities are directly fused to obtain a multimodal semantic feature vector, and the rest of the model operations remain unchanged for rumor detection. The design of this variant aims to discuss the influence of the modality alignment module on the model performance.
DMFL-ATT: For multimodal basic semantic features and multimodal logical features, instead of using cross-modal cross-attention for multimodal fusion, a weighted sum is directly performed to obtain fused multimodal features for rumor detection. The design of this variant aims to discuss the influence of using the cross-modal cross-attention mechanism for multimodal fusion on the model performance.
DMFL-TCNN: Only the basic semantic features of the text modality are used for rumor detection. The design of this variant aims to discuss the influence of the basic semantic features of the single text modality on the rumor detection results.
DMFL-TTRAS: Only the logical features of the text modality are used for rumor detection. The design of this variant aims to discuss the influence of the logical features of the single text modality on the rumor detection results.
DMFL-I: Only the image modality features are used for rumor detection. The design of this variant aims to discuss the influence of the single image modality features on the rumor detection results.
Table 4 and
Figure 6 show the performance comparison between the seven variants of DMFL and the original DMFL on the Pheme and Weibo datasets. The experiments prove that the accuracy and F1-score values of the DMFL algorithm model are higher than those of all DMFL variants. The four main modules of DMFL, namely, the multimodal semantic feature extraction module, the multimodal logical feature extraction module, the modality alignment module, and the cross-modal cross-attention mechanism, are all reasonable and effective and positively impact the model performance.
By comparing DMFL-TB and DMFL-TL, the influence on multimodal semantic features and multimodal logical features is analyzed. From the experimental results, it can be seen that on the Pheme dataset, the overall experimental results of DMFL-TB have the most significant decline, which indicates that for the Pheme dataset mainly composed of short texts, the essential semantic features of text and images play a more critical role in the rumor detection task. On the Weibo dataset, the accuracy of DMFL-TL drops the most, which shows that for the Weibo dataset with long texts, paying attention to the multi-level content features within the text and the text–image logical connection features that focus on the connection between text and images contributes more significantly to the rumor detection task. In addition, it can be found from the experimental results that the variation ranges of DMFL-TB and DMFL-A are almost the same, which is in line with the principle that modality alignment operates based on the basic semantic features of text and images.
To explore the influence of the modality alignment and cross-modal cross-attention mechanism acting on multimodal fusion, the experimental results of DMFL-A and DMFL-ATT are compared and analyzed. The experimental results show that on the Pheme dataset, the accuracy of DMFL-A drops by 2.71%, and the accuracy of DMFL-ATT drops by 1.19%, while on the Weibo dataset, the accuracies of both DMFL-A and DMFL-ATT drop by about 1.6%. The decreased accuracy in the experimental results indicates that the modality alignment and cross-modal cross-attention mechanism are effective for multimodal fusion. At the same time, the variant with the modality alignment removed has a more significant decline on the Pheme dataset than the variant with the cross-modal cross-attention removed, while the variation ranges are almost the same on the Weibo dataset. This shows that the differences between text semantic and image features in the Pheme dataset are more significant. A better multimodal fusion effect can be obtained after the modality alignment reduces the differences between the two modalities.
Three variants using a single modality for rumor detection, namely, DMFL-TCNN, DMFL-TTRAS, and DMFL-I, are set up to analyze the performance of text semantic features, text logical features, and image features. According to the experimental results, compared with the complete DMFL model, the accuracies of DMFL-TCNN, DMFL-TTRAS, and DMFL-I on the Pheme dataset drop by 2.26%, 6.7%, and 4.89%, respectively, while on the Weibo dataset, the accuracies drop by 3.23%, 4.88%, and 4.88%, respectively. By comparing the performance of each single variant on the two datasets, DMFL-TCNN performs better on the Weibo dataset, while DMFL-TTRAS and DMFL-I perform better on the Pheme dataset. This indicates that the Weibo dataset has richer text semantic features than the Pheme dataset and is helpful for the rumor detection task. By comparing the performance of the three variants, DMFL-TCNN performs better than the other two variants on both datasets. In contrast, the performance gap between DMFL-TTRAS and DMFL-I is relatively tiny. The results show that text semantic features help the rumor detection task more than text logical features and image features.
6.3. Analysis of Important Parameters of DMFL
(1) Classification loss coefficient .
is used to adjust the weight of the classification loss. The value of
is increased with a step size of 0.4 for experiments to find the range of values with the best performance. Then, the step size is reduced for further experiments to find the optimal value for the best performance. As can be seen from
Figure 7, the overall influence of the classification coefficient
on the model performance shows a trend of first increasing and then decreasing, and the performance differences on the two datasets are relatively small, which proves that the performance of the classification task on the two datasets has little difference. The optimal value of
is 1.8 on the Pheme dataset and 1.2 on the Weibo dataset.
(2) Modality alignment loss coefficient .
is used to adjust the weight of the modality alignment loss. Similarly, the value of
is increased with a step size of 0.4 to find the optimal range, and then, the bisection method is used to find the optimal value of
within the optimal range. The optimal value of the modality alignment loss coefficient
is 2.4 for both the Pheme and Weibo datasets, as shown in
Figure 8.
By comparing the trends of the line charts, the increase and decrease trend of on the Pheme dataset is more tortuous, while its performance on the Weibo dataset is smoother. The experimental results show that the weight of the modality alignment task is more sensitive on the Pheme dataset, and it has a more prominent impact on the rumor detection results.
(3) Comprehensive analysis of the weight parameters of the loss function of DMFL.
Combined with the above experiments, it can be seen that on the two datasets, the value of is smaller than that of . Therefore, the modality analysis task has a more significant impact on the rumor detection task in the DMFL model. Furthermore, since the optimal value of the ratio of to on the Pheme dataset is more significant than that on the Weibo dataset, this indicates that the modality alignment task plays a more significant role on the Weibo dataset, proving that the difference between the text and image modalities in the Weibo dataset is more prominent.
(4) The influence of the number of heads h in the cross-modal attention mechanism
The cross-modal cross-attention mechanism divides the hidden state vectors into multiple heads, and each head forms an independent sub-semantic space, enabling the model to capture different types of features simultaneously. This greatly enriches the expressive ability of the model, allowing it to understand and process input data more comprehensively, thus improving the performance and generalization ability of the model. The choice of the number of heads will affect the performance and computational complexity of the model, so the experiment on the number of heads parameter is of great importance. This section sets the initial number of heads to 2, gradually increasing with a step size of 2. The accuracy and F1-score performance indicators for each number of heads on the Pheme and the Weibo datasets are recorded, respectively, and drawn into bar charts, as shown in
Figure 9.
According to the experimental results on the Pheme dataset, as the number of heads increases, the overall accuracy and F1-score of the model show a trend of decreasing first, then rising to the highest point, and then reducing. When the number of heads is two, the model performs well, with an accuracy of 0.8807 and an F1-score of 0.8812. This is because a smaller number of heads reduces the complexity of the model, decreases the risk of overfitting, and it can effectively capture the key information in the input multimodal features when the number of heads is four and six, both the accuracy and F1-score of the model decrease. This indicates that as the number of heads increases, the model becomes more complex, leading to a certain degree of overfitting. Especially when the amount of training data is not large, more heads do not effectively improve the representation ability of the model but instead increase the instability of training. When the number of heads is eight, the DMFL model performs the best, with an accuracy of 88.83% and an F1-score of 88.81%. This shows that under this setting, the increase in the number of heads helps to capture more diverse features, enhance the representation ability of the model, and thus improve the performance of rumor detection and classification. Having eight heads is a balance point, which increases the complexity of the model without significantly increasing the risk of overfitting. Finally, when the number of heads is 10, the accuracy and F1-score decrease again because further increasing the number of heads makes the model too complex, increasing the risk of overfitting. More heads make the features learned by each head overly focused on the specific patterns of the training data and unable to generalize well to the test data.
On the Weibo dataset, as the number of heads increases, the model’s accuracy shows a trend of first rising, then falling, then rising to the highest point, and then falling again. Analyzing the reasons for this trend, when the number of heads is two, the accuracy is relatively high but not outstanding. This is because the complexity of the model is low, and it can capture some basic features, but it may not be able to fully utilize the rich semantic information of the text and images. This results in the model having a specific generalization ability but limited representation ability. Subsequently, when the number of heads is four, the complexity and representation ability of the model is improved, and it can capture more features and patterns. The model can better understand and process the input data, thus increasing the accuracy. However, when the number of heads is six, the accuracy decreases. As the number of heads increases, the model becomes too complex, possibly leading to overfitting. This indicates that the model performs well on the training data but fails to generalize effectively on the test data. Then, the accuracy reaches the highest point when the number of heads is eight. At this time, the model balances complexity and generalization ability, can effectively capture various complex features in the input data, and avoids the overfitting problem. Finally, the accuracy decreases again when the number of heads is 10. The complexity of the model continues to increase, and the risk of overfitting becomes greater. More heads introduce more noise and unnecessary complexity, affecting the model’s generalization ability.
Through the experiments, we can conclude that a moderate number of heads can provide sufficient feature representation ability, thereby improving the model’s performance. Too few heads, although reducing the complexity of the model, may not be sufficient to capture the rich features in the data. Furthermore, too many heads may lead to overfitting of the model. Although it increases the complexity of the model, it also introduces more noise and instability. Therefore, for the Pheme and Weibo datasets, a number of eight heads is the most appropriate setting.
6.4. Correlation Analysis
A rumor detection model needs to make inferences and decisions from a large amount of information, and these decisions directly affect the final rumor detection results. Correlation analysis plays a crucial role in this process, as it can help us better understand the model’s decision-making mechanism. For example, correlation analysis can determine which specific features or data points play a key role in the model’s judgment when processing specific information. In this way, we can see the results output by the model and understand the evidence or logic based on which the model arrives at these results.
This section selects a cross-modal attention mechanism for the multimodal fusion of text semantics and image features. In each round of iterative training, the same batch of processed data is selected, and its attention scores are visualized as a heatmap. Then, a correlation analysis is conducted on the situation of the model learning the correlation between text semantics and image features.
(1) Visualization of attention scores in the Pheme dataset
Experiments were conducted on the Pheme dataset. The attention scores of the cross-modal attention mechanism for a multimodal fusion of text semantic features and image features were visualized as a heatmap. The changes in these scores with the number of iterations are shown in
Figure 10. The cross-modal attention mechanism increases the scores of vectors with strong correlations and decreases the vectors of features with weak correlations. In the heatmap, this is manifested as the darker the color, the stronger the correlation between the text semantic features and the image features in that part.
In the initial stage of model training, when the number of iterations is one, the color blocks in the heatmap of the attention scores are evenly distributed, and the colors are all relatively light, with no apparent distribution of dark areas. This indicates that the model has learned the feature correlations between text semantics and images to a certain extent, but the generalization ability on the test dataset is limited. When the number of iterations is equal to five, the color blocks in the heatmap of the attention scores begin to show a trend of regional distribution, and prominent dark areas can be divided in the figure. This indicates that the model has further learned the feature correlations between text semantics and images, and the increase in the model’s accuracy shows that the model’s generalization ability has also been improved. When the number of iterations is seven, the trained model achieves the best model performance, and the accuracy is the highest. Compared with the previous two images, the dark color blocks in the attention heatmap are more abundant, and at this time, the generalization ability reaches a balance. Finally, when the number of iterations reaches 10, the model’s accuracy no longer increases but shows a downward trend. In the attention heatmap, the shape of the dark areas has not changed compared with the best performance, but the number of dark color blocks has increased based on the original. This introduces unnecessary complexity and noise to the model, resulting in overfitting.
(2) Visualization of attention scores in the Weibo dataset
Experiments were conducted on the Weibo dataset. To ensure the comparability of the experiments, the attention scores of the cross-modal attention mechanism for a multimodal fusion of text semantic features and image features were also visualized in the form of a heatmap. The changes in these scores with the number of iterations are shown in
Figure 11. The cross-modal attention mechanism enhances the weights of high-correlation feature vectors while weakening the weights of low-correlation features. This process is intuitively reflected in the heatmap, where the darker the area, the stronger the correlation between the text semantic features and the image features in that part.
At the initial stage of model training, when the number of iterations is 1, there are already prominent dark areas in the distribution of color blocks in the heatmap of the attention scores. This indicates that the model has learned the feature correlations between text semantics and images to a certain extent and has a specific generalization ability on the test dataset. When the number of iterations is equal to five, the number of dark color blocks in the heatmap of the attention scores decreases, but the shape of the dark areas does not change. This indicates that the model has further learned the feature correlations between text semantics and images, weakened the weights of features with correlations in the noisy part, and improved the model’s generalization ability, which is reflected in the increase in accuracy. When the number of iterations is nine, the trained model achieves the best model performance, and the accuracy is the highest.
The distribution of dark color blocks in the attention heatmap is further changed. At this time, the darkest area is different from that at the beginning of the training, which shows that during the training process, the model has achieved noise reduction, reducing the weights of correlations in the noisy part and enhancing the weights of favorable high-correlation feature vectors. Finally, when the number of iterations reaches 20, the model’s accuracy no longer increases but shows a downward trend. In the attention heatmap, the shape of the dark areas has not changed compared with the best performance, but the number of dark color blocks has been further reduced on the original basis. This causes the model to perform excessive noise reduction operations, increasing the unnecessary complexity of the model and resulting in the phenomenon of model overfitting.
(3) Comprehensive analysis
Through the analysis of
Figure 10 and
Figure 11, it can be seen that for the multimodal fusion of text semantic features and image features, the training situations of the model on the Pheme and Weibo datasets are significantly different. First, in the early stage of training, the correlations between text semantics and images learned by the model show an apparent strong–weak distribution on the Weibo dataset. In contrast, the Pheme dataset has a uniform weak distribution. This indicates that the Weibo dataset contains more noise. One possible reason is that the Weibo dataset is Chinese, while the Pheme dataset is English. Under fields of equal length, Chinese texts contain more semantic information than English texts. During the process of learning the correlations between text semantics and images, more noise will be introduced.
Then, for the Pheme dataset, the correlations between text semantics and image features are learned from scratch. This is mainly reflected in the changes in the heatmap, which is a process of learning the distribution of dark areas, that is, discovering features with strong correlations during training. Learning the correlations between text semantics and image features is a noise-reduction process for the Weibo dataset. The primary manifestation of the changes in the heatmap is the gradual reduction of the number of dark color blocks, reducing the noise weights and retaining the features with favorable strong correlations.
6.5. Time Complexity Analysis
In our model, the time complexity of the propagation feature extraction module is . The time complexity of the contrastive learning optimization fusion feature module is . The time complexity of the propagation feature extraction and contrastive learning modules is . The time complexity of multimodal basic semantic and logical features is . Let the time complexity of obtaining image representation by CLIP be . Then, the final time complexity of our model is .












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}