Abstract
The intelligent maintenance of coal mining equipment is crucial for ensuring safe production in coal mines. Despite the rapid development of large language models (LLMs) injecting new momentum into the intelligent transformation and upgrading of coal mining, their application in coal mining equipment maintenance still faces challenges due to the diversity and technical complexity of the equipment. To address the scarcity of domain knowledge and poor model adaptability in multi-task scenarios within the coal mining equipment maintenance field, a method for constructing a large language model based on multi-dimensional prompt learning and improved LoRA (MPL-LoRA) is proposed. This method leverages multi-dimensional prompt learning to guide LLMs in generating high-quality multi-task datasets for coal mining equipment maintenance, ensuring dataset quality while improving construction efficiency. Additionally, a fine-tuning approach based on the joint optimization of a mixture of experts (MoE) and low-rank adaptation (LoRA) is introduced, which employs multiple expert networks and task-driven gating functions to achieve the precise modeling of different maintenance tasks. Experimental results demonstrate that the self-constructed dataset achieves fluency and professionalism comparable to manually annotated data. Compared to the base LLM, the proposed method shows significant performance improvements across all maintenance tasks, offering a novel solution for intelligent coal mining maintenance.
MSC:
68T50
1. Introduction
With the rapid development and technological advancements in the coal industry, the intelligence and automation levels of coal mining equipment have continuously improved [1,2], placing higher demands on equipment maintenance. Efficient maintenance not only ensures the continuity and safety of coal production but also significantly reduces production costs and enhances economic benefits. However, the wide variety and complex structures of coal mining equipment, coupled with the varying technical skills of maintenance personnel, often result in untimely or improper maintenance, severely impacting the normal operation and service life of the equipment. Therefore, improving the efficiency and quality of equipment maintenance has become an urgent issue that needs to be addressed.
In traditional coal mining equipment maintenance, when faced with sudden equipment failures, reliance is primarily placed on paper-based repair manuals, technical documents, and guidance from experienced engineers. However, this approach suffers from issues such as slow information retrieval, unreliable accuracy, and the inefficient dissemination of expert knowledge, leading to low maintenance efficiency. To overcome these limitations, intelligent question-answering models have emerged. These models integrate extensive technical resources and fault case studies, combined with natural language processing (NLP) technologies, to provide fast and accurate maintenance guidance. In recent years, significant progress has been made in LLMs such as ChatGPT [3], LLaMA [4], Baichuan [5], and ChatGLM [6], which demonstrate robust capabilities in knowledge comprehension, fluent dialogue, and logical reasoning, providing a substantial impetus to the development of general artificial intelligence. Leveraging their powerful NLP capabilities and extensive knowledge coverage, these models have been widely applied in vertical domains such as healthcare [7], agriculture [8], law [9], and finance [10], offering innovative solutions for domain-specific question-answering challenges.
Although general-purpose LLMs have demonstrated remarkable performance across various domains, their limitations become increasingly apparent in specialized scenarios such as coal mining equipment maintenance. Due to the differences in tasks, general LLMs tend to experience “hallucinations” when dealing with professional domain issues, generating false, incorrect, or even harmful information. As shown in Table 1, compared to general-purpose LLMs that cover a wide range of fields, vertical LLMs tailored for coal mining equipment maintenance excel in professionalism and practicality by focusing on domain-specific knowledge and skills. To address this issue, researchers typically employ domain knowledge fine-tuning methods to adapt general-purpose LLMs to specific tasks. Current fine-tuning techniques for large models primarily include Full Fine-Tuning [11] (FFT) and Parameter-Efficient Fine-Tuning [12] (PEFT). FFT involves training the model on specific data to update its original parameters for downstream tasks. However, due to the vast number of parameters in LLMs, FFT incurs high training costs [13]. In contrast, PEFT achieves comparable performance to FFT by updating only a small fraction of parameters. Representative PEFT methods include Prefix Tuning [14], Low-Rank Adaptation [15] (LoRA), and Adapter Tuning [16]. Prefix Tuning introduces continuous, differentiable soft prompts as additional parameters at the beginning of the input sequence, which are fine-tuned, while keeping the original model parameters frozen. LoRA reduces the number of parameters to be adjusted by decomposing the original model’s weight matrices into the product of two low-rank matrices. Adapter Tuning inserts small adapter modules into specific layers of the model, fine-tuning these additional parameters to adapt the model.

Table 1.
Differences between LLMs for coal mining equipment maintenance and general-purpose LLMs.
Consequently, PEFT has gradually emerged as the mainstream approach for fine-tuning domain-specific large models. For instance, Li Jiayi et al. [17] fine-tuned a base large language model by constructing question–answer pairs from court judgments and their summaries, enabling the model to acquire expertise in the judicial domain. The EduChat model [18] integrated diverse educational data into the Qwen1.5 model through fine-tuning, facilitating personalized intelligent education. The PMC-LLaMA project [19] introduced a pretrained language model based on the biomedical literature, enhancing its performance in the medical field by fine-tuning the LLaMA model and infusing medical knowledge. Xiangang Cao et al. [20] proposed a triple LoRA fine-tuning architecture and a direct preference optimization model based on a self-constructed coal mining equipment maintenance dataset. By fine-tuning the model with data from different types of coal mining equipment, they improved the model’s ability to provide professional responses across various tasks.
Despite significant advancements in LLMs for vertical domains, research specifically targeting coal mining equipment maintenance remains limited, and there is a lack of high-quality datasets in this field. The construction of high-quality datasets depends not only on the volume of raw data but also necessitates rigorous preprocessing (e.g., noise removal, information enhancement) to improve data clarity and usability. In computer vision, analogous data optimization techniques have been widely adopted, such as Variational Nighttime Dehazing with Hybrid Regularization (VNDHR) [21] and generative adversarial dehazing networks [22], which significantly improve subsequent analytical accuracy through enhanced image visibility. Inspired by these approaches, our study similarly implements preprocessing strategies including data cleansing and knowledge augmentation when constructing the coal mine maintenance text dataset, thereby ensuring superior input data quality. Moreover, existing fine-tuning methods for vertical domain LLMs are predominantly designed for single-task or weakly interdependent task scenarios, which may underperform in complex multi-task environments. In multi-task settings, models often encounter issues such as task conflicts and low response accuracy, leading to degraded overall performance.
To address the aforementioned challenges, a method for constructing a large language model for coal mining equipment maintenance based on multi-dimensional prompt learning and improved LoRA (MPL-LoRA) is proposed. This method employs multi-dimensional prompt design to guide LLMs in generating high-quality datasets for multiple tasks, including preventive maintenance, fault diagnosis, repair recommendations, and safety knowledge dissemination, ensuring dataset quality while improving construction efficiency. Additionally, a fine-tuning approach based on the joint optimization of a mixture of experts (MoE) and low-rank adaptation (LoRA) is introduced. By incorporating multiple task-specific experts and task-driven gating functions, the method achieves the precise modeling of different maintenance tasks, significantly enhancing the professional capabilities of the LLMs for coal mining equipment maintenance in multi-task scenarios. This approach provides a novel solution for the intelligent development of the coal mining equipment maintenance field. In summary, our contributions are as follows:
- Aiming at the problem of scarce knowledge in the field of mine equipment maintenance, a construction method of coal mine equipment maintenance dataset based on multi-dimensional prompt learning is proposed. Combined with technical documents such as the coal mine equipment maintenance manual, the generation scope of LLMs is focused on the professional task field through the design of task-oriented prompt words, improving the professionalism of the generated data.
- Aiming at the problems of task conflicts and insufficient generalization ability existing in the multi-task scenarios of coal mine equipment maintenance by traditional fine-tuning methods, a method based on the combination of a hybrid expert model and low-rank adaptation is proposed to fine-tune the base LLM. By introducing multiple expert networks and task-driven gating functions, the refined modeling of different maintenance tasks is achieved. And the fine-tuning efficiency of the model has been improved through the low-rank adaptive idea of LoRA.
- A proprietary LLM in the field of coal mine equipment maintenance has been constructed. The model can answer and process tasks related to coal mine equipment maintenance, improve maintenance efficiency, and provide a new solution for the intelligent development of the field of coal mine equipment maintenance.
- Comprehensive evaluations were conducted on the self-constructed dataset to validate the proposed method. Experimental results demonstrate that the dataset built using multi-dimensional prompt learning achieves high accuracy and information completeness in coal mining equipment maintenance applications, confirming its practical utility. Compared to base LLMs, the proposed method exhibits superior overall performance in complex multi-task scenarios, outperforming baseline models across all evaluation metrics.
2. Construction of Datasets Based on Multi-Dimensional Prompt Learning (MPL)
The field of coal mining equipment maintenance encompasses a vast and diverse array of data, characterized by its unique attributes [23]. For instance, coal mining equipment often involves domain-specific policies, regulations, and highly technical terminology, requiring a higher level of professional expertise. This significantly distinguishes it from general-purpose question-answering datasets. Despite extensive research in coal mining equipment maintenance, there remains a notable scarcity of high-quality QA datasets in this field. Available texts are often limited in quantity, subpar in quality, and costly to annotate manually. To address these challenges, a method for constructing coal mining equipment maintenance datasets based on multi-dimensional prompt learning is proposed. As illustrated in Figure 1, the methodology comprises three key modules: coal mining task identification, coal mining maintenance data preprocessing, and multi-dimensional prompt learning-based dataset construction. The following sections elaborate on each module in detail.
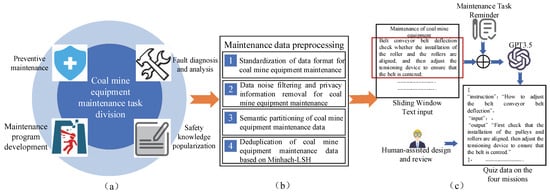
Figure 1.
Coal mining equipment maintenance dataset construction framework. (a) Coal mine equipment maintenance task division; (b) Maintenance data preprocessing; (c) Construction of a Question-Answering Dataset Based on MPL.
2.1. Coal Mine Equipment Maintenance Task Division
To build an LLM specialized in coal mining equipment maintenance, this section focuses on collecting and organizing large-scale, high-quality datasets in the coal mining equipment maintenance domain. The datasets primarily cover six major coal mining equipment systems: coal mining, tunneling, electromechanical, transportation, ventilation, and drainage. These systems encompass the main stages of coal production, from coal extraction to safety assurance. Each system is equipped with specific devices and functions, and, through in-depth analysis and maintenance of these systems, the critical aspects of coal mining equipment operations can be comprehensively addressed.
To address the maintenance needs of coal mining equipment systems, as illustrated in Figure 1a, four primary maintenance tasks have been identified: preventive maintenance, fault diagnosis and analysis, repair plan formulation, and safety knowledge dissemination. As shown in Table 2, these tasks aim to enhance the operational efficiency and safety of coal mining equipment while reducing the risk of production interruptions caused by equipment failures. To ensure the validity and scientific rigor of maintenance tasks, multi-dimensional knowledge was systematically collected from both offline sources and web crawlers, encompassing the following: technical documentation for various types of coal mining equipment, fault case studies, expert experience, and industry standards. These sources provide theoretical support and practical insights, ensuring the diversity and reliability of the data.
Table 2.
Coal mining equipment maintenance task categorization.
2.2. Data Preprocessing
To ensure data quality, a coarse-grained preprocessing step was applied to the collected coal mining equipment maintenance data. This preprocessing aims to extract high-quality textual information from the diverse types of collected data, providing a reliable foundation for the subsequent construction of the maintenance question-answering dataset. As illustrated in Figure 1b, the following is a detailed description of the coarse-grained preprocessing workflow:
2.2.1. Standardization of Data Format for Coal Mine Equipment Maintenance
For various types of data involved in coal mining equipment maintenance (such as PDF documents, web pages, and structured tables), a method combining big data processing technology with optical character recognition (OCR) technology is adopted to uniformly parse and standardize all documents. All data are converted into TXT format for easy model reading, ensuring consistency and processability. Let represent the raw data, represent the standardized text, and represent the standardization conversion function. The conversion process can be expressed as follows:
2.2.2. Data Noise Filtering and Privacy Information Removal for Coal Mine Equipment Maintenance
Since the raw data come from diverse sources and may contain a large amount of irrelevant information or noise (e.g., external links, non-technical terms), such noise can severely affect the accuracy of subsequent data analysis and model training. We use regular expressions to match and remove external links, advertisements, and private information while automatically filtering out domain-irrelevant generic terms and non-professional descriptions. Finally, domain experts manually review the automated filtering results to ensure accuracy and reliability. Let represent the filtered text and represent the filtering function. This process can be formalized as follows:
2.2.3. Semantic Partitioning of Coal Mine Equipment Maintenance Data
Since pre-trained language models for downstream tasks have a maximum token length limit for input text (e.g., BERT typically handles 512 tokens), we segmented and concatenated the original text data into appropriately sized chunks to ensure the efficient processing of coal mining equipment-related texts and achieve better performance. Let represent the chunked text, and represent the chunking function. This process can be expressed as follows:
where is the window size, and is the step size. Contextual integrity is optimized by concatenating overlapping chunks.
2.2.4. Deduplication of Coal Mine Equipment Maintenance Data Based on Minhach-LSH
To reduce data redundancy and enhance diversity, a deduplication algorithm based on MinHash [24] and Locality Sensitive Hashing [25] (MinHash-LSH) is employed. Let represent the deduplicated text, and represent the deduplication function. The Jaccard similarity [26] between two text blocks A and B is calculated as follows:
Text blocks with a similarity exceeding the threshold will be removed:
The above preprocessing steps effectively improved the standardization and usability of the dataset, establishing a high-quality data foundation for subsequent model training.
2.3. Construction of a Question-Answering Dataset Based on MPL
For the preprocessed coal mining equipment maintenance text data, a method for generating question–answer pairs based on MPL is proposed. The core idea of this method is to collaborate with LLMs (such as GPT-3.5) using high-quality, human-designed prompts [27] to construct a multi-task coal mining equipment maintenance question–answer dataset. The specific workflow is illustrated in Figure 1c below.
First, the prompt defines a specific role—a coal mining equipment maintenance assistant, as shown in Table 3. This role is endowed with professional domain knowledge to ensure that the generated questions and answers are highly relevant and specialized in the coal mining equipment maintenance field. In addition to the role definition, the prompt composition includes task descriptions (such as preventive maintenance, fault diagnosis, and analysis, etc.), input instructions, rule constraints, and output examples to guide the model in generating question–answer pairs that meet the needs of the coal mining domain. Next, the sliding window technique is used to extract fixed-length text segments from the coal mining equipment maintenance texts as input for the large language model. Each time the sliding window moves, the text segment is combined with the multi-dimensional prompt template, and GPT-3.5’s API Key is called to generate question–answer pair data for four major tasks. By adjusting the size and step length of the sliding window, the integrity and diversity of the input text are ensured. Finally, the generated question–answer pairs are exported in JSON file format to provide high-quality data support for subsequent model fine-tuning. This method not only significantly improves the efficiency and quality of question–answer pair generation but also lays a data foundation for intelligent research and application development in the coal mining equipment maintenance field.
Table 3.
Design and construction of multi-dimensional prompt engineering for coal mining equipment maintenance.
3. Methodology
To accommodate multi-task learning in coal mining equipment maintenance, this study proposes an enhanced LoRA-based fine-tuning approach for large language models specialized in this domain.
In conventional LoRA methodology, all task data collectively optimize a single set of parameters, resulting in inadequate task-specific adaptation during multi-task processing and consequently diminished prediction accuracy. Conversely, the MoE framework addresses this limitation by incorporating multiple expert networks to handle distinct tasks, with dynamic expert selection based on input characteristics. However, MoE implementations require full-model parameter updates, exhibiting computational inefficiency and excessive resource demands. To synergize these advantages, our approach integrates both paradigms, aiming to enhance model performance through task-specific knowledge acquisition while preserving parameter efficiency. For terminological clarity, we designate this refined LoRA variant as MoELoRA in subsequent discussions. Figure 2 illustrates the framework for multi-task fine-tuning based on MoELoRA.
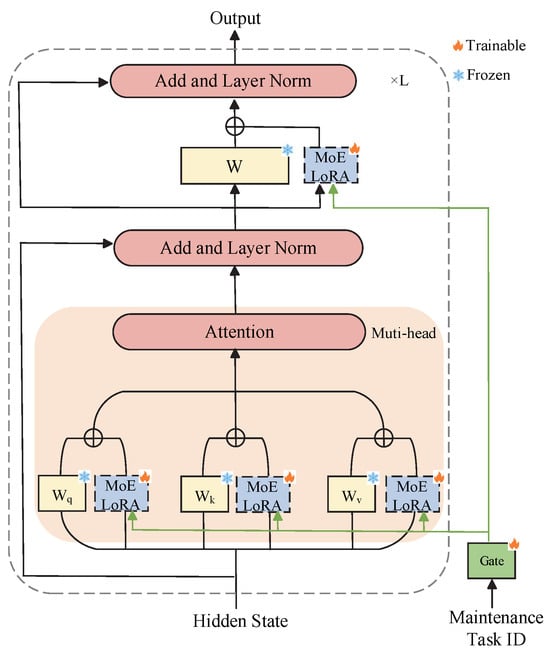
Figure 2.
Fine-tuning framework for multi-task maintenance of coal mine equipment based on MoELoRA.
3.1. Task Definition
For multi-task fine-tuning in coal mining equipment maintenance, assume a set of maintenance tasks as . The structured data corresponding to each task can be represented as , where and denote the formatted input and output of the maintenance task data, respectively, and represents each data sample. Thus, the overall objective can be formulated as follows: given multiple maintenance task datasets , optimize the parameters of the large language model to ensure optimal performance on each task . Therefore, the objective function for multi-task fine-tuning can be expressed as follows:
where represents the parameters of the LLMs, is the number of tasks, is the dataset for task , and is a sample in the dataset, where is the input, is the output, and is the length of the output . And denotes the probability of the model predicting the next token , given the input and the prefix .
The objective of this function is to maximize the sum of the conditional probabilities of the model across all tasks. Specifically, the model needs to predict the next token as accurately as possible at each position of every sample in each task. Through this approach, the model can learn shared knowledge across different tasks while also capturing the specific characteristics of each individual task.
3.2. Large Language Model Fine-Tuning Based on Improved LoRA
To adapt to multi-task learning in coal mining equipment maintenance, a fine-tuning method for LLMs of coal mine equipment maintenance based on improved LoRA was proposed. In conventional LoRA approaches, all task data jointly optimize the same set of parameters, resulting in insufficient task-specific adaptation during multi-task processing and compromised prediction accuracy. While MoE models address this by employing multiple expert networks to handle different tasks and dynamically selecting experts based on input features, they require full-model parameter updates, leading to computational inefficiency and high resource consumption. To combine the advantages of both methods, we decomposed each expert network into two low-rank matrices, aiming to enhance model performance through task-specific knowledge learning while maintaining parameter efficiency.
MoELoRA introduces multiple experts to learn the fine-tuned matrix , where each expert consists of two low-rank matrices, as illustrated in Figure 3. Based on this structure, the forward process of MoELoRA can be expressed as follows:
where and represent the input and output of the intermediate LLM layer for a sample from task , respectively. The matrices and form the expert . The hyperparameter N denotes the number of maintenance task experts, and is a scaling factor used to adjust the influence of rank r of the low-rank matrix. For each task expert, the rank of matrices A and B is , and represents the contribution weight of each expert to , which is determined by the gating function and detailed in Section 3.3. During the fine-tuning process of MoELoRA, all parameters in the large language model remained frozen, and only the low-rank matrix Ai and Bi corresponding to each task expert needed to be optimized and adjusted.
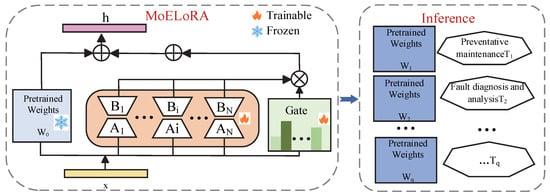
Figure 3.
Fine-tuning principle of multi-task maintenance based on MoELoRA.
For LoRA, the two low-rank matrices and contained all the trainable parameters, so the trainable parameters of LoRA amounted to . For MoELoRA, since there are N trainable experts and each expert has trainable parameters of , the total trainable parameters for N experts are . In summary, both methods have the same number of trainable parameters, but MoELoRA achieves higher performance and efficiency.
3.3. Task-Driven Gating Network Layer
To regulate the contribution weights of each expert, a task-driven gating function was designed. Since the expert contribution weights were generated for different maintenance tasks, the input to the gating function is the coal mining equipment maintenance task embedding matrix , where represents the dimensionality of the maintenance task embedding matrix. After identifying the maintenance task , the p-th row of the task matrix was extracted as the representation vector for that task, denoted as . This vector was then transformed linearly to generate the expert weights for task :
Using the task representation vector and the weight matrix , the gating function generated unique expert weights for each task. These weights determine the contribution of each expert to a specific maintenance task, enabling task-specific parameter adjustments. Here, represents the expert weight vector for task , and is the weight matrix of the gating function. To prevent the weights from becoming excessively large or small, a Softmax operation was applied for normalization.
In traditional MoE model designs, the input data (denoted as ) were directly fed into the gating function, which determines which experts should handle the task based on the characteristics of the input data. However, in MoELoRA, as illustrated in Figure 2, the input data were not directly passed to the gating function. Instead, only the task type was input into the gating function. This approach allows the model to generate a unique set of parameters for each maintenance task, thereby better adapting to different task requirements.
During the training process, the parameters of the pre-trained LLMs remained frozen, and only the parameters of the MoELoRA layer were fine-tuned. For the data of each batch, forward propagation was carried out first; then, the error was calculated based on the loss function, and the MoELoRA parameter and the gate function parameter were updated. In the reasoning stage, based on specific task , the fine-tuning parameter corresponding to this task was restored through formula (9), thereby completing the specified task using the corresponding LLM parameters.
4. Experiments and Discussion
4.1. Datasets and Experimental Setup
This study evaluates the proposed method based on a self-constructed coal mining equipment maintenance dataset. The dataset was built through LLM-assisted human annotation and integration, aiming to provide reliable data support for the intelligent maintenance of coal mining equipment. It comprises approximately 44,754 question–answer text samples, each manually reviewed and annotated to ensure accuracy and domain relevance. As illustrated in Figure 4, the dataset is divided into four major categories by task: preventive maintenance, fault diagnosis and analysis, maintenance program development, and safety knowledge popularization. Each category includes a wealth of real-world cases and solutions. Of the total data, 80% is used for baseline model training, 10% of the data is used for model testing, and 10% of the data is used for model validation. To prevent data bias, the random sampling method is used to allocate the task data to different subsets to ensure that the data distribution within each subset is as close as possible to the overall distribution characteristics of the original data.
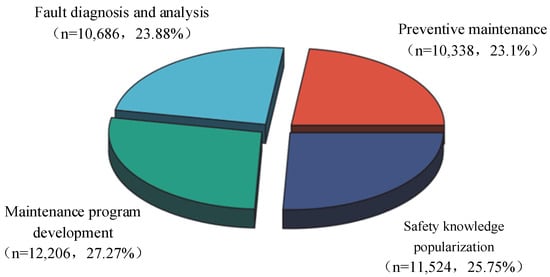
Figure 4.
Distribution of multi-task datasets for coal mining equipment maintenance.
The experiments were conducted on a deep learning server with the following system configuration, as shown in Table 4: Ubuntu 18.04, GPU model A100, and 40 GB of memory. The proposed model in this study was developed using the PyTorch 1.12.0 deep learning framework, with Python interpreter version 3.10 and CUDA version 11.6. The base LLM selected was ChatGLM3-6B, an open-source bilingual (Chinese–English) dialogue model with 6 billion parameters.
Table 4.
Experimental environment configuration.
4.2. Baselines
In this section, the optimized LLMs for coal mining equipment maintenance is compared with mainstream question-answering models, including Qwen2-7B (Qwen), ChatGLM3-6B (ChatGLM), Llama3-8B (Llama), and GPT-4. Moreover, comparative experiments were conducted between the fine-tuning method in this paper and the mainstream fine-tuning methods Adapter, Prefix-tuning, Prompt-tuning, and LoRA.
Qwen2-7B [28]: Developed by Alibaba, this lightweight large language model has seven billion parameters (7B) and focuses on Chinese-language tasks, making it suitable for resource-constrained scenarios.
ChatGLM3-6B: Developed by Tsinghua University, this model has six billion parameters (6B) and is optimized for bilingual Chinese–English capabilities, excelling in Chinese-language tasks.
Llama3-8B [4]: An efficient open-source model released by Meta (Menlo Park, CA, USA), with eight billion parameters (8B), designed for multilingual and multi-task scenarios.
GPT-4 [29]: OpenAI’s state-of-the-art model, with approximately 1.8 trillion parameters (1.8T), boasts powerful general-purpose capabilities and excels in handling complex tasks, supporting multilingual and multi-domain applications.
4.3. Evaluation Metrics
To validate the quality of the generated question–answer dataset, three evaluation metrics were adopted: BLEU, ROUGE-L, and BERT Score, all recognized as important indicators for assessing text generation quality. BLEU evaluates quality by comparing n-gram matches between generated and reference texts, with particular focus on the accuracy of generated text descriptions. The calculation method is as follows:
where represents n-gram precision (n = 1 to 4), BP denotes the brevity penalty factor, indicates the weighting coefficients (typically set to uniform weights of 1/4).
ROUGE-L evaluates the matching degree by calculating the length of the longest common subsequence (LCS) between generated answers and reference answers. This metric measures content overlap between texts, where the proportion of LCS reflects their similarity. The calculation formula is shown in the equation below:
where denotes the length of the LCS between reference text and generated text , represents the length of the reference text, and indicates the length of the generated text.
BERTScore measures the similarity between the generated text and the reference text by comparing their embedded representations, providing three key metrics: precision, recall, and F1 score. The calculation method is shown in the following formula:
where represents the reference text, denotes the i-th reference text, represents the generated text, denotes the j-th generated text, and represents the transpose operation.
To complement the limitations of automated metrics (BLEU and ROUGE-L) in dataset evaluation, this study introduced a manual assessment conducted by five domain experts. As shown in Table 5, the evaluation criteria included two aspects: Language fluency, that is, evaluating the fluency and naturalness of the sentences generated in the problem. The scoring range is from 1 to 5 points, with 5 points being the highest. The professionalism of the problem, that is, the relevance and semantic accuracy of the generated problem to the field of coal mine equipment maintenance, is evaluated on a scale of 1 to 5 points, with 5 points being the highest.
Table 5.
Expert scoring criteria.
4.4. Dataset Quality Evaluation Experiments
4.4.1. Analysis of the Evaluation Results of Automated Indicators for Dataset Quality
Through the comprehensive evaluation of the multi-task dataset for coal mine equipment maintenance assisted by the LLMs, the scores of each index show obvious task difference characteristics.
As shown in Figure 5, on the whole, the F1 values of all tasks’ data exceed 0.70, which indicates that its content has high accuracy and information completeness in the field of coal mine equipment maintenance and has practical application value. Among them, the data of the fault diagnosis and analysis task performed the most outstandingly, with the F1 value reaching 0.83 and the recall rate R value reaching 0.85. This indicates that the method based on multi-dimensional prompt learning can enable the model to capture the correlation between fault features and solutions more comprehensively.
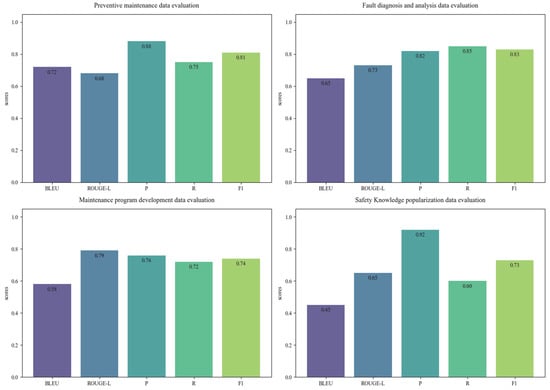
Figure 5.
Evaluation results of different task datasets.
The data of preventive maintenance tasks exhibit unique advantageous characteristics. Both the precision rate P and the degree of professional term matching BLEU are the highest for each task, which are 0.88 and 0.72, respectively. This is attributed to the highly standardized nature of the maintenance procedure documents. However, its semantic coherence ROUGE-L is relatively insufficient, reaching only 0.68, reflecting that the model has certain limitations when converting technical key points into natural language descriptions and still lacks training in the field of coal mine equipment maintenance data. The task data of the maintenance program development shows an obvious polarization phenomenon. Although the integrity of the generated data is relatively good, with the ROUGE-L value reaching 0.79, the accuracy of professional term recognition is significantly insufficient, and the BLEU value is only 0.58. This may be related to the complexity and diversity of the maintenance scenarios exceeding the current understanding ability of the model. The data precision rate P of the safety knowledge popularization task reached the peak of 0.92, but the recall rate R was 0.60, which was significantly low. This indicates that the model adopted an overly cautious strategy in the generation of safety-related content. Because errors in safety knowledge may cause serious consequences, the model avoids risks by raising the generation threshold. Although this conservatism ensures the accuracy of the content, it also limits the breadth of knowledge coverage.
These results indicate that, when current LLMs generate professional domain data through the method of multi-dimensional prompt learning, although they can grasp the overall technical framework, there are still shortcomings in terms of detail accuracy, language fluency, and scene adaptability. Simple automated indicators are difficult to comprehensively assess the actual value of professional data. It is necessary to combine quality verification by domain experts, especially in scenarios involving safety-critical information, where manual review is an indispensable quality assurance link.
4.4.2. Analysis of the Evaluation Results of Manual Indicators for Dataset Quality
The dataset constructed based on the multi-dimensional prompt learning method was evaluated. For each task, 500 samples were randomly selected, respectively, for assessment, totaling 2000 samples. The evaluations of the five reviewers on different task datasets are shown in Figure 6:
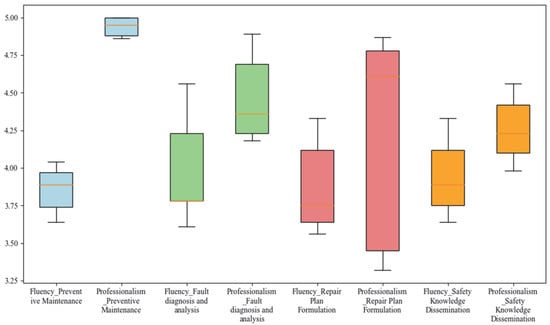
Figure 6.
Score distribution of datasets for different maintenance tasks.
Through the analysis of the box plots showing the distribution of evaluators’ scores for different task data, the overall scores are primarily concentrated between 4.00 and 4.75, indicating that the generated content received high evaluations in terms of language fluency and question professionalism. The highest score of 5.00 demonstrates that the preventive maintenance data exhibit exceptional professionalism. The score distribution is relatively concentrated, with no scores below 3.25, further confirming the overall high quality and strong professionalism of the generated content. Notably, the fluency scores for datasets constructed with LLM assistance across different tasks are generally lower than the professionalism scores, suggesting that, while the datasets exhibit strong professionalism in the coal mining equipment maintenance domain, there is still room for improvement in language expression fluency. This phenomenon may stem from the model’s incomplete grasp of the specific language style and expression habits in the coal mining equipment maintenance field, resulting in excellent performance in professionalism but slightly lacking in language fluency. Additionally, in the professionalism evaluation for the repair plan formulation task, the evaluators’ scores show significant variation, with a gap of 1.55 between the highest and lowest scores. This discrepancy may arise from differences in evaluators’ understanding of task criteria or subjective perceptions, highlighting the need for further standardization of scoring criteria or additional evaluator training in future assessments to improve consistency and reliability. Overall, the experimental results validate that the data generated based on MPL exhibit high professionalism and reliability in the coal mining equipment maintenance domain and can significantly reduce the time required for dataset construction.
4.5. Comparison Experiments
4.5.1. Analysis of the Comparison Results of Different Models
To deeply evaluate the performance of the MoELoRA method proposed in this paper in the field of coal mine equipment maintenance, the model fine-tuned with MoELoRA is named “Coalglm”, and comparative experiments are conducted with Qwen2.5-7B (Qwen), ChatGLM3-6B (ChatGLM), Llama, and GPT4. The result is shown in Figure 7.
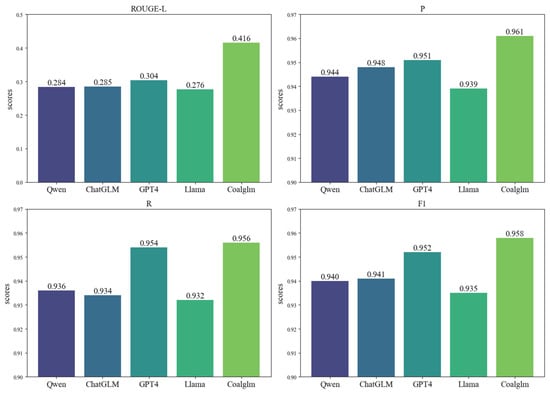
Figure 7.
Comparison results of different models.
The experiments demonstrate that the Coalglm model, fine-tuned with the self-constructed coal mining equipment maintenance dataset, outperforms the other models across all evaluation metrics. Specifically, Coalglm achieves a ROUGE-L score of 0.416, significantly higher than the other models, indicating its superior performance in semantic matching between generated answers and reference texts in the specialized field of coal mining equipment maintenance. Additionally, Coalglm achieves the highest scores in P (0.961), R (0.956), and F1 (0.958), further validating its advantage in understanding tasks within the coal mining equipment maintenance domain. In contrast, ChatGLM and Qwen, which were not fine-tuned with coal mining domain data, perform similarly but significantly lower than Coalglm, highlighting the importance of domain-specific fine-tuning for enhancing model expertise. GPT-4, as the most advanced general-purpose large language model, exhibits stronger capabilities in handling general tasks but falls slightly short of Coalglm in professional expertise due to the lack of specialized coal mining equipment maintenance data. Llama’s performance is relatively weaker, likely due to its model architecture and training data being primarily in English.
Overall, the experimental results validate the effectiveness of the proposed method and demonstrate that Coalglm holds a significant advantage in answering domain-specific questions in the coal mining equipment maintenance field.
4.5.2. Analysis of the Comparison Results of Different Fine-Tuning Methods
To deeply evaluate the performance differences between the fine-tuning method in this paper and other fine-tuning methods, a systematic comparative experiment is designed in this paper. As shown in Figure 8 and Table 6, the experimental results indicate that the MoELoRA method proposed in this paper demonstrates significant advantages in multiple key indicators. This method combines MoE with LoRA technology and achieves a ROUGE-L score of 0.416, an accuracy rate of 0.961, and an F1 value of 0.958 while only updating 1.5% of the model parameters. This performance is significantly superior to other efficient parameter fine-tuning methods.
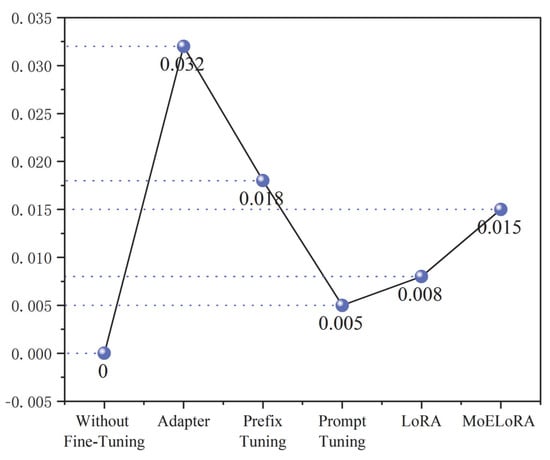
Figure 8.
Different fine-tuning methods require the update of parameter ratios.
Table 6.
Comparison results of different fine-tuning methods.
Specifically, compared with the current mainstream parametric efficient fine-tuning techniques, the LoRA method has achieved a decent performance with only 0.8% of the parameters. Its F1 value of 0.947 fully demonstrates the powerful potential of low-rank adaptation technology. Its performance is second only to MoELoRA, as LoRA is still relatively weak when dealing with complex tasks. In contrast, although the Adapter method uses 3.2% of the trainable parameters, its performance improvement is relatively limited, which reflects the limitations of the traditional adapter structure in professional field tasks. Prefix-tuning achieved a ROUGE-L value of 0.395 with 1.8% of the parameters, and its overall performance was superior to the Adapter method with a larger number of parameters. This phenomenon reveals the unique advantages of the method based on continuous prompt optimization in specific scenarios. With prompt tuning, as the method with the least number of parameters, although its F1 value of 0.942 is better than that of the unfine-tuned model, there is still a significant gap compared with the mainstream methods. This indicates that simple prompt optimization is difficult to fully capture the complex knowledge in the professional field. Although the unfine-tuned baseline model performed fairly well in terms of accuracy, its ROUGE-L score of 0.285 was significantly lower than that of other methods. This huge gap fully verified the necessity of knowledge adaptation in the field of coal mine equipment maintenance.
4.6. Ablation Study
To provide an in-depth analysis of the contributions of each module in the proposed method, this study designed ablation experiments. These experiments evaluate the impact of each component on overall performance by sequentially removing key modules from the model. For clarity, the following notations are used:
R-gate: Represents the removal of the task-driven gating module in the MoELoRA method. R-MoE: Represents the removal of the mixture of task expert module, meaning that only LoRA is used to fine-tune the base model. R-MoELoRA: Represents the removal of the entire MoELoRA module, equivalent to the base ChatGLM model without fine-tuning. The experimental results are illustrated in Figure 9.
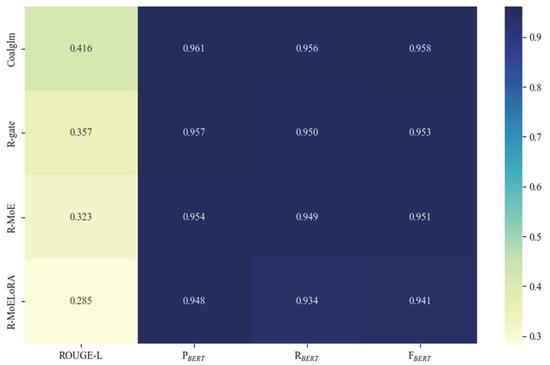
Figure 9.
Results of ablation experiments.
The experimental results show that, compared with the benchmark model Coalglm, the R-gate model without the gating network module shows a significant decrease in the comprehensive performance index. Its F1 value and ROUGE-L value have decreased by 0.015 and 0.024, respectively. This phenomenon verifies the core role of the dynamic gating mechanism in task-specific adaptation. Although the model can still maintain the basic performance, the absence of the gated network leads to the degradation of the expert selection strategy into a static mode, significantly weakening the model’s adaptability when dealing with heterogeneous tasks. On the other hand, the R-MoE model with the MoE module removed also shows a trend of performance degradation, with its F1 score and ROUGE-L score decreasing by 0.007 and 0.015, respectively. This confirms the necessity of the hybrid expert architecture in multi-task expert modeling, and its absence will directly limit the performance of the model in handling complex tasks. It is worth noting that the ablation experiments revealed the differential influence of module functions. The absence of the gating mechanism mainly impaired the task adaptation flexibility of the model, specifically manifested as the deterioration of the recall rate index, while the removal of the MoE structure more directly affected the model’s ability to handle multiple tasks, which was reflected in the feature that the accuracy index remained relatively stable, but the overall performance declined. The superior performance of the benchmark model Coalglm fully demonstrates that only by synergistically integrating the multi-expert architecture and dynamic gating mechanism can the application potential of MoELoRA in the professional field of coal mine equipment maintenance be maximized, achieving the optimal balance between performance and adaptability.
5. Conclusions
This study first assisted LLMs in constructing a high-quality multi-task dataset through the multi-dimensional prompt learning method. Subsequently, using the self-construct dataset, Chatgm3-6b was fine-tuned through the MoELoRA method to construct a LLM for coal mine equipment maintenance. After evaluating the multi-task dataset, it can be found that the F1 values of all task data exceed 0.70, and the overall manual scores are mainly concentrated between 4.00 and 4.75. This indicates that its content has high accuracy and information completeness in the field of coal mine equipment maintenance, has practical application value, and can greatly reduce the time for dataset construction. Compared with the base model, our method performs exceptionally well in all indicators. With only 1.5% of the model parameters updated, it achieves a ROUGE-L score of 0.416, which is much higher than other models. This indicates that it performs best in generating the semantic matching degree between the answers in the proprietary domain of coal mine equipment maintenance and the reference text, and it reduces the proportion of parameter updates. It further explains the importance of the MPL-MoELoRA method for the construction of LLMs for coal mine equipment maintenance, providing reliable technical support for the intelligence in the field of coal mine equipment maintenance.
This paper mainly focuses on the construction and application of text-based knowledge, and, more importantly, it proposes an efficient method for constructing a large language model for the maintenance of coal mine equipment. However, the fusion of multimodal data (such as images, sensor data, etc.) is not considered, which, to some extent, limits the adaptability of the model under complex working conditions. Moreover, the processing of multimodal data requires stronger local computing power, which poses higher requirements for high-performance computing equipment actually deployed in coal mine sites.
In future research, the fusion methods of multimodal data will be explored. There are plans to introduce a multimodal Transformer to combine multi-source information such as images and sensor data with text knowledge and achieve the joint modeling of multimodal data through a cross-modal attention mechanism, with the aim to further enhance the model’s understanding and decision-making capabilities under complex working conditions, ensure the seamless integration of the model with the existing coal mine equipment maintenance system, and thereby promote the practical application of intelligent maintenance technology in coal mines.
Author Contributions
Methodology, X.C. and X.W.; dataset construction, X.W. and L.S.; validation, X.W. and X.Y.; writing—original draft preparation, X.W. and Y.D.; writing—review and editing, X.W. and X.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Natural Science Foundation of China, grant numbers 52274158, and the Key Science and Technology Program of Shananxi Province, grant numbers 2024QY2-GJHX-09.
Data Availability Statement
The data and materials used in this research are available upon reasonable request to the corresponding author. The data are not publicly available due to privacy.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Wang, T.; Han, X.; Wu, Z.; Zhao, X.; Cao, A.; Zhang, B.; Cheng, Y.; Li, C.; Sun, P.; Wang, W.; et al. Theoretical framework, key technologies and engineering applications of geological layer modification in mining. J. China Coal Soc. 2025, 50, 491–505. [Google Scholar]
- Ma, H.; Xue, X.; Mao, Q.; Qi, A.; Wang, P.; Nie, Z.; Zhang, X.; Cao, X.; Zhao, Y.; Guo, Y. On the Academic Ideology of ‘Coal Mining is Data Mining’. Coal Sci. Technol. 2025, 53, 272–283. [Google Scholar]
- Liu, Y.; Han, T.; Ma, S.; Zhang, J.; Yang, Y.; Tian, J.; He, H.; Li, A.; He, M.; Liu, Z.; et al. Summary of ChatGPT-related research and perspective towards the future of large language models. Meta-Radiol. 2023, 1, 100017. [Google Scholar] [CrossRef]
- Grattafiori, A.; Dubey, A.; Jauhri, A.; Pandey, A.; Kadian, A.; Al-Dahle, A.; Letman, A.; Mathur, A.; Schelten, A.; Vaughan, A.; et al. The llama 3 herd of models. arXiv 2024, arXiv:2407.21783. [Google Scholar]
- Yang, A.; Xiao, B.; Wang, B.; Zhang, B.; Bian, C.; Yin, C.; Lv, C.; Pan, D.; Wang, D.; Yan, D.; et al. Baichuan 2: Open large-scale language models. arXiv 2023, arXiv:2309.10305. [Google Scholar]
- GLM, T.; Zeng, A.; Xu, B.; Wang, B.; Zhang, C.; Yin, D.; Zhang, D.; Rojas, D.; Feng, G.; Zhao, H.; et al. ChatGLM: A family of large language models from glm-130b to glm-4 all tools. arXiv 2024, arXiv:2406.12793. [Google Scholar]
- Zhang, H.; Chen, J.; Jiang, F.; Yu, F.; Chen, Z.; Li, J.; Chen, G.; Wu, X.; Zhang, Z.; Xiao, Q.; et al. HuatuoGPT, towards taming language model to be a doctor. arXiv 2023, arXiv:2305.15075. [Google Scholar]
- Wang, T.; Wang, N.; Cui, Y.; Li, J. Agricultural Technology Knowledge Intelligent Question-Answering System Based on Large Language Model. Smart Agric. 2023, 5, 105–116. [Google Scholar]
- Zhou, Z.; Shi, J.X.; Song, P.X.; Yang, X.W.; Jin, Y.X.; Guo, L.Z.; Li, Y.F. LawGPT: A Chinese legal knowledge-enhanced large language model. arXiv 2024, arXiv:2406.04614. [Google Scholar]
- Wu, S.; Irsoy, O.; Lu, S.; Dabravolski, V.; Dredze, M.; Gehrmann, S.; Kambadur, P.; Rosenberg, D.; Mann, G. BloombergGPT: A large language model for finance. arXiv 2023, arXiv:2303.17564. [Google Scholar]
- Lv, K.; Yang, Y.; Liu, T.; Gao, Q.; Guo, Q.; Qiu, X. Full parameter fine-tuning for large language models with limited resources. arXiv 2023, arXiv:2306.09782. [Google Scholar]
- Ding, N.; Qin, Y.; Yang, G.; Wei, F.; Yang, Z.; Su, Y.; Hu, S.; Chen, Y.; Chan, C.M.; Chen, W.; et al. Parameter-efficient fine-tuning of large-scale pre-trained language models. Nat. Mach. Intell. 2023, 5, 220–235. [Google Scholar] [CrossRef]
- Gao, Y.; Wang, R.; Wang, D. Research on the prospects of application of AI large-scale model technology in the coal industry. Coal Econ. Res. 2024, 44, 109–115. [Google Scholar]
- Li, X.; Liang, P. Prefix-Tuning: Optimizing Continuous Prompts for Generation. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Online, 1–6 August 2021; pp. 4582–4597. [Google Scholar]
- Hu, E.J.; Shen, Y.; Wallis, P.; Allen-Zhu, Z.; Li, Y.; Wang, S.; Wang, L.; Chen, W. Lora: Low-rank adaptation of large language models. arXiv 2022, arXiv:2106.09685v1. [Google Scholar]
- Rebuffi, S.; Bilen, H.; Vedaldi, A. Learning multiple visual domains with residual adapters. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: New York City, NY, USA, 2017; Volume 30. [Google Scholar]
- Li, J.; Huang, R.; Chen, Y. A Method for Summarizing Judgment Documents Based on Prompt Learning and the Qwen Large Language Model. J. Tsinghua Univ. (Sci. Technol.) 2024, 64, 2007–2018. [Google Scholar]
- Dan, Y.; Lei, Z.; Gu, Y.; Li, Y.; Yin, J.; Lin, J.; Ye, L.; Tie, Z.; Zhou, Y.; Wang, Y.; et al. Educhat: A large-scale language model-based chatbot system for intelligent education. arXiv 2023, arXiv:2308.02773. [Google Scholar]
- Wu, C.; Lin, W.; Zhang, X.; Zhang, Y.; Xie, W.; Wang, Y. PMC-LLaMA: Toward building open-source language models for medicine. J. Am. Med. Inform. Assoc. 2024, 31, 1833–1843. [Google Scholar] [CrossRef]
- Cao, X.; Xu, W.; Zhao, J.; Duan, Y.; Yang, X. Research on Large Language Model for Coal Mine Equipment Maintenance Based on Multi-Source Text. Appl. Sci. 2024, 14, 2946. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, X.; Hu, E.; Wang, A.; Shiri, B.; Lin, W. VNDHR: Variational Single Nighttime Image Dehazing for Enhancing Visibility in Intelligent Transportation Systems Via Hybrid Regularization. IEEE Trans. Intell. Transp. Syst. 2025, 1–15. [Google Scholar] [CrossRef]
- Zhang, S.; Zhang, X.; Wan, S.; Ren, W.; Zhao, L.; Shen, L. Generative Adversarial and Self-Supervised Dehazing Network. IEEE Trans. Ind. Inform. 2024, 20, 4187–4197. [Google Scholar] [CrossRef]
- Cao, X.; Duan, Y.; Wang, G.; Zhao, J.; Ren, H.; Zhao, F.; Yang, X.; Zhang, X.; Fan, H.; Xue, X.; et al. Research review on life-cycle health management and intelligent maintenance of coal mining equipment. J. China Coal Soc. 2025, 50, 694–714. [Google Scholar]
- Wu, W.; Li, B.; Chen, L.; Gao, J.; Zhang, C. A review for weighted minhash algorithms. IEEE Trans. Knowl. Data Eng. 2020, 34, 2553–2573. [Google Scholar] [CrossRef]
- Jafari, O.; Maurya, P.; Nagarkar, P.; Islam, K.M.; Crushev, C. A survey on locality sensitive hashing algorithms and their applications. arXiv 2021, arXiv:2102.08942. [Google Scholar]
- Niwattanakul, S.; Singthongchai, J.; Naenudorn, E.; Wanapu, S. Using of Jaccard coefficient for keywords similarity. In Proceedings of the International Multiconference of Engineers and Computer Scientists, Hong Kong, China, 13–15 March 2013; pp. 380–384. [Google Scholar]
- Liu, P.; Yuan, W.; Fu, J.; Jiang, Z.; Hayashi, H.; Neubig, G. Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing. ACM Comput. Surv. 2023, 55, 1–35. [Google Scholar] [CrossRef]
- Yang, A.; Yang, B.; Zhang, B.; Hui, B.; Zheng, B.; Yu, B.; Li, C.; Liu, D.; Huang, F.; Wei, H.; et al. Qwen2 technical report. arXiv 2024, arXiv:2412.15115. [Google Scholar]
- Mao, R.; Chen, G.; Zhang, X.; Guerin, F.; Cambria, E. GPTEval: A survey on assessments of ChatGPT and GPT-4. arXiv 2023, arXiv:2308.12488. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).