


DREFNet: Deep Residual Enhanced Feature GAN for VVC Compressed Video Quality Improvement


Abstract
1. Introduction
- The proposed post-processing network is designed for both Random Access (RA) and All Intra (AI) scenarios by utilizing a single model generation method for each specific scenario across different QP ranges.
- The input to the generator network consists of the reconstructed image, which is accompanied by a QP map to enhance the generator’s generalization across different QP ranges.
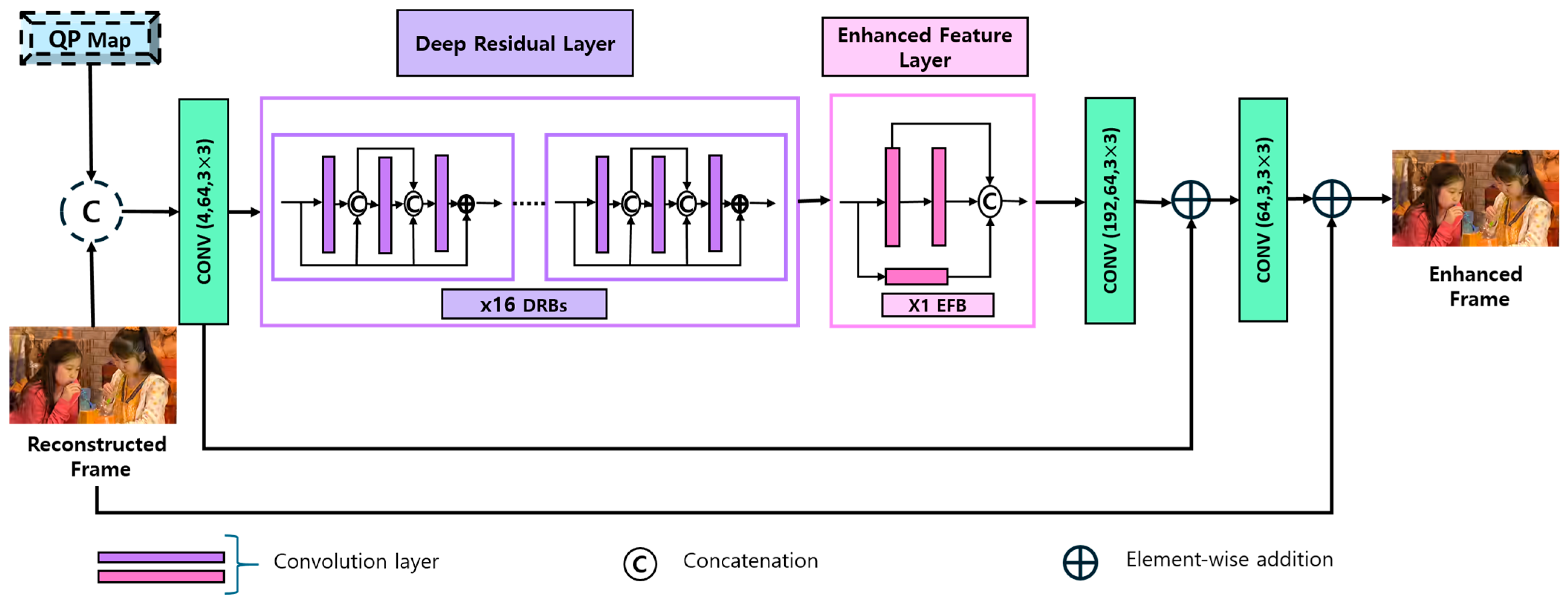
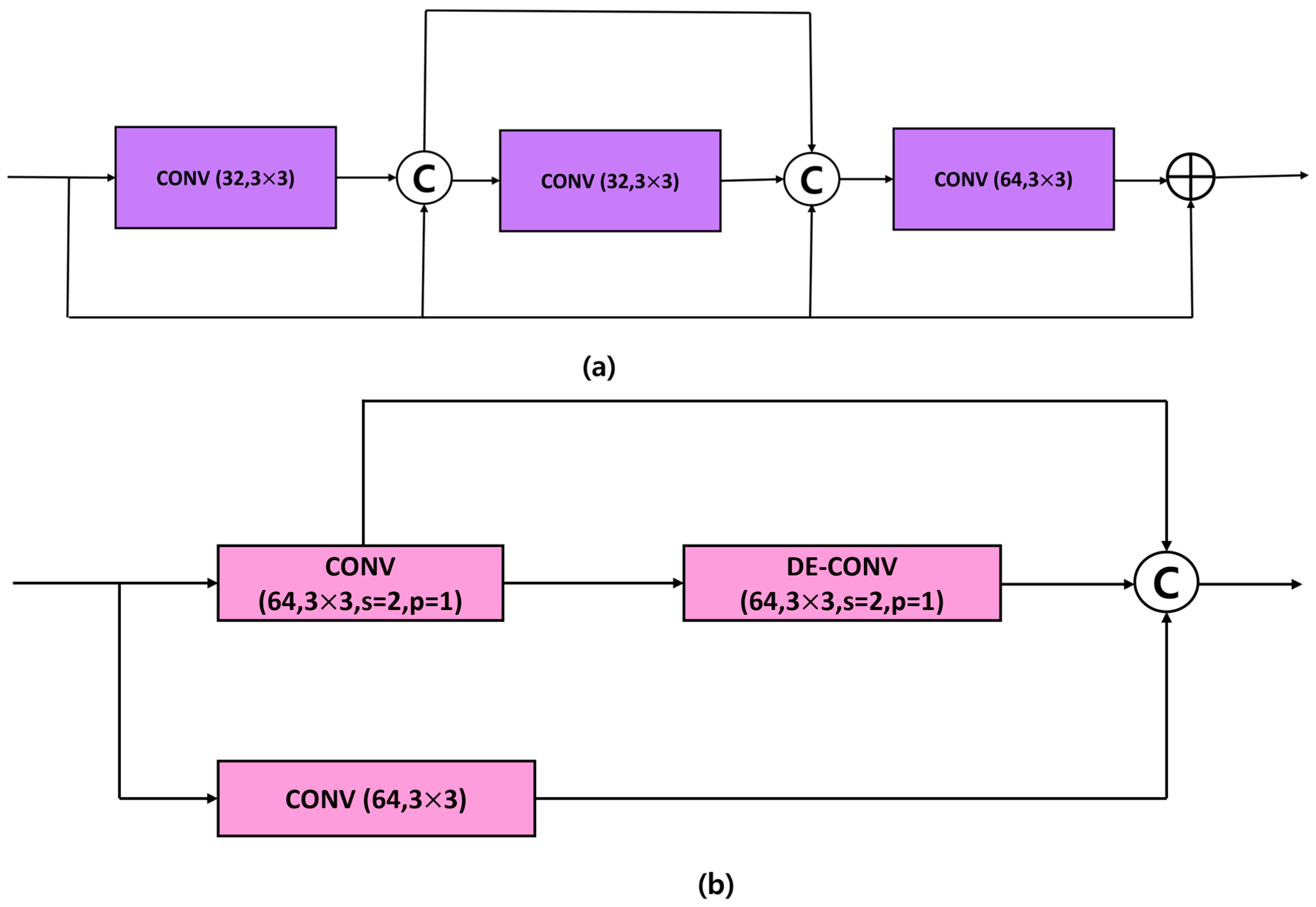
- The proposed network utilizes Deep Residual Blocks (DRBs) and Enhanced Feature Blocks (EFBs) within the generator network, enabling it to learn robust features while effectively training deeper architecture.
- A two-stage training strategy is implemented in which the generator network is initially trained using the Structural Similarity Index Measure (SSIM) loss function, followed by the training of GAN architecture in the second stage, which employs a perceptual loss function.
2. Related Works
2.1. Deep Learning-Based Image Enhancement Approach
2.2. Deep Learning-Based Video Enhancement Approach
3. Proposed Method
3.1. Generator Architecture
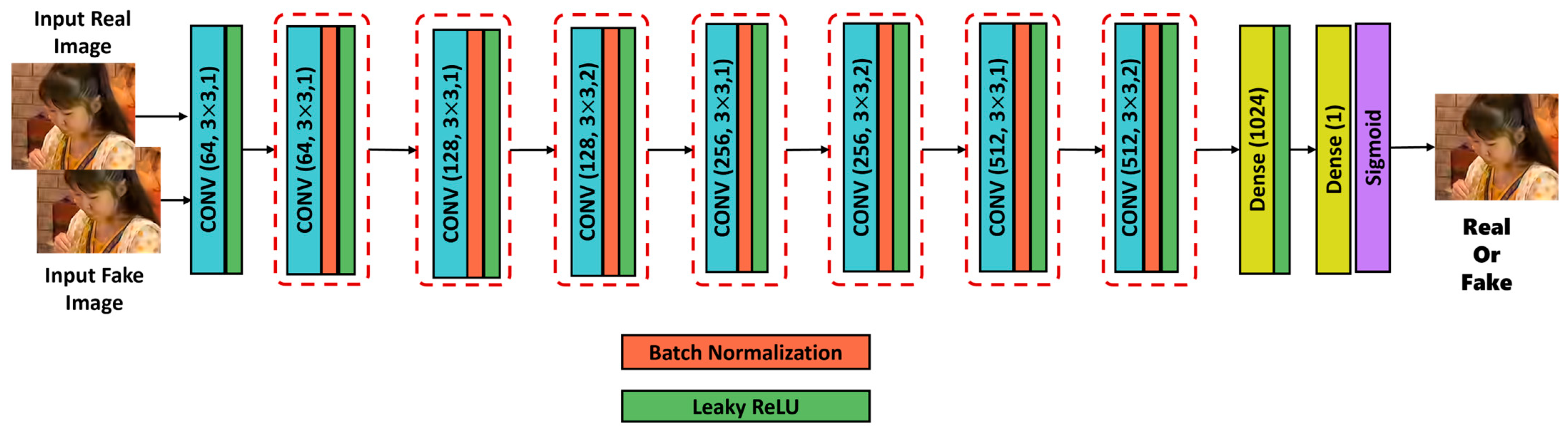
3.2. Discriminator Architecture
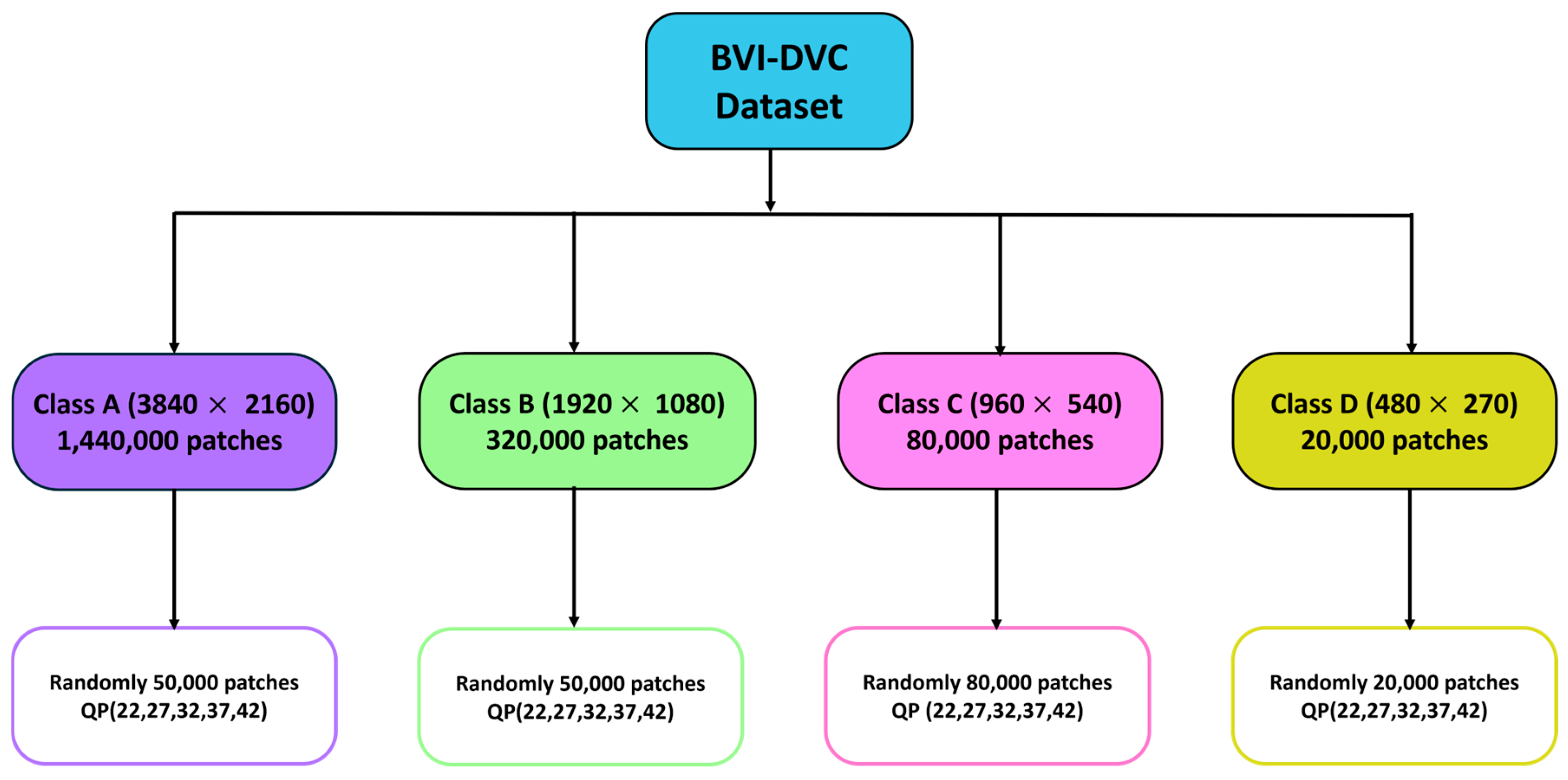
3.3. Train Dataset Preparation
3.4. Training Methodology
- 1.
- Stage I: In stage I for both the RA and AI configurations, the generator model is created using the SSIM [34] loss function. Utilizing SSIM loss in stage I for the generator network offers significant advantages in enhancing the perceptual quality of generated images. SSIM, which focuses on structural similarity, evaluates images based on luminance, contrast, and structural information, allowing the generator to produce outputs that are more visually coherent and aligned with human perception. This focus on structural fidelity helps the generator learn to preserve important details and textures, resulting in images that are not only closer to the target distribution but also more aesthetically pleasing. When transitioning to stage II, where the model operates as a GAN architecture, the foundation established by the SSIM loss ensures that the adversarial training process is more effective. The generator is better equipped to create high quality images that can effectively challenge the discriminator, leading to improved overall performance of the GAN. This synergy between the SSIM loss in the initial training phase and the adversarial framework in the subsequent stage results in a more robust model capable of generating realistic and high-fidelity images. The SSIM loss function is represented as shown in Equation (3):where mean, variance, and covariance for a tile around a pixel are expressed as , , and , respectively. are two constants while calculating contrast and structure components.
- 2.
- Stage II: In stage II, the entire GAN architecture is trained utilizing a perceptual loss function. During this phase, the generator is optimized using a combined loss function denoted as . Equation (4) represents the combined loss for the generator.Here, represents the SSIM loss between the output of the generator and the target, while denotes the loss between the two. The values of γ and η are assigned as 0.025 and 0.005, respectively. Here, γ and η are used to indicate the weights we put on L2 loss and adversarial loss, respectively. Since we are dealing here with a balance between quantitative and qualitative improvements of compressed frames through our proposed model, we had to choose the weights of different components of loss functions very carefully. For example, Structural Multi Similarity Index (SSIM) loss was given the most priority, then L2 loss, and at last the adversarial loss where the discriminator’s network output has influence. In our research the values for γ and η were adopted from [28]. is defined as the adversarial loss for the generator, as illustrated in Equation (5):In this context, represents the probability that the reconstructed image is a real image. N signifies the number of samples.At the same time, the discriminator network is optimized by utilizing the discriminator loss function as stated in (6):where and are discriminator loss for real and fake images, respectively.In the above two equations, and denotes the reference or real image and input image, respectively. Utilizing a combined loss of SSIM loss, mean squared error (MSE) loss, and adversarial loss in a GAN architecture provides several benefits. SSIM loss helps preserve the perceptual quality and structural consistency of the generated images by evaluating similarity at a structural level. MSE loss focuses on pixel-level precision and smoothness, aiding in the refinement of finer details and minimizing high-frequency noise. Adversarial loss pushes the generator to create more realistic images by making them indistinguishable from real ones, enhancing their overall visual quality. This blend of losses encourages the generator to learn both fine-grained details and broader structural patterns, leading to images that are both realistic and visually cohesive. The combined loss provides significant advantages to the discriminator during the second stage of training. In Stage I, the generator is initially trained using SSIM loss, which helps it generate images that closely resemble the structural patterns of real data. In Stage II, as the discriminator is trained, the incorporation of SSIM, MSE, and adversarial losses allows it to better generalize by considering not only pixel-wise differences but also the structural and perceptual characteristics of the images. The adversarial loss enhances the discriminator’s ability to distinguish between real and fake images, while SSIM and MSE losses help evaluate the overall quality and authenticity of the generated images. This comprehensive approach strengthens the discriminator, enabling it to more effectively assess generated images, leading to improved performance and better generalization across various types of images and conditions.
3.5. Training Configuration
4. Experimental Evaluations and Discussion
4.1. Test Environment Configuration
4.2. Quality Metric
- a.
- VMAF: Video Multimethod Assessment Fusion (VMAF) is a perceptual video quality metric developed by Netflix to evaluate the visual quality of compressed and distorted videos in a way that aligns with human perception. VMAF combines multiple quality assessment features, including image quality metrics such as Visual Information Fidelity (VIF) and Detail Loss Metric (DLM), fused by support vector machine (SVM) regression to predict subjective video quality scores accurately. The VMAF score is computed as a weighted combination of these features, where a regression model, typically trained on human opinion scores, maps the extracted features to a final quality prediction. The VMAF model can be represented as:where represent different quality assessment features, and is a machine learning model, often a support vector machine (SVM) or a neural network, trained on a dataset of subjective quality ratings.
- b.
- MS-SSIM: MS-SSIM is a widely used quality assessment metric for evaluating the perceptual similarity between an original and a distorted image. It extends the Structural Similarity Index (SSIM) by considering image structures at multiple scales, thereby improving its correlation with human visual perception. MS-SSIM is computed by progressively downsampling the image and combining SSIM measurements at different scales using a weighted geometric mean. The formulation of MS-SSIM is given by:where and represent the luminance, contrast, and structure components at scale j, respectively, while and are the corresponding weighting factors.
- c.
- BD-Rate: BD-Rate is a widely used metric for evaluating the performance of video codecs, particularly in terms of bitrate efficiency and quality. It quantifies the difference in bitrate required to achieve the same level of video quality between two different encoding methods or codec implementations. The BD-Rate is expressed as a percentage, indicating how much more or less bitrate is needed for one codec to match the quality of another. To calculate BD-Rate, the rate-distortion curves of the two codecs are analyzed, and the area between these curves is computed. A negative BD-Rate indicates that the new codec is more efficient, requiring less bitrate for the same quality, while a positive BD-Rate suggests that it requires more bitrate.
4.3. Experimental Setup
4.4. Quantitative Analysis
4.5. Ablation Study
4.6. Qualitative Analysis
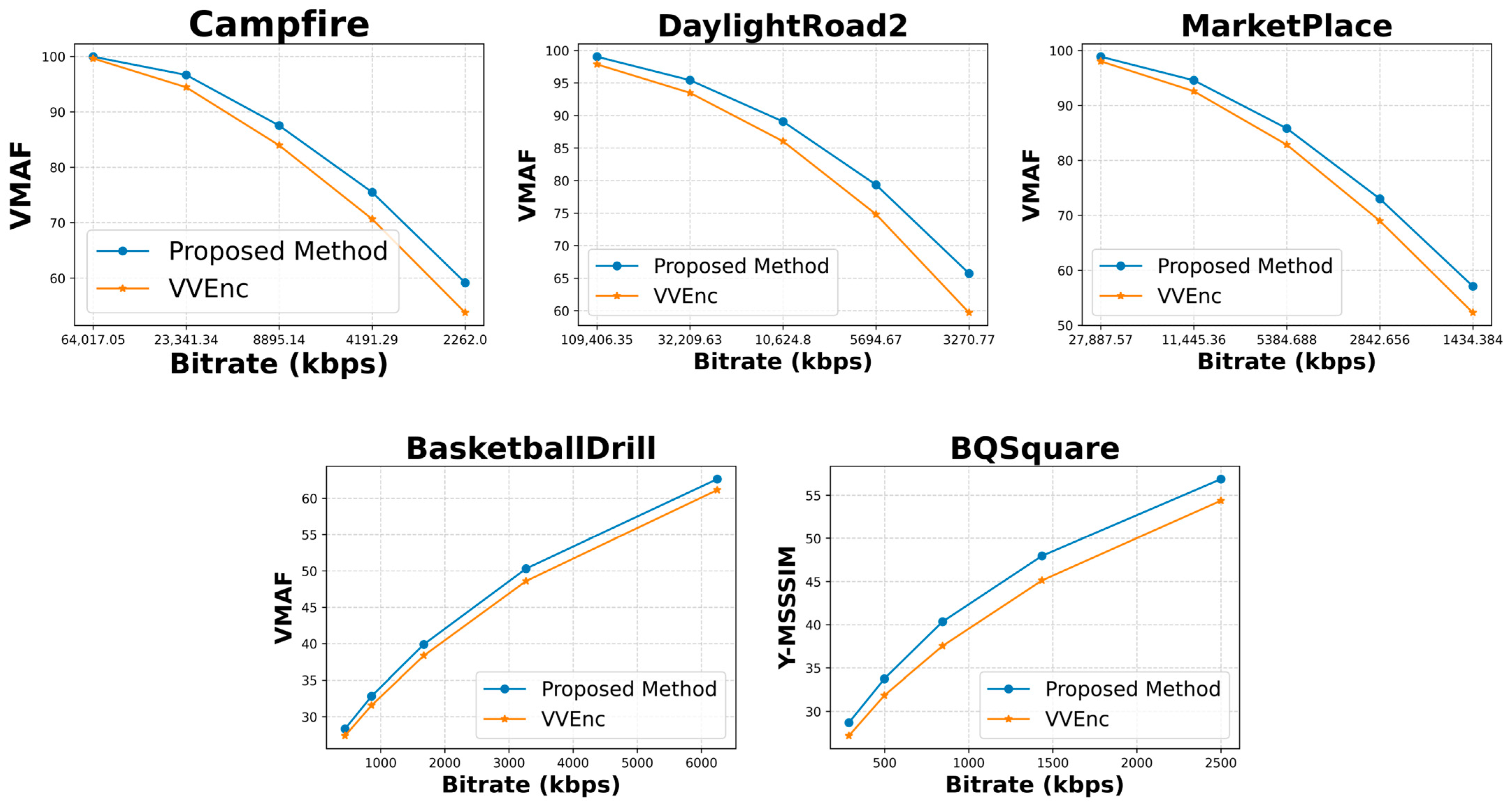
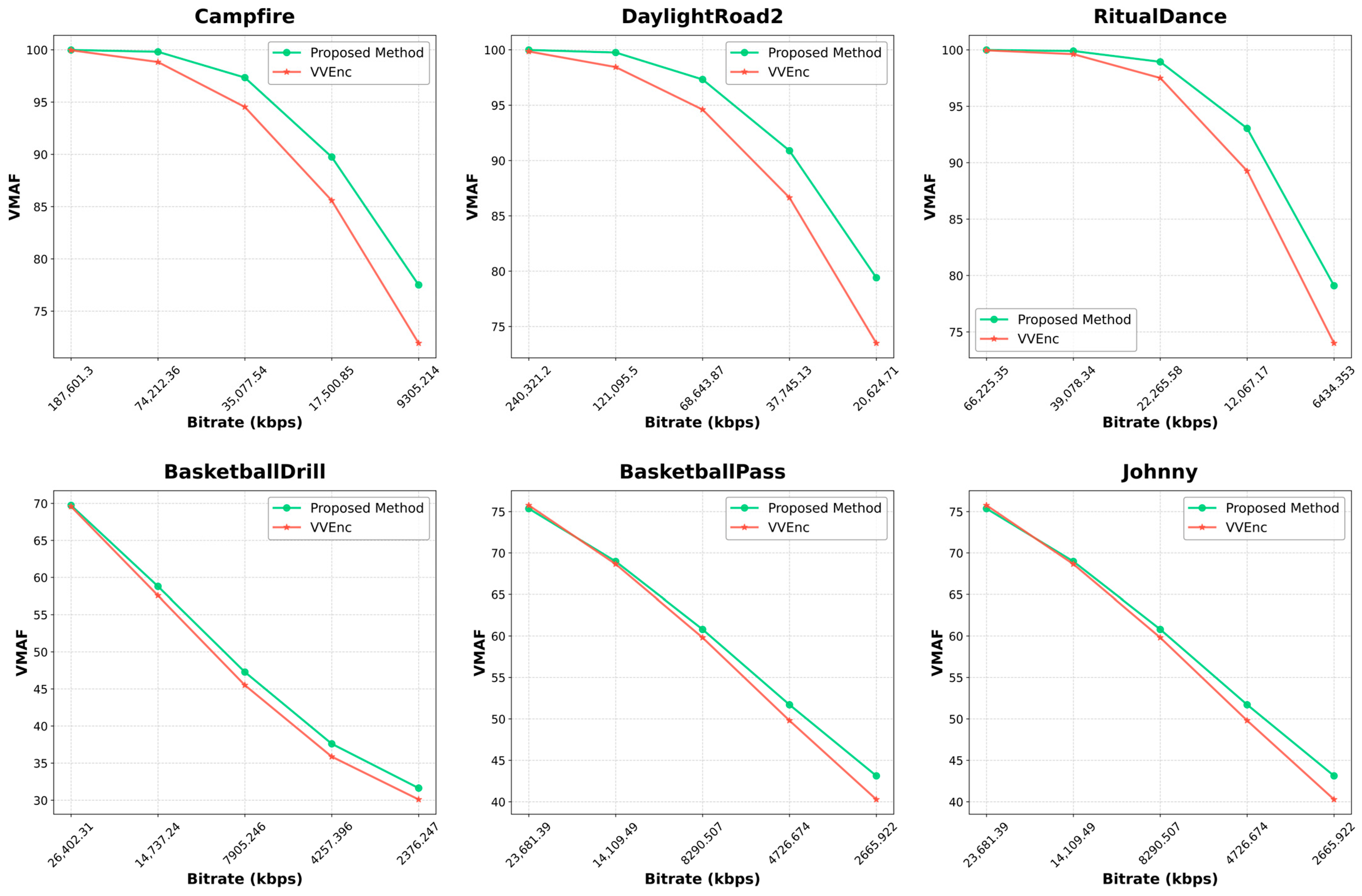
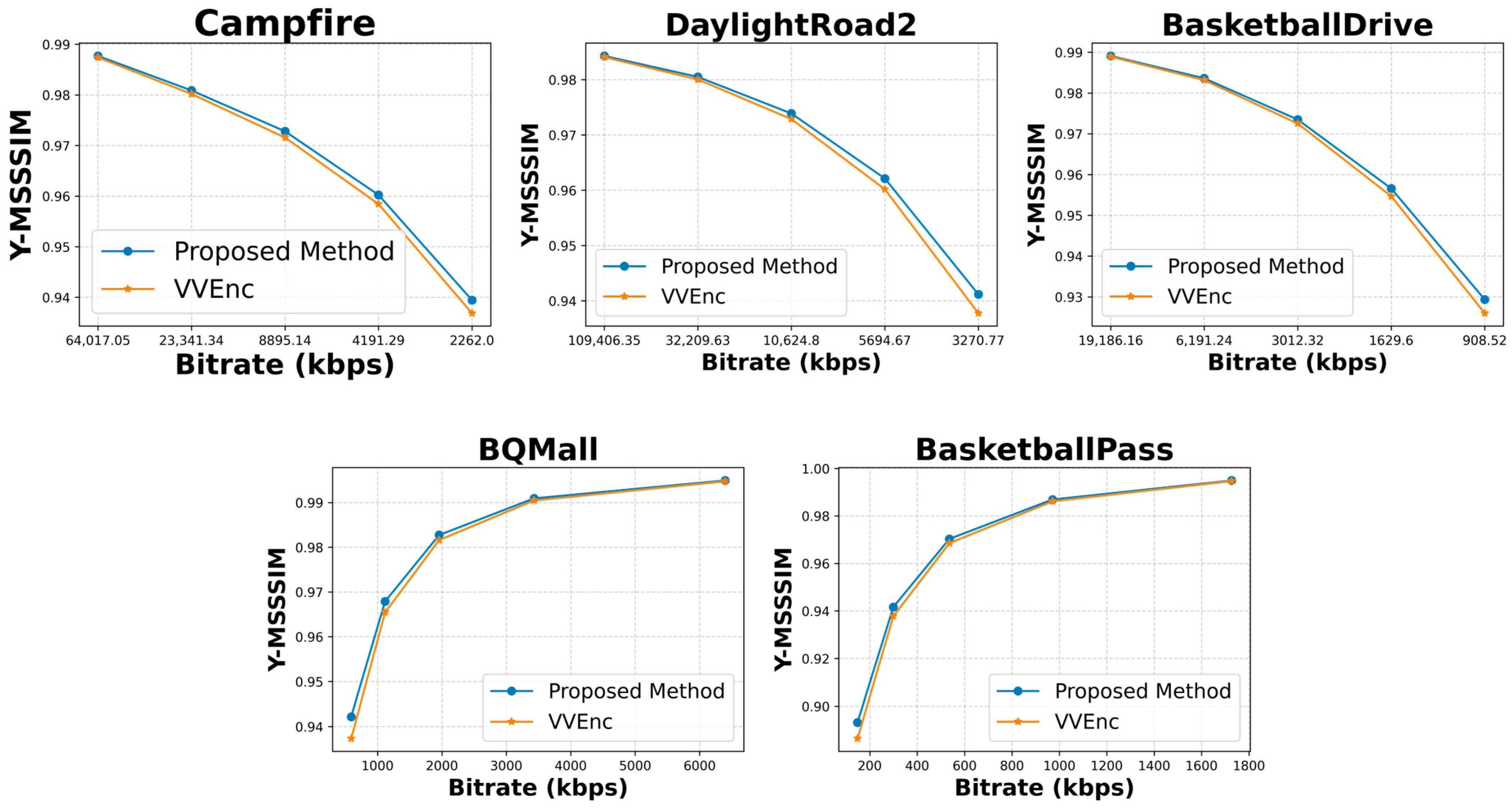
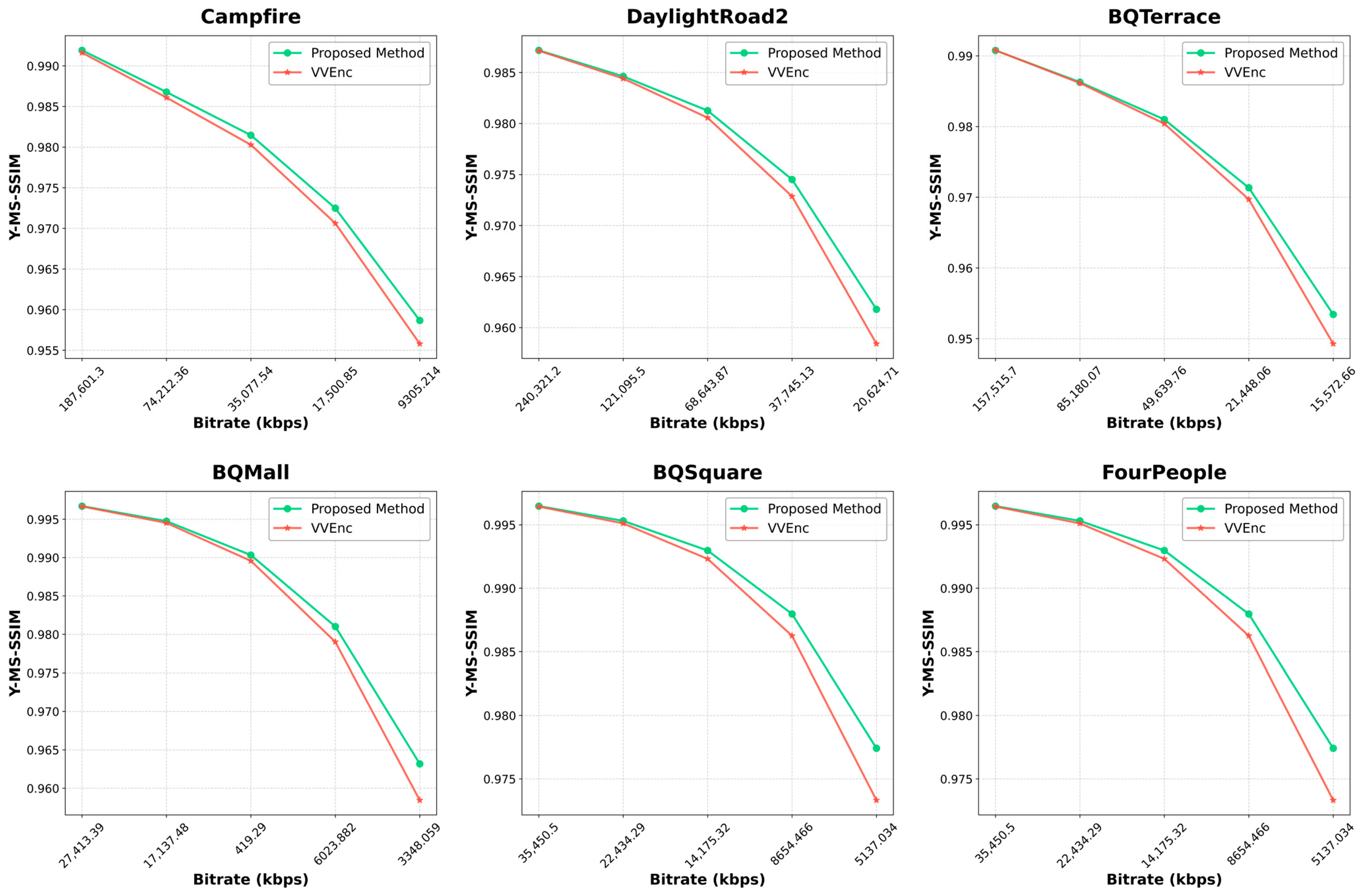
4.7. Rate Distortion Plot Analysis
4.8. Model Complexity
4.9. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A
Selection of Hyperparameters
- Learning rate
- Batch Size
- Number of Epochs
- Optimizer
- Number of residual blocks
- Activation function
- Weight on different components
References
- Sullivan, G.J.; Ohm, J.-R.; Han, W.-J.; Wiegand, T. Overview of the High Efficiency Video Coding (HEVC) Standard. IEEE Trans. Circuits Syst. Video Technol. 2012, 22, 1649–1668. [Google Scholar] [CrossRef]
- Bross, B.; Wang, Y.K.; Ye, Y.; Liu, S.; Chen, J.; Sullivan, G.J.; Ohm, J.R. Overview of the Versatile Video Coding (VVC) Standard and Its Applications. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 3736–3764. [Google Scholar] [CrossRef]
- Xu, S.; Nan, C.; Yang, H. Low-Light Image Enhancement Network Based on Hierarchical Residual and Attention Mechanism. In Proceedings of the 2024 43rd Chinese Control Conference (CCC), Kunming, China, 28–31 July 2024; pp. 7498–7503. [Google Scholar] [CrossRef]
- Zhao, S.; Mei, X.; Ye, X.; Guo, S. MSFE-UIENet: A Multi-Scale Feature Extraction Network for Marine Underwater Image Enhancement. J. Mar. Sci. Eng. 2024, 12, 1472. [Google Scholar] [CrossRef]
- Kalaivani, A.; Jayapriya, P.; Devi, A.S. Innovative Approaches in Deep Neural Networks: Enhancing Performance through Transfer Learning Techniques. In Proceedings of the 2024 3rd International Conference on Automation, Computing and Renewable Systems (ICACRS), Pudukkottai, India, 4–6 December 2024; pp. 857–864. [Google Scholar] [CrossRef]
- Wang, M.-Z.; Wan, S.; Gong, H.; Ma, M.-Y. Attention-Based Dual-Scale CNN In-Loop Filter for Versatile Video Coding. IEEE Access 2019, 7, 145214–145226. [Google Scholar] [CrossRef]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image Super-Resolution Using Deep Convolutional Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 295–307. [Google Scholar] [CrossRef] [PubMed]
- Dong, C.; Loy, C.C.; Tang, X. Accelerating the Super-Resolution Convolutional Neural Network. arXiv 2016, arXiv:1608.00367. [Google Scholar] [CrossRef]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate Image Super-Resolution Using Very Deep Convolutional Networks. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1646–1654. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015; Available online: https://ora.ox.ac.uk/objects/uuid:60713f18-a6d1-4d97-8f45-b60ad8aebbce (accessed on 16 March 2025).
- Tai, Y.; Yang, J.; Liu, X. Image Super-Resolution via Deep Recursive Residual Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2790–2798. [Google Scholar] [CrossRef]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Lee, K.M. Enhanced Deep Residual Networks for Single Image Super-Resolution. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 1132–1140. [Google Scholar] [CrossRef]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.P.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 105–114. [Google Scholar] [CrossRef]
- Wang, X.; Yu, K.; Wu, S.; Gu, J.; Liu, Y.; Dong, C.; Qiao, Y.; Loy, C.C. ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks. In Computer Vision—ECCV 2018 Workshops; Leal-Taixé, L., Roth, S., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2019; Volume 11133, pp. 63–79. [Google Scholar] [CrossRef]
- Rakotonirina, N.C.; Rasoanaivo, A. ESRGAN+: Further Improving Enhanced Super-Resolution Generative Adversarial Network. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–9 May 2020; pp. 3637–3641. [Google Scholar] [CrossRef]
- Cai, J.; Meng, Z.; Ho, C.M. Residual Channel Attention Generative Adversarial Network for Image Super-Resolution and Noise Reduction. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020; IEEE: Seattle, WA, USA, 2020; pp. 1852–1861. [Google Scholar] [CrossRef]
- Wang, W.; Guo, R.; Tian, Y.; Yang, W. CFSNet: Toward a Controllable Feature Space for Image Restoration. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; IEEE: Seoul, Republic of Korea, 2019; pp. 4139–4148. [Google Scholar] [CrossRef]
- Zhao, Y.; Lin, K.; Wang, S.; Ma, S. Joint Luma and Chroma Multi-Scale CNN In-loop Filter for Versatile Video Coding. In Proceedings of the 2022 IEEE International Symposium on Circuits and Systems (ISCAS), Austin, TX, USA, 27 May–1 June 2022; pp. 3205–3209. [Google Scholar] [CrossRef]
- Chen, S.; Chen, Z.; Wang, Y.; Liu, S. In-Loop Filter with Dense Residual Convolutional Neural Network for VVC. In Proceedings of the 2020 IEEE Conference on Multimedia Information Processing and Retrieval (MIPR), Shenzhen, China, 6–8 August 2020; pp. 149–152. [Google Scholar] [CrossRef]
- Huang, Z.; Sun, J.; Guo, X.; Shang, M. One-for-all: An Efficient Variable Convolution Neural Network for In-loop Filter of VVC. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 2342–2355. [Google Scholar] [CrossRef]
- Zhang, H.; Jung, C.; Liu, Y.; Li, M. Lightweight CNN-Based in-Loop Filter for VVC Intra Coding. In Proceedings of the 2023 IEEE International Conference on Image Processing (ICIP), Kuala Lumpur, Malaysia, 8–11 October 2023; pp. 1635–1639. [Google Scholar] [CrossRef]
- Zhang, H.; Liu, Y.; Jung, C.; Liu, Y.; Li, M. RTNN: A Neural Network-Based In-Loop Filter in VVC Using Resblock and Transformer. IEEE Access 2024, 12, 104599–104610. [Google Scholar] [CrossRef]
- Wang, M.; Wan, S.; Gong, H.; Yu, Y.; Liu, Y. An Integrated CNN-based Post Processing Filter For Intra Frame in Versatile Video Coding. In Proceedings of the 2019 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Lanzhou, China, 18–21 November 2019; pp. 1573–1577. [Google Scholar] [CrossRef]
- Zhang, H.; Jung, C.; Zou, D.; Li, M. WCDANN: A Lightweight CNN Post-Processing Filter for VVC-Based Video Compression. IEEE Access 2023, 1, 83400–83413. [Google Scholar] [CrossRef]
- Lin, W.; He, X.; Han, X.; Liu, D.; See, J.; Zou, J.; Xiong, H.; Wu, F. Partition-Aware Adaptive Switching Neural Networks for Post-Processing in HEVC. IEEE Trans. Multimed. 2020, 22, 2749–2763. [Google Scholar] [CrossRef]
- Guan, Z.; Xing, Q.; Xu, M.; Yang, R.; Liu, T.; Wang, Z. MFQE 2.0: A New Approach for Multi-Frame Quality Enhancement on Compressed Video. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 949–963. [Google Scholar] [CrossRef] [PubMed]
- Ma, D.; Zhang, F.; Bull, D.R. MFRNet: A New CNN Architecture for Post-Processing and In-loop Filtering. IEEE J. Sel. Top. Signal Process. 2021, 15, 378–387. [Google Scholar] [CrossRef]
- Zhang, F.; Ma, D.; Feng, C.; Bull, D.R. Video Compression with CNN-based Post Processing. IEEE Multimed. 2021, 28, 74–83. [Google Scholar] [CrossRef]
- Das, T.; Liang, X.; Choi, K. Versatile Video Coding-Post Processing Feature Fusion: A Post-Processing Convolutional Neural Network with Progressive Feature Fusion for Efficient Video Enhancement. Appl. Sci. 2024, 14, 8276. [Google Scholar] [CrossRef]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks. arXiv 2016, arXiv:1511.06434. [Google Scholar] [CrossRef]
- Ma, D.; Zhang, F.; Bull, D.R. BVI-DVC: A Training Database for Deep Video Compression. IEEE Trans. Multimed. 2022, 24, 3847–3858. [Google Scholar] [CrossRef]
- Wieckowski, A.; Brandenburg, J.; Hinz, T.; Bartnik, C.; George, V.; Hege, G.; Helmrich, C.; Henkel, A.; Lehmann, C.; Stoffers, C.; et al. Vvenc: An Open And Optimized Vvc Encoder Implementation. In Proceedings of the 2021 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), Shenzhen, China, 5–9 July 2021; pp. 1–2. [Google Scholar] [CrossRef]
- Wieckowski, A.; Hege, G.; Bartnik, C.; Lehmann, C.; Stoffers, C.; Bross, B.; Marpe, D. Towards A Live Software Decoder Implementation For The Upcoming Versatile Video Coding (VVC) Codec. In Proceedings of the 2020 IEEE International Conference on Image Processing (ICIP), Abu Dhabi, United Arab Emirates, 25–28 October 2020; pp. 3124–3128. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2017, arXiv:1412.6980. [Google Scholar] [CrossRef]
- Alshina, E.; Liao, R.-L.; Liu, S.; Segall, A. JVET common test conditions and evaluation procedures for neural network based video coding technology. In Proceedings of the Joint Video Experts Team (JVET) 30th Meeting, JVET-AC2016-v1, Virtually, 23–27 January 2023. [Google Scholar]
- Wang, Z.; Simoncelli, E.P.; Bovik, A.C. Multiscale structural similarity for image quality assessment. In Proceedings of the Thrity-Seventh Asilomar Conference on Signals, Systems & Computers, Pacific Grove, CA, USA, 9–12 November 2003; Volume 2, pp. 1398–1402. [Google Scholar] [CrossRef]
- Blog, N.T. Toward A Practical Perceptual Video Quality Metric. Medium. Available online: https://netflixtechblog.com/toward-a-practical-perceptual-video-quality-metric-653f208b9652 (accessed on 6 November 2023).
- Bjontegaard, G. Calculation of average PSNR differences between RD-curves. In Proceedings of the Video Coding Experts Group (VCEG) Thirteenth Meeting, VCEG-M33, Austin, TX, USA, 2–4 April 2001. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: San Francisco, CA, USA, 2019; Available online: https://proceedings.neurips.cc/paper/2019/hash/bdbca288fee7f92f2bfa9f7012727740-Abstract.html (accessed on 4 March 2023).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Sequence | BD-Rate (%) | |||
|---|---|---|---|---|---|
| VMAF | Y-MSSSIM | U-MSSSIM | V-MSSSIM | ||
| A1 | Tango2 | −15.11% | −5.99% | −29.82% | −21.67% |
| FoodMarket4 | −12.80% | −4.16% | −12.14% | −13.81% | |
| Campfire | −22.05% | −7.54% | −11.88% | −27.63% | |
| Average | −16.65% | −5.90% | −17.95% | −21.04% | |
| A2 | CatRobot | −20.47% | −6.62% | −23.29% | −17.91% |
| DaylightRoad2 | −24.47% | −7.57% | −25.71% | −22.67% | |
| ParkRunning3 | −11.58% | −2.97% | −7.31% | −7.31% | |
| Average | −18.84% | −5.72% | −18.77% | −15.97% | |
| B | MarketPlace | −17.44% | −3.41% | −21.26% | −17.61% |
| RitualDance | −14.81% | −4.52% | −16.56% | −18.46% | |
| Cactus | −6.52% | −4.61% | −20.42% | −15.71% | |
| BasketballDrive | −12.92% | −5.00% | −20.58% | −23.12% | |
| BQTerrace | −9.16% | −4.70% | −15.99% | −21.03% | |
| Average | −12.17% | −4.45% | −18.96% | −19.19% | |
| C | BasketballDrill | −10.70% | −4.55% | −21.31% | −25.82% |
| BQMall | −8.29% | −6.61% | −20.63% | −22.37% | |
| PartyScene | −9.54% | −4.27% | −7.46% | −13.21% | |
| RaceHorses | −7.45% | −3.54% | −17.94% | −23.26% | |
| Average | −8.99% | −4.74% | −16.83% | −21.17% | |
| D | BasketballPass | −13.80% | −5.72% | −24.88% | −23.22% |
| BQSquare | −17.32% | −5.49% | −14.73% | −23.12% | |
| BlowingBubbles | −4.30% | −3.90% | −14.17% | −14.11% | |
| RaceHorses | −9.17% | −3.87% | −21.56% | −24.52% | |
| Average | −11.15% | −4.74% | −18.83% | −21.24% | |
| Overall | −13.05% | −5.00% | −18.30% | −19.82% | |
| Class | Sequence | BD-Rate (%) | |||
|---|---|---|---|---|---|
| VMAF | Y-MSSSIM | U-MSSSIM | V-MSSSIM | ||
| A1 | Tango2 | −17.14% | −5.58% | −17.81% | −14.78% |
| FoodMarket4 | −17.54% | −5.21% | −12.75% | −13.50% | |
| Campfire | −26.35% | −10.06% | −5.79% | −17.43% | |
| Average | −20.34% | −6.95% | −12.12% | −15.24% | |
| A2 | CatRobot | −23.01% | −8.72% | −15.34% | −15.18% |
| DaylightRoad2 | −26.12% | −8.70% | −20.62% | −18.84% | |
| ParkRunning3 | −16.24% | −2.19% | −4.99% | −8.24% | |
| Average | −21.79% | −6.54% | −13.65% | −14.09% | |
| B | MarketPlace | −18.75% | −3.87% | −17.28% | −14.72% |
| RitualDance | −20.80% | −5.15% | −15.97% | −16.70% | |
| Cactus | −1.90% | −5.35% | −10.94% | −13.84% | |
| BasketballDrive | −7.21% | −5.10% | −16.24% | −19.75% | |
| BQTerrace | −3.51% | −5.77% | −14.90% | −18.23% | |
| Average | −10.44% | −5.05% | −15.07% | −16.65% | |
| C | BasketballDrill | −8.40% | −4.82% | −16.89% | −23.17% |
| BQMall | −6.53% | −7.58% | −17.91% | −20.24% | |
| PartyScene | −4.67% | −4.14% | −10.12% | −13.83% | |
| RaceHorses | −4.85% | −3.74% | −12.94% | −17.88% | |
| Average | −6.11% | −5.07% | −14.46% | −18.78% | |
| D | BasketballPass | −9.73% | −4.28% | −20.27% | −22.92% |
| BQSquare | −7.92 | −5.34% | −10.69% | −15.21% | |
| BlowingBubbles | −1.72% | −4.42% | −13.04% | −14.27% | |
| RaceHorses | −7.47% | −3.31% | −18.54% | −22.08% | |
| Average | −6.71% | −4.34% | −15.64% | −18.62% | |
| E | FourPeople | −3.52% | −10.01% | −11.67% | −14.92% |
| Johnny | −6.78% | −8.61% | −16.59% | −18.06% | |
| KristenAndSara | −3.74% | −7.28% | −12.13% | −15.92% | |
| Average | −4.68% | −8.63% | −13.47% | −16.30% | |
| Overall | −11.09% | −5.87% | −14.25% | −16.81% | |
| Class | VVC-PPFF [29] | Proposed | ||||||
|---|---|---|---|---|---|---|---|---|
| BD-Rate (%) | BD-Rate (%) | |||||||
| VMAF | Y-MSSSIM | U-MSSSIM | V-MSSIM | VMAF | Y-MSSSIM | U-MSSSIM | V-MSSIM | |
| A1 | −5.78% | −3.89% | −14.59% | −15.67% | −16.55% | −5.90% | −17.95% | −21.04% |
| A2 | −4.43% | −3.54% | −14.83% | −10.52% | −18.84% | −5.72% | −18.77% | −15.97% |
| B | 1.16% | −2.78% | −16.21% | −15.13% | −12.17% | −4.45% | −18.96% | −19.19% |
| C | −3.82% | −3.94% | −16.48% | −17.60% | −8.99% | −4.74% | −16.83% | −21.17% |
| D | −4.38% | −3.58% | −16.32% | −17.00% | −11.15% | −4.74% | −18.83% | −21.24% |
| Overall | −3.04% | −3.49% | −15.82% | −15.40% | −13.05% | −5.00% | −18.30% | −19.82% |
| Class | Proposed | [28] | ||
|---|---|---|---|---|
| BD-Rate (%) | BD-Rate (%) | |||
| VMAF | Y-PSNR | VMAF | Y-PSNR | |
| A | −18.06% | −11.57% | −11.7% | +0.1% |
| B | −12.17% | −4.83% | −16.05% | 0.0% |
| C | −9.3% | −4.78% | −13.05% | −1.2% |
| D | −11.4% | −5.88% | −13.4% | −2.45% |
| Overall | −13.27% | −5.20% | −13.85% | −0.9% |
| Class | Excluded Part | |||
|---|---|---|---|---|
| DRB | QP Map | |||
| RA | AI | RA | AI | |
| C | −2.37% | +2.58% | −0.27% | +1.49% |
| D | −2.40% | +2.66% | −0.19% | +0.57% |
| Class | Resolution | Inference Time/Frame | FLOPs (G) | Total Parameters (M) |
|---|---|---|---|---|
| A1 | 3840 × 2160 | 6~7 s | 8769 | 2.14 |
| A2 | 3480 × 2160 | 6~7 s | 8768 | 2.14 |
| B | 1920 × 1080 | ~3 s | 2192 | 2.14 |
| C | 832 × 480 | <1 s | 422.5 | 2.14 |
| D | 416 × 240 | <1 s | 105.5 | 2.14 |
| E | 1280 × 720 | ~2 s | 974 | 2.14 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Das, T.; Choi, K. DREFNet: Deep Residual Enhanced Feature GAN for VVC Compressed Video Quality Improvement. Mathematics 2025, 13, 1609. https://doi.org/10.3390/math13101609
Das T, Choi K. DREFNet: Deep Residual Enhanced Feature GAN for VVC Compressed Video Quality Improvement. Mathematics. 2025; 13(10):1609. https://doi.org/10.3390/math13101609
Chicago/Turabian StyleDas, Tanni, and Kiho Choi. 2025. "DREFNet: Deep Residual Enhanced Feature GAN for VVC Compressed Video Quality Improvement" Mathematics 13, no. 10: 1609. https://doi.org/10.3390/math13101609
APA StyleDas, T., & Choi, K. (2025). DREFNet: Deep Residual Enhanced Feature GAN for VVC Compressed Video Quality Improvement. Mathematics, 13(10), 1609. https://doi.org/10.3390/math13101609