1. Introduction
Uncertainty is prevalent in decision-making processes across various domains, such as maritime logistics. When confronted with uncertain parameters in objective functions, a conventional approach involves transforming stochastic problems into deterministic formulations. A prominent methodology in this context is the Sample Average Approximation (SAA) method, which substitutes the true distributions of random variables with their empirical distributions, derived from observed samples [
1]. However, practical implementations reveal that SAA cannot obtain the optimal decisions in some cases [
2]. This limitation stems from SAA’s reliance on empirical distributions that inadequately capture the underlying stochastic characteristics of the true distributions. In contrast, distribution estimation techniques offer enhanced capabilities for data characterization, thereby providing more informative insights for decision making, especially for few-shot scenarios, as only a limited number of samples are available for decisions, hindering the model’s ability to effectively learn their characteristics.
The ship fleet deployment problem (SFDP), as a classical challenge in maritime logistics, focuses on optimizing ship allocation strategies to satisfy transport demand. The SFDP has been used for reducing carbon emissions [
3,
4], reducing delivery costs [
5], and enhancing market efficiency [
6]. Under the uncertainty of demand, this stochastic programming problem becomes particularly complex when determining fleet sizes, given the inherent randomness of cargo demand between port pairs [
7]. Developing reliable solutions for the SFDP under uncertain demand holds significant potential for enhancing operational efficiency and management quality for shipping companies.
To solve the SFDP under uncertain demand, we adopt the Sample Distribution Approximation (SDA) method. This method leverages historical data to estimate a probabilistic distribution that characterizes the random variables in the objective function—specifically, the stochastic demand in the SFDP. While numerous techniques exist for demand distribution estimation, the challenge lies in selecting an optimal estimation method. Inspired by the leave-one-out cross-validation (LOOCV) framework from machine learning [
8,
9], we iteratively exclude a single data point to train the distribution estimator, then evaluate its performance based on the decision cost metrics, rather than using the traditional predictive accuracy measures. This approach explicitly integrates distribution estimation with downstream decision optimization. Finally, the selected estimator leverages the complete dataset to generate the final distribution and make decisions based on it.
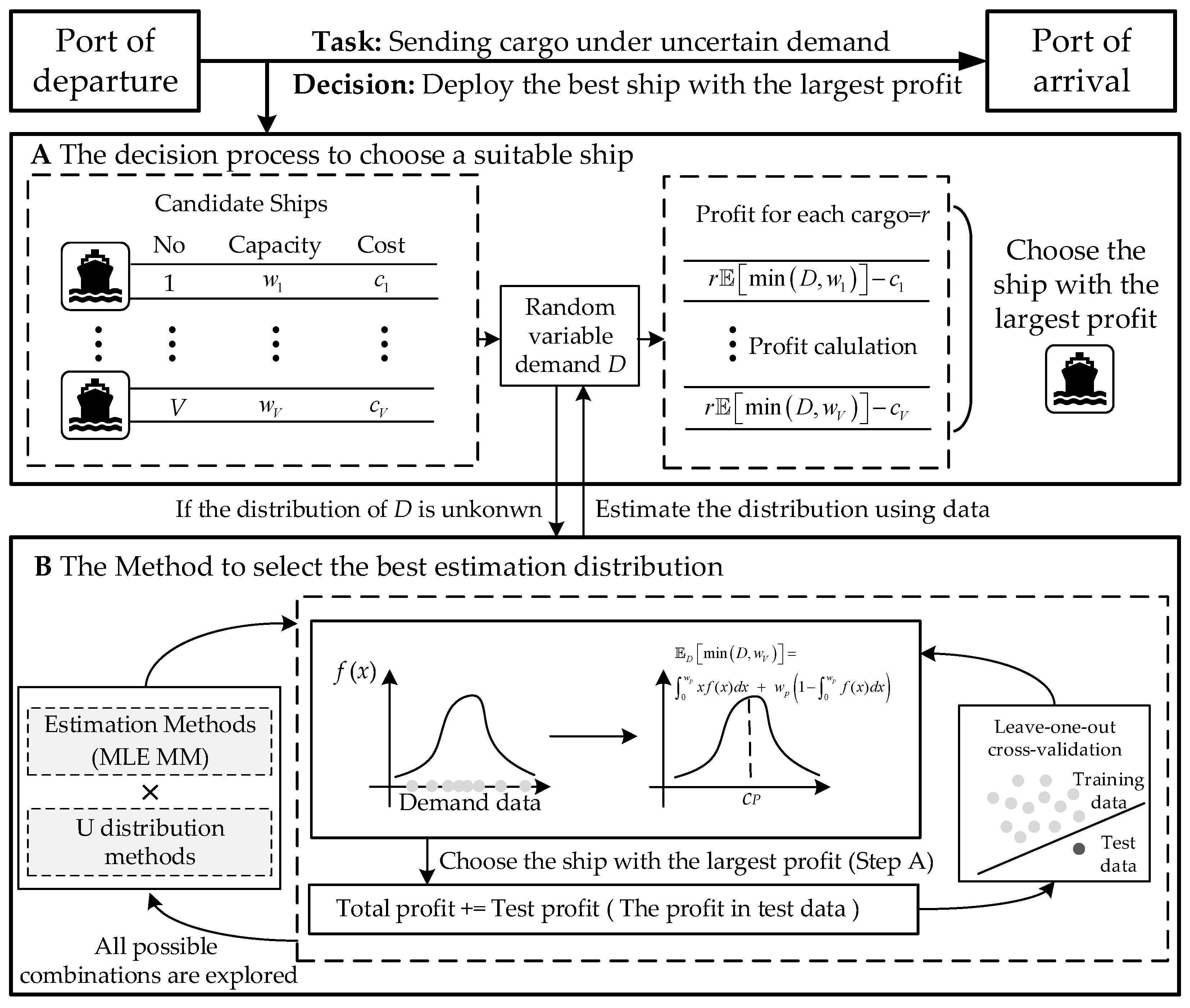
The overall workflow of our method is illustrated in
Figure 1. Specifically,
Figure 1A depicts the decision-making process used to select suitable ships based on estimated demand distributions, while
Figure 1B shows the procedure for choosing the best-fitting estimation method using LOOCV, with decision cost as the evaluation criterion. Together, these components highlight how our framework combines data-driven estimation with robust operational decision-making. The core contributions of this paper lie in the following:
SDA for stochastic demand modeling: This method leverages historical data to construct an empirical probability distribution, explicitly modeling demand uncertainty in the SFDP through data-driven distribution estimation.
Integration of LOOCV with decision-based evaluation: Unlike traditional approaches that focus on predictive accuracy, this framework validates distribution estimators based on their impacts on downstream decision costs.
Demonstrated superiority under realistic operational settings: Extensive computational experiments show that SDA outperforms SAA, particularly in practical fleet deployment scenarios involving two to six candidate vessel types, offering shipping operators more reliable decisions under uncertainty.
The remainder of this paper is organized as follows.
Section 2 reviews existing studies relevant to this work.
Section 3 introduces the SFDP and its SAA model.
Section 4 introduces the SDA method.
Section 5 presents the results of numerical experiments.
Section 6 concludes this paper.
2. Literature Review
The SFDP, as a pivotal operational challenge in maritime transportation, focuses on optimizing vessel allocation to meet shipping demands efficiently. Perakis and Jaramillo [
10,
11] pioneered a linear programming model to minimize fleet operational costs, establishing a theoretical foundation for subsequent research. Subsequent studies further explored deterministic model formulations and solution methodologies, developing approaches such as mixed-integer programming [
12,
13]. However, most studies on the SFDP are concerned with models and solution methods under deterministic contexts, where all the parameters, especially shipment demand, are given before making fleet deployment decisions [
12,
13,
14,
15,
16,
17]. Optimization problems with stochastic parameters also have wide applications in fields like transportation and logistics. For example, our approach can be used in ship berthing management [
18], service network design [
19], and hub-and-spoke network design [
20], all of which require managing uncertainty in demand.
To address real-world stochasticity, recent research has shifted toward demand uncertainty modeling [
21,
22].
Table 1 outlines four general methods for the SFDP and highlights their respective limitations. In addition to the deterministic optimization mentioned before, Meng et al. [
23] proposed a two-stage stochastic programming framework, incorporating container transshipment mechanisms, employing SAA combined with Lagrangian relaxation to maximize expected profits. Wang et al. [
24] proposed an FDP model with a joint-chance constraint, used to guarantee the probability of demand satisfied by all of the service routes, also utilizing SAA for obtaining approximate solutions. Some works [
25] introduced distribution-free models that eliminated traditional probabilistic assumptions, requiring only demand parameters (mean, standard deviation, and upper bounds) for optimization. Stochastic programming has also been adopted in the SFDP, which often involves multi-stage planning issues [
26,
27,
28]. Initial deployment decisions should be made at the outset, with subsequent adjustments based on actual requirements [
29]. At the same time, some robust optimization frameworks are used for fleet deployment problems [
30,
31,
32]. Furthermore, Zhang et al. [
33] employed a distributionally robust optimization framework to address a fleet deployment problem with stochastic route-based shipment demands, incorporating distributional robust chance constraints to manage the risk of unmet demand. With the development of artificial intelligence technologies, machine learning models are used to predict demand distribution or construct approximate models, which are integrated with optimization models to form end-to-end learning, and this approach has been applied to maritime transportation problems [
8,
18]. Among these methods, SAA is simple to implement, scalable to large instances, and works well with real-world data. It does not require exact knowledge of the underlying distribution, relying on empirical data for approximation. Summarizing the above methods, by bringing in the empirical distribution of observations, SAA has become a typical approach to addressing the SFDP.
SAA is a numerical method widely applied to stochastic optimization problems. Its core idea is to approximate the intractable expected objective function through the empirical distribution of random variables. Since the 1990s, SAA has gradually become an effective tool for solving high-dimensional stochastic programming and risk optimization problems. The theoretical foundation of SAA stems from the law of large numbers and asymptotic analysis in stochastic programming [
36]. Shapiro et al. [
37] systematically proved that, as the sample size approaches infinity, the optimal solutions and values of SAA almost surely converge to those of the true problem, with a convergence rate independent of the problem’s dimensionality. Kleywegt et al. [
1] further explored its performance under finite samples, proposing sample size selection strategies to balance computational costs with solution reliability. However, current challenges reveal that large-scale problems require massive samples, leading to a significant increase in computational time. Meanwhile, practical implementations reveal that SAA cannot obtain the optimal decisions in some cases [
1]. Furthermore, SAA uses all historical data for training, but lacks a systematic understanding of the underlying patterns within the data. When the sample size is small, this may lead to decision errors due to insufficient information. On the other hand, with large sample sizes, SAA may overfit to redundant or noisy data, which can also negatively affect decision quality [
38,
39,
40,
41]. Considering the limited demand data in the SFDP, the SAA method may be restricted by the lack of effective information, leading to solutions with poor robustness. Therefore, we introduce the SDA method, replacing the empirical distribution with an estimated distribution, where the same approach has been adopted in relevant studies [
1,
23,
24,
37], to account for more complex distribution forms, thereby enhancing the robustness of the solution in addressing future demand.
3. Problem Statement
This section provides a general overview of the SFDP. The problem is visualized in
Figure 1A. Consider a ship fleet deployment problem on a route connecting two ports with random demand, denoted by
. Consider that there are
candidate ships. One, and only one, ship will be deployed. Suppose ship
has a known cost
and capacity
(
). Without loss of generality, we assume
and
. Based on the economies of scale, these parameters should satisfy the following requirement:
The known revenue from shipping one container is denoted by
. We further assume that
, which means that the ship must generate a profit when fully loaded. The distribution of the demand is denoted by
. We let
be a binary decision variable that equals 1 if ship
is deployed (
) and equals 0 otherwise. The SFDP under the uncertain demand is formulated as follows:
subject to the following:
Objective function (2) aims to maximize the expected profit from shipping containers. Constraint (3) requires that only one ship can and must be used. Constraints (4) define the binary variables.
Nevertheless, we do not know the distribution
, but only have a sample
of independent and identically distributed (
) observations. One typical method is to use the empirical distribution to approximate the distribution
. Thus, we can transform the stochastic program into a deterministic program, following the SAA method, shown as follows:
subject to Constraints (3) and (4). Objective function (5) uses the empirical distribution to approximate
and maximizes the average profit from transporting containers, given the empirical distribution.
4. Methodology
4.1. The Optimal Solution Under an Estimated Distribution
In this paper, we propose a method to solve the stochastic program by using the estimated distribution.
Figure 1 presents the overall algorithm design of SDA, including the selection of the optimal demand distribution and the most suitable estimation method. For each deterministic problem corresponding to a given dataset, its optimal solution is uniquely determined when the distribution of
is estimated. Assuming that we have obtained the parameterized demand probability density function (PDF)
through the data samples
, where
is the demand quantity, under Constraints (3) and (4), we obtain
feasible solutions by enumeration. Let
denote the solution vector, where the
-th entry is set to 1 (i.e.,
) and, in all other entries,
for
(
). Here,
, meaning there are
feasible solution vectors
.
By systematically evaluating each candidate solution
(
) and computing their corresponding objective function values, we identify the optimal solution by comparing these values. This reduces the problem to calculating the objective function values under all possible feasible solutions. Under the solution vector
(
), the value of Objective function (2) is computed as follows:
The central task now focuses on rigorously characterizing the distribution of
and calculating its expectation
under the true distribution
F. To formalize this, note that the random variable
exhibits a mixed distribution comprising both continuous and discrete components. For the continuous region
,
, inheriting the original distribution of
truncated at
. The PDF remains
for
, scaled by the cumulative probability
. For the discrete part, when
, the minimum value collapses to
, creating the following discrete probability mass:
The expectation
is therefore decomposed into the following two components:
Thus, the optimal solution
can be mathematically expressed as the solution vector that maximizes the objective function value
, shown as follows:
where
is as follows:
4.2. Methodology for Determining the Estimation Method
The key challenge lies in determining the optimal estimation methodology. Specifically, we can employ common parametric distributions like normal, uniform, lognormal, and Poisson for our analysis, estimating their parameters through two distinct approaches: maximum likelihood estimation (MLE) and method of moments (MM). Therefore, suppose we have historical data, and assume that we calibrate a total of distributions. We will have methods (each distribution is estimated using two methods, MLE and MM).
MLE identifies parameter values that maximize the likelihood function, which measures the probability of observing the given data under a specific distribution. For a parametric distribution with parameter set
and independent observations of demand
, the likelihood function is defined as follows:
where
is the probability density/mass function. To simplify computations, we often maximize the following log-likelihood function:
The MLE estimate
is obtained by solving the following:
MM estimates parameters by equating sample moments to theoretical moments. is the number of parameters to be estimated. The basic idea of MM is to calculate the moments of population and sample. The moments of the same order are then made equal in one-to-one correspondence. Assume the PDF has unknown parameters . The population moments and sample moments are defined as follows.
For population moments, after ensuring the PDF, we can calculate the function of the
-th moment about parameters
.
where
is a function of the parameters
.
For sample moments, the
-th sample moment calculated from the observed sample
is as follows:
The core idea of the MM is to equate the population moments to the sample moments
This forms the following system of equations:
By solving the system of equations, we obtain the estimated parameters
. Then, we can obtain the PDF of distribution with estimated
.
In method selection and parameter estimation, different combinations of distributional assumptions and estimation methods often exhibit significant performance differences. For instance, MLE provides asymptotically efficient and unbiased estimates when the distribution is correctly specified, but it is sensitive to model misspecification. In contrast, MM, while computationally simpler and more robust than distributional assumptions, may yield estimators with larger variances. Furthermore, the characteristics of different distributions—such as the symmetry of the normal distribution or the discreteness of the Poisson distribution—can lead to divergent performances of the same estimation method across scenarios. To identify the optimal estimation strategy, it is essential to systematically evaluate all possible combinations.
In order to evaluate these methods, we train each method times, using training examples, and evaluate the method over only one validation example. That is, for each method, we use LOOCV to assess the performance (here, performance means decision cost). After selecting the optimal estimation method, we can utilize all available examples to estimate the distribution. The estimated distribution can then be used for decision making.
The pseudo-code of the SDA method is shown in Algorithm 1.
| Algorithm 1. The pseudo-code of the SDA method. |
Input: Ship cost , ship capacity , the revenue from shipping one container , candidate parameter estimation method and some demand sample of observations.
Output: The optimal solution
For each method in candidate methods:
Set to initialize evaluation metric
For :
Remove the
-th sample to form the training set:
Use method to estimate parameters from , obtaining the distribution .
Determine the optimal solution based on (9).
Calculate the value of profit under the demand and solution.
Update .
Select optimal method .
Use method and recompute on the full dataset .
Based on the estimated , determine the optimal solution based on (9).
Output: The optimal solution |
5. Case Study
5.1. Parameter Settings
To demonstrate the universality of the SDA method, we developed a systematic parameter generation approach with the following implementation steps. We firstly discussed the attribute parameters of the fleet, including the number of ships, their capacities, and their costs. The primary parameter configuration began with determining the number of ship types (
), which required satisfying the fundamental condition specified in Constraint (1). Accordingly, we established the critical relationship between ship capacities and costs through the following derivation. The progressive ratio between adjacent ship types
follows a linearly decreasing pattern, as follows:
Specifically, we set
. This ensured the cost increment decreased proportionally with ship type indexation.
We defined ship capacities using an arithmetic progression scheme, as follows:
This linear scaling provided consistent capacity increments across ship types. The number of ship types (i.e., the number of ships) ranges from 2 to 10.
Through simultaneous application of these equations, we could systematically generate a complete parameter set for any specified
value. To further clarify the parameter settings,
Table 2 presents a concrete implementation when
, showing the derived parameters for four distinct ship types. The results validate the parameter generation methodology, while maintaining compliance with the fundamental Constraint (1).
Next, we set the profit of each container , according to the assumption that . The candidate fitting distributions included the normal distribution, uniform distribution, log-normal distribution, and Poisson distribution.
To verify the effectiveness of our method, we set the demand range from 5 (minimal demand) to (maximal demand) and generated specific demand values using random numbers. Finally, we described how the experimental richness was expanded by varying the parameters. The number of total samples generated ranges from 5 to 50, which means we conducted 45 experiments for each . Thereafter, 80% of the total samples were randomly selected as the training set, while the remaining 20% were used as the test set. Thus, . The LOOCV mentioned before was used for validation using the training set. The cumulative profit was calculated by applying the decisions obtained from the training set to the test set, and the results were compared with the benchmark SAA method using the same decision approach as introduced above, which involved exhaustively evaluating all feasible decisions in the objective function to identify the optimal one.
5.2. Experimental Results
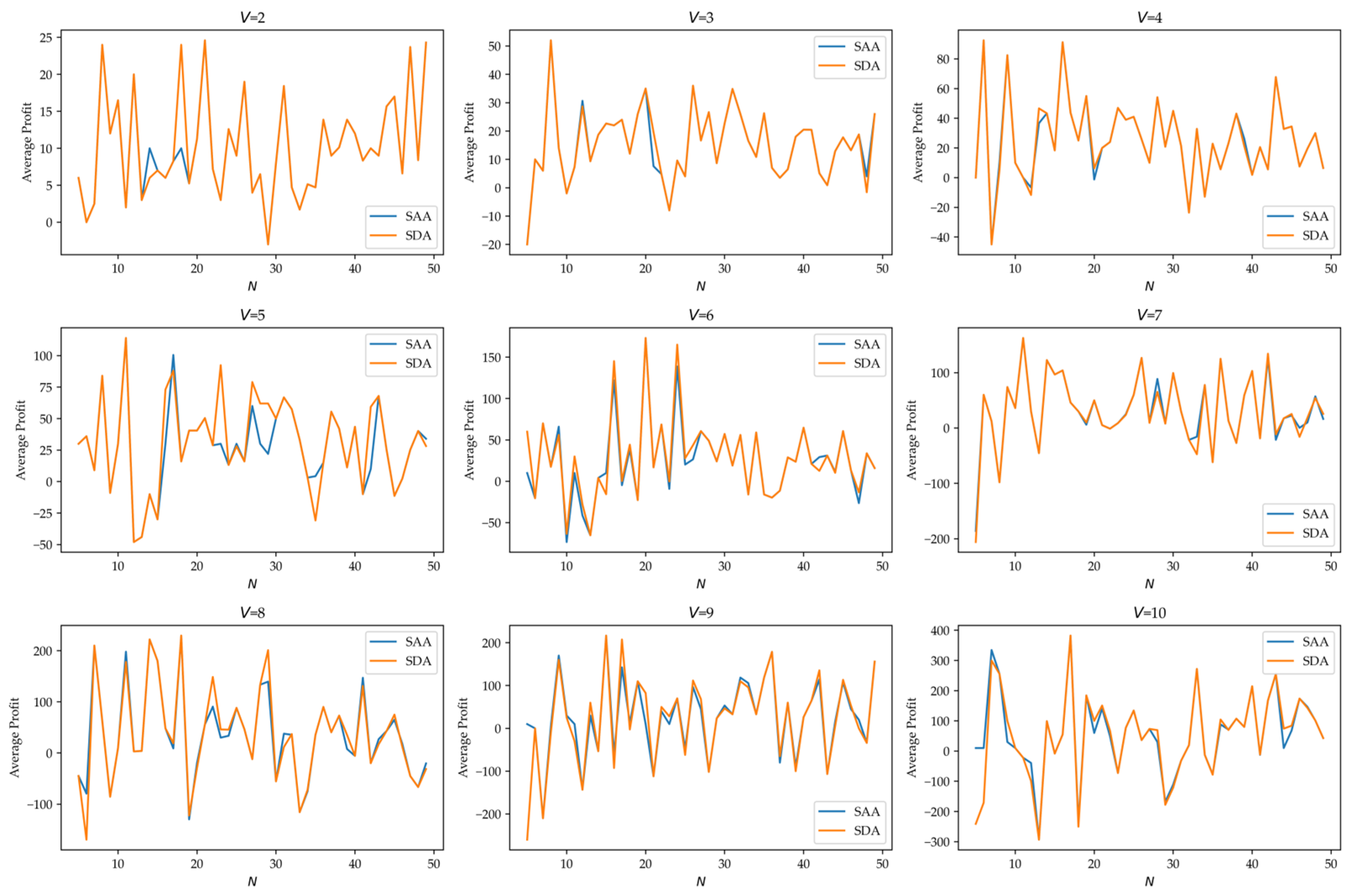
Figure 2 presents a comparative analysis of the SDA and SAA methods across varying candidate fleet sizes
(2–10 ships), offering a visual comparison of their average profits in the test set. While both methods demonstrate consistent results in most operational scenarios, notable divergences emerged under specific conditions.
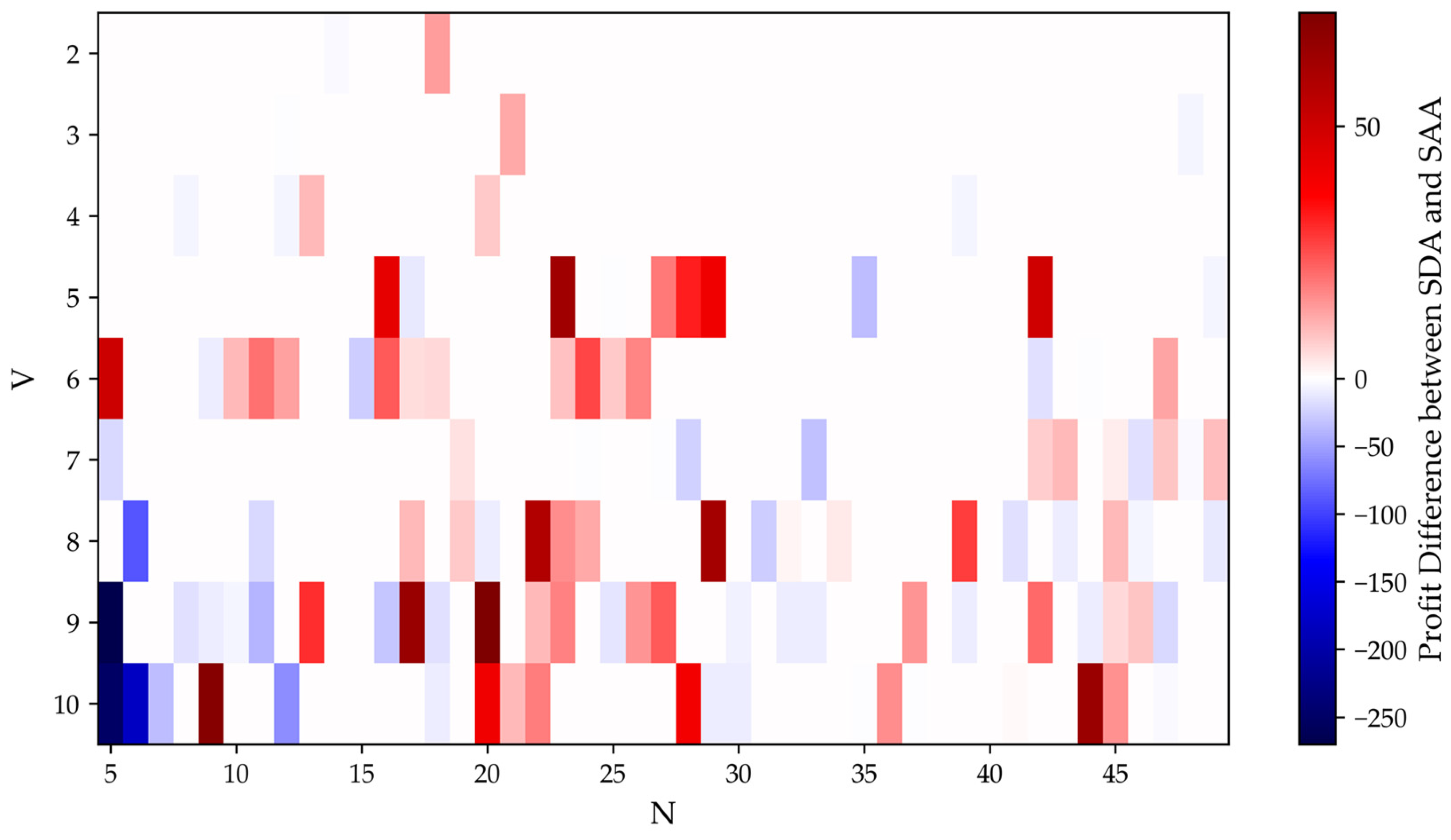
Figure 3 computes the profit difference (profit of SDA minus profit SAA), presented as a heatmap. We found that our method outperformed when 15 to 25 samples were observed.
This comparative study is further extended through numerical evaluations in
Figure 4.
Figure 4a quantifies the absolute performance difference by calculating the total profit margin (SDA minus SAA) across the entire test dataset.
Figure 4b provides a more intuitive illustration on the superiority of each method, highlighting cases (i.e., the number of experiments) where SDA outperformed SAA and vice versa in terms of profit. In some cases, the decisions of SDA and SAA were same, which is not presented in this figure. We compared the number of experiments in which the SDA method outperformed the SAA method under different numbers of observed samples. Similarly, we also calculated the number of experiments in which the SAA method outperformed the SDA method. “Count” represents the number of such experiments.
When the number of ships is small, the SDA method demonstrates superior performance compared to the SAA method, particularly when the number of ships is five or six. Specifically, when there are five ships, the average profit difference between SDA and SDD is 190.3, while, for six ships, it is 146.8. Furthermore, as the number of ships increases, the disparity in decisions between the SDA and SAA methods becomes more pronounced.
Figure 5 presents the decision analysis for ship selection under the SAA and SDA methods. “Count” represents the number of times different ships are selected under different
values in 45 experiments for SAA and SDA. From these results, we observe that both methods tend to favor high-capacity ships, reflecting the impact of economies of scale. Additionally, the decisions made using SDA are more concentrated on several specific choices compared to those of SAA.
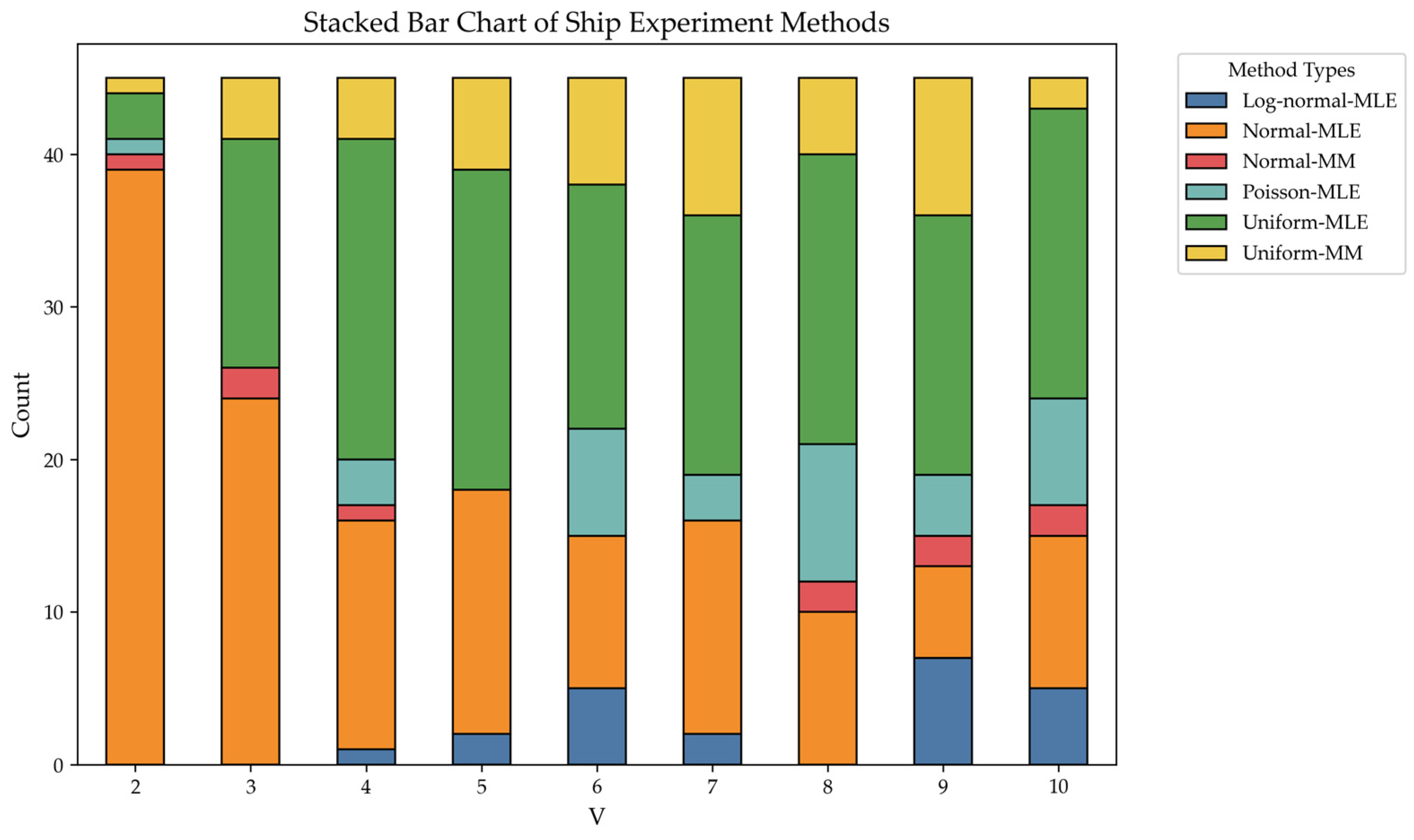
Figure 6 illustrates the variation in the chosen estimation methods for different numbers of candidate ships under SDA. “Count” represents the number of times different estimation methods were selected under different
values in 45 experiments for SDA. Although there were eight available estimation methods, only six were chosen and utilized, with the MM method based on Poisson and log-normal distributions not being selected. For the Poisson distribution, the estimation outcomes for MLE and MM are identical because the first-order moment serves as a sufficiently complete statistic. Thus, we can analyze Poisson-MM and Poisson-MLE together. Regarding log-normal-MM, although MLE is used for estimation in the log-normal distribution, the selection frequency is quite low. This suggests that the log-normal distribution may not be well-suited for this problem, leading to the exclusion of log-normal-MLE.
Furthermore, a noticeable trend is that the percentage of normal-MLE selections decreases as the number of ships increases, while the use of the uniform distribution for estimation becomes more frequent. The other four methods are also applied, though not to significant extents.
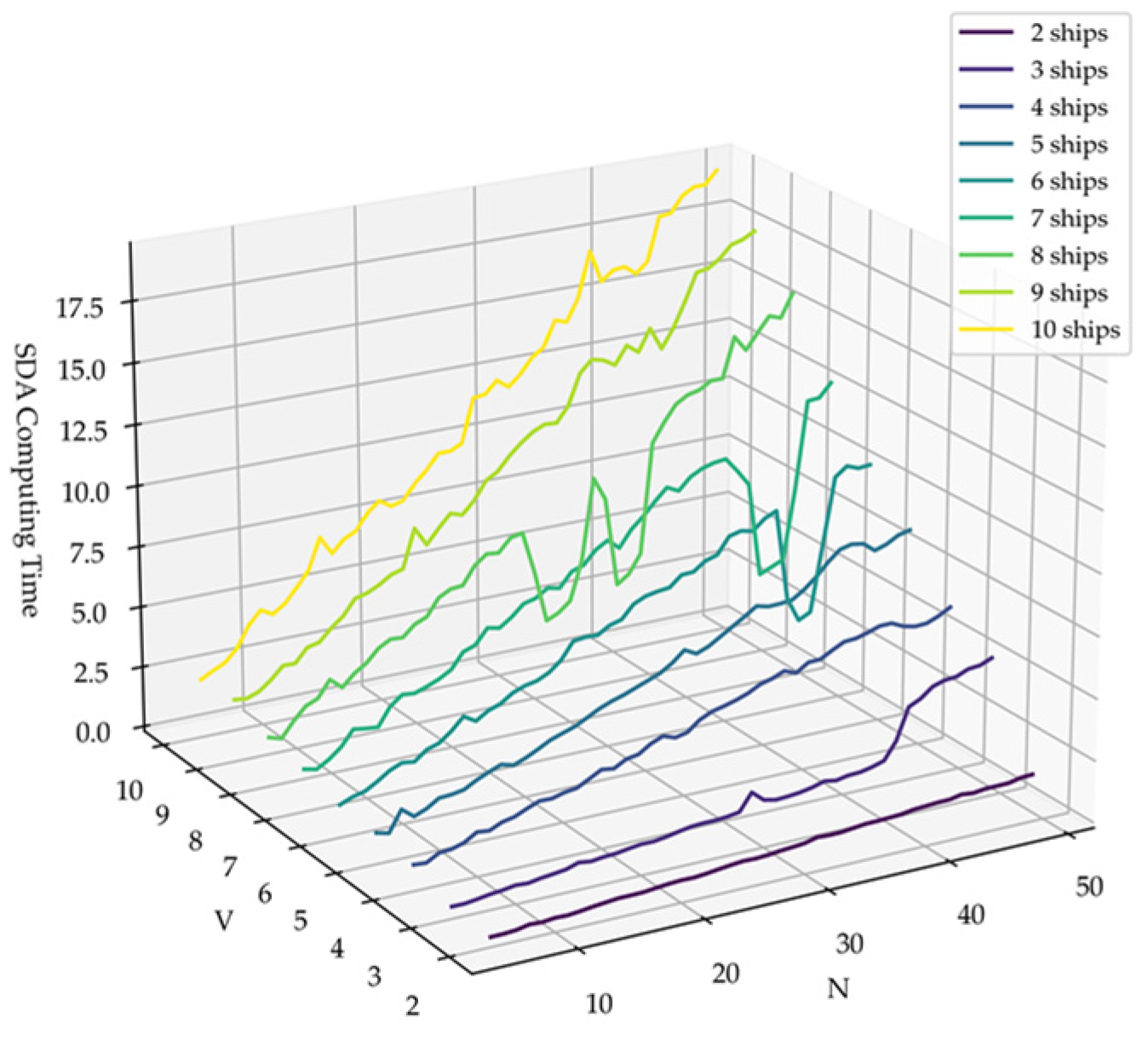
5.3. Computational Time Analysis of SDA
As shown in
Figure 7, we summarized the computation time across all experiments. Theoretically, LOOCV involves
iterations, and in each iteration, the algorithm evaluates
candidate solutions. Assuming that each candidate solution evaluated using
fitting methods has a time complexity of
, the overall computational complexity is approximately
. This analysis reveals that the computational cost increases linearly with the candidate solutions
and validation rounds
, implying that the complexity remains tractable and does not grow excessively with problem size. The results in
Figure 7 also support our analysis.
5.4. Comparison of Well-Specified and Mis-Specified Distribution Sets
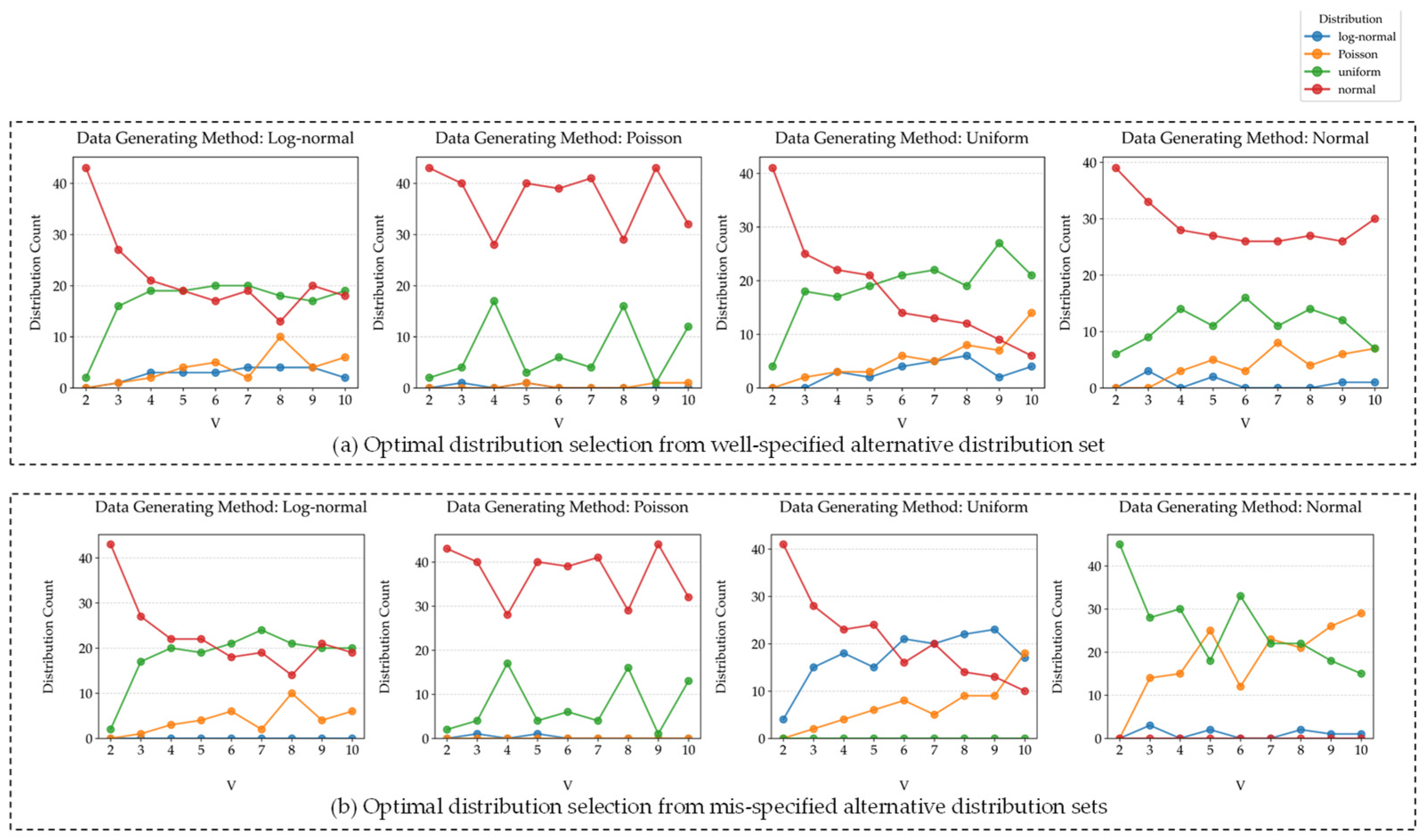
To comprehensively evaluate the impacts of candidate distribution sets on model performance, we conducted controlled experiments comparing well-specified and mis-specified conditions. In the well-specified case, the candidate set includes the true data-generating distribution, while the mis-specified case deliberately excludes this distribution to simulate model mismatch. The data generation process follows four distinct parametric distributions: for normal distributions, we set and to ensure that approximately 95% of samples fall within the specified range; uniform distributions are sampled directly between the minimum and maximum demand values; log-normal distributions use with as a tunable parameter; and Poisson distributions employ . This systematic approach enables rigorous assessment of distribution selection robustness under well-specified and mis-specified conditions.
Figure 8 demonstrates the differences in estimated distribution selection. The results reveal that, despite variations in data generation methods, the normal distribution exhibits strong robustness, consistently maintaining a high selection proportion across all four experimental groups. Following closely is the uniform distribution, while the log-normal and Poisson distributions perform less satisfactorily, even when the data generation processes follow these distributions. Due to the relatively low selection rates of log-normal and Poisson distributions, the difference between well-specified and mis-specified scenarios is not pronounced.
Focusing on the normal distribution generation method, the proportion of uniform distribution increases in the mis-specified experiments, further highlighting its good adaptability. Notably, the selection rate of the Poisson distribution also rises significantly. Further observation shows that, as the value of increases, the selection proportion of the Poisson distribution exhibits an upward trend across all experiments, suggesting its favorable adaptability in scenarios with larger candidate solution sets.
In the case of uniform-distribution-generated data, the proportion of log-normal distribution increases markedly. This phenomenon may be attributed to the fact that the log-normal distribution, with its right-skewed characteristics, can approximate certain uniform distribution patterns when the variance is large, thereby improving its fitting performance.
Additionally, in the experiments with uniform distribution, the proportion of log-normal models selected increases significantly in the mis-specified setting compared to the well-specified case. This may be because, as the sample size grows, the log-normal distribution can better approximate uniform distribution.
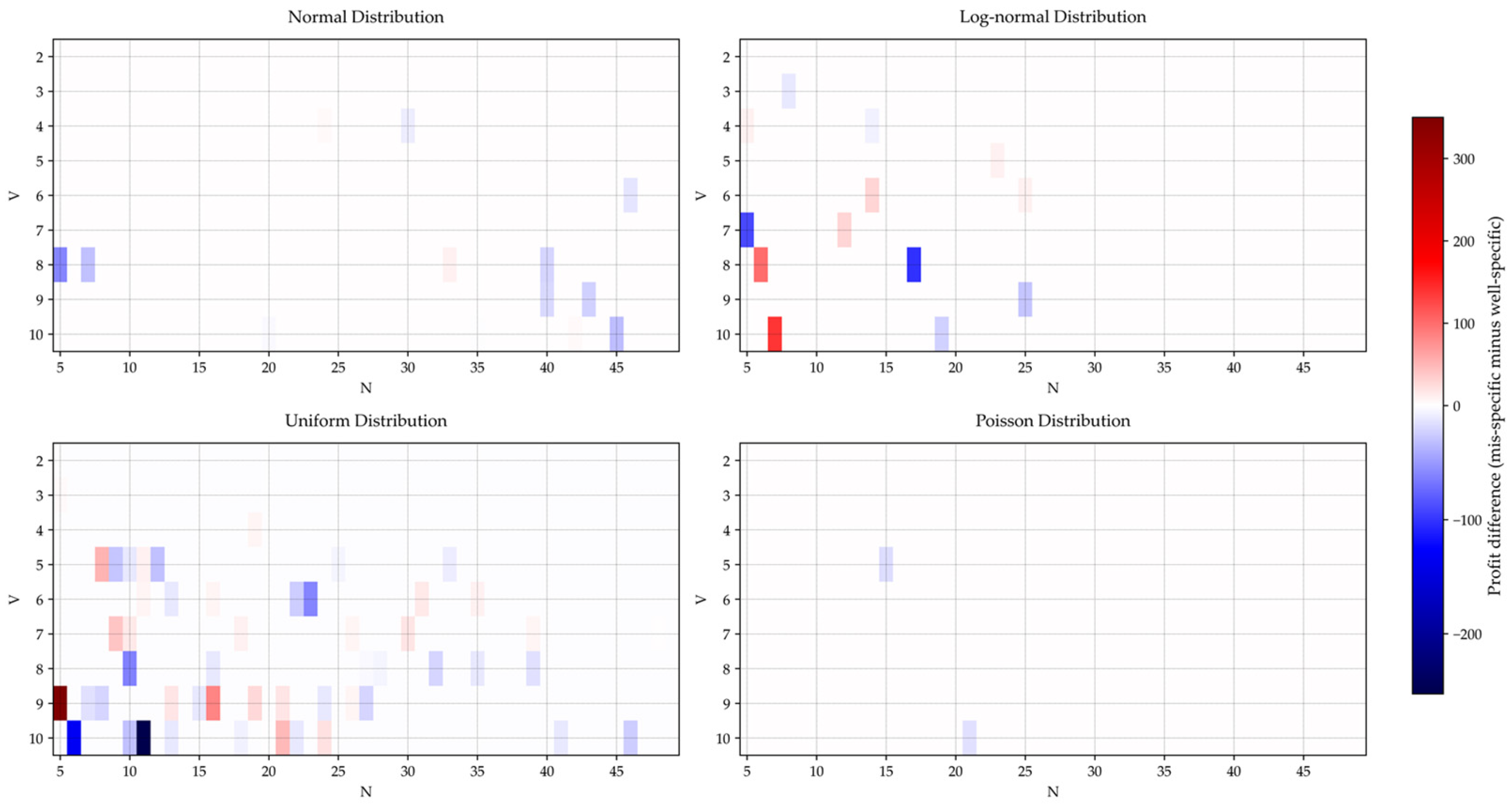
Figure 9 illustrates the profit differences, defined as the profit achieved under the mis-specified model minus that achieved under the well-specified model. The results indicate a general decline in performance when the model is mis-specified, as evidenced by the predominance of blue-shaded cells in the figure, which correspond to negative profit differences across most scenarios, with this effect being particularly pronounced for uniformly distributed data. This phenomenon may stem from the fundamental divergence between uniform distributions and other distribution types. Notably, as the sample size
increases, the profit difference diminishes. This trend likely occurs because larger historical datasets better represent the underlying population distribution, thereby decreasing the model’s sensitivity to distributional assumptions.
5.5. Discussion
Overall, the SDA method outperforms the traditional SAA method in managing demand uncertainty. By leveraging historical data to construct a PDF, SDA explicitly models demand uncertainty through data-driven estimation, improving resilience against random demand fluctuations. Furthermore, SDA integrates LOOCV with decision-cost evaluation, shifting focus from mere predictive accuracy to optimization-aligned distribution validation. This approach proves especially effective in fleet deployment, delivering superior decision-making reliability when candidate vessel types range from two to six.
While promising, SDA’s performance hinges on distribution estimation accuracy, which may degrade with sparse or noisy data. Although LOOCV enhances robustness, it incurs higher computational costs—albeit with linear scalability. Additionally, the framework assumes historical demand patterns persist, which may not hold under structural market shifts. Further validation is needed across diverse operational scales and constraint complexities.
6. Conclusions
This study addresses the stochastic SFDP by proposing a novel SDA framework through which to overcome the limitations of the conventional SAA method in data-scarce scenarios. The SDA framework replaces empirical distributions derived solely from historical data with estimated probability distributions, optimized via leave-one-out cross-validation. This approach significantly enhances decision robustness in small-sample scenarios (15–25 historical demand data points) and limited ship types (two to six candidate ship types). Experimental results demonstrate SDA’s superiority over SAA in minimizing the decision cost, offering maritime operators an improved uncertainty-aware decision-making tool.
For maritime operators, the proposed methodology offers a paradigm shift in stochastic fleet deployment decision making, particularly in data-constrained environments where traditional methods falter. Future research could extend this framework to incorporate multi-dimensional uncertainties (e.g., fuel price volatility or port congestion) and explore hybrid approaches combining SDA with reinforcement learning for adaptive decision policies. Furthermore, future studies could investigate the psychological dimensions of maritime decision-making, particularly how cognitive biases like the sunk cost fallacy influence operational choices under uncertainty. The SDA framework not only advances the theoretical foundations of stochastic maritime optimization, but also provides actionable insights for enhancing operational resilience in dynamic shipping networks.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}