
A Hybrid Genetic Algorithm with Tabu Search Using a Layered Process for High-Order QAM in MIMO Detection


Abstract
1. Introduction
- First, an HGA scheme embedding tabu search is proposed for high-order quadrature amplitude modulation (QAM) in MIMO detection. The hybrid techniques of GA and TS enable efficient MIMO detection by balancing global and local searches.
- A layered detection technique is applied to the proposed HGA scheme, which not only dramatically improves BER performance but also reduces computational complexity.
- The advantages of the proposed HGA scheme over the conventional scheme are verified through various simulations considering up to 1024-QAM. Notably, the proposed HGA scheme shows enhanced performance compared to conventional detection schemes.
- A complexity comparison between the proposed HGA and conventional detection schemes was performed. The HGA scheme leads to a substantial reduction in the complexity of MIMO detection for high-order QAM.
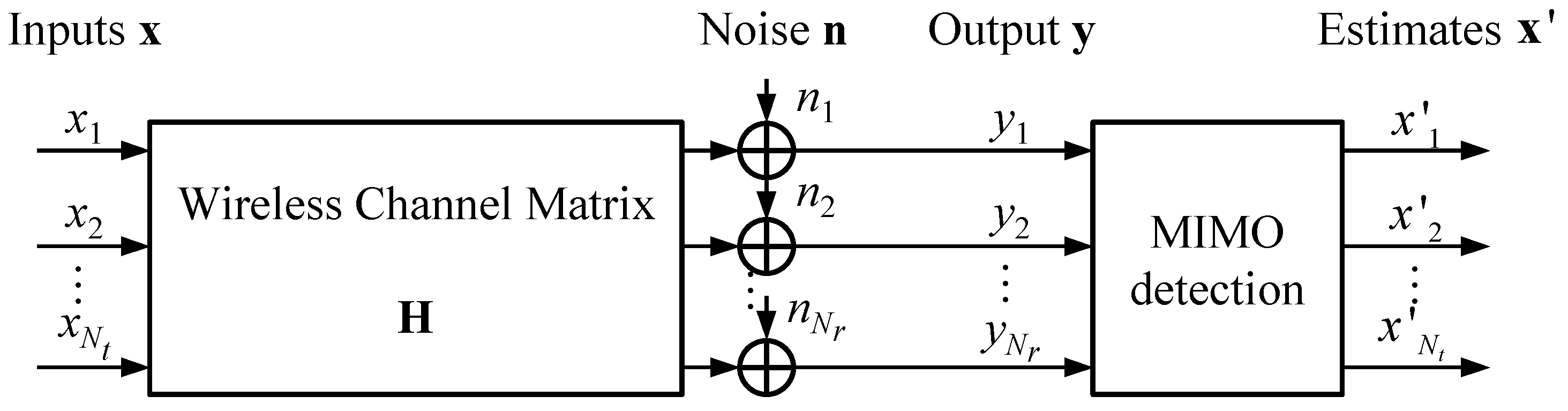
2. System Model
2.1. MIMO Channel Model
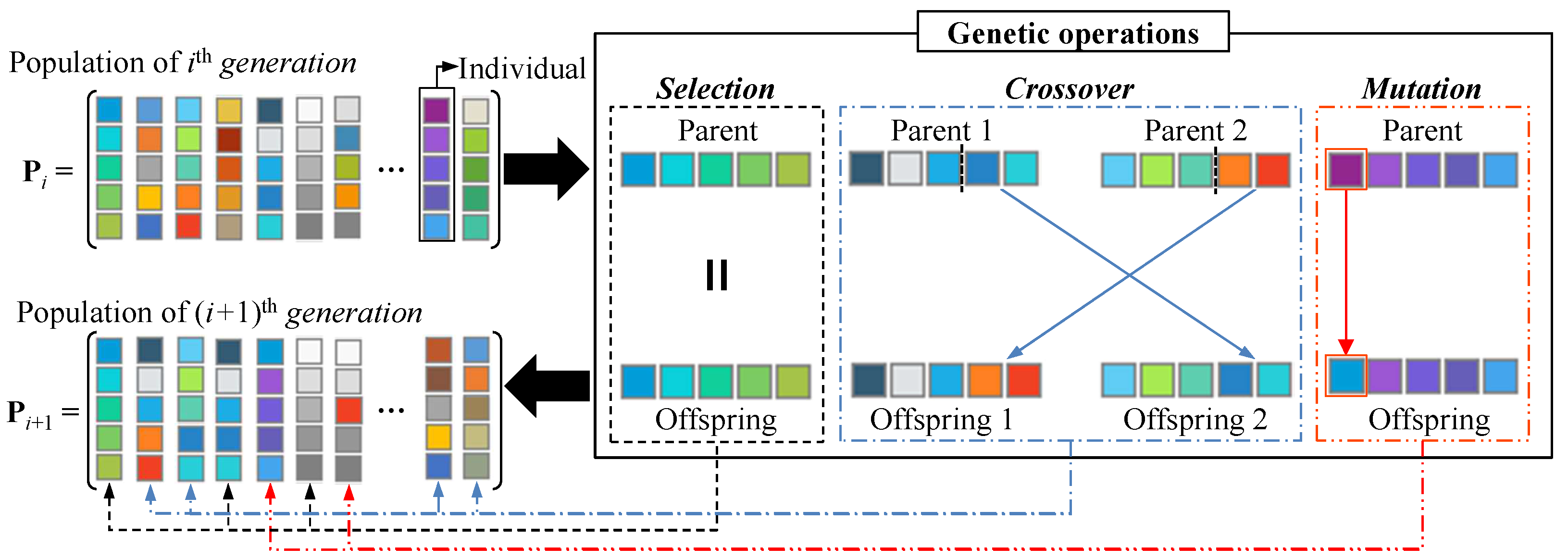
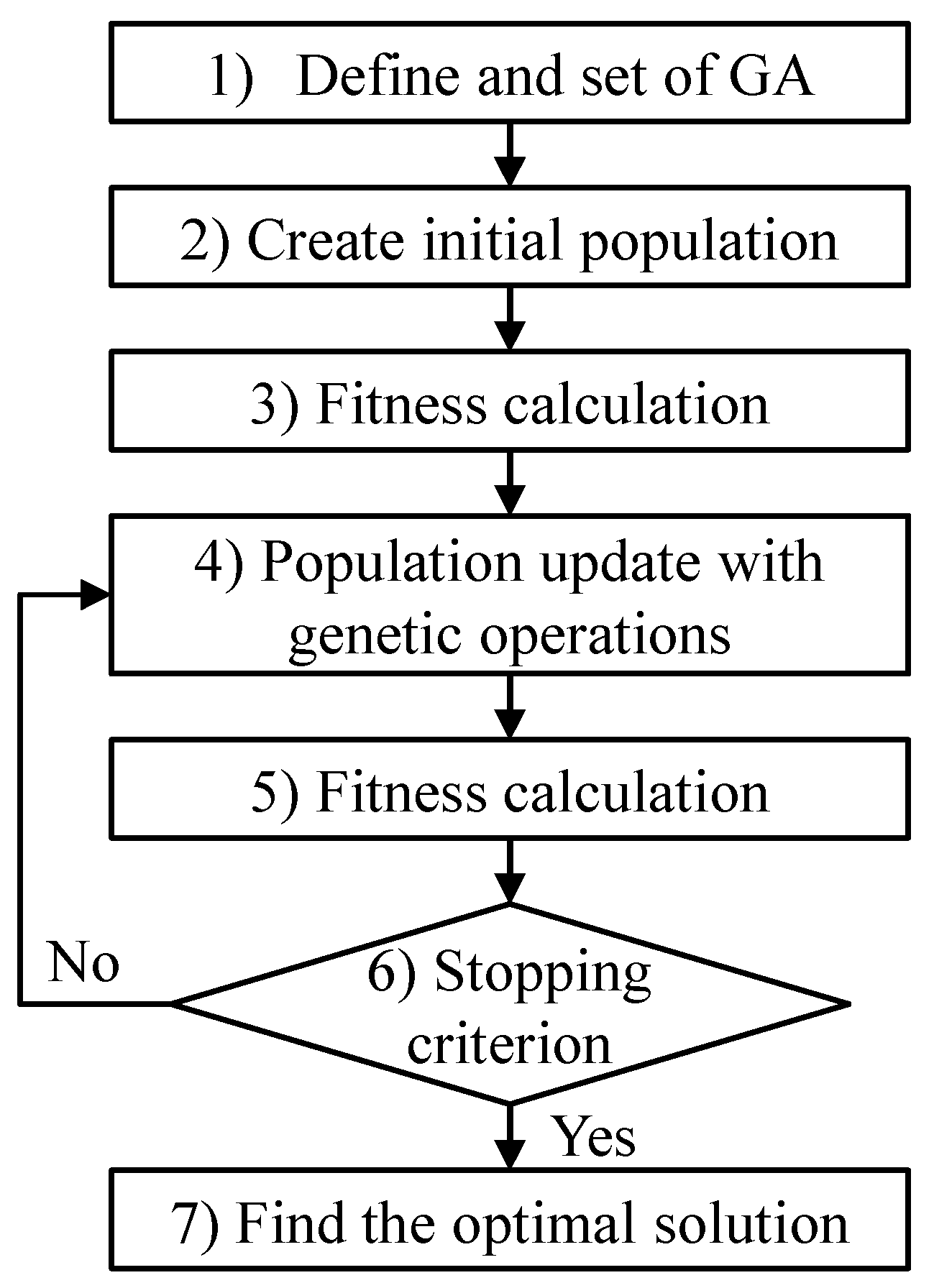
2.2. Genetic Algorithm
- (a)
- Define a fitness function, and set the GA operations (such as population size P, maximum number of generations G, parent selection method, selection probability, crossover probability, and mutation probability).
- (b)
- Generate the initial population.
- (c)
- Evaluate the fitness of each individual in the initial population.
- (d)
- Generate an offspring(s) by using one of the genetic operations. The genetic operation to generate the offspring(s) is selected according to each rate, and the parent(s) for the genetic operation is determined according to the parent selection method. Insert the offspring(s) into the next population.
- (e)
- Evaluate the fitness of each individual in the new population.
- (f)
- If a stopping criterion is satisfied, then the procedure is halted. Otherwise, go to Step (d).
2.3. GA-Based MIMO Detection
3. Hybrid GA with Layered Process for MIMO Detection
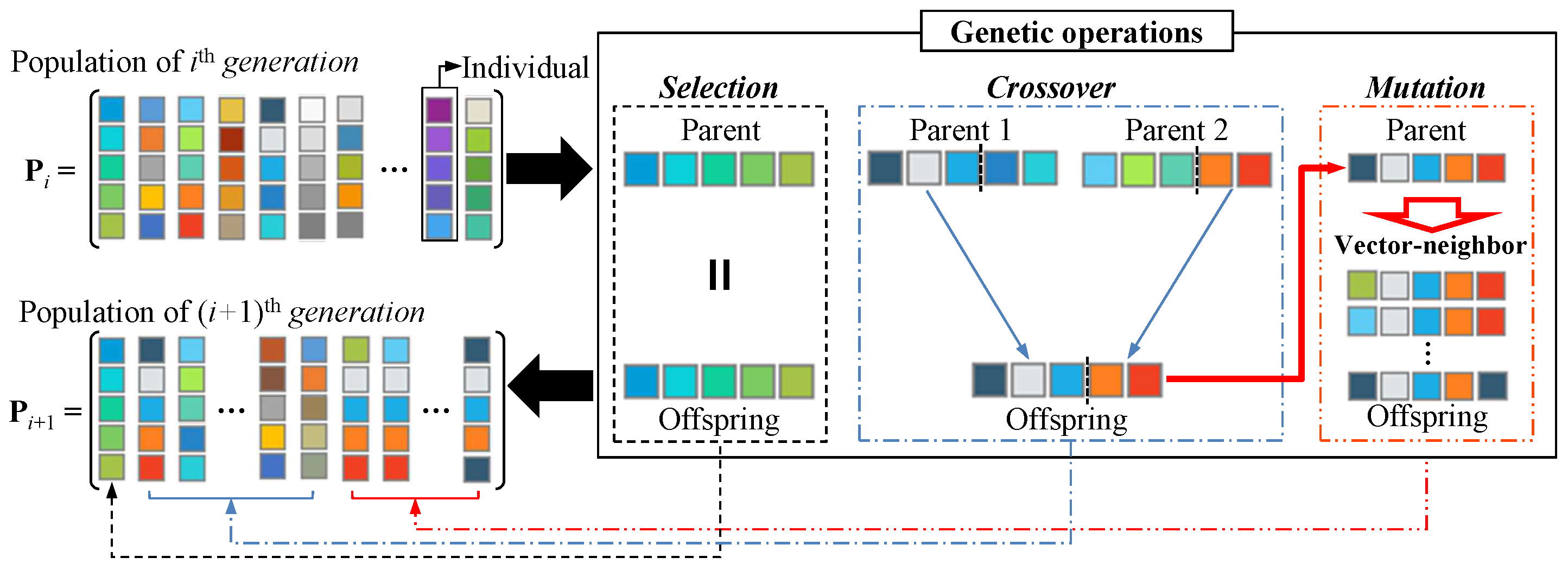
3.1. Proposed Hybrid Genetic Algorithm
3.1.1. Selection
3.1.2. Crossover
3.1.3. Mutation
3.1.4. Procedure of the Proposed HGA
- (a)
- Define an fitness function, and set the GA operations.
- (b)
- Initialize the algorithm.
- (1)
- Generate the initial population .
- (2)
- Evaluate the fitness of the initial population .
- (3)
- Generate the mutation list as a empty set.
- (c)
- Update the population by using the genetic operations.
- (1)
- Initialize the current population and the checker for selection .
- (2)
- Selection: select the fittest individual of and copy to . If is not an element of , set to one.
- (3)
- Crossover
- i
- Generate the crossover result set as a empty set and , which is the number of times crossover has been performed is zero.
- ii
- Select the two different parents from the using the roulette wheel selection method, and randomly select the crossover length .
- iii
- Perform a single-point crossover using two parents and the to generate crossover offspring .
- iv
- If the is not an element of , insert the into and increase by one.
- v
- If is less than the crossover size , go back to step (ii).
- vi
- Insert the to .
- (4)
- Mutation
- i
- Generate the mutation result set as a empty set and , which is the number of times mutation has been performed is zero.
- ii
- Select a single parent from the using the roulette wheel selection.
- iii
- Remove the individual selected as the parent from . If the parent is not an element of , insert the parent and vector-neighbor of the parent into the . Furthermore, insert the parent into the and increase by one.
- iv
- If is less than the mutation size , go back to step (ii).
- v
- If is one, insert the and vector-neighbor of into the and insert the into the .
- vi
- Insert the to .
- (d)
- Evaluate the fitness of the current population .
- (e)
- If the stop criterion is met, the procedure is stopped. Otherwise, go to Step (d).
| Algorithm 1 The proposed hybrid genetic algorithm |
| Require: , , |
| Generate and evaluate . base on |
| Generate |
| for do |
| Generate , |
| Fittest individual in is copy and insert to |
| if then |
| end if |
| Generate , |
| while do |
| Randomly choose the crossover length |
| if then |
| Insert into |
| . |
| end if |
| end while |
| Insert into |
| Generate , |
| while do |
| if then |
| Insert and the vector-neighbor of |
| into |
| Insert into |
| . |
| end if |
| end while |
| if then |
| Insert and the vector-neighbor of into |
| into |
| end if |
| Insert into |
| Calculate base on |
| end for |
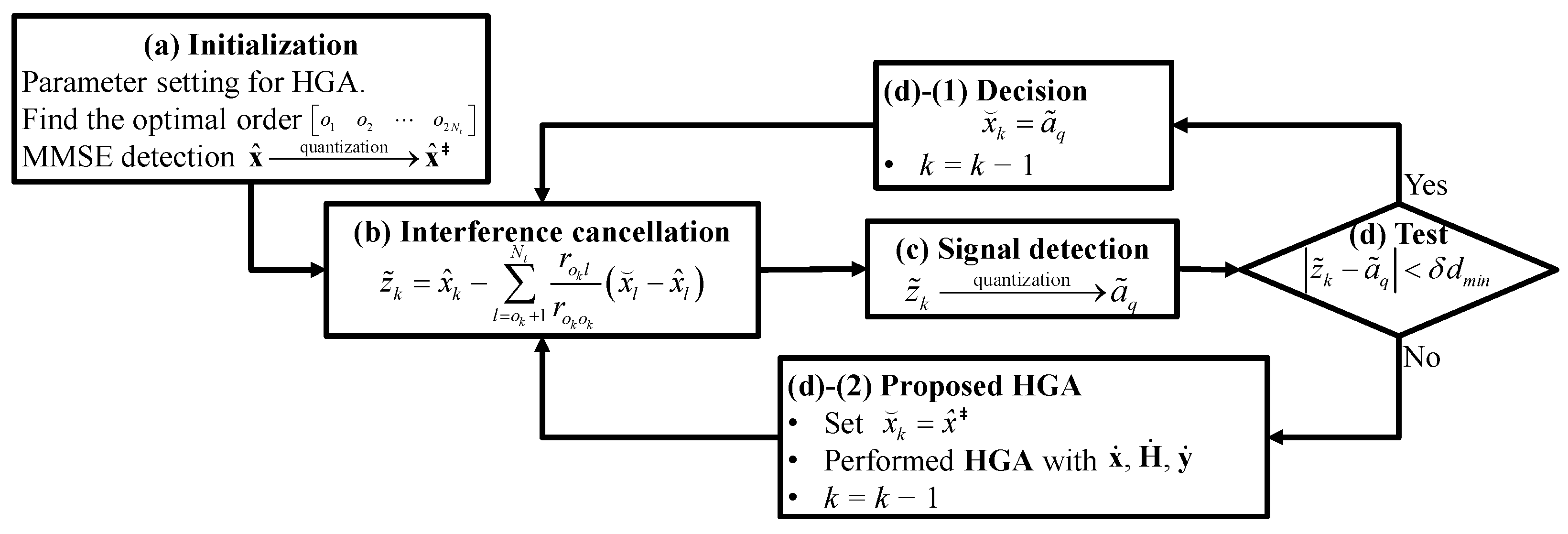
3.2. Hybrid GA-Based MIMO Detection with Layered Process
- (i)
- Find the where is obtained by zeroing columns of .
- (ii)
- Find , the index that corresponds to the row with the lowest norm among all rows of .
- (a)
- Initialization.Define the Euclidean distance in (4) as an fitness function, and set the HGA operations such as G, and .
- (b)
- Interference cancellation.Calculatewhich is a cancellation operation that removes the interference due to the symbols detected in the previous layer (i.e., ’s).
- (c)
- Signal detection.Find the symbol in the alphabet which is closest to in Euclidean distance.
- (d)
- Test: ,
- (1)
- Decision.
- If , then . Make and return to (b)
- (2)
- Proposed HGA.
- If , then set . Perform the proposed HGA by replacing the initial individual with , with , with , where , , and for the kth layer are taken asThe output vector form is made as the update subvector. Make and return to (b)
4. Simulation Results
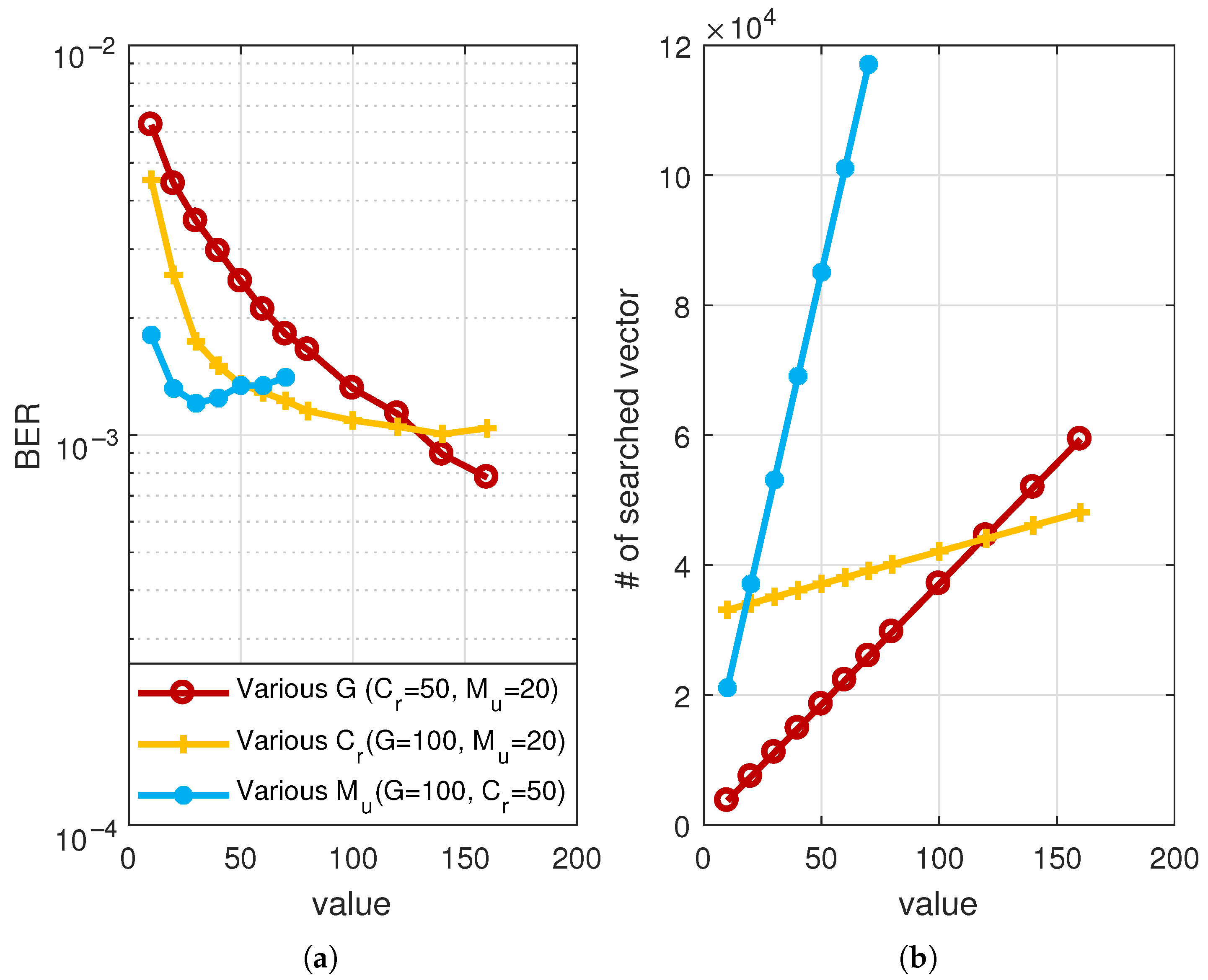
4.1. Parameter Setting
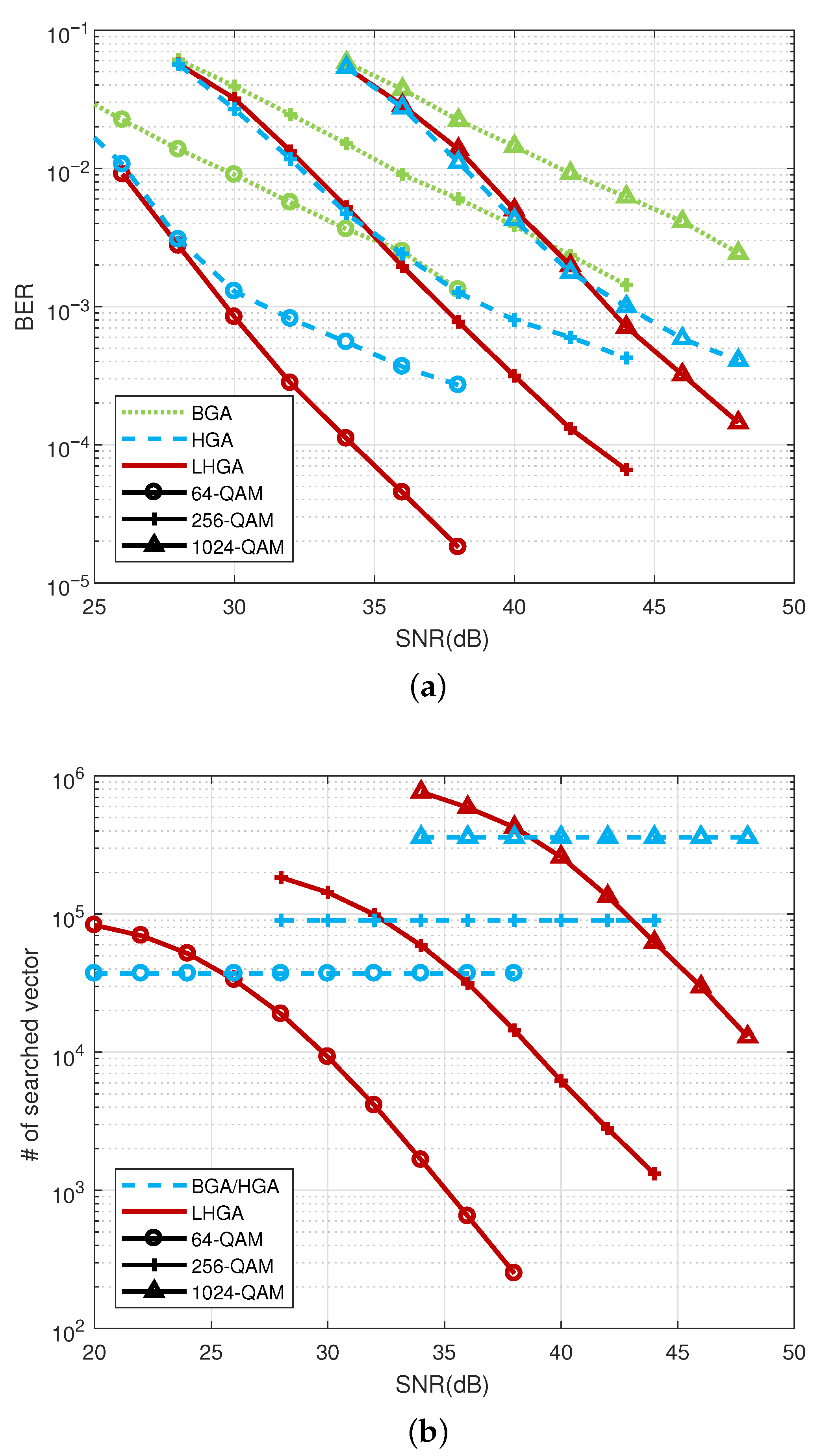
4.2. BER and Complexity Analysis
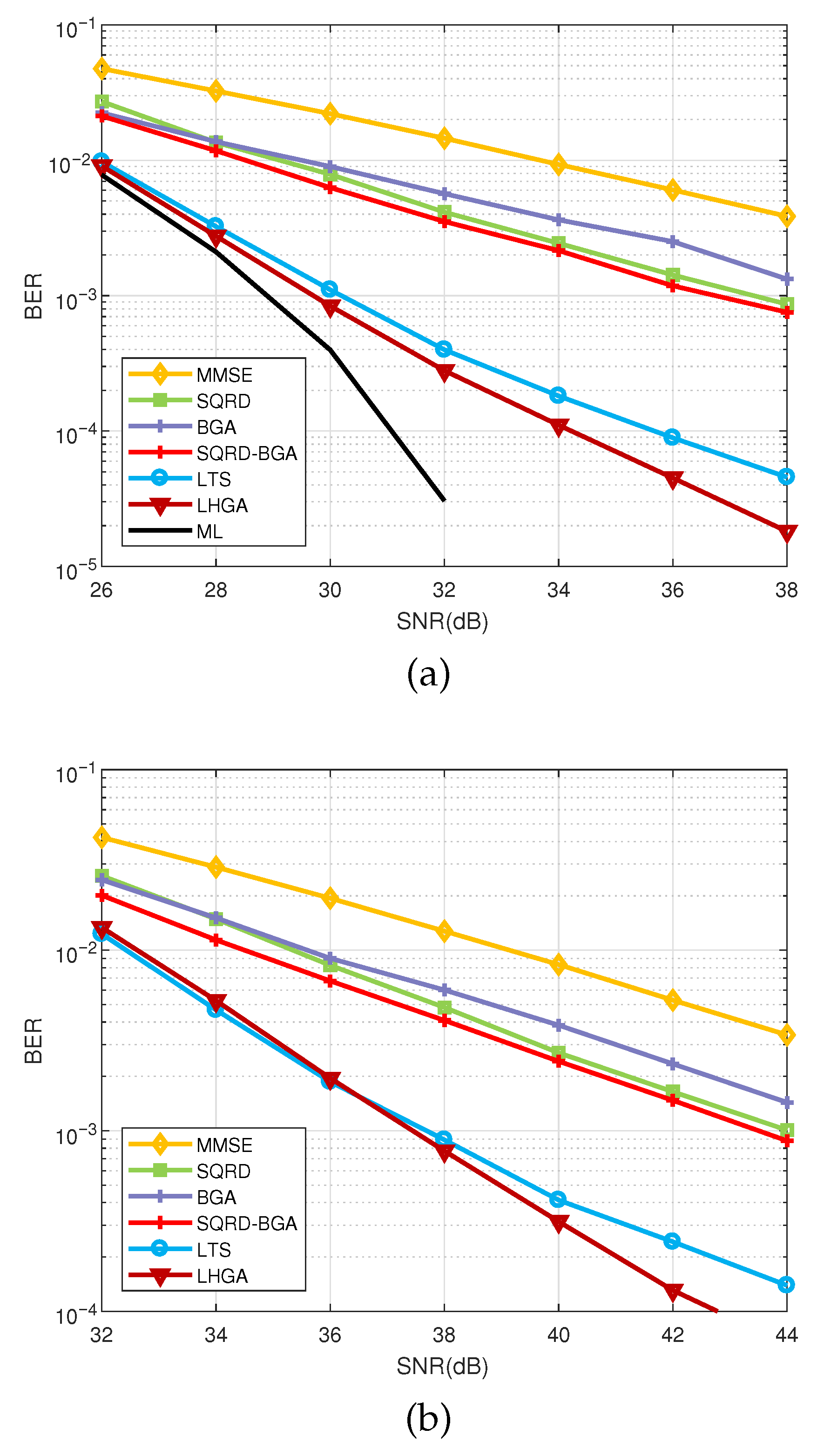
4.3. BER Comparison with Other Detectors
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Foschini, G.J.; Gans, M.J. On limits of wireless communications in a fading Environment when using multiple antennas. Wirel. Pers. Commun. 1998, 6, 315–335. [Google Scholar] [CrossRef]
- Telatar, E. Capacity of multi-antenna Gaussian channels. Eur. Trans. Telecommun. 1999, 10, 585–595. [Google Scholar] [CrossRef]
- Xu, J.; Zhou, Z.; Li, H.; Zheng, L.; Liu, L. RC-Struct: A structure-based neural network approach for MIMO-OFDM detection. IEEE Trans. Wirel. Commun. 2022, 21, 7181–7193. [Google Scholar] [CrossRef]
- Ali, M.S.; Ehossai, N.; Kim, D. Non-Orthogonal Multiple Access (NOMA) for Downlink Multiuser MIMO Systems: User Clustering, Beamforming, and Power Allocation. IEEE Access 2017, 5, 565–577. [Google Scholar] [CrossRef]
- Wang, Y.; Cao, Y.; Yeo, T.-S.; Cheng, Y.; Zhang, Y. Sparse reconstruction-Based joint signal processing for MIMO-OFDM-IM integrated radar and communication systems. Remote Sens. 2024, 16, 1773. [Google Scholar] [CrossRef]
- Naeem, M.; Bashir, S.; Ullah, Z.; Syed, A.A. A Near Optimal Scheduling Algorithm for Efficient Radio Resource Management in Multi-user MIMO Systems. Wirel. Pers. Commun. 2019, 106, 1411–1427. [Google Scholar] [CrossRef]
- Yang, S.; Hanzo, L. Fifty years of MIMO detection: The road to large-scale MIMOs. IEEE Commun. Surv. Tutor. 2015, 17, 1941–1988. [Google Scholar] [CrossRef]
- Zhai, K.; Zheng, M.A.; Lei, X. Accurate Performance Analysis of Coded Large-Scale Multiuser MIMO Systems with MMSE Receivers. Sensors 2019, 19, 2884. [Google Scholar] [CrossRef]
- Wong, K.; Cheng, R.; Letaeif, K.B.; Murch, R.D. Adaptive antennas at the mobile and base stations in an OFDM/TDMA system. IEEE Trans. Commun. 2001, 49, 195–206. [Google Scholar] [CrossRef]
- Verdú, S. Computational complexity of optimum multiuser detection. Algorithmica 1989, 4, 303–312. [Google Scholar] [CrossRef]
- Micciancio, D. The hardness of the closest vector problem with preprocessing. IEEE Trans. Inf. Theory 2001, 47, 1212–1215. [Google Scholar] [CrossRef]
- Golub, G.H.; Van Loan, C.F. Matrix Computations; Johns Hopkins University Press: Baltimore, MD, USA, 2013. [Google Scholar]
- Kay, S.M. Statistical Signal Processing: Estimation Theory; Prentice Hall: Hoboken, NJ, USA, 1993. [Google Scholar]
- Foschini, G.J. Layered space-time architecture for wireless communication in a fading environment when using multi-element antennas. Bell Labs Tech. J. 1996, 1, 41–59. [Google Scholar] [CrossRef]
- Wubben, D.; Bohnke, R.; Rinas, J.; Kuhn, V.; Kammeyer, K.D. Efficient algorithm for decoding layered space-time codes. Electron. Lett. 2001, 37, 1348–1350. [Google Scholar] [CrossRef]
- Holland, J.H. Adaptation in Natural and Artificial Systems; MIT Press: Cambridge, MA, USA, 1992. [Google Scholar]
- Man, K.F.; Tang, K.S.; Kwong, S. Genetic algorithms: Concepts and applications. IEEE Trans. Ind. Electron. 1996, 43, 519–534. [Google Scholar] [CrossRef]
- Agrell, E.; Eriksson, T.; Vardy, A.; Zeger, K. Closest point search in lattices. IEEE Trans. Inf. Theory 2002, 48, 2201–2214. [Google Scholar] [CrossRef]
- Hong, Y.; Dong, Z. Genetic algorithms with applications in wireless communications. Int. J. Syst. Sci. 2004, 35, 751–762. [Google Scholar] [CrossRef]
- Pan, C.-H. An efficient MIMO detection algorithm employed in imperfect noise estimation. WSEAS Trans. Commun. 2009, 8, 941–958. [Google Scholar]
- Fogel, D.B. An Introduction to simulated evolutionary optimization. IEEE Trans. Neural Netw. 1994, 5, 3–14. [Google Scholar] [CrossRef] [PubMed]
- Grefenstette, J.J. Incorporating problem specific knowledge into genetic algorithms. Genet. Algorithms Simulated Annealing 1987, 42–60. [Google Scholar]
- Alhamad, K.; Alkhezi, Y. Hybrid genetic algorithm and tabu search for solving preventive maintenance scheduling problem for cogeneration plants. Mathematics 2021, 9, 1705. [Google Scholar] [CrossRef]
- Ju, C.; Yuan, G.; Shareduwan, K.; Chengfeng, Z.; Atiqah, R.; Asyraf, M.; Ezlin, Z.; Chuanbiao, W. MTS-PRO2SAT: Hybrid mutation tabu search algorithm in optimizing probabilistic 2 satisfiability in discrete hopfield neural network. Mathematics 2024, 12, 721. [Google Scholar] [CrossRef]
- Xu, L.; Yu, C.; Wu, B.; Gao, M. A hybrid genetic algorithm for ground station scheduling problems. Appl. Sci. 2024, 14, 5045. [Google Scholar] [CrossRef]
- Maroof, A.; Ayvaz, B.; Naeem, K. Logistics optimization using hybrid genetic algorithm (HGA): A solution to the vehicle routing problem with time windows (VRPTW). IEEE Access 2024, 12, 369074. [Google Scholar] [CrossRef]
- Srinidhi, N.; Datta, T.; Chockalingam, A.; Rajan, B.S. Layered Tabu search algorithm for large-MIMO detection and a lower bound on ML performance. IEEE Trans. Commun. 2010, 59, 2955–2963. [Google Scholar] [CrossRef]
- Mansour, M.M.; Alex, S.P.; Jalloul, L.M.A. Reduced complexity soft-output MIMO sphere detectors-Part I: Algorithmic optimizations. IEEE Trans. Signal Process. 2014, 62, 5505–5520. [Google Scholar] [CrossRef]
- Jiang, M.; Hanzo, L. Multiuser MIMO-OFDM for next-generation wireless systems. Proc. IEEE 2007, 95, 1430–1469. [Google Scholar] [CrossRef]
- Colman, G.; Willink, T. Overloaded array processing using genetic algorithms with soft-biased initialization. IEEE Trans. Veh. Technol. 2008, 57, 2123–2131. [Google Scholar] [CrossRef]
- Chockalingam, A.; Rajan, B.S. Large MIMO Systems; Cambridge University Press: Cambridge, UK, 2014. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 64-QAM | 256-QAM | 1024-QAM | |
|---|---|---|---|
| 100 | 100 | 200 | |
| 2 | 2 | 2 | |
| 50 | 100 | 200 | |
| 20 | 50 | 100 |
| 64-QAM | 256-QAM | 1024-QAM | |
|---|---|---|---|
| 100 | 100 | 200 | |
| 371 | 901 | 1801 | |
| Selection probability | 0.01 | 0.01 | 0.01 |
| Crossover probability | 0.13 | 0.11 | 0.11 |
| Mutation probability | 0.86 | 0.88 | 0.88 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, T.; Kong, G. A Hybrid Genetic Algorithm with Tabu Search Using a Layered Process for High-Order QAM in MIMO Detection. Mathematics 2025, 13, 2. https://doi.org/10.3390/math13010002
Kim T, Kong G. A Hybrid Genetic Algorithm with Tabu Search Using a Layered Process for High-Order QAM in MIMO Detection. Mathematics. 2025; 13(1):2. https://doi.org/10.3390/math13010002
Chicago/Turabian StyleKim, Taehyoung, and Gyuyeol Kong. 2025. "A Hybrid Genetic Algorithm with Tabu Search Using a Layered Process for High-Order QAM in MIMO Detection" Mathematics 13, no. 1: 2. https://doi.org/10.3390/math13010002
APA StyleKim, T., & Kong, G. (2025). A Hybrid Genetic Algorithm with Tabu Search Using a Layered Process for High-Order QAM in MIMO Detection. Mathematics, 13(1), 2. https://doi.org/10.3390/math13010002