
EFE-LSTM: A Feature Extension, Fusion and Extraction Approach Using Long Short-Term Memory for Navigation Aids State Recognition



Abstract
1. Introduction
- This study represents the first introduction of a new feature-processing framework in the field of maritime safety, with a specific focus on navigation aids under complex conditions. By employing advanced feature-processing techniques, our approach accurately captures relationships among features and comprehensively considers the impact of multidimensional characteristics, leading to a more precise identification of the operational status of navigation aids.
- We propose three independent feature-processing modules. The feature expansion module utilizes the rank entropy operator to capture associations between features. The feature fusion module integrates features from the time domain, frequency domain, and time–frequency domain, capturing the correlation of signals in both the time and frequency domains, providing a more comprehensive reflection of the dynamic evolution of navigation aids states. The feature extraction module, through the BiLSTM model, better captures the abstract representation of navigation aids signals.
- We conducted a comprehensive comparison of our model with deep learning network models such as LSTM, BiLSTM, 1DCNN, and LSTM-CNN. Through experimental validation on four actual navigation aids datasets collected by the Guangzhou Maritime Safety Administration, the results indicate that our proposed model significantly surpasses current leading methods in terms of performance. This provides strong support for research and practical applications in the field of maritime navigation.
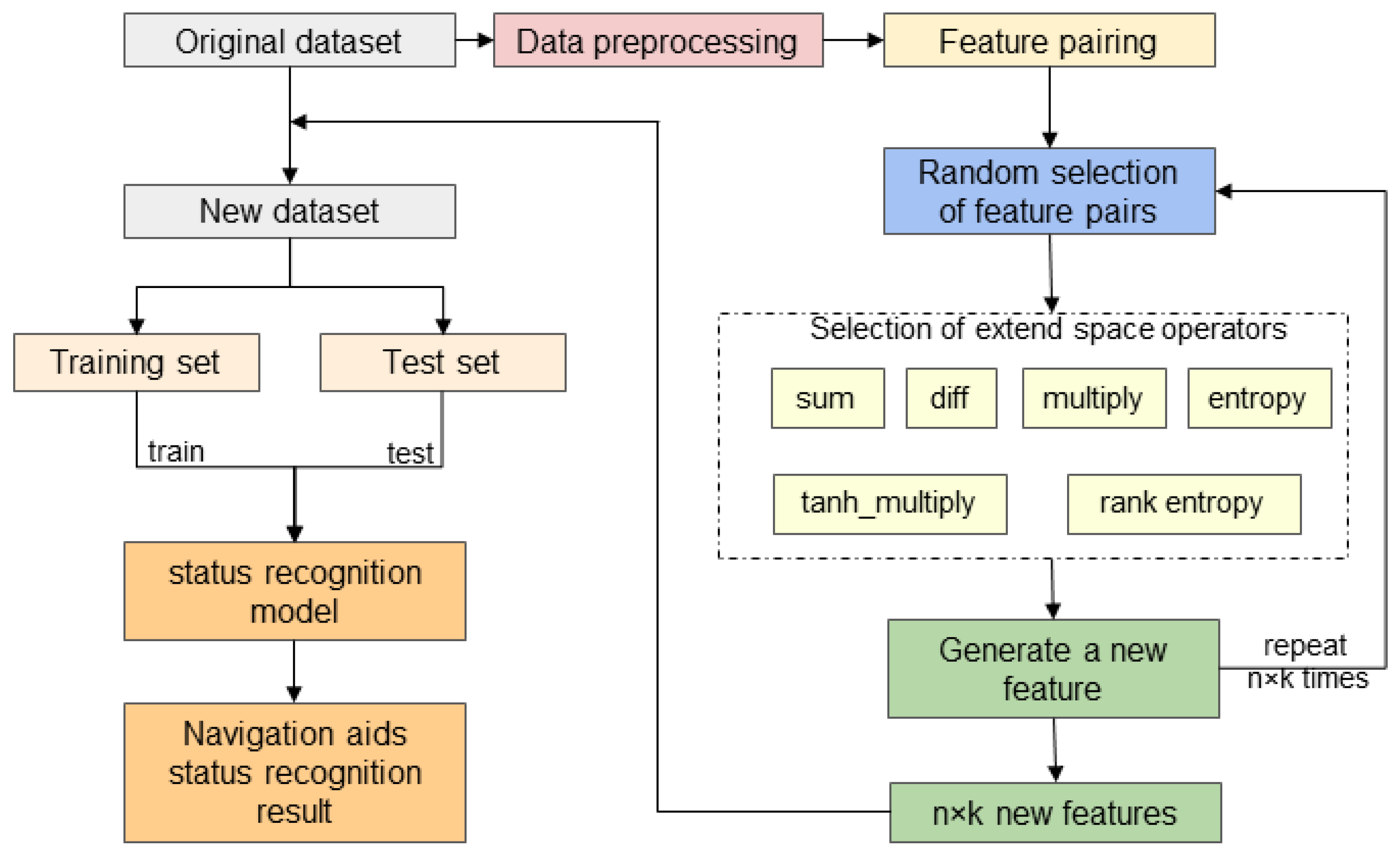
2. Materials and Methods
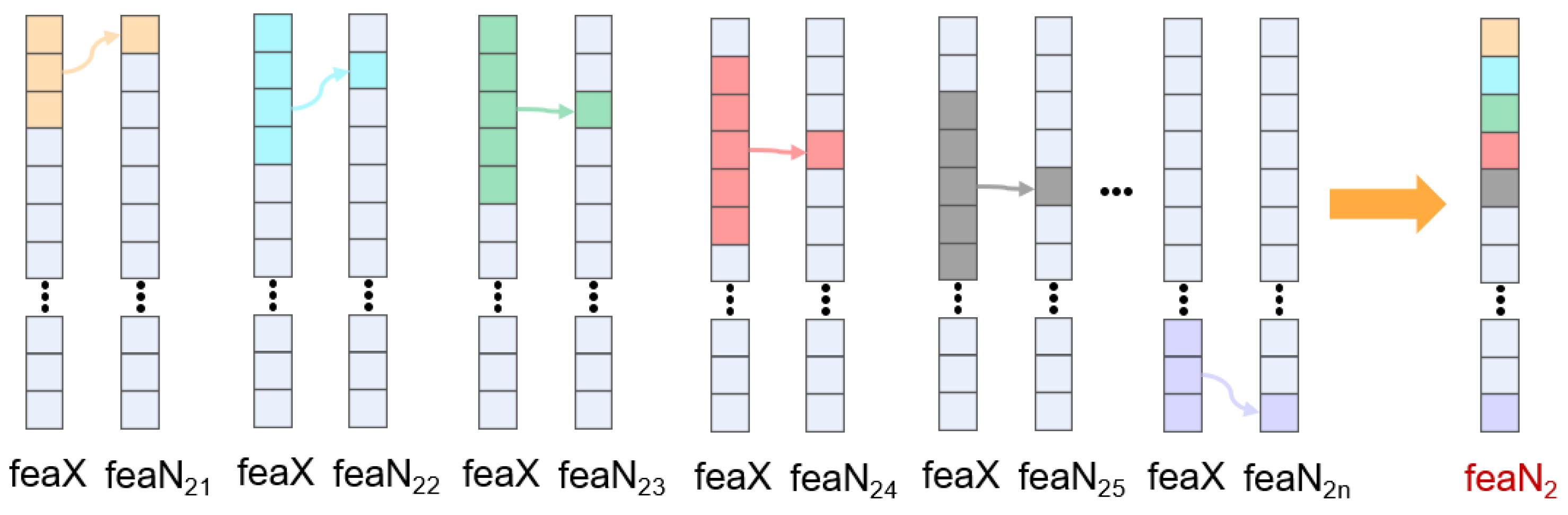
2.1. Feature Extension Module
2.2. Feature Fusion Module
- (1)
- Time domain features: The temporal features employed in this study include the following: the mean value , variance , mean square value , root mean square value , maximum value , minimum value , peak value , peak-to-peak value , and root amplitude . Additionally, dimensionless indicators include skewness , kurtosis , a waveform indicator , a peak indicator , an impulse indicator , a clearance indicator , a skewness indicator , and a kurtosis indicator [30].
- (2)
- Frequency domain features: The frequency domain describes the relationship between the frequency and amplitude of a signal, usually with frequency as the independent variable and amplitude as the dependent variable. By employing a Fourier transform, the time-domain signal is mapped to the frequency domain. Subsequently, based on the frequency distribution characteristics and trends of the signal, the navigation state or fault conditions of the beacon can be determined. Frequency domain analyses include methods such as spectrum analysis, energy spectrum analysis, and envelope analysis. A basic introduction to these methods is provided below.
- (1)
- Spectral analysis: A spectrum analysis usually provides more intuitive feature information than time-domain waveforms. For a time-domain signal , its spectrum can be obtained through the Fourier transform:Here, is the frequency domain representation, f is the frequency, and is the original time-domain signal.
- (2)
- Energy spectral analysis: The energy spectrum is the magnitude squared of the signal’s Fourier transform, representing the distribution of energy across different frequencies. The energy spectrum of a signal can be expressed as follows:where is the magnitude of the Fourier transform of the signal .
- (3)
- Envelope analysis: An envelope analysis extracts low-frequency signals from high-frequency signals. From a time-domain perspective, it is equivalent to extracting the envelope trajectory of a time-domain waveform. First, the analytic signal of the signal can be obtained via the Hilbert transform:where is the Hilbert transform of . The envelope can then be determined by calculating the magnitude of the analytic signal:
- (3)
- Time–frequency domain features: Time–frequency analysis methods provide a more comprehensive description of the relationship between frequency, energy, and time for non-stationary signals. Classical methods for analyzing non-stationary signals include the short-time Fourier transform (STFT) [31] and wavelet decomposition [32], both of which serve as important tools in the analysis of non-stationary signals. These methods can effectively illustrate variations in the frequency and energy of a signal at different time points. The STFT is suited for signals whose frequency content changes gradually over time, whereas wavelet decomposition is more appropriate for signals with sharp transitions or localized features.
- (1)
- Short-time Fourier transform: The STFT operates by sliding a window across the signal and performing a Fourier transform on the signal within this window. This approach reveals the frequency content of the signal at various time instances. The formula for STFT is expressed as follows:Here, represents the original signal, denotes the window function centered at , and is the frequency variable.
- (2)
- Wavelet decomposition: Wavelet decomposition involves analyzing the signal using a series of wavelet functions derived by scaling and translating a mother wavelet. This method provides insights into the signal’s characteristics at different scales (frequencies) and locations (times). The wavelet decomposition is formulated as follows:In this equation, is the original signal, is the mother wavelet function, a is the scaling parameter, and b is the translation parameter.
- (a)
- For each feature column, we employ a time window with a length of n to slide over each sampling data point, including the current sampling point and its adjacent two sampling points.
- (b)
- Calculate specific time domain or frequency domain features, such as the standard deviation, spectral analysis short-time Fourier transform, etc.
- (c)
- Finally, add the calculated new features to the original feature columns to extend the feature set.
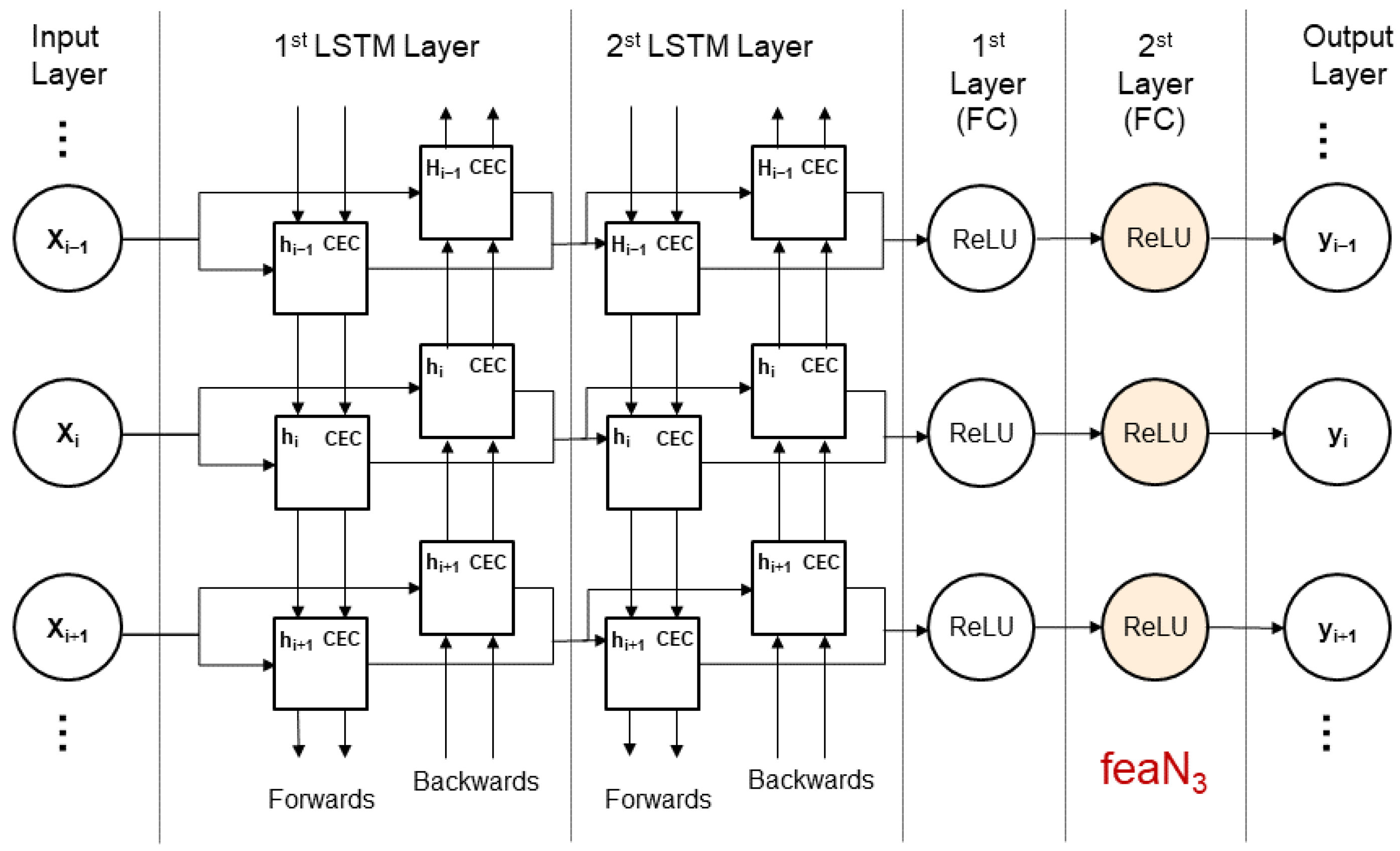
2.3. Feature Extraction Module
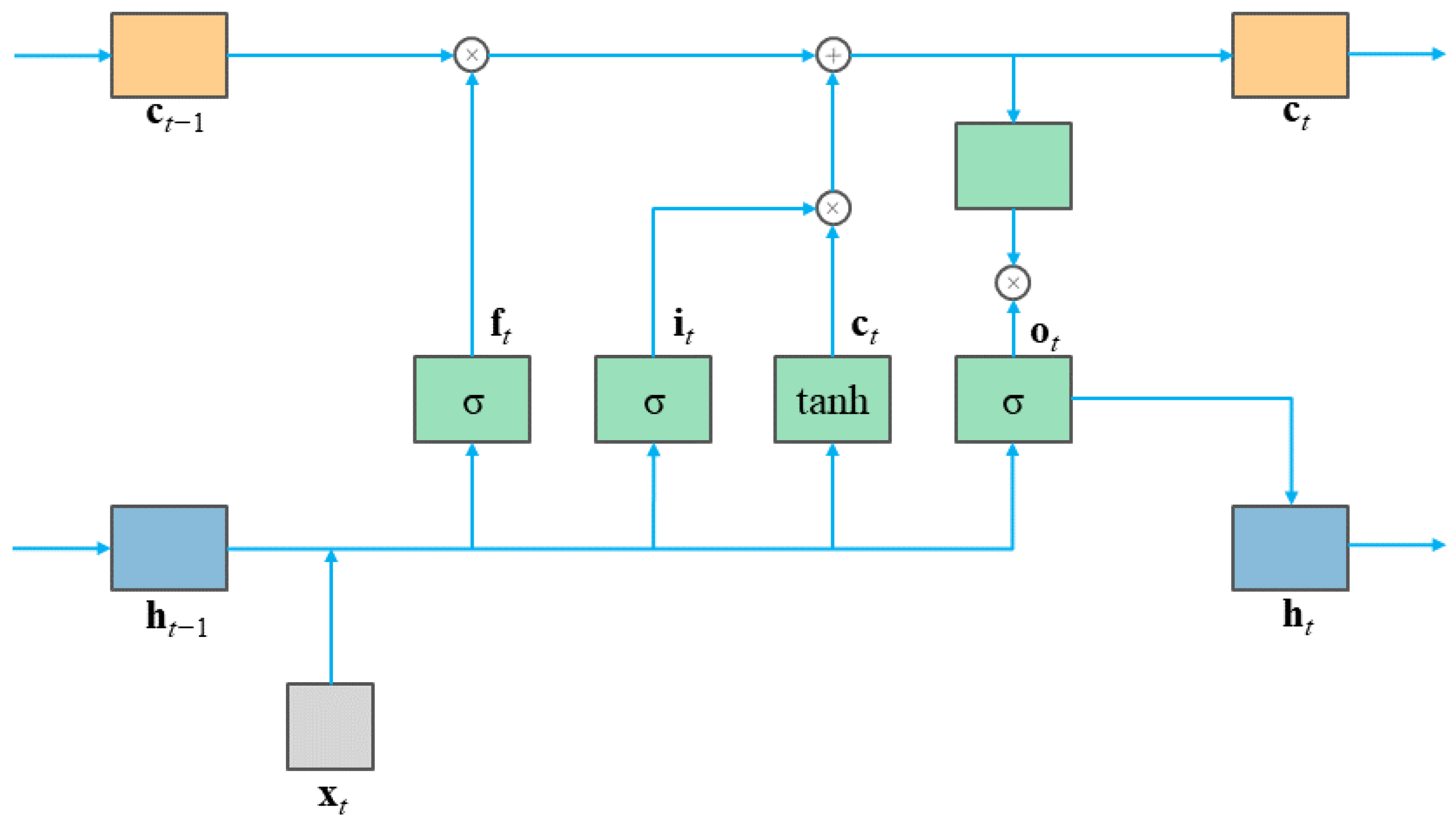
2.4. LSTM
2.5. Hyperparameter Optimization
3. Data Source Description and Analysis of Results
3.1. Data Description and Preprocessing
3.2. Model Evaluation Metrics
3.3. Assessment Results
3.3.1. Experimental Comparison of Extended Space Operators
3.3.2. Select Multi-Domain Features
3.3.3. Comparison with Other Feature Extraction Models
3.3.4. Comparison of Performance among Different Modules
3.3.5. Comparison of Performance among Different Models
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Redondo, R.; Atienza, R.; Pecharroman, L.; Pires, L. Aids to navigation improvement to optimize ship navigation. In Smart Rivers; Springer: Berlin/Heidelberg, Germany, 2022; pp. 803–813. [Google Scholar]
- Sang, L.; Hong, S. Development of navigational aids telemetry and telecontrol system in south China sea. Navig. China 2020, 43, 35–40. [Google Scholar]
- Wen, Z.; Cao, J.; Huang, L.; Li, D.; Sun, L.; Huang, X. Enhancing Navigation Aids Status Recognition Based on Extended Space Forest and Time Domain Features Fusion. In Proceedings of the 2023 IEEE International Symposium on Product Compliance Engineering—Asia (ISPCE-ASIA), Shanghai, China, 3–5 November 2023; pp. 1–6. [Google Scholar]
- Muhammad Irsyad Hasbullah, N.A.O.; Salleh, N.H.M. A systematic review and meta-analysis on the development of aids to navigation. Aust. J. Marit. Ocean. Aff. 2023, 15, 247–267. [Google Scholar] [CrossRef]
- Cho, M.; Choi, H.R.; Kwak, C. A study on the navigation aids management based on IoT. Int. J. Control Autom. 2015, 8, 193–204. [Google Scholar] [CrossRef]
- Cho, M.; Choi, H.; Kwak, C. A Study on the method of IoT-based navigation aids management. Adv. Sci. Technol. Lett. 2015, 98, 55–58. [Google Scholar]
- Ostroumov, I.; Kuzmenko, N. Risk analysis of positioning by navigational aids. In Proceedings of the 2019 Signal Processing Symposium (SPSympo), Krakow, Poland, 17–19 September 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 92–95. [Google Scholar]
- Ostroumov, I.; Kuzmenko, N. Risk assessment of mid-air collision based on positioning performance by navigational aids. In Proceedings of the 2020 IEEE 6th International Conference on Methods and Systems of Navigation and Motion Control (MSNMC), Kyiv, Ukraine, 20–23 October 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 34–37. [Google Scholar]
- Wu, F.; Qu, Y. The positive impact of intelligent aids to navigation on maritime transportation. In Proceedings of the Seventh International Conference on Traffic Engineering and Transportation System (ICTETS 2023), Dalian, China, 22–24 September 2023; SPIE: Washington, DC, USA, 2024; Volume 13064, pp. 959–966. [Google Scholar]
- Liang, Y. Route planning of aids to navigation inspection based on intelligent unmanned ship. In Proceedings of the 2021 4th International Symposium on Traffic Transportation and Civil Architecture (ISTTCA), Suzhou, China, 12–14 November 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 95–98. [Google Scholar]
- Alharbi, N.S.; Jahanshahi, H.; Yao, Q.; Bekiros, S.; Moroz, I. Enhanced classification of heartbeat electrocardiogram signals using a long short-term memory–convolutional neural network ensemble: Paving the way for preventive healthcare. Mathematics 2023, 11, 3942. [Google Scholar] [CrossRef]
- Mustaqeem; Kwon, S. CLSTM: Deep feature-based speech emotion recognition using the hierarchical ConvLSTM network. Mathematics 2020, 8, 2133. [Google Scholar] [CrossRef]
- Chen, Y.; Niu, G.; Li, Y.; Li, Y. A modified bidirectional long short-term memory neural network for rail vehicle suspension fault detection. Veh. Syst. Dyn. 2023, 61, 3136–3160. [Google Scholar] [CrossRef]
- Dong, L.; Zhang, H.; Yang, K.; Zhou, D.; Shi, J.; Ma, J. Crowd counting by using Top-k relations: A mixed ground-truth CNN framework. IEEE Trans. Consum. Electron. 2022, 68, 307–316. [Google Scholar] [CrossRef]
- An, Z.; Li, S.; Wang, J.; Jiang, X. A novel bearing intelligent fault diagnosis framework under time-varying working conditions using recurrent neural network. ISA Trans. 2020, 100, 155–170. [Google Scholar] [CrossRef]
- Alotaibi, N.D.; Jahanshahi, H.; Yao, Q.; Mou, J.; Bekiros, S. An ensemble of long short-term memory networks with an attention mechanism for upper limb electromyography signal classification. Mathematics 2023, 11, 4004. [Google Scholar] [CrossRef]
- Wang, H.; Fu, S.; Peng, B.; Wang, N.; Gao, H. Equipment health condition recognition and prediction based on CNN-LSTM deep learning. In Proceedings of the International Conference on Maintenance Engineering, Online, 15–17 April 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 830–842. [Google Scholar]
- Zhao, H.; Hou, C.; Alrobassy, H.; Zeng, X. Recognition of transportation state by smartphone sensors using deep BiLSTM neural network. J. Comput. Netw. Commun. 2019, 2019, 830–842. [Google Scholar]
- Mekruksavanich, S.; Jitpattanakul, A. Lstm networks using smartphone data for sensor-based human activity recognition in smart homes. Sensors 2021, 21, 1636. [Google Scholar] [CrossRef] [PubMed]
- Wang, C.; Luo, H.; Zhao, F.; Qin, Y. Combining residual and LSTM recurrent networks for transportation mode detection using multimodal sensors integrated in smartphones. IEEE Trans. Intell. Transp. Syst. 2020, 22, 5473–5485. [Google Scholar] [CrossRef]
- Wang, H.; Luo, H.; Zhao, F.; Qin, Y.; Zhao, Z.; Chen, Y. Detecting Transportation Modes with Low-Power-Consumption Sensors Using Recurrent Neural Network; IEEE: Piscataway, NJ, USA, 2018; pp. 1098–1105. [Google Scholar]
- Drosouli, I.; Voulodimos, A.; Miaoulis, G.; Mastorocostas, P.; Ghazanfarpour, D. Transportation mode detection using an optimized long short-term memory model on multimodal sensor data. Entropy 2021, 23, 1457. [Google Scholar] [CrossRef] [PubMed]
- Shi, L.; Liu, Z.; Zhou, K.; Shi, Y.; Jing, X. Novel deep learning network for gait recognition using multimodal inertial sensors. Sensors 2023, 23, 849. [Google Scholar] [CrossRef] [PubMed]
- Amasyali, M.F.; Ersoy, O.K. Classifier ensembles with the extended space forest. IEEE Trans. Knowl. Data Eng. 2013, 26, 549–562. [Google Scholar] [CrossRef]
- Dhibi, K.; Mansouri, M.; Bouzrara, K.; Nounou, H.; Nounou, M. An enhanced ensemble learning-based fault detection and diagnosis for grid-connected PV systems. IEEE Access 2021, 9, 155622–155633. [Google Scholar] [CrossRef]
- Sun, H.; Zhao, S. Fault diagnosis for bearing based on 1DCNN and LSTM. Shock Vib. 2021, 2021, 1–17. [Google Scholar] [CrossRef]
- Malik, A.K.; Ganaie, M.; Tanveer, M.; Suganthan, P.N. Extended features based random vector functional link network for classification problem. IEEE Trans. Comput. Soc. Syst. 2022. [Google Scholar] [CrossRef]
- Xu, Y.; Yu, Z.; Cao, W.; Chen, C.P. A novel classifier ensemble method based on subspace enhancement for high-dimensional data classification. IEEE Trans. Knowl. Data Eng. 2021, 35, 16–30. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, S.; Sima, X.; Song, Y.; Cui, S.; Wang, D. Expanded feature space-based gradient boosting ensemble learning for risk prediction of type 2 diabetes complications. Appl. Soft Comput. 2023, 144, 110451. [Google Scholar] [CrossRef]
- Duan, Y.; Cao, X.; Zhao, J.; Xu, X. Health indicator construction and status assessment of rotating machinery by spatiotemporal fusion of multi-domain mixed features. Measurement 2022, 205, 112170. [Google Scholar] [CrossRef]
- Boashash, B. Time-Frequency Signal Analysis and Processing: A Comprehensive Reference; Academic Press: Cambridge, MA, USA, 2015. [Google Scholar]
- Mallat, S.G. A theory for multiresolution signal decomposition: The wavelet representation. IEEE Trans. Pattern Anal. Mach. Intell. 1989, 11, 674–693. [Google Scholar] [CrossRef]
- Abduljabbar, R.L.; Dia, H.; Tsai, P.W. Development and evaluation of bidirectional LSTM freeway traffic forecasting models using simulation data. Sci. Rep. 2021, 11, 23899. [Google Scholar] [CrossRef]
- Xia, K.; Huang, J.; Wang, H. LSTM-CNN architecture for human activity recognition. IEEE Access 2020, 8, 56855–56866. [Google Scholar] [CrossRef]
- Khan, P.; Reddy, B.S.K.; Pandey, A.; Kumar, S.; Youssef, M. Differential channel-state-information-based human activity recognition in IoT networks. IEEE Internet Things J. 2020, 7, 11290–11302. [Google Scholar] [CrossRef]
- Du, X.; Ma, C.; Zhang, G.; Li, J.; Lai, Y.K.; Zhao, G.; Deng, X.; Liu, Y.J.; Wang, H. An efficient LSTM network for emotion recognition from multichannel EEG signals. IEEE Trans. Affect. Comput. 2020, 13, 1528–1540. [Google Scholar] [CrossRef]
- Xiao, H.; Sotelo, M.A.; Ma, Y.; Cao, B.; Zhou, Y.; Xu, Y.; Wang, R.; Li, Z. An improved LSTM model for behavior recognition of intelligent vehicles. IEEE Access 2020, 8, 101514–101527. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 7–9 July 2015; Volume 37, pp. 448–456. [Google Scholar]
- Dogan, G.; Ford, M.; James, S. Predicting ocean-wave conditions using buoy data supplied to a hybrid RNN-LSTM neural network and machine learning models. In Proceedings of the 2021 IEEE International Conference on Machine Learning and Applied Network Technologies (ICMLANT), Soyapango, El Salvador, 16–17 December 2021; pp. 1–6. [Google Scholar]
- Powers, D.M.W. Evaluation: From precision, recall and F-measure to ROC, informedness, markedness and correlation. arXiv 2020, arXiv:2010.16061. [Google Scholar]
- Sherstinsky, A. Fundamentals of recurrent neural network (RNN) and long short-term memory (LSTM) network. Phys. D Nonlinear Phenom. 2020, 404, 132306. [Google Scholar] [CrossRef]
- Woźniak, M.; Wieczorek, M.; Siłka, J. BiLSTM deep neural network model for imbalanced medical data of IoT systems. Future Gener. Comput. Syst. 2023, 141, 489–499. [Google Scholar] [CrossRef]
- Huang, S.; Tang, J.; Dai, J.; Wang, Y. Signal status recognition based on 1DCNN and its feature extraction mechanism analysis. Sensors 2019, 19, 2018. [Google Scholar] [CrossRef]
- Kim, T.; Kim, H.Y. Forecasting stock prices with a feature fusion LSTM-CNN model using different representations of the same data. PLoS ONE 2019, 14, e0212320. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Operator Name | Equation |
|---|---|
| Sum | |
| Diff | |
| Multiply | |
| Tanh_multiply |
| Layer (Type) | Output Shape | Param |
|---|---|---|
| lstm_1 (LSTM) | (None, 256) | 268,288 |
| dense_3 (Dense)) | (None, 256) | 65,792 |
| activation_3 (Activation) | (None, 256) | 0 |
| dropout_2 (Dropout) | (None, 256) | 0 |
| batch_normalization_2 (Batch Normalization) | (None, 256) | 1024 |
| dense_4 (Dense) | (None, 64) | 16,448 |
| activation_4 (Activation) | (None, 64) | 0 |
| dropout_3 (Dropout) | (None, 64) | 0 |
| batch_normalization_3 (Batch Normalization) | (None, 64) | 256 |
| dense_5 (Dense) | (None, 2) | 130 |
| activation_5 (Activation) | (None, 2) | 0 |
| Dataset ID | Dataset Name | Sample Quantity | Feature Quantity |
|---|---|---|---|
| 1 | Beihai No. 19 | 26,727 | 5 |
| 2 | Huizhou No. 5 | 5152 | 5 |
| 3 | Houjiang No. 3 | 4891 | 5 |
| 4 | Guang’ao No. 1 | 17,016 | 5 |
| Acquisition Time | Latitude | Longitude | Voltage | Current | Offset Distance |
|---|---|---|---|---|---|
| 9 September 2019 15:04:36 | 21.48142333 | 109.08951500 | 12.3 | 0 | 9.7579337793 |
| 9 September 2019 15:30:43 | 21.48151500 | 109.47328333 | 12.3 | 0 | 8.4548264142 |
| 9 September 2019 17:30:46 | 21.48174833 | 109.08964500 | 12.3 | 0 | 10.062118750 |
| … | … | … | … | … | … |
| 11 July 2023 13:38:13 | 21.49850000 | 109.09360500 | 13.700 | 0 | 13.305813355 |
| 11 July 2023 13:48:59 | 21.49850000 | 109.09360500 | 13.700 | 0.35 | 9.8824060802 |
| 11 July 2023 14:00:47 | 21.49850500 | 109.09360500 | 13.700 | 0.36 | 9.6478582663 |
| Operator | Mean Accuracy | Mean Recall | Mean Precision | Mean F1 |
|---|---|---|---|---|
| / | 60.53% | 74.87% | 60.53% | 53.59% |
| Sum | 61.03% | 71.86% | 61.02% | 55.39% |
| Diff | 63.10% | 74.44% | 63.09% | 58.22% |
| Multiply | 62.65% | 74.10% | 62.65% | 57.59% |
| Tanh_multiply | 62.99% | 73.89% | 62.97% | 58.31% |
| Entropy | 62.06% | 73.31% | 62.05% | 56.80% |
| Rank entropy (Proposed) | 71.63% | 78.66% | 71.62% | 69.68% |
| Domain | Reserved Features |
|---|---|
| Time domain | root amplitude variance skewness indicator kurtosis indicator |
| Frequency domain | spectral analysis |
| Time–frequency domain | wavelet decomposition |
| Model | Mean Accuracy | Mean Recall | Mean Precision | Mean F1 |
|---|---|---|---|---|
| / | 60.53% | 74.87% | 60.53% | 53.59% |
| LSTM | 62.60% | 73.45% | 62.60% | 57.02% |
| 1DCNN | 66.86% | 74.48% | 66.87% | 63.15% |
| LSTM_CNN | 67.10% | 73.87% | 67.11% | 63.97% |
| BiLSTM | 68.35% | 74.85% | 68.35% | 65.51% |
| Beihai No. 19 | ||||||
| Method | Confusion Matrix | Mean Accuracy | Mean Precision | Mean Recall | Mean F1 | |
| LSTM | 961.8 | 48.4 | 0.6511 | 0.7505 | 0.6507 | 0.6134 |
| 656.6 | 353.6 | |||||
| BiLSTM | 907.8 | 102.4 | 0.6602 | 0.7124 | 0.6606 | 0.6352 |
| 584.2 | 426 | |||||
| 1DCNN | 947.2 | 63 | 0.7821 | 0.8125 | 0.7821 | 0.7767 |
| 377.2 | 633 | |||||
| LSTM-CNN | 971.8 | 38.4 | 0.7614 | 0.8119 | 0.7614 | 0.7514 |
| 443.6 | 566.6 | |||||
| EFE-LSTM | 1004.2 | 6 | 0.9922 | 0.9921 | 0.9922 | 0.9922 |
| 9.8 | 1000.4 | |||||
| Huizhou No. 5 | ||||||
| Method | Confusion Matrix | Mean Accuracy | Mean Precision | Mean Recall | Mean F1 | |
| LSTM | 185 | 14 | 0.7010 | 0.7547 | 0.7008 | 0.6841 |
| 105 | 94 | |||||
| BiLSTM | 164.8 | 34.2 | 0.7020 | 0.7173 | 0.7022 | 0.6969 |
| 84.4 | 114.6 | |||||
| 1DCNN | 180.6 | 18.4 | 0.7231 | 0.7584 | 0.7233 | 0.7133 |
| 91.8 | 107.2 | |||||
| LSTM-CNN | 181.2 | 17.8 | 0.7085 | 0.7497 | 0.7087 | 0.6959 |
| 98.2 | 100.8 | |||||
| EFE-LSTM | 189.4 | 9.6 | 0.9191 | 0.9212 | 0.9191 | 0.9189 |
| 22.6 | 176.4 | |||||
| Houjiang No. 3 | ||||||
| Method | Confusion Matrix | Mean Accuracy | Mean Precision | Mean Recall | Mean F1 | |
| LSTM | 175.4 | 8.8 | 0.5994 | 0.7013 | 0.5996 | 0.5418 |
| 138.8 | 45.4 | |||||
| BiLSTM | 177.2 | 7 | 0.5874 | 0.7001 | 0.5875 | 0.5199 |
| 145 | 39.2 | |||||
| 1DCNN | 173.6 | 10.6 | 0.5993 | 0.6890 | 0.5995 | 0.5456 |
| 137 | 47.2 | |||||
| LSTM-CNN | 171.6 | 12.6 | 0.5988 | 0.6788 | 0.5995 | 0.5456 |
| 135.2 | 49 | |||||
| EFE-LSTM | 166 | 18.2 | 0.8334 | 0.8404 | 0.8339 | 0.8325 |
| 43.2 | 141 | |||||
| Method | Confusion Matrix | Mean Accuracy | Mean Precision | Mean Recall | Mean F1 | |
| LSTM | 598.4 | 21.2 | 0.5734 | 0.6913 | 0.5734 | 0.4956 |
| 507.4 | 112.2 | |||||
| BiLSTM | 584.2 | 35.4 | 0.5689 | 0.6636 | 0.5699 | 0.4978 |
| 498.8 | 120.8 | |||||
| 1DCNN | 577.6 | 42 | 0.6067 | 0.6876 | 0.6074 | 0.5599 |
| 445.4 | 174.2 | |||||
| LSTM-CNN | 598.2 | 21.4 | 0.5778 | 0.6947 | 0.5778 | 0.5030 |
| 501.8 | 117.8 | |||||
| EFE-LSTM | 588.4 | 31.2 | 0.9385 | 0.9387 | 0.9387 | 0.9385 |
| 45 | 574.6 | |||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cao, J.; Wen, Z.; Huang, L.; Dai, J.; Qin, H. EFE-LSTM: A Feature Extension, Fusion and Extraction Approach Using Long Short-Term Memory for Navigation Aids State Recognition. Mathematics 2024, 12, 1048. https://doi.org/10.3390/math12071048
Cao J, Wen Z, Huang L, Dai J, Qin H. EFE-LSTM: A Feature Extension, Fusion and Extraction Approach Using Long Short-Term Memory for Navigation Aids State Recognition. Mathematics. 2024; 12(7):1048. https://doi.org/10.3390/math12071048
Chicago/Turabian StyleCao, Jingjing, Zhipeng Wen, Liang Huang, Jinshan Dai, and Hu Qin. 2024. "EFE-LSTM: A Feature Extension, Fusion and Extraction Approach Using Long Short-Term Memory for Navigation Aids State Recognition" Mathematics 12, no. 7: 1048. https://doi.org/10.3390/math12071048
APA StyleCao, J., Wen, Z., Huang, L., Dai, J., & Qin, H. (2024). EFE-LSTM: A Feature Extension, Fusion and Extraction Approach Using Long Short-Term Memory for Navigation Aids State Recognition. Mathematics, 12(7), 1048. https://doi.org/10.3390/math12071048