
Commit-Level Software Change Intent Classification Using a Pre-Trained Transformer-Based Code Model



Abstract
1. Introduction
- (1)
- We propose a novel method for extracting semantic features of code changes in order to represent a commit as a vector embedding for commit intent classification into software maintenance activities.
- (2)
- We provide an ablation study and in-depth analyses demonstrating the effectiveness of the proposed method and its steps when used for commit intent classification into software maintenance activities.
- (3)
- We provide empirical evaluations of commit intent classification performance when using the proposed method compared to the existing methods of code-based commit representations for intent categorization.
2. Related Work
2.1. Commit Classification
2.2. Pre-Trained Models in Code-Related Tasks
3. Background
3.1. Commit-Level Software Changes
3.2. Commit Intent Classification
3.3. Intent-Based Categorization of Software Maintenance Activities
3.4. Transformer-Based Models for Programming Languages
CodeBERT and GraphCodeBERT
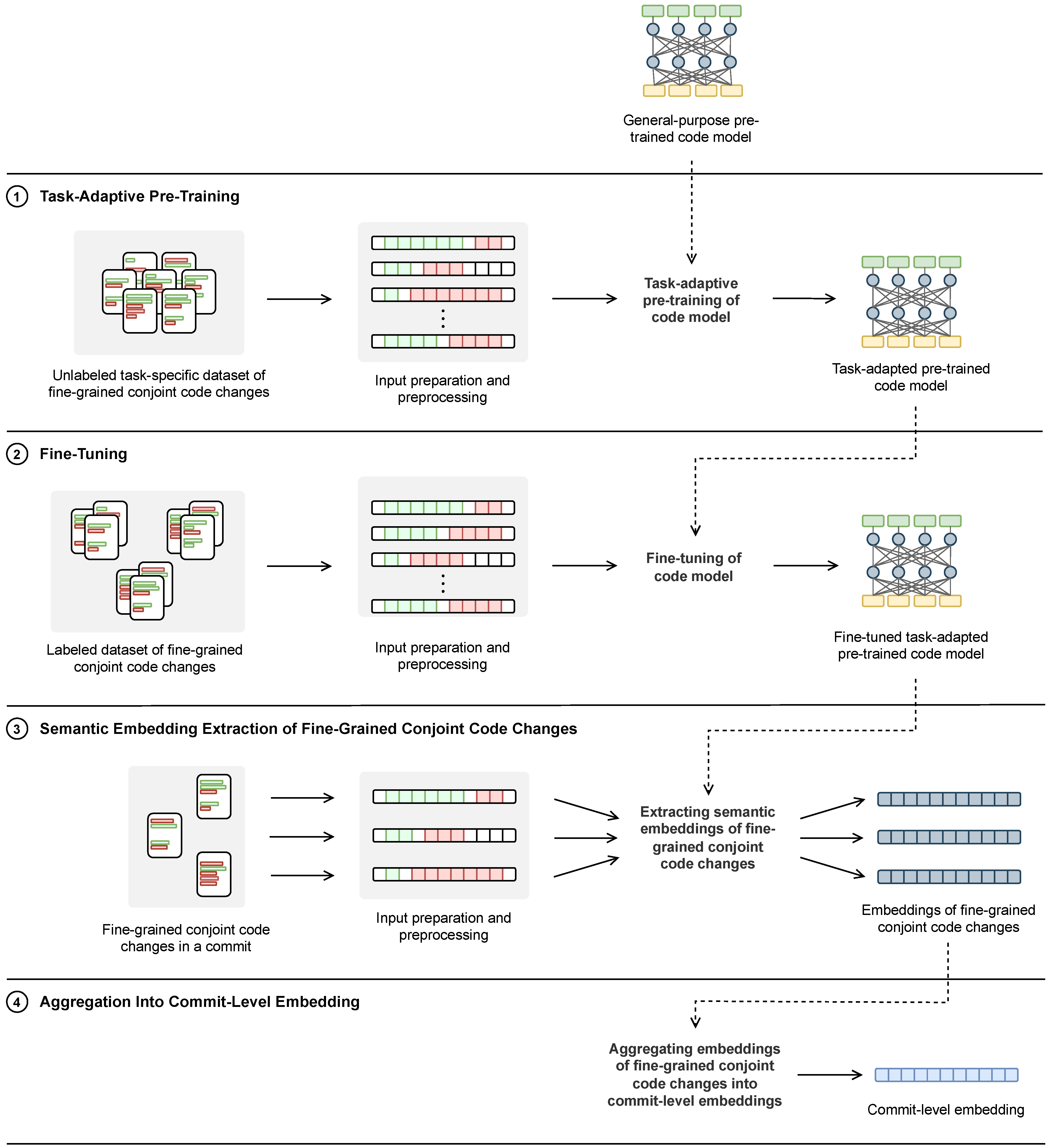
4. Proposed Semantic Commit Feature Extraction Method
4.1. Task-Adaptive Pre-Training
| Algorithm 1 Input preparation and processing for a BERT-based code model with dynamic token length allocation, truncation, and padding |
 |
4.2. Fine-Tuning
4.3. Semantic Embedding Extraction of Fine-Grained Conjoint Code Changes
4.4. Aggregation into Commit-Level Embedding
5. Experiments
5.1. Research Questions
- RQ1 How effective is the proposed method when used for commit intent classification?This question aims to empirically assess the effectiveness of the proposed semantic commit feature extraction method for commit intent classification. By focusing on classification performance, this evaluation aims to determine the resulting model’s ability to accurately distinguish between various types of intents behind commit-level software changes. Such an assessment is crucial as it directly relates to the practical applicability and relevance of the method in the field of software engineering.
- RQ2 How does the proposed method compare to the SOTA when used for commit intent classification?This question aims to benchmark the proposed method against the current SOTA in commit intent classification. By conducting this comparative analysis, the research aims to position the proposed method within the broader context of commit intent classification.
5.2. Datasets
| Algorithm 2 Data preparation and preprocessing steps to obtain the extended dataset used in the experiments |
 |
5.3. Experimental Settings of the Proposed Method
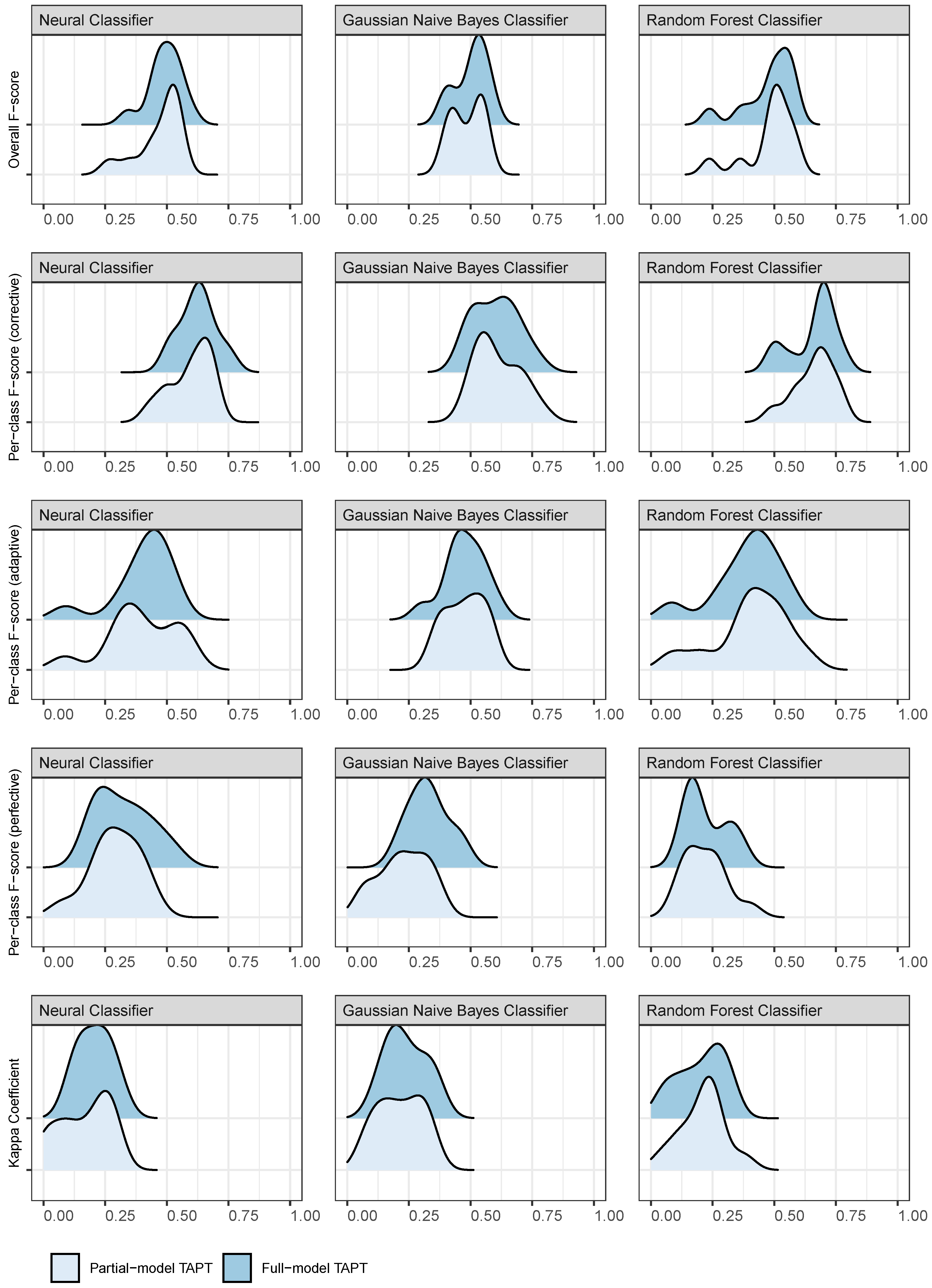
5.3.1. Task-Adaptive Pre-Training
5.3.2. Fine-Tuning
5.3.3. Semantic Embedding Extraction of Fine-Grained Conjoint Code Changes
5.3.4. Aggregation into Commit-Level Embedding
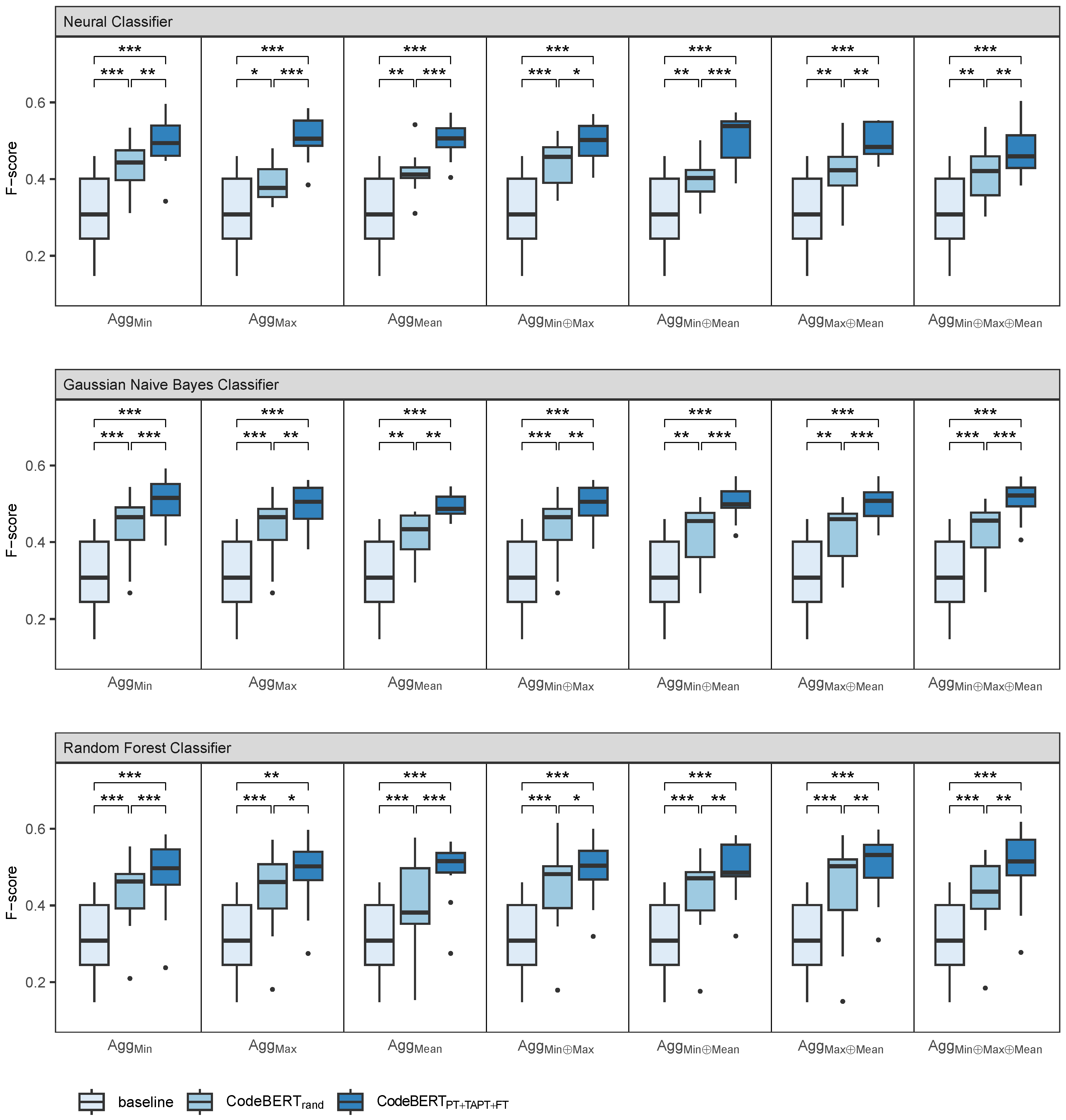
5.4. Commit Intent Classification
5.5. Evaluation
5.6. Experiment Setup and Implementation Details
6. Results and Discussion
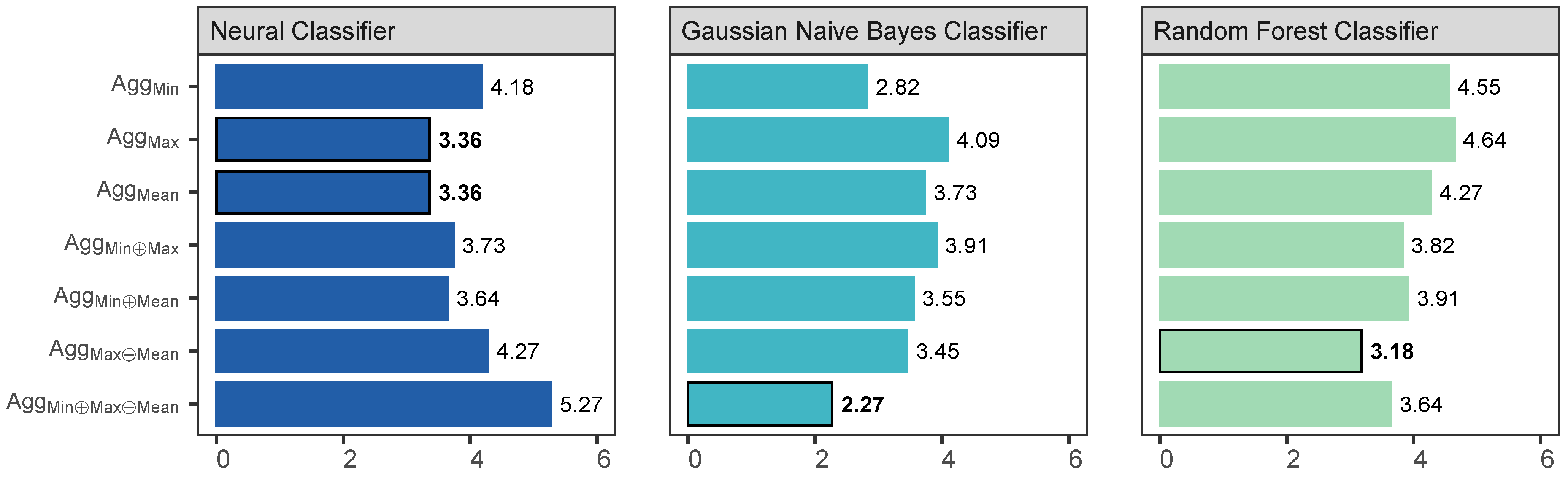
6.1. RQ1 How Effective Is the Proposed Method When Used for Commit Intent Classification?
6.2. RQ2 How Does the Proposed Method Compare to the SOTA When Used for Commit Intent Classification?
7. Threats to Validity
7.1. Threats to Construct Validity
7.2. Threats to Internal Validity
7.3. Threats to External Validity
7.4. Threats to Conclusion Validity
8. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. Characteristics of the Extended Dataset

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. Affected Files Per Commit | No. Added and Deleted Lines Per File | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| # | Software Project | Med | IQR | Avg | Std | Min | Max | Med | IQR | Avg | Std | Min | Max | |
| P1 | Apache Camel | 2.50 | 4.00 | 6.42 | 15.89 | 1.00 | 135.00 | 7.00 | 13.00 | 16.03 | 26.75 | 1.00 | 254.00 | |
| P2 | Apache HBase | 2.00 | 2.00 | 3.39 | 4.33 | 1.00 | 23.00 | 9.00 | 27.00 | 32.29 | 161.76 | 1.00 | 2885.00 | |
| P3 | Drools | 2.00 | 4.00 | 4.88 | 6.85 | 1.00 | 40.00 | 12.00 | 27.00 | 46.82 | 186.41 | 1.00 | 3176.00 | |
| P4 | Elasticsearch | 2.00 | 3.50 | 5.66 | 9.83 | 1.00 | 55.00 | 9.00 | 17.00 | 24.06 | 43.42 | 1.00 | 338.00 | |
| P5 | Hadoop | 3.00 | 4.00 | 6.41 | 9.65 | 1.00 | 74.00 | 10.00 | 28.00 | 31.62 | 64.37 | 1.00 | 761.00 | |
| P6 | IntelliJ IDEA Community | 1.00 | 1.25 | 2.13 | 2.14 | 1.00 | 15.00 | 8.00 | 19.00 | 21.96 | 58.09 | 1.00 | 631.00 | |
| P7 | Kotlin | 2.50 | 3.00 | 3.63 | 5.12 | 1.00 | 34.00 | 6.00 | 13.00 | 16.07 | 34.46 | 1.00 | 342.00 | |
| P8 | OrientDB | 2.00 | 4.00 | 4.67 | 6.94 | 1.00 | 41.00 | 8.00 | 21.00 | 50.49 | 236.59 | 1.00 | 3444.00 | |
| P9 | Restlet Framework | 2.00 | 3.00 | 6.73 | 23.86 | 1.00 | 215.00 | 4.00 | 5.00 | 14.62 | 45.25 | 1.00 | 563.00 | |
| P10 | RxJava | 2.00 | 1.00 | 2.70 | 4.40 | 1.00 | 30.00 | 15.50 | 35.50 | 30.14 | 47.07 | 1.00 | 392.00 | |
| P11 | Spring Framework | 2.00 | 2.00 | 2.87 | 3.10 | 1.00 | 15.00 | 10.00 | 24.75 | 22.58 | 29.22 | 1.00 | 155.00 | |
| Overall | 2.00 | 3.00 | 4.59 | 10.56 | 1.00 | 215.00 | 8.00 | 20.00 | 28.41 | 116.42 | 1.00 | 3444.00 | ||
Appendix B. Search Space for Hyperparameter Tuning of Classification Models Used in Experiments for RQ2
| Hyperparameter | Possible Values |
|---|---|
| hidden_layer_sizes | [(20), (20, 10), (512, 265), (512, 265, 128)] |
| learning_rate_init | [0.0001, 0.001] |
| max_iter | [200, 500, 1000] |
| alpha | [0.0001, 0.001] |
| Hyperparameter | Possible Values |
|---|---|
| var_smoothing | [1e-10, 1e-9, 1e-8, 1e-7] |
| Hyperparameter | Possible Values |
|---|---|
| n_estimators | [50, 100, 200] |
| min_samples_split | [2, 5, 10] |
| min_samples_leaf | [3, 5, 7] |
| max_depth | [None, 10] |
| criterion | [‘entropy’] |
Appendix C. Characteristics of the Folds of Group 11-Fold Cross-Validation
| Train Set | Test Set | ||||||
|---|---|---|---|---|---|---|---|
| Fold | No. Commits | No. Files | Software Projects | No. Commits | No. Files | Software Project | |
| Fold1 | 845 (90.4%) | 3717 (86.5%) | P2–P11 | 90 (9.6%) | 578 (13.5%) | P1 | |
| Fold2 | 838 (89.6%) | 3966 (92.3%) | P1, P3–P11 | 97 (10.4%) | 329 (7.7%) | P2 | |
| Fold3 | 832 (89.0%) | 3792 (88.3%) | P1, P2, P4–P11 | 103 (11.0%) | 503 (11.7%) | P3 | |
| Fold4 | 868 (92.8%) | 3916 (91.2%) | P1–P3, P5–P11 | 67 (7.2%) | 379 (8.8%) | P4 | |
| Fold5 | 836 (89.4%) | 3654 (85.1%) | P1–P4, P6–P11 | 99 (10.6%) | 641 (14.9%) | P5 | |
| Fold6 | 843 (90.2%) | 4099 (95.4%) | P1–P5, P7–P11 | 92 (9.8%) | 196 (4.6%) | P6 | |
| Fold7 | 853 (91.2%) | 3997 (93.1%) | P1–P6, P8–P11 | 82 (8.8%) | 298 (6.9%) | P7 | |
| Fold8 | 839 (89.7%) | 3847 (89.6%) | P1–P7, P9–P11 | 96 (10.3%) | 448 (10.4%) | P8 | |
| Fold9 | 849 (90.8%) | 3716 (86.5%) | P1–P8, P10, P11 | 86 (9.2%) | 579 (13.5%) | P9 | |
| Fold10 | 874 (93.5%) | 4129 (96.1%) | P1–P9, P11 | 61 (6.5%) | 166 (3.9%) | P10 | |
| Fold11 | 873 (93.4%) | 4117 (95.9%) | P1–P10 | 62 (6.6%) | 178 (4.1%) | P11 | |
Appendix D. Detailed Results of Statistical Tests
| Aggregation Technique | Paired Comparison | Shapiro–Wilk Test | Student’s t-Test |
|---|---|---|---|
| AggMin | baseline-CodeBERTrand | W (11) = 0.950, p = 0.648 | t (10) = −5.575, p < 0.001 *** |
| baseline-CodeBERTPT+TAPT+FT | W (11) = 0.984, p = 0.983 | t (10) = −6.845, p < 0.001 *** | |
| CodeBERTrand-CodeBERTPT+TAPT+FT | W (11) = 0.937, p = 0.486 | t (10) = −3.947, p = 0.003 ** | |
| AggMax | baseline-CodeBERTrand | W (11) = 0.956, p = 0.719 | t (10) = −2.679, p = 0.023 * |
| baseline-CodeBERTPT+TAPT+FT | W (11) = 0.901, p = 0.189 | t (10) = −6.777, p < 0.001 *** | |
| CodeBERTrand-CodeBERTPT+TAPT+FT | W (11) = 0.977, p = 0.951 | t (10) = −5.784, p < 0.001 *** | |
| AggMean | baseline-CodeBERTrand | W (11) = 0.932, p = 0.429 | t (10) = −4.334, p = 0.001 ** |
| baseline-CodeBERTPT+TAPT+FT | W (11) = 0.939, p = 0.504 | t (10) = −8.194, p < 0.001 *** | |
| CodeBERTrand-CodeBERTPT+TAPT+FT | W (11) = 0.925, p = 0.366 | t (10) = −6.456, p < 0.001 *** | |
| AggMin⊕Max | baseline-CodeBERTrand | W (11) = 0.880, p = 0.104 | t (10) = −5.331, p < 0.001 *** |
| baseline-CodeBERTPT+TAPT+FT | W (11) = 0.858, p = 0.055 | t (10) = −7.117, p < 0.001 *** | |
| CodeBERTrand-CodeBERTPT+TAPT+FT | W (11) = 0.904, p = 0.207 | t (10) = −2.856, p = 0.017 * | |
| AggMin⊕Mean | baseline-CodeBERTrand | W (11) = 0.903, p = 0.199 | t (10) = −3.394, p = 0.007 ** |
| baseline-CodeBERTPT+TAPT+FT | W (11) = 0.953, p = 0.686 | t (10) = −6.156, p < 0.001 *** | |
| CodeBERTrand-CodeBERTPT+TAPT+FT | W (11) = 0.961, p = 0.781 | t (10) = −4.643, p < 0.001 *** | |
| AggMax⊕Mean | baseline-CodeBERTrand | W (11) = 0.959, p = 0.762 | t (10) = −3.739, p = 0.004 ** |
| baseline-CodeBERTPT+TAPT+FT | W (11) = 0.916, p = 0.287 | t (10) = −5.403, p < 0.001 *** | |
| CodeBERTrand-CodeBERTPT+TAPT+FT | W (11) = 0.932, p = 0.428 | t (10) = −4.300, p = 0.002 ** | |
| AggMin⊕Max⊕Mean | baseline-CodeBERTrand | W (11) = 0.943, p = 0.556 | t (10) = −3.742, p = 0.004 ** |
| baseline-CodeBERTPT+TAPT+FT | W (11) = 0.942, p = 0.546 | t (10) = −7.210, p < 0.001 *** | |
| CodeBERTrand-CodeBERTPT+TAPT+FT | W (11) = 0.984, p = 0.985 | t (10) = −3.903, p = 0.003 ** |
| Aggregation Technique | Paired Comparison | Shapiro–Wilk Test | Student’s t-Test |
|---|---|---|---|
| AggMin | baseline-CodeBERTrand | W (11) = 0.963, p = 0.805 | t (10) = −5.790, p < 0.001 *** |
| baseline-CodeBERTPT+TAPT+FT | W (11) = 0.921, p = 0.327 | t (10) = −6.424, p < 0.001 *** | |
| CodeBERTrand-CodeBERTPT+TAPT+FT | W (11) = 0.924, p = 0.353 | t (10) = −4.853, p < 0.001 *** | |
| AggMax | baseline-CodeBERTrand | W (11) = 0.962, p = 0.801 | t (10) = −5.794, p < 0.001 *** |
| baseline-CodeBERTPT+TAPT+FT | W (11) = 0.923, p = 0.343 | t (10) = −6.316, p < 0.001 *** | |
| CodeBERTrand-CodeBERTPT+TAPT+FT | W (11) = 0.943, p = 0.555 | t (10) = −4.126, p = 0.002 ** | |
| AggMean | baseline-CodeBERTrand | W (11) = 0.929, p = 0.400 | t (10) = −3.297, p = 0.008 ** |
| baseline-CodeBERTPT+TAPT+FT | W (11) = 0.882, p = 0.111 | t (10) = −5.451, p < 0.001 *** | |
| CodeBERTrand-CodeBERTPT+TAPT+FT | W (11) = 0.934, p = 0.456 | t (10) = −4.456, p = 0.001 ** | |
| AggMin⊕Max | baseline-CodeBERTrand | W (11) = 0.966, p = 0.845 | t (10) = −5.874, p < 0.001 *** |
| baseline-CodeBERTPT+TAPT+FT | W (11) = 0.926, p = 0.375 | t (10) = −6.444, p < 0.001 *** | |
| CodeBERTrand-CodeBERTPT+TAPT+FT | W (11) = 0.949, p = 0.635 | t (10) = −4.272, p = 0.002 ** | |
| AggMin⊕Mean | baseline-CodeBERTrand | W (11) = 0.955, p = 0.707 | t (10) = −3.746, p = 0.004 ** |
| baseline-CodeBERTPT+TAPT+FT | W (11) = 0.907, p = 0.223 | t (10) = −6.305, p < 0.001 *** | |
| CodeBERTrand-CodeBERTPT+TAPT+FT | W (11) = 0.877, p = 0.094 | t (10) = −5.829, p < 0.001 *** | |
| AggMax⊕Mean | baseline-CodeBERTrand | W (11) = 0.955, p = 0.707 | t (10) = −3.928, p = 0.003 ** |
| baseline-CodeBERTPT+TAPT+FT | W (11) = 0.880, p = 0.104 | t (10) = −6.152, p < 0.001 *** | |
| CodeBERTrand-CodeBERTPT+TAPT+FT | W (11) = 0.957, p = 0.736 | t (10) = −5.628, p < 0.001 *** | |
| AggMin⊕Max⊕Mean | baseline-CodeBERTrand | W (11) = 0.967, p = 0.855 | t (10) = −4.871, p < 0.001 *** |
| baseline-CodeBERTPT+TAPT+FT | W (11) = 0.886, p = 0.123 | t (10) = −7.150, p < 0.001 *** | |
| CodeBERTrand-CodeBERTPT+TAPT+FT | W (11) = 0.953, p = 0.683 | t (10) = −7.096, p < 0.001 *** |
| Aggregation Technique | Paired Comparison | Shapiro–Wilk Test | Student’s t-Test/Wilcoxon Signed-Rank Test |
|---|---|---|---|
| AggMin | baseline-CodeBERTrand | W (11) = 0.945, p = 0.579 | t (10) = −7.296, p < 0.001 *** |
| baseline-CodeBERTPT+TAPT+FT | W (11) = 0.885, p = 0.121 | t (10) = −9.483, p < 0.001 *** | |
| CodeBERTrand-CodeBERTPT+TAPT+FT | W (11) = 0.951, p = 0.663 | t (10) = −5.389, p < 0.001 *** | |
| AggMax | baseline-CodeBERTrand | W (11) = 0.953, p = 0.678 | t (10) = −5.203, p < 0.001 *** |
| baseline-CodeBERTPT+TAPT+FT | W (11) = 0.849, p = 0.042 * | Z = 2.934, p = 0.003 ** | |
| CodeBERTrand-CodeBERTPT+TAPT+FT | W (11) = 0.957, p = 0.728 | t (10) = −2.517, p = 0.031 * | |
| AggMean | baseline-CodeBERTrand | W (11) = 0.947, p = 0.610 | t (10) = −7.342, p < 0.001 *** |
| baseline-CodeBERTPT+TAPT+FT | W (11) = 0.890, p = 0.138 | t (10) = −8.770, p < 0.001 *** | |
| CodeBERTrand-CodeBERTPT+TAPT+FT | W (11) = 0.920, p = 0.315 | t (10) = −4.733, p < 0.001 *** | |
| AggMin⊕Max | baseline-CodeBERTrand | W (11) = 0.961, p = 0.783 | t (10) = −6.407, p < 0.001 *** |
| baseline-CodeBERTPT+TAPT+FT | W (11) = 0.948, p = 0.614 | t (10) = −10.243, p < 0.001 *** | |
| CodeBERTrand-CodeBERTPT+TAPT+FT | W (11) = 0.930, p = 0.407 | t (10) = −2.451, p = 0.034 * | |
| AggMin⊕Mean | baseline-CodeBERTrand | W (11) = 0.981, p = 0.973 | t (10) = −6.896, p < 0.001 *** |
| baseline-CodeBERTPT+TAPT+FT | W (11) = 0.934, p = 0.453 | t (10) = −8.912, p < 0.001 *** | |
| CodeBERTrand-CodeBERTPT+TAPT+FT | W (11) = 0.894, p = 0.157 | t (10) = −3.993, p = 0.003 ** | |
| AggMax⊕Mean | baseline-CodeBERTrand | W (11) = 0.963, p = 0.813 | t (10) = −5.107, p < 0.001 *** |
| baseline-CodeBERTPT+TAPT+FT | W (11) = 0.934, p = 0.457 | t (10) = −10.523, p < 0.001 *** | |
| CodeBERTrand-CodeBERTPT+TAPT+FT | W (11) = 0.955, p = 0.709 | t (10) = −3.371, p = 0.007 ** | |
| AggMin⊕Max⊕Mean | baseline-CodeBERTrand | W (11) = 0.889, p = 0.135 | t (10) = −6.231, p < 0.001 *** |
| baseline-CodeBERTPT+TAPT+FT | W (11) = 0.920, p = 0.321 | t (10) = −7.609, p < 0.001 *** | |
| CodeBERTrand-CodeBERTPT+TAPT+FT | W (11) = 0.783, p = 0.006 ** | Z = 2.934, p = 0.003 ** |
| Aggregation Technique | Performance Metric | Shapiro–Wilk Test | Student’s t-Test |
|---|---|---|---|
| AggMin | F-score | W (11) = 0.959, p = 0.762 | t (10) = −1.455, p = 0.176 |
| Per-class F-score (corrective) | W (11) = 0.963, p = 0.807 | t (10) = −1.728, p = 0.115 | |
| Per-class F-score (adaptive) | W (11) = 0.970, p = 0.888 | t (10) = −0.393, p = 0.702 | |
| Per-class F-score (perfective) | W (11) = 0.895, p = 0.162 | t (10) = −1.062, p = 0.313 | |
| Kappa Coefficient | W (11) = 0.948, p = 0.621 | t (10) = −1.883, p = 0.089 | |
| AggMean | F-score | W (11) = 0.956, p = 0.717 | t (10) = −1.664, p = 0.127 |
| Per-class F-score (corrective) | W (11) = 0.877, p = 0.096 | t (10) = −1.585, p = 0.144 | |
| Per-class F-score (adaptive) | W (11) = 0.920, p = 0.316 | t (10) = −0.212, p = 0.836 | |
| Per-class F-score (perfective) | W (11) = 0.921, p = 0.328 | t (10) = −1.164, p = 0.272 | |
| Kappa Coefficient | W (11) = 0.947, p = 0.606 | t (10) = −1.551, p = 0.152 | |
| AggMax | F-score | W (11) = 0.867, p = 0.070 | t (10) = −1.463, p = 0.174 |
| Per-class F-score (corrective) | W (11) = 0.909, p = 0.239 | t (10) = −0.452, p = 0.661 | |
| Per-class F-score (adaptive) | W (11) = 0.960, p = 0.775 | t (10) = −0.712, p = 0.493 | |
| Per-class F-score (perfective) | W (11) = 0.943, p = 0.560 | t (10) = −1.698, p = 0.120 | |
| Kappa Coefficient | W (11) = 0.920, p = 0.318 | t (10) = −1.543, p = 0.154 | |
| AggMin⊕Max | F-score | W (11) = 0.938, p = 0.494 | t (10) = −0.759, p = 0.465 |
| Per-class F-score (corrective) | W (11) = 0.988, p = 0.994 | t (10) = −0.317, p = 0.758 | |
| Per-class F-score (adaptive) | W (11) = 0.890, p = 0.139 | t (10) = −0.379, p = 0.713 | |
| Per-class F-score (perfective) | W (11) = 0.944, p = 0.566 | t (10) = −1.406, p = 0.190 | |
| Kappa Coefficient | W (11) = 0.904, p = 0.206 | t (10) = −0.927, p = 0.376 | |
| AggMin⊕Mean | F-score | W (11) = 0.936, p = 0.473 | t (10) = −1.574, p = 0.147 |
| Per-class F-score (corrective) | W (11) = 0.913, p = 0.264 | t (10) = −0.385, p = 0.708 | |
| Per-class F-score (adaptive) | W (11) = 0.941, p = 0.527 | t (10) = −2.401, p = 0.037 * | |
| Per-class F-score (perfective) | W (11) = 0.984, p = 0.983 | t (10) = −1.663, p = 0.127 | |
| Kappa Coefficient | W (11) = 0.872, p = 0.082 | t (10) = −1.670, p = 0.126 | |
| AggMax⊕Mean | F-score | W (11) = 0.918, p = 0.300 | t (10) = −0.561, p = 0.587 |
| Per-class F-score (corrective) | W (11) = 0.931, p = 0.422 | t (10) = 0.322, p = 0.754 | |
| Per-class F-score (adaptive) | W (11) = 0.954, p = 0.690 | t (10) = −0.056, p = 0.956 | |
| Per-class F-score (perfective) | W (11) = 0.931, p = 0.423 | t (10) = −1.327, p = 0.214 | |
| Kappa Coefficient | W (11) = 0.892, p = 0.146 | t (10) = −0.587, p = 0.570 | |
| AggMin⊕Max⊕Mean | F-score | W (11) = 0.947, p = 0.608 | t (10) = 0.813, p = 0.435 |
| Per-class F-score (corrective) | W (11) = 0.875, p = 0.091 | t (10) = 0.203, p = 0.843 | |
| Per-class F-score (adaptive) | W (11) = 0.913, p = 0.263 | t (10) = 0.512, p = 0.620 | |
| Per-class F-score (perfective) | W (11) = 0.937, p = 0.488 | t (10) = −0.311, p = 0.762 | |
| Kappa Coefficient | W (11) = 0.973, p = 0.913 | t (10) = −0.209, p = 0.839 |
| Aggregation Technique | Performance Metric | Shapiro–Wilk Test | Student’s t-Test/Wilcoxon Signed-Rank Test |
|---|---|---|---|
| AggMin | F-score | W (11) = 0.811, p = 0.013 * | Z = 1.334, p = 0.182 |
| Per-class F-score (corrective) | W (11) = 0.900, p = 0.187 | t (10) = 0.848, p = 0.416 | |
| Per-class F-score (adaptive) | W (11) = 0.945, p = 0.578 | t (10) = −0.011, p = 0.992 | |
| Per-class F-score (perfective) | W (11) = 0.968 p = 0.865 | t (10) = −3.321, p = 0.008 ** | |
| Kappa Coefficient | W (11) = 0.877, p = 0.095 | t (10) = −1.920, p = 0.084 | |
| AggMean | F-score | W (11) = 0.869, p = 0.076 | t (10) = −0.154, p = 0.881 |
| Per-class F-score (corrective) | W (11) = 0.937, p = 0.491 | t (10) = −0.174, p = 0.865 | |
| Per-class F-score (adaptive) | W (11) = 0.910, p = 0.241 | t (10) = 0.804, p = 0.440 | |
| Per-class F-score (perfective) | W (11) = 0.969, p = 0.874 | t (10) = −1.231, p = 0.246 | |
| Kappa Coefficient | W (11) = 0.940, p = 0.519 | t (10) = −0.223, p = 0.828 | |
| AggMax | F-score | W (11) = 0.951, p = 0.658 | t (10) = −1.585, p = 0.144 |
| Per-class F-score (corrective) | W (11) = 0.850, p = 0.043 * | Z = 0.356, p = 0.722 | |
| Per-class F-score (adaptive) | W (11) = 0.979, p = 0.960 | t (10) = 0.744, p = 0.474 | |
| Per-class F-score (perfective) | W (11) = 0.951, p = 0.657 | t (10) = −2.829, p = 0.018 * | |
| Kappa Coefficient | W (11) = 0.982, p = 0.978 | t (10) = −2.127, p = 0.059 | |
| AggMin⊕Max | F-score | W (11) = 0.980, p = 0.966 | t (10) = −2.394, p = 0.038 * |
| Per-class F-score (corrective) | W (11) = 0.918, p = 0.302 | t (10) = 0.166, p = 0.872 | |
| Per-class F-score (adaptive) | W (11) = 0.980, p = 0.964 | t (10) = 0.489, p = 0.635 | |
| Per-class F-score (perfective) | W (11) = 0.951, p = 0.653 | t (10) = −3.638, p = 0.005 ** | |
| Kappa Coefficient | W (11) = 0.926, p = 0.371 | t (10) = −3.285, p = 0.008 ** | |
| AggMin⊕Mean | F-score | W (11) = 0.883, p = 0.115 | t (10) = −1.209, p = 0.255 |
| Per-class F-score (corrective) | W (11) = 0.935, p = 0.467 | t (10) = −0.596, p = 0.565 | |
| Per-class F-score (adaptive) | W (11) = 0.971, p = 0.895 | t (10) = 1.168, p = 0.270 | |
| Per-class F-score (perfective) | W (11) = 0.970, p = 0.890 | t (10) = −3.314, p = 0.008 ** | |
| Kappa Coefficient | W (11) = 0.946, p = 0.592 | t (10) = −1.480, p = 0.170 | |
| AggMax⊕Mean | F-score | W (11) = 0.883, p = 0.113 | t (10) = −0.859, p = 0.411 |
| Per-class F-score (corrective) | W (11) = 0.980, p = 0.968 | t (10) = −0.419, p = 0.684 | |
| Per-class F-score (adaptive) | W (11) = 0.914, p = 0.269 | t (10) = 0.762, p = 0.463 | |
| Per-class F-score (perfective) | W (11) = 0.902, p = 0.194 | t (10) = −2.654, p = 0.024 * | |
| Kappa Coefficient | W (11) = 0.960, p = 0.771 | t (10) = −1.041, p = 0.323 | |
| AggMin⊕Max⊕Mean | F-score | W (11) = 0.921, p = 0.330 | t (10) = −2.132, p = 0.059 |
| Per-class F-score (corrective) | W (11) = 0.893, p = 0.151 | t (10) = −1.007, p = 0.338 | |
| Per-class F-score (adaptive) | W (11) = 0.766, p = 0.003 ** | Z = −0.178, p = 0.859 | |
| Per-class F-score (perfective) | W (11) = 0.956, p = 0.721 | t (10) = −3.349, p = 0.007 ** | |
| Kappa Coefficient | W (11) = 0.960, p = 0.773 | t (10) = −2.447, p = 0.034 * |
| Aggregation Technique | Performance Metric | Shapiro–Wilk Test | Student’s t-Test/Wilcoxon Signed-Rank Test |
|---|---|---|---|
| AggMin | F-score | W (11) = 0.859, p = 0.056 | t (10) = 0.276, p = 0.788 |
| Per-class F-score (corrective) | W (11) = 0.960, p = 0.777 | t (10) = 0.107, p = 0.917 | |
| Per-class F-score (adaptive) | W (11) = 0.893, p = 0.149 | t (10) = 0.422, p = 0.682 | |
| Per-class F-score (perfective) | W (11) = 0.888, p = 0.131 | t (10) = −0.305, p = 0.767 | |
| Kappa Coefficient | W (11) = 0.911, p = 0.252 | t (10) = 0.423, p = 0.682 | |
| AggMean | F-score | W (11) = 0.953, p = 0.686 | t (10) = −225, p = 0.826 |
| Per-class F-score (corrective) | W (11) = 0.919, p = 0.308 | t (10) = 0.123, p = 0.904 | |
| Per-class F-score (adaptive) | W (11) = 0.942, p = 0.547 | t (10) = 0.479, p = 0.642 | |
| Per-class F-score (perfective) | W (11) = 0.952, p = 0.670 | t (10) = −0.906, p = 0.386 | |
| Kappa Coefficient | W (11) = 0.912, p = 0.260 | t (10) = −0.334, p = 0.745 | |
| AggMax | F-score | W (11) = 0.949, p = 0.628 | t (10) = 0.699, p = 0.500 |
| Per-class F-score (corrective) | W (11) = 0.956, p = 0.727 | t (10) = 0.258, p = 0.801 | |
| Per-class F-score (adaptive) | W (11) = 0.961, p = 0.786 | t (10) = 0.146, p = 0.887 | |
| Per-class F-score (perfective) | W (11) = 0.967, p = 0.850 | t (10) = 0.396, p = 0.700 | |
| Kappa Coefficient | W (11) = 0.954, p = 0.701 | t (10) = 0.546, p = 0.597 | |
| AggMin⊕Max | F-score | W (11) = 0.948, p = 0.614 | t (10) = 0.559, p = 0.589 |
| Per-class F-score (corrective) | W (11) = 0.811, p = 0.013 * | Z = −0.764, p = 0.445 | |
| Per-class F-score (adaptive) | W (11) = 0.899, p = 0.182 | t (10) = 1.115, p = 0.291 | |
| Per-class F-score (perfective) | W (11) = 0.958, p = 0.745 | t (10) = 0.073, p = 0.943 | |
| Kappa Coefficient | W (11) = 0.914, p = 0.274 | t (10) = 0.548, p = 0.596 | |
| AggMin⊕Mean | F-score | W (11) = 0.851, p = 0.044 * | Z = 0.000, I = 1.000 |
| Per-class F-score (corrective) | W (11) = 0.888, p = 0.133 | t (10) = −0.115, p = 0.910 | |
| Per-class F-score (adaptive) | W (11) = 0.777, p = 0.005 ** | Z = 0.764, p = 0.445 | |
| Per-class F-score (perfective) | W (11) = 0.971, p = 0.896 | t (10) = −0.085, p = 0.934 | |
| Kappa Coefficient | W (11) = 0.928, p = 0.388 | t (10) = −0.551, p = 0.593 | |
| AggMax⊕Mean | F-score | W (11) = 0.961, p = 0.785 | t (10) = −0.965, p = 0.357 |
| Per-class F-score (corrective) | W (11) = 0.892, p = 0.146 | t (10) = −0.277, p = 0.787 | |
| Per-class F-score (adaptive) | W (11) = 0.945, p = 0.584 | t (10) = −0.343, p = 0.739 | |
| Per-class F-score (perfective) | W (11) = 0.960, p = 0.778 | t (10) = −1.370, p = 0.201 | |
| Kappa Coefficient | W (11) = 0.935, p = 0.469 | t (10) = −0.835, p = 0.423 | |
| AggMin⊕Max⊕Mean | F-score | W (11) = 0.983, p = 0.980 | t (10) = −0.090, p = 0.930 |
| Per-class F-score (corrective) | W (11) = 0.812, p = 0.013 * | Z = −0.968, p = 0.333 | |
| Per-class F-score (adaptive) | W (11) = 0.940, p = 0.517 | t (10) = −0.205, p = 0.841 | |
| Per-class F-score (perfective) | W (11) = 0.800, p = 0.010 * | Z = 1.260, p = 0.208 | |
| Kappa Coefficient | W (11) = 0.939, p = 0.505 | t (10) = 0.048, p = 0.962 |
References
- Rajlich, V. Software Evolution and Maintenance. In Proceedings of the Future of Software Engineering Proceedings (FOSE), Hyderabad, India, 31 May–7 June 2014; Association for Computing Machinery: New York, NY, USA, 2014; pp. 133–144. [Google Scholar] [CrossRef]
- International Organization for Standardization. ISO/IEC/IEEE 12207:2017; Systems and Software Engineering—Software Life Cycle Processes; International Organization for Standardization: Geneva, Switzerland, 2022; Available online: https://www.iso.org/standard/63712.html (accessed on 10 January 2024).
- Lehman, M.M. On understanding laws, evolution, and conservation in the large-program life cycle. J. Syst. Softw. 1979, 1, 213–221. [Google Scholar] [CrossRef]
- International Organization for Standardization. ISO/IEC/IEEE 14764:2022; Software Engineering—Software Life Cycle Processes—Maintenance; International Organization for Standardization: Geneva, Switzerland, 2022; Available online: https://www.iso.org/standard/80710.html (accessed on 10 January 2024).
- Heričko, T.; Šumak, B. Commit Classification Into Software Maintenance Activities: A Systematic Literature Review. In Proceedings of the IEEE 47th Annual Computers, Software, and Applications Conference (COMPSAC), Torino, Italy, 26–30 June 2023; IEEE: New York, NY, USA, 2023; pp. 1646–1651. [Google Scholar] [CrossRef]
- Meqdadi, O.; Alhindawi, N.; Alsakran, J.; Saifan, A.; Migdadi, H. Mining software repositories for adaptive change commits using machine learning techniques. Inf. Softw. Technol. 2019, 109, 80–91. [Google Scholar] [CrossRef]
- Hönel, S.; Ericsson, M.; Löwe, W.; Wingkvist, A. Using source code density to improve the accuracy of automatic commit classification into maintenance activities. J. Syst. Softw. 2020, 168, 110673. [Google Scholar] [CrossRef]
- Meng, N.; Jiang, Z.; Zhong, H. Classifying Code Commits with Convolutional Neural Networks. In Proceedings of the 2021 International Joint Conference on Neural Networks (IJCNN), Shenzhen, China, 18–22 July 2021; IEEE: New York, NY, USA, 2021; pp. 1–8. [Google Scholar] [CrossRef]
- Meqdadi, O.; Alhindawi, N.; Collard, M.L.; Maletic, J.I. Towards Understanding Large-Scale Adaptive Changes from Version Histories. In Proceedings of the 2013 IEEE International Conference on Software Maintenance (ICSM), Eindhoven, The Netherlands, 22–28 September 2013; IEEE: New York, NY, USA, 2013; pp. 416–419. [Google Scholar] [CrossRef]
- Hindle, A.; German, D.M.; Godfrey, M.W.; Holt, R.C. Automatic Classification of Large Changes into Maintenance Categories. In Proceedings of the IEEE 17th International Conference on Program Comprehension (ICPC), Vancouver, BC, Canada, 17–19 May 2009; IEEE: New York, NY, USA, 2009; pp. 30–39. [Google Scholar] [CrossRef]
- Levin, S.; Yehudai, A. Boosting Automatic Commit Classification Into Maintenance Activities By Utilizing Source Code Changes. In Proceedings of the 13th International Conference on Predictive Models and Data Analytics in Software Engineering (PROMISE), Toronto, ON, Canada, 8 November 2017; Association for Computing Machinery: New York, NY, USA, 2017; pp. 97–106. [Google Scholar] [CrossRef]
- Zafar, S.; Malik, M.Z.; Walia, G.S. Towards Standardizing and Improving Classification of Bug-Fix Commits. In Proceedings of the ACM/IEEE International Symposium on Empirical Software Engineering and Measurement (ESEM), Porto de Galinhas, Brazil, 19–20 September 2019; IEEE: New York, NY, USA, 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Sarwar, M.U.; Zafar, S.; Mkaouer, M.W.; Walia, G.S.; Malik, M.Z. Multi-label Classification of Commit Messages using Transfer Learning. In Proceedings of the IEEE International Symposium on Software Reliability Engineering Workshops (ISSREW), Coimbra, Portugal, 12–15 October 2020; IEEE: New York, NY, USA, 2020; pp. 37–42. [Google Scholar] [CrossRef]
- Ghadhab, L.; Jenhani, I.; Mkaouer, M.W.; Ben Messaoud, M. Augmenting commit classification by using fine-grained source code changes and a pre-trained deep neural language model. Inf. Softw. Technol. 2021, 135, 106566. [Google Scholar] [CrossRef]
- Mariano, R.V.; dos Santos, G.E.; Brandão, W.C. Improve Classification of Commits Maintenance Activities with Quantitative Changes in Source Code. In Proceedings of the 23rd International Conference on Enterprise Information Systems (ICEIS), Virtual Event, 26–28 April 2021; SciTePress: Setúbal, Portugal, 2021; Volume 2, pp. 19–29. [Google Scholar] [CrossRef]
- Heričko, T.; Brdnik, S.; Šumak, B. Commit Classification Into Maintenance Activities Using Aggregated Semantic Word Embeddings of Software Change Messages. In Proceedings of the Ninth Workshop on Software Quality Analysis, Monitoring, Improvement, and Applications, CEUR-WS (SQAMIA), Novi Sad, Serbia, 11–14 September 2022; Volume 1613. [Google Scholar]
- Trautsch, A.; Erbel, J.; Herbold, S.; Grabowski, J. What really changes when developers intend to improve their source code: A commit-level study of static metric value and static analysis warning changes. Empir. Softw. Eng. 2023, 28, 30. [Google Scholar] [CrossRef]
- Lientz, B.P.; Swanson, E.B. Problems in Application Software Maintenance. Commun. ACM 1981, 24, 763–769. [Google Scholar] [CrossRef]
- Erlikh, L. Leveraging legacy system dollars for e-business. IT Prof. 2000, 2, 17–23. [Google Scholar] [CrossRef]
- Swanson, E.B. The dimensions of maintenance. In Proceedings of the 2nd International Conference on Software Engineering (ICSE), San Francisco, CA, USA, 13–15 October 1976; pp. 492–497. [Google Scholar]
- Abou Khalil, Z.; Constantinou, E.; Mens, T.; Duchien, L. On the impact of release policies on bug handling activity: A case study of Eclipse. J. Syst. Softw. 2021, 173, 110882. [Google Scholar] [CrossRef]
- Levin, S.; Yehudai, A. Using Temporal and Semantic Developer-Level Information to Predict Maintenance Activity Profiles. In Proceedings of the IEEE International Conference on Software Maintenance and Evolution (ICSME), Raleigh, NC, USA, 2–7 October 2016; IEEE: New York, NY, USA, 2016; pp. 463–467. [Google Scholar] [CrossRef]
- Tsakpinis, A. Analyzing Maintenance Activities of Software Libraries. In Proceedings of the 27th International Conference on Evaluation and Assessment in Software Engineering (EASE), Oulu, Finland, 14–16 June 2023; Association for Computing Machinery: New York, NY, USA, 2023; pp. 313–318. [Google Scholar] [CrossRef]
- Heričko, T. Automatic Data-Driven Software Change Identification via Code Representation Learning. In Proceedings of the 27th International Conference on Evaluation and Assessment in Software Engineering (EASE), Oulu, Finland, 14–16 June 2023; Association for Computing Machinery: New York, NY, USA, 2023; pp. 319–323. [Google Scholar] [CrossRef]
- Pan, C.; Lu, M.; Xu, B. An empirical study on software defect prediction using codebert model. Appl. Sci. 2021, 11, 4793. [Google Scholar] [CrossRef]
- Ma, W.; Yu, Y.; Ruan, X.; Cai, B. Pre-trained Model Based Feature Envy Detection. In Proceedings of the 2023 IEEE/ACM 20th International Conference on Mining Software Repositories (MSR), Melbourne, Australia, 15–16 May 2023; IEEE: New York, NY, USA, 2023; pp. 430–440. [Google Scholar] [CrossRef]
- Fatima, S.; Ghaleb, T.A.; Briand, L. Flakify: A Black-Box, Language Model-Based Predictor for Flaky Tests. IEEE Trans. Softw. Eng. 2023, 49, 1912–1927. [Google Scholar] [CrossRef]
- Zeng, P.; Lin, G.; Zhang, J.; Zhang, Y. Intelligent detection of vulnerable functions in software through neural embedding-based code analysis. Int. J. Netw. Manag. 2023, 33, e2198. [Google Scholar] [CrossRef]
- Mashhadi, E.; Hemmati, H. Applying CodeBERT for Automated Program Repair of Java Simple Bugs. In Proceedings of the 2021 IEEE/ACM 18th International Conference on Mining Software Repositories (MSR), Madrid, Spain, 17–19 May 2021; IEEE: New York, NY, USA, 2021; pp. 505–509. [Google Scholar] [CrossRef]
- Zhou, X.; Han, D.; Lo, D. Assessing Generalizability of CodeBERT. In Proceedings of the 2021 IEEE International Conference on Software Maintenance and Evolution (ICSME), Luxembourg, 27 September–1 October 2021; IEEE: New York, NY, USA, 2021; pp. 425–436. [Google Scholar] [CrossRef]
- Zhou, J.; Pacheco, M.; Wan, Z.; Xia, X.; Lo, D.; Wang, Y.; Hassan, A.E. Finding A Needle in a Haystack: Automated Mining of Silent Vulnerability Fixes. In Proceedings of the 2021 36th IEEE/ACM International Conference on Automated Software Engineering (ASE), Melbourne, Australia, 15–19 November 2021; IEEE: New York, NY, USA, 2021; pp. 705–716. [Google Scholar] [CrossRef]
- Yang, G.; Zhou, Y.; Chen, X.; Zhang, X.; Han, T.; Chen, T. ExploitGen: Template-augmented exploit code generation based on CodeBERT. J. Syst. Softw. 2023, 197, 111577. [Google Scholar] [CrossRef]
- Barrak, A.; Eghan, E.E.; Adams, B. On the Co-evolution of ML Pipelines and Source Code—Empirical Study of DVC Projects. In Proceedings of the IEEE International Conference on Software Analysis, Evolution and Reengineering, Honolulu, HI, USA, 9–12 March 2021; IEEE: New York, NY, USA, 2021; pp. 422–433. [Google Scholar] [CrossRef]
- Heričko, T.; Šumak, B. Analyzing Linter Usage and Warnings Through Mining Software Repositories: A Longitudinal Case Study of JavaScript Packages. In Proceedings of the 2022 45th Jubilee International Convention on Information, Communication and Electronic Technology (MIPRO), Opatija, Croatia, 23–27 May 2022; IEEE: New York, NY, USA, 2022; pp. 1375–1380. [Google Scholar] [CrossRef]
- Feng, Q.; Mo, R. Fine-grained analysis of dependency cycles among classes. J. Softw. Evol. Process. 2023, 35, e2496. [Google Scholar] [CrossRef]
- Li, J.; Ahmed, I. Commit Message Matters: Investigating Impact and Evolution of Commit Message Quality. In Proceedings of the IEEE/ACM 45th International Conference on Software Engineering (ICSE), Melbourne, Australia, 14–20 May 2023; IEEE: New York, NY, USA, 2023; pp. 806–817. [Google Scholar] [CrossRef]
- Sabetta, A.; Bezzi, M. A Practical Approach to the Automatic Classification of Security-Relevant Commits. In Proceedings of the 2018 IEEE International Conference on Software Maintenance and Evolution (ICSE), Madrid, Spain, 23–29 September 2018; IEEE: New York, NY, USA, 2018; pp. 579–582. [Google Scholar] [CrossRef]
- Nguyen, T.G.; Le-Cong, T.; Kang, H.J.; Le, X.B.D.; Lo, D. VulCurator: A Vulnerability-Fixing Commit Detector. In Proceedings of the 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE), Singapore, 14–18 November 2022; Association for Computing Machinery: New York, NY, USA, 2022; pp. 1726–1730. [Google Scholar] [CrossRef]
- Barnett, J.G.; Gathuru, C.K.; Soldano, L.S.; McIntosh, S. The Relationship between Commit Message Detail and Defect Proneness in Java Projects on GitHub. In Proceedings of the 13th International Conference on Mining Software Repositories (MSR), Austin, TX, USA, 14–22 May 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 496–499. [Google Scholar] [CrossRef]
- Khanan, C.; Luewichana, W.; Pruktharathikoon, K.; Jiarpakdee, J.; Tantithamthavorn, C.; Choetkiertikul, M.; Ragkhitwetsagul, C.; Sunetnanta, T. JITBot: An Explainable Just-in-Time Defect Prediction Bot. In Proceedings of the 35th IEEE/ACM International Conference on Automated Software Engineering (ACE), Virtual Event, 21–25 December 2020; Association for Computing Machinery: New York, NY, USA, 2021; pp. 1336–1339. [Google Scholar] [CrossRef]
- Nguyen-Truong, G.; Kang, H.J.; Lo, D.; Sharma, A.; Santosa, A.E.; Sharma, A.; Ang, M.Y. HERMES: Using Commit-Issue Linking to Detect Vulnerability-Fixing Commits. In Proceedings of the 2022 IEEE International Conference on Software Analysis, Evolution and Reengineering (SANER), Honolulu, HI, USA, 15–18 March 2022; IEEE: New York, NY, USA, 2022; pp. 51–62. [Google Scholar] [CrossRef]
- Fluri, B.; Gall, H. Classifying Change Types for Qualifying Change Couplings. In Proceedings of the 14th IEEE International Conference on Program Comprehension (ICPC), Athens, Greece, 14–16 June 2006; IEEE: New York, NY, USA, 2006; pp. 35–45. [Google Scholar] [CrossRef]
- Mauczka, A.; Brosch, F.; Schanes, C.; Grechenig, T. Dataset of Developer-Labeled Commit Messages. In Proceedings of the IEEE/ACM 12th Working Conference on Mining Software Repositories (MSR), Florence, Italy, 16–17 May 2015; IEEE: New York, NY, USA, 2015; pp. 490–493. [Google Scholar] [CrossRef]
- AlOmar, E.A.; Mkaouer, M.W.; Ouni, A. Can Refactoring Be Self-Affirmed? An Exploratory Study on How Developers Document Their Refactoring Activities in Commit Messages. In Proceedings of the IEEE/ACM 3rd International Workshop on Refactoring (IWOR), Montreal, QC, Canada, 28 May 2019; IEEE: New York, NY, USA, 2019; pp. 51–58. [Google Scholar] [CrossRef]
- Aggarwal, C.C. Data Classification: Algorithms and Applications, 1st ed.; Chapman & Hall/CRC: Boca Raton, FL, USA, 2014. [Google Scholar]
- Kovačević, A.; Slivka, J.; Vidaković, D.; Grujić, K.G.; Luburić, N.; Prokić, S.; Sladić, G. Automatic detection of Long Method and God Class code smells through neural source code embeddings. Expert Syst. Appl. 2022, 204, 117607. [Google Scholar] [CrossRef]
- Karakatič, S.; Miloševič, A.; Heričko, T. Software system comparison with semantic source code embeddings. Empir. Softw. Eng. 2022, 27, 70. [Google Scholar] [CrossRef]
- Huang, K.; Yang, S.; Sun, H.; Sun, C.; Li, X.; Zhang, Y. Repairing Security Vulnerabilities Using Pre-trained Programming Language Models. In Proceedings of the 2022 52nd Annual IEEE/IFIP International Conference on Dependable Systems and Networks Workshops (DSN-W), Baltimore, MD, USA, 27–30 June 2022; IEEE: New York, NY, USA, 2022; pp. 111–116. [Google Scholar] [CrossRef]
- Tripathy, P.; Naik, K. Software Evolution and Maintenance: A Practitioner’s Approach; John Wiley & Sons: Hoboken, NJ, USA, 2014. [Google Scholar] [CrossRef]
- Lientz, B.P.; Swanson, E.B.; Tompkins, G.E. Characteristics of Application Software Maintenance. Commun. ACM 1978, 21, 466–471. [Google Scholar] [CrossRef]
- Schach, S.R.; Jin, B.; Yu, L.; Heller, G.Z.; Offutt, J. Determining the distribution of maintenance categories: Survey versus measurement. Empir. Softw. Eng. 2003, 8, 351–365. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Feng, Z.; Guo, D.; Tang, D.; Duan, N.; Feng, X.; Gong, M.; Shou, L.; Qin, B.; Liu, T.; Jiang, D.; et al. Codebert: A pre-trained model for programming and natural languages. arXiv 2020, arXiv:2002.08155. [Google Scholar]
- Guo, D.; Ren, S.; Lu, S.; Feng, Z.; Tang, D.; Liu, S.; Zhou, L.; Duan, N.; Svyatkovskiy, A.; Fu, S.; et al. GraphCodeBERT: Pre-training code representations with data flow. arXiv 2021, arXiv:2009.08366. [Google Scholar]
- Kanade, A.; Maniatis, P.; Balakrishnan, G.; Shi, K. Learning and evaluating contextual embedding of source code. In Proceedings of the International Conference on Machine Learning, JMLR.org (ICML), Virtual Event, 13–18 July 2020; pp. 5110–5121. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, W.; Joty, S.; Hoi, S.C. Codet5: Identifier-aware unified pre-trained encoder-decoder models for code understanding and generation. arXiv 2021, arXiv:2109.00859. [Google Scholar]
- Chen, M.; Tworek, J.; Jun, H.; Yuan, Q.; Pinto, H.P.d.O.; Kaplan, J.; Edwards, H.; Burda, Y.; Joseph, N.; Brockman, G.; et al. Evaluating large language models trained on code. arXiv 2021, arXiv:2107.03374. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Clark, K.; Luong, M.T.; Le, Q.V.; Manning, C.D. Electra: Pre-training text encoders as discriminators rather than generators. arXiv 2020, arXiv:2003.10555. [Google Scholar]
- Husain, H.; Wu, H.H.; Gazit, T.; Allamanis, M.; Brockschmidt, M. Codesearchnet challenge: Evaluating the state of semantic code search. arXiv 2019, arXiv:1909.09436. [Google Scholar]
- Gururangan, S.; Marasović, A.; Swayamdipta, S.; Lo, K.; Beltagy, I.; Downey, D.; Smith, N.A. Don’t stop pretraining: Adapt language models to domains and tasks. arXiv 2020, arXiv:2004.10964. [Google Scholar]
- Nugroho, Y.S.; Hata, H.; Matsumoto, K. How different are different diff algorithms in Git? Use–histogram for code changes. Empir. Softw. Eng. 2020, 25, 790–823. [Google Scholar] [CrossRef]
- Ladkat, A.; Miyajiwala, A.; Jagadale, S.; Kulkarni, R.; Joshi, R. Towards Simple and Efficient Task-Adaptive Pre-training for Text Classification. arXiv 2022, arXiv:2209.12943. [Google Scholar]
- Sun, C.; Qiu, X.; Xu, Y.; Huang, X. How to fine-tune bert for text classification? In Proceedings of the Chinese Computational Linguistics: 18th China National Conference, CCL 2019, Kunming, China, 18–20 October 2019; Proceedings 18. Springer: Berlin/Heidelberg, Germany, 2019; pp. 194–206. [Google Scholar] [CrossRef]
- Rogers, A.; Kovaleva, O.; Rumshisky, A. A primer in BERTology: What we know about how BERT works. Trans. Assoc. Comput. Linguist. 2021, 8, 842–866. [Google Scholar] [CrossRef]
- Compton, R.; Frank, E.; Patros, P.; Koay, A. Embedding java classes with code2vec: Improvements from variable obfuscation. In Proceedings of the 17th International Conference on Mining Software Repositories. Association for Computing Machinery (MSR), Seoul, Republic of Korea, 29–30 June 2020; pp. 243–253. [Google Scholar] [CrossRef]
- Pandas. 2024. Available online: https://pandas.pydata.org (accessed on 15 January 2024).
- Git Python. 2023. Available online: https://github.com/gitpython-developers/GitPython (accessed on 13 November 2023).
- Karampatsis, R.M.; Babii, H.; Robbes, R.; Sutton, C.; Janes, A. Big Code != Big Vocabulary: Open-Vocabulary Models for Source Code. In Proceedings of the ACM/IEEE 42nd International Conference on Software Engineering (ICSE), Seoul, Republic of Korea, 27 June–19 July 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 1073–1085. [Google Scholar] [CrossRef]
- GitHub REST API. 2023. Available online: https://docs.github.com/en/rest?apiVersion=2022-11-28 (accessed on 13 November 2023).
- Hugging Face Transformers. 2023. Available online: https://github.com/huggingface/transformers (accessed on 13 November 2023).
- NumPy. 2024. Available online: https://numpy.org (accessed on 20 January 2024).
- Scikit-Learn. 2023. Available online: https://scikit-learn.org (accessed on 13 November 2023).
- Imbalanced-Learn. 2024. Available online: https://imbalanced-learn.org (accessed on 20 January 2024).
- 1151 Commits with Software Maintenance Activity Labels (Corrective, Perfective, Adaptive). 2023. Available online: https://zenodo.org/records/835534 (accessed on 13 November 2023).
- 359,569 Commits with Source Code Density; 1149 Commits of Which Have Software Maintenance Activity Labels (Adaptive, Corrective, Perfective). 2023. Available online: https://zenodo.org/records/2590519 (accessed on 2 November 2023).
- Replication Package of Augmenting Commit Classification by Using Fine-Grained Source Code Changes and a Pre-trained Deep Neural Language Model. 2023. Available online: https://zenodo.org/records/4266643 (accessed on 2 November 2023).
- GitHub GraphQL API. 2023. Available online: https://docs.github.com/en/graphql (accessed on 13 November 2023).
- IBM SPSS Statistics. 2024. Available online: https://www.ibm.com/products/spss-statistics (accessed on 20 January 2024).
- ggplot2. 2024. Available online: https://ggplot2.tidyverse.org (accessed on 20 January 2024).
- Wieting, J.; Kiela, D. No training required: Exploring random encoders for sentence classification. arXiv 2019, arXiv:1901.10444. [Google Scholar]
- Fu, M.; Nguyen, V.; Tantithamthavorn, C.K.; Le, T.; Phung, D. VulExplainer: A Transformer-Based Hierarchical Distillation for Explaining Vulnerability Types. IEEE Trans. Softw. Eng. 2023, 49, 4550–4565. [Google Scholar] [CrossRef]






| Authors | Novel Independent Variables | Dependent Variables | Dataset | Best Model Performance |
|---|---|---|---|---|
| Levin and Yehudai [11] | 48 code change metrics following Fluri’s taxonomy [42] extracted from commits using the ChangeDistiller tool | Corrective, adaptive, and perfective labels following Swanson’s classification scheme [20] | 1151 manually labeled instances sampled from commit histories of eleven open-source Java projects [11] | |
| Meqdadi et al. [6] | Eight proposed code change metrics extracted from commits using a custom tool | Adaptive and non-adaptive labels following Swanson’s classification scheme [20] | 70,226 manually labeled instances sampled from commit histories of six open-source C++ software projects [6,9] | |
| Hönel et al. [7] | 22 proposed code change metrics extracted from commits using the Git Density tool | Corrective, adaptive, and perfective labels following Swanson’s classification scheme [20] | 1150 manually labeled instances sampled from commit histories of eleven open-source Java projects [11] | |
| Ghadhab et al. [14] | 24 proposed code change metrics extracted from commits using the RefactoringMiner tool and FixMiner tool | Corrective, adaptive, and perfective labels following Swanson’s classification scheme [20] | 1793 instances sampled and semi-manually labeled from three existing datasets [11,43,44], including commits from 109 open-source Java projects [14] | |
| Mariano et al. [15] | Three proposed code change metrics extracted from commits using the GitHub GraphQL API | Corrective, adaptive, and perfective labels following Swanson’s classification scheme [20] | 1151 manually labeled instances sampled from commit histories of eleven open-source Java projects [11] | |
| Meng et al. [8] | Node and edge embeddings in the change dependency graph, constructed from commits using tools ChangeDistiller, InterPart, WALA, RefactoringMiner, and a custom tool | Bug fixes, functionality additions, and other labels that can be mapped to Swanson’s classification scheme (corrective, adaptive, and perfective, respectively) [20] | 7414 issue-tracking-system-based labeled instances sampled from commit history of five open-source Java software projects [8] |
| No. Commits | ||||||
|---|---|---|---|---|---|---|
| # | Software Project | Repository | Total | Corrective | Adaptive | Perfective |
| P1 | Apache Camel | github.com/apache/camel † | 90 | 38 (42.2%) | 21 (23.3%) | 31 (34.5%) |
| P2 | Apache HBase | github.com/apache/hbase † | 97 | 59 (60.8%) | 22 (22.7%) | 16 (16.5%) |
| P3 | Drools | github.com/kiegroup/drools † | 103 | 60 (58.2%) | 28 (27.2%) | 15 (14.6%) |
| P4 | Elasticsearch | github.com/elastic/elasticsearch † | 67 | 28 (41.8%) | 24 (35.8%) | 15 (22.4%) |
| P5 | Hadoop | github.com/apache/hadoop † | 99 | 53 (53.5%) | 26 (26.3%) | 20 (20.2%) |
| P6 | IntelliJ IDEA Community | github.com/JetBrains/intellij-community † | 92 | 49 (53.3%) | 21 (22.8%) | 22 (23.9%) |
| P7 | Kotlin | github.com/JetBrains/kotlin † | 82 | 34 (41.5%) | 15 (18.3%) | 33 (40.2%) |
| P8 | OrientDB | github.com/orientechnologies/orientdb † | 96 | 57 (59.3%) | 21 (21.9%) | 18 (18.8%) |
| P9 | Restlet Framework | github.com/restlet/restlet-framework-java † | 86 | 41 (47.7%) | 23 (26.7%) | 22 (25.6%) |
| P10 | RxJava | github.com/ReactiveX/RxJava † | 61 | 19 (31.2%) | 21 (34.4%) | 21 (34.4%) |
| P11 | Spring Framework | github.com/spring-projects/spring-framework † | 62 | 24 (38.7%) | 22 (35.5%) | 16 (25.8%) |
| Overall | 935 | 462 (49.4%) | 244 (26.1%) | 229 (24.5%) | ||
| Aggregation Technique | Formula for Commit Aggregation |
|---|---|
| AggMin | |
| AggMax | |
| AggMean | |
| AggMin⊕Max | |
| AggMin⊕Mean | |
| AggMax⊕Mean | |
| AggMin⊕Max⊕Mean |
| Neural Classifier | |||||||
| AggMin | AggMax | AggMean | AggMin⊕Max | AggMin⊕Mean | AggMax⊕Mean | AggMin⊕Max⊕Mean | |
| CodeBERTrand | 0.435 ± 0.06 | 0.392 ± 0.05 | 0.417 ± 0.06 | 0.440 ± 0.06 | 0.403 ± 0.06 | 0.423 ± 0.07 | 0.412 ± 0.07 |
| CodeBERTPT | 0.475 ± 0.07 | 0.474 ± 0.07 | 0.474 ± 0.06 | 0.467 ± 0.04 | 0.459 ± 0.08 | 0.477 ± 0.07 | 0.474 ± 0.06 |
| CodeBERTPT+FT | 0.481 ± 0.09 | 0.491 ± 0.08 | 0.492 ± 0.09 | 0.479 ± 0.08 | 0.485 ± 0.07 | 0.481 ± 0.06 | 0.480 ± 0.08 |
| CodeBERTPT+TAPT+FT | 0.493 ± 0.07 | 0.508 ± 0.06 | 0.503 ± 0.05 | 0.498 ± 0.05 | 0.502 ± 0.07 | 0.497 ± 0.05 | 0.472 ± 0.07 |
| GraphCodeBERTrand | 0.435 ± 0.06 | 0.392 ± 0.05 | 0.417 ± 0.06 | 0.440 ± 0.06 | 0.403 ± 0.06 | 0.423 ± 0.07 | 0.412 ± 0.07 |
| GraphCodeBERTPT | 0.491 ± 0.04 | 0.468 ± 0.07 | 0.478 ± 0.05 | 0.482 ± 0.06 | 0.481 ± 0.06 | 0.481 ± 0.04 | 0.476 ± 0.06 |
| GraphCodeBERTPT+FT | 0.482 ± 0.09 | 0.450 ± 0.10 | 0.463 ± 0.07 | 0.452 ± 0.09 | 0.479 ± 0.07 | 0.452 ± 0.09 | 0.484 ± 0.06 |
| GraphCodeBERTPT+TAPT+FT | 0.478 ± 0.09 | 0.461 ± 0.09 | 0.483 ± 0.08 | 0.464 ± 0.08 | 0.466 ± 0.09 | 0.470 ± 0.08 | 0.460 ± 0.07 |
| Gaussian Naive Bayes Classifier | |||||||
| AggMin | AggMax | AggMean | AggMin⊕Max | AggMin⊕Mean | AggMax⊕Mean | AggMin⊕Max⊕Mean | |
| CodeBERTrand | 0.437 ± 0.09 | 0.436 ± 0.09 | 0.415 ± 0.06 | 0.436 ± 0.09 | 0.416 ± 0.08 | 0.418 ± 0.08 | 0.422 ± 0.08 |
| CodeBERTPT | 0.481 ± 0.07 | 0.484 ± 0.07 | 0.439 ± 0.06 | 0.481 ± 0.07 | 0.478 ± 0.05 | 0.475 ± 0.05 | 0.482 ± 0.06 |
| CodeBERTPT+FT | 0.498 ± 0.08 | 0.491 ± 0.07 | 0.491 ± 0.08 | 0.499 ± 0.08 | 0.485 ± 0.08 | 0.488 ± 0.07 | 0.497 ± 0.07 |
| CodeBERTPT+TAPT+FT | 0.504 ± 0.07 | 0.495 ± 0.06 | 0.495 ± 0.03 | 0.497 ± 0.06 | 0.503 ± 0.05 | 0.500 ± 0.05 | 0.511 ± 0.05 |
| GraphCodeBERTrand | 0.437 ± 0.09 | 0.436 ± 0.09 | 0.415 ± 0.06 | 0.436 ± 0.09 | 0.416 ± 0.08 | 0.418 ± 0.08 | 0.422 ± 0.08 |
| GraphCodeBERTPT | 0.439 ± 0.10 | 0.445 ± 0.09 | 0.438 ± 0.05 | 0.442 ± 0.09 | 0.433 ± 0.08 | 0.430 ± 0.07 | 0.432 ± 0.08 |
| GraphCodeBERTPT+FT | 0.456 ± 0.08 | 0.461 ± 0.08 | 0.483 ± 0.07 | 0.461 ± 0.08 | 0.468 ± 0.07 | 0.464 ± 0.07 | 0.457 ± 0.07 |
| GraphCodeBERTPT+TAPT+FT | 0.456 ± 0.08 | 0.451 ± 0.08 | 0.487 ± 0.05 | 0.454 ± 0.08 | 0.470 ± 0.05 | 0.463 ± 0.06 | 0.461 ± 0.07 |
| Random Forest Classifier | |||||||
| AggMin | AggMax | AggMean | AggMin⊕Max | AggMin⊕Mean | AggMax⊕Mean | AggMin⊕Max⊕Mean | |
| CodeBERTrand | 0.435 ± 0.10 | 0.436 ± 0.11 | 0.404 ± 0.12 | 0.447 ± 0.12 | 0.433 ± 0.11 | 0.439 ± 0.13 | 0.430 ± 0.11 |
| CodeBERTPT | 0.485 ± 0.09 | 0.474 ± 0.10 | 0.473 ± 0.09 | 0.482 ± 0.10 | 0.476 ± 0.09 | 0.481 ± 0.08 | 0.490 ± 0.08 |
| CodeBERTPT+FT | 0.503 ± 0.10 | 0.488 ± 0.09 | 0.495 ± 0.10 | 0.510 ± 0.10 | 0.500 ± 0.09 | 0.502 ± 0.10 | 0.504 ± 0.09 |
| CodeBERTPT+TAPT+FT | 0.481 ± 0.10 | 0.485 ± 0.09 | 0.489 ± 0.08 | 0.495 ± 0.08 | 0.495 ± 0.08 | 0.503 ± 0.09 | 0.499 ± 0.10 |
| GraphCodeBERTrand | 0.435 ± 0.10 | 0.436 ± 0.11 | 0.404 ± 0.12 | 0.447 ± 0.12 | 0.433 ± 0.11 | 0.439 ± 0.13 | 0.430 ± 0.11 |
| GraphCodeBERTPT | 0.419 ± 0.11 | 0.448 ± 0.12 | 0.430 ± 0.10 | 0.440 ± 0.11 | 0.444 ± 0.12 | 0.422 ± 0.11 | 0.448 ± 0.09 |
| GraphCodeBERTPT+FT | 0.465 ± 0.10 | 0.466 ± 0.12 | 0.449 ± 0.11 | 0.465 ± 0.11 | 0.478 ± 0.10 | 0.464 ± 0.12 | 0.464 ± 0.12 |
| GraphCodeBERTPT+TAPT+FT | 0.473 ± 0.12 | 0.453 ± 0.11 | 0.449 ± 0.11 | 0.472 ± 0.11 | 0.482 ± 0.11 | 0.478 ± 0.10 | 0.468 ± 0.09 |
| Neural Classifier | |||||
| Paired Comparison | Performance Metric | Avg1 | Avg2 | Shapiro–Wilk Test | Student’s t-Test |
| proposed method–Levin and Yehudai [22] | F-score | 0.509 | 0.516 | W(11) = 0.957, p = 0.735 | t(10) = −0.287, p = 0.780 |
| Kappa Coefficient | 0.232 | 0.221 | W(11) = 0.963, p = 0.804 | t(10) = 0.317, p = 0.758 | |
| proposed method–Hönel et al. [7] | F-score | 0.509 | 0.525 | W(11) = 0.938, p = 0.492 | t(10) = −0.870, p = 0.405 |
| Kappa Coefficient | 0.232 | 0.248 | W(11) = 0.920, p = 0.320 | t(10) = −0.542, p = 0.599 | |
| proposed method–Ghadhab et al. [14] | F-score | 0.509 | 0.414 | W(11) = 0.914, p = 0.274 | t(10) = 3.728, p = 0.004 ** |
| Kappa Coefficient | 0.232 | 0.109 | W(11) = 0.980, p = 0.964 | t(10) = 3.738, p = 0.004 ** | |
| proposed method–Mariano et al. [15] | F-score | 0.509 | 0.529 | W(11) = 0.882, p = 0.110 | t(10) = −1.285, p = 0.228 |
| Kappa Coefficient | 0.232 | 0.250 | W(11) = 0.911, p = 0.251 | t(10) = −0.637, p = 0.539 | |
| Gaussian Naive Bayes Classifier | |||||
| Paired Comparison | Performance Metric | Avg1 | Avg2 | Shapiro–Wilk Test | Student’s t-Test/Wilcoxon Signed-Rank Test |
| proposed method–Levin and Yehudai [22] | F-score | 0.511 | 0.450 | W(11) = 0.911, p = 0.249 | t(10) = 1.600, p = 0.141 |
| Kappa Coefficient | 0.248 | 0.166 | W(11) = 0.955, p = 0.708 | t(10) = 2.016, p = 0.072 | |
| proposed method–Hönel et al. [7] | F-score | 0.511 | 0.429 | W(11) = 0.940, p = 0.521 | t(10) = 3.524, p = 0.006 ** |
| Kappa Coefficient | 0.248 | 0.126 | W(11) = 0.929, p = 0.400 | t(10) = 6.305, p < 0.001 *** | |
| proposed method–Ghadhab et al. [14] | F-score | 0.511 | 0.373 | W(11) = 0.969, p = 0.872 | t(10) = 6.034, p < 0.001 *** |
| Kappa Coefficient | 0.248 | 0.058 | W(11) = 0.958, p = 0.752 | t(10) = 9.758, p < 0.001 *** | |
| proposed method–Mariano et al. [15] | F-score | 0.511 | 0.406 | W(11) = 0.917, p = 0.295 | t(10) = 3.518, p = 0.006 ** |
| Kappa Coefficient | 0.248 | 0.100 | W(11) = 0.701, p < 0.001 *** | Z = −2.845, p = 0.004 ** | |
| Random Forest Classifier | |||||
| Paired Comparison | Performance Metric | Avg1 | Avg2 | Shapiro–Wilk Test | Student’s t-Test |
| proposed method–Levin and Yehudai [22] | F-score | 0.501 | 0.467 | W(11) = 0.894, p = 0.157 | t(10) = 2.768, p = 0.020 * |
| Kappa Coefficient | 0.220 | 0.164 | W(11) = 0.878, p = 0.097 | t(10) = 2.425, p = 0.036 * | |
| proposed method–Hönel et al. [7] | F-score | 0.501 | 0.503 | W(11) = 0.976, p = 0.939 | t(10) = −0.101, p = 0.922 |
| Kappa Coefficient | 0.220 | 0.217 | W(11) = 0.969, p = 0.879 | t(10) = 0.100, p = 0.922 | |
| proposed method–Ghadhab et al. [14] | F-score | 0.501 | 0.402 | W(11) = 0.932, p = 0.429 | t(10) = 3.945, p = 0.003 ** |
| Kappa Coefficient | 0.220 | 0.102 | W(11) = 0.947, p = 0.603 | t(10) = 3.289, p = 0.008 ** | |
| proposed method–Mariano et al. [15] | F-score | 0.501 | 0.533 | W(11) = 0.951, p = 0.656 | t(10) = −1.633, p = 0.133 |
| Kappa Coefficient | 0.220 | 0.256 | W(11) = 0.968, p = 0.869 | t(10) = −1.461, p = 0.175 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Heričko, T.; Šumak, B.; Karakatič, S. Commit-Level Software Change Intent Classification Using a Pre-Trained Transformer-Based Code Model. Mathematics 2024, 12, 1012. https://doi.org/10.3390/math12071012
Heričko T, Šumak B, Karakatič S. Commit-Level Software Change Intent Classification Using a Pre-Trained Transformer-Based Code Model. Mathematics. 2024; 12(7):1012. https://doi.org/10.3390/math12071012
Chicago/Turabian StyleHeričko, Tjaša, Boštjan Šumak, and Sašo Karakatič. 2024. "Commit-Level Software Change Intent Classification Using a Pre-Trained Transformer-Based Code Model" Mathematics 12, no. 7: 1012. https://doi.org/10.3390/math12071012
APA StyleHeričko, T., Šumak, B., & Karakatič, S. (2024). Commit-Level Software Change Intent Classification Using a Pre-Trained Transformer-Based Code Model. Mathematics, 12(7), 1012. https://doi.org/10.3390/math12071012