


Boundary-Match U-Shaped Temporal Convolutional Network for Vulgar Action Segmentation
 ,
,
Abstract
1. Introduction
- Development of a U-shaped TCN for enhanced temporal information utilization: We introduce a novel U-shaped TCN architecture that effectively leverages the temporal information present in videos, specifically addressing the issue of ambiguous boundaries in vulgar content.
- Introduction of the BM Module for precise action boundaries: Through the implementation of the BM Module, we refine predictions using boundary information, resulting in a marked improvement in the accuracy of action boundary delineation.
- Creation of the AIBS for mitigating over-segmentation: Our AIBS technique, an unsupervised refinement method, is capable of adaptively adjusting hyperparameters, thereby effectively reducing over-segmentation errors while maintaining high accuracy.
- Extensive model comparison across three challenging datasets: Our model has been rigorously evaluated against other methods on the 50Salads dataset [15], the Georgia Tech Egocentric Activities (GTEA) dataset [16], and our self-constructed vulgar action dataset. The results demonstrate that our approach sets a new benchmark for action segmentation on the vulgar action dataset.
2. Related Work
2.1. Action Recognition
2.2. Action Detection
2.3. Action Segmentation
3. Method
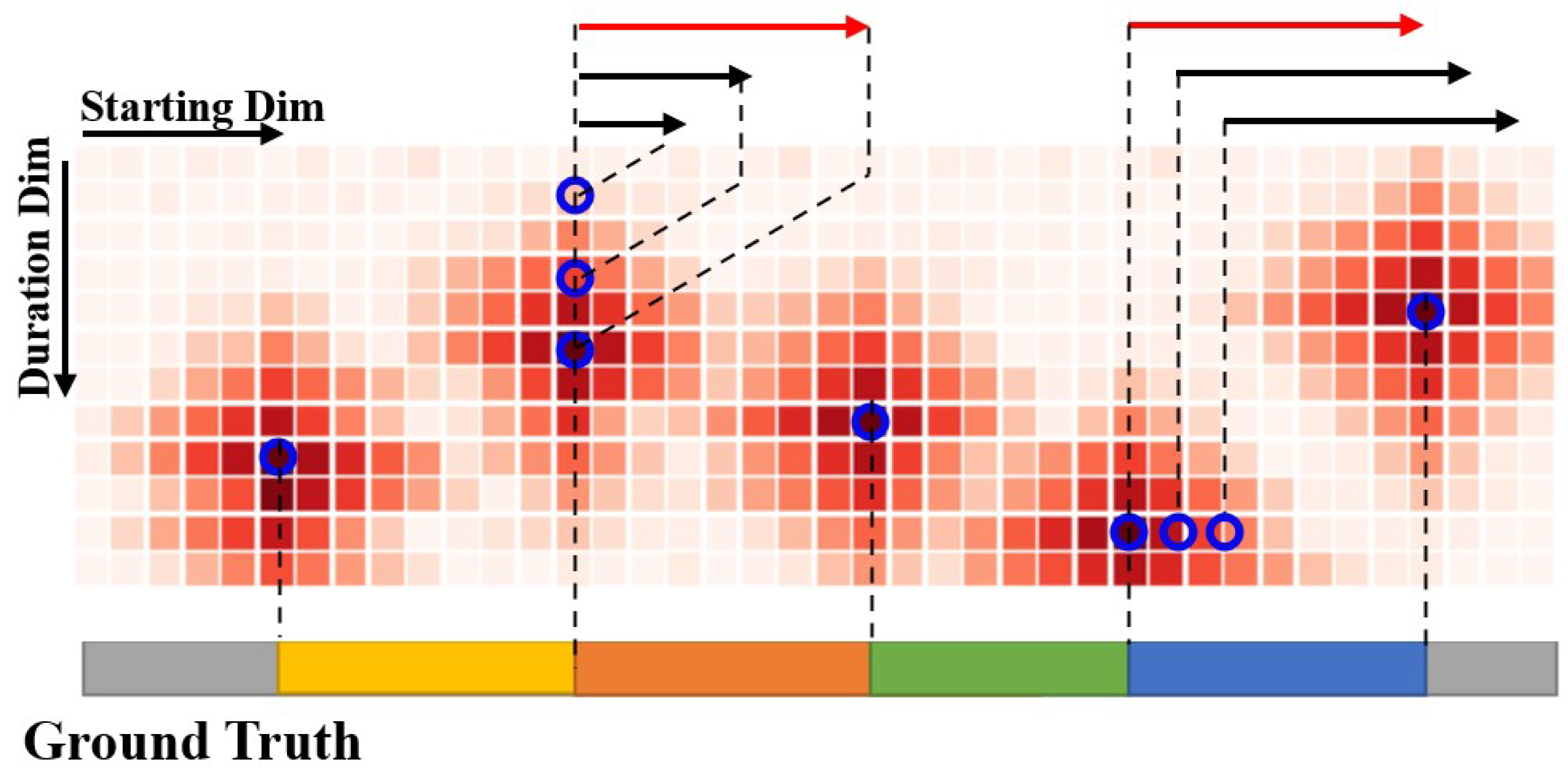
3.1. Boundary-Match Module
3.1.1. Boundary-Match Intersection over Union
3.1.2. Boundary-Match Map
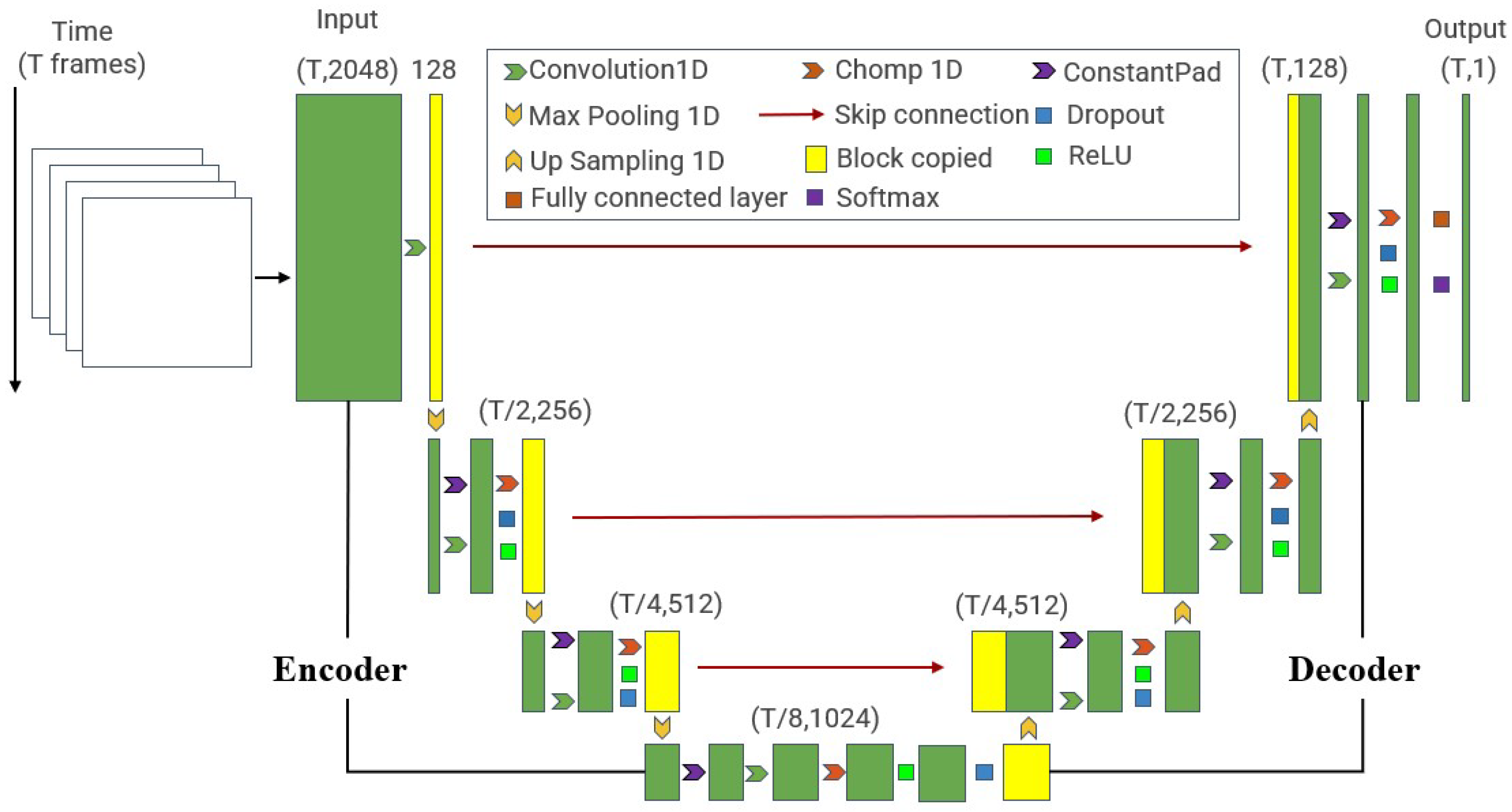
3.2. U-Shaped Temporal Convolutional Module
3.3. Loss Function
3.3.1. Loss Function for Boundary-Match Module
3.3.2. Loss Function for U-Shaped Temporal Convolutional Module
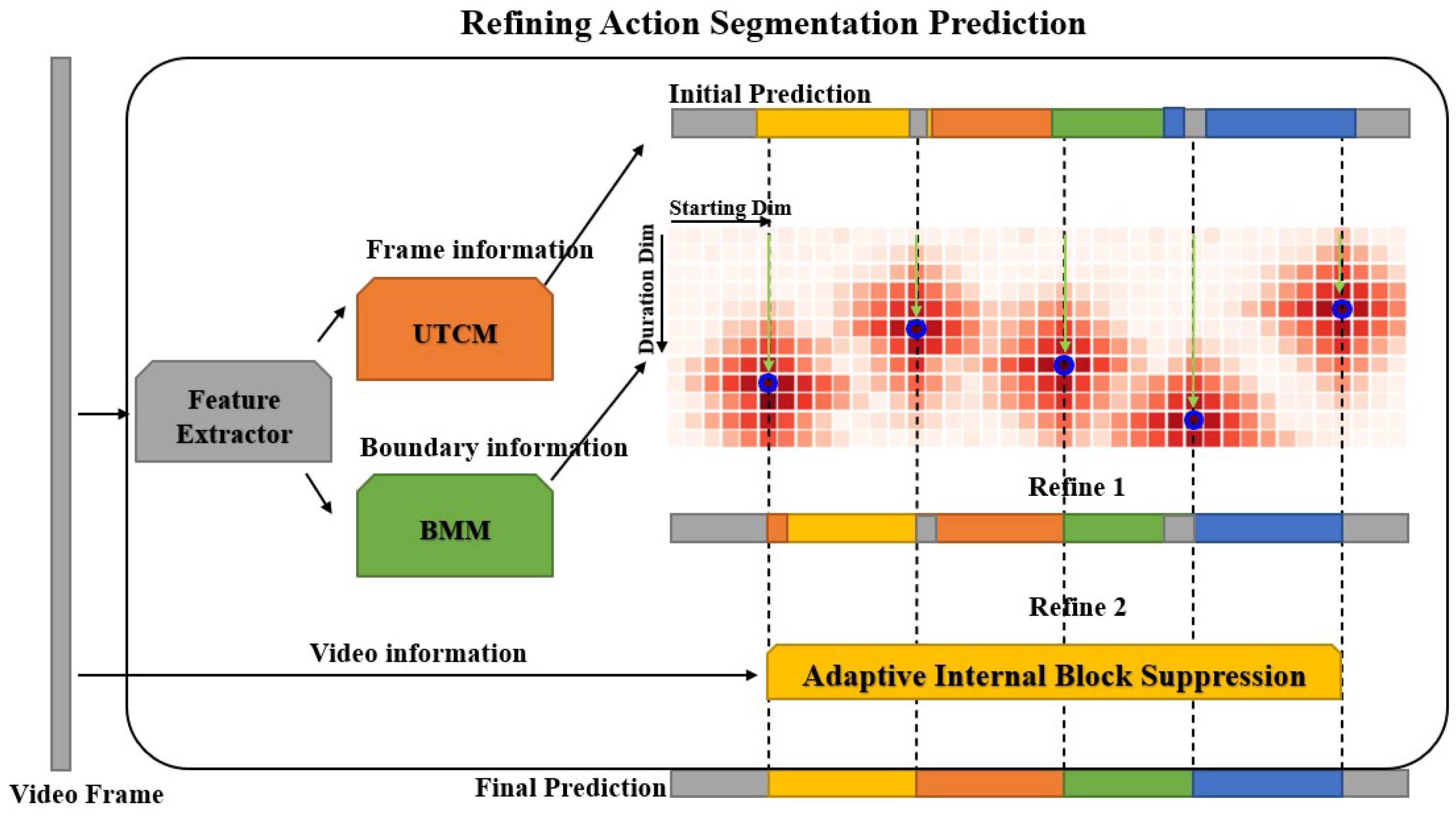
3.4. Refining Action Segmentation Prediction
3.4.1. Boundary Refine
3.4.2. Adaptive Internal Block Suppression
| Algorithm 1 Adaptive Internal Block Suppression |
|
| where represents the maximum allowable action length, denotes the minimum allowable action length, refers to the initial prediction output, indicates the pre-defined window size, and is the adaptive confidence threshold employed in the refinement process. |
4. Experiments
4.1. Datasets
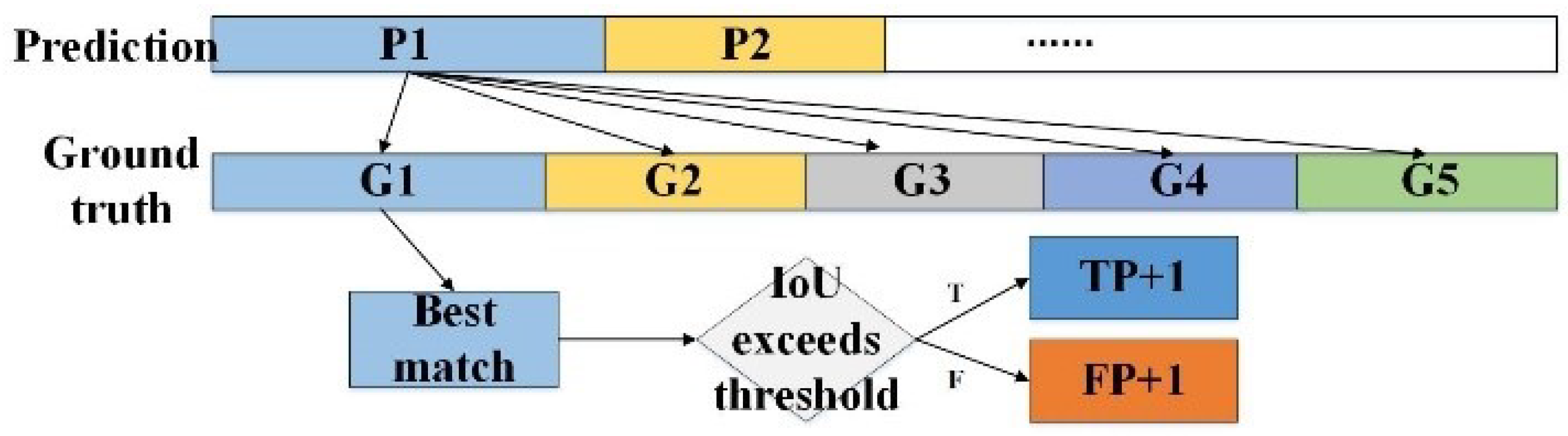
4.2. Evaluation Metrics
4.3. Experimental Settings
4.4. Comparison with State-of-the-Art
4.5. Ablation Studies
4.5.1. Impact of Codec Structure for U-Shaped Temporal Convolutional Module
4.5.2. Impact of T and D for Boundary-Match Module
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Owens, E.W.; Behun, R.J.; Manning, J.C.; Reid, R.C. The impact of Internet pornography on adolescents: A review of the research. Sex. Addict. Compuls. 2012, 19, 99–122. [Google Scholar] [CrossRef]
- Vitorino, P.; Avila, S.; Perez, M.; Rocha, A. Leveraging deep neural networks to fight child pornography in the age of social media. J. Vis. Commun. Image Represent. 2018, 50, 303–313. [Google Scholar] [CrossRef]
- Papadamou, K.; Papasavva, A.; Zannettou, S.; Blackburn, J.; Kourtellis, N.; Leontiadis, I.; Stringhini, G.; Sirivianos, M. Disturbed YouTube for kids: Characterizing and detecting inappropriate videos targeting young children. In Proceedings of the International AAAI Conference on Web and Social Media, Atlanta, GA, USA, 8–11 June 2020; Volume 14, pp. 522–533. [Google Scholar]
- Du, H.; Shi, H.; Zeng, D.; Zhang, X.P.; Mei, T. The elements of end-to-end deep face recognition: A survey of recent advances. Acm Comput. Surv. (CSUR) 2022, 54, 1–42. [Google Scholar] [CrossRef]
- Moustafa, M. Applying deep learning to classify pornographic images and videos. arXiv 2015, arXiv:1511.08899. [Google Scholar]
- Caetano, C.; Avila, S.; Schwartz, W.R.; Guimarães, S.J.F.; Araújo, A.d.A. A mid-level video representation based on binary descriptors: A case study for pornography detection. Neurocomputing 2016, 213, 102–114. [Google Scholar] [CrossRef]
- Mei, M.; He, F. Multi-label learning based target detecting from multi-frame data. IET Image Process. 2021, 15, 3638–3644. [Google Scholar] [CrossRef]
- Zeng, D.; Chen, S.; Chen, B.; Li, S. Improving remote sensing scene classification by integrating global-context and local-object features. Remote. Sens. 2018, 10, 734. [Google Scholar] [CrossRef]
- Ge, S.; Li, C.; Zhao, S.; Zeng, D. Occluded face recognition in the wild by identity-diversity inpainting. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 3387–3397. [Google Scholar] [CrossRef]
- Perez, M.; Avila, S.; Moreira, D.; Moraes, D.; Testoni, V.; Valle, E.; Goldenstein, S.; Rocha, A. Video pornography detection through deep learning techniques and motion information. Neurocomputing 2017, 230, 279–293. [Google Scholar] [CrossRef]
- Arif, M. A systematic review of machine learning algorithms in cyberbullying detection: Future directions and challenges. J. Inf. Secur. Cybercrimes Res. 2021, 4, 01–26. [Google Scholar] [CrossRef]
- Cao, J.; Xu, R.; Lin, X.; Qin, F.; Peng, Y.; Shao, Y. Adaptive receptive field U-shaped temporal convolutional network for vulgar action segmentation. Neural Comput. Appl. 2023, 35, 9593–9606. [Google Scholar] [CrossRef]
- Lea, C.; Flynn, M.D.; Vidal, R.; Reiter, A.; Hager, G.D. Temporal convolutional networks for action segmentation and detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 156–165. [Google Scholar]
- Li, Y.; Dong, Z.; Liu, K.; Feng, L.; Hu, L.; Zhu, J.; Xu, L.; Liu, S. Efficient two-step networks for temporal action segmentation. Neurocomputing 2021, 454, 373–381. [Google Scholar] [CrossRef]
- Stein, S.; McKenna, S.J. Combining embedded accelerometers with computer vision for recognizing food preparation activities. In Proceedings of the 2013 ACM International Joint Conference on Pervasive and Ubiquitous Computing, Zurich, Switzerland, 8–12 September 2013; pp. 729–738. [Google Scholar]
- Li, Y.; Ye, Z.; Rehg, J.M. Delving into egocentric actions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 287–295. [Google Scholar]
- Wehrmann, J.; Simões, G.S.; Barros, R.C.; Cavalcante, V.F. Adult content detection in videos with convolutional and recurrent neural networks. Neurocomputing 2018, 272, 432–438. [Google Scholar] [CrossRef]
- Mallmann, J.; Santin, A.O.; Viegas, E.K.; dos Santos, R.R.; Geremias, J. PPCensor: Architecture for real-time pornography detection in video streaming. Future Gener. Comput. Syst. 2020, 112, 945–955. [Google Scholar] [CrossRef]
- Song, K.H.; Kim, Y.S. Pornographic video detection scheme using multimodal features. J. Eng. Appl. Sci. 2018, 13, 1174–1182. [Google Scholar]
- Gao, J.; Chen, K.; Nevatia, R. Ctap: Complementary temporal action proposal generation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 68–83. [Google Scholar]
- Lin, T.; Zhao, X.; Su, H.; Wang, C.; Yang, M. Bsn: Boundary sensitive network for temporal action proposal generation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Yu, H.; He, F.; Pan, Y. A scalable region-based level set method using adaptive bilateral filter for noisy image segmentation. Multimed. Tools Appl. 2020, 79, 5743–5765. [Google Scholar] [CrossRef]
- Liu, Y.; Ma, L.; Zhang, Y.; Liu, W.; Chang, S.F. Multi-granularity generator for temporal action proposal. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3604–3613. [Google Scholar]
- Lin, T.; Liu, X.; Li, X.; Ding, E.; Wen, S. Bmn: Boundary-matching network for temporal action proposal generation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3889–3898. [Google Scholar]
- Yu, H.; He, F.; Pan, Y. A novel segmentation model for medical images with intensity inhomogeneity based on adaptive perturbation. Multimed. Tools Appl. 2019, 78, 11779–11798. [Google Scholar] [CrossRef]
- Alwassel, H.; Giancola, S.; Ghanem, B. Tsp: Temporally-sensitive pretraining of video encoders for localization tasks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 3173–3183. [Google Scholar]
- Farha, Y.A.; Gall, J. Ms-tcn: Multi-stage temporal convolutional network for action segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3575–3584. [Google Scholar]
- Wang, Z.; Gao, Z.; Wang, L.; Li, Z.; Wu, G. Boundary-aware cascade networks for temporal action segmentation. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 34–51. [Google Scholar]
- Ishikawa, Y.; Kasai, S.; Aoki, Y.; Kataoka, H. Alleviating over-segmentation errors by detecting action boundaries. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2021; pp. 2322–2331. [Google Scholar]
- Singhania, D.; Rahaman, R.; Yao, A. Coarse to fine multi-resolution temporal convolutional network. arXiv 2021, arXiv:2105.10859. [Google Scholar]
- Park, J.; Kim, D.; Huh, S.; Jo, S. Maximization and restoration: Action segmentation through dilation passing and temporal reconstruction. Pattern Recognit. 2022, 129, 108764. [Google Scholar] [CrossRef]
- Ahn, H.; Lee, D. Refining action segmentation with hierarchical video representations. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 16302–16310. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Levenshtein, V.I. Binary codes capable of correcting deletions, insertions, and reversals. Sov. Phys. Dokl. 1966, 10, 707–710. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Lea, C.; Reiter, A.; Vidal, R.; Hager, G.D. Efficient segmental inference for spatiotemporal modeling of fine-grained actions. arXiv 2016, arXiv:1602.02995. [Google Scholar]
- Singh, B.; Marks, T.K.; Jones, M.; Tuzel, O.; Shao, M. A multi-stream bi-directional recurrent neural network for fine-grained action detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1961–1970. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 50Salads | GTEA | Vulgar | |
|---|---|---|---|
| Videos | 50 | 28 | 264 |
| Classes | 17 | 11 | 4 |
| Instances | 20 | 20 | 13 |
| Cross-val | 5 | 4 | 5 |
| Category | Size | Counts | Proportion |
|---|---|---|---|
| Normal | 555 MB | 645 | 43.11% |
| Caress breast | 208 MB | 325 | 21.72% |
| Hip shake | 400 MB | 395 | 26.40% |
| Suck | 82 MB | 131 | 8.75% |
| Dataset | 50salads | GTEA | Vulgar | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Method | F1@{10,25,50} | Edit | Acc | F1@{10,25,50} | Edit | Acc | F1@{10,25,50} | Edit | Acc | ||||||
| Spatial-CNN [36] | 32.3 | 27.1 | 18.9 | 24.8 | 54.9 | 41.8 | 36.0 | 25.1 | – | 54.1 | 28.6 | 23.2 | 14.3 | 22.7 | 53.2 |
| Bi-LSTM [37] | 62.6 | 58.3 | 47.0 | 55.6 | 55.7 | 66.5 | 59.0 | 43.6 | – | 55.5 | 52.1 | 47.6 | 37.4 | 39.2 | 54.6 |
| Dilated TCN [13] | 52.2 | 47.6 | 37.4 | 43.1 | 59.3 | 58.8 | 52.2 | 42.2 | – | 58.3 | 46.3 | 41.3 | 32.7 | 39.8 | 58.7 |
| ED-TCN [13] | 68.0 | 63.9 | 52.6 | 59.8 | 64.7 | 72.2 | 69.3 | 56.0 | – | 64.0 | 53.6 | 50.2 | 43.8 | 41.6 | 68.5 |
| BCN [28] | 82.3 | 81.3 | 74.0 | 74.3 | 84.4 | 88.5 | 87.1 | 77.3 | 84.4 | 79.8 | 71.2 | 69.3 | 62.5 | 68.9 | 77.6 |
| ETSN [14] | 85.2 | 83.9 | 75.4 | 78.8 | 82.0 | 91.1 | 90.0 | 77.9 | 86.2 | 78.2 | 75.6 | 74.3 | 66.4 | 68.8 | 75.3 |
| ASRF [29] | 84.9 | 83.5 | 77.3 | 79.3 | 84.5 | 89.4 | 87.8 | 79.8 | 83.7 | 77.3 | 73.1 | 71.5 | 65.6 | 69.4 | 79.7 |
| UTCM | 59.3 | 57.9 | 47.7 | 49.6 | 76.3 | 78.2 | 74.8 | 58.7 | 70.6 | 76.4 | 45.4 | 43.2 | 33.8 | 31.1 | 80.1 |
| UTCM + BMM | 68.9 | 66.5 | 58.1 | 55.7 | 84.2 | 86.8 | 82.6 | 67.2 | 83.2 | 78.9 | 53.2 | 51.1 | 42.7 | 37.6 | 84.5 |
| UTCM + AIBS | 78.6 | 75.3 | 61.2 | 72.8 | 81.6 | 85.3 | 81.4 | 61.1 | 80.3 | 77.2 | 70.5 | 69.5 | 64.5 | 68.3 | 81.9 |
| BMUTCN | 79.8 | 76.7 | 63.1 | 73.3 | 86.2 | 84.6 | 82.4 | 76.4 | 80.8 | 82.4 | 82.2 | 81.6 | 72.9 | 72.8 | 85.6 |
| Encoder Structures | F1@{10,25,50} | Edit | Acc | ||
|---|---|---|---|---|---|
| 128, 256 | 70.2 | 68.3 | 62.5 | 66.5 | 75.6 |
| 128, 256, 512 | 76.7 | 73.9 | 69.2 | 70.2 | 82.4 |
| 128, 256, 512, 1024 | 82.2 | 81.6 | 72.9 | 72.8 | 85.6 |
| 128, 256, 512, 1024, 2048 | 74.8 | 71.3 | 66.8 | 67.9 | 80.3 |
| Impact of T | F1@{10,25,50} | Edit | Acc | ||
|---|---|---|---|---|---|
| BMUTCN (, ) | 79.7 | 77.2 | 70.5 | 73.3 | 83.2 |
| BMUTCN (, ) | 82.2 | 81.6 | 72.9 | 72.8 | 85.6 |
| BMUTCN (, ) | 81.4 | 79.3 | 72.5 | 72.5 | 84.9 |
| BMUTCN (, ) | 82.5 | 81.2 | 72.8 | 73.0 | 85.7 |
| Impact of D | F1@{10,25,50} | Edit | Acc | ||
| BMUTCN (, ) | 80.1 | 78.5 | 71.6 | 70.5 | 82.9 |
| BMUTCN (, ) | 81.3 | 79.8 | 72.1 | 70.9 | 83.6 |
| BMUTCN (, ) | 82.2 | 81.6 | 72.9 | 72.8 | 85.6 |
| BMUTCN (, ) | 81.8 | 78.9 | 72.5 | 71.9 | 80.3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shen, Z.; Xu, R.; Zhang, Y.; Qin, F.; Ge, R.; Wang, C.; Toyoura, M. Boundary-Match U-Shaped Temporal Convolutional Network for Vulgar Action Segmentation. Mathematics 2024, 12, 899. https://doi.org/10.3390/math12060899
Shen Z, Xu R, Zhang Y, Qin F, Ge R, Wang C, Toyoura M. Boundary-Match U-Shaped Temporal Convolutional Network for Vulgar Action Segmentation. Mathematics. 2024; 12(6):899. https://doi.org/10.3390/math12060899
Chicago/Turabian StyleShen, Zhengwei, Ran Xu, Yongquan Zhang, Feiwei Qin, Ruiquan Ge, Changmiao Wang, and Masahiro Toyoura. 2024. "Boundary-Match U-Shaped Temporal Convolutional Network for Vulgar Action Segmentation" Mathematics 12, no. 6: 899. https://doi.org/10.3390/math12060899
APA StyleShen, Z., Xu, R., Zhang, Y., Qin, F., Ge, R., Wang, C., & Toyoura, M. (2024). Boundary-Match U-Shaped Temporal Convolutional Network for Vulgar Action Segmentation. Mathematics, 12(6), 899. https://doi.org/10.3390/math12060899