
KDTM: Multi-Stage Knowledge Distillation Transfer Model for Long-Tailed DGA Detection


Abstract
1. Introduction
- We propose DBRM, which is a sampling method to transform long-tailed distribution data into a relatively balanced dataset. This method is used during the transfer learning phase to reduce the gap between the head and tail categories.
- We propose the Knowledge Transfer Model (KTM), which divides weight transfer into multi-stages and gradually transfers head category knowledge to tail categories to improve the classification performance of tail categories. The experimental results show that when all categories of data are equally divided into two stages, KTM has the best performance, with an overall performance of 79%.
- We propose KDTM, which applies knowledge distillation to compensate for the forgetting of head categories with large sample sizes during the transfer of the KTM. Further, it improves the detection accuracy of categories with small sample sizes. The experimental results show that the overall performance of all categories can reach 84.5%, and the accuracy of the tail categories has been improved by 12%.
2. Related Work
2.1. DGA Detection
2.2. Long-Tailed Problem
2.3. Knowledge Distillation
3. Method
3.1. Long-Tailed DGA Detection Problem
| Algorithm 1 Knowledge distillation transfer model |
|
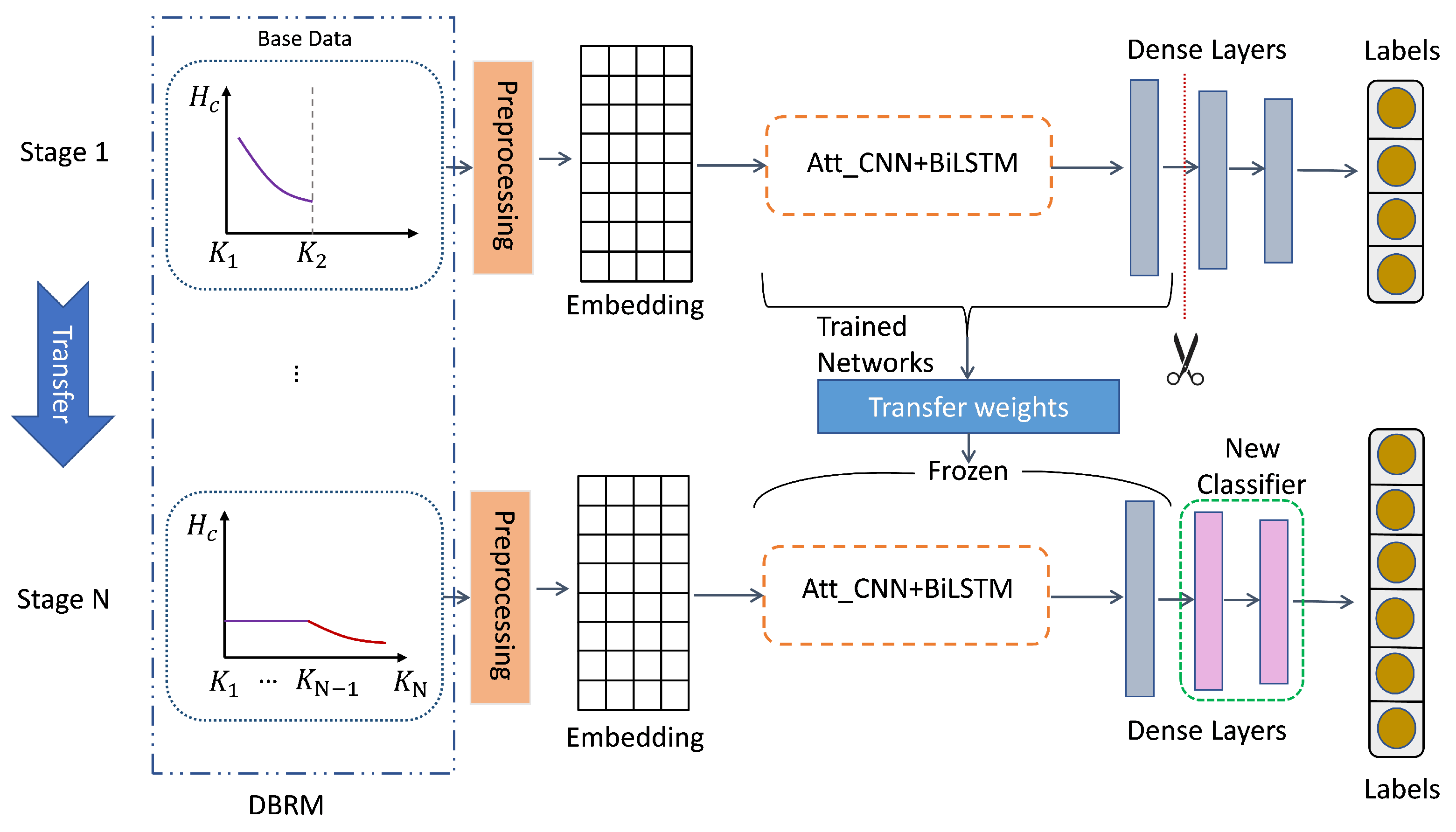
3.2. DBRM
- (1)
- is the step size for each stage category, and for stage N, is the step size of stage n. Categories are termed as base categories and . For stage n, categories are the old categories, are the new categories, and are the future categories. Datasets contain new categories and contain old categories.
- (2)
- Obtain the review datasets : For each category in , randomly sample samples from .
- (3)
- By using the balanced datasets of the old categories, we replay into each stage to obtain a relatively balanced datasets as the training datasets.
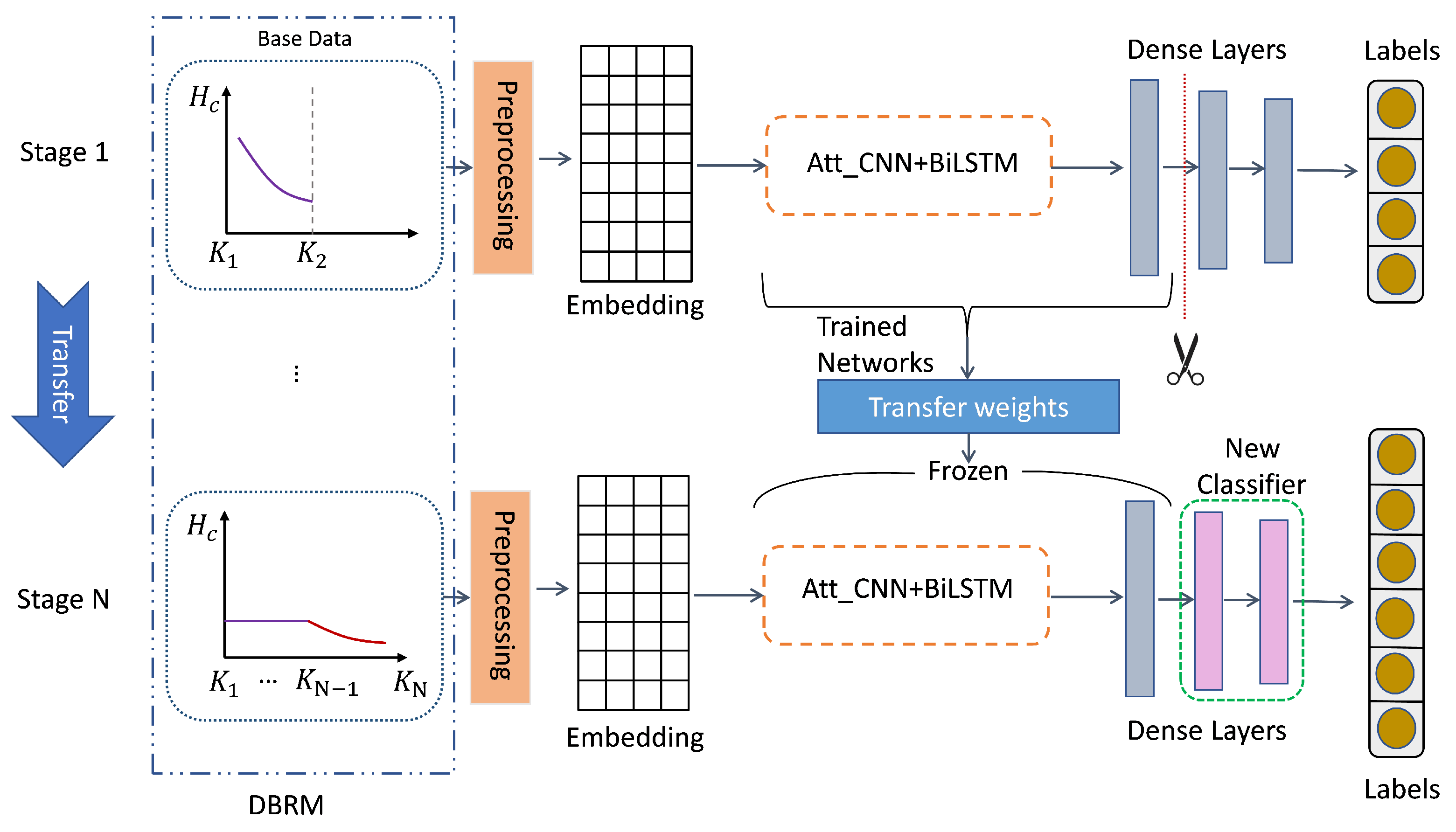
3.3. KTM
3.3.1. Base Data
3.3.2. Preprocessing
3.3.3. Embedding
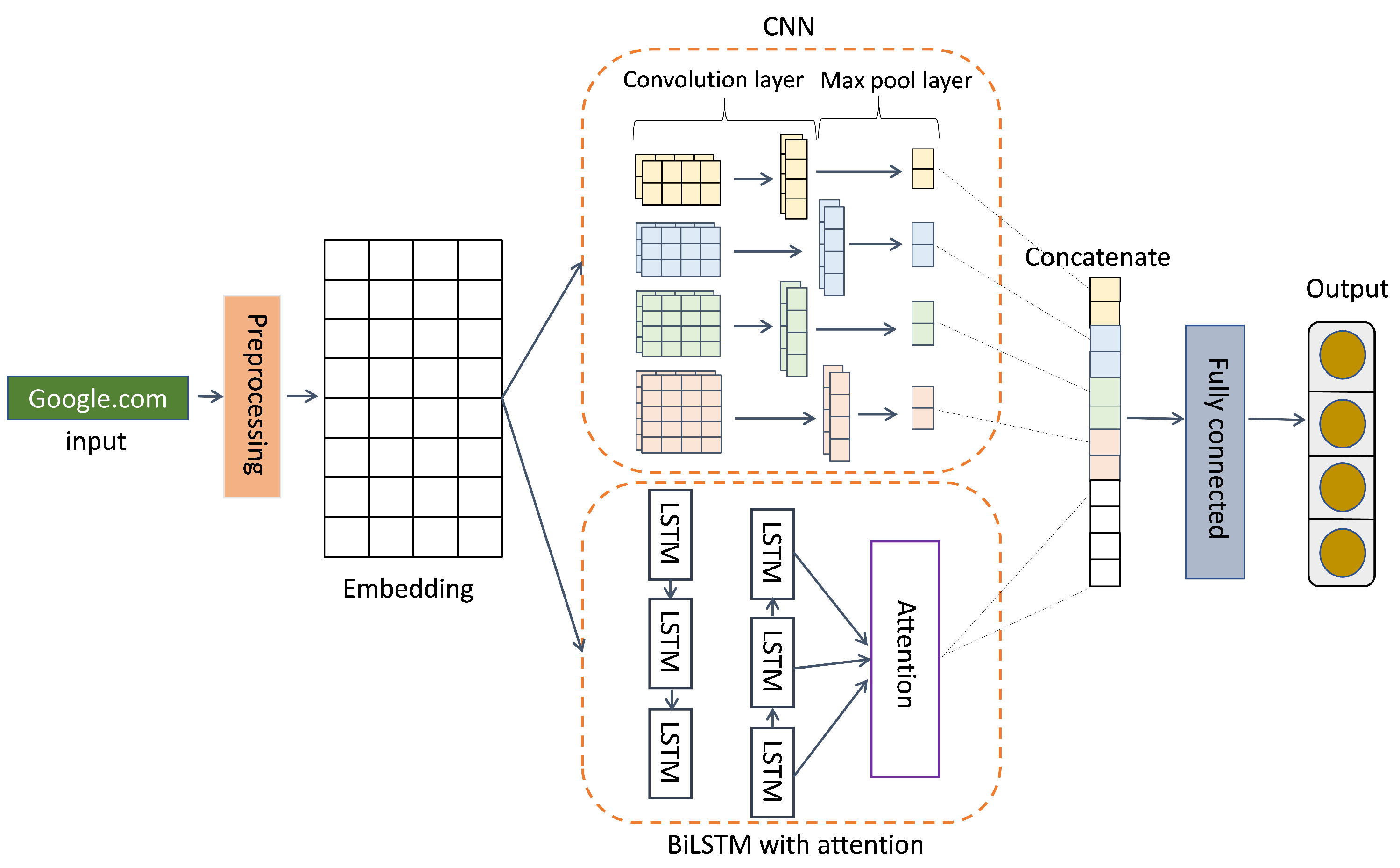
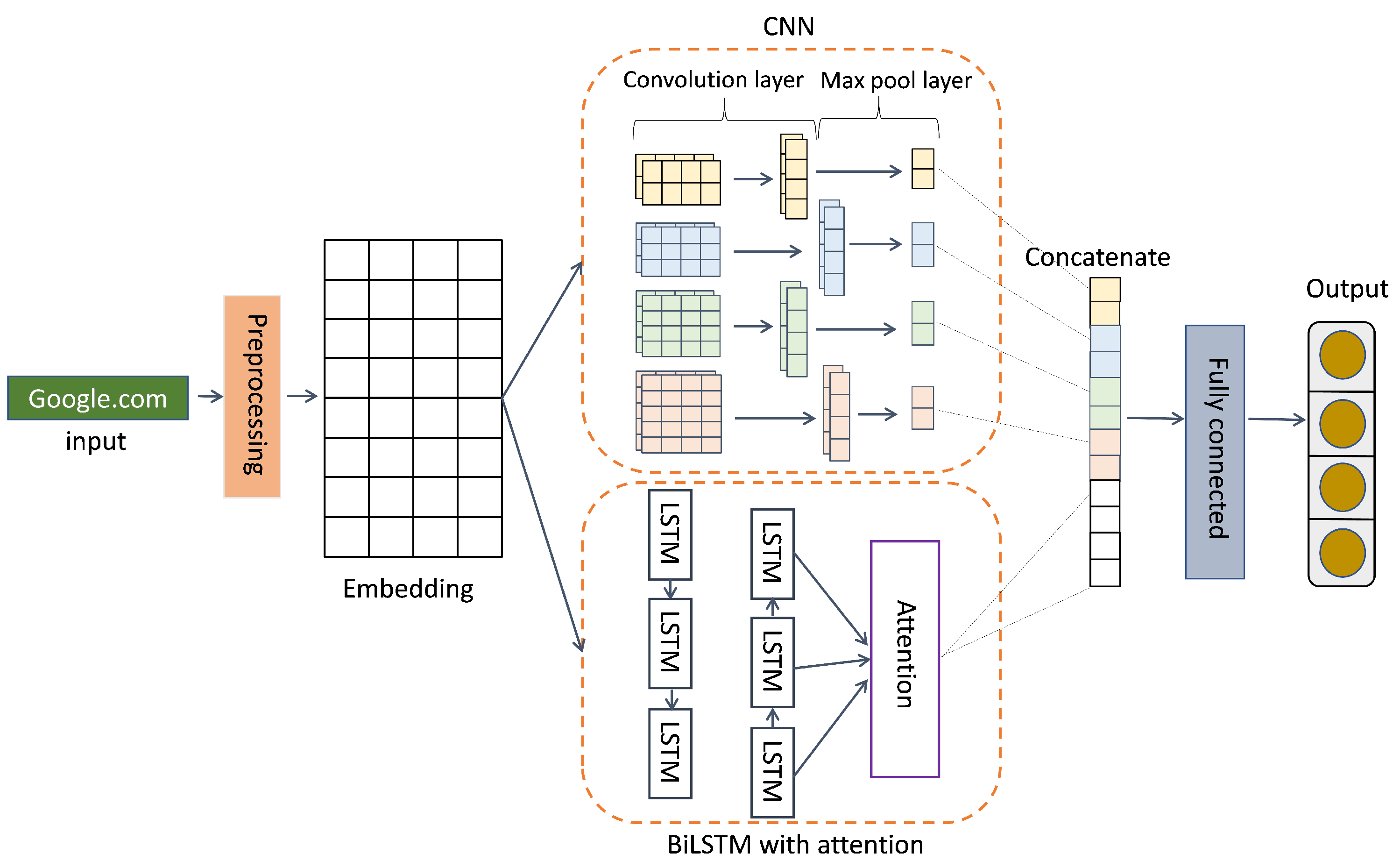
3.3.4. Att_BiLSTM + CNN Model
3.3.5. Transfer Weights
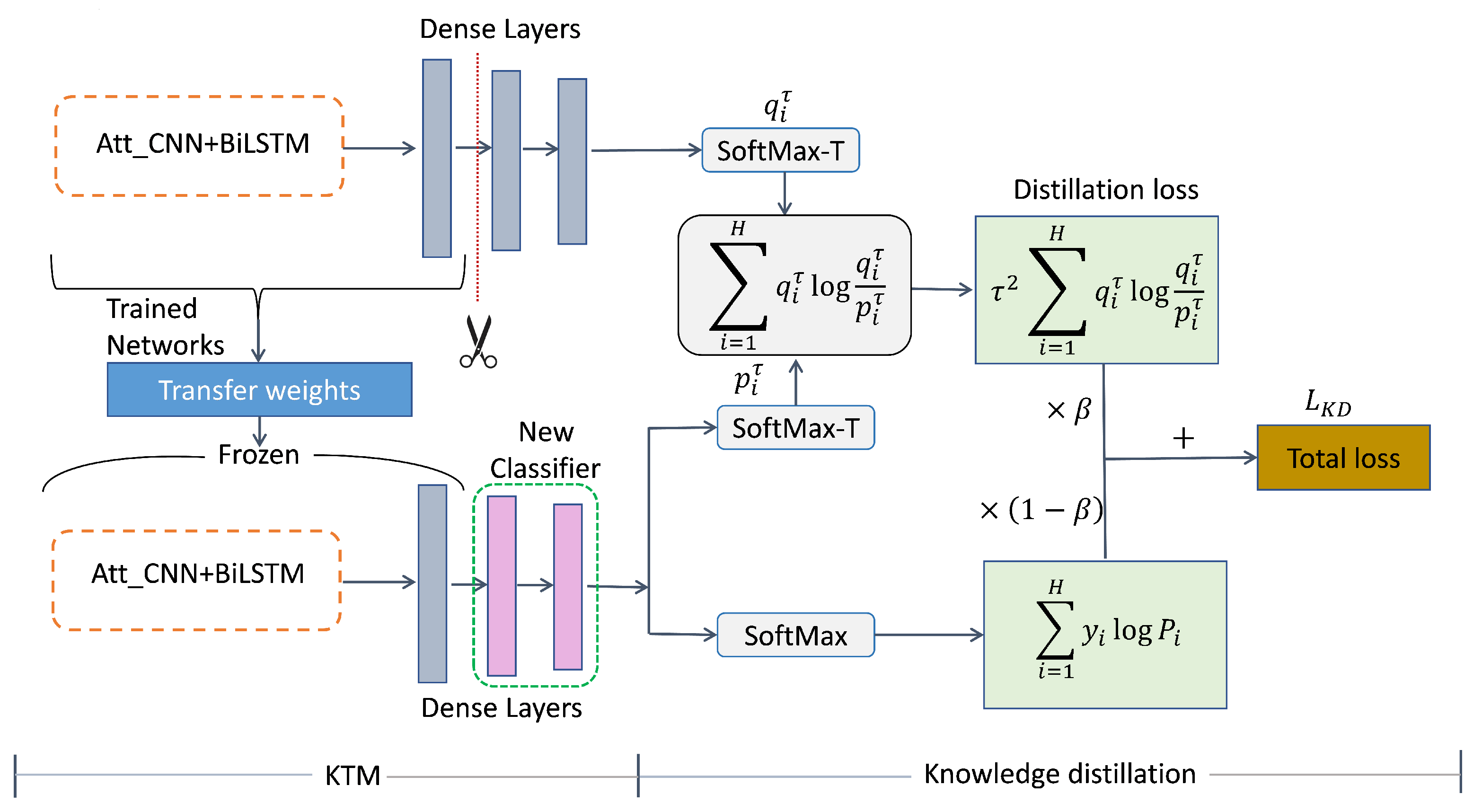
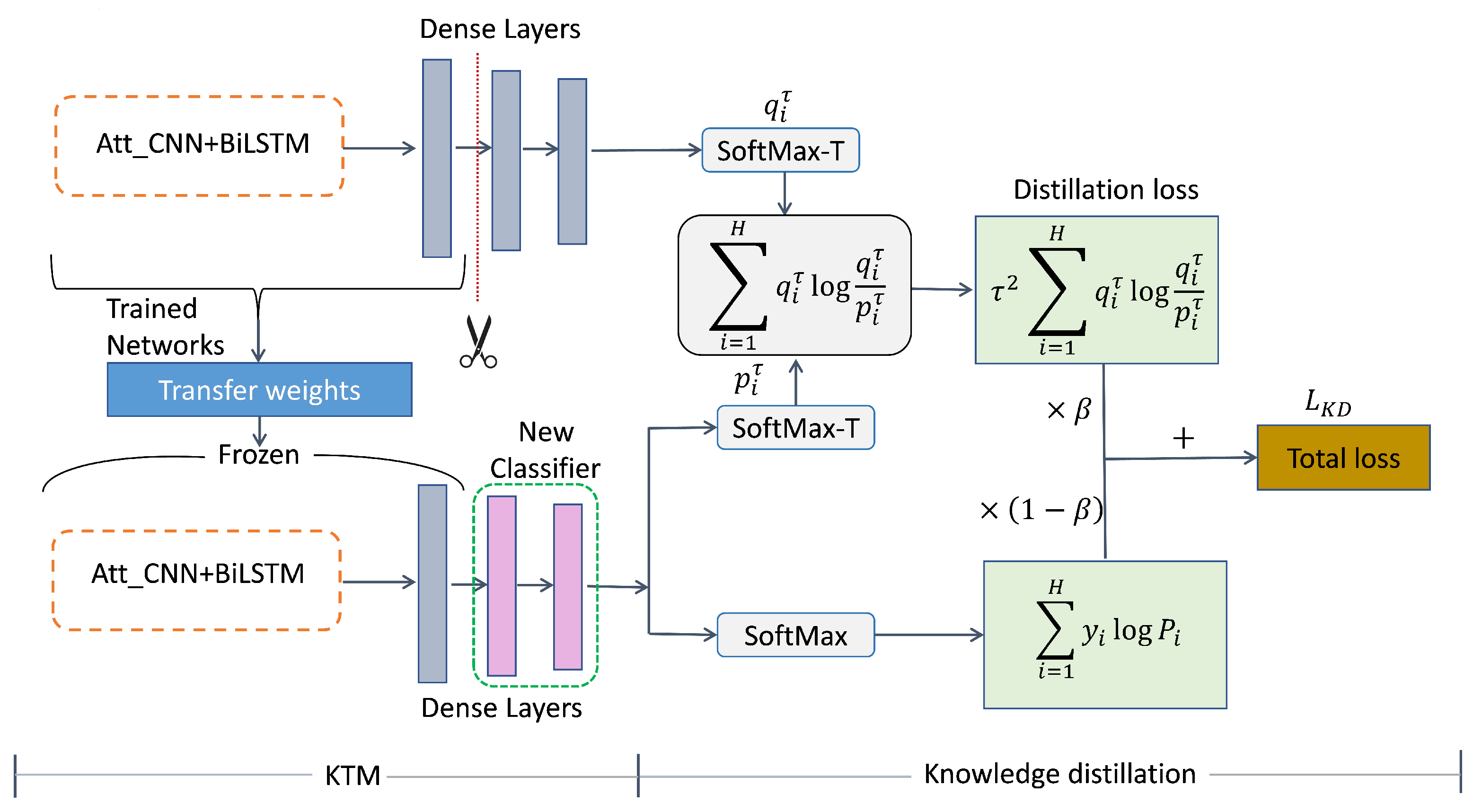
3.4. KDTM
Knowledge Distillation
4. Experiments
4.1. Datasets
4.2. Evaluation
4.3. Ablation Study
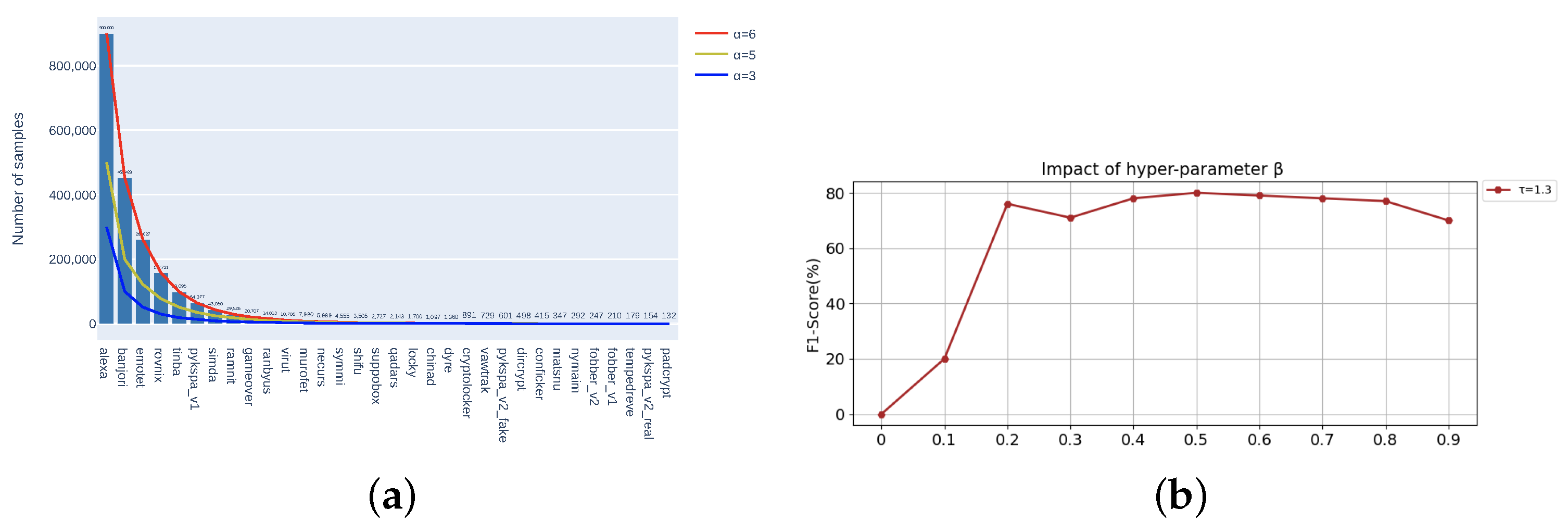
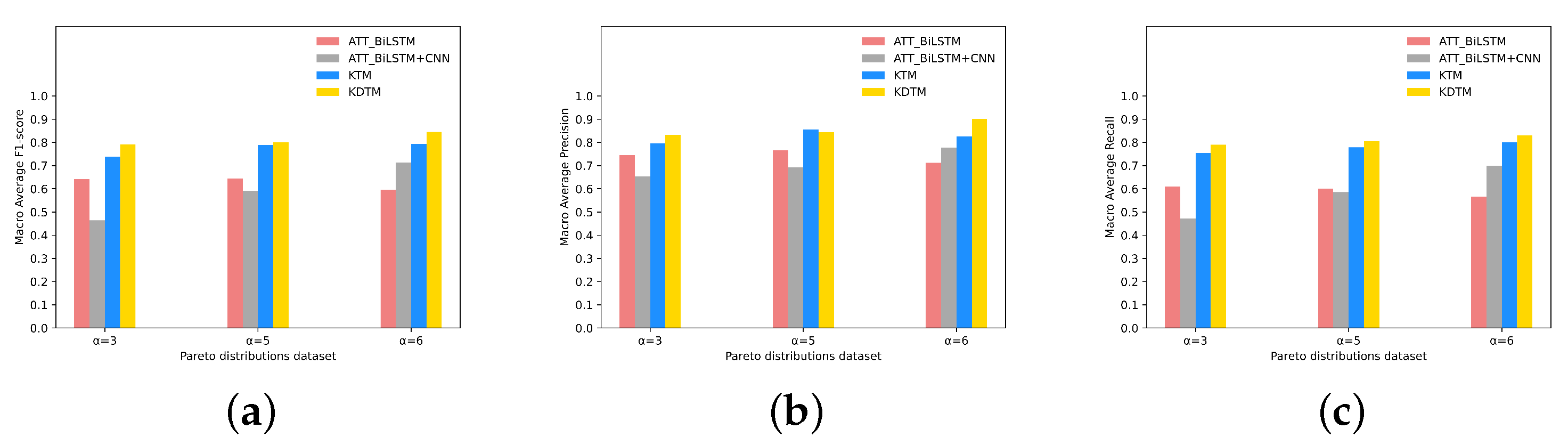
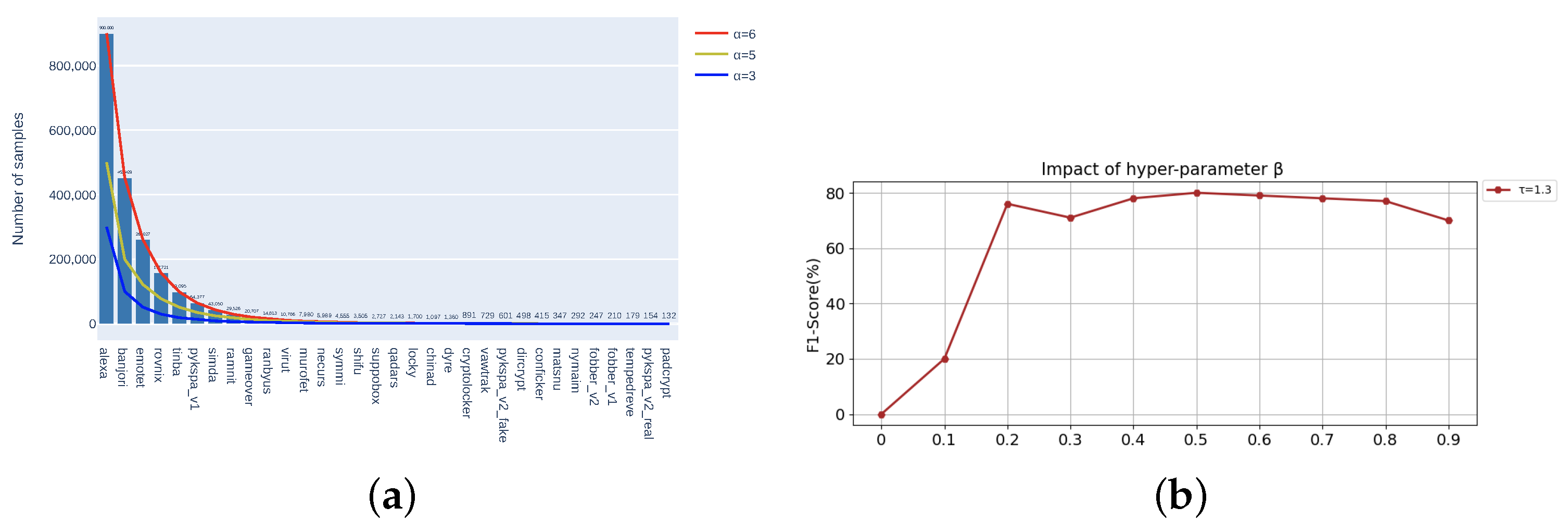
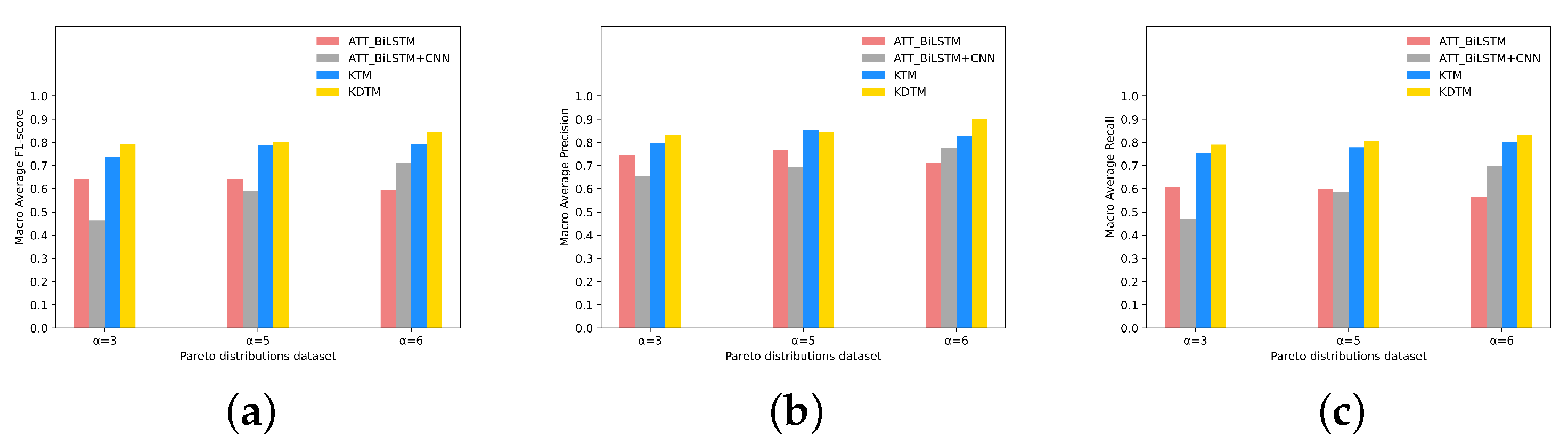
4.3.1. Hyperparameter Tuning
4.3.2. Choosing N-Stage in KTM
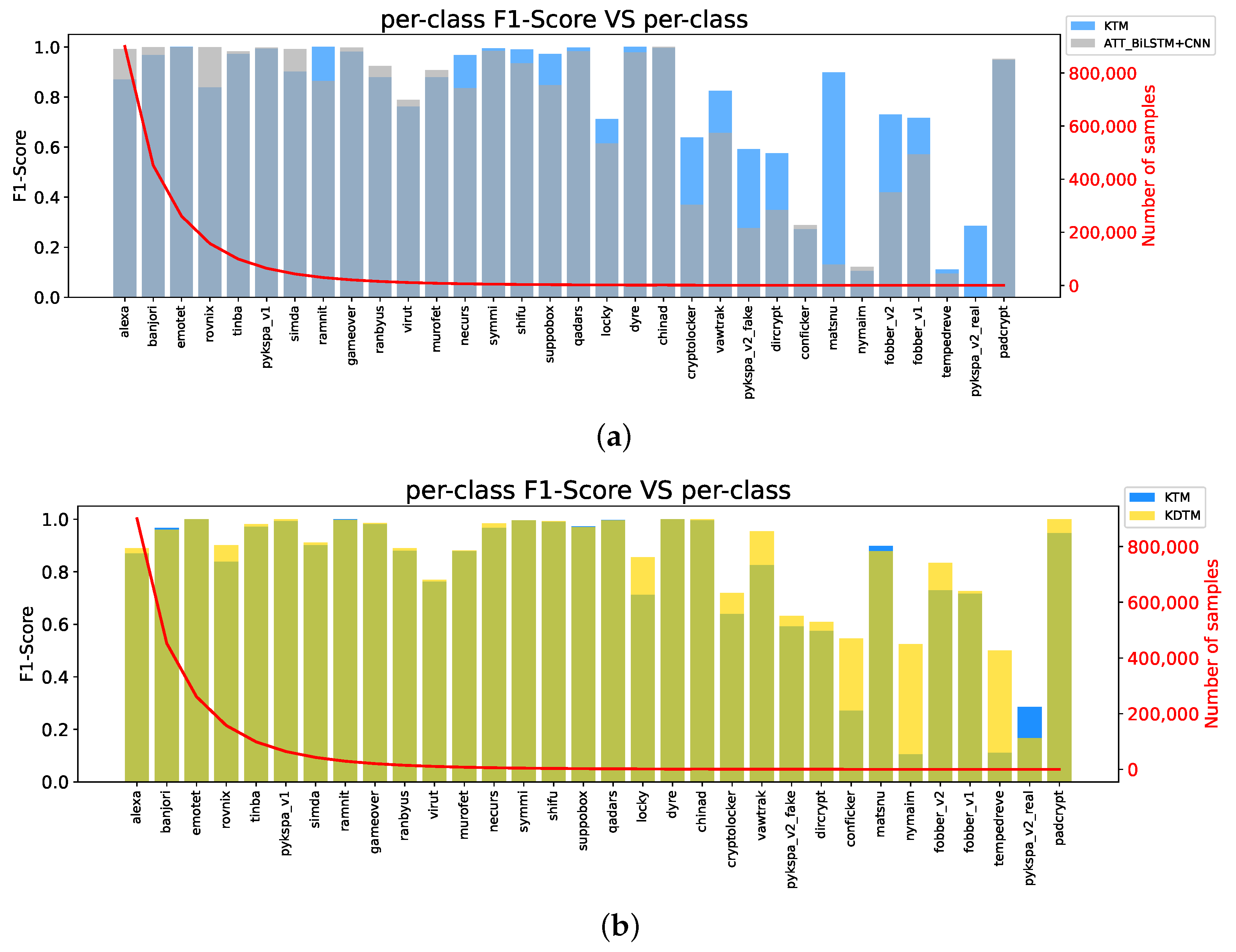
4.3.3. Baseline and KTM
4.3.4. Knowledge Distillation
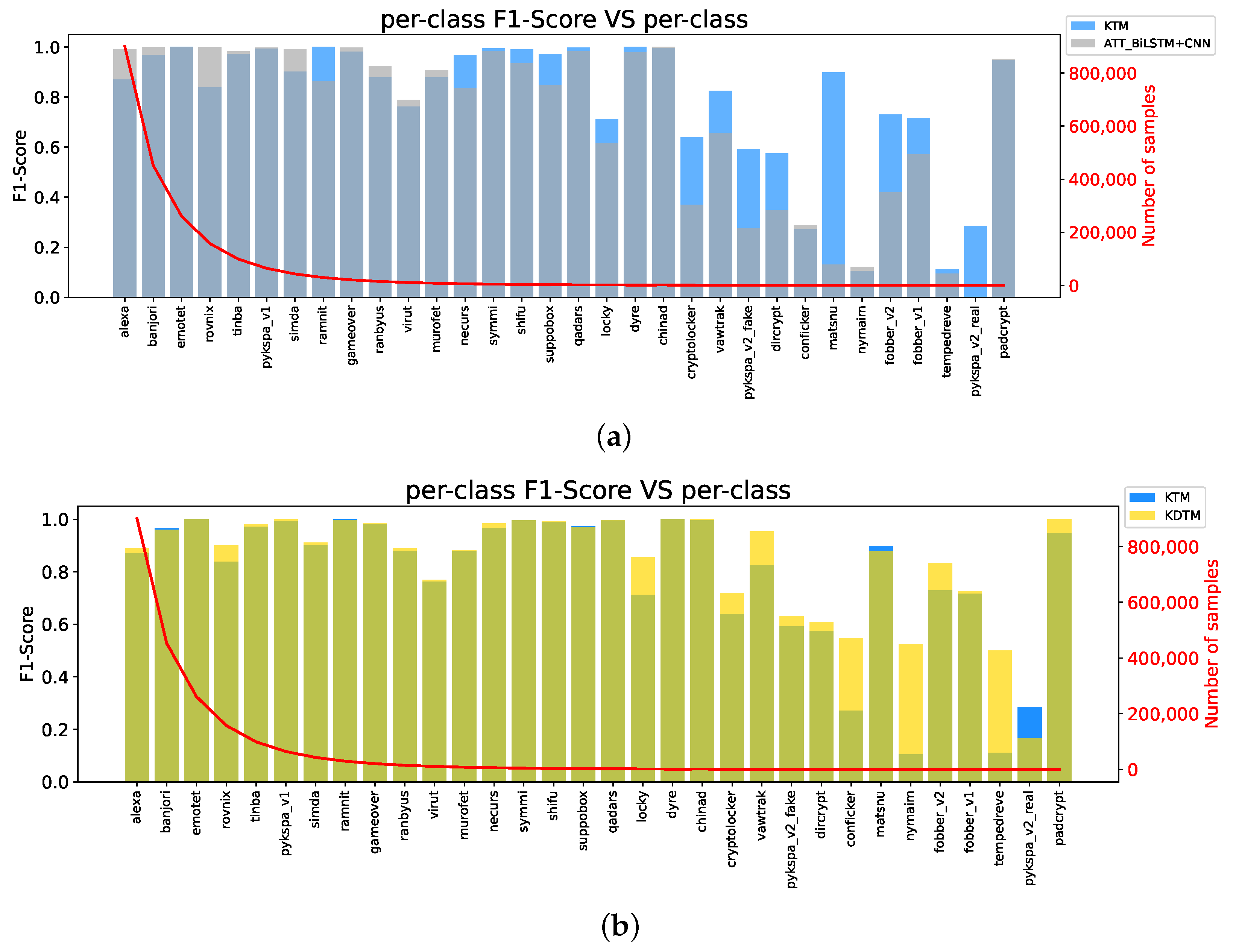
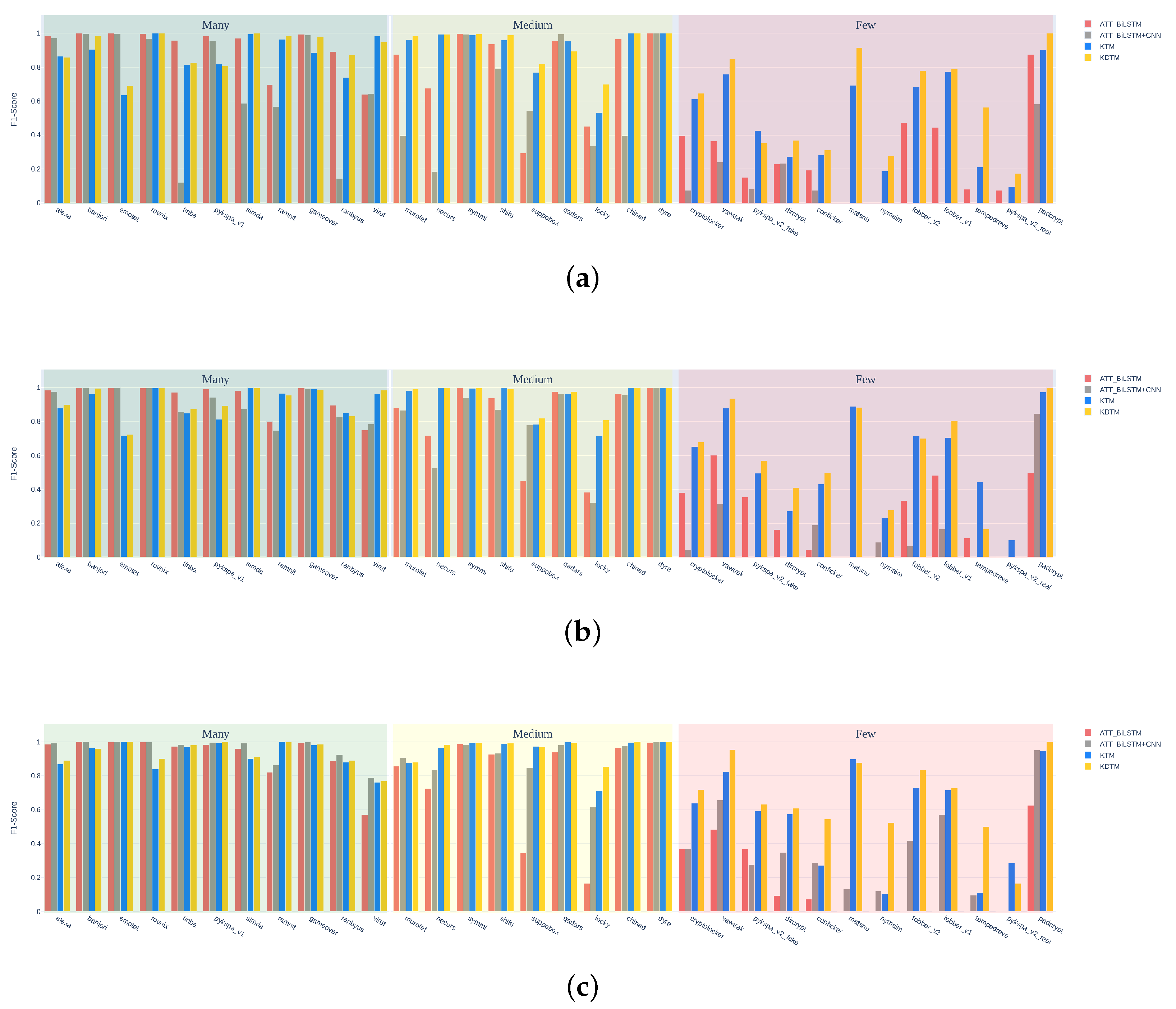
4.4. Comparison Methods and Results
4.4.1. Compared Methods
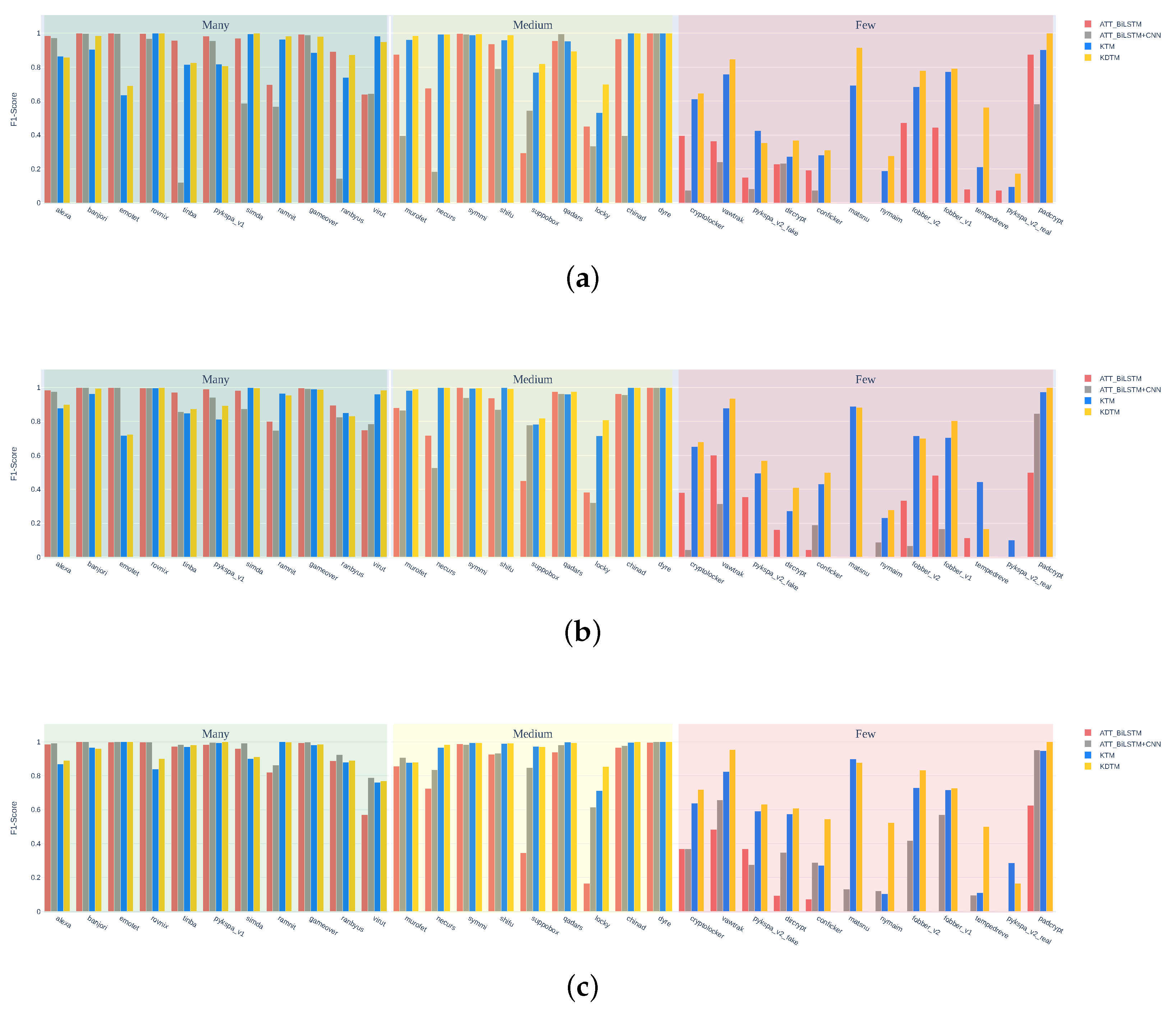
4.4.2. Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Hoque, N.; Bhattacharyya, D.K.; Kalita, J.K. Botnet in DDoS attacks: Trends and challenges. IEEE Commun. Surv. Tutorials 2015, 17, 2242–2270. [Google Scholar] [CrossRef]
- Feily, M.; Shahrestani, A.; Ramadass, S. A survey of botnet and botnet detection. In Proceedings of the 2009 Third International Conference on Emerging Security Information, Systems and Technologies, Athens, Greece, 18–23 June 2009; pp. 268–273. [Google Scholar]
- Silva, S.S.; Silva, R.M.; Pinto, R.C.; Salles, R.M. Botnets: A survey. Comput. Netw. 2013, 57, 378–403. [Google Scholar] [CrossRef]
- Curts, R.J.; Campbell, D.E. Rethinking Command & Control. In Proceedings of the 2006 Command and Control Research and Technology Symposium, San Diego, CA, USA, 20–22 June 2006. [Google Scholar]
- Zargar, S.T.; Joshi, J.; Tipper, D. A survey of defense mechanisms against distributed denial of service (DDoS) flooding attacks. IEEE Commun. Surv. Tutorials 2013, 15, 2046–2069. [Google Scholar] [CrossRef]
- Cormack, G.V. Email spam filtering: A systematic review. Found. Trends® Inf. Retr. 2008, 1, 335–455. [Google Scholar] [CrossRef]
- Odlyzko, A.M. Internet traffic growth: Sources and implications. In Optical Transmission Systems and Equipment for WDM Networking II; SPIE: Bellingham, WA, USA, 2003; Volume 5247, pp. 1–15. [Google Scholar]
- Antonakakis, M.; Perdisci, R.; Nadji, Y.; Vasiloglou, N.; Dagon, D. From Throw-Away Traffic to Bots: Detecting the Rise of DGA-Based Malware. In Proceedings of the Usenix Conference on Security Symposium, Bellevue, WA, USA, 8–10 August 2012. [Google Scholar]
- Stone-Gross, B.; Cova, M.; Cavallaro, L.; Gilbert, B.; Szydlowski, M. Your Botnet is My Botnet: Analysis of a Botnet Takeover. In Proceedings of the 2009 ACM Conference on Computer and Communications Security, CCS 2009, Chicago, IL, USA, 9–13 November 2009. [Google Scholar]
- Davuth, N.; Kim, S.R. Classification of Malicious Domain Names using Support Vector Machine and Bi-gram Method. Int. J. Secur. Its Appl. 2013, 7, 51–58. [Google Scholar]
- Bilge, L.; Kirda, E.; Kruegel, C.; Balduzzi, M. EXPOSURE: Finding Malicious Domains Using Passive DNS Analysis. In Proceedings of the Network and Distributed System Security Symposium, NDSS 2011, San Diego, CA, USA, 6–9 February 2011. [Google Scholar]
- Zhou, Y.L.; Li, Q.S.; Miao, Q.; Team, C.; Beijing; Yim, K. DGA-Based Botnet Detection Using DNS Traffic. J. Internet Serv. Inf. Secur. 2013, 3, 116–123. [Google Scholar]
- Anderson, H.S.; Woodbridge, J.; Filar, B. DeepDGA: Adversarially-Tuned Domain Generation and Detection. In Proceedings of the 2016 ACM Workshop on Artificial Intelligence and Security 2016, Vienna, Austria, 28 October 2016. [Google Scholar]
- Woodbridge, J.; Anderson, H.S.; Ahuja, A.; Grant, D. Predicting Domain Generation Algorithms with Long Short-Term Memory Networks. arXiv 2016, arXiv:1611.00791. [Google Scholar]
- Yu, B.; Gray, D.L.; Jie, P.; Cock, M.; Nascimento, A. Inline DGA Detection with Deep Networks. In Proceedings of the IEEE International Conference on Data Mining Workshops, New Orleans, LA, USA, 18–21 November 2017. [Google Scholar]
- Chen, Y.; Zhang, S.; Liu, J.; Li, B. Towards a Deep Learning Approach for Detecting Malicious Domains. In Proceedings of the 2018 IEEE International Conference on Smart Cloud (SmartCloud), New York, NY, USA, 21–23 September 2018; pp. 190–195. [Google Scholar]
- Zhang, Z.; Pfister, T. Learning fast sample re-weighting without reward data. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 725–734. [Google Scholar]
- Yin, X.; Yu, X.; Sohn, K.; Liu, X.; Chandraker, M. Feature transfer learning for face recognition with under-represented data. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 5704–5713. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Tuan, T.A.; Anh, N.V.; Luong, T.T.; Long, H.V. UTL_DGA22-a dataset for DGA botnet detection and classification. Comput. Netw. 2023, 221, 109508. [Google Scholar] [CrossRef]
- Yadav, S.; Reddy, A.K.K.; Reddy, A.N.; Ranjan, S. Detecting algorithmically generated malicious domain names. In Proceedings of the 10th ACM SIGCOMM Conference on Internet Measurement, Melbourne, Australia, 1–3 November 2010; pp. 48–61. [Google Scholar]
- Wang, W.; Shirley, K. Breaking bad: Detecting malicious domains using word segmentation. arXiv 2015, arXiv:1506.04111. [Google Scholar]
- Hsu, C.H.; Huang, C.Y.; Chen, K.T. Fast-flux bot detection in real time. In Proceedings of the Recent Advances in Intrusion Detection: 13th International Symposium, RAID 2010, Ottawa, ON, Canada, 15–17 September 2010; Proceedings 13. Springer: Berlin/Heidelberg, Germany, 2010; pp. 464–483. [Google Scholar]
- Zaremba, W.; Sutskever, I.; Vinyals, O. Recurrent neural network regularization. arXiv 2014, arXiv:1409.2329. [Google Scholar]
- Tuan, T.A.; Long, H.V.; Taniar, D. On detecting and classifying DGA botnets and their families. Comput. Secur. 2022, 113, 102549. [Google Scholar] [CrossRef]
- Ren, F.; Jiang, Z.; Wang, X.; Liu, J. A DGA domain names detection modeling method based on integrating an attention mechanism and deep neural network. Cybersecurity 2020, 3, 4. [Google Scholar] [CrossRef]
- Lison, P.; Mavroeidis, V. Automatic detection of malware-generated domains with recurrent neural models. arXiv 2017, arXiv:1709.07102. [Google Scholar]
- Mac, H.; Tran, D.; Tong, V.; Nguyen, L.G.; Tran, H.A. DGA botnet detection using supervised learning methods. In Proceedings of the 8th International Symposium on Information and Communication Technology, Nha Trang, Vietnam, 7–8 December 2017; pp. 211–218. [Google Scholar]
- Ravi, V.; Alazab, M.; Srinivasan, S.; Arunachalam, A.; Soman, K. Adversarial defense: DGA-based botnets and DNS homographs detection through integrated deep learning. IEEE Trans. Eng. Manag. 2021, 70, 249–266. [Google Scholar] [CrossRef]
- Ren, F.; Jiang, Z.; Liu, J. Integrating an attention mechanism and deep neural network for detection of DGA domain names. In Proceedings of the 2019 IEEE 31st International Conference on Tools with Artificial Intelligence (ICTAI), Portland, OR, USA, 4–6 November 2019; pp. 848–855. [Google Scholar]
- Pan, R.; Chen, J.; Ma, H.; Bai, X. Using extended character feature in Bi-LSTM for DGA domain name detection. In Proceedings of the 2022 IEEE/ACIS 22nd International Conference on Computer and Information Science (ICIS), Zhuhai, China, 26–28 June 2022; pp. 115–118. [Google Scholar]
- Namgung, J.; Son, S.; Moon, Y.S. Efficient Deep Learning Models for DGA Domain Detection. Secur. Commun. Netw. 2021, 2021. [Google Scholar] [CrossRef]
- Sarojini, S.; Asha, S. Detection for domain generation algorithm (DGA) domain botnet based on neural network with multi-head self-attention mechanisms. Int. J. Syst. Assur. Eng. Manag. 2022, 1–16. [Google Scholar] [CrossRef]
- Cui, Y.; Jia, M.; Lin, T.Y.; Song, Y.; Belongie, S. Class-balanced loss based on effective number of samples. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9268–9277. [Google Scholar]
- Calvo, R.A.; Lee, J.M. Coping with the news: The machine learning way. In Proceedings of the AusWEB 2003, Gold Coast, Australian, 5–9 July 2003. [Google Scholar]
- Tran, D.; Mac, H.; Tong, V.; Tran, H.A.; Nguyen, L.G. A LSTM based framework for handling multiclass imbalance in DGA botnet detection. Neurocomputing 2018, 275, 2401–2413. [Google Scholar] [CrossRef]
- Zhou, S.; Lin, L.; Yuan, J.; Wang, F.; Ling, Z.; Cui, J. CNN-based DGA detection with high coverage. In Proceedings of the 2019 IEEE International Conference on Intelligence and Security Informatics (ISI), Shenzhen, China, 1–3 July 2019; pp. 62–67. [Google Scholar]
- Simran, K.; Balakrishna, P.; Vinayakumar, R.; Soman, K. Deep learning based frameworks for handling imbalance in DGA, Email, and URL Data Analysis. In Proceedings of the Computational Intelligence, Cyber Security and Computational Models. Models and Techniques for Intelligent Systems and Automation: 4th International Conference, ICC3 2019, Coimbatore, India, 19–21 December 2019; Springer: Singapore, 2020; pp. 93–104. [Google Scholar]
- Huang, W.; Zong, Y.; Shi, Z.; Wang, L.; Liu, P. PEPC: A Deep Parallel Convolutional Neural Network Model with Pre-trained Embeddings for DGA Detection. In Proceedings of the 2022 International Joint Conference on Neural Networks (IJCNN), Padua, Italy, 18–23 July 2022; pp. 1–8. [Google Scholar]
- Fan, B.; Liu, Y.; Cuthbert, L. Improvement of DGA Long Tail Problem Based on Transfer Learning. In Computer and Information Science; Lee, R., Ed.; Springer International Publishing: Cham, Switzerland, 2023; pp. 139–152. [Google Scholar] [CrossRef]
- Pouyanfar, S.; Tao, Y.; Mohan, A.; Tian, H.; Kaseb, A.S.; Gauen, K.; Dailey, R.; Aghajanzadeh, S.; Lu, Y.H.; Chen, S.C.; et al. Dynamic sampling in convolutional neural networks for imbalanced data classification. In Proceedings of the 2018 IEEE conference on multimedia information processing and retrieval (MIPR), Miami, FL, USA, 10–12 April 2018; pp. 112–117. [Google Scholar]
- He, H.; Garcia, E.A. Learning from imbalanced data. IEEE Trans. Knowl. Data Eng. 2009, 21, 1263–1284. [Google Scholar]
- Ren, J.; Yu, C.; Sheng, S.; Ma, X.; Zhao, H.; Yi, S.; Li, H. Balanced meta-softmax for long-tailed visual recognition. arXiv 2020, arXiv:2007.10740. [Google Scholar]
- Wang, Y.X.; Ramanan, D.; Hebert, M. Learning to model the tail. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 7032–7042. [Google Scholar]
- Chu, P.; Bian, X.; Liu, S.; Ling, H. Feature space augmentation for long-tailed data. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XXIX 16. Springer: Cham, Switzerland, 2020; pp. 694–710. [Google Scholar]
- Wang, J.; Lukasiewicz, T.; Hu, X.; Cai, J.; Xu, Z. RSG: A Simple but Effective Module for Learning Imbalanced Datasets. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 3784–3793. [Google Scholar]
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2009, 22, 1345–1359. [Google Scholar] [CrossRef]
- Tan, C.; Sun, F.; Kong, T.; Zhang, W.; Yang, C.; Liu, C. A survey on deep transfer learning. In Proceedings of the International Conference on Artificial Neural Networks, Rhodes, Greece, 4–7 October 2018; Springer: Cham, Switzerland, 2018; pp. 270–279. [Google Scholar]
- Ma, H.; Ng, B.K.; Lam, C.T. PK-BERT: Knowledge Enhanced Pre-trained Models with Prompt for Few-Shot Learning. In Computer and Information Science; Lee, R., Ed.; Springer International Publishing: Cham, Switzerland, 2023; pp. 31–44. [Google Scholar] [CrossRef]
- Liu, J.; Sun, Y.; Han, C.; Dou, Z.; Li, W. Deep representation learning on long-tailed data: A learnable embedding augmentation perspective. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2970–2979. [Google Scholar]
- Liu, B.; Li, H.; Kang, H.; Hua, G.; Vasconcelos, N. Gistnet: A geometric structure transfer network for long-tailed recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 8209–8218. [Google Scholar]
- Lee, S.W.; Kim, J.H.; Jun, J.; Ha, J.W.; Zhang, B.T. Overcoming catastrophic forgetting by incremental moment matching. Adv. Neural Inf. Process. Syst. 2017, 30, e08475. [Google Scholar] [CrossRef]
- Gou, J.; Yu, B.; Maybank, S.J.; Tao, D. Knowledge distillation: A survey. Int. J. Comput. Vis. 2021, 129, 1789–1819. [Google Scholar] [CrossRef]
- Hu, X.; Jiang, Y.; Tang, K.; Chen, J.; Miao, C.; Zhang, H. Learning to segment the tail. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 14045–14054. [Google Scholar]
- Xiang, L.; Ding, G.; Han, J. Learning from multiple experts: Self-paced knowledge distillation for long-tailed classification. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 247–263. [Google Scholar]
- Wang, X.; Lian, L.; Miao, Z.; Liu, Z.; Yu, S.X. Long-tailed recognition by routing diverse distribution-aware experts. arXiv 2020, arXiv:2010.01809. [Google Scholar]
- Arnold, B.C. Pareto distribution. Wiley StatsRef Stat. Ref. Online 2014, 1–10. [Google Scholar] [CrossRef]
- Weston, J.; Ratle, F.; Mobahi, H.; Collobert, R. Deep Learning via Semi-supervised Embedding. In Proceedings of the 25th International Conference on Machine Learning, Edinburgh, UK, 26 June 26–1 July 2012. [Google Scholar]
- Zhang, J.; Tao, D. Empowering things with intelligence: A survey of the progress, challenges, and opportunities in artificial intelligence of things. IEEE Internet Things J. 2020, 8, 7789–7817. [Google Scholar] [CrossRef]
- Niu, Z.; Zhong, G.; Yu, H. A review on the attention mechanism of deep learning. Neurocomputing 2021, 452, 48–62. [Google Scholar] [CrossRef]
- Jang, E.; Gu, S.; Poole, B. Categorical reparameterization with gumbel-softmax. arXiv 2016, arXiv:1611.01144. [Google Scholar]
- Censor, B.Y. Proximity Function Minimization Using Multiple Bregman Projections, with Applications to Split Feasibility and Kullback–Leibler Distance Minimization. Ann. Oper. Res. 2001, 105, 77–98. [Google Scholar]
- Ye, J. Single valued neutrosophic cross-entropy for multicriteria decision making problems. Appl. Math. Model. 2014, 38, 1170–1175. [Google Scholar] [CrossRef]
- Salakhutdinov, R.; Hinton, G.E. Replicated Softmax: An Undirected Topic Model. In Proceedings of the International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 7–10 December 2009. [Google Scholar]
- Pang, B.; Nijkamp, E.; Wu, Y.N. Deep learning with tensorflow: A review. J. Educ. Behav. Stat. 2020, 45, 227–248. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Tang, J.; Shivanna, R.; Zhao, Z.; Lin, D.; Singh, A.; Chi, E.H.; Jain, S. Understanding and improving knowledge distillation. arXiv 2020, arXiv:2002.03532. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Year | Datasets | DGA Families | Family Sample Range (Max–Min) | Imbalance Factor | Macro Average F1 score | ||
|---|---|---|---|---|---|---|---|---|
| Many | Medium | Few | ||||||
| LSTM [14] | 2016 | Bambenek Consulting (DGA) Alexa(whitelist) | 30 | 81,281–9 | 9031 | 0.541 | ||
| RNN [27] | 2017 | Bambenek Consulting and DGArchive (DGA) Alexa (whitelist) | 42 | 11 | 10 | 434,215–52 | 8157 | 0.66 |
| SVM and LSTM-based models [28] | 2017 | Bambenek Consulting (DGA) Alexa (whitelist) | 1 | 9 | 27 | 42,166–25 | 1686 | 0.2695 |
| LSTM.MI [36] | 2018 | Bambenek Consulting (DGA) Alexa (whitelist) | 1 | 9 | 27 | 42,166–25 | 1686 | 0.5671 |
| CNN [37] | 2019 | DGArchive (DGA) Alexa (whitelist) | 73 | - | - | 0.6123 | ||
| ATT_CNN + BiLSTM [30] | 2019 | 360netlab and Bambenek Consulting (DGA) Alexa (whitelist) | 13 | 3 | 3 | 25,000–210 | 119 | 0.81 |
| ATT_CNN + BiLSTM [26] | 2020 | 360netlab Alexa (whitelist) | 13 | 8 | 3 | 26,520–210 | 126 | 0.83 |
| CNN_LSTM [38] | 2020 | OSINT Feeds (DGA) Alexa and OpenDNS (whitelist) | - | - | - | - | - | - |
| B-LSTM/B-RNN/B-GRU [29] | 2021 | Bambenek Consulting (DGA) Alexa (whitelist) | 1 | 9 | 27 | 42,166–25 | 1686 | 0.47 |
| ATT_BiLSTM [32] | 2021 | Bambenek Consulting (DGA) Alexa (whitelist) | 11 | 9 | 0 | 439,223–2000 | 219 | 0.8369 |
| LA_Bin07/LA_Mul07 [25] | 2022 | UMUDGA (DGA) Alexa (whitelist) | 50 | 0 | 0 | 500,000–10,000 | 50 | - |
| Extended Character Feature in BiLSTM [31] | 2022 | 360netlab (DGA) Alexa (whitelist) | 10 | 16 | 13 | 498,620–193 | 2583 | 0.7514 |
| MHSA-RCNN-SABILSTM [33] | 2022 | 360netlab and Bambenek Consulting (DGA) Alexa (whitelist) | 11 | 9 | 0 | 439,223–2000 | 219 | 0.8397 |
| PEPC [39] | 2022 | DGArchive, Bambenek Consulting and 360netlab (DGA) Alexa (whitelist) | 20 | - | - | 0.8046 | ||
| TLM [40] | 2023 | 360netlab (DGA) Alexa (whitelist) | 10 | 9 | 12 | 452,428–132 | 3427 | 0.766 |
| DGA Family | Sample | DGA Family | Sample |
|---|---|---|---|
| Alexa (whitelist) | google.com | qadars | 9u78d6349qf8.top |
| banjori | bplbfordlinnetavox.com | locky | tcrgkleyeivrlix.work |
| emotet | fdfptbhnadweuudl.eu | dyre | g6a8ff179bf317e57b2b6665d3fdc47dc0.to |
| rovnix | oysyt45p4r3ul7sbdo.com | chinad | j0xx9q0a0p57o0up.cn |
| tinba | lkhhrrnldtoy.me.uk | cryptolocker | lmnlbvkcomdoh.biz |
| pykspa_v1 | vjdibcn.cc | vawtrak | agifdocg.top |
| simda | welorav.info | pykspa_v2_fake | bvuhnesrlz.net |
| ramnit | hpgfsqdgbwvonp.com | dircrypt | extuhmqqtzwavpmfw.com |
| gameover | 2okay8f2i4l7xadz0c1tt8rlw.biz | conficker | bxsujqbjrz.cc |
| ranbyus | eruvxfflddfkekhvd.su | matsnu | half-page-belt.com |
| virut | uiufzg.com | nymaim | yxcaitrv.in |
| murofet | wjspslenzlfruiy.com | fobber_v2 | nqietkrebr.com |
| necurs | twxsbhjatburhmg.nf | fobber_v1 | ayppvfettvcxdosqu.net |
| symmi | tucapefube.ddns.net | tempedreve | crpejdbfqf.net |
| shifu | updesxi.info | pykspa_v2_real | rjsxrxre.info |
| suppobox | alexandriawashington.net | padcrypt | cccdocfealldbnbf.tk |
| Metrics | N-Stage | Many | Medium | Few | All |
|---|---|---|---|---|---|
| F1 | N = 2 | 0.941 | 0.930 | 0.558 | 0.792 |
| N = 3 | 0.686 | 0.660 | 0.245 | 0.497 | |
| N = 4 | 0.870 | 0.875 | 0.580 | 0.766 | |
| N = 8 | 0.761 | 0.678 | 0.349 | 0.561 | |
| Recall | N = 2 | 0.952 | 0.929 | 0.562 | 0.799 |
| N = 3 | 0.626 | 0.711 | 0.257 | 0.512 | |
| N = 4 | 0.916 | 0.860 | 0.596 | 0.780 | |
| N = 8 | 0.704 | 0.763 | 0.368 | 0.594 | |
| Precision | N = 2 | 0.922 | 0.935 | 0.652 | 0.825 |
| N = 3 | 0.798 | 0.782 | 0.353 | 0.627 | |
| N = 4 | 0.853 | 0.900 | 0.594 | 0.769 | |
| N = 8 | 0.818 | 0.677 | 0.421 | 0.630 |
| Model | Metrics | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Many | Medium | Few | All | Many | Medium | Few | All | Many | Medium | Few | All | ||
| ATT_BiLSTM [32] | Precision | 0.984 | 0.873 | 0.515 | 0.746 | 0.972 | 0.897 | 0.491 | 0.766 | 0.949 | 0.907 | 0.344 | 0.711 |
| Recall | 0.99 | 0.79 | 0.36 | 0.608 | 0.962 | 0.772 | 0.247 | 0.601 | 0.918 | 0.735 | 0.122 | 0.565 | |
| F1 | 0.987 | 0.797 | 0.415 | 0.641 | 0.967 | 0.813 | 0.247 | 0.645 | 0.918 | 0.767 | 0.167 | 0.596 | |
| ATT_BiLSTM + CNN [26] | Precision | 0.983 | 0.687 | 0.506 | 0.652 | 0.946 | 0.834 | 0.367 | 0.691 | 0.943 | 0.889 | 0.536 | 0.777 |
| Recall | 0.796 | 0.683 | 0.208 | 0.472 | 0.916 | 0.83 | 0.108 | 0.585 | 0.967 | 0.913 | 0.287 | 0.697 | |
| F1 | 0.808 | 0.583 | 0.25 | 0.464 | 0.926 | 0.802 | 0.142 | 0.591 | 0.954 | 0.898 | 0.352 | 0.714 | |
| KTM | Precision | 0.984 | 0.836 | 0.724 | 0.794 | 0.955 | 0.886 | 0.761 | 0.855 | 0.917 | 0.948 | 0.652 | 0.824 |
| Recall | 0.943 | 0.916 | 0.58 | 0.753 | 0.947 | 0.938 | 0.514 | 0.779 | 0.946 | 0.943 | 0.561 | 0.799 | |
| F1 | 0.942 | 0.87 | 0.588 | 0.739 | 0.948 | 0.908 | 0.565 | 0.787 | 0.929 | 0.945 | 0.558 | 0.792 | |
| KDTM | Precision | 0.888 | 0.901 | 0.775 | 0.833 | 0.963 | 0.915 | 0.695 | 0.844 | 0.926 | 0.97 | 0.836 | 0.902 |
| Recall | 0.975 | 0.941 | 0.633 | 0.79 | 0.971 | 0.933 | 0.575 | 0.805 | 0.954 | 0.958 | 0.618 | 0.829 | |
| F1 | 0.927 | 0.916 | 0.67 | 0.792 | 0.966 | 0.919 | 0.577 | 0.801 | 0.939 | 0.963 | 0.674 | 0.845 | |
| Method | Year | Macro Average F1 Score |
|---|---|---|
| LSTM [14] | 2016 | 0.542 |
| RNN [27] | 2017 | 0.660 |
| SVM and LSTM-based models [28] | 2017 | 0.267 |
| LSTM.MI [36] | 2018 | 0.567 |
| CNN [37] | 2019 | 0.612 |
| B-LSTM/B-RNN/B-GRU [29] | 2020 | 0.470 |
| ATT_BiLSTM [32] | 2021 | 0.837 |
| Extended Character Feature in BiLSTM [31] | 2022 | 0.751 |
| MHSA-RCNN-SABILSTM [33] | 2022 | 0.838 |
| PEPC [39] | 2022 | 0.805 |
| TLM [40] | 2023 | 0.766 |
| KTM | 2024 | 0.792 |
| KDTM | 2024 | 0.845 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fan, B.; Ma, H.; Liu, Y.; Yuan, X.; Ke, W. KDTM: Multi-Stage Knowledge Distillation Transfer Model for Long-Tailed DGA Detection. Mathematics 2024, 12, 626. https://doi.org/10.3390/math12050626
Fan B, Ma H, Liu Y, Yuan X, Ke W. KDTM: Multi-Stage Knowledge Distillation Transfer Model for Long-Tailed DGA Detection. Mathematics. 2024; 12(5):626. https://doi.org/10.3390/math12050626
Chicago/Turabian StyleFan, Baoyu, Han Ma, Yue Liu, Xiaochen Yuan, and Wei Ke. 2024. "KDTM: Multi-Stage Knowledge Distillation Transfer Model for Long-Tailed DGA Detection" Mathematics 12, no. 5: 626. https://doi.org/10.3390/math12050626
APA StyleFan, B., Ma, H., Liu, Y., Yuan, X., & Ke, W. (2024). KDTM: Multi-Stage Knowledge Distillation Transfer Model for Long-Tailed DGA Detection. Mathematics, 12(5), 626. https://doi.org/10.3390/math12050626