1. Introduction
The recognition of sign language motions presents a significant challenge in the discipline of computer vision in the rapidly evolving world of artificial intelligence (AI) and machine learning (ML) models [
1]. Visual sign language recognition is a complex field for research in computer vision. Given that every sign language in the world has unique and distinct gestures, it is difficult to generalize potential problems for all of them. This study and dataset that was collected, assessed, processed, and presented form the basis for the development of fresh machine learning models and AI systems that will assist hearing-impaired people in Serbia to communicate with others. The provided algorithm is generalizable, and the technique can be used to create and gather similar datasets based on recording and identifying human motions. These types of data can be utilized as the foundation for the development of machine learning models that might be used in a variety of applications and projects. Machine learning models that have been taught to recognize generic or specialized hand gestures can be used to develop educational applications, games, or communication platforms for hearing-impaired persons. They can also be used in a variety of devices such as mobile phones, tablets, desktop computers, video conferencing devices, TVs, and others. Various sensor-based devices, such as Intel RealSenseTM, Microsoft Kinect, LeapMotion Controller, and others [
2], have also been created for similar computer vision purposes. The assignment defined in this article is adaptable to numerous sign languages and other computer vision purposes.
Hearing-disabled people have numerous communication issues with the rest of the community. Research findings indicate that knowledge of sign language and the availability of sign language interpreters represent one of the indicators of the quality of life from the perception of deaf people [
3,
4]. Helping the hearing disabled learn the sign language alphabet using interactive computer software or to convert their gestures into computer-recognized alphabets is how SSL software can help with these challenges. The SSL dataset is designed to serve as a foundation for the creation of various machine learning-based software. Future machine learning models created and based on SSL can be used on different hardware platforms (mobile phones, tablets, PCs, etc.), offering various functionalities (recognizing presented SSL alphabets and making use of that information).
Along with the usual use of sign language in communication, dactylology and the finger alphabet are also used in case a sign for a certain term does not exist or the user does not know an adequate sign. Dactylology is an important part of sign languages because it allows people to spell out words or convey certain thoughts using manual signs that represent letters or words. In summary, dactylology and sign language are related because dactylology is a method of communication that uses physical signs and is an essential component of sign language. Dactylology is used for spelling people’s first and last names, names of streets, squares, geographical terms, and terms from the field of politics and professional and non-academic terminology [
5].
Creating tools and services that can help include the hearing impaired in work and everyday life can contribute to reducing the current barriers mostly present in communication with others. According to data from the World Health Organization in 2020, more than 450 million people were hearing impaired; therefore, sign language was their basic means of communication with others [
6]. Due to difficult communication, hearing-impaired people face numerous obstacles when it comes to employment, socializing, and fitting into the wider social community, and, as a result, they are often ostracized from society. Therefore, as an imperative of social sustainability, the need to include these people in all segments of the social environment is emphasized. After the Serbian National Assembly passed the “Law on the Use of Sign Language” in 2015 [
7], there have not been enough attempts to address issues concerning linguistic processes, such as the standardization of Serbian Sign Language, the creation of new lexical items, dictionaries, grammar reference books, etc. [
8]. For this reason, numerous tools and applications are being developed to overcome existing barriers and create the basis for improving the position of hearing-impaired people in the wider social community. According to Marković, M. [
9], 2% of the population in Serbia reported hearing problems of any level. Based on the latest available data for the census of the population from 2011, there were 144.648 persons with hearing disabilities. This corresponds to more than 25% of the population suffering from any disability. According to the previous findings, almost 30% of habitants in Serbia younger than 65 are in the hearing-impaired group, which is a serious social challenge [
9].
Recognition of sign language motions presents a significant challenge in the discipline of computer vision in the rapidly evolving world of artificial intelligence (AI) and machine learning (ML) models. Given that every language in the world has unique and distinct gestures, it is difficult to generalize potential problems for all of them. This study was focused on collecting datasets that were assessed, processed, and presented to aid the creation of fresh ML models and AI systems that would assist hearing-impaired people in communicating with others. The provided algorithm is generalizable, and the technique can be used to create and gather similar datasets based on recording and identifying human motions. These types of data can be utilized as the foundation for the development of ML models that could be used in a variety of applications and projects. ML models that have been taught to recognize generic or specialized hand gestures can be used to develop educational applications, games, or communication platforms for hearing-impaired persons. They can also be used in a variety of devices such as mobile phones, tablets, desktop computers, video conferencing devices, TVs, and others. This type of work is easily adaptable to numerous sign languages and other computer vision purposes.
Bearing in mind the numerous challenges of hearing-disabled people in social environments, this paper provides practical guidelines for building a strong communication bridge between people with hearing and speech impairments and the rest of society. One of the most important obstacles to creating more universal sign language datasets is the regionalization of these languages. Regarding significant differences in dialects within one region, country, and city—even among different languages—the importance of creating a large number of region-specific sign language datasets for sign language applications is of high importance. This paper explains the collection procedure, creation, preparation, processing, and analysis of a unique dataset for the SSL alphabet to improve the social status of hearing-impaired persons. The obtained dataset is applicable for a community that expands to neighboring countries because of their numerous regional-wise similarities. With slight corrections to the dataset, it can become useable in the countries bordering Serbia.
2. Materials and Methods’ Selection Process
This paper explains the way the configuration of a unique dataset that contains Serbian Sign Language (SSL) alphabets in a numerical form can be used in ML model training. The dataset was composed of a series of numbers that represented hand and body key points during movements and were identified using the MediaPipe [
10] ML architecture. MediaPipe, which is based on a Python 3.11 software library for machine learning and the artificial intelligence TensorFlow [
11], can produce very accurate 3D (x, y, z) numerical values that reflect meaningful spatial point locations on provided pictures or video clips.
In this study, the process of creating and preparing datasets was an essential component of creating machine learning models, as shown in
Figure 1. Following the collection of video samples, important body and hand points were identified, converted to numerical values, and recorded in the database. Following that, data were assessed, and records made in error and extreme values were eliminated. The SSL dataset was built and based on short video clips, having 40 successive photographs in a 720p resolution. The resolution and number of frames required for machine learning model development could be decreased if required and sized to a performance-appropriate subset of data. Data were finally split into two sub-sets, for training and testing, before they were used for machine learning model training. If the dataset provided to the ML model was relevant, descriptive, and contained a large number of unique records, the ML model would be able to perform with more accuracy and reliability.
Using Python (software version 3.11), a program was developed to collect recordings and build the SSL dataset. It was used on a PC running in a Windows operating system. This type of scene setup could be readily rebuilt for data capture and could run the ML model using a standard laptop configuration with a common 720p webcam while running Python source code.
Figure 2 depicts the conceptual process behind the SSL dataset creation process.
2.1. Data Type Selection
The following 5 sign language alphabets in SSL were not static but represented with a movement: J (J), R (P), DZ (Џ), C (Ц), and CC (Ћ). To capture motion, dynamic images (videos) were chosen as the dataset’s base for all gestures. In contrast to photographs, the machine learning system based on this dataset with dynamic values would be able to differentiate between very similarly displayed letters using video clips.
All video clips were stored and compressed with the XVID video codec inside a universal AVI container. The Python source code containing file recording details is presented in
Figure 3. The full-sized camera recording frame of 1280 × 720 px was reduced to 720 × 720 px, lowering the image size by 43.75%. Separate images during video capture were forwarded to a MediaPipe framework for the detection of hand and body key points and were automatically saved in a numerical NumPy file. Video recordings were saved alongside numerical datasets for future data validation, error removal, classification, and potential changes. Video files were saved in *.avi format, and NumPy numerical values were saved in *.npy files with the same names. File names were generated automatically and were based on a computer clock.
2.2. Hardware and Software Selection Process
When deciding on the hardware platform to be used, personal computers, mobile devices (phones and tablets), and other hardware (Arduino, Raspberry PI, gloves, wearable sensors [
12], and so on) were all considered. To evaluate this type of solution on mobile devices, an Android application was developed. Several recordings were collected, but the quality was inadequate. The recordings were made on a mobile phone and then uploaded to the cloud. Some of the main reasons for abandoning this way of development were inconsistent records, cloud limitations, storage costs, and the slowness of the process.
Since webcam specifications have remained relatively constant over the years (720p), and personal computers are now widely accessible, PC programming has emerged as the preferred method for developing SSL software. As a result, the chosen platform simplified the process of sharing dataset collection software between contributors. Python, an object-oriented, high-level programming language, was selected for its universality, adaptability, resources, and wide programming community support. As a cross-platform language, it is compatible with and can run on a variety of operating systems, including Windows, Linux, and macOS.
This project also examined the usage of certain hardware devices such as Arduino or Raspberry PI. These devices have some hardware and, more significantly, software constraints. It is possible to create this kind of sign language recognition system on them, but it is a much more complex process. This was an important factor for why these devices were not the preferred choice for the SSL software development process, and we decided to use a standard Windows-based PC.
3. The Dataset Collection Process
The dataset collection process is essential to an ML model development procedure. It is of great importance that the objects in the dataset be of appropriate and applicable quality and quantity. If the dataset is too small or does not accurately reflect the problem data, the resulting machine learning model may be ineffective and imprecise, often producing wrong results. When the dataset is of high quality, containing relevant data, modifying and adapting machine learning parameters, such as the number, structure, and type of layers, is possible. For satisfactory and effective outcomes, creating ML models on large and accurate datasets is required.
3.1. Participant Structure and Ethical Standard Compliance
In this exercise, 41 participants recorded all 30 gestures that represent letters in Serbian Sign Language. Students, faculty professors, and special education teachers aged 19 to 50 took part. They were all informed about the study and signed consent forms before the recording began. This study was conducted in accordance with the Declaration of Helsinki, and the protocol was approved by the Ethics Committee of the Faculty of Contemporary Arts in Belgrade (Project code: SSL23). Also, all participants were trained in the video recording process by a short video that explained the process and proper recording procedure. Participants were instructed to use standard SSL gestures when recording them so that the dataset would not contain many deviations.
Artificial intelligence raises questions about privacy and ethics every time it is used. Questions concerning data privacy and user consent are valid and should be raised whenever activities involve recording and analyzing sensitive personal information that is presented through gestures.
The only output from the generated and released SSL dataset were numerical key points, with no way to identify individuals or return to an original image. Both the SSL dataset and the process of creating it followed and satisfied ethical and data security standards. Real video recordings will not be disseminated; instead, they were only utilized to generate numerical values that correlated to hand and body movements. These numerical values served as the foundation of a dataset and could not be associated with video recordings of the participants. They are the real value of the published dataset, as they were the basis for ML model creation. Video recordings were temporarily stored locally and could potentially be re-used to change the resolution or frame rate of a future machine learning model. Furthermore, the videos were used for visual control of the recorded gestures in the process of data cleanup and validation.
3.2. Setting up the Environment and the Recording Scene
Recordings needed to include subjects of various sizes and proportions to produce a usable and meaningful dataset. The camera needed to be positioned close to or far away from the participants (as indicated in
Figure 4). In this study, the subjects were asked to display sign language letters in a variety of speeds and styles, positioning their hands in different positions. A larger number of variables in a dataset should be used to generate higher-quality datasets for training more effective machine learning models.
Color and patterns in the background, and on the participants’ clothing, can have an impact on the hand and body recognition framework, either positively or negatively. Highly colorful backgrounds and clothing on the recorded subjects were found to harm the MediaPipe recognition framework. If the background and/or clothing were very colorful, the model provided less accurate results. By contrast, if the background and/or clothing were only one color, the MediaPipe framework detected key points much more accurately.
3.3. Recording Procedure
Before initiating recording, the participant needed to be positioned in an optimal camera area, without displaying their hands. When their hands entered the camera recording scene, they were recognized, and recording began immediately after. The program then began to save 40 subsequent frames while displaying a red line timer to the subject to ensure that the entire movement had been recorded as expected. The full movement included hands entering the scene, exhibiting a gesture sign, and leaving the recorded scene. If the hands remained in the scene for longer than 40 frames, the application would not begin recording the next movie clip until the hands left the scene. The application limited the recording to exactly 40 frames. As there was a chance that some key points on the hands would not be identified in some of the frames during the recording of a video, a fail-safe had been programmed to recognize the hands outside of the recording window for 5 consecutive frames in order for them to be considered out. The next recording sequence could only start after both hands left the scene.
Figure 5 depicts a section of source code illustrating certain MediaPipe options. The parameter “holistic” activates, a part of the framework that was based on the provided photo, recognizes individual key points for the whole-body posture, face, and both hands.
As a result of the recording process, the application saved two files: a brief video clip (about 4 s long) and a corresponding NumPy array with numerical values of the detected hands and body key points (10.320 values per file). The NumPy array files were to be used as components of the dataset in the development of machine learning models, and the stored video clips would be used to visually examine and validate the recordings. As recordings can be generated by mistake or because they might belong to a different class, files containing visual information are important for further data processing.
Figure 6 and
Figure 7 represent two files that were saved.
Figure 6 shows a selection of static frames (out of 40) from a recorded video clip of the letter “J”. With this example, it is demonstrated that a single static photo would not be sufficient to detect the meaning of the gesture. The gesture shown could not be distinguished using only one photo. The use of full video clips for data processing will allow for the detection of more complex movements and gestures.
Figure 7 depicts the corresponding frames to
Figure 6 of the MediaPipe body and hand key point identification procedure. Key point numerical values were recognized and saved as NumPy files before being included in the final dataset.
3.4. Recording Goal: 30 Sign Language Alphabets
The purpose of creating a dataset is to have a sufficient number of distinct recordings of each of the 30 Serbian alphabet signs. The dataset collection and Python source code have been made public, allowing for existing dataset upgrades, the development of new applications, and the implementation of further theoretical and practical research.
The entire dataset creation process is depicted in
Figure 8. Before the dataset collection process started, the recording scene needed to be set up according to the instructions. The subject needed to sit across from the computer, keeping his torso in the targeted frame, with his hands away from it. The subjects were instructed on the recording procedure and goals to create better-quality video clips with fewer errors. Following data collection, the data evaluation and cleanup phase employed both visual data verification and numerical validation. Dataset values could be processed further by reducing their size to improve processing performance. Then, data were separated into subsets for testing and training. Finally, the created dataset was sent for further AI/ML use.
Table 1 includes the 30 alphabets for which we have video recordings. The original SSL alphabet can be found in the bottom row. The middle row of the table depicts a readable and computer-friendly alternative form of the original Serbian Cyrillic letters. The middle row characters were used in the SSL Python program as well in order to organize the dataset file and folder structure.
4. Results
The final SSL dataset includes 8.346 video recording clips and accompanying files containing numerical values of recognized body and hand key points. As seen in
Figure 9, each letter was recorded an average of 278 times. The database developed is approximately 4.15 GB in size and contains a total of 16.740 files. With an average duration of 4 s for each video recording, the total net time spent creating the dataset without preparations or pauses is approximately 33.384 s or 9.3 h.
Figure 10 presents the folder structure for all 30 alphabets for accepted and deleted records. All not-validated recordings were moved to corresponding deleted files folders for later evaluation and statistical processing. For further upgrades and expansions of the database, all dataset files and folders, as well as Python source code that can be used to create new recordings, have been made available online.
4.1. Recorded Video Clips
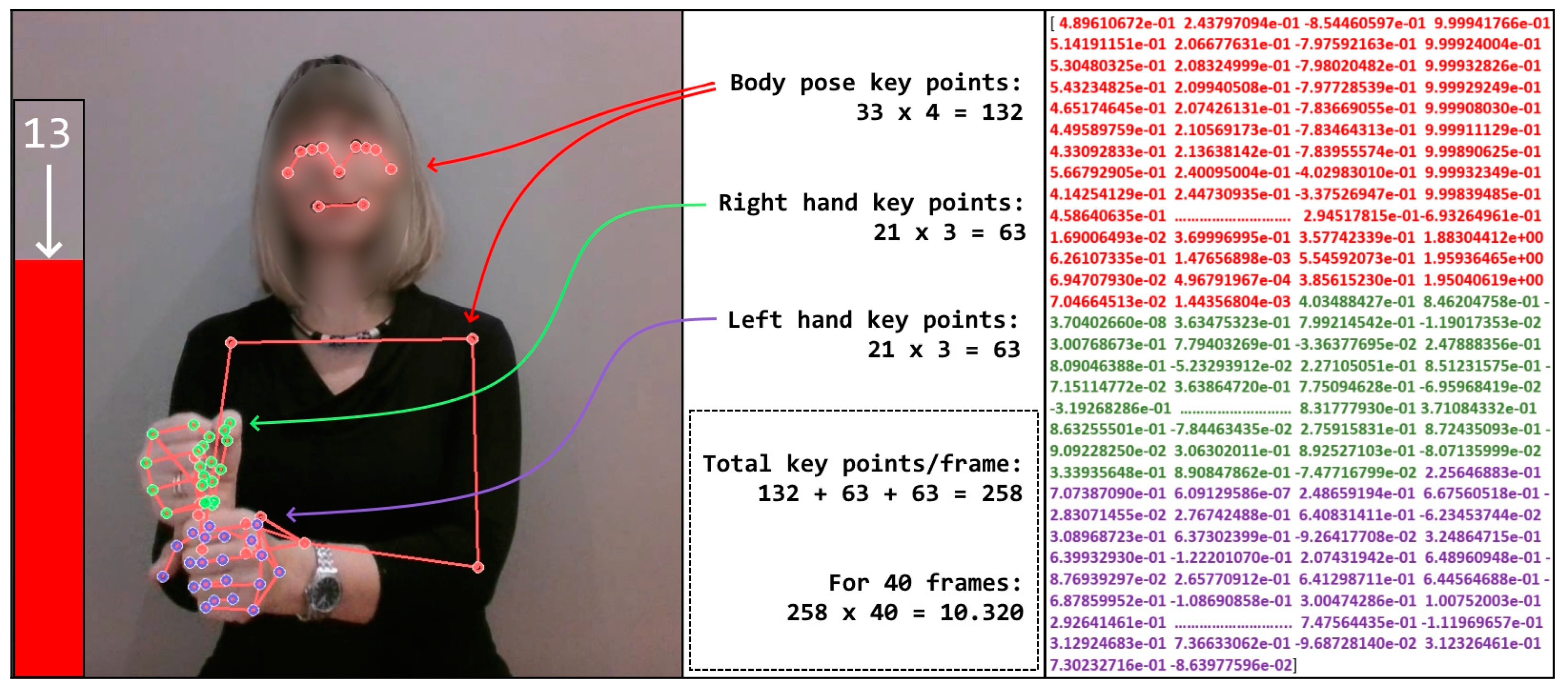
As indicated in
Figure 11, the red line on the left side of the video functioned as a timer. When the recording began, the red timer was expanded completely, indicating that 40 frames remained to be recorded. The red line reduced as the recording progressed, and, in the example shown, it showed the status of the timer on the 13th frame.
On the right side of the image, some of the real data values that form the foundation of the dataset are displayed. As shown in
Figure 11, there are 258 numerical values recorded for one recorded frame. Arrows from the center of the image point to the body and hand key points where these numerical values are created. As a result of the key point recognition process, the software generates matrices that are converted to a one-dimensional numerical array of 10.320 items for each video clip.
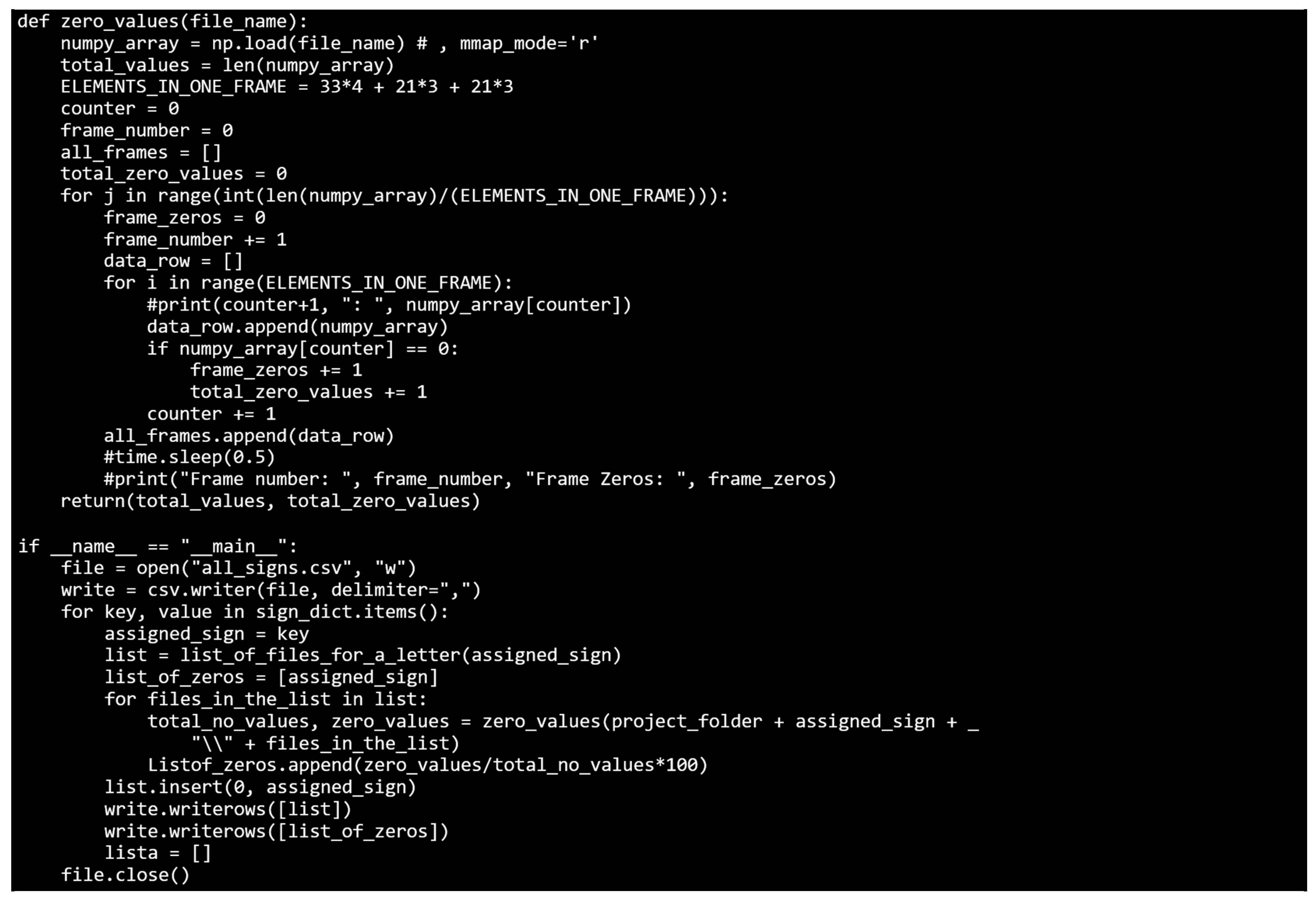
If a MediaPipe framework does not recognize a body or a key point, a 0 value is written into the resulting array. In the case of a video clip from
Figure 11, which only shows frame number 13, there are some zero values in other frames. They are mostly present in the first and last frames, when hands enter and exit the recording scene.
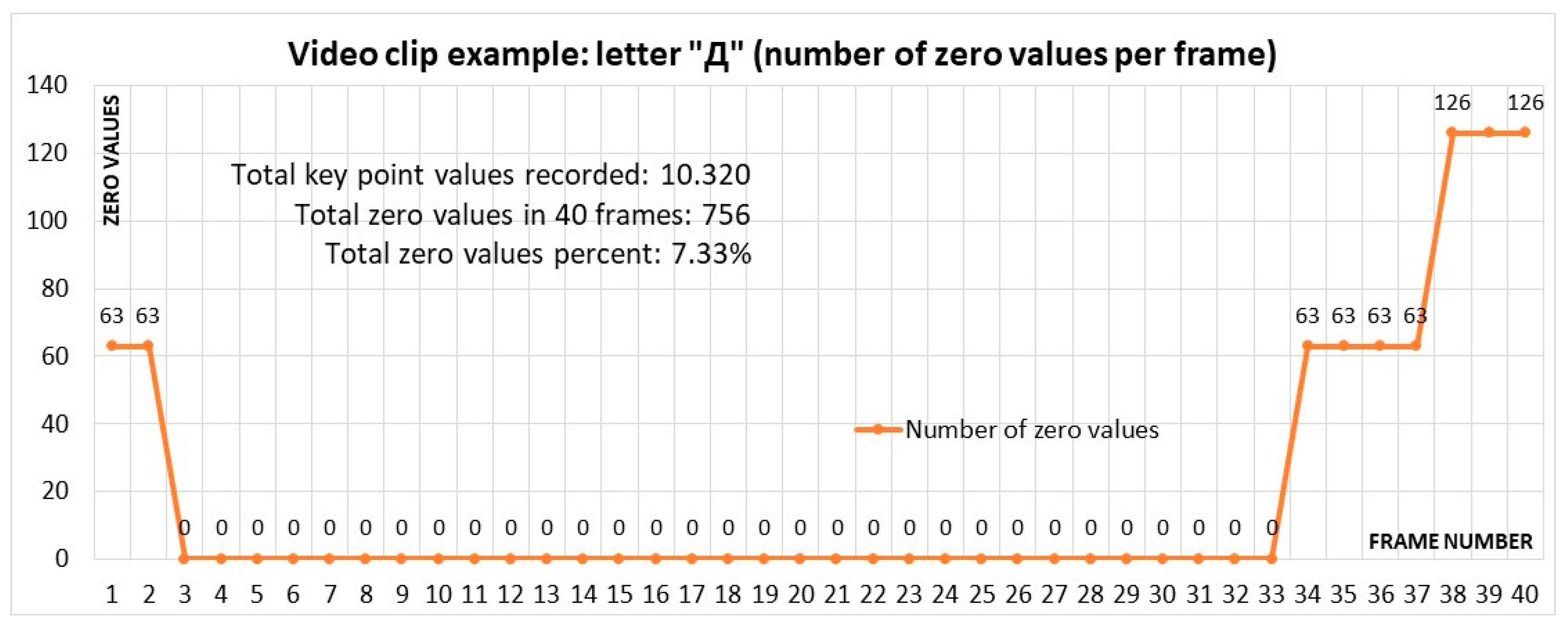
The number of frames with zero key point values is shown in
Figure 12. From the start of the recording, the subject had one hand in the scene (63 key points signify key points for one hand), and the other hand entered the scene in the third frame. Beginning with frame 3, both the left and right hands, as well as all body posture key points, were being detected, recognized, and recorded (zero records). All the key points were recognized and documented from frame 3 to frame 33. One hand exited the recording scene in frame 33, whereas the other exited in frame 37, as confirmed by the number of zero values.
4.2. Numpy Dataset
The number of recognized key points for left and right hands is 21 each. In addition, there are also 33 body pose key points that can be detected on the scene. Depicted in Equation (7) are the total number of collected numerical values. The returning values for detected key points on the right and left hands are represented in an array of x, y, and z coordinates [Hand landmarks det...]. Matrix “Handedness” returns the detected hand’s value—left or right (Equation (1)). “WorldLandmarks” (Equation (2)) contains absolute recognized values in meters with the origin at the hand’s geometric center, and the “Landmarks” matrix contains normalized relative numerical values between −1 and 1 (Equation (3)). To create a dataset, it is required to save “Landmarks” values.
Right-hand (
rh) and left-hand (
lh) key points can be expressed in a matrix, as shown in Equation (4):
Three-dimensional values with
x,
y, and
z coordinates are “flattened” via conversion into a numerical one-dimensional array. Body posture key points are reduced from four dimensions to one. One additional matrix dimension for body posture represents the visibility coefficient array. The body pose detection function, similar to the hand detection function, produces the matrix shown in Equation (5).
Presented in
Figure 13 is a visual transformation procedure for creating a resulting one-dimensional array with values that represent all detected key points in one frame. Three matrices represent coordinates of recognized 33 body and general face landmarks (poseLandmarks), 21 left-hand key points (
lh), and 21 right-hand (
rh) key points.
All the numerical values representing key point coordinates are grouped in one frame of detected right and left hands and general body posture. More precisely, the right hand has 21 points defined by three number values, the left hand has the same, and the body posture has 33 points defined by four numerical values. When matrices are converted to a one-dimensional vector, the resultant array representing one video frame has 258 key points, as shown in Equation (7).
The Python source code that transforms matrices into a one-dimensional array is presented in
Figure 14. The Python method “flatten()” returns a copy of the two-dimensional array collapsed into one dimension.
Each sign language alphabet is recorded in a single file that contains data for the 40 frames. Each file is saved in NumPy format and contains exactly 258 key points multiplied by 40 frames for a total of 10.320 numerical values. This presents a good base that can optionally be reduced and used in an appropriate quantity for further processing.
4.3. Dataset Validation and Cleanup
Cleaning and validating a dataset are critical steps in the data preparation process for any machine learning project. This ensures the accuracy, reliability, and suitability of the data used to train and test models for an intended task. The SSL database generation technique did not allow for the fabrication of duplicates because it recorded unique video snippets. In the produced dataset, there were also no empty data or information that needed to be additionally filled in.
Reasons for dismissing and removing video recordings from the final dataset comprised the following:
- -
Records made accidentally by presenting hands to the camera;
- -
Footage recorded while a person was settling themselves in front of the camera;
- -
Records classified as a wrong letter (wrong letter recording);
- -
The presented sign gesture not conforming to the SSL standard;
- -
The speed of the gesture movement being inadequate for a 40-frame-per-video clip.
The dataset validation, cleanup, and classification methods used in the SSL database creation process were as follows:
- -
Visual validation and classification of data based on video clips;
- -
Numerical validation and classification based on Python source code-generated data.
Visual validation of video recordings for a dataset is the first step in the data cleanup process. This involves inspecting the films to make sure they conform to the desired standards and criteria. All inadequately recorded video clips were removed and placed in separate folders for deleted letters.
Figure 15 illustrates a collection of wrongfully recorded video clips.
Various programming languages and libraries can also be used to automate dataset cleanup. The tools used are determined by the nature of the dataset and the specific cleanup tasks required. Python was used for this task because it was chosen as the primary programming platform for the project, and
Figure 16 presents a procedure for this task.
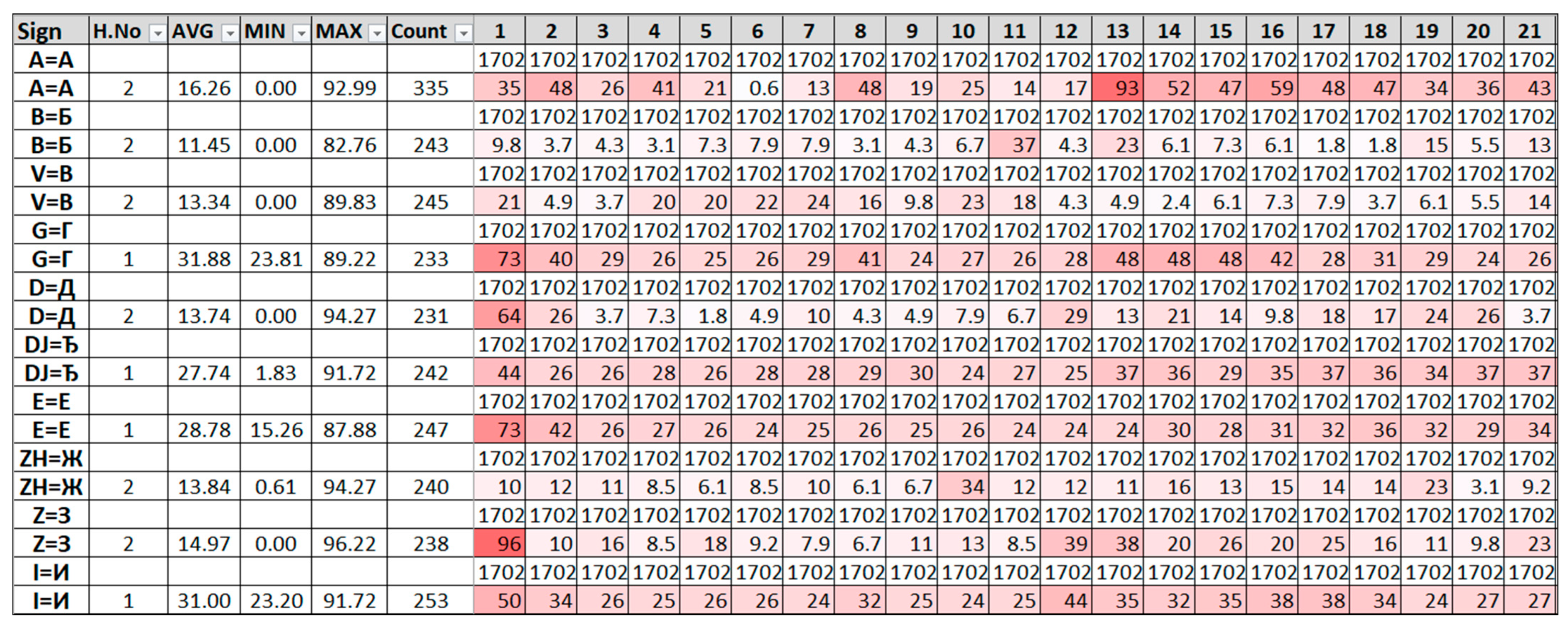
The file “all_signs.csv” produced by the source code in
Figure 16 shows the total percentage of zeros present within a video clip. Zero values represent “unrecognized” body poses and left- and right-hand key points. The “AVG” column displays the average percent of zero values for a specific alphabet, whereas the “MIN” and “MAX” columns display extreme values, and “H.No” denotes the number of hands used to present a particular sign/letter.
Figure 17 displays darker values that require additional visual inspection or removal from the dataset due to a higher percentage of zero values. By comparing these percentages, the process of removing recordings with extreme values can be automated.
When one hand is missing from the scene, the program generates zero values for it because the missing hand key points are not recognized, resulting in zeros. Consequently, gestures used to present signs with only one hand have a higher number of zero-value percentages. Two-handed gestures have an average of 9.6% of zero values per video clip, whereas one-handed gestures have an average of 27.8% zero values per video clip.
Figure 18 illustrates the percentage of zero values before and after data cleanup. The red line shows the extreme, maximum zero value percentages of video clips that were mistakenly recorded. The blue line represents the new maximum values after the extremes have been removed. The “AVG Before” and “AVG After” lines represent the difference after data cleanup.
The difference between two-handed (on the left) and one-handed (on the right) sign gestures is shown in
Figure 19. It is noticeable that two-handed gestures have fewer zero-values in their files.
4.4. Final Dataset Shape and Size
After recording and data cleanup, the dataset reached its final shape and size. The proportion of all recorded video clips and the ones removed after data validation are presented visually in
Figure 20.
The total number of recorded video clips is 8.346, out of which 621 have been removed, leaving 7.725 in the final dataset. With an average of 257.5 records per alphabet, all of them are well described and supported by validated data.
5. Discussion of Results
The dataset developed and presented in this paper is based on SSL gestures and can be used to build ML models. Key points extracted from video clips can be used as a foundation for future data processing using computer vision techniques and the MediaPipe machine learning framework.
The recordings were collected from 41 individuals while they were in classrooms, offices, or at home using an ordinary computer. This method of gathering data is not impacted by external conditions and may be replicated in various environments. The subject was sitting in a natural position, while the computer was on the desk. With this configuration, it is possible to expand the dataset further by replicating similar scenarios. Furthermore, when using the ML model based on this dataset for recognizing sign language gestures, users will be in a similar position as during the data collection process. Therefore, the model will be more reliable and will produce more accurate results.
To achieve higher quality outcomes and less useless data, an instructional video was prepared and presented to all participants. The standardization of gestures, movement dynamics, and general recording procedures resulted in the generation of a more effective SSL dataset.
The average recording duration is composed mostly of 20% of hands entering the scene, 60% of hands showing sign language movement, and 20% of hands leaving the recording scene. Having 40 frames in these recordings allows researchers to modify the number of frames utilized in the building of the ML model. Using computer vision techniques, the moment that hands enter the recording scene is recognized, and the recording of 40 frames begins automatically, making the process faster and more efficient.
As various recording participants entered and exited the scene, a couple of recording errors occurred. A final number of 621 video clips were removed out of a total of 8.436. Together with recordings that were not compliant with SSL criteria (wrong hand, improper movement, etc.), only 7.44% of records were made in error, which is a very good result.
A reliable measure of the importance of the data is the number of zero values in the identified frames of the hands and body key points. One useful way to identify recordings that are not compliant is to process all of the resultant data files and identify those that have a higher percentage of zero values or that deviate from the average. Visual control of video files was utilized to ensure the removal of the records from the final dataset, following numerical evaluation and labeling of the files with extreme values.
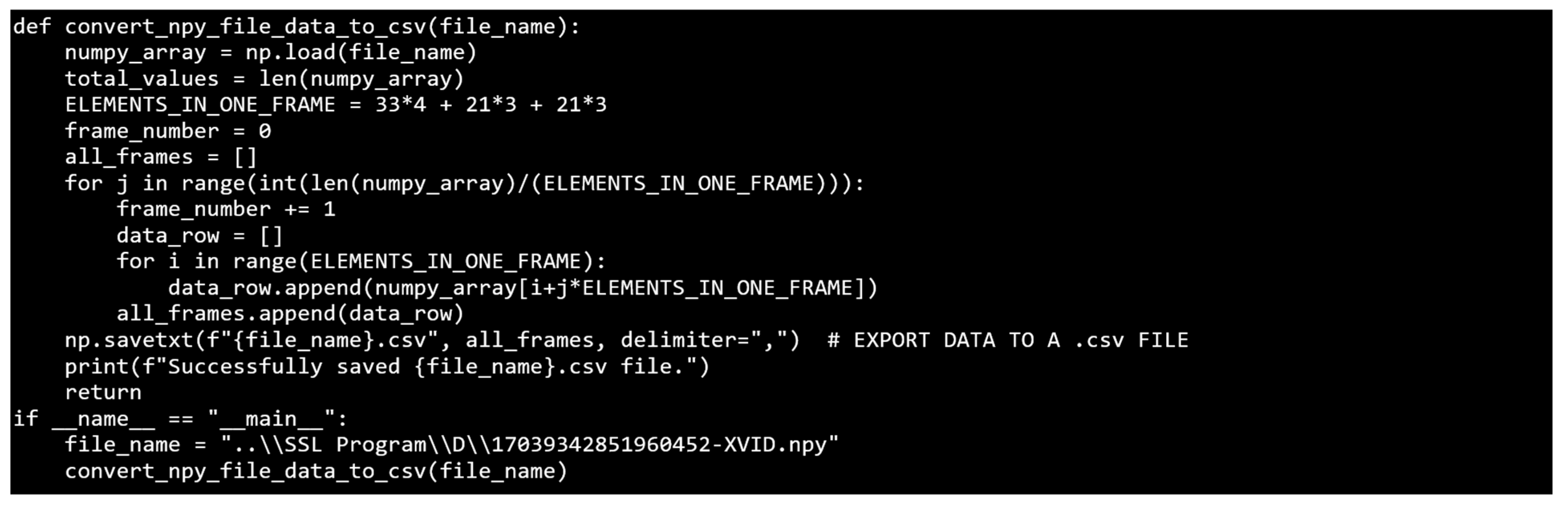
The resulting dataset of NumPy arrays can be loaded and manipulated using the source code shown in
Figure 21. This loads data from one “npy” file into a Python list before saving it to a “csv” human-readable file type. Data, like in this source code, can be used for a variety of similar purposes.
Depending on its intended use, the dataset can be reduced to a more manageable size. Downsizing from 40 frames per second and 720 × 720-pixel videos can lead to faster data manipulation and less machine learning processing time. Each frame’s data can be reduced from 40 to a smaller subset proportionally, arbitrarily, or by using custom data distribution.
After the creation of a validated dataset with a large number of files with data, splitting a dataset into subsets is an important step in the process of training and testing machine learning models. Subsets are created for training, validation, and testing. The data splitting strategy to be used is determined by the features of the dataset, the problem that is being solved, and the aims of the planned machine learning project. It is critical to carefully select a split strategy to ensure the model’s generalization and performance on unknown input.
Some documented attempts have been implemented globally to establish databases for sign language research purposes. Each has unique characteristics and varies in terms of technology. Some of the existing datasets that can be found worldwide are shown in
Table 2. SSL describes 30 alphabets in comparison to other datasets that describe 104 to 9083 signs.
As seen in
Figure 22, comparable datasets have between 3 and 304 entries per sign, whereas SSL has an average of 280 records per sign. All 30 alphabets in the SSL dataset are well represented and recorded, and there are enough records to describe sign gestures for all of them in detail and in a variety of ways. A greater quantity of records per alphabet ensures more accurate training of future machine learning models. As the source code for collecting SSL records and the dataset are available online, the quantity of records is projected to grow over time.
The number of existing datasets presented in
Table 2, which were previously used for sign language recognition in research papers, focuses predominantly on continuous sign language recognition and sign language production. They can be separated into a group of datasets that is based on recognizing isolated signs (one sign recognized at a time) and a group that is based on continuous sign recognition (co-articulated) [
13]. The shortfalls in several of the following datasets are in their limited numbers of participants demonstrating gestures: ASLLVD (3), BSLDict (1), Devisign (12), WLASL (11), BOSTON104 (10), S-pot (5), INCLUDES (16), etc. The SSL dataset, with 41 presenters for 30 signs, has a very good number of unique demonstrators. Many datasets have many signs but only a few records per gesture. Datasets with a very low average of videos per sign include BSLDict (1), ASLLVD (3), S-pot (5), BOSTON104 (10), WLASL (11), Devisign (12), INCLUDE (16), etc. The SSL dataset, with 280 records per sign, is well supported and describes all 30 possible outcomes.
Intelligent machine learning classifiers commonly used for sign language identification include Deep Learning [
31], K-nearest neighbor (KNN), artificial neural network (ANN), support vector machine (SVM), hidden Markov Model (HMM), Convolutional Neural Network (CNN), fuzzy logic, and ensemble learning [
32]. With the dataset generated, all of these predictors can also be used for further SSL software development.
6. Conclusions
The World Federation of the Deaf (WFD) is a global organization led by the deaf, and their vision is to promote the human right to sign language for all deaf people, i.e., to ensure equal rights for over 70 million deaf people worldwide [
33,
34]. In Serbia alone, around 150,000 people with hearing impairment are registered [
9]. Faced with inequality every day, they struggle to improve communication opportunities and the quality of their lives. Research findings show that there is insufficient knowledge and use of sign language and typing not only by professionals who participate in the process of education and upbringing of the hearing impaired but also by parents and the wider social community [
35]. Nevertheless, the notable significance of the application of sign language and typing can be found in social situations, education, the workplace and areas of professional development, access to legal and administrative services, as well as health and social care services [
36]. In addition, an open approach to communication significantly contributes to the improvement of social interactions in the everyday environment and the achievement of the successful social inclusion of hearing-impaired people, which is the ultimate goal of all-inclusive practices in the world [
1].
Intending to advance in the direction of improving the communication possibilities of deaf people and increasing the availability of various services, this paper presents a unique dataset of values describing 30 SSL alphabets. It shows 8.346 distinct dynamic video records and corresponding files containing numerical values with recognized hand and body key points. The dataset created is intended to be used in the development of machine learning models capable of recognizing SSL alphabets. The setup and positioning of participants recording gestures during dataset creation were typical. Therefore, the final machine learning model can be employed in everyday situations and environments.
Other datasets may consist of a spoken language source (interpreted into signed language, for example, with a picture-in-picture translator) or a sign language source (interpreted into spoken language via voice-over). The interpretation of broadcasts, especially television weather broadcasts, has been the most commonly used source of data for sign machine learning datasets [
35]. These databases are derived from a variety of sources, including continuous natural studio-recorded datasets initially meant for linguistic use [
37,
38], project-specific isolated studio-recorded datasets [
15,
16], and sign-interpreted broadcast footage [
39,
40]. Comparatively, SSL records were collected in a regular, everyday classroom environment.
The records collected are related to the Serbian alphabet, which comprises 30 letters. Future research could focus on increasing the number of samples for the same dataset to improve precision, reduce errors, and increase reliability. Data cleaning and validation processes can be additionally improved and automated. Considering that the dataset described in this paper was produced for 30 alphabets, future research can be expanded to include more gestures that represent full words. The SSL dataset is limited to the Serbian alphabet, which is insufficient for developing advanced language recognition and translation systems. It allows developers to create machine learning models that will only recognize 30 predetermined alphabets. Extending the dataset to include a broader variety of identifiable gestures will require significantly more resources, participants, time, and effort, but it might cover a larger section of the already-used spoken sign language.
This article provides a software solution that can also be used for increasing the number of records in the existing dataset. The same method can be applied to other sign languages or similar computer vision applications. The proposed methodology for dataset collecting is flexible, widely applicable, and can be easily extended to include an unlimited number of sign languages. Different sign languages, body gestures, and movements can be analyzed and recognized similarly. The SSL dataset has the potential to be a valuable resource for the further growth of machine-learning models that can make use of it. This dataset can be used as the foundation for future machine learning models that can be used to construct educational applications (with interactive content) and computer games (that children can use to master sign language gestures), translate gestures into computer commands (to recognize alphabets and use them in other programs), or be incorporated into communicational programs (add-ons for alphabet recognition in MS Teams, Viber, WhatsApp, Webex, Zoom, etc.); alternatively, the SSL recognition model can be integrated into the software of existing video conferencing hardware devices (Polycom, Cisco, Avaya, Logitech, etc.). Interacting with computers using simple hand gestures can provide users with a natural and intuitive interface while also assisting hearing-impaired individuals with communication issues [
41]. The quality of life, level of workplace participation, status in society, and general everyday communication abilities of people with impaired hearing are all intended to be improved by the applications proposed.




 ,
, 








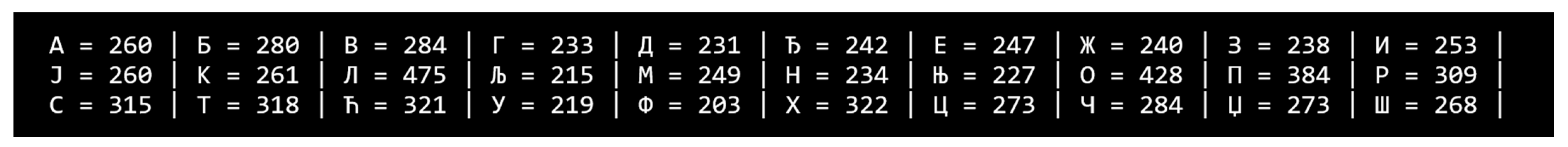








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}