1. Introduction
The model of observations of the output MLS signals, which is used to estimate MLS parameters, has the form:
where
,
, and
are observations of the output MLS signals
distorted by the noise
;
is the impulse response of MLS; and
,
is the input signal of MLS, whose values are unknown nuisance parameters.
The value
of the parameter of observations
is unknown and belongs to the open set
of the
-dimensional vector space
. The functions
and
are supposed to be known. The noise
is the
m-dimensional random Gaussian stationary time series with zero mean value and known complex matrix power spectral density (MPSD)
,
. We also suppose that the noise
is the regular random process of the maximal rank satisfying the strong mixing condition [
1,
2].
In this article, we synthesized the estimate
of the value
in a situation where there is no detailed prior information about the MLS input signal
. Such problems arise in many technologies, such as radio engineering, acoustics, and seismology, when it is necessary to determine the characteristics of a physical linear medium based on the results of its sounding by propagating waves emitted by natural or man-made sources [
3,
4,
5,
6]. It is impossible in such problems to observe the medium deformations in the inner regions of the Earth’s crust, caused by the action of an unknown probing signal
. Therefore, the characteristics of the medium can only be determined by analyzing the wave field excited by the signal
and recorded by an array of spatially distributed sensors located at the Earth’s surface.
The problems of estimating the characteristics of the Earth’s medium that arise in seismology are, as a rule, the most complex. If the propagation of waves in the Earth’s medium can be described by a system of linear partial differential equations, then the signals recorded by an array consisting of m seismic sensors can be interpreted as output signals of an MLS with one input and m outputs. In this case, the physical characteristics of the Earth’s medium can be considered mathematically as some parameters of this MLS.
Because the input signal of the MLS belongs to a one-dimensional subspace of the m-dimensional space of the MLS output signals, the observations , even distorted by interferences , provide enough information about the value , of the MLS parameters to construct a consistent statistical estimate of this value.
The problem of statistical estimation of parameters of multivariate observations, closest in formulation to our problem, was considered in [
7]. This is the problem of estimating the parameter
of the model of observations known as “multivariate linear functional relationship”:
where
is a sequence of unknown nuisance parameters and the errors
are independent Gaussian vectors with a mean equal to zero and a covariance matrix equal to
. That is, the parameter
should be estimated from the observations
.
As noted in [
7], if a priori restrictions on an infinite sequence of nuisance parameters are not imposed, then the nonparametric model
does not correspond to traditional nonparametric models, where observations belong to some metric space and for which asymptotically efficient (AE) estimates can be constructed. Nevertheless, in [
7], the local asymptotically minimax estimate of the parameter
was constructed, which has been proposed in [
8].
The model of observations
differs significantly from the model
, since it does not assume observations
,
of the nuisance parameters
. Also, for
, we have additive time series
,
, a sample from the stationary Gaussian random time series with a known MPSD
, while for
,
are independent Gaussian vectors. In addition, the estimated parameter
is “hidden” in the impulse response
of the MLS. For these reasons, it is impossible to construct a local asymptotically minimax estimate for the parameter
in our problem. Nevertheless, in this problem, it is possible to construct a
-consistent estimate of the parameter value
u. This will be performed in detail in
Section 3.
2. Basics of Efficiency Criteria for Statistical Estimates
In denoting
as a criterion of quality for estimates
, we will use the mean square error (MSE) matrix
It is said that one estimate
is better than
when the corresponding MSE matrices satisfy the inequality,
where inequality
means that
is a nonnegative semi-definite matrix.
If
is a vector of true values of parameters for so-called
regular parametric probability models of the observations, a lower boundary for matrices
in a class of unbiased estimators
exists; it is defined by Fisher’s information matrix
[
9]:
where
;
is the probability density of random observations ; and .
In this case, an estimate is said to be statistically effective if the following equality holds:
However, effective estimates exist, even theoretically, only in some special parametric probability models of the observations, which rarely correspond to practical needs. Instead, in some cases, it is possible to construct the asymptotically efficient (AE) estimate
, which has a limit error covariance matrix
equal to the limit of the inverse Fisher’s information matrix
[
10]:
For instance, in certain applications,
can be considered a realization of the stationary Gaussian random process
with a zero mean and known power spectral density (PSD)
. Hence, the Gaussian probability density
of the random sample
, whose
-matrix covariance function depends on the parameter
, does not belong to the exponential family of distributions [
11]. Therefore, in this case, there is no efficient estimate
that has an error covariance matrix
equal to the inverse Fisher’s information matrix
at each number of observations
n, but an AE estimate exists, and its analytical form is given in [
12]. However, the most common situation occurs when
are unknown, and the observation model for
becomes nonparametric and the AE estimate cannot be constructed in the sense of
.
3. The Estimate of MLS Parameters in the Case of Unknown Input MLS Signal
In many applications, the values of the MLS input signal
are unknown and are not observed. In this case, the estimation of
based on the sample of observations
of MLS output signals becomes a statistical problem with nuisance parameters, which are the unknown values of the signal
. This problem was studied in [
13] for cases where the number of nuisance parameters does not increase with the increase in the number
n of observations. In our case, the number of nuisance parameters
is equal to the number
n of observations
, and it is impossible to construct a consistent estimate of the informative parameter
without introducing some constraints on the asymptotical properties of the nuisance parameters
. Such constraints were proposed in [
11]:
1.a. The signal has finite average power: .
1.b. For any , the signal satisfies the inequality , where .
Note that almost all sample functions of stationary random processes satisfy such restrictions [
14].
It is shown in [
11] that, in cases where all the values of the input MLS signal
are known and constraints 1.a and 1.b are satisfied (and also some restrictions on the MLS impulse response
and the noise MPSD
), the likelihood function
of observations
admits the LAN [
15] expansion in the vicinity of value
:
where
;
is any constant;
;
;
and the probability distribution of the random function
converges as
to the
-dimensional Gaussian distribution with the moments
.
When the values
are unknown for any
, it is impossible to consistently estimate all unknown parameters of the observations
(i.e., the MLS parameter value
together with the nuisance parameters
,
) using only the main terms (2) of the LAN expansion (1) of the likelihood function of the observations. But in our problem, it is necessary to estimate only the MLS parameter value
, and it is not necessary to estimate the nuisance parameters
. The approach to solving such an unconventional estimation problem was first proposed in [
16]. With some modifications, this approach was implemented in [
12] to solve our problem. The method proposed in these publications was as follows:
It is easy to show that if the values
are known, the family of statistics
in Equation (2) is the gradient of the function
with respect to parameters
:
where
Note that the function
in Equation (3) is the asymptotic approximation of the probability density for spectral observations of
, which are asymptotically mutually independent [
1].
Hence, the AE estimate
of parameters
in cases of known
can be obtained as the root of equation
and has the form:
When the values of
are unknown, one can, according to [
14], construct some estimate of the value
of the informative parameter together with the unknown nuisance parameters
by formally applying the maximum likelihood approach to the right side of Equation (4). That is, this estimate can be obtained by maximizing the right side of Equation (4) through all unknown parameters
, where
is a bounded set of
:
Estimates (5) can be calculated by solving the following system of equations:
By representing a positively definite Hermitian matrix
in the form
, we obtain:
where
.
Then, subsystem (6.1) can be written in the form:
The system of Equation (8) has the following solution:
To construct an estimate of the parameter value
, it is necessary to substitute the estimate
according to Equation (9) into subsystem (6.2):
Thus, we define some estimate
of the value
of the MLS parameter as a solution to the nonlinear system of equations:
where
.
It is easy to check that the matrices
are the idempotent Hermitian matrices, i.e.,
for all
and
. Hence, Equation (11) can be rewritten in the following form:
Therefore, the estimate of the value
of the MLS parameter at which the observations
were obtained can be found by maximizing the objective function
that is,
According to the definitions of quantities
, we can write objective Function (13) as:
where
;
, in which
is the value of parameter
under which the sample
(DFFT of the sample
) was obtained; and
.
It is important to note that estimate (14) does not depend on the unknown values of the nuisance parameters, i.e., the input MLS signals . For calculating estimate (14), we must process only the spectral observations at the output of MLS.
In what follows, we will take into account the assumptions under which estimate (14) was obtained in [
12]:
A. The MLS frequency response
has second partial derivatives in the components of the vector
, and these derivatives are continuous in
,
:
B. .
Under assumptions
A and
B, the matrix functions
exist, are uniformly bounded in norm, and are continuous in
,
for all
.
Let us note an equation that will be needed later. From (11) and (15), it follows that
Assumptions
A and
B may have a physical explanation. The considered MLS model arises in tasks such as wave field source localization in acoustics, radio, or slowness vector estimation in seismology, where the vector function
describes wave propagation. As a rule, such functions are sufficiently smoothed to have second and even third partial derivatives in the components of the vector
. Assumption B is related to the definition of regularity [
1] of additive noise, which always holds for stationary Gaussian processes.
Estimate (14) belongs to the class of M-estimates. M-estimates may have the property of robustness, i.e., their accuracy depends less on changes in the probability distribution of observations, unlike AE-estimates [
17]. For this reason, M-estimators are used in many applications of mathematical statistics in the natural sciences and in econometrics for statistical estimation problems where complete probabilistic models of observations are not known [
10,
18]. In these problems, the estimates are found by maximizing some objective function
,
instead of the likelihood function. Despite the fact that likelihood-based estimate (14) is obtained from a parametric observation model, taking into account an infinite number of estimated parameters
, it is not an AE estimate but could still be robust.
The asymptotic properties of M-estimates were studied in [
10] for the problem of estimating the distribution parameter of a one-dimensional random variable from a sample of independent observations of this variable, while determining the probability distribution of estimate (14) is a rather difficult task. This task will be simplified if we consider the equivalent problem of determining the probability distribution of the root
of the equation
.
The analysis of the asymptotic statistical properties of the random estimate
when
is based on the following theorem proved in [
19], Theorem 1 and Corollary 1.
Theorem 1. Let an objective function , satisfy the following conditions:
A. The objective function admits the following asymptotic expansion in a small vicinity of the value whereB. The vector statistic has a Gaussian limiting distribution for with the following moments:C. Let some statistic have the following properties: a.
The statistic is a solution of the system of equations for any and almost each with respect to the probability distribution
b.
The statistic is the -consistent estimate of the value .
Then, the random variable has a Gaussian distribution in the asymptotic with the following moments:.
It has been proven in
Section 5 that objective Function (13) satisfies the conditions
A and
C of Theorem 1. The proof of the asymptotic normality of
, which is part of condition
B, is quite challenging (it will be discussed in the end), but we will assume that it holds. Then, the random variable
has Gaussian distribution in the asymptotic
with the following moments:
where
;
;
;
+
;
;
;
;
; and
is the largest integer
j for which
.
4. Numerical Comparison of and the SRP-PHAT Estimator
As mentioned in the introduction, the particular case of MLS parameter estimation problem is wavefield source localization by antenna arrays. The SRP-PHAT estimator of source coordinates is the most popular, well-recommended, and robust method, as described in [
3,
6]. In order to demonstrate the effectiveness of
given by (14) compared to SRP-PHAT, Monte-Carlo simulations for two different cases of noise
properties were performed in [
4]. A set of 150 MLS outputs was considered in this experiment. For the known value of the estimated parameter (x*, y*), a set of 110 mixtures of 150 MLS outputs and time series
was simulated.
A simple and known metric was used to numerically compare the effectiveness of the algorithms:
where
is the known value of the unknown parameter
and
is the set of independent estimated values of the parameter
. In the current modeling,
= 2 and
p = 110. Two different sets of
were obtained by two different estimates:
and SRP-PHAT.
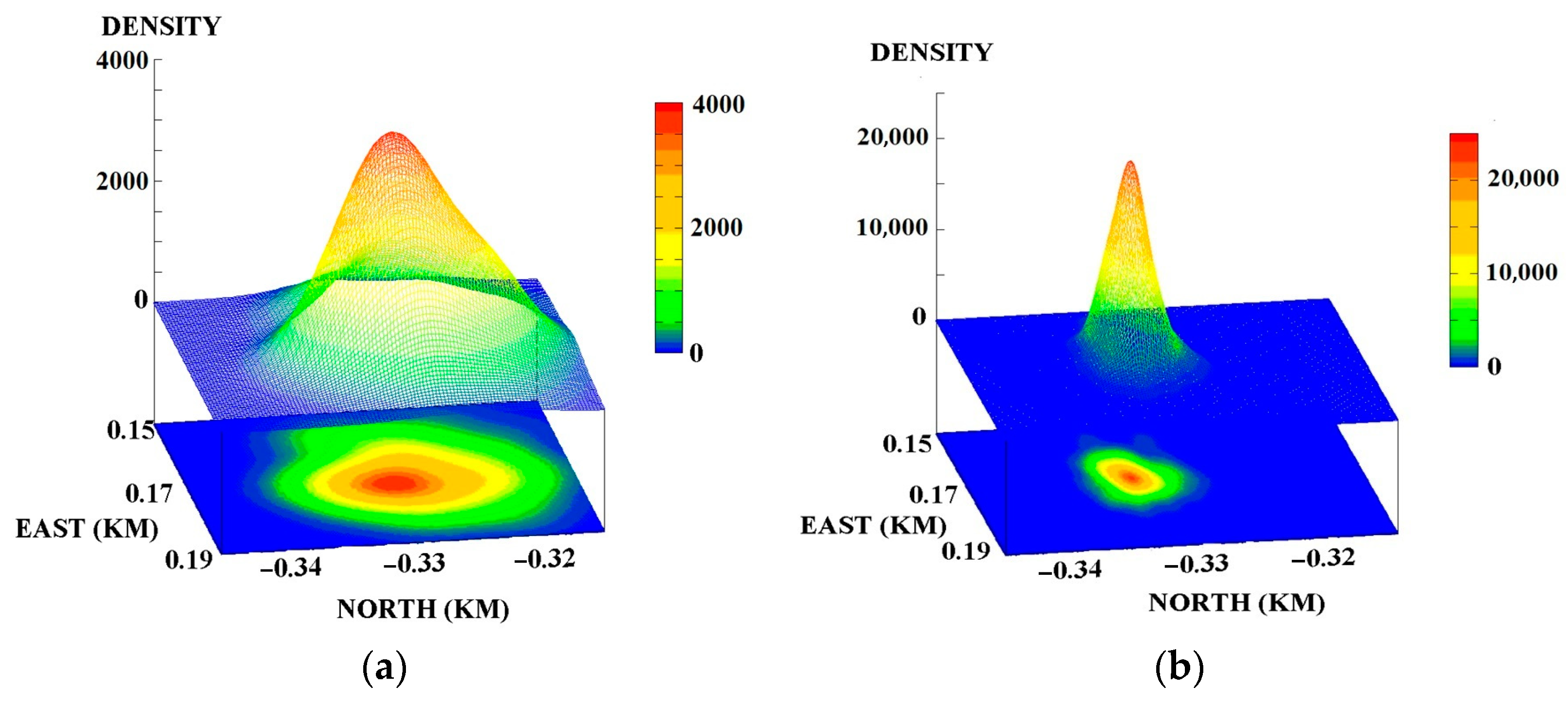
Below, in
Figure 1, the empirical two-dimensional probability density functions for averaged (among MLS outputs) signal-to-noise ratio SNR = 0.05 are obtained for 110 independent estimates of source coordinates
in the presence of real correlated noise with matrix power spectral density
. In
Figure 2, similar probability density functions are provided for
, where
is the unit matrix. That means that
is represented as multidimensional white Gaussian noise with equal power spectral densities.
As can be seen from
Figure 1 and
Figure 2, in both cases, the
value of
is approximately two times greater than the
value of SRP-PHAT. That is, the changing properties of additive noise
lead estimate
to be more efficient than SRP-PHAT. But while varying the additive noise properties, both estimators show nondramatic changes in estimation accuracy, so they are both robust. More detailed information and a straight numerical comparison are given in [
4].
5. Asymptotic Properties of the Objective Function
The proof that the objective function satisfies conditions A and C of Theorem 1 consists of a sequence of lemmas.
Lemma 1. The objective function, ,, satisfies conditions A
of Theorem 1.
Proof. Let us write the Tailor expansion of the objective function
in the vicinity
,
of the parameter value
with the remainder term in the Lagrange form:
where
;
;
The remainder term
on the right side of Equation (19) has the form:
where
,
.
We use the Lagrange form of the remainder term
above because it is the simplest form of the Tailor expansion of the objective function
by Equation (13) given on the closed set
, but this form requires the existence of third bounded partial derivatives of the objective function
. Let us assume that this is true for the sake of simplicity. Due to this assumption, there exists a matrix function:
where
;
;
,
, which is continuous on
and is bounded for all valid values of its arguments.
In accordance with Equation (7), we have:
The term
is bounded for all
,
. The pairs of random vectors
,
are mutually asymptotically independent for
; the Gaussian random vectors
have asymptotic covariance matrices equal to
for
. That is, we have (see
Appendix A):
where
,
for all
.
Taking into account Equation (21) and the boundedness of the terms
in Equation (20), we conclude that the sequence of random variables
tends to zero in probability as
, in accordance with the Law of Large Numbers [
18] (Lemma 2.4):
□
Let us assume that the vector statistic
where
particularly satisfies conditions
B of Theorem 1. That is,
has a Gaussian limit distribution. Let us prove that the moments of this distribution are
Lemma 2. The statistics given by (24):have zero mean in the asymptotic : Proof of Lemma 2. The term
has the following form:
where
Statement 1. The first term on the right side of Equation (25) is equal to zero: Proof of Statement 1. Let us rewrite the terms
for any
,
using the associative law for products of several vectors:
□
The mathematical expectation of the last term on the right side of Equation (25) is also equal to zero due to Equation (22): .
Statement 2. The limit of the mathematical expectation of the second term on the right side of Equation (25) is equal to zero: Proof of Statement 2. As follows from Equation (22):
where
,
for all
.
Let us first prove that
for any
. The following equalities are held:
Therefore,
for any
. Consequently:
where
,
.
The matrix functions
have continuous partial derivatives with respect to
for any
,
. Consequently,
for any
,
. As follows from Equation (28):
Finally, we deduce from (26)–(29) that
□ □
It follows from Lemmas 1 and 2 that the components of the family of statistics
in the limit
have a zero mathematical expectation:
Lemma 3. The covariance matrix of the statistic has the limitwhere +
;
,
;
is the largest integer n for which ;
;
.
Proof of Lemma 3. According to Lemma 2,
,
. Consequently,
According to Equation (25) and Statement S.1, we have:
Therefore,
can be written as:
where
;
.
The double sum on the right side of Equation (32) can be calculated as:
According to (23), the complex vectors become mutually independent for large values of n:
, where
,
. It is easy to show that the term
in Equation (33) has the form:
The first limit on the right side of (34) is equal to zero due to Statement S1:
The second limit on the right side of (34) is also equal to zero since
. Hence,
The quantities , are the sums of terms having the forms . That is, they are the sums of the products of three random variables having Gaussian distributions with zero mean values. The factors in these products belong to the sets , . Due to the properties of Gaussian distributions, the mathematical expectations of these products are equal to zero.
To find the expression for the mathematical expectation
, we can use the following theorem proven in [
20] (Theorem 5.2c, p. 109):
Theorem 2. If the random vector has the complex Gaussian distribution , then the covariance of the product of quadratic forms , where u are Hermitian matrices, is determined by the following equation: .
Using this theorem when
,
,
,
, we obtain:
Since
, the first term on the right side of (37) takes the following form:
Let us find an expression for the last term on the right side of Equation (36):
Since
are Hermitian matrices, then the terms of sum (39) can be rewritten as
, where
;
;
;
. The following equalities are valid for the Hermitian matrices
,
and for the vectors
:
where
and
due to the property of the scalar product, and
due to the property of Hermitian matrices. Since
, we can write:
where
,
, and
is some constant.
Finally, we obtain:
where
and
.
Equation (36) can then be written in integral form:
where
;
;
is the largest integer less than
. □
Now it is not difficult to write an analytical expression for the elements of matrix
. According to expression (17), we have
Let us prove that condition C of Theorem 1 is satisfied.
Lemma 4. ([
18])
. Let the objective function , , generating the estimate by the equation have the following properties:Then, the estimate
is the consistent one: Lemma 4 can be formulated in the following equivalent form:
Lemma 5. Let the vector random functiongenerating the estimate
as the root of the equation have the following properties: Then, the estimate , which is the root of the equation , is the consistent one: .
Let us prove that the random function
from the left side of Equation (12), normalized to
as
satisfies the conditions of Lemma 4. To do this, we analyze the limits in probability of the random functions
,
,
when
. These functions have the form:
The following statement is proven similarly to Theorem 1 in [
18]:
Since the random values
have their properties defined by Equation (22), and functions
,
are continuous on the compact set
, the random functions (44) converge in probability to the limits of their mathematical expectations when
uniformly in
due to the Law of Large Numbers:
Let us find expressions for the values
. Since
then
According to (27), the first term in (46) is equal to zero for all
. The second term in (46) converges as
to the following integrals uniformly in
:
where
,
is the largest integer
n for which
.
Due to the properties of , the integrals (47) are continuous in , and the functions , have the unique roots on the compact set .
Then, according to the statement of Lemma 5, the estimate
, which is the root of the equation
, i.e.,
is the consistent estimate of the value
of the MLS parameter.
Lemma 6. The consistent estimate , satisfying Equation (48), is the -consistent estimate, i.e., it has the following property: for any , there exists a for which for every .
Proof Let us formulate the definitions of consistency and -consistency in the equivalent forms:
- (a)
For any
,
, there exists a
for which
- (b)
For any , , there exists a for which .
Let us consider the random event
Then, condition (a) means that:
Let us consider the value and the event .
Then, condition (b) means that: .
The estimate
, as the root of the equation
with a probability equal to 1, is determined by the following relation:
Using the above designations, the statement of Lemma 5 can be written in the following form:
Hence, the consistent estimator is also the -consistent one. □
It follows from Lemmas 1–6 that all conditions of Theorem 1 are satisfied, and hence the random variable
has, in asymptotic
, a zero mean and bounded covariance:
where the elements of the matrices
and
are represented in the form of integral expressions (42) and (43).
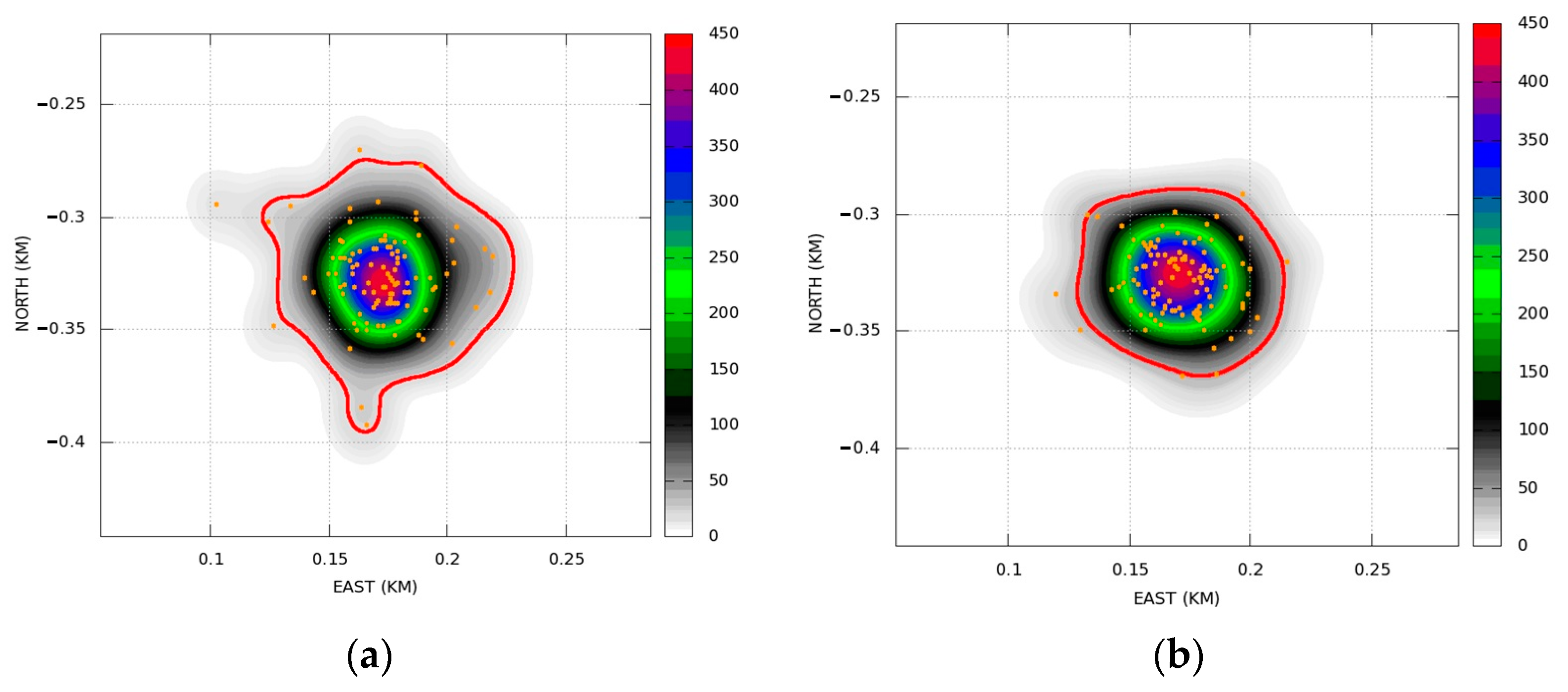
In order to understand the meaning of Formula (50), let us return to
Section 2 and consider a case where
and
. Then, Formula (50) represents the covariance matrix of a Gaussian two-dimensional distribution that, for certain
and
(used in Monte-Carlo modeling), will be very close to the empirical distribution shown in
Figure 1b.
Discussion on the asymptotic normality of .
As it was noted before, the fact of the asymptotic normality of statistics (24) is not obvious and poses a separate problem that is more difficult than the Law of Large Numbers. It is required to establish central limit theorem (CLT) conditions for the weak dependent random variables that are represented as quadratic forms of functions of the discrete Fourier transform of stationary time series.
The CLT formulated for cases of dependent random variables are presented, for instance, in [
21,
22]. However, the conditions under which these theorems are stated are very restrictive, which makes them difficult to apply to statistics (24). In addition to the existence of finite first- and high-order moments ([
21], theorem 27.4), there is a strong mixing condition for the measure of dependency between random variables, which cannot be applied to the terms of sum (24). The author believes that there is no ready solution to this problem in the form of a suitable theorem. At the moment, the author leaves this problem open for investigation in the future.

{kind=link}
{kind=link}