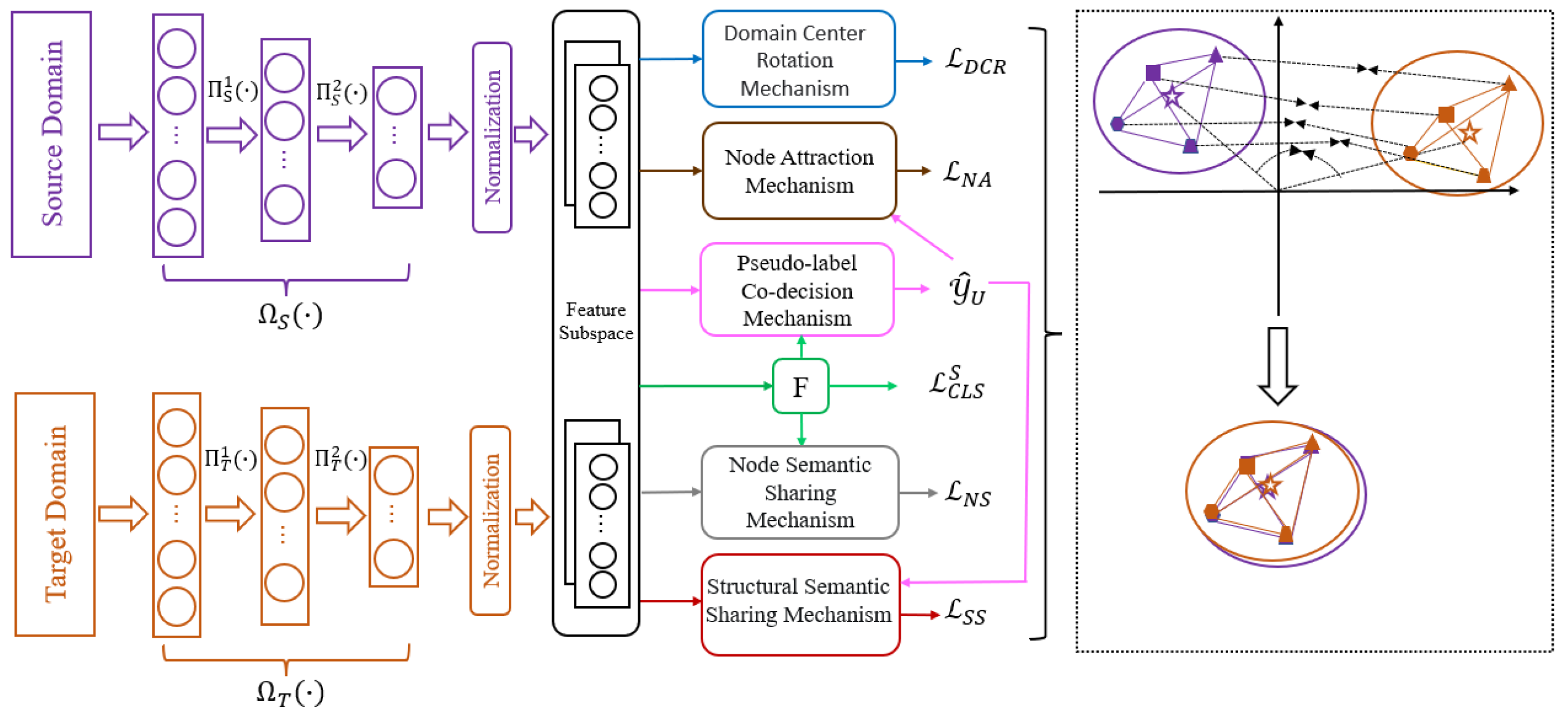
3.3. Centroid-Connected Structure Matching Network
(1) Feature Representation
Due to the different feature representations and dimensions of the source and target domain data, the learned classification model cannot be directly applied to the target domain. To solve the problem, a shared public feature subspace needs to be constructed. Firstly, a standard feature subspace learning network is constructed for the source and target domains, respectively, which contains two feature encoders
, where
and
and where
and
. The two feature encoders can embed heterogeneous data into a domain-invariant feature space, and both of them consist of a three-layer neural network.
and
are the transformation functions between the input and intermediate layers, and
and
are the transformation functions between the intermediate and output layers. The dimensions of the three-layer network of the feature encoders are
and
,
respectively. The input layer dimensions
and
of the two feature encoders are set to be equal to the feature dimensions of the input samples of the source and target domains, respectively, and the output layer dimensions
and
are set to be equal to the dimensions of the feature space
. That is,
=
=
. In order to avoid the lack of effective feature information caused by the direct feature transformation [
25,
29,
40,
41] and to ensure deep feature information can be learned, the intermediate layer dimensions are set as
+
)/2⌋,
+
)/2⌋, where
denotes a downward rounding operation. After learning the feature space, the transformed source domain feature
,
is the
th sample feature of
, and similarly, the transformed target domain feature
,
is the
th sample of
features. By learning the feature space, a new shared feature representation is obtained, which helps knowledge transfer to the target domain.
(2) Basic concepts
A centroid-connected structure is constructed for each domain separately to realize the alignment across domains. The three basic concepts are given below:
Domain center: the centroid of the source or target domain in the standard feature subspace;
Node: the centroid of category k set of the source or target domain;
Point distance: the weight of the domain centers or between any two nodes, measured by the square of the Euclidean distance.
The expression for the domain center is given in Equation (1):
where |·| is the number of samples in the set.
The node representations of the source and target domains are shown in Equation (2):
where
K is the number of all categories and the number of nodes per domain.
(3) Domain center rotation mechanism
Considering the heterogeneous features are interconnected in the mapping space, the probability distributions still have a large divergence. Unlike the simple normalization in [
41,
42], the CCSMN does not directly minimize the distance between the two domain centers (
and
) to solve the angular difference. Instead, the source and the target domain features are normalized with the center of
based on Equation (1), and the inter-domain difference in the mapping space is reduced through a unified scale, as in Equation (3).
where
is
-normalize,
is the initial centroid of the source domain,
,
,
,
,
and
are the normalized source and target domain features of
and
, respectively, and
and
are labeled and unlabeled features normalized to the target domain. Then the centroid, i.e., the domain center, of the entire feature space after normalization is recalculated according to Equation (4).
There is an angular difference between the two structures. To be able to align the structures better, the structures are rotated by minimizing the loss in Equation (5) so that the angle between domain centers is 0 degrees, which completes the feature fusion between the global domains and avoids the angular difference of the structures in the global domain.
where
denotes the cosine similarity.
(4) Node attraction mechanism
The above mechanisms realize the global inter-domain alignment. It forces the angle between the domain centers to be zero. Still, it is a coarse-grained alignment that can only ensure an inevitable overlap of the geometric structure, and the nodes of different categories may be very close to each other. There is an overlap of the nodes of different categories. In contrast, if the nodes in the same category cannot overlap, this leads to negative transfer. To effectively reduce the appearance of negative transfer, this paper adopts the node attraction mechanism to further strengthen the node alignment between cross-domains, to complete the fine-grained coverage and calculate the nodes of category
k in the source and target domains using Equation (6).
Considering the existence of a large number of unlabeled target samples, inspired by [
43], a pseudo-labeling strategy is used to assign pseudo-labels to each unlabeled target sample. Once the complete labeled target domain is obtained, the respective nodes can be constructed simultaneously with the labeled source domain. By minimizing the loss in Equation (7), the two structures are aligned in a finer way.
where
is the square Euclidean distance. The node attraction mechanism can go a step further to effectively alleviate the problem of the difference, improve the utilization of the data in the process of knowledge transfer, fully explore the knowledge information, and help to improve the transfer performance.
(5) Node semantic sharing mechanism
The above two mechanisms in (4) focus on realizing the alignment of geometric structures from domain centers and nodes, which cannot effectively solve the problem of the difference in the shapes of the initial structures of the two domains. When aligning the whole geometric structure, it is necessary to ensure the consistency of the shapes of the two structures. Therefore, two semantic sharing mechanisms are designed to promote the target domain to generate a geometric structure shape as similar as possible to the source domain to make the structure alignment more accurate and efficient.
In a connected structure, each node has a corresponding category. Nodes in different domains belonging to the same category should exhibit a characteristic probabilistic category similarity in model prediction. Sharing the potential knowledge of the source domain with the target domain completes the first step of similar shape generation, facilitates the generation of nodes in the target domain, and ensures the meaning of the semantics. In detail, for a node of category
k in the source domain, the potential knowledge it contains can be expressed as follows:
where
T is a temperature hyperparameter that guarantees the smooth output of potential knowledge; for the source domain potential knowledge
to be shared with the labeled samples in the target domain, the potential knowledge of the labeled target samples is also computed:
where
is the subset consisting of labeled target samples belonging to category
k. Sharing potential knowledge and facilitatying the generation of target domain nodes by minimizing the loss in Equation (10),
In addition, the supervised loss of labeled target domain samples is added, and the complete node semantic sharing loss is defined as
where
is the equilibrium hyperparameter of the loss
and
is the cross-entropy loss. By minimizing the final loss
, the classification performance of the target domain is improved, the generation of target domain nodes is perfected, and the intra-class compactness of the nodes is achieved by ensuring the purity of semantics.
(6) Structural semantic sharing mechanism
The first step of similar shape generation through (5) emphasizes the probabilistic category similarity of nodes. It refines the generation of nodes in the target domain. Secondly, although there are a small number of labeled samples in the target domain, the semantics cannot generate a good structure for unlabeled samples, which is likely to make the nodes very close to each other. Therefore, a structure semantic sharing mechanism is designed, which mainly focuses on the semantic similarity of the overall structure, i.e., the semantic similarity between the nodes in the centroid-connected structure, and ensures that the target domain nodes have the same reasonable distinguishing distance from each other, and further generates a highly similar structure, which reduces the structural differences.
Specifically, the geometric semantic similarity between nodes in each domain, based on the relationship between nodes and domain centers, i.e., the semantic similarity between category node
i and category node
j, is calculated as follows:
Then, Equation (13) is used to realize the association of semantic similarity of all pairs of nodes across domains. Through semantic sharing, the inter-class distance of the target domain is well controlled, and the distinguishability of the target domain nodes is strengthened.
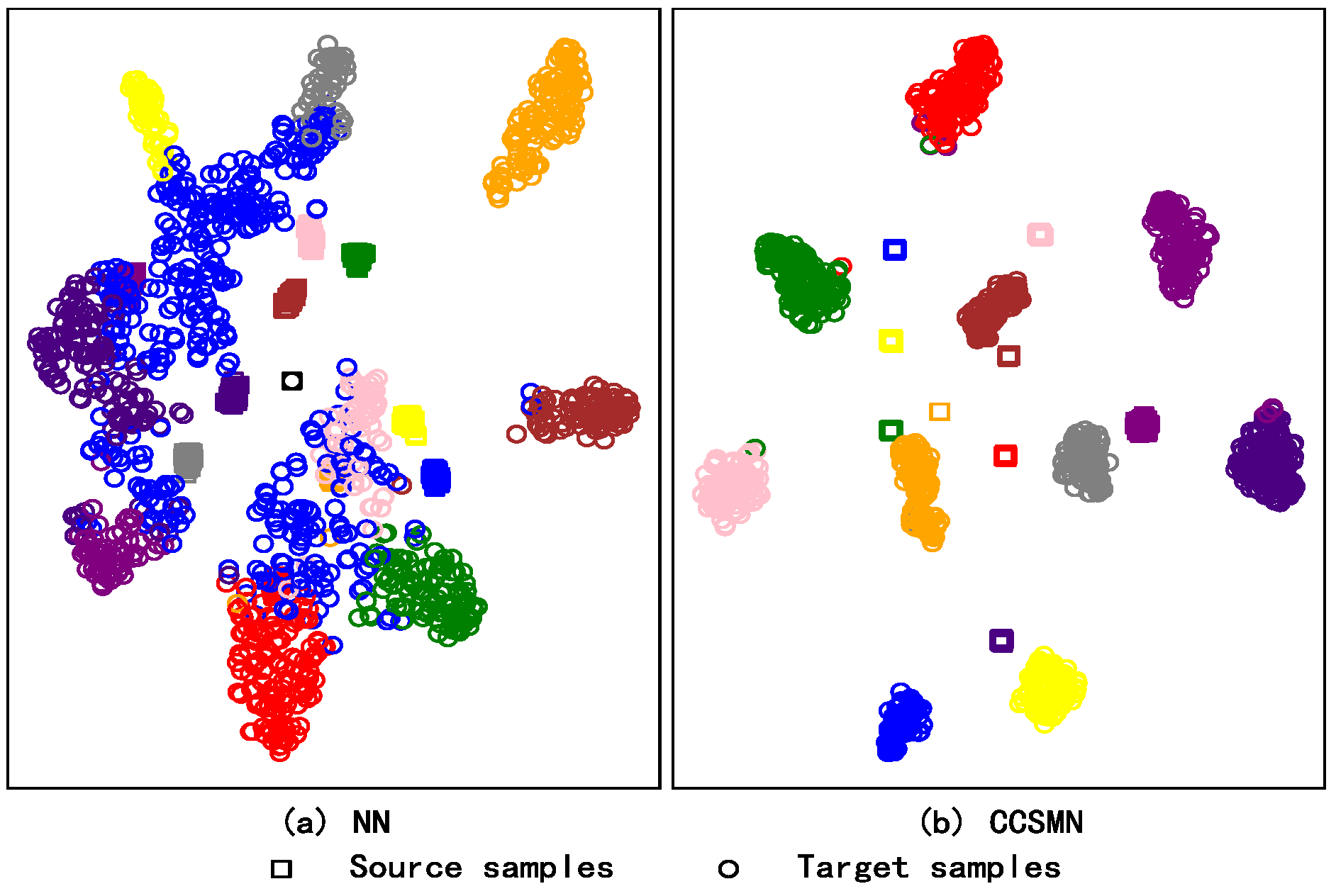
Through the joint action of the above two semantic sharing mechanisms, a high degree of structural similarity between the source and target domains is achieved, which ensures the intra-class compactness of the target domain and controls the separability of the inter-class distance.
(7) Pseudo-label co-decision mechanism
The source and target domains would have sufficient labeled data to achieve a more fine-grained alignment of the structure. However, the target domain has only a tiny number of labeled samples but a large amount of unlabeled target data [
43,
44]. Solely using a shared classifier to make predictions, the labels obtained are not accurate enough, which can lead to negative transfer. This paper introduces progressive pseudo-labeling to mitigate the negative transfer effect and integrates a pseudo-label co-decision mechanism (PLCDM) to help select pseudo-labeled samples with high confidence. The specific implementation process is as follows: Firstly, the centroid
of category k is computed according to Equation (14) using labeled data in the source and target domains.
After obtaining the centroid set
, the PLCDM uses Equation (15) to assign pseudo-labels to each unlabeled target sample based on geometric similarity.
Finally, the PLCDM compares the geometrically similar label with the pseudo-label that has been assigned by the classifier F(··), and for the same unlabeled target sample; only if the two predictions are the same, the sample will be selected and the pseudo-label will be assigned, and the sample will be used for structural alignment. As training continues, more and more unlabeled target samples are assigned high-confidence pseudo-labels, and the prediction accuracy of the proposed model increases.
(8) Classifier training loss
In order to make full use of the supervised information, the empirical error in the labeled source domain data needs to be minimized. To calculate the supervised classification loss for the source domain, see Equation (16):
(9) Overall objective function
Based on the above discussion, the overall optimization objective of the CCSMN is to minimize the following loss function:
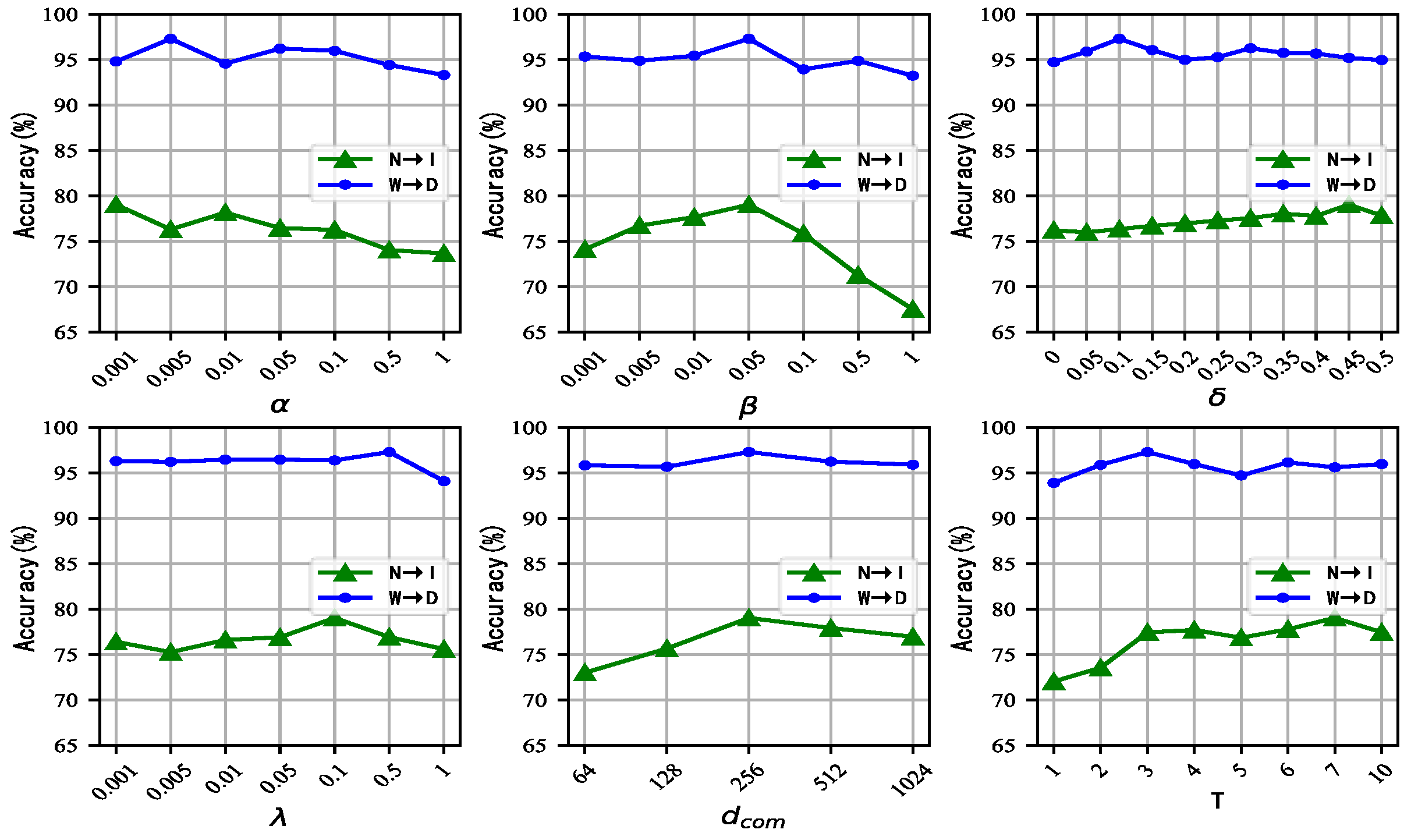
where
,
, and
are the corresponding balancing parameters for balancing losses. Algorithm 1 summarizes the proposed CCSMN algorithm.
| Algorithm 1. CCSMN |
| Input: Source domain: ; target domain:; hyperparameters: T; iteration: N; Common subspace dimension: |
Output: Feature encoders and Classifier F(··)- 1:
Initialize the source and target feature encoders: and Classifier F(··). - 2:
for to N do - 3:
Get embedded features in common subspaces and network outputs. - 4:
Compute normalized embedded features by (3). - 5:
The domain centers of the two domains are calculated by (4), and by (5) the global Angle difference of the connected structure of the center of mass is avoided. - 6:
Only the pseudo-label predicted by the neural network is consistent with formula (15), the pseudo-label is assigned to an unlabeled target domain sample, and this sample is allowed to participate in model training. - 7:
Compute the nodes of two domains by (6) and further strengthen the alignment of nodes between the cross-domains by (7). - 8:
Ensure a high degree of similarity in the shape of the two centroid-connected structures by (11) and (13). - 9:
Update the network by minimizing losses (17). - 10:
end for - 11:
Return the optimal model feature encoder and classifier F(·).
|
(10) Time complexity
The time complexity of the proposed method mainly depends on the embedded feature extraction and the pseudo-label prediction of two domain datasets. Assuming there are n samples in the datasets, using a three-layer neural network for label classification prediction, the mapping time complexity is and the time complexity of three-layer neural network classification is O (m*n), where m is the number of neurons. In the process of calculating class centroid similarity, the time complexity is . Therefore, it can be seen that the time complexity of the method proposed is . The spatial complexity is , where d is the feature dimension.



{kind=link}
{kind=link}
{kind=link}
{kind=link}