1. Introduction
Complex systems can be defined as structures in which at least one element is a human. On the one hand, the action of many random factors leads to the stochastic properties of such systems. In addition to stochasticity, uncertainty also arises, associated in some cases with the irrationality of human behavior. On the other hand, the presence of the human factor creates prerequisites for the self-organization of such systems and can determine the existence of memory of their previous states. All this leads to the appearance of organized complexity (emergence).
This cannot be considered as the result of a simple summation of the characteristics of the elements, but rather the result of the emergence of systemic connections and adaptive redistribution of functions between the elements. It should be noted that the models for describing most of the processes observed in complex social and economic systems can be classified as non-stationary time series.
Due to the nonlinearity and variability of the characteristics of processes occurring in complex social and economic systems, traditional methods of analyzing and modeling their time series, such as the integrated autoregressive moving average model (ARIMA, Box–Jenkins model) and many other models, often lead to inaccurate or erroneous results.
The use of differential equations of various types for the analysis and modeling of the dynamics of economic and social processes, as well as for forecasting the evolution of states in social and economic systems, is very important and is widely used. For example, the Fokker–Planck equation and its analogues are often used in the analysis of time series of financial and commodity market indices, currency pair ratios, and much more. In this regard, one can, for example, mention the well-known Black–Scholes efficient market model.
However, the approaches currently used for this, including neural network models, for example, for solving problems of regression restoration, although showing good results in a number of cases, do not consider the possibility of self-organization in complex systems and the presence of memory but are limited to considering Markov processes. In this regard, in our opinion, it is more acceptable to create models for analyzing and describing the dynamics of processes in complex systems based on fractional differential equations in partial derivatives. Fractional equations, both in terms of time and the variable describing changes in the time series, can be used to account for memory effects and the possibility of self-organization.
The fractional nature of the derivatives of operators with respect to time and the variable determining the level of the series makes it possible to describe non-local processes in which the transition to a given state of the system (or process) depends not only on the local characteristics of the process or the behavior of the system in the vicinity of the point under consideration, but also on the values it takes on the entire range of values (i.e., memory) under consideration, and non-locality with respect to time can lead to self-organization.
Currently, fractional differential models are being developed to describe the dynamics of processes in complex systems. For example, [
1] discusses the development of a fractional hyperchaotic economic system of variable order with a nonlinear model predictive regulator. In the presented work, the authors develop a model of the dynamics of an economic system based on a system of four differential equations with fractional time derivatives of indicators of changes in system characteristics.
The results of the model analysis show that the presented approach not only allows the suppression of the chaotic behavior of the parameters describing the system and stabilization of the closed system, but also the rejection of limited external perturbations.
In [
2] is described the use of Mittag–Leffler fractional integrals (ML) to solve a system of two related fractional stochastic differential equations. The fractional stochastic process, according to the author, can be described through the fractional stochastic integral relative to the standard Brownian motion, and the studied processes are Gaussian, not Markov, processes, with the property of a long-acting dependence, which allows for considering memory. Thanks to the obtained solutions for covariance of such processes, the author [
2] developed algorithms for modeling neural dynamics.
Unfortunately, this article only considers the solution of a system of two fractional differential equations for the case when the value of the orders of fractional derivatives does not exceed 1, which somewhat limits the scope of the resulting model.
Solutions of fractional differential equations described in the literature are usually considered when the value of the value of the fractional time derivative is in the range: , and the fractional derivative by state (variable describing the state of the process) is in the range: , which limits the use of fractional differential models for time series dynamics analysis.
The purpose of the work is to find an analytical function of the probability density of observing the amplitude of deviation of the levels of the time series depending on the time interval for calculating these amplitudes for the infinite axis based on the fractional differential equation of the diffusion type with arbitrary values of the indices of fractional derivatives.
2. Differential Equations with Fractional Partial Derivatives
A diffusion-type differential equation with fractional partial derivatives in the general case has the following form:
where
and
are fractional derivative indices (according to Caputo) and positive real numbers,
is the probability density function of observing state
at time
, depending on time
and state
, and
is a certain constant coefficient. For example, when describing diffusion,
plays the role of the concentration of the diffusing substance, and
is the diffusion coefficient.
In general, the fractional derivative of order
ν for a function
is defined as follows [
3]:
where
is the fractional part of the exponent
ν, and
is the rounding of the fractional exponent
ν to the nearest largest integer value, i.e.,
.
The Caputo definition of fractional derivatives differs from the Riemann–Liouville definition in that the function is first differentiated to integer order , greater than the non-integer order after rounding to an integer (), and then the result is integrated to order .
At present, an analytical solution of the fractional diffusion Equation (1) has been obtained only for the case
and
; see [
4,
5,
6,
7,
8,
9,
10,
11]. Solutions outside the boundaries of the specified values of
and
are not presented in the literature.
When solving practical issues related to the analysis and forecasting of the dynamics of time series for complex processes, it may turn out that the condition and is a limitation of the model, and the values of and may go beyond the specified ranges.
Due to the complexity of the problems to be solved and the significant difficulties in obtaining analytical solutions, numerical methods are very often used in practice. For example, in the work [
12], using numerical methods, the solution of an equation of the form was investigated for a segment:
And in the work [
13], the solution for a segment of an equation of the form:
It is interesting to compare the fractional differential Equation (1) with the equation of ordinary diffusion:
, the solution of which on the infinite axis allows us to obtain the Poisson distribution law:
The function for example, can be interpreted as the probability density of observing some value of the level of the time series at time , if these levels can randomly change over time.
In case of Poisson distribution, the dispersion
will have a linear law of its dependence on time (
)). If there is a slower growth
from
(
, where
), then such a process is qualified as subdiffusion [
14,
15]; if there is a faster growth
from
t (
, where
), then such a process is qualified as superdiffusion [
16]. The distribution function describing subdiffusion type processes is obtained from the solution of a fractional differential equation of the form:
, and superdiffusion from the equation,
, where
and
are the exponents of fractional derivatives, and
is a certain coefficient (for example, the diffusion coefficient). Anomalous diffusion processes can also be observed [
17,
18] described by a fractional differential equation of mixed type (see Equation (1)).
In addition to the fractional diffusion equation, other types of fractional differential equations are of considerable interest. For example, in [
19,
20,
21,
22,
23], the solution of the fractional Zener wave equation is considered:
where
in the case of elastic waves is the displacement of the particles of the medium from the equilibrium position at the point with coordinates
at time
;
is the wave propagation velocity;
and
are some positive time constants. In this case,
and
are different values of fractional derivatives with respect to time, and the operator
is not fractional.
The Zener stress–strain relationship is utilized for elastic wave propagation, alongside the linearized conservation of mass and momentum. The Zener wave equation facilitates the description of three distinct modes of wave attenuation that exhibit power law characteristics [
19]. Models derived from this equation find applications in fields such as medical elastography and acoustics.
In [
21], a detailed description of the solution of the Zener equation for the case
(
and
can be derivative fractional positive numbers that define derivatives with respect to time
) is presented. This result is very important, since the solution of any fractional differential equations in analytical form has significant problems.
The solution of wave equations with a fractional time derivative was further developed in [
22] to describe the behavior of waves in non-Newtonian fluids.
Note that the solution of the Schrödinger equation with fractional derivatives is also of interest.
Currently, the most developed and studied are fractional differential models created to describe various types of physical problems, mainly devoted to the study of processes of physical kinetics, diffusion and relaxation in various environments [
23,
24,
25,
26,
27,
28,
29,
30], in [
31] the analysis of time series of sociodynamic processes based on fractional differential equations was considered.
It should be noted that several studies [
32] have developed models that describe complex processes while incorporating memory effects and self-organization, albeit without the consideration of fractional differential equations.
3. Formulation of the Boundary Value Problem
Let us consider the following problem: Let there be a differential equation with fractional derivatives of the diffusion type:
where
is the probability density function of observing the state
of some process (for example, the magnitude of the deviation of the levels of a time series) from time
(for example, the time interval for calculating the amplitudes of the deviation of the levels of a time series),
is a certain constant coefficient, and
and
are the indices of the fractional derivative (
and
). Note that the values of
and
do not necessarily have to lie, as is usually considered in other studies, in the ranges
and
.
Using the following boundary conditions:
and the initial condition:
let us consider the boundary value problem of finding the function
for the given conditions with arbitrary positive real values of
and
.
4. Solution of the Boundary Value Problem
Let us perform the Laplace transform for Equation (1) with respect to
t (we move from t to s) and the Fourier transform with respect to x (we move from
x to
k), which allows us to obtain a double image
for the function
:
You can find detailed information about Laplace transformations of franctional derivatives in the book [
18]. The following is the Fourier transform:
Substituting Fourier images into the equation obtained after the Laplace transform, we write the following:
Then we obtain the following:
Let us denote
and, taking (
), we carry out the binomial expansion:
Next, we perform the inverse Laplace transform and move from the image s to the original
:
According to the tables, for inverse Laplace transforms:
Note that
is the Mittag–Leffler function. To perform the inverse Fourier transform of this function and find the distribution density, we move from calculating the infinite sum to the integral representation of the Mittag–Leffler function through the contour integral [
33]. For this, we use the Hankel representation for the Euler gamma function:
where
is the integration contour that starts from
, reaches
, goes around it counterclockwise, and returns back, and
is the integration contour that starts from
, reaches
, goes around the point
counterclockwise, and returns back. Using this representation of the gamma function and the contour,
we obtain the following:
Let us perform the inverse Fourier transform of the function
:
To calculate the resulting integral, we can use the theory of residues. We can consider an analytical continuation of the function to the imaginary plane and go to a closed contour G, inside which the poles of the function will be located.
According to the fundamental theorem of residue theory, the integral over a chosen closed contour G will be equal to the sum of the residues at the singular points enclosed by that contour, with one side corresponding to the integral over the real axis, which must be found to solve the problem.
When finding residues, it is necessary to consider that the integrand possesses (5) a simple pole:
Thus, the function meets the normalization conditions and can be considered as a probability density function of some distribution.
The contour integral can be represented as the sum of the integrals over the corresponding sides of the contour. The integral that must be computed to obtain the inverse Fourier transform is determined by the side of the contour lying on the real axis.
The whole contour will consist of the side lying on the real axis (the integral that we need to calculate), the arc of the circle (radius R→∞), integration over which will give 0, and the beam (denote it
), integral over which is equal to
A replacement was made here:
Obviously, this approach does not give the desired result.
In order to try to obtain a solution, we formulated the hypothesis that the integral , if it is represented through the sum of the integrals on the sides of the contour, is equal to the sum of the residues covered by the contour multiplied by some constant (C), which appears due to the fact that the integral over the beam can be expressed through the integral over the side of the contour lying on the real axis.
Next, to find special points, write
. The denominator turns to 0 at
; it will be a simple pole of the first order. In accordance with the theory of residues, the res will be equal:
Here, we substituted k into res. Further, the u integral was already calculated.
This allows us to
hypothesize that to find the integral,
we cannot consider the integral over the closed contour
and calculate it on all sections, but write
where
is some constant, which can be found from the condition of normalization of the function as follows:
Further, considering that normalization must be performed for any t, we write
Thus, we obtain that
. This allows us to write
Further, expanding
in a series, and considering the Hankel representation for the gamma function,
we can write
Further, given that an analysis of the behavior of the function will be carried out at different values α and
β, to shorten the description, we will denote ρ
as
. For negative values of the gamma function argument, you can use the complement equation:
Accordingly, the desired probability density function
will have the form:
Numerical analysis shows that the condition for the convergence of series (7) is that the values of α and β must be such that the inequality is satisfied: .
We could not establish the exact value of this number; perhaps it is irrational. We have added the procedure for calculating this value to the text.
When we found the applicability limit of the model, we used the following algorithm. First, a range of values β (for example, 0 < β ≤ 1), was selected, then an α value was set at a given step and the convergence of the series in Equation (7) for .
When convergence occurred, the β/α value near the point when convergence occurred was refined. Repeating this procedure can come close to the exact value. The test showed that, regardless of the range of values, convergence is always observed if condition 0 < β/α ≤ 0.865 is met.
5. Analysis of the Solution of a Boundary Value Problem
First, it should be noted that the normalization condition is satisfied for the obtained probability density function
, and when
and
, it becomes a Poisson distribution:
Secondly, for the function
, let us consider the dependences on time
t of the magnitude of the following moments: mathematical expectation
, dispersion
, asymmetry
, and excess
.
It is also of interest to consider the behavior of the third (asymmetry) and fourth (excess) moments of the distribution function (see Equations (10) and (11)). The asymmetry of distributions characterizes the so-called “skewness” of the distribution function, and for symmetric functions (for example, the Poisson distribution), it is equal to 0. “Skewing” can arise as a result of a purposeful “drift” of the process characteristic to some selected state.
The excess characterizes the “tail” of the distribution. For large positive excess values, the distribution function decreases more slowly with distance from the mean than for small values.
For the Poisson distribution, the excess is 3. For an excess greater than 3, the distribution density graph will lie above the normal distribution graph, and for less than 3, below (for this reason, the number 3 is subtracted from Equation (11) to compare the results).
When calculating the moments of the distribution function, one can use Equation (6) and first calculate the corresponding moments, and then move from the contour integral back to the gamma function.
Equation (8) does not consider the sign of the change but describes the dependence of the value of the mathematical expectation on . Note that for and , the moments of the distribution function coincide with the moments for the Poisson distribution, which is a solution to the ordinary differential diffusion equation.
Let us conduct a simulation study of the obtained model. For example, let us take the parameter (conventional units) and several different ranges of values α and β from the region .
Figure 1a shows a graphical representation of the function
obtained for
and
(
). Curve 1 is plotted for
conventional units, curve 2 is plotted for
conventional units, curve 3 for
.
Figure 1b shows a graphical representation of the function
obtained for
and
(
). Curve 1 is plotted for
conventional units, curve 2 for
conventional units, curve 3 for
.
Figure 1c shows a graphical representation of the function
obtained for
and
(
). Curve 1 is plotted for
conventional units, curve 2 for
conventional units, curve 3 for
.
Figure 1d shows a graphical representation of the function
obtained for
and
(
). Curve 1 is plotted for
conventional units, curve 2 is plotted for
conventional units, curve 3 for
.
Figure 1e shows a graphical representation of the function
obtained for
and
(
). Curve 1 is plotted for
conventional units, curve 2 for
conventional units, curve 3 for
.
Figure 1f shows a graphical representation of the function
obtained for
and
(
). Curve 1 is plotted for
conventional units, curve 2 for
conventional units, curve 3 for
.
Graphical analysis of the simulation results shows that the range of
and
values can be conditionally divided into two areas:
(see
Figure 1d) and
(see
Figure 1c,f). The value
corresponds to the case when the probability density function
corresponds to a Poisson-like distribution (see
Figure 1b,e). Note that the function
exactly corresponds to the Poisson distribution only when
and
.
An analysis of
Figure 1a–f shows that when the values of
and
change, a change in the scales of the presentation of the results of simulation modeling is observed, but the general form of the dependencies for the two selected areas is preserved, which is clearly seen when comparing
Figure 1a,d,
Figure 1b,e, and
Figure 1c,f in pairs.
As t increases, the height of the distribution function graphs decreases and the width increases, and they remain symmetrical relative to the line passing vertically through zero. However, in the region
, although the graph is symmetrical, the position of the maxima shifts to the right and to the left with increasing
t (see
Figure 1a,d).
It should also be noted that as x increases, the probability density function quickly drops to zero.
As the value of the coefficient varies, changes in the scales of the presentation of the results from simulation modeling are observed; however, the overall shape of the dependencies for the two selected regions remains consistent.
The indices of fractional derivatives can also be integers, but if their ratio corresponds to the areas under consideration, then the behavior of the probability density function
corresponds to that shown in
Figure 1a–f.
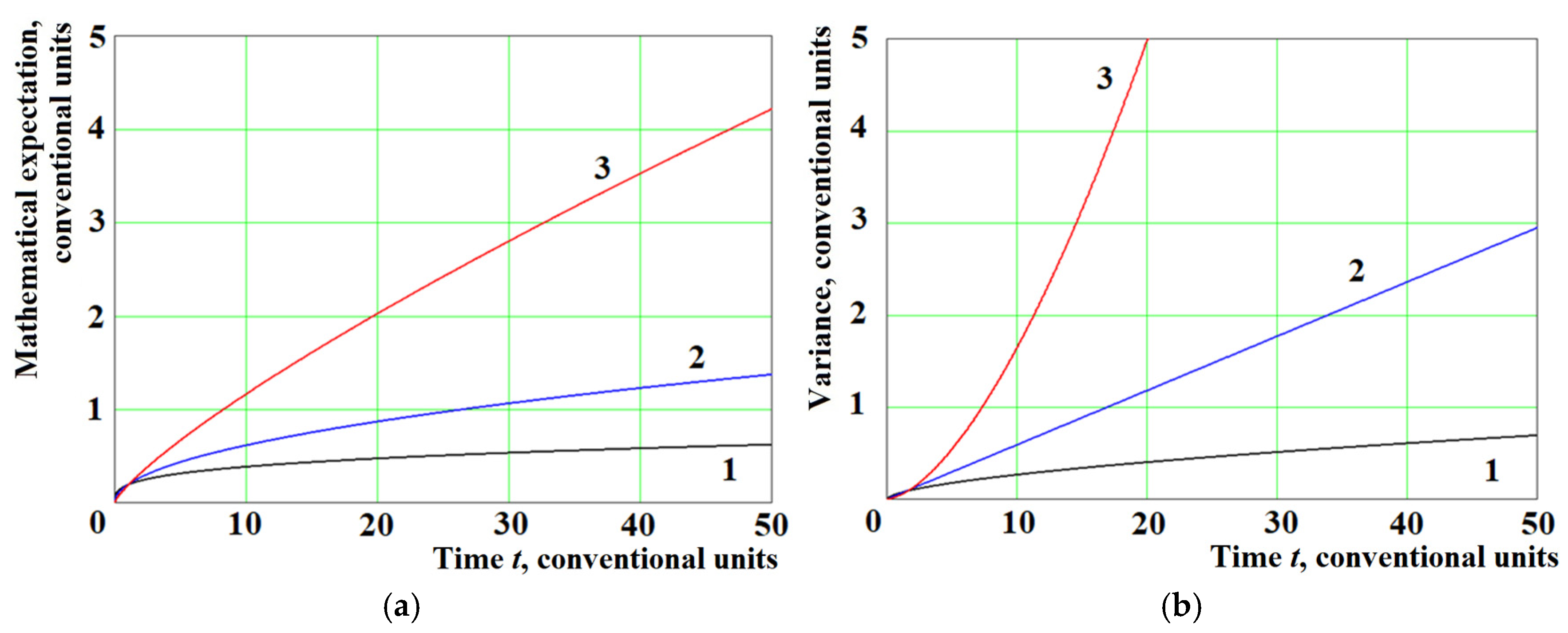
Let us analyze the behavior of the time dependences of the mathematical expectation
and dispersion
. For simulation modeling, we take the value
,
and consider two regions,
and
.
Figure 2a shows the results of the theoretical calculation of the mathematical expectation using Equation (8)
, and
Figure 2b shows the dispersion (Equations (9) and
). Curves 1 in
Figure 2 and
Figure 3 are plotted for
; curves 2 for
and curves 3 for
.
Figure 2 shows that in the region
, the behavior of the graphs for the mathematical expectation and dispersion is very similar; they grow more monotonically than the linear dependence (see line 2 in
Figure 2b), and at
, a stronger growth is observed.
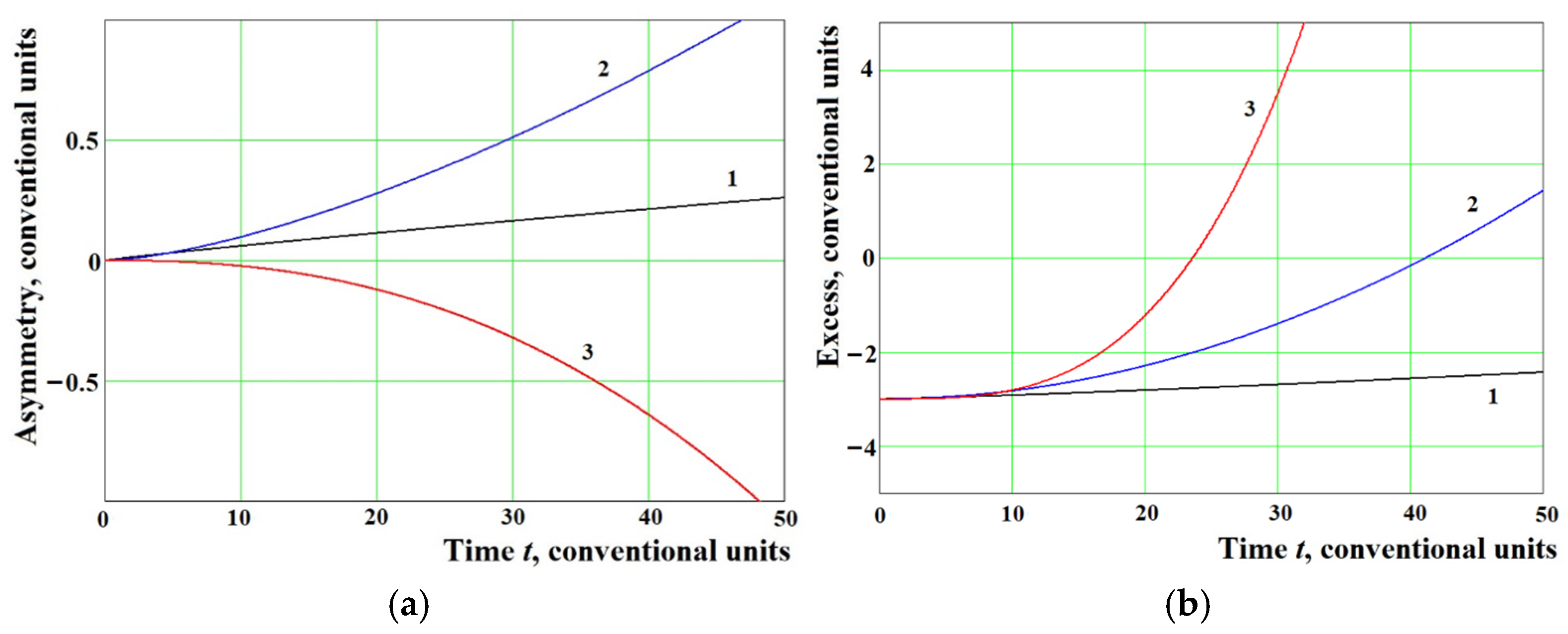
Figure 3 shows the results of the calculation
of asymmetry using Equation (10) (see
Figure 3a) and
of excess using Equation (11) (see
Figure 3b).
The dependence of the amplitude asymmetry on the time interval of its calculation in the region is almost linear. In the region there is growth in the positive range of values. In the region , there is a decrease in growth, and the dependence goes into the region of negative values. The excess can be in the region of negative values at short times, and with an increase in the time interval of amplitude calculation, their excess goes into the positive region.
6. Analysis of the Dynamics of Time Series of Non-Local Processes in Complex Systems
To compare the results that can be obtained using the developed model and the results of observations of real processes, it is necessary to find time series whose characteristics would be non-local in time and state .
To analyze the non-locality of the time series dynamics and determine their characteristics, the Hurst normalized range method [
34] can be used, which allows determining their fractal dimension and classifying the type of behavior. It is possible to normalize the range of the values of the levels of the series R by the standard deviation of the values of the levels of the series S and present their ratio (normalized range) as an equation:
(after logarithm
), where
is a certain constant, n is the number of observations (levels of the series) that make up the time series (
) under consideration, and the exponent
is the so-called Hurst coefficient or exponent. The presence of breaks in the dependence of
on
may indicate the presence of characteristic time scales and/or periodicities. The value of the coefficient
allows classification of time series by the nature of their behavior.
For a random process with independent increments and finite dispersion, it has been rigorously proven [
35] that the
exponent is equal to
.
The difference of the Hurst exponent from
reflects the fractal properties of the processes generating time series. At
, the observed tendency of the process is maintained (the property of persistence), and at
, the tendency changes to the opposite (anti-persistence); i.e., the growth of the observed value is replaced by a decrease and vice versa [
36].
As an example of time series reflecting complex processes with a strong influence of the human factor, we can consider, for example, the dynamics of changes in voter preferences during the US presidential elections.
Figure 4 shows, as an example, time series of voter preferences in the Clinton–Trump presidential campaign of 2016 [
37].
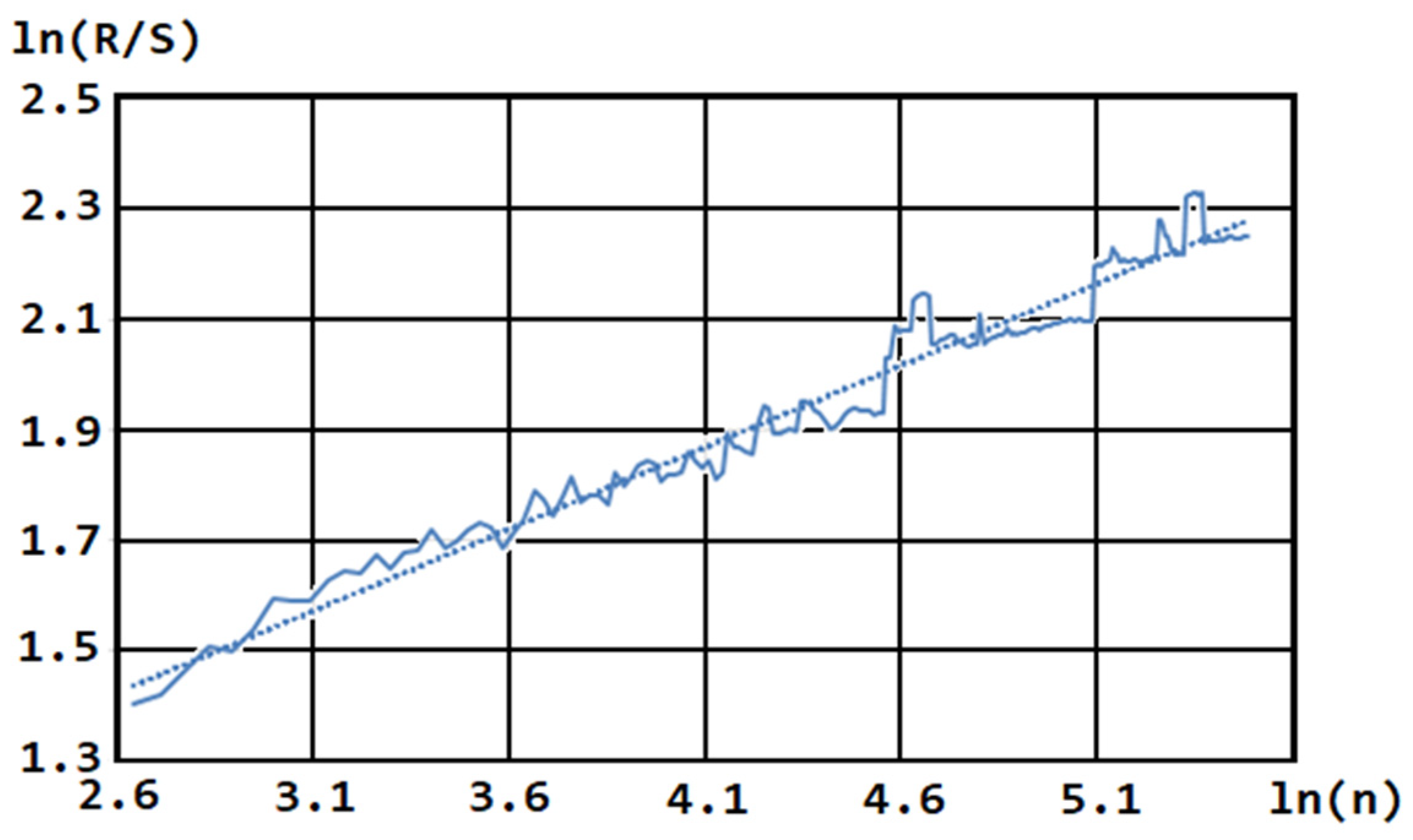
Figure 5 shows, as an example, a plot of the natural logarithm of
versus the natural logarithm of the number of observations (series levels—
) for the preferences of voters voting for Trump in the 2016 US presidential campaign.
After processing the time series of US presidential election campaigns in 2016–2020 [
37], we can obtain the following linear dependencies
on
:
In 2020: Biden—; Trump—;
In 2016: Trump—; Clinton—;
In 2012: Obama—; Romney—;
In 2008: Obama—; McCain—.
To confirm the conclusion about the linear approximation, we can examine the behavior of the residuals and test the hypothesis that they are normally distributed with a mean value equal to zero and have a homogeneous dispersion. The calculated value of the mathematical expectation for the distribution of residuals is , and the dispersion is .
Testing the hypothesis about the slope (two-sample F-test for dispersions) shows that the dispersion of the residuals (calculated relative to the trend line) is significantly less than the dispersion of the deviation of the linear regression points from the mean value of the observed data. It is equal to ().
Thus, from the obtained data, we can conclude that the distribution of the residuals is very close to normal, and the obtained regression is significant.
Note that in all cases for the studied time series, the value of
is significantly less than
, and, therefore, the observed time series is antipersistent (ergodic). Since the value of the Hurst coefficient is significantly different from
, it follows that the structure of these series has fractality [
38], and the processes described by it can have short-term memory (aftereffect). Hurst also suggested that the shift in values from
occurs due to the existence of memory.
It should be noted that the study of fractality of time series allows us to obtain forecasts of their dynamics, which are useful from a practical point of view. In [
39], issues of fractality analysis of heart rate time series were considered.
The aim of the work was to determine the parameter of fractal dimension calculated for a sequence of RR interval durations, to identify the boundaries of its change for healthy and sick patients, as well as the possibility of using it as an additional factor in identifying cardiac pathology.
A significant difference of the Hurst exponent from a value equal to indicates that the observed characteristics of the time series under study may differ significantly from the normal distribution law.
To determine the properties of the observed time series and the distribution functions of their parameters (probability density), for example, the magnitude of the amplitude of the change in the levels of the series depending on the time interval of calculation of this amplitude (this is necessary for the analysis of the characteristics and dynamics of the observed processes), we can use the following algorithm developed by us:
First, you can set the size of the “sliding window” (the time interval between the observed levels of the series, for example, one day, two days, three, etc.) and select data from the time series for the specified time range (the size of the “sliding window”).
Next, based on the selected data, it is possible to calculate the amplitudes of the change in the series levels for various selected time intervals (sizes of the “sliding window”).
Then, one can sort in ascending order (from negative to positive) the sets of values obtained for each of the measured intervals, and, for each size of the “sliding window”, construct histograms of the distribution density of the deviation amplitudes.
Then, using the obtained histograms, it is possible to calculate the distribution moments (mean value: mathematical expectation, dispersion, asymmetry, excess) for the selected time intervals for calculating the deviation amplitudes.
Next, we can construct dependencies for the mathematical expectation, dispersion, asymmetry, and excess of the amplitudes of deviations of the series levels from the time intervals of calculation of these amplitudes (the sizes of the “sliding window”).
The study of the dependence of the mathematical expectation, dispersion, asymmetry (
the third moment of distribution), and excess (
the fourth moment of distribution) of the amplitudes of deviations of the levels of time series on the calculation time intervals (the sizes of the “sliding window”) allows us to determine whether the studied time series are non-stationary and to use the observed characteristics to build a model of their evolution, which is necessary for predicting their dynamics. The observed value of the mathematical expectation, dispersion, asymmetry, and excess were calculated using the following equations:
and
—is calculated based on the number of amplitude values
.
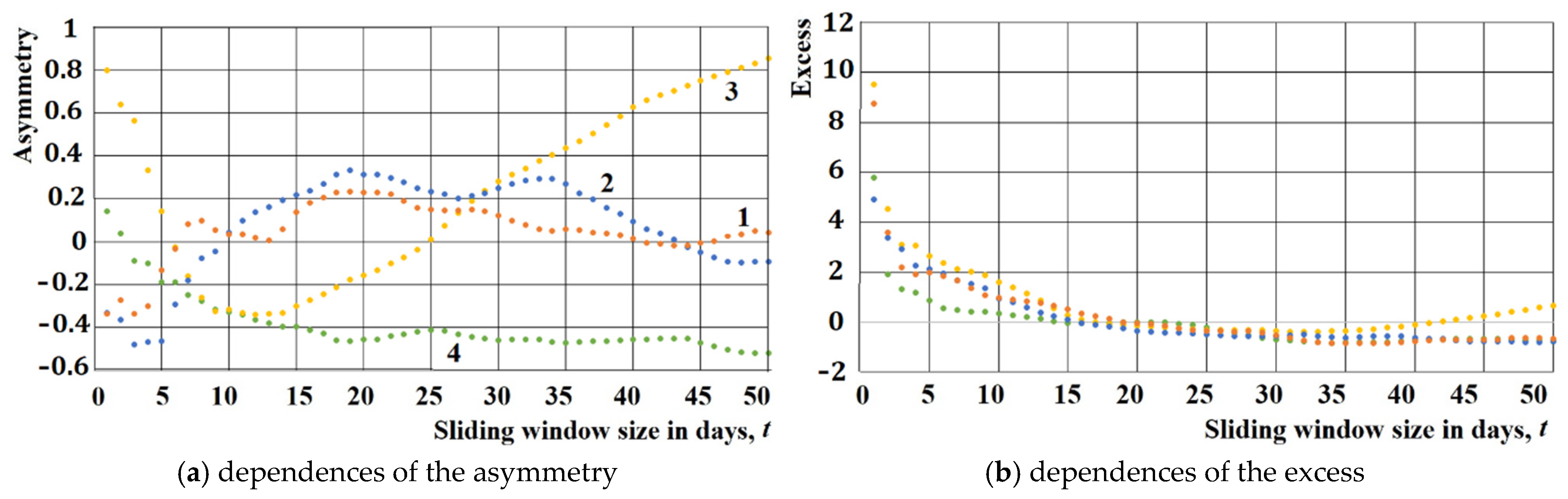
Figure 6 shows the dependences of the mathematical expectation (see
Figure 6a) and dispersion (see
Figure 6b) of the amplitudes of the time series levels on the time interval of their calculation for voter preferences in the US presidential election campaigns in 2008–2020 (for their winners); in
Figure 7a—asymmetry, in
Figure 7b—excess. Curves 1 in
Figure 6 and
Figure 7 are constructed after analyzing the change in Obama’s popularity in 2008; curves 2—Obama (2012), curves 3—Trump (2016) and curves 4—Biden (2020). The mathematical expectation, dispersion, asymmetry, and excess were calculated for the entire period of each of the election campaigns.
Figure 6 and
Figure 7 show that the values of the mathematical expectation of the amplitudes, their dispersion, asymmetry, and excess depend in a complex nonlinear way on the time interval of calculation of these amplitudes (“sliding window”), which indicates that the studied time series are not stationary.
For example, when performing the Poisson distribution for a stationary time series
, the value of the mathematical expectation
should be equal to zero (or be a constant):
where
x is the amplitude value, and t is the time interval for its calculation (the value of the “sliding window”).
In addition, when the Poisson distribution is implemented, the amplitude dispersion should show a linear dependence on the size of the “sliding window”:
For the studied time series, a deviation of the distribution from the Poisson law is observed, which indicates that the observed time series are non-stationary.
The dependences of the values of the mathematical expectation and dispersion of the amplitudes of the change in the levels of time series on the time interval of calculating these amplitudes, presented in
Figure 6, have a form close to the dependence
, where
is some positive, possibly fractional number. This indicates that the process has fractality in time, and it can be assumed that when modeling the dynamics of non-stationary time series based on differential equations, they can contain a fractional derivative in time of any value.
The complex relationship between the asymmetry of the amplitude distribution and the time interval of their calculation (see
Figure 7a) suggests that the process under investigation exhibits some degree of self-organization.
This is evidenced by the varying “drift” of the characteristics of the time series towards a certain state for different time intervals used in the asymmetry calculations. In the examined cases (see
Figure 7b), it is observed that for small time intervals in amplitude calculations, the value of the distribution excess is significant.
Conversely, for larger “sliding windows”, this value gradually decreases to zero, approaching the excess characteristic of the Poisson distribution, which may further indicate the self-organization of the processes.
Processing and analysis of the observed data allows us to draw a number of conclusions:
The time series describing the processes under consideration are non-stationary (the values of the mathematical expectation and dispersion of the amplitudes depend in a complex way on the time interval of calculation of these amplitudes (“sliding window”) , where is some positive, possibly fractional number), which indicates that the observed processes have fractality in time, and fractional differential equations can be used in their modeling.
Analysis of the observed non-stationary time series shows that the processes they describe have fractality and short-term memory (the value of the Hurst exponent is significantly less than ).
The complex dependence of the asymmetry and excess of the amplitudes of the change in the levels of the series on the time interval of its calculation indicates that for the process under consideration, some self-organization is observed, which is manifested in the fact that for different time intervals there will be different asymmetries, and the value of the excess at large intervals tends to that characteristic of the Poisson distribution.
Comparison of
Figure 2 (theoretical calculation) and
Figure 6 (results of processing the observed data) shows that the observed dependencies of the mathematical expectation and dispersion are in good agreement with those calculated theoretically, using the developed model, if the value of
lies in the region
.
The observed dependencies of the asymmetry and excess of the amplitudes of deviations of time series on the time interval of calculation of these amplitudes are complex in nature and comparison of their behavior with theoretical calculations is very difficult and does not allow for unambiguous conclusions.
The model of approximating functions of the distribution density of parameters of non-stationary time series should consider all the above characteristics of the observed processes, and considering the fact that the processes under consideration are non-local in time t and state x, then for their modeling, one can try to use fractional differential equations with an arbitrary value of the orders of derivatives.
7. Evaluation of the Accuracy of the Model in Forecasting the Dynamics of Time Series
Let us consider the possibility of using the proposed model to forecast the dynamics of time series, for example, the electoral campaigns of the US presidential elections in 2008–2020. For validation and accuracy assessment, we will use data from the resource [
2].
The choice of the optimal sample size of the time series for finding the model parameters , , and is determined by the following factors. If it is taken very large, then it will include a significant number of information events that can cause high volatility. If it is taken too short, then the reduction in the amount of statistical data will introduce a significant error, which will negatively affect the accuracy of determining the model parameters.
Let us define the parameters of the model and evaluate its accuracy using the following algorithm:
Let us take the original time series and consider some part of it included in the selected time interval (), which will contain n-values of the series levels.
Next, for the selected part of the time series, we find the differences between its different levels (deviation amplitudes). We denote these differences as , where is the number of intervals between the selected levels. For example, if the number of values of the series levels was selected, then the number of values of the amplitudes will be equal to 14 (the nearest levels); the amplitudes separated by , two intervals between the nearest levels, will also be equal to 14; the amplitudes separated by three intervals between the nearest levels, will be equal to 13 (levels separated by three intervals); the amplitudes separated by , four intervals between the nearest levels, will be equal to 12, etc. The last value of the number will be determined by the fact that it must be statistically significant for subsequent averaging; for example, there must be at least four values.
Then we find the square of the value of each difference
and average them over the total amount (we find the observed value
). Next, using Equation (8) for
, we find the parameters of the model.
gives the advantage, compared to using the mathematical expectation,
that we can ignore the sign of the change
. Taking the logarithm
(see expression 9), we obtain
Having processed the observed data (see
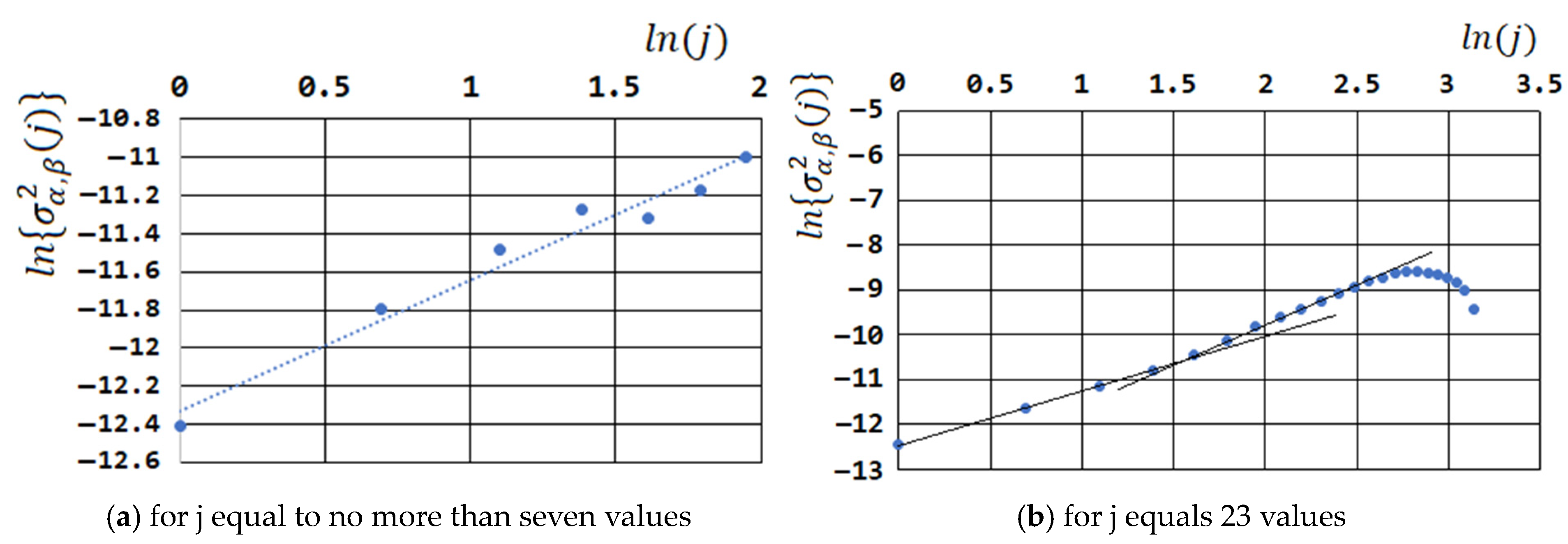
Figure 7) using the obtained linear dependence, we determine the tangent of its slope (
), and we can calculate the value of
and
. Further, by extrapolating the obtained linear dependence to the axis,
we can find
.
Figure 8 shows the linearization of the observed data for a randomly selected part of the time series with a length of 25 days, showing the change in the preferences of Trump voters in 2016 (
Figure 8a for j equal to no more than seven values,
Figure 8b for j—23 values).
Then, we can calculate the predicted amplitude values for each of the time intervals . For this, we can use the found values of the model parameters and the equation for the mathematical expectation:
. Next, using the last observed value of the time series level in the time interval tn and the predicted change we can build a forecast for its selected depth j (j determines the forecast time interval ). Note that when finding the forecast value, it is necessary to consider the trend observed in the interval . If a general decrease is observed, then is subtracted from the last observed value; if an increase, then it is added.
Next, using the predicted value of the series level and the observed value, we can determine the relative forecast error by modulus. To achieve this, we subtract the observed value from the predicted value and divide by the value of the observed value.
We return to the original time series and shift by one level count number of the series to the right. The new interval will also contain n levels, but there will be only one new one in it—the one on the far right.
Next, we perform steps 1–6 of this algorithm until all values of the levels of the original time series have been processed.
Then, for a given selected and each selected in it, we determine the average error over all predictions made.
Next, we return to point 1 of this algorithm and increase the time interval for finding the parameter , i.e., the number of -values of the series levels included in it (for example, so that τn increases by 1). After that, we perform steps 1–8 of this algorithm until all the values of the levels of the original time series are processed.
Figure 9 shows 3D graphs of the dependence of the relative forecast error on the sample size
and the forecast depth
, obtained based on the processing of observed data on voter preferences of the winners of the US presidential election campaigns in 2008–2020, using the previously described algorithm for determining the model parameters and assessing its accuracy.
Figure 9a—Biden (2020),
Figure 9b—Trump (2016),
Figure 9c—Obama (2012),
Figure 9d—Obama (2008).
When determining the accuracy of forecasting, the sample size range for determining the model parameters was considered from 10 to 100 days and the forecast depth from 1 to 100 days.
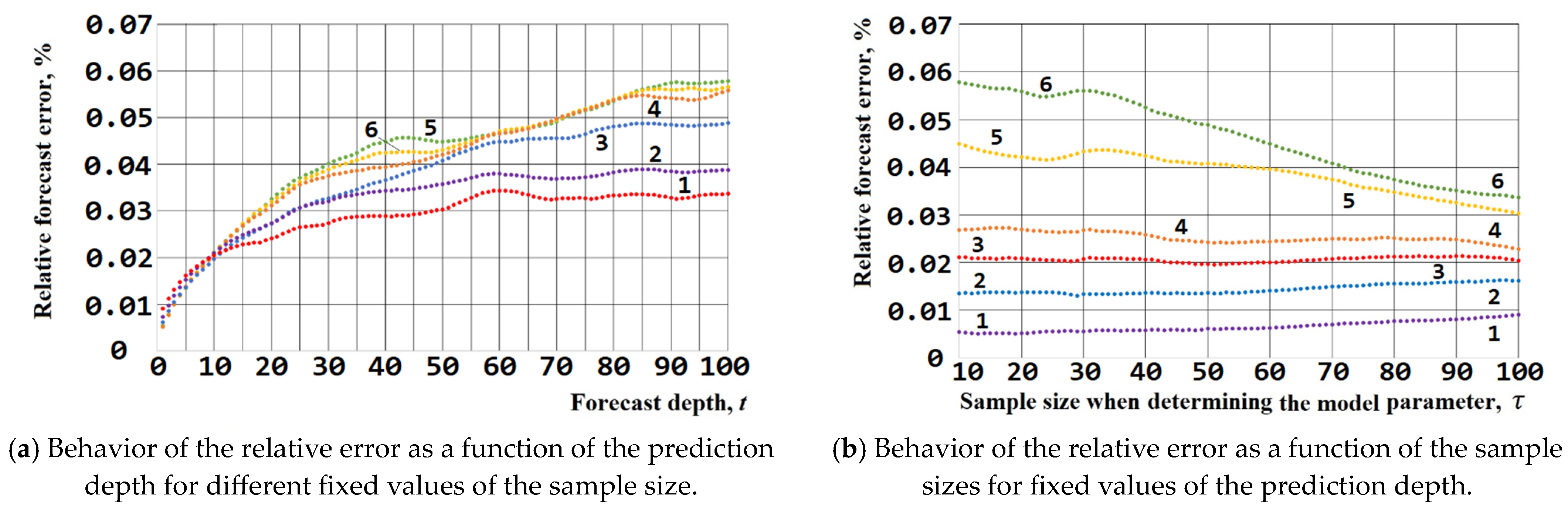
Figure 10 shows, as an example, cross-sections of the surface describing the dependence of the relative forecast error on the sample size
τn and the forecast depth t for the preferences of Biden voters in 2020.
Figure 10a illustrates the behavior of the relative error as a function of the prediction depth for different fixed values of the sample size (curve 1 for the sample size
, curve 2—
, curve 3—
, curve 4—
, curve 5—
and curve 6—
), and
Figure 10b as a function of the sample sizes for fixed values of the prediction depth (curve 1 for the prediction depth of 1, curve 2—5, curve 3—10, curve 4—15, curve 5—50, and curve 6—100). Curves 1–6 shown in
Figure 10 are the result of processing the observed data using different sizes of time series samples.
The dependence of forecast accuracy on sample size and depth has a complex form with local maxima and minima, but their numerical characteristics allow us to draw the following conclusions:
For any sample size used to determine the model parameters, in general, the accuracy of the forecast decreases with increasing depth (the relative error increases), which demonstrates the adequacy of the accuracy assessment methodology used.
At a shallow depth of 1–2 days, the relative error is from 0.5–1.0% (for different winners) with a small sample of the series for determining the model parameters (10 days) and about 1.0–1.5% (for different winners) with a sample of 100 days.
With a forecast depth of about 10–14 days, its relative error is practically independent of the sample size taken to determine the model parameters and is about 2.0–2.5% (Biden 2020), 3.0–3.5% (Trump 2016), and 1.5–2.0% (Obama 2012) for any sample. From a practical point of view, forecasts for 1–2 weeks are of the greatest interest for managing an election campaign, and given that acceptable accuracy in the proposed methodology can be ensured using small samples of the time series, the proposed forecasting method is technologically easy to implement.
With a large forecast depth (about 100 days), the relative error is about 2.0 to 3.5% (for different winners) with a small sample of the series for determining the model parameters (10 days) and 3.4–6.9% (for different winners) with a sample of 100 days. The increase in forecast error with an increase in forecast depth also confirms the adequacy of the proposed accuracy assessment method.
Similar results are obtained when analyzing the preferences of voters of the losing candidates. In conclusion, it should be noted that all the results obtained show that the developed model of time series analysis shows a very high accuracy of forecasting the dynamics of electoral processes and can be used in practice.
8. Conclusions and Findings
As a result of the research, a new solution was obtained for the problem of finding the probability density function of the observation of the state of a certain process (for example, the magnitude of the deviation of the levels of a time series) from time (for example, the time interval for calculating the amplitudes of the deviation of the levels of a time series) for an infinite axis based on a fractional differential equation of the diffusion type. The presented solution differs from the existing ones in that it was obtained for arbitrary values of the orders of derivatives. The solutions described in the literature, as a rule, are considered in the case when the value of the fractional derivative with respect to time lies in the range , and the fractional derivative with respect to state (the variable describing the state of the process) is in the range . The presented solution allows us to consider any ranges for and, if the inequality is satisfied, for their ratio . When solving practical problems of analyzing and forecasting the dynamics of time series of complex processes, it may turn out that the condition and is a limitation of the model, and the values of and may go beyond the specified ranges.
In practical terms, for example, when analyzing the dynamics of time series, it is necessary to determine the parameters of the model using the observed sample of the series. Once determined, they can be used to predict new values of series levels at a given point in time.
Such tasks are widespread, not only in sociology, but also in economics, for example, when predicting financial processes (changing stock indicators, etc.). In order to ensure the necessary prediction accuracy, it is necessary to make as accurate a determination of model parameters as possible.
The research conducted by us showed that the received estimates of high precision of forecasting very often are reached only if α and β lie out of ranges 0 < β ≤ 1 and 1 ≤ α ≤ 2.
In this regard, existing solutions cannot be used, because they limit the analysis only to the specified ranges, and the accuracy of forecasts is significantly reduced.
In addition, the existing solutions of fractional diffusion equations do not always allow obtaining various moments of the partition function, for example, the mathematical expectation of deviations of the time level.
In particular, [
7,
26] indicates that all moments of the solutions described in the literature exist only at α = 2, while the solution presented by us shows that it is possible to find moments of any order, which also expands the possibilities of its application for practical purposes compared to existing ones.
In the analysis of observed data, for example, it is possible to define dependence of expected value of amplitude of a deviation between row levels from an interval of calculation of amplitude. However, the existing models with ranges of values of fractional derivatives 0 < β ≤ 1 and 1 ≤ α ≤ 2 indicate that mathematical expectation does not exist, and this does not allow them to be applied to the processing of observed data, while our proposed solution removes this contradiction.
Analysis of the developed model shows that when changing the values of
and
, a change in the scales of the presentation of the results of simulation modeling is observed, but the general form of the dependencies is preserved for all the studied areas, which is clearly seen in a pairwise comparison of
Figure 1a,d,
Figure 1b,e, and
Figure 1c,f.
As the time t increases, the height of the distribution function graphs decreases and the width increases, and they remain symmetrical relative to the line passing vertically through zero. However, in the region
, although the graph is symmetrical, the position of the maxima shifts to the right and to the left with increasing t (see
Figure 1a,d).
It should also be noted that as x increases, the probability density function quickly drops to zero.
When the value of the coefficient changes, a change in the scales of the presentation of the results of simulation modeling is observed, but the general form of the dependencies for the two selected areas is preserved.
The indices of fractional derivatives may take integer values; however, when their ratio aligns with the characteristics of the analyzed domains, the behavior of the probability density function
corresponds to the patterns illustrated in
Figure 1a–f.
Figure 2 shows that in the region
, the behavior of the graphs for the mathematical expectation and dispersion is very similar; they grow more monotonically than the linear dependence (see line 2 in
Figure 2b).
The analysis of the obtained model shows that it is not inconsistent, and the behavior of the moments of the distribution function (mathematical expectation and dispersion) obtained theoretically coincides with those observed in practice for the time series of electoral processes of the US presidential elections in 2008, 2012, and 2016 (see comparison of
Figure 2 and
Figure 6). The observed dependencies are in good agreement with those calculated theoretically using the developed model if the value of
lies in the region
.
The proposed model for describing the dynamics of time series allows us to develop a forecasting algorithm with high accuracy. At a shallow forecast depth of 1–2 days, the relative error is from 0.5–1.0% (for different winners) with a small sample of the series for determining the model parameters (10 days) and about 1.0–1.5% (for different winners) with a sample of 100 days. With a forecast depth of about 10–14 days, its relative error is practically independent of the sample size taken to determine the model parameters and is about 2.0–2.5% for any sample. With a large forecast depth (about 100 days), the relative error is about 2.0 to 3.5% (for different winners) with a small sample of the series for determining the model parameters (10 days) and 3.4–6.9% (for different winners) with a sample of 100 days.
Similar results are obtained when analyzing the preferences of voters for the losing candidates.
For any sample size τn employed in determining the model parameters, the forecasting accuracy generally decreases with increasing depth, as evidenced by the growth in relative error. This trend underscores the validity of the applied accuracy assessment methodology.
From a practical point of view, forecasts for 1–2 weeks are of the greatest interest for managing an election campaign, and given that acceptable accuracy in the proposed methodology can be ensured using small samples of the time series, the proposed forecasting method is technologically easy to implement.
Summing up our research, we can say the following:
The solution we obtained for the fractional diffusion differential equation of the boundary value problem with the initial condition , the distribution function o meets the normalization condition and passes in the limit case at α = 2 and β = 1 into a Poisson distribution (i.e., in a broad sense, it can be a distribution function).
Unlike existing solutions of the fractional diffusion equation, the model presented in this article allows you to find any moments of the distribution function, while existing approaches allow you to find all moments only if α = 2. The solution described in this article allows us to remove the contradiction between the fact that, in practice, it is possible, for example, to calculate the mathematical expectation of deviations between the levels of the time series, and the existing models are not applicable because they claim that the mathematical expectation does not exist; i.e., they are not applicable for a possible description of the observed data.
The further direction of our research will focus, firstly, on a strict proof in the form of theorems of the results we obtained. Secondly, we plan to continue our research described in the work [
40]. In this article, we examined the schemes of probabilistic transitions between process states that can be observed in complex systems and obtained a fractional-differential telegraph-type equation with multiple (in time:
β, 2
β, 3, . . . and the state: α, 2α, 3α, . . .) orders of derivatives.
If we consider the derivative of the form as the rate of change of process states over time, then the term of the form can be considered as the acceleration of the process. Of interest is the solution of the resulting telegraph equation for the boundary value problem with the initial condition and comparing it with the resulting solution for the fractional diffusion equation. It is possible that this will provide new opportunities for analyzing and describing the dynamics of time series in order to predict the evolution of the processes they describe.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}