1. Introduction
Weibull distribution, which is named after the Swedish mathematician Waloddi Weibull [
1], has been widely used in diverse disciplines to study many different issues. Some examples are food science, survival analysis, reliability engineering, and weather forecasting. One is referred to Lai et al. (2006) [
2] for some detailed discussions on the applications of this model. Moreover, Weibull distribution is related to many other probability distributions, such as the exponential distribution and the Rayleigh distribution, which makes it a more versatile and flexible model.
The probability density of a random variable,
S, following Weibull distribution is
with
being the shape parameter and
being the scale parameter.
Weibull distribution accommodates increasing and decreasing failure rates. However, it does not allow non-monotone failure rates, while the non-monotone failure rate situation is very common in real life. Particularly, engineering and biological sciences often involve bathtub-shaped failure rates. Thus, a generalized Weibull distribution handling bathtub failure rate was introduced by [
3], and then it was further explored and applied in [
4]. They named it exponentiated Weibull distribution (EW). The added shaped parameter allows the distribution to represent increasing, decreasing, and bathtub-shaped hazard functions. Then, Mudholkar and Hutson (1996) [
5] introduced a generalized form of Weibull distribution, which goes beyond the EW distribution. This generalization provides even greater flexibility than the EW distribution, with applications specifically highlighted in survival data and more complex time-to-event analyses.
Over the last few years, many variations of Weibull distribution have been introduced. Lai (2014) [
6] presented a thorough discussion of generalized Weibull distributions. One can find the details, such as the density function, moment function, and hazard rate function, for many different variations of Weibull distribution, such as inverse Weibull distribution, exponentiated Weibull distribution, and Stacy’s Weibull distribution. Shama et al. (2023) [
7] proposed a modified generalized Weibull distribution, providing theoretical insights and demonstrating applications across various fields. Through applications, the authors demonstrated the modified distribution’s effectiveness in fitting real-world data across fields such as reliability engineering, survival analysis, and environmental studies. Alsaggaf et al. (2024) [
8] introduced a new generalization of the inverse generalized Weibull distribution, enhancing estimation methods and exploring its applications in medicine and engineering. There are other generalized distributions and their inversed versions. XLindley is a great example to mention here. Gemeay et al. (2023) [
9] developed a modified XLindley distribution, detailing its properties, estimation techniques, and applications in reliability and risk assessment. Beghriche et al. (2023) [
10] introduced inverse XLindley distribution, examining its properties and demonstrating its applications in modeling lifetime data.
Statistical inference is frequently performed using an existing data set or a data set that is readily accessible. However, some statistical inference problems have no fixed-sample-size solutions, according to [
11]. And that is why sequential analysis is necessary and important, as it provides a way to decide on the necessary sample size and conducts statistical inference under certain accuracy requirements in the meantime. Anscombe (1952), Chow and Robbins (1965) [
12,
13] provided sequential procedures, creating a fixed-width confidence interval for the mean parameter of a normal distribution when the variance is also unknown. Sequential procedures for point estimation when one wants to limit the risk to its minimum or a certain value are also well developed in the literature; one may refer to Mukhopadhyay (1987), Zacks and Mukhopadhyay (2006), and Mahmoudi et al. (2019) [
14,
15,
16]. A comprehensive review of sequential methodologies can be found in [
17]. Recently, Mukhopadhyay and Banerjee (2014) [
18] developed a new class of fixed-accuracy confidence interval methodologies with a confidence coefficient for the mean of a negative binomial distribution. They provided appropriate ways to develop confidence intervals that lie completely inside the parameter space when an unknown parameter under consideration is positive. In light of this wonderful idea, many other confidence interval estimation methodologies were developed. Mukhopadhyay and Zhuang (2016) [
19] created a fixed-accuracy confidence interval for the parameter from Fisher’s “Nile” example; Bapat (2018) [
20] discussed fixed-accuracy confidence intervals for
under bivariate exponential models, and Zhuang et al. (2020) [
21] developed a fixed-accuracy confidence interval of
for a two-parameter gamma population.
In this paper, we will focus on the statistical inference of the
parameter of the inverse generalized Weibull distribution, including both point estimation and confidence interval estimation procedures. If a random variable,
X, follows inverse generalized Weibull distribution (IGW), then its probability distribution function (p.d.f.) can be written as follows:
with
. Here,
is the shape parameter that we will be focusing on, and we will discuss it in cases where
and
are unknown and known to us. To maintain brevity and consistency, we will refer to the shape parameter as
throughout this paper.
It is in the light of [
22] that we used the IGW simplified name for the distribution. This distribution is also highly related to the EW distribution we mentioned earlier in [
3,
4]. However, the EW distribution is exponentiated Weibull, while the distribution we investigate here is exponentiated inverse Weibull.
is an the exponentiation parameter. It is an important parameter that controls how the distribution behaves, particularly in terms of the tail heaviness and shape. To the best of our knowledge, we did not find any literature on bounded-risk point estimation or confidence interval estimation of
, especially when one wants to use a minimal required sample with the required accuracy.
The estimation of parameters from exponentiated distributions is not rare in the literature. Mudholkar and Srivastava (1993) [
3] discussed the exponentiated Weibull distribution and used maximum likelihood estimation (MLE) to estimate the parameters. NAG routines (COSNCF and COSPBF) were used to solve the MLE. Balakrishnan and Sandhu (1995) [
23] used MLE and the method of moments for estimating the parameters of the exponentiated exponential distribution. They also emphasized the flexibility introduced via the exponentiation parameter
, which allows for a wider variety of decay rates in modeling lifetime or reliability data. Sharma and Shanker (2010) [
24] introduced the exponentiated generalized exponential distribution, which generalizes both the exponential and Weibull distributions by incorporating an exponentiation parameter
. They also discussed using MLE to estimate all parameters of the EGE distribution, including
, but the likelihood function is nonlinear and requires numerical methods. Similarly, Zhao and Zhang (2012) [
25] explored exponentiated Pareto distribution and investigated the MLE method for estimating all parameters through numerical optimization techniques. In this work, we provide methodologies for estimating
through a well-designed procedure for both point estimation and confidence interval estimation. Our methods require the least amount of sample observations while satisfying the required accuracy in estimation risk or confidence level.
We want to emphasize that it is common in the literature that one may focus on estimating one parameter or even the function of one parameter while assuming the other involved parameters are known. Zhuang et al. (2020) [
21] developed fixed-accuracy confidence interval estimation methodologies for a function of the rate parameter when the shape parameter is both unknown and known. Chaturvedi and Pathak (2015) [
26] developed Bayes estimation strategies for the reliability function under type II censoring for a three-parameter exponentiated Weibull distribution, assuming that one of the shape parameters is unknown while the other two parameters are known. Chaturvedi et al. (2022) [
27] worked on sequential estimation for an inverse Gaussian mean when the coefficient of variation is known.
The structure of the rest of the paper is as follows: In
Section 2, we start with the maximum likelihood estimator of the shape parameter of the inverse generalized Weibull distribution. We propose the bounded-risk point estimation for the shape parameter, given that the other two parameters are known, in
Section 2.1. We then introduce the fixed-accuracy confidence interval estimation for the shape parameter, regardless of the other two parameters, in
Section 2.2.
Section 2 also includes appealing properties for both inference methodologies.
Section 3 discusses simulation studies to double-validate the theoretical results, as well as real data analysis for illustrative purposes. We conclude in
Section 5, sharing some final thoughts.
3. Simulation Study
In this section, we first simulate a random sample from the IGW distribution, using the R software (R 4.3.1). Thus, we used a rejection sampling technique to generate samples from the IGW distribution. The basic idea of the rejection sampling method is to generate a random sample from a given density function and reject the sample observation that goes beyond the IGW distribution. The steps of generating n independent random observations of using rejection sampling are included in the following steps.
One may note that we are discussing the sampling method for , and we are generating 1500 observations. It can be generalized to any IGW distributions with different parameter values, with a desired sample size. Moreover, following similar steps, one can generate a random sample from any new distribution function that is not previously defined or developed in R.
Step 1: Generate a random observation, , from a uniform distribution, Uniform , namely , where and . The values of a and b are chosen to cover all possible observations from . One may note that b is chosen on purpose here to ensure that the integral from 0 to b of its density function is approximately 1.
Step 2: Generate a random observation, , from , where C is the maximum value of the IGW density function, and is the density function of the uniform distribution. Specifically, for our simulation, is the maximum value of the IGW density function, and it turns out to be .
Step 3: Make the acceptance and rejection decision. Compare with the density value given by . If is less than or equal to the density function value of , then we accept as one sample observation from the IGW distribution; if not, we reject it and continue the sampling.
Step 4: Repeat steps 1–3 until we have our desired number of sample observations from the IGW distribution.
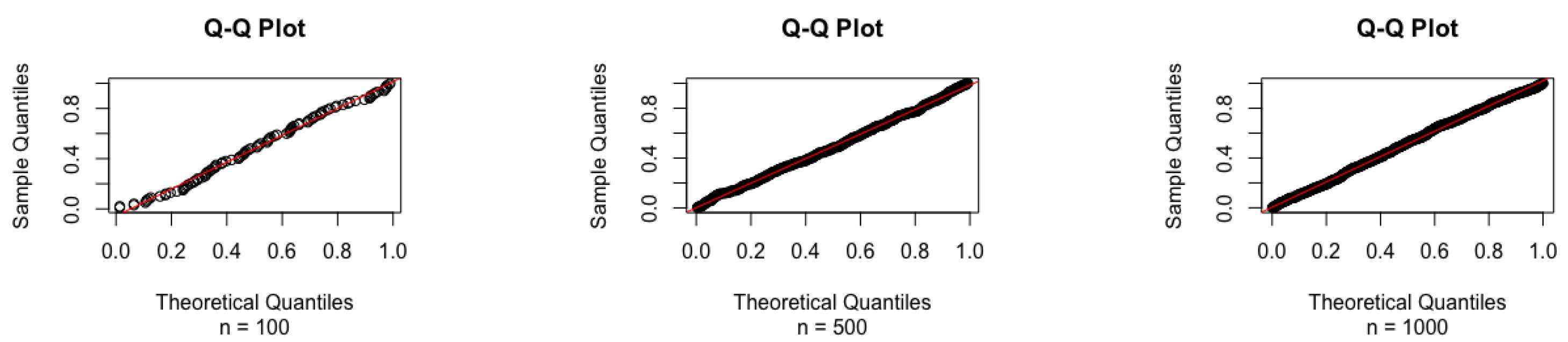
After following the steps above, we have successfully generated a random sample from the IGW distribution. However, we need to verify that the sample data are actually from the required IGW distribution. Thus, we make use of the standard approach via a quantile–quantile plot (Q-Q plot) to conduct the validation. This can be easily implemented in R using the function qqnorm(). However, there is no such function in R to draw a Q-Q plot using sample data from an IGW distribution. Hence, we carry out the following steps to create a Q-Q plot for comparing the sample data with an IGW distribution. Again, similar steps can be utilized to create a Q-Q plot for any other distributions, especially for the newly established ones.
Step 1: generate a random sample of size n from IGW distribution, , using the method described above, .
Step 2: Obtain the theoretical quantiles, say . Loop through each observation from the sample, X; for each , obtain its theoretical quantile, , using the density function of the specific distribution. As an aside, note that the integrate() function in the statistical software R is very helpful in finding such quantiles. More specifically, , where .
Step 3: Find the sample quantiles, say . Here, is the ratio of the number of observations that are not greater than and sample size n.
Step 4: plot the sample quantiles against the theoretical quantiles
From the plots given in
Figure 1, we can see that the sample data indeed come from an IGW distribution, no matter whether the sample size is small (n = 100), medium (n = 500), or large (n = 1000).
In
Table 1,
Table 2,
Table 3,
Table 4 and
Table 5, we summarized a number of selective simulation results. We included results from five different IGW distributions, IGW
, IGW
, IGW
, IGW
, and IGW
. From
Figure 2, with five different parameter value combinations, we observe five distinct shapes of the IGW distribution. Thus, the simulation results from these five distributions would provide a solid double-validation in addition to the theoretical findings we provided in Theorems 1 and 2. Moreover, the preassigned risk upper bound,
, is chosen in order to show the results for small, moderate, and large sample sizes.
Sample data are simulated while exactly following the simulation procedure, as discussed in the first part of
Section 3. The sampling procedure is implemented following the stopping rule, as per (
16). For each simulation scenario, that is, for a given combination of parameter values, say
,
,
, and
, we replicate the whole process in order to obtain the average of the stopping variable,
, as per (
16). Also, we were able to calculate the standard error of
. Additionally, estimated risk,
, can be calculated based on data upon termination, as per (
24). The pilot sample size,
m, was fixed to be 10 in each case (iteration). One may note that
should be close to the optimal sample size,
.
should be close to the bounded-risk
. The last two columns of
Table 1,
Table 2,
Table 3,
Table 4 and
Table 5 show the estimated
parameter averaged over 10,000 replicates and its standard errors.
The results consistently show the following: (1) the ratio of and hangs around 1 with small standard errors, which doubly validates the properties in Theorem 1; (2) the ratio of the estimated risk, , and the theoretical risk, , is close to 1, which doubly validates the properties in Theorem 2.
Further, we highlight the simulation performance of our developed procedures of creating fixed-accuracy confidence intervals for
. Interestingly, as seen earlier in (
27), since the rule for determining the sample size does not depend on any of the unknown parameters, one need not attempt a sequential rule to obtain the optimal sample size,
N. We, hence, adopt the following simple approach in order to obtain
N, with only pre-fixed
and
d.
Step 1: fix the constant d and the required confidence level (say , etc.)
Step 2: For every value of the possible optimal sample size, N, starting from 1, generate a single random observation from a gamma distribution with parameters N and . Let this be denoted as T.
Step 3: find for every value of N.
Step 4: stop the process when exceeds , which yields the final optimal sample size, N.
In
Table 6, we summarized the results from
Section 2.2, which discusses the fixed-accuracy confidence interval estimation on the parameter
. According to (
27), the only parameters that affect the sample size would be the fixed-accuracy measurement
d and the confidence level
.
Table 6 includes the summarized results when the sample data are simulated from IGW
. For different values of
d, with fixed
, following steps 1–4, we can determine the number of observations we need, which is shown in column 2 of
Table 6. Clearly, if we fix
d to be very small, one would require more samples to be able to meet the
level. We replicate the sampling procedure
times to check on the performance of
, as well as the coverage probability. As is seen from column 3, we listed the average of
values of
, which are all close to
. Moreover, the last column showed us that the coverage probability, in all the cases, is close to the corresponding level, which was set to be
. It is worth mentioning that one does not need to know the values of the other two parameters,
and
, to create the desired confidence interval for
.
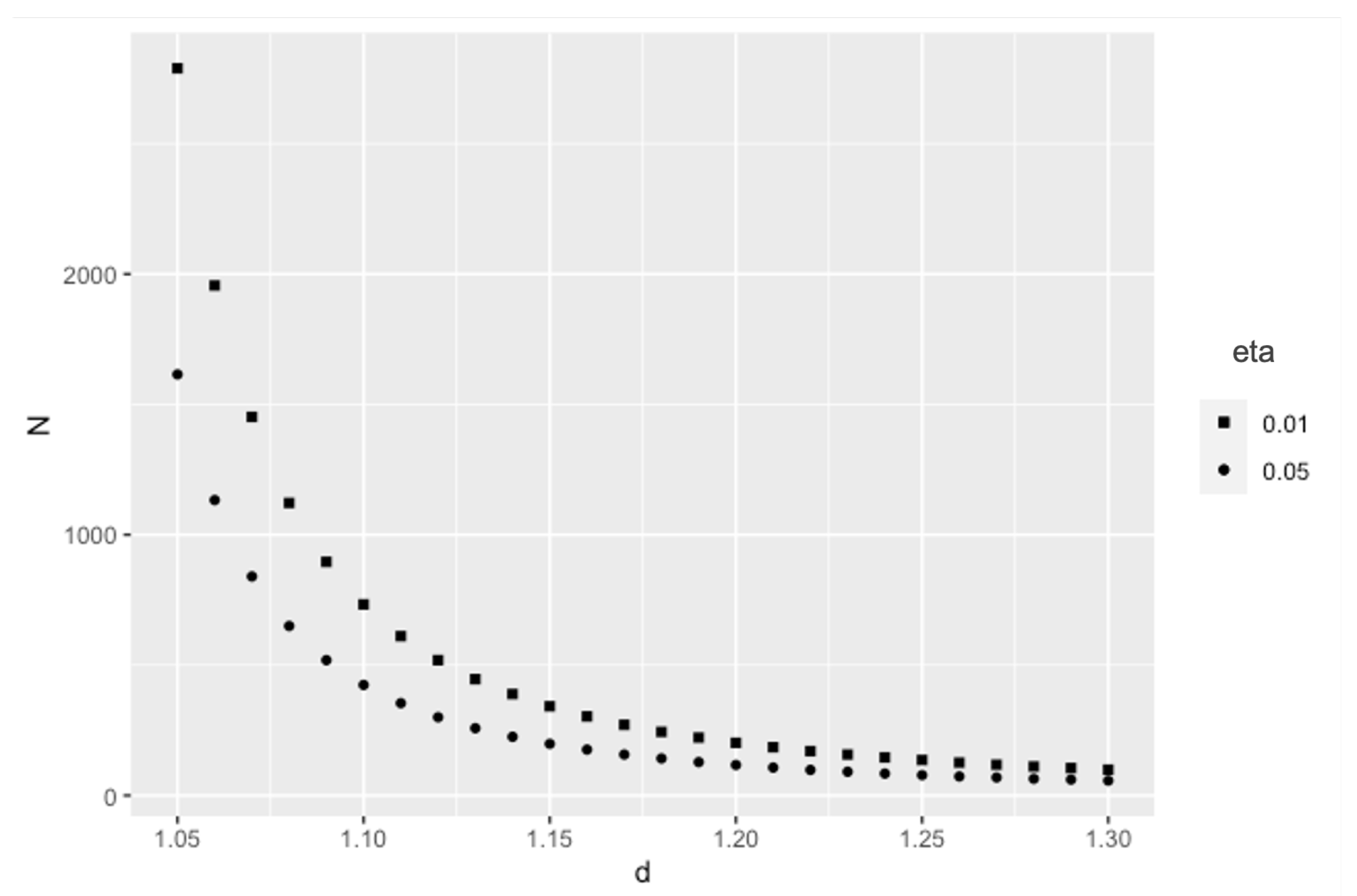
Further,
Figure 3 shows the relationship between varying optimal sample sizes over a range of
d values for fixed values of
. Clearly, as seen from the above table also, as
d reduces, one would require more samples to still find the confidence interval at the
level. This makes a lot of sense because a smaller
d means a tighter confidence interval, and one needs more observations to achieve that tighter interval. Also, for the same
d, a smaller
means that a larger sample is required, due to a higher confidence level.
4. Real Data Applications
In this section, we apply the proposed methodologies to a couple of practical scenarios. The first set of data we consider is the remission time (in months) of 128 patients suffering from bladder cancer. This data set has been given wide attention. The original data were brought up by Ref. [
28]. Ref. [
29] discussed this data set using McDonald Lomax distribution. Ref. [
30] used this data set on Marshall–Olkin generalized defective Gompertz distribution. Ref. [
22] showed the adequacy of inverse generalized Weibull distribution in modeling this data through some goodness of fit measures such as AIC and BIC.
It is reasonable to assume that the remission times of bladder cancer patients follow an IGW distribution. Based on the given data for the 128 patients, as well as the information from [
22], we further assume the distribution is IGW
.
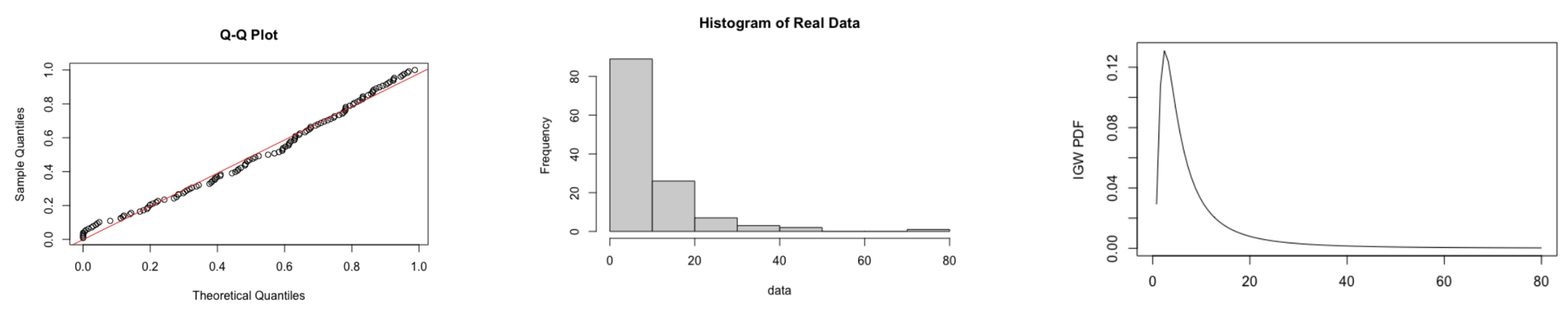
Figure 3 displays the Q-Q plot for the observed data versus the theoretical IGW distribution, given that
, which confirms that this data set would be suitable for the proposed methodologies. We have also included the histogram of the observed data, and the density curve, to provide further insight.
To start with, we randomize the original data set and pretend the patients’ data come in this randomized order.
Table 7 is a copy of the randomized data records.
We then further set
. Now, as per (
16), we implement the sequential sampling procedure. We start with the first two observations and then continue taking one observation at a time, according to
Table 5. The sampling procedure is terminated at the 76th record. That is, in real-life situations, if we are collecting the data and waiting to get an estimation for
, we would only require 76 observations. And there is no need to continue sampling, which would, for sure, waste time and money. Upon termination, the estimated
is
, which is a close estimation of
that is assumed to be the population shape parameter. Again, the stopping rule (
16) was created based on an upper estimation risk bound, and we set it to be
in this case.
Now, using this real data set, we illustrate the procedures we discussed for constructing a fixed-accuracy confidence interval for .
Suppose a group of researchers has decided to create a
confidence interval for
with
. According to (
27), we search for the sample size that is needed under such requirements. The smallest sample size that is needed turns out to be 73.
Figure 4 shows the relationship between the coverage probability and the required sample size, as per (
27). It is clear that, as we increase the sample size
N, the coverage probability goes up for fixed values of
d and
. Thus, sample size 73 is the minimum number of observations that we need to achieve the targeted level,
.
Now, using the data that we set up from
Table 5, we just take the first 73 observations and construct the confidence interval for
. These observations give us a
confidence interval as
. This interval covers the true value of
, which is
, by only utilizing 73 observations.
We will now work with the second data set and try to put forward a similar approach to finding the fixed accuracy confidence interval for
, as was conducted for the first one. This data set contains waiting times (in minutes) before access to customer service at 100 banks. The data set can be found to have been analyzed in [
31], where the author fitted Lindley distribution to the data. However, the applicability of an IGW distribution can be seen in [
22]. It is reasonable to assume that the waiting times follow an IGW distribution. Based on the given data, and the information given in [
22], we further confirm the distribution as IGW
. As before, we first randomize the entire data set and pretend the data come from this randomized order.
Table 8 is a copy of the randomized data for reference.
Now suppose one needs to create a
confidence interval for
with
. According to (
27), we search for the sample size that is needed under such requirements. The smallest sample size that is needed turns out to be 58. Again, it can be shown that, as we increase the sample size,
N, the coverage probability goes up, for fixed values of
d and
. Thus, sample size 58 is the minimum number of observations that we need to achieve the targeted level,
.
Now, using the data that we set up from
Table 6, we just take the first 58 observations and construct the confidence interval for
. These observations give us a
confidence interval as
. This interval covers the true value of
, which is
, by only utilizing 58 observations.
5. Conclusions
In this paper, we developed two methodologies for statistical inference of the shape parameter of the inverse generalized Weibull distribution (IGW). IGW distribution involves three parameters, , , and . The first methodology is created to build a bounded-risk point estimator of when both and are known. For this, we developed a purely sequential procedure to determine the optimal sample size, when the estimation risk is bounded by a pre-assigned value. The purely sequential rules enjoy a number of appealing properties, which were proved in theorems, as well as validated via simulation studies. The second methodology is for constructing a fixed-accuracy confidence interval for . For this, one is not required to have any knowledge of the other two parameters, and , in order to decide on the desired sample size. The sample size can be determined directly for any given confidence level and pre-fixed accuracy parameter, d.
Simulations on many traditional distributions are very easy using the statistical software R. However, the simulation for the IGW distribution is not as straightforward. Using the rejection sampling technique, we designed a detailed procedure for simulating sample data from any given distribution, regardless of its complexity. This also enabled us to conduct simulation studies and illustrate the real-world application of the newly designed methodologies.
An important consideration is how to choose appropriate parameter values, such as the risk bound or the fixed-accuracy measure d. For bounded-risk point estimation, one needs to set up an upper bound () for the risk on estimating the parameter . There is no golden rule on deciding the value of . Historical data may help if one can obtain any helpful historical data. Moreover, the cost of sampling and the time required to obtain sample data in different situations can also affect the decision. If one wants to have a general estimation of , they may fix at a higher value so that fewer observations are needed. If one requires higher accuracy, then may be set up to a much smaller number. Similarly, for fixed-accuracy confidence interval estimations, one needs to decide on the values of d and based on specific problems. Again, a tighter confidence interval means a smaller d and it requires more sample observations; a higher confidence level means a smaller , and it requires a larger sample size.
Generalized Weibull distributions take many different forms with different numbers of parameters. Its flexibility allows its wide use in real-life problems. In the future, we will try to work on estimating all three parameters involved in this inverse generalized Weibull distribution with a minimal required sample since people may not have any prior knowledge of any of the parameters. For brevity, we want to bring up an idea using an iterative estimation approach to estimate all parameters. (1) Begin with a small pilot sample of observations from the population, say . In this initial step, set to simplify the estimation of and . Using this pilot sample, estimate and through the MLE method. Let these initial estimates be denoted as and . (2) Using the initial estimates and , obtain the initial estimate for . Following the stopping rule we developed on bounded-risk point estimation, we will take one more observation at a time. As new observations are sequentially added, re-estimate with the most recent values of and ; then, update and based on the new estimate. This iterative procedure is repeated until the stopping criterion is met for . (3) Once the stopping criterion is met, the current estimates of , , and are taken as the final estimates. Similarly, for the fixed-accuracy confidence interval estimation, using the determined sample size, one can achieve MLE for and first and then obtain the confidence interval for .





{kind=link}
{kind=link}
{kind=link}
{kind=link}