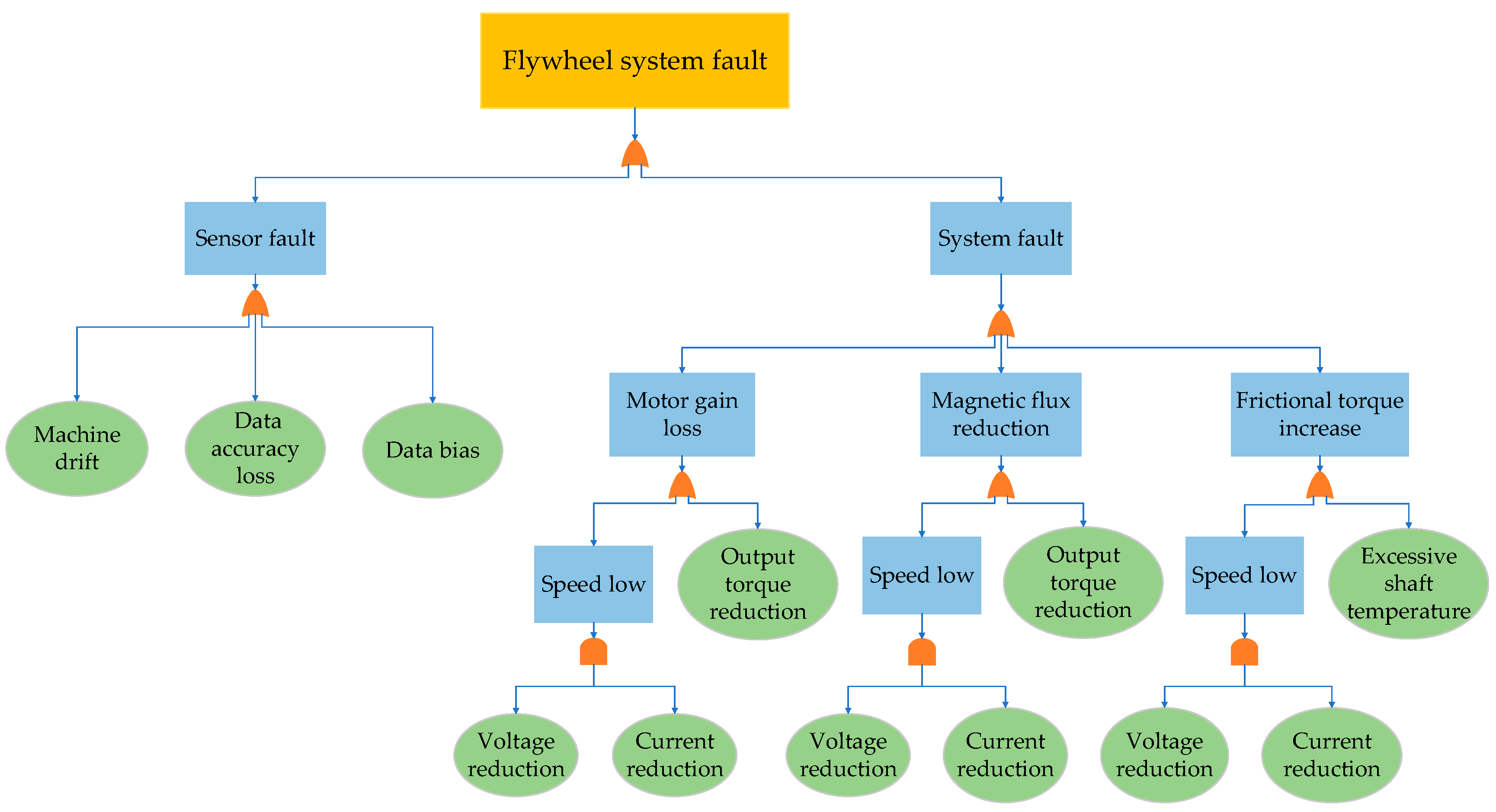
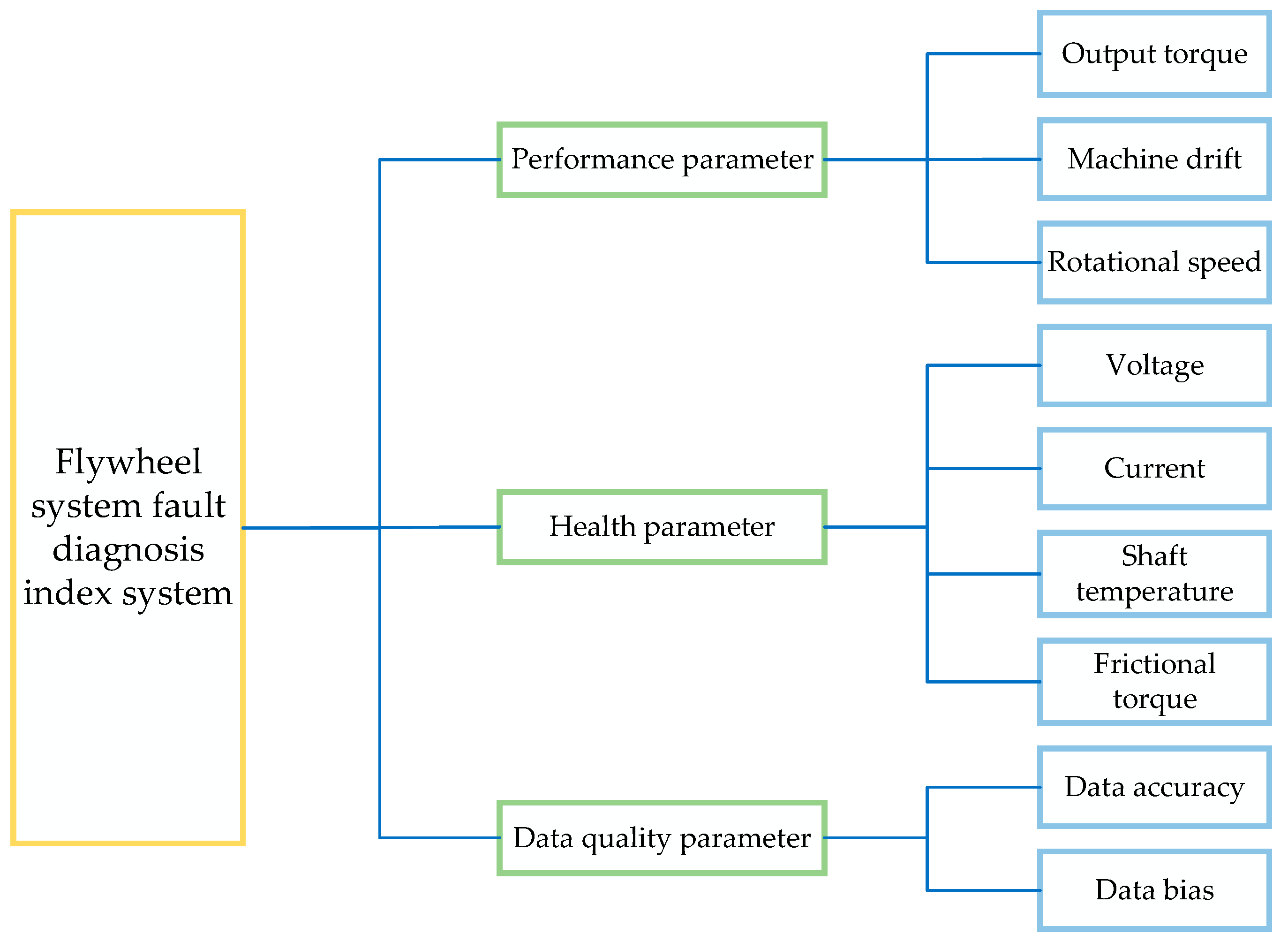
Aerospace equipment can encounter problems in its work at any time. For example, a flywheel system fault diagnosis faces multiple challenges such as location and coverage limitations and complex environmental factors. These problems not only increase the complexity and difficulty of diagnosis but also make the collected data highly ambiguous. Relying on these data for fault diagnosis may have a direct impact on the accuracy and reliability of the diagnosis results. The combination of FFTA and an interpretable IBRB can effectively address the multiple challenges in fault diagnosis. FFTA quantifies uncertainty in data through fuzzy logic to improve the accuracy of information. An interpretable IBRB integrates multiple sources of information through clear rules to ensure the transparency and reliability of the diagnostic results. This improves the data processing efficiency, reduces diagnostic delays, and ensures the stable operation of aerospace equipment.
3.2. IBRB Reasoning Process for Aerospace Equipment Fault Diagnosis
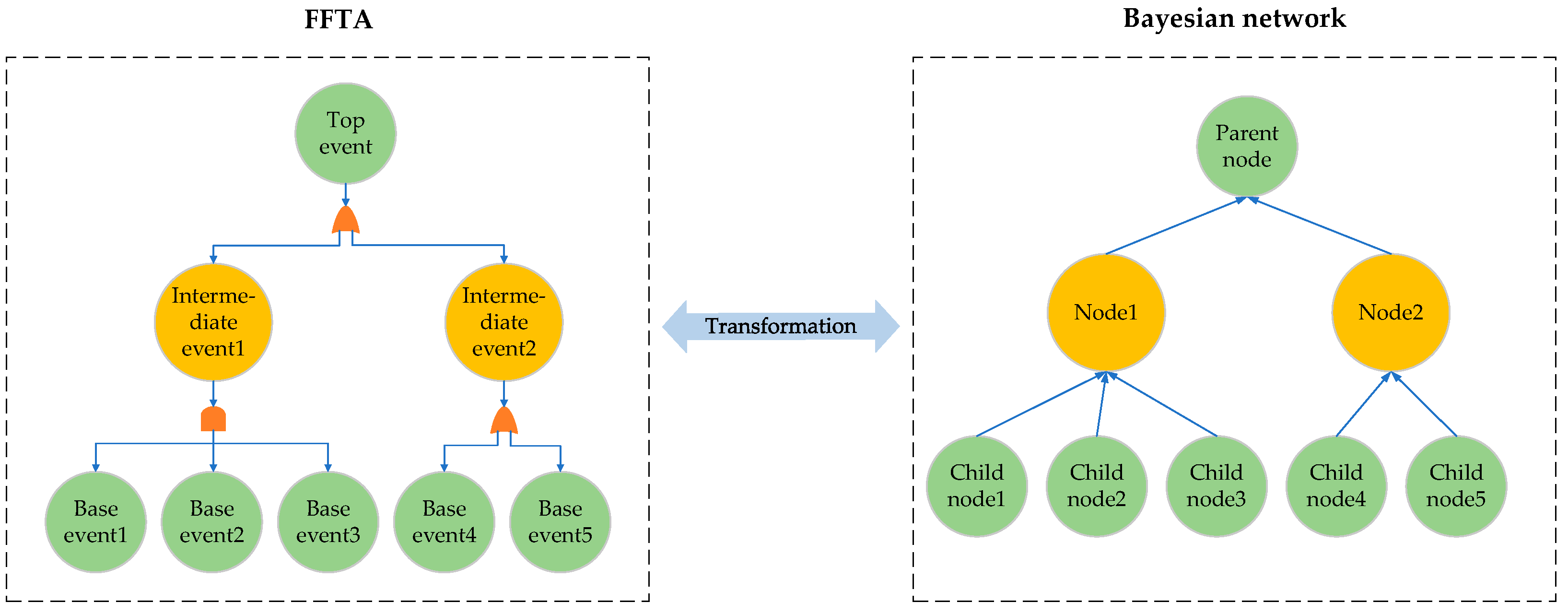
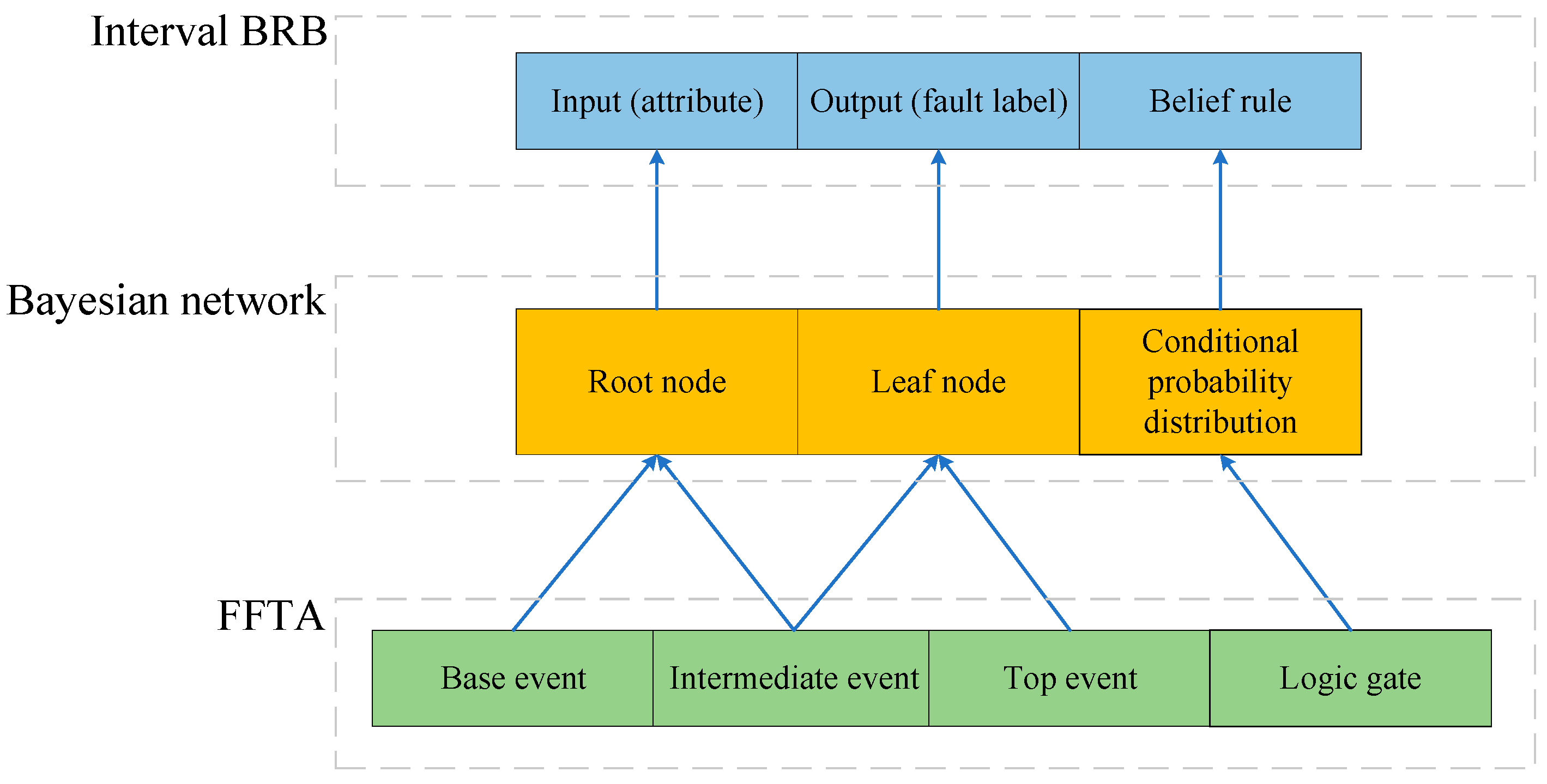
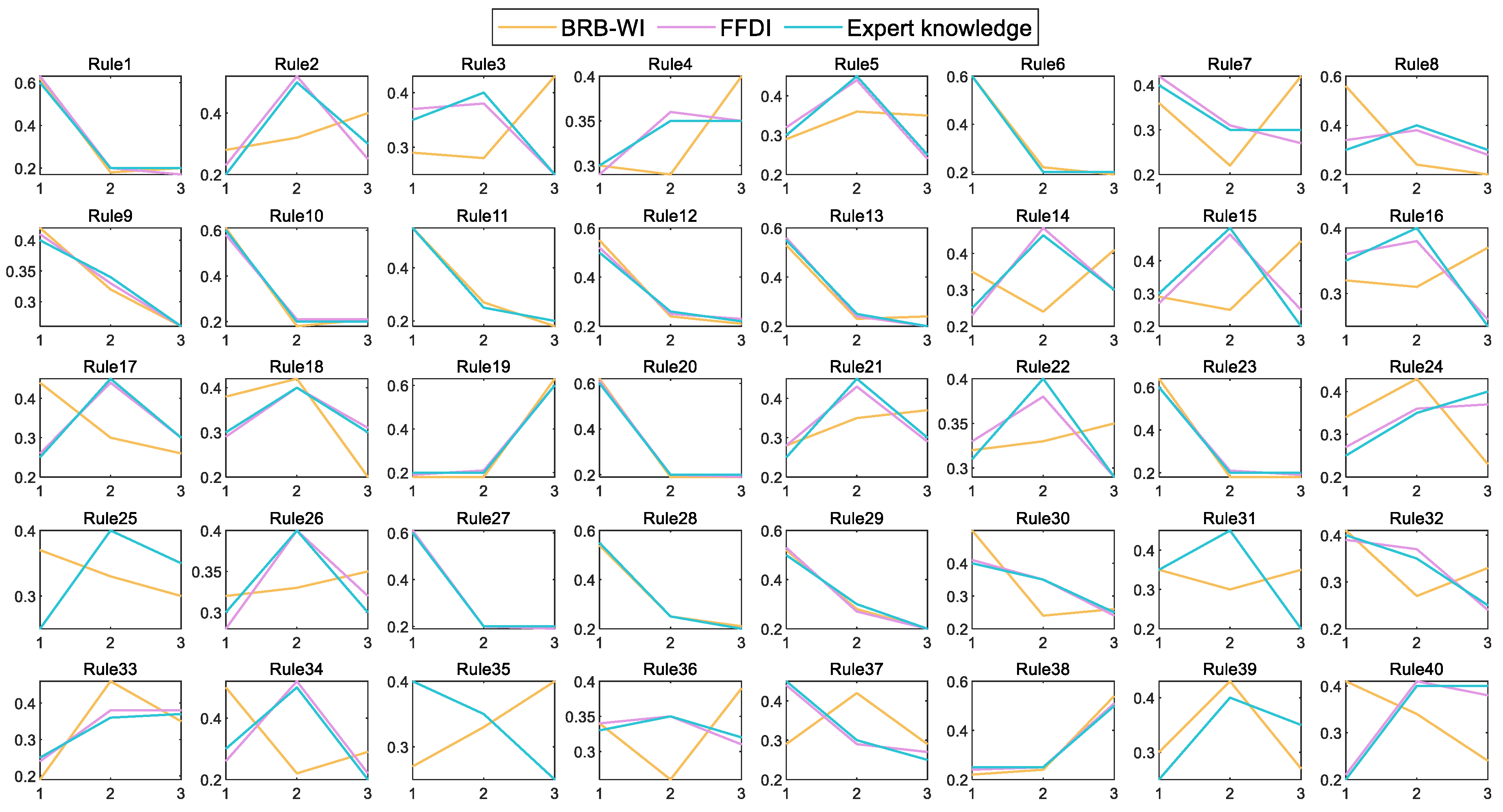
The FFDI represents the probability of an event through the fuzzy triangular number of FFTA. The fuzzy triangle number is divided into three groups, representing the upper limit, the lower limit, and the reference value, respectively. This can correspond to the reference intervals in the IBRB. After the data in FFTA are transformed to IBRB by the BN, the model is optimized for the fitting effect of the triangular fuzzy number of the top event probability. The conversion mechanism between FFTA, BN, and IBRB is used to solve the problem that expert knowledge is difficult to embed [
27].
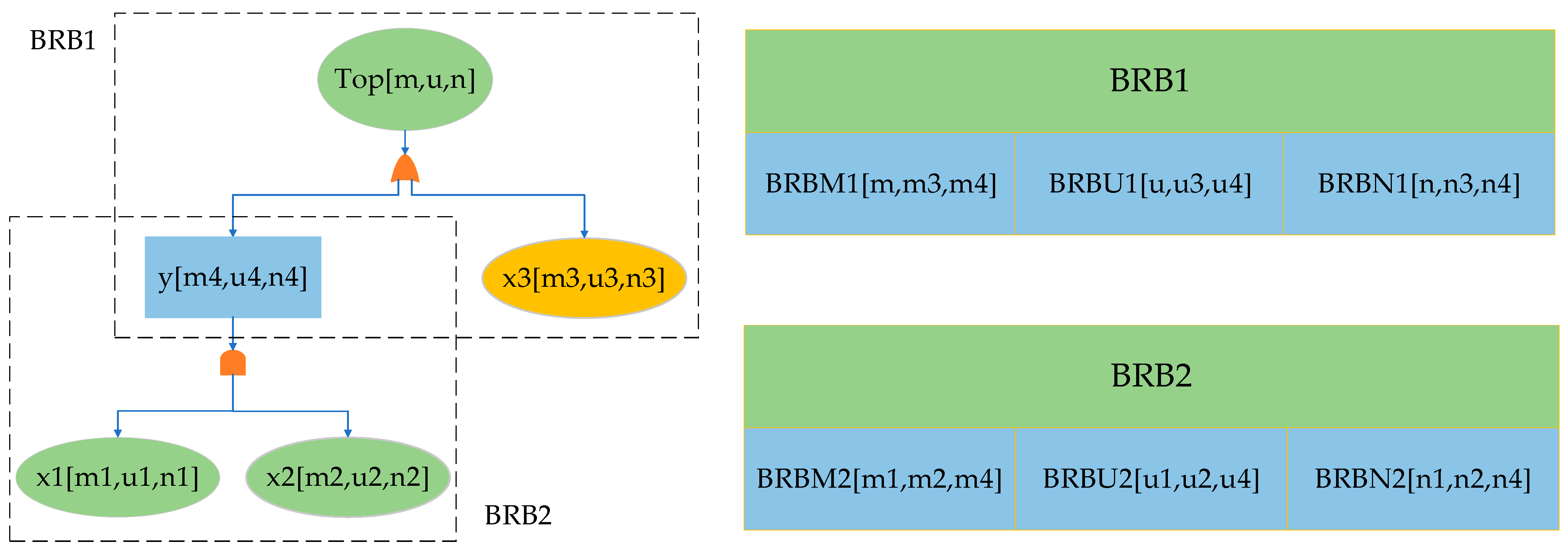
Figure 6 shows a schematic diagram of the model reasoning process.
After normalizing the data, the belief distribution is described as follows:
where
denotes the belief degree that the fault diagnosis solution is assessed as
under evidence
,
denotes global ignorance, and
denotes the identification framework, which consists of
assessment levels
.
The evidence weight is denoted by
, and the evidence reliability is denoted by
. The new belief distribution is generated by mixing and weighting
and
as follows:
where
denotes the basic probability mass,
represents the mixed probability mass of the
-th evidence under the evaluation level
, and
denotes the normalization factor, which satisfies
.
The joint support
of
independent evidence is calculated as below.
where after fusing the first
pieces of evidence, the belief degree for assessment level
is denoted by
, and the formula satisfies
.
In summary of the above analysis, the following output belief distribution and expected utility value can be obtained:
where
represents the expected utility value, that is, the predicted output.
represents the utility value at evaluation level
.
In conclusion, the IBRB inference process for aerospace equipment fault diagnosis can be obtained as follows.
Step 1: Define the reference interval value.
Step 2: After inputting the initial parameter, determine the interval in which the parameter falls, and activate its corresponding rule according to this interval.
Step 3: Calculate the activation rule reliability corresponding to the current logic gate. The calculation formula in “and” gates is shown in expression (17) and that in “or” gates is shown in expression (18).
Step 4: The belief level of the fault diagnosis result is calculated.
Step 5: Calculate the expected utility value of the output.
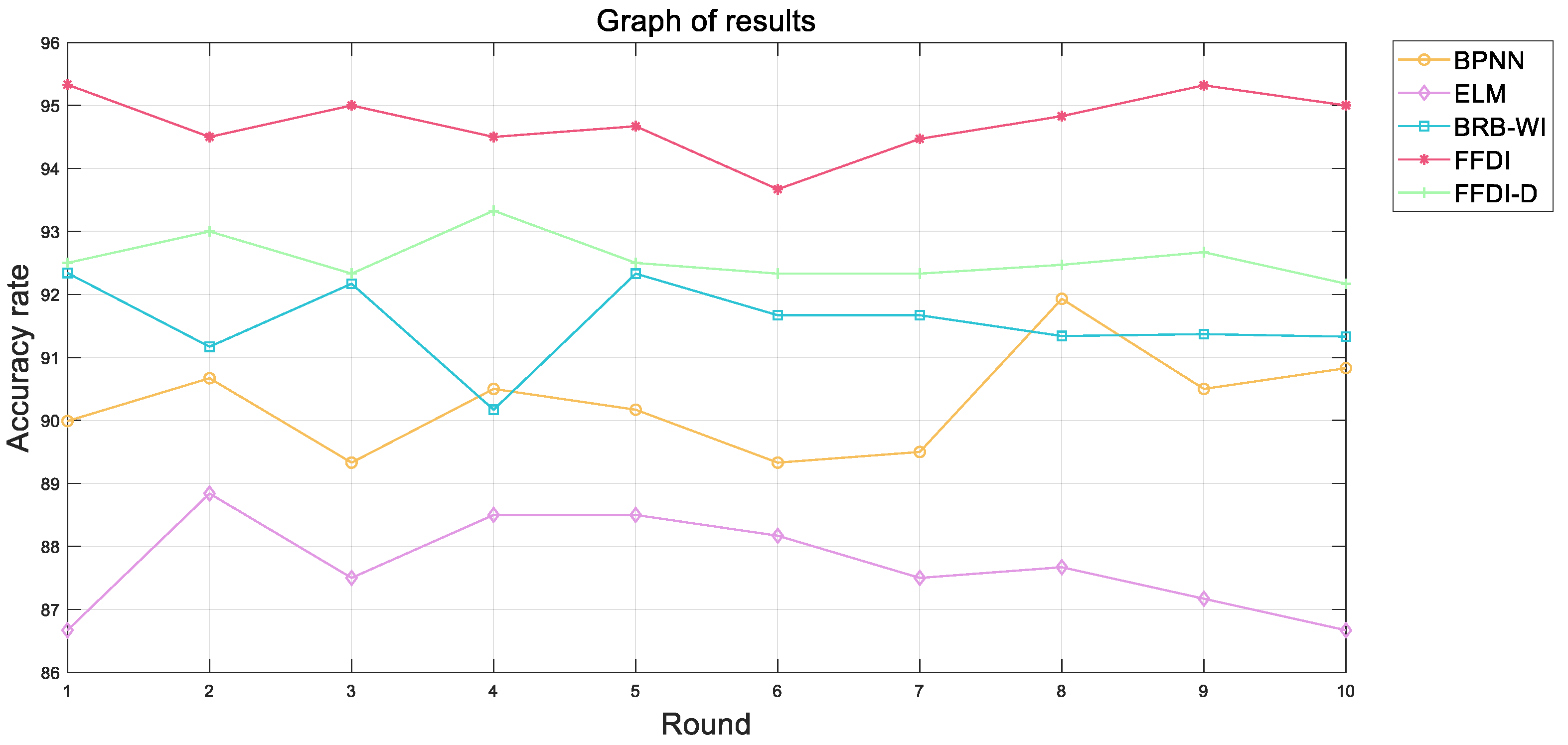
3.3. Optimization of the FFDI Using the IP-CMA-ES Algorithm
In the experimental process, the initial parameters are established by experts based on historical experience [
28]. The accuracy of the initial model cannot be guaranteed. Therefore, the model parameters must be optimized by the optimization algorithm. Among the current optimization algorithms, the projection covariance matrix adaptive evolution strategy algorithm (P-CMA-ES) has characteristics such as a high convergence speed, high precision, and diffusion rotational invariance. It is widely used in various BRB models [
29]. Therefore, the FFDI can be optimized by the P-CMA-ES algorithm.
However, when the P-CMA-ES algorithm is used to optimize parameters, more emphasis is placed on the model accuracy, which may destroy the interpretability of the IBRB itself [
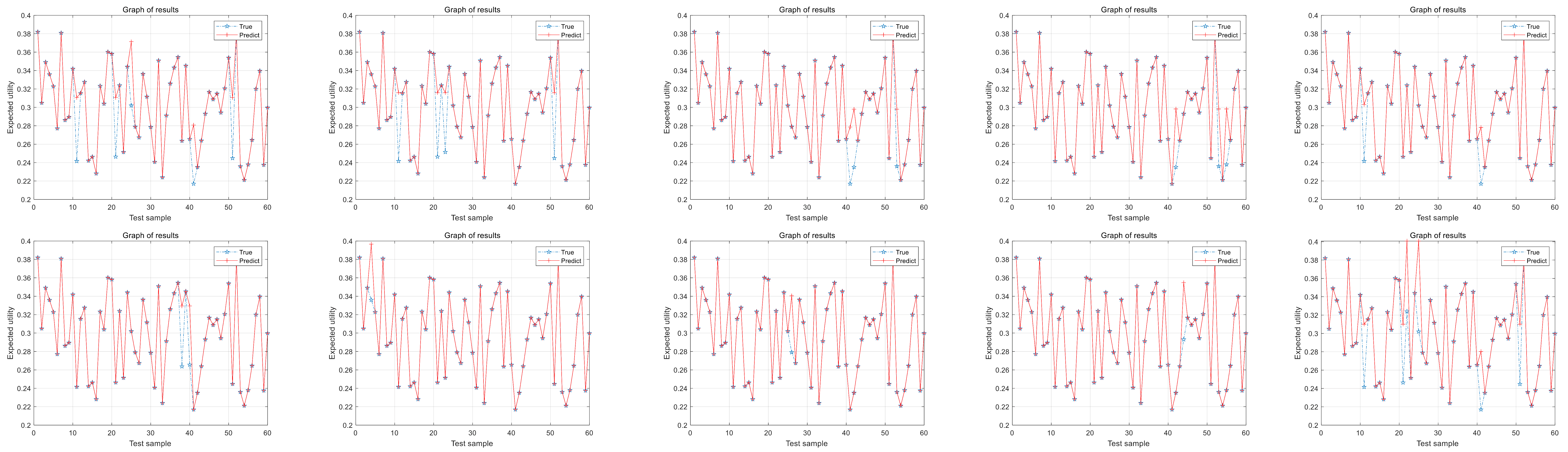
30]. It may produce errors that contradict common sense during optimizing. For example, suppose that are three evaluation levels for aerospace equipment fault diagnosis, “unqualified”, “medium”, and “excellent”, if the model output is {(unqualified, 0.4), (medium, 0.2), (excellent, 0.4)}. It is obvious that the belief degree at both ends is higher than the belief degree in the middle. It violates the practical significance of the model and should not exist. In summary, the belief distribution should not be “concave”. As shown in
Figure 7, when the optimized belief distribution is increasing, decreasing, or “convex”, the belief distribution can be considered reasonable; when the belief distribution is “concave”, the belief distribution is not reliable. In this case, the model parameter needs to be reoptimized until the actual belief distribution is generated [
31].
To solve this problem, the P-CMA-ES algorithm is improved. That is, constraint conditions are introduced. First, the upper and lower threshold can be set to ensure that the belief degree is between them to make the assessment level effective, which can rule out unqualified data [
32]. Then the belief degree can be normalized to guarantee that it sums to one. This can generate a reasonable belief distribution.
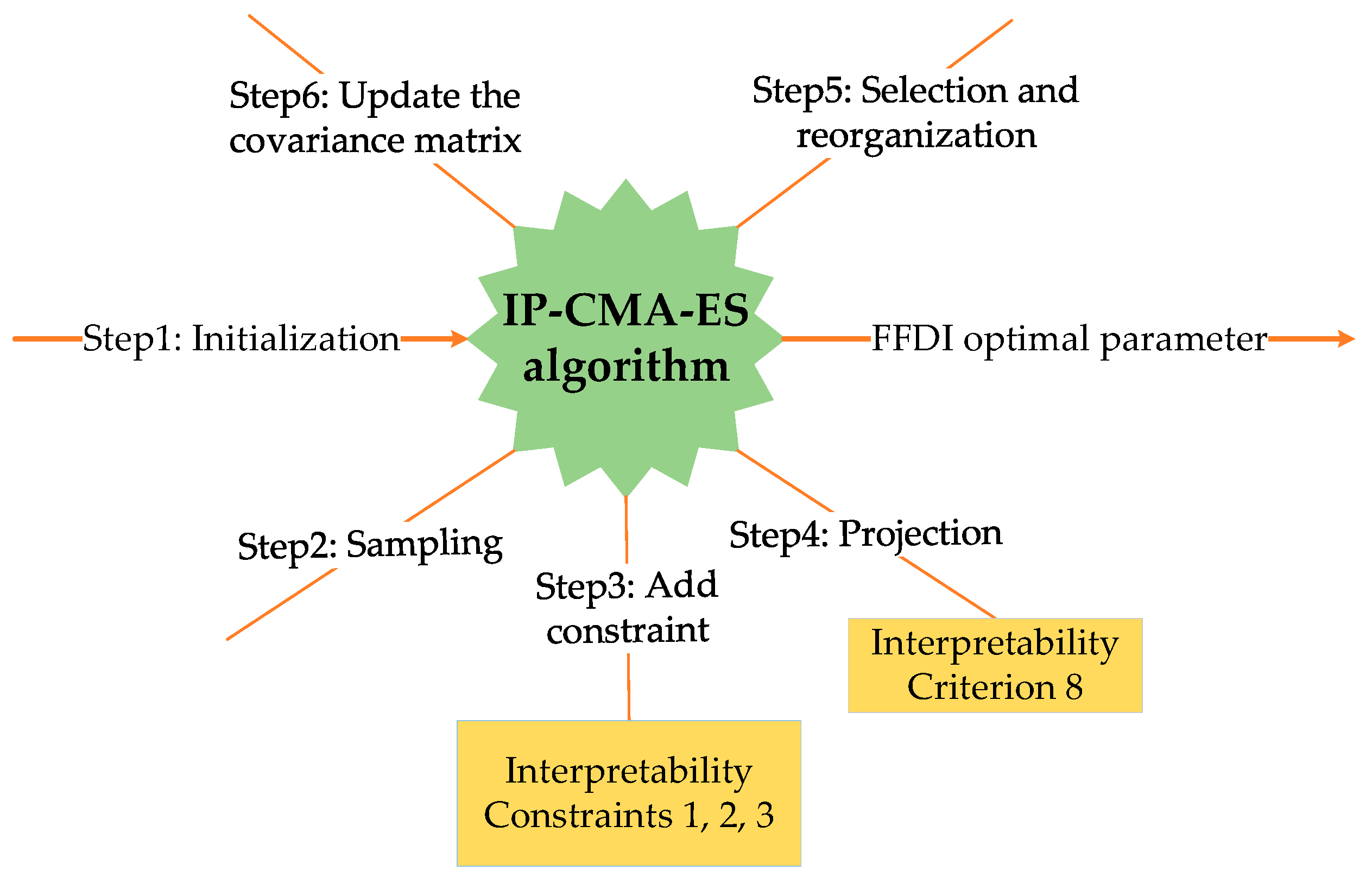
This section describes the optimization mechanism and the procedure of the IP-CMA-ES algorithm. The FFDI optimization structure is shown in
Figure 8.
First, it needs to construct an objective function for the optimization model, which can be represented as follows:
where
is the deviation degree between the utility value output of the FFDI and the actual value,
represents the number of training samples, and
represents the actual output result of the model.
The steps of the IP-CMA-ES algorithm are described in detail as follows:
Step 1: Initialization. The parameter set to be optimized is described, which includes the belief degree, rule reliability, and rule weight.
Step 2: Sampling. The parameter for each generation can be obtained by sampling, and the formula is described below.
where
denotes the
-th solution of the
-th generation,
denotes the evolutionary step of the
-th generation,
denotes the average of the search distribution of the
-th generation,
denotes the covariance matrix of the
-th generation,
denotes the normal distribution function of the parameters, and
denotes the number of offspring.
Step 3: Add interpretability constraints. This step is to protect the interpretability of the FFDI. The constraints added to the belief distribution are shown below.
where
denotes the interpretable constraints on the belief distribution under the
-th rule;
,
, and
denote the upper bounds on the belief degree, rule reliability, and rule weight, respectively; and
,
, and
denote the lower bounds on the belief degree, rule reliability, and rule weight, respectively. There is no specific criterion for the constraints, which is usually decided by experts based on experience and reality.
Step 4: Projection. To satisfy the equation constraints, the projection operation can be used to transform them into constraints in a hyperplane [
33].
where
denotes the number of variables in the equation constraints,
denotes the number of equation constraints in
, and
denotes the parameter vector.
Step 5: Select and reconstruct. Filter the optimal subgroups in the population and update the average of the next generation.
where
is the weight coefficient of the
-th solution,
denotes the size of the offspring population, and
denotes the
-th solution in the
-th solution.
Step 6: Update the covariance matrix. Update the covariance matrix and its evolution steps, step size, etc., according to the strategy.
where
denotes the evolutionary step under the
-th generation,
and
denote the learning rate, and
is the step size in the
-th generation.
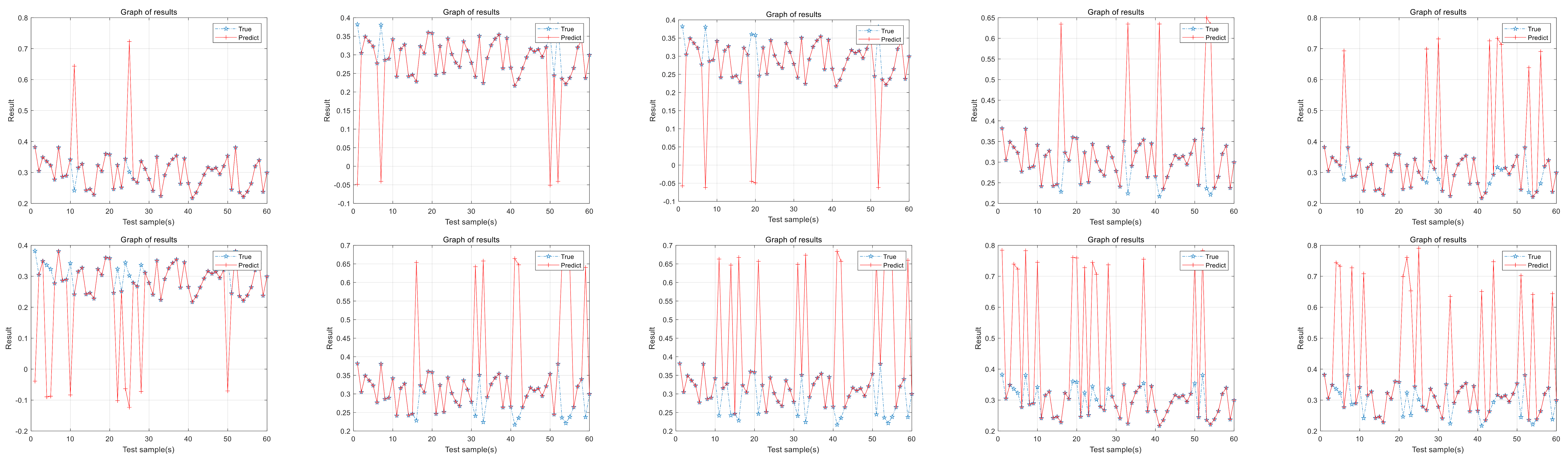
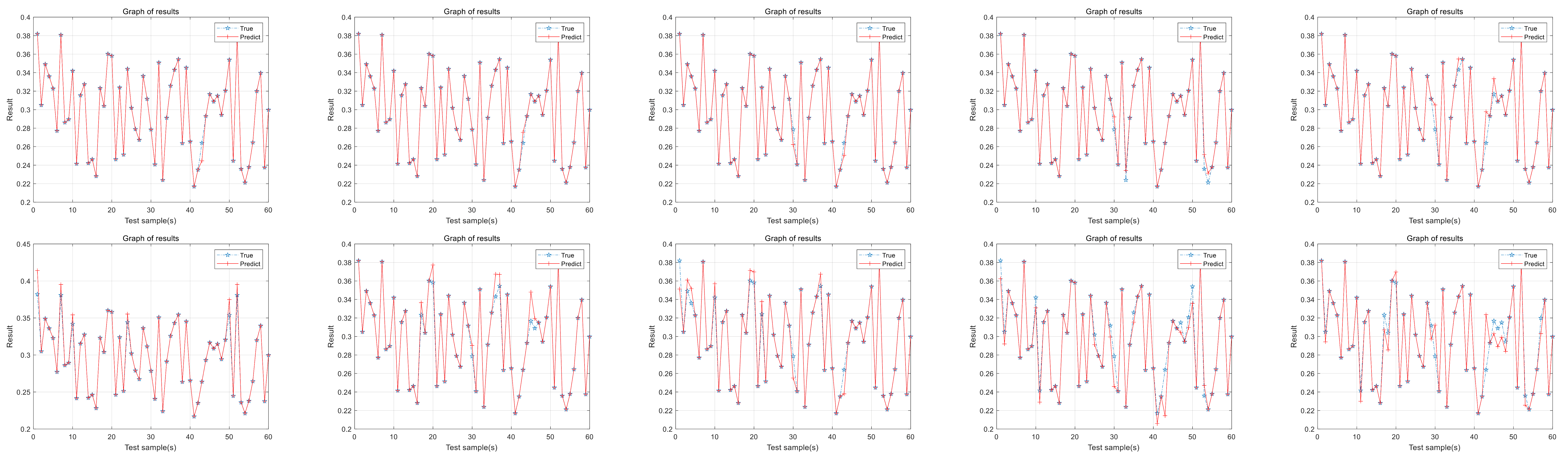
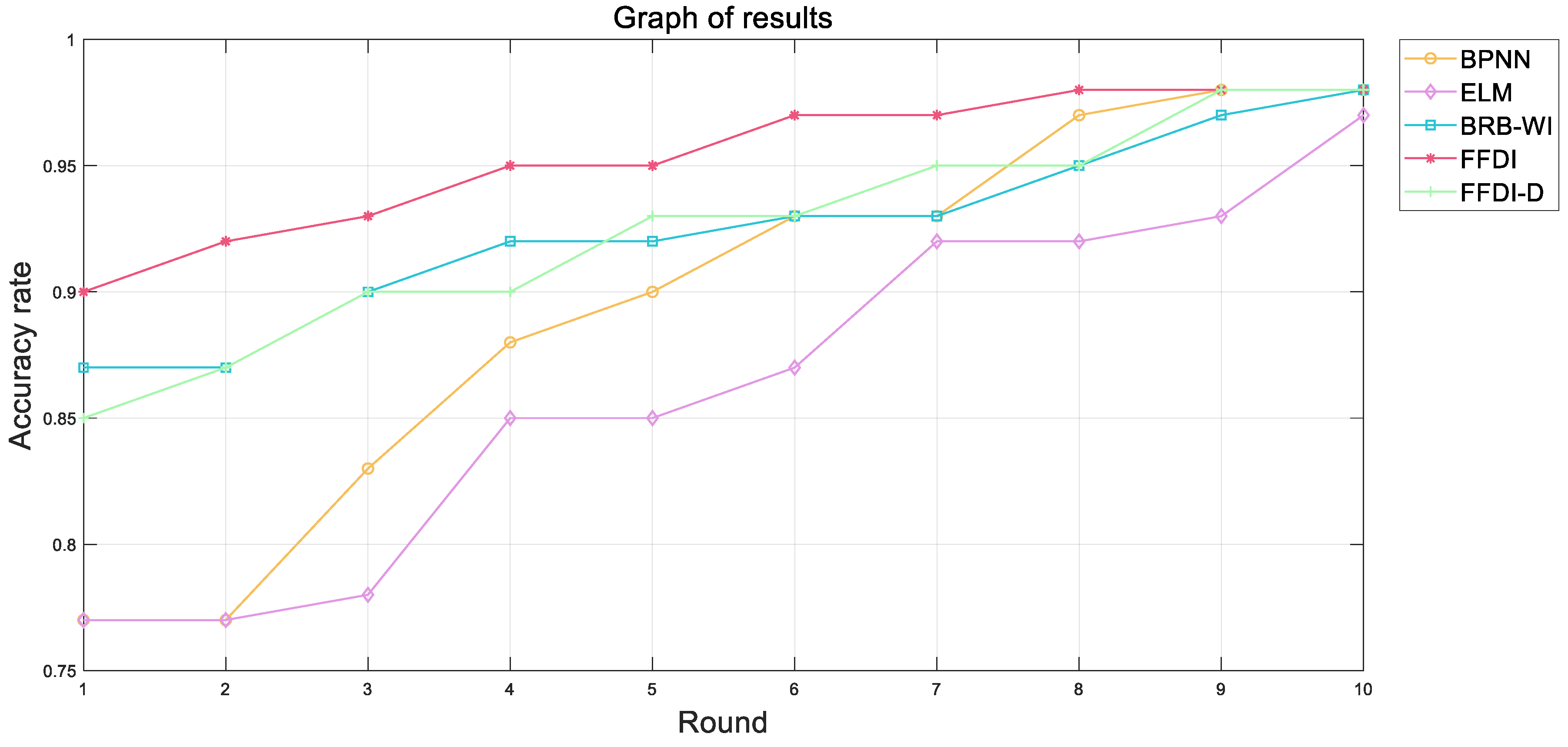
Repeat the above steps until the model reaches the desired optimization result. The IP-CMA-ES algorithm ensures that the realism of the parameter is consistent with public perception. The algorithm ensures the balance between high precision and interpretability, which facilitates the detection of potential faults in aerospace equipment.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}