
A Variant of the Growing Neural Gas Algorithm for the Design of an Electric Vehicle Charger Network

 ,
,  , , and
, , and
Abstract
1. Introduction
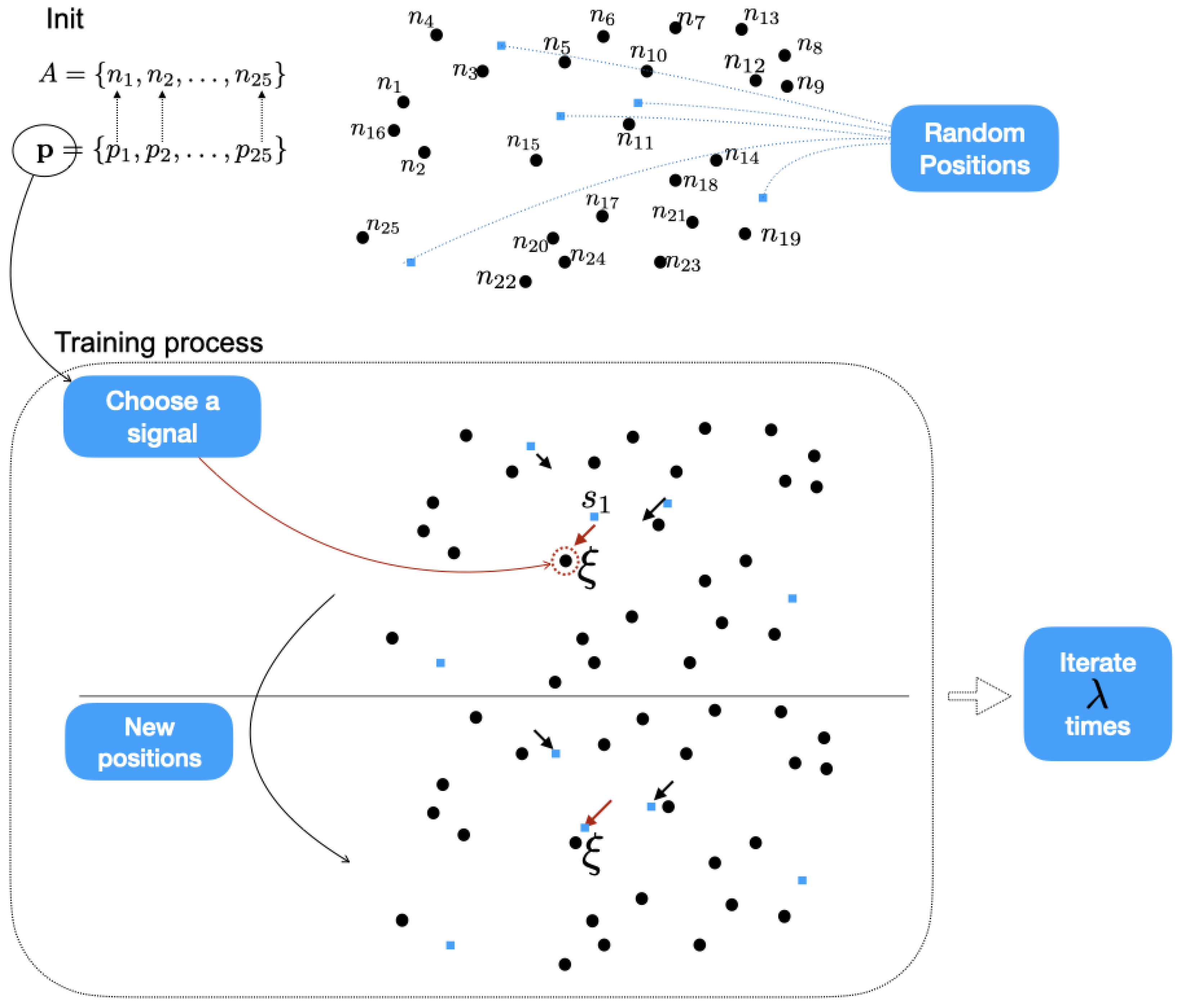
2. A Variant of the Growing Neural Gas Algorithm: GNG2D+
| Algorithm 1 GNG2D+ algorithm. |
INIT: Start with M points at random positions in . Initialize a local counter to zero for every point.
|
- A probability vector is associated with the initial set of points A. This fact implies that the choice of each signal, in each iteration, is not purely random. If we review the SOM-type algorithms (see the different Appendices), it is characteristic that the initial signal in each iteration is chosen randomly, that is, all the points have the same probability of being chosen as a signal. However, in the proposed algorithm, the probability vector associated with these points is introduced in order to somehow avoid the equal probability of each point being chosen, taking into account any characteristic or weighting that may be considered. In the case that we want randomness in the choice of the points, we assign a constant probability vector.
- To start the construction of the cloud of points, we select M points. This number of points can be parameterized depending on each application. The fact that the algorithm runs every iteration with the same number of final points (the set P) is crucial as it eliminates the need to add or remove nodes, allowing the model to focus on self-learning the topology of the original point set.
- The training process involves three parameters: , and . The parameter ensures that any node in the initial set of random points remains isolated throughout the entire execution of the algorithm. determines the displacement of the winning node, while determines the displacement of the neighboring nodes.
3. A Case Study: Methodology
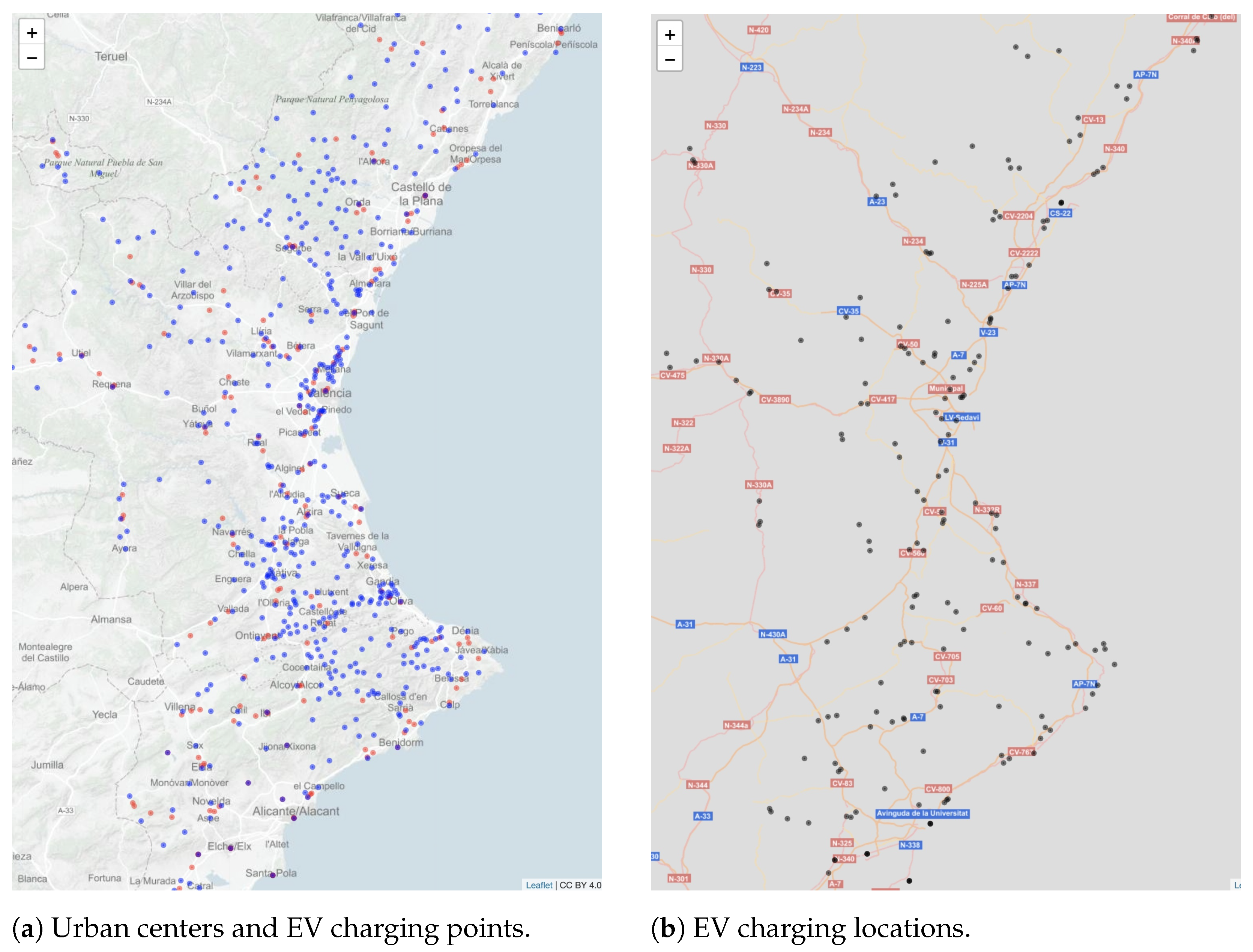
3.1. Data Collection
- Gas stations.
- EV charging points.
- Municipalities and population.
- Updates and accuracy, since it is the users themselves who provide the information.
- Coverage and accuracy, especially in less favored areas where the community is less participatory.
3.2. Processing Data
- Elimination of duplicate nodes. The decision to eliminate duplicate nodes by rounding coordinates to three decimal places is based on an important consideration, for the specific purpose of finding areas with gas stations rather than simply counting the number of these points (geographic location is prioritized over quantification).
- Geographic coordinates obtained from the Openstreetmap API must be transformed into UTM coordinates. The reason for this is that geographic coordinates measure degrees, while UTM coordinates allow us to work with distances in meters on the Earth’s surface. Due to the characteristics and meaning of the data used, by working with UTM coordinates, we ensure that distances are measured linearly. So, it will be possible to establish linear distances between points if necessary for our analysis.
3.3. Application and Visualization of the GNG2D+ Model
4. Numerical Results
4.1. Preliminary Issues
4.2. Analysis of Numerical Results
- is the parameter that sets the number of iterations in the main loop (steps 1–6 of the algorithm).
- Iterations represent the global iterations performed to remove isolated points (step 7).
- is the displacement of the winning neuron in the self-organizing process.
- is the displacement of the nearest neurons in the self-organizing process.
- The implementation of the algorithm was not optimized regarding the search for the nearest neighbors.
- Only the execution time of steps 1 to 8 of the algorithm were measured.
- The tests were performed on a computer with an Apple M2 Ultra processor with 64 GB of RAM.
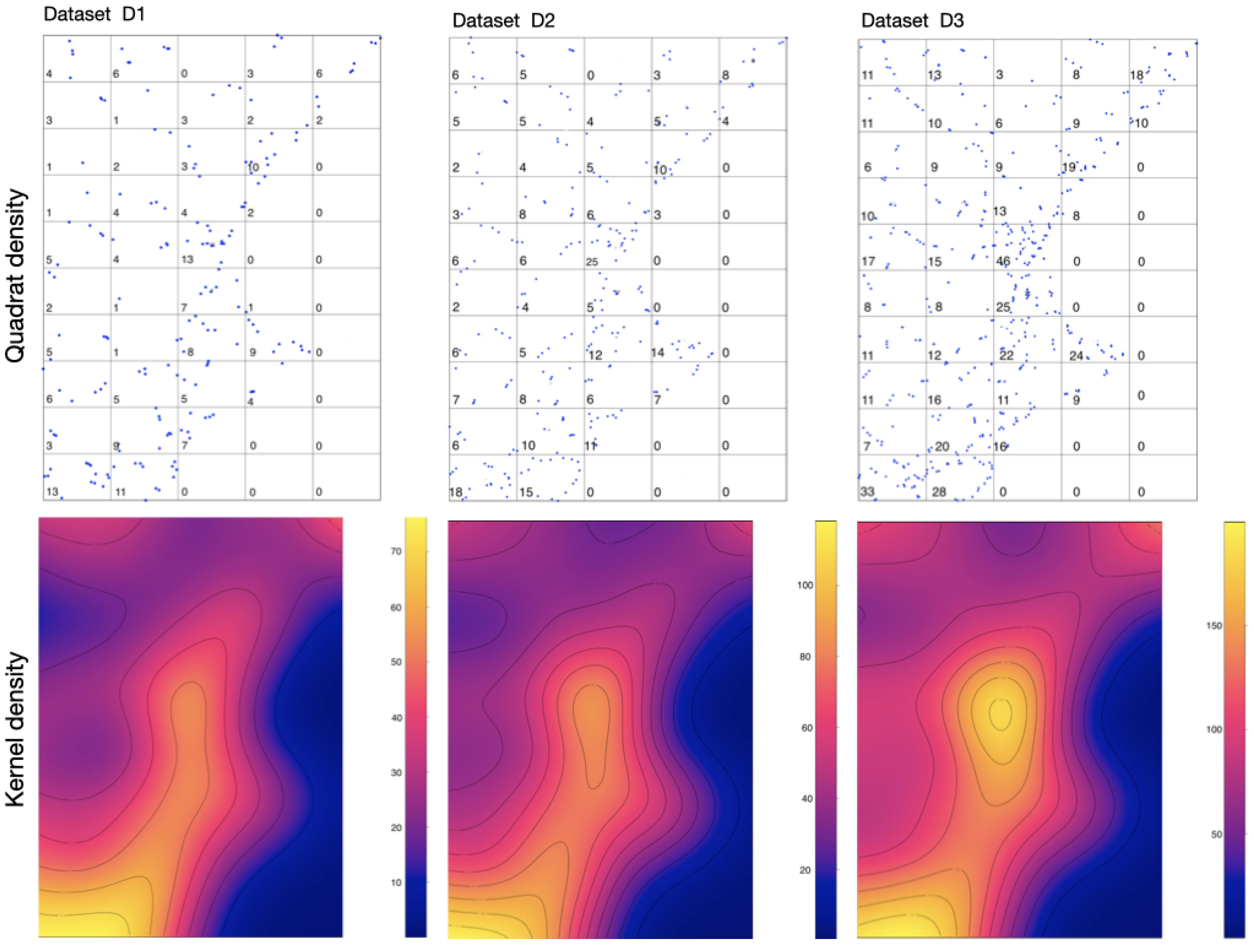
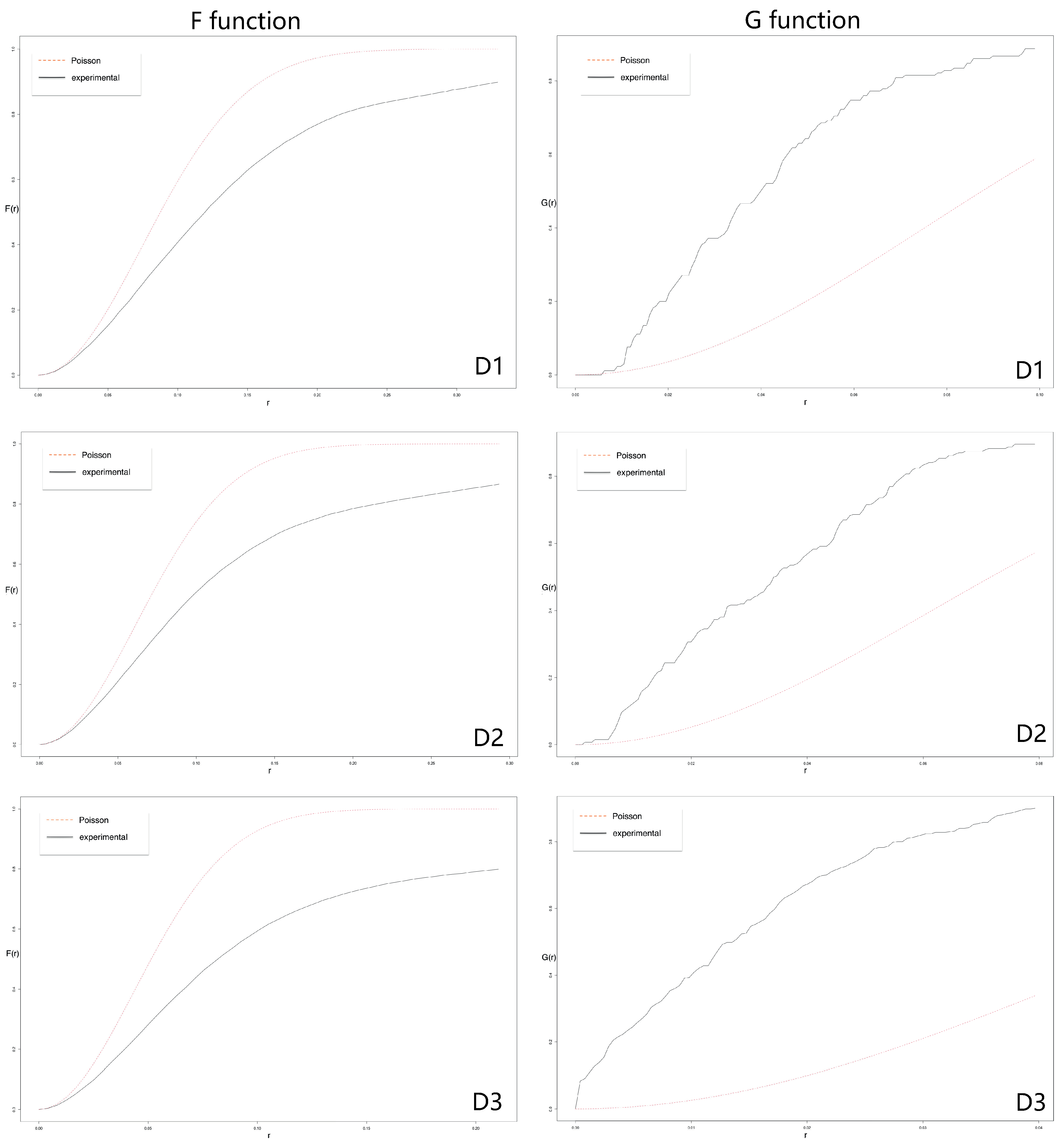
- D1: dataset 1. ; factor scale: .
- D2: dataset 2. ; factor scale: .
- D3: dataset 3. ; factor scale: .
- Quadrat density: Quadrat counting is a simple way to inspect point pattern data. The window of observation is divided into a grid of rectangular tiles, and the number of data points in each tile is counted.
- Kernel density: Kernel density calculates the magnitude-per-unit area from point or polyline features using a Kernel function to fit a smoothly tapered surface to each point or polyline.
- F: empty space function. The empty space function F of a stationary point process X is the cumulative distribution function of the distance from a fixed point in space to the nearest point of X.
- G: nearest neighbor distance function. The nearest neighbour function G is the cumulative distribution function of the distance from a point of the pattern X to the nearest other point of X.
- K: The K function, also known as Ripley’s K function, is a statistical tool used in spatial analysis to evaluate the distribution of points in a given space. The K function is defined so that K(r) equals the expected number of additional points of X within a distance r of a point of X, where is the intensity (expected number of points per unit area).
- P: Pair correlation function. The pair correlation function is a modified version of the K function where instead of summing all points within a distance r, points falling within a narrow distance band are summed instead. This function may be seen as the probability of observing a pair of points of the process separated by a distance r, divided by the corresponding probability for a Poisson process.
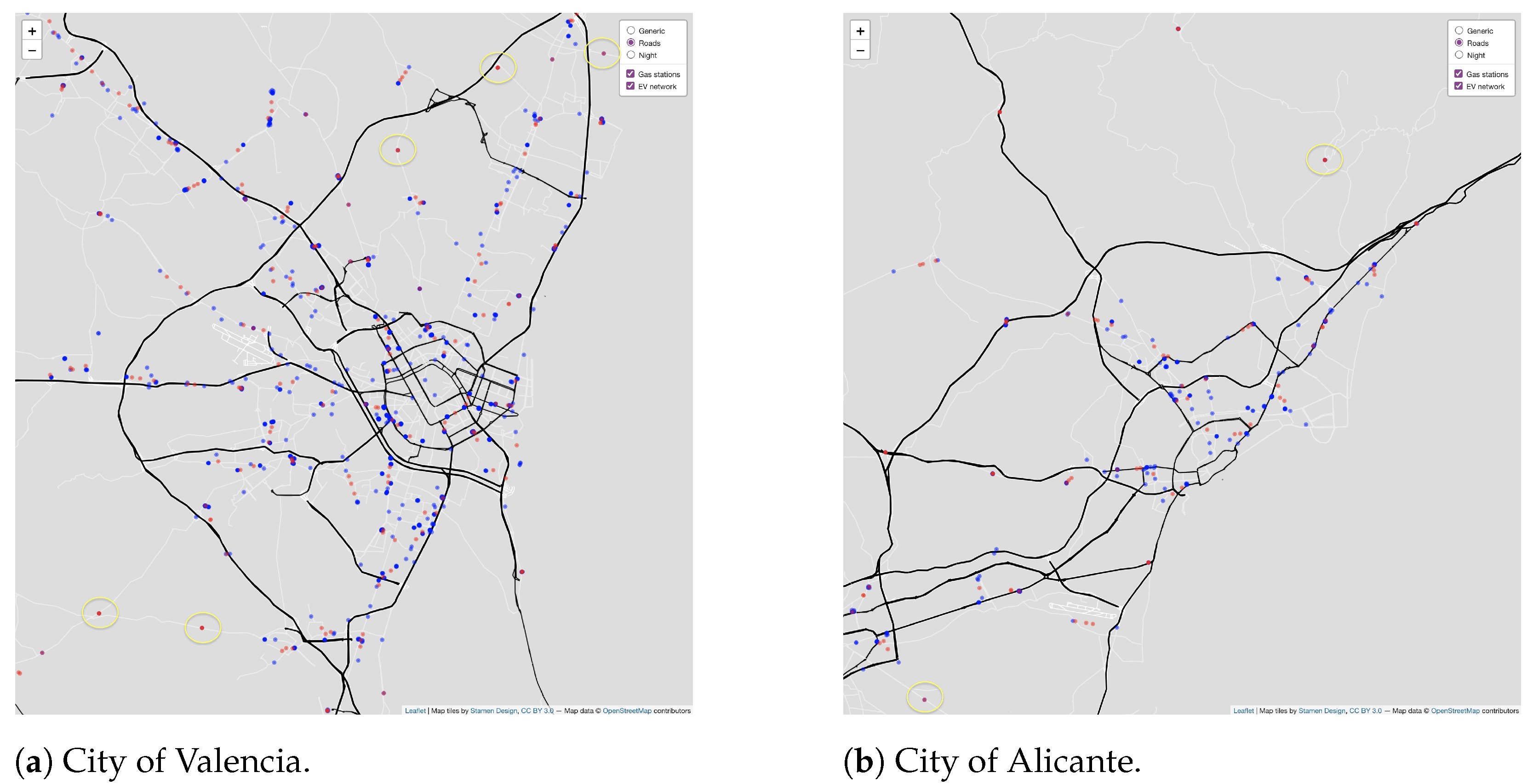
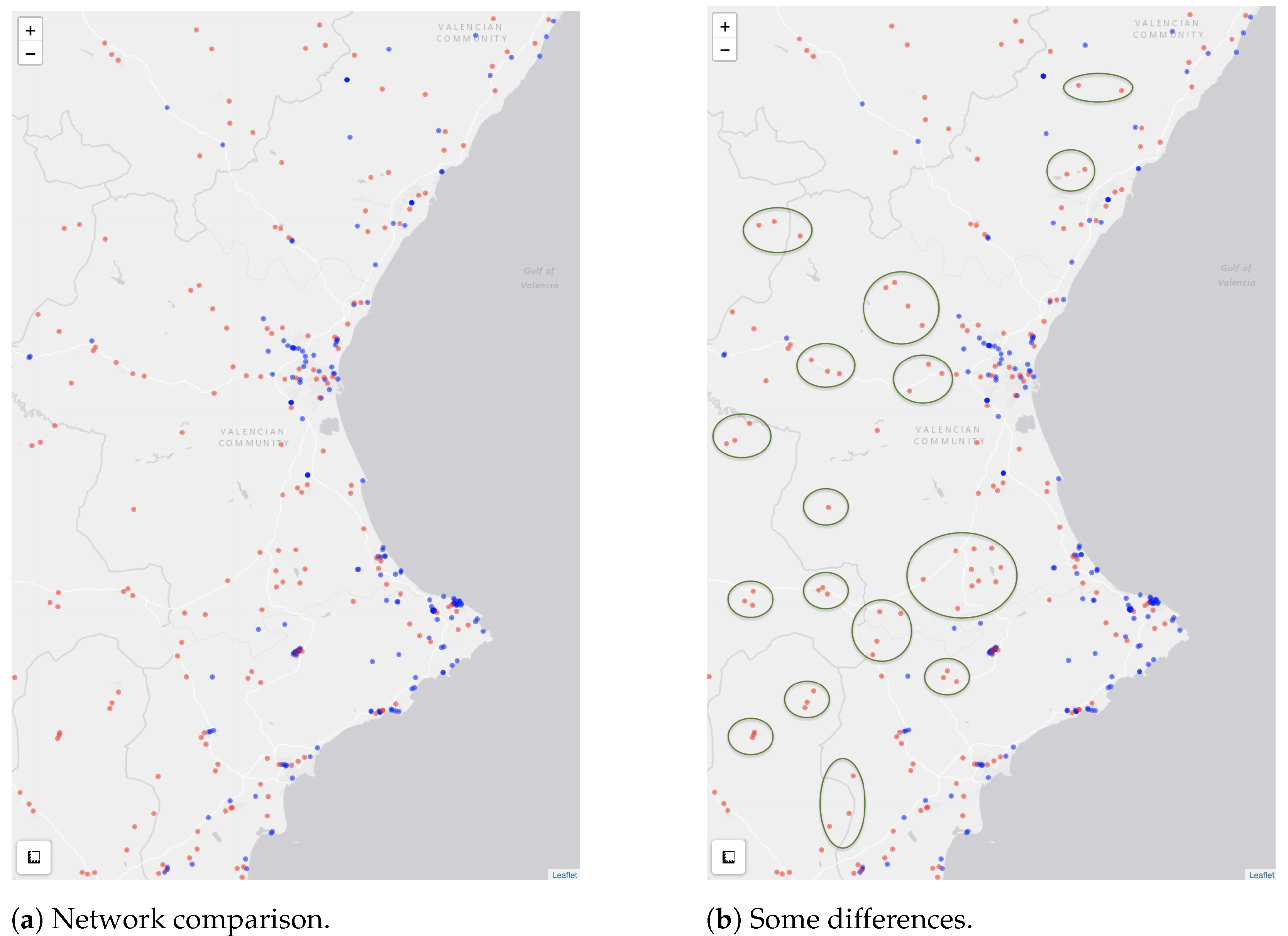
4.3. Visualization of the Numerical Results
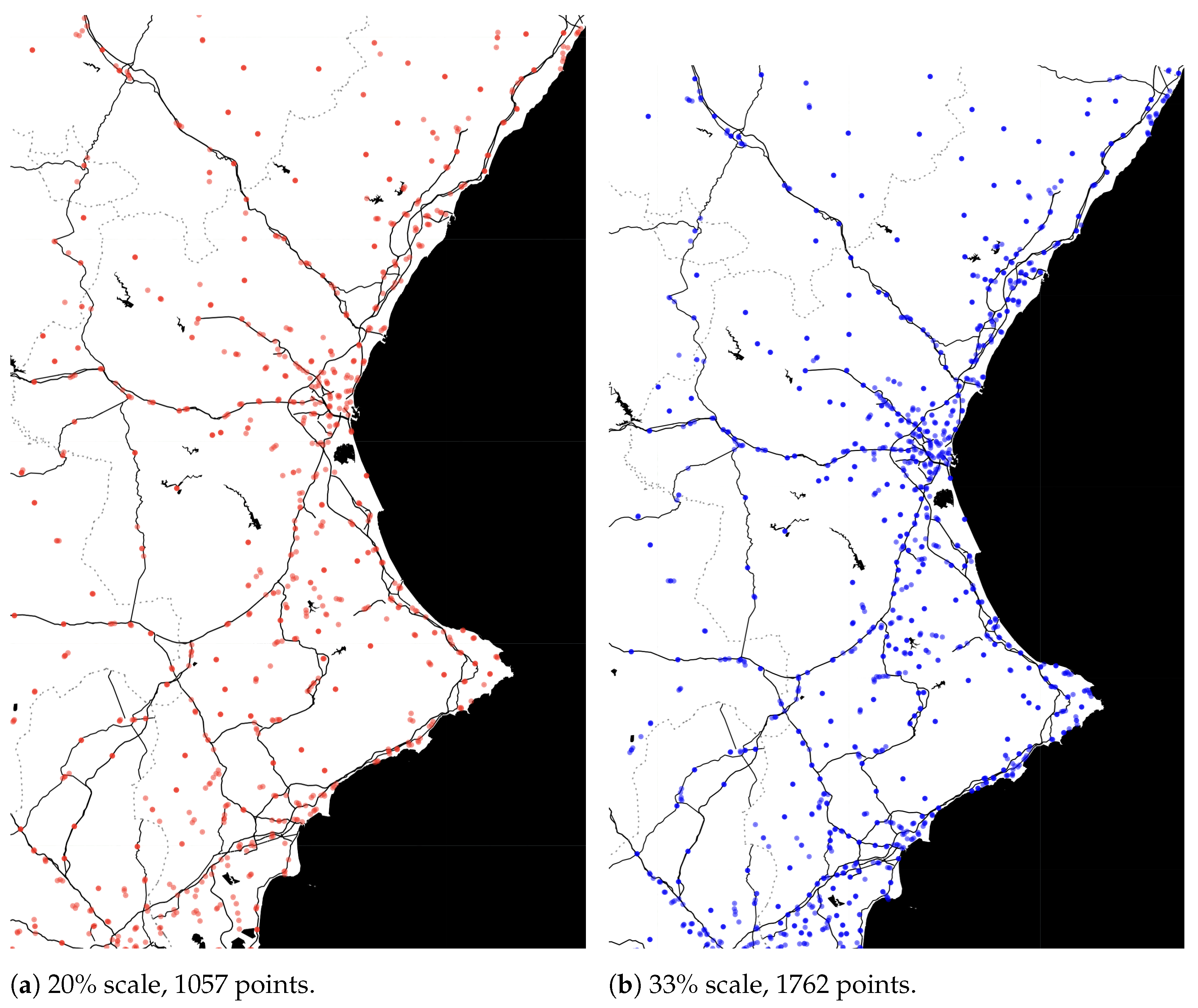
- Initial gas station dataset: 5287 points. Final dataset: , i.e., 1057 points.
- Initial gas station dataset: 5287 points. Final dataset: , i.e., 1762 points.
- The original network used and that introduced as an input parameter will be formed by the urban centers of the geographical area studied.
- The probability vector p associated with this dataset will be the normalized population density vector of each urban center.
- The initial set of points, randomly generated at the beginning of the algorithm, is replaced by the final set of points obtained in the first execution of the algorithm, represented in Figure 6.
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| SOM | Self-Organizing Map |
| NG | Neural Gas |
| GRGA | Growing Neural Gas |
| GNG2D+ | Growing Neural Gas modified |
| EV | Electric vehicle |
Appendix A. Some Data on the Context of Electric Mobility in Spain
- Global electromobility indicator.
- Charging infrastructure indicator.
- The Recharging Infrastructure Indicator for the Motorizable Population: This evaluates the current state considering a target of charging points for every 1000 people of motorizable age.
- The Rapid Charging Infrastructure Indicator for the Motorizable Population: This measures the distance of the current rapid charging infrastructures (more than 50 kW) in reference to a target of points for every 1000 people of motorizable age.
Appendix B. Neural Gas Algorithm (NG)
- Sample data vector x from (input signals).
- Compute the distance between x and each vector .
- Let be the index of the closest vector, the index of the second closest vector, and so on.
- Update each of the vectors using the equation
Appendix C. Growing Neural Gas Algorithm (GNG)
- A set A of N nodes or units. Each unit has an associated reference vector .Remark that the reference vectors can be understood as positions in input space.
- A set of connections (or edges) among pairs of units (not weighted).
- A probability density function .
- Start with the two units and at random positions and .
- Generate an input signal from .
- Locate the nearest node and the second-nearest unit .
- Increment the age of all edges emanating from .
- Add the square distance between the input signal and the nearest unit in the input space to a local counter-variable:
- Move and its direct topological neighbors toward by fractions of and , respectively, of the total distance for all direct neighbors n of :
- If and are connected by an edge, set the age of this edge to zero. If that edge does not exist, create it.
- Remove edges with an age larger than . If this results in points having no emanating edges, remove them as well.
- If the number of input signals generated so far is an integer multiple of a parameter , insert a new unit as follows:
- (a)
- Determine the unit q with the maximum accumulated error.
- (b)
- Insert a new unit r halfway between q and its neighbor f with the largest error variable:
- (c)
- Insert edges connecting the new unit r with units q and f, and remove the original edge between q and f.
- (d)
- Decrease the error variables of q and f by multiplying them with a constant .Initialize the error variable of r with the new value of the error variable of q.
- Decrease all error variables by multiplying them with a constant d.
- If a stopping criterion is not yet fulfilled, go to step 1.
Appendix D. GNG 2D Triangle Mesh Algorithm
- A set of vertices or nodes;
- A set of triangles among node pairs.
- Generate an input signal that will be a random point from the original mesh.
- Find the nearest node .
- Find the second- and third-nearest nodes, and , to the input signal.
- Increment the local counter of the winning node .
- Move towards by fractions of with respect to the total distance
- Move and towards by fractions of with respect to the total distance:
- Repeat steps 1 to 6 times, with being an integer of order .We have the local counter vector .For ,
- If , then
- –
- Randomly choose a node from the original mesh.
- –
- Make .
- –
- Go to point 1.
- If ; then, continue.
- Stop when the maximum number of iterations has been reached.
- Associate each node of the original mesh with a node of the set K.For every , for , find such thatwhere represents the position of the node .Save . We say that is the node associated with .
- Replace the nodes of the original triangles with their associated nodes.For every , substitutewhere are the associated nodes of , with .
- If , then save .
- If , or , or , then continue.
- Graph the set
- If a node is isolated, we add a new triangle, linking this node with its adjacent nodes.
References
- Rafaj, P.; Kiesewetter, G.; Gül, T.; Schöpp, W.; Cofala, J.; Klimont, Z.; Purohit, P.; Heyes, C.; Amann, M.; Borken-Kleefeld, J.; et al. Outlook for clean air in the context of sustainable development goals. Glob. Environ. Change 2018, 53, 1–11. [Google Scholar] [CrossRef]
- Rohde, R.A.; Muller, R.A. Air Pollution in China: Mapping of Concentrations and Sources. PLoS ONE 2015, 10, e0135749. [Google Scholar] [CrossRef] [PubMed]
- Ruggieri, R.; Ruggeri, M.; Vinci, G.; Poponi, S. Electric Mobility in a Smart City: European Overview. Energies 2021, 14, 315. [Google Scholar] [CrossRef]
- Oladunni, O.J.; Mpofu, K.; Olanrewaju, O.A. Greenhouse gas emissions and its driving forces in the transport sector of South Africa. Energy Rep. 2022, 8, 2052–2061. [Google Scholar] [CrossRef]
- Zuo, J.; Zhong, Y.; Yang, Y.; Fu, C.; He, X.; Bao, B.; Qian, F. Analysis of carbon emission, carbon displacement and heterogeneity of Guangdong power industry. Energy Rep. 2022, 8, 438–450. [Google Scholar] [CrossRef]
- Morfeldt, J.; Davidsson Kurland, S.; Johansson, D.J. Carbon footprint impacts of banning cars with internal combustion engines. Transp. Res. Part D Transp. Environ. 2021, 95, 102807. [Google Scholar] [CrossRef]
- Tran, M.K.; Bhatti, A.; Vrolyk, R.; Wong, D.; Panchal, S.; Fowler, M.; Fraser, R. A Review of Range Extenders in Battery Electric Vehicles: Current Progress and Future Perspectives. World Electr. Veh. J. 2021, 12, 54. [Google Scholar] [CrossRef]
- Hossain Lipu, M.S.; Miah, M.S.; Ansari, S.; Wali, S.B.; Jamal, T.; Elavarasan, R.M.; Kumar, S.; Naushad Ali, M.M.; Sarker, M.R.; Aljanad, A.; et al. Smart Battery Management Technology in Electric Vehicle Applications: Analytical and Technical Assessment toward Emerging Future Directions. Batteries 2022, 8, 219. [Google Scholar] [CrossRef]
- Biresselioglu, M.E.; Demirbag Kaplan, M.; Yilmaz, B.K. Electric mobility in Europe: A comprehensive review of motivators and barriers in decision making processes. Transp. Res. Part A Policy Pract. 2018, 109, 1–13. [Google Scholar] [CrossRef]
- Ray, S.; Kasturi, K.; Patnaik, S.; Nayak, M.R. Review of electric vehicles integration impacts in distribution networks: Placement, charging/discharging strategies, objectives and optimisation models. J. Energy Storage 2023, 72, 108672. [Google Scholar] [CrossRef]
- Campaña, M.; Inga, E. Optimal deployment of fast-charging stations for electric vehicles considering the sizing of the electrical distribution network and traffic condition. Energy Rep. 2023, 9, 5246–5268. [Google Scholar] [CrossRef]
- Chaturvedi, B.; Nautiyal, A.; Kandpal, T.; Yaqoot, M. Projected transition to electric vehicles in India and its impact on stakeholders. Energy Sustain. Dev. 2022, 66, 189–200. [Google Scholar] [CrossRef]
- Cui, D.; Wang, Z.; Liu, P.; Wang, S.; Dorrell, D.G.; Li, X.; Zhan, W. Operation optimization approaches of electric vehicle battery swapping and charging station: A literature review. Energy 2023, 263, 126095. [Google Scholar] [CrossRef]
- Zhuang, R.; Jiang, D.; Wang, Y. An approach to optimize building area ratios scheme of urban complex in different climatic conditions based on comprehensive energy performance evaluation. Appl. Energy 2023, 329, 120309. [Google Scholar] [CrossRef]
- Tsoi, K.H.; Loo, B.P.; Tal, G.; Sperling, D. Pioneers of electric mobility: Lessons about transport decarbonisation from two bay areas. J. Clean. Prod. 2022, 330, 129866. [Google Scholar] [CrossRef]
- Lu, G.; Zhou, X.; Mahmoudi, M.; Shi, T.; Peng, Q. Optimizing resource recharging location-routing plans: A resource-space-time network modeling framework for railway locomotive refueling applications. Comput. Ind. Eng. 2019, 127, 1241–1258. [Google Scholar] [CrossRef]
- Zhang, X.; Rey, D.; Waller, S.T.; Chen, N. Range-Constrained Traffic Assignment with Multi-Modal Recharge for Electric Vehicles. Netw. Spat. Econ. 2019, 19, 633–668. [Google Scholar] [CrossRef]
- Almansour, M. Electric vehicles (EV) and sustainability: Consumer response to twin transition, the role of e-businesses and digital marketing. Technol. Soc. 2022, 71, 102135. [Google Scholar] [CrossRef]
- Erbaş, M.; Kabak, M.; Özceylan, E.; Çetinkaya, C. Optimal siting of electric vehicle charging stations: A GIS-based fuzzy Multi-Criteria Decision Analysis. Energy 2018, 163, 1017–1031. [Google Scholar] [CrossRef]
- Griffith, D.A.; Chun, Y.; Kim, H. Spatial autocorrelation informed approaches to solving location–allocation problems. Spat. Stat. 2022, 50, 100612. [Google Scholar] [CrossRef]
- Kohonen, T. Self-organized formation of topologically correct feature maps. Biol. Cybern. 1982, 43, 59–69. [Google Scholar] [CrossRef]
- Martinetz, T.; Schulten, K. A “neural-gas” network learns topologies. Artif. Neural Netw. 1991, 1, 397–402. [Google Scholar]
- Fritzke, B. Growing Cell Structures—A Self-organizing Network in k Dimensions. In Artificial Neural Networks; Aleksander, I., Taylor, J., Eds.; North-Holland: Amsterdam, The Netherlands, 1992; pp. 1051–1056. [Google Scholar] [CrossRef]
- Licen, S.; Astel, A.; Tsakovski, S. Self-organizing map algorithm for assessing spatial and temporal patterns of pollutants in environmental compartments: A review. Sci. Total Environ. 2023, 878, 163084. [Google Scholar] [CrossRef]
- Tortosa, L.; Vicent, J.; Zamora, A. A model to simplify 2D triangle meshes with irregular shapes. Appl. Math. Comput. 2010, 216, 2937–2946. [Google Scholar] [CrossRef]
- Jose, L.; Oliver, L.T.; Vicent, J.F. A neural network model to develop actions in urban complex systems represented by 2D meshes. Int. J. Comput. Math. 2011, 88, 3361–3379. [Google Scholar] [CrossRef]
- Jose, L.; Oliver, L.T.; Vicent, J.F. An application of a self-organizing model to the design of urban transport networks. J. Intell. Fuzzy Syst. 2011, 22, 141–154. [Google Scholar]
- Fišer, D.; Faigl, J.; Kulich, M. Growing neural gas efficiently. Neurocomputing 2013, 104, 72–82. [Google Scholar] [CrossRef]
- Bentley, J.L. Multidimensional binary search trees used for associative searching. Commun. ACM 1975, 18, 509–517. [Google Scholar] [CrossRef]
- Baddeley, A.; Rubak, E.; Turner, R. Spatial Point Patterns: Methodology and Applications with R; Chapman and Hall/CRC Press: London, UK, 2015. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Gas Stations | EV Charging Points | Municipalities |
|---|---|---|---|
| Size | 5287 | 222 | 542 |
| Date | September 2023 | December 2023 | 2023 |
| Source | OpenStreetMap | OpenStreetMap | ICV |
| API | Overpass | Overpass | Open Data |
| Tag | ‘fuel’ | ‘charging_station’ | |
| Library | osmdata | osmdata |
| N | M | Scale | Iterations | Time | |||
|---|---|---|---|---|---|---|---|
| 5287 | 176 | 100 | |||||
| 5287 | 176 | 150 | |||||
| 5287 | 264 | 100 | |||||
| 5287 | 264 | 100 | |||||
| 5287 | 264 | 150 | |||||
| 5287 | 528 | 100 | |||||
| 5287 | 528 | 150 | |||||
| 5287 | 1057 | 100 | |||||
| 5287 | 1057 | 150 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Curado, M.; Hidalgo, D.; Oliver, J.L.; Tortosa, L.; Vicent, J.F. A Variant of the Growing Neural Gas Algorithm for the Design of an Electric Vehicle Charger Network. Mathematics 2024, 12, 3485. https://doi.org/10.3390/math12223485
Curado M, Hidalgo D, Oliver JL, Tortosa L, Vicent JF. A Variant of the Growing Neural Gas Algorithm for the Design of an Electric Vehicle Charger Network. Mathematics. 2024; 12(22):3485. https://doi.org/10.3390/math12223485
Chicago/Turabian StyleCurado, Manuel, Diego Hidalgo, Jose L. Oliver, Leandro Tortosa, and Jose F. Vicent. 2024. "A Variant of the Growing Neural Gas Algorithm for the Design of an Electric Vehicle Charger Network" Mathematics 12, no. 22: 3485. https://doi.org/10.3390/math12223485
APA StyleCurado, M., Hidalgo, D., Oliver, J. L., Tortosa, L., & Vicent, J. F. (2024). A Variant of the Growing Neural Gas Algorithm for the Design of an Electric Vehicle Charger Network. Mathematics, 12(22), 3485. https://doi.org/10.3390/math12223485