
Explaining the Anomaly Detection in Additive Manufacturing via Boosting Models and Frequency Analysis

 , ,
, ,  , ,
, ,  and
and 
Abstract
1. Introduction
2. Materials and Methods
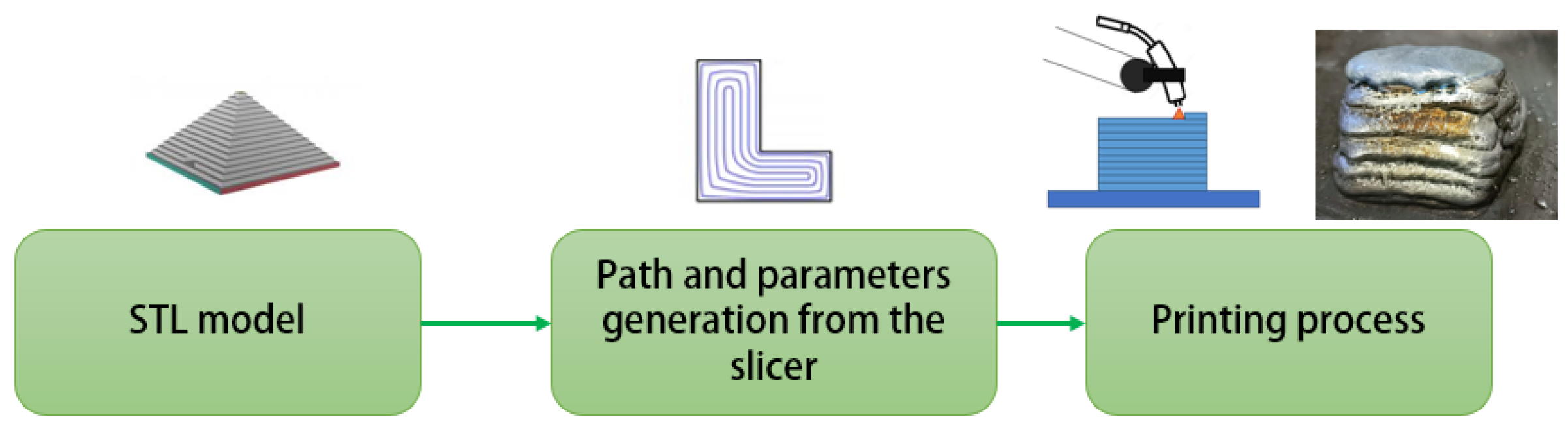
2.1. Experimental Setup
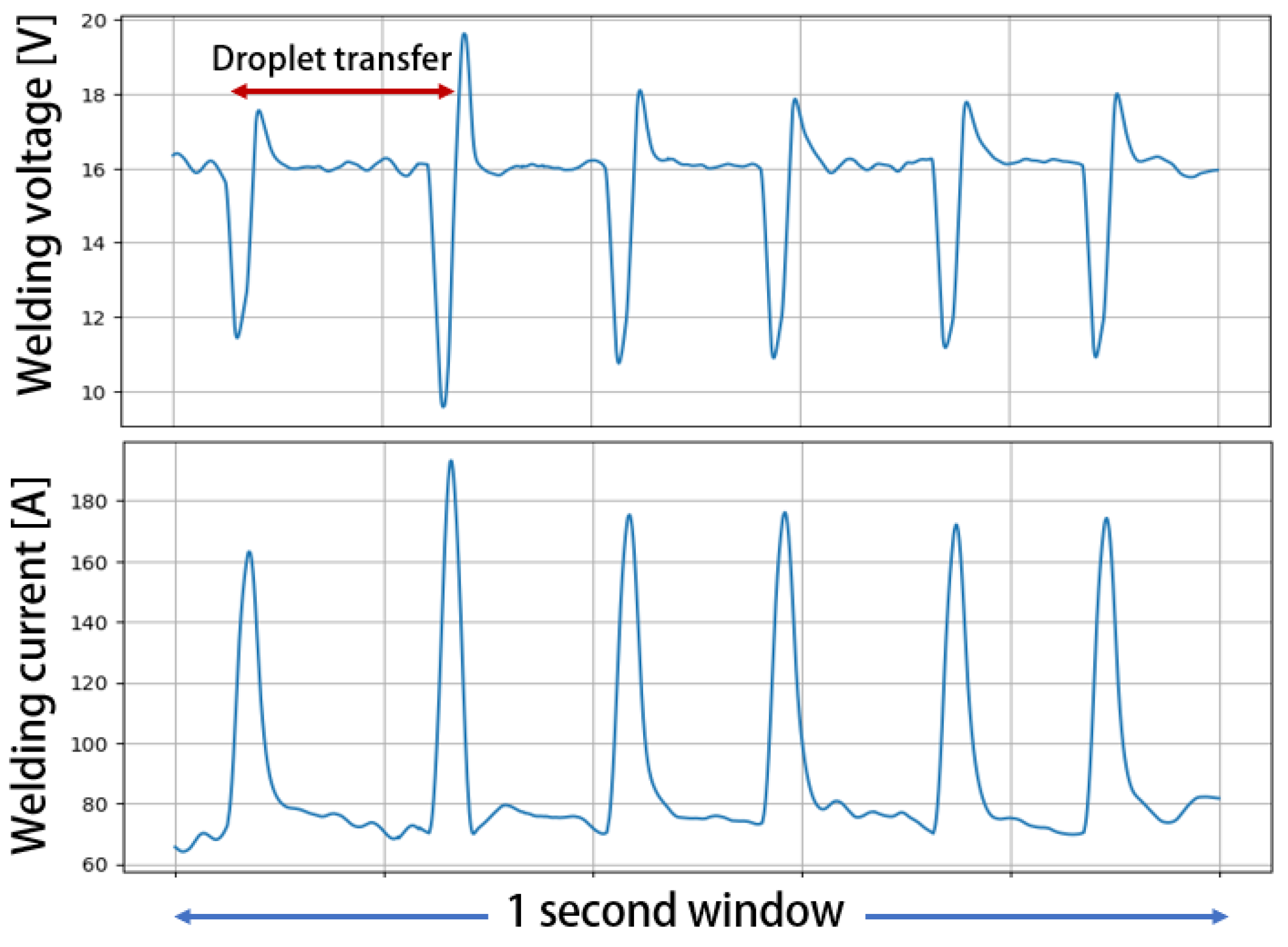
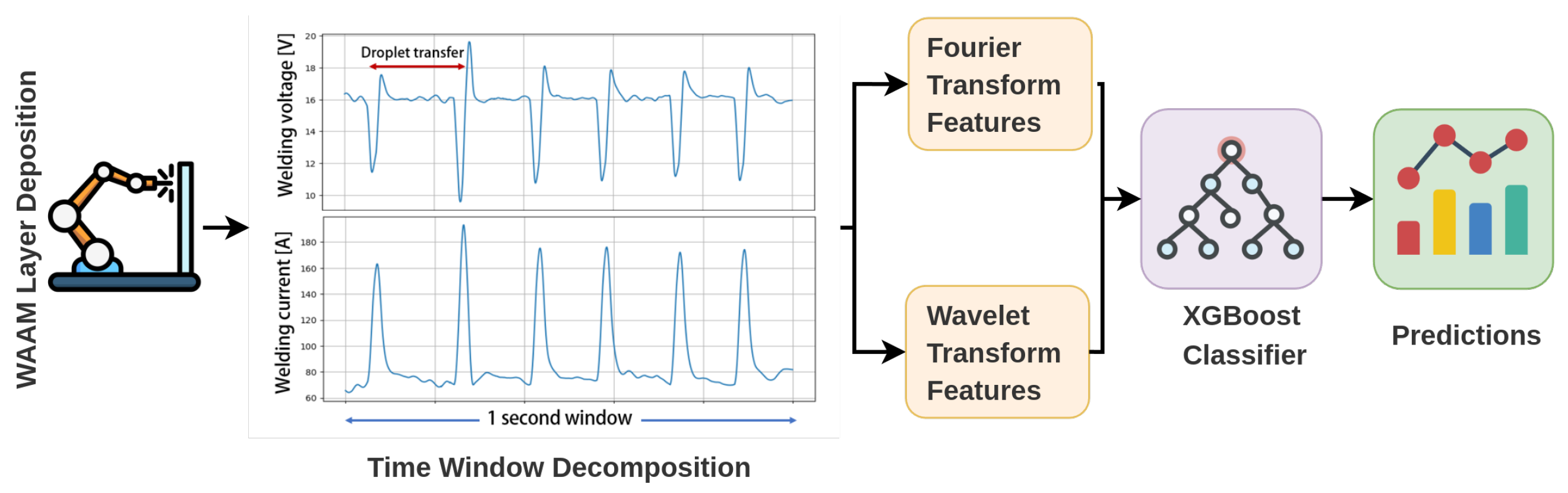
2.2. Data Preprocessing and Features Extraction
2.2.1. Fast Fourier Transform Features
2.2.2. Discrete Wavelet Transform Features
- The Haar wavelet, known for its simplicity, is the most basic wavelet. Its scaling function is a step function, making it easy to compute and suitable for certain applications, particularly those requiring piecewise constant approximations. However, a notable drawback of the Haar wavelet is its lack of translational invariance. This means that a small shift in the signal can result in a significantly different wavelet decomposition. In practical terms, this can lead to instability or inconsistent results when analyzing signals that do not align perfectly with the wavelet’s step-like structure. As a result, Haar wavelets may not perform well in applications like complex waveform welding processes.
- Daubechies wavelets are a popular family of wavelets distinguished by their compact support and the ability to efficiently capture both time and frequency information. Their effectiveness increases with the order of the wavelet, allowing them to handle signals with sharp transitions or high-frequency components due to their vanishing moments, which facilitate precise signal approximation. Despite these advantages, Daubechies wavelets have a lack of symmetry, which can make them less suitable for tasks such as image reconstruction or certain filtering applications where symmetry is beneficial. Nevertheless, Daubechies wavelets are extensively used in welding applications, where their properties are particularly well-suited for analyzing and processing signals related to welding processes [43,44].
- Coiflets wavelets are designed to enhance symmetry and vanishing moments, improving signal approximation compared to other wavelets. However, the increased computational complexity associated with Coiflets may not always be justified, especially when compared to Daubechies wavelets. Coiflets are particularly beneficial when Daubechies wavelets struggle with symmetry, as Coiflets provide better phase alignment and feature reconstruction. Therefore, Coiflets are a preferable choice in scenarios where symmetry is crucial and Daubechies wavelets’ performance is insufficient due to their asymmetry.
2.3. Boosting Models
2.4. Metrics for Performance Evaluation
3. Results
3.1. Recap of the Proposed Methodology
3.2. Model Hyperparameters
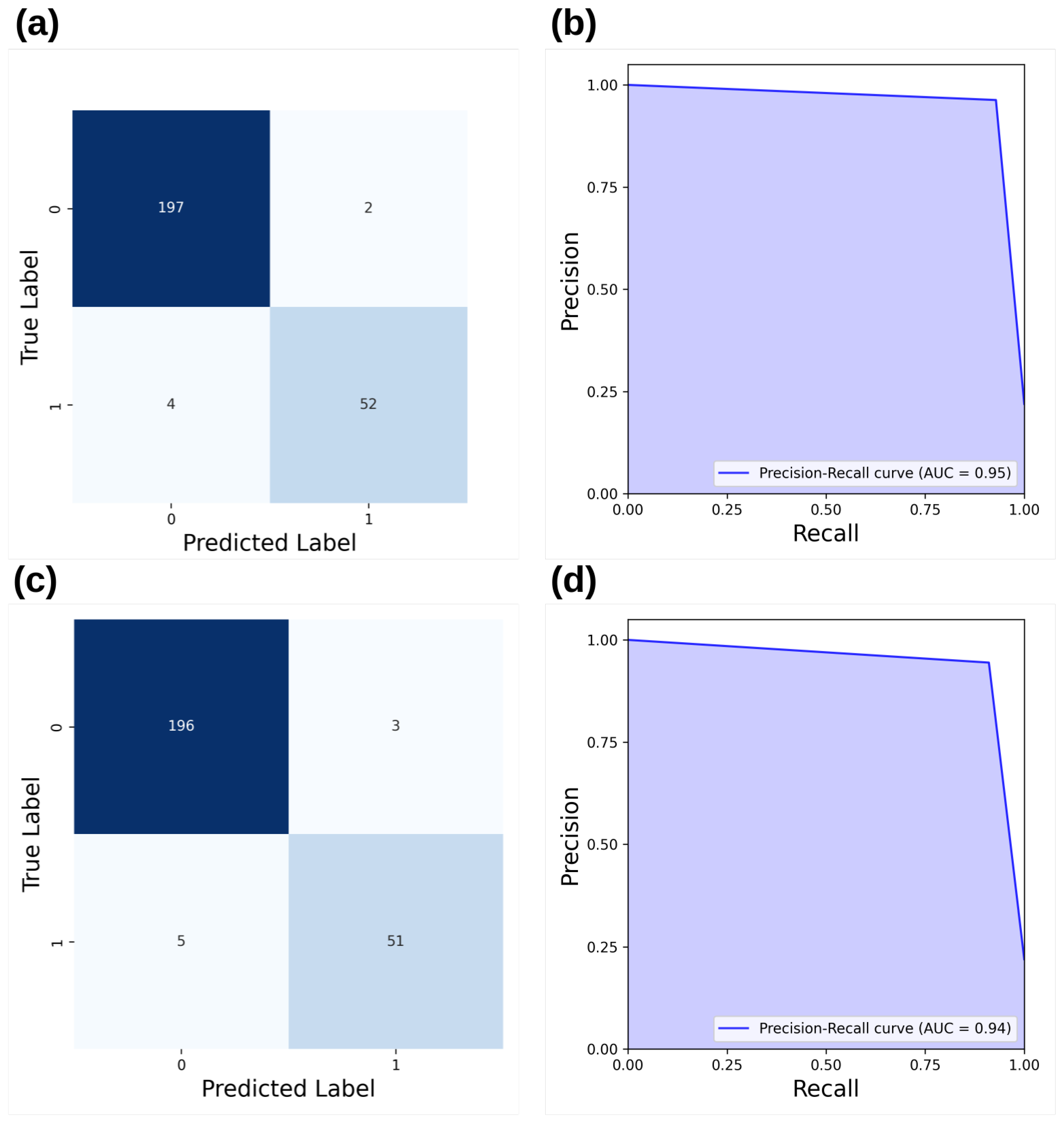
3.3. Discussion of the Results
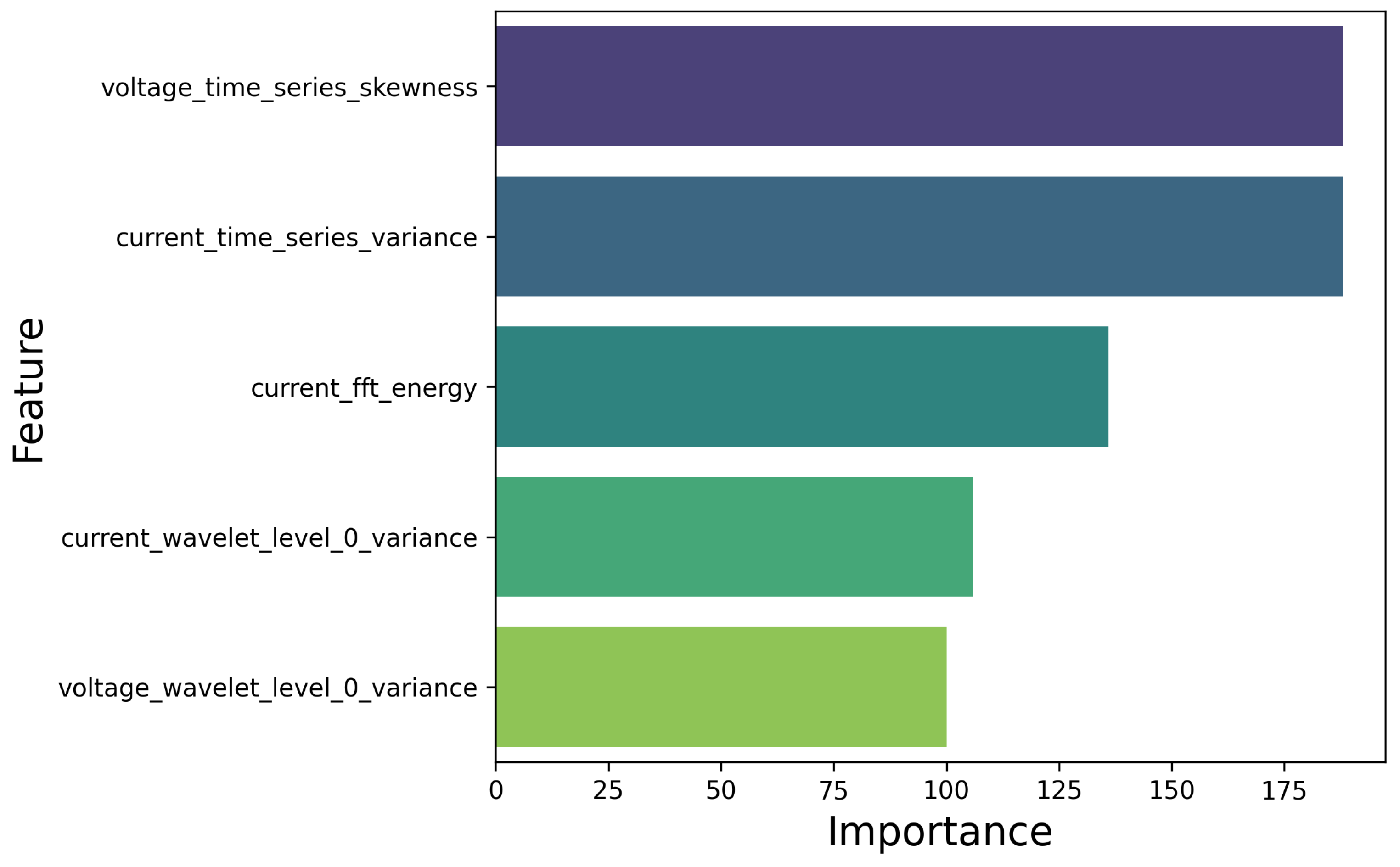
3.4. Explainability of the Model
3.5. Future Developments
4. Conclusions
- We compared performance in online anomaly detection of different ML models once a small and unbalanced dataset is available.
- The results showed high performance from XGBoost (F1 score: 0.927) and LGBM (F1 score: 0.945), proving their effectiveness on small and unbalanced datasets. The k-Nearest Neighbors method achieved 0.916, while Isolation Forest and ANN scored 0.507 and 0.56, respectively, highlighting the superiority of boosting methods in this scenario.
- For the INVAR36 alloy printed under the conditions of this study, feature importance revealed that the key factors were the variance in the 0–357 Hz frequency response of welding current and voltage, as well as the mean energy of the voltage FFT spectrum, highlighting the importance of frequency domain study of those signals for anomaly detection.
- The use of this model enables the development of more intelligent and automated decision-making support systems. By leveraging meaningful features and linking them to potential actions based on their values, the system can provide actionable insights. For instance, a narrow standard deviation but higher FFT energy can indicate the presence of porosity, whereas a wider standard deviation may signal process instability caused by an increased contact tip to workpiece distance.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Tao, F.; Qi, Q.; Liu, A.; Kusiak, A. Data-driven smart manufacturing. J. Manuf. Syst. 2018, 48, 157–169. [Google Scholar] [CrossRef]
- Kusiak, A. Predictive models in digital manufacturing: Research, applications, and future outlook. Int. J. Prod. Res. 2023, 61, 6052–6062. [Google Scholar] [CrossRef]
- Kordestani, H.; Zhang, C.; Arab, A. An Investigation into the Application of Acceleration Responses’ Trendline for Bridge Damage Detection Using Quadratic Regression. Sensors 2024, 24, 410. [Google Scholar] [CrossRef] [PubMed]
- Kusiak, A. Smart manufacturing must embrace big data. Nature 2017, 544, 23–25. [Google Scholar] [CrossRef] [PubMed]
- Zhang, W.; Li, Z.; Li, G.; Zhuang, P.; Hou, G.; Zhang, Q.; Li, C. Gacnet: Generate adversarial-driven cross-aware network for hyperspectral wheat variety identification. IEEE Trans. Geosci. Remote Sens. 2023, 62, 1–14. [Google Scholar] [CrossRef]
- Yao, R.; Ge, Z.; Wang, D.; Shang, N.; Shi, J. Self-sensing joints for in-situ structural health monitoring of composite pipes: A piezoresistive behavior-based method. Eng. Struct. 2024, 308, 118049. [Google Scholar] [CrossRef]
- Dilberoglu, U.M.; Gharehpapagh, B.; Yaman, U.; Dolen, M. The role of additive manufacturing in the era of industry 4.0. Procedia Manuf. 2017, 11, 545–554. [Google Scholar] [CrossRef]
- Williams, S.W.; Martina, F.; Addison, A.C.; Ding, J.; Pardal, G.; Colegrove, P. Wire+ arc additive manufacturing. Mater. Sci. Technol. 2016, 32, 641–647. [Google Scholar] [CrossRef]
- Norrish, J.; Polden, J.; Richardson, I. A review of wire arc additive manufacturing: Development, principles, process physics, implementation and current status. J. Phys. D Appl. Phys. 2021, 54, 473001. [Google Scholar] [CrossRef]
- Priarone, P.C.; Pagone, E.; Martina, F.; Catalano, A.R.; Settineri, L. Multi-criteria environmental and economic impact assessment of wire arc additive manufacturing. CIRP Ann. 2020, 69, 37–40. [Google Scholar] [CrossRef]
- Mattera, G.; Polden, J.; Norrish, J. Monitoring the gas metal arc additive manufacturing process using unsupervised machine learning. Weld. World 2024, 68, 2853–2867. [Google Scholar] [CrossRef]
- Mattera, G.; Piscopo, G.; Longobardi, M.; Giacalone, M.; Nele, L. Improving the Interpretability of Data-Driven Models for Additive Manufacturing Processes Using Clusterwise Regression. Mathematics 2024, 12, 2559. [Google Scholar] [CrossRef]
- Wu, B.; Pan, Z.; Ding, D.; Cuiuri, D.; Li, H.; Xu, J.; Norrish, J. A review of the wire arc additive manufacturing of metals: Properties, defects and quality improvement. J. Manuf. Process. 2018, 35, 127–139. [Google Scholar] [CrossRef]
- Mattera, G.; Nele, L.; Paolella, D. Monitoring and control the Wire Arc Additive Manufacturing process using artificial intelligence techniques: A review. J. Intell. Manuf. 2023, 35, 467–497. [Google Scholar] [CrossRef]
- Mattera, G.; Caggiano, A.; Nele, L. Optimal data-driven control of manufacturing processes using reinforcement learning: An application to wire arc additive manufacturing. J. Intell. Manuf. 2024, 1–20. [Google Scholar] [CrossRef]
- Mattera, G.; Caggiano, A.; Nele, L. Reinforcement learning as data-driven optimization technique for GMAW process. Weld. World 2023, 68, 805–817. [Google Scholar] [CrossRef]
- Li, Y.; Polden, J.; Pan, Z.; Cui, J.; Xia, C.; He, F.; Mu, H.; Li, H.; Wang, L. A defect detection system for wire arc additive manufacturing using incremental learning. J. Ind. Inf. Integr. 2022, 27, 100291. [Google Scholar] [CrossRef]
- Li, W.; Zhang, H.; Wang, G.; Xiong, G.; Zhao, M.; Li, G.; Li, R. Deep learning based online metallic surface defect detection method for wire and arc additive manufacturing. Robot. Comput.-Integr. Manuf. 2023, 80, 102470. [Google Scholar] [CrossRef]
- Alcaraz, J.Y.I.; Foqué, W.; Sharma, A.; Tjahjowidodo, T. Indirect porosity detection and root-cause identification in WAAM. J. Intell. Manuf. 2024, 35, 1607–1628. [Google Scholar] [CrossRef]
- Li, Y.; Mu, H.; Polden, J.; Li, H.; Wang, L.; Xia, C.; Pan, Z. Towards intelligent monitoring system in wire arc additive manufacturing: A surface anomaly detector on a small dataset. Int. J. Adv. Manuf. Technol. 2022, 120, 5225–5242. [Google Scholar] [CrossRef]
- Mattera, G.; Polden, J.; Caggiano, A.; Nele, L.; Pan, Z.; Norrish, J. Semi-supervised Learning for Real-Time Anomaly Detection in Pulsed Transfer Wire Arc Additive Manufacturing. J. Manuf. Process. 2024, 128, 84–97. [Google Scholar] [CrossRef]
- Xia, C.; Pan, Z.; Li, Y.; Chen, J.; Li, H. Vision-based melt pool monitoring for wire-arc additive manufacturing using deep learning method. Int. J. Adv. Manuf. Technol. 2022, 120, 551–562. [Google Scholar] [CrossRef]
- Song, H.; Li, C.; Fu, Y.; Li, R.; Zhang, H.; Wang, G. A two-stage unsupervised approach for surface anomaly detection in wire and arc additive manufacturing. Comput. Ind. 2023, 151, 103994. [Google Scholar] [CrossRef]
- Norrish, J. Evolution of Advanced Process Control in GMAW: Innovations, Implications, and Application. Weld. Res. 2024, 103, 161–175. [Google Scholar] [CrossRef]
- Saarela, M.; Jauhiainen, S. Comparison of feature importance measures as explanations for classification models. SN Appl. Sci. 2021, 3, 272. [Google Scholar] [CrossRef]
- Kotsiantis, S. Feature selection for machine learning classification problems: A recent overview. Artif. Intell. Rev. 2011, 42, 157–176. [Google Scholar] [CrossRef]
- Chen, R.C.; Dewi, C.; Huang, S.W.; Caraka, R.E. Selecting critical features for data classification based on machine learning methods. J. Big Data 2020, 7, 52. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. arXiv 2016, arXiv:1603.02754. [Google Scholar] [CrossRef]
- Pattawaro, A.; Polprasert, C. Anomaly-based network intrusion detection system through feature selection and hybrid machine learning technique. In Proceedings of the 2018 IEEE 16th International Conference on ICT and Knowledge Engineering (ICT&KE), Bangkok, Thailand, 21–23 November 2018; pp. 1–6. [Google Scholar]
- Tian, J.; Jiang, Y.; Zhang, J.; Wang, Z.; Rodríguez-Andina, J.J.; Luo, H. High-performance fault classification based on feature importance ranking-XgBoost approach with feature selection of redundant sensor data. Curr. Chin. Sci. 2022, 2, 243–251. [Google Scholar] [CrossRef]
- Alcaraz, J.Y.; Sharma, A.; Tjahjowidodo, T. Predicting porosity in wire arc additive manufacturing (WAAM) using wavelet scattering networks and sparse principal component analysis. Weld. World 2024, 68, 843–853. [Google Scholar] [CrossRef]
- Mu, H.; He, F.; Yuan, L.; Commins, P.; Ding, D.; Pan, Z. A digital shadow approach for enhancing process monitoring in wire arc additive manufacturing using sensor fusion. J. Ind. Inf. Integr. 2024, 40, 100609. [Google Scholar] [CrossRef]
- Mattera, G.; Polden, J.; Nele, L. A Time-Frequency Domain Feature Extraction Approach Enhanced by Computer Vision for Wire Arc Additive Manufacturing Monitoring Using Fourier and Wavelet Transform. J. Adv. Manuf. Syst. 2024. [Google Scholar] [CrossRef]
- Shin, S.; Jin, C.; Yu, J.; Rhee, S. Real-time detection of weld defects for automated welding process base on deep neural network. Metals 2020, 10, 389. [Google Scholar] [CrossRef]
- Alfaro, S.A.; Carvalho, G.; Da Cunha, F. A statistical approach for monitoring stochastic welding processes. J. Mater. Process. Technol. 2006, 175, 4–14. [Google Scholar] [CrossRef]
- Mattera, G.; Yap, E.W.; Polden, J.; Brown, E.; Nele, L.; Duin, S.V. Utilising Unsupervised Machine Learning and IoT for Cost-Effective Anomaly Detection in multi-layer Wire Arc Additive Manufacturing. Int. J. Adv. Manuf. Technol. 2024, 135, 2957–2974. [Google Scholar] [CrossRef]
- Mattera, G.; Vozza, M.; Polden, J.; Nele, L.; Pan, Z. Frequency Informed Convolutional Autoencoder for in situ anomaly detection in Wire Arc Additive Manufacturing. J. Intell. Manuf. 2024. [Google Scholar] [CrossRef]
- Nigam, H.; Srivastava, H.M. Filtering of audio signals using discrete wavelet transforms. Mathematics 2023, 11, 4117. [Google Scholar] [CrossRef]
- Gowthami, V.; Bagan, K.B.; Pushpa, S.E.P. A novel approach towards high-performance image compression using multilevel wavelet transformation for heterogeneous datasets. J. Supercomput. 2023, 79, 2488–2518. [Google Scholar] [CrossRef]
- Yang, H.; Zhang, J.; Chen, J.; Cai, H.; Jiao, Y.; Wang, M.; Liu, E.; Li, B. Denoising of laser cladding crack acoustic emission signals based on wavelet thresholding method. J. Phys. Conf. Ser. 2024, 2713, 012069. [Google Scholar] [CrossRef]
- Kumar, V.; Ghosh, S.; Parida, M.K.; Albert, S.K. Application of continuous wavelet transform based on Fast Fourier transform for the quality analysis of arc welding process. Int. J. Syst. Assur. Eng. Manag. 2024, 15, 917–930. [Google Scholar] [CrossRef]
- Jang, S.; Lee, W.; Jeong, Y.; Wang, Y.; Won, C.; Lee, J.; Yoon, J. Machine learning-based weld porosity detection using frequency analysis of arc sound in the pulsed gas tungsten arc welding process. J. Adv. Join. Process. 2024, 10, 100231. [Google Scholar] [CrossRef]
- Zhang, H.; Wu, Q.; Tang, W.; Yang, J. Acoustic Signal-Based Defect Identification for Directed Energy Deposition-Arc Using Wavelet Time–Frequency Diagrams. Sensors 2024, 24, 4397. [Google Scholar] [CrossRef] [PubMed]
- Mattera, G.; Polden, J.; Nele, L. Monitoring Wire Arc Additive Manufacturing process of Inconel 718 thin-walled structure using wavelet decomposition and clustering analysis of welding signal. J. Adv. Manuf. Sci. Technol. 2024. [Google Scholar] [CrossRef]
- Saito, T.; Rehmsmeier, M. The precision-recall plot is more informative than the ROC plot when evaluating binary classifiers on imbalanced datasets. PLoS ONE 2015, 10, e0118432. [Google Scholar] [CrossRef] [PubMed]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Mechanical Properties | Value |
|---|---|
| Tensile strength [MPa] | >450 |
| Elongation on 5d [%] | >25 |
| Chemical Composition | Weight % |
| C | 0.01 |
| Mn | 0.3 |
| Si | 0.12 |
| S | 0.004 |
| P | <0.003 |
| Ni | 36 |
| Ti | <0.003 |
| Pb | 0.001 |
| Fe | 63 |
| Wall No. | Wire Feed Speed [m/min] | Welding Voltage [V] | Welding Speed [mm/s] |
|---|---|---|---|
| 1 | 3.5 | 19.0 | 6.5 |
| 2 | 4.0 | 19.0 | 9.0 |
| 3 | 3.5 | 22.5 | 4.0 |
| 4 | 3.5 | 21.0 | 8.0 |
| 5 | 3.5 | 19.0 | 9.0 |
| 6 | 3.5 | 20.0 | 4.0 |
| 7 | 3.0 | 19.0 | 6.5 |
| 8 | 2.0 | 20.0 | 6.5 |
| 9 | 6.0 | 19.0 | 9.0 |
| 10 | 6.0 | 21.0 | 9.0 |
| 11 | 4.0 | 22.5 | 6.5 |
| 12 | 3.0 | 22.5 | 9.0 |
| 13 | 4.0 | 19.0 | 8.0 |
| 14 | 3.0 | 20.0 | 9.0 |
| Model | Recall | Precision | F1-Score | MCC |
|---|---|---|---|---|
| Light Gradient-Boosting Machine (LightGBM) | 0.929 | 0.963 | 0.945 | 0.931 |
| eXtreme Gradient-Boosting (XGB) | 0.911 | 0.911 | 0.927 | 0.908 |
| K-Neighbors Classifier | 0.875 | 0.875 | 0.916 | 0.895 |
| Isolation Forest | 0.339 | 0.339 | 0.507 | 0.504 |
| Neural Network | 0.5 | 0.63 | 0.56 | 0.52 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vozza, M.; Polden, J.; Mattera, G.; Piscopo, G.; Vespoli, S.; Nele, L. Explaining the Anomaly Detection in Additive Manufacturing via Boosting Models and Frequency Analysis. Mathematics 2024, 12, 3414. https://doi.org/10.3390/math12213414
Vozza M, Polden J, Mattera G, Piscopo G, Vespoli S, Nele L. Explaining the Anomaly Detection in Additive Manufacturing via Boosting Models and Frequency Analysis. Mathematics. 2024; 12(21):3414. https://doi.org/10.3390/math12213414
Chicago/Turabian StyleVozza, Mario, Joseph Polden, Giulio Mattera, Gianfranco Piscopo, Silvestro Vespoli, and Luigi Nele. 2024. "Explaining the Anomaly Detection in Additive Manufacturing via Boosting Models and Frequency Analysis" Mathematics 12, no. 21: 3414. https://doi.org/10.3390/math12213414
APA StyleVozza, M., Polden, J., Mattera, G., Piscopo, G., Vespoli, S., & Nele, L. (2024). Explaining the Anomaly Detection in Additive Manufacturing via Boosting Models and Frequency Analysis. Mathematics, 12(21), 3414. https://doi.org/10.3390/math12213414