
Boosted Whittaker–Henderson Graduation


Abstract
1. Introduction
2. Preliminaries
2.1. Data
2.2. Notations
2.3. Key Matrices
2.3.1. and
2.3.2.
2.3.3. and
2.3.4. and for
2.4. Results Regarding the Key Matrices
- (i)
- the degree of smoothness of is the highest, and
- (ii)
- the degree of smoothness of is higher than or equal to that of for .
2.5. WH Graduation
2.6. Spectral Representation of WH Graduation
3. Boosted WH Graduation
3.1. Boosted WH Graduation
3.2. Spectral Representation of bWH Graduation
- Given that is a diagonal matrix, from (32), it follows thatThat is, is a symmetric matrix.
- Let . Then, it follows thatThus, it follows from (26) thatThen, given that is a symmetric matrix whose eigenvalues, for , are all positive, is a positive definite matrix.
- Let and . Then, given that , the spectral decomposition of in (32) becomesMoreover, from (15), can be represented as follows:
- Given (16), postmultiplying (37) by yields the following:
4. Properties of the bWH Graduation
- (i)
- (a) The average of the entries of in (27) is equal to that of . That is, it follows that(b) The bWH graduation residuals, , sum to zero. That is, it follows that
- (ii)
- The result in (i)(a) can be generalized as follows.
- (iii)
- Each row of the smoother matrix in (28) sums to unity. That is, it follows that
- (iv)
- in (7) satisfiesAccordingly, in (27) can be represented by as follows:
- (v)
- When n and m are fixed, as , .
- (vi)
- When n and m are fixed, as , .
- (vii)
- When n and are fixed, as , .
- (viii)
- When n, m, and are fixed, as , .
- (ix)
- in (7) can be considered as the solution of a penalized least squares problem. More specifically, it follows that
- (x)
- Here, is a diagonal matrix such that its first p diagonal entries are zeros; therefore, the first p entries of are not penalized.
- (xi)
- (i)
- is one of the columns of in (6). Then, its orthogonal projection onto is itself; i.e., it follows that . In addition, from (16), it follows that for . Accordingly, pre-multiplying (40) by yieldswhich implies that the average of the entries of equals that of . In addition, from (52), it immediately follows thatThus, the bWH(p) graduation trend residuals sum to zero.
- (ii)
- (iii)
- Thus, each row of the smoother matrix sums to unity.
- (iv)
- (v)
- (vi)
- Therefore, we have
- (vii)
- Therefore, we have
- (viii)
- Accordingly, it follows from (15) that
- (ix)
- From the definition of given by (41), it immediately follows that . Accordingly, we have
- (x)
- Based on the spectral decomposition of in (32), i.e., , in (41) can be decomposed as follows:by which we haveLetThen, , and from the inequalities given in (36), it follows that
- (xi)
- Given that in (8) is an orthogonal matrix, from (53), is similar to , and they have the same eigenvalues. Then, based on (55), is a non-negative definite matrix such that its nullity is p. Based on Lemma 1(i) and (39), is a positive definite matrix such that . Then, it follows thatfrom which we haveThus, belong to the null space of .
- 1.
- 2.
- Since is symmetric, from , it follows that , from which we haveThis is another proof of Proposition 1(i)(a).
- 3.
- for in Proposition 1(ii) is a generalization of for in Weinert (2007, p. 960) [4]. Here, equals the t-th entry of .
- 4.
- in Proposition 1(iv) is a generalization of the result in Kim et al. (2009, p. 342) [21], and Yamada (2018, Equation (3)) [23]. Given that is a low-pass filter, it indicates that is the sum of the polynomial time trend estimated by OLS, , and low-frequency components in the polynomial time trend residuals, .
- 5.
- Given that , for example, it follows that . Thus, in Proposition 1(viii) represents the result of h times repeated bWH graduation. In addition, from Proposition 1(viii), it follows thatwhich is a generalization of the result in Weinert (2007, p. 961) [4].
- 6.
- Proposition 1(ix) and (x) are generalizations of the results in Knight (2021) [10]. Given that , by its definition, it follows thatTherefore, if , then (49) becomeswhich is the WH graduation. From (25), (35), and (54), it also follows thatAccordingly, we obtain , which is consistent with (58).
- 7.
- The penalized least squares problem in (51) is a generalized ridge regression representation of the bWH graduation.
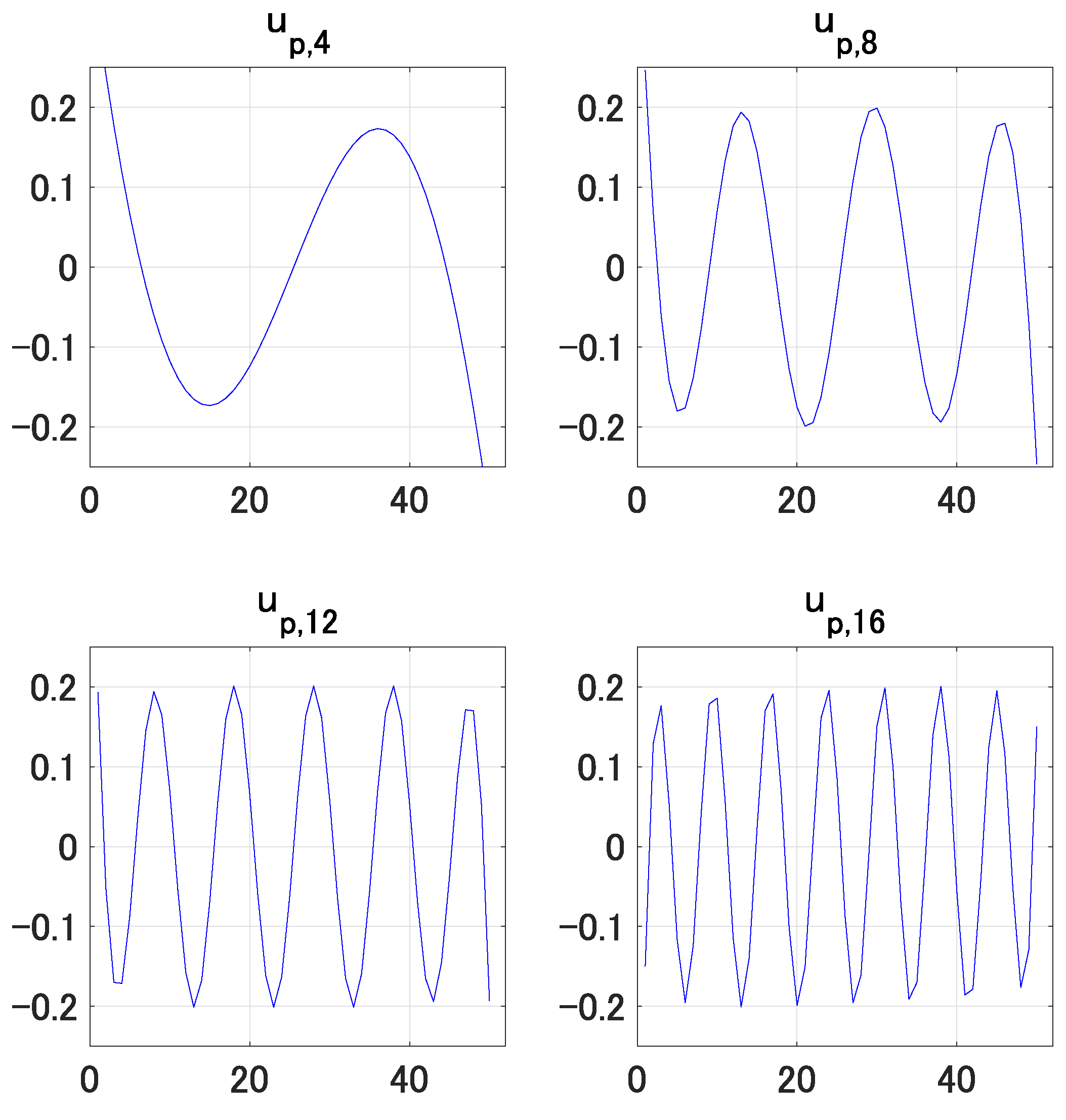
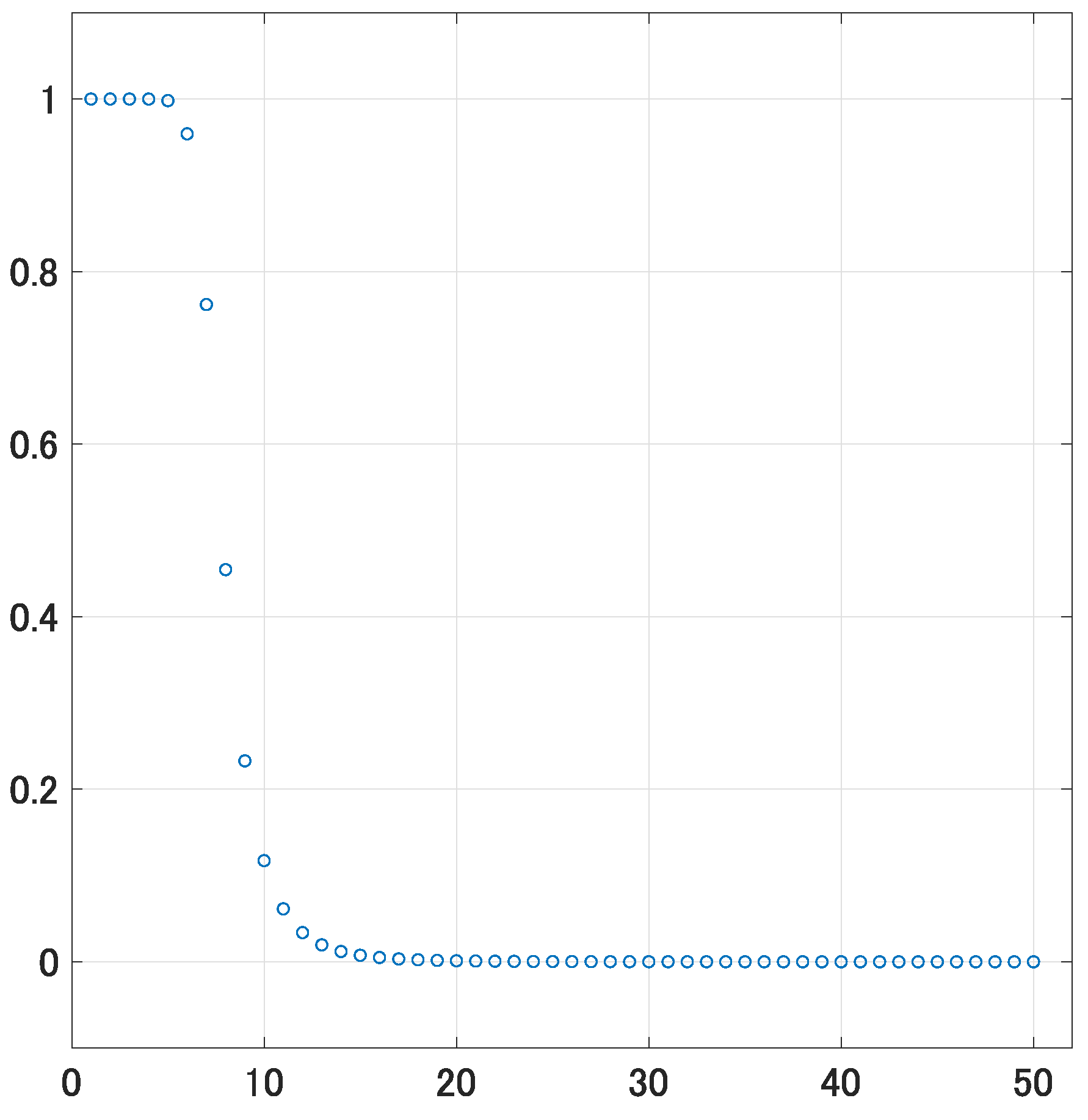
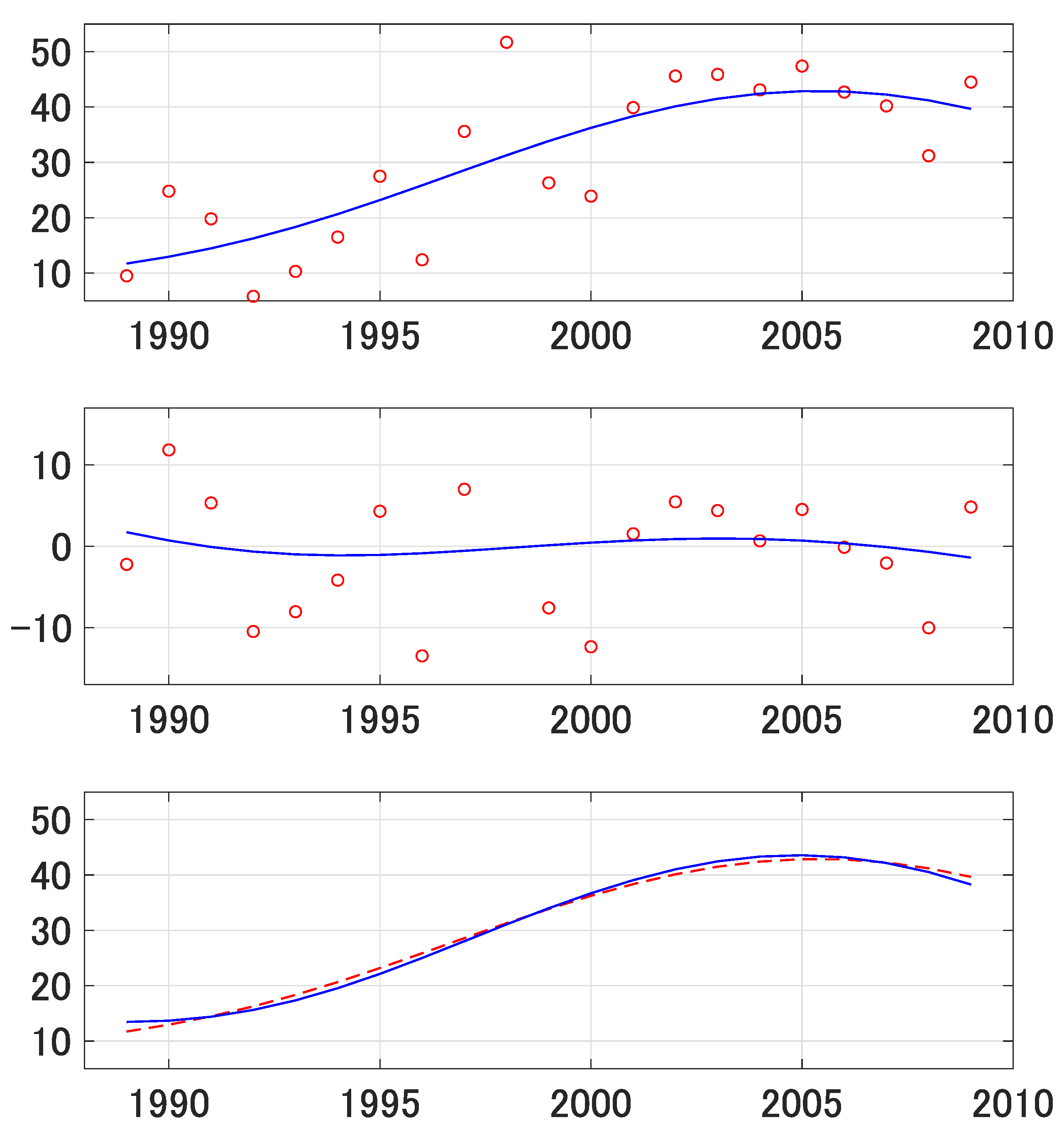
5. An Empirical Illustration
6. Concluding Remarks
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Proofs
Appendix A.1. Proof of (10)
Appendix A.2. Proof of (11)
References
- Bohlmann, G. Ein Ausgleichungsproblem. Nachrichten von der Gesellschaft der Wissenschaften zu Gottingen Mathematisch-Physikalische Klasse 1899, 1899, 260–271. [Google Scholar]
- Hodrick, R.J.; Prescott, E.C. Postwar U.S. business cycles: An empirical investigation. J. Money Credit. Bank. 1997, 29, 1–16. [Google Scholar] [CrossRef]
- Whittaker, E.T. On a new method of graduation. Proc. Edinb. Math. Soc. 1923, 41, 63–75. [Google Scholar] [CrossRef]
- Weinert, H.L. Efficient computation for Whittaker–Henderson smoothing. Comput. Stat. Data Anal. 2007, 52, 959–974. [Google Scholar] [CrossRef]
- Phillips, P.C.B. Two New Zealand pioneer econometricians. N. Z. Econ. Pap. 2010, 44, 1–26. [Google Scholar]
- Nocon, A.S.; Scott, W.F. An extension of the Whittaker–Henderson method of graduation. Scand. Actuar. J. 2012, 1, 70–79. [Google Scholar] [CrossRef]
- Biessy, G. Revisiting Whittaker–Henderson smoothing. arXiv 2023, arXiv:2306.06932. [Google Scholar]
- Phillips, P.C.B.; Shi, Z. Boosting: Why you can use the HP filter. Int. Econ. Rev. 2021, 62, 521–570. [Google Scholar] [CrossRef]
- Yamada, H. Linear trend, HP trend, and bHP trend. SSRN 2024. [Google Scholar] [CrossRef]
- Knight, K. The Boosted Hodrick–Prescott Filter, Penalized Least Squares, and Bernstein Polynomials. Unpublished Manuscript. 2021. Available online: https://utstat.utoronto.ca/keith/papers/hp-pls.pdf (accessed on 26 October 2024).
- Tomal, M. Testing for overall and cluster convergence of housing rents using robust methodology: Evidence from Polish provincial capitals. Empir. Econ. 2022, 62, 2023–2055. [Google Scholar] [CrossRef] [PubMed]
- Trojanek, R.; Gluszak, M.; Kufel, P.; Tanas, J.; Trojanek, M. Pre and post-financial crisis convergence of metropolitan housing markets in Poland. J. Hous. Built Environ. 2023, 38, 515–540. [Google Scholar] [CrossRef]
- Hall, V.B.; Thomson, P. Selecting a boosted HP filter for growth cycle analysis based on maximising sharpness. J. Bus. Cycle Res. 2024. [Google Scholar] [CrossRef]
- Mei, Z.; Phillips, P.C.B.; Shi, Z. The boosted Hodrick–Prescott filter is more general than you might think. J. Appl. Econom. 2024. [Google Scholar] [CrossRef]
- Biswas, E.; Sabzikar, F.; Phillips, P.C.B. Boosting the HP filter for trending time series with long-range dependence. Econom. Rev. 2024. [Google Scholar] [CrossRef]
- Yamada, H. Boosted HP filter: Several properties derived from its spectral representation. In Computational Science and Its Applications—ICCSA 2024; Gervasi, O., Murgante, B., Garau, C., Taniar, D., C. Rocha, A.M.A., Faginas Lago, M.N., Eds.; Springer: Cham, Switzerland, 2024. [Google Scholar] [CrossRef]
- Bao, R.; Yamada, H. Boosted Whittaker–Henderson Graduation of Order 1: A Graph Spectral Filter Using Discrete Cosine Transform. Contemp. Math. 2024. Forthcoming. Available online: https://www.researchgate.net/publication/384363420_Boosted_Whittaker-Henderson_Graduation_of_Order_1_A_Graph_Spectral_Filter_Using_Discrete_Cosine_Transform (accessed on 26 October 2024).
- Anderson, T.W. The Statistical Analysis of Time Series; John Wiley and Sons: New York, NY, USA, 1971. [Google Scholar]
- Strang, G. The discrete cosine transform. SIAM Rev. 1999, 41, 135–147. [Google Scholar] [CrossRef]
- Nakatsukasa, Y.; Saito, N.; Woei, E. Mysteries around the graph Laplacian eigenvalue 4. Linear Algebra Its Appl. 2013, 438, 3231–3246. [Google Scholar] [CrossRef]
- Kim, S.; Koh, K.; Boyd, S.; Gorinevsky, D. ℓ1 trend filtering. SIAM Rev. 2009, 51, 339–360. [Google Scholar] [CrossRef]
- Yamada, H. A smoothing method that looks like the Hodrick–Prescott filter. Econom. Theory 2020, 36, 961–981. [Google Scholar] [CrossRef]
- Yamada, H. Why does the trend extracted by the Hodrick–Prescott filtering seem to be more plausible than the linear trend? Appl. Econ. Lett. 2018, 25, 102–105. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| WH(p) Graduation | bWH(p) Graduation | |
|---|---|---|
| Smoother matrix | ||
| Spectral decomposition of smoother matrix | ||
| Penalty matrix | ||
| Spectral decomposition of penalty matrix |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jin, Z.; Yamada, H. Boosted Whittaker–Henderson Graduation. Mathematics 2024, 12, 3377. https://doi.org/10.3390/math12213377
Jin Z, Yamada H. Boosted Whittaker–Henderson Graduation. Mathematics. 2024; 12(21):3377. https://doi.org/10.3390/math12213377
Chicago/Turabian StyleJin, Zihan, and Hiroshi Yamada. 2024. "Boosted Whittaker–Henderson Graduation" Mathematics 12, no. 21: 3377. https://doi.org/10.3390/math12213377
APA StyleJin, Z., & Yamada, H. (2024). Boosted Whittaker–Henderson Graduation. Mathematics, 12(21), 3377. https://doi.org/10.3390/math12213377