
Universal Network for Image Registration and Generation Using Denoising Diffusion Probability Model

Abstract
1. Introduction
2. Background and Related Works
2.1. Deformable Image Registration Model
2.2. Denoising Diffusion Probabilistic Model
2.3. Conditional Diffusion Models
2.3.1. Iterative Latent Variable Refinement Model
2.3.2. Classifier-Guided Diffusion Model
2.4. DiffuseMorph
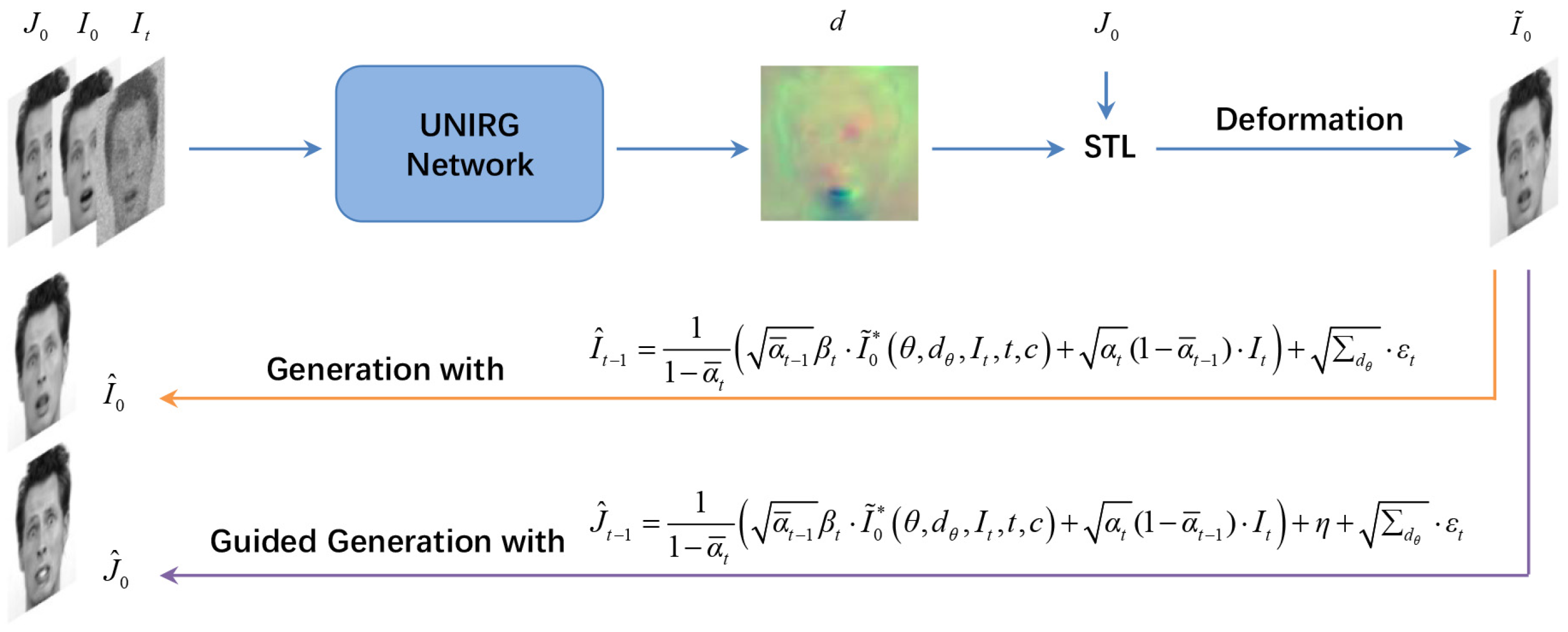
3. Proposed Method
3.1. Universal Training Process of UNIRG
| Algorithm 1: Training Process |
 |
3.2. Image Generation via Reverse Diffusion
3.2.1. Generation
| Algorithm 2: Sampling Process |
 |
3.2.2. Guided Generation
3.3. Network Architecture
- Adding a multihead attention module to enhance the model’s attention regarding the input features.
- Embedding time information to help the model determine the time step.
- Using the low-pass filtering operation in ILVR instead of the downsampling or pooling operation to retain more features and improve the accuracy of image registration.
4. Experimental Results
4.1. Radboud Faces Database
4.1.1. Dataset and Preprocessing
4.1.2. Implementation Details
4.1.3. Image Registration
4.1.4. Guided Generation
4.2. Automated Cardiac Diagnosis Challenge Dataset
4.2.1. Dataset and Preprocessing
4.2.2. Implementation Details
4.2.3. Continuous Image Registration
4.2.4. Ablation Study on Module Modifications
5. Discussion and Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Linger, M.E.; Goshtasby, A.A. Aerial image registration for tracking. IEEE Trans. Geosci. Remote. Sens. 2014, 53, 2137–2145. [Google Scholar] [CrossRef]
- Seetharaman, G.; Gasperas, G.; Palaniappan, K. A Piecewise Affine Model for Image Registration in Nonrigid Motion Analysis. In Proceedings of the 2000 International Conference on Image Processing (Cat. No. 00CH37101), Vancouver, BC, Canada, 10–13 September 2000; Volume 1, pp. 561–564. [Google Scholar]
- Stockman, G.; Kopstein, S.; Benett, S. Matching images to models for registration and object detection via clustering. IEEE Trans. Pattern Anal. Mach. Intell. 1982, 3, 229–241. [Google Scholar] [CrossRef] [PubMed]
- Brown, L.G. A survey of image registration techniques. ACM Comput. Surv. (CSUR) 1992, 24, 325–376. [Google Scholar] [CrossRef]
- Sheng, Y.; Shah, C.A.; Smith, L.C. Automated image registration for hydrologic change detection in the lake-rich Arctic. IEEE Geosci. Remote Sens. Lett. 2008, 5, 414–418. [Google Scholar] [CrossRef]
- El-Gamal, F.E.Z.A.; Elmogy, M.; Atwan, A. Current trends in medical image registration and fusion. Egypt. Inform. J. 2016, 17, 99–124. [Google Scholar] [CrossRef]
- Crum, W.R.; Hartkens, T.; Hill, D. Non-rigid image registration: Theory and practice. Br. J. Radiol. 2004, 77, S140–S153. [Google Scholar] [CrossRef]
- Wyawahare, M.V.; Patil, P.M.; Abhyankar, H.K. Image registration techniques: An overview. Int. J. Signal Process. Image Process. Pattern Recognit. 2009, 2, 11–28. [Google Scholar]
- Yang, X.; Kwitt, R.; Styner, M.; Niethammer, M. Quicksilver: Fast predictive image registration—A deep learning approach. NeuroImage 2017, 158, 378–396. [Google Scholar] [CrossRef]
- Haskins, G.; Kruger, U.; Yan, P. Deep learning in medical image registration: A survey. Mach. Vis. Appl. 2020, 31, 1–18. [Google Scholar] [CrossRef]
- Fu, Y.; Lei, Y.; Wang, T.; Curran, W.J.; Liu, T.; Yang, X. Deep learning in medical image registration: A review. Phys. Med. Biol. 2020, 65, 20TR01. [Google Scholar] [CrossRef]
- De Vos, B.D.; Berendsen, F.F.; Viergever, M.A.; Staring, M.; Išgum, I. End-to-End Unsupervised Deformable Image Registration with a Convolutional Neural Network. In Proceedings of the Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support: Third International Workshop, DLMIA 2017, and 7th International Workshop, ML-CDS 2017, Held in Conjunction with MICCAI 2017, Québec City, QC, Canada, 14 September 2017; pp. 204–212. [Google Scholar]
- Balakrishnan, G.; Zhao, A.; Sabuncu, M.R.; Guttag, J.; Dalca, A.V. An Unsupervised Learning Model for Deformable Medical Image Registration. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 9252–9260. [Google Scholar]
- Dalca, A.V.; Balakrishnan, G.; Guttag, J.; Sabuncu, M.R. Unsupervised learning of probabilistic diffeomorphic registration for images and surfaces. Med. Image Anal. 2019, 57, 226–236. [Google Scholar] [CrossRef] [PubMed]
- Creswell, A.; White, T.; Dumoulin, V.; Arulkumaran, K.; Sengupta, B.; Bharath, A.A. Generative adversarial networks: An overview. IEEE Signal Process. Mag. 2018, 35, 53–65. [Google Scholar] [CrossRef]
- Han, C.; Hayashi, H.; Rundo, L.; Araki, R.; Shimoda, W.; Muramatsu, S.; Furukawa, Y.; Mauri, G.; Nakayama, H. GAN-Based Synthetic Brain MR Image Generation. In Proceedings of the 2018 IEEE 15th International Symposium on Biomedical Imaging (ISBI 2018), Washington, DC, USA, 4–7 April 2018; pp. 734–738. [Google Scholar]
- Semeniuta, S.; Severyn, A.; Barth, E. A hybrid convolutional variational autoencoder for text generation. arXiv 2017, arXiv:1702.02390. [Google Scholar]
- Zhu, X.; Zhang, L.; Zhang, L.; Liu, X.; Shen, Y.; Zhao, S. GAN-based image super-resolution with a novel quality loss. Math. Probl. Eng. 2020, 2020, 1–12. [Google Scholar] [CrossRef]
- Mahapatra, D. GAN based medical image registration. arXiv 2018, arXiv:1805.02369. [Google Scholar]
- Fan, J.; Cao, X.; Wang, Q.; Yap, P.T.; Shen, D. Adversarial learning for mono-or multi-modal registration. Med. Image Anal. 2019, 58, 101545. [Google Scholar] [CrossRef]
- Fan, J.; Cao, X.; Xue, Z.; Yap, P.T.; Shen, D. Adversarial Similarity Network for Evaluating Image Alignment in Deep Learning Based Registration. In Proceedings of the Medical Image Computing and Computer Assisted Intervention–MICCAI 2018: 21st International Conference, Granada, Spain, 16–20 September 2018; pp. 739–746. [Google Scholar]
- Rezayi, H.; Seyedin, S.A. A Joint Image Registration and Superresolution Method Using a Combinational Continuous Generative Model. IEEE Trans. Circuits Syst. Video Technol. 2016, 28, 834–848. [Google Scholar] [CrossRef]
- Ho, J.; Jain, A.; Abbeel, P. Denoising diffusion probabilistic models. Adv. Neural Inf. Process. Syst. 2020, 33, 6840–6851. [Google Scholar]
- Choi, J.; Kim, S.; Jeong, Y.; Gwon, Y.; Yoon, S. Ilvr: Conditioning method for denoising diffusion probabilistic models. arXiv 2021, arXiv:2108.02938. [Google Scholar]
- Dhariwal, P.; Nichol, A. Diffusion models beat gans on image synthesis. Adv. Neural Inf. Process. Syst. 2021, 34, 8780–8794. [Google Scholar]
- Kim, B.; Han, I.; Ye, J.C. DiffuseMorph: Unsupervised Deformable Image Registration Using Diffusion Model. In Proceedings of the Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, 23–27 October 2022; pp. 347–364. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Jaderberg, M.; Simonyan, K.; Zisserman, A.; Kavukcuoglu, K. Spatial transformer networks. Adv. Neural Inf. Process. Syst. 2015, 28, 2017–2025. [Google Scholar]
- Langner, O.; Dotsch, R.; Bijlstra, G.; Wigboldus, D.H.; Hawk, S.T.; Van Knippenberg, A. Presentation and validation of the Radboud Faces Database. Cogn. Emot. 2010, 24, 1377–1388. [Google Scholar] [CrossRef]
- Bernard, O.; Lalande, A.; Zotti, C.; Cervenansky, F.; Yang, X.; Heng, P.A.; Cetin, I.; Lekadir, K.; Camara, O.; Ballester, M.A.G.; et al. Deep learning techniques for automatic MRI cardiac multi-structures segmentation and diagnosis: Is the problem solved? IEEE Trans. Med. Imaging 2018, 37, 2514–2525. [Google Scholar] [CrossRef] [PubMed]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | NMSE × | SSIM | PSNR | |Ja(d)|≤ 0 |
|---|---|---|---|---|
| Origin | 0.301 (0.213) | 0.668 (0.100) | 19.692 (3.172) | |
| DM | 0.279 (0.100) | 0.643 (0.065) | 19.210 (1.347) | 0.424 (0.047) |
| VM | 0.098 (0.037) | 0.828 (0.058) | 23.770 (1.664) | 0.506 (0.013) |
| VM-diff | 0.103 (0.038) | 0.823 (0.060) | 23.567 (1.647) | 0.510 (0.021) |
| UNIRG | 0.049 (0.030) | 0.859 (0.054) | 27.280 (2.617) | 0.500 (0.026) |
| Phase | Method | NMSE | PSNR | |Ja(d)|≤ 0 |
|---|---|---|---|---|
| Origin | 0.102 (0.168) | 26.307 (6.149) | ||
| DM | 0.112 (0.162) | 24.330 (4.775) | 0.498 (0.001) | |
| VM | 0.091 (0.178) | 30.068 (6.863) | 0.501 (0.005) | |
| VM-diff | 0.095 (0.179) | 28.947 (6.622) | 0.501 (0.006) | |
| UNIRG | 0.079 (0.159) | 31.162 (6.690) | 0.506 (0.009) | |
| Origin | 0.135 (0.163) | 22.644 (4.292) | ||
| DM | 0.144 (0.158) | 21.915 (3.720) | 0.498 (0.001) | |
| VM | 0.092 (0.165) | 27.540 (5.251) | 0.498 (0.004) | |
| VM-diff | 0.099 (0.166) | 26.499 (4.938) | 0.499 (0.006) | |
| UNIRG | 0.079 (0.149) | 28.914 (5.117) | 0.502 (0.009) |
| Method | Dice | PSNR | NMSE | Time |
|---|---|---|---|---|
| Origin | 0.708 (0.184) | 10.753 (1.745) | 0.197 (0.091) | |
| DM | 0.708 (0.182) | 10.691 (1.671) | 0.202 (0.090) | 0.533 (0.549) |
| VM | 0.770 (0.145) | 11.500 (1.981) | 0.279 (0.311) | 0.160 (0.441) |
| VM-diff | 0.786 (0.139) | 11.986 (1.855) | 0.235 (0.233) | 0.182 (0.233) |
| UNIRG | 0.795 (0.124) | 12.050 (2.126) | 0.227 (0.160) | 0.516 (0.536) |
| ResConv | ResAtten | Resizer | Dice | PSNR | NMSE |
|---|---|---|---|---|---|
| 0.791 (0.132) | 11.943 (2.191) | 0.255 (0.245) | |||
| ✓ | 0.783 (0.145) | 11.949 (2.286) | 0.275 (0.335) | ||
| ✓ | 0.789 (0.140) | 11.953 (2.187) | 0.284 (0.413) | ||
| ✓ | 0.790 (0.129) | 11.975 (2.132) | 0.241 (0.187) | ||
| ✓ | ✓ | 0.789 (0.137) | 11.962 (2.267) | 0.254 (0.235) | |
| ✓ | ✓ | 0.794 (0.122) | 11.983 (2.064) | 0.230 (0.164) | |
| ✓ | ✓ | 0.789 (0.139) | 12.005 (2.254) | 0.272 (0.348) | |
| ✓ | ✓ | ✓ | 0.795 (0.124) | 12.050 (2.126) | 0.227 (0.160) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ji, H.; Xue, P.; Dong, E. Universal Network for Image Registration and Generation Using Denoising Diffusion Probability Model. Mathematics 2024, 12, 2462. https://doi.org/10.3390/math12162462
Ji H, Xue P, Dong E. Universal Network for Image Registration and Generation Using Denoising Diffusion Probability Model. Mathematics. 2024; 12(16):2462. https://doi.org/10.3390/math12162462
Chicago/Turabian StyleJi, Huizhong, Peng Xue, and Enqing Dong. 2024. "Universal Network for Image Registration and Generation Using Denoising Diffusion Probability Model" Mathematics 12, no. 16: 2462. https://doi.org/10.3390/math12162462
APA StyleJi, H., Xue, P., & Dong, E. (2024). Universal Network for Image Registration and Generation Using Denoising Diffusion Probability Model. Mathematics, 12(16), 2462. https://doi.org/10.3390/math12162462