
A Novel Modified Discrete Differential Evolution Algorithm to Solve the Operations Sequencing Problem in CAPP Systems
 , , ,
, , ,
Abstract
1. Introduction
1.1. Literature Review
1.2. Differential Evolution Algorithm for Combinatorial Optimization Problems
1.3. Summary
2. Problem Formulation
Evaluation Criteria
3. Discrete Differential Evolution Algorithm for Operations Sequence Problem
3.1. Description
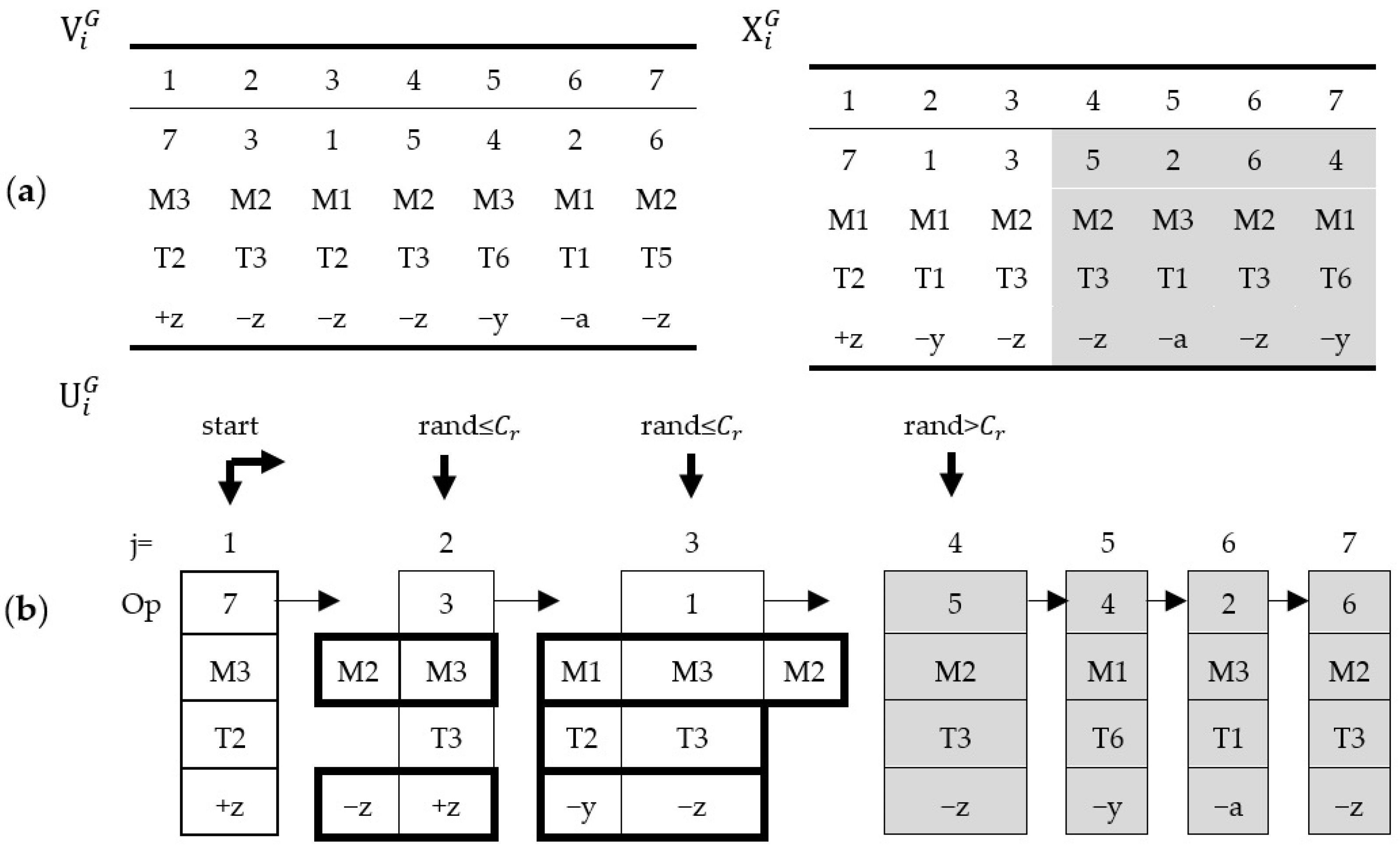
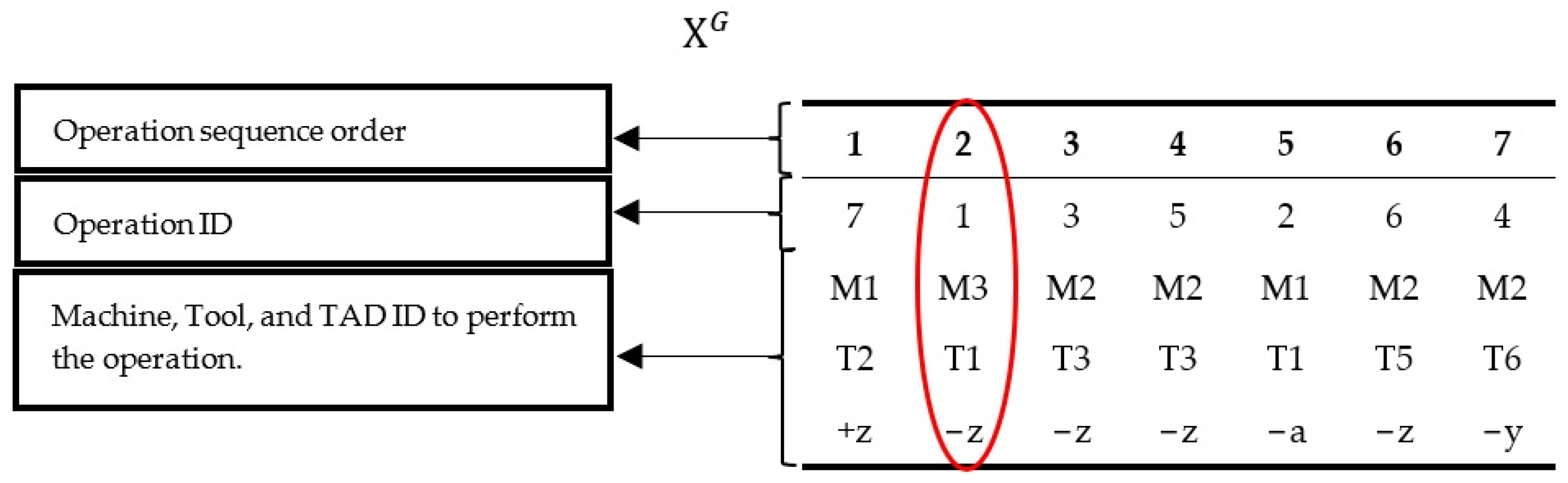
3.2. Solution Representation
3.3. Initialization
3.4. Discrete Mutation (DM)
- Step 1:
- ; .
- Step 2:
- For each operation in the columns and , were.
- Step 3:
- If the operation in column is equal to the operation in the column , then, the operation in is assigned to .
- Step 3.1:
- If the machine ID in is equal to machine ID in then assign the machine ID to column , else,the cost of the machine ID in the column and is obtained.If the cost of the machine ID in is less than the cost of the machine ID in , then, the machine ID in is assigned to column .elseif, the machine ID in is greater than the cost of machine ID in , then, the machine ID in is assigned to column .else the machine ID is selected randomly.
- Step 3.2:
- Carry out the same procedure in step 3.1 for the tool ID.
- Step 3.3:
- If the TAD ID in column is equal to TAD ID in column , then assign TAD ID in to column , else,Select one TAD ID randomly between and , and assign to
- Step 4:
- output
- Step 1:
- If has all the operations, then .
- Step 2:
- Elseif is null, then .
- Step 3:
- Elseif have between 1 and operations, then.
- Step 3.1:
- .
- Step 3.2:
- Delete the columns of whose operations are in .
- Step 3.3:
- Set ; ; .
- Step 3.4:
- While , then
- Step 3.5:
- Verify if the operations in and have restrictions.
- Step 3.6:
- If the operation in has no restrictions, then,Delete its edges from the graph.Assign the column to .Delete column .;.
- Step 3.7:
- If the operation in has no restrictions, then,Delete its edges from the graph.Assign the column to .Delete;.
- Step 3.8:
- If both operations in and have no restrictions,if , then, do Step 3.6.else do Step 3.7.
- Step 3.9:
- If both operations in and have restrictions,if , thenelse, .Go back to Step 3.5.
- Step 3.10:
- If is null, then assign the remaining columns of to ,elseif, is null, then assign the remaining columns of to
- Step 3.11:
- output .
3.5. Discrete Crossover (DC)
- Step 1:
- Assign to .
- Step 2:
- Select the first column in .
- Step 3:
- While and do,
- If the machine ID of the operation could find the candidate machines in the operation ; then, the machine ID of the operation will be the machine ID in .
- If the TAD ID of the operation could find the candidate TAD in the operation , then, the TAD ID of the operation will be the TAD ID in , else, select a TAD randomly from the candidate TADs.
- If the tool ID of the operation could find the candidate tools in the operation , then the tool ID in the operation will be the tool ID in .
- Step 4:
- If and , then the missing operations are assigned from ; output .
3.6. Selection
3.7. Local Search Strategy
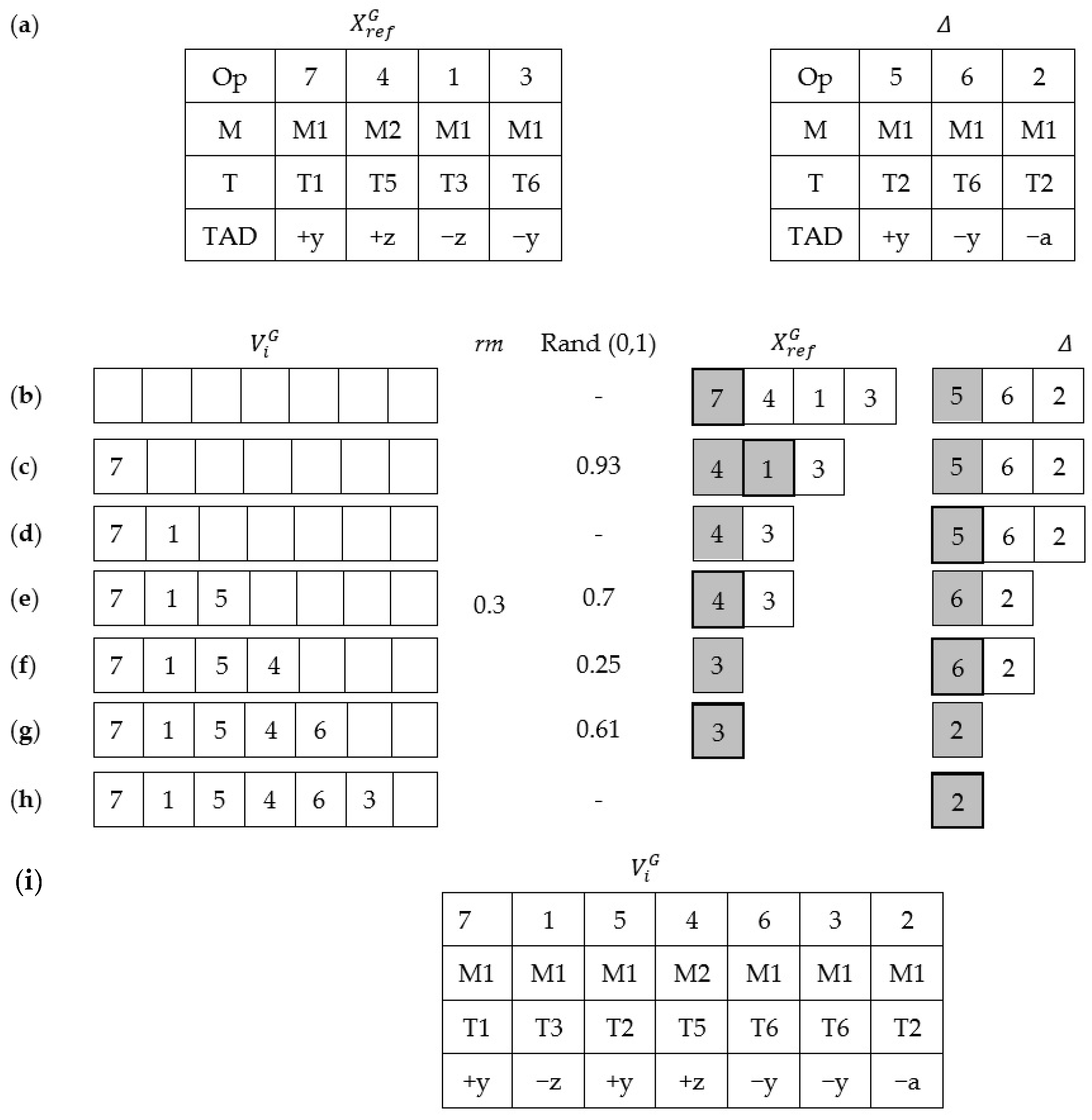
- Step 1:
- Assign to ; Set .
- Step 2:
- While
- Step 3:
- Select a column randomly in the .
- Step 4:
- Select randomly a position between and .
- Step 5:
- Insert the column in position .
- Step 6:
- If the movement of generates a valid OS, then
- Step 6.1:
- To verify the operations machine ID of column ,If the operation of could be developed for the machine ID of the operation it will be changed in column ,Elseif the operation of could be developed for the machine ID of the operation it will be changed in column . If the operation machine ID could be changed for both, one is selected randomly; when there is no possibility of change, the current machine ID is kept.
- Step 6.2:
- Do the same procedure in 6.1 for Tool ID and TAD ID.
- Step 6.3:
- Compare the TC value; if the TC value of , then assign to .
- Step 7:
- . Go back to step 2.
- Step 8:
- output .

4. Time Complexity
- ▪
- Population initialization, the time complexity of generating a feasible sequence for solutions, .
- ▪
- The complexity of population evaluation, in every individual of population ; the , and are calculated, .
- ▪
- The complexity of discrete mutation (MC), in each generation for every solution in , a feasible mutant solution is generated where the verification has time complexity ,
- ▪
- Discrete crossover (DC), .
- ▪
- Selection, .
- ▪
- Local search strategy, .
5. Determination of DDEA Parameters
6. Case Studies and Results Analysis
6.1. Part 1
6.2. Part 2
6.3. Part 3
6.4. Part 4
6.5. Part 5
6.6. Statistical Analysis to Performance Measure
6.7. Computing Time for the Approaches
7. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wu, W.; Huang, Z.; Wu, K.; Chen, Y. An optimization approach for setup planning and operation sequencing with tolerance constraints. Int. J. Adv. Manuf. Technol. 2020, 106, 4965–4985. [Google Scholar] [CrossRef]
- Su, Y.; Chu, X.; Chen, D.; Sun, X. A genetic algorithm for operation sequencing in CAPP using edge selection based encoding strategy. J. Intell. Manuf. 2018, 29, 313–332. [Google Scholar] [CrossRef]
- Falih, A.; Shammari, A.Z.M. Hybrid constrained permutation algorithm and genetic algorithm for process planning problem. J. Intell. Manuf. 2020, 31, 1079–1099. [Google Scholar] [CrossRef]
- Wang, J.F.; Wu, X.; Fan, X. A two-stage ant colony optimization approach based on a directed graph for process planning. Int. J. Adv. Manuf. Technol. 2015, 80, 839–850. [Google Scholar] [CrossRef]
- Guo, Y.W.; Mileham, A.R.; Owen, G.W.; Li, W.D. Operation sequencing optimization using a particle swarm optimization approach. Proc. Inst. Mech. Eng. B J. Eng. Manuf. 2006, 220, 1945–1958. [Google Scholar] [CrossRef]
- Dou, J.; Wang, S.; Zhang, C.; Shi, Y. A genetic algorithm with path-relinking for operation sequencing in CAPP. Int. J. Adv. Manuf. Technol. 2023, 125, 3667–3690. [Google Scholar] [CrossRef]
- Liu, X.J.; Yi, H.; Ni, Z.H. Application of ant colony optimization algorithm in process planning optimization. J. Intell. Manuf. 2013, 24, 1–13. [Google Scholar] [CrossRef]
- Dou, J.; Li, J.; Su, C. A discrete particle swarm optimisation for operation sequencing in CAPP. Int. J. Prod. Res. 2018, 56, 3795–3814. [Google Scholar] [CrossRef]
- Ma, G.H.; Zhang, Y.F.; Nee, A.Y.C. A simulated annealing-based optimization algorithm for process planning. Int. J. Prod. Res. 2000, 38, 2671–2687. [Google Scholar] [CrossRef]
- Nallakumarasamy, G.; Srinivasan, P.S.S.; Raja, K.V.; Malayalamurthi, R. Optimization of operation sequencing in CAPP using simulated annealing technique (SAT). Int. J. Adv. Manuf. Technol. 2011, 54, 721–728. [Google Scholar] [CrossRef]
- Li, W.D.; Ong, S.K.; Nee, A.Y.C. Optimization of process plans using a constraint-based tabu search approach. Int. J. Prod. Res. 2004, 42, 1955–1985. [Google Scholar] [CrossRef]
- Zhang, F.; Zhang, Y.F.; Nee, A.Y.C. Using genetic algorithms in process planning for job shop machining. IEEE Trans. Evol. Comput. 1997, 1, 278–289. [Google Scholar] [CrossRef]
- Salehi, M.; Tavakkoli-Moghaddam, R. Application of genetic algorithm to computer-aided process planning in preliminary and detailed planning. Eng. Appl. Artif. Intell. 2009, 22, 1179–1187. [Google Scholar] [CrossRef]
- Guo, Y.W.; Mileham, A.R.; Owen, G.W.; Maropoulos, P.G.; Li, W.D. Operation sequencing optimization for five-axis prismatic parts using a particle swarm optimization approach. Proc. Inst. Mech. Eng. B J. Eng. Manuf. 2009, 223, 485–497. [Google Scholar] [CrossRef]
- Guo, Y.W.; Li, W.D.; Mileham, A.R.; Owen, G.W. Applications of particle swarm optimisation in integrated process planning and scheduling. Robot. Comput. Integr. Manuf. 2009, 25, 280–288. [Google Scholar] [CrossRef]
- Kafashi, S.; Shakeri, M.; Abedini, V. Automated setup planning in CAPP: A modified particle swarm optimisation-based approach. Int. J. Prod. Res. 2012, 50, 4127–4140. [Google Scholar] [CrossRef]
- Li, X.; Gao, L.; Wen, X. Application of an efficient modified particle swarm optimization algorithm for process planning. Int. J. Adv. Manuf. Technol. 2013, 67, 1355–1369. [Google Scholar] [CrossRef]
- Wang, J.F.; Kang, W.L.; Zhao, J.L.; Chu, K.Y. A simulation approach to the process planning problem using a modified particle swarm optimization. Adv. Prod. Eng. Manag. 2016, 11, 77–92. [Google Scholar] [CrossRef]
- Hu, Q.; Qiao, L.; Peng, G. An ant colony approach to operation sequencing optimization in process planning. Proc. Inst. Mech. Eng. Part B J. Eng. Manuf. 2017, 231, 470–489. [Google Scholar] [CrossRef]
- Wang, J.; Fan, X.; Wan, S. A graph-based ant colony optimization approach for process planning. Sci. World J. 2014, 2014, 271895. [Google Scholar] [CrossRef]
- Lian, K.; Zhang, C.; Shao, X.; Gao, L. Optimization of process planning with various flexibilities using an imperialist competitive algorithm. Int. J. Adv. Manuf. Technol. 2012, 59, 815–828. [Google Scholar] [CrossRef]
- Wen, X.Y.; Li, X.Y.; Gao, L.; Sang, H.Y. Honey bees mating optimization algorithm for process planning problem. J. Intell. Manuf. 2014, 25, 459–472. [Google Scholar] [CrossRef]
- Li, W.D.; Ong, S.K.; Nee, A.Y.C. Hybrid genetic algorithm and simulated annealing approach for the optimization of process plans for prismatic parts. Int. J. Prod. Res. 2002, 40, 1899–1922. [Google Scholar] [CrossRef]
- Li, L.; Fuh, J.Y.H.; Zhang, Y.F.; Nee, A.Y.C. Application of genetic algorithm to computer-aided process planning in distributed manufacturing environments. Robot. Comput. Integr. Manuf. 2005, 21, 568–578. [Google Scholar] [CrossRef]
- Salehi, M.; Bahreininejad, A. Optimization process planning using hybrid genetic algorithm and intelligent search for job shop machining. J. Intell. Manuf. 2011, 22, 643–652. [Google Scholar] [CrossRef]
- Huang, W.; Hu, Y.; Cai, L. An effective hybrid graph and genetic algorithm approach to process planning optimization for prismatic parts. Int. J. Adv. Manuf. Technol. 2012, 62, 1219–1232. [Google Scholar] [CrossRef]
- Luo, Y.; Pan, Y.; Li, C.; Tang, H. A hybrid algorithm combining genetic algorithm and variable neighborhood search for process sequencing optimization of large-size problem. Int. J. Comput. Integr. Manuf. 2020, 33, 962–981. [Google Scholar] [CrossRef]
- Huang, W.; Lin, W.; Xu, S. Application of graph theory and hybrid GA-SA for operation sequencing in a dynamic workshop environment. Comput. Aided Des. Appl. 2017, 14, 148–159. [Google Scholar] [CrossRef]
- Wang, Y.F.; Zhang, Y.F.; Fuh, J.Y.H. A hybrid particle swarm based method for process planning optimisation. Int. J. Prod. Res. 2012, 50, 277–292. [Google Scholar] [CrossRef]
- Kennedy, J.; Eberhart, R. Particle Swarm Optimization. In Proceedings of the ICNN’95—International Conference on Neural Networks, Perth, Australia, 27 November–1 December 1995; Volume 4, pp. 1942–1948. [Google Scholar] [CrossRef]
- Santucci, V.; Baioletti, M.; Milani, A. Algebraic differential evolution algorithm for the permutation flowshop scheduling problem with total flowtime criterion. IEEE Trans. Evol. Comput. 2016, 20, 682–694. [Google Scholar] [CrossRef]
- Storm, R.; Price, K. Differential Evolution—A Simple and Efficient Heuristic for Global Optimization over Continuous Spaces. J. Glob. Optim. 1997, 11, 341–359. [Google Scholar] [CrossRef]
- Zhang, G.; Xing, K.; Cao, F. Discrete differential evolution algorithm for distributed blocking flowshop scheduling with makespan criterion. Eng. Appl. Artif. Intell. 2018, 76, 96–107. [Google Scholar] [CrossRef]
- Piotrowski, A.P.; Piotrowska, A.E. Differential Evolution and Particle Swarm Optimization against COVID-19. Artif. Intell. Rev. 2022, 55, 2149–2219. [Google Scholar] [CrossRef]
- Ali, I.M.; Essam, D.; Kasmarik, K. A novel differential evolution mapping technique for generic combinatorial optimization problems. Appl. Soft Comput. J. 2019, 80, 297–309. [Google Scholar] [CrossRef]
- Ali, I.M.; Essam, D.; Kasmarik, K. A novel design of differential evolution for solving discrete traveling salesman problems. Swarm Evol. Comput. 2020, 52, 100607. [Google Scholar] [CrossRef]
- Onwubolu, G.C.; Davendra, D. Differential Evolution: A Handbook for Global Permutation-Based Combinatorial Optimization; Springer: Berlin/Heidelberg, Germany, 2009; Volume 175. [Google Scholar] [CrossRef]
- Yuan, S.; Li, T.; Wang, B. A discrete differential evolution algorithm for flow shop group scheduling problem with sequence-dependent setup and transportation times. J. Intell. Manuf. 2021, 32, 427–439. [Google Scholar] [CrossRef]
- Yun, Y.; Moon, C. Genetic algorithm approach for precedence-constrained sequencing problems. J. Intell. Manuf. 2011, 22, 379–388. [Google Scholar] [CrossRef]
- Price, K.V.; Storm, R.M.; Laminen, J.A. Differential Evolution A Practical Approach to Global Optimization, 1st ed.; Springer: Berlin/Heidelberg, Germany, 2005. [Google Scholar] [CrossRef]
- Mohamed, A.W.; Sabry, H.Z. Constrained optimization based on modified differential evolution algorithm. Inf. Sci. 2012, 194, 171–208. [Google Scholar] [CrossRef]
- Ivkovic, N.; Jakobovic, D.; Golub, M. Measuring Performance of Optimization Algorithms in Evolutionary Computation. Int. J. Mach. Learn. Comput. 2016, 6, 167–171. [Google Scholar] [CrossRef]
- Yang, X.; Wang, X.; Liu, Z.; Shu, F. M2Coder: A Fully Automated Translator from Matlab M-functions to C/C++ Codes for ACS Motion Controllers. In Advances in Guidance, Navigation and Control; Yan, L., Duan, H., Deng, Y., Eds.; Springer Nature: Singapore, 2023; pp. 3130–3139. [Google Scholar]
- Jiang, R.M.; Bouridane, A.; Amira, A. Color Saliency Evaluation for Video Game Design. In Advances in Low-Level Color Image Processing; Celebi, M.E., Smolka, B., Eds.; Springer: Dordrecht, The Netherlands, 2014; pp. 409–425. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Part 1 | Part 2 | Part 3 | Part 4 | Part 5 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Case 1 | Case 1 | Case 1 | Case 1 | Case 2 | Case 1 | |||||
| Cond. 1 | Cond. 1 | Cond. 2 | Cond. 3 | Cond. 1 | Cond. 1 | Cond. 2 | Cond. 1 | Cond. 2 | Cond. 1 | |
| 120 | 400 | 300 | 500 | 90 | 500 | 500 | 500 | 500 | 600 | |
| 120 | 100 | 100 | 100 | 110 | 400 | 400 | 400 | 400 | 450 | |
| 0.001 | 0.001 | 0.001 | 0.01 | 0.001 | 0.01 | 0.01 | 0.01 | 0.01 | 0.001 | |
| 0.5 | 0.85 | 0.75 | 0.1 | 0.99 | 0.9 | 0.9 | 0.9 | 0.9 | 0.9 | |
| 0.95 | 0.9 | 0.9 | 0.7 | 0.85 | 0.9 | 0.9 | 0.9 | 0.9 | 0.9 | |
| 60 | 50 | 50 | 50 | 60 | 50 | 100 | 250 | 100 | 200 | |
| 20 | 50 | 10 | 40 | 20 | 50 | 20 | 50 | 30 | 50 | |
| 50 | 10 | 10 | 10 | 30 | 20 | 20 | 50 | 60 | 30 | |
| Condition 1 | Condition 2 | Condition 3 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Algorithm | References | Minimum | Maximum | Mean | Minimum | Maximum | Mean | Minimum | Maximum | Mean |
| Part 1 | ||||||||||
| ICA | [21] | 1739 | 1749 | 1741 | ||||||
| FSDPSO | [8] | 1739 | - | 1740.7 | ||||||
| DDEA | 1739 | 1759 | 1739.3 | |||||||
| Part 2 | ||||||||||
| ACO | [19] | 2530 | 2667 | 2090 | 2115 | |||||
| ESGA | [2] | 2530 | 2562 | 2539.1 | 2090 | 2590 | ||||
| FSDPSO | [8] | 2530 | 2532.5 | 2090 | 2090 | |||||
| CPAGA | [3] | 2530 | 2535 | 2530.5 | 2090 | 2090 | 2090 | 2500 | 2500 | 2500 |
| PR-GA | [6] | 2530 | 2530.5 | 2090 | 2090 | |||||
| DDEA | 2530 | 2537 | 2531.1 | 2090 | 2120 | 2096 | 2590 | 2600 | 2594.5 | |
| GA-SA | [23] | 2527 | 2120 | 2590 | ||||||
| TS | [11] | 2527 | 2690 | 2609.6 | 2120 | 2390 | 2208 | 2580 | 2740 | 2630 |
| HBMO | [22] | 2525 | 2557 | 2543.5 | 2090 | 2120 | 2098 | 2590 | 2600 | 2592 |
| PSO | [18] | 2525 | 2535 | 2527.2 | 2090 | 2120 | 2093.0 | 2590 | 2600 | 2593.2 |
| HGGA | [26] | 2527 | 2585 | 2120 | 2590 | |||||
| ACO | [4] | 2525 | 2557 | 2552.4 | 2090 | 2380 | 2120.5 | 2590 | 2740 | 2600.8 |
| PR-GA | [6] | 2525 | 2525 | 2090 | 2090 | |||||
| DDEA | 2525 | 2532 | 2526.5 | 2090 | 2120 | 2096 | 2590 | 2600 | 2594 | |
| Part 3 | ||||||||||
| PSO | [5] | 1361 | 1430 | |||||||
| GA | [5] | 1381 | 1447.4 | |||||||
| SA | [5] | 1421 | 1447.4 | |||||||
| ICA | [21] | 1357 | 1364.1 | |||||||
| ACO | [19] | 1357 | 1419 | |||||||
| FSDPSO | [8] | 1357 | 1359 | |||||||
| PR-GA | [6] | 1357 | 1357 | |||||||
| DDEA | 1357 | 1357 | 1357 | |||||||
| Part 4 | ||||||||||
| Case 1 | ||||||||||
| GA-SA | [28] | 4368 | - | - | 4450 | - | - | |||
| DDEA | 4206 | 4635 | 4373.2 | 4310 | 4805 | 4492.7 | ||||
| Part 4 | ||||||||||
| Case 2 | ||||||||||
| CPAGA | [3] | 4299 | 4315 | 4302 | 4503 | 4503 | - | |||
| PR-GA | [6] | 4098 | 4232.8 | 4151 | 4298.4 | |||||
| DDEA | 4098 | 4524 | 4271.1 | 4151 | 4530 | 4324.9 | ||||
| Part 5 | ||||||||||
| Standard GA | [27] | 29.7 | 29.31 | |||||||
| Hybrid GA | [27] | 27.3 | 27.82 | |||||||
| DDEA | 23.9 | 26.7 | 25.51 | |||||||
| Case (1), Condition (1) | |||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Order | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| Op | 1 | 10 | 13 | 11 | 14 | 22 | 9 | 2 | 3 | 24 | 25 | 27 | 26 | 28 | 34 | 35 | 36 | 37 | 45 | 46 | 4 | 5 | 6 |
| M | 1 | 5 | 5 | 5 | 5 | 5 | 5 | 2 | 2 | 9 | 9 | 9 | 9 | 9 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 |
| T | 1 | 8 | 8 | 8 | 8 | 8 | 8 | 1 | 1 | 11 | 22 | 13 | 12 | 14 | 28 | 24 | 17 | 25 | 19 | 27 | 4 | 5 | 5 |
| TAD | +z | −z | −z | −z | −z | −z | +z | +z | +z | +z | +z | +z | +z | +z | −c | −c | −c | −c | −x | −x | −y | −y | −y |
| Continued | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 | 37 | 38 | 39 | 40 | 41 | 42 | 43 | 44 | 45 | 46 |
| Op cont. | 29 | 30 | 17 | 19 | 20 | 18 | 7 | 31 | 32 | 33 | 8 | 15 | 16 | 12 | 41 | 39 | 40 | 42 | 23 | 38 | 21 | 43 | 44 |
| M cont. | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 4 | 4 | 4 | 4 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 |
| T cont. | 6 | 6 | 7 | 7 | 7 | 7 | 7 | 15 | 16 | 23 | 8 | 8 | 8 | 8 | 18 | 18 | 26 | 26 | 20 | 21 | 10 | 18 | 26 |
| TAD cont. | −y | −y | −b | −b | −b | −b | −a | −a | −a | −a | −a | −z | −z | −z | −b | −b | −b | −b | −z | −z | −z | −z | −z |
| TMC = 1529 | TTC = 277 | MCC = 720 | TCC = 420 | SCC = 1260 | TC = 4206 | ||||||||||||||||||
| Case (1), Condition (2) | |||||||||||||||||||||||
| Order | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| Op | 1 | 11 | 13 | 14 | 10 | 22 | 9 | 2 | 3 | 26 | 27 | 24 | 25 | 28 | 45 | 46 | 34 | 35 | 36 | 37 | 29 | 30 | 4 |
| M | 1 | 5 | 5 | 5 | 5 | 5 | 5 | 2 | 2 | 9 | 9 | 9 | 9 | 9 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 |
| T | 1 | 9 | 9 | 9 | 9 | 9 | 9 | 1 | 1 | 12 | 13 | 11 | 22 | 14 | 19 | 27 | 28 | 24 | 17 | 25 | 6 | 6 | 4 |
| TAD | +z | −z | −z | −z | −z | −z | +z | +z | +z | +z | +z | +z | +z | +z | −x | −x | −c | −c | −c | −c | −y | −y | −y |
| Continued | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 | 37 | 38 | 39 | 40 | 41 | 42 | 43 | 44 | 45 | 46 |
| Op cont. | 5 | 6 | 7 | 31 | 32 | 33 | 8 | 17 | 18 | 19 | 20 | 15 | 16 | 12 | 21 | 43 | 44 | 23 | 38 | 39 | 41 | 40 | 42 |
| M cont. | 8 | 8 | 8 | 8 | 8 | 8 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 |
| T cont. | 5 | 5 | 7 | 15 | 16 | 23 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 9 | 10 | 18 | 26 | 20 | 21 | 18 | 18 | 26 | 26 |
| TAD cont. | −y | −y | −a | −a | −a | −a | −a | −b | −b | −b | −b | −z | −z | −z | −z | −z | −z | −z | −z | −b | −b | −b | −b |
| TMC = 1614 | TTC = 281 | MCC = 720 | TCC = 435 | SCC = 1260 | TC = 4310 | ||||||||||||||||||
| Order | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| Op | 66 | 18 | 47 | 71 | 35 | 5 | 10 | 11 | 7 | 8 | 9 | 12 | 62 | 63 | 39 | 40 | 30 | 33 | 34 | 75 | 76 | 1 | 2 |
| M | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 |
| T | 6 | 6 | 6 | 6 | 6 | 6 | 9 | 26 | 7 | 8 | 25 | 10 | 23 | 34 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 2 |
| TAD | E | B | D | F | C | A | A | A | A | A | A | A | E | E | D | D | C | C | C | F | F | A | A |
| Continued | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 | 37 | 38 | 39 | 40 | 41 | 42 | 43 | 44 | 45 | 46 |
| Op cont. | 3 | 69 | 70 | 73 | 74 | 72 | 6 | 37 | 27 | 28 | 29 | 36 | 24 | 25 | 26 | 43 | 38 | 41 | 44 | 49 | 50 | 42 | 48 |
| M cont. | 2 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| T cont. | 3 | 13 | 28 | 24 | 31 | 5 | 5 | 17 | 16 | 39 | 29 | 5 | 12 | 27 | 36 | 37 | 18 | 19 | 20 | 13 | 28 | 30 | 5 |
| TAD cont. | A | F | F | F | F | F | A | C | C | C | C | C | C | C | C | D | D | D | D | D | D | D | D |
| Continued | 47 | 48 | 49 | 50 | 51 | 52 | 53 | 54 | 55 | 56 | 57 | 58 | 59 | 60 | 61 | 62 | 63 | 64 | 65 | 66 | 67 | 68 | 69 |
| Op cont. | 64 | 60 | 61 | 54 | 55 | 53 | 56 | 51 | 52 | 65 | 67 | 68 | 57 | 58 | 13 | 31 | 32 | 45 | 46 | 59 | 14 | 20 | 23 |
| M cont. | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 2 | 2 | 2 | 2 | 2 | 2 | 1 | 1 | 1 | 1 |
| T cont. | 41 | 8 | 25 | 19 | 30 | 21 | 35 | 12 | 27 | 37 | 6 | 6 | 22 | 33 | 32 | 2 | 3 | 3 | 3 | 40 | 38 | 13 | 15 |
| TAD cont. | E | E | E | E | E | E | E | E | E | E | E | E | E | E | B | C | C | D | D | E | B | B | B |
| Continued | 70 | 71 | 72 | 73 | 74 | 75 | 76 | ||||||||||||||||
| Op cont. | 15 | 16 | 17 | 21 | 22 | 19 | 4 | ||||||||||||||||
| M cont. | 1 | 1 | 1 | 1 | 1 | 1 | 3 | ||||||||||||||||
| T cont. | 11 | 12 | 27 | 28 | 14 | 5 | 4 | ||||||||||||||||
| TAD cont. | B | B | B | B | B | B | A | ||||||||||||||||
| TMC = 0 | TTC = 0 | MCC = 5 | TCC = 59 | SCC = 23 | TC = 23.9 | ||||||||||||||||||
| Part 1 | Part 2 | Part 3 | Part 4 | Part 5 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Case 1 | Case 1 | Case 1 | Case 1 | Case 2 | Case 1 | |||||
| Cond. 1 | Cond. 1 | Cond. 2 | Cond. 3 | Cond. 1 | Cond. 1 | Cond. 2 | Cond. 1 | Cond. 2 | Cond. 1 | |
| 1739 | 2530 | 2090 | 2590 | 1357 | 4231.5 | 4313.9 | 4134 | 4200 | 23.96 | |
| 1739 | 2530 | 2090 | 2590 | 1357 | 4258.2 | 4433 | 4134 | 4200 | 24.66 | |
| 1739 | 2530 | 2090 | 2590 | 1357 | 4365 | 4460 | 4254 | 4321 | 25.37 | |
| 1739 | 2532 | 2090 | 2600 | 1357 | 4451 | 4592 | 4368.8 | 4425 | 26.43 | |
| 1739 | 2535 | 2120 | 2600 | 1357 | 4568.9 | 4661.6 | 4474.8 | 4509 | 26.67 | |
| Part 1 | Part 2 | Part 3 | Part 4 | Part 5 | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Case 1 | Case 1 | Case 1 | Case 1 | Case 2 | Case 1 | ||||||
| Algorithm | References | Cond. 1 | Cond. 1 | Cond. 2 | Cond. 3 | Cond. 1 | Cond. 1 | Cond. 2 | Cond. 1 | Cond. 2 | Cond. 1 |
| ESGA | [2] | - | 5.07 | - | - | - | - | - | - | ||
| TSGA | [2] | - | 4.91 | - | - | - | - | - | - | ||
| FSDPSO | [8] | - | 0.727 | 0.742 | - | 0.427 | - | - | - | ||
| CPAGA | [3] | - | 1.94 | 1.24 | 1.3 | - | 3.26 | - | - | ||
| PR-GA | [6] | - | 1.10 | 0.46 | - | 2.08 | 9.605 | - | - | ||
| DDEA | 4.274 | 6.164 | 4.614 | 8.687 | 1.317 | 61.865 | 65.559 | 61.167 | 59.125 | 141.167 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alvarez-Flores, O.A.; Rivera-Blas, R.; Flores-Herrera, L.A.; Rivera-Blas, E.Z.; Funes-Lora, M.A.; Niño-Suárez, P.A. A Novel Modified Discrete Differential Evolution Algorithm to Solve the Operations Sequencing Problem in CAPP Systems. Mathematics 2024, 12, 1846. https://doi.org/10.3390/math12121846
Alvarez-Flores OA, Rivera-Blas R, Flores-Herrera LA, Rivera-Blas EZ, Funes-Lora MA, Niño-Suárez PA. A Novel Modified Discrete Differential Evolution Algorithm to Solve the Operations Sequencing Problem in CAPP Systems. Mathematics. 2024; 12(12):1846. https://doi.org/10.3390/math12121846
Chicago/Turabian StyleAlvarez-Flores, Oscar Alberto, Raúl Rivera-Blas, Luis Armando Flores-Herrera, Emmanuel Zenén Rivera-Blas, Miguel Angel Funes-Lora, and Paola Andrea Niño-Suárez. 2024. "A Novel Modified Discrete Differential Evolution Algorithm to Solve the Operations Sequencing Problem in CAPP Systems" Mathematics 12, no. 12: 1846. https://doi.org/10.3390/math12121846
APA StyleAlvarez-Flores, O. A., Rivera-Blas, R., Flores-Herrera, L. A., Rivera-Blas, E. Z., Funes-Lora, M. A., & Niño-Suárez, P. A. (2024). A Novel Modified Discrete Differential Evolution Algorithm to Solve the Operations Sequencing Problem in CAPP Systems. Mathematics, 12(12), 1846. https://doi.org/10.3390/math12121846