

A Multi-Party Privacy-Preserving Record Linkage Method Based on Secondary Encoding
Abstract
1. Introduction
- (1)
- By introducing secondary encoding, security is enhanced. The BFS is divided into multiple splits, and by setting certain rules, secondary encoding is generated for each split. Moreover, each secondary encoding corresponds to multiple BFS combinations, making it impossible to deduce a unique corresponding BFS. Therefore, our method has higher security.
- (2)
- Introducing error limits has improved efficiency. By setting an error limit, the degree of fault tolerance can be controlled. When the error limit is larger, the pass rate is smaller, thus filtering out unnecessary computations. Only when the number of identical splits is greater than or equal to the error limit will inconsistent splits be backtracked and similarity calculations performed, thus achieving efficiency improvement.
- (3)
- Experimental verification has demonstrated that the introduction of secondary encoding provides higher security compared to BFS, with minimal impact on matching quality. Our method exhibits equivalent computational efficiency and linkage quality to BFS. Therefore, our approach enables efficient PPRL with good matching quality and higher security compared to the existing methods.
2. Related Work
3. Problem Definition
Problem Formulation
4. A Multi-Party PPRL Method Based on Secondary Encoding
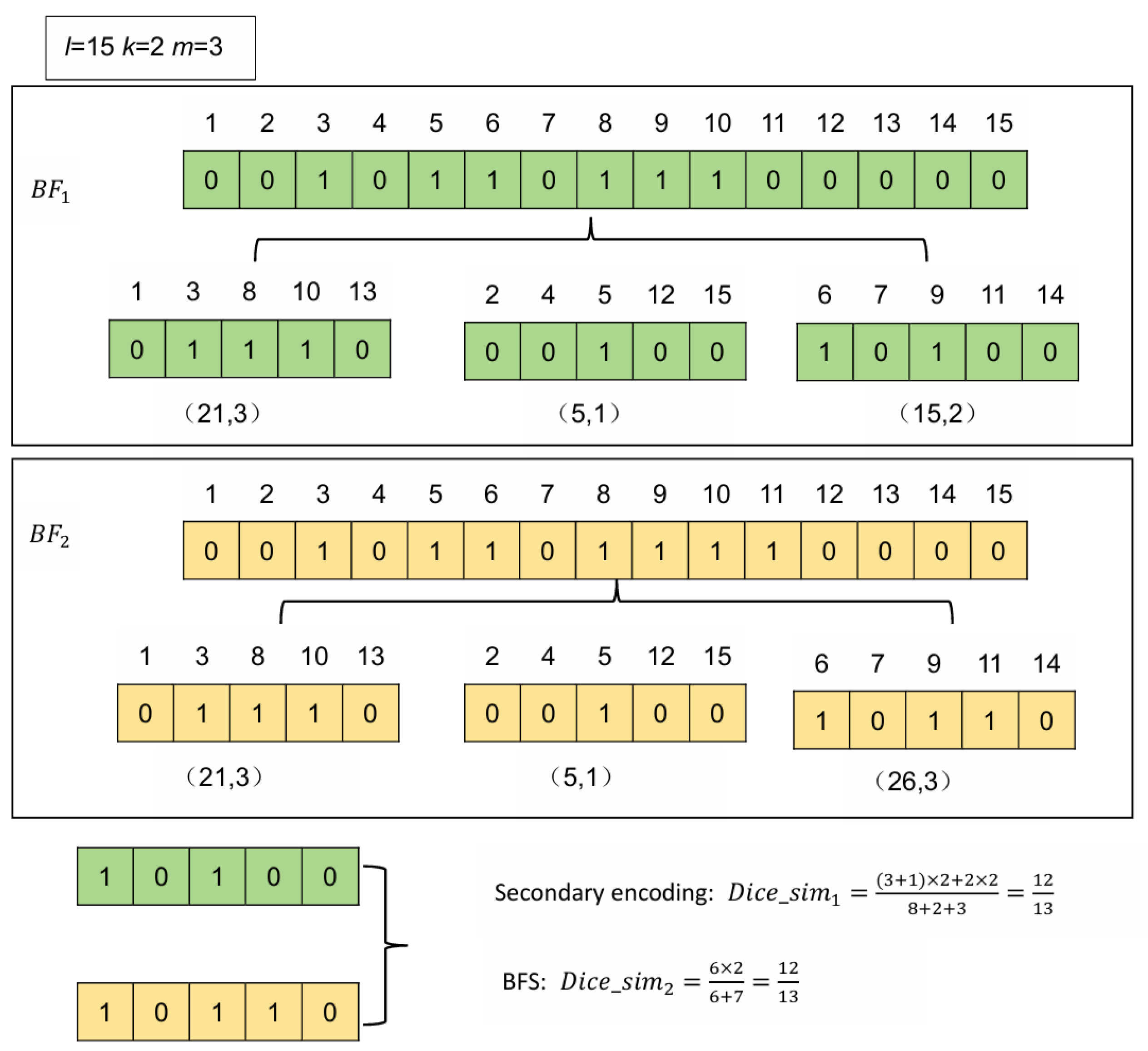
4.1. Data Preparation and Generation
| Algorithm 1 Data preparation and generation algorithm | |
| Output: Secondary encoding of P participants | |
| 1: | FOR (int i = 1; i <= P; i++){ |
| 2: | , A); |
| 3: | }; |
| 4: | THEN: |
| 5: | |
| 6: | |
| 7: | RETURN);} |
| 8: | } |
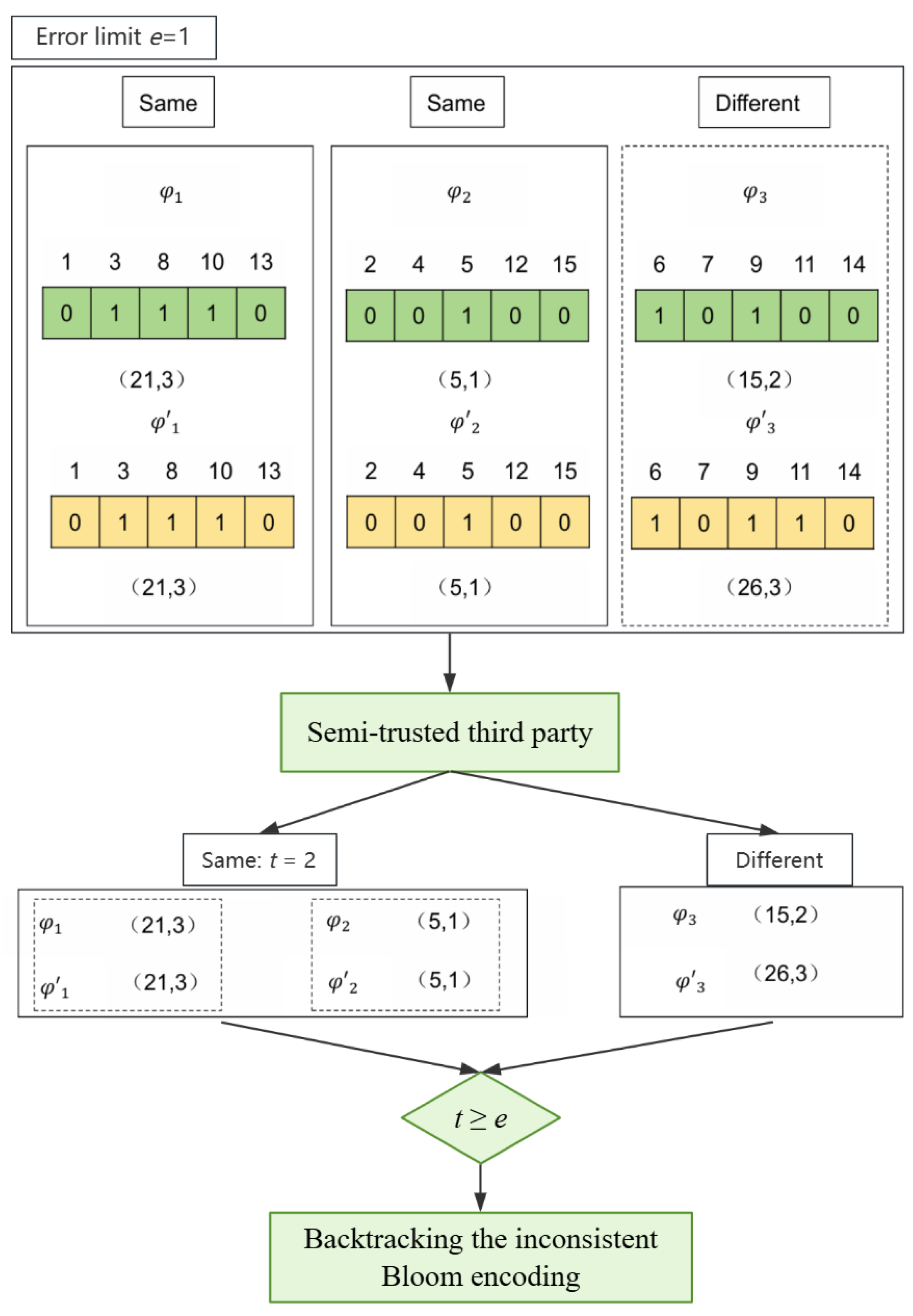
4.2. Approximate Record Linkage
| Algorithm 2 Approximate record linkage algorithm | |
| Input: Secondary encoding of P participants | |
| Output: Match or Non-Match | |
| 1: | FOR(int i = 1; i <= P; i++){ |
| 2: | THEN: |
| 3: | Return TRUE; |
| 4: | ELSE IF THEN: |
| 5: | IF e = m − ak ≤ t THEN: |
| 6: | Backtrack the inconsistent splits of the BFS; |
| 7: | ELSE IF e = m − ak > t THEN: |
| 8: | RETURN FALSE; |
| 9: | } |
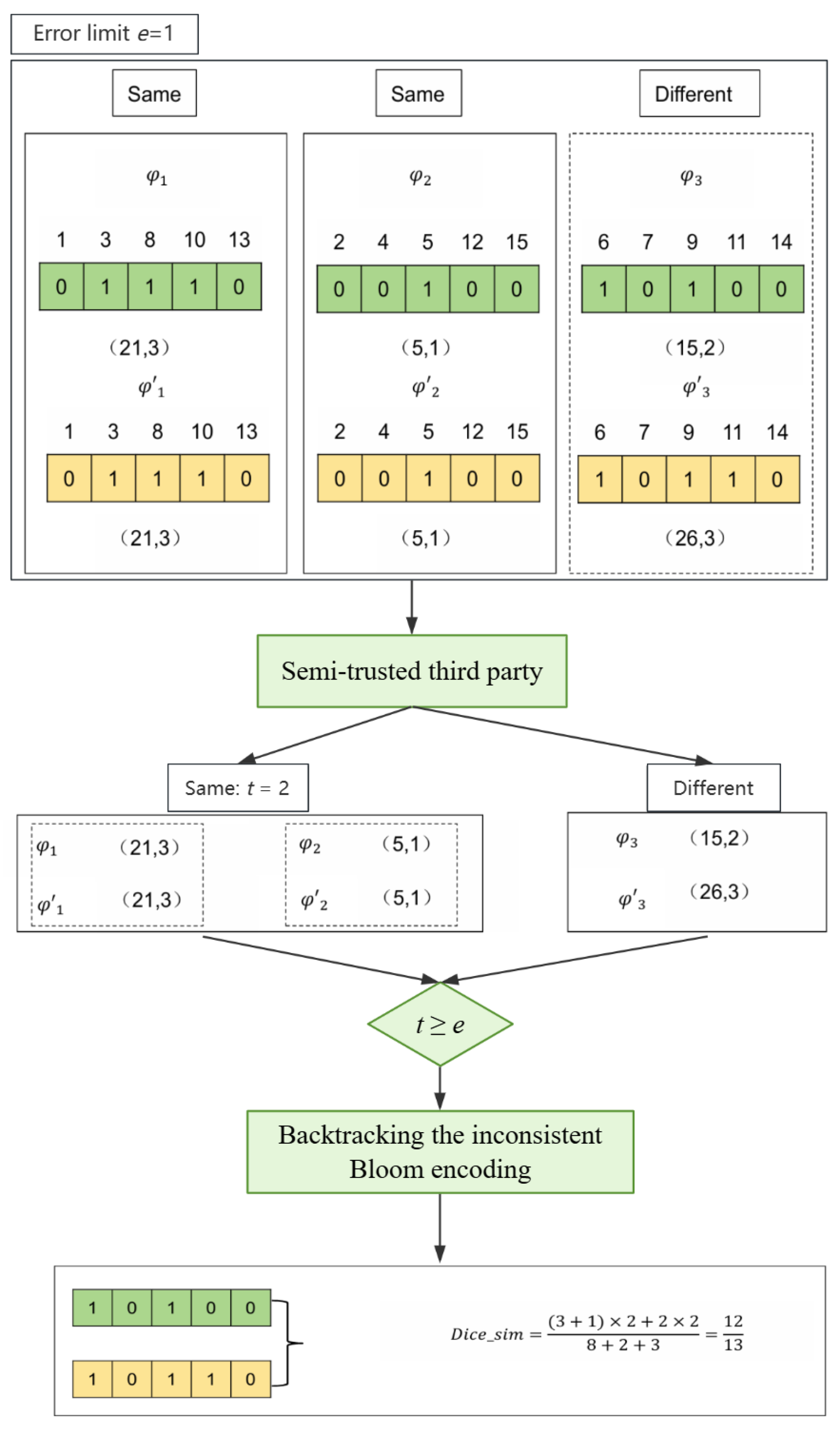
4.3. Similarity Matching Module
| Algorithm 3 Similarity calculation algorithm | |
| Input: Secondary encoding of the inconsistent splits | |
| Output: Dice coefficient similarity and whether it matches | |
| 1: | |
| 2: | IF Dice_sim ≥ α THEN: |
| 3: | RETURN Dice_sim; |
| 4: | ELSE |
| 5: | RETURN FALSE; |
4.4. Analysis of Linkage Quality and Security
5. Experimental Preparation
5.1. Experimental Preparation
5.2. Experimental Analysis and Results
5.2.1. Scalability Evaluation
5.2.2. Method Performance Evaluation
5.2.3. Security Analysis
5.2.4. Experimental Results
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Elmagarmid, A.K.; Ipeirotis, P.G.; Verykios, V.S. Duplicate record detection: A survey. IEEE Trans. Knowl. Data Eng. 2006, 19, 1–16. [Google Scholar] [CrossRef]
- Clifton, C.; Kantarcioglu, M.; Vaidya, J.; Lin, X.; Zhu, M.Y. Tools for privacy preserving distributed data mining. ACM Sigkdd Explor. Newsl. 2002, 4, 28–34. [Google Scholar] [CrossRef]
- Vatsalan, D.; Sehili, Z.; Christen, P.; Rahm, E. Privacy-preserving record linkage for big data: Current approaches and research challenges. Handb. Big Data Technol. 2017, 851–895. [Google Scholar] [CrossRef] [PubMed]
- Gkoulalas-Divanis, A.; Vatsalan, D.; Karapiperis, D.; Kantarcioglu, M. Modern privacy-preserving record linkage techniques: An overview. IEEE Trans. Inf. Forensics Secur. 2021, 16, 4966–4987. [Google Scholar] [CrossRef]
- Hall, R.; Fienberg, S.E. Privacy-preserving record linkage. In Proceedings of the International Conference on Privacy in Statistical Databases, Paris, France, 21–23 September 2010; pp. 269–283. [Google Scholar]
- Danni, T.; Derong, S.; Shumin, H.; Tiezheng, N.; Yue, K.; Ge, Y. Multi-party strong-privacy-preserving record linkage method. J. Front. Comput. Sci. Technol. 2019, 13, 394. [Google Scholar]
- Nguyen, N.; Connolly, T.; Overcash, J.; Hubbard, A.; Sudaria, T. RWD103 Evaluating a Privacy Preserving Record Linkage (PPRL) Solution to Link De-Identified Patient Records in Rwd Using Default Matching Methods and Machine Learning Methods. Value Health 2022, 25, S595. [Google Scholar] [CrossRef]
- Malin, B.A.; Emam, K.E.; O’Keefe, C.M. Biomedical data privacy: Problems, perspectives, and recent advances. J. Am. Med. Inform. Assoc. 2013, 20, 2–6. [Google Scholar] [CrossRef] [PubMed]
- Vatsalan, D.; Christen, P.; Verykios, V.S. A taxonomy of privacy-preserving record linkage techniques. Inf. Syst. 2013, 38, 946–969. [Google Scholar] [CrossRef]
- Li, T.; Gu, Y.; Zhou, X.; Ma, Q.; Yu, G. An effective and efficient truth discovery framework over data streams. In Proceedings of the International Conference on Extending Database Technology (EDBT), Venice, Italy, 21–24 March 2017; pp. 180–191. [Google Scholar]
- Nguyen, L.; Stoové, M.; Boyle, D.; Callander, D.; McManus, H.; Asselin, J.; Guy, R.; Donovan, B.; Hellard, M.; El-Hayek, C. Privacy-preserving record linkage of deidentified records within a public health surveillance system: Evaluation study. J. Med. Internet Res. 2020, 22, e16757. [Google Scholar] [CrossRef]
- Schnell, R. Privacy Preserving Record Linkage in the Context of a National Statistical Institute. In German Record Linkage Center Working Paper Series No. WP-GRLC-2021-01; University of Duisburg-Essen: Duisburg, Germany, 2021. [Google Scholar]
- Boyd, J.H.; Randall, S.M.; Ferrante, A.M. Application of privacy-preserving techniques in operational record linkage centres. Med. Data Priv. Handb. 2015, 267–287. [Google Scholar]
- Bian, J.; Loiacono, A.; Sura, A.; Mendoza Viramontes, T.; Lipori, G.; Guo, Y.; Shenkman, E.; Hogan, W. Implementing a hash-based privacy-preserving record linkage tool in the OneFlorida clinical research network. Jamia Open 2019, 2, 562–569. [Google Scholar] [CrossRef] [PubMed]
- Jin, L.; Li, C.; Mehrotra, S. Efficient record linkage in large data sets. In Proceedings of the Eighth International Conference on Database Systems for Advanced Applications, 2003. (DASFAA 2003). Proceedings, Kyoto, Japan, 26–28 March 2003; pp. 137–146. [Google Scholar] [CrossRef]
- Murray, J.S. Probabilistic record linkage and deduplication after indexing, blocking, and filtering. arXiv 2016, arXiv:1603.07816. [Google Scholar] [CrossRef]
- Lim, D.; Randall, S.; Robinson, S.; Thomas, E.; Williamson, J.; Chakera, A.; Napier, K.; Schwan, C.; Manuel, J.; Betts, K. Unlocking potential within health systems using privacy-preserving record linkage: Exploring chronic kidney disease outcomes through linked data modelling. Appl. Clin. Inform. 2022, 13, 901–909. [Google Scholar] [CrossRef]
- Randall, S.M.; Ferrante, A.M.; Boyd, J.H.; Bauer, J.K.; Semmens, J.B. Privacy-preserving record linkage on large real world datasets. J. Biomed. Inform. 2014, 50, 205–212. [Google Scholar] [CrossRef] [PubMed]
- Karapiperis, D.; Gkoulalas-Divanis, A.; Verykios, V.S. Fast schemes for online record linkage. Data Min. Knowl. Discov. 2018, 32, 1229–1250. [Google Scholar] [CrossRef]
- Christen, P.; Ranbaduge, T.; Vatsalan, D.; Schnell, R. Precise and fast cryptanalysis for Bloom filter based privacy-preserving record linkage. IEEE Trans. Knowl. Data Eng. 2018, 31, 2164–2177. [Google Scholar] [CrossRef]
- Li, T.; Chen, L.; Jensen, C.S.; Pedersen, T.B.; Gao, Y.; Hu, J. Evolutionary clustering of moving objects. In Proceedings of the 2022 IEEE 38th International Conference on Data Engineering (ICDE), Kuala Lumpur, Malaysia, 9–12 May 2022; pp. 2399–2411. [Google Scholar]
- Li, T.; Huang, R.; Chen, L.; Jensen, C.S.; Pedersen, T.B. Compression of uncertain trajectories in road networks. Proc. VLDB Endow. 2020, 13, 1050–1063. [Google Scholar] [CrossRef]
- Li, T.; Chen, L.; Jensen, C.S.; Pedersen, T.B. TRACE: Real-time compression of streaming trajectories in road networks. Proc. VLDB Endow. 2021, 14, 1175–1187. [Google Scholar] [CrossRef]
- Lai, P.K.; Yiu, S.-M.; Chow, K.-P.; Chong, C.; Hui, L.C.K. An Efficient Bloom Filter Based Solution for Multiparty Private Matching. In Proceedings of the Security and Management, Las Vegas, NV, USA, 26-29 June 2006; pp. 286–292. [Google Scholar]
- Vatsalan, D.; Christen, P.; Rahm, E. Scalable privacy-preserving linking of multiple databases using counting Bloom filters. In Proceedings of the 2016 IEEE 16th International Conference on Data Mining Workshops (ICDMW), Barcelona, Spain, 12–15 December 2016; pp. 882–889. [Google Scholar]
- Wang, J.; Li, T.; Wang, A.; Liu, X.; Chen, L.; Chen, J.; Liu, J.; Wu, J.; Li, F.; Gao, Y. Real-time Workload Pattern Analysis for Large-scale Cloud Databases. arXiv 2023, arXiv:2307.02626. [Google Scholar] [CrossRef]
- Vatsalan, D.; Christen, P.; Rahm, E. Incremental clustering techniques for multi-party privacy-preserving record linkage. Data Knowl. Eng. 2020, 128, 101809. [Google Scholar] [CrossRef]
- Schnell, R.; Borgs, C. Randomized response and balanced bloom filters for privacy preserving record linkage. In Proceedings of the 2016 IEEE 16th International Conference on Data Mining Workshops (ICDMW), Barcelona, Spain, 12–15 December 2016; pp. 218–224. [Google Scholar]
- Mohanta, B.K.; Jena, D.; Sobhanayak, S. Multi-party computation review for secure data processing in IoT-fog computing environment. Int. J. Secur. Netw. 2020, 15, 164–174. [Google Scholar] [CrossRef]
- Ranbaduge, T.; Christen, P.; Schnell, R. Secure and accurate two-step hash encoding for privacy-preserving record linkage. In Proceedings of the Advances in Knowledge Discovery and Data Mining: 24th Pacific-Asia Conference, PAKDD 2020, Proceedings, Part II 24, Singapore, 11–14 May 2020; pp. 139–151. [Google Scholar]
- Shelake, V.M.; Shekokar, N.M. Privacy Preserving Record Linkage Using Phonetic and Bloom Filter Encoding. Int. J. Adv. Res. Eng. Technol. 2020, 11, 350–362. [Google Scholar]
- Han, S.; Shen, D.; Nie, T.; Kou, Y.; Yu, G. An enhanced privacy-preserving record linkage approach for multiple databases. Clust. Comput. 2022, 25, 3641–3652. [Google Scholar] [CrossRef]
- Stammler, S.; Kussel, T.; Schoppmann, P.; Stampe, F.; Tremper, G.; Katzenbeisser, S.; Hamacher, K.; Lablans, M. Mainzelliste SecureEpiLinker (MainSEL): Privacy-preserving record linkage using secure multi-party computation. Bioinformatics 2022, 38, 1657–1668. [Google Scholar] [CrossRef] [PubMed]
- He, X.; Wei, H.; Han, S.; Shen, D. Multi-party privacy-preserving record linkage method based on trusted execution environment. In Proceedings of the International Conference on Web Information Systems and Applications, Dalian, China, 16–18 September 2022; pp. 591–602. [Google Scholar]
- Han, S.M.; Shen, D.R.; Nie, T.Z.; Yue, K.; Yu, G. Multi-party privacy-preserving record linkage approach. J. Softw. 2017, 28, 2281–2292. [Google Scholar]
- Niedermeyer, F.; Steinmetzer, S.; Kroll, M.; Schnell, R. Cryptanalysis of Basic Bloom Filters Used for Privacy Preserving Record Linkage; German Record Linkage Center, Working Paper Series, No. WP-GRLC-2014-04; University of Duisburg-Essen: Duisburg, Germany, 2014. [Google Scholar]
- Thada, V.; Jaglan, V. Comparison of jaccard, dice, cosine similarity coefficient to find best fitness value for web retrieved documents using genetic algorithm. Int. J. Innov. Eng. Technol. 2013, 2, 202–205. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Description |
|---|---|
| P | Participant of PPRL |
| Dataset | |
| k | Bloom Filter hash functions h1, …, hk |
| i | i-th participant (1 ≤ i ≤ P) |
| u-th split (1 ≤ u ≤ m) | |
| n | Bloom Filter length |
| m | Number of splits |
| X | Sum of positions encoded as 1 |
| Y | Number of positions encoded as 1 |
| A | Common attribute set among all participants |
| α | Threshold |
| e | Error limit (e = m − ak) |
| a | Tolerance level |
| l | Encoding length |
| t | Number of consistent splits |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Han, S.; Wang, Y.; Shen, D.; Wang, C. A Multi-Party Privacy-Preserving Record Linkage Method Based on Secondary Encoding. Mathematics 2024, 12, 1800. https://doi.org/10.3390/math12121800
Han S, Wang Y, Shen D, Wang C. A Multi-Party Privacy-Preserving Record Linkage Method Based on Secondary Encoding. Mathematics. 2024; 12(12):1800. https://doi.org/10.3390/math12121800
Chicago/Turabian StyleHan, Shumin, Yizi Wang, Derong Shen, and Chuang Wang. 2024. "A Multi-Party Privacy-Preserving Record Linkage Method Based on Secondary Encoding" Mathematics 12, no. 12: 1800. https://doi.org/10.3390/math12121800
APA StyleHan, S., Wang, Y., Shen, D., & Wang, C. (2024). A Multi-Party Privacy-Preserving Record Linkage Method Based on Secondary Encoding. Mathematics, 12(12), 1800. https://doi.org/10.3390/math12121800